1. Introduction
Seismic signals recorded by sensors onshore or offshore are usually contaminated by random noise, which leads to poor seismic data quality with low signal-to-noise ratio (SNR). Improving SNR of the seismic data is one of the targets of seismic data processing in which random noise suppression plays a key role in either pre-stack or post-stack seismic data processing.
There have been various denoising methods in recent decades such as prediction-based noise suppression method: t-x predictive filtering [
1,
2] and non-stationary predictive filtering [
3,
4], the sparse transform domain method including wavelet transform [
5], curvelet transform [
6], seislet transform [
7], contourlets transform [
8], dictionary learning-based sparse transform [
9], singular spectrum analysis [
10,
11], etc. These traditional methods separate noise from signals mainly based on the features of signal and noise itself or their distribution characteristics in different transform domains. These methods usually require knowledge of prior information for the signal or the noise. Moreover, the features of seismic signals are complex in real situations and the distribution of characteristics of the signal and noise are overlapped in transform domain, so it is almost impossible to accurately separate the noise from noisy signals.
Recently, deep learning methods are popular and successfully deal with various tasks in different fields such as computer science, information engineering and earth science, and remote sensing. Deep learning methods have shown great potential for different tasks in the field of remote sensing such as image retrieval, road extraction, remote-sensing scene classification, semantic segmentation, and intelligent transport systems [
12,
13,
14,
15,
16] as well as geophysics such as seismic inversion, interpretation, and seismic signal recognition [
17,
18,
19,
20,
21,
22,
23,
24,
25,
26,
27,
28,
29,
30,
31]. In addition, deep learning approaches have also been successfully applied to suppress random noise in seismic data processing [
18,
32,
33,
34,
35,
36,
37,
38,
39,
40,
41].
There are several classic deep learning methods for denoising. He et al. [
42] presented a residual learning framework named ResNet (Deep Residual Network), which achieves an increase in the network depth without causing training difficulties. Compared with plain networks, ResNet adds a shortcut connection between every two layers to form residual learning. Residual learning solves the degradation problem of deep networks, allowing us to train deeper networks. Zhang et al. [
43] proposed DnCNN (denoising convolutional neural network) for image denoising tasks based on the ideas of ResNet. The difference is that DnCNN does not add a shortcut connection every two layers like ResNet, but it directly changes the output of the network to a residual image. DnCNN learns the image residuals between the noisy image and the clean image. It can be converged quickly and has excellent performance under the condition of a deeper network. Ronneberger et al. [
44] developed the U-net architecture, which consists of a contraction path and an expanding path. The common encoder–decoder structure is adopted, and skip connection is added to the original structure. It can effectively remain the edge detail information in the original image and prevent the loss of excessive edge information through up-sampling and down-sampling. Srivastava et al. [
45] solved the overfitting problem which is difficult to deal with in deep learning by setting the dropout layers, that is, randomly discarding some units in the training process. Saad and Chen [
46] proposed a new approach named DDAE (deep-denoising autoencoder) to attenuate seismic random noise. DDAE encodes the input seismic data into multiple levels of abstraction, then decodes them to reconstruct a noise-free seismic signal.
Contrary to many physical or model-based algorithms, the fully trained machine-learning algorithms have great advantages that they often do not need to specify any prior information (i.e., the signal or noise characteristics) or impose limited prior knowledge while they set multiple tuning parameters to obtain suitable results [
40]. Consequently, the machine-learning algorithms are more user-friendly and offer possibly even fully automated applications. However, several factors determine the successfulness of the deep learning methods: (1) many more training examples must be provided than free parameters in the machine-learning algorithm avoiding the risk that the network memorizes the training data rather than learning the underlying trends [
47,
48]; (2) the provided training examples must be complete and the examples must span the full solution space [
40].
In practice, deep neural networks usually have many hidden layers with thousands to millions of free parameters, thereby the requirement of more training examples than free parameters during training is often problematic and even unrealizable for geophysical applications. There are often two approaches to augment seismic training data. One is to use synthetic seismic data that is variable and easy to acquire the corresponding clean data. However, the synthetic data are not complete and representative generally, it is challenging for practical applications because the synthetic data do not contain all the features of the field data. The other strategy to augment training data is to use the preprocessing field data, but the trained network is unlikely to surpass the quality of the preprocessing training examples. Moreover, the clean data (ground truth) is unknown in complex geophysical applications.
The training examples are essential in deep learning methods, however, for the geophysical problems, the complete training data are not easy to be acquired especially for solving the actual problems. On the one hand, acquisition of seismic data is expensive and the field data is limited and complex, so the clean data is challenging to obtain. On the other hand, the synthetic seismic data can provide noise-free data but they cannot completely solve the problem of the field seismic data. It is well known that the natural images are available anywhere with abundant detail features. To solve the problem, several researchers have proven that the deep denoising network can be trained by the natural images and then it is likely to be capable of denoising the seismic data [
49,
50]. A similar strategy is to reconstruct images of black holes using a network trained with only natural images [
51]. Zhang and van der Baan [
40] proposed a generalization study for the neural networks to make the training examples complete and representative by using double noise injection and natural images. Double noise injection can increase the number of available training samples, which is more flexible for field data processing by training the algorithm to recognize and remove certain types of noise. Saad and Chen [
38] proposed an unsupervised deep learning algorithm (PATCHUNET) to suppress random noise of seismic data with strategy of patching technique and skip connections. The proposed algorithm encodes the patched seismic data to extract the features of the input data and uses the decoder to map these extracted features to the clean signal without random noise.
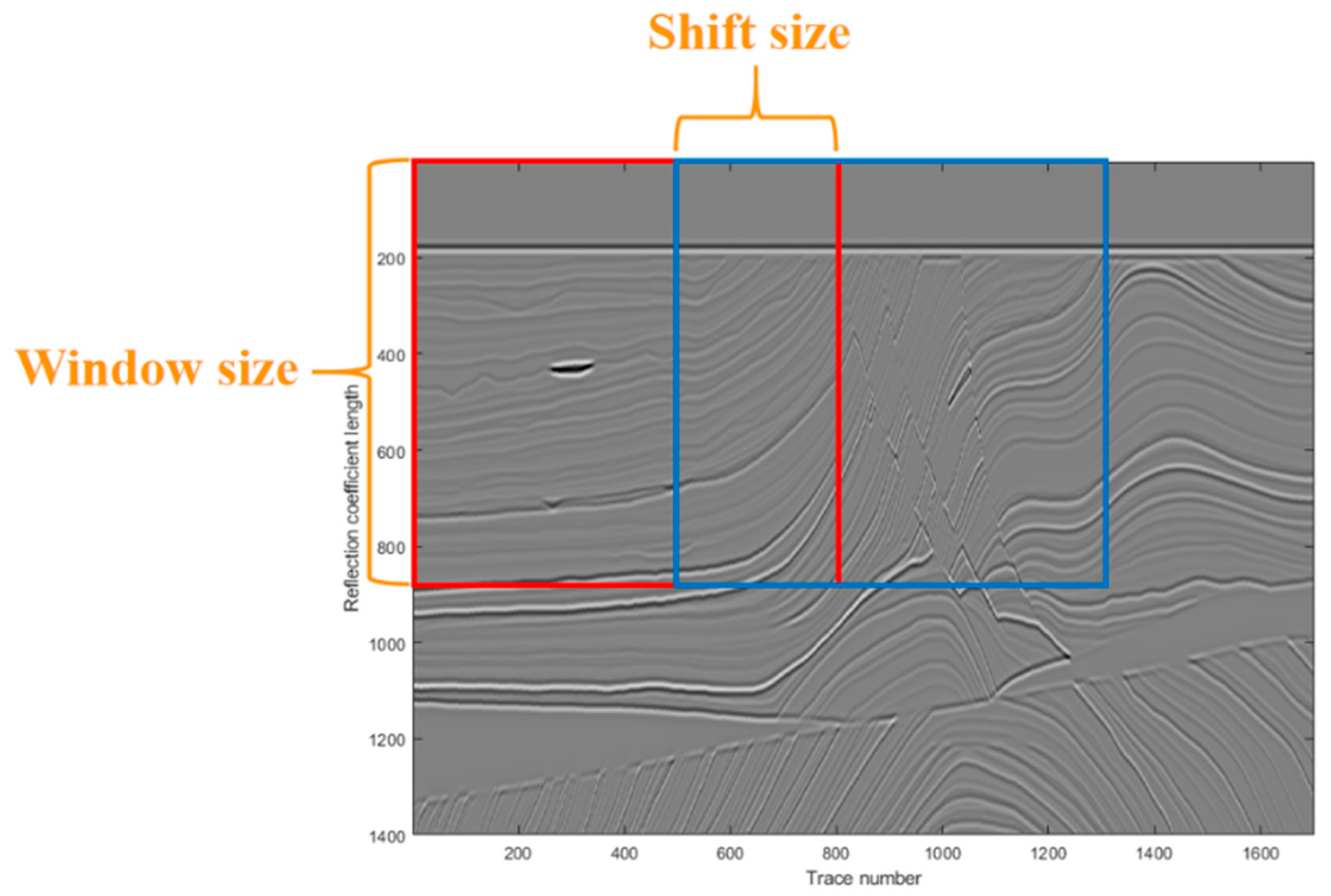
In this work, we propose a new network architecture to suppress seismic random noise. Compared with previous work, the advancements of our new architecture are summarized as follows:
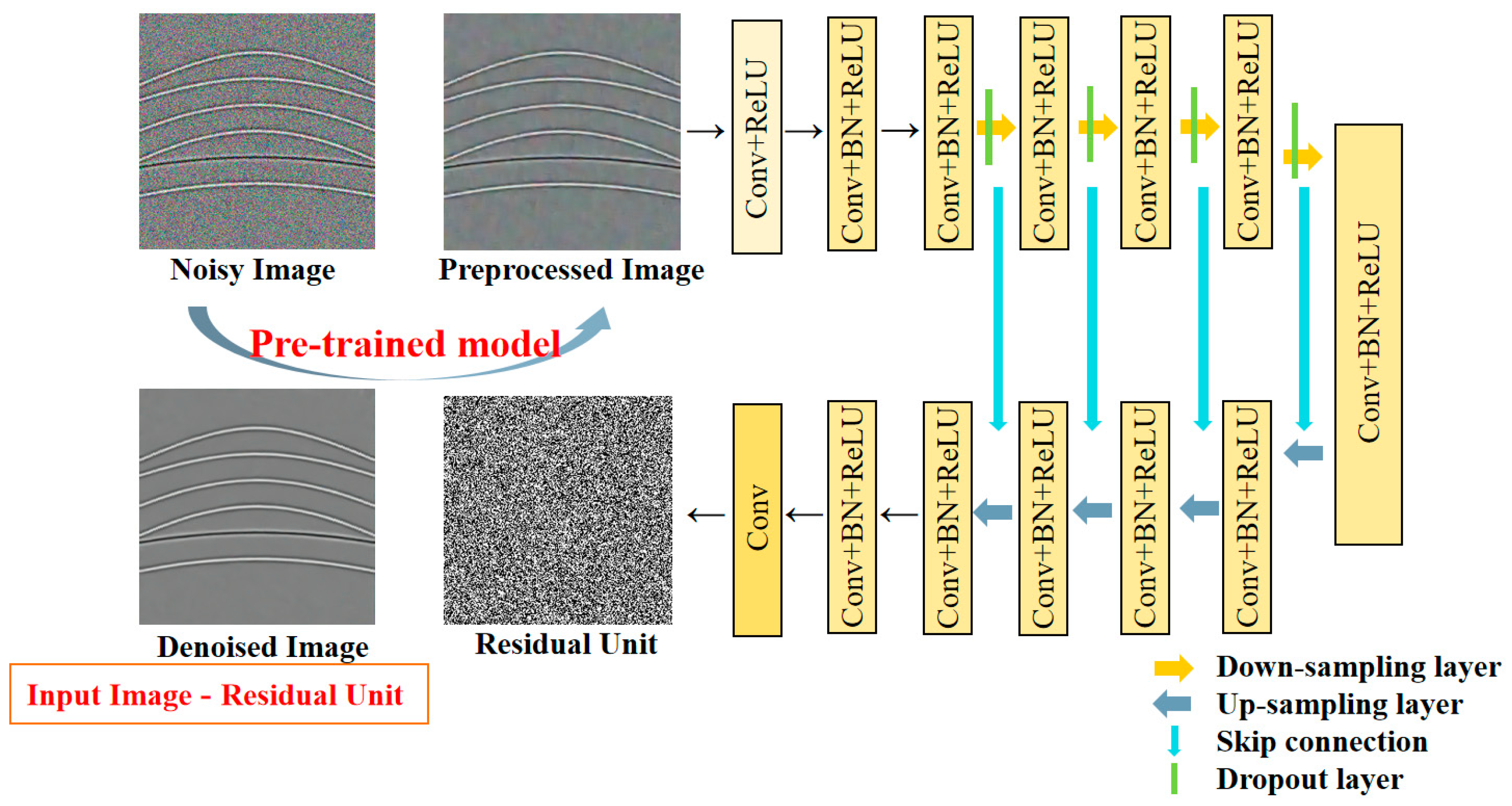
We treat the seismic data as an image throughout our network. Firstly, we train the network using exclusively natural images, then we transfer it to synthetic seismic image through the transfer learning. Secondly, we utilize the migrated seismic images to train a network different from the one used in the first step.
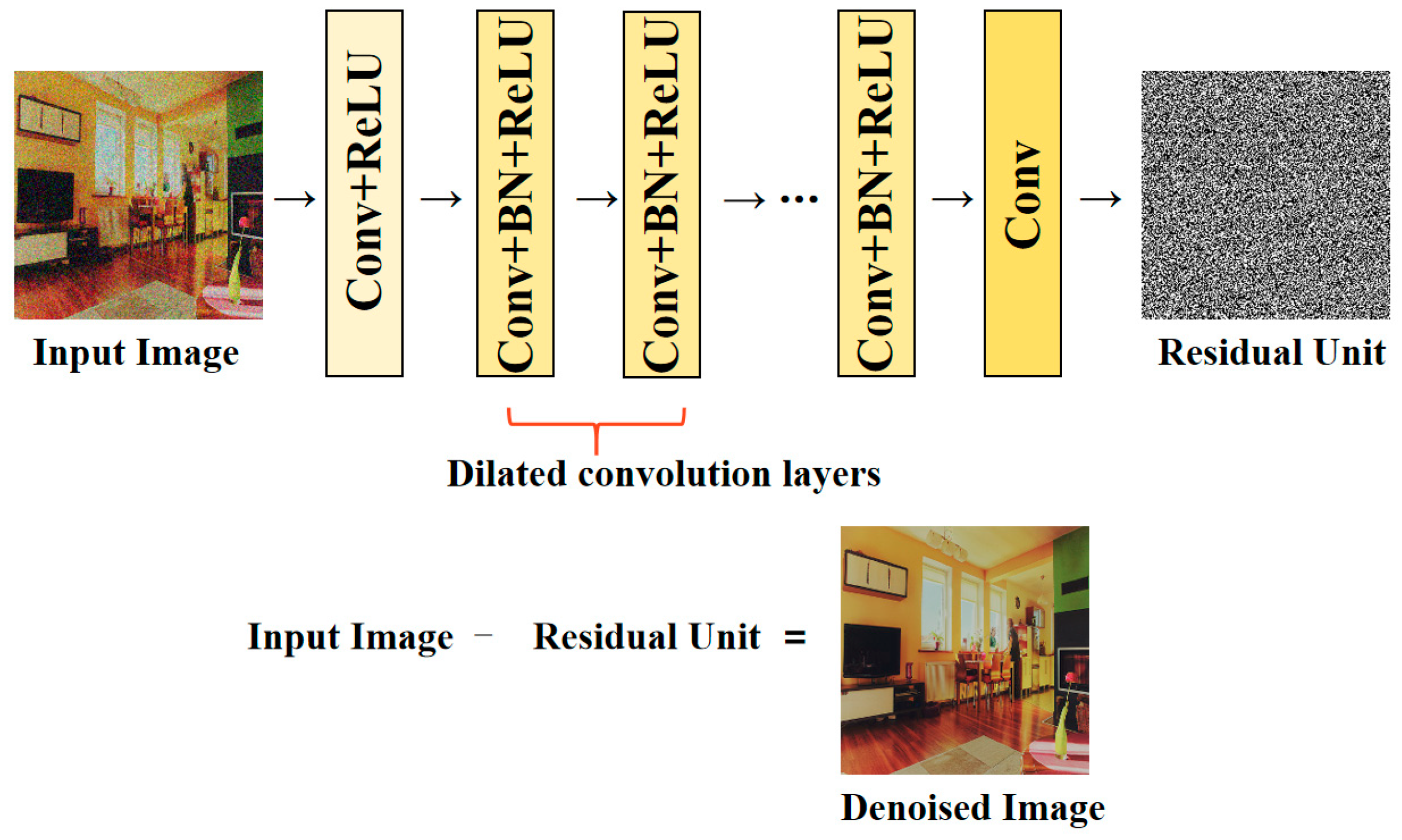
The dilated convolution is added in DnCNN to increase the size of the receptive field as well as to improve the training efficiency. This network is taken as a pre-trained network trained by only natural images.
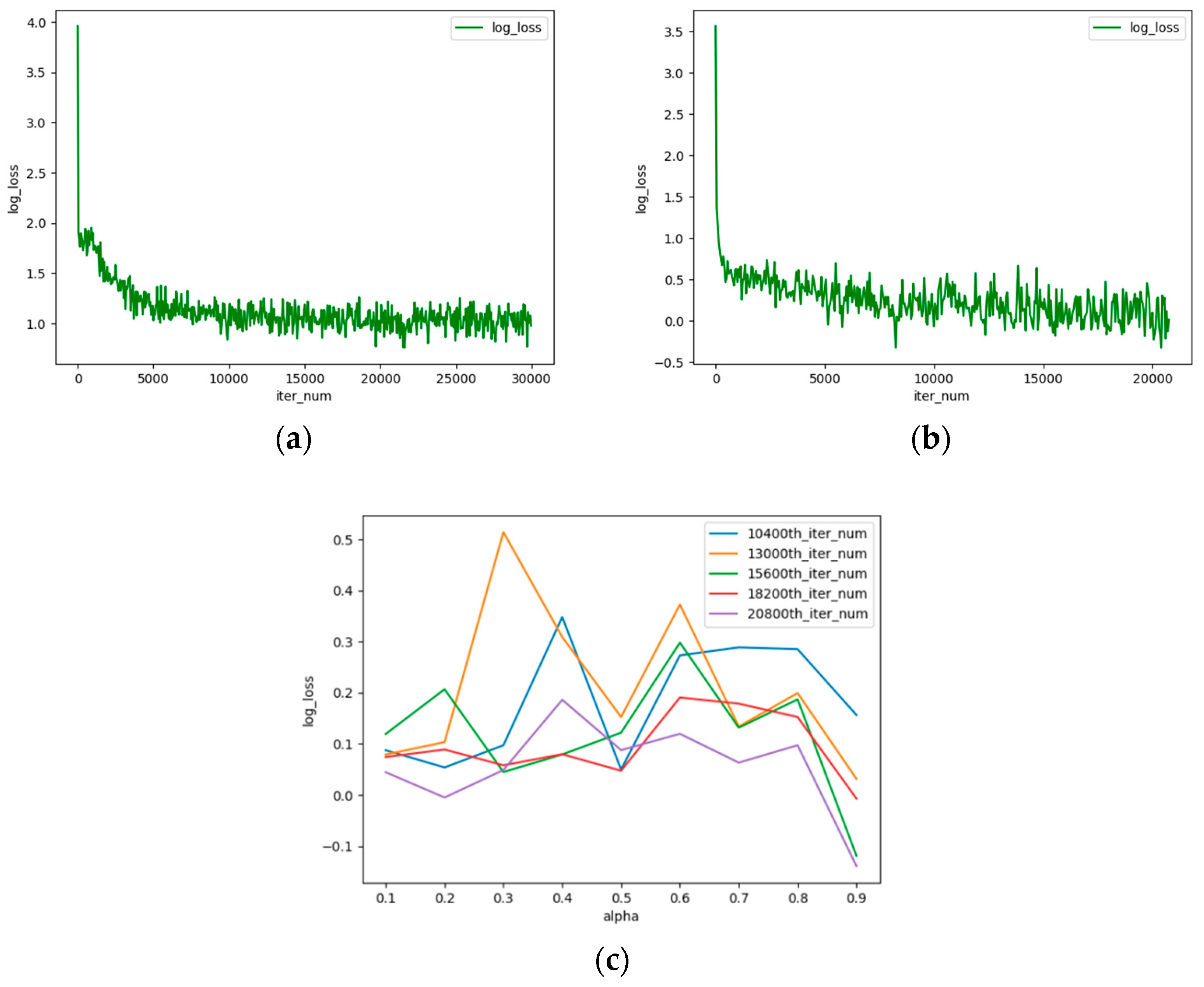
In order to fine-tune the denoising result of the pre-trained network, we design a post-trained network trained on synthetic seismic data in a way of semi-supervised learning. The network is the modified U-net with several dropout layers. We set the output of the network as a residual image to solve the difficulties of network training, in other words, the final denoised seismic images can be obtained by subtracting the output from the input.
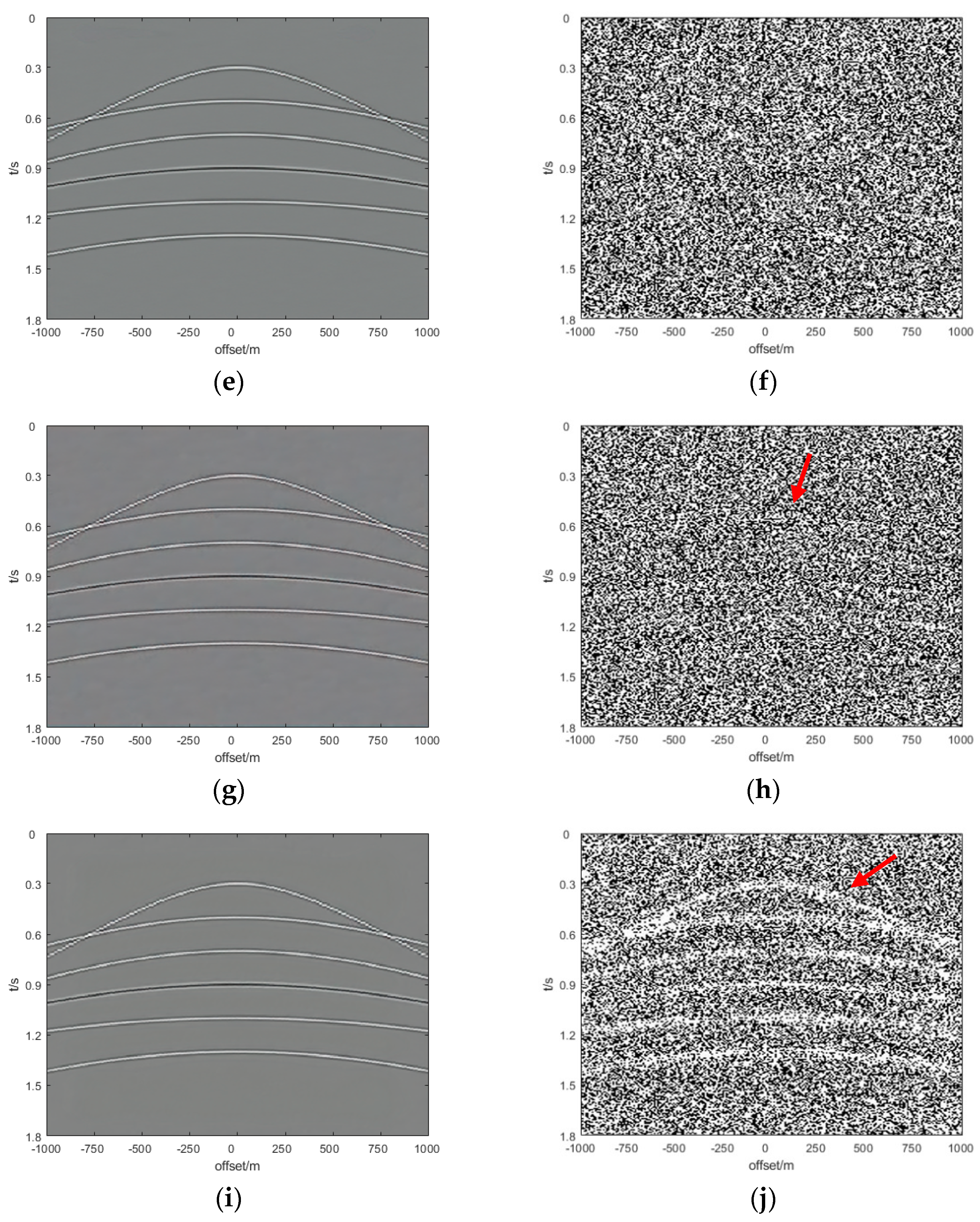
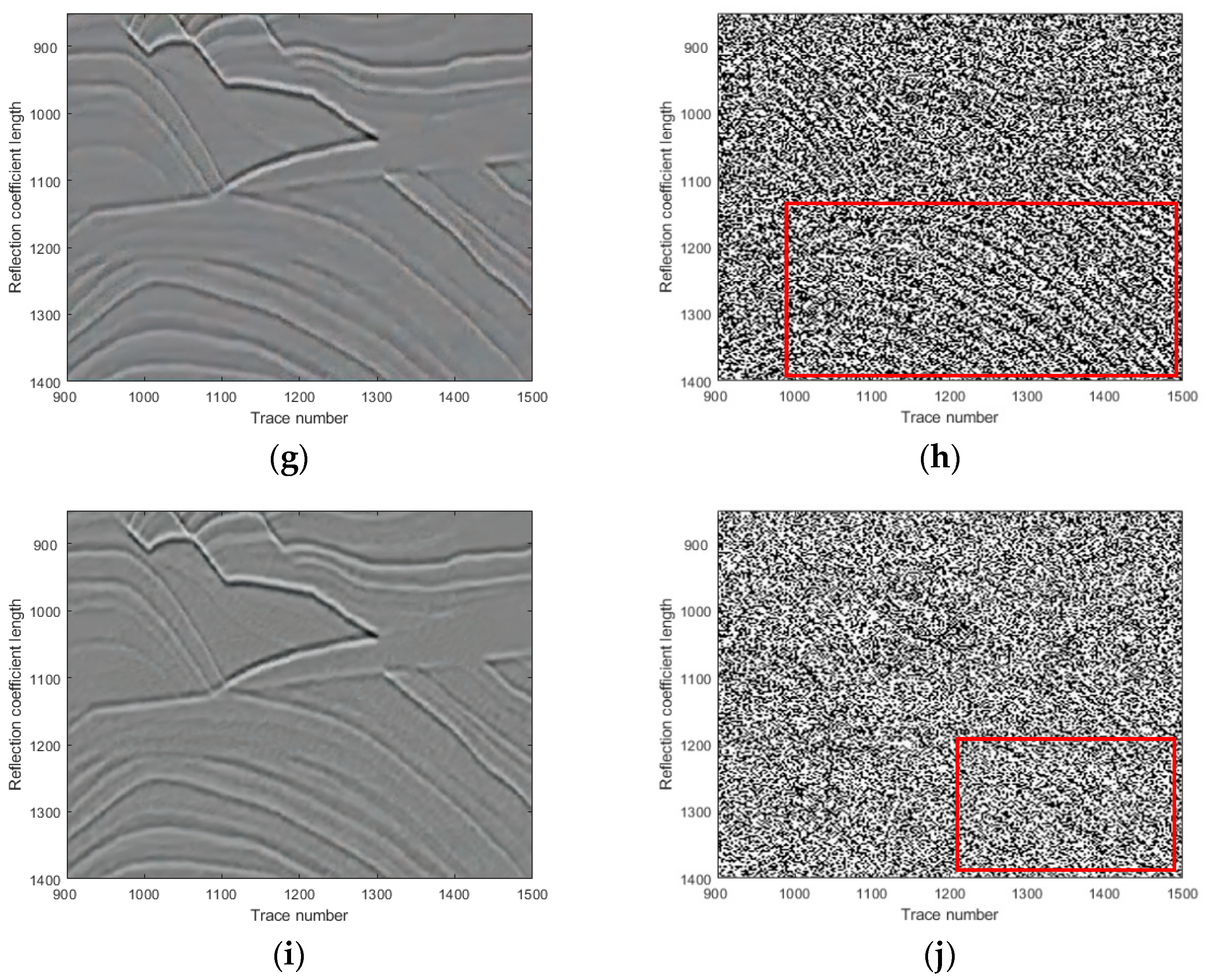
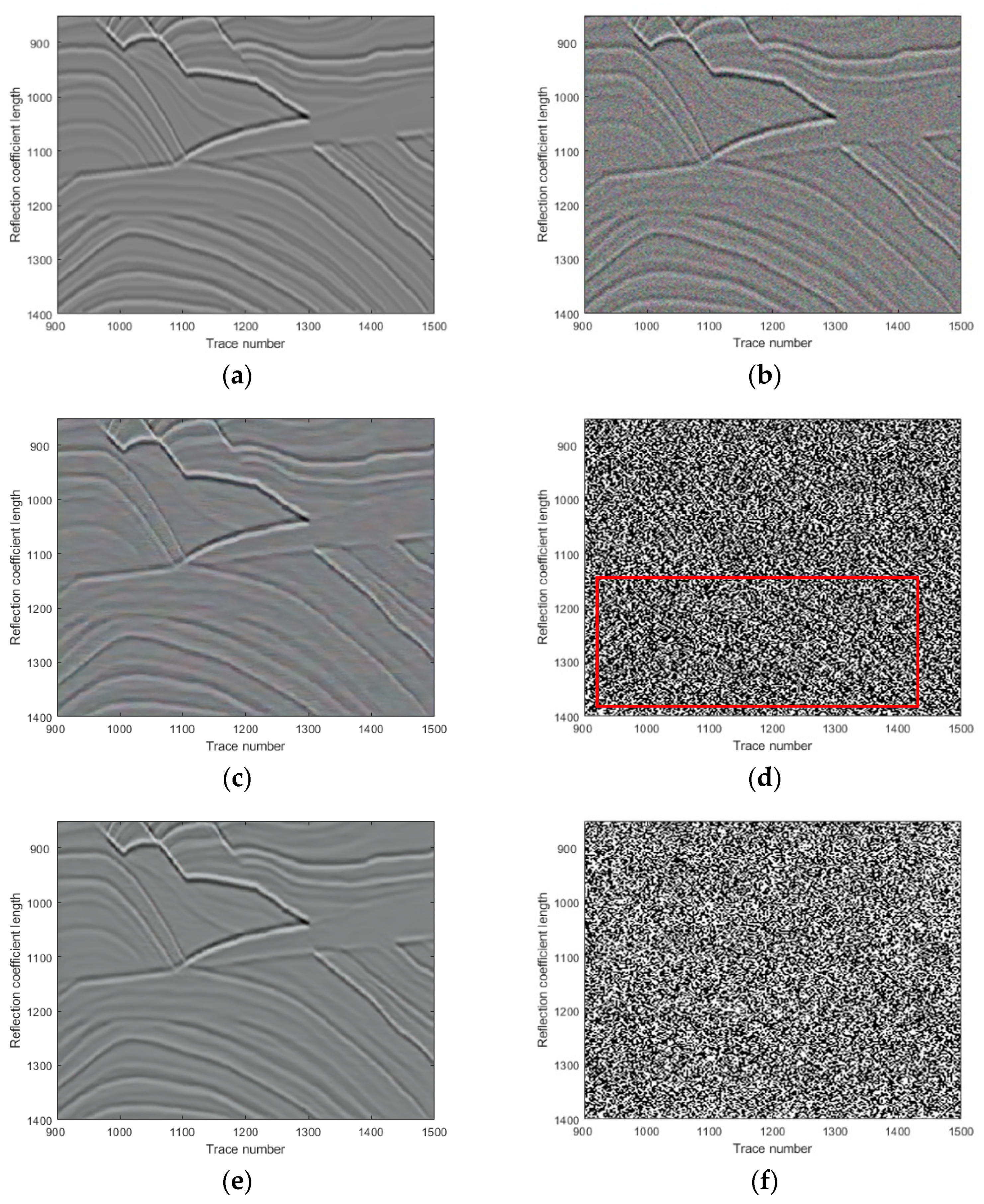
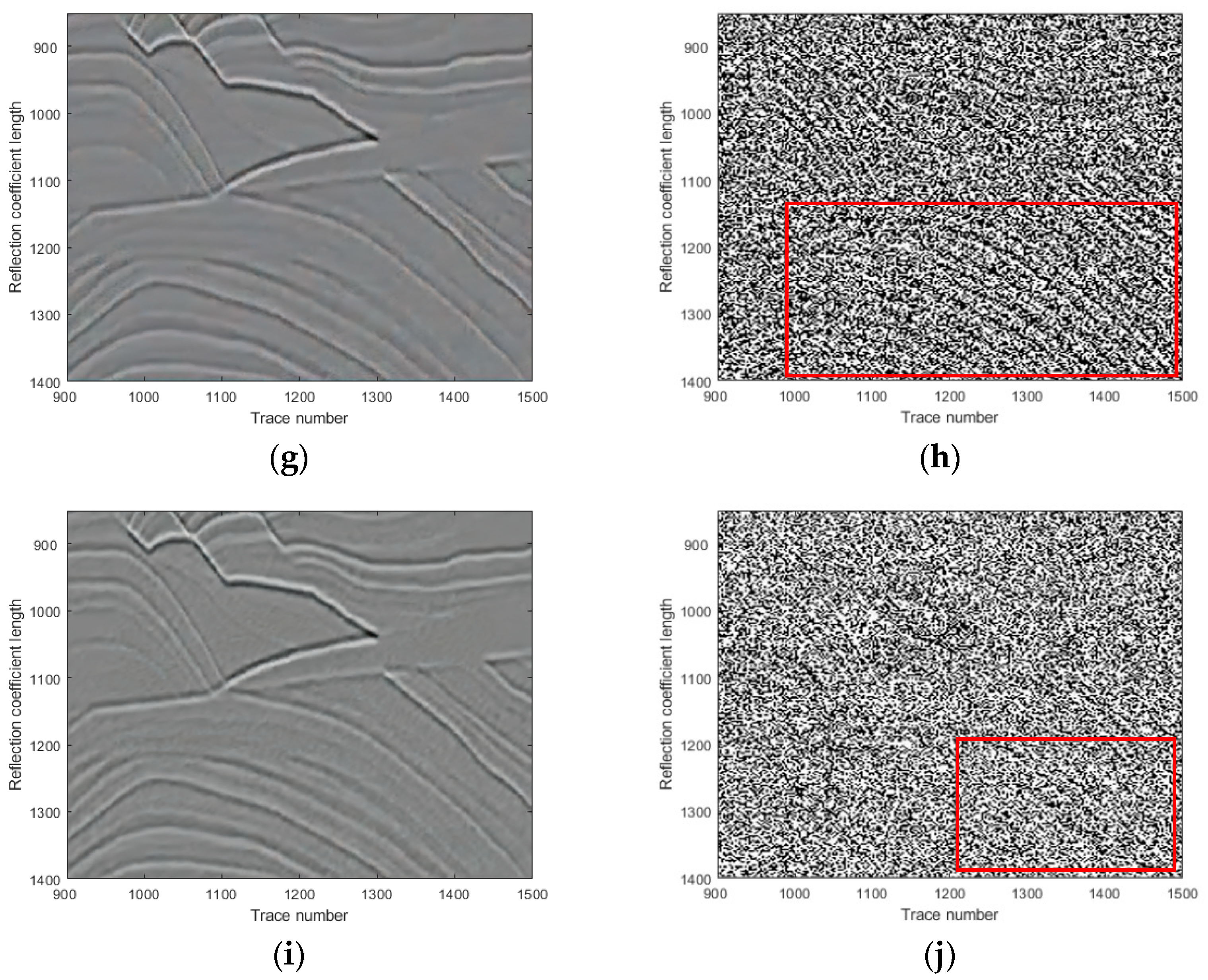
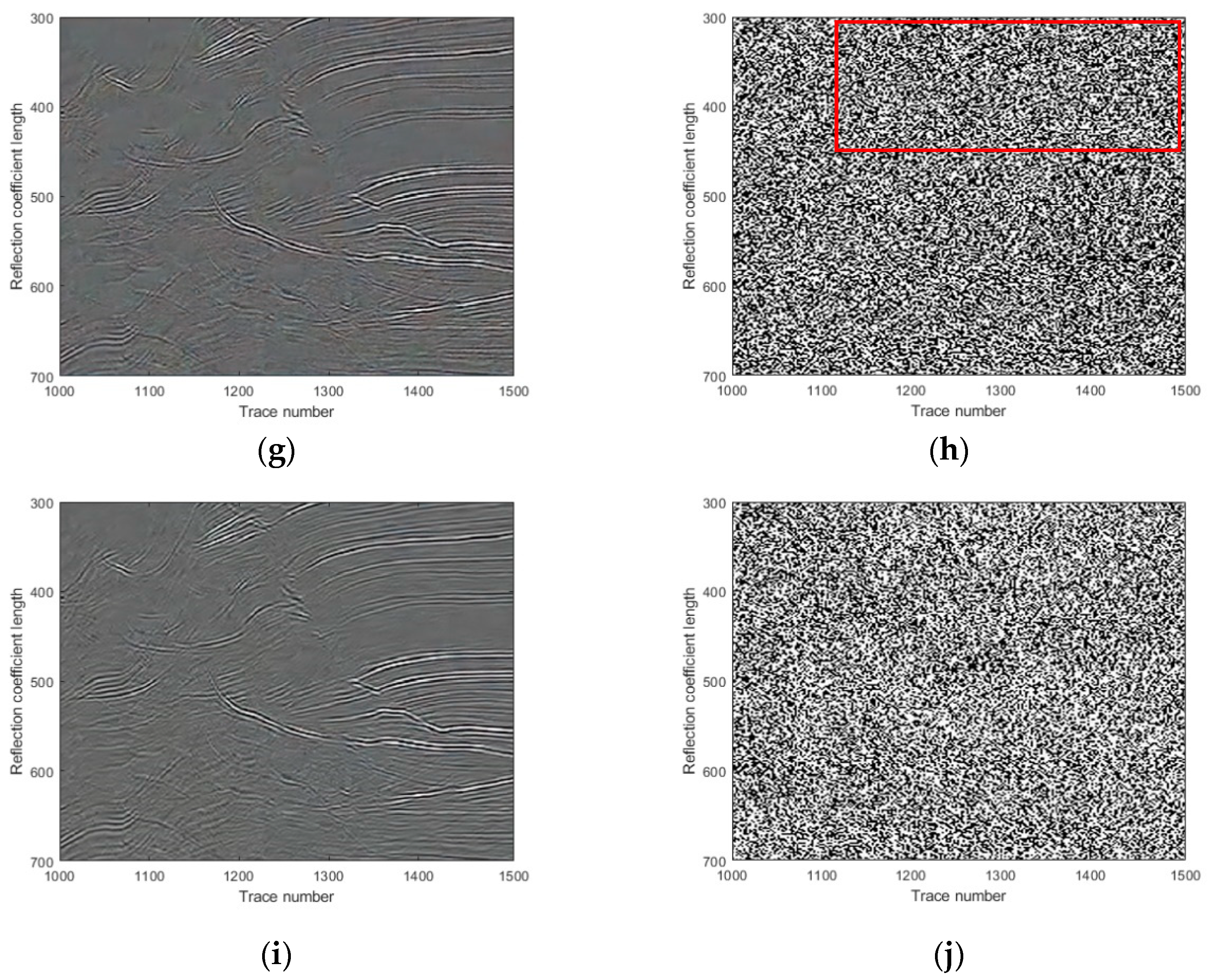
This paper is organized as follows. In
Section 2, we introduce the natural images pre-trained network for seismic random noise removal. In
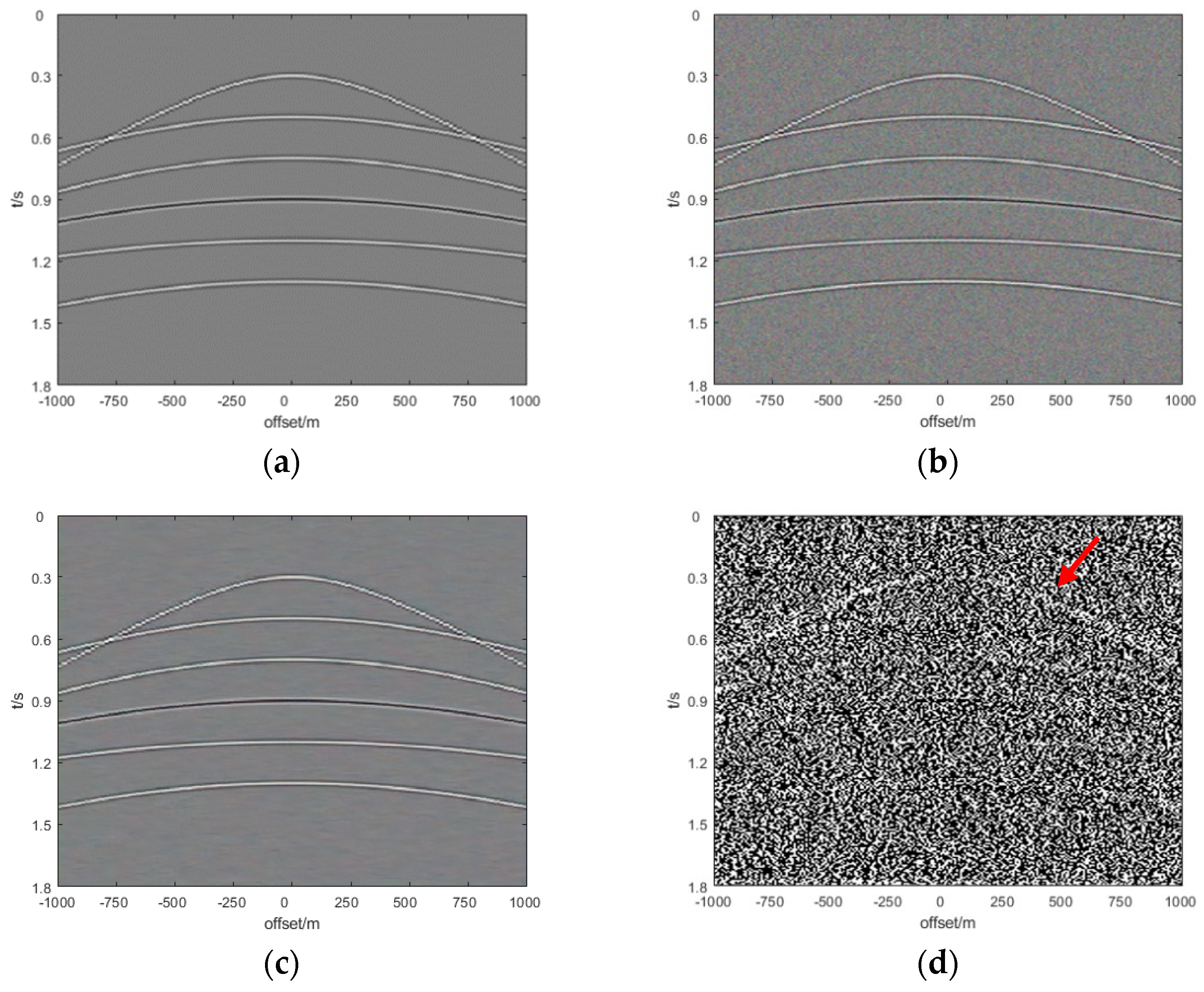
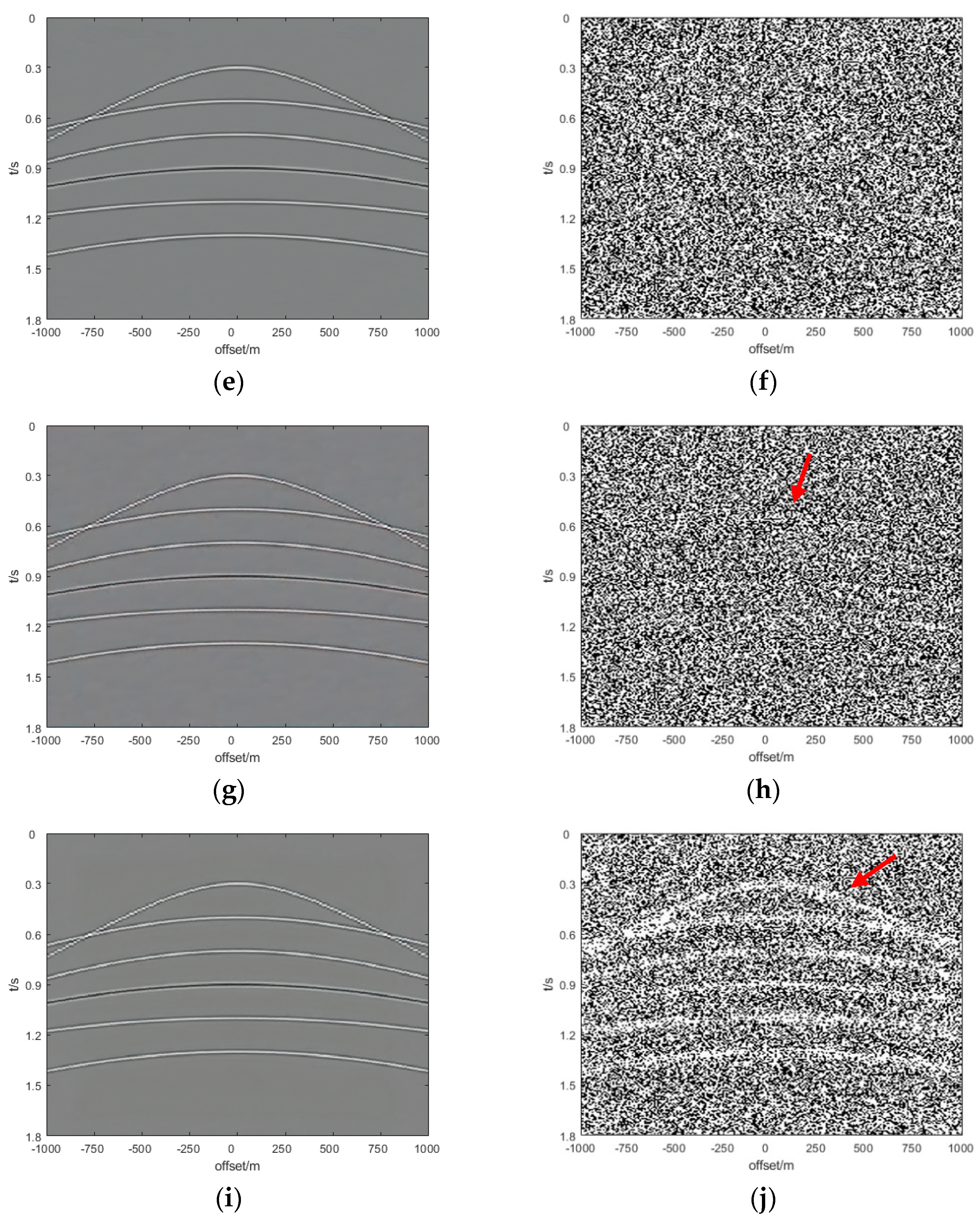
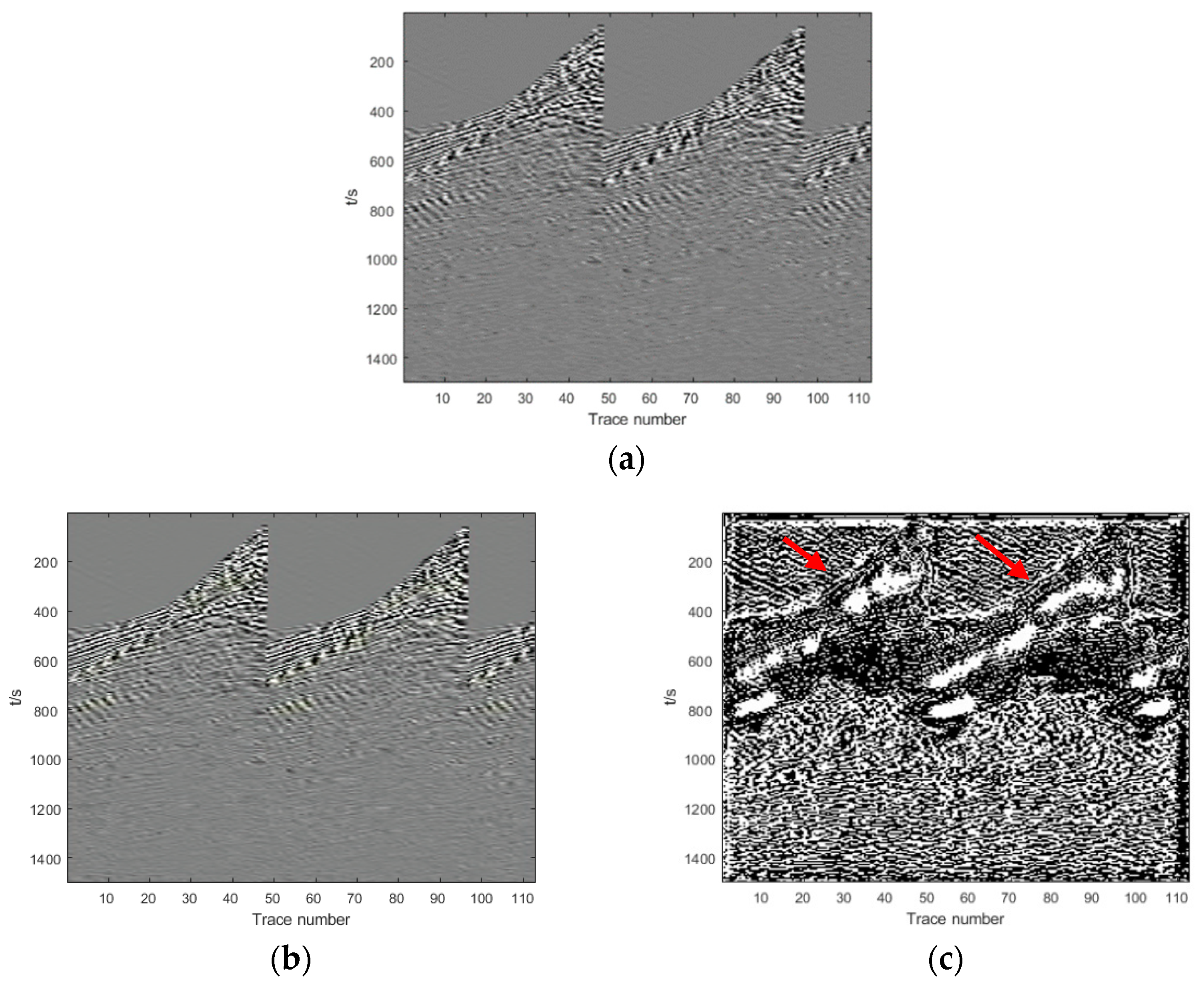
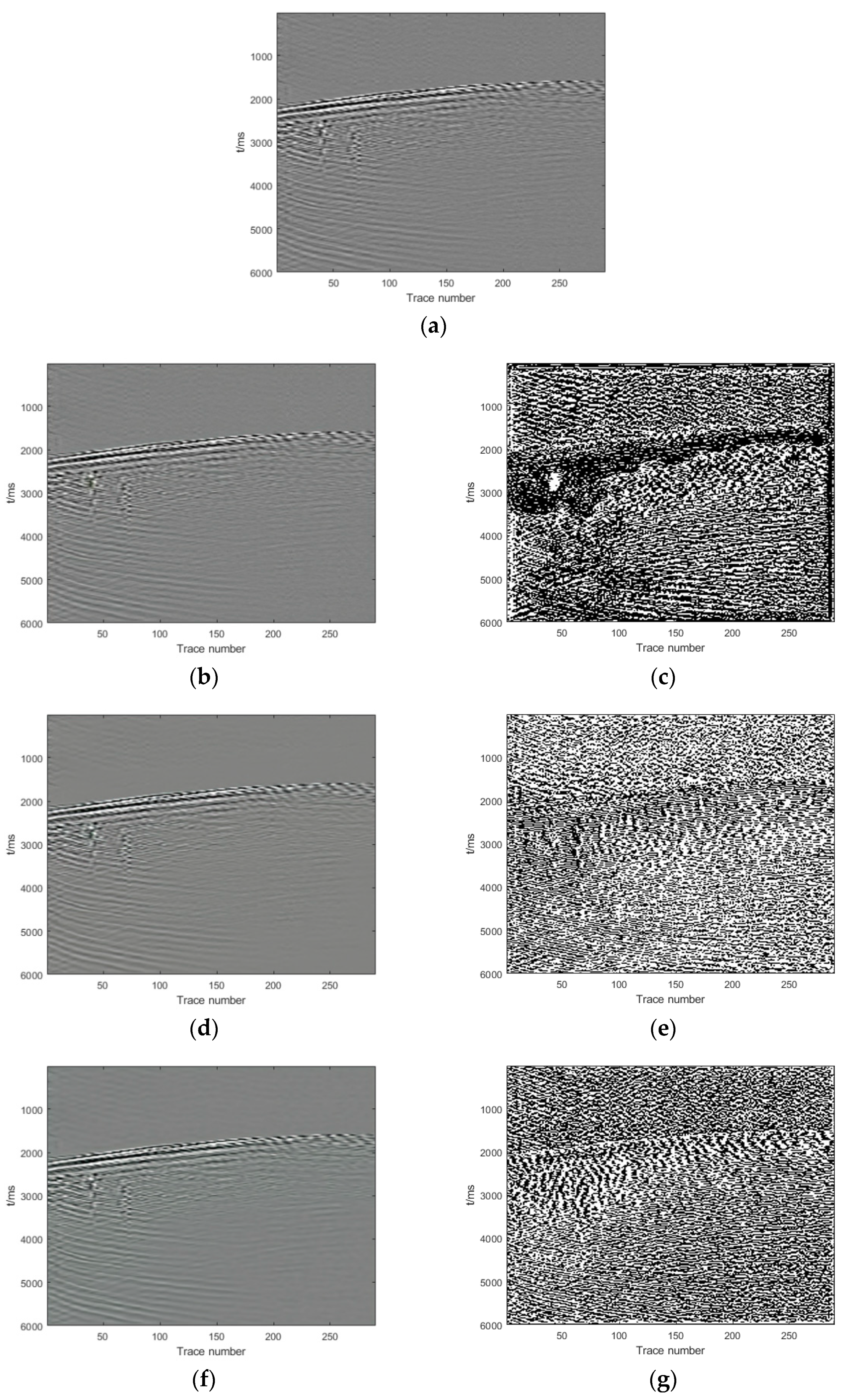
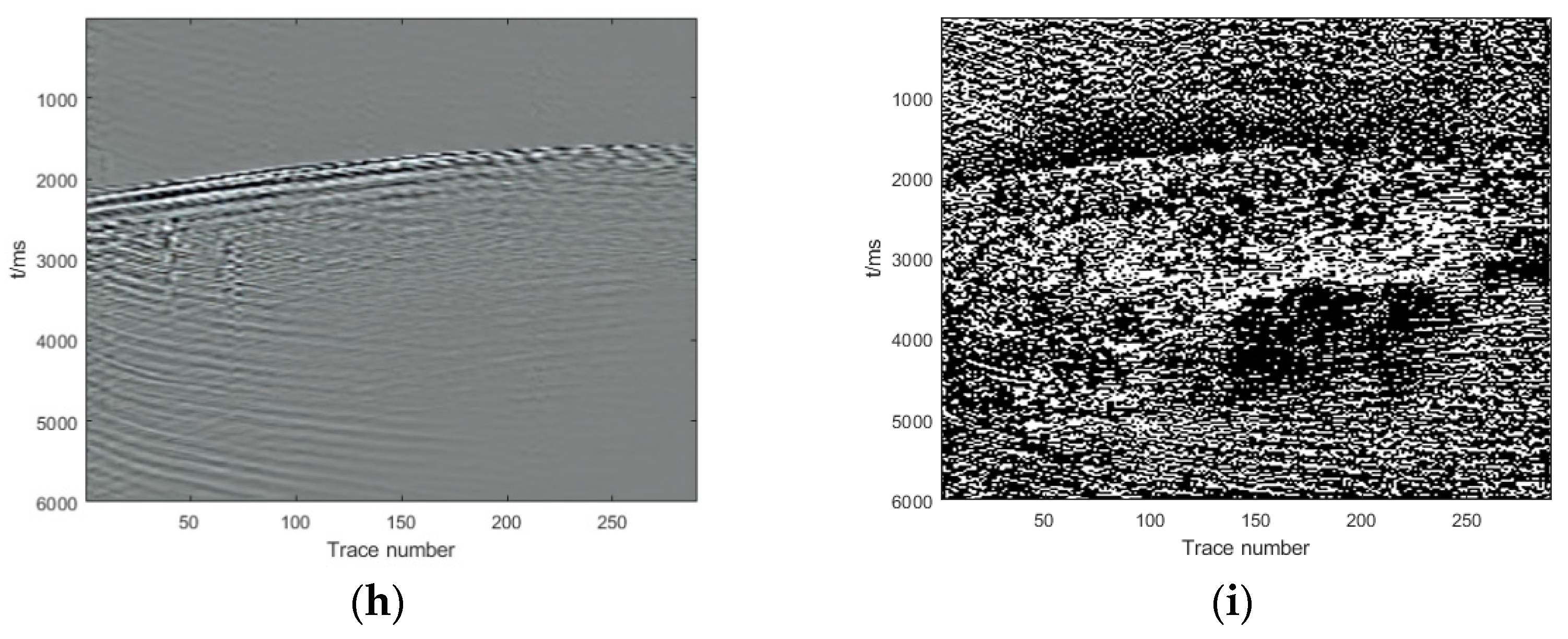
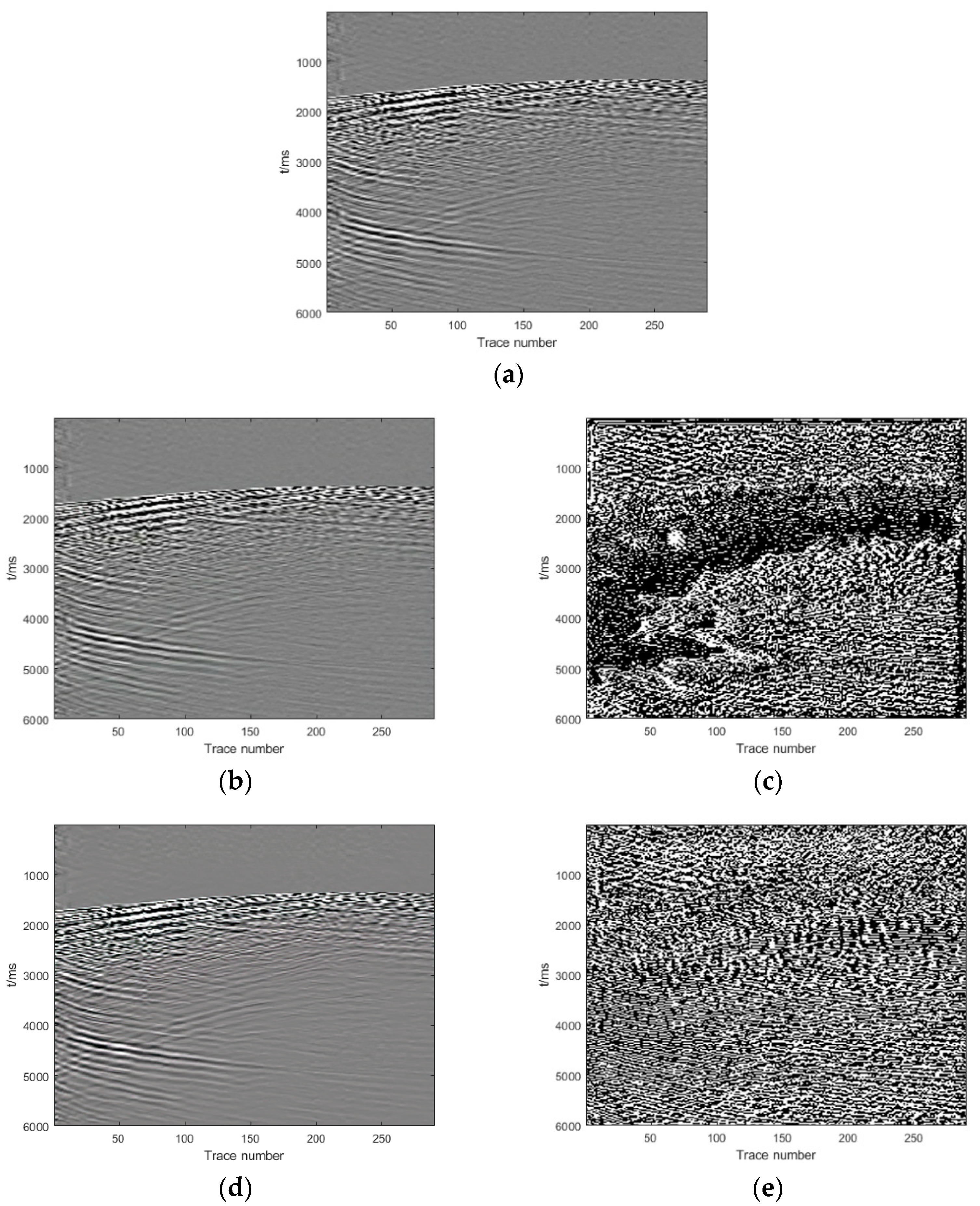
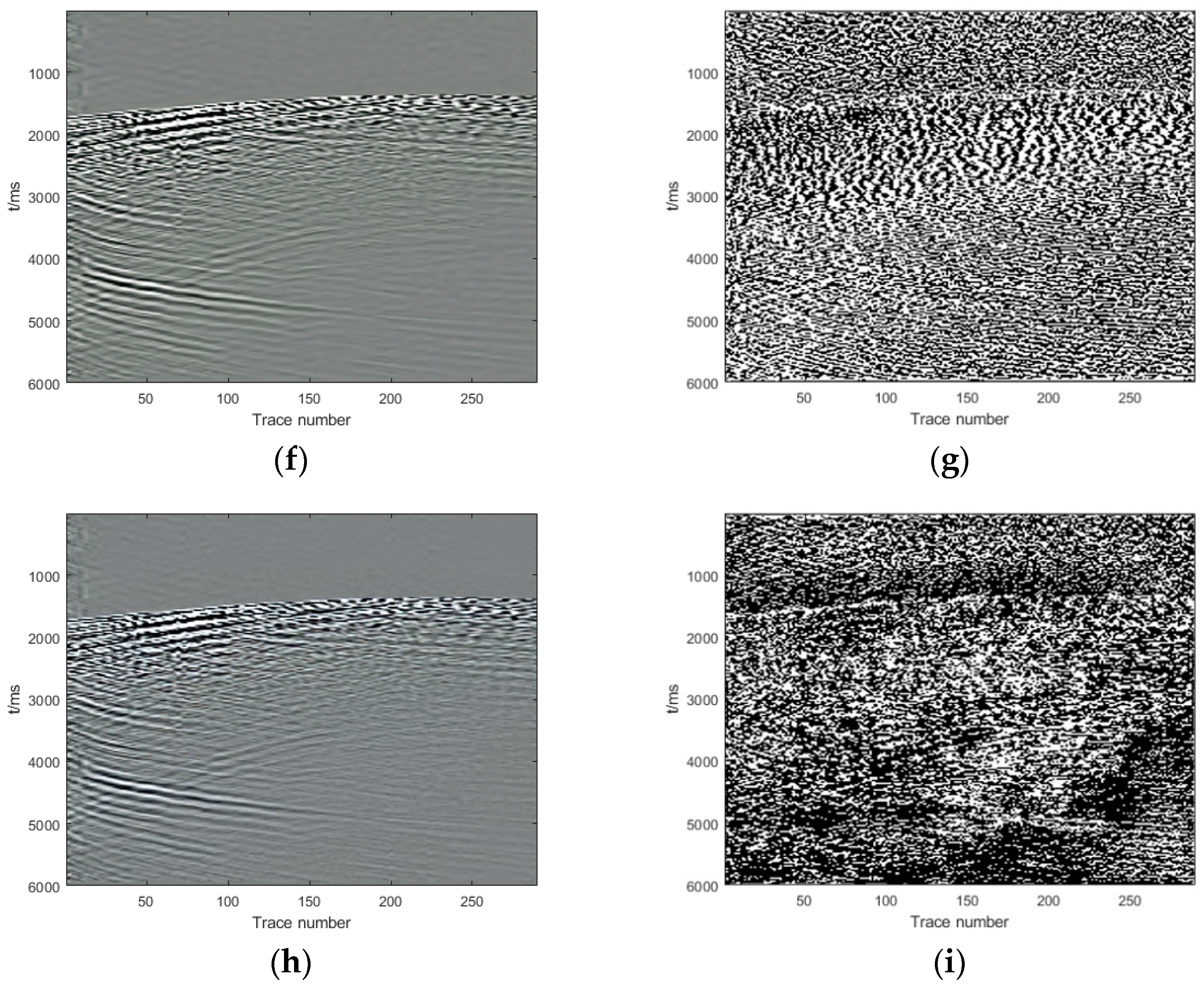
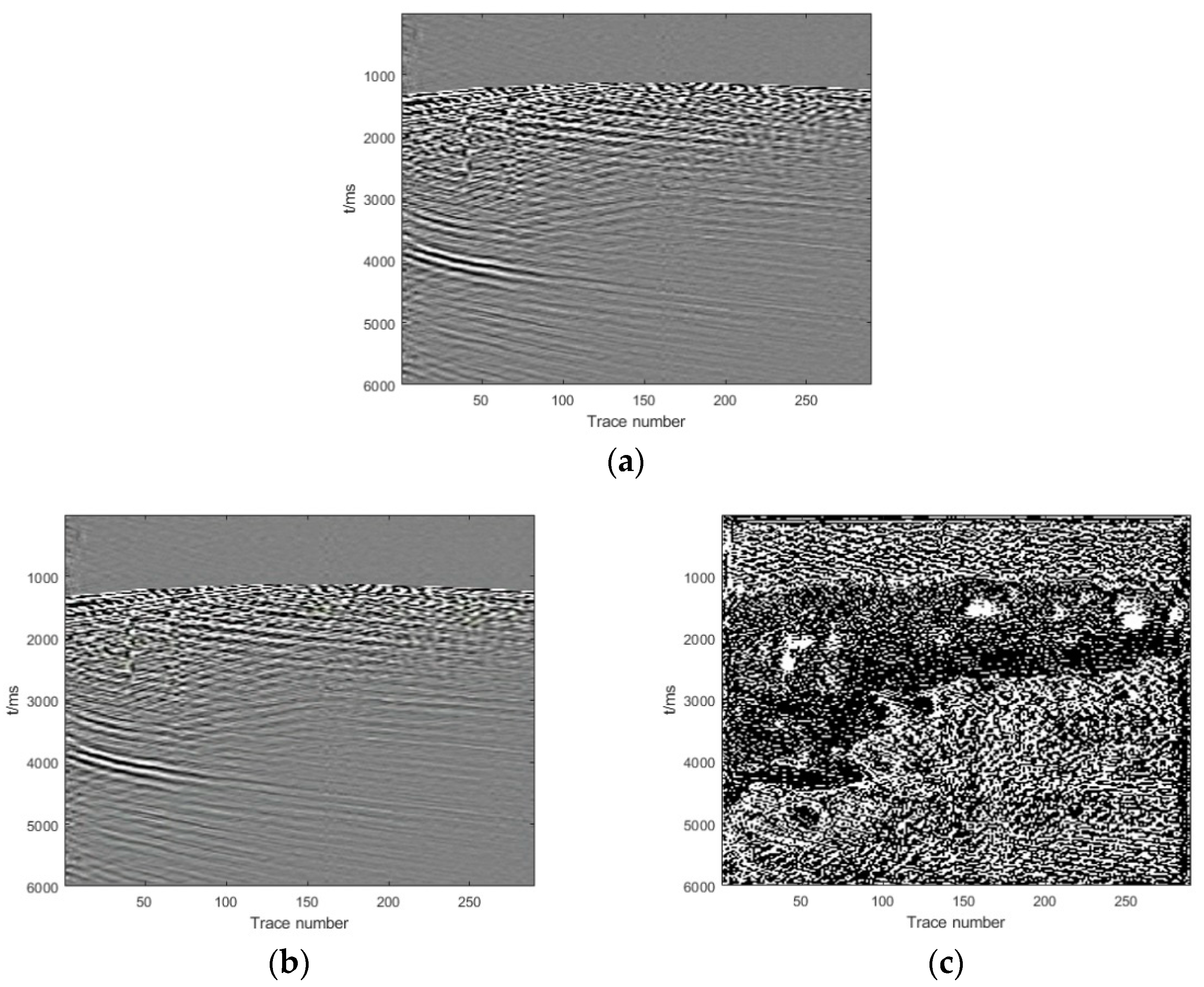
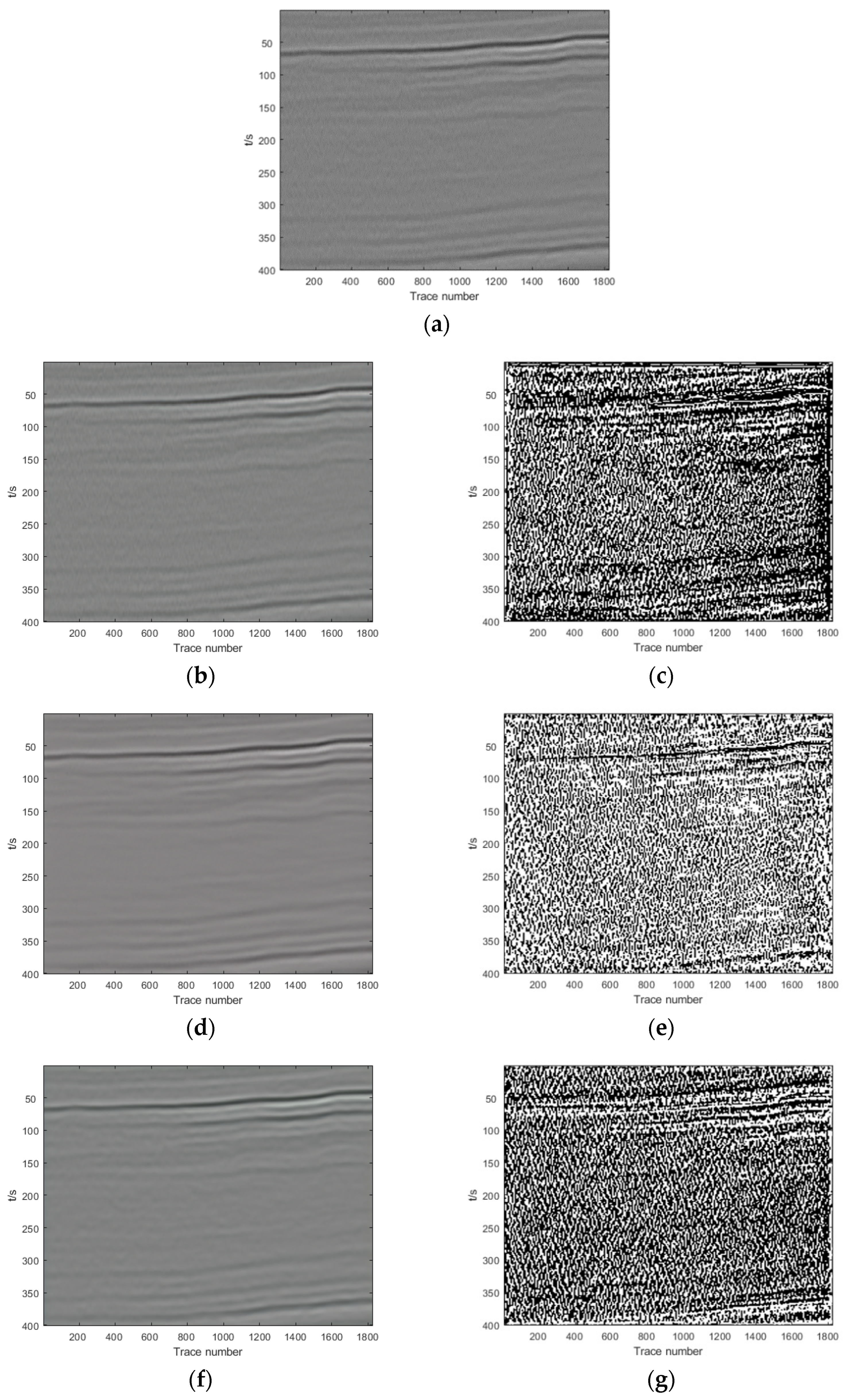
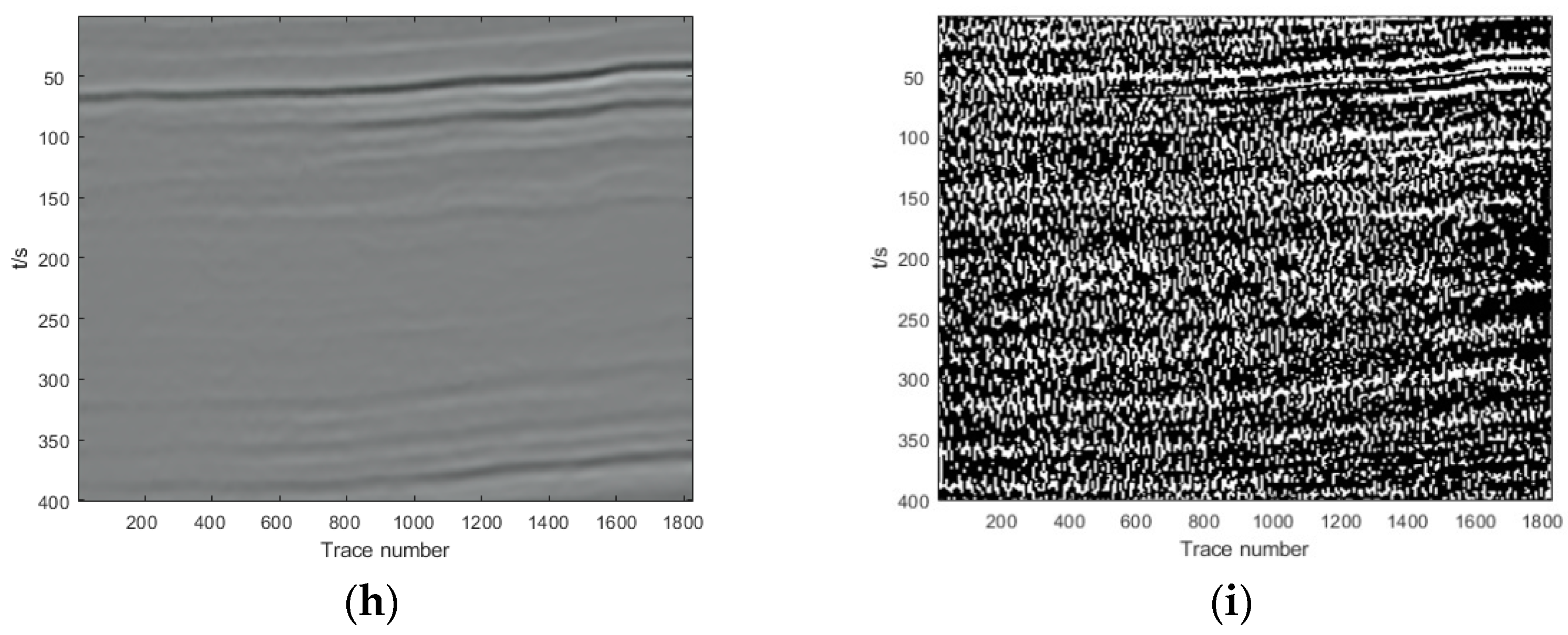
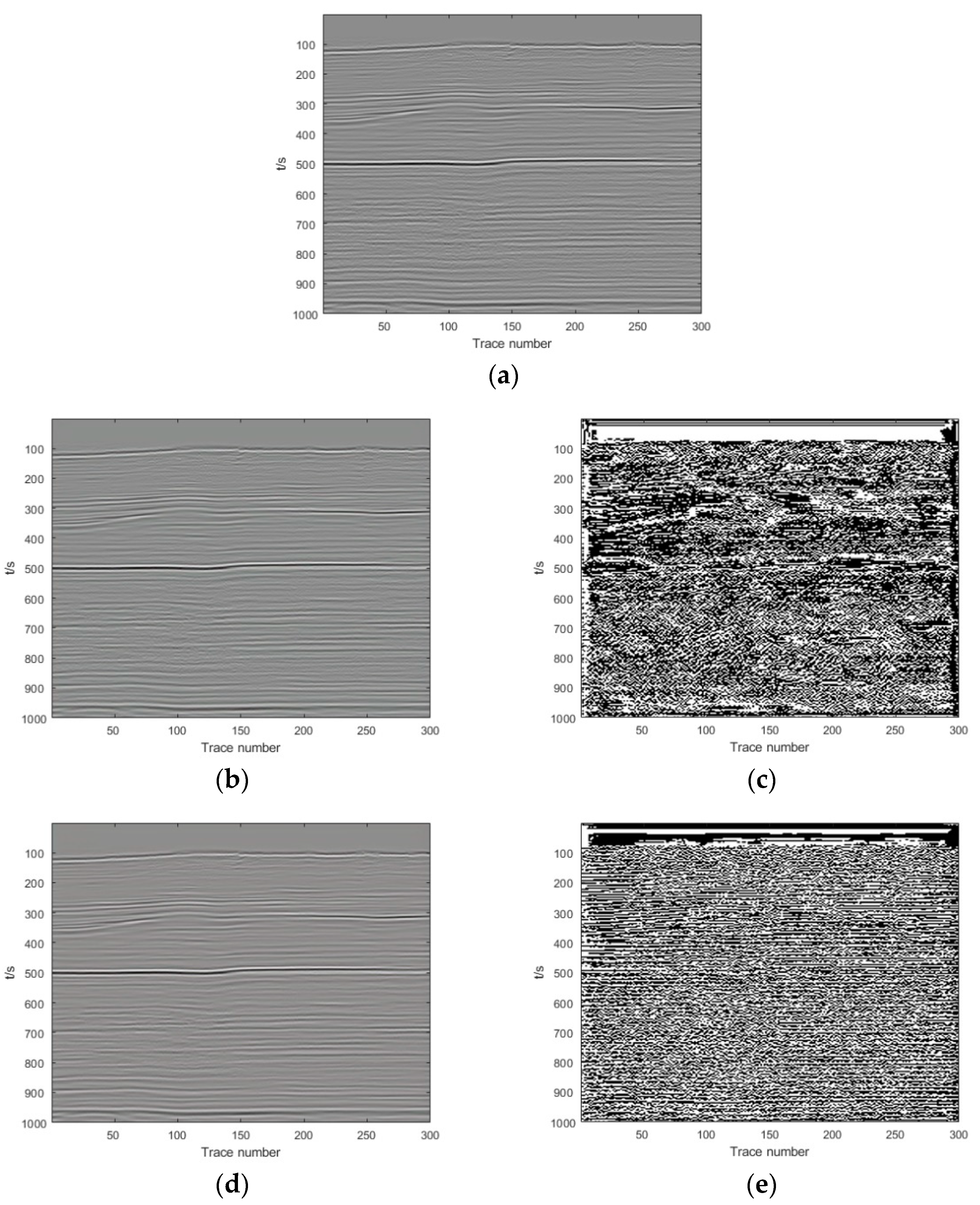
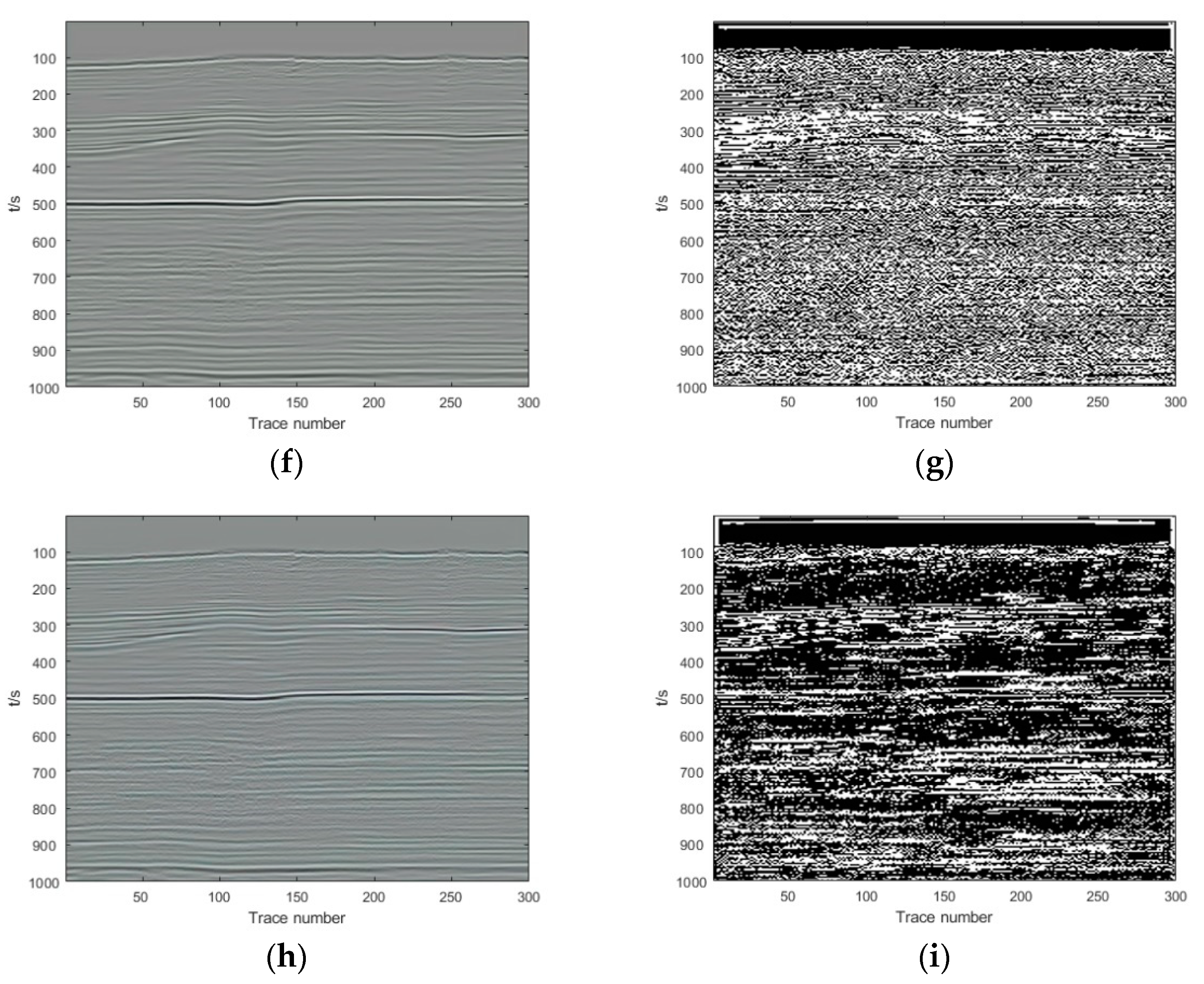
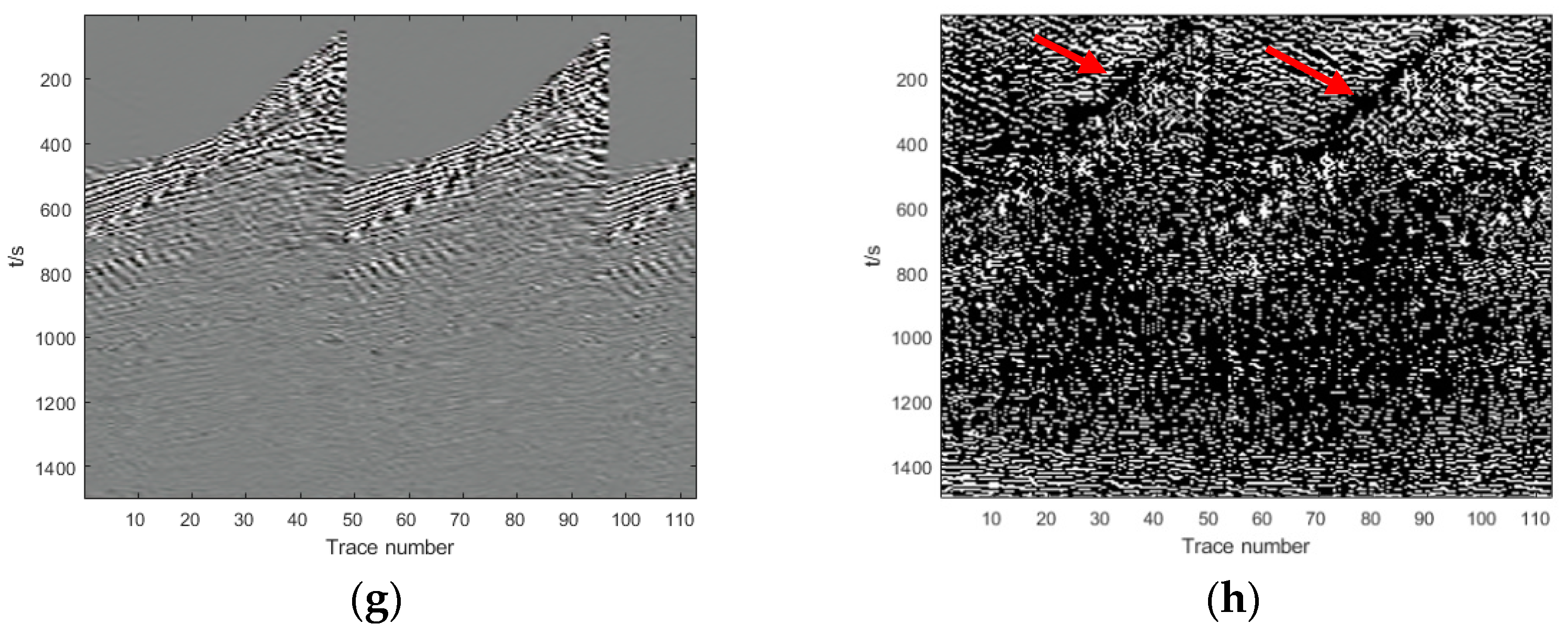
Section 3, we show and analyze the denoising results of four synthetic examples and six field examples comparing the denoising results with those obtained with DnCNN and U-net.
Section 4 discusses the need for transfer learning and the importance of reasonable selection of parameters. Finally, we present a conclusion of this paper in
Section 5.






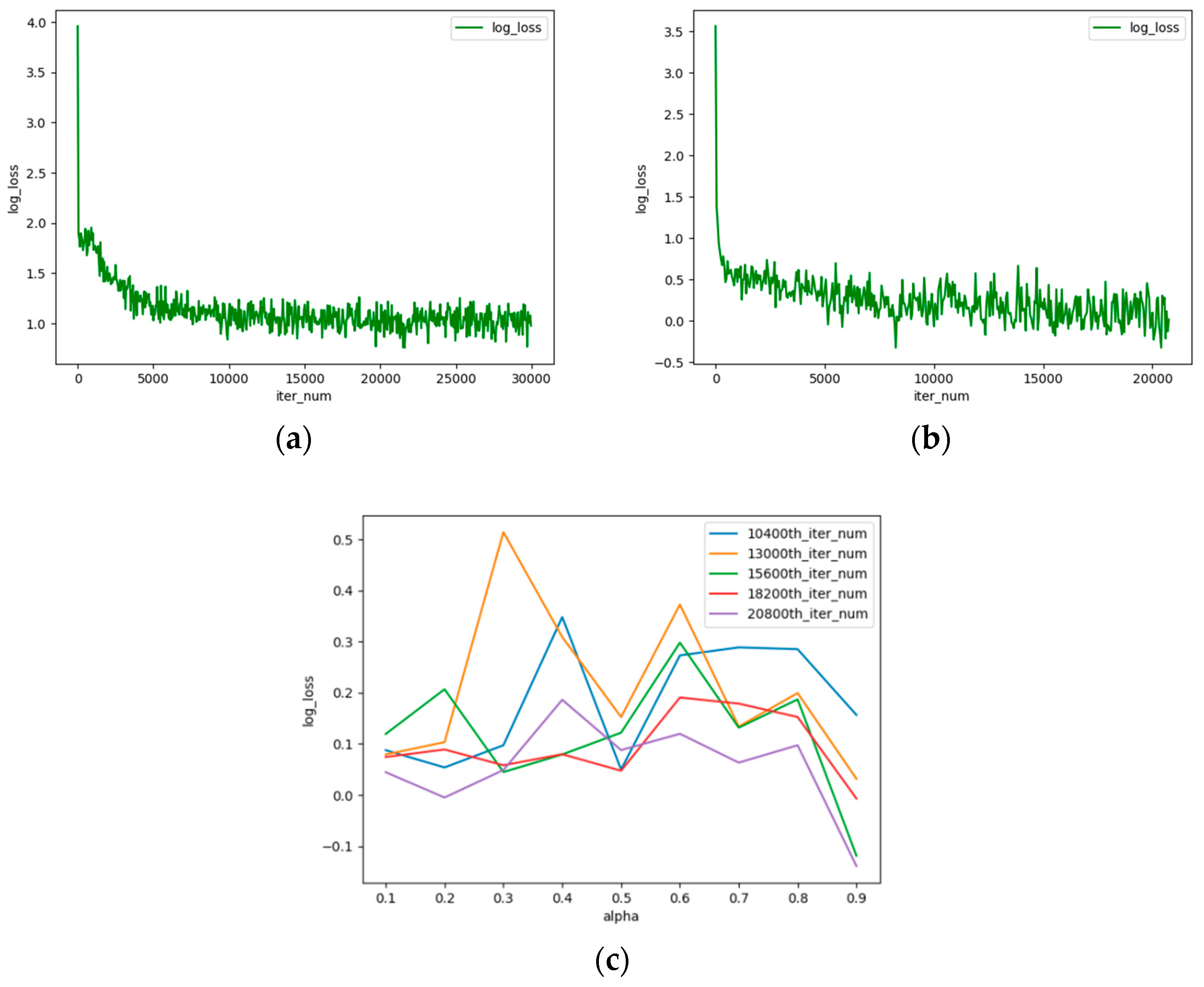
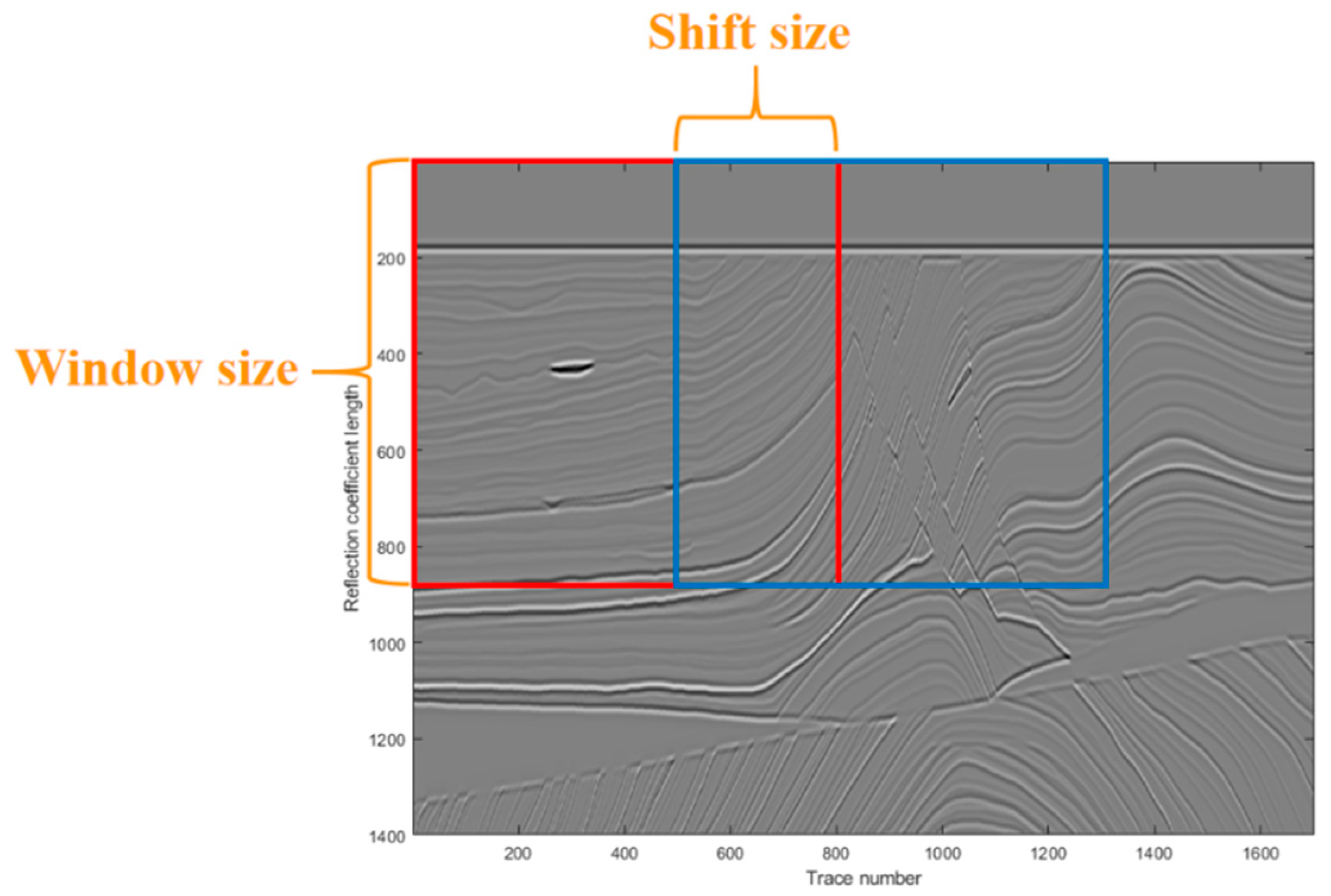

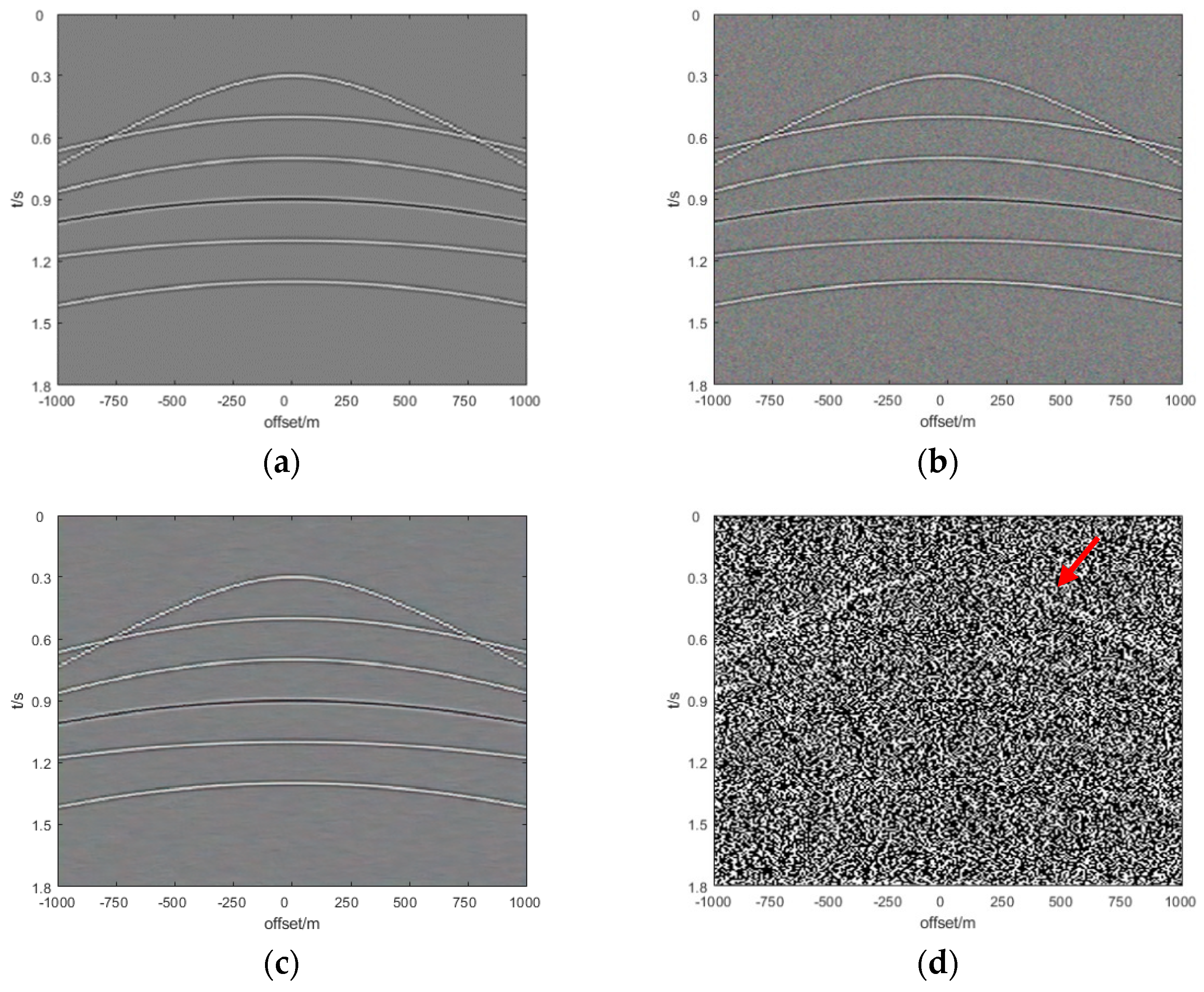
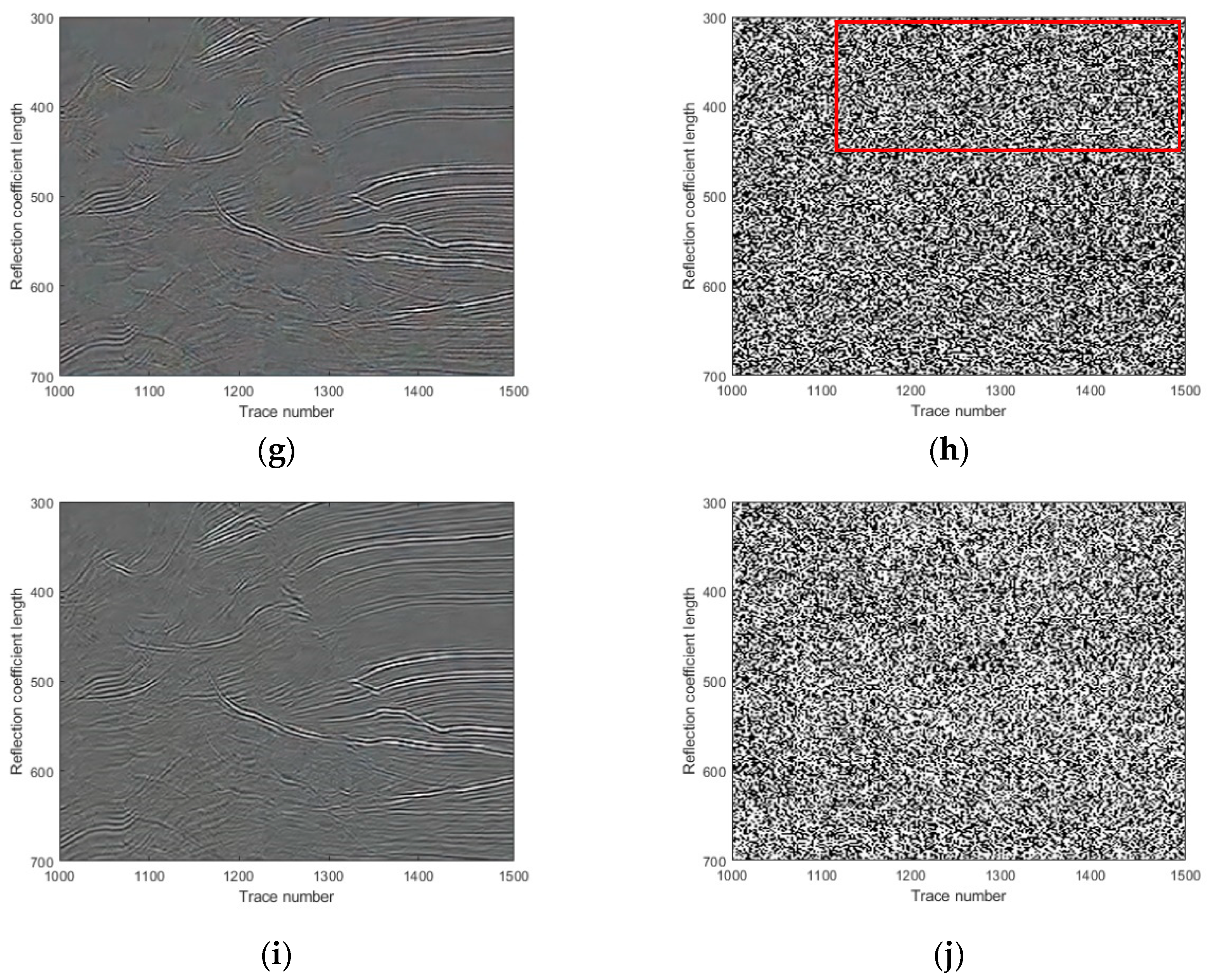

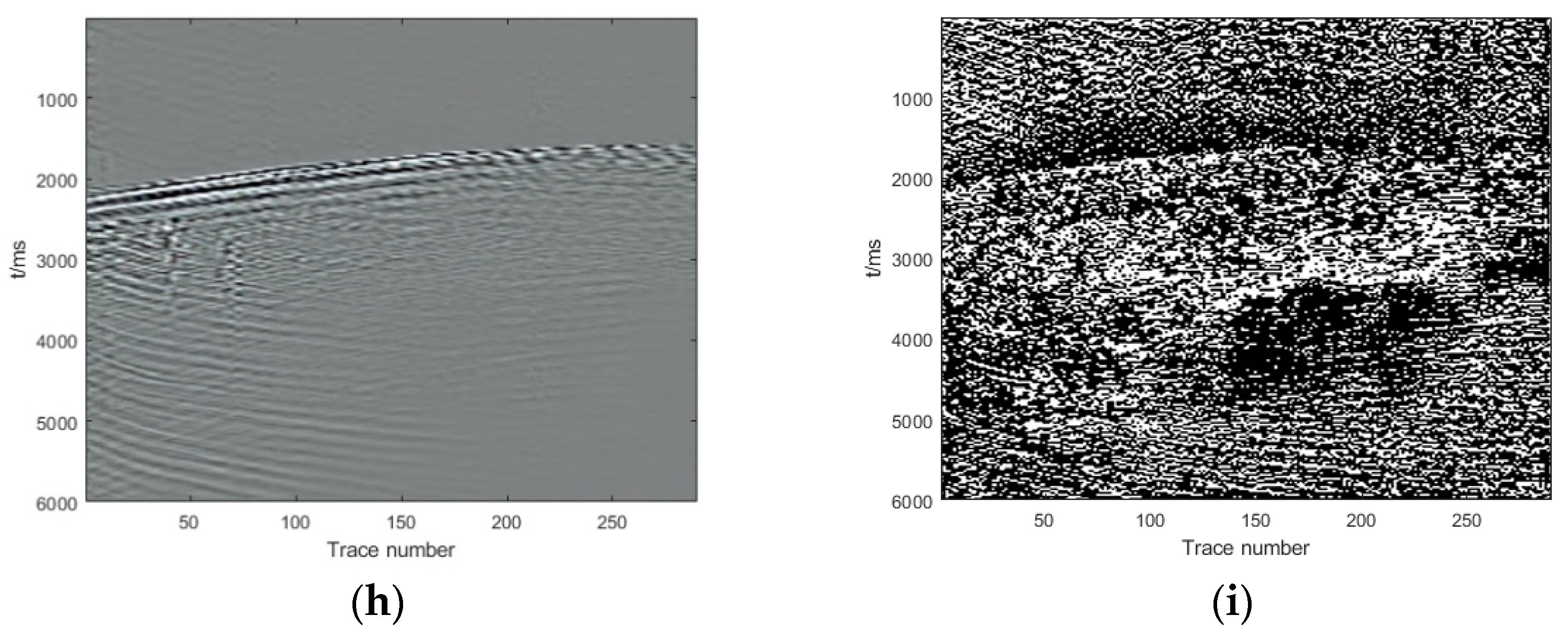


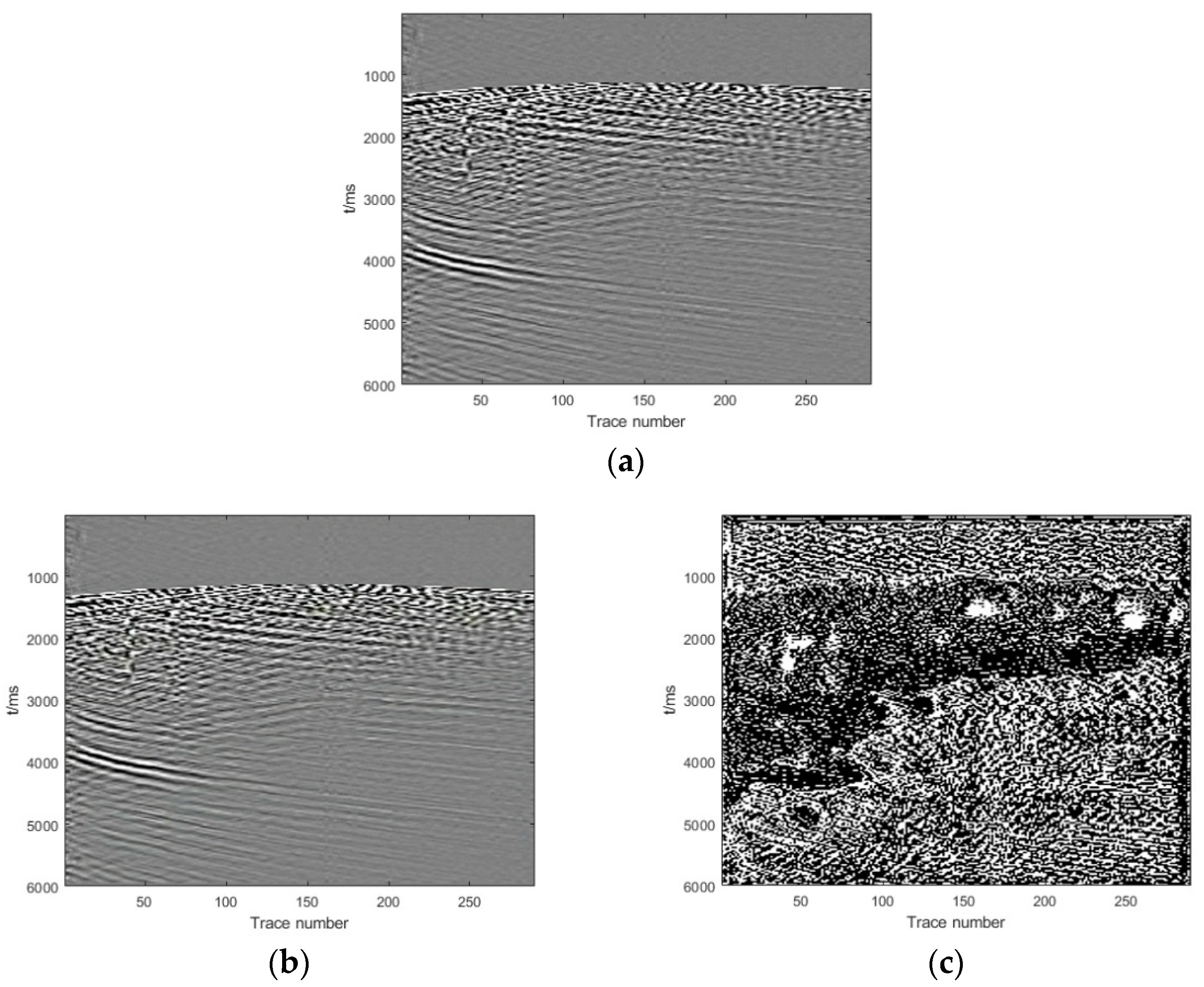

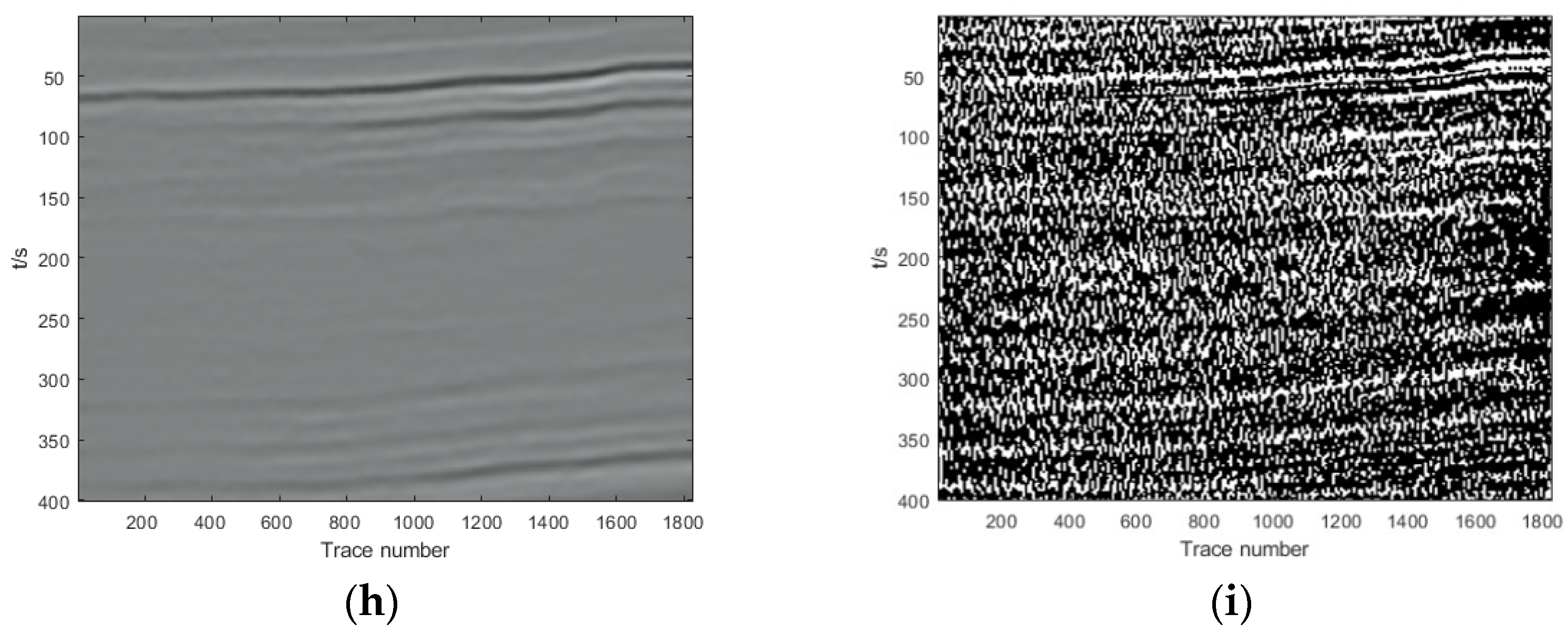

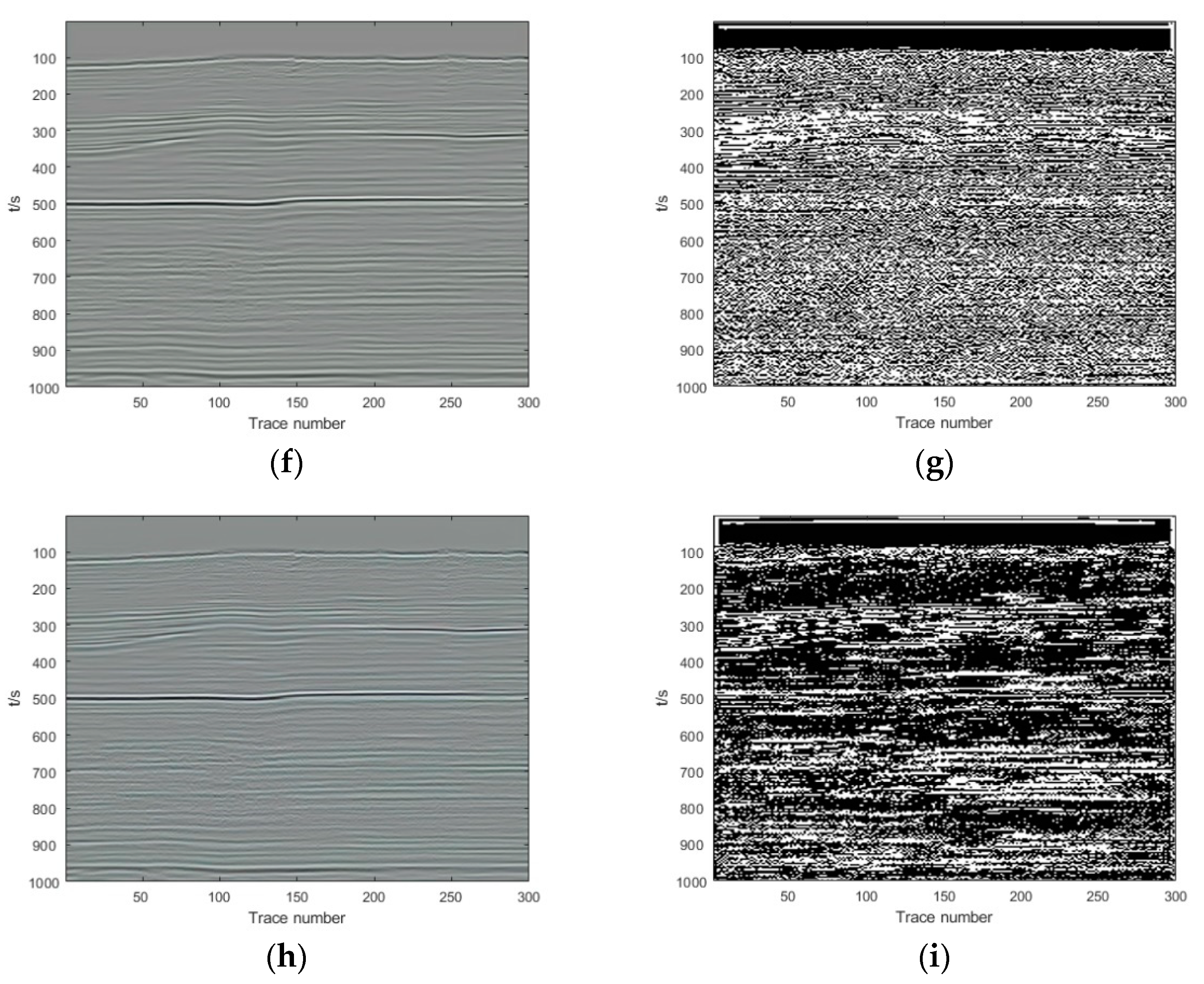


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}