

S2-PCM: Super-Resolution Structural Point Cloud Matching for High-Accuracy Video-SAR Image Registration



Abstract
:1. Introduction
- A super-resolution structural point cloud matching framework for inter-frame registration of video-SAR is first proposed by integrating FRSR-Net, SPCE-Net with RPM-Net, which can significantly improve the registration accuracy and stableness of SAR images.
- A feature recurrent super-resolution network for video-SAR image super-resolution is proposed by refining the low-level features with the high-level features through feature recurrence, which is able to achieve elaborate image reconstruction.
2. Review on Point Cloud Matching
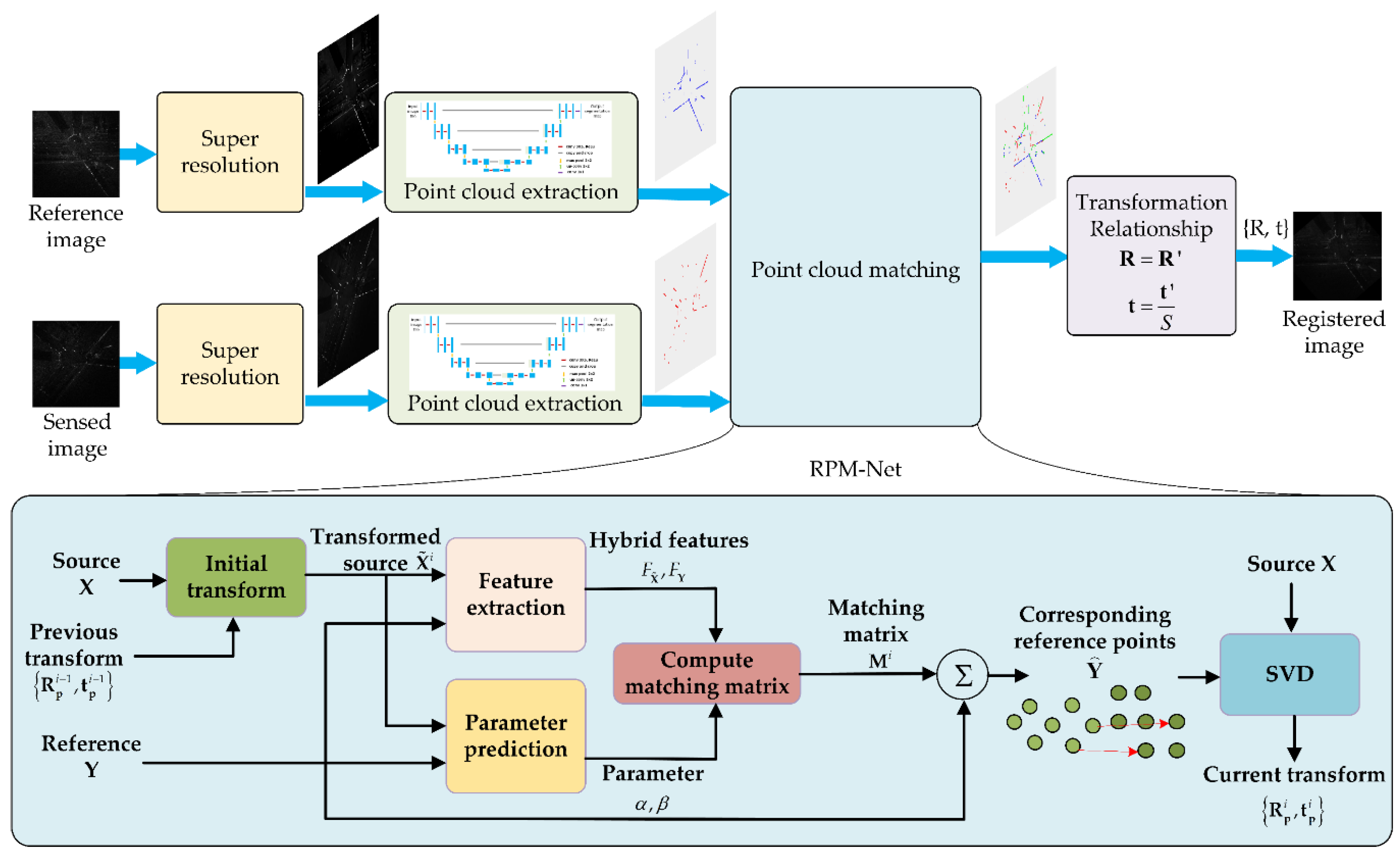
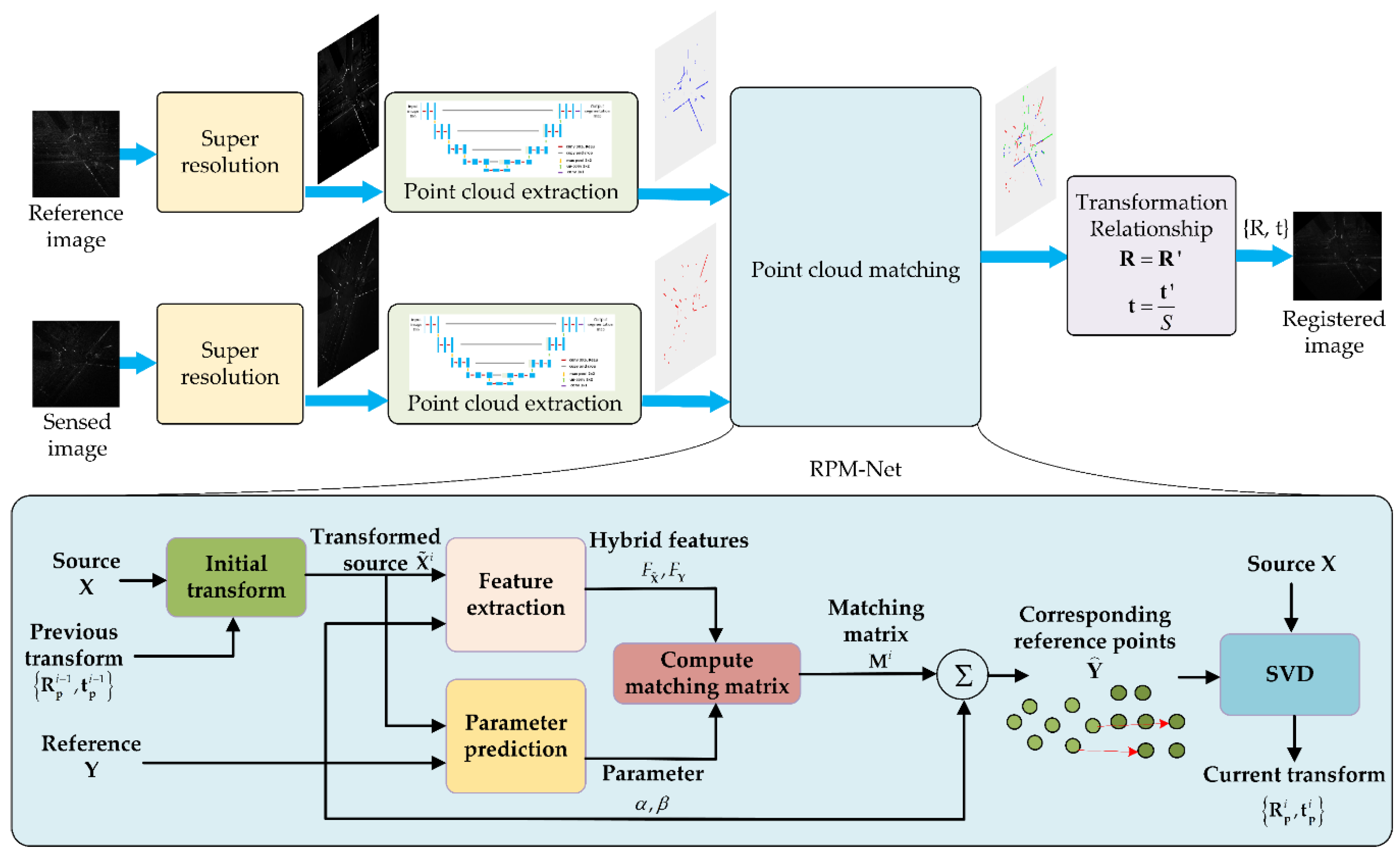
3. Super-Resolution Structural Point Cloud Matching Framework
3.1. Network Structure
3.2. Transformation Relationship
3.3. Training Strategy
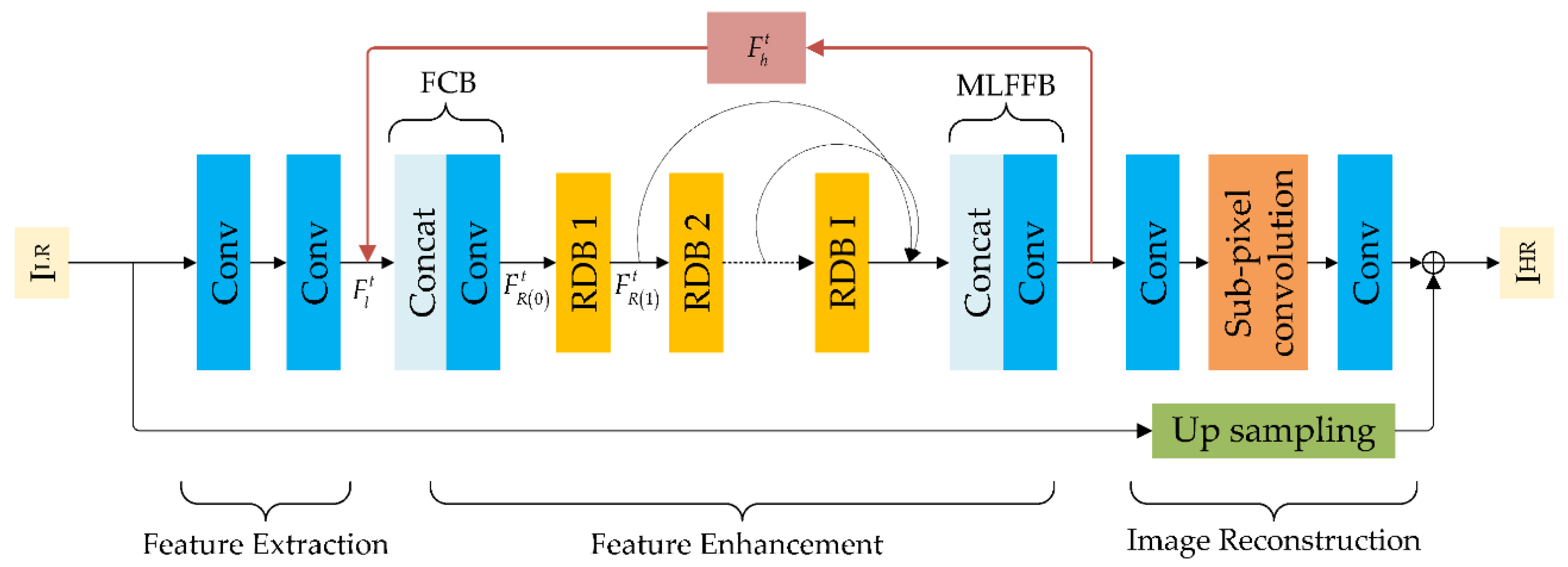
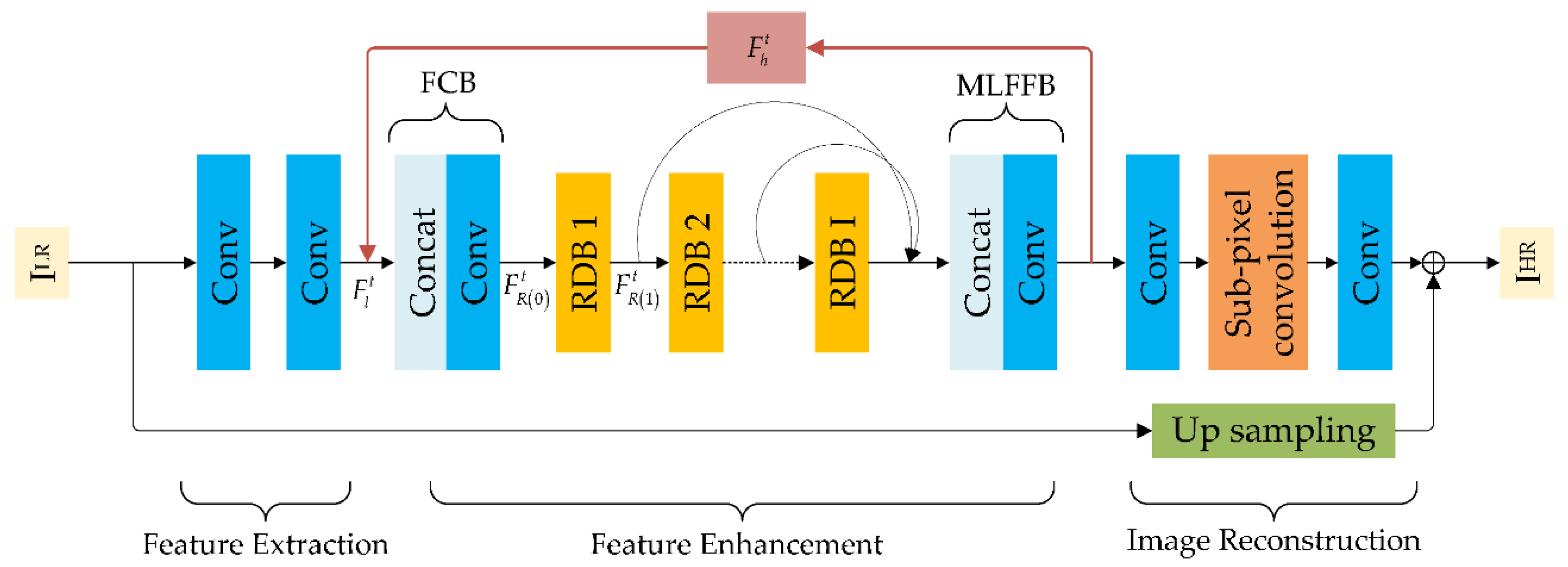
4. Feature Recurrence Super-Resolution Network
4.1. Super-Resolution Sub-Network via Feature Recurrence
4.2. Residual Dense Block
4.3. Sub-Pixel Convolution
5. Experiments and Results
5.1. Dataset and Setting
5.2. Evaluation Metrics
5.2.1. Super-Resolution Evaluation Metrics
5.2.2. Registration Evaluation Metrics
- Pearson correlation coefficient (PCC):
- 2.
- Mean squared differences (MSD):
- 3.
- Mutual information (MI):
- 4.
- Normalized mutual information (NMI):
- 5.
- Entropy correlation coefficient (ECC):
- 6.
- SSIM is given in Section 5.2.1.
5.3. Analysis of Super-Resolution Performance
5.4. Analysis of Registration Performance
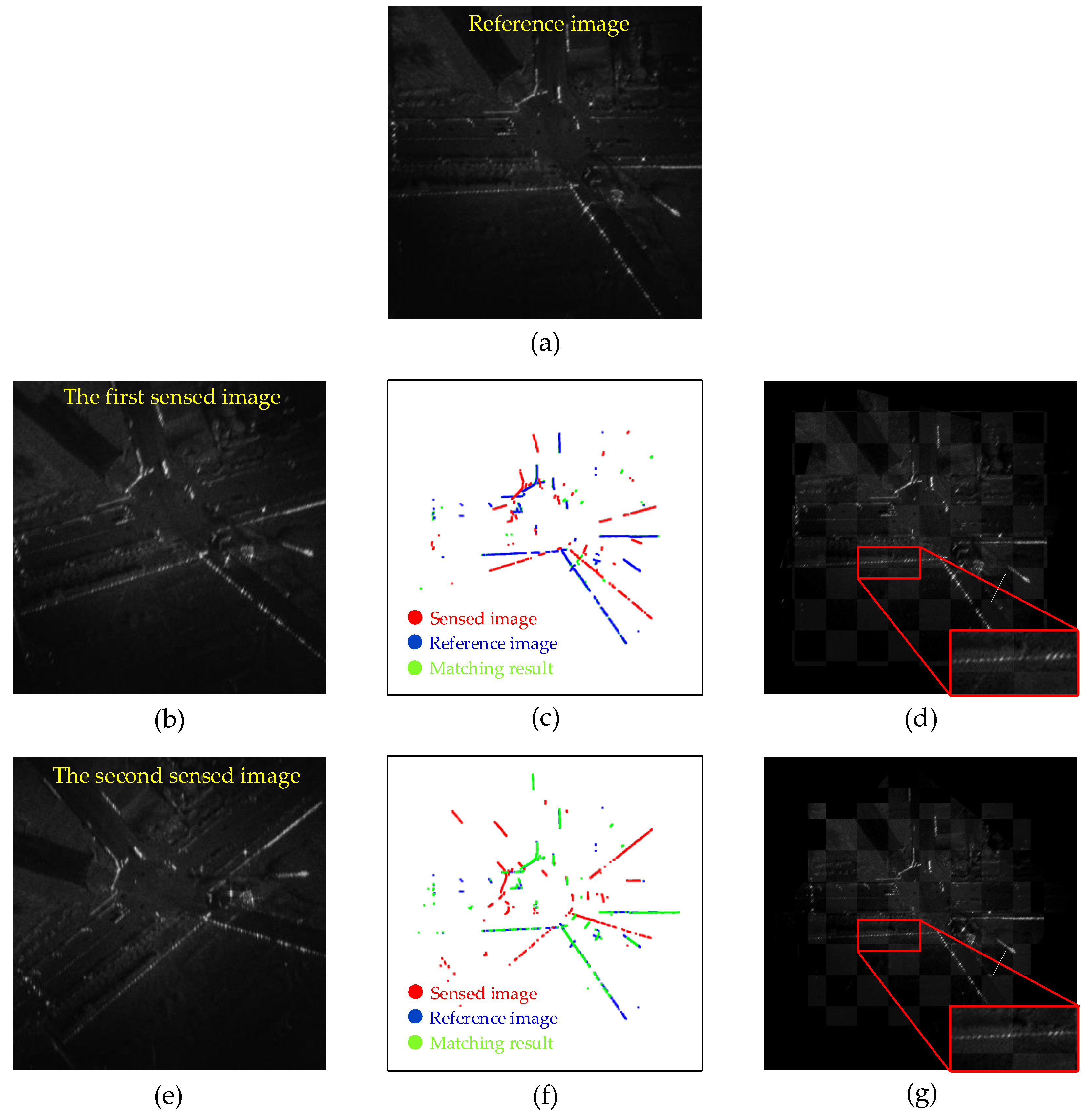
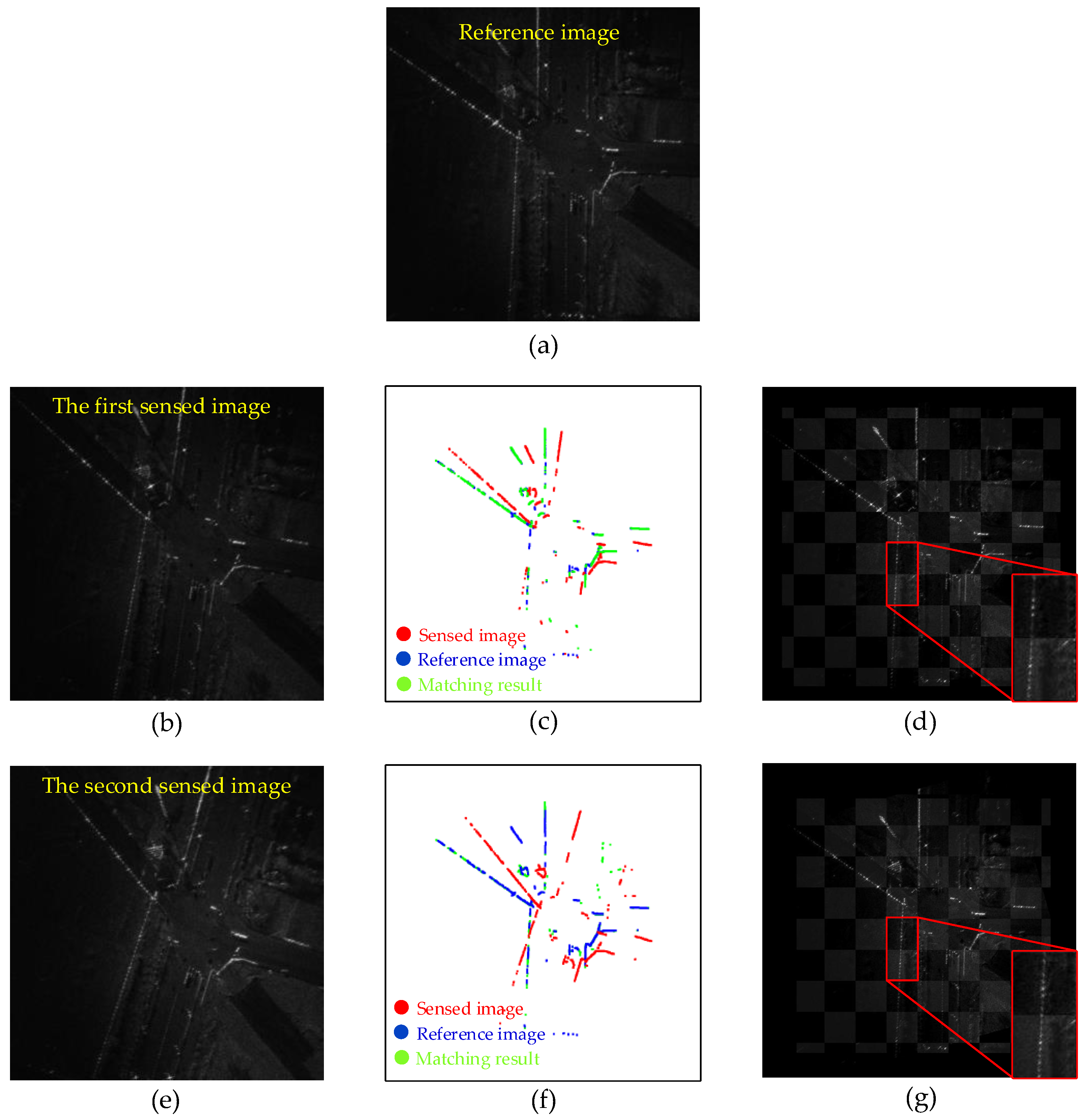
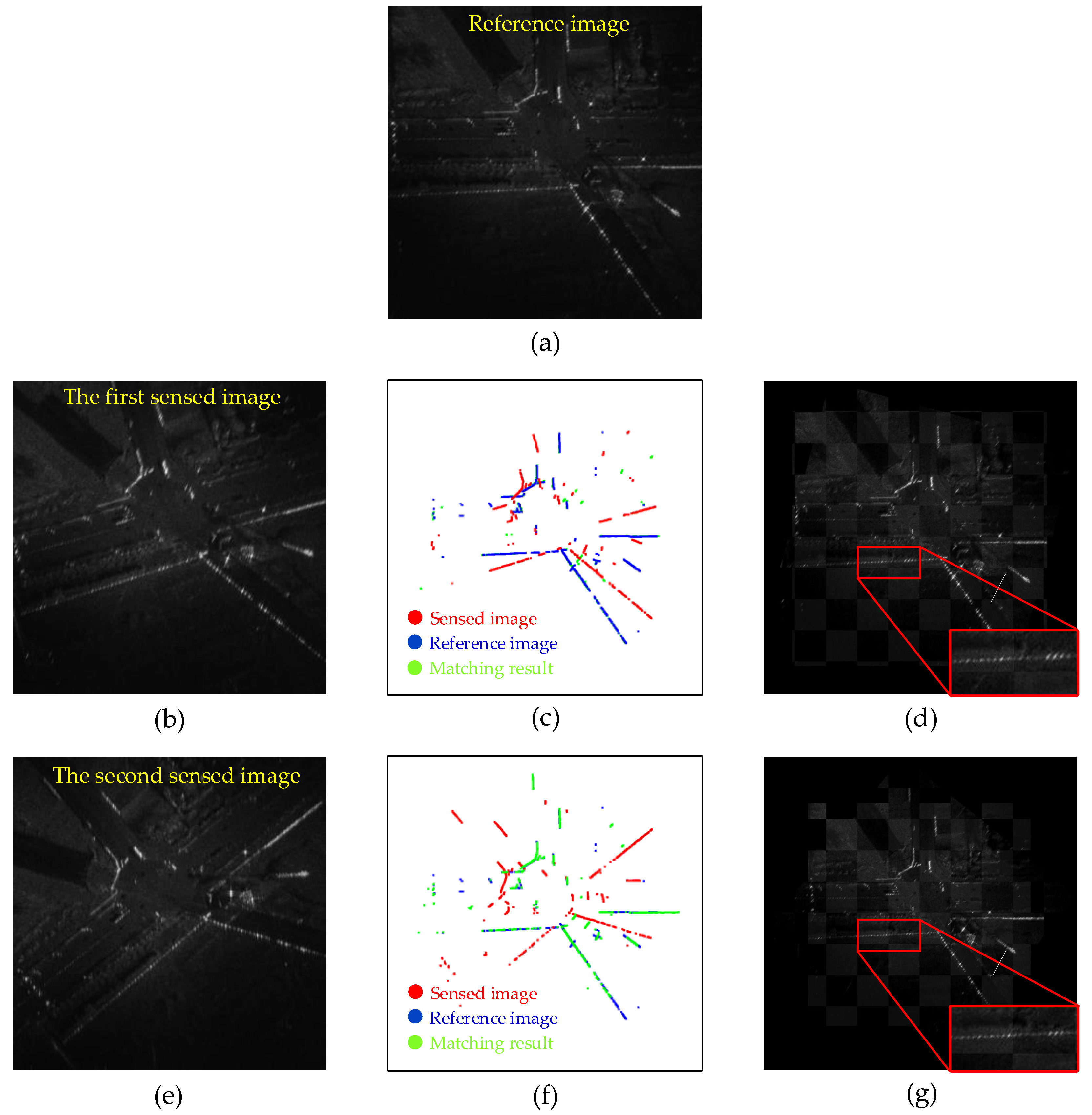
5.4.1. Registration Results of Simulation Dataset
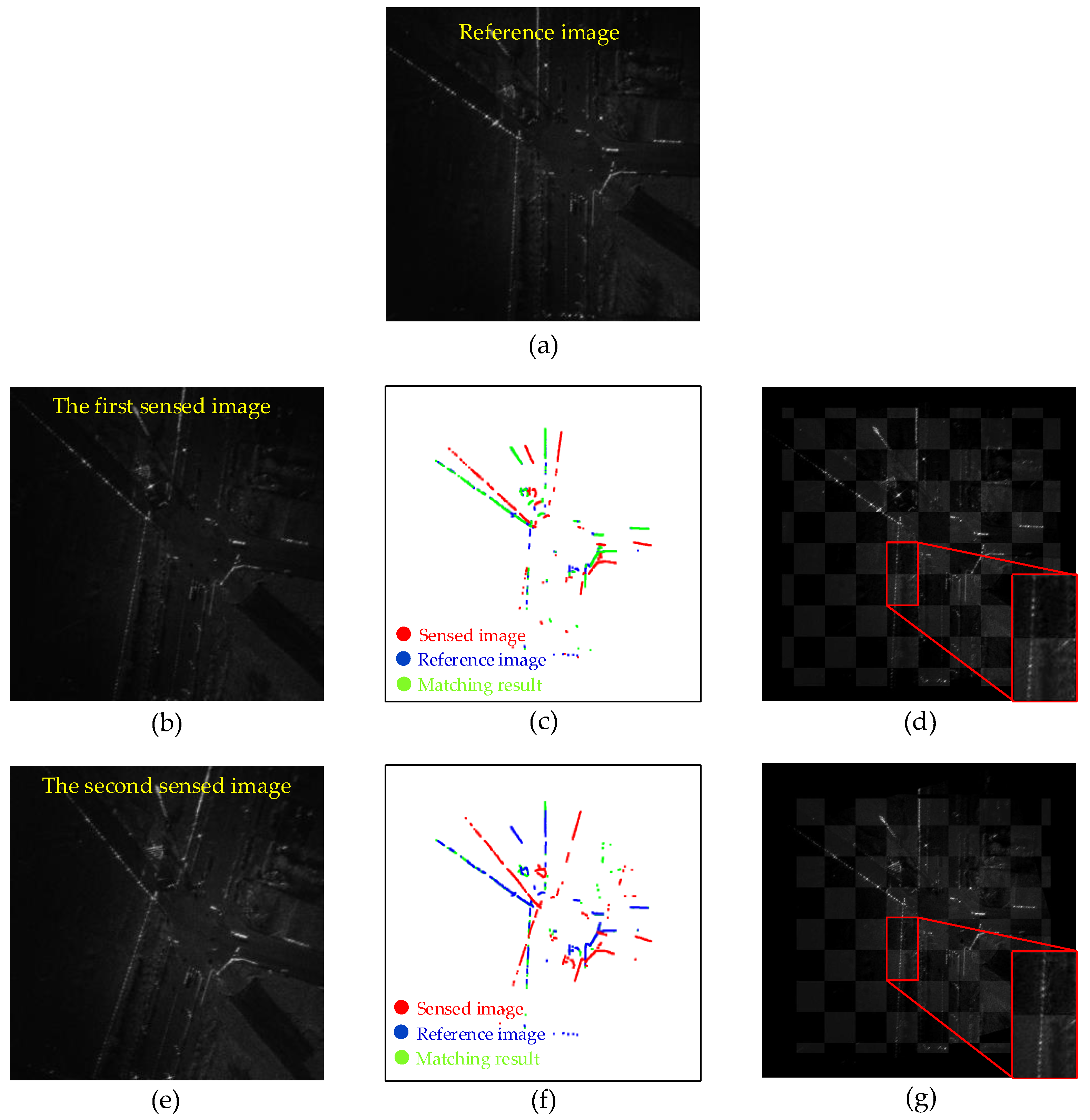
5.4.2. Registration Results of Real Datasets
5.5. Ablation Study
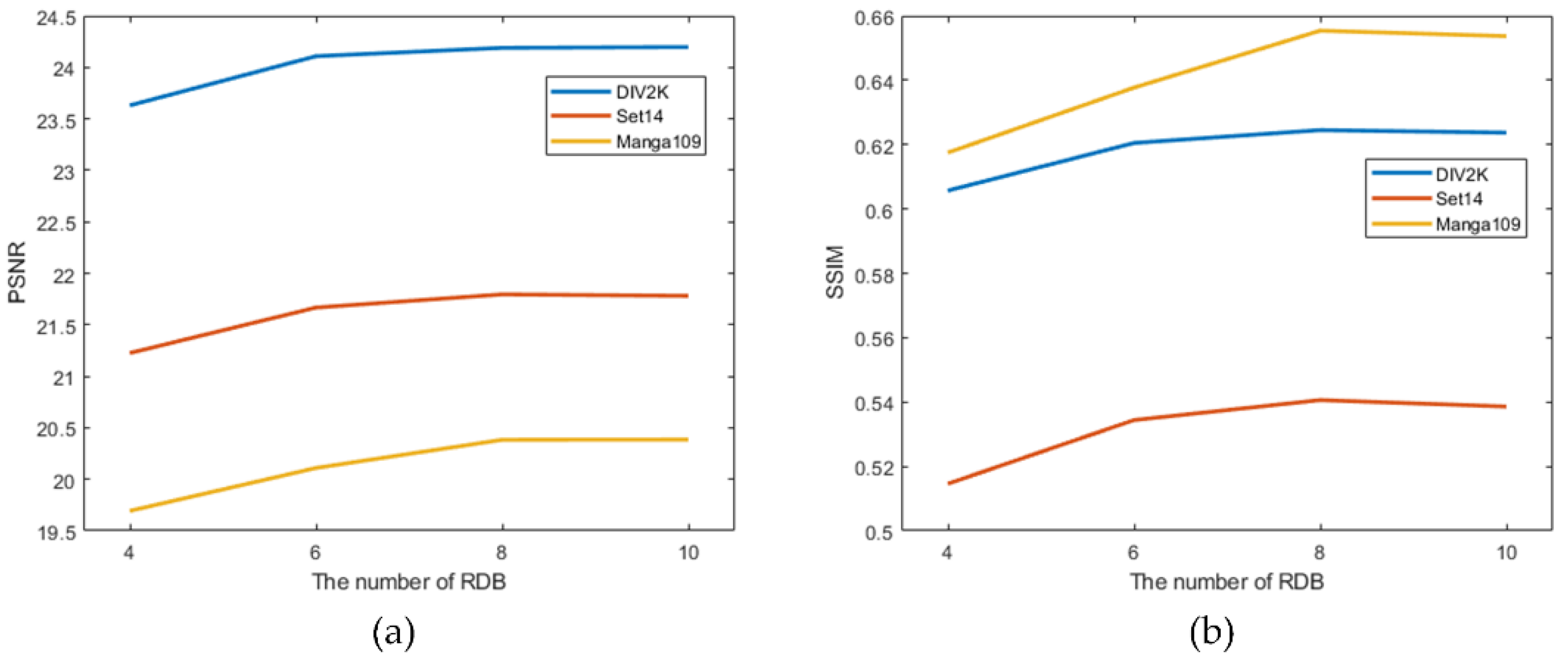
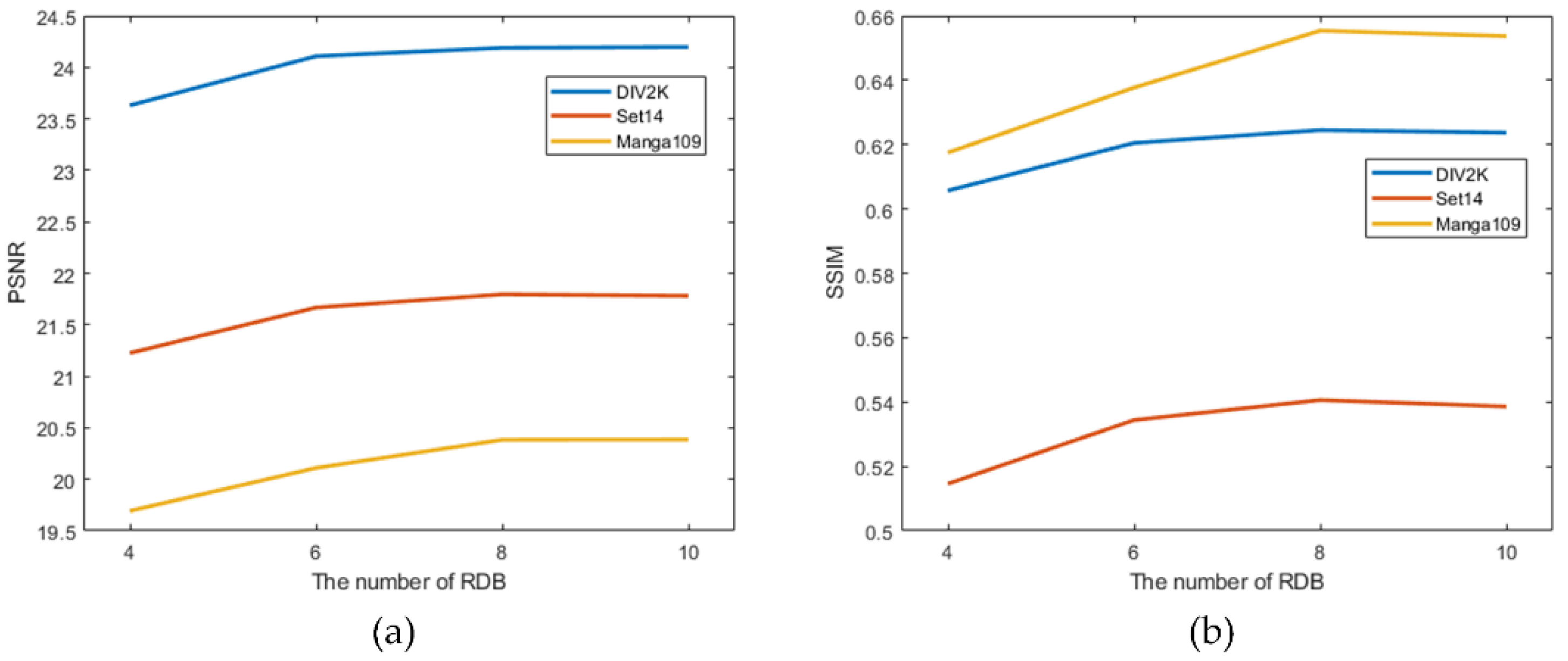
5.5.1. Super-Resolution Performance with Different Numbers of RDBs
5.5.2. Super-Resolution Registration Results with Different Scaling Factors
6. Conclusions
- Compared with the classical SIFT-like algorithms, S2-PCM has higher registration accuracy for video-SAR images under diverse evaluation metrics, such as MI, NMI, ECC, SSIM, etc.
- By integrating feature recurrence structure and RDB, the proposed FRSR-Net can significantly improve the quality of video-SAR images and point cloud extraction accuracy. Combining FRSR-Net with S2-PCM, we can obtain higher registration accuracy.
- Increasing the number of RDBs is beneficial in improving the super-resolution performance of FRSR-Net. Experimental results show that when the number of RDBs is eight, an excellent balance between network complexity and performance is achieved.
- The scaling factor has a significant effect on the results, and a reasonable super-resolution scale should be chosen. Too high a super-resolution scaling factor may lead to the unstable performance of FRSR-Net. Experimental results show that the highest registration accuracy can be obtained when the scaling factor is three.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Song, X.; Yu, W. Processing video-SAR data with the fast backprojection method. IEEE Trans. Aerosp. Electron. Syst. 2016, 52, 2838–2848. [Google Scholar] [CrossRef]
- Yang, X.; Shi, J.; Zhou, Y.; Wang, C.; Hu, Y.; Zhang, X.; Wei, S. Ground moving target tracking and refocusing using shadow in video-SAR. Remote Sens. 2020, 12, 3083. [Google Scholar] [CrossRef]
- Jun, S.; Long, M.; Xiaoling, Z. Streaming BP for non-linear motion compensation SAR imaging based on GPU. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 2035–2050. [Google Scholar] [CrossRef]
- Chen, F.; Lasaponara, R.; Masini, N. An overview of satellite synthetic aperture radar remote sensing in archaeology: From site detection to monitoring. J. Cult. Herit. 2017, 23, 5–11. [Google Scholar] [CrossRef]
- Zhou, Y.; Shi, J.; Wang, C.; Hu, Y.; Zhou, Z.; Yang, X.; Wei, S. SAR Ground Moving Target Refocusing by Combining mRe³ Network and TVβ-LSTM. IEEE Trans. Geosci. Remote Sens. 2020, 60, 1–14. [Google Scholar]
- Yang, X.; Shi, J.; Chen, T.; Hu, Y.; Zhou, Y.; Zhang, X.; Wu, J. Fast Multi-Shadow Tracking for Video-SAR Using Triplet Attention Mechanism. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Ding, J.; Wen, L.; Zhong, C.; Loffeld, O. Video SAR moving target indication using deep neural network. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7194–7204. [Google Scholar] [CrossRef]
- Rui, J.; Wang, C.; Zhang, H.; Jin, F. Multi-Sensor SAR Image Registration Based on Object Shape. Remote Sens. 2016, 8, 923. [Google Scholar] [CrossRef]
- Cui, S.; Xu, M.; Ma, A.; Zhong, Y. Modality-free feature detector and descriptor for multimodal remote sensing image registration. Remote Sens. 2020, 12, 2937. [Google Scholar] [CrossRef]
- Fan, J.; Wu, Y.; Wang, F.; Zhang, P.; Li, M. New point matching algorithm using sparse representation of image patch feature for SAR image registration. IEEE Trans. Geosci. Remote Sens. 2016, 55, 1498–1510. [Google Scholar] [CrossRef]
- Xing, C.; Qiu, P. Intensity-based image registration by nonparametric local smoothing. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2081–2092. [Google Scholar] [CrossRef]
- Sarvaiya, J.N.; Patnaik, S.; Bombaywala, S. Image Registration by Template Matching Using Normalized Cross-Correlation. In Proceedings of the 2009 International Conference on Advances in Computing, Control, and Telecommunication Technologies, Bangalore, India, 28–29 December 2009; pp. 819–822. [Google Scholar]
- Mahmood, A.; Khan, S. Correlation-coefficient-based fast template matching through partial elimination. IEEE Trans. Image process. 2011, 21, 2099–2108. [Google Scholar] [CrossRef]
- Kern, J.P.; Pattichis, M.S. Robust multispectral image registration using mutual-information models. IEEE Trans. Geosci. Remote Sens. 2007, 45, 1494–1505. [Google Scholar] [CrossRef]
- Suri, S.; Reinartz, P. Mutual-information-based registration of TerraSAR-X and Ikonos imagery in urban areas. IEEE Trans. Geosci. Remote Sens. 2009, 48, 939–949. [Google Scholar] [CrossRef]
- Thévenaz, P.; Unser, M. Optimization of mutual information for multiresolution image registration. IEEE Trans. Image Process. 2000, 9, 2083–2099. [Google Scholar] [PubMed]
- Lowe, D. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 20, 91–110. [Google Scholar] [CrossRef]
- Ke, Y.; Sukthankar, R.; Society, I.C. PCA-SIFT: A More Distinctive Representation for Local Image Descriptors. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2004), Washington, DC, USA, 27 June–2 July 2004; pp. 506–513. [Google Scholar]
- Dellinger, F.; Delon, J.; Gousseau, Y.; Michel, J.; Tupin, F. Sar-sift: A sift-like algorithm for sar images. IEEE Trans. Geosci. Remote Sens. 2013, 53, 453–466. [Google Scholar] [CrossRef]
- Xiang, Y.; Wang, F.; Wan, L.; You, H. An Advanced Rotation Invariant Descriptor for SAR Image Registration. Remote Sens. 2017, 9, 686. [Google Scholar] [CrossRef]
- Fan, B.; Wu, F.; Hu, Z. Aggregating gradient distributions into intensity orders: A novel local image descriptor. In Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; pp. 2377–2384. [Google Scholar]
- Wang, S.; Quan, D.; Liang, X.; Ning, M.; Guo, Y.; Jiao, L. A deep learning framework for remote sensing image registration. ISPRS J. Photogramm. Remote Sens. 2018, 145, 148–164. [Google Scholar] [CrossRef]
- Han, X.; Leung, T.; Jia, Y.; Sukthankar, R.; Berg, A.C. Matchnet: Unifying feature and metric learning for patch-based matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3279–3286. [Google Scholar]
- Mao, S.; Yang, J.; Gou, S.; Jiao, L.; Xiong, T.; Xiong, L. Multi-Scale Fused SAR Image Registration Based on Deep Forest. Remote Sens. 2021, 13, 2227. [Google Scholar] [CrossRef]
- Besl, P.J.; McKay, N.D. Method for registration of 3-D shapes. In Sensor Fusion IV: Control Paradigms and Data Structures; SPIE: Bellingham, WA, USA, 1992; pp. 586–606. [Google Scholar]
- Yang, J.; Li, H.; Campbell, D.; Jia, Y. Go-ICP: A globally optimal solution to 3D ICP point-set registration. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 2241–2254. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Solomon, J.M. Deep closest point: Learning representations for point cloud registration. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 3523–3532. [Google Scholar]
- Aoki, Y.; Goforth, H.; Srivatsan, R.A.; Lucey, S. Pointnetlk: Robust & efficient point cloud registration using pointnet. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2019; pp. 7163–7172. [Google Scholar]
- Sarode, V.; Li, X.; Goforth, H.; Aoki, Y.; Srivatsan, R.A.; Lucey, S.; Choset, H. Pcrnet: Point cloud registration network using pointnet encoding. arXiv 2019, arXiv:1908.07906. [Google Scholar]
- Yew, Z.J.; Lee, G.H. Rpm-net: Robust point matching using learned features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11824–11833. [Google Scholar]
- Gold, S.; Rangarajan, A.; Lu, C.P.; Pappu, S.; Mjolsness, E. New algorithms for 2D and 3D point matching: Pose estimation and correspondence. Pattern Recognit. 1998, 31, 1019–1031. [Google Scholar] [CrossRef]
- Sinkhorn, R. A relationship between arbitrary positive matrices and doubly stochastic matrices. Ann. Math. Stat. 1964, 35, 876–879. [Google Scholar] [CrossRef]
- Kirkpatrick, S.; Gelatt, C.D., Jr.; Vecchi, M.P. Optimization by simulated annealing. Science 1983, 220, 671–680. [Google Scholar] [CrossRef]
- Papadopoulo, T.; Lourakis, M.I. Estimating the jacobian of the singular value decomposition: Theory and applications. In European Conference on Computer Vision; Springer: Berlin, Heidelberg, 2000; pp. 554–570. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the super-resolution convolutional neural network. In Lecture Notes in Computer Science, Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 391–407. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1874–1883. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1646–1654. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 June 2017; pp. 136–144. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2472–2481. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Slabaugh, G.G. Computing Euler angles from a rotation matrix. Retrieved August 1999, 6, 39–63. [Google Scholar]
- De Boor, C. Bicubic spline interpolation. J. Math. Phys. 1962, 41, 212–218. [Google Scholar] [CrossRef]
- Shamir, R.R.; Duchin, Y.; Kim, J.; Sapiro, G.; Harel, N. Continuous dice coefficient: A method for evaluating probabilistic segmentations. arXiv 2019, arXiv:1906.11031. [Google Scholar]
- Goodman, J.W. Statistical properties of laser speckle patterns. In Laser Speckle and Related Phenomena; Springer: Berlin/Heidelberg, Germany, 1975; pp. 9–75. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Penney, G.P.; Weese, J.; Little, J.A.; Desmedt, P.; Hill, D.L. A comparison of similarity measures for use in 2-D-3-D medical image registration. IEEE Trans. Med. Imaging 1998, 17, 586–595. [Google Scholar] [CrossRef] [PubMed]
- Razlighi, Q.R.; Kehtarnavaz, N.; Yousefi, S. Evaluating similarity measures for brain image registration. J. Vis. Commun. Image Represent. 2013, 24, 977–987. [Google Scholar] [CrossRef] [PubMed]
- Ma, W.; Wen, Z.; Wu, Y.; Jiao, L.; Gong, M.; Zheng, Y. Remote sensing image registration with modified sift and enhanced feature matching. IEEE Geosci. Remote Sens. Lett. 2016, 14, 3–7. [Google Scholar] [CrossRef]
- Wu, Y.; Ma, W.; Gong, M.; Su, L.; Jiao, L. A novel point-matching algorithm based on fast sample consensus for image registration. IEEE Geosci. Remote Sens. Lett. 2015, 12, 43–47. [Google Scholar] [CrossRef]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]

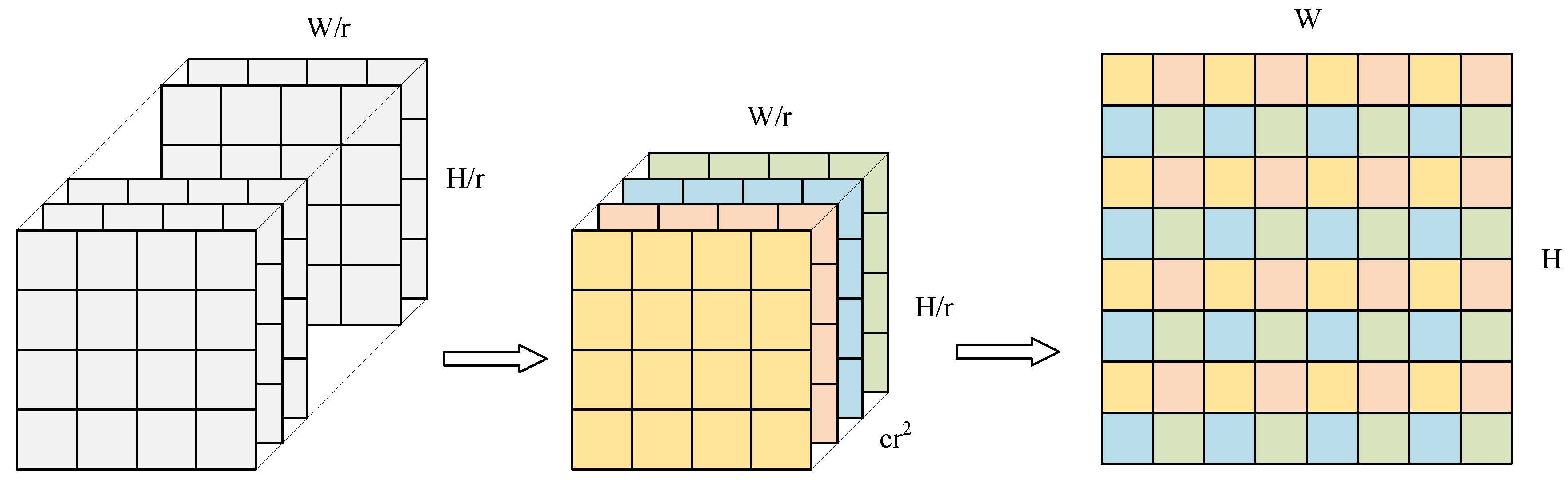



{kind=link}
{kind=link}
{kind=link}
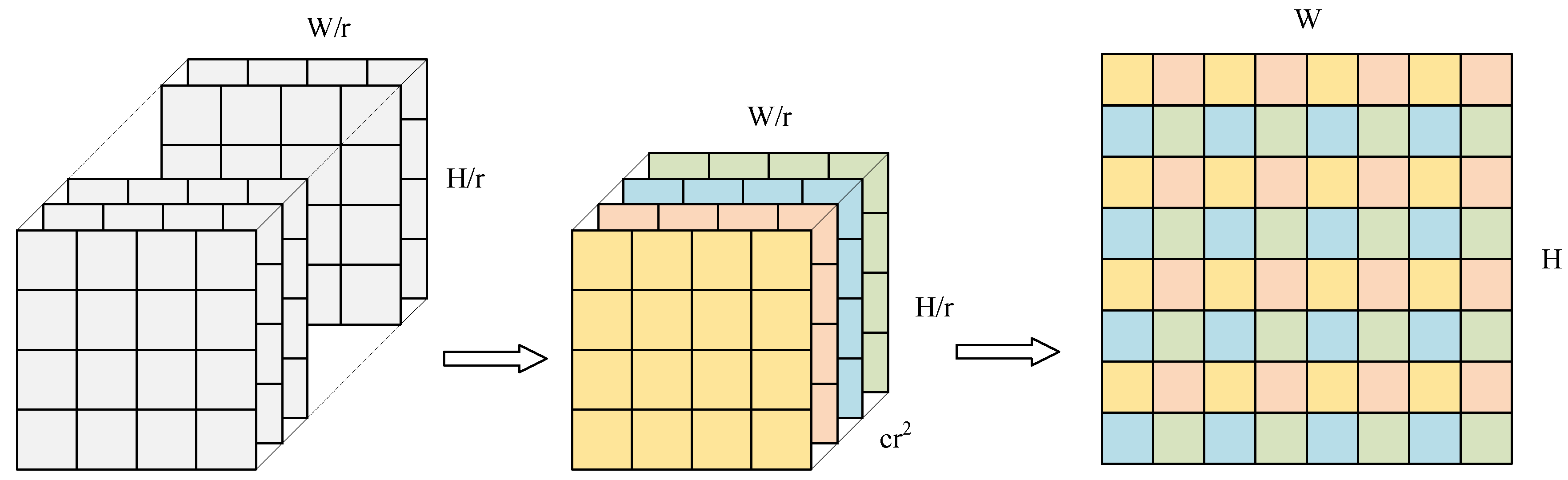{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Scaling Factor | Bicubic | RDN | FRSR-Net |
|---|---|---|---|---|
| Set14 | 2 | 16.8536/0.1850 | 23.1123/0.5920 | 23.3392/0.6015 |
| 3 | 16.3669/0.1696 | 21.5473/0.5301 | 21.7953/0.5406 | |
| 4 | 16.0525/0.1734 | 20.4009/0.4907 | 20.6160/0.4986 | |
| Manga109 | 2 | 15.2934/0.1592 | 21.8103/0.7003 | 22.3246/0.7189 |
| 3 | 14.7603/0.1473 | 20.0737/0.6393 | 20.3832/0.6554 | |
| 4 | 14.4211/0.1583 | 18.9417/0.6042 | 19.1847/0.6156 | |
| DIV2K | 2 | 17.3878/0.1789 | 25.2677/0.6623 | 25.5155/0.6679 |
| 3 | 17.0843/0.1766 | 23.9786/0.6190 | 24.1894/0.6245 | |
| 4 | 16.9035/0.1918 | 23.0580/0.5954 | 23.2885/0.6007 |
| MI | NMI | ECC | MSD | PCC | SSIM | |
|---|---|---|---|---|---|---|
| SIFT | 4.0214 | 1.5011 | 0.8167 | 758.6585 | 0.5180 | 0.2684 |
| SAR-SIFT | 4.2285 | 1.5053 | 0.8192 | 622.5073 | 0.5566 | 0.2867 |
| PSO-SIFT | 4.2582 | 1.5031 | 0.8179 | 616.7051 | 0.5426 | 0.2929 |
| Proposed | 4.2764 | 1.5058 | 0.8196 | 551.6772 | 0.5921 | 0.2702 |
| MI | NMI | ECC | MSD | PCC | SSIM | |
|---|---|---|---|---|---|---|
| SIFT | 3.6440 | 1.5976 | 0.8639 | 136.6799 | 0.6462 | 0.6936 |
| SAR-SIFT | 3.7013 | 1.6105 | 0.8698 | 118.1341 | 0.7014 | 0.7229 |
| PSO-SIFT | 3.7276 | 1.6138 | 0.8714 | 119.7662 | 0.7135 | 0.7269 |
| Proposed | 3.8130 | 1.6271 | 0.8777 | 102.6517 | 0.7458 | 0.7544 |
| MI | NMI | ECC | MSD | PCC | SSIM | |
|---|---|---|---|---|---|---|
| SIFT | 3.5571 | 1.5852 | 0.8572 | 187.7355 | 0.6203 | 0.6051 |
| SAR-SIFT | 3.7284 | 1.6057 | 0.8674 | 147.3779 | 0.7181 | 0.6564 |
| PSO-SIFT | 3.7644 | 1.5979 | 0.8640 | 149.6696 | 0.6639 | 0.6667 |
| Proposed | 3.8850 | 1.6217 | 0.8753 | 111.4737 | 0.7586 | 0.7083 |
| Scaling Factor | MI | NMI | ECC | MSD | PCC | SSIM |
|---|---|---|---|---|---|---|
| 1 | 4.1025 | 1.6166 | 0.8734 | 134.2960 | 0.7652 | 0.7007 |
| 2 | 4.1840 | 1.6401 | 0.8834 | 98.3499 | 0.8570 | 0.7504 |
| 3 | 4.1887 | 1.6413 | 0.8839 | 95.8823 | 0.8611 | 0.7530 |
| 4 | 4.1779 | 1.6384 | 0.8827 | 101.3225 | 0.8480 | 0.7471 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, Z.; Shi, J.; Zhou, Y.; Yang, X.; Guo, W.; Zhang, X. S2-PCM: Super-Resolution Structural Point Cloud Matching for High-Accuracy Video-SAR Image Registration. Remote Sens. 2022, 14, 4302. https://doi.org/10.3390/rs14174302
Xie Z, Shi J, Zhou Y, Yang X, Guo W, Zhang X. S2-PCM: Super-Resolution Structural Point Cloud Matching for High-Accuracy Video-SAR Image Registration. Remote Sensing. 2022; 14(17):4302. https://doi.org/10.3390/rs14174302
Chicago/Turabian StyleXie, Zhikun, Jun Shi, Yihang Zhou, Xiaqing Yang, Wenxuan Guo, and Xiaoling Zhang. 2022. "S2-PCM: Super-Resolution Structural Point Cloud Matching for High-Accuracy Video-SAR Image Registration" Remote Sensing 14, no. 17: 4302. https://doi.org/10.3390/rs14174302
APA StyleXie, Z., Shi, J., Zhou, Y., Yang, X., Guo, W., & Zhang, X. (2022). S2-PCM: Super-Resolution Structural Point Cloud Matching for High-Accuracy Video-SAR Image Registration. Remote Sensing, 14(17), 4302. https://doi.org/10.3390/rs14174302