
Forest Fire Segmentation from Aerial Imagery Data Using an Improved Instance Segmentation Model




Abstract
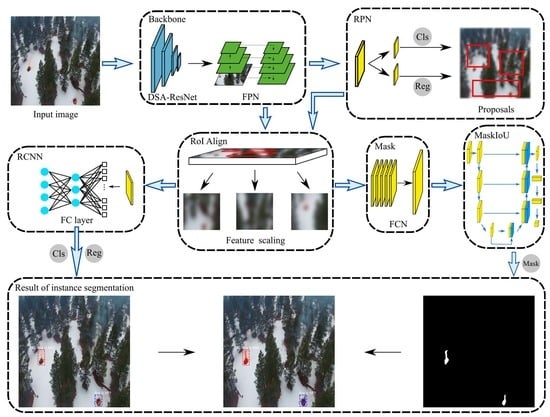
:
1. Introduction
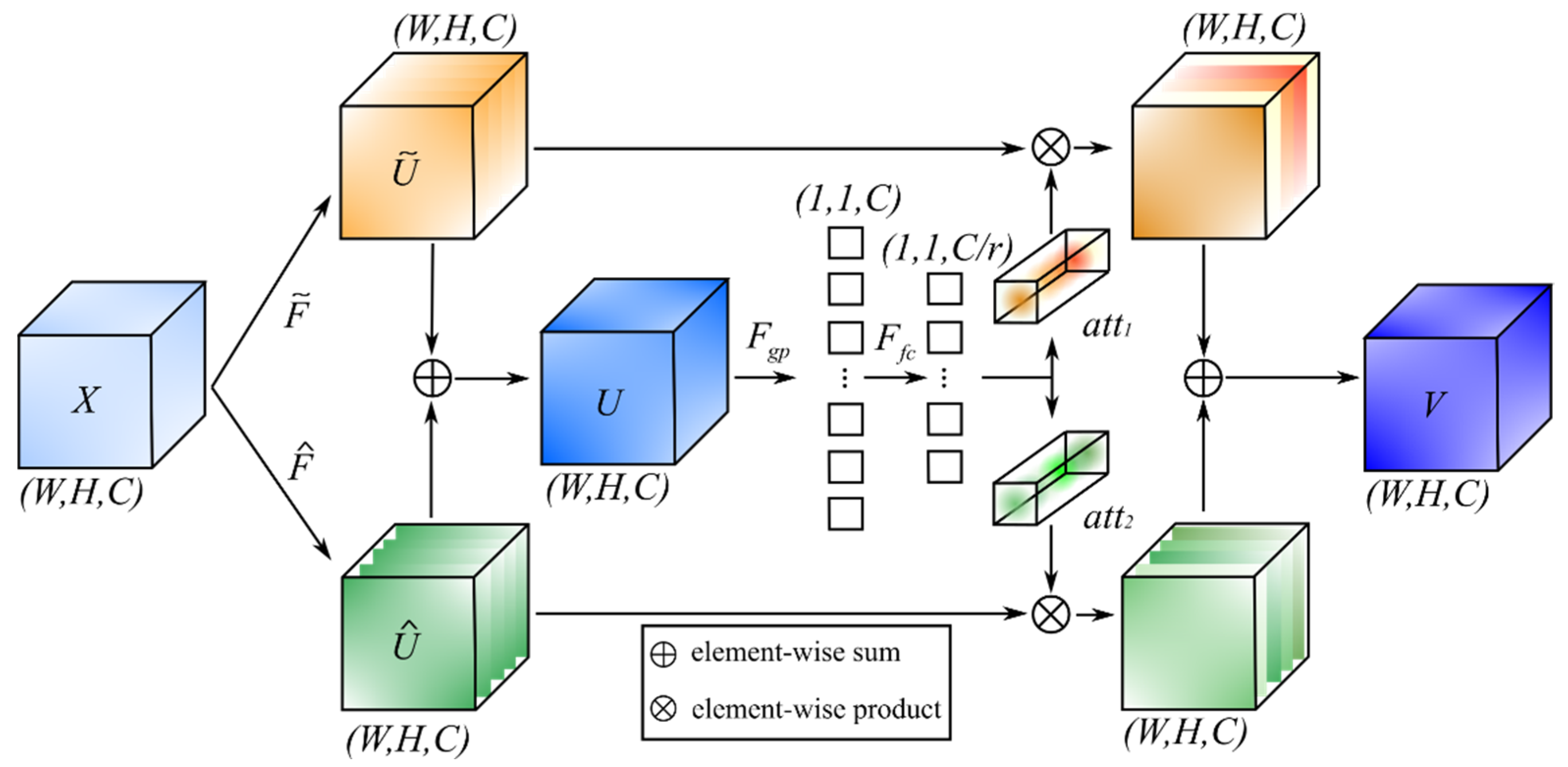
- We design a novel attention mechanism module, which consists of two independent branches for learning semantic information between different channels to enrich feature representation capability;
- We utilize a U-shaped network to reconstruct the MaskIoU branch of MS R-CNN with the aim of correcting forest-fire edge pixels and reducing segmentation errors; and
- Experimental results show that the proposed MaskSU R-CNN outperforms many existing CNN-based models on forest-fire instance segmentation.
2. Materials and Methods
2.1. Dataset
2.1.1. Data Source
2.1.2. Data Collection and Annotation
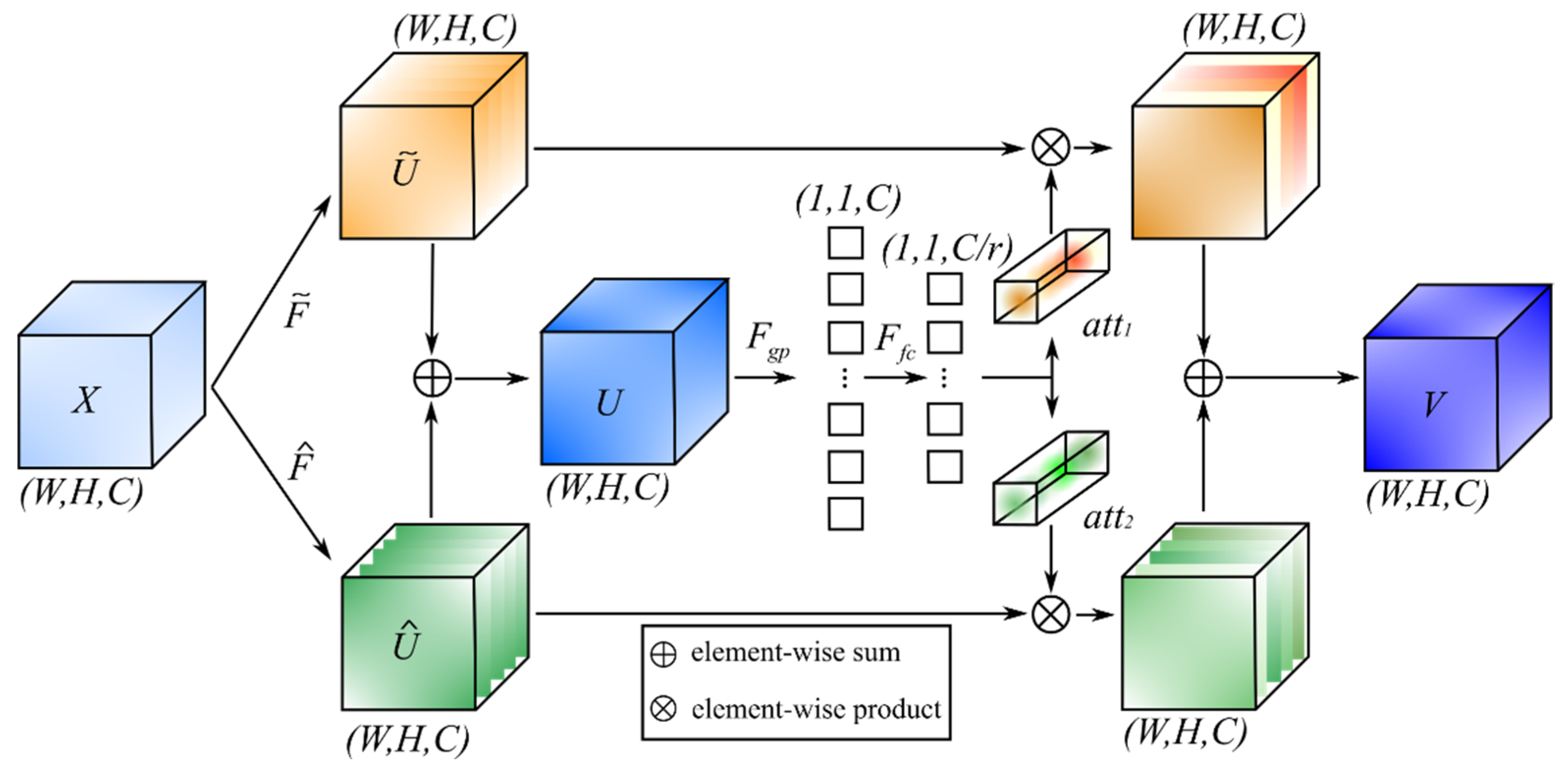
2.2. Fire Image Classification Using DSA-ResNet
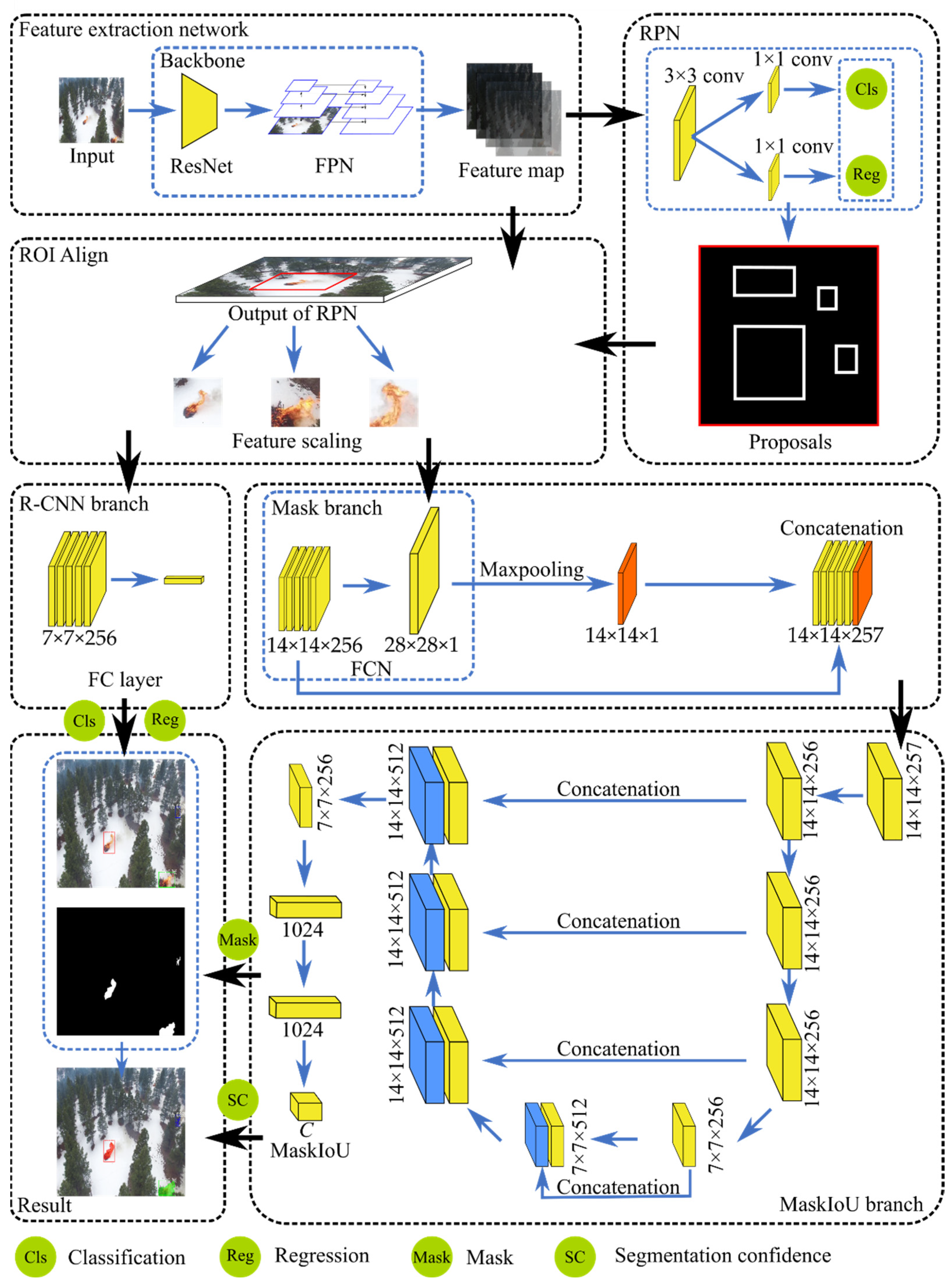
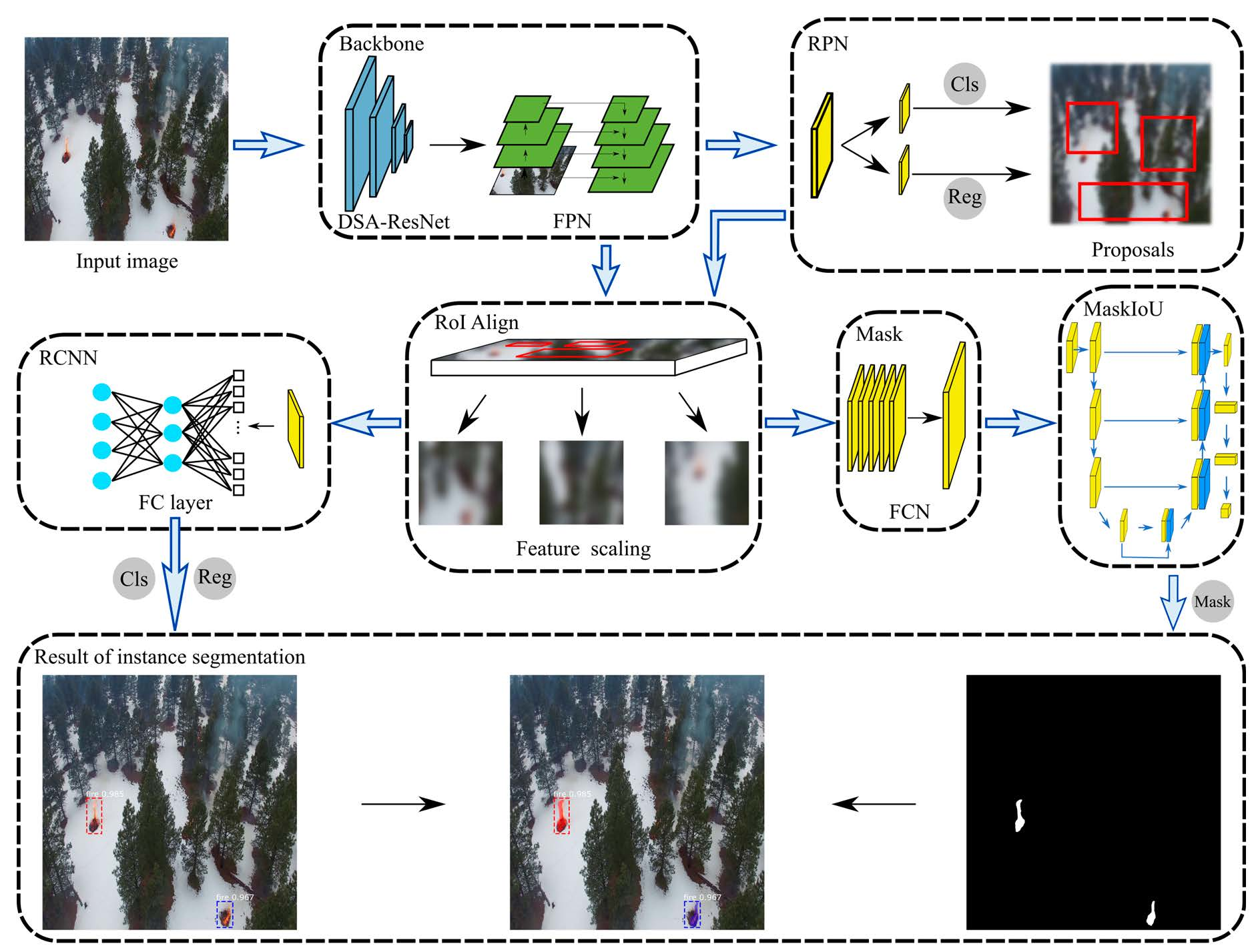
2.3. Fire Instance Segementation Using MaskSU R-CNN
2.3.1. Feature Extraction Network
2.3.2. Region Proposal Network (RPN) and Region of Interest (RoI) Align
2.3.3. Multi-branch Prediction for Classes, Bounding Boxes, and Masks
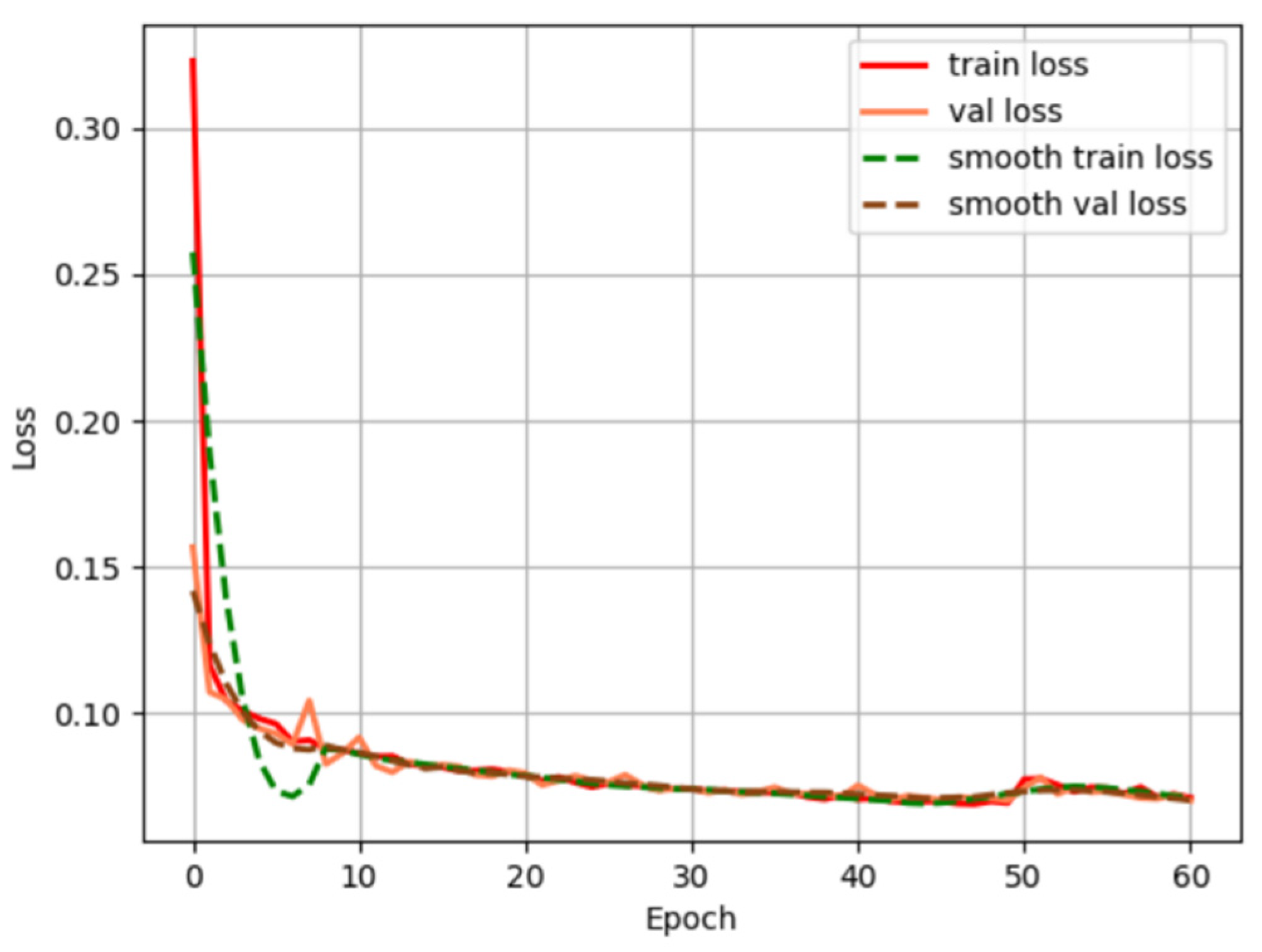
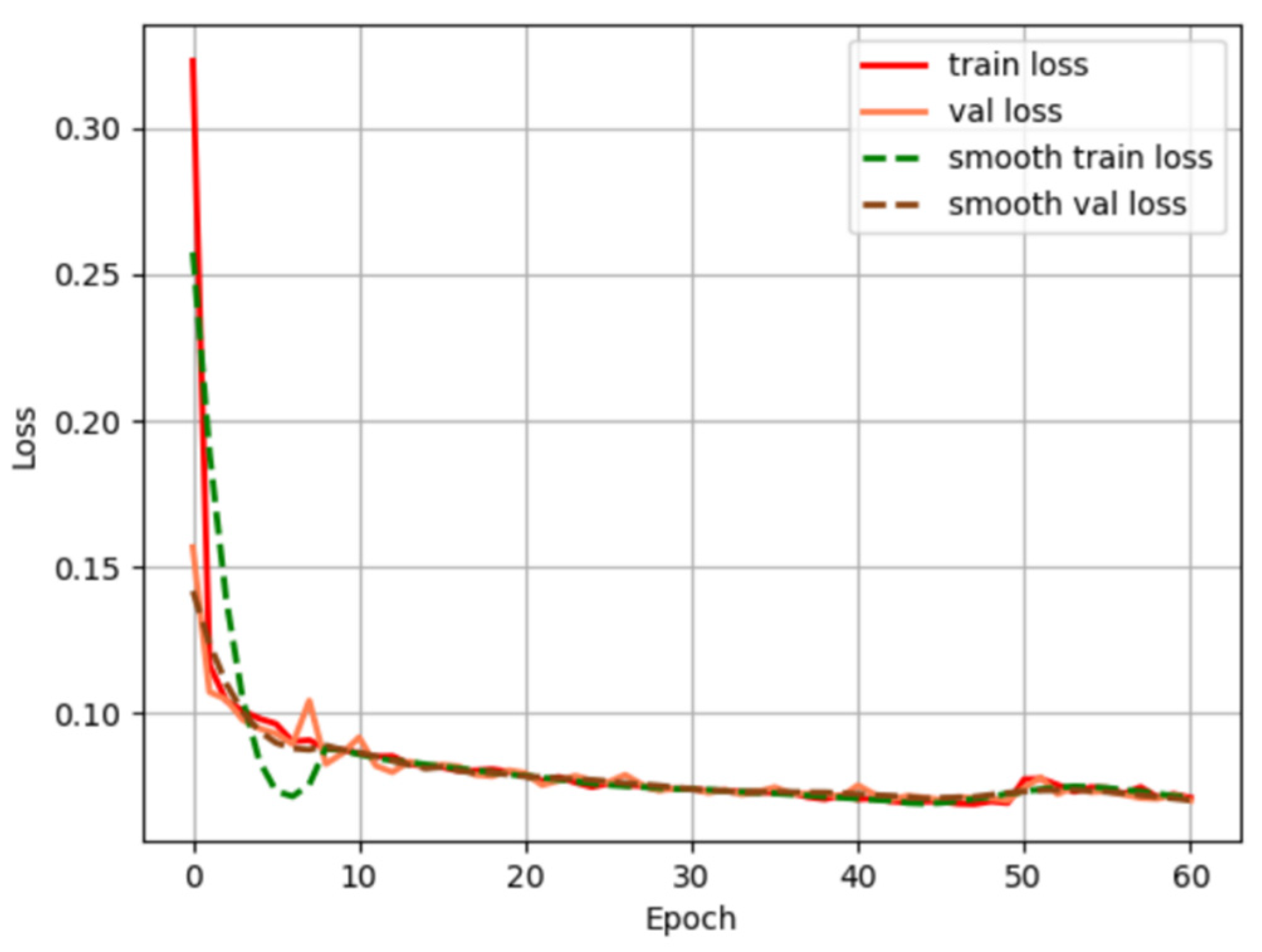
2.3.4. Model Training and Loss Function
3. Results
3.1. Fire Image Classification
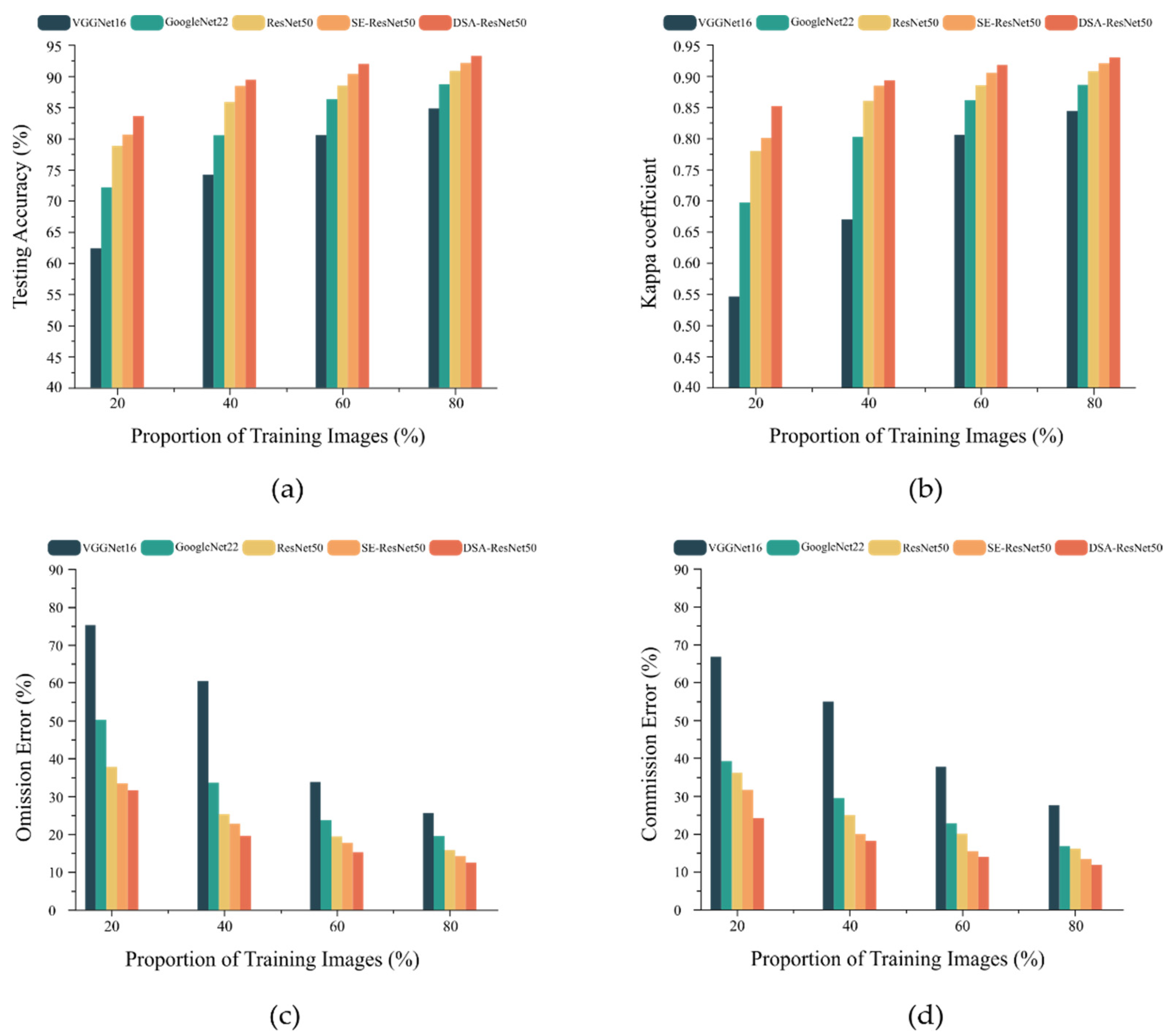
3.1.1. Accuracy Assessment
3.1.2. Visualization Analysis
3.2. Fire Detection and Segmentation
3.2.1. Evaluation Metrics
3.2.2. Performance Analysis and Comparison
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ryu, J.-H.; Han, K.-S.; Hong, S.; Park, N.-W.; Lee, Y.-W.; Cho, J. Satellite-based evaluation of the post-fire recovery process from the worst forest fire case in South Korea. Remote Sens. 2018, 10, 918. [Google Scholar] [CrossRef] [Green Version]
- Yun, T.; Jiang, K.; Li, G.; Eichhorn, M.P.; Fan, J.; Liu, F.; Chen, B.; An, F.; Cao, L. Individual tree crown segmentation from airborne LiDAR data using a novel Gaussian filter and energy function minimization-based approach. Remote Sens. Environ. 2021, 256, 112307. [Google Scholar] [CrossRef]
- Lucas-Borja, M.; Hedo, J.; Cerdá, A.; Candel-Pérez, D.; Viñegla, B. Unravelling the importance of forest age stand and forest structure driving microbiological soil properties, enzymatic activities and soil nutrients content in Mediterranean Spanish black pine (Pinus nigra Ar. ssp. salzmannii) Forest. Sci. Total Environ. 2016, 562, 145–154. [Google Scholar] [CrossRef] [PubMed]
- Burrell, A.L.; Sun, Q.; Baxter, R.; Kukavskaya, E.A.; Zhila, S.; Shestakova, T.; Rogers, B.M.; Kaduk, J.; Barrett, K. Climate change, fire return intervals and the growing risk of permanent forest loss in boreal Eurasia. Sci. Total Environ. 2022, 831, 154885. [Google Scholar] [CrossRef]
- Wu, Z.; He, H.S.; Keane, R.E.; Zhu, Z.; Wang, Y.; Shan, Y. Current and future patterns of forest fire occurrence in China. Int. J. Wildland Fire 2020, 29, 104. [Google Scholar] [CrossRef]
- Yang, X.; Chen, R.; Zhang, F.; Zhang, L.; Fan, X.; Ye, Q.; Fu, L. Pixel-level automatic annotation for forest fire image. Eng. Appl. Artif. Intell. 2021, 104, 104353. [Google Scholar] [CrossRef]
- Chai, J.; Zeng, H.; Li, A.; Ngai, E.W. Deep learning in computer vision: A critical review of emerging techniques and application scenarios. Mach. Learn. Appl. 2021, 6, 100134. [Google Scholar] [CrossRef]
- Fu, L.; Li, Z.; Ye, Q.; Yin, H.; Liu, Q.; Chen, X.; Fan, X.; Yang, W.; Yang, G. Learning robust discriminant subspace based on joint L2, p-and L2, s-Norm distance metrics. IEEE Trans. Neural Netw. Learn. Syst. 2020, 33, 130–144. [Google Scholar] [CrossRef]
- Ye, Q.; Huang, P.; Zhang, Z.; Zheng, Y.; Fu, L.; Yang, W. Multiview learning with robust double-sided twin SVM. IEEE Trans. Cybern. 2021, 1–14. [Google Scholar] [CrossRef]
- Zhan, J.; Hu, Y.; Zhou, G.; Wang, Y.; Cai, W.; Li, L. A high-precision forest fire smoke detection approach based on ARGNet. Comput. Electron. Agric. 2022, 196, 106874. [Google Scholar] [CrossRef]
- Yu, Z.; Zhang, Y.; Jiang, B.; Yu, X. Fault-tolerant time-varying elliptical formation control of multiple fixed-wing UAVs for cooperative forest fire monitoring. J. Intell. Robot. Syst. 2021, 101, 48. [Google Scholar] [CrossRef]
- Peng, Y.; Wang, Y. Real-time forest smoke detection using hand-designed features and deep learning. Comput. Electron. Agric. 2019, 167, 105029. [Google Scholar] [CrossRef]
- Yan, Y.; Wu, X.; Du, J.; Zhou, J.; Liu, Y. Video fire detection based on color and flicker frequency feature. J. Front. Comput. Sci. Technol. 2014, 8, 1271–1279. [Google Scholar]
- Çelik, T.; Demirel, H. Fire detection in video sequences using a generic color model. Fire Saf. J. 2009, 44, 147–158. [Google Scholar] [CrossRef]
- Borges, P.V.K.; Izquierdo, E. A probabilistic approach for vision-based fire detection in videos. IEEE Trans. Circuits Syst. Video Technol. 2010, 20, 721–731. [Google Scholar] [CrossRef]
- Li, X.; Chen, Z.; Wu, Q.M.J.; Liu, C. 3D Parallel Fully Convolutional Networks for Real-Time Video Wildfire Smoke Detection. IEEE Trans. Circuits Syst. Video Technol. 2018, 30, 89–103. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Wang, Y.; Zhao, J.-H.; Zhang, D.-Y.; Ye, W. Forest fire image classification based on deep neural network of sparse autoencoder. Comput. Eng. Appl. 2014, 50, 173–177. [Google Scholar]
- Yin, M.; Lang, C.; Li, Z.; Feng, S.; Wang, T. Recurrent convolutional network for video-based smoke detection. Multimed. Tools Appl. 2018, 78, 237–256. [Google Scholar] [CrossRef]
- Friedlingstein, P.; Jones, M.W.; O’sullivan, M.; Andrew, R.M.; Hauck, J.; Peters, G.P.; Peters, W.; Pongratz, J.; Sitch, S.; le Quéré, C.; et al. Global carbon budget 2019. Earth Syst. Sci. Data 2019, 11, 1783–1838. [Google Scholar] [CrossRef] [Green Version]
- Huang, Q.; Razi, A.; Afghah, F.; Fule, P. Wildfire spread modeling with aerial image processing. In Proceedings of the 2020 IEEE 21st International Symposium on “A World of Wireless, Mobile and Multimedia Networks” (WoWMoM), Cork, Ireland, 31 August–3 September 2020; pp. 335–340. [Google Scholar]
- De Sousa, J.V.R.; Gamboa, P.V. Aerial forest fire detection and monitoring using a small UAV. KnE Eng. 2020, 5, 242–256. [Google Scholar] [CrossRef]
- Ciprián-Sánchez, J.F.; Ochoa-Ruiz, G.; Gonzalez-Mendoza, M.; Rossi, L. FIRe-GAN: A novel deep learning-based infrared-visible fusion method for wildfire imagery. Neural Comput. Appl. 2021. [Google Scholar] [CrossRef]
- Pan, H.; Badawi, D.; Zhang, X.; Cetin, A.E. Additive neural network for forest fire detection. Signal Image Video Process. 2019, 14, 675–682. [Google Scholar] [CrossRef]
- Zhang, J.; Zhu, H.; Wang, P.; Ling, X. ATT squeeze U-Net: A lightweight network for forest fire detection and recognition. IEEE Access 2021, 9, 10858–10870. [Google Scholar] [CrossRef]
- Yuan, C.; Liu, Z.; Zhang, Y. UAV-based forest fire detection and tracking using image processing techniques. In Proceedings of the 2015 International Conference on Unmanned Aircraft Systems (ICUAS), Denver, CO, USA, 9–12 June 2015; pp. 639–643. [Google Scholar]
- Sudhakar, S.; Vijayakumar, V.; Kumar, C.S.; Priya, V.; Ravi, L.; Subramaniyaswamy, V. Unmanned Aerial Vehicle (UAV) based Forest Fire Detection and monitoring for reducing false alarms in forest-fires. Comput. Commun. 2019, 149, 1–16. [Google Scholar] [CrossRef]
- Shamsoshoara, A.; Afghah, F.; Razi, A.; Zheng, L.; Fulé, P.Z.; Blasch, E. Aerial imagery pile burn detection using deep learning: The FLAME dataset. Comput. Netw. 2021, 193, 108001. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, Z.; Huang, L.; Gong, Y.; Huang, C.; Wang, X. Mask scoring R-Cnn. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6409–6418. [Google Scholar]
- Xu, Y.-H.; Li, J.-H.; Zhou, W.; Chen, C. Learning-empowered resource allocation for air slicing in UAV-assisted cellular V2X communications. IEEE Syst. J. 2022, 1–4. [Google Scholar] [CrossRef]
- Chelali, F.Z.; Cherabit, N.; Djeradi, A. Face recognition system using skin detection in RGB and YCbCr color space. In Proceedings of the 2015 2nd World Symposium on Web Applications and Networking (WSWAN), Sousse, Tunisia, 21–23 March 2015; pp. 1–7. [Google Scholar]
- Umar, M.M.; Silva, L.C.D.; Bakar, M.S.A.; Petra, M.I. State of the Art of Smoke and Fire Detection Using Image Processing. Int. J. Signal Imaging Syst. Eng. 2017, 10, 22–30. [Google Scholar] [CrossRef]
- Hackel, T.; Usvyatsov, M.; Galliani, S.; Wegner, J.D.; Schindler, K. Inference, learning and attention mechanisms that exploit and preserve sparsity in CNNs. Int. J. Comput. Vis. 2020, 128, 1047–1059. [Google Scholar] [CrossRef] [Green Version]
- Mnih, V.; Heess, N.; Graves, A. Recurrent models of visual attention. Adv. Neural Inf. Process. Syst. 2014, 2, 2204–2212. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Li, Y.; Yuan, Y. Convergence analysis of two-layer neural networks with relu activation. Adv. Neural. Inf. Process. Syst. 2017, 30, 597–607. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-Cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft Coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Huh, M.; Agrawal, P.; Efros, A.A. What makes ImageNet good for transfer learning? arXiv 2016, arXiv:1608.08614. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-Cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Ba, R.; Chen, C.; Yuan, J.; Song, W.; Lo, S. SmokeNet: Satellite smoke scene detection using convolutional neural network with spatial and channel-wise attention. Remote Sens. 2019, 11, 1702. [Google Scholar] [CrossRef] [Green Version]
- Zhang, F.; Dong, Y.; Xu, S.; Yang, X.; Lin, H. An approach for improving firefighting ability of forest road network. Scand. J. For. Res. 2020, 35, 547–561. [Google Scholar] [CrossRef]
- Xu, R.; Lin, H.; Lu, K.; Cao, L.; Liu, Y. A forest fire detection system based on ensemble learning. Forests 2021, 12, 217. [Google Scholar] [CrossRef]
- Ye, Q.; Li, Z.; Fu, L.; Zhang, Z.; Yang, W.; Yang, G. Nonpeaked Discriminant Analysis for Data Representation. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3818–3832. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Number of Images | Proportion |
|---|---|---|
| Training set | 1600 | 20% |
| 3200 | 40% | |
| 4800 | 60% | |
| 6400 | 80% | |
| Validation | 800 | 10% |
| Testing set | 800 | 10% |
| Total | 8000 | 100% |
| Operation | Kernel/Stride | Output | |
|---|---|---|---|
| Block1 | Conv + ReLU | 3 × 3 × 256 | 14 × 14 × 256 |
| Conv + ReLU | 3 × 3 × 256 | 14 × 14 × 256 | |
| Conv + ReLU | 3 × 3 × 256 | 14 × 14 × 256 | |
| Block2 | Maxpooling | 2 × 2 | 7 × 7 × 256 |
| Conv + ReLU + Concat | 3 × 3 × 256 | 7 × 7 × 512 | |
| Block3 | Up-sampling | 2 × 2 | 14 × 14 × 512 |
| Conv + ReLU + Concat | 3 × 3 × 256 | 14 × 14 × 512 | |
| Conv + ReLU + Concat | 3 × 3 × 256 | 14 × 14 × 512 | |
| Conv + ReLU + Concat | 3 × 3 × 256 | 14 × 14 × 512 | |
| Block4 | Conv + ReLU | 3 × 3 × 256 | 14 × 14 × 512 |
| Maxpooling | 2 × 2 | 7 × 7 × 256 | |
| Block5 | FC + ReLU | / | 1024 |
| FC + ReLU | / | 1024 | |
| FC + ReLU | / | C (MaskIoU) |
| Model | Layers | Acc (%) | K | OE (%) | CE (%) | Params (Million) |
|---|---|---|---|---|---|---|
| VGGNet | 16 | 84.86 | 0.743 | 37.54 | 16.84 | 138.53 |
| GoogleNet | 22 | 88.23 | 0.784 | 34.52 | 11.61 | 8.97 |
| ResNet | 50 | 91.28 | 0.839 | 29.87 | 8.35 | 26.85 |
| SE-ResNet | 50 | 92.46 | 0.851 | 25.62 | 5.62 | 28.65 |
| DSA-ResNet (ours) | 50 | 93.65 | 0.864 | 20.59 | 4.23 | 28.43 |
| Method | Metrics | |||
|---|---|---|---|---|
| (%) | (%) | (%) | mIoU (%) | |
| SegNet | 71.37 | 41.33 | 52.35 | 35.45 |
| UNet | 86.18 | 85.96 | 86.07 | 77.85 |
| PSPNet | 83.12 | 81.25 | 82.17 | 69.74 |
| DeepLabv3 | 90.95 | 89.64 | 90.29 | 81.12 |
| MaskSU R-CNN (ours) | 91.85 | 88.81 | 90.30 | 82.31 |
| Model | Backbone | MaskIoU | Metrics | |||
|---|---|---|---|---|---|---|
| (%) | (%) | (%) | mIoU (%) | |||
| Mask R-CNN | ResNet | / | 85.62 | 82.61 | 84.09 | 75.97 |
| DSA-ResNet | / | 87.94 | 85.69 | 86.80 | 77.55 | |
| MS R-CNN | ResNet | FCN | 88.95 | 83.16 | 85.96 | 78.61 |
| DSA-ResNet | FCN | 90.15 | 87.94 | 89.03 | 80.42 | |
| MaskSU R-CNN (ours) | ResNet | U-shaped network | 88.63 | 88.89 | 88.76 | 80.77 |
| DSA-ResNet | U-shaped network | 91.85 | 88.81 | 90.30 | 82.31 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guan, Z.; Miao, X.; Mu, Y.; Sun, Q.; Ye, Q.; Gao, D. Forest Fire Segmentation from Aerial Imagery Data Using an Improved Instance Segmentation Model. Remote Sens. 2022, 14, 3159. https://doi.org/10.3390/rs14133159
Guan Z, Miao X, Mu Y, Sun Q, Ye Q, Gao D. Forest Fire Segmentation from Aerial Imagery Data Using an Improved Instance Segmentation Model. Remote Sensing. 2022; 14(13):3159. https://doi.org/10.3390/rs14133159
Chicago/Turabian StyleGuan, Zhihao, Xinyu Miao, Yunjie Mu, Quan Sun, Qiaolin Ye, and Demin Gao. 2022. "Forest Fire Segmentation from Aerial Imagery Data Using an Improved Instance Segmentation Model" Remote Sensing 14, no. 13: 3159. https://doi.org/10.3390/rs14133159
APA StyleGuan, Z., Miao, X., Mu, Y., Sun, Q., Ye, Q., & Gao, D. (2022). Forest Fire Segmentation from Aerial Imagery Data Using an Improved Instance Segmentation Model. Remote Sensing, 14(13), 3159. https://doi.org/10.3390/rs14133159