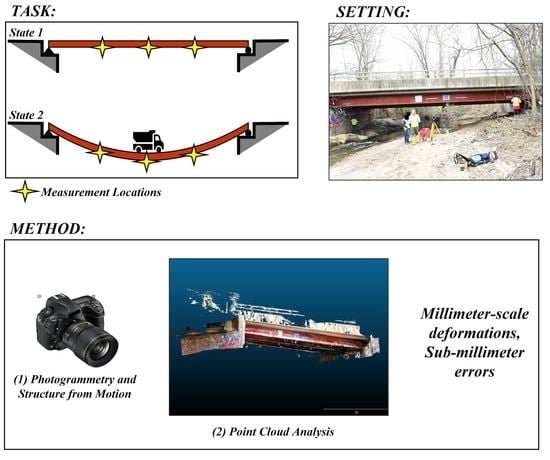
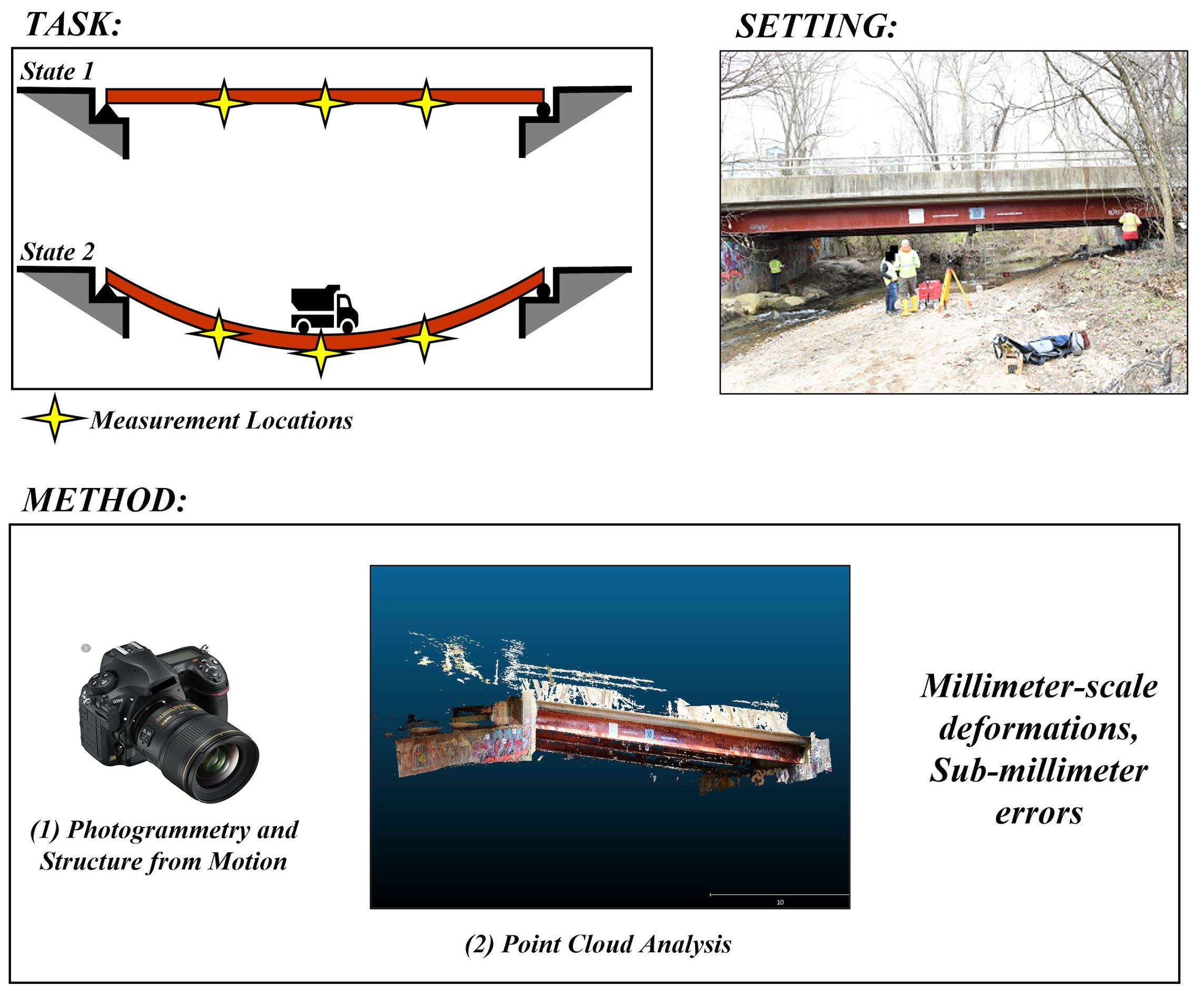
Figure 1 provides an overview of the 3D measurement methodology. In order to quantify deformations, photogrammetric point cloud data are collected from a structure in two states of deformation. The first state is referred to as the “reference” point cloud, representing the unloaded state of the structure, and the second state is referred to as the “compared” point cloud, representing the loaded state of the structure. Prior efforts demonstrated accuracy at the millimeter scale under laboratory conditions for a similar, but simplified, measurement method [
36,
37,
38]. Translating this approach to full-scale field conditions required significant modifications that included specialized image preprocessing, and modifications to the registration algorithm. The overall process is more complex than what is presented in
Figure 1, and details are presented in the remainder of this section.
2.1.1. Data Preprocessing
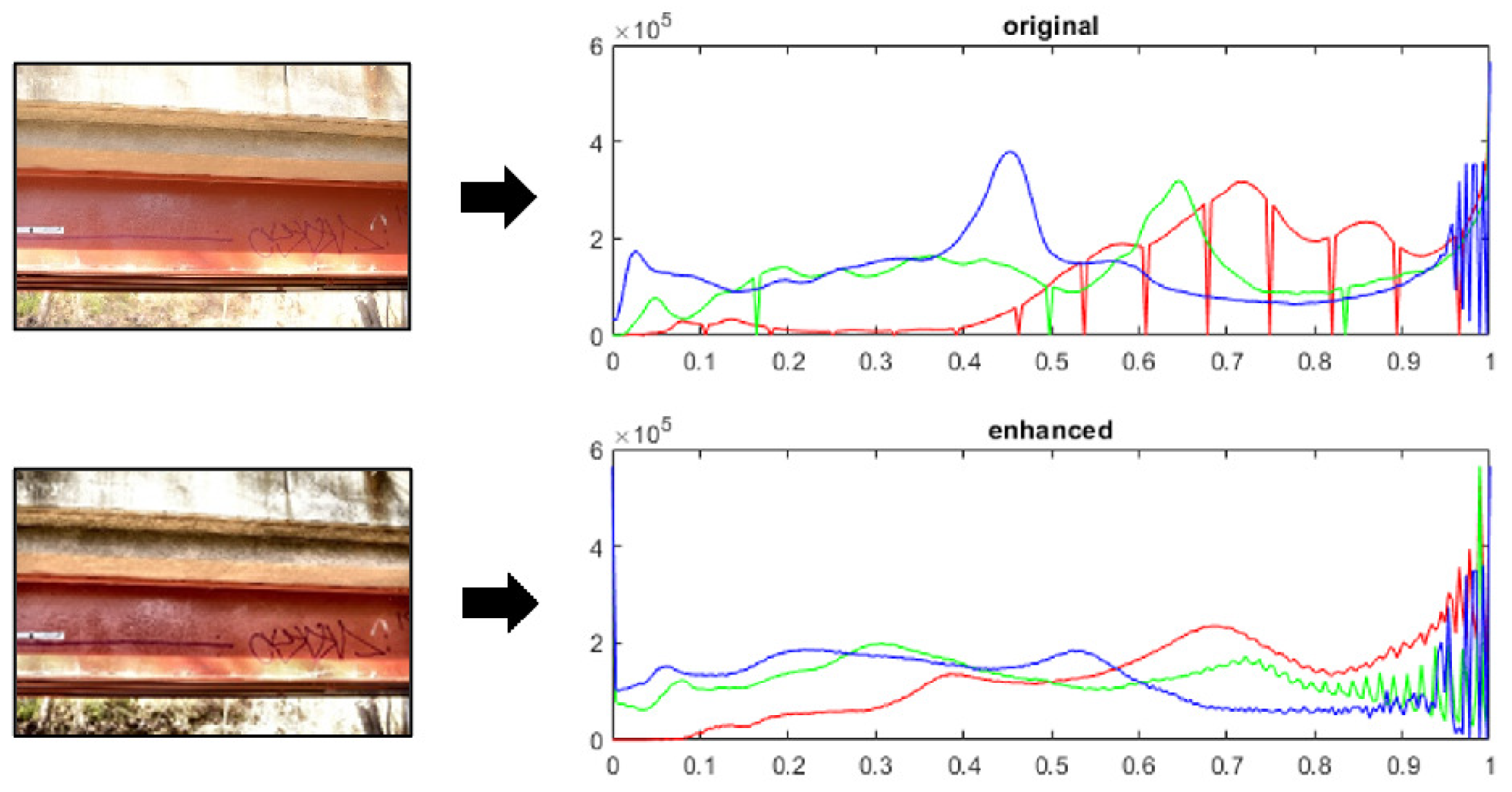
Upon completion of image data collection for both the undeformed and deformed bridge, the digital images must be processed to enhance their brightness and texture. One of the inevitable issues in field photogrammetry is luminance variation between each image due to changes in camera angles and environmental conditions, especially in bright sunlight. SfM is highly dependent on the localized high-contrast regions in the image of an object [
39], and histogram equalization results in a more uniform brightness in the images, which enhances the texture of the target and leads to a better 3D reconstruction.
In this work, contrast-limited adaptive histogram equalization (CLAHE) is employed [
40]. This algorithm is a specialized form of the adaptive histogram equaliztion (AHE) algorithm that was originally designed to overcome the challenges of performing global histogram equalization on images with a wide range of intensity values across their pixels. However, the AHE algorithm suffers from over-enhancement and noise amplification in regions of the image that have a relatively homogeneous distribution of pixel intensities, a common occurrence for large-scale structures [
40,
41,
42].
CLAHE limits the contrast by clipping and redistributing the histogram of the pixel intensities in the image and therefore avoids the over-enhancement and noise amplification of the AHE algorithm. This step is performed after subdividing the image into several equally sized partitions, and the established clip limit enforces a more uniform contrast across the entirety of the image, thus providing benefit for the SfM process. For additional details on the algorithmic approach for CLAHE, the reader is referred to [
43].
It is worth noting that an exhaustive evaluation of multiple image processing algorithms was not conducted. It was shown in other studies that CLAHE is beneficial for 3D point cloud reconstruction by increasing the number of tie points across images and, ultimately, the total number of data points in the point cloud [
44,
45]. The original motivation for the use of CLAHE resulted from the demonstration of its effectiveness in underwater environments, in which enhancing image visibility and removing artifacts and noise from the images are necessary [
46,
47]. Thus, because there were similar issues with noise in the images for this work, the authors decided to apply CLAHE to solve non-uniform illumination and brightness problems in the dataset images.
After image processing, the reference and compared point clouds are generated using a dense structure-from-motion algorithm, such as multiview stereo approaches [
48,
49] or approaches based on semi-global matching [
50]. The point clouds are then scaled into a global reference frame that accommodates an effective interpretation of the results for deformation tracking. This scaling is typically achieved using a metric, either through calibration targets placed within a scene or through known dimensions of objects within a point cloud [
51]. The experiments in this work employed calibration targets, as will be discussed in
Section 3.
After point cloud generation and scaling, the next step is to remove clear outliers in the point cloud. Three-dimensional data points are classified as either inlier or outlier points based on the local neighborhood structure, and follow the approach found in [
52]. First, a local neighborhood structure of the k-nearest neighbors is established for each point in the dataset. Next, the average distance,
d, from a point to its
k local neighbors is computed, and the mean,
, and standard deviation,
, of these distances (across the entirety of the dataset) are determined. Data points are classified as outliers when their average distances,
d, to their associated local neighborhoods meet the following condition:
The values for k and are determined empirically such that a small percentage of the data points are classified as outliers and can then be deleted from the dataset. The intent of this statistical approach is to delete points that are far away from neighboring data points while still preserving the curvature and local features of the data.
2.1.2. Registration
The geometric registration of the reference and compared point sets is broken into two steps: an approximate manual alignment, followed by a fine alignment that minimizes registration errors. For the first step, the point sets are aligned manually by identifying eight pairs of common points. An important detail of point pair selection is that the common points between the datasets must be in the same location between the two load states of the structure. In other words, no point pairs may be selected on a portion of the structure that deforms to a different spatial location during its loading. As a general rule, point pairs should be located on the wall of the supporting abutments or convenient locations not attached to the bridge that can be captured in the scene with point cloud data. Such locations could include areas on immobile objects such as rock faces or artificially placed fiducial objects. Having selected the point pairs, a transformation is applied to the compared point cloud to roughly align the entirety of the loaded structure into the same globally-scaled 3D space as the unloaded structure represented by the reference point cloud.
Due to noise (defined with respect to point cloud data herein as residuals between the surface represented by the data point and the true surface location) in the data and the limitation of the point pair selection with respect to alignment accuracy, manual alignment is typically not accurate enough for deformation tracking at the millimeter scale. Preliminary manual alignment is critical though, as the algorithms used for fine registration tend to converge to a local optimum. The intent of the manual registration is to set the initial position of the compared point cloud such that the solution to the fine registration algorithm is the global solution.
The fine registration process in this work uses the iterative closest point (ICP) algorithm [
35], a point-to-point registration algorithm based on Euclidean distances between the points in the two point clouds (
Figure 2). First, the algorithm finds the nearest neighbor point correspondences between the point clouds using kd-tree space partitioning to reduce the search complexity [
53]. Given the reference point cloud
P, where all points
, and the compared point cloud
Q, where all points
, the ICP calculates the Euclidean distances of the m correspondences between all points
and
(denoted as a correspondence pair). ICP then iteratively calculates the 3 × 3 rotation matrix,
R, and 3 × 1 translation vector,
t, of the registration for the target point cloud,
Q, through the minimization of the cost function shown in Equation (
2).
Because the ICP minimizes Euclidean distances between point correspondences, it is commonly referred to as point-to-point ICP. A variant of this algorithm, known as point-to-plane ICP [
54], seeks to overcome the complications from the unsigned directionality of point-to-point Euclidean distances. This variant can be beneficial in cases where the point sets are representative of planar surfaces. For the point-to-plane version, the Euclidean distances between the point correspondences are projected along the direction of the surface normal vector from the point in the reference point cloud for each correspondence (
Figure 3).
As a result, the cost function includes the surface normal vector,
, for the corresponding point,
(Equation (
3)).
For either point-to-point ICP or point-to-plane ICP, it is not required to have the same number of data points in each point cloud, as the algorithm runs based on the correspondences between nearest neighbors. At the scale of the point clouds used in structural assessment, this is algorithmically beneficial because it is unrealistic to expect the point cloud datasets to have the same number of data points without point set subsampling. However, this characteristic leads to countless correspondence arrangements where one data point will be a nearest neighbor to multiple data points in the opposing point cloud and therefore makes the performance of the registration algorithms sensitive to noise, outliers, and the initial pose from manual registration.
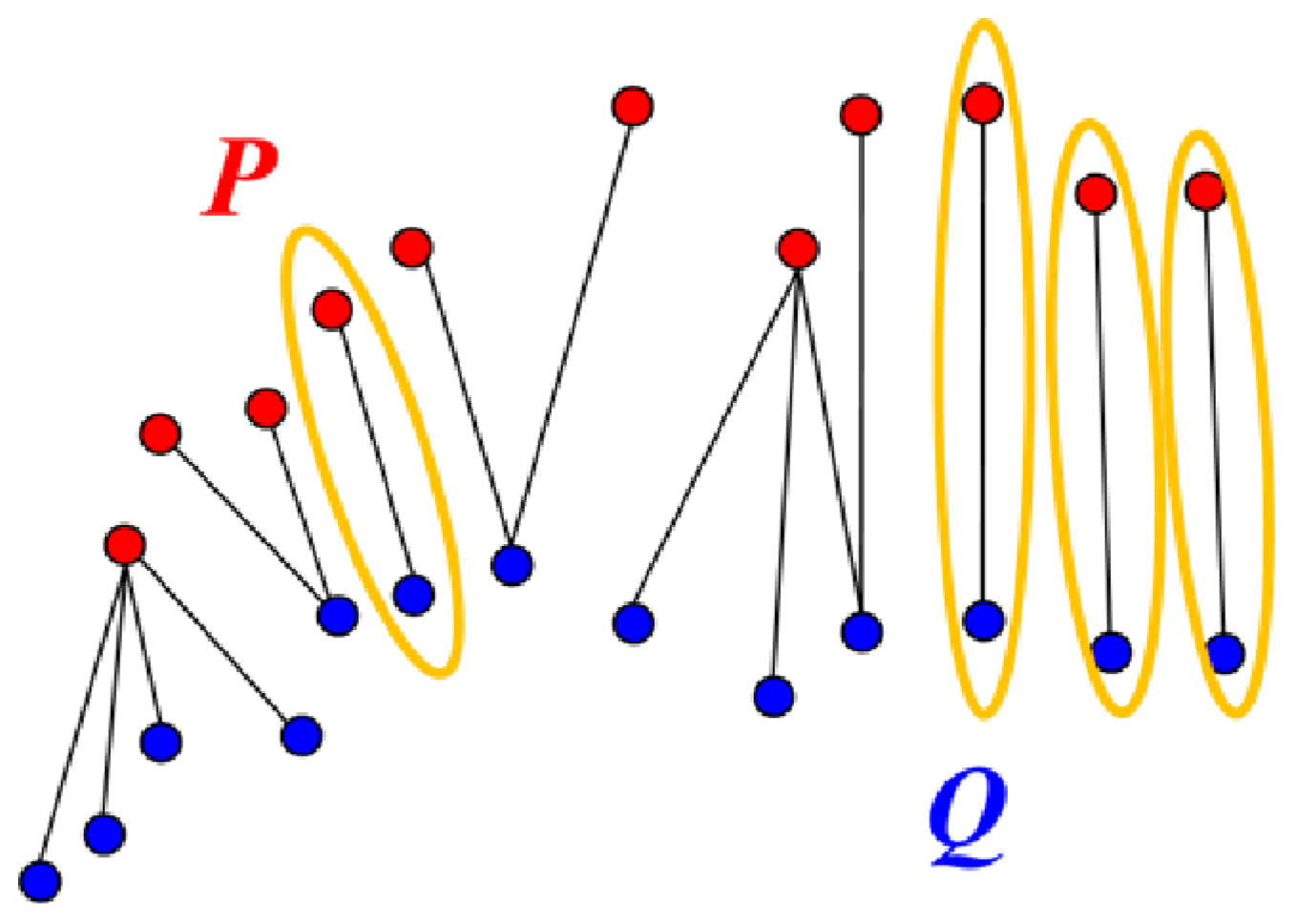
In response to this shortcoming, researchers developed a version of the ICP [
55] that adopts characteristics of a generalized Procrustes analysis (GPA). For GPA, point cloud datasets have the same number of points, and the point correspondences are known a priori. The GPA-ICP algorithm mimics this arrangement by only using point correspondences from mutual nearest neighbors before executing the ICP algorithm. A data point
is defined as the mutual nearest neighbor to
when the nearest neighbor to
p in
Q is
q and the nearest neighbor to
q in
P is
p. Thus, the mutual nearest neighbors have an exclusive nearest neighbor relationship from the remainder of the points in the datasets (
Figure 4). Using the mutual nearest neighbors to define the point correspondences for the ICP algorithm results in less sensitivity to outliers at the expense of a higher computational cost.
The version of the algorithm in this work determines the mutual nearest neighbors between the two point sets and runs the ICP algorithm based on these correspondences. After converging to a registration solution, the algorithm then iterates the process by determining a new set of mutual nearest neighbors based on the position of the moving point cloud from the previous iteration. The iterations are continued until a given criteria is met (such as a set number of iterations or a given differential between subsequent transformations).
Other registration algorithms explored for this work included the coherent point drift (CPD) [
56] and the normal distributions transform (NDT) [
57]. These algorithms are probability-based metrics that use the expectation-maximization algorithm while treating the data points in the compared point cloud treated as centroids of Gaussian mixture models (the approach for the CPD algorithm), or break the datasets into voxels and transform the compared point cloud based on mean and variance of the data locations in each voxel (the approach for the NDT algorithm). However, initial research with these algorithms did not provide sufficiently accurate results and is therefore not discussed further.
2.1.3. Deformation Measurement
Once the registration step is complete, the deformations of the structure are determined through the comparison of the two sets of point cloud data. The algorithms considered in this work to make these calculations are the direct cloud-to-cloud (C2C) distance [
58], the multi-scale model-to-model cloud comparison (M3C2) [
59], and a new approach referred to here as direct point-to-point (P2P) distance metric. While there are many techniques that calculate distances from point cloud data to best fit planes and mesh surfaces, the three algorithms in this work directly compare the distances between individual points in the point sets. This limits unquantifiable uncertainties and undesireable data manipulation that implicitly occur when working with a best-fit plane or meshed surface.
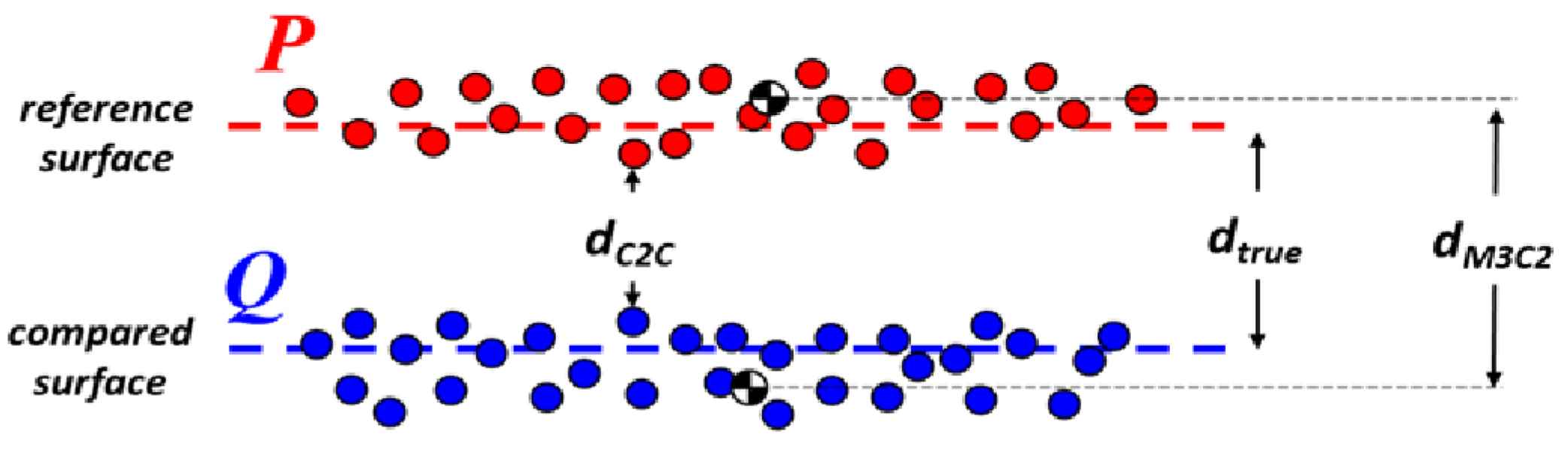
The C2C distance metric is based on a form of the directed Hausdorff distance [
60]. In this case, the C2C metric computes the Euclidean distance,
d, from a given point in the compared point cloud,
Q, to its nearest neighbor in the reference point cloud,
P (Equation (
4)):
In order to speed up the computation, the point clouds are divided into an octree structure such that the nearest neighbor search includes only an immediate neighborhood of octree cells to a given point,
p.
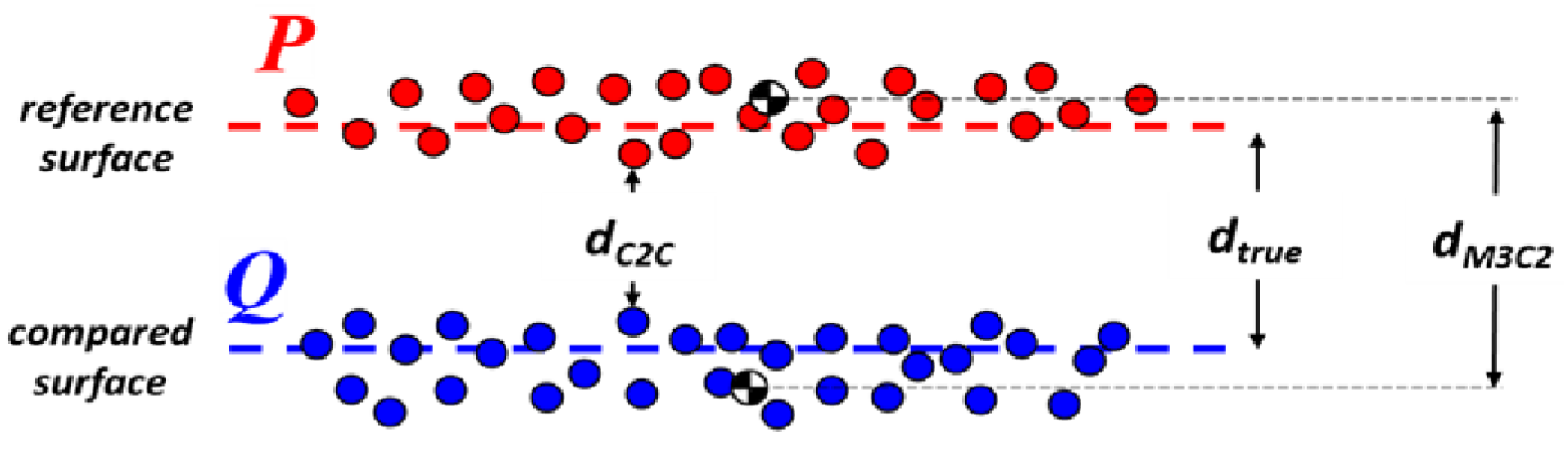
Given Equation (
4), the C2C metric necessarily suffers in situations where the point densities between the two sets of point cloud data are different, specifically when the point density of the reference cloud is lower than that of the compared cloud. In such cases, there are many reported distance values among data points in the compared point cloud that are calculated from the same nearest neighbor point in the reference point cloud (
Figure 5). However, the benefit of this algorithm is that it is fast and direct.
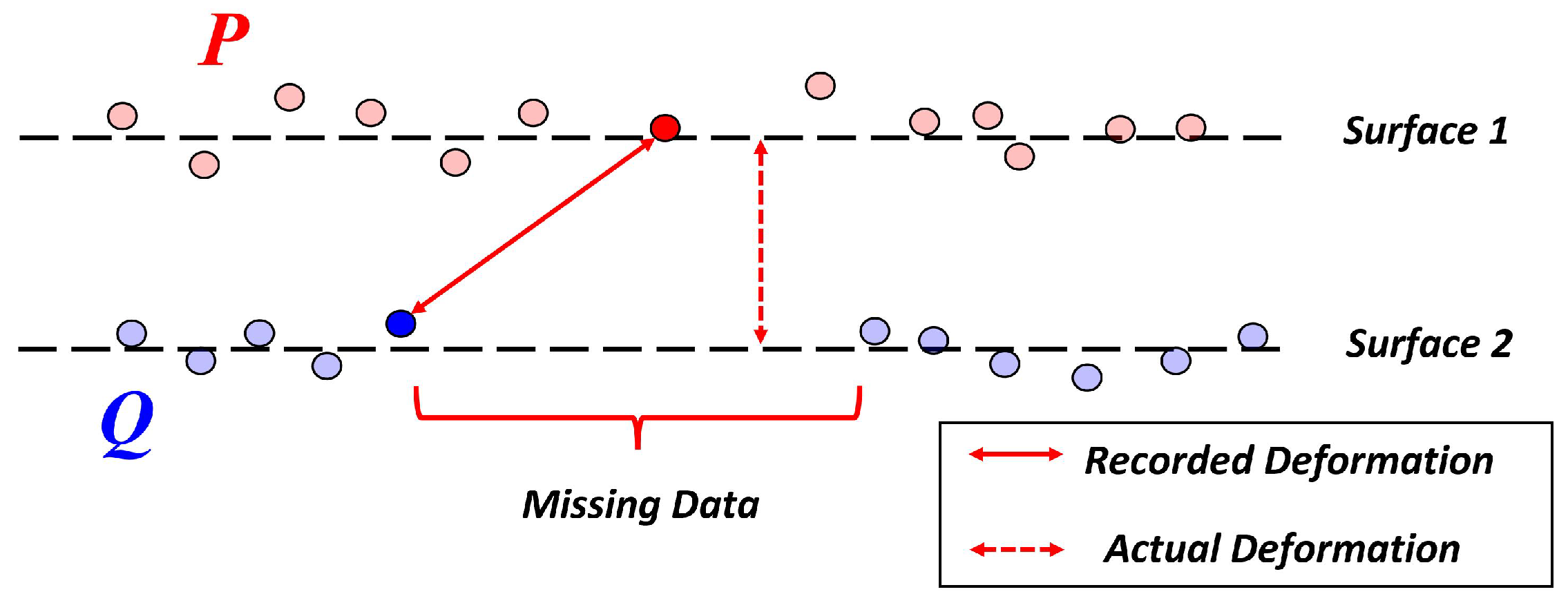
As an alternate to the fast and direct C2C metric, the M3C2 algorithm accounts for the geometry of the point cloud through the incorporation of the surface normal vectors of the reference point cloud, albeit at the expense of higher computational complexity. For a given set of core points, the M3C2 algorithm determines the surface normal vector through an eigen analysis of the corresponding local neighborhood of points. The spatial covariance matrix of the neighborhood is determined (Equation (
5)), and then the smallest eigenvector resulting from a singular value decomposition of this covariance matrix provides a good approximation of the surface normal vector.
Next, a cylindrical spatial volume at each core point is projected along the surface normal vector. Once this volume is defined, it captures two subsets of data, one from each of the point clouds. The average spatial locations are determined, then the reported distance from the M3C2 algorithm is calculated as the Euclidean distance between the two locations projected on the direction of the calculated surface normal vector for the associated core point. Of note, in cases where the compared point cloud is missing data and no associated data points fall within the spatial volume defined from a given core point, then no M3C2 distance is calculated or reported at that core point (
Figure 6).
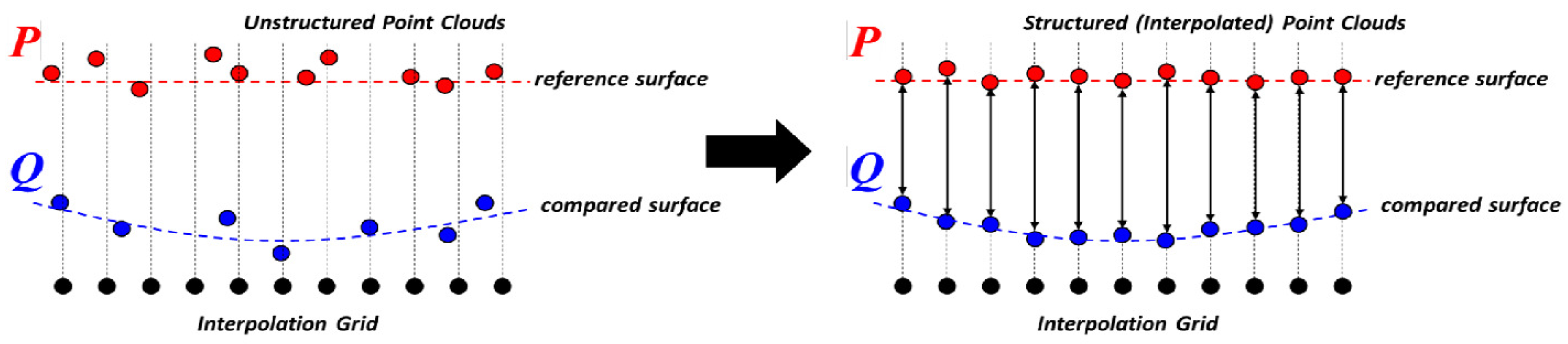
One of the drawbacks of the C2C and M3C2 metrics is that neither algorithm establishes exact correspondences between identical locations on the target structure represented by the point clouds. As a result, the nearest neighbor correspondence for C2C and the mean position correspondence within the core point search volume for M3C2 do not necessarily measure the same exact position on the surface of the structure, leading to measurement error. These algorithms also struggle in instances where data collection is sparse, leading to potential error and an overall lack of confidence in the results. To address this issue, this paper presents a new distance metric, P2P, that establishes point correspondences via interpolation of point cloud data onto a regularized grid that is shared between the two datasets (
Figure 7). An interpolation grid is established in the plane that is orthogonal to the direction of primary deformation (i.e., the direction of loading). Gaussian process regression (also known as kriging) [
61,
62] is conducted on the grid points for each dataset. While other interpolators could also be considered, kriging was selected due to its ability to provide explicit uncertainty quantification, a highly desirable characteristic for structural monitoring applications [
63,
64].
Once the kriging predictions are made on the orthogonal grid for each dataset, the deformations can be measured through the differences of the kriging predictions. Of note, the kriging process is executed on one-meter-wide local regions of the bottom flange of the outer bridge girder. Results from a cross-validation (not reported here for brevity purposes) support the stationary assumption for the kriging process.
The primary advantage of this approach is that it is robust to locations of missing data (a common occurrence in many practical field applications). Given data point locations in the interpolation grid that lie in the areas of missing data, kriging uses the spatial autocorrelation of the observations in the point cloud to make predictions at these locations to fill in the missing data. While the accuracy of this feature is dependent on the ability to accurately capture and model the spatial autocorrelation, it is preferable in relevant situations.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}