3.1. Experimental Setup
This experiment was carried out on an Ubuntu 20.04 system with RTX 3090 (24 G of video memory), adopted a Pytorch 1.8 operation framework, and selected SGD as the pre-optimizer. The initial learning rate was 0.01, and the learning rate for each epoch was 95% of the original. Random seeds were used to input pictures to ensure the stability of the experimental data. The training set and test set in this article are from the Kaggle Disaster Classification Competition and the internal data set of the State Key Laboratory of Information Engineering in Surveying, Mapping and Remote Sensing, Wuhan University. There are 11,243 data sets in this experiment, comprising 8997 training sets and 2246 test sets, each of which is a color image. However, in order to increase the robustness of model training, the length, width, and size of the images are not limited. When the models were input, the images were randomly cropped to a size of 224*224, and data enhancement was used to further improve the data.
3.2. Experimental Procedure
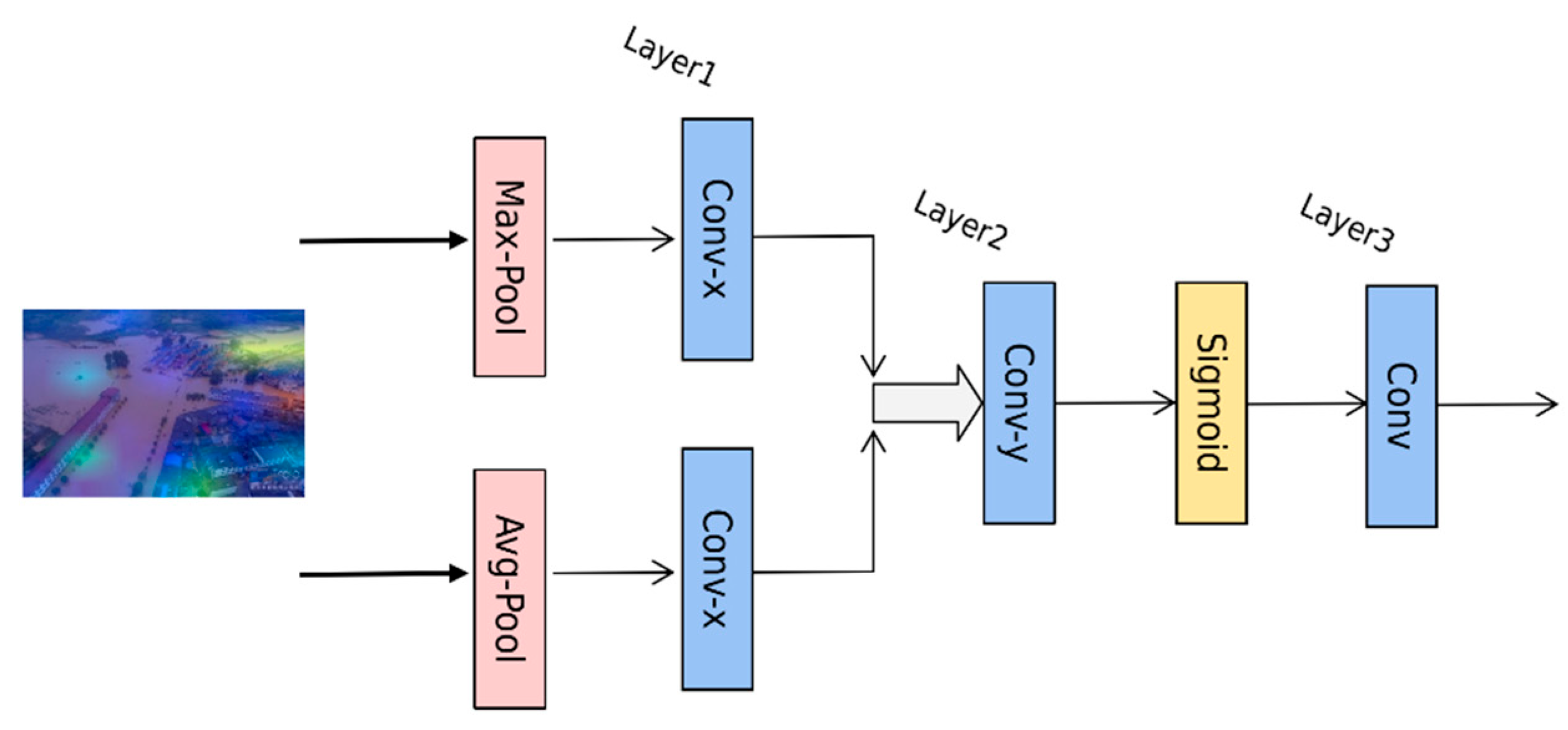
This paper first used the spatial attention mechanism module to improve the accuracy of the algorithm, and then it introduced deep separable convolution to reduce the calculations and parameters of the algorithm while ensuring accuracy; finally, the hyperparameters were fine-tuned to optimize the model and obtain the SDS-Network algorithm model in this paper. The evaluation indicators used in this article include floating point operations (FLOPs), parameters, accuracy (Acc top1), and memory.
In
Table 3, ResNet50 + Spatial represents the use of the spatial attention mechanism on ResNet50; ResNet50 + Spatial + DepthWise represents the further use of the depthwise separable convolution; and SDS-Network is the algorithm model proposed in this paper. It can be seen in
Table 3 that the Acc of the original model ResNet50 was 0.8998 and that the optimized Acc was 0.9248, which increased by 2.5%; the parameters were reduced by about 6 times compared with those of ResNet50, FLOPs were reduced by about 4 times, and memory was reduced 2 times. Therefore, the SDS-Network algorithm proposed in this paper has achieved good results and is suitable for disaster classification.
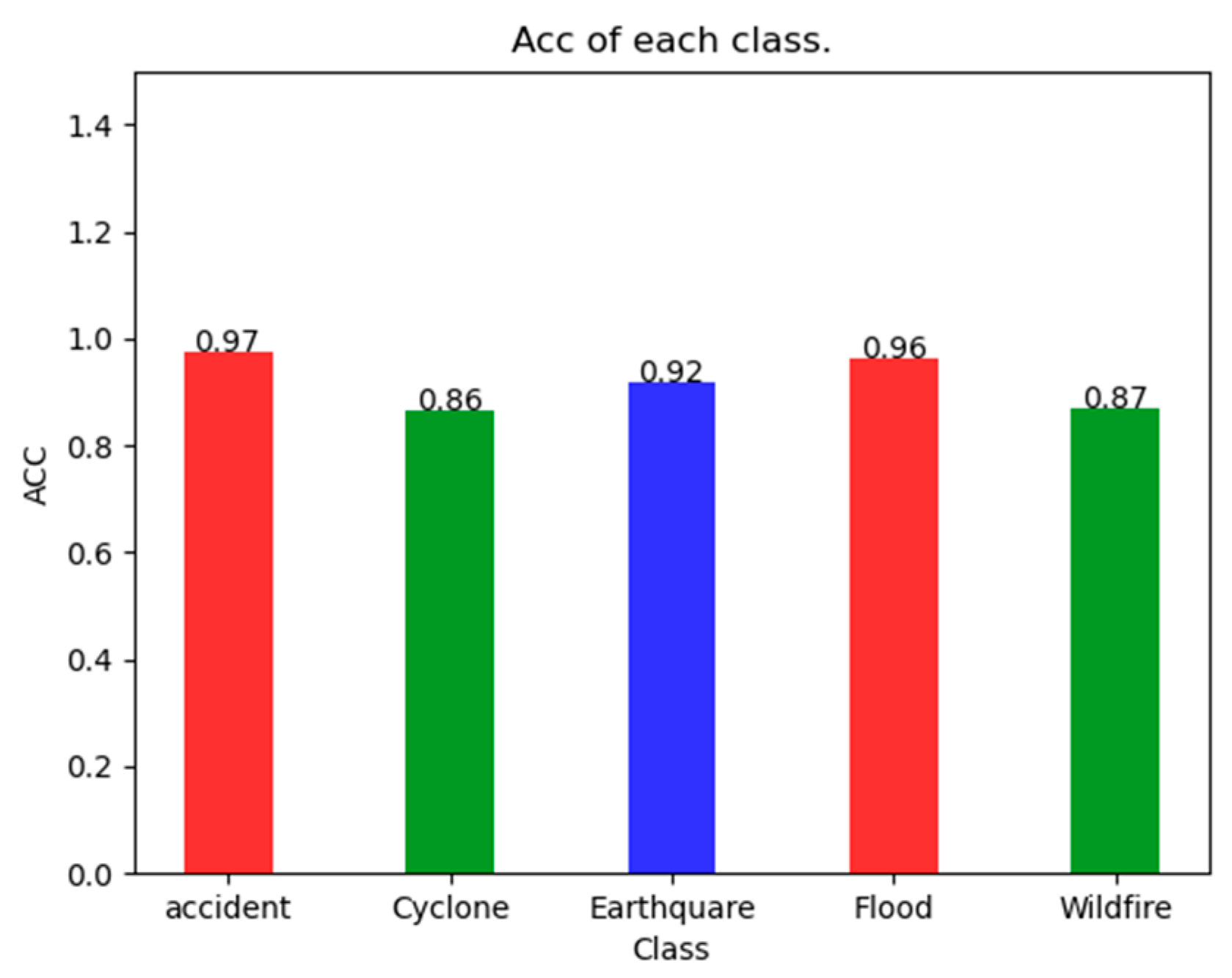
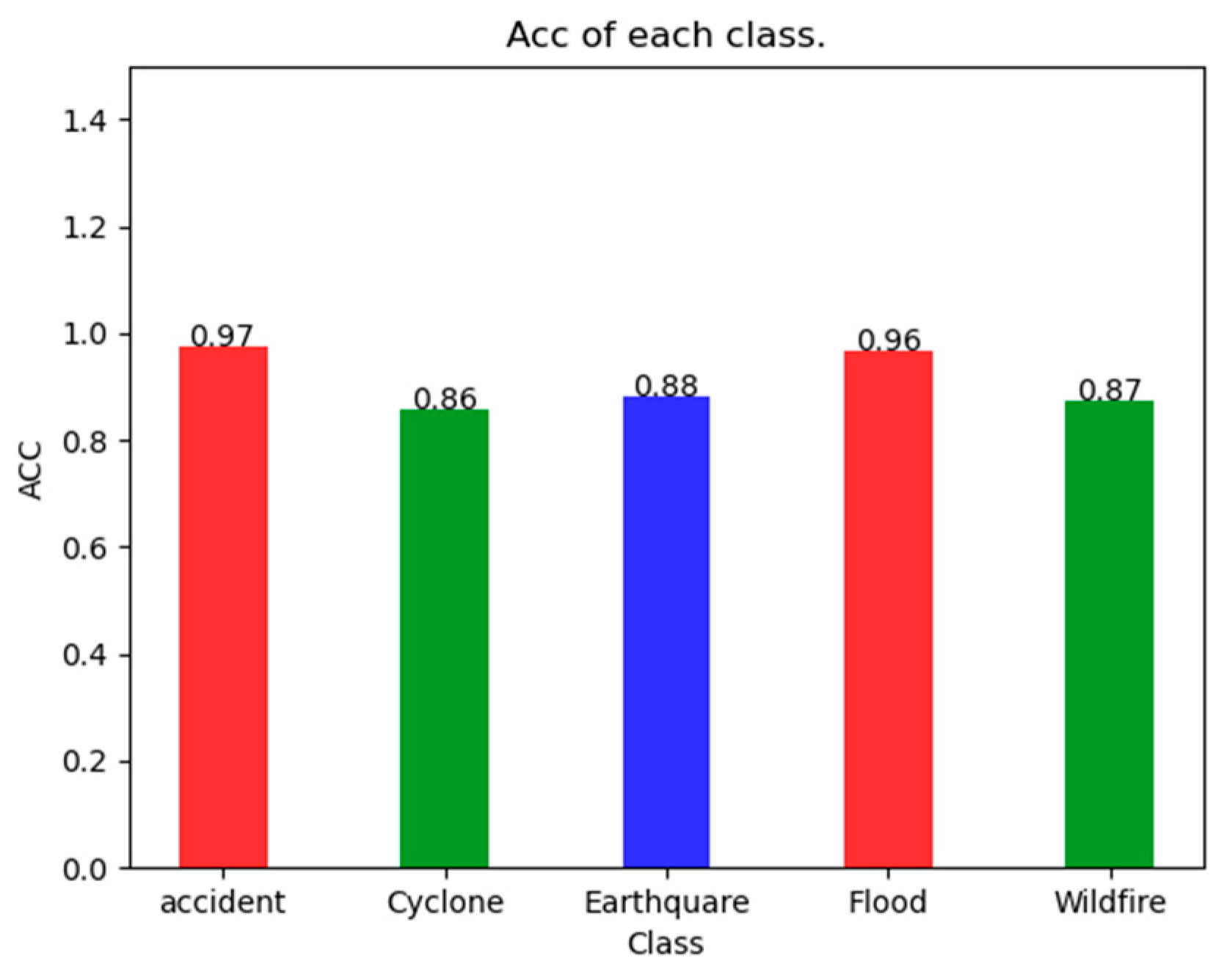
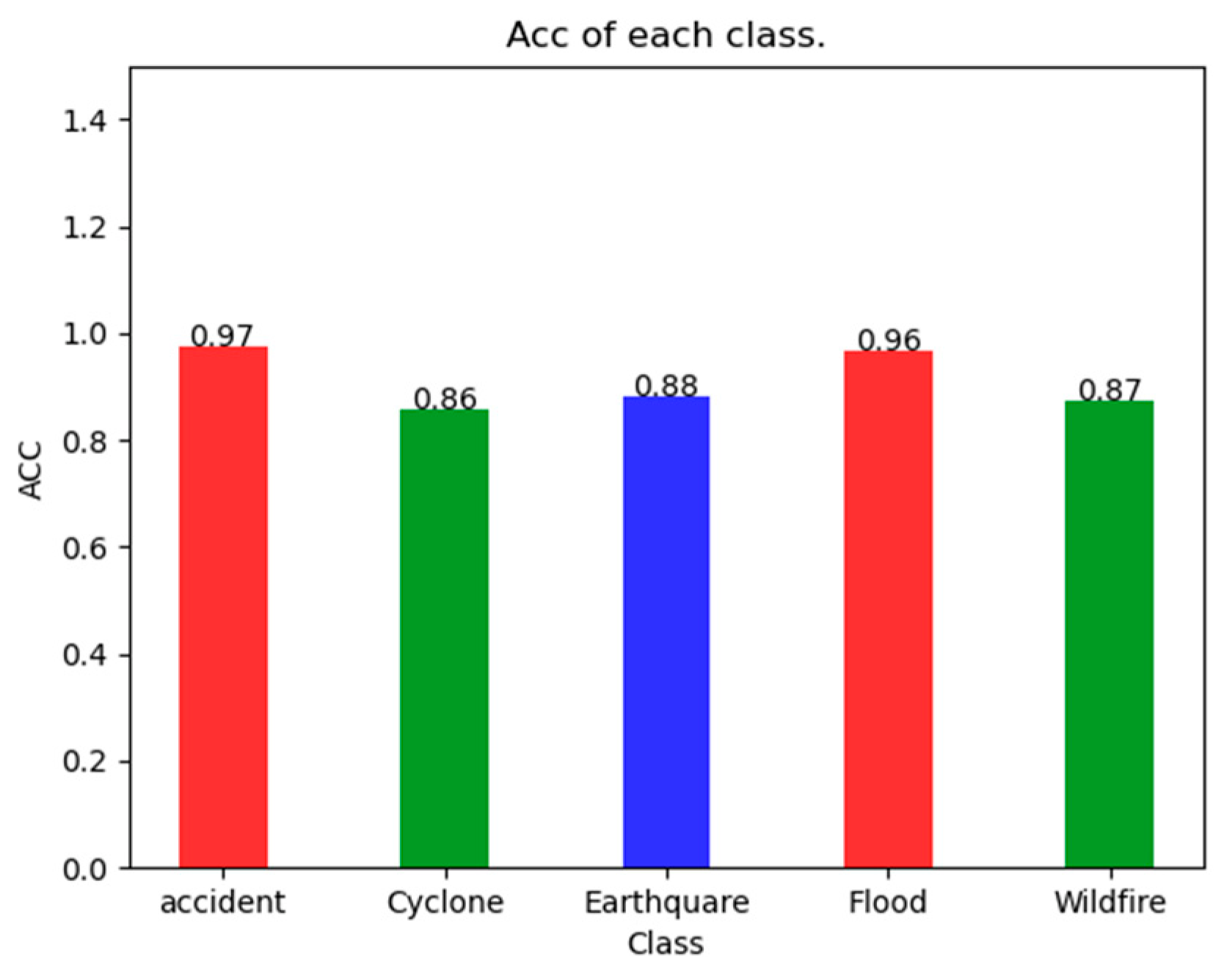
As can be seen in
Figure 4, the SDS-Network classification algorithm has an Acc of 97% for Accident, 86% for Cyclone, 92% for Earthquake, 95% for Flood, and 87% for Wildfire, which are all greater than 85%. It can also be seen that the Acc of Accident is 0.11 higher than that of Cyclone, with a smaller difference. Because the SDS-Network is applicable to each category of disaster classification, there is no notable difference.
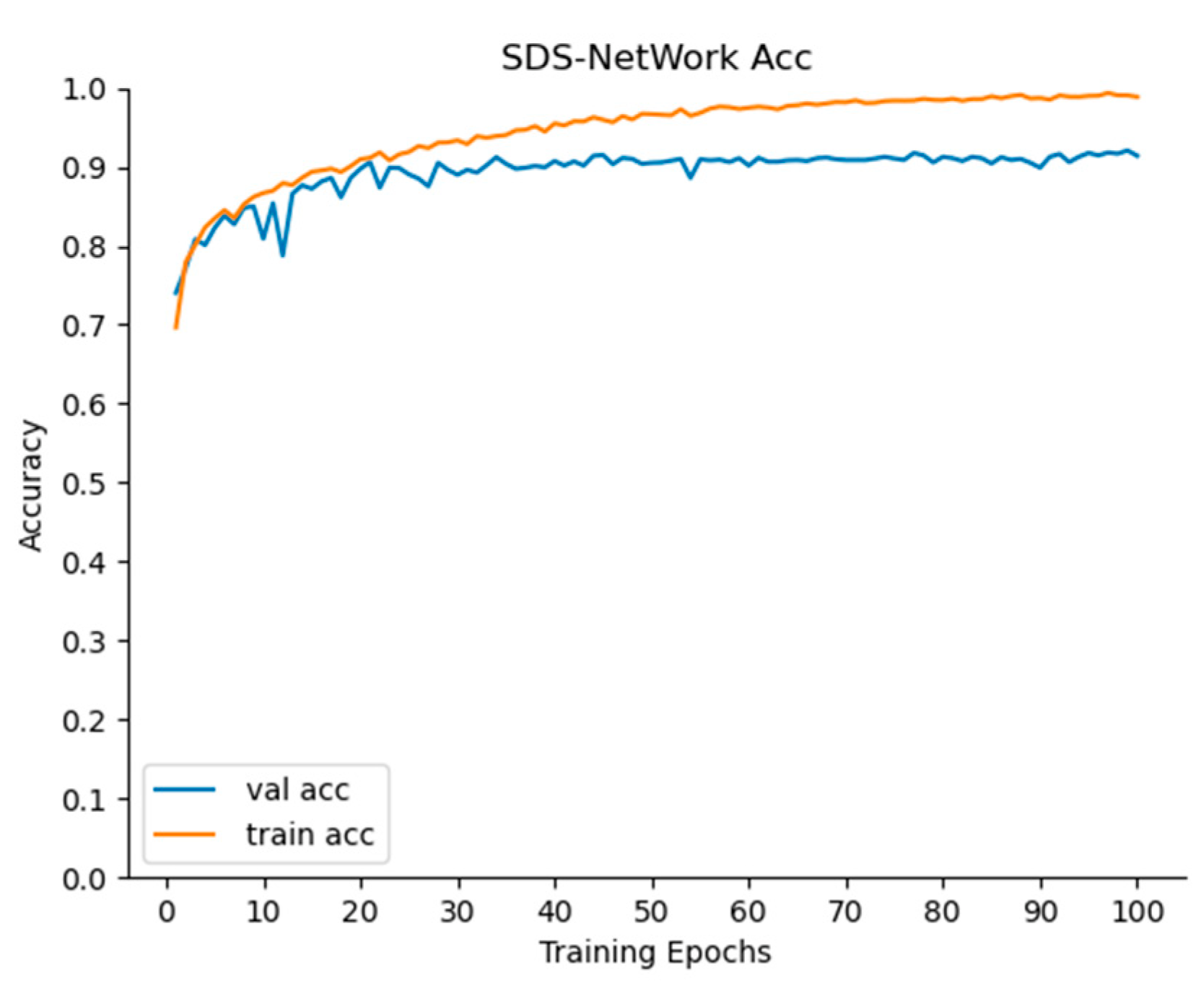
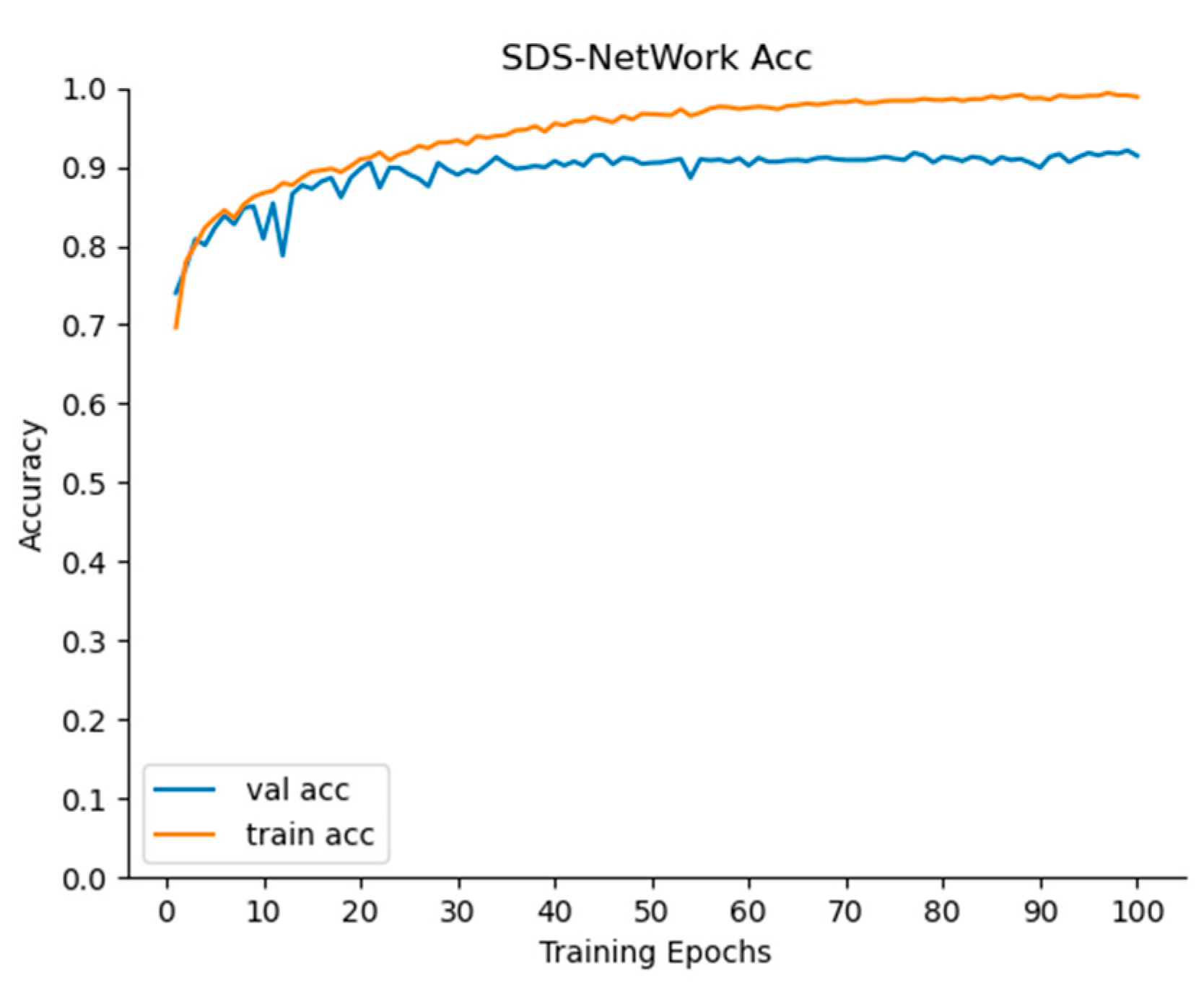
It can be seen in
Figure 5 and
Figure 6 that, as the iterations of the SDS-Network algorithm increased, the Acc also increased, and Loss decreased. In the graph, it can be seen that the trained Acc was slightly higher than that in the testing phase, and the trained Loss was slightly lower than that in the testing phase. In order to ensure practicability and applicability, the Acc values selected in this article were all from the test phase. When the epoch was iterated 100 times, both Acc and Loss tended to be stable, indicating that setting the epoch to 100 in this article was consistent with the experimental environment.
This article first compared the SDS-Network with some classic classification algorithms. It can be seen in
Table 4 that the Acc of Densenet121 was higher than that of AlexNet and ResNet18, but the Acc of the SDS-Network was higher than that of Densenet121, and the Acc of the SDS-Network algorithm was lower than that of AlexNet, ResNet18, and Densenet121. Although AlexNet was better than the SDS-Network algorithm in FLOPs and memory, its Acc was lower, and Vgg16 and Vgg19 performed poorly in Acc testing. Therefore, the SDS-Network algorithm proposed in this paper performed best in disaster classification.
In order to further verify the lightweight performance of the SDS-Network algorithm, this paper conducted further experimental research and compared the SDS-Network algorithm with the lightweight algorithms mobilenet series, shufflenet series, squeezenet series, and mnasnet series [
44].
First of all, in the mobilenet series, mobilenet_v3_large had the best overall performance. However, the FLOPs in mobilenet_v3_large were slightly higher than those of the SDS-Network algorithm, and mobilenet_v3_large performed slightly lower than the SDS-Network algorithm in Acc, parameters, and memory. After a comprehensive evaluation, the SDS-Network algorithm was found to be slightly better than the mobilenet_V3_large algorithm in lightweight performance. Secondly, among the shufflenet series of algorithms, shufflenet_v2_x1_0 had the best overall performance. Its performance was better than the SDS-Network algorithm in parameters, FLOPs, and memory, but its Acc was slightly lower than that of the SDS-Network algorithm. We can see in
Figure 7 that the SDS-Network algorithm was more stable than the shufflenet_V2_X1_0 algorithm in each Acc value when comparing the effects of each category. Therefore, it is concluded that both the SDS-Network and shufflenet_v2_x1_0 algorithms are more suitable for lightweight disaster classifications. Finally,
Table 5 proves that the squeezenet and mnasnet series are very low in Acc and that the algorithm model has an overfitting problem, so it is not suitable for disaster classifications.
Next, the algorithm proposed in this paper was further compared with the algorithms in the efficient series [
45], which are relatively new image classification models. In
Table 6, it can be seen that the SDS-Network still maintains the highest Acc while also maintaining the best effect on memory, FLOPs, and parameters (state of the art). Although the parameters of efficientnet_b0 were slightly lower than those of the SDS-Network algorithm, its comprehensive performance was significantly worse than that of the SDS-Network algorithm. Therefore, the SDS-Network algorithm is better than the efficient series of algorithms.
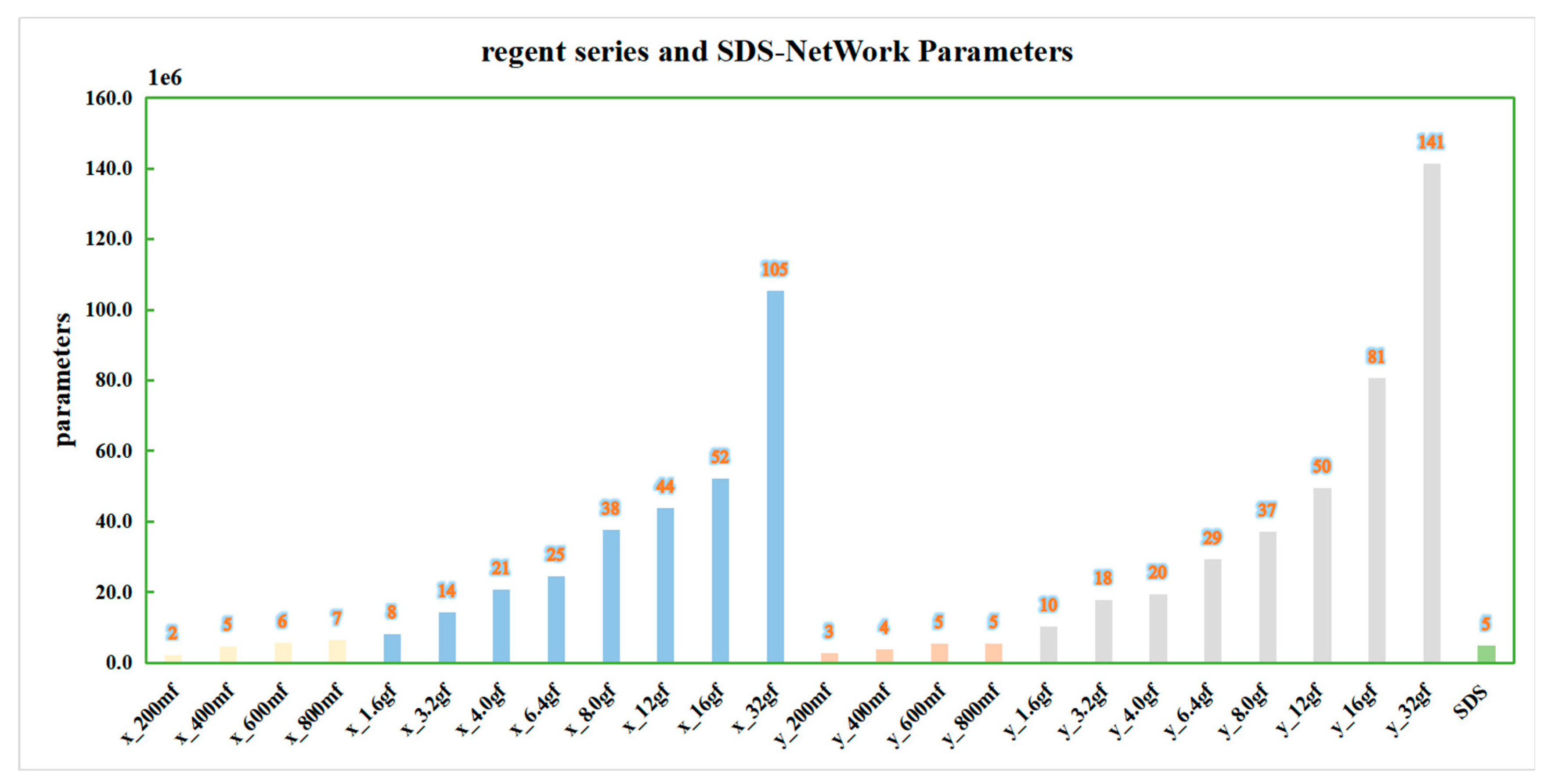
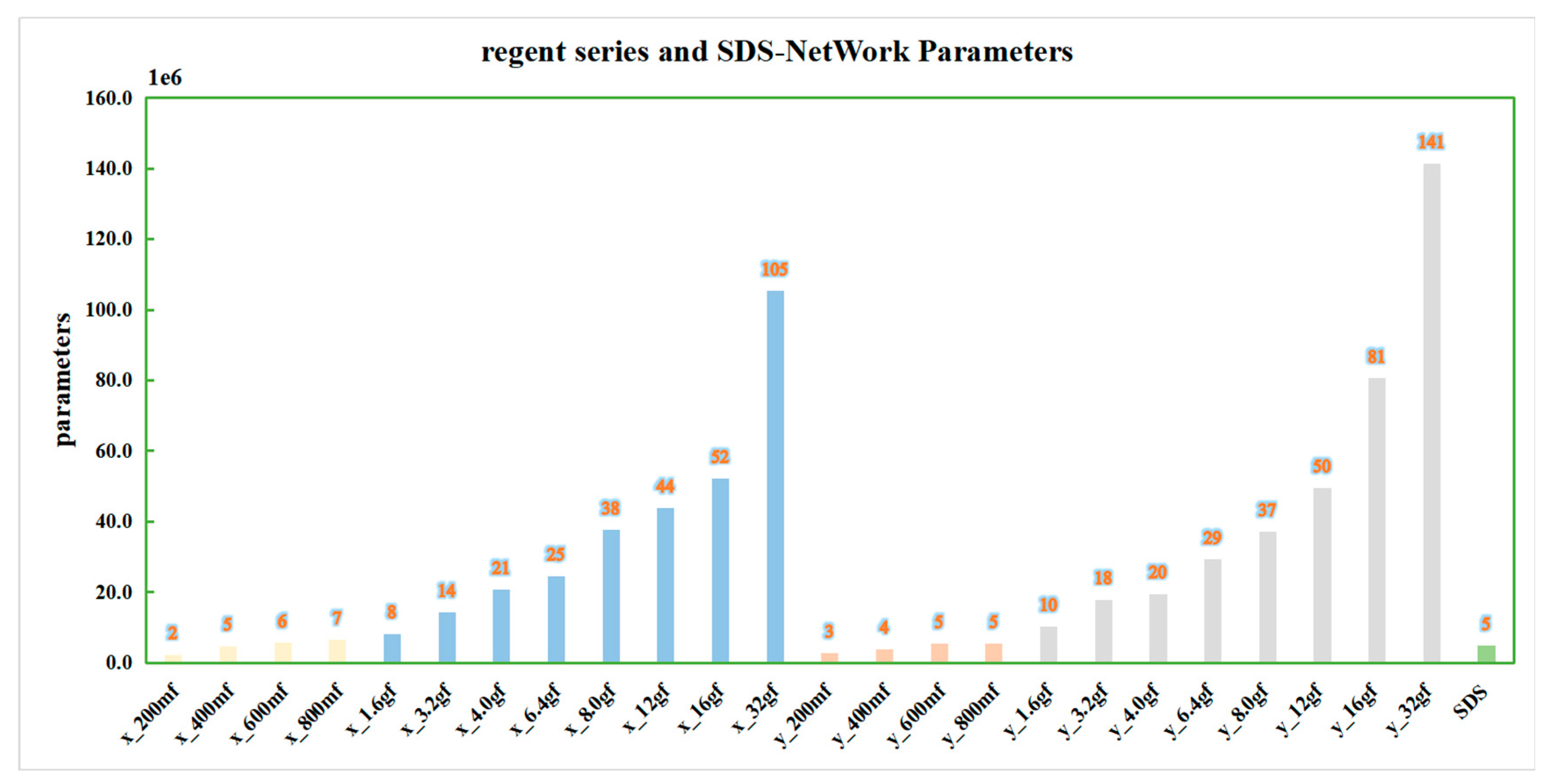
In order to ensure the effectiveness of the algorithm, this paper continued to compare the data with those of the regnet series [
46] algorithm, and it conducted experiments in the same experimental environment. In order to obtain a more intuitive comparison, this paper drew a bar chart according to the algorithm data in
Table 7, as shown in
Figure 8,
Figure 9,
Figure 10 and
Figure 11. In order to facilitate understanding, in the figures, regnetx_200mf is abbreviated as x_200mf and the SDS-Network is abbreviated as SDS.
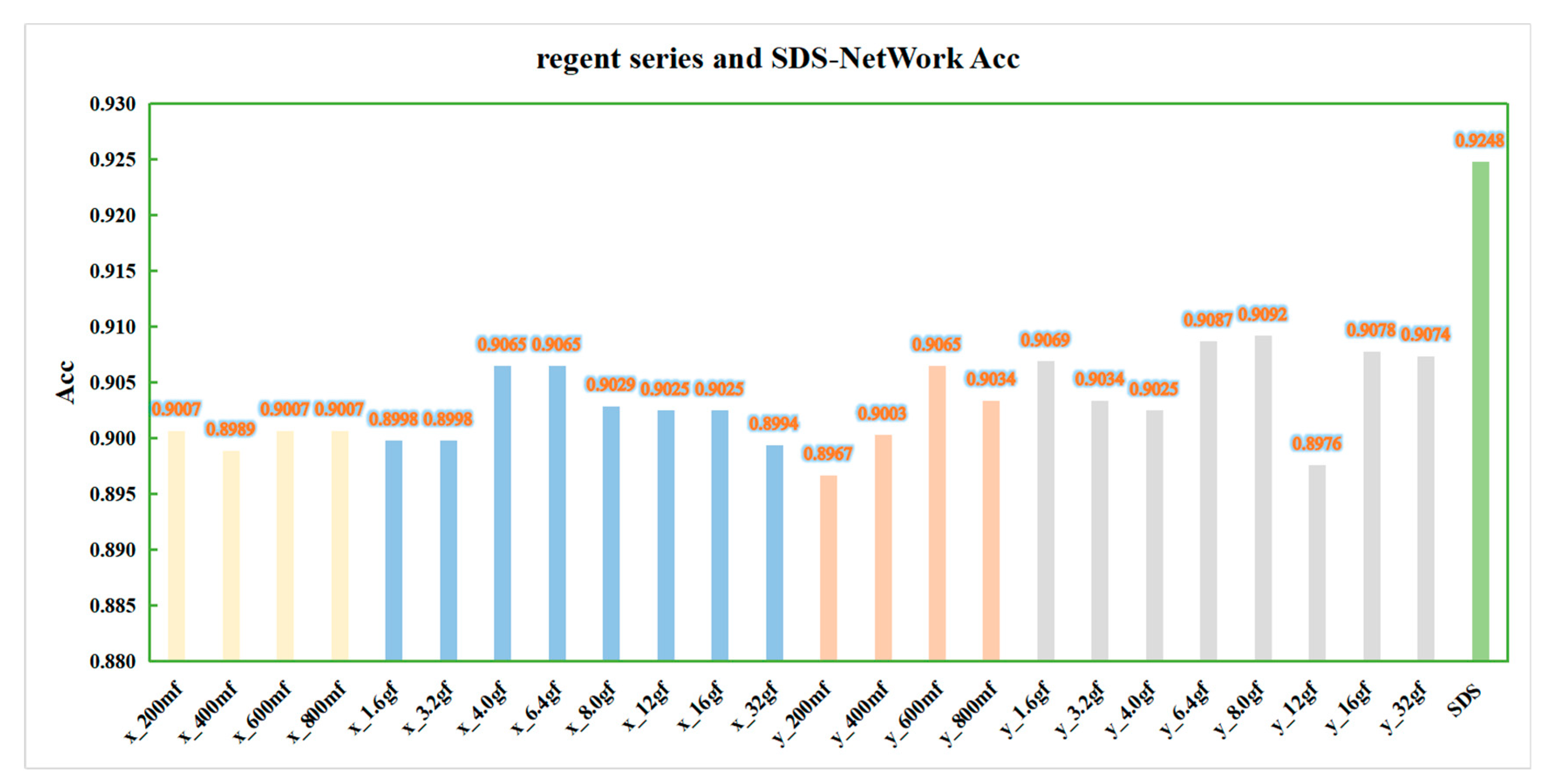
It can be seen in
Figure 8 that the data of the regnetx_y series of algorithms are slightly higher quality than those of the regnetx_x series of algorithms, but they are all lower quality than those of the SDS-Network algorithm. Therefore, the SDS-Network algorithm performs better in disaster classifications.
It can be seen in
Figure 9 that the regnetx_32gf and regnety_32gf algorithms have the highest FLOPs, and the regnetx_200mf and regnety_200mf algorithms have the lowest FLOPs. As the strength of the algorithms continued to increase, the FLOPs also continued to increase. The FLOPs of the SDS-Network algorithm in the regnet algorithm series were still very low. This further proves that the SDS-Network algorithm achieves a better lightweight effect.
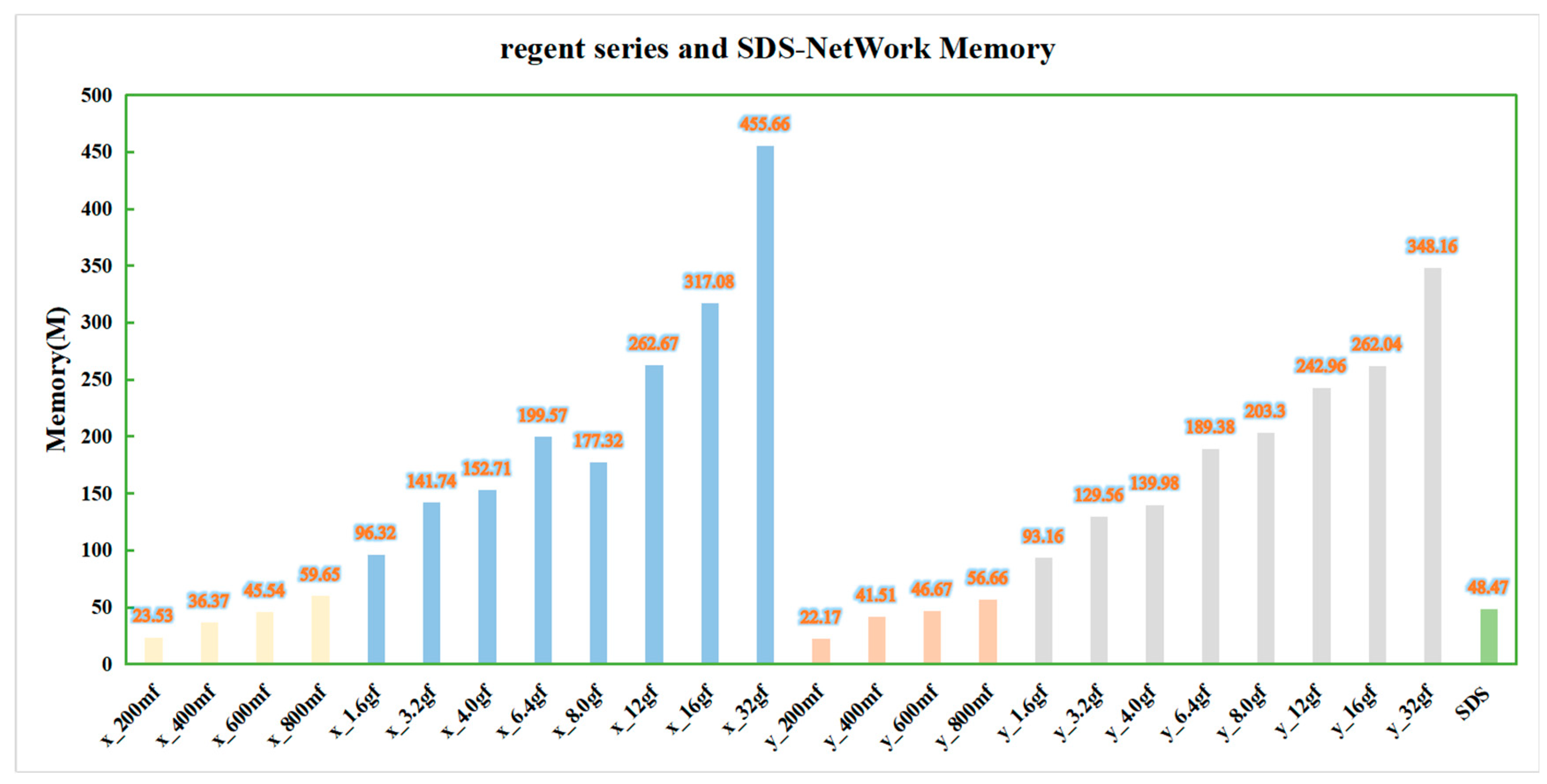
It can be seen in
Figure 10 that, as the strength of the algorithm increased, the memory of the regnet series of algorithms also increased. Among them, the memory of the regnetx_32gf and regnety_32gf algorithms was still the highest, while that of the SDS-Network algorithm was the lowest at about 48.47 M.
It can be seen in
Figure 11 that the change curve of parameters is similar to that of FLOPs and memory occupancy. The parameters of the SDS-Network algorithm in this paper are lower than those of the regnet series, and they are suitable for disaster classifications.
3.3. Class Activation Diagram
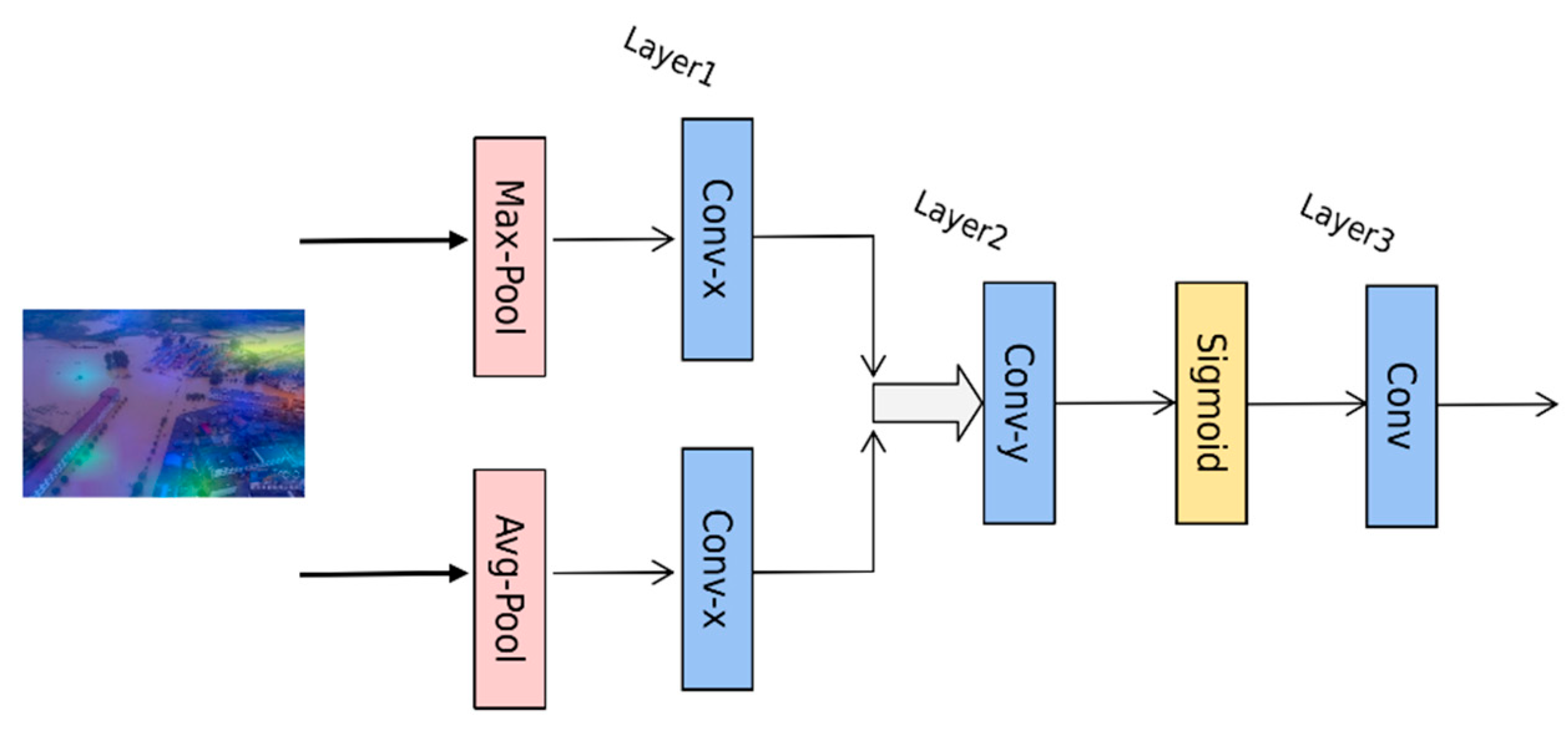
A Class Activation Map (CAM) [
47] visualizes the process of algorithm recognition and presents it with an intuitive visual effect. In detail, red represents the recognized part, and blue represents the unattended part. This paper introduced Gradient-weighted Class Activation Mapping (Grad-CAM) [
48], took the gradient of the feature map as the average, and obtained the N average gradient values corresponding to the N feature maps as the weight values. The information in the feature map can be used for discrimination when there is no observable difference. Compared with CAM, Grad-CAM can visualize the CNN of any structure without modifying the network structure or retraining, which further enhances the effect of algorithm recognition and visualization.
It can be seen in
Table 8 that, in this paper, the final convolutional layer of the SDS-Network algorithm was classified and output by Grad-CAM to verify the quality of the algorithm. When determining the image category, the algorithm mainly uses the relevant part, which is displayed in red. Each category of the algorithm in this paper always has a red part, which proves that the algorithm in this paper recognizes an image by its characteristics rather than by accidental prediction. The darker the color of the picture, the stronger the attention of the model. It can be observed that there are about three attention points in each category in the no-background picture in
Table 8. However, the blue is neglected, and the algorithm recognition effect is better; thus, it is suitable for disaster classifications.
3.4. Open Data Set
(1) Cifar-100 data set
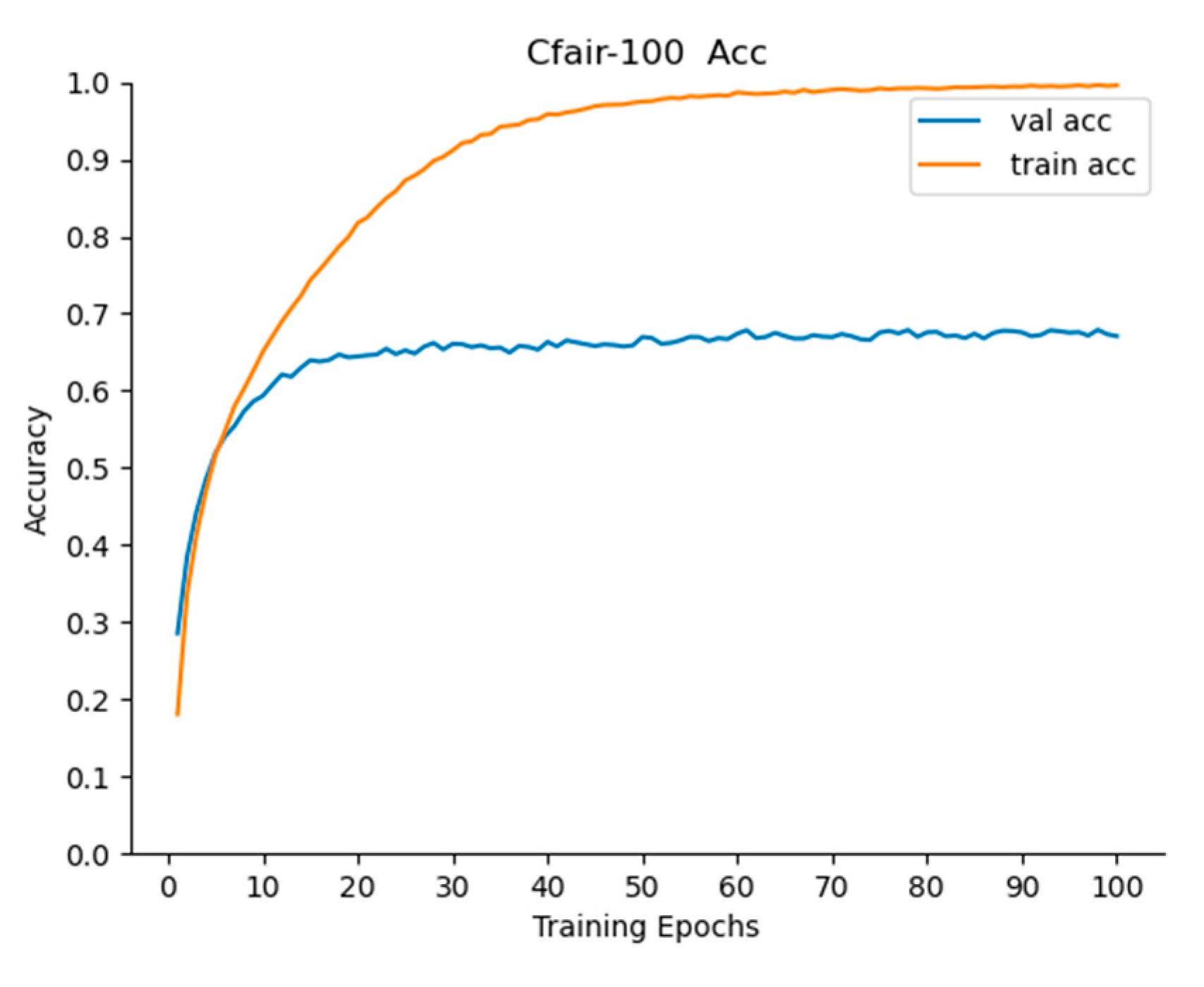
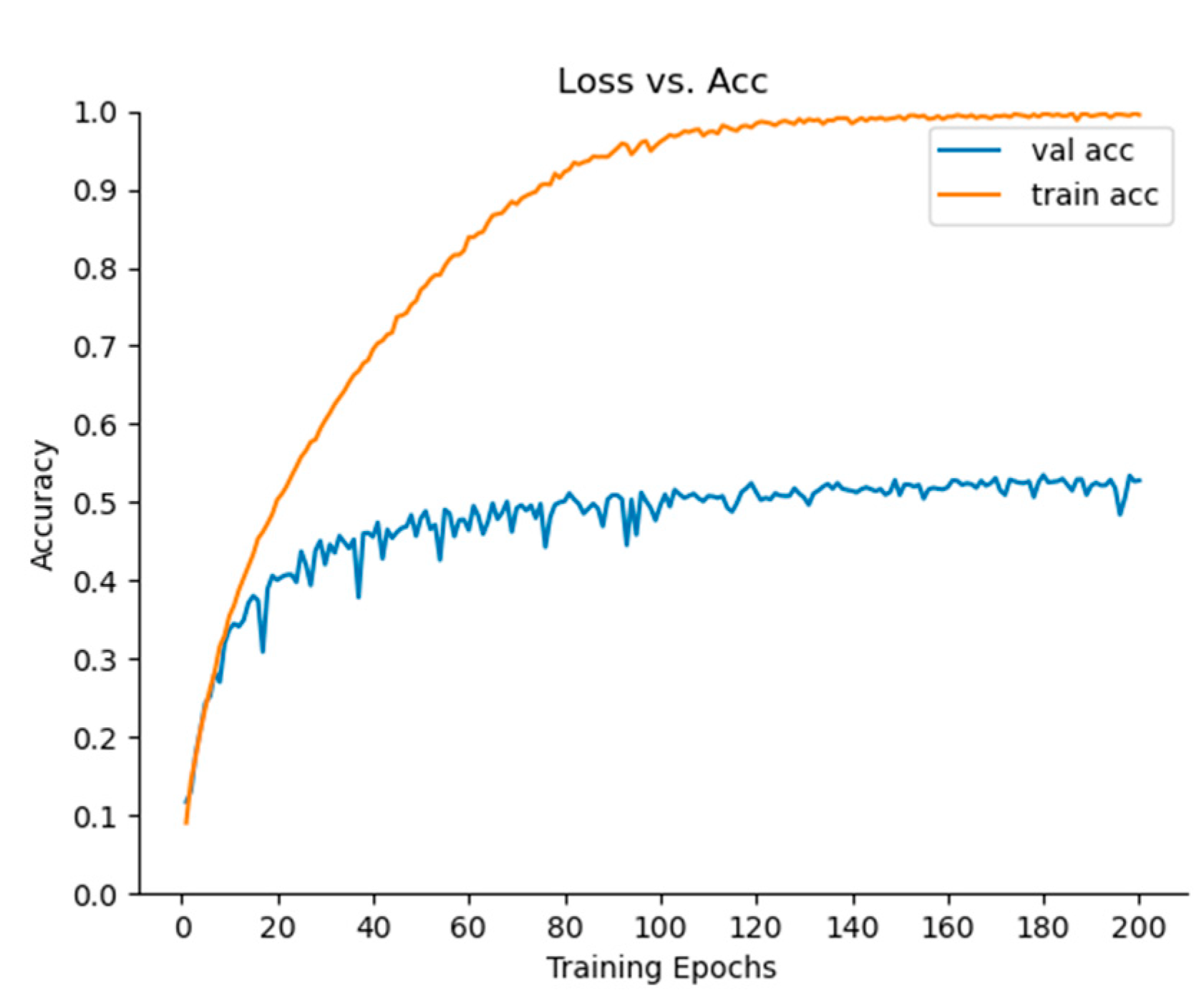
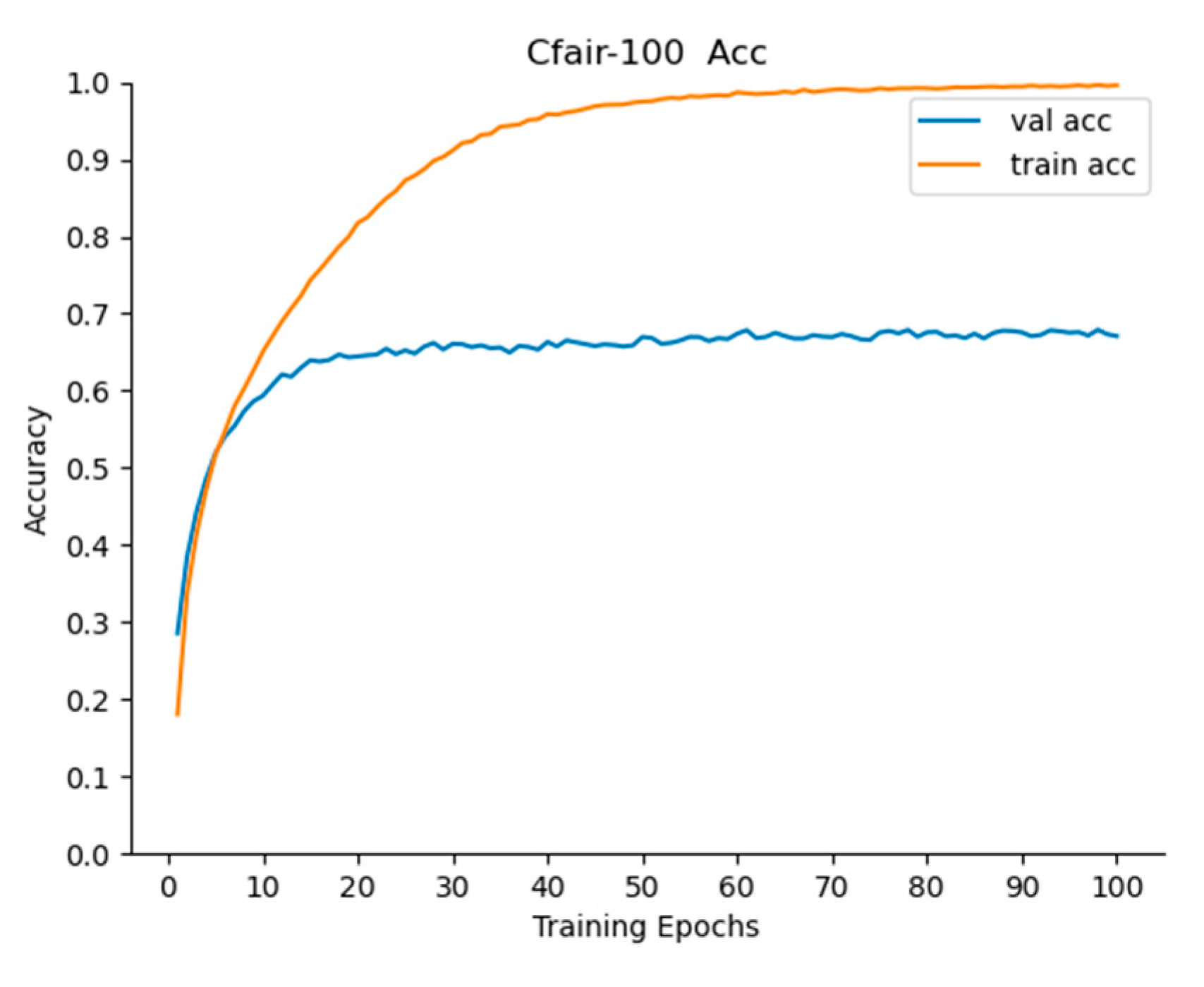
In order to further study the superiority of the algorithm, this paper classified the open data set Cifar-100 [
49] into 100 categories, including 50,000 training sets and 10,000 test sets, which were iterated 50 times, 100 times, 150 times, and 200 times, and the Acc change graphs for the iterations of 100 times and 200 times were obtained.
In
Table 9 and
Figure 12, it can be seen that the algorithm reached equilibrium after 100 iterations, and after 200 iterations, the Acc of the algorithm was lower than that after 100 iterations. It can be stated that the algorithm has an overfitting problem after 200 iterations. Therefore, the algorithm can be iterated 150 times. After 50 iterations, the Acc of Top-1 reached 66.98, and that of Top-3 and Top-5 reached 83.85% and 88.97%, respectively, which indicates that the algorithm in this paper performed well and that it had a faster effect. After 150 iterations, the Acc of Top-1, Top-3, and Top-5 reached 68.78%, 84.70%, and 89.75%, respectively, which proves that this algorithm was better and had a strong generalization ability.
(2) Caltech data set
The Caltech pedestrian data set [
50] used in this article has two categories: one is Caltech-101, and the other is Caltech-256. This article used Caltech-256, and each image had a size of 300 * 200, with 24, 581 images in the training set and 6026 images in the test set. It can be seen in
Figure 13 that, when the SDS-Network algorithm was iterated 200 times, the model tended to be stable. It can be seen in
Table 10 that, when the algorithm was iterated 200 times, the Acc of Top-1, Top-3, and Top-5 reached 53.50%, 67.24%, and 72.93%, respectively. We can therefore see that the Acc of Top-1 exceeds 50%, and after 50 iterations, it is close to 50%. In summary, the algorithm in this paper has a fast convergence speed, a high accuracy, and only 1.02 G FLOPs, so it is suitable for application in other classification tasks.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}









