
RANet: A Reliability-Guided Aggregation Network for Hyperspectral and RGB Fusion Tracking





Abstract
:
1. Introduction
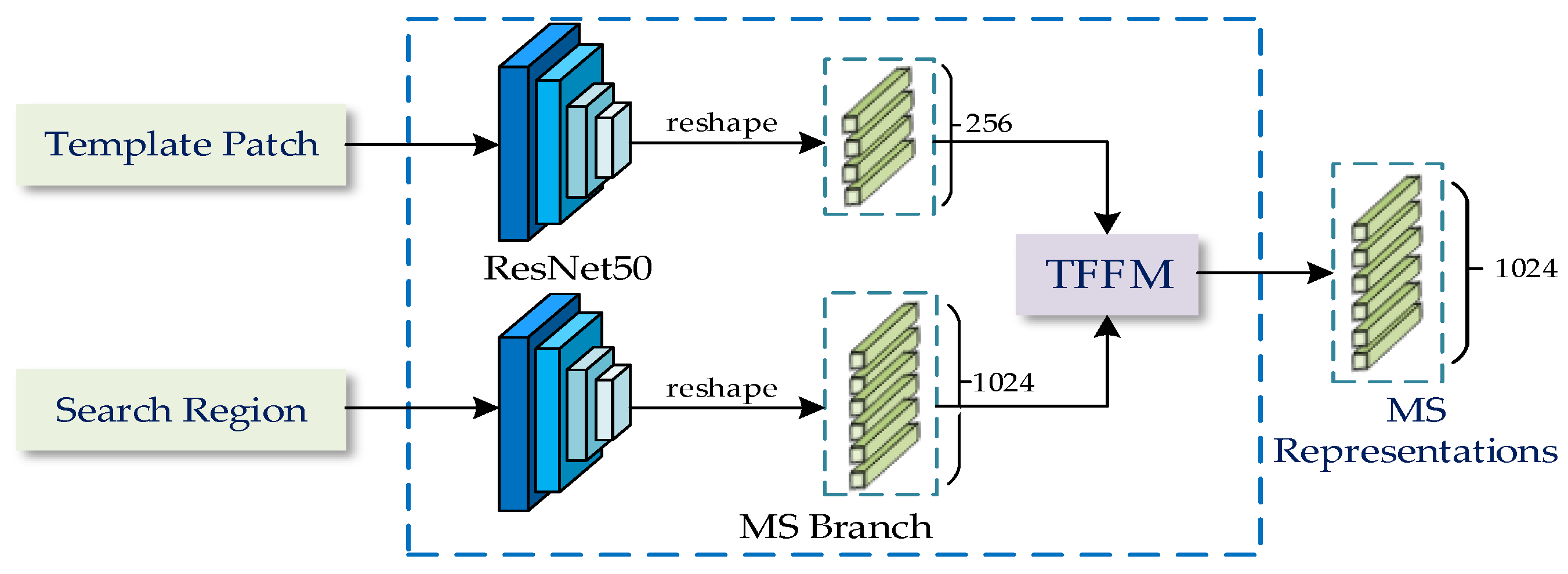
- We construct a dual TransT structure as MS branches to fully extract semantic features of muti-modality images. Two branches are employed to process hyperspectral and RGB images to obtain MS representations, respectively. To the best of our knowledge, this is the first work that Transformer is introduced into fusion tracking based on hyperspectral and RGB images;
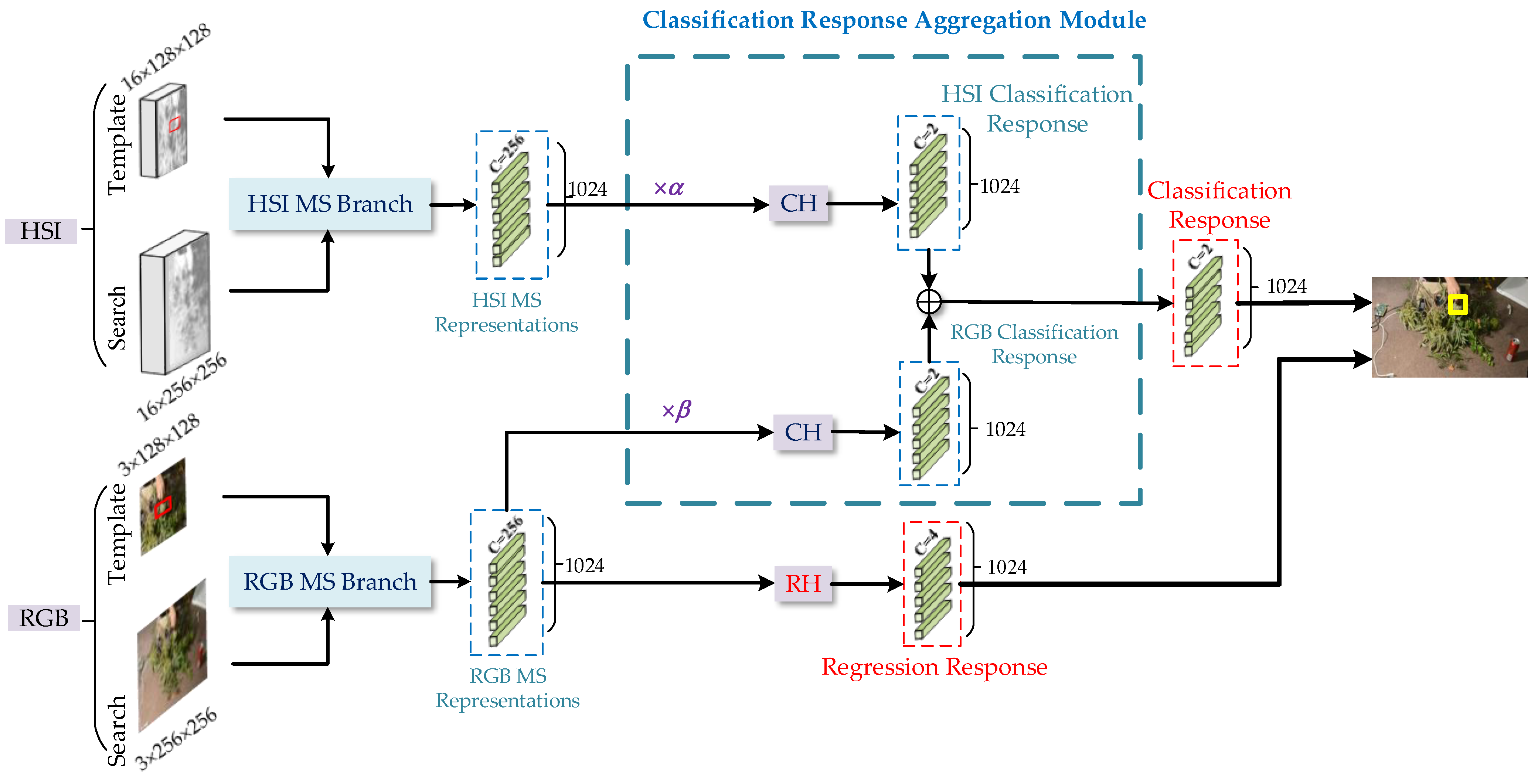
- We design a classification response aggregation module to combine the complementary information of different modality images effectively. Different responses generated by the MS representations predicted by the classification head are fused as the final classification response. The purpose is to enhance the ability of the tracking network to distinguish objects and backgrounds by using multi-modality information;
- We propose a method to evaluate the reliability of hyperspectral and RGB modalities to predict the contribution of different modalities for the tracking task. By reducing the noise effect of low-reliability modality data and making a more reliable modality play a greater contribution in the classification task to guide the aggregation of different modality information, which can maximize the aggregation module in improving the tracking performance.
2. Methods
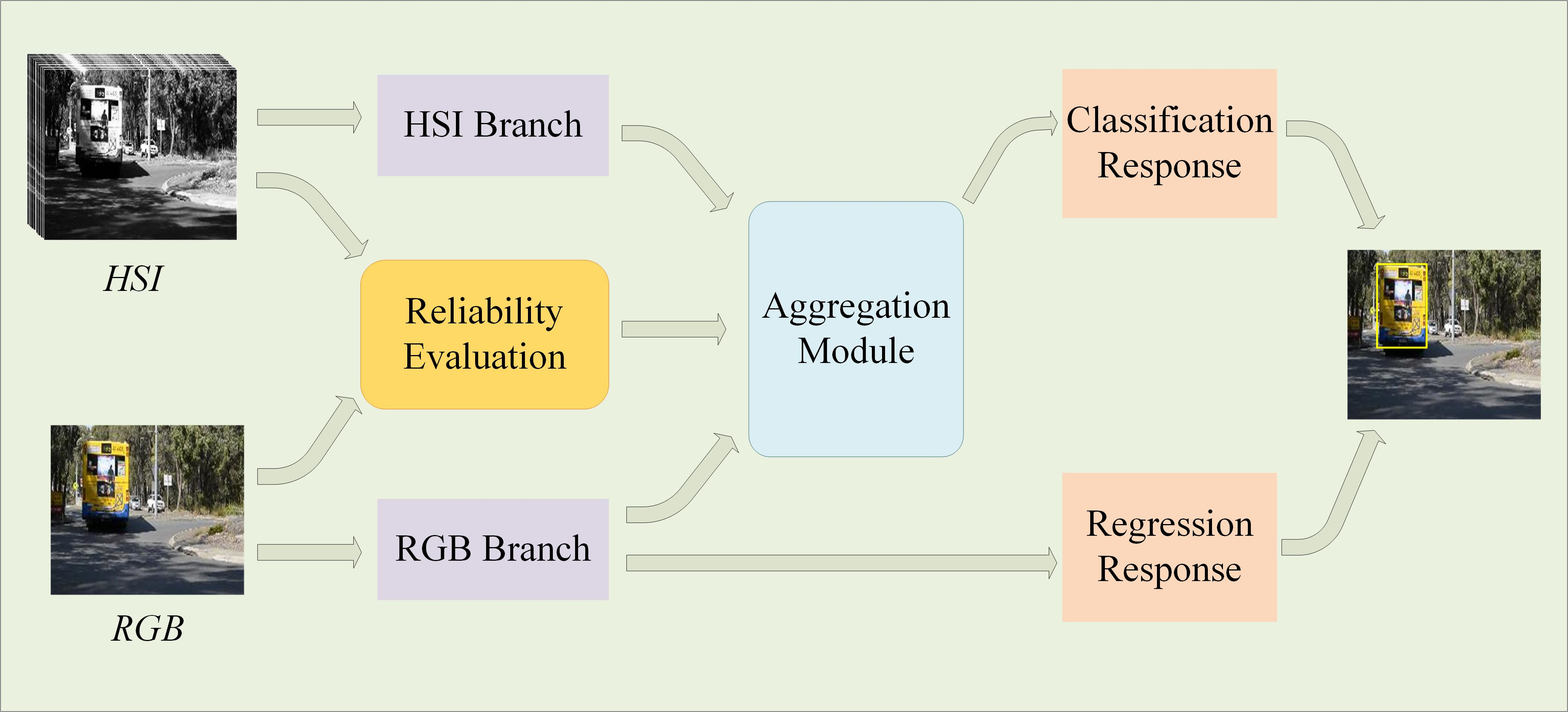
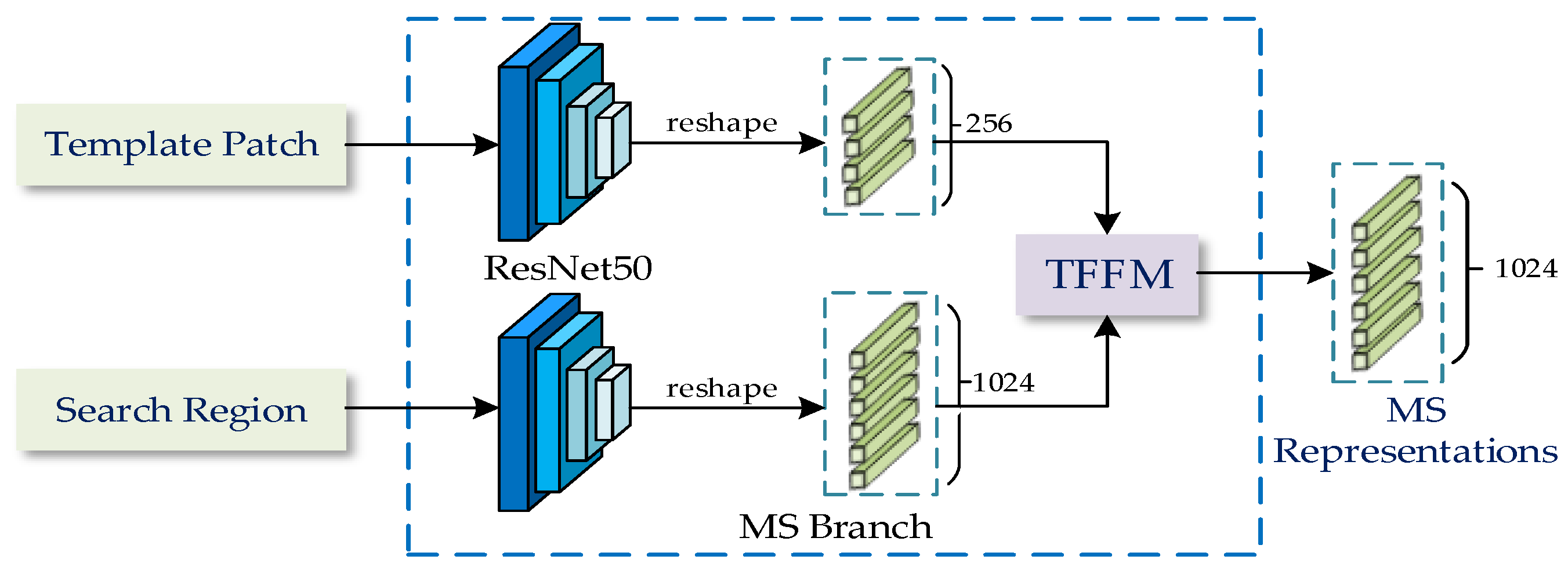
2.1. Network Architecture
| Algorithm 1 Reliability-guided Aggregation Network (RANet) |
| Input: HSI and RGB sequences and the object state (ground truth) in first frame, and and are the contribution values of hyperspectral modality and RGB modality, respectively; Output: State (position and size) of the object in each frame;
|
2.2. Modality-Specific Branch
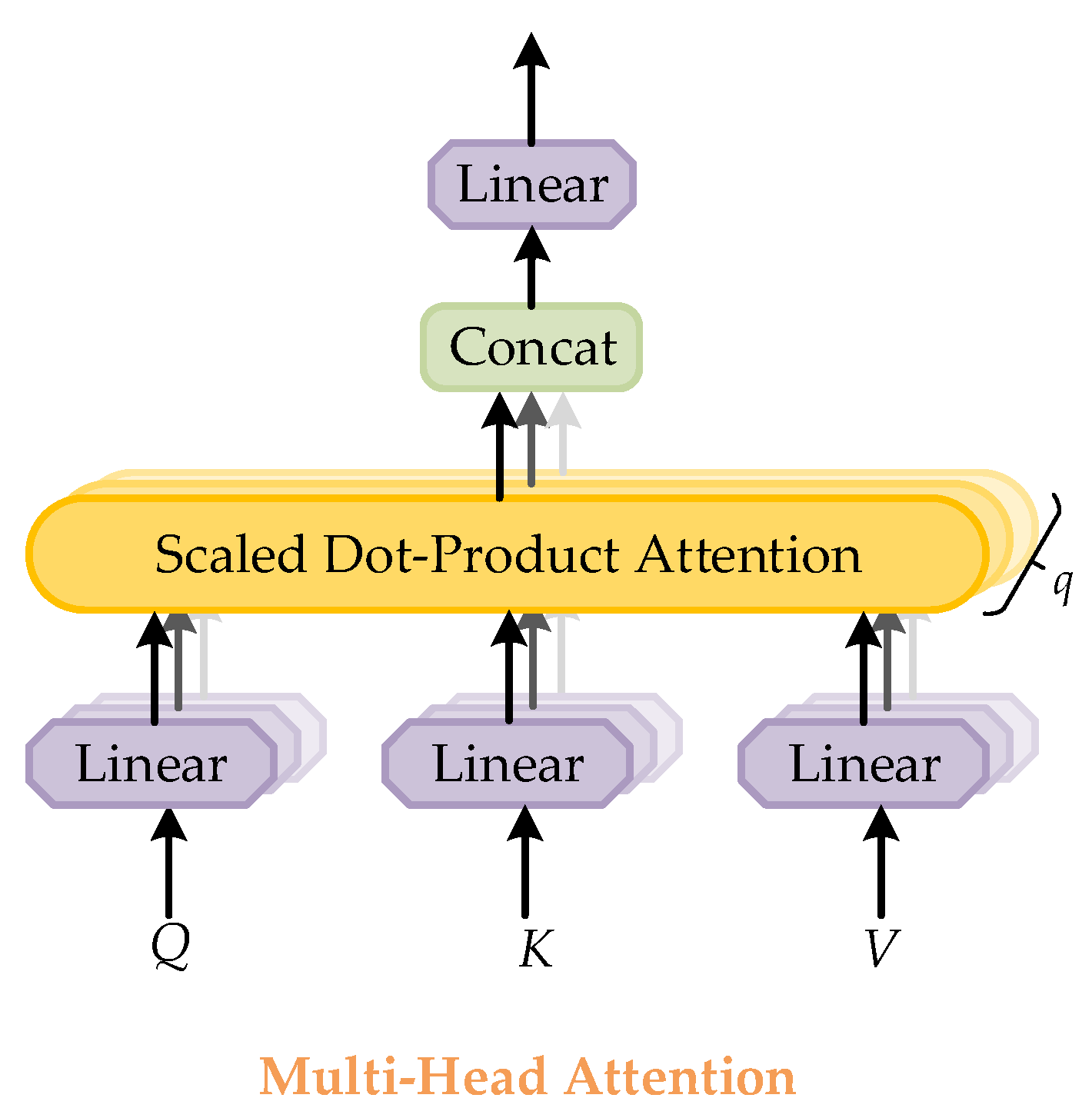
2.2.1. The Attention of Transformer
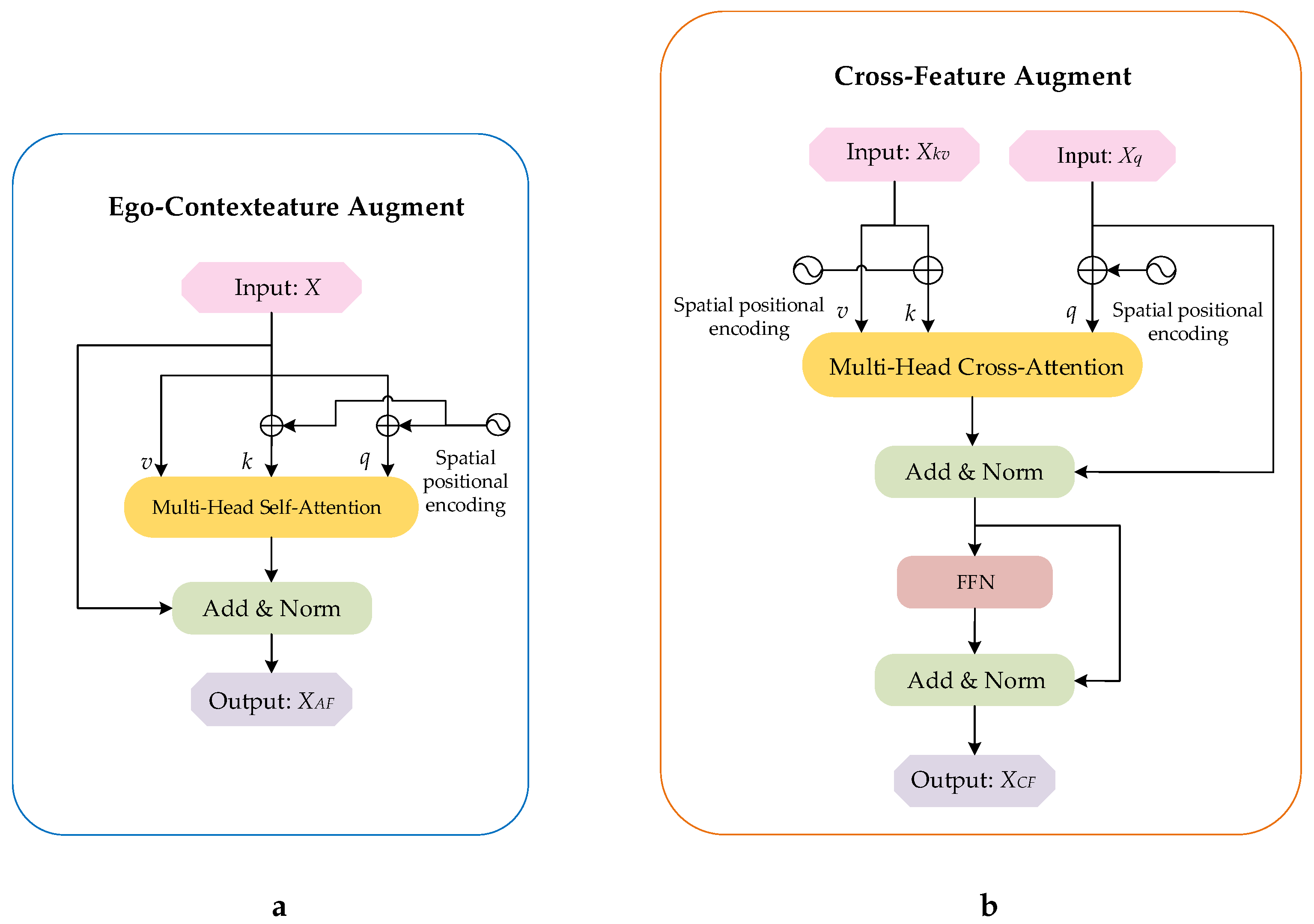
2.2.2. Ego-Context Augment Module
2.2.3. Cross-Feature Augment Module
2.3. Classification Response Aggregation Module
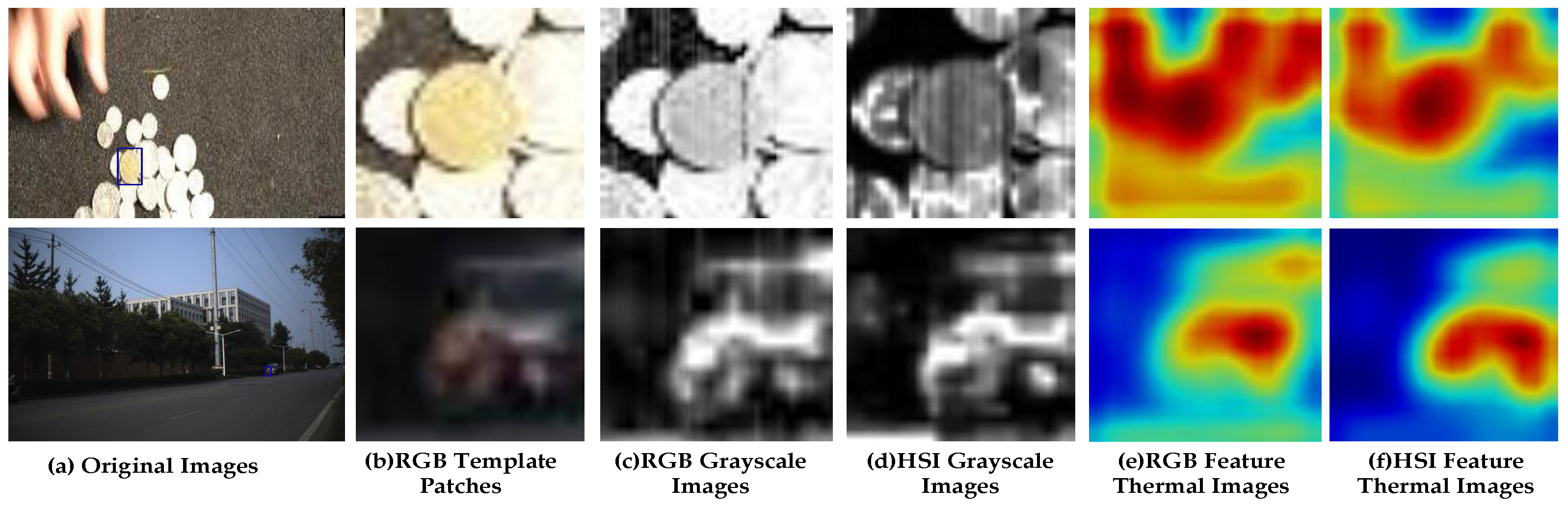
2.3.1. The Evaluation Method of Modality Reliability
2.3.2. Classification Response Aggregation Module
3. Experiments
3.1. Dataset and Compared Trackers
3.2. Implementation Details
3.3. Evaluation Metrics
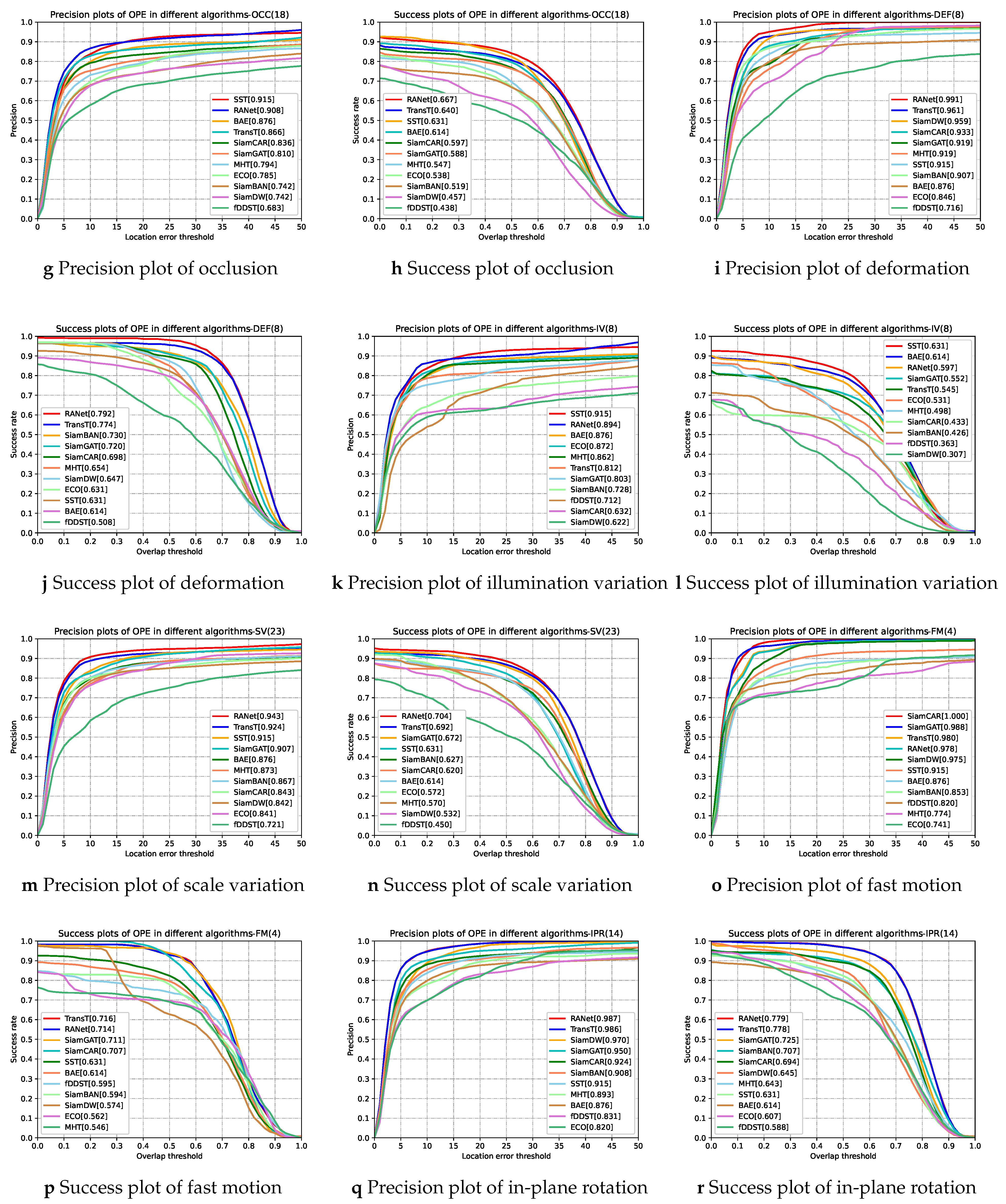
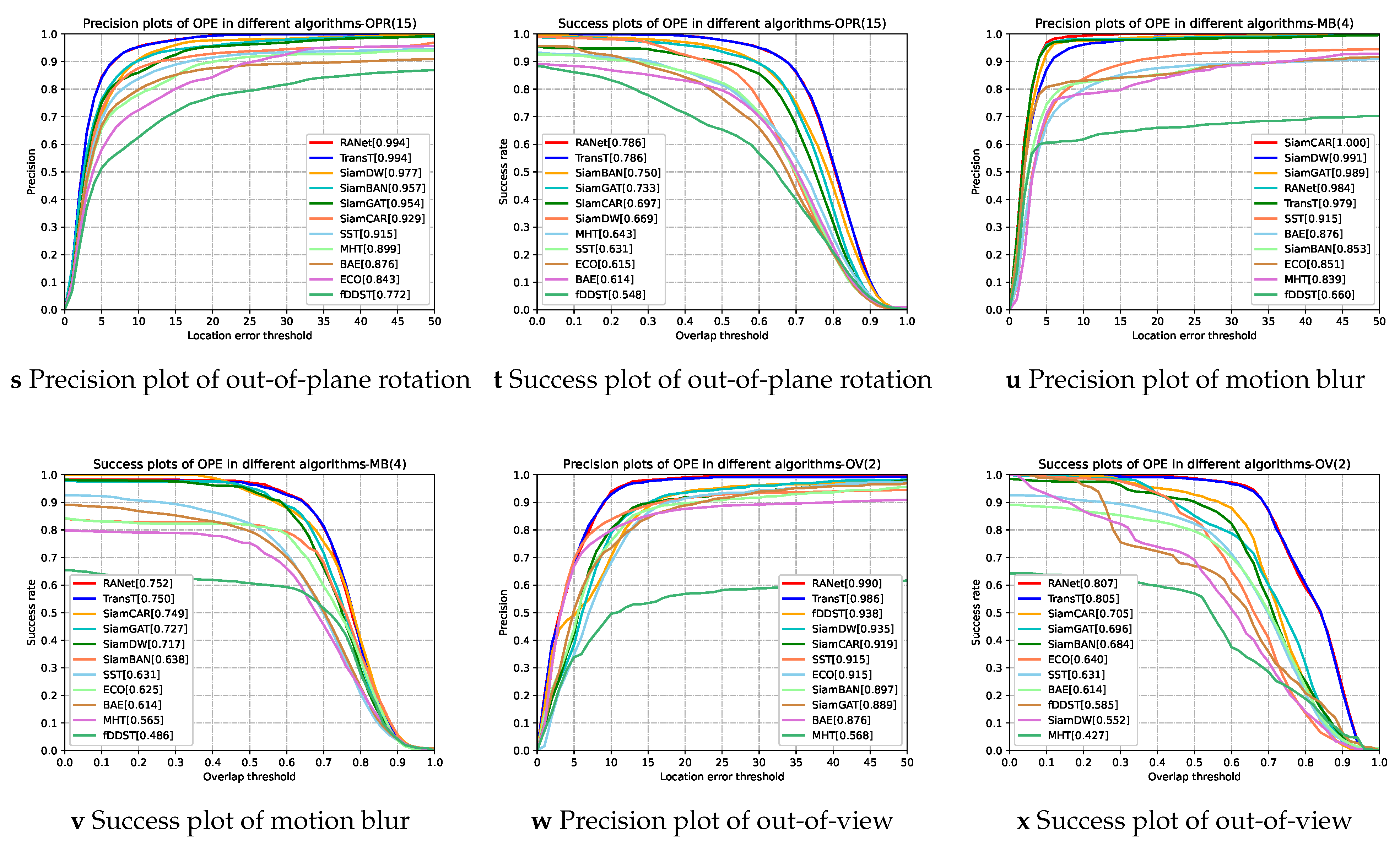
3.4. Results and Analysis
3.4.1. Quantitative Analyze
3.4.2. Qualitative Analyze
4. Ablation Study and Analysis
4.1. The Ablation Study of the Fusion Structure
4.1.1. Single Modality-Specific Representations Layers Fusion
4.1.2. Single Response Layers Fusion
4.1.3. Results and Analysis
4.2. The Ablation Study of the Contribution Value of Different Modalities
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Tian, X.; Liu, J.; Mallick, M.; Huang, K. Simultaneous Detection and Tracking of Moving-Target Shadows in ViSAR Imagery. IEEE Trans. Geosci. Remote Sens. 2021, 59, 1182–1199. [Google Scholar] [CrossRef]
- Henke, D.; Mendez Dominguez, E.; Small, D.; Schaepman, M.E.; Meier, E. Moving Target Tracking in Single- and Multichannel SAR. IEEE Trans. Geosci. Remote Sens. 2015, 53, 3146–3159. [Google Scholar] [CrossRef]
- Yang, X.; Wang, Y.; Wang, N.; Gao, X. An Enhanced SiamMask Network for Coastal Ship Tracking. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–11. [Google Scholar] [CrossRef]
- Thomas, M.; Kambhamettu, C.; Geiger, C.A. Motion Tracking of Discontinuous Sea Ice. IEEE Trans. Geosci. Remote Sens. 2011, 49, 5064–5079. [Google Scholar] [CrossRef]
- Xuan, S.; Li, S.; Han, M.; Wan, X.; Xia, G.S. Object Tracking in Satellite Videos by Improved Correlation Filters with Motion Estimations. IEEE Trans. Geosci. Remote Sens. 2020, 58, 1074–1086. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, T.; Zhang, G.; Cheng, Q.; Wu, J. Small Target Tracking in Satellite Videos Using Background Compensation. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7010–7021. [Google Scholar] [CrossRef]
- Guo, Q.; Feng, W.; Gao, R.; Liu, Y.; Wang, S. Exploring the Effects of Blur and Deblurring to Visual Object Tracking. IEEE Trans. Image Process. 2021, 30, 1812–1824. [Google Scholar] [CrossRef]
- Zhao, F.; Zhang, T.; Song, Y.; Tang, M.; Wang, X.; Wang, J. Siamese Regression Tracking with Reinforced Template Updating. IEEE Trans. Image Process. 2021, 30, 628–640. [Google Scholar] [CrossRef] [PubMed]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-Speed Tracking with Kernelized Correlation Filters. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 583–596. [Google Scholar] [CrossRef] [Green Version]
- Shao, J.; Du, B.; Wu, C.; Zhang, L. Can We Track Targets From Space? A Hybrid Kernel Correlation Filter Tracker for Satellite Video. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8719–8731. [Google Scholar] [CrossRef]
- Fu, C.; Cao, Z.; Li, Y.; Ye, J.; Feng, C. Onboard Real-Time Aerial Tracking with Efficient Siamese Anchor Proposal Network. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–13. [Google Scholar] [CrossRef]
- Dasari, M.M.; Gorthi, R.K.S.S. IOU—Siamtrack: IOU Guided Siamese Network For Visual Object Tracking. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 2061–2065. [Google Scholar]
- Sodhro, A.H.; Sennersten, C.; Ahmad, A. Towards Cognitive Authentication for Smart Healthcare Applications. Sensors 2022, 22, 2101. [Google Scholar] [CrossRef] [PubMed]
- Danelljan, M.; Khan, F.S.; Felsberg, M.; Van De Weijer, J. Adaptive Color Attributes for Real-Time Visual Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 1090–1097. [Google Scholar]
- Shao, J.; Du, B.; Wu, C.; Zhang, L. Tracking Objects From Satellite Videos: A Velocity Feature Based Correlation Filter. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7860–7871. [Google Scholar] [CrossRef]
- Cen, M.; Jung, C. Fully Convolutional Siamese Fusion Networks for Object Tracking. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 3718–3722. [Google Scholar]
- Shao, J.; Du, B.; Wu, C.; Gong, M.; Liu, T. HRSiam: High-Resolution Siamese Network, Towards Space-Borne Satellite Video Tracking. IEEE Trans. Image Process. 2021, 30, 3056–3068. [Google Scholar] [CrossRef]
- Abdelpakey, M.H.; Shehata, M.S. DP-Siam: Dynamic Policy Siamese Network for Robust Object Tracking. IEEE Trans. Image Process. 2020, 29, 1479–1492. [Google Scholar] [CrossRef] [PubMed]
- Li, B.; Yan, J.; Wu, W.; Zhu, Z.; Hu, X. High Performance Visual Tracking with Siamese Region Proposal Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 8971–8980. [Google Scholar]
- Guo, D.; Wang, J.; Cui, Y.; Wang, Z.; Chen, S. SiamCAR: Siamese Fully Convolutional Classification and Regression for Visual Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 14–19 June 2020; pp. 6268–6276. [Google Scholar]
- Xu, Y.; Wang, Z.; Li, Z.; Yuan, Y.; Yu, G. SiamFC++: Towards robust and accurate visual tracking with target estimation guidelines. In Proceedings of the 34th AAAI Conference on Artificial Intelligence (AAAI), New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12549–12556. [Google Scholar]
- Chen, X.; Yan, B.; Zhu, J.; Wang, D.; Yang, X.; Lu, H. Transformer tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 8126–8135. [Google Scholar]
- Lan, X.; Zhang, W.; Zhang, S.; Jain, D.K.; Zhou, H. Robust Multi-modality Anchor Graph-based Label Prediction for RGB-Infrared Tracking. IEEE Trans. Ind. Inf. 2019, 1. [Google Scholar] [CrossRef]
- Shang, X.; Song, M.; Wang, Y.; Yu, C.; Yu, H.; Li, F.; Chang, C.I. Target-Constrained Interference-Minimized Band Selection for Hyperspectral Target Detection. IEEE Trans. Geosci. Remote Sens. 2021, 59, 6044–6064. [Google Scholar] [CrossRef]
- Yu, C.; Han, R.; Song, M.; Liu, C.; Chang, C.I. Feedback Attention-Based Dense CNN for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–16. [Google Scholar] [CrossRef]
- Yuan, Q.; Zhang, Q.; Li, J.; Shen, H.; Zhang, L. Hyperspectral Image Denoising Employing a Spatial–Spectral Deep Residual Convolutional Neural Network. IEEE Trans. Geosci. Remote Sens. 2019, 57, 1205–1218. [Google Scholar] [CrossRef] [Green Version]
- Li, S.; Song, W.; Fang, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Deep Learning for Hyperspectral Image Classification: An Overview. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6690–6709. [Google Scholar] [CrossRef] [Green Version]
- Xiong, F.; Zhou, J.; Qian, Y. Material Based Object Tracking in Hyperspectral Videos. IEEE Trans. Image Process. 2020, 29, 3719–3733. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Qian, K.; Du, J.; Zhou, H. Multi-Features Integration Based Hyperspectral Videos Tracker. In Proceedings of the Workshop Hyperspectral Image Signal Procesing: Evolution in Remote Sensing (WHISPERS), Amsterdam, The Netherlands, 24–26 March 2021; pp. 1–5. [Google Scholar]
- Li, Z.; Xiong, F.; Zhou, J.; Wang, J.; Lu, J.; Qian, Y. BAE-Net: A Band Attention Aware Ensemble Network for Hyperspectral Object Tracking. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 2106–2110. [Google Scholar]
- Li, Z.; Ye, X.; Xiong, F.; Lu, J.; Zhou, J.; Qian, Y. Spectral-Spatial-Temporal Attention Network for Hyperspectral Tracking. In Proceedings of the Workshop Hyperspectral Image Signal Processing: Evolution in Remote Sensing (WHISPERS), Amsterdam, The Netherlands, 24–26 March 2021; pp. 1–5. [Google Scholar]
- Dian, R.; Li, S.; Fang, L. Learning a Low Tensor-Train Rank Representation for Hyperspectral Image Super-Resolution. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 2672–2683. [Google Scholar] [CrossRef]
- Lan, X.; Ye, M.; Shao, R.; Zhong, B.; Yuen, P.C.; Zhou, H. Learning Modality-Consistency Feature Templates: A Robust RGB-Infrared Tracking System. IEEE Trans. Ind. Electron. 2019, 66, 9887–9897. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Ye, P.; Peng, S.; Liu, J.; Xiao, G. DSiamMFT: An RGB-T fusion tracking method via dynamic Siamese networks using multi-layer feature fusion. Signal Process. Image Commun. 2020, 84, 115756. [Google Scholar] [CrossRef]
- Zhang, X.; Ye, P.; Peng, S.; Liu, J.; Gong, K.; Xiao, G. SiamFT: An RGB-Infrared Fusion Tracking Method via Fully Convolutional Siamese Networks. IEEE Access 2019, 7, 122122–122133. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, I.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Annual Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Guo, D.; Shao, Y.; Cui, Y.; Wang, Z.; Zhang, L.; Shen, C. Graph Attention Tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 9543–9552. [Google Scholar]
- Chen, Z.; Zhong, B.; Li, G.; Zhang, S.; Ji, R. Siamese Box Adaptive Network for Visual Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 14–19 June 2020; pp. 6667–6676. [Google Scholar]
- Danelljan, M.; Bhat, G.; Khan, F.S.; Felsberg, M. ECO: Efficient Convolution Operators for Tracking. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6931–6939. [Google Scholar]
- Zhang, Z.; Peng, H. Deeper and Wider Siamese Networks for Real-Time Visual Tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 4586–4595. [Google Scholar]
- Danelljan, M.; Häger, G.; Khan, F.S.; Felsberg, M. Discriminative Scale Space Tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1561–1575. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Maire, M.; Belongie, S.J.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the 13th European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Müller, M.; Bibi, A.; Giancola, S.; Al-Subaihi, S.; Ghanem, B. TrackingNet: A Large-Scale Dataset and Benchmark for Object Tracking in the Wild. In Proceedings of the 15th European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Fan, H.; Lin, L.; Yang, F.; Chu, P.; Deng, G.; Yu, S.; Bai, H.; Xu, Y.; Liao, C.; Ling, H. LaSOT: A High-Quality Benchmark for Large-Scale Single Object Tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 5369–5378. [Google Scholar]
- Huang, L.; Zhao, X.; Huang, K. GOT-10k: A Large High-Diversity Benchmark for Generic Object Tracking in the Wild. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 2021, 43, 1562–1577. [Google Scholar] [CrossRef] [Green Version]
- Wu, Y.; Lim, J.; Yang, M.H. Online Object Tracking: A Benchmark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 2411–2418. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Attribute | Name | Attribute |
|---|---|---|---|
| Ball | SV, MB, OCC | Forest2 | BC, OCC |
| Basketball | FM, MB, OCC, LR | Fruit | BC, OCC |
| Board | IPR, OPR, BC | Hand | BC, SV, DEF, OPR |
| Book | IPR, DEF, OPR | Kangaroo | BC, SV, DEF, OPR, MB |
| Bus | LR, BC, FM | Paper | IPR, DEF, OPR, SV |
| Bus2 | IV, SV, OCC, FM | Pedestrian | IV, SV |
| Campus | IV, SV, OCC | Pedestrian2 | LR, OCC, IV, DEF |
| Car | SV, IPR, OPR | Player | IPR, DEF, OPR, SV |
| Car2 | SV, IPR, OPR | Playground | SV, OCC |
| Car3 | SV, LR, OCC, IV | Rider1 | LR, OCC, IV, SV |
| Card | IPR, BC, OCC | Rider2 | LR, OCC, IV, SV |
| Coin | BC | Rubik | DEF, IPR, OPR |
| Coke | BC, IPR, OPR, FM, SV | Student | IV, SV |
| Drive | BC, IPR, OPR, SV | Toy1 | BC, OCC |
| Excavator | IPR, OPR, SV, OCC, DEF | Toy2 | BC, OCC, SV, IPR, OV, OPR |
| Face | SV, MB, IPR, OPR | Truck | OCC, OV, SV |
| Face2 | IPR, OPR, SV, OCC | worker | SV, LR, BC |
| Forest | BC, OCC |
| Attribute | Video Numbers | Attribute | Video Numbers |
|---|---|---|---|
| OCC | 18 | FM | 4 |
| IV | 8 | IPR | 14 |
| BC | 14 | OPR | 15 |
| SV | 23 | OV | 2 |
| DEF | 8 | LR | 7 |
| MB | 4 |
| MHT | BAE | SST | TransT | SiamGAT | SiamCAR | SiamBAN | ECO | SiamDW | fDSST | RANet | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| AUC | 0.592 | 0.614 | 0.631 | 0.687 | 0.636 | 0.613 | 0.608 | 0.570 | 0.547 | 0.467 | 0.709 |
| DP_20 | 0.882 | 0.876 | 0.915 | 0.920 | 0.864 | 0.841 | 0.833 | 0.840 | 0.854 | 0.725 | 0.952 |
| Fusion Structure | AUC | DP_20 |
|---|---|---|
| RANet | 0.709 | 0.952 |
| RANet-mf | 0.693 | 0.927 |
| RANet-rf | 0.702 | 0.942 |
| 0.5 | 0.55 | 0.6 | 0.65 | 0.7 | 0.75 | 0.8 | 0.85 | 0.9 | 0.95 | 1.0 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| AUC | 0.695 | 0.698 | 0.694 | 0.695 | 0.698 | 0.702 | 0.705 | 0.705 | 0.709 | 0.702 | 0.699 |
| DP_20 | 0.934 | 0.936 | 0.934 | 0.933 | 0.939 | 0.941 | 0.948 | 0.951 | 0.952 | 0.942 | 0.938 |
| AUC | Δ(AUC) | DP_20 | Δ(DP_20) | |
|---|---|---|---|---|
| SiamCAR | 0.613 | - | 0.841 | - |
| SiamCAR_fusion | 0.643 | ↑ 0.030 | 0.911 | ↑ 0.070 |
| SiamGAT | 0.636 | - | 0.864 | - |
| SiamGAT_fusion | 0.652 | ↑ 0.016 | 0.877 | ↑ 0.03 |
| TransT | 0.687 | - | 0.920 | - |
| TransT_fusion | 0.709 | ↑ 0.022 | 0.952 | ↑ 0.032 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, C.; Liu, H.; Su, N.; Wang, L.; Yan, Y. RANet: A Reliability-Guided Aggregation Network for Hyperspectral and RGB Fusion Tracking. Remote Sens. 2022, 14, 2765. https://doi.org/10.3390/rs14122765
Zhao C, Liu H, Su N, Wang L, Yan Y. RANet: A Reliability-Guided Aggregation Network for Hyperspectral and RGB Fusion Tracking. Remote Sensing. 2022; 14(12):2765. https://doi.org/10.3390/rs14122765
Chicago/Turabian StyleZhao, Chunhui, Hongjiao Liu, Nan Su, Lu Wang, and Yiming Yan. 2022. "RANet: A Reliability-Guided Aggregation Network for Hyperspectral and RGB Fusion Tracking" Remote Sensing 14, no. 12: 2765. https://doi.org/10.3390/rs14122765
APA StyleZhao, C., Liu, H., Su, N., Wang, L., & Yan, Y. (2022). RANet: A Reliability-Guided Aggregation Network for Hyperspectral and RGB Fusion Tracking. Remote Sensing, 14(12), 2765. https://doi.org/10.3390/rs14122765