
Infrared and Visible Image Fusion with Deep Neural Network in Enhanced Flight Vision System

Abstract
:
1. Introduction
2. Materials and Methods
2.1. Related Work
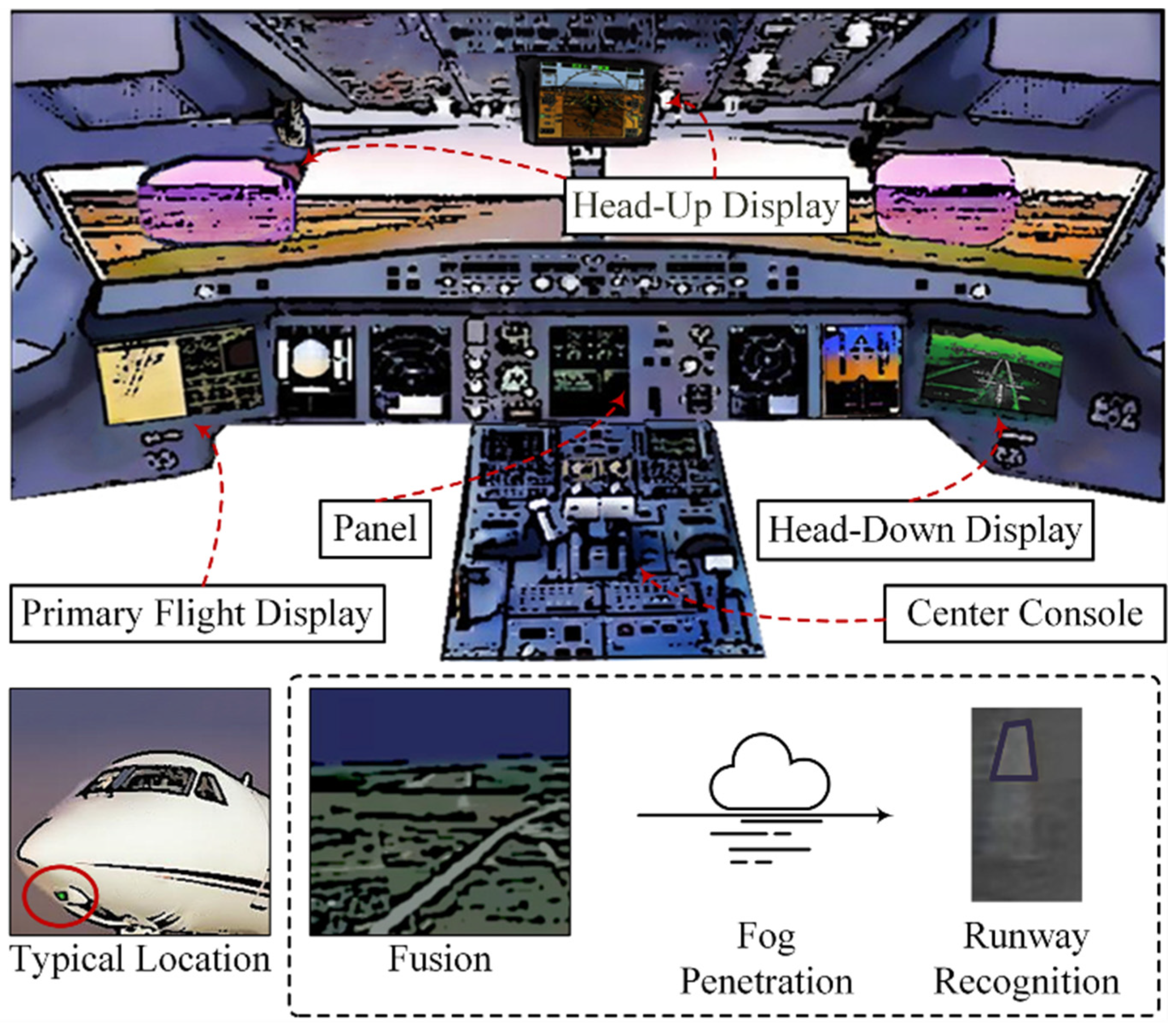
2.1.1. Airborne Vision Calibration
2.1.2. Infrared and Visible Fusion
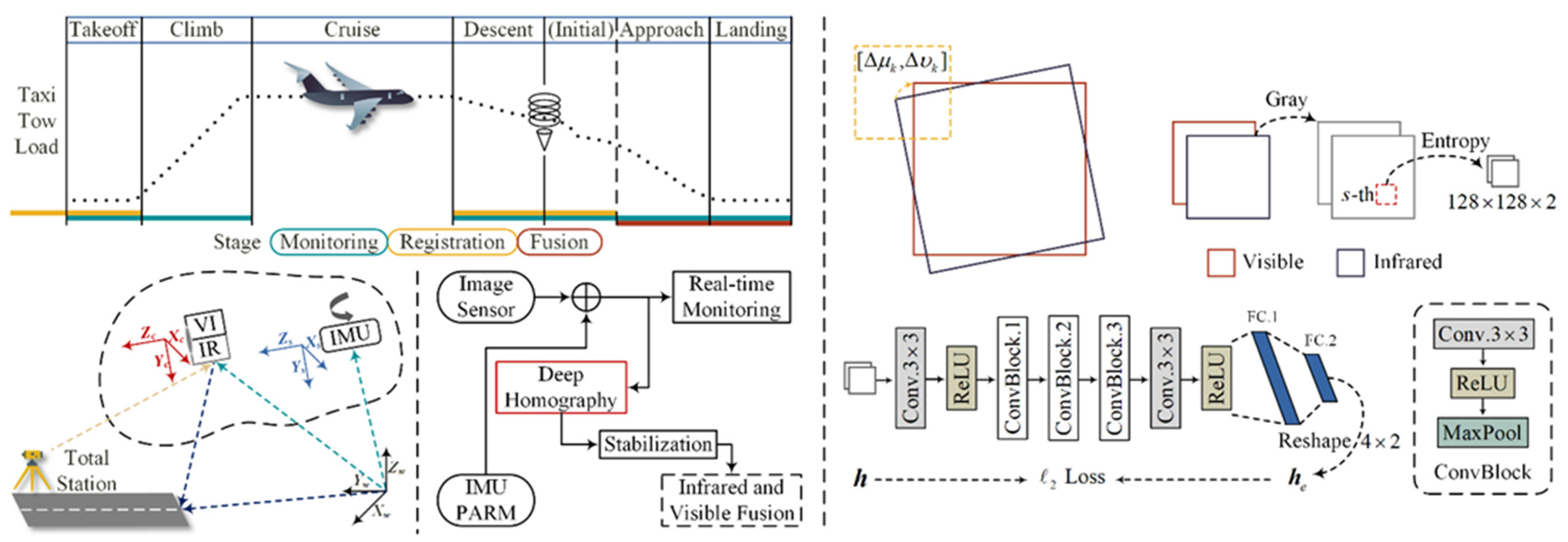
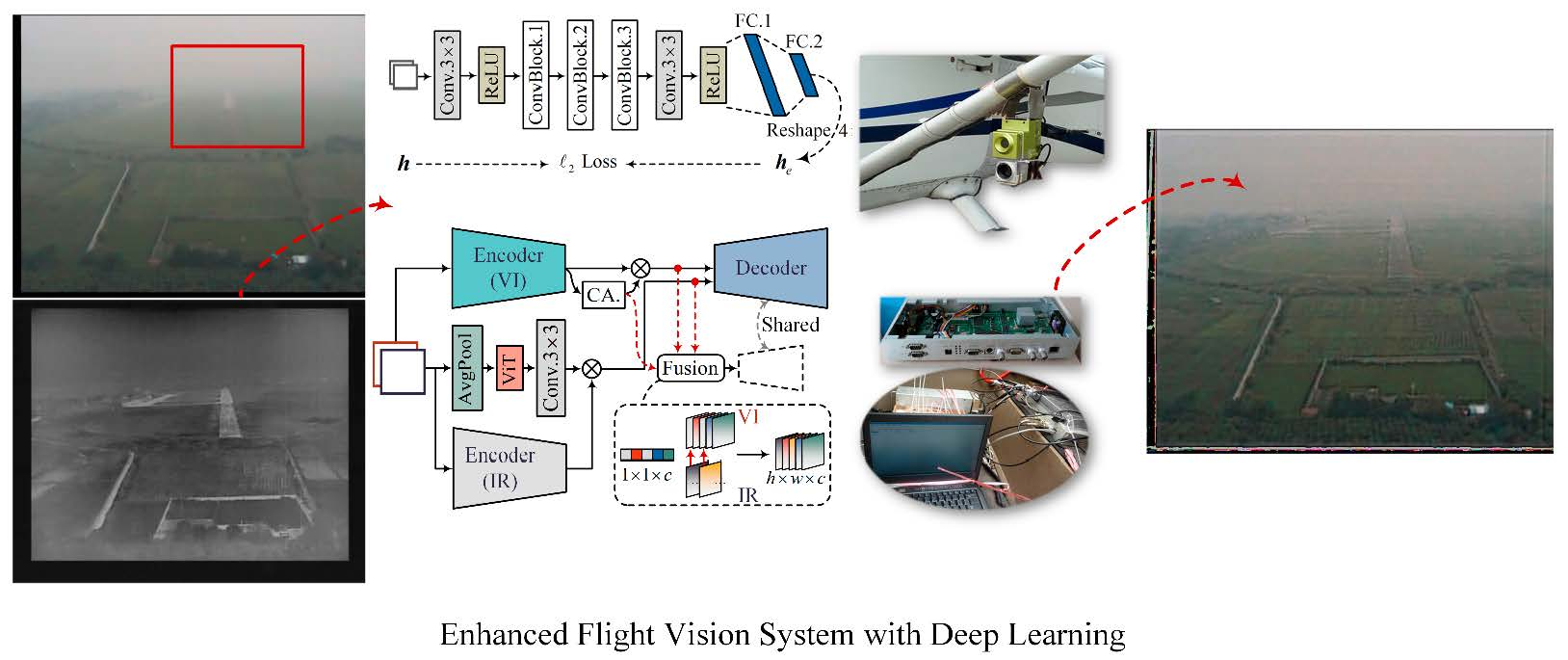
2.2. Multi-Modal Image Calibration
2.3. Infrared and Visible Fusion with Transformer
3. Experiments
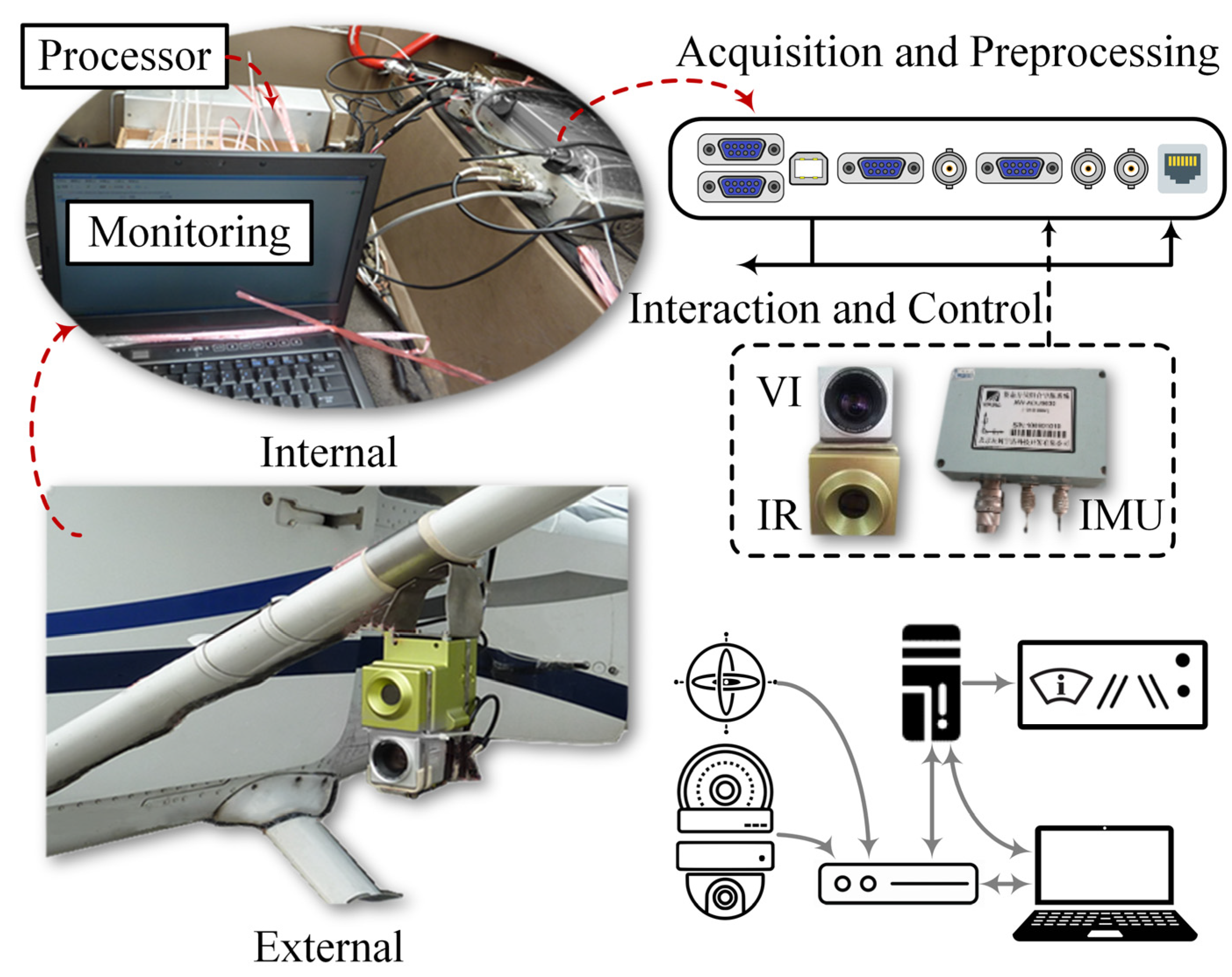
3.1. Flight Test Platform
3.2. Experimental Settings
3.2.1. Training Details
3.2.2. Comparison Algorithms and Evaluation Metrics
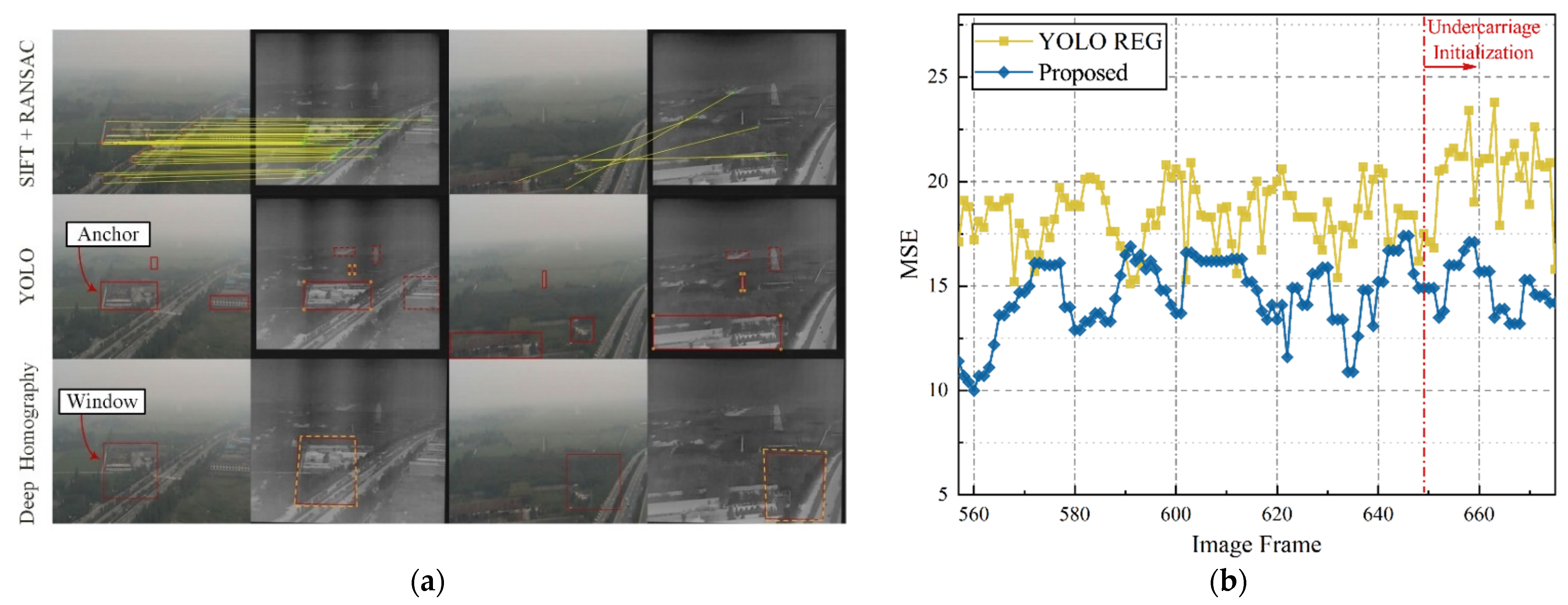
3.3. Visual Calibration Evaluation
3.4. Fusion Enhancement Evaluation
3.4.1. Qualitative Analysis
3.4.2. Quantitative Analysis
3.5. Implement Efficiency Evaluation
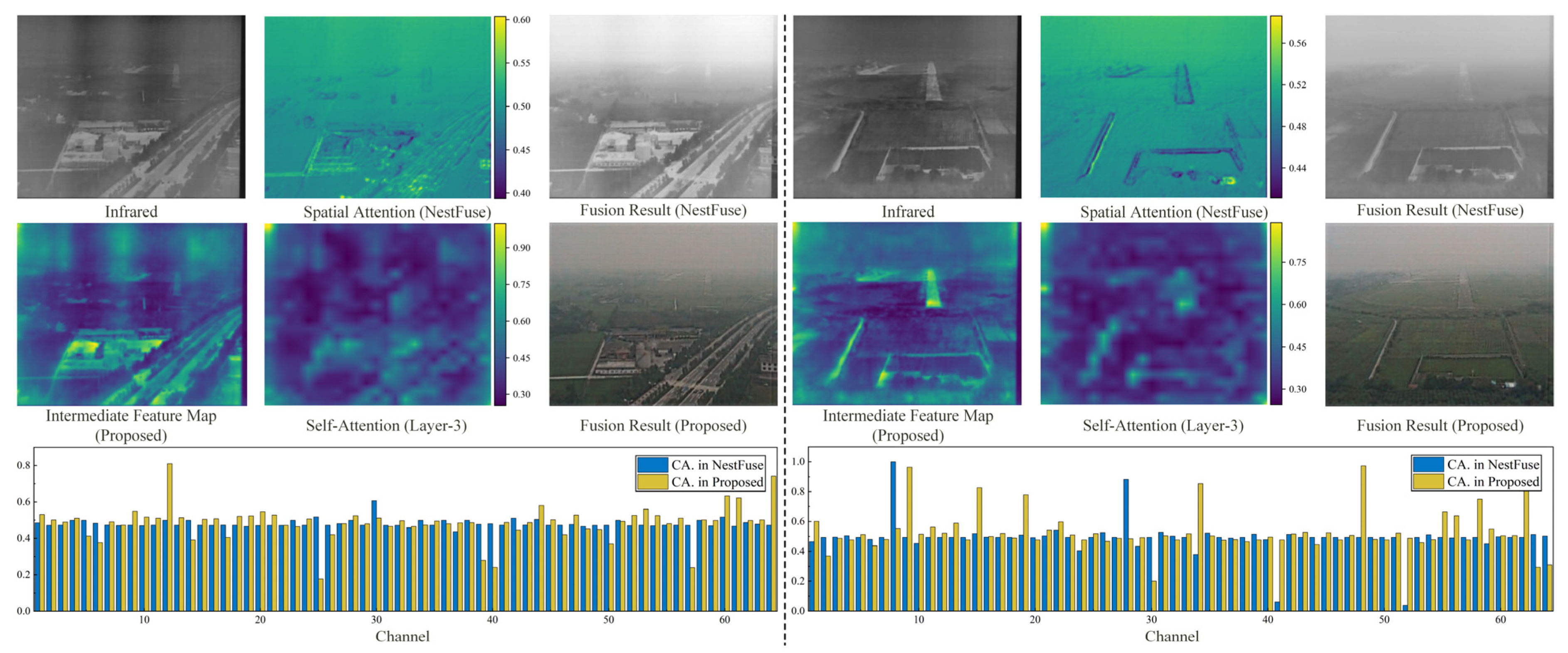
3.6. Mechanism Analysis
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

References
- Kramer, L.J.; Etherington, T.J.; Severance, K.; Bailey, R.E.; Williams, S.P.; Harrison, S.J. Assessing Dual-Sensor Enhanced Flight Vision Systems to Enable Equivalent Visual Operations. J. Aerosp. Inf. Syst. 2017, 14, 533–550. [Google Scholar] [CrossRef]
- Fadhil, A.F.; Kanneganti, R.; Gupta, L.; Eberle, H.; Vaidyanathan, R. Fusion of Enhanced and Synthetic Vision System Images for Runway and Horizon Detection. Sensors 2019, 19, 3802. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cross, J.; Schneider, J.; Cariani, P. MMW radar enhanced vision systems: The Helicopter Autonomous Landing System (HALS) and Radar-Enhanced Vision System (REVS) are rotary and fixed wing enhanced flight vision systems that enable safe flight operations in degraded visual environments. In Proceedings of the Degraded Visual Environments: Enhanced, Synthetic, and External Vision Solutions 2013, Baltimore, MA, USA, 1 May 2013; p. 87370G. [Google Scholar] [CrossRef]
- Shelton, K.J.; Kramer, L.J.; Ellis, K.; Rehfeld, S.A. Synthetic and Enhanced Vision Systems (SEVS) for NextGen simulation and flight test performance evaluation. In Proceedings of the 2012 IEEE/AIAA 31st Digital Avionics Systems Conference (DASC), Williamsburg, VA, USA, 14–18 October 2012; pp. 2D5-1–2D5-12. [Google Scholar] [CrossRef] [Green Version]
- Goshi, D.S.; Rhoads, C.; McKitterick, J.; Case, T. Millimeter wave imaging for fixed wing zero visibility landing. In Proceedings of the Passive and Active Millimeter-Wave Imaging XXII, Baltimore, MA, USA, 13 May 2019; p. 1099404. [Google Scholar] [CrossRef]
- Iradukunda, K.; Averyanova, Y. Cfit Prevention with Combined Enhanced Flight Vision System and Synthetic Vision System. Adv. Aerosp. Technol. 2021, 87, 12–17. [Google Scholar] [CrossRef]
- Cheng, Y.; Li, Y.; Han, W.; Liu, Z.; Yu, G. Infrared Image Enhancement by Multi-Modal Sensor Fusion in Enhanced Synthetic Vision System. J. Phys. Conf. Ser. 2020, 1518, 012048. [Google Scholar] [CrossRef]
- Zhang, L.; Zhai, Z.; Niu, W.; Wen, P.; He, L. Visual–inertial fusion-based registration between real and synthetic images in airborne combined vision system. Int. J. Adv. Robot. Syst. 2019, 16, 1729881419845528. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Ye, P.; Leung, H.; Gong, K.; Xiao, G. Object fusion tracking based on visible and infrared images: A comprehensive review. Inf. Fusion 2020, 63, 166–187. [Google Scholar] [CrossRef]
- Ma, J.; Ma, Y.; Li, C. Infrared and visible image fusion methods and applications: A survey. Inf. Fusion 2019, 45, 153–178. [Google Scholar] [CrossRef]
- Ma, J.; Chen, C.; Li, C.; Huang, J. Infrared and visible image fusion via gradient transfer and total variation minimization. Inf. Fusion 2016, 31, 100–109. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, L.; Bai, X.; Zhang, L. Infrared and visual image fusion through infrared feature extraction and visual information preservation. Infrared Phys. Technol. 2017, 83, 227–237. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Wang, Z.; Wang, Z.J.; Ward, R.K.; Wang, X. Deep learning for pixel-level image fusion: Recent advances and future prospects. Inf. Fusion 2018, 42, 158–173. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Cheng, J.; Peng, H.; Wang, Z. Infrared and visible image fusion with convolutional neural networks. Int. J. Wavelets Multiresolut. Inf. Process. 2018, 16, 1850018. [Google Scholar] [CrossRef]
- Li, W.; Cao, D.; Peng, Y.; Yang, C. MSNet: A Multi-Stream Fusion Network for Remote Sensing Spatiotemporal Fusion Based on Transformer and Convolution. Remote Sens. 2021, 13, 3724. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.J. DenseFuse: A Fusion Approach to Infrared and Visible Images. IEEE Trans. Image Process. 2019, 28, 2614–2623. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xu, H.; Ma, J.; Jiang, J.; Guo, X.; Ling, H. U2Fusion: A Unified Unsupervised Image Fusion Network. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 502–518. [Google Scholar] [CrossRef]
- Jia, X.; Zhu, C.; Li, M.; Tang, W.; Zhou, W. LLVIP: A Visible-infrared Paired Dataset for Low-light Vision. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021; pp. 3489–3497. [Google Scholar] [CrossRef]
- Lebedev, M.A.; Stepaniants, D.G.; Komarov, D.V.; Vygolov, O.V.; Vizilter, Y.V.; Zheltov, S.Y. A real-time photogrammetric algorithm for sensor and synthetic image fusion with application to aviation combined vision. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2014, XL-3, 171–175. [Google Scholar] [CrossRef] [Green Version]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Tuytelaars, T.; Van Gool, L. SURF: Speeded Up Robust Features. In Proceedings of the European Conference on Computer Vision, Berlin, Heidelberg, 7–13 May 2006; pp. 404–417. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar] [CrossRef]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Tustison, N.J.; Avants, B.B.; Gee, J.C. Learning image-based spatial transformations via convolutional neural networks: A review. Magn. Reson. Imaging 2019, 64, 142–153. [Google Scholar] [CrossRef]
- Chang, C.H.; Chou, C.N.; Chang, E.Y. CLKN: Cascaded Lucas-Kanade Networks for Image Alignment. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3777–3785. [Google Scholar] [CrossRef]
- Nguyen, T.; Chen, S.W.; Shivakumar, S.S.; Taylor, C.J.; Kumar, V. Unsupervised Deep Homography: A Fast and Robust Homography Estimation Model. IEEE Robot. Autom. Lett. 2018, 3, 2346–2353. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Q.; Ma, Y.; Zhu, C.; Yao, C.; Feng, B.; Dai, F. Image stitching via deep homography estimation. Neurocomputing 2021, 450, 219–229. [Google Scholar] [CrossRef]
- Zhang, X.; Ye, P.; Xiao, G. VIFB: A Visible and Infrared Image Fusion Benchmark. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 468–478. [Google Scholar] [CrossRef]
- Malini, S.; Moni, R.S. Image Denoising Using Multiresolution Singular Value Decomposition Transform. Procedia Comput. Sci. 2015, 46, 1708–1715. [Google Scholar] [CrossRef] [Green Version]
- Shreyamsha Kumar, B.K. Image fusion based on pixel significance using cross bilateral filter. Signal Image Video Process. 2015, 9, 1193–1204. [Google Scholar] [CrossRef]
- Bavirisetti, D.P.; Dhuli, R. Fusion of Infrared and Visible Sensor Images Based on Anisotropic Diffusion and Karhunen-Loeve Transform. IEEE Sens. J. 2016, 16, 203–209. [Google Scholar] [CrossRef]
- Zhou, Z.; Dong, M.; Xie, X.; Gao, Z. Fusion of infrared and visible images for night-vision context enhancement. Appl. Opt. 2016, 55, 6480–6490. [Google Scholar] [CrossRef]
- Bavirisetti, D.P.; Dhuli, R. Two-scale image fusion of visible and infrared images using saliency detection. Infrared Phys. Technol. 2016, 76, 52–64. [Google Scholar] [CrossRef]
- Bavirisetti, D.P.; Xiao, G.; Zhao, J.; Dhuli, R.; Liu, G. Multi-scale Guided Image and Video Fusion: A Fast and Efficient Approach. Circuits Syst. Signal Process. 2019, 38, 5576–5605. [Google Scholar] [CrossRef]
- Bavirisetti, D.P.; Xiao, G.; Liu, G. Multi-sensor image fusion based on fourth order partial differential equations. In Proceedings of the 20th International Conference on Information Fusion (Fusion), Xi’an, China, 10–13 July 2017; pp. 1–9. [Google Scholar] [CrossRef]
- Ma, J.; Zhou, Z.; Wang, B.; Zong, H. Infrared and visible image fusion based on visual saliency map and weighted least square optimization. Infrared Phys. Technol. 2017, 82, 8–17. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.J.; Durrani, T. NestFuse: An Infrared and Visible Image Fusion Architecture Based on Nest Connection and Spatial/Channel Attention Models. IEEE Trans. Instrum. Meas. 2020, 69, 9645–9656. [Google Scholar] [CrossRef]
- Ma, J.; Tang, L.; Xu, M.; Zhang, H.; Xiao, G. STDFusionNet: An Infrared and Visible Image Fusion Network Based on Salient Target Detection. IEEE Trans. Instrum. Meas. 2021, 70, 1–13. [Google Scholar] [CrossRef]
- Fu, Y.; Wu, X.J. A Dual-Branch Network for Infrared and Visible Image Fusion. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 10675–10680. [Google Scholar] [CrossRef]
- Ma, J.; Yu, W.; Liang, P.; Li, C.; Jiang, J. FusionGAN: A generative adversarial network for infrared and visible image fusion. Inf. Fusion 2019, 48, 11–26. [Google Scholar] [CrossRef]
- Ma, J.; Xu, H.; Jiang, J.; Mei, X.; Zhang, X.P. DDcGAN: A Dual-Discriminator Conditional Generative Adversarial Network for Multi-Resolution Image Fusion. IEEE Trans. Image Process. 2020, 29, 4980–4995. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Wu, X.; Kittler, J. Infrared and Visible Image Fusion using a Deep Learning Framework. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 2705–2710. [Google Scholar] [CrossRef] [Green Version]
- Yang, T.; Li, G.; Li, J.; Zhang, Y.; Zhang, X.; Zhang, Z.; Li, Z. A Ground-Based Near Infrared Camera Array System for UAV Auto-Landing in GPS-Denied Environment. Sensors 2016, 16, 1393. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Abdel-Aziz, Y.I.; Karara, H.M.; Hauck, M. Direct Linear Transformation from Comparator Coordinates into Object Space Coordinates in Close-Range Photogrammetry. Photogramm. Eng. Remote Sens. 2015, 81, 103–107. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar] [CrossRef] [Green Version]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020. [Google Scholar] [CrossRef]
- Zhou, W.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [Green Version]
- Cvejic, N.; Canagarajah, C.N.; Bull, D.R. Image fusion metric based on mutual information and Tsallis entropy. Electron. Lett. 2006, 42, 626–627. [Google Scholar] [CrossRef]
- Chen, Y.; Blum, R.S. A new automated quality assessment algorithm for image fusion. Image Vis. Comput. 2009, 27, 1421–1432. [Google Scholar] [CrossRef]
- Chen, H.; Varshney, P.K. A human perception inspired quality metric for image fusion based on regional information. Inf. Fusion 2007, 8, 193–207. [Google Scholar] [CrossRef]
- Wang, Q.; Shen, Y.; Zhang, J.Q. A nonlinear correlation measure for multivariable data set. Phys. D Nonlinear Phenom. 2005, 200, 287–295. [Google Scholar] [CrossRef]
- Shanshan, L.; Richang, H.; Xiuqing, W. A novel similarity based quality metric for image fusion. In Proceedings of the International Conference on Audio, Language and Image Processing, Shanghai, China, 7–9 July 2008; pp. 167–172. [Google Scholar] [CrossRef]
- Sheikh, H.R.; Bovik, A.C. Image information and visual quality. IEEE Trans. Image Process. 2006, 15, 430–444. [Google Scholar] [CrossRef]
- Hasler, D.; Suesstrunk, S.E. Measuring colorfulness in natural images. In Proceedings of the Human Vision and Electronic Imaging VIII, Santa Clara, CA, USA, 17 June 2003; pp. 87–95. [Google Scholar] [CrossRef] [Green Version]
- Tan, M.; Chen, B.; Pang, R.; Vasudevan, V.; Sandler, M.; Howard, A.; Le, Q.V. MnasNet: Platform-Aware Neural Architecture Search for Mobile. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 2815–2823. [Google Scholar] [CrossRef] [Green Version]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Category | RGB 1 | REG 2 | Device |
|---|---|---|---|---|
| MSVD | Singular Value | CPU/GPU | ||
| CBF | Filter and Weight | CPU | ||
| ADF | Karhunen–Loeve | CPU | ||
| GFCE | Filter and Weight | CPU | ||
| TIF | Filter and Weight | CPU | ||
| IFEVIP | Quadtree | CPU | ||
| MGFF | Filter and Saliency | CPU | ||
| FPDE | Manual Feature | CPU/FPGA | ||
| GTF | -TV | CPU | ||
| VSMWLS | LS and Saliency | CPU | ||
| DenseFuse | Dense Block | GPU | ||
| NestFuse | Nest Connection | GPU | ||
| DualFuse | Dual-branch | GPU | ||
| DDcGan | Adversarial Game | GPU | ||
| U2Fusion | Pre-trained Model | GPU | ||
| DeepFuse | Pre-trained Model | CPU/GPU |
| Method | 2 | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MSVD | 0.911 | 6.230 | 0.497 | 61.431 | 1.814 | 0.043 | 0.984 | 0.339 | 10.502 | 25.067 | 4.411 | 1.753 | 0.375 | 1561.842 | 0.371 | 0.805 | 0.576 | 0.463 | 3.205 |
| ADF | 0.821 | 6.231 | 0.494 | 61.443 | 1.816 | 0.044 | 0.995 | 0.362 | 10.727 | 25.083 | 3.753 | 1.751 | 0.384 | 1571.392 | 0.379 | 0.805 | 0.584 | 0.497 | 3.270 |
| CBF | 0.643 | 6.678 | 0.382 | 60.712 | 1.246 | 0.055 | - | 0.445 | - | 29.832 | 10.481 | 0.980 | 0.376 | 2692.538 | 0.378 | 0.803 | 0.348 | 0.099 | 13.511 |
| GFCE | 3.597 | - | 0.435 | 57.143 | 1.457 | 0.126 | 2.819 | 0.394 | 30.601 | - | 9.757 | 1.550 | 0.486 | 4430.811 | 0.479 | 0.804 | 0.539 | 0.212 | 6.633 |
| TIF | 1.322 | 6.464 | 0.435 | 61.326 | 1.769 | 0.048 | 1.574 | 0.490 | 16.984 | 28.816 | 6.045 | 1.523 | 0.495 | 1187.934 | 0.492 | 0.804 | 0.633 | 0.282 | 3.554 |
| IFEVIP | 1.260 | 6.872 | 0.413 | 59.720 | 1.680 | 0.070 | 1.725 | 0.440 | 18.908 | 37.66 | 6.201 | 2.547 | 0.439 | 842.188 | 0.426 | 0.810 | 0.710 | 0.239 | 4.384 |
| MGFF | 1.461 | 6.509 | 0.414 | 61.287 | 1.760 | 0.048 | 1.690 | 0.441 | 18.4 | 29.892 | 6.011 | 1.434 | 0.509 | 2252.851 | 0.509 | 0.804 | 0.654 | 0.263 | 4.123 |
| FPDE | 0.870 | 6.253 | 0.494 | 61.426 | 1.801 | 0.046 | 1.100 | 0.367 | 11.852 | 25.144 | 4.269 | 1.700 | 0.380 | 1561.004 | 0.374 | 0.805 | 0.575 | 0.492 | 3.368 |
| GTF 1 | 0.893 | 6.316 | 0.469 | 61.121 | 1.759 | 0.050 | 1.202 | 0.379 | 12.92 | 23.035 | 4.399 | - | 0.468 | 4520.789 | 0.471 | 0.816 | 0.658 | 0.151 | - |
| VSMWLS | 1.100 | 6.651 | 0.450 | 61.197 | 1.771 | 0.049 | 1.621 | 0.466 | 17.601 | 33.253 | 5.040 | 1.719 | 0.506 | 4027.63 | 0.507 | 0.805 | 0.671 | 0.465 | 3.469 |
| DenseFuse | 0.697 | 6.221 | 0.499 | 61.433 | 1.817 | 0.047 | 0.945 | 0.347 | 10.297 | 24.990 | 7.523 | 1.768 | 0.394 | 1593.696 | 0.391 | 0.805 | 0.581 | 0.459 | 3.227 |
| NestFuse | 2.473 | 7.208 | 0.431 | 58.038 | 1.638 | 0.105 | 1.583 | 0.471 | 17.147 | 50.561 | 8.118 | - | 0.386 | 576.614 | 0.398 | 0.808 | 0.678 | 0.316 | - |
| DualFuse | 0.739 | 6.19 | 0.505 | 61.427 | 1.819 | 0.047 | 0.950 | 0.356 | 10.321 | 24.626 | 3.654 | - | 0.383 | 1710.18 | 0.389 | 0.805 | 0.584 | 0.453 | - |
| DDcGan | 0.702 | 7.007 | 0.416 | 60.793 | 1.749 | 0.054 | 1.608 | 0.514 | 17.406 | 43.331 | 6.154 | 2.051 | 0.486 | 2216.064 | 0.483 | 0.807 | 0.670 | 0.316 | 5.004 |
| U2Fusion | 1.070 | 7.026 | 0.415 | 60.505 | 1.745 | 0.058 | 1.700 | 0.501 | 18.391 | 41.852 | 6.579 | 1.911 | 0.453 | 2736.103 | 0.443 | 0.806 | 0.659 | 0.362 | 5.015 |
| DeepFuse | 0.931 | 6.230 | 0.487 | 61.432 | 1.824 | 0.047 | 1.016 | 0.414 | 10.970 | 25.083 | 4.002 | 1.768 | 0.404 | 1617.584 | 0.392 | 0.805 | 0.656 | 0.260 | 4.401 |
| Proposed | 1.253 | 7.195 | 0.475 | 61.438 | 1.841 | 0.062 | 2.545 | 0.337 | 27.418 | 39.199 | 15.130 | 2.370 | 0.421 | 2094.580 | 0.411 | 0.809 | 0.535 | 0.466 | 11.341 |
| Method/Runtime | |||||
|---|---|---|---|---|---|
| SIFT + RANSAC | 0.008 ± 0.002 | ||||
| YOLO | 0.023 | ||||
| Proposed (H) 1 | 0.092 | ||||
| MSVD | 0.443 | MGFF | 1.485 | DenseFuse | 0.621 |
| ADF | 1.231 | FPDE | 4.299 | NestFuse | 0.732 |
| CBF | 22.297 | GTF | 8.914 | DualFuse | 1.521 |
| GFCE | 3.342 | VSMWLS | 0.662 | DDcGan | 1.043 |
| TIF | 1.297 | DeepFuse (Base) | 11.508 | U2Fusion | 1.415 |
| IFEVIP | 0.126 | DeepFuse (Tiny) | 9.782 | Proposed (F) | 0.998 |
| Method/Inference FPS | |||||
| IFEVIP | 23~24 | ||||
| DenseFuse | 19~22 | ||||
| Proposed | 16~20 | ||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, X.; Shi, Y.; Zhu, Q.; Fu, Q.; Wu, Y. Infrared and Visible Image Fusion with Deep Neural Network in Enhanced Flight Vision System. Remote Sens. 2022, 14, 2789. https://doi.org/10.3390/rs14122789
Gao X, Shi Y, Zhu Q, Fu Q, Wu Y. Infrared and Visible Image Fusion with Deep Neural Network in Enhanced Flight Vision System. Remote Sensing. 2022; 14(12):2789. https://doi.org/10.3390/rs14122789
Chicago/Turabian StyleGao, Xuyang, Yibing Shi, Qi Zhu, Qiang Fu, and Yuezhou Wu. 2022. "Infrared and Visible Image Fusion with Deep Neural Network in Enhanced Flight Vision System" Remote Sensing 14, no. 12: 2789. https://doi.org/10.3390/rs14122789
APA StyleGao, X., Shi, Y., Zhu, Q., Fu, Q., & Wu, Y. (2022). Infrared and Visible Image Fusion with Deep Neural Network in Enhanced Flight Vision System. Remote Sensing, 14(12), 2789. https://doi.org/10.3390/rs14122789