
LiDAR Odometry by Deep Learning-Based Feature Points with Two-Step Pose Estimation


Abstract
:
1. Introduction
- Accurate LiDAR odometry algorithm using deep learning-based feature point detection and description. Feature points are extracted from the BEV image of the 3D LiDAR data. Accurate and robust keypoint associations than handcrafted feature descriptors can be provided.
- A two-step feature matching and pose estimation strategy is proposed to improve the accuracy of the keypoint association and length of feature tracking. The first step is to ensure the accuracy of the data association, and the second step is to add more reliable feature points for long-range tracking.
- The proposed method is evaluated by processing a commonly used benchmark, the KITTI dataset [43], and it is compared with the SLAM algorithm based on handcrafted feature points. The contributions of deep learning-based feature extraction and two-step pose estimation are verified experimentally. In addition, the generalization of the proposed algorithm is proved by performing field tests using low-resolution LiDAR, Velodyne VLP-16.
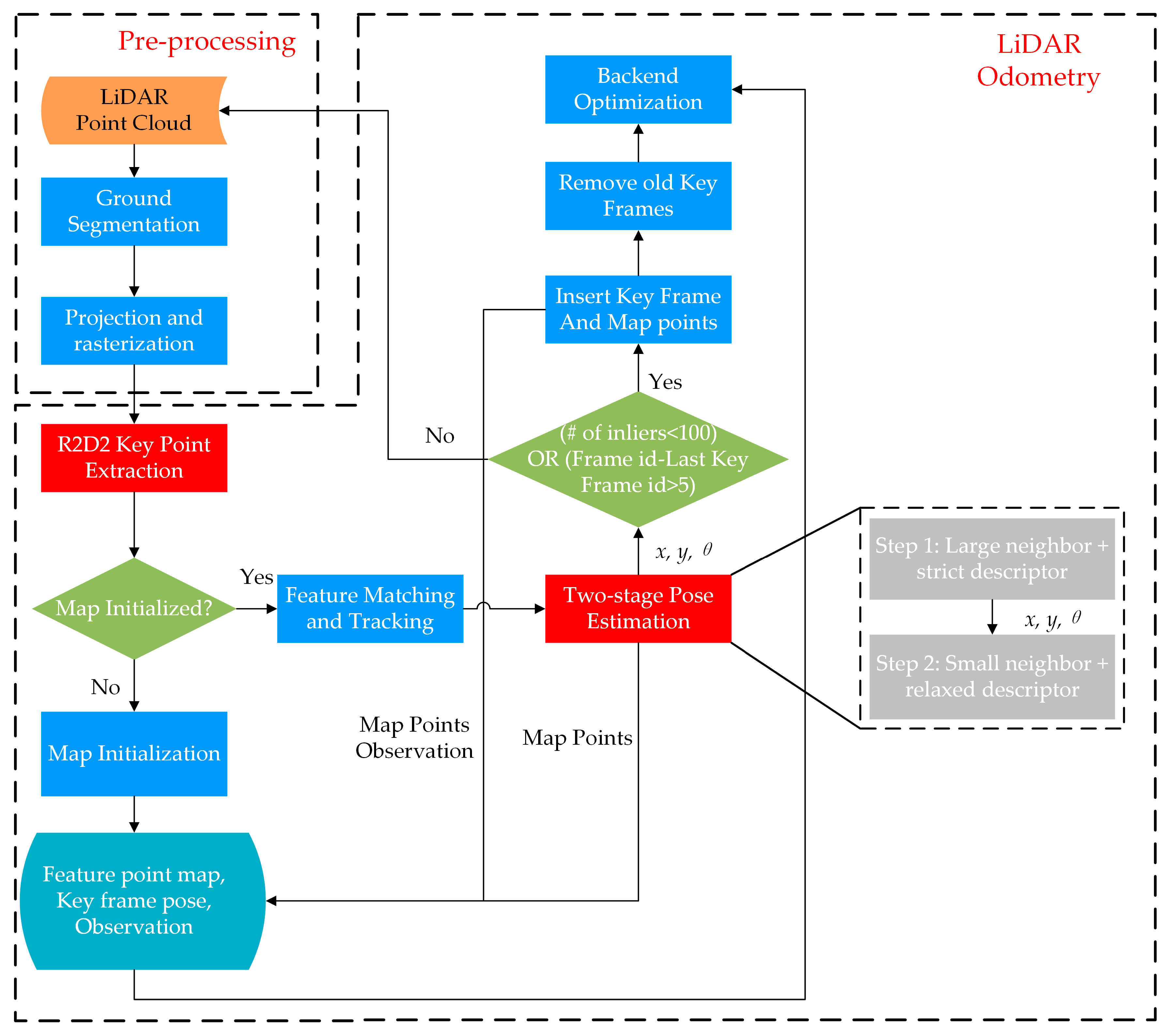
2. System Overview
2.1. Pre-Processing
2.2. LiDAR Odometry
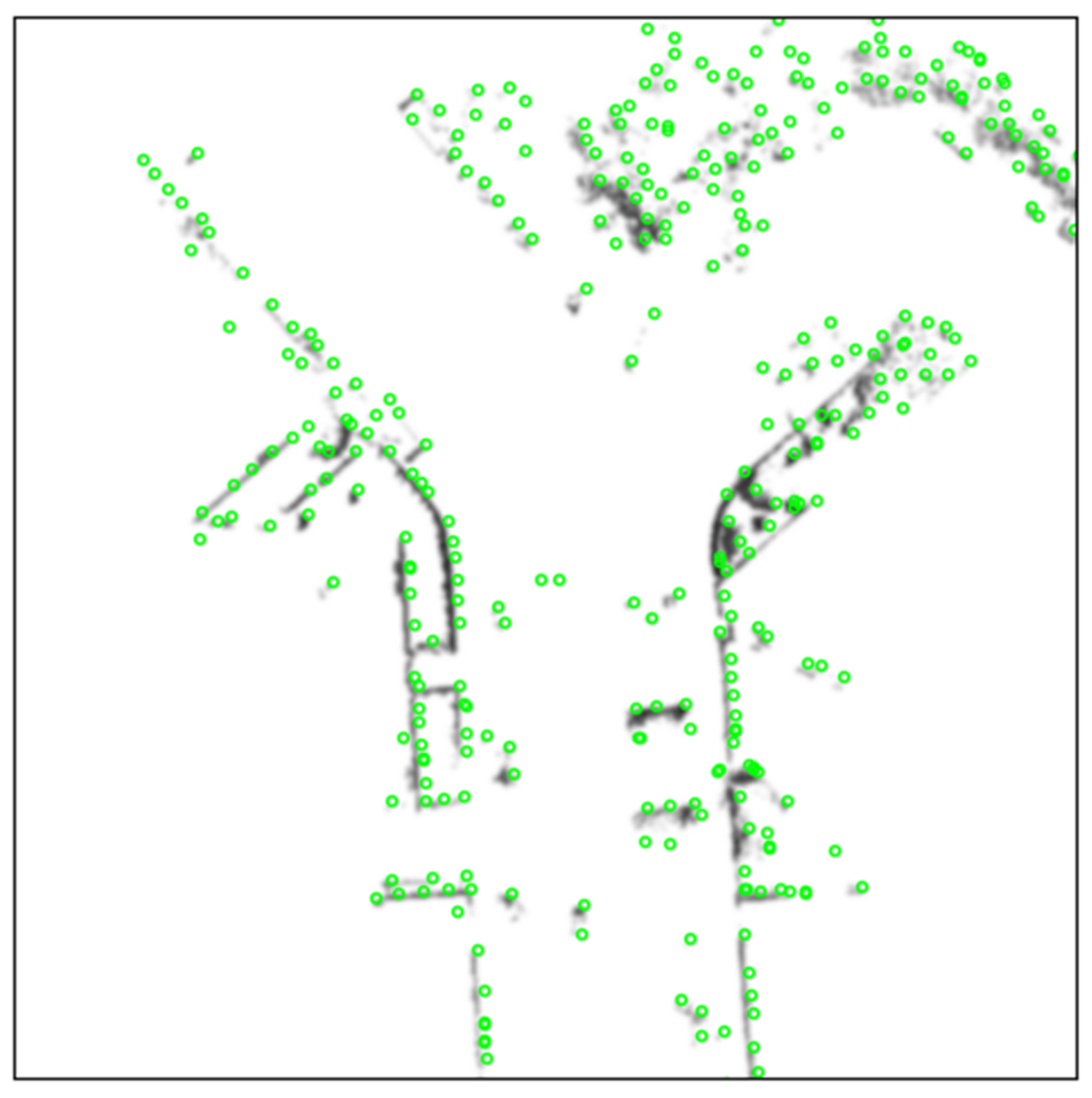
2.2.1. Feature Extraction and Matching
2.2.2. Two-Step Pose Estimation
2.2.3. Map Management
2.2.4. Key Frame Selection and Backend Optimization
3. Experiments
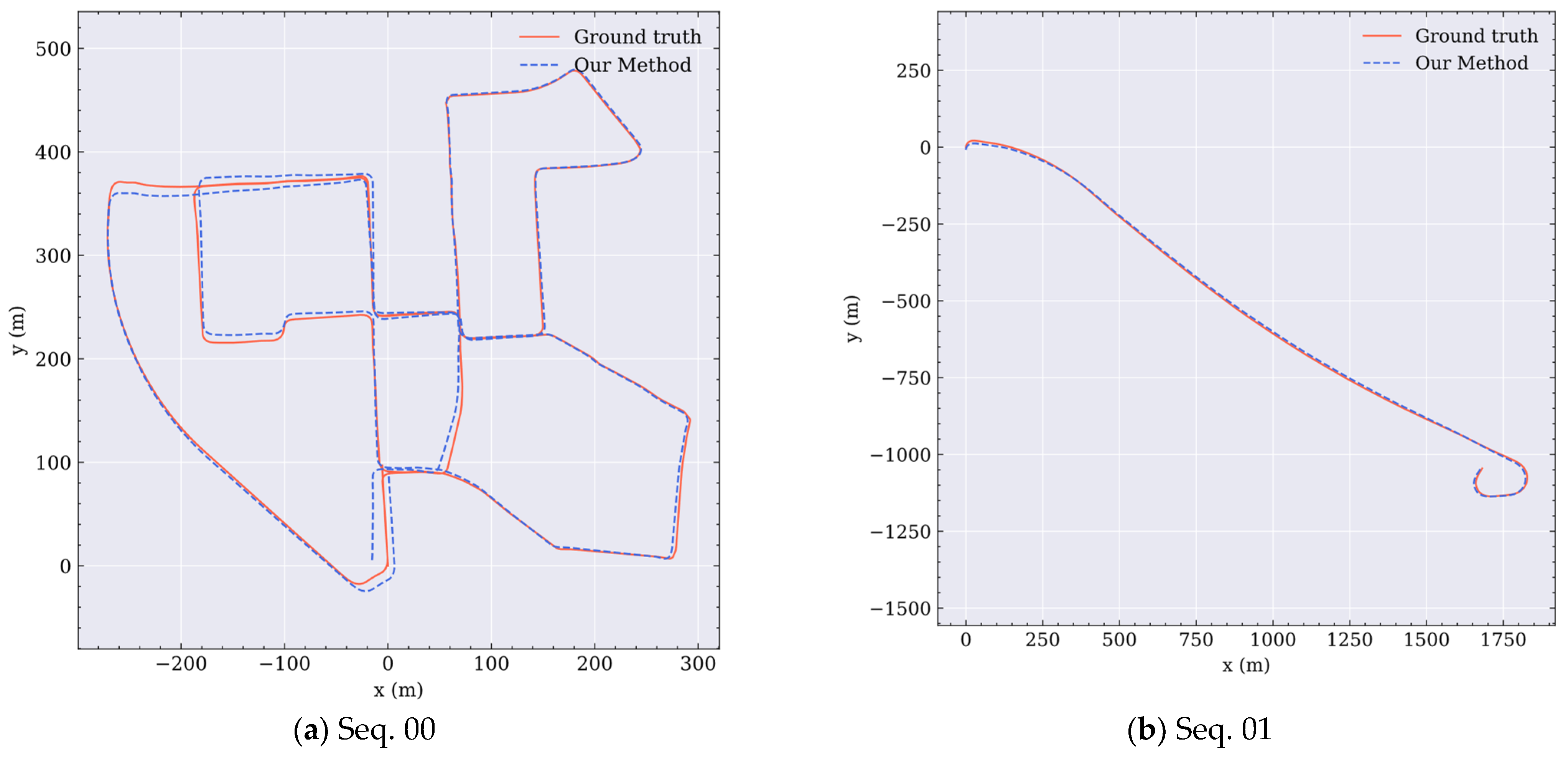
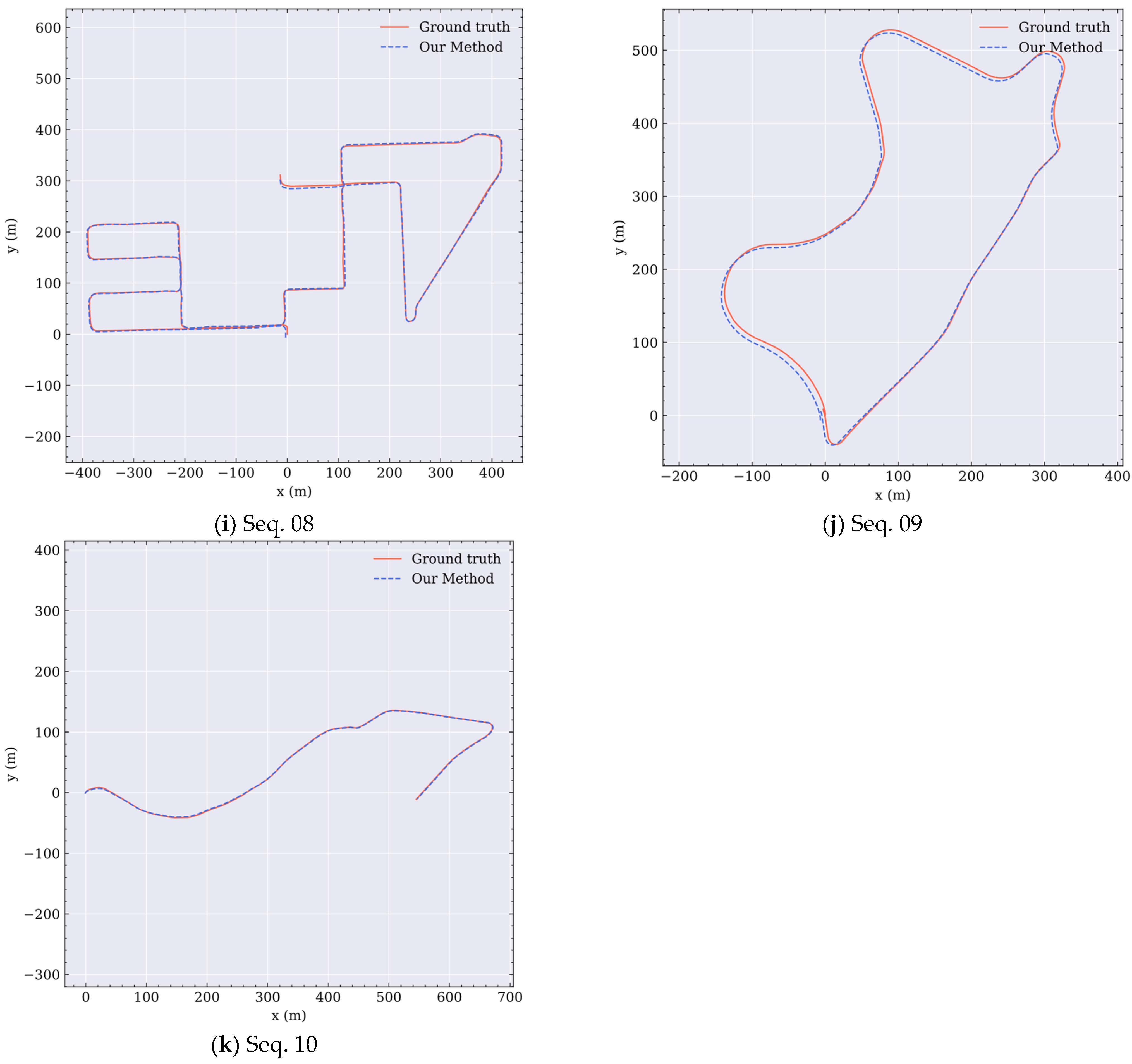
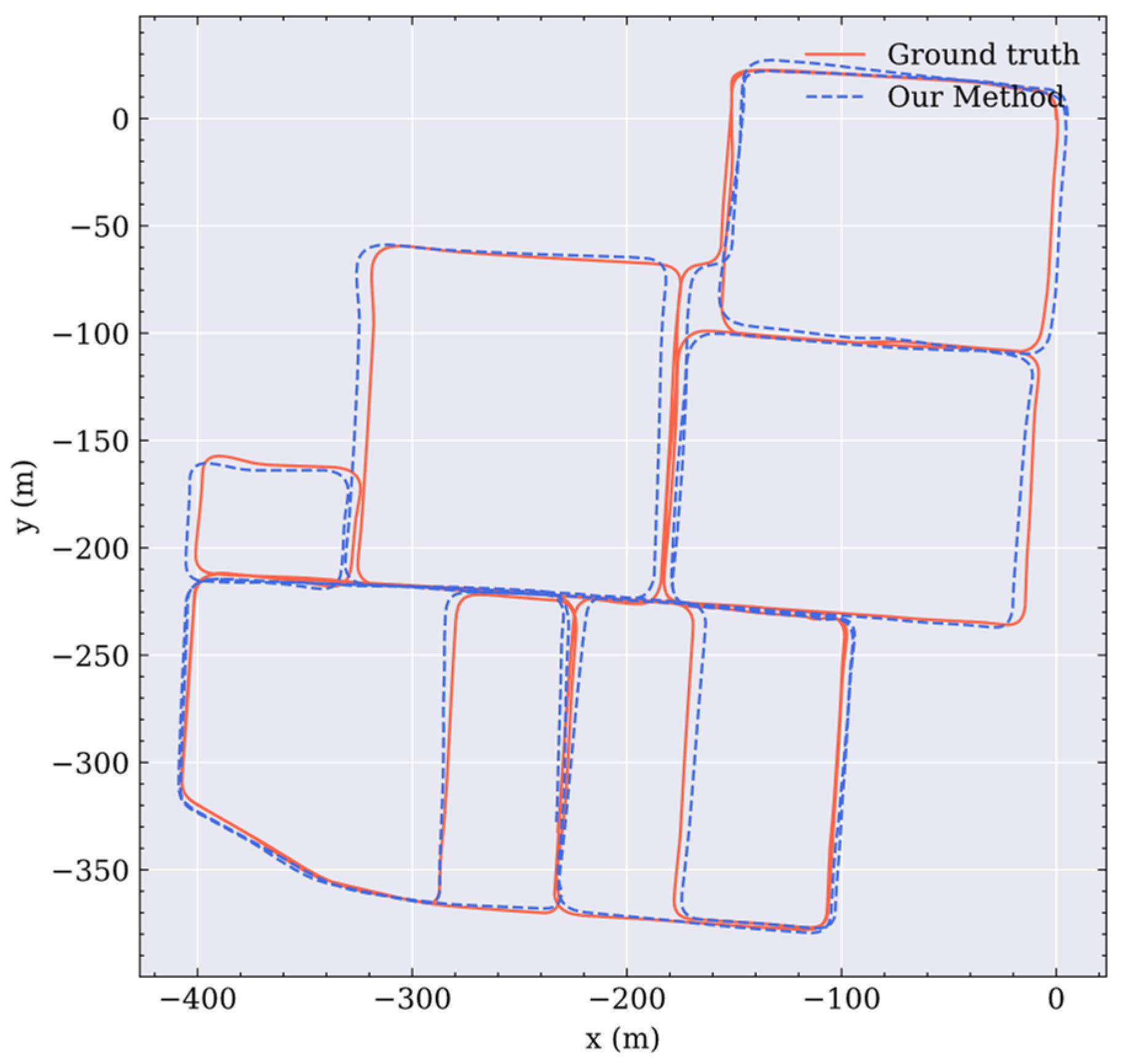
3.1. Evaluation of LiDAR Odometry
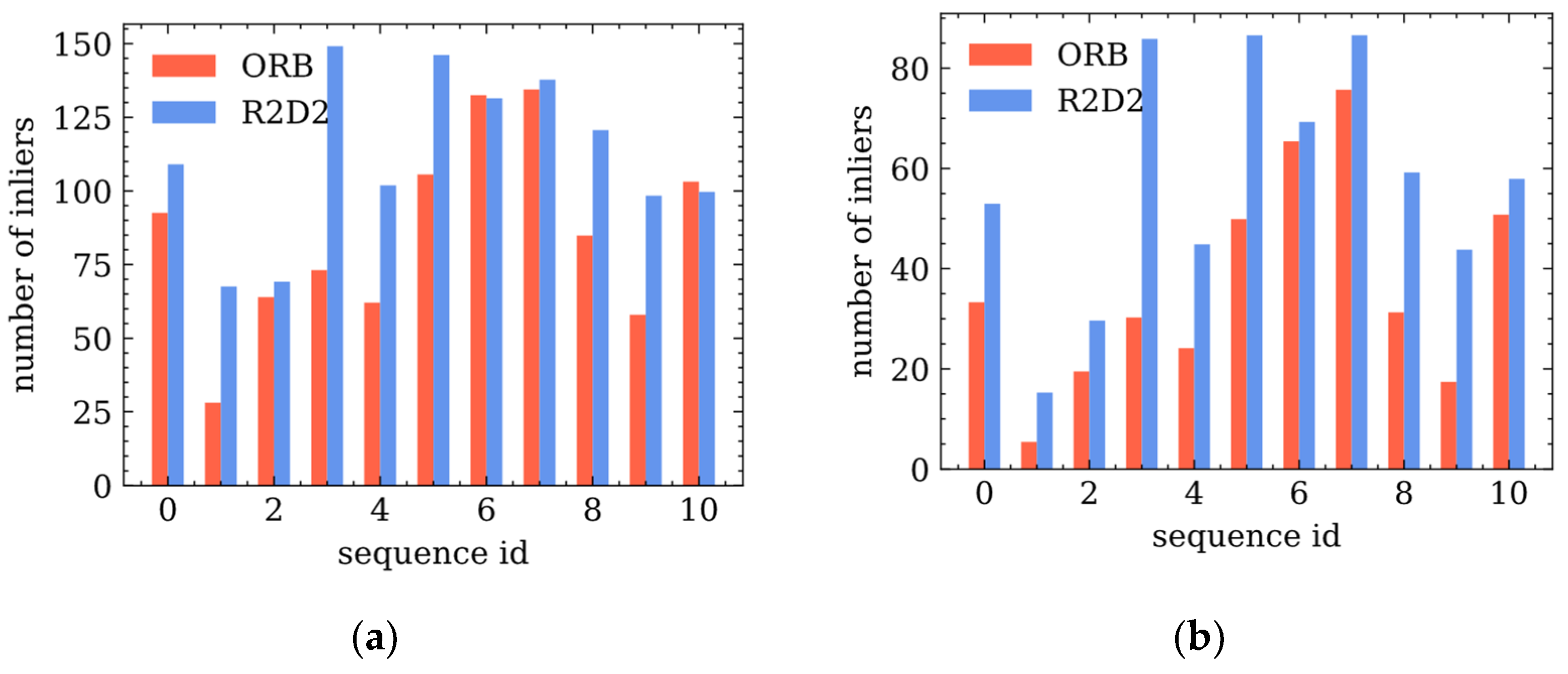
3.2. Performance Comparison between ORB and R2D2 Net
- First, there are richer and more complex patterns in optical images than in the BEV LiDAR images. Filters trained by optical images in the network can represent the feature space of the LiDAR BEV images.
- Second, 128-dimensional floating-point descriptors are inferred by the network, leading to a more powerful description of those keypoints than the 256-bit descriptors of the ORB feature.
- Third, the network constructed by a multi-layer convolutional neural network has a larger receptive field to capture global features to make feature points distinguishable.
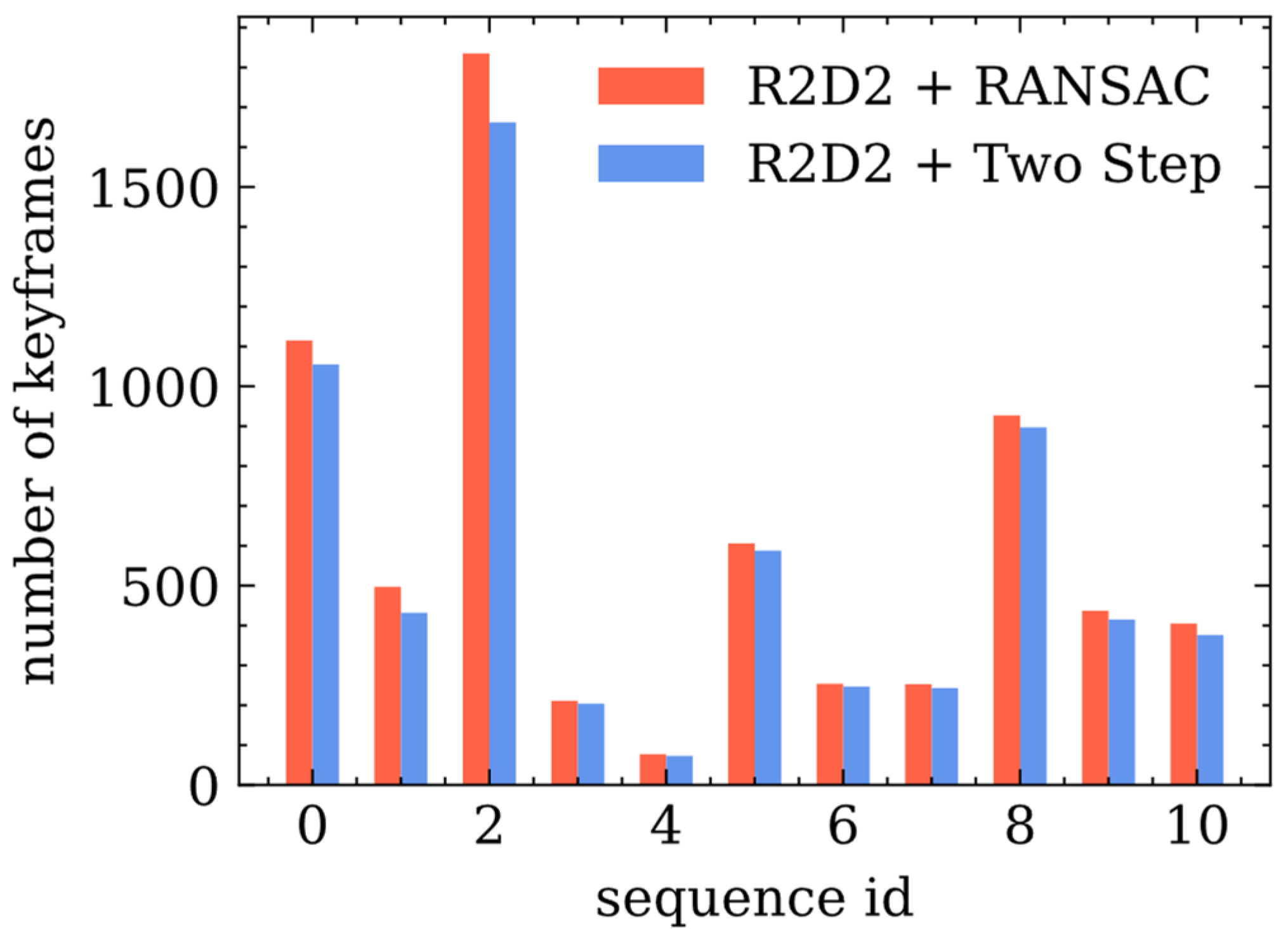
3.3. Performance Comparison between RANSAC and Two-Step Pose Estimation
3.4. Evaluation of Velodyne VLP-16 Dataset
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

References
- Chang, L.; Niu, X.; Liu, T.; Tang, J.; Qian, C. GNSS/INS/LiDAR-SLAM integrated navigation system based on graph optimization. Remote Sens. 2019, 11, 1009. [Google Scholar] [CrossRef] [Green Version]
- Hengjie, L.; Hong, B.; Cheng, X. Fast Closed-Loop SLAM based on the fusion of IMU and Lidar. J. Phys. Conf. Ser. 2021, 1914, 012019. [Google Scholar] [CrossRef]
- Li, X.; Wang, H.; Li, S.; Feng, S.; Wang, X.; Liao, J. GIL: A tightly coupled GNSS PPP/INS/LiDAR method for precise vehicle navigation. Satell. Navig. 2021, 2, 26. [Google Scholar] [CrossRef]
- Chang, L.; Niu, X.; Liu, T. GNSS/IMU/ODO/LiDAR-SLAM Integrated Navigation System Using IMU/ODO Pre-Integration. Sensors 2020, 20, 4702. [Google Scholar] [CrossRef]
- Li, C.; Sun, H.; Ye, P. Multi-sensor fusion localization algorithm for outdoor mobile robot. J. Phys. Conf. Ser. 2020, 1453, 012042. [Google Scholar] [CrossRef]
- Chiang, K.-W.; Tsai, G.-J.; Li, Y.-H.; Li, Y.; El-Sheimy, N. Navigation engine design for automated driving using INS/GNSS/3D LiDAR-SLAM and integrity assessment. Remote Sens. 2020, 12, 1564. [Google Scholar] [CrossRef]
- Wang, C.; Zhang, G.; Zhang, M. Research on improving LIO-SAM based on Intensity Scan Context. J. Phys. Conf. Ser. 2021, 1827, 012193. [Google Scholar] [CrossRef]
- Wang, W.; Liu, J.; Wang, C.; Luo, B.; Zhang, C. DV-LOAM: Direct visual lidar odometry and mapping. Remote Sens. 2021, 13, 3340. [Google Scholar] [CrossRef]
- Liu, J.; Gao, K.; Guo, W.; Cui, J.; Guo, C. Role, path, and vision of “5G + BDS/GNSS”. Satell. Navig. 2020, 1, 23. [Google Scholar] [CrossRef]
- Du, Y.; Wang, J.; Rizos, C.; El-Mowafy, A. Vulnerabilities and integrity of precise point positioning for intelligent transport systems: Overview and analysis. Satell. Navig. 2021, 2, 3. [Google Scholar] [CrossRef]
- Zhang, J.; Singh, S. LOAM: Lidar Odometry and Mapping in Real-time. Robot. Sci. Syst. 2014, 2, 1–9. [Google Scholar]
- Wang, H.; Wang, C.; Chen, C.-L.; Xie, L. F-LOAM: Fast LiDAR Odometry And Mapping. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021. [Google Scholar]
- Shan, T.; Englot, B. Lego-loam: Lightweight and ground-optimized lidar odometry and mapping on variable terrain. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 4758–4765. [Google Scholar]
- Pan, Y.; Xiao, P.; He, Y.; Shao, Z.; Li, Z. MULLS: Versatile LiDAR SLAM via multi-metric linear least square. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 11633–11640. [Google Scholar]
- Schaefer, A.; Büscher, D.; Vertens, J.; Luft, L.; Burgard, W. Long-term urban vehicle localization using pole landmarks extracted from 3-D lidar scans. In Proceedings of the 2019 European Conference on Mobile Robots (ECMR), Prague, Czech Republic, 4–6 September 2019; pp. 1–7. [Google Scholar]
- Liu, T.; Chang, L.; Niu, X.; Liu, J. Pole-Like Object Extraction and Pole-Aided GNSS/IMU/LiDAR-SLAM System in Urban Area. Sensors 2020, 20, 7145. [Google Scholar] [CrossRef] [PubMed]
- Steinke, N.; Ritter, C.-N.; Goehring, D.; Rojas, R. Robust LiDAR Feature Localization for Autonomous Vehicles Using Geometric Fingerprinting on Open Datasets. IEEE Robot. Autom. Lett. 2021, 6, 2761–2767. [Google Scholar] [CrossRef]
- Sun, L.; Zhao, J.; He, X.; Ye, C. Dlo: Direct lidar odometry for 2.5 d outdoor environment. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 1–5. [Google Scholar]
- Li, J.; Zhao, J.; Kang, Y.; He, X.; Ye, C.; Sun, L. DL-SLAM: Direct 2.5 D LiDAR SLAM for Autonomous Driving. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 1205–1210. [Google Scholar]
- Zheng, X.; Zhu, J. Efficient LiDAR odometry for autonomous driving. IEEE Robot. Autom. Lett. 2021, 6, 8458–8465. [Google Scholar] [CrossRef]
- Ali, W.; Liu, P.; Ying, R.; Gong, Z. A life-long SLAM approach using adaptable local maps based on rasterized LIDAR images. IEEE Sens. J. 2021, 21, 21740–21749. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Li, Q.; Chen, S.; Wang, C.; Li, X.; Wen, C.; Cheng, M.; Li, J. Lo-net: Deep real-time lidar odometry. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8473–8482. [Google Scholar]
- Lu, W.; Wan, G.; Zhou, Y.; Fu, X.; Yuan, P.; Song, S. Deepvcp: An end-to-end deep neural network for point cloud registration. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 12–21. [Google Scholar]
- Cho, Y.; Kim, G.; Kim, A. Unsupervised geometry-aware deep lidar odometry. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 2145–2152. [Google Scholar]
- Yoon, D.J.; Zhang, H.; Gridseth, M.; Thomas, H.; Barfoot, T.D. Unsupervised Learning of Lidar Features for Use ina Probabilistic Trajectory Estimator. IEEE Robot. Autom. Lett. 2021, 6, 2130–2138. [Google Scholar] [CrossRef]
- Serafin, J.; Grisetti, G. NICP: Dense normal based point cloud registration. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 742–749. [Google Scholar]
- Besl, P.J.; McKay, N.D. Method for registration of 3-D shapes. In Proceedings of the Sensor Fusion IV: Control Paradigms and Data Structures, Boston, MA, USA, 30 April 1992; pp. 586–606. [Google Scholar]
- Zhang, D.; Yao, L.; Chen, K.; Wang, S.; Chang, X.; Liu, Y. Making Sense of Spatio-Temporal Preserving Representations for EEG-Based Human Intention Recognition. IEEE Trans. Cybern. 2020, 50, 3033–3044. [Google Scholar] [CrossRef]
- Luo, M.; Chang, X.; Nie, L.; Yang, Y.; Hauptmann, A.G.; Zheng, Q. An Adaptive Semisupervised Feature Analysis for Video Semantic Recognition. IEEE Trans. Cybern. 2018, 48, 648–660. [Google Scholar] [CrossRef]
- Chen, K.; Yao, L.; Zhang, D.; Wang, X.; Chang, X.; Nie, F. A semisupervised recurrent convolutional attention model for human activity recognition. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 1747–1756. [Google Scholar] [CrossRef]
- Li, Z.; Wang, N. Dmlo: Deep matching lidar odometry. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October–24 January 2021; pp. 6010–6017. [Google Scholar]
- Ambrus, R.; Guizilini, V.; Li, J.; Gaidon, S.P.A. Two stream networks for self-supervised ego-motion estimation. In Proceedings of the Conference on Robot Learning, Osaka, Japan, 30 October–1 November 2019; pp. 1052–1061. [Google Scholar]
- Zheng, C.; Lyu, Y.; Li, M.; Zhang, Z. Lodonet: A deep neural network with 2d keypoint matching for 3d lidar odometry estimation. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 2391–2399. [Google Scholar]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; pp. 1150–1157. [Google Scholar]
- Streiff, D.; Bernreiter, L.; Tschopp, F.; Fehr, M.; Siegwart, R. 3D3L: Deep Learned 3D Keypoint Detection and Description for LiDARs. arXiv 2021, arXiv:2103.13808. [Google Scholar]
- Ali, W.; Liu, P.; Ying, R.; Gong, Z. 6-DOF Feature based LIDAR SLAM using ORB Features from Rasterized Images of 3D LIDAR Point Cloud. arXiv 2021, arXiv:2103.10678. [Google Scholar]
- Dusmanu, M.; Rocco, I.; Pajdla, T.; Pollefeys, M.; Sivic, J.; Torii, A.; Sattler, T. D2-net: A trainable cnn for joint detection and description of local features. arXiv 2019, arXiv:1905.03561. [Google Scholar]
- Tian, Y.; Fan, B.; Wu, F. L2-net: Deep learning of discriminative patch descriptor in euclidean space. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 661–669. [Google Scholar]
- Yi, K.M.; Trulls, E.; Lepetit, V.; Fua, P. Lift: Learned invariant feature transform. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 467–483. [Google Scholar]
- Revaud, J. R2d2: Reliable and repeatable detectors and descriptors for joint sparse keypoint detection and local feature extraction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshop, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Bay, H.; Tuytelaars, T.; Van Gool, L. Surf: Speeded up robust features. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 404–417. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Revaud, J.; De Souza, C.; Humenberger, M.; Weinzaepfel, P. R2d2: Reliable and repeatable detector and descriptor. Adv. Neural Inf. Processing Syst. 2019, 32, 12405–12415. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Rusu, R.B.; Cousins, S. 3D is here: Point Cloud Library (PCL). In Proceedings of the 2011 IEEE International Conference on Robotics and Automation (ICRA), Shanghai, China, 9–13 May 2011. [Google Scholar]
- Agarwal, S.; Mierle, K.; Team, T.C.S. Ceres Solver; Google Inc.: Mountain View, CA, USA, 2022. [Google Scholar]
- Grupp, M. evo: Python Package for the Evaluation of Odometry and SLAM. 2017. Available online: https://github.com/MichaelGrupp/evo (accessed on 6 June 2022).
- Ali, W.; Liu, P.; Ying, R.; Gong, Z. A Feature based Laser SLAM using Rasterized Images of 3D Point Cloud. IEEE Sens. J. 2021, 21, 24422–24430. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Seq. | LOAM | ORB + RANSAC [49] | MULLS [14] | Our Method | ||||
|---|---|---|---|---|---|---|---|---|
| RMSE | STD | RMSE | STD | RMSE | STD | RMSE | STD | |
| 00 | 13.89 | 6.37 | 7.66 | 3.15 | 5.84 | 3.16 | 6.08 | 3.48 |
| 01 | 47.91 | 29.44 | 21.08 | 9.58 | 2.94 | 1.03 | 5.99 | 1.79 |
| 02 | 19.88 | 5.86 | 16.62 | 9.36 | 13.97 | 5.29 | 12.47 | 4.60 |
| 03 | 3.68 | 2.08 | 1.65 | 0.74 | 0.97 | 0.33 | 1.20 | 0.45 |
| 04 | 2.73 | 1.47 | 0.94 | 0.47 | 0.41 | 0.14 | 0.28 | 0.13 |
| 05 | 4.39 | 1.99 | 4.48 | 2.52 | 2.32 | 1.07 | 1.13 | 0.49 |
| 06 | 3.68 | 1.92 | 3.51 | 1.31 | 0.63 | 0.23 | 0.66 | 0.24 |
| 07 | 1.82 | 0.69 | 3.51 | 1.66 | 0.59 | 0.26 | 0.50 | 0.22 |
| 08 | 15.02 | 6.83 | 11.67 | 2.16 | 4.10 | 2.46 | 2.65 | 1.31 |
| 09 | 7.94 | 3.06 | 6.31 | 2.79 | 6.56 | 3.47 | 6.13 | 3.46 |
| 10 | 7.18 | 3.61 | 5.28 | 2.95 | 2.53 | 1.33 | 2.72 | 1.25 |
| Sequence | R2D2 + RANSAC | R2D2 + Two Step | ||
|---|---|---|---|---|
| RMSE | STD | RMSE | STD | |
| 00 | 6.98 | 3.76 | 6.08 | 3.48 |
| 01 | 9.47 | 3.72 | 5.99 | 1.79 |
| 02 | 14.31 | 6.07 | 12.47 | 4.60 |
| 03 | 1.27 | 0.46 | 1.20 | 0.45 |
| 04 | 0.21 | 0.09 | 0.28 | 0.13 |
| 05 | 2.85 | 1.36 | 1.13 | 0.49 |
| 06 | 1.10 | 0.50 | 0.66 | 0.24 |
| 07 | 1.21 | 0.64 | 0.50 | 0.22 |
| 08 | 4.23 | 2.11 | 2.65 | 1.31 |
| 09 | 7.27 | 3.77 | 6.13 | 3.46 |
| 10 | 2.84 | 1.46 | 2.72 | 1.25 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, T.; Wang, Y.; Niu, X.; Chang, L.; Zhang, T.; Liu, J. LiDAR Odometry by Deep Learning-Based Feature Points with Two-Step Pose Estimation. Remote Sens. 2022, 14, 2764. https://doi.org/10.3390/rs14122764
Liu T, Wang Y, Niu X, Chang L, Zhang T, Liu J. LiDAR Odometry by Deep Learning-Based Feature Points with Two-Step Pose Estimation. Remote Sensing. 2022; 14(12):2764. https://doi.org/10.3390/rs14122764
Chicago/Turabian StyleLiu, Tianyi, Yan Wang, Xiaoji Niu, Le Chang, Tisheng Zhang, and Jingnan Liu. 2022. "LiDAR Odometry by Deep Learning-Based Feature Points with Two-Step Pose Estimation" Remote Sensing 14, no. 12: 2764. https://doi.org/10.3390/rs14122764
APA StyleLiu, T., Wang, Y., Niu, X., Chang, L., Zhang, T., & Liu, J. (2022). LiDAR Odometry by Deep Learning-Based Feature Points with Two-Step Pose Estimation. Remote Sensing, 14(12), 2764. https://doi.org/10.3390/rs14122764