
Using Open Vector-Based Spatial Data to Create Semantic Datasets for Building Segmentation for Raster Data


Abstract
:1. Introduction
- Verification of the state of the cadastral databases in order to identify unpermitted buildings;
- Verification of the actual state of an area in the initial phase of an infrastructural investment process for a more reliable cost assessment;
- Mapping of buildings for unmapped areas;
- Verification of the validity of open building databases.
2. Study Area and Datasets
2.1. Open Spatial Data
2.2. Selection of Study Areas
- Urban area;
- Architecture varying in terms of time of construction (historic buildings, often with more complicated architecture and contours, and modern buildings with simpler shapes);
- Architecture varying in terms of use (residential, industrial, public buildings, etc.);
- Building density and diversity;
- Availability of actual orthophotomap (max. up to one year back) with terrain pixel of max. 10 cm;
- Availability of data from the cadastral vector database: The Land and Building Register (EGiB).
- Area A—incorrectly determined outline of the building in the OSM database (the car park located next to the building was included in the building projection);
- Areas B1, B2, B3, B4, B5, B6—no buildings that actually exist in the OSM database;
- Area C1—presence in the OSM database of buildings which in fact do not exist;
- Area D—generalisation of building outline (simplification of building outline shape).
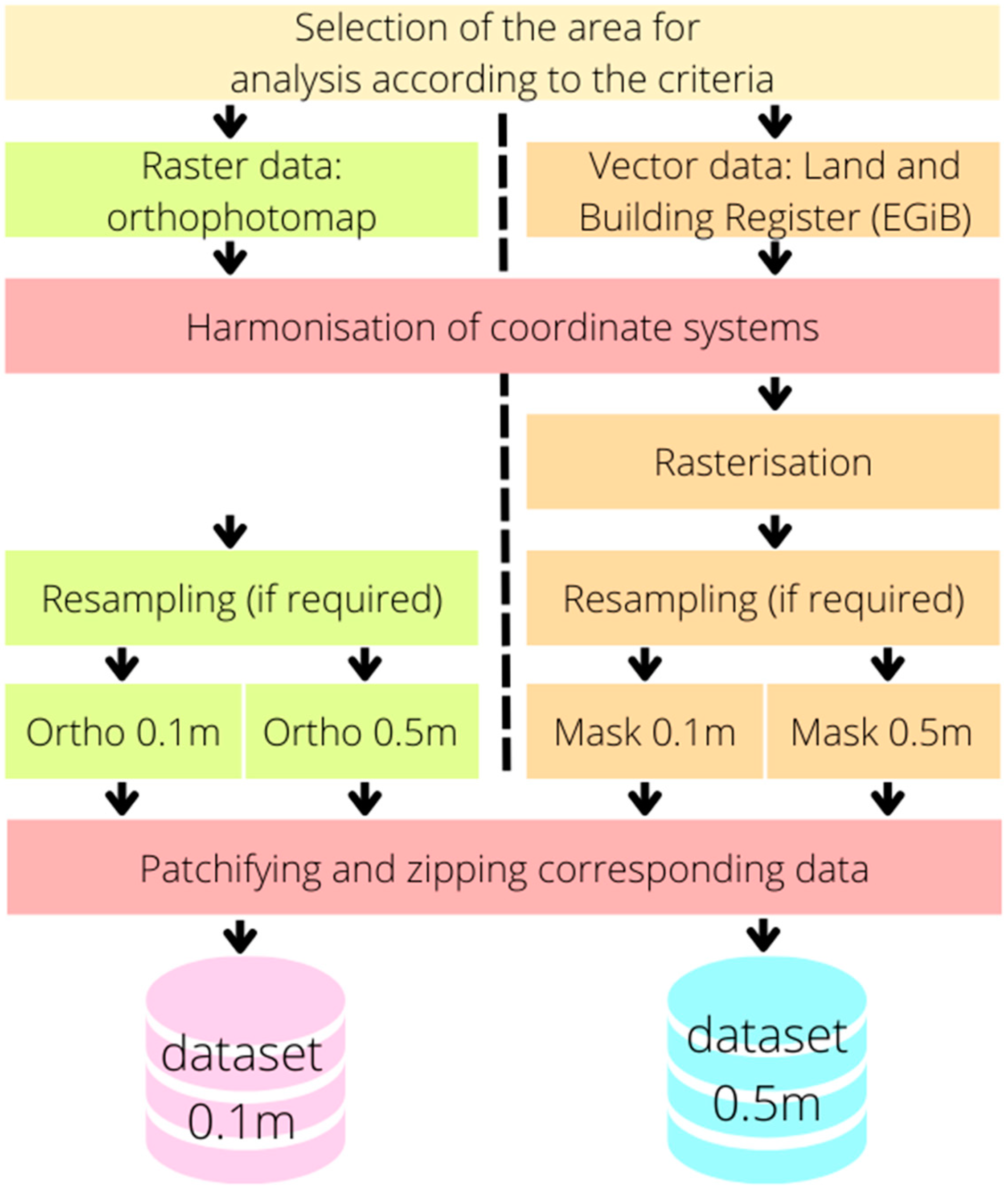
2.3. Data Preprocessing
3. Materials and Methods
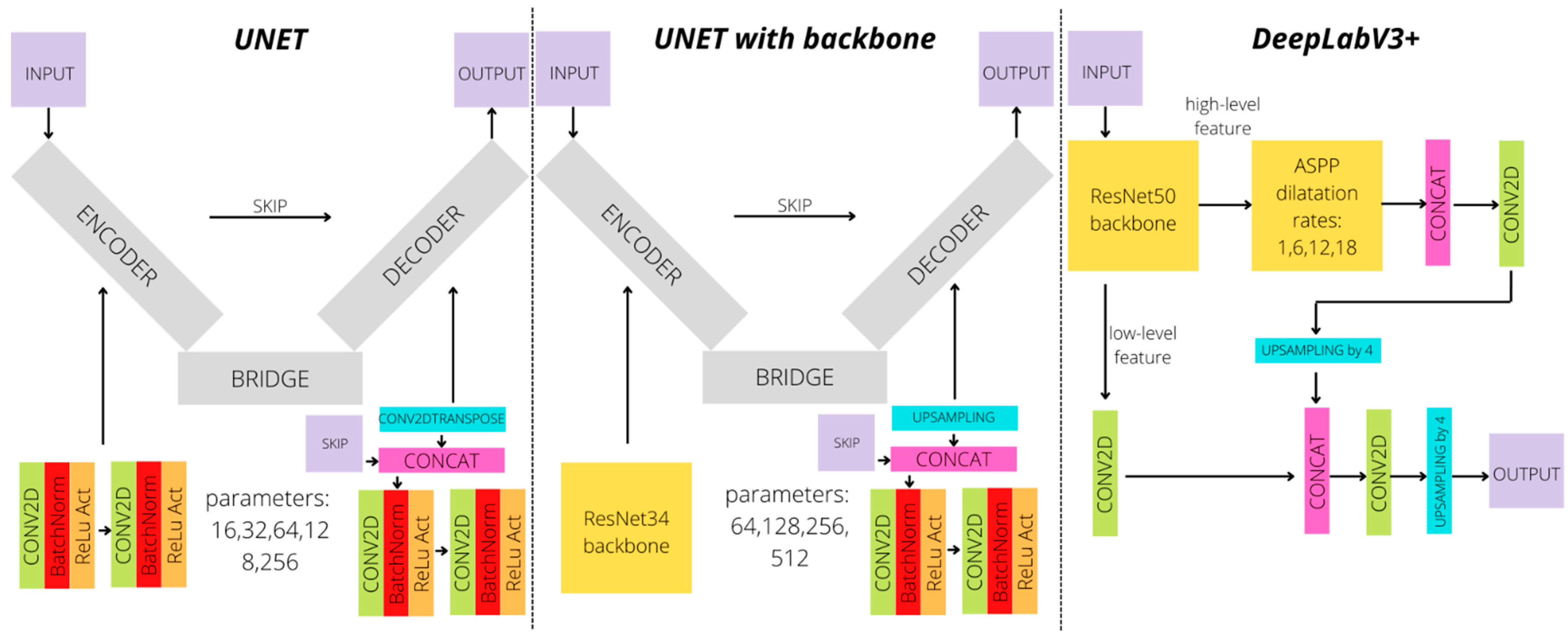
3.1. Semantic Image Segmentation Architectures
3.2. Data Augmentation
3.3. Semantic Image Segmentation
3.4. Results Evaluation
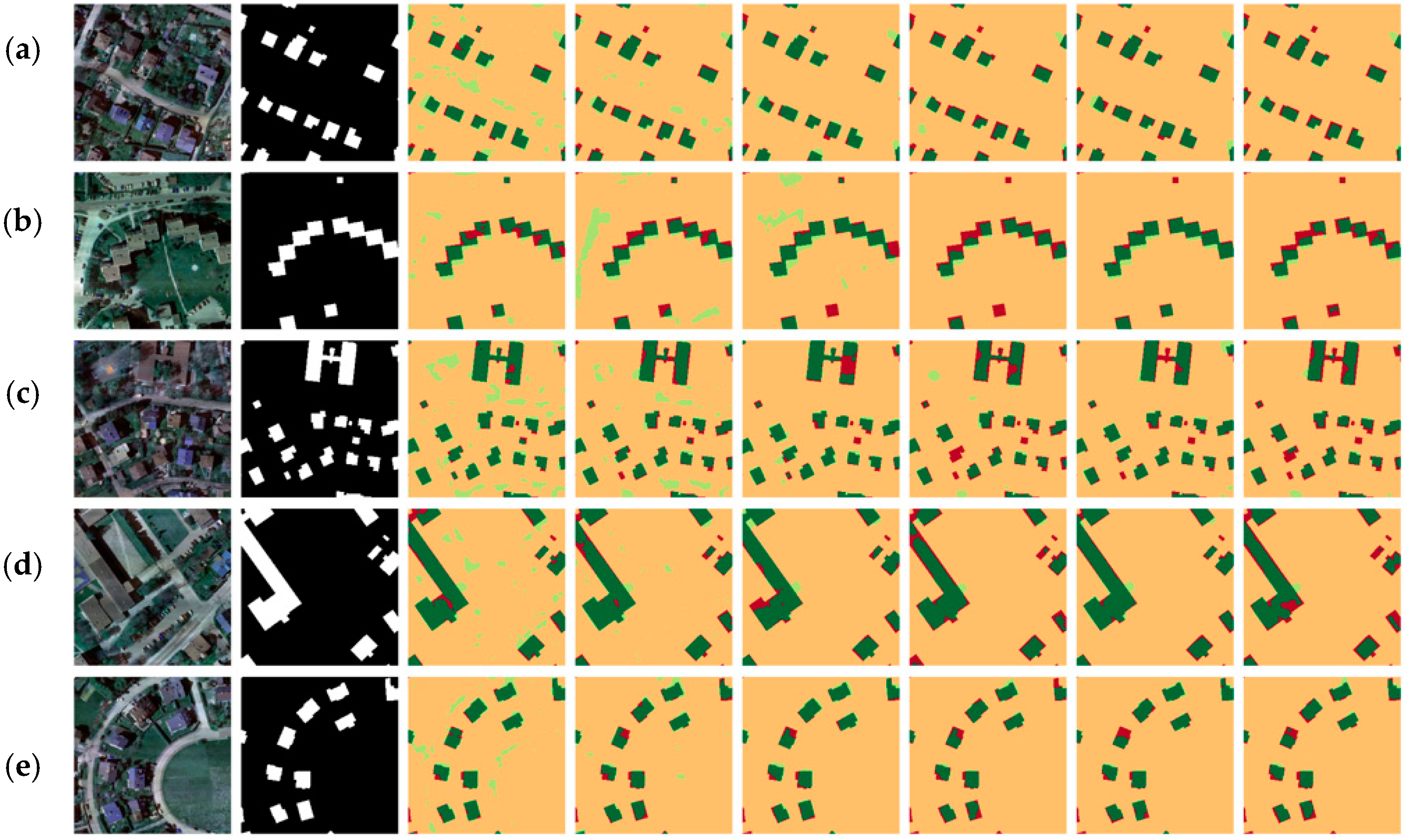
4. Results
4.1. Dataset with 0.5 m Terrain Pixel
4.2. Dataset with 0.1 m Terrain Pixel
4.3. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- European Commission. Open Data Maturity Report 2020; European Commission: Brussels, Belgium, 2020. [Google Scholar]
- Liu, P.; Liu, X.; Liu, M.; Shi, Q.; Yang, J.; Xu, X.; Zhang, Y. Building footprint extraction from high-resolution images via spatial residual inception convolutional neural network. Remote Sens. 2019, 11, 830. [Google Scholar] [CrossRef] [Green Version]
- Touzani, S.; Granderson, J. Open data and deep semantic segmentation for automated extraction of building footprints. Remote Sens. 2021, 13, 2578. [Google Scholar] [CrossRef]
- Liu, J.; Wang, S.; Hou, X.; Song, W. A deep residual learning serial segmentation network for extracting buildings from remote sensing imagery. Int. J. Remote Sens. 2020, 41, 5573–5587. [Google Scholar] [CrossRef]
- Li, W.; He, C.; Fang, J.; Fu, H. Semantic segmentation based building extraction method using multi-source GIS map datasets and satellite imagery. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 233–236. [Google Scholar] [CrossRef]
- Chen, Z.; Li, D.; Fan, W.; Guan, H.; Wang, C.; Li, J. Self-attention in reconstruction bias U-net for semantic segmentation of building rooftops in optical remote sensing images. Remote Sens. 2021, 13, 2524. [Google Scholar] [CrossRef]
- Wang, H.; Miao, F. Building extraction from remote sensing images using deep residual U-Net. Eur. J. Remote Sens. 2022, 55, 71–85. [Google Scholar] [CrossRef]
- Bischke, B.; Helber, P.; Folz, J.; Borth, D.; Dengel, A. Multi-Task Learning for Segmentation of Building Footprints with Deep Neural Networks. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 1480–1484. [Google Scholar] [CrossRef] [Green Version]
- Yi, Y.; Zhang, Z.; Zhang, W.; Zhang, C.; Li, W.; Zhao, T. Semantic segmentation of urban buildings from VHR remote sensing imagery using a deep convolutional neural network. Remote Sens. 2019, 11, 1774. [Google Scholar] [CrossRef] [Green Version]
- He, H.; Yang, D.; Wang, S.; Wang, S.; Li, Y. Road extraction by using atrous spatial pyramid pooling integrated encoder-decoder network and structural similarity loss. Remote Sens. 2019, 11, 1015. [Google Scholar] [CrossRef] [Green Version]
- Boonpook, W.; Tan, Y.; Bai, B.; Xu, B. Road Extraction from UAV Images Using a Deep ResDCLnet Architecture. Can. J. Remote Sens. 2021, 47, 450–464. [Google Scholar] [CrossRef]
- Gupta, A.; Watson, S.; Yin, H. Deep learning-based aerial image segmentation with open data for disaster impact assessment. Neurocomputing 2021, 439, 22–33. [Google Scholar] [CrossRef]
- Robinson, C.; Hohman, F.; Dilkina, B. A deep learning approach for population estimation from satellite imagery. In Proceedings of the 1st ACM SIGSPATIAL Workshop on Geospatial Humanities, Online, 7 November 2017; pp. 47–54. [Google Scholar] [CrossRef] [Green Version]
- Cai, L.; Xu, X.; Liew, J.H.; Sheng Foo, C. Revisiting Superpixels for Active Learning in Semantic Segmentation with Realistic Annotation Costs. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 10983–10992. [Google Scholar] [CrossRef]
- Li, Y.; Chen, J.; Xie, X.; Ma, K.; Zheng, Y. Self-loop uncertainty: A novel pseudo-label for semi-supervised medical image segmentation. In Medical Image Computing and Computer Assisted Intervention—MICCAI 2020; Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2020; Volume 12621, pp. 614–623. [Google Scholar] [CrossRef]
- Sun, W.; Zhang, J.; Barnes, N. 3D Guided Weakly Supervised Semantic Segmentation. In Computer Vision—ACCV 2020; Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2020; Volume 12622, pp. 585–602. [Google Scholar] [CrossRef]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Can semantic labeling methods generalize to any city? the inria aerial image labeling benchmark. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 3226–3229. [Google Scholar] [CrossRef] [Green Version]
- Farasin, A.; Colomba, L.; Garza, P. Double-step U-Net: A deep learning-based approach for the estimation ofwildfire damage severity through sentinel-2 satellite data. Appl. Sci. 2020, 10, 4332. [Google Scholar] [CrossRef]
- Ulmas, P.; Liiv, I. Segmentation of Satellite Imagery using U-Net Models for Land Cover Classification. arXiv 2020, arXiv:2003.02899. [Google Scholar]
- Gargiulo, M.; Dell’aglio, D.A.G.; Iodice, A.; Riccio, D.; Ruello, G. Integration of sentinel-1 and sentinel-2 data for land cover mapping using w-net. Sensors 2020, 20, 2969. [Google Scholar] [CrossRef] [PubMed]
- Karra, K.; Kontgis, C.; Statman-Weil, Z.; Mazzariello, J.C.; Mathis, M.; Brumby, S.P. Global Land Use/Land Cover with Sentinel 2 and Deep Learning. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 4704–4707. [Google Scholar] [CrossRef]
- Pan, Z.; Xu, J.; Guo, Y.; Hu, Y.; Wang, G. Deep learning segmentation and classification for urban village using a worldview satellite image based on U-net. Remote Sens. 2020, 12, 1574. [Google Scholar] [CrossRef]
- Shahi, K.; Shafri, H.Z.M.; Taherzadeh, E.; Mansor, S.; Muniandy, R. A novel spectral index to automatically extract road networks from WorldView-2 satellite imagery. Egypt. J. Remote Sens. Sp. Sci. 2015, 18, 27–33. [Google Scholar] [CrossRef] [Green Version]
- Boguszewski, A.; Batorski, D.; Ziemba-Jankowska, N.; Dziedzic, T.; Zambrzycka, A. LandCover.ai: Dataset for automatic mapping of buildings, woodlands, water and roads from aerial imagery. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Nashville, TN, USA, 19–25 June 2021; pp. 1102–1110. [Google Scholar]
- Directive 2007/2/EC of the European Parliament and of the Council of 14 March 2007 Establishing an Infrastructure for Spatial Information in the European Community (INSPIRE). Available online: https://eur-lex.europa.eu/legal-content/EN/ALL/?uri=CELEX%3A32007L0002 (accessed on 15 March 2022).
- Geoportal Krajowy (National Geoportal). Available online: https://www.geoportal.gov.pl/ (accessed on 15 March 2022).
- Ewidencja Zbiorów i Usług Danych Przestrzennych (Register of Spatial Data Sets and Services). Available online: https://integracja.gugik.gov.pl/eziudp/ (accessed on 15 March 2022).
- Habib, A.F.; Kim, E.M.; Kim, C.J. New methodologies for true orthophoto generation. Photogramm. Eng. Remote Sens. 2007, 73, 25–36. [Google Scholar] [CrossRef] [Green Version]
- Glinka, S. Keras Segmentation Models. Available online: https://github.com/sajmonogy/keras_segmentation_models (accessed on 1 May 2022).
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Abdollahi, A.; Pradhan, B.; Alamri, A.M. An ensemble architecture of deep convolutional Segnet and Unet networks for building semantic segmentation from high-resolution aerial images. Geocarto Int. 2020, 35, 1856199. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar] [CrossRef] [Green Version]
- Weng, W.; Zhu, X. UNet: Convolutional Networks for Biomedical Image Segmentation. IEEE Access 2021, 9, 16591–16603. [Google Scholar] [CrossRef]
- Li, R.; Liu, W.; Yang, L.; Sun, S.; Hu, W.; Zhang, F.; Li, W. DeepUNet: A Deep Fully Convolutional Network for Pixel-Level Sea-Land Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3954–3962. [Google Scholar] [CrossRef] [Green Version]
- Sofla, R.A.D.; Alipour-Fard, T.; Arefi, H. Road extraction from satellite and aerial image using SE-Unet. J. Appl. Remote Sens. 2021, 15, 014512. [Google Scholar] [CrossRef]
- He, N.; Fang, L.; Plaza, A. Hybrid first and second order attention Unet for building segmentation in remote sensing images. Sci. China Inf. Sci. 2020, 63, 140305. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. arXiv 2015, arXiv:1412.7062. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Computer Vision—ECCV 2018; Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2018; Volume 11211, pp. 833–851. [Google Scholar] [CrossRef] [Green Version]
- Liu, C.; Chen, L.C.; Schroff, F.; Adam, H.; Hua, W.; Yuille, A.L.; Fei-Fei, L. Auto-deeplab: Hierarchical neural architecture search for semantic image segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 82–92. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.; Liu, W.; Qi, H.; Li, Y.; Zhang, G.; Zhang, T. Extracting River Illegal Buildings from UAV Image Based on Deeplabv3+. In Geoinformatics in Sustainable Ecosystem and Society, Proceedings of the 7th International Conference, GSES 2019, and First International Conference, GeoAI 2019, Guangzhou, China, 21–25 November 2019; Springer: Singapore, 2020; Volume 1228, pp. 259–272. [Google Scholar] [CrossRef]
- Xiang, S.; Xie, Q.; Wang, M. Semantic Segmentation for Remote Sensing Images Based on Adaptive Feature Selection Network. In IEEE Geoscience and Remote Sensing Letters; IEEE: New York, NY, USA, 2022; Volume 19. [Google Scholar] [CrossRef]
- Zhang, D.; Ding, Y.; Chen, P.; Zhang, X.; Pan, Z.; Liang, D. Automatic extraction of wheat lodging area based on transfer learning method and deeplabv3+ network. Comput. Electron. Agric. 2020, 179, 105845. [Google Scholar] [CrossRef]
- Yakubovskiy, P. Segmentation Models. Available online: https://github.com/qubvel/segmentation_models (accessed on 5 March 2022).
- Jadon, S. A survey of loss functions for semantic segmentation. In Proceedings of the 2020 IEEE Conference on Computational Intelligence in Bioinformatics and Computational Biology (CIBCB), Via del Mar, Chile, 27–29 October 2020. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J.L. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference for Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]
- Schneider, F.; Balles, L.; Hennig, P. Deepobs: A deep learning optimizer benchmark suite. In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019; pp. 1–14. [Google Scholar]
- Yaqub, M.; Jinchao, F.; Zia, M.S.; Arshid, K.; Jia, K.; Rehman, Z.U.; Mehmood, A. State-of-the-art CNN optimizer for brain tumor segmentation in magnetic resonance images. Brain Sci. 2020, 10, 427. [Google Scholar] [CrossRef]
- Minaee, S.; Boykov, Y.Y.; Porikli, F.; Plaza, A.J.; Kehtarnavaz, N.; Terzopoulos, D. Image Segmentation Using Deep Learning: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 14, 3523–3542. [Google Scholar] [CrossRef]
- Wang, Z.; Ji, S. Smoothed dilated convolutions for improved dense prediction. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD 2018, London, UK, 19–23 August 2018; pp. 2486–2495. [Google Scholar] [CrossRef] [Green Version]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Resolution [m] | Image Size [pix] | Image Size [m] | Training Images Number | Validation Images Number | Test Images Number |
|---|---|---|---|---|---|
| 0.1 | 512 × 512 × 3 | 51.2 × 51.2 | 5092 | 636 | 637 |
| 0.5 | 256 × 256 × 3 | 128.0 × 128.0 | 1010 | 126 | 127 |
| Model | Description | Backbone | Number of Parameters for Input 512 × 512 |
|---|---|---|---|
| UNET | Parameters: 16, 32, 64, 128, 256 | does not exist | 1,947,010 |
| UNET_bb | UNET with backbone | Resnet34 | 24,456,299 |
| DeepLabV3+ | DeepLabV3+ with backbone | Resnet50 | 17,830,466 |
| Neural Network Architecture | Augmentation | mIoU | F1-Score | Precision | Recall |
|---|---|---|---|---|---|
| UNET | NO | 90.64 | 95.02 | 94.89 | 95.15 |
| UNET with backbone | NO | 92.24 | 95.91 | 95.83 | 95.99 |
| DeepLabV3+ | NO | 79.96 | 88.37 | 88.28 | 88.46 |
| UNET | YES | 90.33 | 94.85 | 94.57 | 95.13 |
| UNET with backbone | YES | 90.24 | 94.79 | 94.53 | 95.06 |
| DeepLabV3+ | YES | 83.83 | 90.81 | 90.03 | 91.62 |
| Neural Network Architecture | Augmentation | mIoU | F1-Score | Precision | Recall |
|---|---|---|---|---|---|
| UNET | NO | 91.08 | 95.31 | 95.19 | 95.43 |
| UNET with backbone | NO | 93.00 | 96.36 | 96.33 | 96.38 |
| DeepLabV3+ | NO | 92.86 | 96.28 | 96.27 | 96.29 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Glinka, S.; Owerko, T.; Tomaszkiewicz, K. Using Open Vector-Based Spatial Data to Create Semantic Datasets for Building Segmentation for Raster Data. Remote Sens. 2022, 14, 2745. https://doi.org/10.3390/rs14122745
Glinka S, Owerko T, Tomaszkiewicz K. Using Open Vector-Based Spatial Data to Create Semantic Datasets for Building Segmentation for Raster Data. Remote Sensing. 2022; 14(12):2745. https://doi.org/10.3390/rs14122745
Chicago/Turabian StyleGlinka, Szymon, Tomasz Owerko, and Karolina Tomaszkiewicz. 2022. "Using Open Vector-Based Spatial Data to Create Semantic Datasets for Building Segmentation for Raster Data" Remote Sensing 14, no. 12: 2745. https://doi.org/10.3390/rs14122745
APA StyleGlinka, S., Owerko, T., & Tomaszkiewicz, K. (2022). Using Open Vector-Based Spatial Data to Create Semantic Datasets for Building Segmentation for Raster Data. Remote Sensing, 14(12), 2745. https://doi.org/10.3390/rs14122745