1. Introduction
Mangrove forests are unique tropical and subtropical ecosystems located at the intersections between land and coastal environments [
1]. Mangrove trees have the unique ability to live in saline ecosystems because they have evolved to use salt in their photosynthesis and struggle to grow in its absence [
2]. Due to their locations, mangroves provide numerous essential ecosystem services to coastal communities [
3]. They sustain marine and terrestrial habitats [
4], mitigate the impacts of tsunamis and storms on coastlines [
5], support local fisheries [
6], and efficiently sequester carbon [
7]. Nonetheless, although mangroves play an essential role within their habitats [
1,
8], their cover has been declining globally for the past two decades due to deforestation, with the most extensive removal occurring in Southeast Asia (SEA) [
9], where exploitative illegal activities [
10] and the growth of agriculture and aquaculture as parts of aggressive economic strategies [
1,
10] are key drivers of mangrove loss [
5].
Although mangrove forests only make up 0.7% of the global tropical forest cover [
8], they account for ~50% of the global carbon stock worldwide [
7], sequestering around four times the amount of carbon of inland tropical forests [
1]. Scientists estimate that mangrove deforestation alone is responsible for ~10% of the global annual carbon released into the atmosphere [
8]. The figure is particularly relevant for SEA, which alone accounts for ~30% of the global mangrove forest cover [
11]. Thus, the aggressive removal of mangroves in SEA disrupts local ecosystems and has global implications, particularly on global net carbon frameworks and climate change mitigation efforts [
12,
13].
Mangrove forests are long strips of trees along coasts and rivers [
11], and studies have often failed to distinguish them from other inland forests using satellite remote sensing imagery (SRSI) [
1,
10]. Although the scientific community has endeavoured to produce highly accurate maps using ever-advancing remote sensing technologies [
14], mapping mangroves remains challenging [
15]. In a study on global mangrove distribution mapping by Bunting et al. [
9], a traditional machine learning (ML) classifier, such as random forest (RF), was used to produce a global baseline map of mangroves for 2010, accurately discerning mangrove forests from other forests. Other scholars have identified four types of mangroves according to their sedimentary properties:
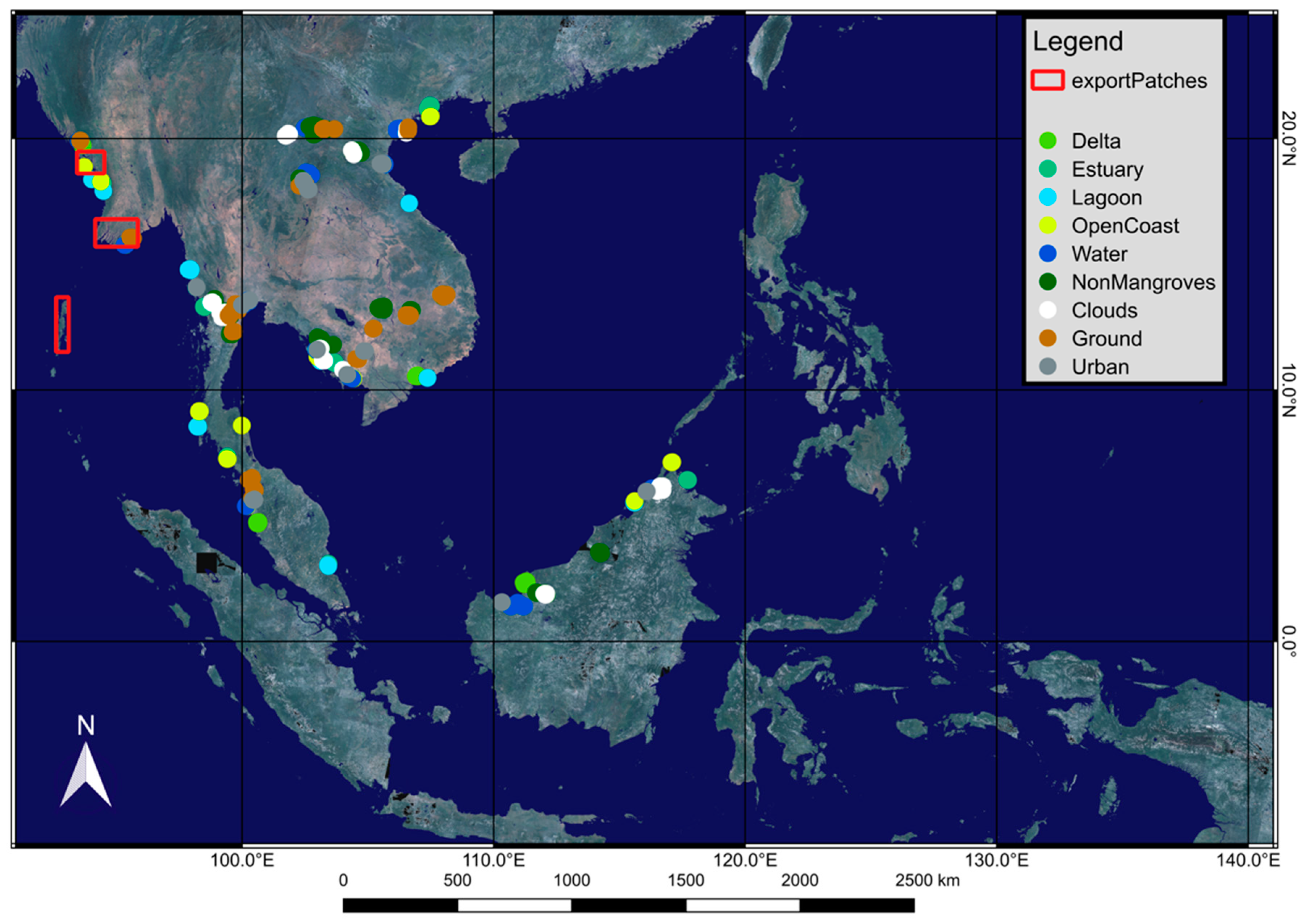
deltaic, estuarine, lagoonal, and open coast [
3].
Scientists widely adopt traditional ML methods, such as support vector machines [
16], k-nearest neighbour [
17], and RF [
10], to classify land cover types in SRSI [
18]. However, researchers have recently started using methods to map mangroves from complex space-borne multi-spectral images and proposed using more sophisticated ML classifiers such as convolutional neural networks (CNNs) [
15,
19]. CNNs are biologically inspired ML architectures that emulate the ability of the visual cortex to decompose and recompose information through interconnected neurons, allowing recognition [
20]. These architectures have several applications, from speech to medical condition recognition [
21], and have excellent large-scale natural image classification performance thanks to their ability to ‘learn’ hierarchical representations [
22].
In recent years, CNNs have proven to be more powerful than traditional ML methods in SRSI classification [
23] because, unlike RF, they can capture the semantics of an image (spatial information) using pixel values alone [
24] and are now preferred when classifying complex landcover types (LCTs), such as vegetation [
18]. Nevertheless, a recurrent limitation of CNNs is the need for a considerable amount of labelled data to ‘learn’ features robustly. Labelling SRSI is an often tedious and lengthy process, and there is a limited amount of pre-labelled datasets available out there, making their use for classification tasks with CNNs challenging [
25].
There are several methods for adapting CNNs to the task of classifying increasingly complex hyperspectral SRSI, such as training from scratch or using pre-trained CNNs as feature extractors [
26,
27]. The latter is called
transfer learning (TL), and it involves using CNNs that are pre-trained on large labelled natural image datasets such as ImageNet [
28] to train target SRSI [
29]. This method overcomes the lack of labelled data [
23] and enables CNNs to be focused on extracting the semantics of observed scenes [
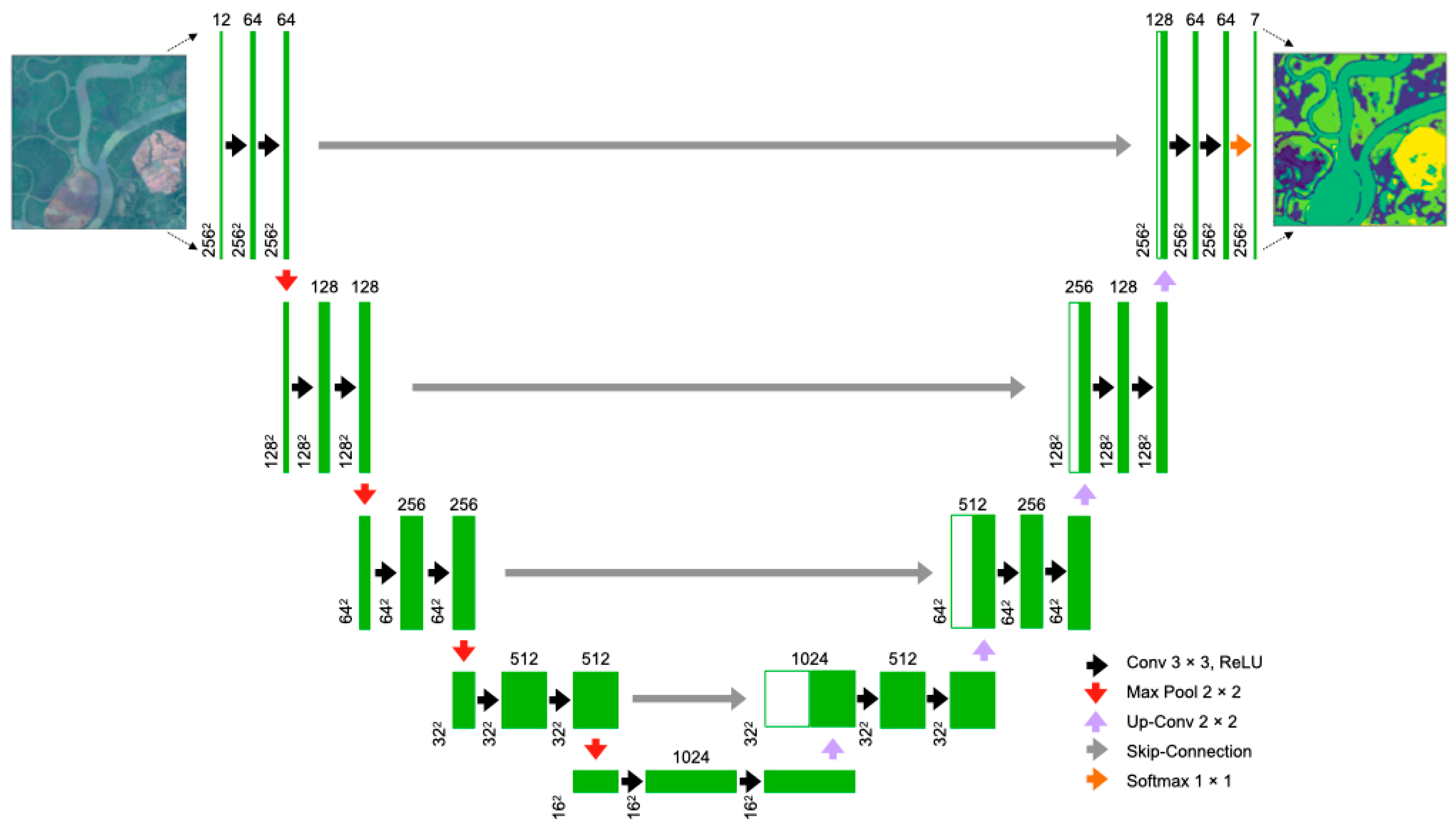
30]. Recently, scientists have deployed CNNs specialised in image segmentation, such as U-Net, because of their efficacy in learning the spatial relations between LCTs, especially with limited labelled images [
31].
Most of the CNNs analysed demonstrated impressive SRSI classification results, many with an accuracy above 97% [
29,
32], but almost all were generated using powerful proprietary computers and supercomputers. Some scholars have reviewed the integration of cloud-based systems such as Google Earth Engine (GEE) and Google Collaboratory (GC) to access and classify SRSI using traditional classifiers such as RF [
33,
34], with some implementing classifications with CNNs [
35,
36]. GEE is widely used in environmental research because it stores and provides access to many SRSI datasets [
32]. GC is a browser-based interface built on Jupyter Notebook’s open-source tools to support code and data visualisation [
37]. It is a fairly new tool and is often used in academia to teach ML [
38].
Several studies have been performed on mangrove forest mapping for SEA. One previous study has used inventories and comparisons on single- and multi-date remotely sensed datasets to identify mangrove deforestation hotspots in the region [
11]. There are studies that demonstrated the utility of GEE for mapping mangroves in SEA, including one that used artificial neural network (ANN) and GEE to develop a mangrove vegetation index mapper [
39], and a simple tool called Google Earth Engine Mangrove Mapping Methodology [
40]. Nevertheless, no studies have attempted to classify mangrove forests in SEA with CNNs using only cloud-based platforms. Furthermore, no study has used a deep learning mangrove classification pipeline to seamlessly use freely available EO data in GEE via Google Colab (GC).
Although cloud platforms may not offer as much computational power as supercomputers, there is a growing need to create accessible monitoring tools to enhance and empower local communities worldwide and meet sustainable development goals [
41]. This research, therefore, aims to create a cloud-based mangrove forest monitoring framework that is computationally less intensive to implement using GEE, GC, Google Drive (GD), and Google Cloud Storage (GCS), which uses freely available earth observation data to distinguish both mangroves from non-mangrove vegetation and map different mangrove typologies. Through this framework, local communities can generate new training data by computing new imagery and feeding them to the model. In doing so, they can use these models to assess how the local landscape is changing and determine if there are activities, such as illegal deforestation, that require tackling. Using a cloud-based system will empower local communities to perform their own monitoring, and not rely on specialists in the field, as it is an affordable resource to process large datasets [
42]. Lastly, GC is a fairly new tool for developing EO-based deep learning models so the frameworks and procedures described in this study can fuel further research.
4. Discussion
The use of GC was surprisingly stable throughout the project, and any drop in the internet connection (provided they were not for too long) did not lead to runtime failures and affected the completion of the training. The stability of GC is an essential aspect of the platform, particularly when the internet connection is not consistently stable. Although the cost of GC’s Pro version is low, the project has indirectly shown that using GC’s free version would not be feasible for a particularly intensive task. This is true unless the user is comfortable with consistently saving and picking up the training multiple times, has a large amount of Google Storage available (which has a monetary cost), and can wait for Google to allow for another training session. Unfortunately, there is no way of saying when the server will be ‘free enough’ to let a free user start training sessions again.
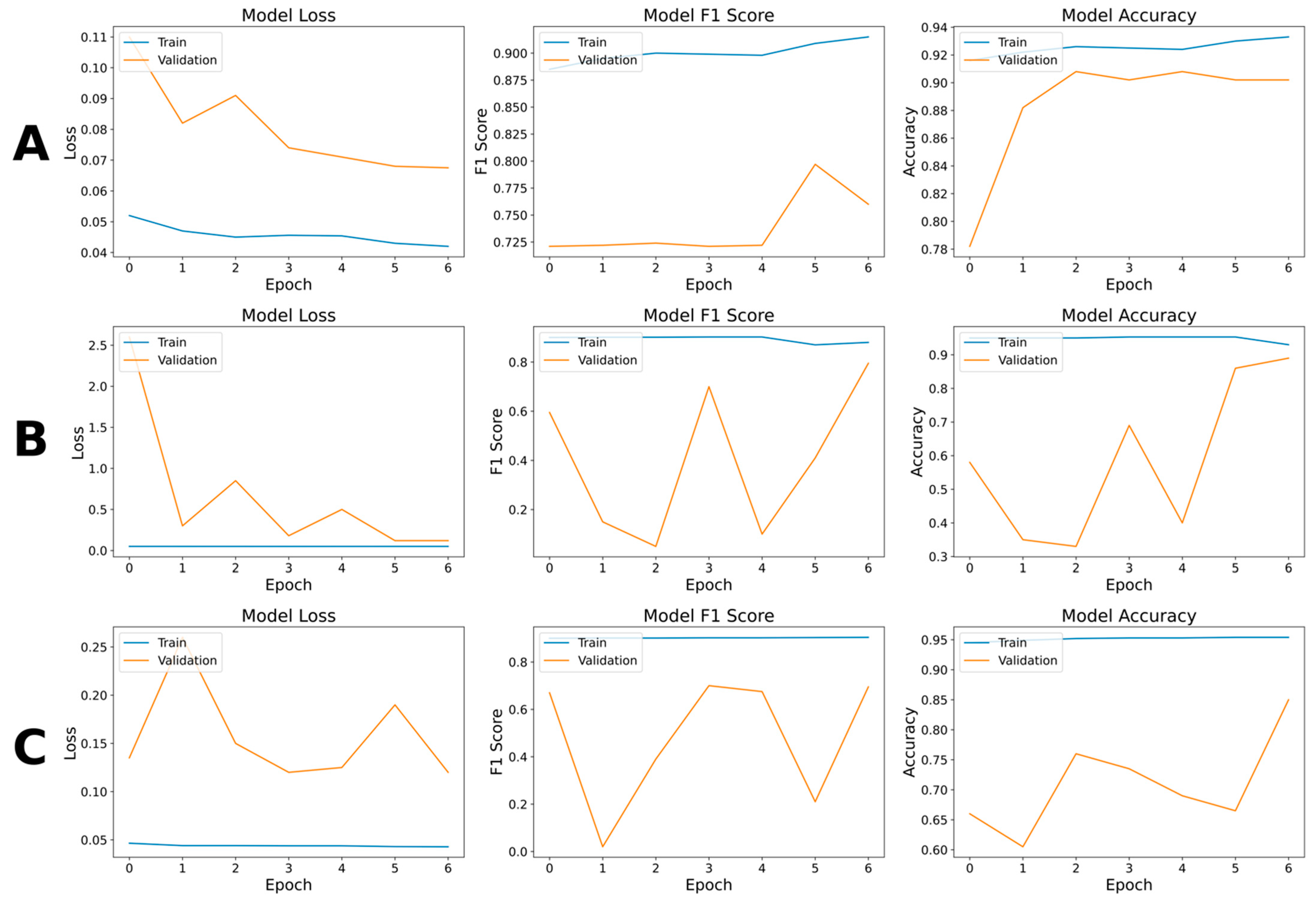
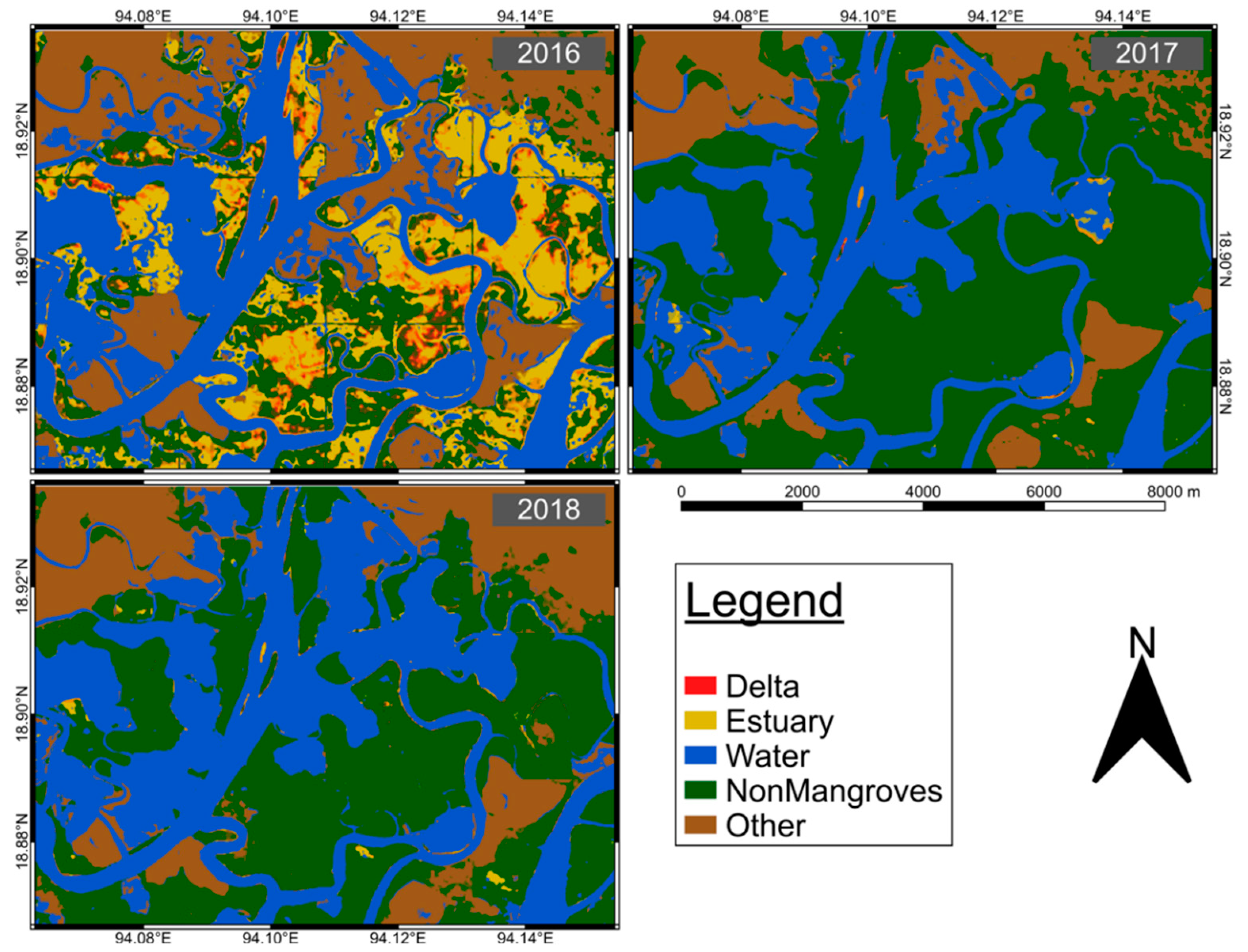
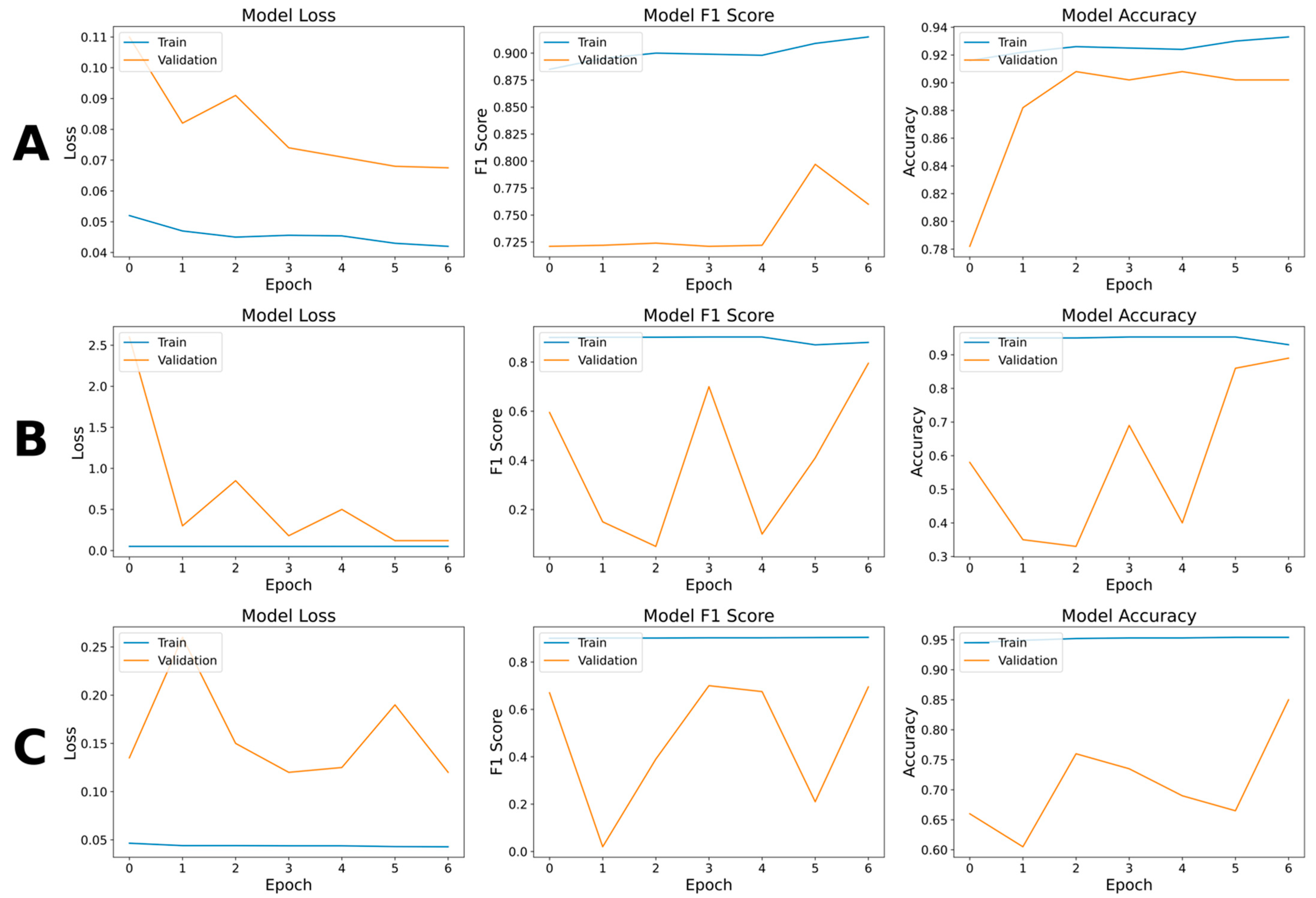
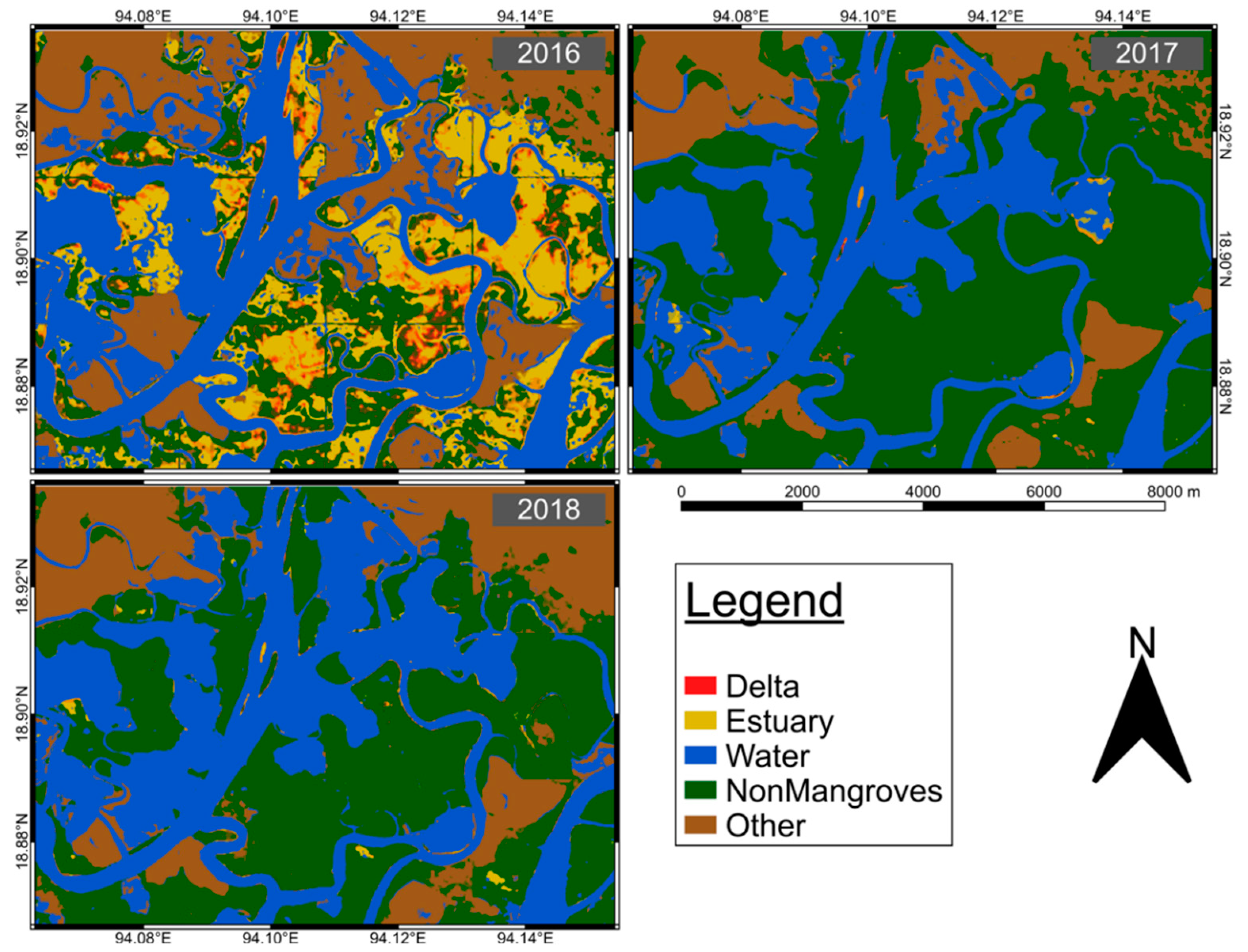
The project has revealed substantial differences between the U-Net model and VGG19 and ResNet50, demonstrating that TL was not appropriate for such a complex classification task. Although all the models failed to classify some mangrove classes, VGG19 and ResNet50 showed an evident inability to segment the images (
Figure 4B,C). Some scholars argue that pre-trained models contain unnecessary information for classifying highly variable SRSI [
71,
72] and that the use of pre-trained models as feature extractors is best-suited for small-scale datasets [
26]. Furthermore, the VGG19 and ResNet50 models could only accept three bands if used with pre-trained weights, potentially losing meaningful SRSI semantics and spectral properties.
The use of seven classes may have overwhelmed the models and identifying fewer classes could improve the results. Some scientists, for example, argue that generating a model for each of the target classes increases the classification accuracy, especially when the scene presents unbalanced distributions of LCTs [
53]. Moreover, given that distinguishing between mangrove typologies was particularly challenging, it may be helpful and may lead to better results to group all mangrove classes into one and maintain the rest as separate (i.e., mangroves, water, non-mangroves, clouds, ground, urban classes).
The pixel-wise classification performed with the RF classifier may have some design issues because the classes were manually identified using a median image composite for a single year. It is evident that selecting the image with which to perform the preliminary classification using RF classifiers (or other ML algorithms) and create training patches requires careful considerations, and using median composite of images captured over a whole year may not be ideal due to the dynamicity of land surfaces [
34]. Seasonality and water availability have a considerable effect on the spectral reflectance of land features, and training classifiers using images of the same year that account for the changes of LCTs over time in the training datasets could lead to more reliable preliminary classifications. To that end, and especially if mapping coastal environments such as mangrove forests, including images with different tide dynamics may help the models to better discern between mangroves and water, allowing to capture features otherwise ‘hidden’ if using median pixel values. Some scholars have developed the Submerged Mangrove Recognition Index (SMRI) using the high-resolution Gaofen satellite to assess the effects of tides across the year, coupling images captured at different tide heights and correcting the classification according to the detected differences and informing on the actual spatial distribution of mangroves [
73]. Nevertheless, while adding SMRI to the bands of the images fed to the classifier could better inform the models of interannual land features’ variability, it would require collecting significant EO data corresponding to high and low tides to better calibrate deep learning models.
Finally, although the U-Net model could cleverly distinguish the semantics of inland LCTs that have subtle spectral differences, features on coastlines and riverbanks resulted more challenging to classify, especially due to the interaction with water. The results of the multi-year classification have demonstrated that training the U-Net model on a median pixel-value image for a single year could be both inaccurate and misleading. It could be inaccurate due to the lack of tide dynamics information (and other seasonal signatures), and misleading because it ‘forces’ the model to generate weights and learn a semantic that may not be correct. To solve the issue, it is important to not only account for interannual land features’ variability, but also to feed images of multiple years to the model to account for different environmental conditions that may alter features’ spectral reflectance over time (e.g., light conditions, sensor errors, different amounts of pollutants in the air). While testing the transferability to the SMRI computation to Sentinel and other coarser spatial resolution satellites is a worthy research endeavour, it is presently outside the scope of our research.
5. Conclusions
Mangrove deforestation jeopardises the survival of tropical coastal communities while contributing to alimenting carbon emissions worldwide. Although the growth of computing power enables scientists to develop better and more accurate monitoring tools to guide interventions, increasingly intensive tasks and complex algorithms are becoming unsuitable for commercial and personal computers.
This paper has presented a cloud-based alternative to owning proprietary supercomputers that enables anyone with a computer and an internet connection to perform complex classification tasks using Google Colab and Google Earth Engine, with the help of the proposed custom Python packages. The mangrove monitoring framework was developed as an attempt to standardise and unify some of the most used tasks to handle TFRecords in a machine learning workflow while providing thorough documentation and guidance. Moreover, the framework has explored novel image segmentation architecture such as U-Nets, comparing the strengths and weaknesses of training from scratch and fine-tuning using pre-trained VGG19 and ResNet50 as encoders to the U-Net model.
The analysis has shown that an untrained U-Net model is superior in segmenting complex satellite remote sensing images compared to U-Net using VGG19 and ResNet50 models as feature extractors. Nevertheless, although the model provided some good results, feeding too-complex semantics (i.e., different mangrove typologies) has hindered the training process and affected the results. In the future, researchers may wish to extend the current work by preliminarily classifying mangroves accounting for interannual land features’ variability, with a particular focus on the effects of tide dynamics to mangroves’ spectral signature. It will also be important to feed the model with images captured across several years to account for ongoing environmental condition changes and to consider mangroves as a single class rather than splitting them by type. In addition, the presented U-Net model could be extended by adding more layers to avoid overfitting and may also be pre-trained using one of the multi-class remote sensing imagery datasets available online (e.g., BigEarthNet—
https://bigearth.net) (accessed on 1 January 2022). However, this last step needs to be taken with care if desiring to maintain storage costs and low training runtimes.
The authors believe that the proposed monitoring framework can lead the way to creating low-cost, cloud-based, open-source tools that governments, environmental agencies, and researchers can deploy to monitor mangroves (and more) in SEA and around the rest of the world.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}