
The Influence of Aerial Hyperspectral Image Processing Workflow on Nitrogen Uptake Prediction Accuracy in Maize




Abstract
:1. Introduction
1.1. Goal of Image Processing
1.2. Understanding the Informative Value of Imagery
1.3. Lack of Streamlined Processing and Training Pipeline
1.4. Analogy to Hyperparameter Tuning
1.5. Objectives
2. Materials and Methods
2.1. Field Experiments
2.2. Tissue Sampling
2.3. Airborne Imaging System and Image Capture
2.4. Definitions
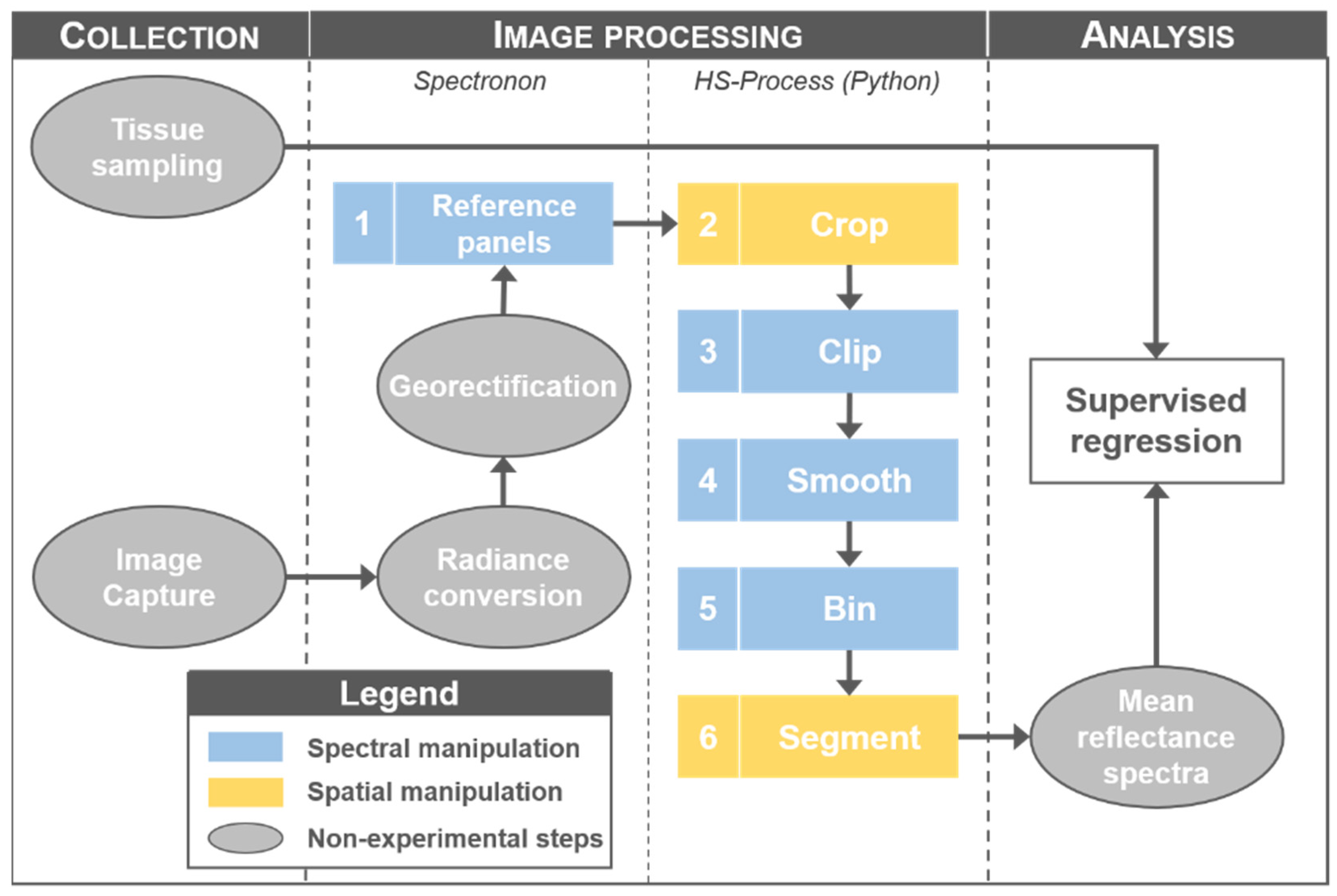
2.5. Image Processing
2.5.1. Reference Panels
2.5.2. Crop
2.5.3. Clip
2.5.4. Smooth
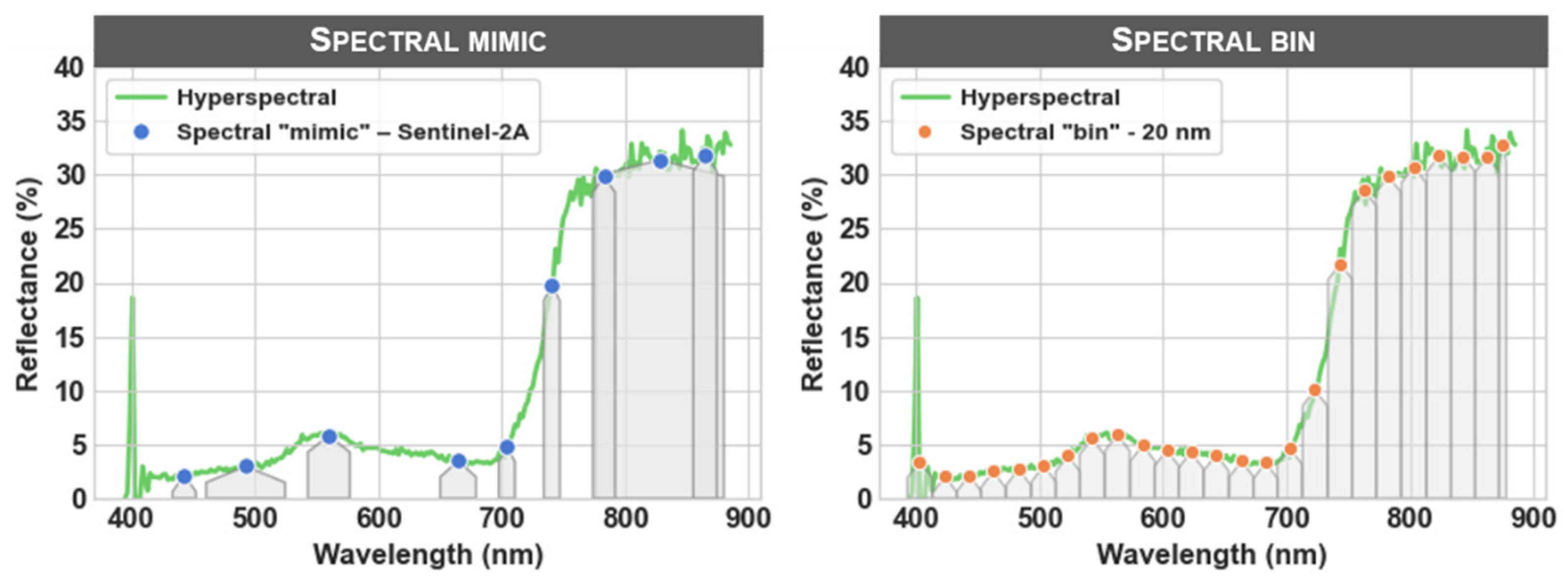
2.5.5. Bin
2.5.6. Segment
2.5.7. Processing Summary
2.6. Cross-Validation
2.7. Feature Selection, Model Tuning, and Prediction
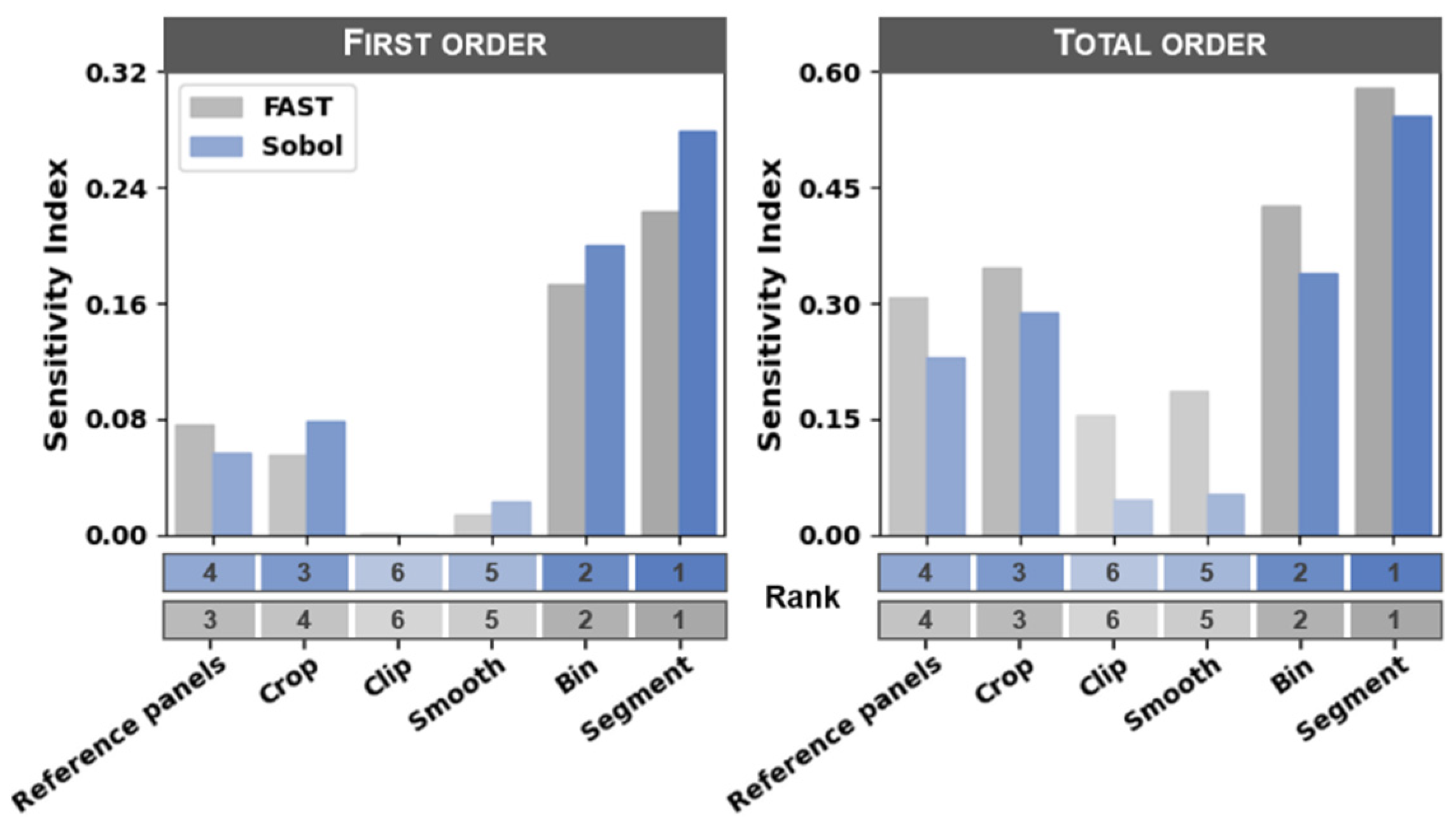
2.8. Sensitivity and Stepwise Analysis
2.9. Distribution and Density Analysis
3. Results
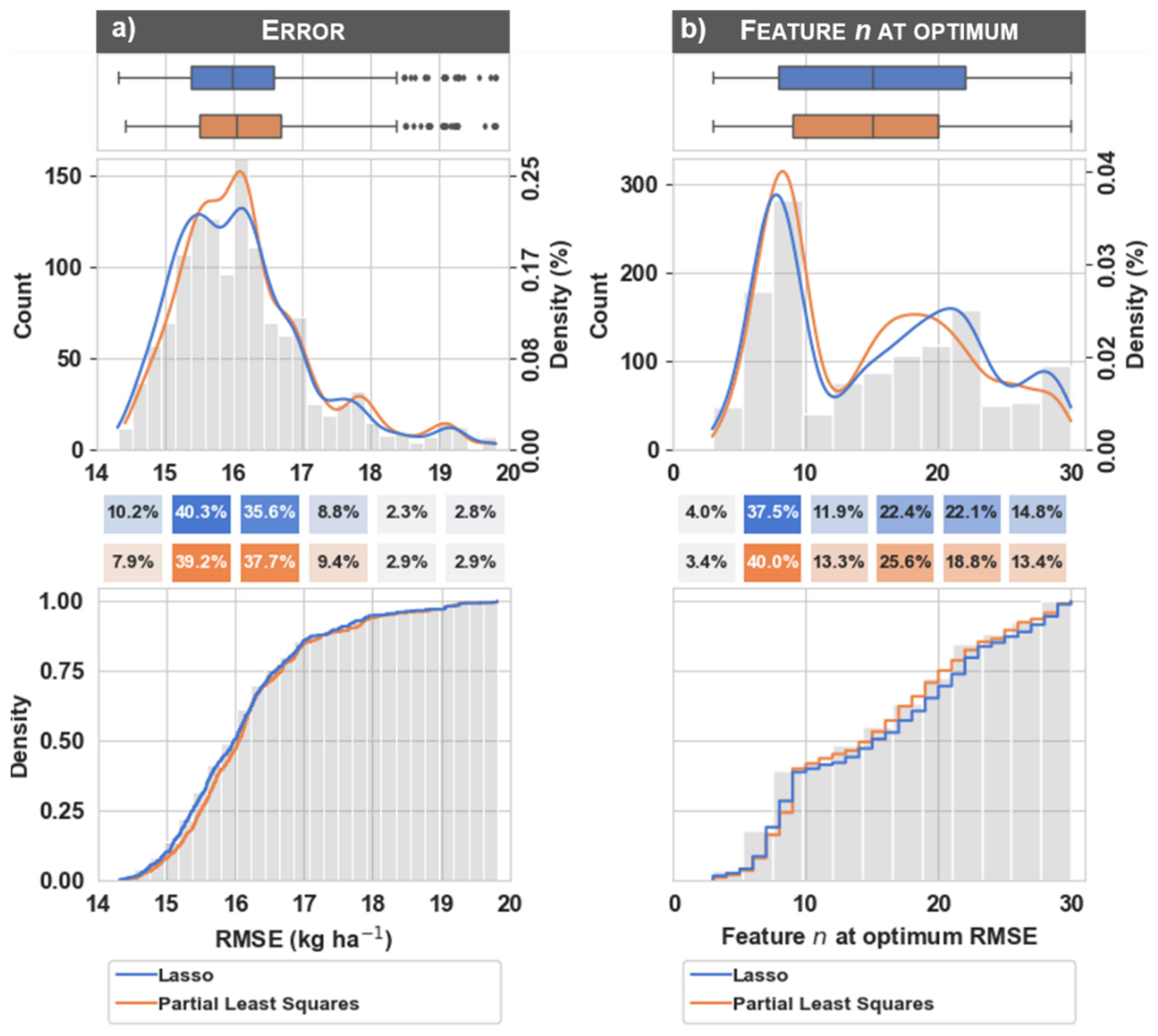
3.1. Distribution of Observations
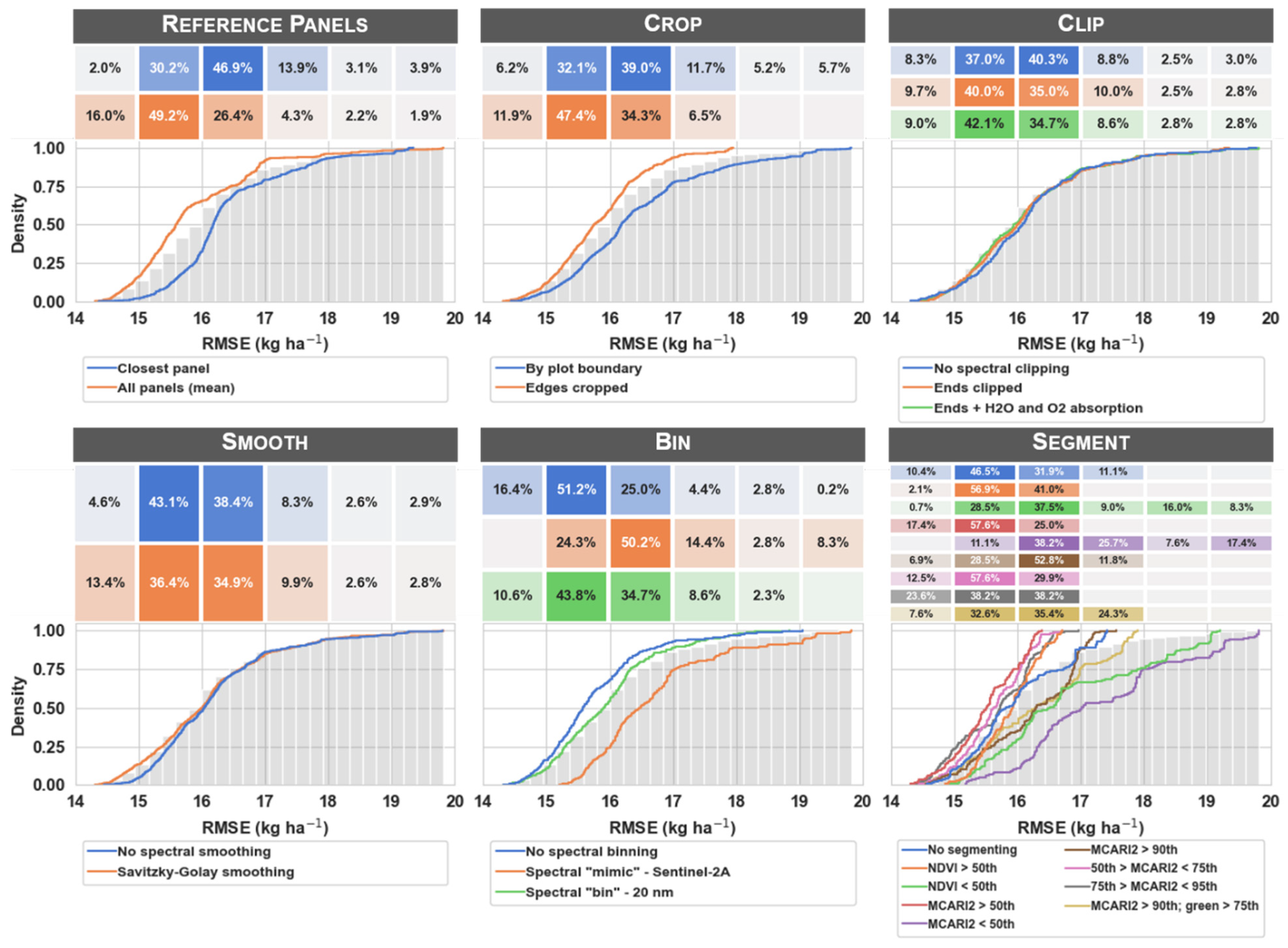
3.2. Error Distribution within Processing Steps
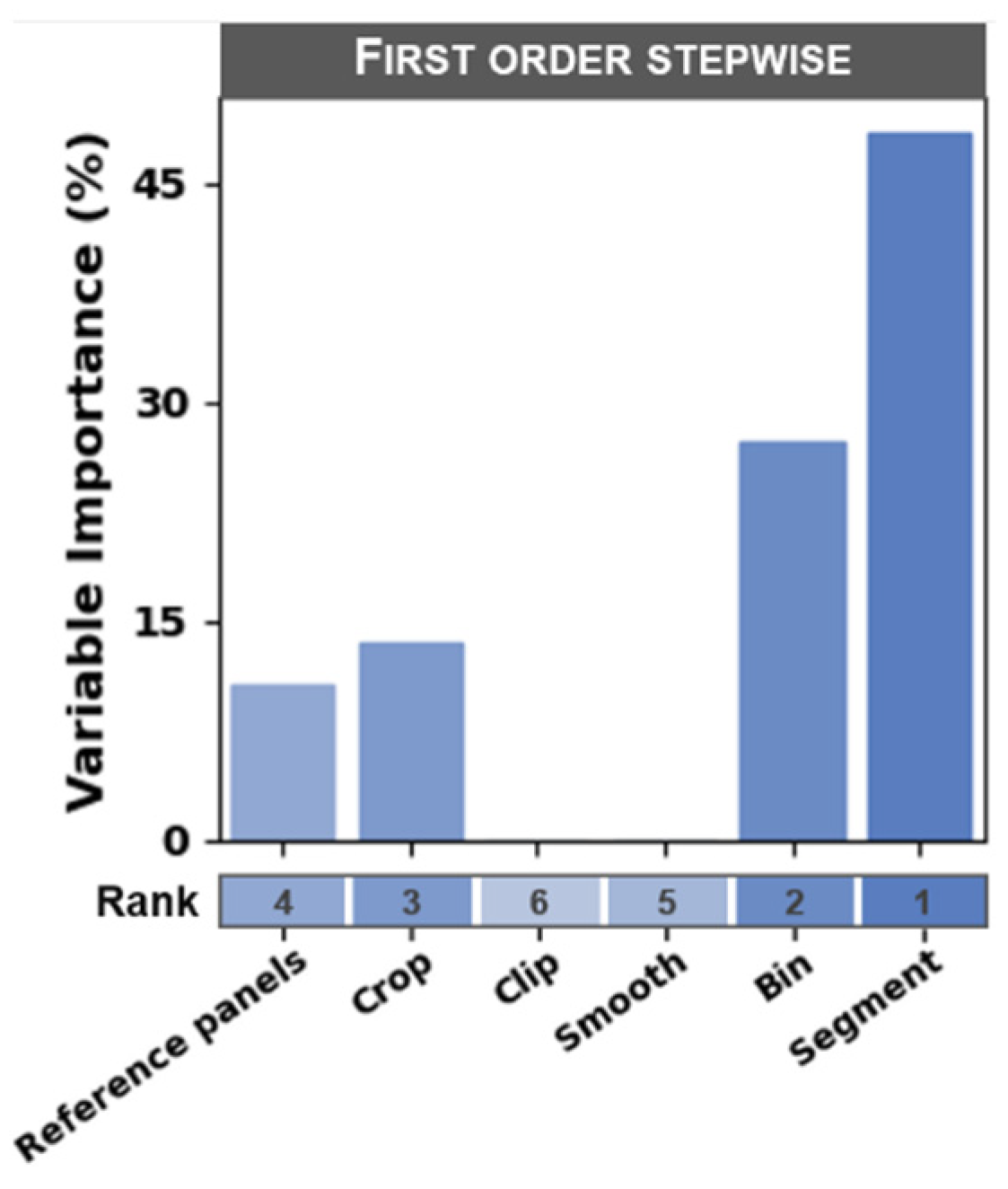
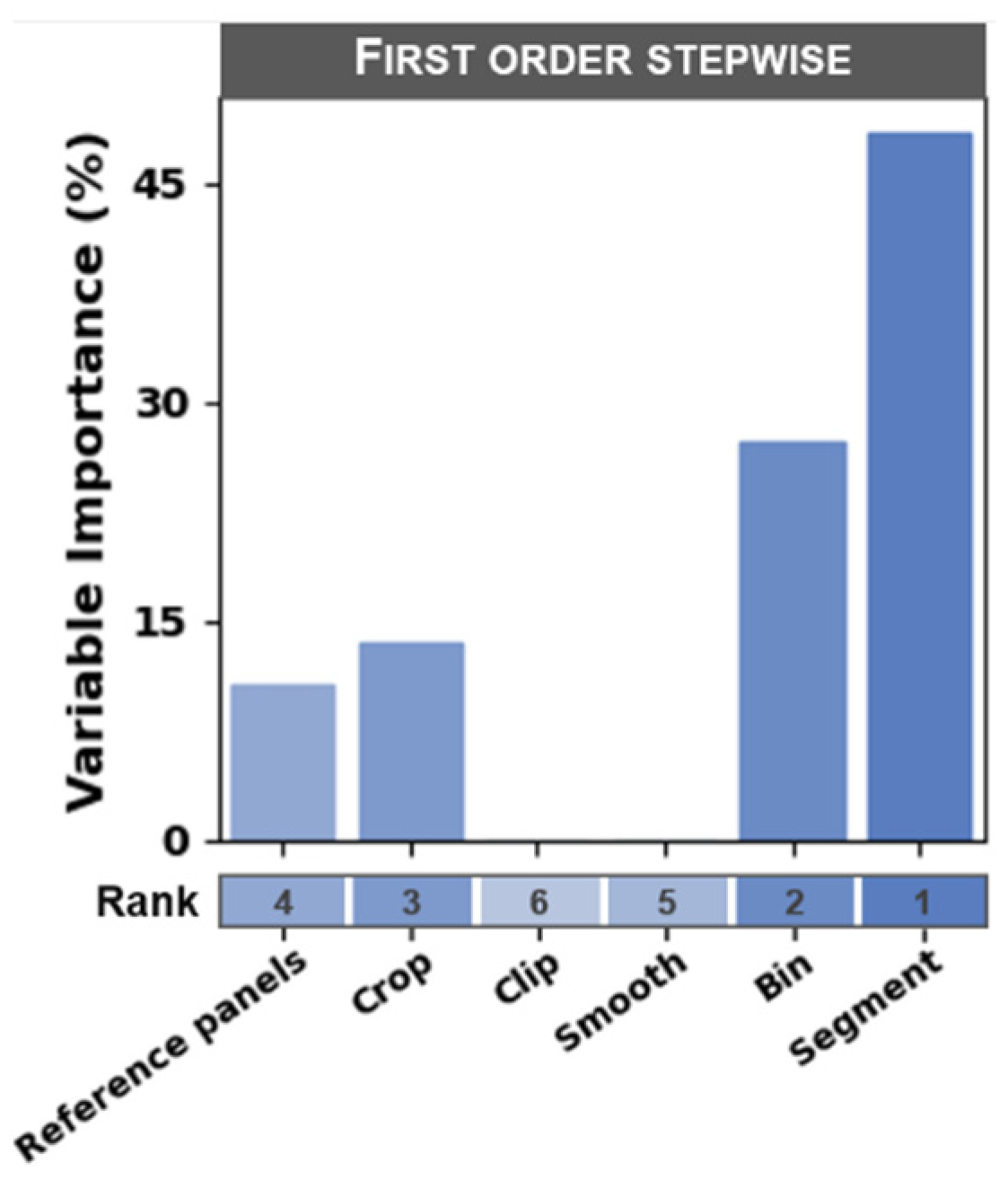
3.3. Ranking of Processing Steps by Influence on Model Error
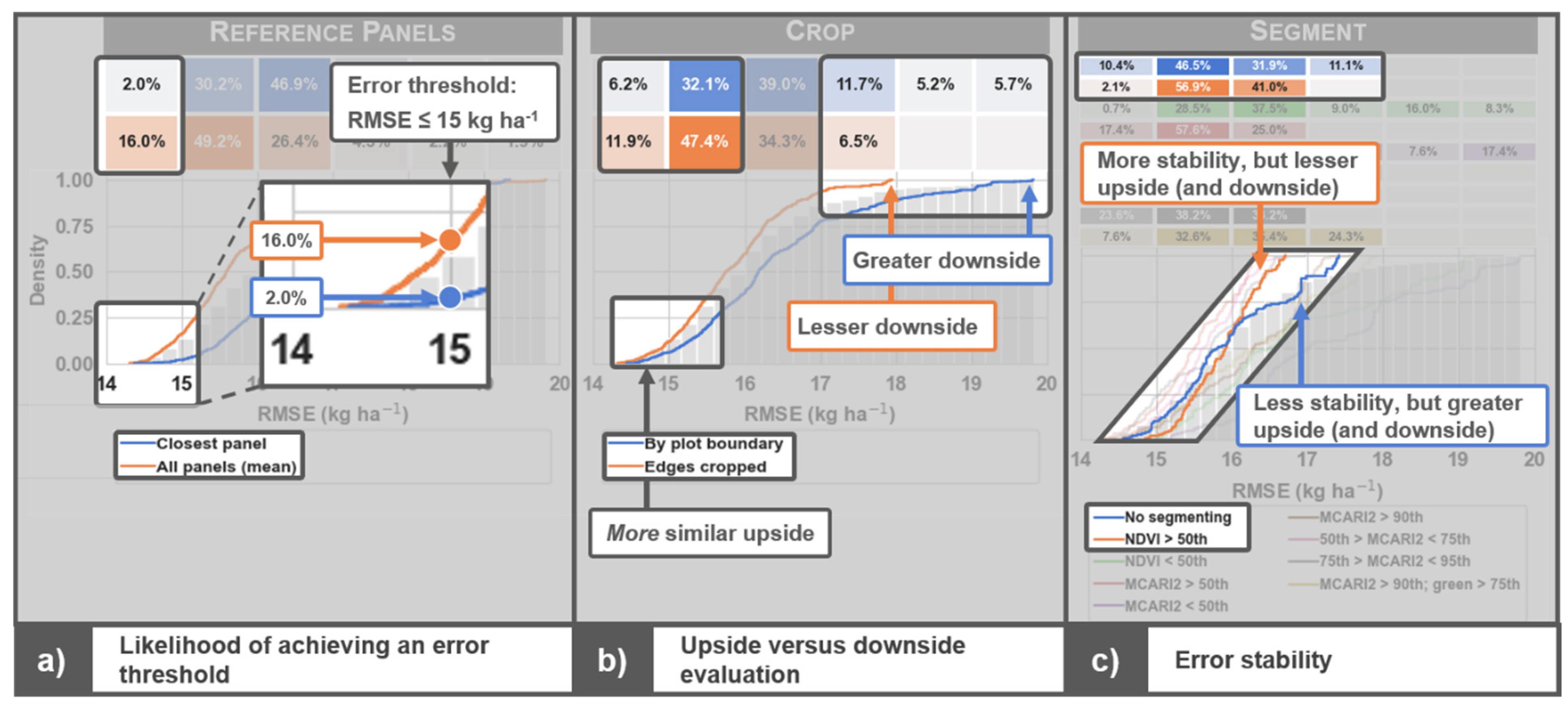
3.4. Cumulative Error at Each Processing Step
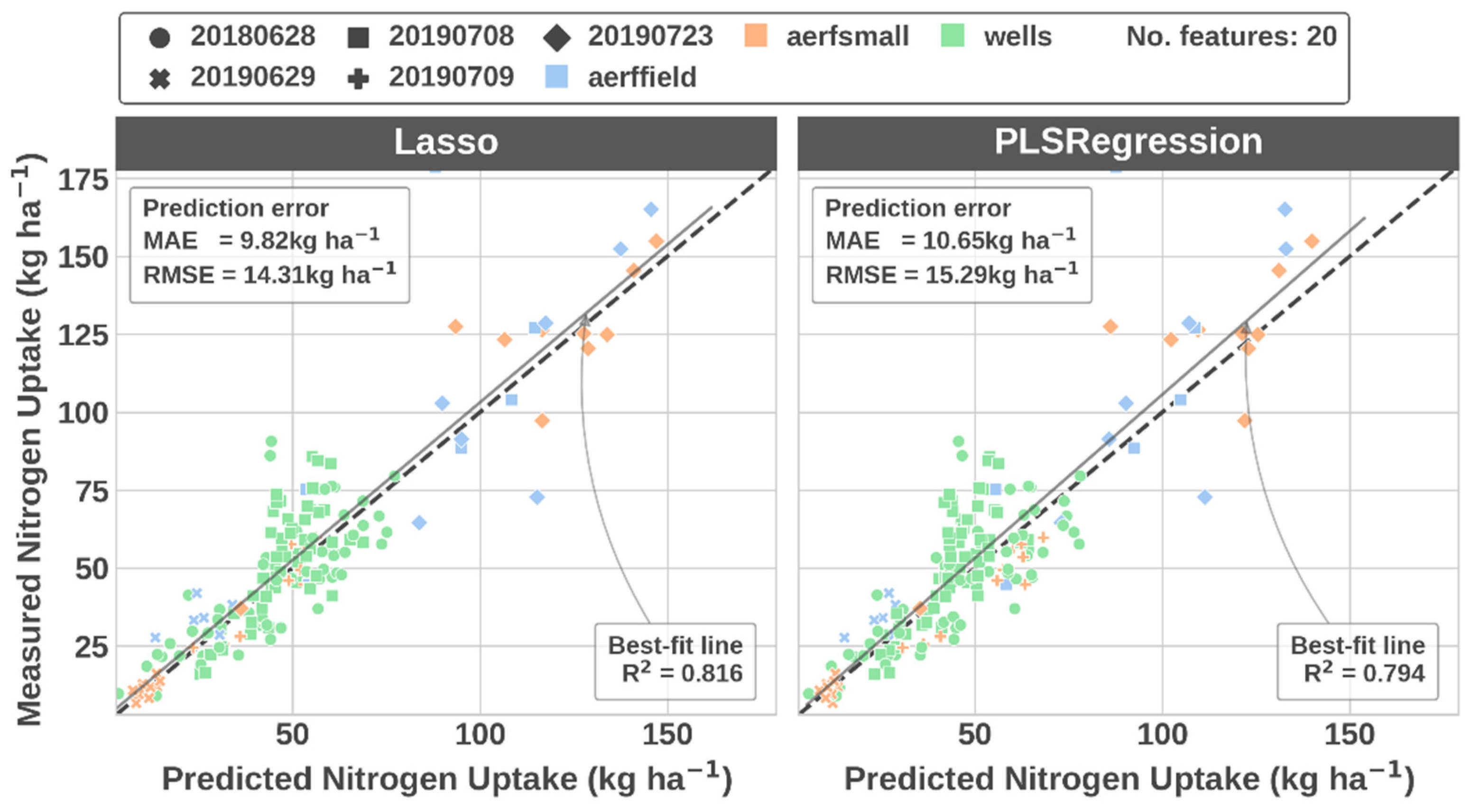
3.5. Comparing the Processing Workflow of a Previous Study
4. Discussion
4.1. Practical Insights for the Use Case Evaluated in this Study
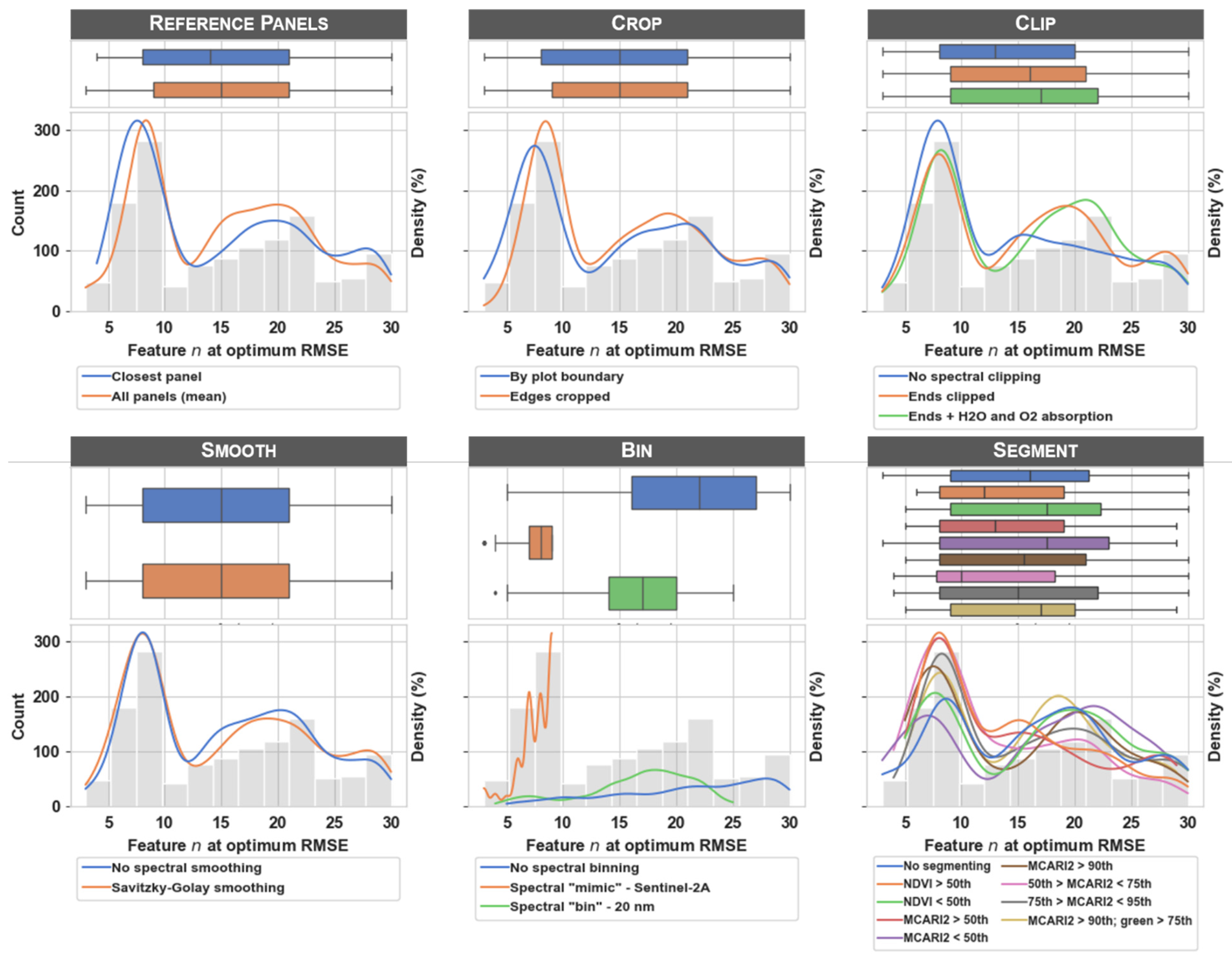
4.1.1. Reference Panels
4.1.2. Crop
4.1.3. Clip and Smooth
4.1.4. Bin
4.1.5. Segment
4.2. Choosing an Image Processing Workflow
4.3. Benefits of Integrating Image Processing and Model Training
4.4. Software and Computation Requirements
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | Experiment | ID | Observation n | Stage | Sampling Date | Image Date | Image Time | Sample Area | Subsample n | Nitrogen Extraction |
|---|---|---|---|---|---|---|---|---|---|---|
| 2018 | Wells | 1 | 143 | V10 | 28 June 2018 | 28 June 2018 | 11:49–12:00 | 1.5 m × 5 m (2 rows) | 6 | Kjeldahl |
| 2019 | Wells | 2 | 144 | V8 | 9 July 2019 | 8 July 2019 | 10:36–10:47 | 1.5 m × 5 m (2 rows) | 6 | Kjeldahl |
| 2019 | Waseca small plot | 3 | 24 | V6 | 29 June 2019 | 29 June 2019 | 12:21–12:28 | 1.5 m × 2 m (2 rows) | 10 | Dry combustion |
| 2019 | 4 | 24 | V8 | 9/10 July 2019 1 | 9 July 2019 | 11:40–11:46 | 1.5 m × 2 m (2 rows) | 10 | Dry combustion | |
| 2019 | 5 | 24 | V14 | 23 July 2019 | 23 July 2019 | 12:03–12:09 | 1.5 m × 2 m (2 rows) | 6 | Dry combustion | |
| 2019 | Waseca whole field | 6 | 16 | V7 | 3 July 2019 | 29 June 2019 | 13:06–13:17 | 5 m × 10 m (6 rows) | 6 | Dry combustion |
| 2019 | 7 | 16 | V8 | 10 July 2019 | 8 July 2019 | 13:06–13:17 | 5 m × 10 m (6 rows) | 6 | Dry combustion | |
| 2019 | 8 | 16 | V14 | 23 July 2019 | 23 July 2019 | 12:32–12:42 | 5 m × 10 m (6 rows) | 6 | Dry combustion |

References
- Aasen, H.; Burkart, A.; Bolten, A.; Bareth, G. Generating 3D hyperspectral information with lightweight UAV snapshot cameras for vegetation monitoring: From camera calibration to quality assurance. ISPRS J. Photogramm. Remote Sens. 2015, 108, 245–259. [Google Scholar] [CrossRef]
- Adão, T.; Hruška, J.; Pádua, L.; Bessa, J.; Peres, E.; Morais, R.; Sousa, J. Hyperspectral Imaging: A Review on UAV-Based Sensors, Data Processing and Applications for Agriculture and Forestry. Remote Sens. 2017, 9, 1110. [Google Scholar] [CrossRef] [Green Version]
- Honkavaara, E.; Saari, H.; Kaivosoja, J.; Pölönen, I.; Hakala, T.; Litkey, P.; Mäkynen, J.; Pesonen, L. Processing and Assessment of Spectrometric, Stereoscopic Imagery Collected Using a Lightweight UAV Spectral Camera for Precision Agriculture. Remote Sens. 2013, 5, 5006–5039. [Google Scholar] [CrossRef] [Green Version]
- Jakob, S.; Zimmermann, R.; Gloaguen, R. The Need for Accurate Geometric and Radiometric Corrections of Drone-Borne Hyperspectral Data for Mineral Exploration: MEPHySTo—A Toolbox for Pre-Processing Drone-Borne Hyperspectral Data. Remote Sens. 2017, 9, 88. [Google Scholar] [CrossRef] [Green Version]
- Lu, B.; Dao, P.; Liu, J.; He, Y.; Shang, J. Recent Advances of Hyperspectral Imaging Technology and Applications in Agriculture. Remote Sens. 2020, 12, 2659. [Google Scholar] [CrossRef]
- Jia, B.; Wang, W.; Ni, X.; Lawrence, K.C.; Zhuang, H.; Yoon, S.-C.; Gao, Z. Essential processing methods of hyperspectral images of agricultural and food products. Chemom. Intell. Lab. Syst. 2020, 198, 103936. [Google Scholar] [CrossRef]
- Duan, S.-B.; Li, Z.-L.; Tang, B.-H.; Wu, H.; Ma, L.; Zhao, E.; Li, C. Land Surface Reflectance Retrieval from Hyperspectral Data Collected by an Unmanned Aerial Vehicle over the Baotou Test Site. PLoS ONE 2013, 8, e66972. [Google Scholar] [CrossRef]
- Tan, K.; Niu, C.; Jia, X.; Ou, D.; Chen, Y.; Lei, S. Complete and accurate data correction for seamless mosaicking of airborne hyperspectral images: A case study at a mining site in Inner Mongolia, China. ISPRS J. Photogramm. Remote Sens. 2020, 165, 1–15. [Google Scholar] [CrossRef]
- Arroyo-Mora, J.P.; Kalacska, M.; Løke, T.; Schläpfer, D.; Coops, N.C.; Lucanus, O.; Leblanc, G. Assessing the impact of illumination on UAV pushbroom hyperspectral imagery collected under various cloud cover conditions. Remote Sens. Environ. 2021, 258, 112396. [Google Scholar] [CrossRef]
- Olsson, P.-O.; Vivekar, A.; Adler, K.; Garcia Millan, V.E.; Koc, A.; Alamrani, M.; Eklundh, L. Radiometric Correction of Multispectral UAS Images: Evaluating the Accuracy of the Parrot Sequoia Camera and Sunshine Sensor. Remote Sens. 2021, 13, 577. [Google Scholar] [CrossRef]
- Poncet, A.M.; Knappenberger, T.; Brodbeck, C.; Fogle, M.; Shaw, J.N.; Ortiz, B.V. Multispectral UAS Data Accuracy for Different Radiometric Calibration Methods. Remote Sens. 2019, 11, 1917. [Google Scholar] [CrossRef] [Green Version]
- Cao, J.; Leng, W.; Liu, K.; Liu, L.; He, Z.; Zhu, Y. Object-Based Mangrove Species Classification Using Unmanned Aerial Vehicle Hyperspectral Images and Digital Surface Models. Remote Sens. 2018, 10, 89. [Google Scholar] [CrossRef] [Green Version]
- Cheng, J.; Bo, Y.; Zhu, Y.; Ji, X. A novel method for assessing the segmentation quality of high-spatial resolution remote-sensing images. Int. J. Remote Sens. 2014, 35, 3816–3839. [Google Scholar] [CrossRef]
- Zhang, C.; Jiang, W.; Zhao, Q. Semantic Segmentation of Aerial Imagery via Split-Attention Networks with Disentangled Nonlocal and Edge Supervision. Remote. Sens. 2021, 13, 1176. [Google Scholar] [CrossRef]
- Saldana Ochoa, K.; Guo, Z. A framework for the management of agricultural resources with automated aerial imagery detection. Comput. Electron. Agric. 2019, 162, 53–69. [Google Scholar] [CrossRef]
- Gewali, U.B.; Monteiro, S.T.; Saber, E. Machine learning based hyperspectral image analysis: A survey. arXiv 2018, arXiv:1802.08701. [Google Scholar]
- Masi, G. Image Segmentation in a Remote Sensing Perspective; University of Naples Federico II: Naples NA, Italy, 2016. [Google Scholar]
- Feurer, M.; Hutter, F. Hyperparameter Optimization. In Studies in Computational Intelligence; Hutter, F., Kotthoff, L., Vanschoren, J., Eds.; The Springer Series on Challenges in Machine Learning; Springer International Publishing: Cham, Switzerland, 2019; Volume 498, pp. 3–33. ISBN 978-3-030-05317-8. [Google Scholar]
- Snoek, J.; Larochelle, H.; Adams, R.P. Practical Bayesian optimization of machine learning algorithms. Adv. Neural Inf. Process. Syst. 2012, 4, 2951–2959. [Google Scholar]
- Nigon, T.J.; Yang, C.; Dias Paiao, G.; Mulla, D.J.; Knight, J.F.; Fernández, F.G. Prediction of Early Season Nitrogen Uptake in Maize Using High-Resolution Aerial Hyperspectral Imagery. Remote Sens. 2020, 12, 1234. [Google Scholar] [CrossRef] [Green Version]
- Earth Observation and Research Branch Team. Crop Identification and BBCH Staging Manual: SMAP-12 Field Campaign; Agriculture and Agri-Food Canada: Ottawa, ON, Canada, 2011; pp. 1–50. Available online: https://smapvex12.espaceweb.usherbrooke.ca/BBCH_STAGING_MANUAL_GENERAL_ALL_CROPS.pdf (accessed on 28 October 2021).
- Kaiser, D.E.; Lamb, J.A.; Eliason, R. Fertilizer Guidelines for Agronomic Crops in Minnesota; University of Minnesota Extension: Saint Paul, MN, USA, 2011; Available online: https://conservancy.umn.edu/bitstream/handle/11299/198924/Fertilizer%20Guidelines%20for%20Agronomic%20Crops%20in%20Minnesota.pdf?sequence=1&isAllowed=y (accessed on 28 October 2021).
- Jones, J.B., Jr.; Case, V.W. Sampling, Handling, and Analyzing Plant Tissue Samples. In Soil Testing and Plant Analysis; Westerman, R.L., Ed.; SSSA Book Series; Soil Science Society of America: Madison, WI, USA, 1990; pp. 389–427. ISBN 9780891188629. [Google Scholar]
- Bradstreet, R.B. Kjeldahl Method for Organic Nitrogen. Anal. Chem. 1954, 26, 185–187. [Google Scholar] [CrossRef]
- Matejovic, I. Total nitrogen in plant material determinated by means of dry combustion: A possible alternative to determination by kjeldahl digestion. Commun. Soil Sci. Plant Anal. 1995, 26, 2217–2229. [Google Scholar] [CrossRef]
- Smith, G.M.; Milton, E.J. The use of the empirical line method to calibrate remotely sensed data to reflectance. Int. J. Remote Sens. 1999, 20, 2653–2662. [Google Scholar] [CrossRef]
- Richter, R.; Schlapfer, D.; Muller, A. Operational Atmospheric Correction for Imaging Spectrometers Accounting for the Smile Effect. IEEE Trans. Geosci. Remote Sens. 2011, 49, 1772–1780. [Google Scholar] [CrossRef]
- Greenblatt, G.D.; Orlando, J.J.; Burkholder, J.B.; Ravishankara, A.R. Absorption measurements of oxygen between 330 and 1140 nm. J. Geophys. Res. 1990, 95, 18577. [Google Scholar] [CrossRef] [Green Version]
- Hill, C.; Jones, R.L. Absorption of solar radiation by water vapor in clear and cloudy skies: Implications for anomalous absorption. J. Geophys. Res. Atmos. 2000, 105, 9421–9428. [Google Scholar] [CrossRef]
- Press, W.H.; Teukolsky, S.A. Savitzky-Golay Smoothing Filters. Comput. Phys. 1990, 4, 669. [Google Scholar] [CrossRef]
- Ravikanth, L.; Jayas, D.S.; White, N.D.G.; Fields, P.G.; Sun, D.-W. Extraction of Spectral Information from Hyperspectral Data and Application of Hyperspectral Imaging for Food and Agricultural Products. Food Bioprocess Technol. 2017, 10, 1–33. [Google Scholar] [CrossRef]
- Savitzky, A.; Golay, M.J.E. Smoothing and Differentiation of Data by Simplified Least Squares Procedures. Anal. Chem. 1964, 36, 1627–1639. [Google Scholar] [CrossRef]
- Space Agency, E. Sentinel-2 Spectral Response Functions. Available online: https://dragon3.esa.int/web/sentinel/technical-guides/sentinel-2-msi/performance (accessed on 29 January 2021).
- Rouse, J.W.; Haas, R.H.; Schell, J.A.; Deering, D.W. Monitoring Vegetation Systems in the Great Plains with ERTS; NASA: Washington, DC, USA, 1974; Volume 1, pp. 309–317.
- Huete, A. A soil-adjusted vegetation index (SAVI). Remote Sens. Environ. 1988, 25, 295–309. [Google Scholar] [CrossRef]
- Haboudane, D.; Miller, J.R.; Pattey, E.; ZarcoTejada, P.J.; Strachan, I.B. Hyperspectral vegetation indices and novel algorithms for predicting green LAI of crop canopies: Modeling and validation in the context of precision agriculture. Remote Sens. Environ. 2004, 90, 337–352. [Google Scholar] [CrossRef]
- Nigon, T.J. HS-Process 2020. Available online: https://hs-process.readthedocs.io/ (accessed on 28 October 2021).
- Boggs, T. Spectral Python 2019. Available online: https://www.spectralpython.net/ (accessed on 28 October 2021).
- GDAL/OGR Geospatial Data Abstraction Library. Available online: https://gdal.org/ (accessed on 28 October 2021).
- Nigon, T.J. SIP. 2021. Available online: https://github.com/tnigon/sip/ (accessed on 28 October 2021).
- Yeo, I.-K.; Johnson, R.A. A new family of power transformations to improve normality or symmetry. Biometrika 2000, 87, 954–959. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression shrinkage and selection via the Lasso. J. R. Stat. Soc. Ser. B 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Cukier, R.I.; Fortuin, C.M.; Shuler, K.E.; Petschek, A.G.; Schaibly, J.H. Study of the sensitivity of coupled reaction systems to uncertainties in rate coefficients. I Theory. J. Chem. Phys. 1973, 59, 3873–3878. [Google Scholar] [CrossRef]
- Saltelli, A.; Tarantola, S.; Chan, K.P.-S. A Quantitative Model-Independent Method for Global Sensitivity Analysis of Model Output. Technometrics 1999, 41, 39–56. [Google Scholar] [CrossRef]
- Sobol, I.M. Global sensitivity indices for nonlinear mathematical models and their Monte Carlo estimates. Math. Comput. Simul. 2001, 55, 271–280. [Google Scholar] [CrossRef]
- Saltelli, A.; Annoni, P.; Azzini, I.; Campolongo, F.; Ratto, M.; Tarantola, S. Variance based sensitivity analysis of model output. Design and estimator for the total sensitivity index. Comput. Phys. Commun. 2010, 181, 259–270. [Google Scholar] [CrossRef]
- Saltelli, A. Making best use of model evaluations to compute sensitivity indices. Comput. Phys. Commun. 2002, 145, 280–297. [Google Scholar] [CrossRef]
- Zhang, X.; Trame, M.; Lesko, L.; Schmidt, S. Sobol Sensitivity Analysis: A Tool to Guide the Development and Evaluation of Systems Pharmacology Models. CPT Pharmacomet. Syst. Pharmacol. 2015, 4, 69–79. [Google Scholar] [CrossRef]
- Waskom, M. Seaborn: Statistical data visualization. J. Open Source Softw. 2021, 6, 3021. [Google Scholar] [CrossRef]
- Sturges, H.A. The Choice of a Class Interval. J. Am. Stat. Assoc. 1926, 21, 65–66. [Google Scholar] [CrossRef]
- Freedman, D.; Diaconis, P. On the histogram as a density estimator:L 2 theory. Z. Wahrscheinlichkeitstheorie Verwandte Geb. 1981, 57, 453–476. [Google Scholar] [CrossRef] [Green Version]
- Scott, D.W. Multivariate Density Estimation; Wiley Series in Probability and Statistics; Wiley: Hoboken, NJ, USA, 1992; ISBN 9780471547709. [Google Scholar]
- Jia, W.; Pang, Y.; Tortini, R.; Schläpfer, D.; Li, Z.; Roujean, J.-L. A Kernel-Driven BRDF Approach to Correct Airborne Hyperspectral Imagery over Forested Areas with Rugged Topography. Remote Sens. 2020, 12, 432. [Google Scholar] [CrossRef] [Green Version]
- Saikai, Y.; Patel, V.; Mitchell, P.D. Machine learning for optimizing complex site-specific management. Comput. Electron. Agric. 2020, 174, 105381. [Google Scholar] [CrossRef]

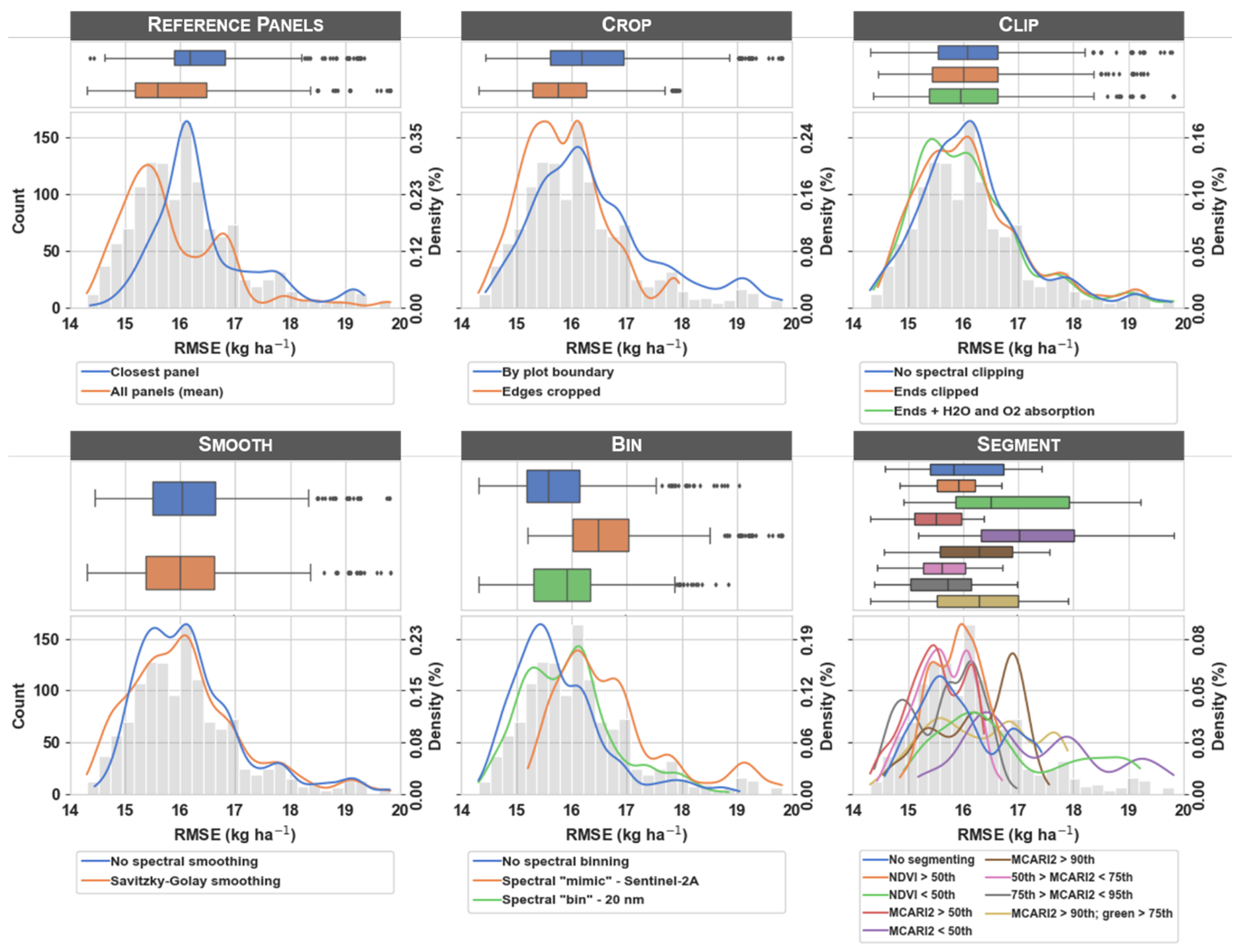
| ID | Processing Step | Scenario |
|---|---|---|
| 1 | Reference panels | |
| (a) | Closest panel | |
| (b) | All panels (mean) | |
| 2 | Crop | |
| (a) | By plot boundary | |
| (b) | Edges cropped | |
| 3 | Clip | |
| (a) | No spectral clipping | |
| (b) | Ends clipped | |
| (c) | Ends + H2O and O2 absorption | |
| 4 | Smooth | |
| (a) | No spectral smoothing | |
| (b) | Savitzky–Golay smoothing | |
| 5 | Bin | |
| (a) | No spectral binning | |
| (b) | Spectral "mimic"—Sentinel-2A | |
| (c) | Spectral "bin"—20 nm | |
| 6 | Segment | |
| (a) | No segmenting | |
| (b) | NDVI > 50th | |
| (c) | NDVI < 50th | |
| (d) | MCARI2 > 50th | |
| (e) | MCARI2 < 50th | |
| (f) | MCARI2 > 90th | |
| (g) | 50th > MCARI2 < 75th | |
| (h) | 75th > MCARI2 < 95th | |
| (i) | MCARI2 > 90th; green > 75th |
| ID | Processing Step | Software | Scenario n | Cumulative Scenario n |
|---|---|---|---|---|
| 1 | Reference panels | Spectronon | 2 | 2 |
| 2 | Crop | hs-process | 2 | 4 |
| 3 | Clip | hs-process | 3 | 12 |
| 4 | Smooth | hs-process | 2 | 24 |
| 5 | Bin | hs-process | 3 | 72 |
| 6 | Segment | hs-process | 9 | 648 |
| --------RMSE (kg ha−1)--------- | |||
|---|---|---|---|
| Segment Scenario | Upside (Minimum) | Downside (Maximum) | Stability (Range) |
| High upside; low downside | (consistently good) | ||
| MCARI2 > 50th | 14.3 1 | 16.4 | 2.1 |
| 50th > MCARI2 < 75th | 14.4 | 16.7 | 2.3 |
| 75th > MCARI2 < 95th | 14.4 | 17.0 | 2.6 |
| High upside; high downside | (variable) | ||
| No segmenting | 14.6 | 17.4 | 2.8 |
| MCARI2 > 90th | 14.6 | 17.6 | 3.0 |
| MCARI2 > 90th; green > 75th | 14.3 2 | 17.9 | 3.6 |
| Low upside; low downside | (consistently mediocre) | ||
| NDVI > 50th | 14.8 | 16.7 | 1.8 |
| Low upside; high downside | (consistently poor) | ||
| NDVI < 50th | 14.9 | 19.2 | 4.3 |
| MCARI2 < 50th | 15.2 | 19.8 | 4.6 |
| All scenarios | 14.3 | 19.8 | 5.5 |
| Lowest Error | Highest Error | Nigon et al. (2020) [20] | ||
|---|---|---|---|---|
| Processing step | ||||
| 1 | Reference panels | All panels | All panels | Closest panel |
| 2 | Crop | Edges cropped | By plot boundary | By plot boundary |
| 3 | Clip | No spectral clipping | Ends + H2O and O2 absorption | Ends + H2O and O2 absorption |
| 4 | Smooth | Savitzky–Golay smoothing | Savitzky–Golay smoothing | Savitzky–Golay smoothing |
| 5 | Bin | No spectral binning | Spectral “mimic”-Sentinel-2A | No spectral binning |
| 6 | Segment | MCARI2 > 90th; green > 75th | MCARI2 < 50th | MCARI2 > 90th |
| RMSE (kg ha−1) | 14.3 (+0.0%) | 19.8 (+38.5%) | 16.5 (+15.4%) | |
| Percentile | 0.309 | 99.9 | 71.5 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nigon, T.; Paiao, G.D.; Mulla, D.J.; Fernández, F.G.; Yang, C. The Influence of Aerial Hyperspectral Image Processing Workflow on Nitrogen Uptake Prediction Accuracy in Maize. Remote Sens. 2022, 14, 132. https://doi.org/10.3390/rs14010132
Nigon T, Paiao GD, Mulla DJ, Fernández FG, Yang C. The Influence of Aerial Hyperspectral Image Processing Workflow on Nitrogen Uptake Prediction Accuracy in Maize. Remote Sensing. 2022; 14(1):132. https://doi.org/10.3390/rs14010132
Chicago/Turabian StyleNigon, Tyler, Gabriel Dias Paiao, David J. Mulla, Fabián G. Fernández, and Ce Yang. 2022. "The Influence of Aerial Hyperspectral Image Processing Workflow on Nitrogen Uptake Prediction Accuracy in Maize" Remote Sensing 14, no. 1: 132. https://doi.org/10.3390/rs14010132
APA StyleNigon, T., Paiao, G. D., Mulla, D. J., Fernández, F. G., & Yang, C. (2022). The Influence of Aerial Hyperspectral Image Processing Workflow on Nitrogen Uptake Prediction Accuracy in Maize. Remote Sensing, 14(1), 132. https://doi.org/10.3390/rs14010132