1. Introduction
In recent years, remote sensing (RS) has found various applications [
1,
2,
3,
4], including in agriculture [
5,
6], forestry, catastrophe, ecological monitoring [
5], land cover classification [
6,
7], and so on. This can be explained by several reasons. First, a great amount of useful information can be retrieved from acquired images, especially if they are high resolution and multichannel, which represents a set of component images of the same territory obtained in parallel or sequentially and co-registered [
3,
5,
6] (using the term “multichannel”, we mean that component images can be acquired for different polarizations, wavelengths, or even by different sensors). Second, the situation with RS data value and volume becomes even more complicated because many modern RS systems can carry out frequent data collection, e.g., once a week or more frequently. Sentinel-1 and Sentinel-2 recently put into operation are examples of sensors producing such large volume multichannel RS data [
7,
8]. Other examples are hyperspectral data provided by different sensors [
9,
10,
11].
Then, problems of big data arise [
9,
10] where efficient transmission, storage, and dissemination of RS data are several of them, alongside others relating to co-registration, filtering, and classification. In RS data transmission, storage, and dissemination, compression are helpful [
12,
13,
14,
15]. Both lossless [
12,
13,
16] and lossy [
14,
15,
17] approaches are intensively studied. Near-lossless methods have been designed and analyzed as well [
18,
19]. Lossless techniques produce undistorted data after decompression, but the compression ratio (CR) is often not large enough. Near-lossless methods allow obtaining larger values of CR, and introduced distortions are controlled (restricted) in one or another manner [
20]. However, CR can be still not large enough. In turn, the lossy compression we focus on in this paper is potentially able to produce CR equal to tens and larger than one hundred [
17,
21]. This can be achieved by the expense of distortions where larger distortions are introduced for larger CR values. A question is what is a reasonable trade-off between an attained CR and introduced distortions [
13,
22,
23,
24,
25] and how can it be reached?
An answer depends upon many factors:
- (1)
Priority of requirements to compression, restrictions that can be imposed;
- (2)
Criteria of compressed image quality, tasks to be solved using compressed images;
- (3)
Image properties and characteristics;
- (4)
Available computational resources, preference of mathematical tools that can be used as compression basis.
Consider all these factors. Compression can be used for different purposes, including reduction of data size before their downlink transferring from a sensor to a point of data reception via a limited bandwidth communication line, to store acquired images for their further use in national or local centers of RS data, and to transfer data to potential customers [
13,
23].
First, providing a given CR with a minimal level of distortions can be of prime importance. Then, the use of efficient spectral and spatial decorrelation transforms is needed [
17,
23,
24], combined with modern coding techniques applied to quantized transform coefficients. Spectral decorrelation and 3D compression allow exploiting spectral redundancy of multichannel data inherent for many types of images as, e.g., multispectral and hyperspectral [
25], to increase CR [
24]. In this paper, we consider three-channel images combined of visible range components of Sentinel-2 images [
25]. The main reason we consider separate compressions of component images with central wavelengths 492 nm (Blue), 560 nm (Green), and 665 nm (Red) of Sentinel-2 data (
https://www.esa.int/Applications/Observing_the_Earth/Copernicus/Sentinel-2, accessed on 27 October 2021) is that they have the equal resolution that differs from the resolution of most other (except NIR-band) component images (in other words, we assume that Sentinel-2 images can be compressed in several groups, taking into account different resolutions in different component images, namely, 10 × 10, 20 × 20, and 60 × 60 m
2). Besides, earlier, discrete atomic compression (DAC) was designed for color images (i.e., for three-channel image compression).
Second, it is possible that the main requirement is to provide the introduced losses below a given level. “Below a given level” can be described quantitatively or qualitatively. In the former case, one needs some criterion or criteria to measure the introduced distortions (see brief analysis below). In the latter case, it can be stated that, e.g., lossy compression should not lead to sufficient reduction of image classification accuracy (although even in this case “sufficient” can be described quantitatively). Here, it is worth recalling that considerable attention has been paid to the classification of lossy compressed images [
17,
26,
27,
28,
29,
30,
31,
32,
33]. It has been shown that lossy compression can sometimes improve classification accuracy or, at least, the classification of compressed data provides approximately the same classification accuracy as classification of uncompressed data [
34,
35,
36]. Thus, if compression is lossy, the procedures of providing appropriate quality of compressed data are needed [
36].
Third, it is often desired to carry out compression quickly enough. In this sense, it is not reasonable to employ iterative procedures, especially if the number of iterations is random and depends on many factors. It is worth applying transforms that can be easily implemented and have fast algorithms, can be parallelized, and so on [
12]. This explains why most efficient methods are based on discrete cosine transform and wavelets [
36,
37,
38,
39]. Here, we consider lossy compression based on discrete atomic transform (DAT) [
40,
41] where atomic functions are a specific kind of compactly supported smooth functions. As it will be shown below, DAT has a set of properties that are useful in the lossy compression of multichannel images.
Fourth, there can also be other important requirements. They can relate to the visual quality of compressed images [
26], the necessity to follow some standards, etc. One of the specific requirements could be the security and privacy of compressed data [
42,
43]. There are many approaches to providing security and privacy of images in general and RS data in particular [
44,
45,
46]. Currently, we concentrate on the problem of unauthorized viewing of image content. Usually, a processing procedure, which provides both compression and content protection, can be constructed as follows: image is compressed and afterward encrypted. This approach requires considerable additional computational resources, especially if a great number of digital images is processed. Another way is to apply a combination of some special image transform at the first step (for example, scramble technique [
46]) with further data compressing. In this case, the following questions arise: (1) what compression efficiency is provided? (2) is it possible to reconstruct an image correctly if a lossy compression algorithm is applied? It has been recently shown that privacy of images compressed by DAT [
47] can be provided practically without increasing the size of compressed files (actually, protection is integrated into compression). This is one of its obvious advantages that will be discussed in this paper in more detail.
As has been mentioned above, criteria of compressed image quality and tasks to be solved using compressed images describe the efficiency of compression and applicability of compressed data for further use. The maximal absolute deviation is often used in characterizing near-lossless compression [
19]. Root mean square error (RMSE), mean square error (MSE) and peak signal-to-noise ratio (PSNR) are conventional metrics used in lossy image compression [
13,
26]. Different visual quality metrics are applied as well [
48,
49,
50]. Criteria typical for image classification (a total (aggregate) probability of correct classification, probabilities of correct classification for particular classes, confusion matrices) are worth using if RS data classification is the final task of image processing [
51]. There is a certain correlation between all these criteria, but they are not strictly established yet [
52]. Because of this, it is worth carrying out studies for establishing such correlations. Note that correlations between aforementioned probabilities and compressed image quality characterized by maximal absolute deviation (MAD) or PSNR depend upon a classifier used [
36,
53,
54]. In this paper, we employ the maximum likelihood (ML) method [
25,
53,
54]. This method has shown itself to be efficient for classifying multichannel data [
53,
54,
55], its efficiency is comparable to the efficiency of neural network classifier [
36].
We have stated above that image properties and characteristics influence CR and coder performance. For simpler structure images, the introduced losses are usually smaller than for complex structure images for the same CR where image complexity can be characterized by, e.g., entropy (a larger entropy relates to more complex structure images). This means that compression should be analyzed for images of different complexity and, desirably, of natural scenes. Besides, noise present in images can influence image compression. First, noisy images are compressed worse than the corresponding noise-free images [
25]. Second, if images are noisy, this should be taken into account in compression performance analysis and coder parameter setting [
18,
56]. Since component images in the visible range of multispectral Sentinel-2 data have a high signal-to-noise ratio (that corresponds to noise invisibility in case of image visual inspection), we further consider these images noise-free.
We assume that available computational resources, preference of mathematical tools to be used for compression are not of prime importance. Meanwhile, we can state that the DAT-based compression analyzed below possesses high computational efficiency [
57].
Aggregating all these, we concentrate on the following:
DAT is used as the basis of compression and we are interested in the analysis of its performance since it is rather fast, allows providing privacy of data, and has some other advantages [
40,
41,
47,
57];
It is worth investigating how compression characteristics of DAT can be varied (adapted to practical tasks) and how the main criteria characterizing compression performance are inter-related;
We are interested in how the DAT-based compression influences classification accuracy and, for this purpose, consider the classification of three-channel Sentinel-2 data using the ML method.
Thus, the goal of this paper is to carry out a thorough analysis of DAT application for compressing and further analysis of multichannel RS images using three-channel Sentinel-2 data. The main contributions of the paper are the following. First, we analyze and show what versions of DAT are the most attractive (preferable) for the considered application. Second, we analyze and propose ways to control distortions introduced by DAC. Third, we study how DAC influences the classification accuracy of RS data and show what parameter values have to be set to avoid sufficient degradation of classification characteristics.
The paper structure is the following.
Section 2 considers DAT-based compression and its variants, basics of privacy providing. In
Section 3, dependencies between the main parameters and criteria of DAT compression are investigated.
Section 4 describes the used classifier and its training for two test images.
Section 5 provides the results of experiments (classification) for the real-life three-channel image. A brief discussion is given in
Section 6. Finally, the conclusions follow.
2. DAT-Based Compression and Its Properties
Below, we describe the discrete atomic compression that is the DAT-based image compression algorithm. Then, we consider the procedure of DAT, which is its core, and quality control mechanism.
2.1. Discrete Atomic Compression
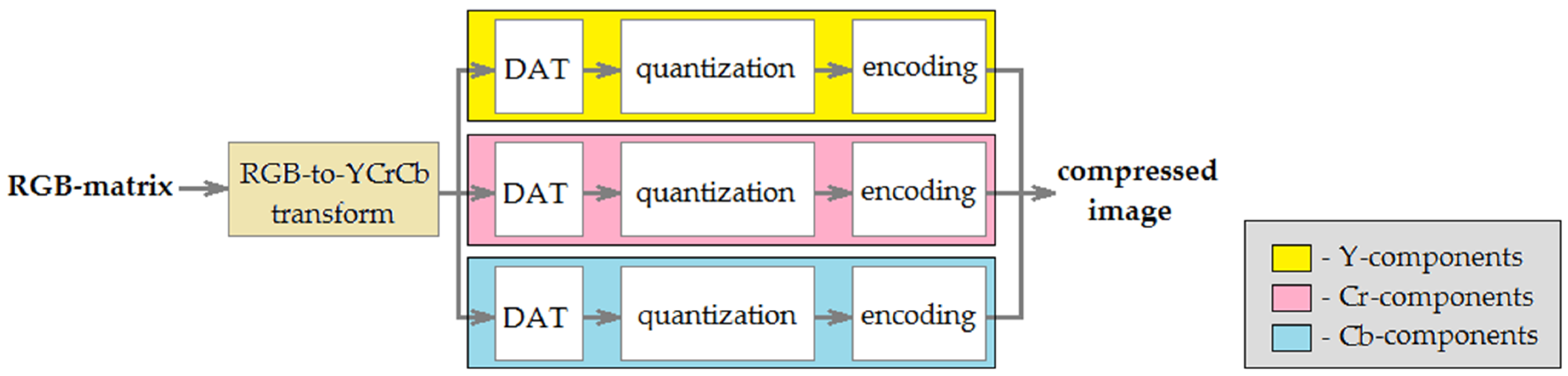
In the algorithm DAC, the following classic lossy image compression approach is used: preprocessing → discrete transform → quantization → encoding. The application of DAC to full-color digital image processing is shown in
Figure 1. In this case, the input is RGB-matrix. At the first step, luma (Y) and chroma (Cr, Cb) components are obtained. Further, each matrix Y, Cr, and Cb is processed separately. The procedure DAT is applied to them and matrices Ω
[Y], Ω
[Cr], Ω
[Cb] of DAT coefficients are computed. Next, elements of these matrices are quantized (further, we consider this process in more detail). Finally, quantized DAT-coefficients are encoded using a lossless compression algorithm. The range of most of these values is small. Moreover, depending on quantization coefficients choice, a significant part of them is equal to zero. A combination of the features described provides effective compression by such algorithms, as Huffman codes, which are often used in combination with run-length encoding, as well as arithmetic coding (AC) [
55]. Consider this in more detail.
In this research, we apply the algorithm AC to compress bit streams obtained from quantized DAT-coefficients. Different ways to transform data into bitstream can be used. For example, the special bit planes bypass is applied in JPEG2000 [
37]. In the current research, we use an approach that is based on Golomb coding [
58]. Our proposition is to apply the following bitstream assignment: 0 ↔ 0, 1 ↔ 10, −1 ↔ 110, 2 ↔ 1110, −2 ↔ 11110, etc. In general, the code for 0 is 0, the code for positive k is the sequence of 2k−1 bits equal to 1 and end-bit 0, the code for negative −k is the sequence of 2k bits equal to 1 and end-bit 0. For example, a binary stream of the sequence {0, 3, 4, −1, −2, 1, 0, 0, 2} is 0111110111111101101111010001110. In addition, we use row-by-row scanning of the coded blocks. The choice of such a scan is based primarily on performance reasons, namely, on the principle of locality, which allows significant speeding up the data processing by effectively using the features of the memory architecture [
59]. Of course, there may be another way to bypass the blocks, which might provide better compression efficiency.
The process of reconstructing a compressed image is carried out in the reverse order to that shown in
Figure 1.
We note that the algorithm DAC can be used to compress grayscale digital images. In this case, the preprocessing step is skipped, and DAT is applied directly to the matrix of the image processed. After that, DAT-coefficients are quantized and encoded in the same way as above.
In the next subsection, we consider the procedure DAT in more detail.
2.2. Discrete Atomic Transform
Discrete atomic transform is based on the following expansion:
where f(x) is the function representing some discrete data D = {d
1, d
2, …, d
m}, n is positive integer, N is non-zero constant and the system
is a system of atomic wavelets [
57]. These wavelets are constructed using the atomic function
In this research, we use the function and .
From (1), it follows that
, where
represents the main value of f(x), i.e., a small copy of the data D, and each function
describes orthogonal components corresponding to the wavelet
. The function f(x) is defined by the system of atomic wavelet coefficients
, which is equivalent to the description of the discrete data D by
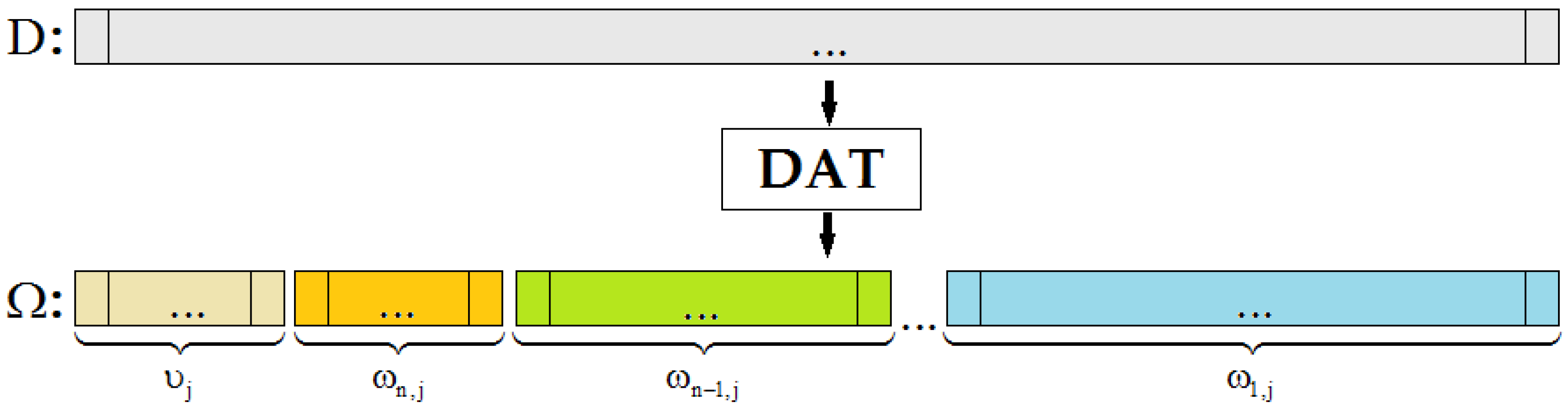
. A procedure of atomic wavelet computation is called discrete atomic transform of the data D (
Figure 2). In addition, the number n is called its depth.
We note that the depth of DAT can be varied. This means that a structure and, therefore, result of DAT can be changed.
There are many ways to construct DAT of multidimensional data. Here, we concentrate on the two-dimensional case, since image processing is considered.
Let D be a rectangular matrix.
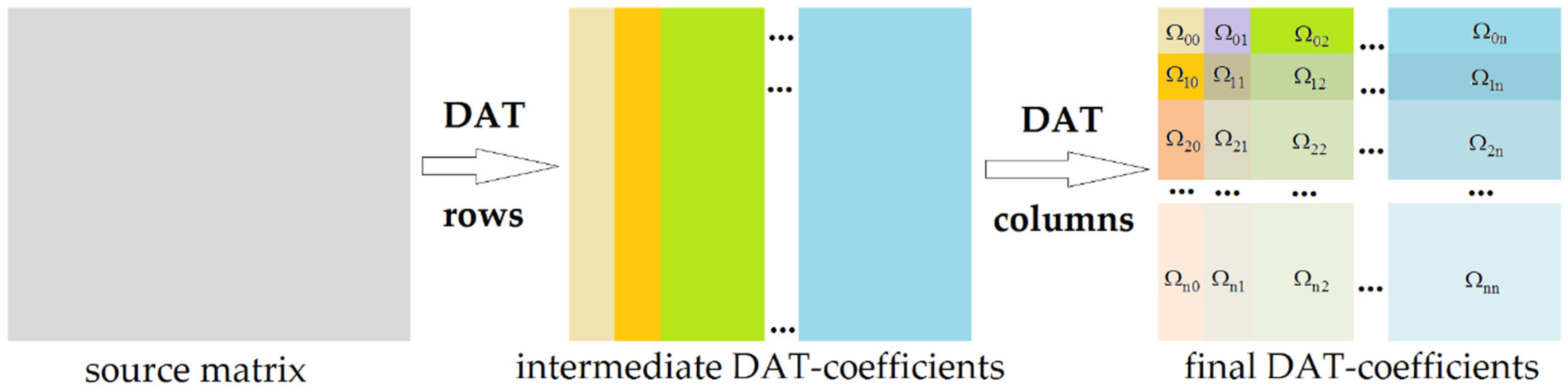
The first way to construct discrete atomic transform of the matrix D is as follows: first, array transform DAT of the depth n is applied to each row of the matrix D and then to each column of the matrix of DAT-coefficients obtained at the previous step (see
Figure 3). We call this procedure DAT1 of the depth n.
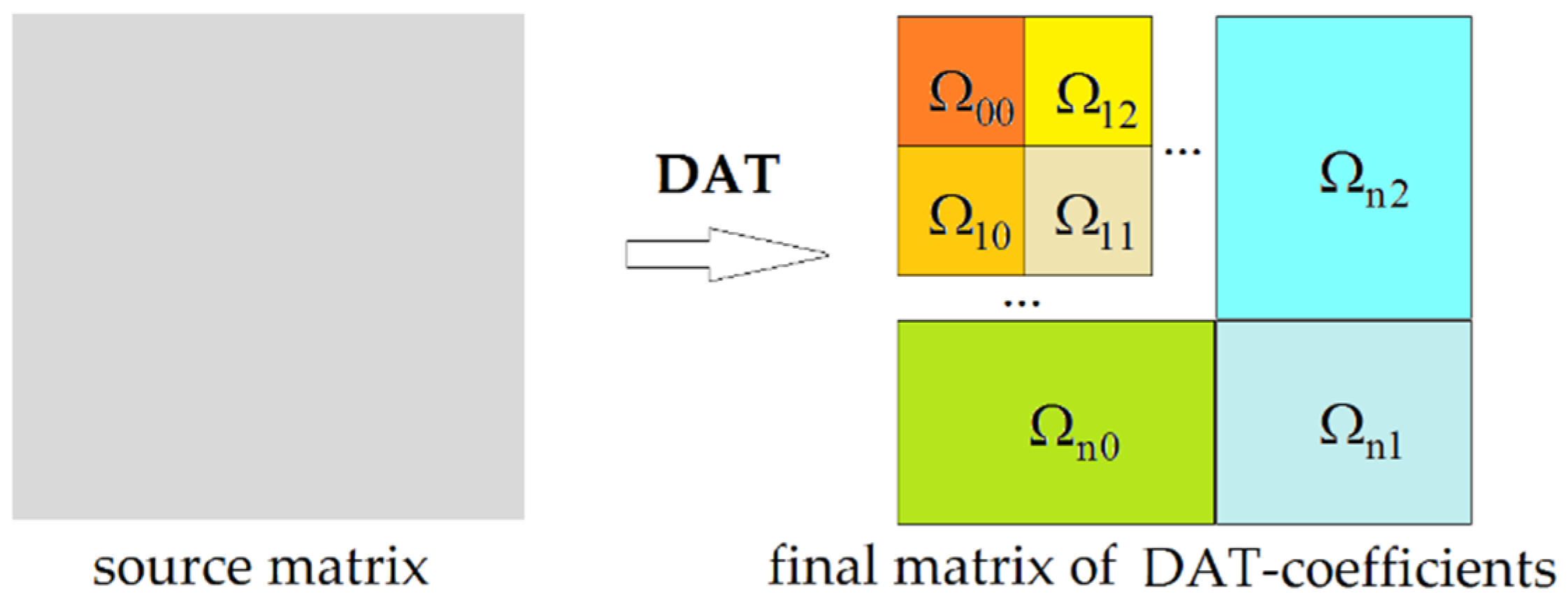
Consider another approach. First, array transform DAT of depth 1 is applied to each row of D and then to each column of the resulting matrix (
Figure 4). In this way, a simple matrix transform, which is called DAT2, of depth 1 is built. The matrix of DAT-coefficients
is a result. This matrix has a block structure: the block
contains a small, aggregated copy of the source data D, all others contain DAT-coefficients of the corresponding orthogonal layers.
If we apply DAT2 of depth 1 to the block
, i.e., left upper block, we obtain the matrix transform, which is called DAT2 of depth 2. In the same way, the matrix transform DAT2 of any valid depth n is constructed (
Figure 5). Such a transform belongs to classic wavelet transforms that are widely used in image compression [
58,
60].
It is clear that DAT1 and DAT2 are significantly different. The output matrices have different structures, and their elements have different meanings. For this reason, complete information about the matrix transform applied is required in order to reconstruct the original matrix D.
Note that various mixtures of DAT1 and DAT2 can be applied. For example, first, DAT2 of the depth 1 can be applied, and then each block of the resulting matrix can be transformed by DAT1 (
Figure 6). In addition, different combinations of DAT-procedure reuse can be applied to blocks of the matrix obtained at the previous step.
Hence, there is a great variety of constructions of the two-dimensional DAT. We stress that any attempt to correctly reconstruct the source matrix D using the given matrix of DAT-coefficients
requires huge computational resources if comprehensive information about DAT-procedure applied is absent. Moreover, the source matrix can be divided into blocks, each of which can be then transformed by DAT. Notice that this approach is used in such algorithms as JPEG [
61] and WebP [
62].
It is obvious that changes in the structure of DAT affect the DAC efficiency including complexity, memory savings, and metrics of quality loss. For this reason, the following question is of particular interest: what is the dependence of the DAC compression efficiency on the structure of DAT applied? An answer to this question makes it possible to choose such a structure of DAT that provides the best results with respect to different criteria.
In [
47], DAT1 of the depth 5 and DAT2 of the depth 5 were considered, and it was shown that they provided almost the same compression ratio with the same distortions measured by RMSE (actually, only one compression mode of DAC, which provides the average RMSE = 2.8913, was considered), i.e., a significant variation of DAT structure does not reduce the efficiency of the DAC. It was proposed to apply this feature in order to provide protection of digital images.
Further, we compare DAT1 and DAT2. In opposite to [
47], in the current research, a greater number of DAT structures is considered. Moreover, analysis is carried out for a wider range of quality loss levels. It will be shown that almost the same results can be obtained using these principally different matrix transforms. In other words, a significant variation of DAT structure does not significantly affect the processing results. For this reason, it is natural to expect that other intermediate structures of DAT provide practically the same compression results.
The following combination of features makes the algorithm DAC a promising tool for image protection and compression:
a great variety of structures of the procedure DAT, which is a core of DAC;
a possibility to reconstruct the source image correctly if and only if the correct inverse transform is applied;
almost the same compression efficiency provided by different structures of DAT.
It is obvious that if DAC is used in some software, a key containing information about the structure of DAT applied should not be stored in the compressed file in order to provide protection of image content. If this requirement is satisfied, then a high level of privacy protection is guaranteed. If unauthorized persons obtain access to file and compression technology, but do not have the key, then correct content reconstruction requires great computational resources. Such a hack can be performed with more complication by encrypting some elements of the file with a compressed image.
Consider some special data structure requirements. Different variants of the matrix form DAT are based on one-dimensional DAT, i.e., DAT of an array. From functional properties of atomic wavelets [
57], which constitute a core of DAT, it follows that a length of the source array A should be equal to
, where n is a depth of the DAT and s is some integer. This restriction is called the length condition. If it is not satisfied, then it is suggested to extend A such that equality holds. We propose to fill extra elements by values, which are equal to the last element of A. In this case, the extended version of A has up to
extra elements. When processing the matrix M, its rows and columns should also satisfy the length condition, defined by the structure of DAT. In order to provide such satisfaction, it is proposed to add extra columns, each of which coincides with the last column of M, and after that to add extra rows using the same approach. This provides a possibility to apply the DAT of any structure to a matrix of any size.
2.3. Quality Loss Control Mechanism
DAC is the lossy compression algorithm. Main distortions occur during the quantization of DAT-coefficients. It is clear that appropriate coefficients of quantization should be used. In the standards of some algorithms (for instance, JPEG), the recommended values are given. However, sometimes developers of software and devices apply their own coefficients. We stress that loss of quality depends a lot on quantization coefficients. For this reason, their choice should provide fulfillment of requirements for the quality in terms of some given metrics.
In [
60], a quality loss control mechanism for the algorithm DAC was introduced. It provides the possibility to obtain the desired distortions measured by maximum absolute deviation (MAD) often used in remote sensing [
22,
23]. Basically, this metric is defined by the formula
where
are the source and reconstructed images, respectively. For the case of full-color digital images, the MAD-metric is built as follows:
where
are RGB-components of pixels
and
.
High sensitivity even to minor distortions is a key feature of MAD. Note that if MAD is small, then quality loss, which is obtained during processing (e.g., due to lossy compression), is insignificant. If MAD is large, then it means that at least one pixel is changed considerably. Although, if only several pixels have significant changes of color intensity, visual quality might remain high, especially when processing high-resolution images. Hence, MAD-metric should be used as a metric of distortions in the case of low-quality loss or near lossless compression.
Consider the quality loss control mechanism, which was proposed in [
60], in more detail. It is based on an estimate concerning the expansion (1).
We start with the transform DAT1 and the case of grayscale image processing. Let D be a source matrix. Using DAT1, we obtain the matrix
that consists of blocks
(see
Figure 3). Denote by
a set of positive real numbers. Consider the following quantization procedure:
It is presented in matrix form. We assume that all operations are applied to each element of blocks. Using (2), (3), the matrix is computed. In DAC, blocks of this matrix are encoded using binary AC.
Dequantization is constructed as follows:
This procedure provides computation of the matrix that is further used in order to obtain , which is a matrix of the decompressed image.
It follows that if (2)–(5) are applied, then
The right part of this inequality is an upper bound of MAD. We denote it by UBMAD. In other words, the proposed quantization and dequantization procedures provides that loss of quality measured by MAD is not greater than UBMAD, which is defined by parameters of quantization . As it can be seen, DAT-coefficients corresponding to the same wavelet layer are quantized using the same quantization coefficient.
When processing full-color digital image, we propose to apply the same approach. Consider three sets of positive real numbers
,
and
. Each of these sets is used in (2)–(5) for quantizing and dequantizing of matrices Ω
[Y], Ω
[Cr], Ω
[Cb] of DAT-coefficients corresponding to Y, Cr, and Cb respectively. In this case,
where the right part is a maximum of three values, each of which is a sum of real numbers introduced above. This maximum is denoted by UBMAD.
Further, consider the transform DAT2, which is used for grayscale image compressing. A result of the application of DAT2 to the matrix D of the image processed is the matrix Ω that consists of blocks
(see
Figure 5). Let
be a set of positive numbers. As before, these values are used in quantizing blocks of the matrix Ω. This procedure is:
Dequantization is built as follows:
Computation of the matrix
, which is used in order to obtain the decompressed image, is provided by (10), (11). Quality loss measured by MAD satisfies the following inequality:
By UBMAD, we denote the right part of this expression.
In the case of full-color image compression using DAC with DAT2, the same can be used. Three sets
,
and
are applied as parameters of quantization. In order to obtain formulas for quantizing and dequantizing the matrices Ω
[Y], Ω
[Cr], Ω
[Cb], one should put these values to (8)–(11). In this case, the following inequality holds:
Further, the right part of (13) is denoted by UBMAD.
This implies that (2)–(5) in combination with (6), (7) and (8)–(11) in combination with (12), (13) provide control of quality loss measured by MAD-metric when compressing digital images by DAC with DAT1 and DAT2, respectively.
It is obvious that (6), (7), (12), and (13) are upper bounds. Application of the proposed methods of quantization and dequantization does not provide obtaining MAD, which is equal to the desired value. Nevertheless, the following property is guaranteed: quality loss measured by this metric does not exceed the given value. This feature is important if a minor loss of quality is required.
The choice of parameters
or
, when processing respectively grayscale or full-color images, defines quality loss settings of DAC. Many lossy compression algorithms, including DAC, have the following feature: if one fixes some setting of quality and processes two images of different content complexity, results of non-equal distortions are usually obtained. Hence, the following question is of particular interest: what is a variation of compression efficiency indicators? In the next section, we study this question. Besides, as has been mentioned above, the metric MAD might be a non-adequate measure of distortions if its value is large. In this case, other quality loss indicators, in particular, RMSE and PSNR can be used:
where
are pixels of RGB-images X and Y, which are respectively the source and the reconstructed images of the size
.
Further, we investigate the correlation of these metrics and MAD, as well as their dependence on UBMAD. For this purpose, a set of 100 test images is used. Each of them is processed using the algorithm DAC with different quality loss settings and structures of DAT.
3. Discrete Atomic Compression of Test Data
In other words, mostly images with complex content are used. However, some of them contain domains of relatively constant color in combination with smooth color changes (
Figure 8b).
For testing purposes, it can be used in situ datasets too. These data can be collected during different land surveys, for example along the roads (
Figure 9), and can be especially useful for crop classification. During data preprocessing, it could be prepared small polygons, which can be some representation of different homogeneous land cover classes.
Each of the test images is processed by the algorithms DAC with DAT1 of the depth 5 and DAT2 with the depth n = 1, 2, 3, 4, and 5. Different quality loss settings, which are defined by the values , are used. The following steps are applied:
- (1)
fix the structure of DAT and its depth in the case of DAT2;
- (2)
fix parameters and compute UBMAD;
- (3)
for each test image perform the following:
- –
compress the current image;
- –
compute compression ratio (CR): ;
- –
decompress image;
- –
compute quality loss measured by MAD, RMSE, and PSNR;
- –
store results in Table.
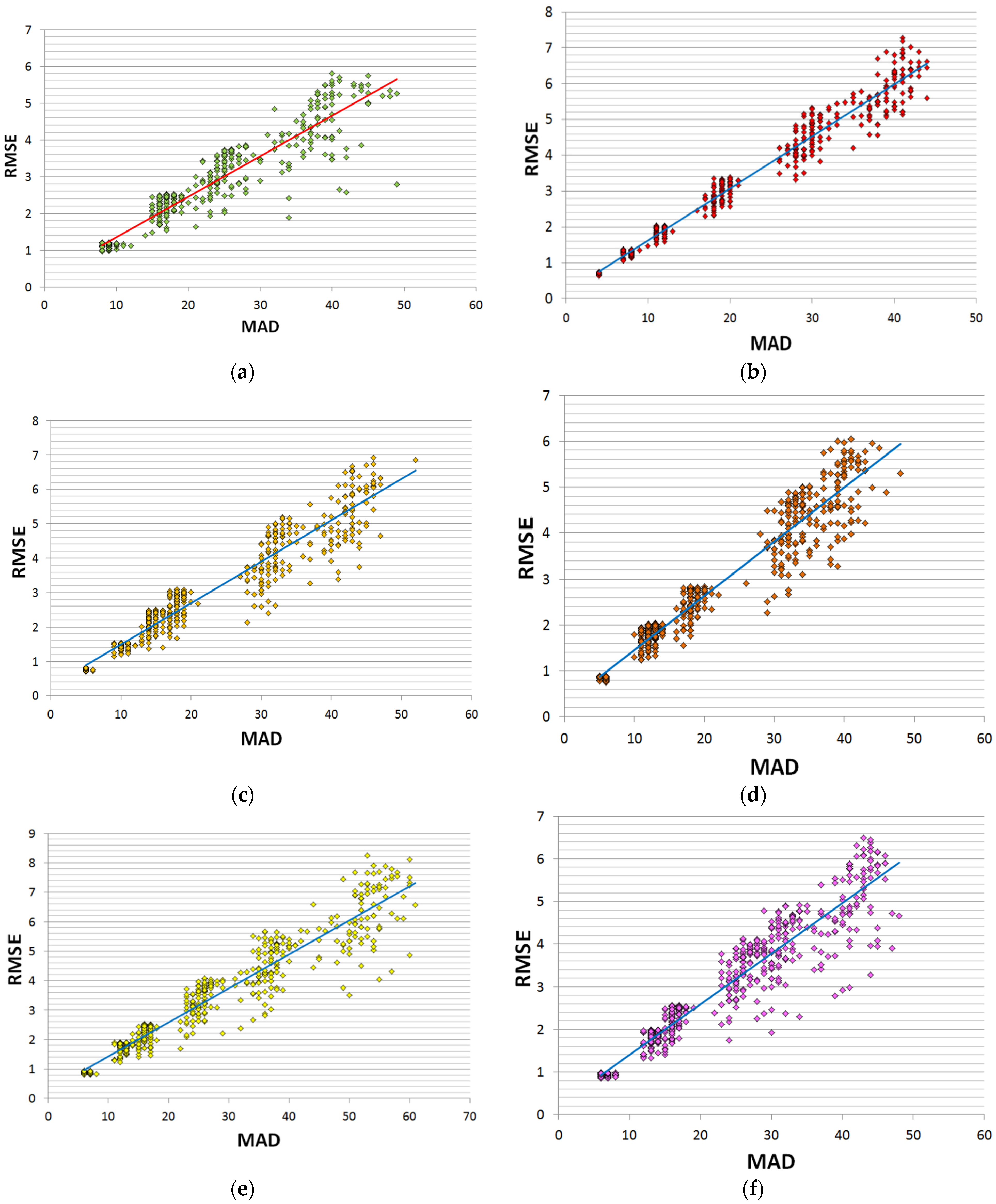
First, we study the correlation of quality loss metrics RMSE, PSNR, and MAD. Since PSNR is a function of RMSE, it is sufficient to investigate the dependence of RMSE on MAD. In
Figure 10, scatter plots of RMSE vs. MAD are shown. In addition, we have computed Pearson’s correlation coefficient R and Spearman’s rank-order correlation coefficient
[
63]. Moreover, using the least-square method [
63], linear regression equations have been constructed. Their graphs are also given in
Figure 10. In
Table 1, values of R,
, as well as coefficients a, b of the linear equation
, where y = RMSE and x = MAD, are presented.
Furthermore, using the ANOVA F-test [
64], we have checked whether there is a linear regression relationship between RMSE and MAD. For this purpose, the following test statistic has been computed:
where n = 100 is the number of analyzed values,
is a set of RMSE-values and
;
, where a, b are coefficients of linear regression,
are values of MAD. Here, we note that the point
is a pair of quality loss values measured by MAD and RMSE for an i-th test image. In
Table 1, values of
are given. This statistic is compared with
from F-table [
64]. Currently,
. If
, then there is a linear regression between y and x, i.e., RMSE and MAD. It follows from
Table 1 that, for each structure of DAT, there is the linear regression between quality loss indicators MAD and RMSE. This is also evidenced by the fact that values of both Pearson’s correlation and Spearman’s rank correlation coefficients are close to 1.
Second, we investigate a dependence of MAD, RMSE, PSNR and CR on UBMAD. For this purpose, we compute mean (E), minimum, maximum values and deviation (
) of these compression efficiency indicators for each value of UBMAD applied. In addition, we calculate percentage of values obtained that belongs to segments
for k = 1, 2 and 3. In other words, we estimate the scatter of experimental data with respect to the mean. In
Table 2 and
Table 3, the results of computation are given for the case of DAT1 of the depth 5 and DAT2 of the depth 2 (the results concerning other cases are presented in the file Efficiency_indicators.pdf that can be found at the link given above). As it can be seen, the difference between minimum and maximum is great. For instance, when processing test images “Southern Bavaria” (
Figure 8a) and “Jewels of the Maldives” (
Figure 8b) by DAC with DAT1 and UBMAD = 155, we obtain, respectively, PSNR = 32.854 dB, CR = 2.146 and PSNR = 42.615 dB, CR = 44.525, which are, respectively, minimum and maximum values of the correspondent indicators. Nevertheless, percent of values, which belong to segments
and
, is great. Besides, we see that
is small if UBMAD is small. Although,
grows as UBMAD increases.
Hence, in the algorithm DAC, there is a mechanism for control of quality loss measured by MAD, RMSE and PSNR. It does not provide obtaining some values of these indicators, but it guarantees with high level of certainty that each of them is within fixed limits.
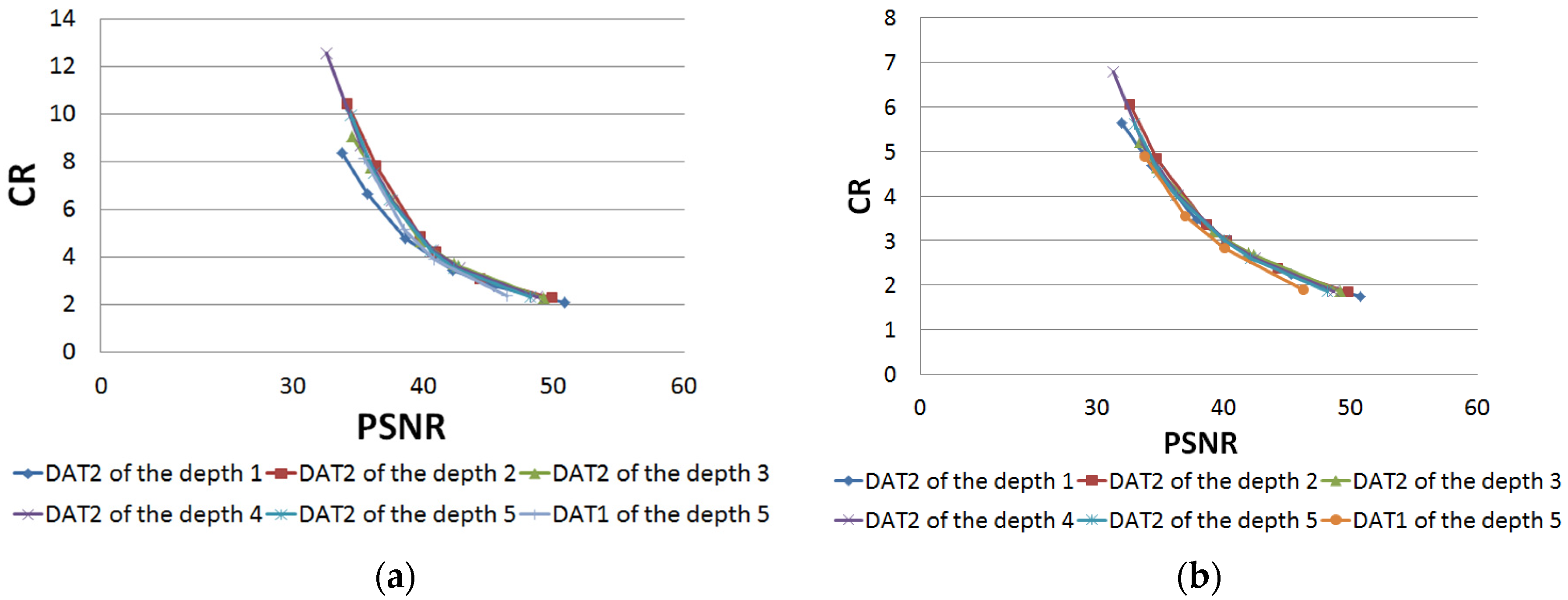
Next, in
Figure 11, dependences of the mean value of CR on the mean value of PSNR for each structure of DAT are shown. We see that curves are close to each other except for the one corresponding to DAT2 of the depth 1. This means that it is not recommended to use DAT2 of the depth 1 and that a structure of DAT can be changed without significant changes of compression efficiency, which is important in the context of privacy protection requirements (see
Section 2.2).
Finally, we verify the results presented above by processing other test data. In
Figure 12, the test images SS3 and SS4 are shown.
Table 4 and
Table 5 contain results of their compressing. We stress that we have used the same quality loss settings as when processing the previous test data set.
Figure 13 shows the dependence of CR on PSNR. It follows that there is no significant difference between results obtained for different structures of DAT. Furthermore, we see that indicators MAD, RMSE, PSNR, and CR belong to segments obtained when processing ESA images.
5. Analysis of Classification Characteristics
Classification accuracy depends on many factors including a used classifier and its parameters, methodology of its training, image properties, and compression parameters. The classifier type, its parameters, and methodology of its training are fixed. Two images of different complexity will be analyzed in this Section. The main emphasis here is on the impact of compression parameters.
Let us start by considering the simpler structure image (
Figure 12a). Let us analyze more in detail confusion matrices for compression with DAT of depth = 1 for different MAD values. The obtained results are presented in
Table 6.
Analysis of data in
Table 6 shows the following. First, classes are recognized with sufficiently different probabilities. The class Water is usually recognized in the best way although this is not the case for MAD = 16. Variations of the probability of correct recognition for the class Water (P
22) are due to two obstacles.
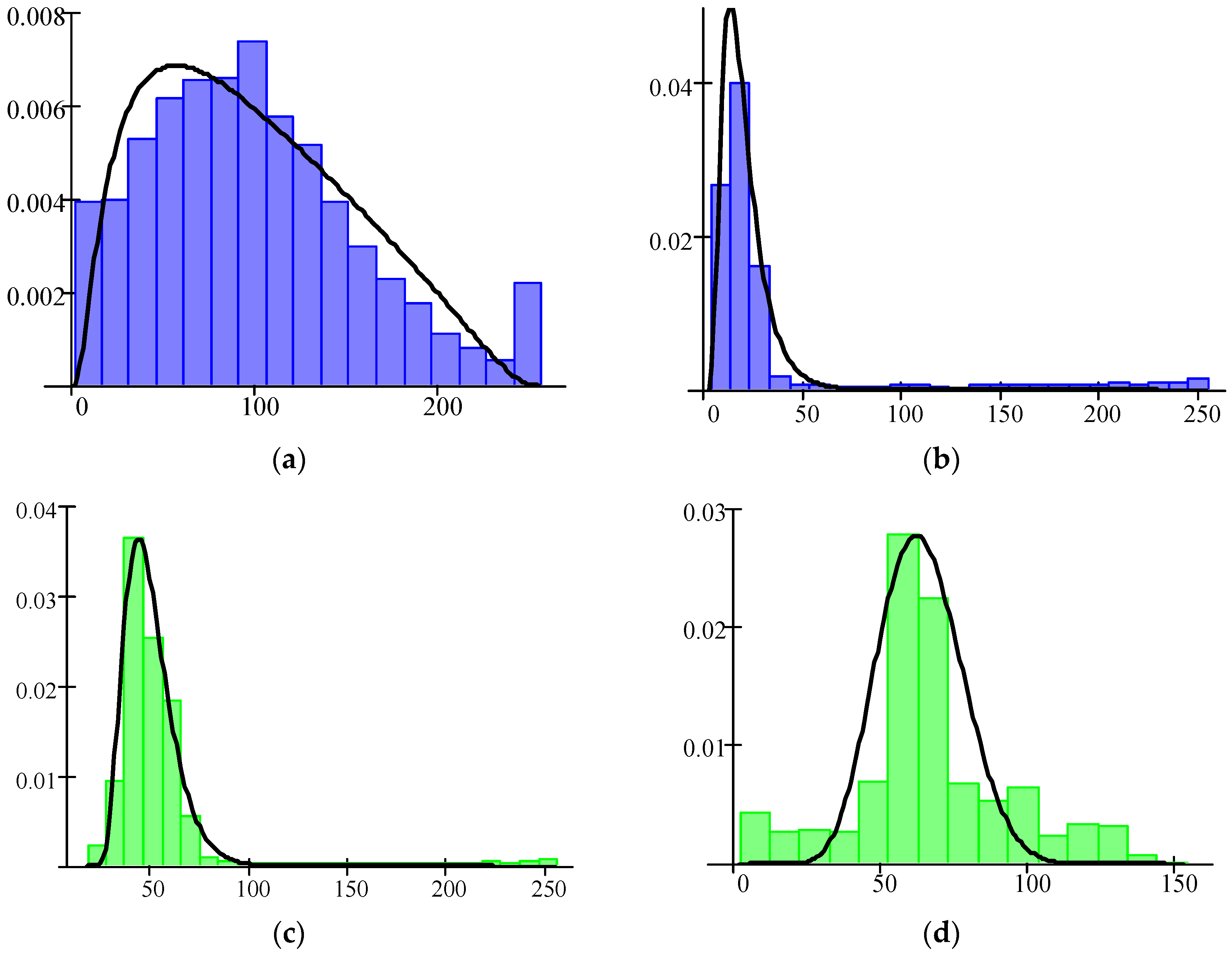
First, this class has sufficient overlapping of features distributions with other classes and probability density functions for this class are “narrow” (see
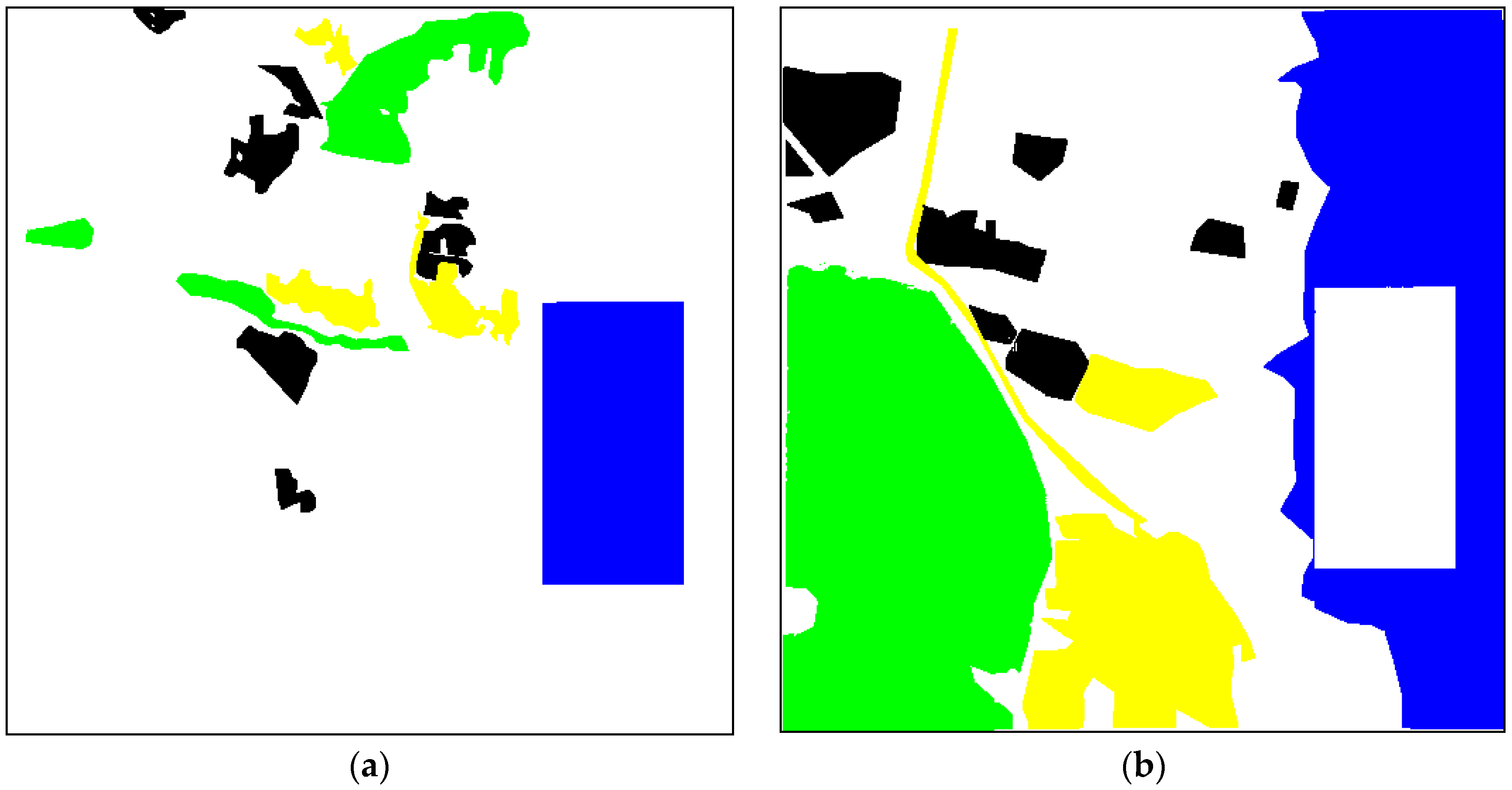
Figure 17). Second, distortions due to lossy compression, in particular, mean shifting for large homogeneous areas, can lead to misclassifications. This effect is illustrated by two classification maps in
Figure 18. For MAD = 16, there are many misclassifications (the pixels that belong to the class Water are related to the class Urban and shown by yellow color). The class Urban is recognized with approximately the same probability of correct recognition P
11. The probability of correct recognition P
33 for the class Vegetation does not change a lot. Finally, the probability of correct recognition P
44 for the class Bare Soil changes a little for small MAD values and sufficiently reduces for the largest MAD = 35.
Second, since there are overlappings in the feature space, there are misclassifications. In particular, the pixels belonging to the class Bare Soil are often recognized as Urban and vice versa. This is not surprising and always happens in RS data classification for classes “close” to each other.
Third, the total probability of correct classification Ptotal depends on MAD. Being equal to 0.876 for original images, it occurs to be equal to 0.87 for MAD = 4, 0.866 for MAD = 7, 0.861 for MAD = 10, 0.825 for MAD = 16, 0.875 for MAD = 22, and 0.839 for MAD = 35. Thus, there is some tendency of reduction of Ptotal with “local variations”.
As one can see, probabilities for particular classes slightly vary depending on the depth of DAT and MAD but not by much. They remain more stable than in the case of DAT with depth 1. Concerning the total probability of correct classification, its small degradation with MAD increasing is observed for depths 3 and 4, but reduction can be considered acceptable, if it does not exceed 0.02.
Let us now consider the second real-life test image that has a complex structure (
Figure 12b). Its classification maps for the original image and three values of MAD are presented in
Figure 19. The comparison shows that there are no essential differences between the classification maps. Another observation is that there are quite many misclassifications from the Vegetation class to Water (authors from Kharkiv live or work in this region). The confusion matrix (
Table 11) confirms this. Here, it is seen that the class Water is recognized worse than in the previous case. The class Urban is also recognized worse while the classes Vegetation and Bare Soil are recognized better than in the previous case. P
total equals 0.811. For comparison,
Table 12 gives an example of a confusion matrix for the compressed image. As one can see, there is no essential difference, at least in probabilities P
11, P
22, P
33, and P
44. P
total = 0.787, i.e., noticeable reduction of P
total takes place, and it is worth analyzing probabilities for different MAD values and depths of DAT.
Thus, let us consider data for different depths of DAT and different values of MAD. They are presented in
Table 13,
Table 14,
Table 15,
Table 16 and
Table 17. As it follows from data analysis in these Tables, there is a tendency of reduction of P
total if MAD increases. This is especially obvious for a depth equal to 1. For MAD = 34, the considerable reduction of P
22 and P
44 takes place.
The smallest reduction takes place for depth = 2. For other depths, the results for depths 3, 4, and 5 are, in general, better than for depth = 1, but worse than for depth = 2. For depth = 2, it is possible to state that classification results are acceptable for all considered MAD values (even MAD = 36) because Ptotal for compressed images is less than Ptotal for the original image by no more than 0.03.
Certainly, these two examples are not enough to obtain full imagination of classification accuracy of compressed images and give some final recommendations. Besides, classification results usually depend on a classifier applied. To partly move around these shortcomings of previous analysis, we have carried out additional experiments for other Sentinel-2 images of different complexity, the Landsat image, and a neural network classifier. The obtained data are briefly presented below (a more detailed data can be found at the following link to the Google drive folder:
https://drive.google.com/drive/folders/14m7TLLM7o836yGzJo9NKlaUc9sLsL5VK?usp=sharing, accessed on 27 October 2021).
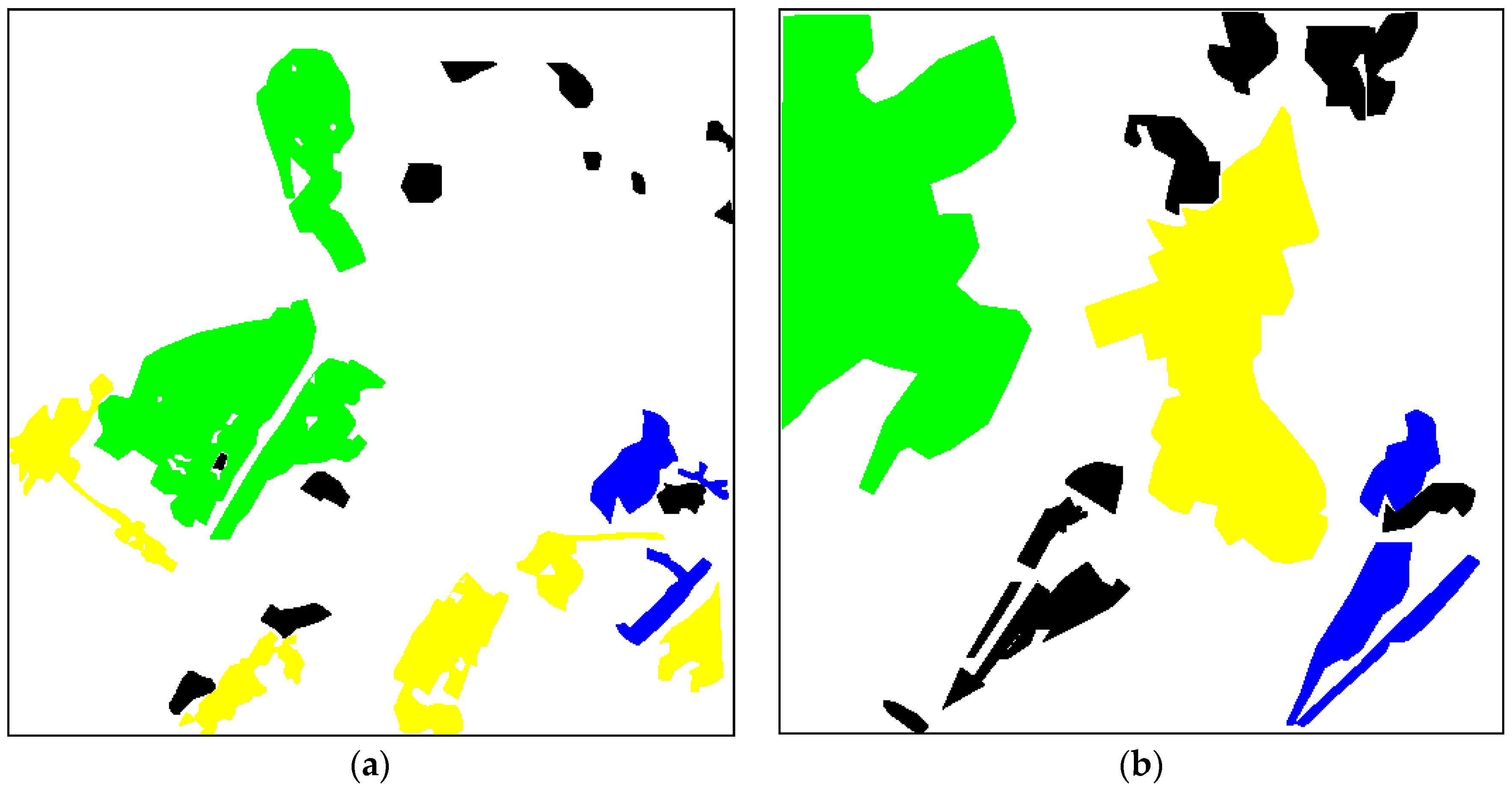
The experiments have been performed for 512 × 512 pixel fragments of Sentinel-2 and Landsat images (
Figure 20).
Table 18 presents the total probabilities of correct classification for the image in
Figure 20, a compressed with depth 2. The three-layer neural network (NN) classifier has been trained using the same fragments as for the ML classifier. The verification fragments are also the same to provide the correctness of comparisons. Classifiers have been trained for non-compressed data. The analysis shows that the probabilities are practically at the same level for all MAD values except the last one where a small reduction of P
total is observed. The classification accuracy for the NN classifier is slightly better but not sufficiently.
Table 19 gives the results (P
total) for the image in
Figure 20b. As one can see, the more complicated structure image is classified worse than a simpler one (compare the data in
Table 18 and
Table 19). Again, the NN classifier performs a little bit better than the ML one. Finally, there is a general tendency to reduction of P
total if the MAD of introduced losses increases. Meanwhile, if MAD is less than 30, the reduction of classification accuracy is acceptable.
Finally,
Table 20 presents a part of the results obtained for the Landsat image in
Figure 20c using the ML classifier. The probabilities for particular five classes and the total probability of correct classification are given. As one can see, the classification results are quite stable if introduced distortions are not too large (MAD < 20, PSNR > 38 dB), then a fast reduction of classification accuracy takes place if MAD increases (PSNR decreases).
In addition, in
Figure 21, the results of compressing the images given in
Figure 20 are presented.
Figure 21a shows almost the same behavior of dependence of PSNR on MAD for all three images. This means that the dependence of PSNR on MAD depends on image content only slightly. In contrast, compression efficiency measured by CR significantly depends on the image content. For instance, the test image shown in
Figure 20b has a lot of small objects and sharp changes of color intensity. As one can see, CR for this image is the smallest for any value of PSNR considered (
Figure 21b).
6. Discussion
Below, we discuss the obtained results and present some recommendations concerning their further applications.
First, computation complexity is of particular interest, especially, when processing a huge amount of digital images. In [
54], it has been shown that computation of DAT-coefficients is linear in the size of data processed, i.e., time complexity of DAT is O(N), where N is the number of pixels. However, one specific feature of digital devices and/or computational systems should be taken into account when applying DAC. In terms of time expenses, data transferring from one memory part to another (needed in the calculation of DAT) can take more time than performing arithmetic operations [
56]. Note that when applying DAT of the depth greater than 1, such a transferring is used and the time needed for it increases if depth becomes larger. For this reason, the use of DAT of the low depth can be recommended if high performance is required.
Second, it follows from the results obtained in the previous sections that DAT2 of the depth 2 can be recommended from the viewpoint of the same performance compared to DAT versions with the larger depth. Since this recommendation is consistent with the observation for computational complexity, the use of DAT2 with depth = 2 can be treated as a reasonable practical choice.
In practice, one might need to provide lossy compression of RS data with providing the desired quality characterized, e.g., by the desired PSNR. In this sense, although inequalities (7) and (12) are upper estimates, there is a possibility to obtain compressed data with loss of quality measured by PSNR, MAD, or RMSE which are close to the desired values. Consider this, e.g., for PSNR. Let a structure of DAT be fixed. For instance, let DAT1 of the depth 5 or DAT2 of the depth 2 be chosen. If PSNR = p is desired, then settings of DAC can be found as follows:
- –
compute ;
- –
find MAD =
, where a and b are parameters of linear regression
,
,
(here, the values presented in
Table 1 can be used);
- –
find UBMAD, using interpolation methods and data from
Table 2 or
Table 3 depending on the structure of DAT.
The value of UBMAD computed defines the settings of DAC. These settings provide distortions measured by PSNR that, with high probability, belong to an appropriately narrow neighborhood of p.
The UBMAD can be also found directly, using the dependence of the mean value of PSNR on UBMAD (see data in
Table 2 and
Table 3). However, the error of providing a desired PSNR might be greater due to non-linear dependence between these two parameters if linear interpolation is applied.
In addition, as is mentioned in
Section 2.1, any matrix M can be processed by DAT of arbitrary structure. Although, in this case, if its rows or columns do not satisfy the length condition mentioned, then application of the extension procedure is required. This leads to an increase in the number of DAT coefficients. Nevertheless, since atomic wavelets have zero mean value [
57], most extra DAT coefficients are equal to zero. Such data are well compressed by the proposed coding. When processing images of a high resolution, a wide variety of the DAT variants can be applied without a significant increase of additional data. Moreover, if the DAC is considered as a data protection coder, then some increase in the compressed file size is insignificant.
Besides, it is shown that there is no significant difference in the mean value of CR provided by DAT1 and DAT2 (except the case of the depth 1) for any distortions measured by PSNR (see
Figure 11). This means that significant variation of the structure of DAT does not affect significant changes in compression efficiency. Such a result provides the possibility to achieve both compression and protection.
Finally, the algorithm DAC was compared with JPEG in [
40,
41,
47]. It has been shown that, on average, DAC provides a higher compression ratio than JPEG for the same quality measured by PSNR. We note that previously Huffman codes and run-length encoding were used to compress quantized DAT-coefficients. In the current research, binary arithmetic coding is applied instead. In [
65], it has been shown that such an approach provides better compression of quantized DAT-coefficients than a combination of Huffman codes with run-length encoding. Hence, the following statement is valid: on average, the algorithm DAC with binary arithmetic coding of quantized DAT-coefficients compresses three-channel better than JPEG with the same distortions measured by PSNR.
Furthermore, the proposed quality loss control mechanism provides distortions measured by MAD that are not greater than UBMAD, which defines quality loss settings. It is only this value that can be varied to obtain different quality losses. In
Section 3, using statistical methods, it is shown that there is linear dependence of RMSE on MAD, and coefficients of linear regression are provided. Hence, a mechanism for controlling the loss of quality measured by RMSE and PSNR is obtained. This result is of particular importance since the metric MAD is adequate only if it is small; other metrics, especially RMSE and PSNR should be used otherwise. Further, inequality MAD
UBMAD is an upper bound. If the value of UBMAD is fixed, then actual MAD can be significantly smaller than UBMAD. This feature is shown in
Table 2 and
Table 3. Nevertheless, in these tables, the dependence of the mean value of MAD (also, RMSE, PSNR, and CR) and its deviation on UBMAD is provided. Moreover, it is shown that a high percentage of values obtained experimentally belongs to segments [E −
, E +
], where E is the mean value and
is deviation. In other words, the limits of efficiency indicators are obtained for each structure of DAT and each value of UBMAD. This provides a possibility to obtain the desired results in terms of MAD, RMSE, PSNR, and CR.
Finally, we have carried out verification of the proposed approach for some other three-channel images acquired by Sentinel-2 and then compressed by DAT2 with depth equal to 2. The obtained results and recommendations are similar to those presented for the two images used in our research above.
In the future for additional assessment of quality and accuracy of the proposed methods, it will be useful to deal with more sensitive classification tasks such as different crop type classification and other applied problems.


 ,
, 














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}