
Learning from Nighttime Observations of Gas Flaring in North Dakota for Better Decision and Policy Making



Abstract
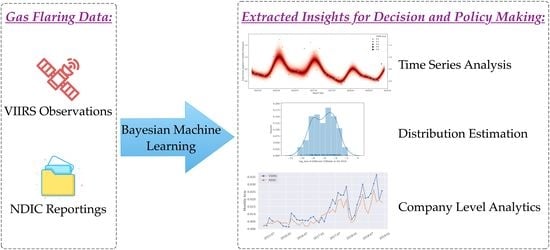
1. Introduction
- Detection of hot pixels
- Noise filtering
- Planck curve fitting
- Calculation of source area
- Calculation of radiant heat

- What insights can be drawn from the VIIRS observations that could lead to better decision and policy making for the state government? Both the time series of a given entity and the whole population of entities at a given time should be studied.
- How good is the quality of the NDIC reporting (i.e., estimated and reported by different companies), by using VIIRS as a benchmark? Although uncertainties are present in the VIIRS estimates (due to the original quality of Cedigaz data as well as the temporal sampling limitations of VIIRS [7]), they are treated as the baseline.
2. Materials and Methods
- Timestamps showing the specific month
- Latitudes and longitudes in WGS 84 coordinates
- Flared volume estimations in billion cubic meters ()
- Store the VIIRS observations as a geospatial data object, with their original coordinates in WGS 84.
- Store the shapefile as a geospatial data object, with its original coordinates in NAD 27.
- Transform all the geometry coordinates in the shapefile to WGS 84.
- Perform a spatial join of the two data objects to obtain the field information for each flare, if a field and the flare share any boundary or interior point.
3. Results
- Time series analysis, where the temporal structure is harnessed for exploring the patterns and trends in flaring performance;
- Cross-sectional data analytics, where the VIIRS observations collected for one point or a period of time (such as a certain month or quarter) are summarized for distributional insights;
- Company level monitoring and analysis, where flare ownership connecting detections with companies is established. The NDIC and VIIRS reporting for a given company can then be compared and contrasted.
3.1. Flaring Time Series Analysis
3.1.1. Modeling VIIRS Detection Count
- ℓ
- is the lengthscale for the Matérn kernel;
- is the marginal deviation controlling the latent functions’ magnitudes in the output space;
- k
- is the kernel for the GP;
- f
- is the latent process;
- is the flaring intensity (unobserved “true” count) of month i. Since is always positive, the natural exponential function is applied to f;
- is the reported count from VIIRS in month i.
- The lightest ribbon (the widest interval for a certain x) represents the 1st to 99th percentile;
- The darkest ribbon (in the center for a certain x) represents the 49th to 51st percentile.
3.1.2. Modeling Scale Factor between VIIRS and NDIC
- is the lengthscale for the Matérn kernel;
- is the marginal deviation for the Matérn kernel;
- T
- is the period for the periodic kernel;
- is the lengthscale for the periodic kernel;
- is the marginal deviation for the periodic kernel;
- is the degrees of freedom for the Student-t likelihood;
- controls the inverse scaling parameter for the Student-t likelihood;
- is the Matérn kernel;
- is the periodic kernel;
- is the white noise kernel;
- f
- denotes the latent process, which is distributed according to a GP whose kernel is the sum of three kernels;
- is the underlying scale factor between VIIRS and NDIC of month i. Since this scale factor is bounded to be positive, the natural exponential function is applied to the latent process;
- is the VIIRS reported volume of month i;
- denotes the unobservable “true” flared volume of month i;
- is the NDIC reported volume of month i, which is modeled using a Student-t likelihood.

3.1.3. Predicting NDIC Reported Volume
3.2. Distribution Approximation
3.2.1. Modeling VIIRS Detection Count
- Poisson
- Negative binomial
- Zero-inflated Poisson (ZIP)
- Zero-inflated negative binomial (ZINB)
- indicates the mean intensity from the perspective of flare count, analogous to the interpretation of a Poisson’s mean. The larger the value of , the greater number of combustion sources are present on average.
- is the overdispersion parameter indicating the diversity of the fields in North Dakota. Specifically, is the additional variance above that of a Poisson with mean . The smaller the value of , the more fields with a huge number of flares exist.
3.2.2. Modeling Flared Volume
- is the vector of concentration parameters for the Dirichlet distribution;
- is the vector of mixture weights (i.e., mixing proportions) which is assigned a Dirichlet prior. This prior with every value inside being 6, is a weakly informative prior, expecting any inside could be greater or less than the others;
- are the lower and upper bound for , respectively;
- is the prior for the location of the k-th mixture component, and represent the K evenly spaced points in ;
- is the mean for the k-th Gaussian component;
- is the standard deviation for the k-th Gaussian component.
3.3. Company Level Monitoring and Analytics
| Algorithm 1: Nearest-Neighbor-Based Flare Owner Assignment |
 |
4. Discussion
4.1. GP’s Attractive Traits
- The observations contain much noise, for example, the estimation and measurement errors.In the context of flaring data, companies estimate and self-report the volumes; satellites inevitably miss some events or overestimate some flares’ duration. Nonetheless, knowledge about the underlying “true” process (i.e., the dominating trend) is desirable in many decision-making situations and helps with anomaly detection from flaring profiles.
- The observations for a given entity are time series.The temporal structure is intrinsic to the dataset, and observations collected at different times are not independent samples. For example, the adjacent months’ observations are typically strongly correlated, while the distant months (such as five years apart) might be weakly associated.
- A probabilistic model is required.When inferring the latent process, a posterior distribution of probable functions is preferable over one “best” function (for instance, the best gradient boosting regressor or the best neural network classifier under a certain type of performance measure).
- A generic framework that embraces automation is beneficial.With more than 200 companies and 500 producing fields in North Dakota, Bayesian nonparametric models are more advantageous than parametric techniques for automated insights extraction, e.g., computing every entity’s KPIs based on the inference results. In a parametric setting, each entity needs its own form of parametric model and the underlying implications could be contrasting, which poses challenges to the development of automation pipelines.
4.2. Use Cases of Negative Binomial Model
- and for the most recent month can be estimated via training Model 6 with the latest VIIRS observations. A comparison study can be conducted by comparing the parameter estimates with those from earlier times, in light of uncertainties characterized by the corresponding credible intervals. Concerning the example in Section 3.2.1, the inference results can be compared with either August/September 2018 or October 2016/2017. From the study, it helps answer questions such as whether more fields with huge flaring magnitude are identified (indicated by a smaller ), or if there are more detected flares on average (indicated by a larger ).
- Following the model training process, it is advisable to carry out the posterior predictive checks to identify any discrepancies between the raw observations and simulations, the results of which are exhibited in Figure 17 and Figure 18. The fields that show large deviations from the simulated observations, especially those on the far tail (e.g., ), are worth further investigation. For instance, to inspect whether the “anomalies” in each month are random fields from the population or almost never change for years. Knowledge is acquired regarding how the grouping of fields behave.
4.3. GMM for Clustering Applications
4.4. Warnings/Limitations Regarding Inconsistencies Discovered in Company Level Data
5. Conclusions
- Gaussian processes are proved to be very successful in inferring the latent process from flaring time series. They act as a generic framework for tackling the tasks including demonstrating field flaring approaches, evaluating the progress in achieving the goals of the North Dakota regulatory policy (Order 24665), and predicting the state reported volumes.
- The VIIRS nighttime observations serve as an important source of information for benchmarking and evaluating flaring performance. However, when the flaring magnitudes are small (e.g., many sporadic flares exist), the satellite estimation might be affected by the truncation effects, characterized by the distinctive scale factors between the NDIC and VIIRS reporting.
- From the perspective of distribution approximations, the negative binomial and Gaussian mixture models competently summarize the fields’ flare count and flared volume, respectively. The learned parameters are interpretable and insightful for the decision-making process.
- A nearest-neighbor-based approach for company level volume allocation and analysis is introduced. The workflow is tested with real data and potential disagreement between the company reporting and remote sensing interpretations are found. To improve the confidence and accuracy when delivering such findings, better resolution remote sensing data are desired when multiple companies have sub-pixel combustion sources that are close to each other.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Srivastava, U.; Oonk, D.; Lange, I.; Bazilian, M. Distributional Impacts of the North Dakota Gas Flaring Policy. Electr. J. 2019, 32, 106630. [Google Scholar] [CrossRef]
- World Bank. Global Gas Flaring Reduction Partnership (GGFR) Flaring Data. Available online: https://www.worldbank.org/en/programs/gasflaringreduction#7 (accessed on 25 December 2020).
- EIA. Natural Gas Vented and Flared. Available online: https://www.eia.gov/dnav/ng/ng_prod_sum_a_EPG0_VGV_mmcf_a.htm (accessed on 25 December 2020).
- Mapsof.Net. Where Is North Dakota Located. Available online: https://www.mapsof.net/north-dakota/where-is-north-dakota-located (accessed on 25 December 2020).
- Elvidge, C.D.; Zhizhin, M.N.; Hsu, F.C.; Baugh, K. VIIRS Nightfire: Satellite Pyrometry at Night. Remote Sens. 2013, 5, 4423–4449. [Google Scholar] [CrossRef]
- Elvidge, C.D.; Baugh, K.; Zhizhin, M.N.; Hsu, F.C.; Ghosh, T. Supporting International Efforts for Detecting Illegal Fishing and Gas Flaring Using VIIRS. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 2802–2805. [Google Scholar] [CrossRef]
- Elvidge, C.D.; Zhizhin, M.N.; Baugh, K.; Hsu, F.C.; Ghosh, T. Methods for Global Survey of Natural Gas Flaring from Visible Infrared Imaging Radiometer Suite Data. Energies 2015, 9, 14. [Google Scholar] [CrossRef]
- Cedigaz. Annual Gas Indicators by Country. Available online: https://www.cedigaz.org/databases/ (accessed on 25 December 2020).
- Elvidge, C.D.; Zhizhin, M.N.; Baugh, K.; Hsu, F.; Ghosh, T. Extending Nighttime Combustion Source Detection Limits with Short Wavelength VIIRS Data. Remote Sens. 2019, 11, 395. [Google Scholar] [CrossRef]
- NDIC. Monthly Production Report Index. Available online: https://www.dmr.nd.gov/oilgas/mprindex.asp (accessed on 25 December 2020).
- NDIC. North Dakota Industrial Commission Order 24665 Policy/Guidance Version 041718. Available online: https://www.dmr.nd.gov/oilgas/GuidancePolicyNorthDakotaIndustrialCommissionorder24665.pdf (accessed on 25 December 2020).
- Rudin, C. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nat. Mach. Intell. 2019, 1, 206–215. [Google Scholar] [CrossRef]
- NDIC. Oil and Gas: ArcIMS Viewer. Available online: https://www.dmr.nd.gov/OaGIMS/viewer.htm (accessed on 25 December 2020).
- Jordahl, K.; den Bossche, J.V.; Fleischmann, M.; Wasserman, J.; McBride, J.; Gerard, J.; Tratner, J.; Perry, M.; Badaracco, A.G.; Farmer, C.; et al. Geopandas/geopandas: V0.8.1. Available online: https://zenodo.org/record/3946761#.YD7aJmhKh6s (accessed on 25 December 2020).
- Betancourt, M. Conditional Probability Theory (For Scientists and Engineers). Available online: https://betanalpha.github.io/assets/case_studies/conditional_probability_theory.html (accessed on 25 December 2020).
- Andrieu, C.; de Freitas, N.; Doucet, A.; Jordan, M.I. An Introduction to MCMC for Machine Learning. Mach. Learn. 2003, 50, 5–43. [Google Scholar] [CrossRef]
- Duane, S.; Kennedy, A.D.; Pendleton, B.J.; Roweth, D. Hybrid Monte Carlo. Phys. Lett. B 1987, 195, 216–222. [Google Scholar] [CrossRef]
- Hoffman, M.D.; Gelman, A. The No-U-Turn Sampler: Adaptively Setting Path Lengths in Hamiltonian Monte Carlo. J. Mach. Learn. Res. 2014, 15, 1593–1623. [Google Scholar]
- Salvatier, J.; Wiecki, T.V.; Fonnesbeck, C. Probabilistic Programming in Python Using PyMC3. PeerJ Comput. Sci. 2016, 2. [Google Scholar] [CrossRef]
- Deisenroth, M.P.; Turner, R.D.; Huber, M.F.; Hanebeck, U.D.; Rasmussen, C.E. Robust Filtering and Smoothing with Gaussian Processes. IEEE Trans. Autom. Control 2012, 57, 1865–1871. [Google Scholar] [CrossRef]
- Roberts, S.; Osborne, M.; Ebden, M.; Reece, S.; Gibson, N.; Aigrain, S. Gaussian Processes for Time-series Modelling. Philos. Trans. R. Soc. A 2013, 371. [Google Scholar] [CrossRef] [PubMed]
- MacKay, D.J.C. Introduction to Gaussian processes. NATO ASI Ser. F Comput. Syst. Sci. 1998, 168, 133–166. [Google Scholar]
- Alexeyev, A.; Ostadhassan, M.; Mohammed, R.A.; Bubach, B.; Khatibi, S.; Li, C.; Kong, L. Well Log Based Geomechanical and Petrophysical Analysis of the Bakken Formation. In Proceedings of the 51st U.S. Rock Mechanics/Geomechanics Symposium; San Francisco, CA, USA, 25–28 June 2017, ARMA-2017-0942; American Rock Mechanics Association: San Francisco, CA, USA, 2017. [Google Scholar]
- Watanabe, S. Asymptotic Equivalence of Bayes Cross Validation and Widely Applicable Information Criterion in Singular Learning Theory. J. Mach. Learn. Res. 2010, 11, 3571–3594. [Google Scholar]
- McElreath, R. Statistical Rethinking: A Bayesian Course with Examples in R and Stan, 2nd ed.; Chapman & Hall/CRC: Boca Raton, FL, USA, 2020. [Google Scholar]
- U.S. Department of Energy. Natural Gas Flaring and Venting: State and Federal Regulatory Overview, Trends, and Impacts. Available online: https://www.energy.gov/sites/prod/files/2019/08/f65/NaturalGasFlaringandVentingReport.pdf (accessed on 25 December 2020).
- Canadian Association of Petroleum Producers. Estimation of Flaring and Venting Volumes from Upstream Oil and Gas Facilities. Available online: http://www.oilandgasbmps.org/docs/GEN23-techniquestomeasureupstreamflaringandventing.pdf (accessed on 25 December 2020).


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Variable | Point Estimate | 90% Credible Interval |
|---|---|---|---|
| Intensity | 1.005 | (0.814, 1.200) | |
| Diversity | 0.168 | (0.135, 0.202) |
| Numbering | Target of Modeling | Page |
|---|---|---|
| Model 3 | VIIRS detection count as time series | 6 |
| Model 4 | Scale factor between VIIRS and NDIC as time series | 9 |
| Model 6 | VIIRS detection count distribution for fields | 15 |
| Model 8 | VIIRS volume distribution for fields | 19 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, R.; Miskimins, J.L.; Zhizhin, M. Learning from Nighttime Observations of Gas Flaring in North Dakota for Better Decision and Policy Making. Remote Sens. 2021, 13, 941. https://doi.org/10.3390/rs13050941
Lu R, Miskimins JL, Zhizhin M. Learning from Nighttime Observations of Gas Flaring in North Dakota for Better Decision and Policy Making. Remote Sensing. 2021; 13(5):941. https://doi.org/10.3390/rs13050941
Chicago/Turabian StyleLu, Rong, Jennifer L. Miskimins, and Mikhail Zhizhin. 2021. "Learning from Nighttime Observations of Gas Flaring in North Dakota for Better Decision and Policy Making" Remote Sensing 13, no. 5: 941. https://doi.org/10.3390/rs13050941
APA StyleLu, R., Miskimins, J. L., & Zhizhin, M. (2021). Learning from Nighttime Observations of Gas Flaring in North Dakota for Better Decision and Policy Making. Remote Sensing, 13(5), 941. https://doi.org/10.3390/rs13050941