
MultEYE: Monitoring System for Real-Time Vehicle Detection, Tracking and Speed Estimation from UAV Imagery on Edge-Computing Platforms



Abstract
:1. Introduction
2. Related Work
2.1. State-of-the-Art Semantic Segmentation
2.2. State-of-the-Art Object Detection
2.3. Multi-Task Learning
2.4. Multi-Object Tracking
2.5. Vehicle Speed Estimation
3. Methodology
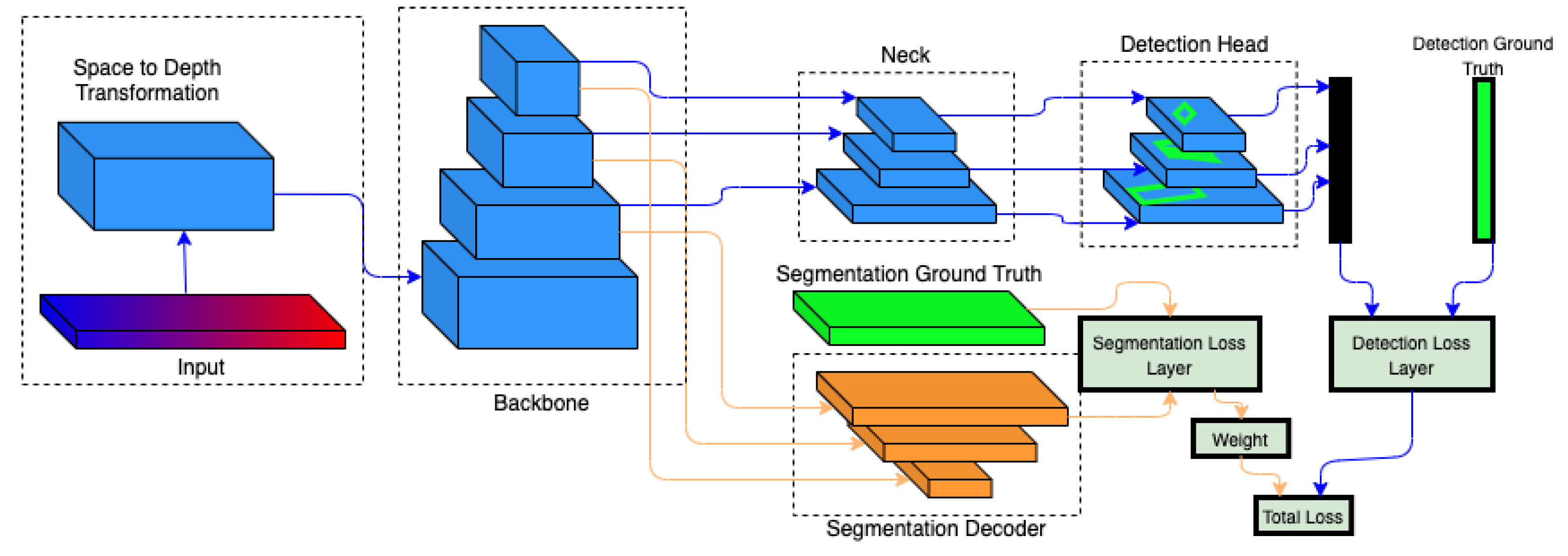
3.1. System Design
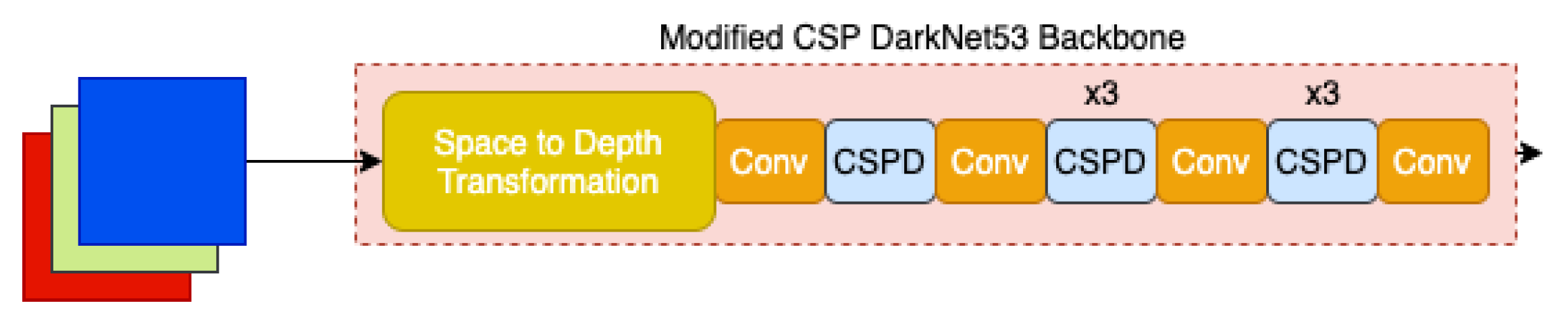
3.1.1. Vehicle Detection Architecture
Backbone
Semantic Segmentation Head
- Two additional up-sampling bottleneck modules were implemented in the decoder (Table 2, bottlenecks 4.1 and 4.2) to compensate for the increase in the latent space dimensionality due to the lack of dilated convolutions in the CPSDarknet53 (Lite) backbone.
- Three skip-connections were implemented to link the backbone to the outputs of bottlenecks 4.0, 4.2, and 5.0, respectively, and to ease the learning of smaller scale features, similar as to the ones used in UNet [39].
Vehicle Detection Head
Vehicle Detection Loss
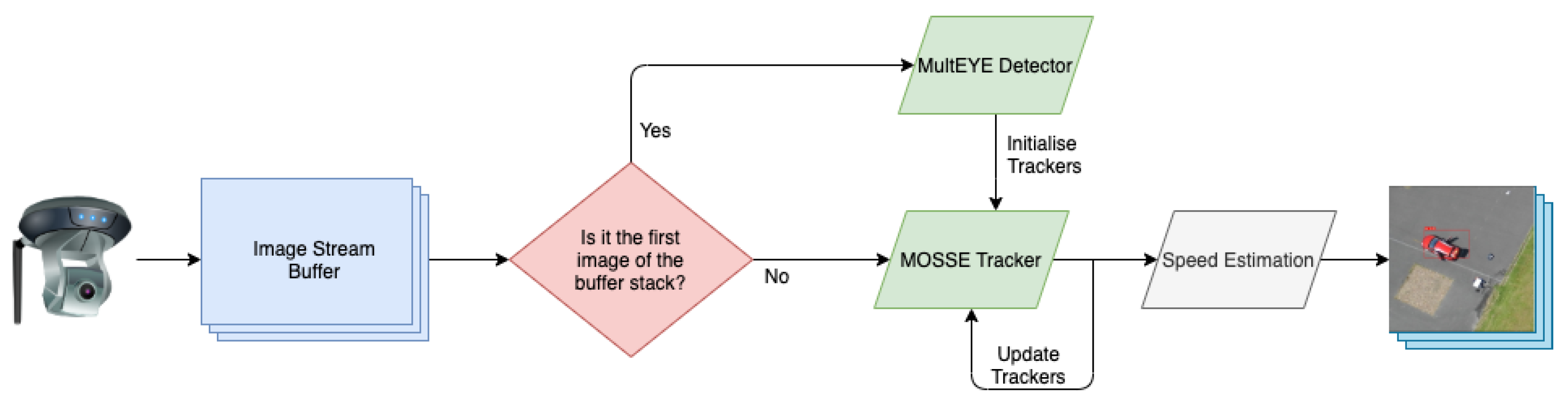
3.1.2. Vehicle Tracking—Minimum Output Sum of Squared Error (MOSSE)
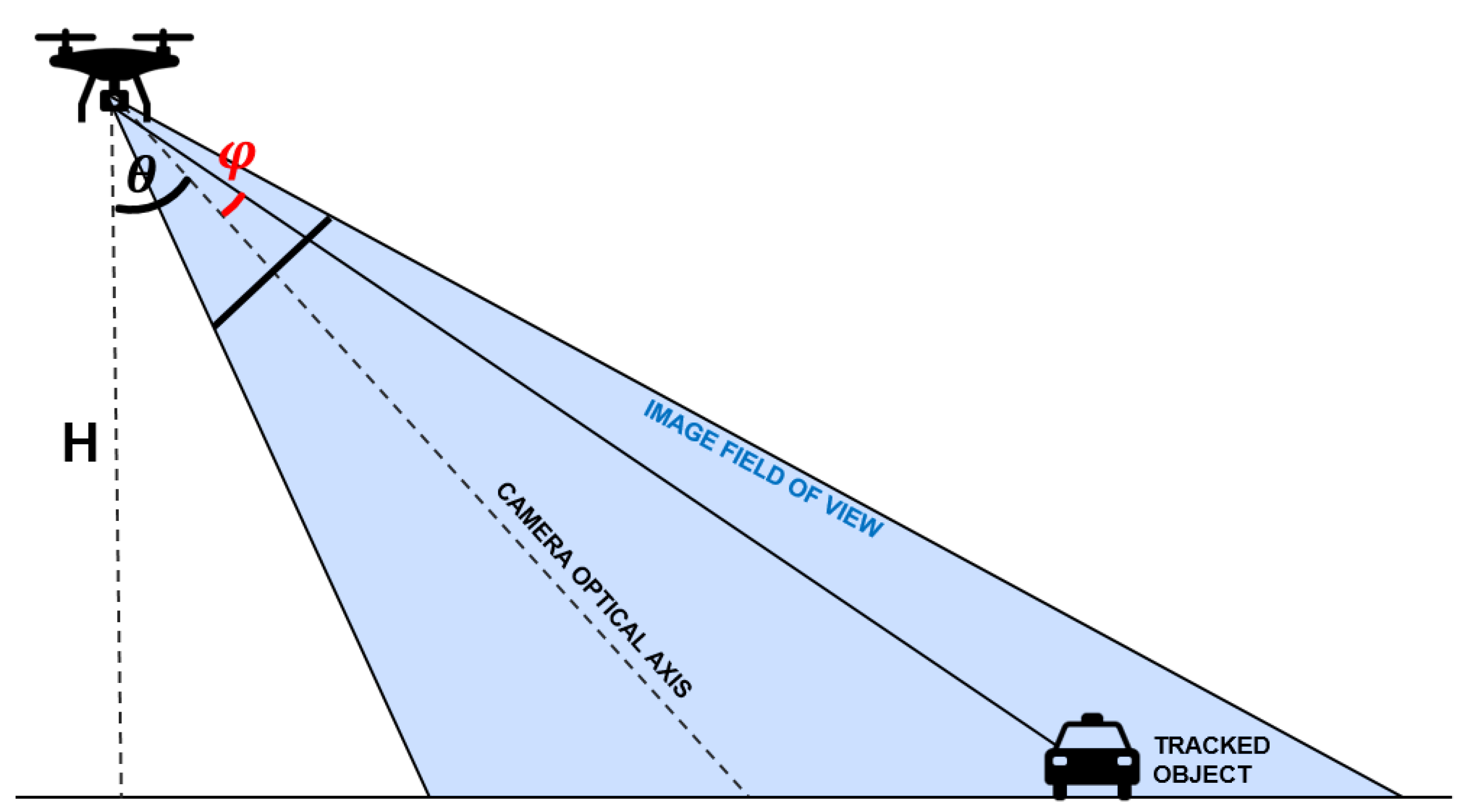
3.1.3. Speed Estimation
3.2. Data
- Altitude: images needed to be captured between 20 m and 150 m flight height to mimic UAV acquisitions [77].
- Number of Classes: the higher the number of classes, the greater the contextual awareness the object detector could learn. A minimum of five annotated classes was, therefore, needed. This eliminated datasets with only segmented road and/or buildings.
- Viewing Angle: to ensure drivers safety, UAV’s are currently not allowed to fly directly over the road but only alongside roads [77]. This essentially rendered all orthographic-only image datasets unusable to our application. Only images depicting the scene in a rough isometric view would be used.
3.2.1. Vehicle Detection and Segmentation Dataset
3.2.2. Vehicle Tracking and Speed Estimation Dataset
3.3. Experiments
3.3.1. Vehicle Detection
3.3.2. Vehicle Tracking and Speed Estimation
3.3.3. Inference on Jetson Xavier NX
4. Results & Discussion
4.1. Vehicle Detection
4.2. Vehicle Tracking
4.3. Speed Estimation
4.4. Inference on Jetson Xavier NX
4.4.1. Vehicle Detection Inference
4.4.2. Complete Pipeline Inference
4.4.3. Streaming Optimization
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Gardner, M.P. Highway Traffic Monitoring; Technical Report; A2B08; Committee on Highway Traffic Monitoring Chairman; South Dakota Department of Transportation: Pierre, SD, USA, 2000. [Google Scholar]
- Frank, H. Expanded Traffic-Cam System in Monroe County Will Cost PennDOT 4.3M. Available online: http://www.poconorecord.com/apps/pbcs.dll/articlAID=/20130401/NEWS/1010402/-1/NEWS (accessed on 27 July 2020).
- Maimaitijiang, M.; Sagan, V.; Sidike, P.; Daloye, A.M.; Erkbol, H.; Fritschi, F.B. Crop Monitoring Using Satellite/UAV Data Fusion and Machine Learning. Remote Sens. 2020, 12, 1357. [Google Scholar] [CrossRef]
- Raeva, P.L.; Šedina, J.; Dlesk, A. Monitoring of crop fields using multispectral and thermal imagery from UAV. Eur. J. Remote Sens. 2019, 52, 192–201. [Google Scholar] [CrossRef] [Green Version]
- Feng, X.; Li, P. A Tree Species Mapping Method from UAV Images over Urban Area Using Similarity in Tree-Crown Object Histograms. Remote Sens. 2019, 11, 1982. [Google Scholar] [CrossRef] [Green Version]
- Wu, X.; Shen, X.; Cao, L.; Wang, G.; Cao, F. Assessment of individual tree detection and canopy cover estimation using unmanned aerial vehicle based light detection and ranging (UAV-LiDAR) data in planted forests. Remote Sens. 2019, 11, 908. [Google Scholar] [CrossRef] [Green Version]
- Noor, N.M.; Abdullah, A.; Hashim, M. Remote sensing UAV/drones and its applications for urban areas: A review. IOP Conf. Ser. Earth Environ. Sci. 2018, 169, 012003. [Google Scholar] [CrossRef]
- Nex, F.; Duarte, D.; Tonolo, F.G.; Kerle, N. Structural Building Damage Detection with Deep Learning: Assessment of a State-of-the-Art CNN in Operational Conditions. Remote Sens. 2019, 11, 2765. [Google Scholar] [CrossRef] [Green Version]
- Zhang, C.; Elaksher, A. An Unmanned Aerial Vehicle-Based Imaging System for 3D Measurement of Unpaved Road Surface Distresses. Comput. Aided Civ. Infrastruct. Eng. 2012, 27, 118–129. [Google Scholar] [CrossRef]
- Tan, Y.; Li, Y. UAV Photogrammetry-Based 3D Road Distress Detection. ISPRS Int. J. GeoInf. 2019, 8, 409. [Google Scholar] [CrossRef] [Green Version]
- Chen, S.; Laefer, D.F.; Mangina, E.; Zolanvari, S.M.I.; Byrne, J. UAV Bridge Inspection through Evaluated 3D Reconstructions. J. Bridge Eng. 2019, 24, 05019001. [Google Scholar] [CrossRef] [Green Version]
- Elloumi, M.; Dhaou, R.; Escrig, B.; Idoudi, H.; Saidane, L.A.; Fer, A. Traffic Monitoring on City Roads Using UAVs. In Proceedings of the 18th International Conference on Ad-Hoc Networks and Wireless, ADHOC-NOW, Luxembourg, 1–3 October 2019; Springer International Publishing: Basel, Switzerland, 2019; pp. 588–600. [Google Scholar]
- Stöcker, C.; Bennett, R.; Nex, F.; Gerke, M.; Zevenbergen, J. Review of the Current State of UAV Regulations. Remote Sens. 2017, 9, 459. [Google Scholar] [CrossRef] [Green Version]
- Press. Dutch Government Successfully Uses Aerialtronics Drones to Control Traffic. Available online: https://www.suasnews.com/2015/07/dutch-government-successfully-uses-aerialtronics-drones-to-control-traffic/ (accessed on 27 July 2020).
- Elloumi, M.; Dhaou, R.; Escrig, B.; Idoudi, H.; Saidane, L.A. Monitoring road traffic with a UAV-based system. In Proceedings of the IEEE Wireless Communications and Networking Conference (WCNC), Barcelona, Spain, 15–18 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–6. [Google Scholar]
- Khan, M.A.; Ectors, W.; Bellemans, T.; Janssens, D.; Wets, G. UAV-based traffic analysis: A universal guiding framework based on literature survey. Transp. Res. Procedia 2017, 22, 541–550. [Google Scholar] [CrossRef]
- Niu, H.; Gonzalez-Prelcic, N.; Heath, R.W. A UAV-based traffic monitoring system—Invited paper. In Proceedings of the IEEE 87th Vehicular Technology Conference (VTC Spring), Porto, Portugal, 3–6 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–5. [Google Scholar]
- Kriegel, H.P.; Schubert, E.; Zimek, A. The (black) art of runtime evaluation: Are we comparing algorithms or implementations? Knowl. Inf. Syst. 2017, 52, 341–378. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 2999–3007. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and PATTERN Recognition, Venice, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 779–788. [Google Scholar]
- Kwan, C.; Chou, B.; Yang, J.; Rangamani, A.; Tran, T.; Zhang, J.; Etienne-Cummings, R. Deep Learning-Based Target Tracking and Classification for Low Quality Videos Using Coded Aperture Camera. Sensors 2019, 19, 3702. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, J.; Dai, Y.; Li, C.; Shu, J.; Li, D.; Yang, T.; Lu, Z. Visual Detail Augmented Mapping for Small Aerial Target Detection. Remote Sens. 2018, 11, 14. [Google Scholar] [CrossRef] [Green Version]
- Caruana, R. Multitask learning. Mach. Learn. 1997, 28, 41–75. [Google Scholar] [CrossRef]
- Hashimoto, K.; Xiong, C.; Tsuruoka, Y.; Socher, R. A joint many-task model: Growing a neural network for multiple nlp tasks. arXiv 2016, arXiv:1611.01587. [Google Scholar]
- McCann, B.; Keskar, N.S.; Xiong, C.; Socher, R. The natural language decathlon: Multitask learning as question answering. arXiv 2018, arXiv:1806.08730. [Google Scholar]
- Teichmann, M.; Weber, M.; Zöllner, M.; Cipolla, R.; Urtasun, R. MultiNet: Real-time Joint Semantic Reasoning for Autonomous Driving. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1013–1020. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. Enet: A deep neural network architecture for real-time semantic segmentation. arXiv 2016, arXiv:1606.02147. [Google Scholar]
- Forsyth, D.A.; Ponce, J. Computer Vision: A Modern Approach; Prentice Hall: Upper Sadle River, NJ, USA, 2003; pp. 1–693. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 565–571. [Google Scholar]
- Kim, J.; Park, C. End-to-end ego lane estimation based on sequential transfer learning for self-driving cars. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1194–1202. [Google Scholar]
- Ullah, M.; Mohammed, A.; Alaya Cheikh, F. Pednet: A spatio-temporal deep convolutional neural network for pedestrian segmentation. J. Imaging 2018, 4, 107. [Google Scholar] [CrossRef] [Green Version]
- Ammar, S.; Bouwmans, T.; Zaghden, N.; Neji, M. Moving objects segmentation based on deepsphere in video surveillance. In Proceedings of the 14th International Symposium on Visual Computing, ISVC 2019, Lake Tahoe, NV, USA, 7–9 October 2019; Springer: Basel, Switzerland, 2019. Part II. pp. 307–319. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 3431–3440. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor segmentation and support inference from rgbd images. In Proceedings of the 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Springer: Berlin/Heidelberg, Germany, 2012. Part V. pp. 746–760. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the 18th International Conference, Munich, Germany, 5–9 October 2015; Springer: Basel, Switzerland, 2015. Part III. pp. 234–241. [Google Scholar]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. Refinenet: Multi-path refinement networks for high-resolution semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 5168–5177. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Wang, P.; Chen, P.; Yuan, Y.; Liu, D.; Huang, Z.; Hou, X.; Cottrell, G. Understanding convolution for semantic segmentation. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1451–1460. [Google Scholar]
- Yang, M.; Yu, K.; Zhang, C.; Li, Z.; Yang, K. Denseaspp for semantic segmentation in street scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 3684–3692. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1440–1448. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 10778–10787. [Google Scholar]
- Yang, M.Y.; Liao, W.; Li, X.; Cao, Y.; Rosenhahn, B. Vehicle detection in aerial images. Photogramm. Eng. Remote Sens. 2019, 85, 297–304. [Google Scholar] [CrossRef] [Green Version]
- Sommer, L.W.; Schuchert, T.; Beyerer, J. Fast deep vehicle detection in aerial images. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 311–319. [Google Scholar]
- Deng, Z.; Sun, H.; Zhou, S.; Zhao, J.; Zou, H. Toward fast and accurate vehicle detection in aerial images using coupled region-based convolutional neural networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3652–3664. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016. Part I. pp. 21–37. [Google Scholar]
- Olshausen, B.A.; Field, D.J. Emergence of simple-cell receptive field properties by learning a sparse code for natural images. Nature 1996, 381, 607–609. [Google Scholar] [CrossRef] [PubMed]
- Bell, A.J.; Sejnowski, T.J. The “independent components” of natural scenes are edge filters. Vis. Res. 1997, 37, 3327–3338. [Google Scholar] [CrossRef] [Green Version]
- Gidaris, S.; Komodakis, N. Object detection via a multi-region and semantic segmentation-aware cnn model. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1134–1142. [Google Scholar]
- Brahmbhatt, S.; Christensen, H.I.; Hays, J. StuffNet: Using ‘Stuff’to improve object detection. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Los Alamitos, CA, USA, 24–31 March 2017; IEEE Computer Society: Piscataway, NJ, USA, 2017; pp. 934–943. [Google Scholar]
- Shrivastava, A.; Gupta, A. Contextual priming and feedback for faster r-cnn. In Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016. Part I. pp. 330–348. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Lu, H.; Li, P.; Wang, D. Visual object tracking: A survey. Pattern Recognit. Artif. Intell. 2018, 31, 61–76. [Google Scholar]
- Cuevas, E.; Zaldivar, D.; Rojas, R. Kalman Filter for Vision Tracking; Technical Report August; Freie Universitat Berlin: Berlin, Germany, 2005. [Google Scholar]
- Okuma, K.; Taleghani, A.; De Freitas, N.; Little, J.J.; Lowe, D.G. A boosted particle filter: Multitarget detection and tracking. In Proceedings of the 8th European Conference on Computer Vision, Prague, Czech Republic, 11–14 May 2004; Springer: Berlin/Heidelberg, Germany, 2004. Part I. pp. 28–39. [Google Scholar]
- Bochinski, E.; Eiselein, V.; Sikora, T. High-speed tracking-by-detection without using image information. In Proceedings of the 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–6. [Google Scholar]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 3464–3468. [Google Scholar]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 3645–3649. [Google Scholar]
- Sadeghian, A.; Alahi, A.; Savarese, S. Tracking the untrackable: Learning to track multiple cues with long-term dependencies. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 300–311. [Google Scholar]
- Kart, U.; Lukezic, A.; Kristan, M.; Kamarainen, J.K.; Matas, J. Object tracking by reconstruction with view-specific discriminative correlation filters. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1339–1348. [Google Scholar]
- Nam, H.; Han, B. Learning Multi-Domain Convolutional Neural Networks for Visual Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 4293–4302. [Google Scholar]
- Held, D.; Thrun, S.; Savarese, S. Learning to track at 100 fps with deep regression networks. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 749–765. [Google Scholar]
- Bolme, D.S.; Beveridge, J.R.; Draper, B.A.; Lui, Y.M. Visual object tracking using adaptive correlation filters. In Proceedings of the IEEE Computer Society Conference on Computer Vision and PATTERN Recognition, San Francisco, CA, USA, 13–18 June 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 2544–2550. [Google Scholar]
- Schoepflin, T.N.; Dailey, D.J. Dynamic camera calibration of roadside traffic management cameras for vehicle speed estimation. IEEE Trans. Intell. Transp. Syst. 2003, 4, 90–98. [Google Scholar] [CrossRef]
- Zhiwei, H.; Yuanyuan, L.; Xueyi, Y. Models of vehicle speeds measurement with a single camera. In Proceedings of the International Conference on Computational Intelligence and Security Workshops (CISW 2007), Harbin, China, 15–19 December 2007; IEEE: Piscataway, NJ, USA, 2007; pp. 283–286. [Google Scholar]
- Li, J.; Chen, S.; Zhang, F.; Li, E.; Yang, T.; Lu, Z. An adaptive framework for multi-vehicle ground speed estimation in airborne videos. Remote Sens. 2019, 11, 1241. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.Y.; Mark Liao, H.Y.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1571–1580. [Google Scholar]
- Ridnik, T.; Lawen, H.; Noy, A.; Friedman, I. TResNet: High Performance GPU-Dedicated Architecture. arXiv 2020, arXiv:2003.13630. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 8759–8768. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schultz van Haegen, M. Model Flying Scheme. Available online: https://wetten.overheid.nl/BWBR0019147/2019-04-01 (accessed on 22 July 2020).
- Nigam, I.; Huang, C.; Ramanan, D. Ensemble knowledge transfer for semantic segmentation. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1499–1508. [Google Scholar]
- Schmidt, F. Data Set for Tracking Vehicles in Aerial Image Sequences. Available online: http://www.ipf.kit.edu/downloads_data_set_AIS_vehicle_tracking.php (accessed on 22 July 2020).
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems 25 (NIPS 2012), Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Salehi, S.S.M.; Erdogmus, D.; Gholipour, A. Tversky loss function for image segmentation using 3D fully convolutional deep networks. In Proceedings of the 8th International Workshop Machine Learning in Medical Imaging, Quebec City, QC, Canada, 10 September 2017; Springer International Publishing: Cham, Switzerland, 2017; pp. 379–387. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection Over Union: A Metric and a Loss for Bounding Box Regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 658–666. [Google Scholar]
- Bernardin, K.; Elbs, A.; Stiefelhagen, R. Multiple object tracking performance metrics and evaluation in a smart room environment. In Proceedings of the The Sixth IEEE International Workshop on Visual Surveillance (in Conjunction with ECCV), Graz, Austria, 13 May 2006; Volume 90, p. 91. [Google Scholar]
- Tan, M.; Le, Q.V. Efficientnet: Rethinking model scaling for convolutional neural networks. arXiv 2019, arXiv:1905.11946. [Google Scholar]
- Howard, A.; Sandler, M.; Chen, B.; Wang, W.; Chen, L.; Tan, M.; Chu, G.; Vasudevan, V.; Zhu, Y.; Pang, R.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 Octomber–2 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1314–1324. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1800–1807. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Grabner, H.; Grabner, M.; Bischof, H. Real-time tracking via on-line boosting. In Proceedings of the The British Machine Vision Conference, Edinburgh, Scotland, 4–7 September 2006; pp. 47–57. [Google Scholar]
- Babenko, B.; Yang, M.H.; Belongie, S. Visual tracking with online multiple instance learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 983–990. [Google Scholar]
- Kalal, Z.; Mikolajczyk, K.; Matas, J. Tracking-learning-detection. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 1409–1422. [Google Scholar] [CrossRef] [Green Version]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-speed tracking with kernelized correlation filters. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 583–596. [Google Scholar] [CrossRef] [Green Version]
- Kalal, Z.; Mikolajczyk, K.; Matas, J. Forward-backward error: Automatic detection of tracking failures. In Proceedings of the 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 2756–2759. [Google Scholar]
- Lukezic, A.; Vojir, T.; Cehovin Zajc, L.; Matas, J.; Kristan, M. Discriminative correlation filter with channel and spatial reliability. Int. J. Comput. Vis. 2018, 126, 671–688. [Google Scholar] [CrossRef] [Green Version]
- Yu, F.; Li, W.; Li, Q.; Liu, Y.; Shi, X.; Yan, J. POI: Multiple object tracking with high performance detection and appearance feature. In Proceedings of the European Conference on Computer Vision 2016 Workshops, Amsterdam, The Netherlands, 8–10 and 15–16 October 2016; Springer: Basel, Switzerland, 2016; pp. 36–42. [Google Scholar]
- Gibbs, J. Drivers Risk fines as Speed Camera Tolerances Revealed. Available online: https://www.confused.com/on-the-road/driving-law/speed-camera-tolerances (accessed on 27 July 2020).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Times Repeated | Filter Size |
|---|---|---|
| Input | 1 | - |
| Space-to-Depth | 1 | 64 |
| Conv | 1 | 128 |
| BottleneckCSP | 1 | 128 |
| Conv | 1 | 256 |
| BottleneckCSP | 3 | 256 |
| Conv | 1 | 512 |
| BottleneckCSP | 3 | 512 |
| Conv | 1 | 1024 |
| Name | Type | Output Size |
|---|---|---|
| CSPDarkNet53 (Lite) | Backbone/Encoder | |
| bottleneck4.0 | upsampling | |
| Concatenate | skip-connection from backbone | |
| bottleneck4.1 | upsampling | |
| bottleneck4.2 | upsampling | |
| Concatenate | skip-connection from backbone | |
| bottleneck4.3 | ||
| bottleneck4.4 | ||
| bottleneck5.0 | upsampling | |
| Concatenate | skip-connection from backbone | |
| bottleneck5.1 | ||
| Transposed Convolution |
| Model | Backbone | mAP@0.5% | No. of Parameters (M) | FPS |
|---|---|---|---|---|
| MultEYE | CSPDarkNet53(Lite) | 0.834 | 12.4 | 43.5 |
| YOLOv4 [28] | CSPDarkNet53 (Lite) | 0.8073 | 12.4 | 43.88 |
| CSPDarkNet53 [28] | 0.8172 | 37.3 | 31.19 | |
| EfficientNet(B1) [84] | 0.824 | 58.6 | 22.72 | |
| MobileNetV3 [85] | 0.746 | 19.13 | 41.5 | |
| MobileNetV3Small [85] | 0.694 | 11.6 | 57.13 | |
| TinyYOLOv4 (Custom) | EfficientNet (B1) [84] | 0.7082 | 27.42 | 37.2 |
| MobileNetV3 Small [85] | 0.6733 | 5.41 | 110.11 | |
| YOLOv3 [86] | Xception [87] | 0.7625 | 42.53 | 20.8 |
| SSD [52] (300 × 300) | VGG16 [88] | 0.7739 | 24.0 | 39 |
| MobileNetV3 [85] | 0.7156 | 9.6 | 59.3 | |
| Faster RCNN [19] | VGG 16 [88] | 0.7910 | 71.93 | 6.62 |
| MOTA | MOTP | Avg.Framerate (FPS) | |
|---|---|---|---|
| BOOSTING [89] | 35.92 | 44.32 | <1 |
| Multiple Instance Learning [90] | 60.4 | 64.0 | <1 |
| Kernalized Correlation Filters [92] | 80.2 | 87.8 | 8.3 |
| Tracking Learning and Detection [91] | 78.34 | 82.3 | <1 |
| MEDIANFLOW [93] | 94.73 | 63.14 | 6.6 |
| GOTURN [68] | 67.5 | 75.2 | 20.0 |
| CSRT [94] | 95.0 | 94.3 | 1.3 |
| MOSSE [69] | 90.91 | 92.11 | 227.5 |
| POI * [95] | 96.83 | 97.71 | 11.2 |
| DeepSORT [64] | 94.85 | 93.29 | 40.4 |
| Avg. Error (km/h) | |
|---|---|
| Sequence 1 | 0.85 |
| Sequence 2 | 1.03 |
| Sequence 3 | 1.43 |
| Sequence 4 | 0.71 |
| Sequence 5 | 1.25 |
| Sequence 6 | 1.52 |
| Mean Avg. Error (km/h) | 1.13 |
| Resolution | % Contribution of Detection | % Contribution of Tracking | % Contribution of Speed Estimation | Total Runtime (seconds) | FPS |
|---|---|---|---|---|---|
| 512 × 320 | 88.54 | 11.45 | ∼0 | 0.0384 | 26.04 |
| 1024 × 576 | 93.74 | 6.25 | ∼0 | 0.0704 | 14.2 |
| 2048 × 1152 | 96.8 | 3.2 | ∼0 | 0.1364 | 7.33 |
| 3072 × 1728 | 98.36 | 1.64 | ∼0 | 0.2674 | 3.74 |
| Resolution | Average FPS |
|---|---|
| 512 × 320 | 142.85 |
| 1024 × 576 | 98.03 |
| 2048 × 1152 | 59.52 |
| 3072 × 1728 | 33.04 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Balamuralidhar, N.; Tilon, S.; Nex, F. MultEYE: Monitoring System for Real-Time Vehicle Detection, Tracking and Speed Estimation from UAV Imagery on Edge-Computing Platforms. Remote Sens. 2021, 13, 573. https://doi.org/10.3390/rs13040573
Balamuralidhar N, Tilon S, Nex F. MultEYE: Monitoring System for Real-Time Vehicle Detection, Tracking and Speed Estimation from UAV Imagery on Edge-Computing Platforms. Remote Sensing. 2021; 13(4):573. https://doi.org/10.3390/rs13040573
Chicago/Turabian StyleBalamuralidhar, Navaneeth, Sofia Tilon, and Francesco Nex. 2021. "MultEYE: Monitoring System for Real-Time Vehicle Detection, Tracking and Speed Estimation from UAV Imagery on Edge-Computing Platforms" Remote Sensing 13, no. 4: 573. https://doi.org/10.3390/rs13040573
APA StyleBalamuralidhar, N., Tilon, S., & Nex, F. (2021). MultEYE: Monitoring System for Real-Time Vehicle Detection, Tracking and Speed Estimation from UAV Imagery on Edge-Computing Platforms. Remote Sensing, 13(4), 573. https://doi.org/10.3390/rs13040573