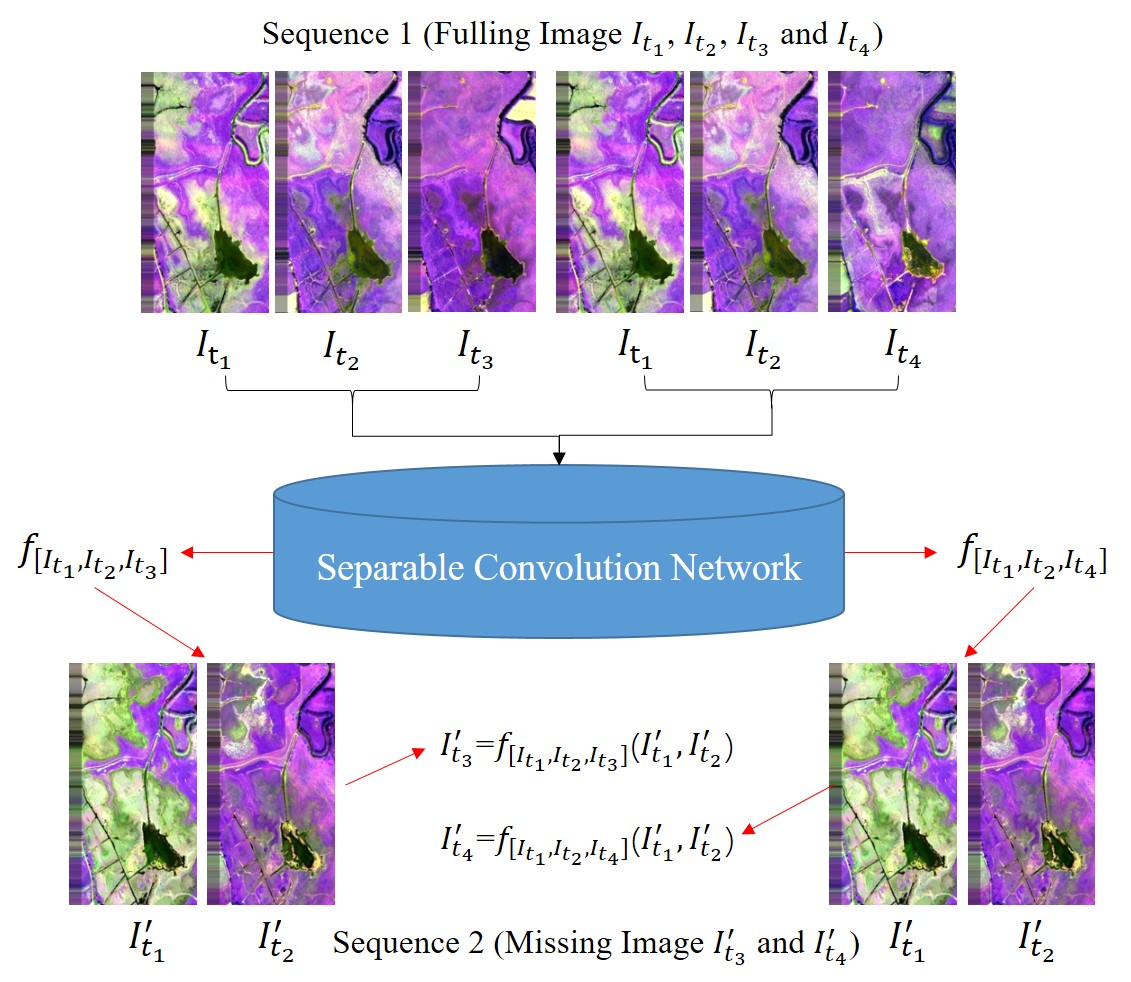
Figure 1.
Location of unmanned aerial vehicle (UAV) dataset.
Figure 1.
Location of unmanned aerial vehicle (UAV) dataset.
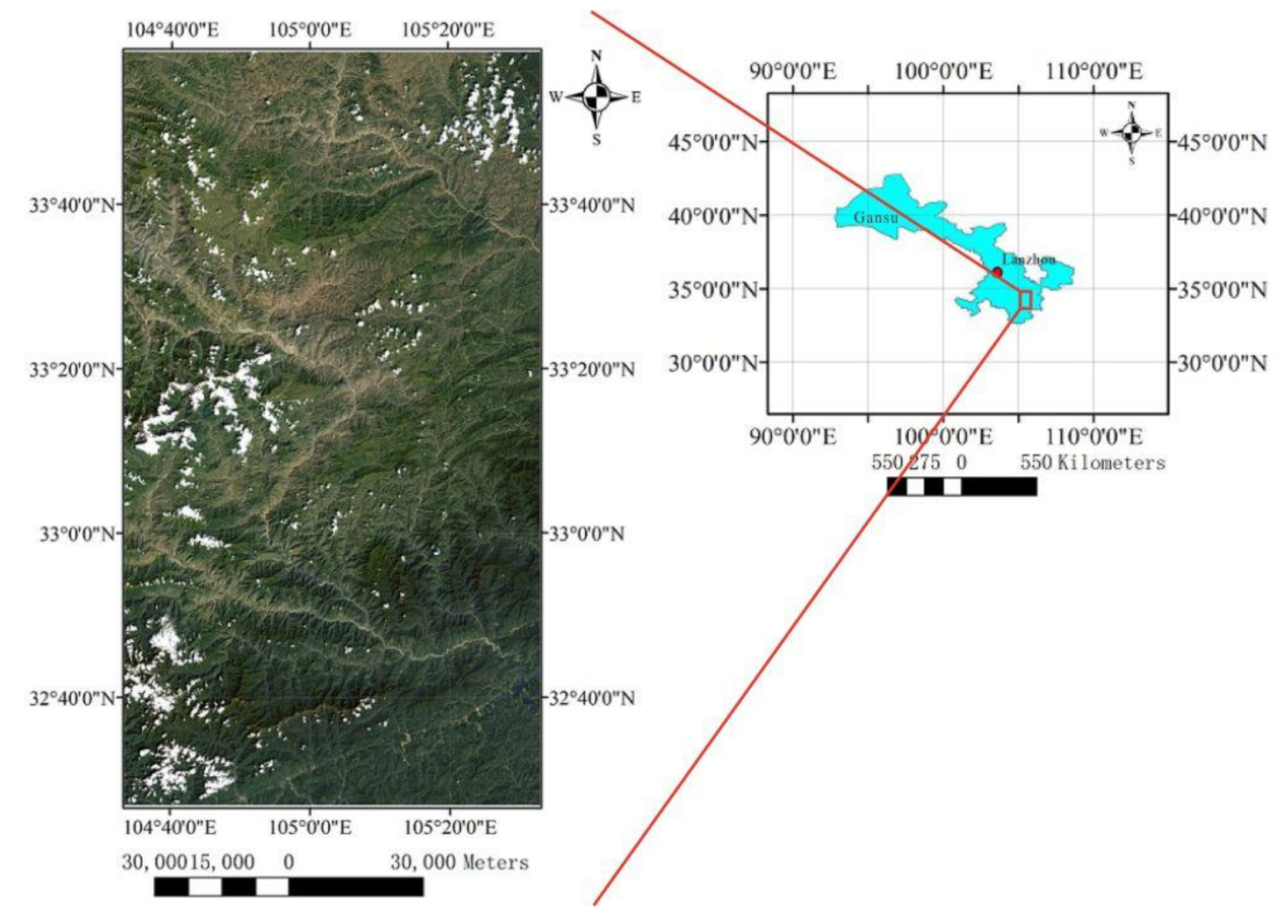
Figure 2.
Location of Landsat-8 dataset.
Figure 2.
Location of Landsat-8 dataset.
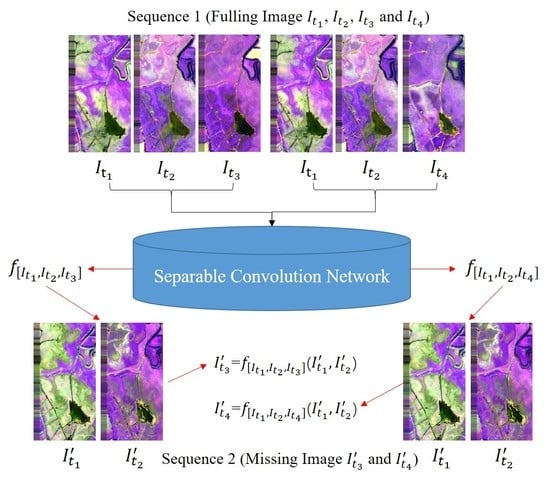
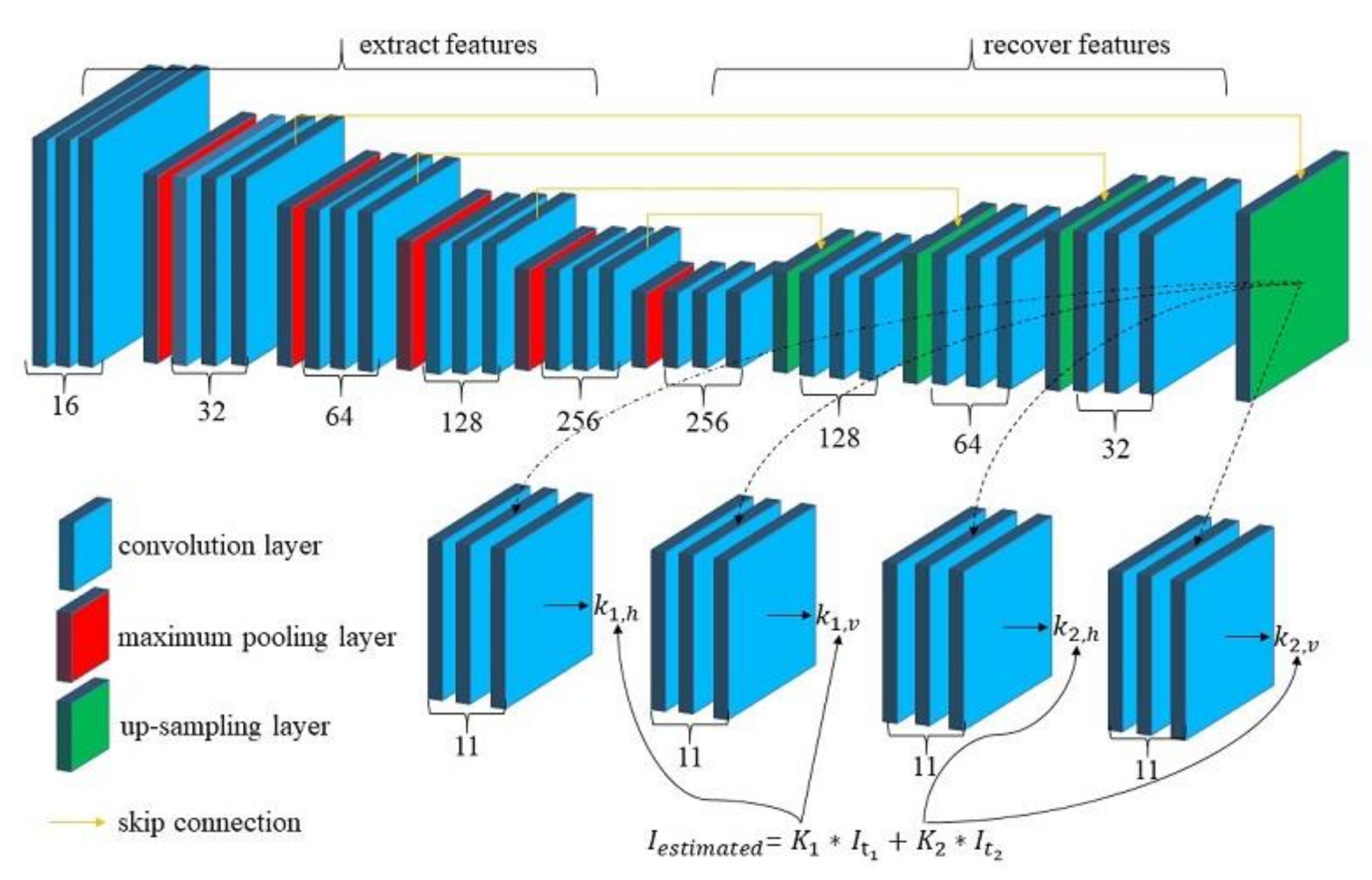
Figure 3.
Overview of our separable convolution network architecture.
Figure 3.
Overview of our separable convolution network architecture.
Figure 4.
Distribution of training, testing, and validation samples in first set of experiment: (A) unmanned aerial vehicle (UAV) and (B) Landsat-8 images; areas inside red and green box and remainder of images show distribution of training, testing, and validation samples, respectively.
Figure 4.
Distribution of training, testing, and validation samples in first set of experiment: (A) unmanned aerial vehicle (UAV) and (B) Landsat-8 images; areas inside red and green box and remainder of images show distribution of training, testing, and validation samples, respectively.
Figure 5.
Visual effect of training and testing images in second set of experiment ( and show visual effect of training image; and show visual effect of testing image).
Figure 5.
Visual effect of training and testing images in second set of experiment ( and show visual effect of training image; and show visual effect of testing image).
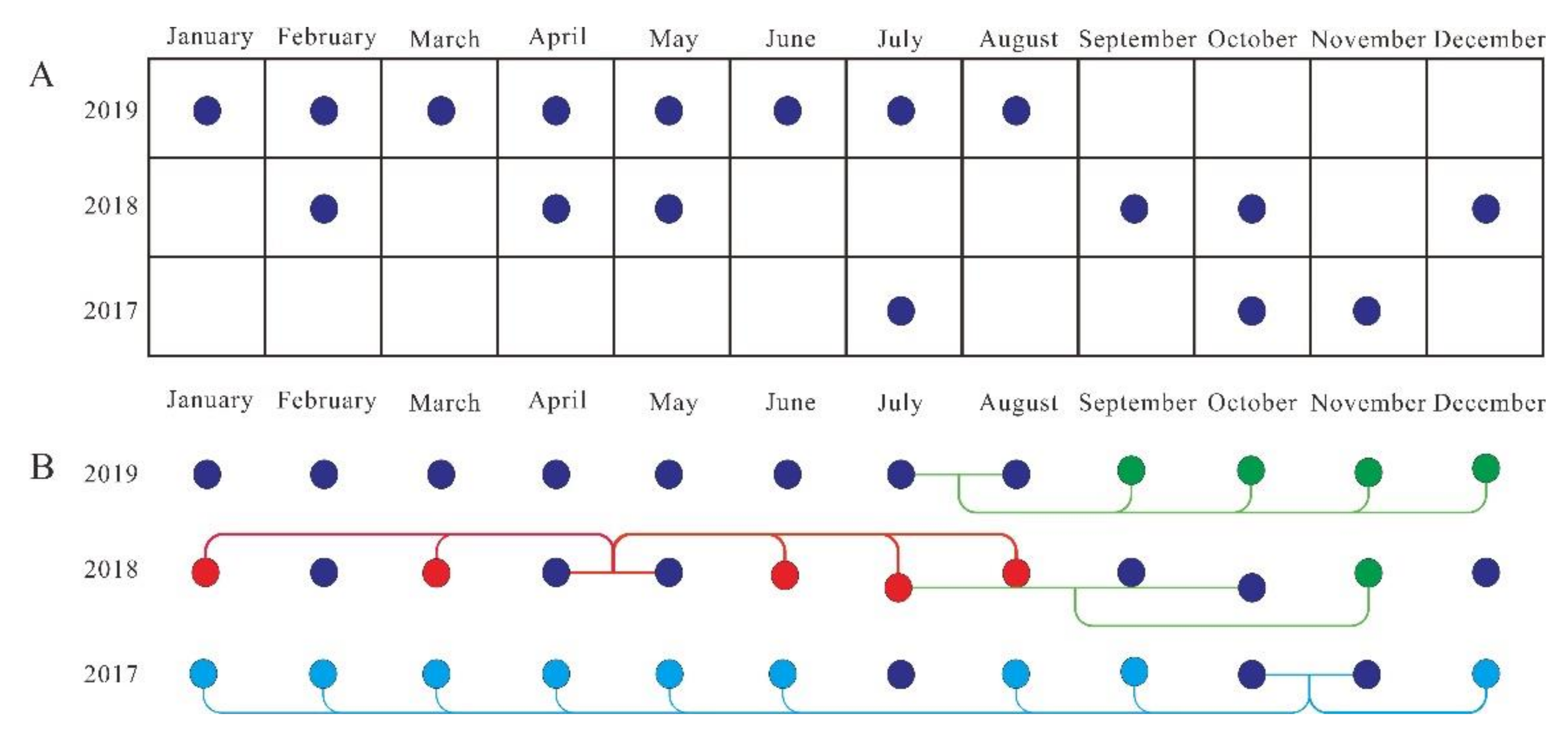
Figure 6.
Strategy for generating missing data in third set of experiment: (A) available UAV images from 2017 to 2019; (B) one generation strategy. Red, green, and cyan-blue curves show lines of first, second, and third level of interpolated result.
Figure 6.
Strategy for generating missing data in third set of experiment: (A) available UAV images from 2017 to 2019; (B) one generation strategy. Red, green, and cyan-blue curves show lines of first, second, and third level of interpolated result.
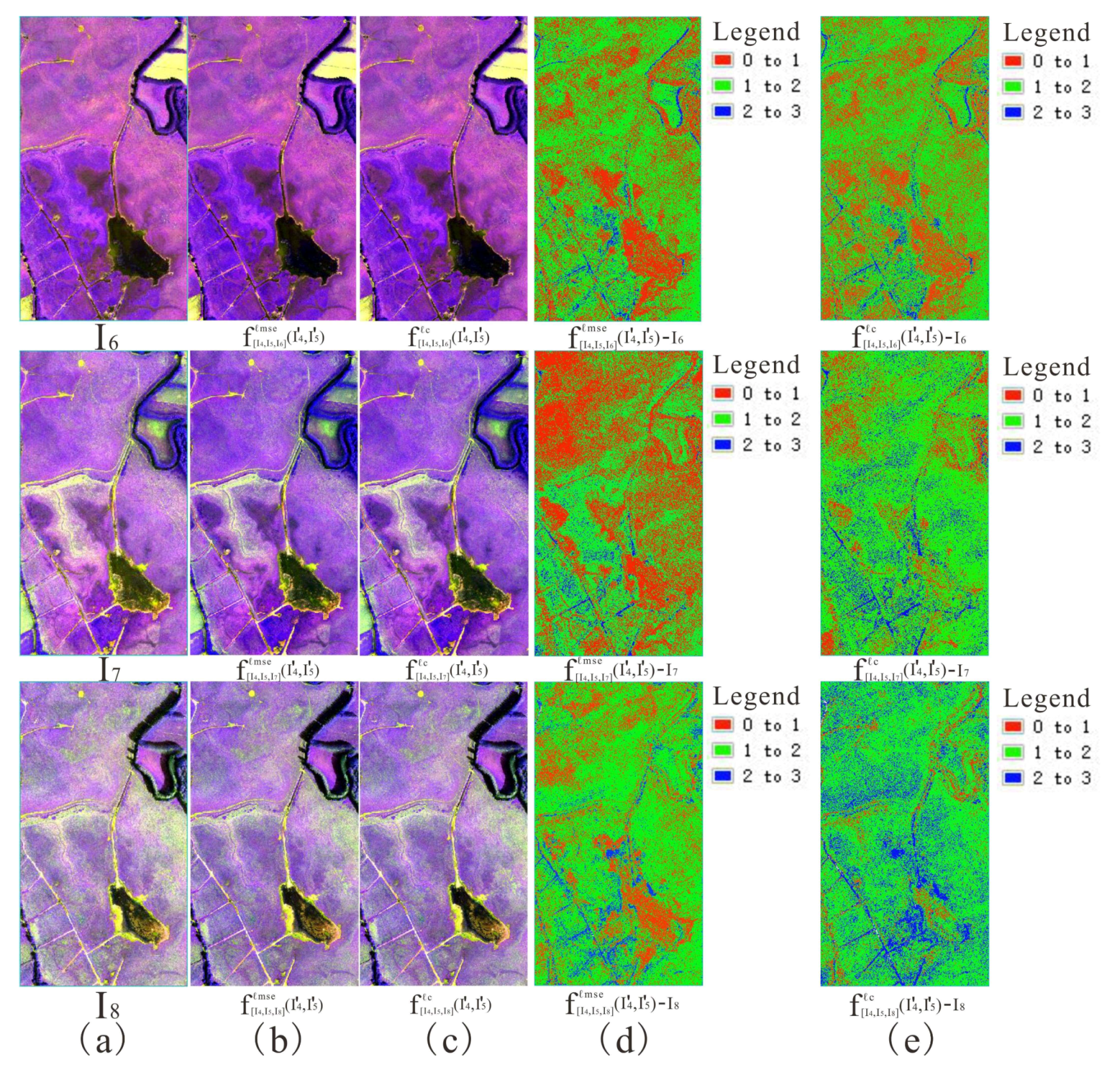
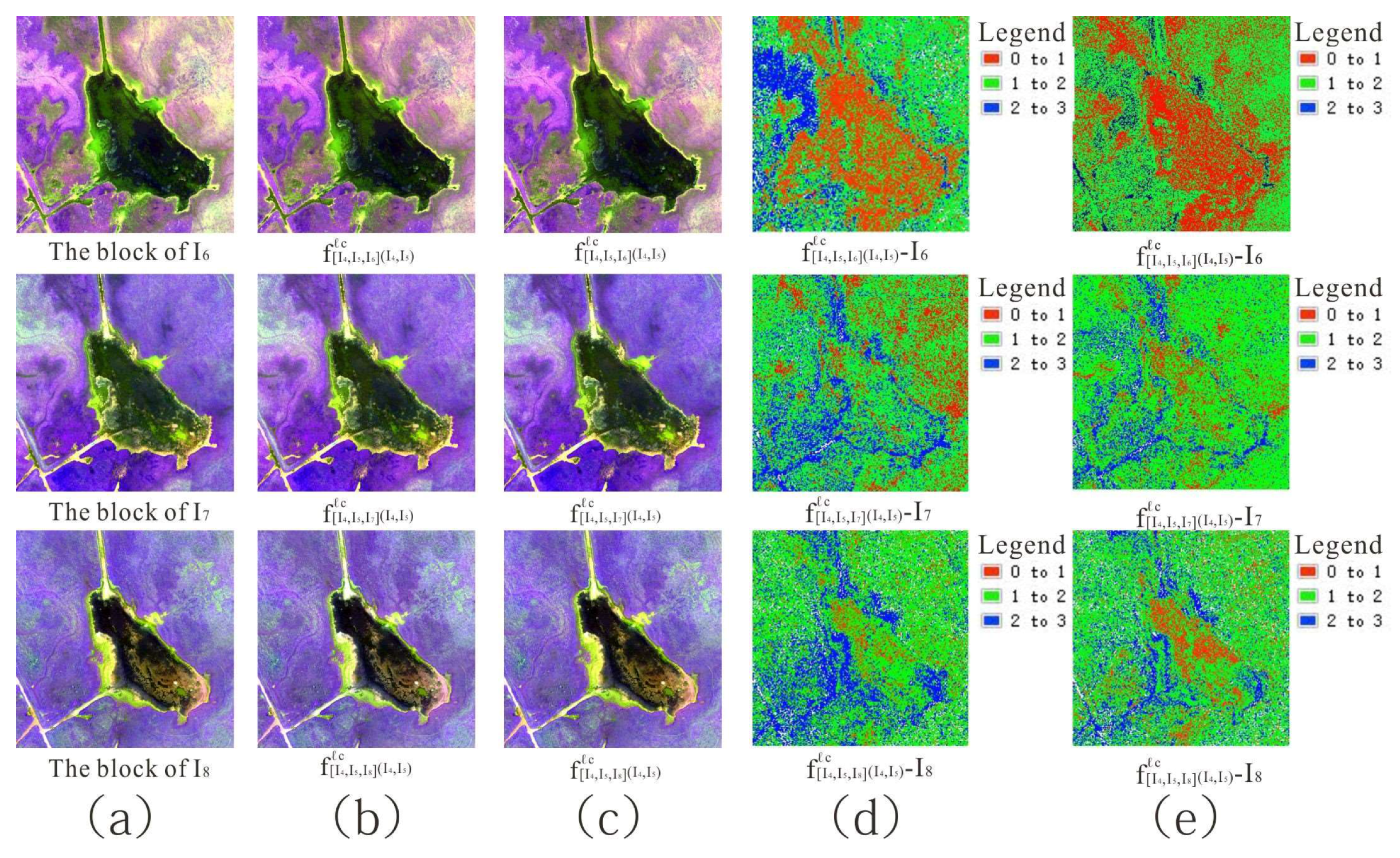
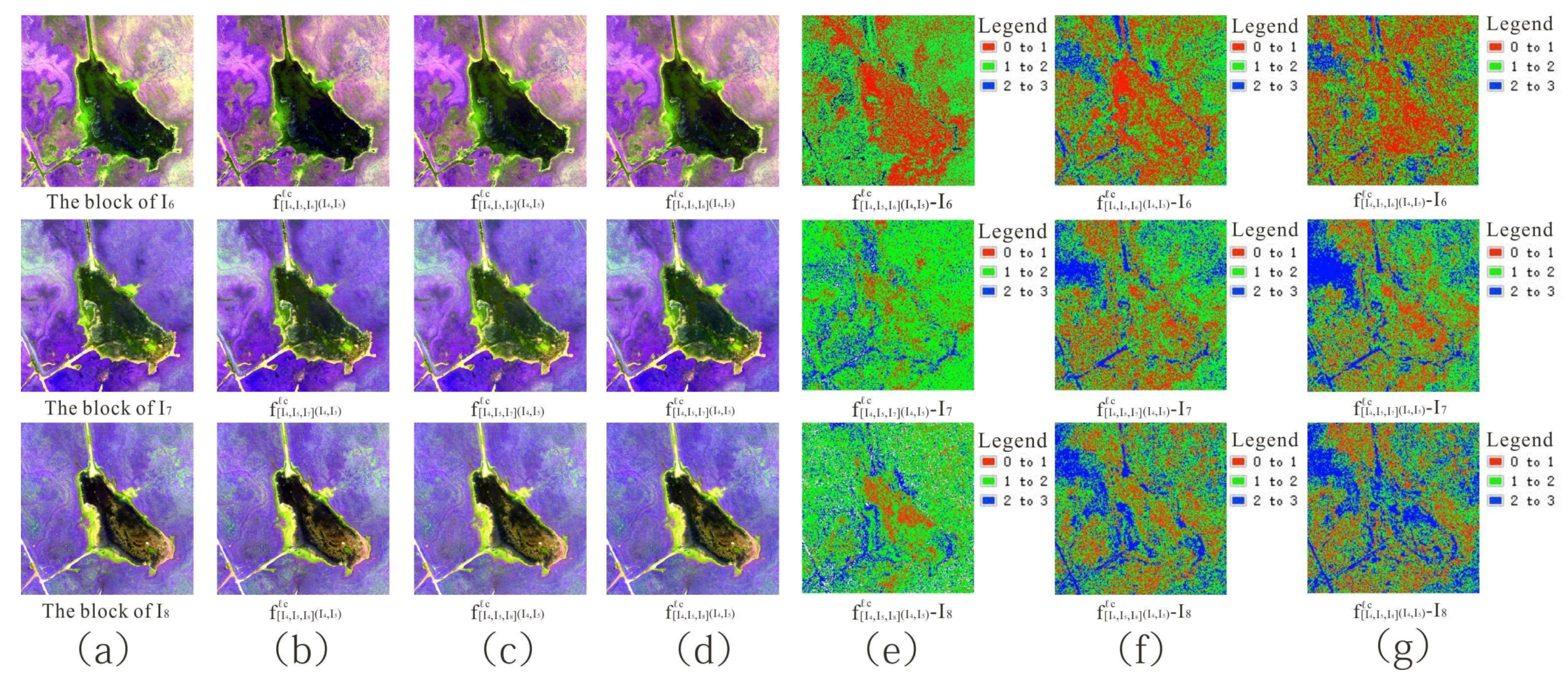
Figure 7.
Visual effect, detailed information, and pixel error between block interpolated result and reference block using (A) UAV and (B) Landsat-8 datasets with (a) initial image (b,d,f) ℓmse loss and (c,e,g) ℓc loss.
Figure 7.
Visual effect, detailed information, and pixel error between block interpolated result and reference block using (A) UAV and (B) Landsat-8 datasets with (a) initial image (b,d,f) ℓmse loss and (c,e,g) ℓc loss.
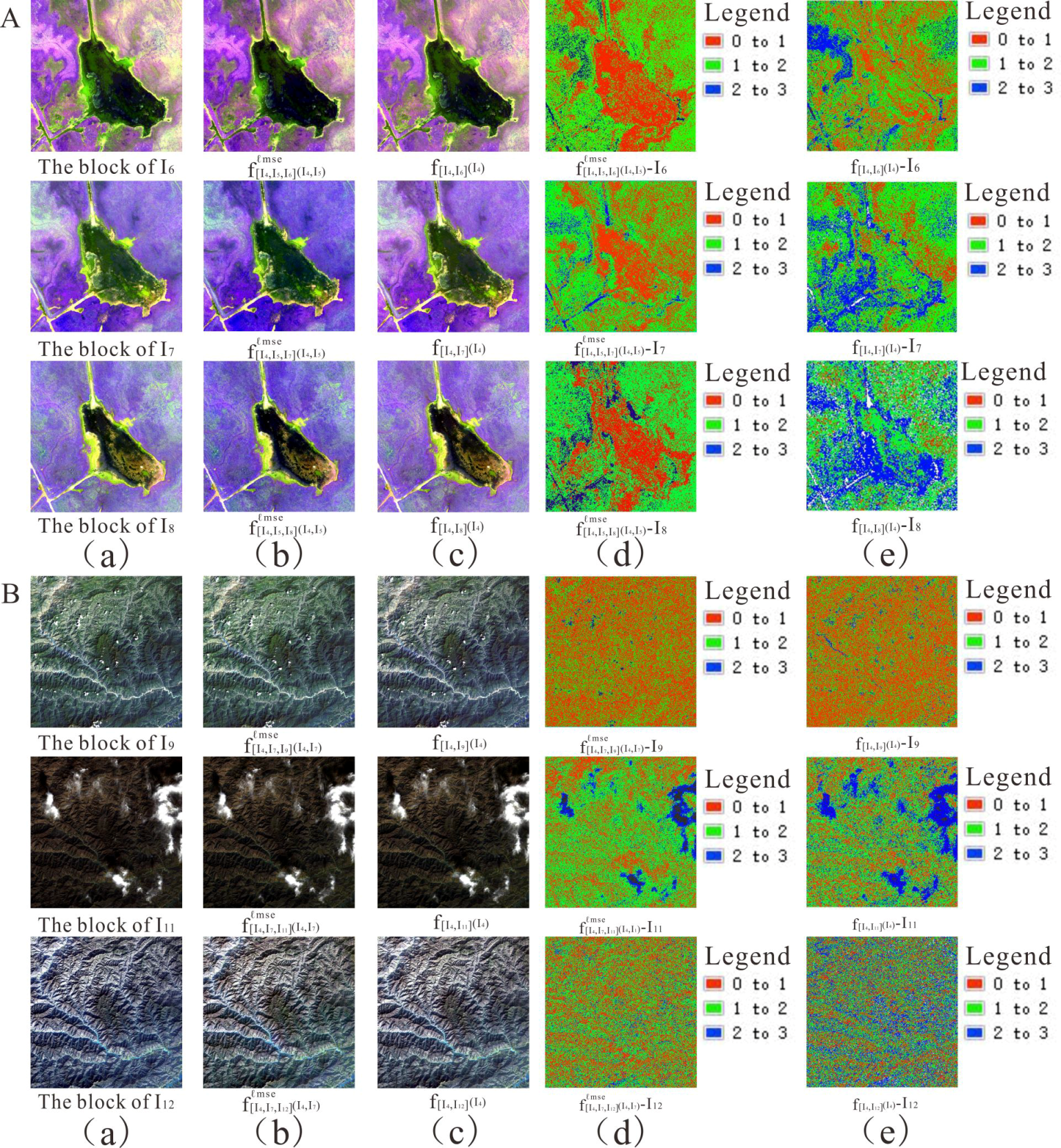
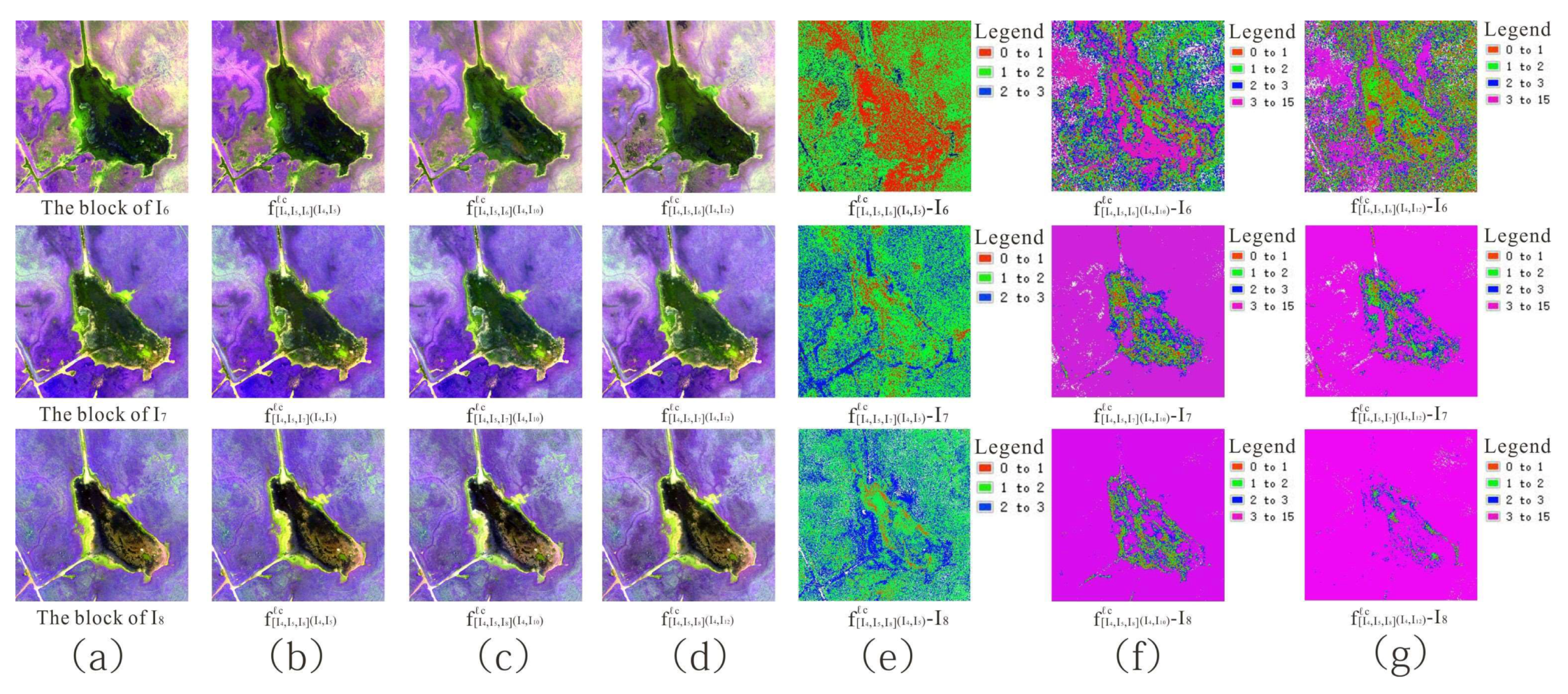
Figure 8.
Visual effect and pixel error between block interpolated result and reference block using (A) UAV and (B) Landsat-8 datasets with (a) initial image (b,d) our proposed method and (c,e) the method of Meyer et al.
Figure 8.
Visual effect and pixel error between block interpolated result and reference block using (A) UAV and (B) Landsat-8 datasets with (a) initial image (b,d) our proposed method and (c,e) the method of Meyer et al.
Figure 9.
Visual effect and pixel error between scene interpolated result and reference scene image using (a) initial image (b,d) ℓmse loss and (c,e) ℓc loss (1, 2, and 3 band composite).
Figure 9.
Visual effect and pixel error between scene interpolated result and reference scene image using (a) initial image (b,d) ℓmse loss and (c,e) ℓc loss (1, 2, and 3 band composite).
Figure 10.
Visual effect and pixel error between scene interpolated result and reference scene image using (a) initial image (b,d) ℓmse loss and (c,e) ℓc loss (1, 2, and 4 band composite).
Figure 10.
Visual effect and pixel error between scene interpolated result and reference scene image using (a) initial image (b,d) ℓmse loss and (c,e) ℓc loss (1, 2, and 4 band composite).
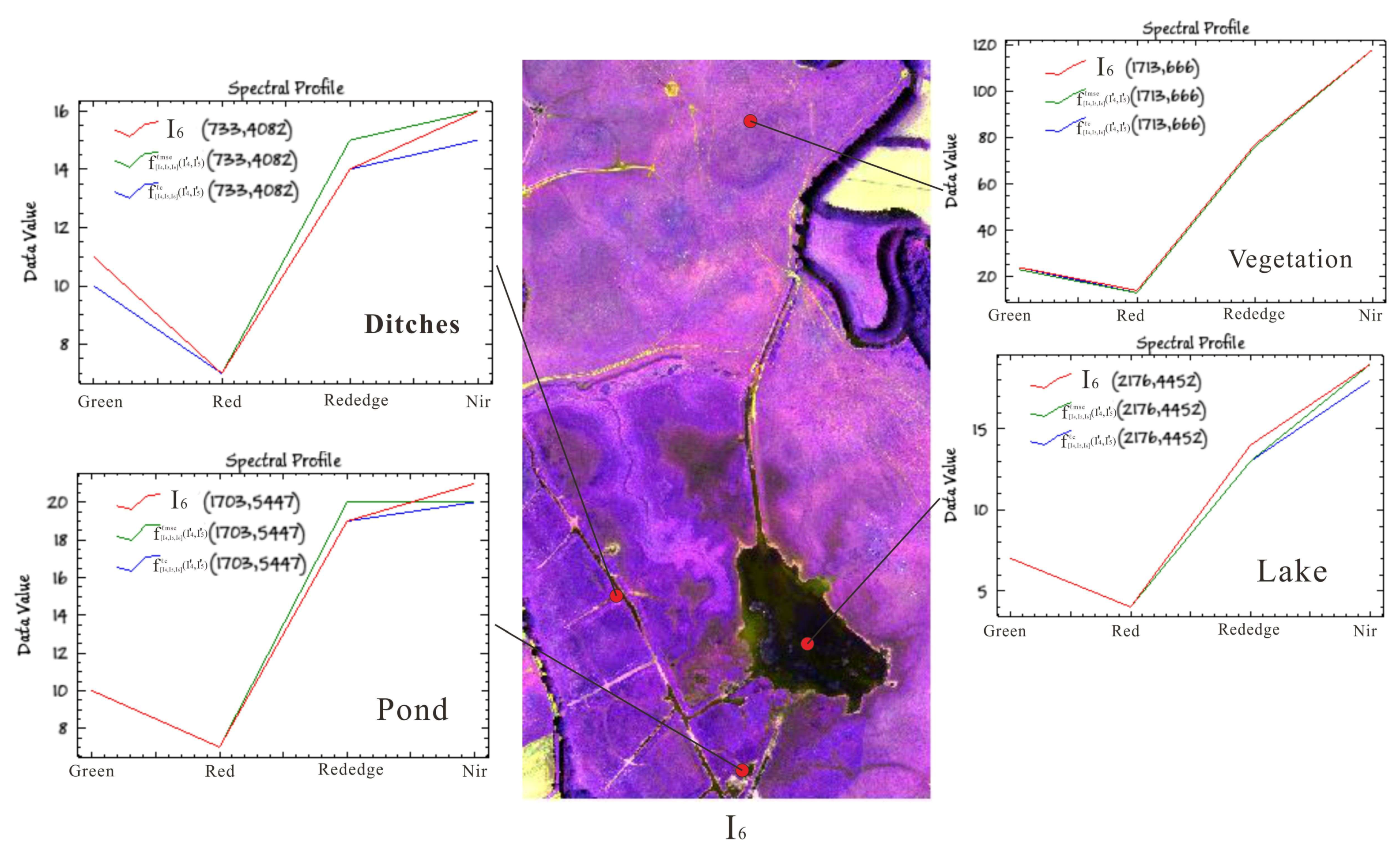
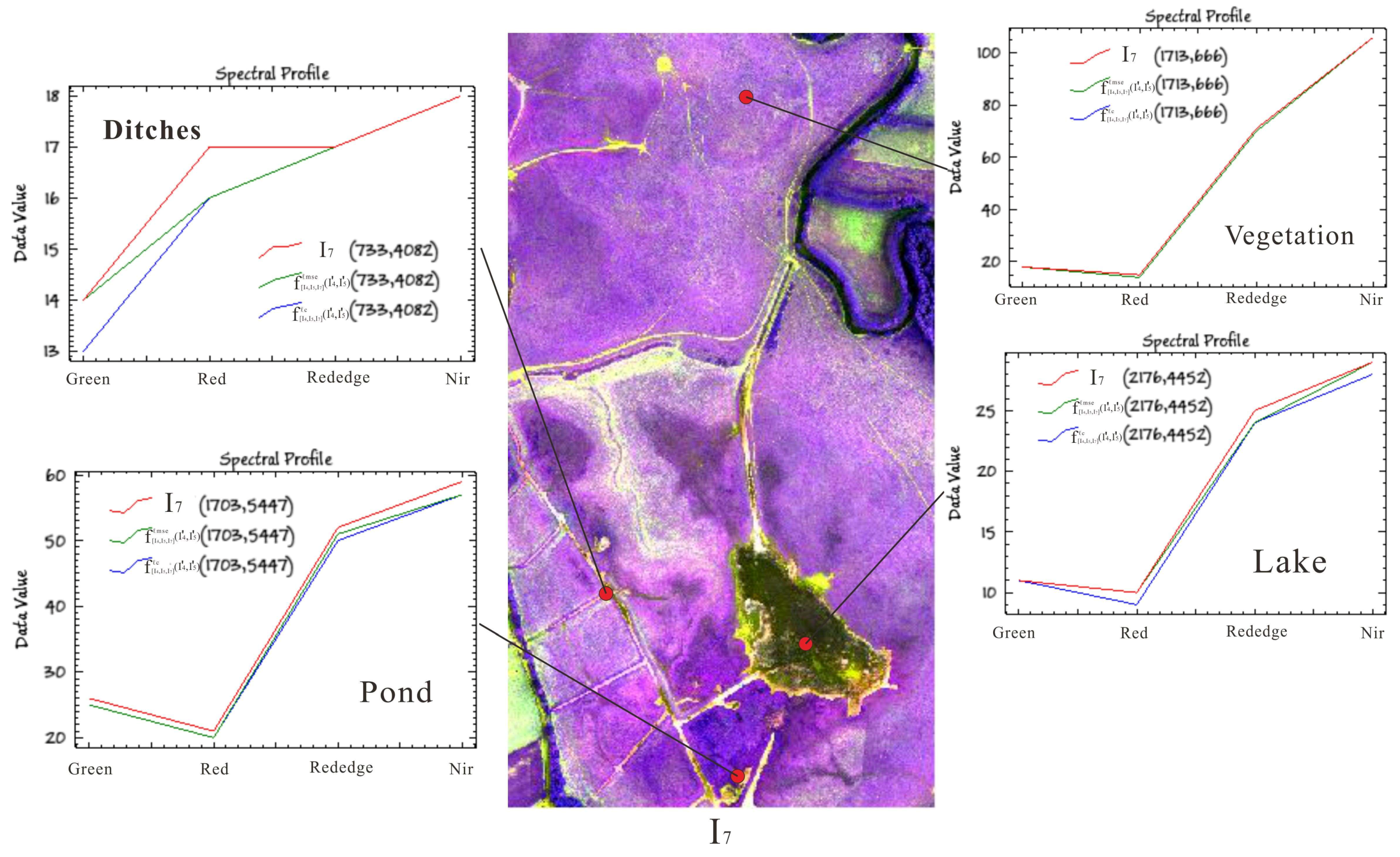
Figure 11.
Spectral curves between scene interpolated result and reference scene image using different loss functions at different coordinates in June 2019.
Figure 11.
Spectral curves between scene interpolated result and reference scene image using different loss functions at different coordinates in June 2019.
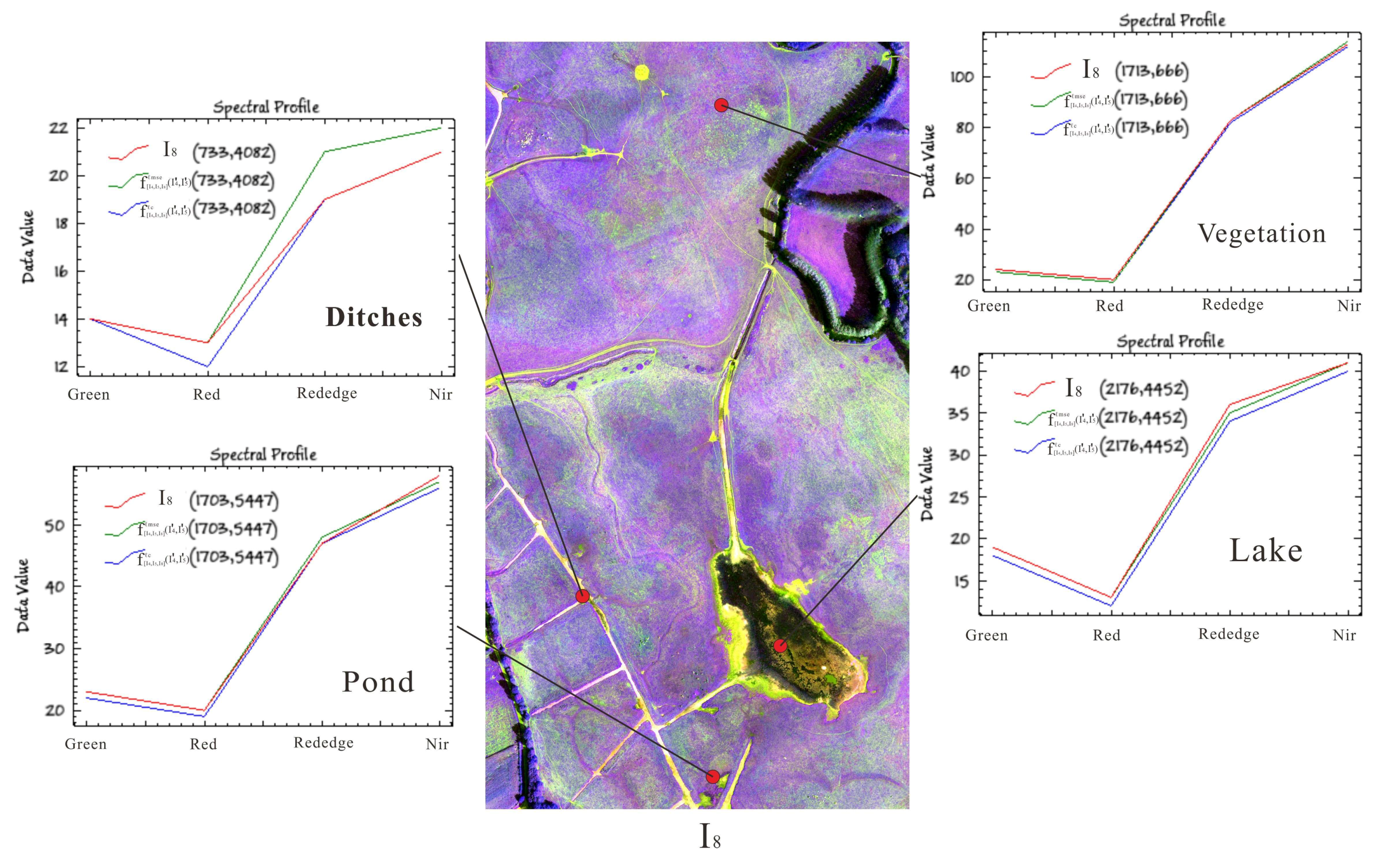
Figure 12.
Spectral curves between scene interpolated result and reference scene image using different loss functions at different coordinates in July 2019.
Figure 12.
Spectral curves between scene interpolated result and reference scene image using different loss functions at different coordinates in July 2019.
Figure 13.
Spectral curves between scene interpolated result and reference scene image using different loss functions at different coordinates in August 2019.
Figure 13.
Spectral curves between scene interpolated result and reference scene image using different loss functions at different coordinates in August 2019.
Figure 14.
Interpolated result of UAV images using
ℓc loss from 2017 to 2019 according to interpolation strategy in
Table 2: existing images and interpolated results in (
A) 2019 sequence, (
B) 2018 sequence, and (
C) 2017 sequence.
Figure 14.
Interpolated result of UAV images using
ℓc loss from 2017 to 2019 according to interpolation strategy in
Table 2: existing images and interpolated results in (
A) 2019 sequence, (
B) 2018 sequence, and (
C) 2017 sequence.
Figure 15.
(a) Initial image (b–d) visual effect and (e–g) pixel error between block interpolated results and reference block using stacks of 1 × 1, 2 × 2, and 3 × 3 convolution layers.
Figure 15.
(a) Initial image (b–d) visual effect and (e–g) pixel error between block interpolated results and reference block using stacks of 1 × 1, 2 × 2, and 3 × 3 convolution layers.
Figure 16.
Visual effect and pixel error between block interpolated result and reference block using (a) initial image (b,d) average pooling and (c,e) maximum pooling.
Figure 16.
Visual effect and pixel error between block interpolated result and reference block using (a) initial image (b,d) average pooling and (c,e) maximum pooling.
Figure 17.
(a) Initial image (b–d) visual effect and (e–g) pixel error between block interpolated result and reference block using testing block pairs April–May, April–October, and April–December 2018.
Figure 17.
(a) Initial image (b–d) visual effect and (e–g) pixel error between block interpolated result and reference block using testing block pairs April–May, April–October, and April–December 2018.
Figure 18.
(a) Initial image (b–d) visual effect and (e–g) pixel error between block interpolated result and reference block using separable convolution kernel sizes 11, 13, and 15.
Figure 18.
(a) Initial image (b–d) visual effect and (e–g) pixel error between block interpolated result and reference block using separable convolution kernel sizes 11, 13, and 15.
Table 1.
Name and date of experimental datasets in first set of experiment.
Table 1.
Name and date of experimental datasets in first set of experiment.
| Dataset | Image Names | Image Dates |
|---|
| UAV | I4 | April 2019 |
| I5 | May 2019 |
| I6 | June 2019 |
| I7 | July 2019 |
| I8 | August 2019 |
| Landsat-8 | I4 | April 2013 |
| I7 | July 2013 |
| I9 | September 2013 |
| I11 | November 2013 |
| I12 | December 2013 |
Table 2.
Training triplet images, testing images, and output images in third set of experiment.
Table 2.
Training triplet images, testing images, and output images in third set of experiment.
| Color of Points | Training Triplet Images | Testing Images | Output Images |
|---|
| Red | April, May, January 2019 | April, May 2018 | January 2018 |
| April, May, March 2019 | March 2018 |
| April, May, June 2019 | June 2018 |
| April, May, July 2019 | July 2018 |
| April, May, August 2019 | August 2018 |
| Green | July, October, November 2017 | July, October 2018 | November 2018 |
| July, August, September 2018 | July, August 2019 | September 2019 |
| July, August, October 2018 | October 2019 |
| July, August, November 2018 | November 2019 |
| July, August, December 2018 | December 2019 |
| Cyan-blue | October, November, January 2018 | October, November 2017 | January 2017 |
| October, November, February 2018 | February 2017 |
| October, November, March 2018 | March 2017 |
| October, November, April 2018 | April 2017 |
| October, November, May 2018 | May 2017 |
| October, November, June 2018 | June 2017 |
| October, November, August 2018 | August 2017 |
| October, November, September 2018 | September 2017 |
| October, November, December 2018 | December 2017 |
Table 3.
Quantitative evaluation between block interpolated result and reference block using our proposed method on both datasets.
Table 3.
Quantitative evaluation between block interpolated result and reference block using our proposed method on both datasets.
| Dataset | Interpolated Results (Block) | Reference Blocks | Entropy | RMSE (Pixel) |
|---|
| UAV | | I6 | 3.719 | 1.052 |
| 3.723 | 1.077 |
| I7 | 3.441 | 1.070 |
| 3.450 | 1.294 |
| I8 | 3.498 | 1.116 |
| 3.508 | 1.429 |
| Landsat-8 | | I9 | 3.143 | 0.817 |
| 3.145 | 1.112 |
| I11 | 3.842 | 1.233 |
| 3.846 | 1.321 |
| I12 | 3.545 | 1.040 |
| 3.550 | 1.476 |
Table 4.
Quantitative comparison between block interpolated result and reference block using our proposed method and method of Meyer et al. on both datasets.
Table 4.
Quantitative comparison between block interpolated result and reference block using our proposed method and method of Meyer et al. on both datasets.
| Dataset | Interpolated Results (Block) | Reference Blocks | Entropy | RMSE (Pixel) |
|---|
| UAV | | I6 | 3.719 | 1.052 |
| 3.701 | 1.320 |
| I7 | 3.441 | 1.070 |
| 3.440 | 1.888 |
| I8 | 3.498 | 1.116 |
| 3.477 | 2.369 |
| Landsat-8 | | I9 | 3.143 | 0.817 |
| 3.125 | 1.550 |
| I11 | 3.842 | 1.233 |
| 3.572 | 1.957 |
| I12 | 3.545 | 1.040 |
| 3.541 | 1.769 |
Table 5.
Quantitative evaluation between scene interpolated result and reference scene image.
Table 5.
Quantitative evaluation between scene interpolated result and reference scene image.
| Interpolated Results (Scene) | Reference Images | Entropy | RMSE (Pixel) |
|---|
| I6 | 3.650 | 1.124 |
| 3.656 | 1.163 |
| I7 | 3.346 | 1.017 |
| 3.346 | 1.381 |
| I8 | 3.494 | 1.210 |
| 3.506 | 1.550 |
Table 6.
Quantitative evaluation between block interpolated result and reference block using different stacked convolution layers.
Table 6.
Quantitative evaluation between block interpolated result and reference block using different stacked convolution layers.
| Stacked Numbers | Interpolated Results (Block) | Reference Blocks | RMSE (Pixel) |
|---|
| 1 × 1 | | I6 | 1.375 |
| I7 | 1.556 |
| I8 | 1.666 |
| 2 × 2 | | I6 | 1.258 |
| I7 | 1.431 |
| I8 | 1.465 |
| 3 × 3 | | I6 | 1.077 |
| I7 | 1.294 |
| I8 | 1.429 |
Table 7.
Quantitative evaluation between block interpolated result and reference block using different pooling types.
Table 7.
Quantitative evaluation between block interpolated result and reference block using different pooling types.
| Pooling Type | Interpolated Results (Block) | Reference Blocks | RMSE (Pixel) |
|---|
| Average pooling | | I6 | 1.326 |
| I7 | 1.492 |
| I8 | 1.700 |
| Maximum pooling | | I6 | 1.077 |
| I7 | 1.294 |
| I8 | 1.429 |
Table 8.
Quantitative evaluation between block interpolated result and reference block using different testing block pairs.
Table 8.
Quantitative evaluation between block interpolated result and reference block using different testing block pairs.
| Testing Image Date | Interpolated Results (Block) | Reference Blocks | RMSE (Pixel) |
|---|
| April, May 2018 | | I6 | 1.341 |
| April, October 2018 | | 3.912 |
| April, December 2018 | | 3.989 |
| April, May 2018 | | I7 | 1.498 |
| April, October 2018 | | 5.096 |
| April, December 2018 | | 5.271 |
| April, May 2018 | | I8 | 1.653 |
| April, October 2018 | | 5.313 |
| April, December 2018 | | 5.568 |
Table 9.
Quantitative evaluation between block interpolated result and reference block using different separable convolution kernel sizes.
Table 9.
Quantitative evaluation between block interpolated result and reference block using different separable convolution kernel sizes.
| Kernel Size | Interpolated Results (Block) | Reference Blocks | RMSE (Pixel) |
|---|
| 11 | | I6 | 1.077 |
| I7 | 1.294 |
| I8 | 1.429 |
| 13 | | I6 | 1.178 |
| I7 | 1.446 |
| I8 | 1.765 |
| 15 | | I6 | 1.217 |
| I7 | 1.656 |
| I8 | 1.868 |

 ,
, 





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}