
Looking for Change? Roll the Dice and Demand Attention


Abstract
:1. Introduction
1.1. Related Work
1.1.1. On Attention
1.1.2. On Change Detection
1.2. Our Contributions
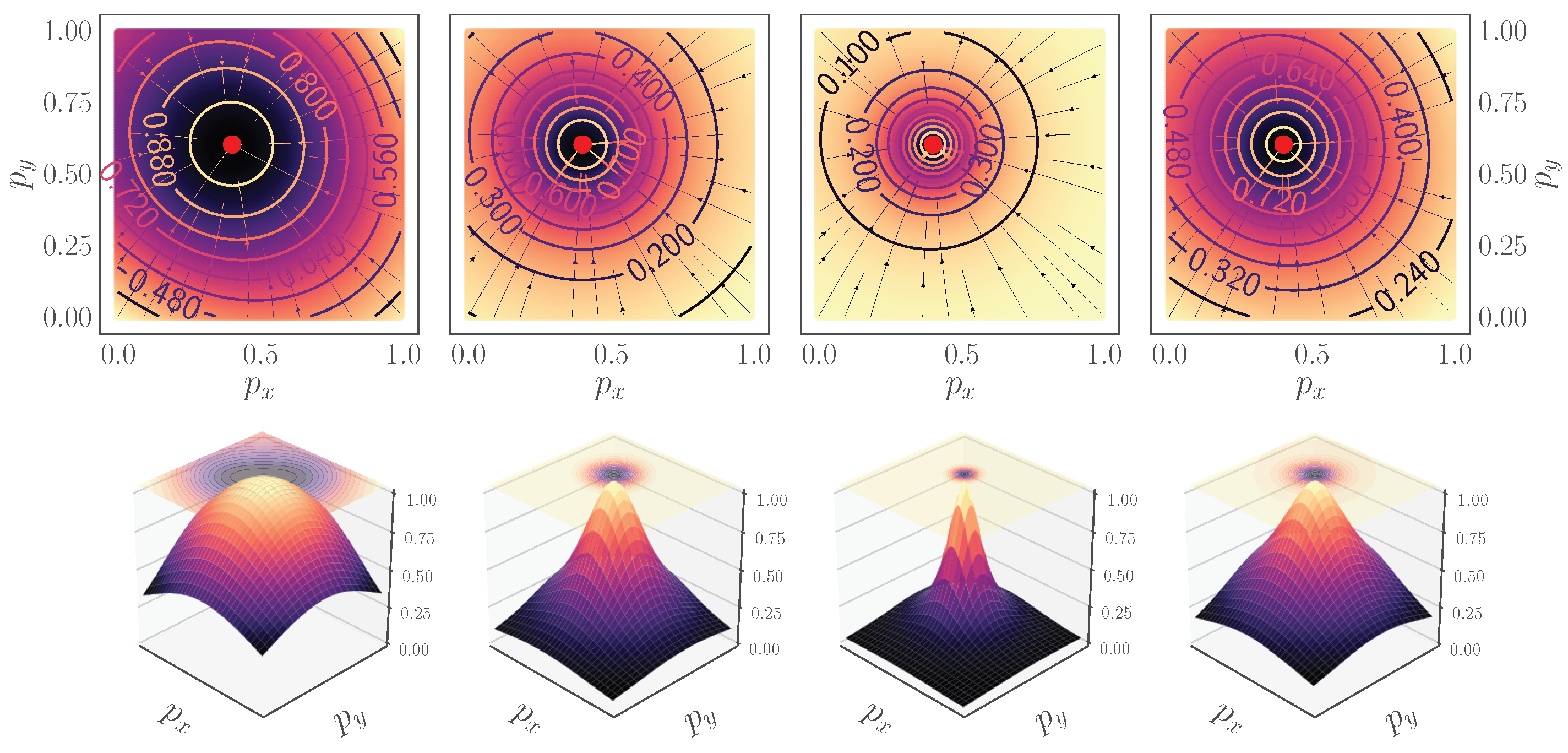
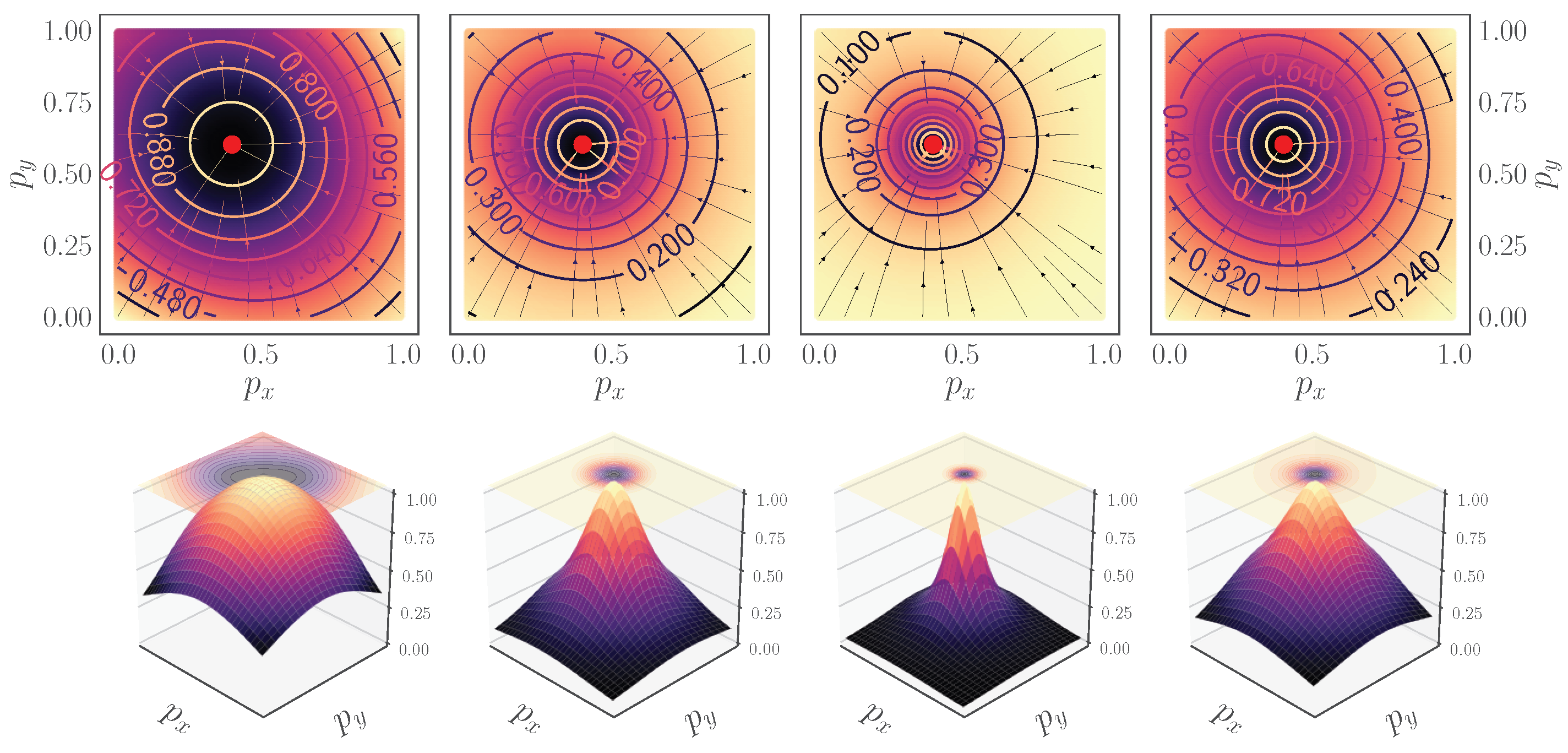
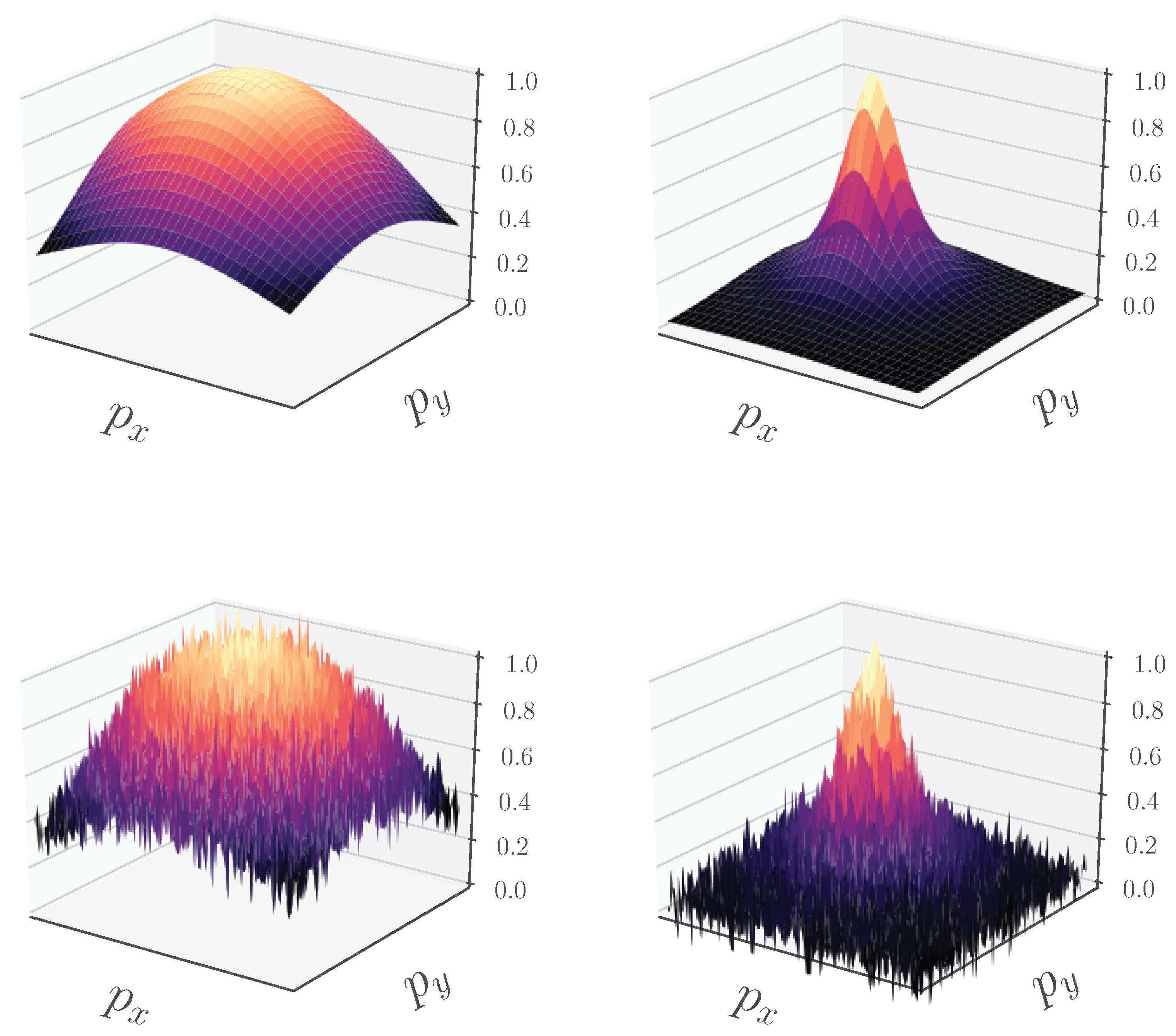
- We introduce a new set similarity metric that is a variant of the Dice coefficient: the Fractal Tanimoto similarity measure (Section 2.1). This similarity measure has the advantage that it can be made steeper than the standard Tanimoto metric towards optimality, thus providing a finer-grained similarity metric between layers. The level of steepness is controlled from a depth recursion hyperparameter. It can be used both as a “sharp” loss function when fine-tuning a model at the latest stages of training, as well as a set similarity metric between feature layers in the attention mechanism.
- Using the above set similarity as a loss function, we propose an evolving loss strategy for fine-tuning the training of neural networks (Section 2.2). This strategy helps to avoid overfitting and improves performance.
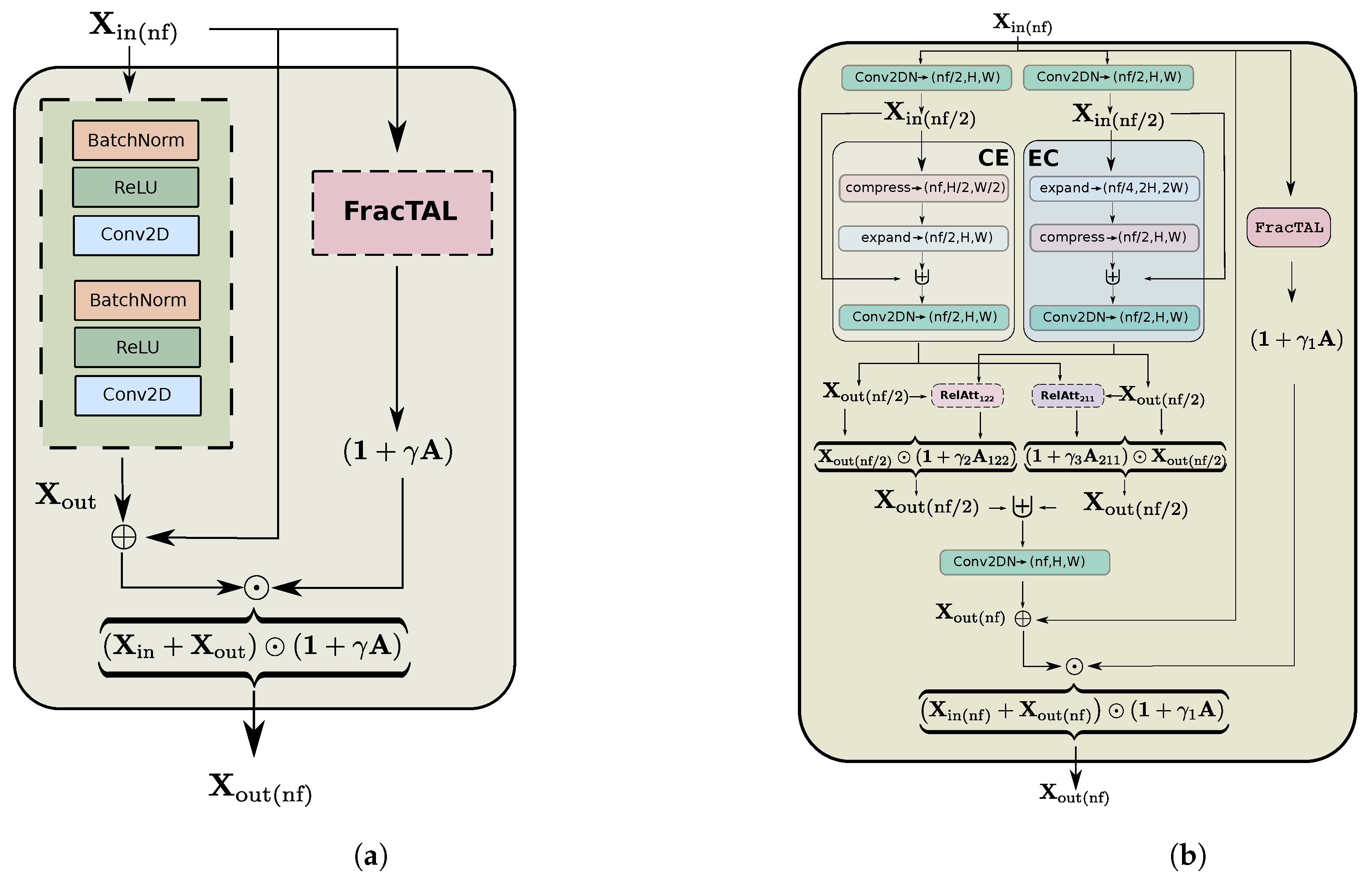
- We introduce the Fractal Tanimoto Attention Layer (hereafter FracTAL), which is tailored for vision tasks (Section 2.3). This layer uses the fractal Tanimoto similarity to compare queries with keys inside the Attention module. It is a form of spatial and channel attention combined.
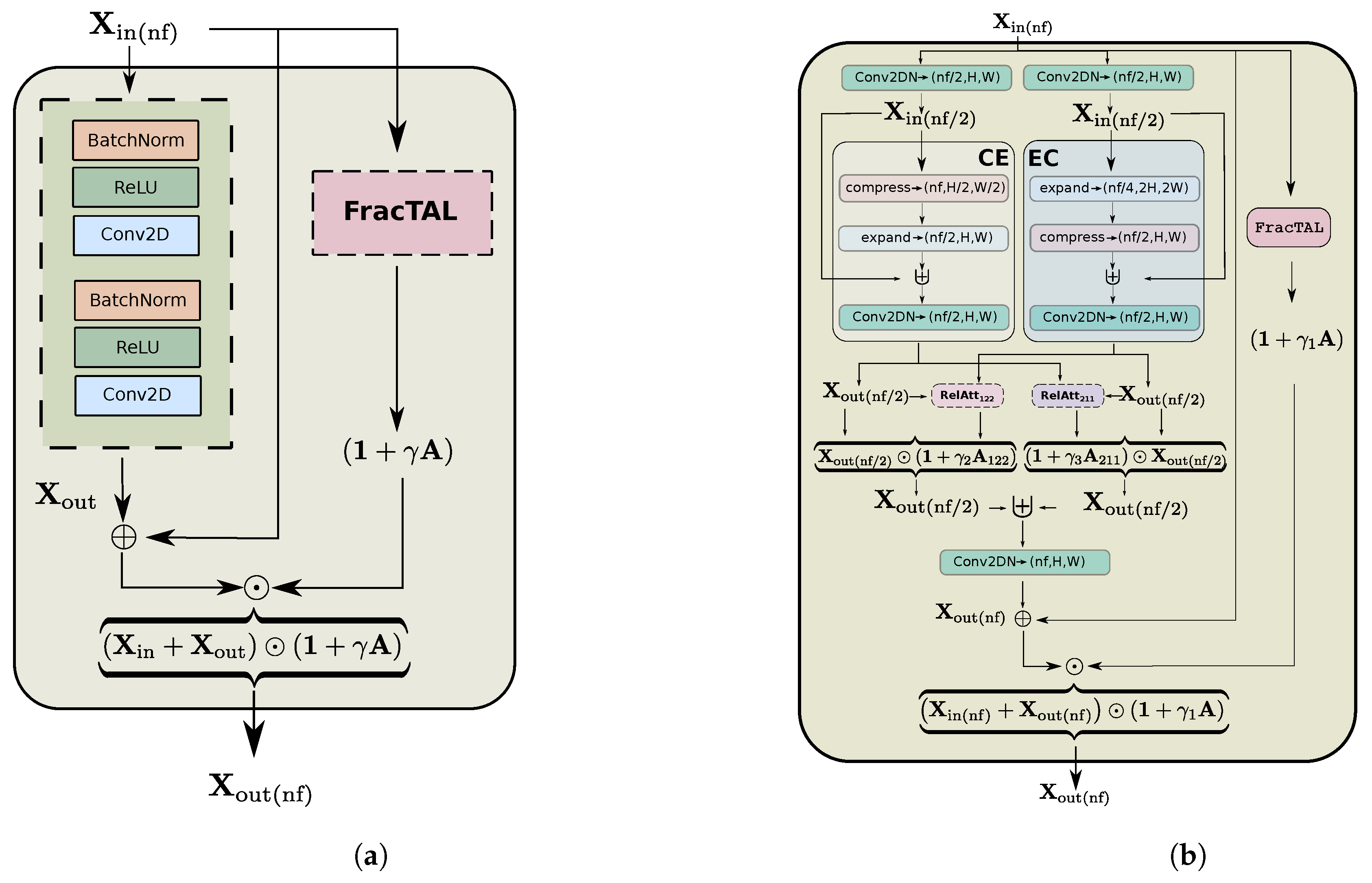
- We introduce a feature extraction building block that is based on the residual neural network [32] and the fractal Tanimoto Attention (Section 2.4.2). The new FracTALResNet converges faster to optimality than standard residual networks and enhances performance.
- We introduce two variants of a new feature extraction building block, the Compress-Expand/Expand-Compress unit (hereafter CEECNet unit—Section 2.5.1). This unit exhibits enhanced performance in comparison with standard residual units and the FracTALResNet unit.
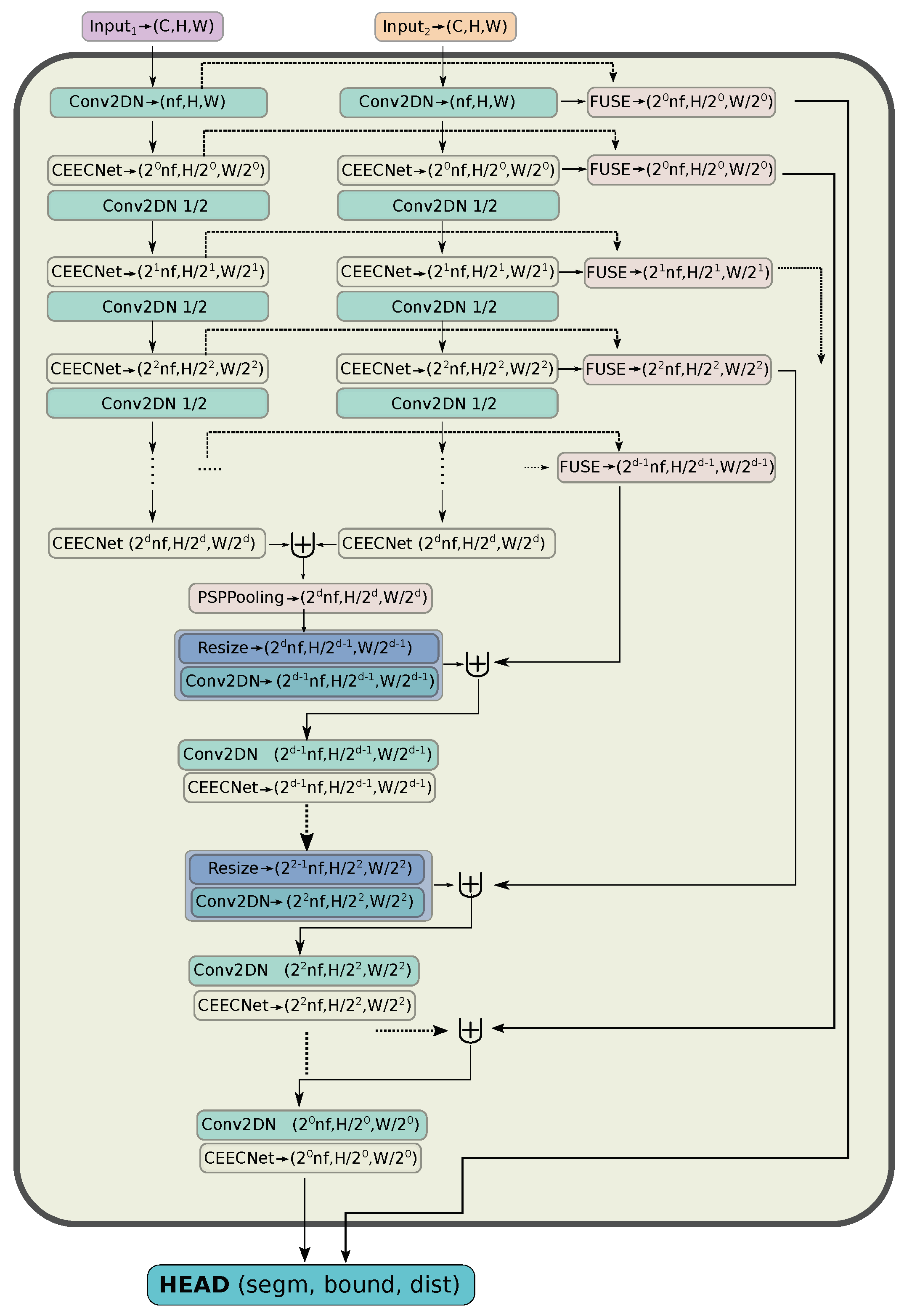
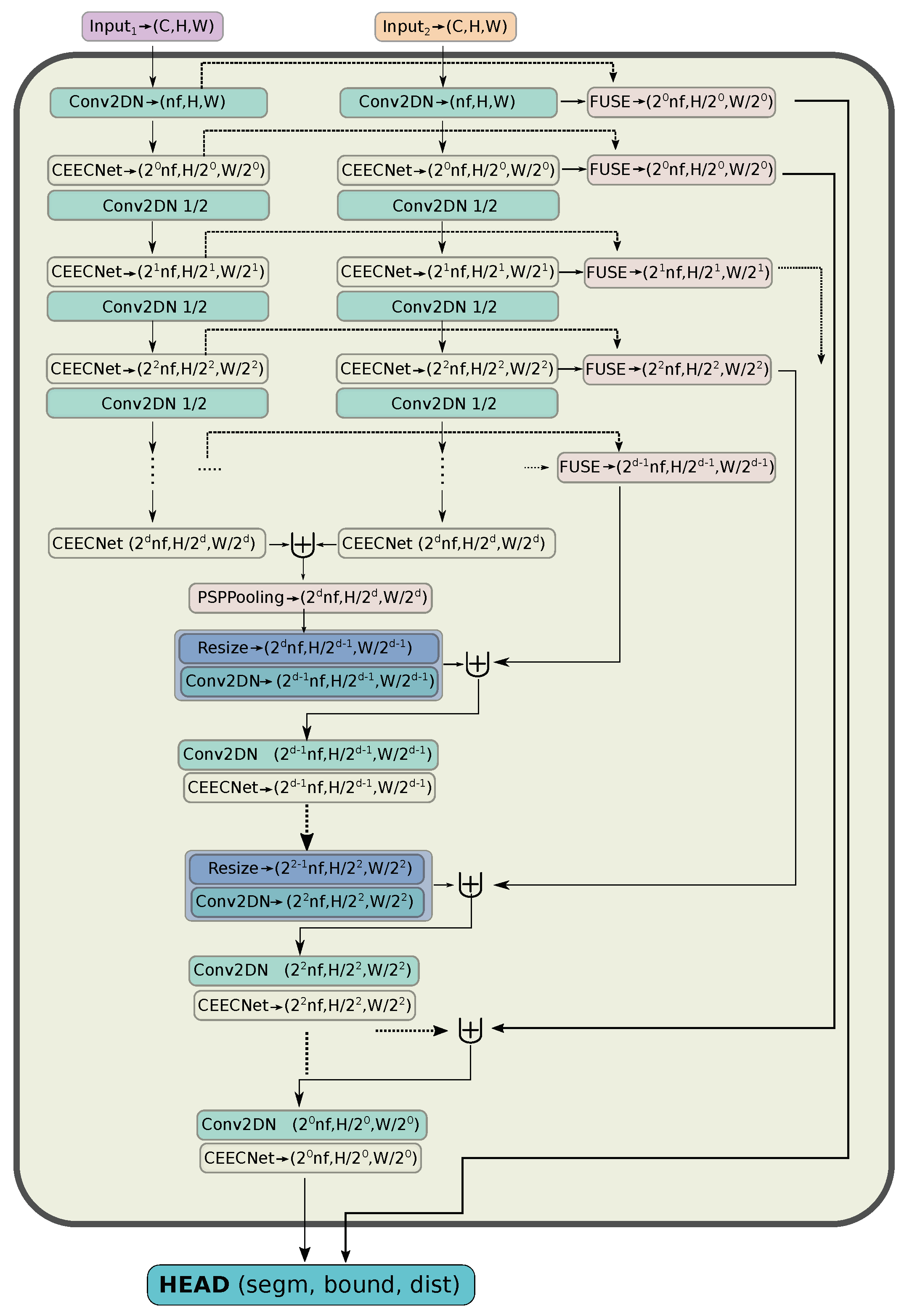
- Capitalising on these findings, we introduce a new backbone encoder/decoder scheme, a macro-topology—the mantis—that is tailored for the task of change detection (Section 2.5.2). The encoder part is a Siamese dual encoder, where the corresponding extracted features at each depth are fused together with FracTALrelative attention. In this way, information exchange between features extracted from bi-temporal images is enforced. There is no need for manual feature subtraction.
- Given the relative fusion operation between the encoder features at different levels, our algorithm achieves state-of-the-art performance on the LEVIRCD and WHU datasets without requiring the use of contrastive loss learning during training (Section 3.2). Therefore, it is easier to implement with standard deep learning libraries and tools.
2. Materials and Methods
2.1. Fractal Tanimoto Similarity Coefficient
2.2. Evolving Loss Strategy
2.3. Fractal Tanimoto Attention
2.4. Fractal Tanimoto Attention Layer
- The similarity is automatically scaled in the region ; therefore, it does not require normalisation or activation to be applied. This simplifies the design and implementation of Attention layers and enables training without ad hoc normalisation operations.
- The dot product does not have an upper or lower bound; therefore, a positive value cannot be a quantified measure of similarity. In contrast, has a bounded range of values in . The lowest value indicates no correlation, and the maximum value perfect similarity. It is thus easier to interpret.
- Iteration d is a form of hyperparameter, such as “temperature” in annealing. Therefore, the can become as steep as we desire (by modification of the temperature parameter d), even steeper than the dot product similarity. This can translate to finer query and key similarity.
- Finally, it is efficient in terms of the GPU memory footprint (when one considers that it does both channel and spatial attention), thus allowing the design of more complex convolution building blocks.
2.4.1. Attention Fusion
2.4.2. Self Attention Fusion
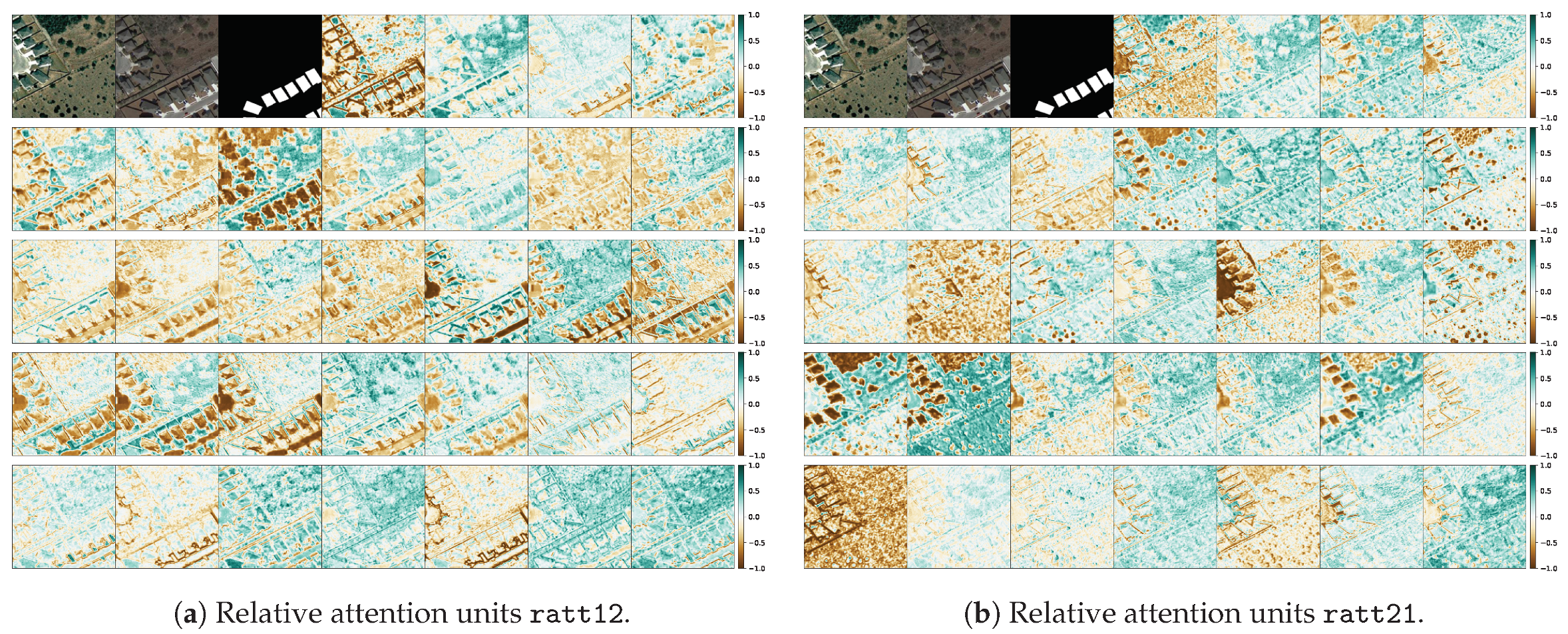
2.4.3. Relative Attention Fusion
2.5. Architecture
2.5.1. Micro-Topology: The CEECNet Unit
2.5.2. Macro-Topology: Dual Encoder, Symmetric Decoder
- We make the hypothesis that the process of change detection between two images requires a mechanism similar to human attention. We base this hypothesis on the fact that the time required for identifying objects that changed in an image correlates directly with the number of changed objects. That is, the more objects a human needs to identify between two pictures, the more time is required. This is in accordance with the feature-integration theory of Attention [11]. In contrast, subtracting features extracted from two different input images is a process that is constant in time, independent of the complexity of the changed features. Therefore, we avoid using ad hoc feature subtraction in all parts of the network.
- In order to identify change, a human needs to look and compare two images multiple times, back and forth. We need things to emphasise on image at date 1, based on information on image at date 2 (Equation (16)) and, vice versa, (Equation (17)). Furthermore, then we combine both of these pieces of information together (Equation (18)). That is, exchange information with relative attention (Section 2.4.3) between the two at multiple levels. A different way of stating this as a question is: what is important on input image 1 based on information that exists on image 2, and vice versa?
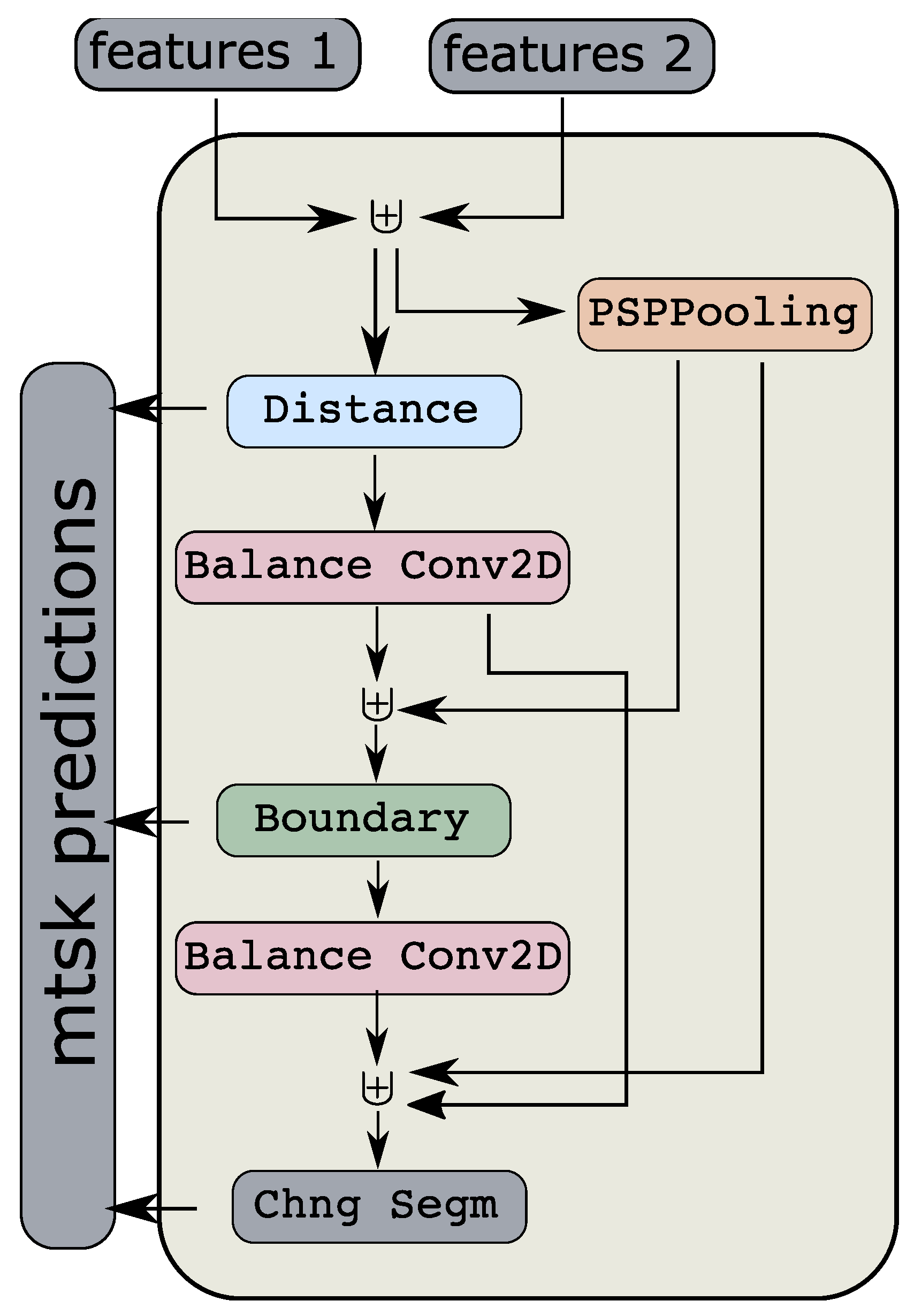
2.5.3. Segmentation HEAD
2.6. Experimental Design
2.6.1. LEVIRCD Dataset
2.6.2. WHU Building Change Detection
2.6.3. Data Preprocessing and Augmentation
2.6.4. Metrics
2.6.5. Inference
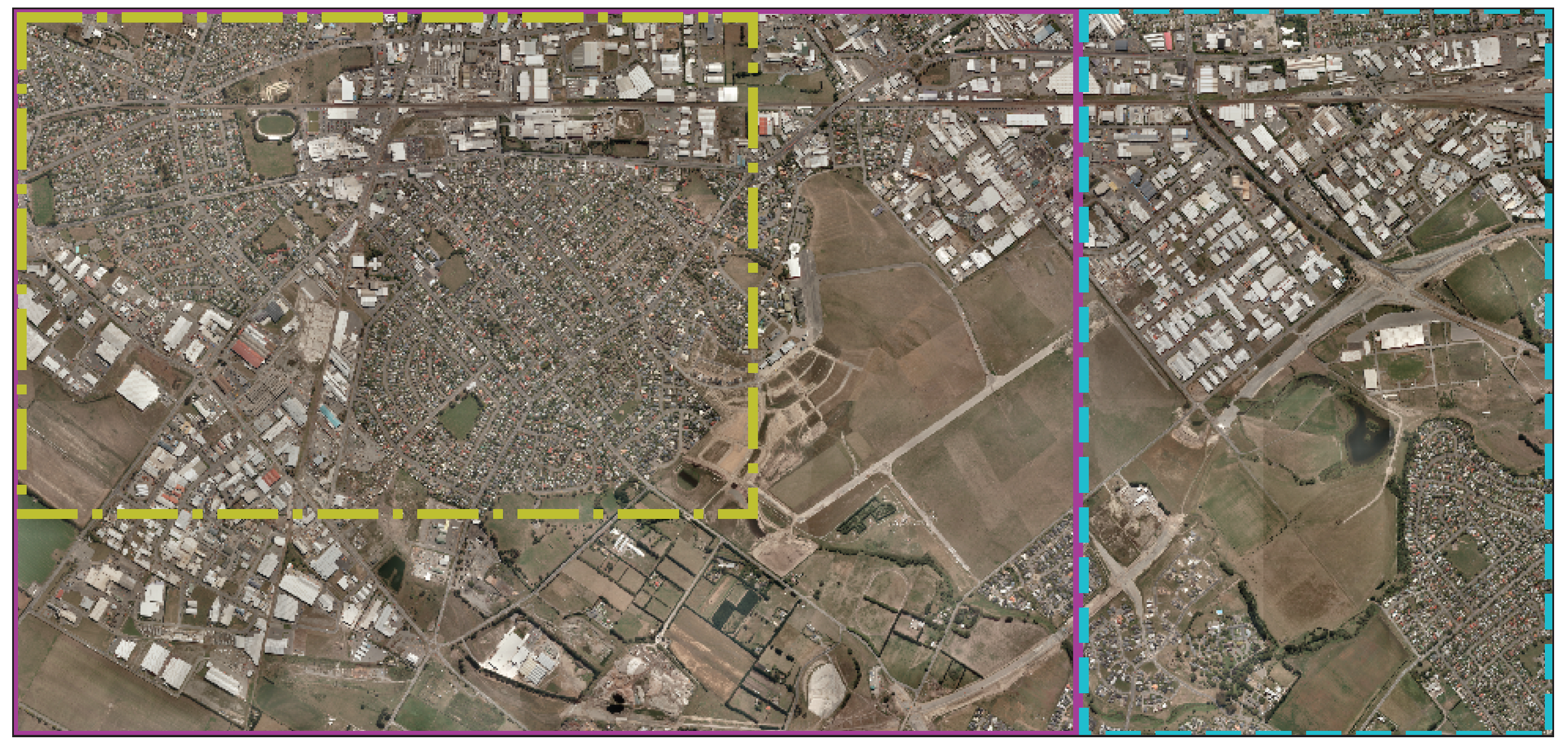
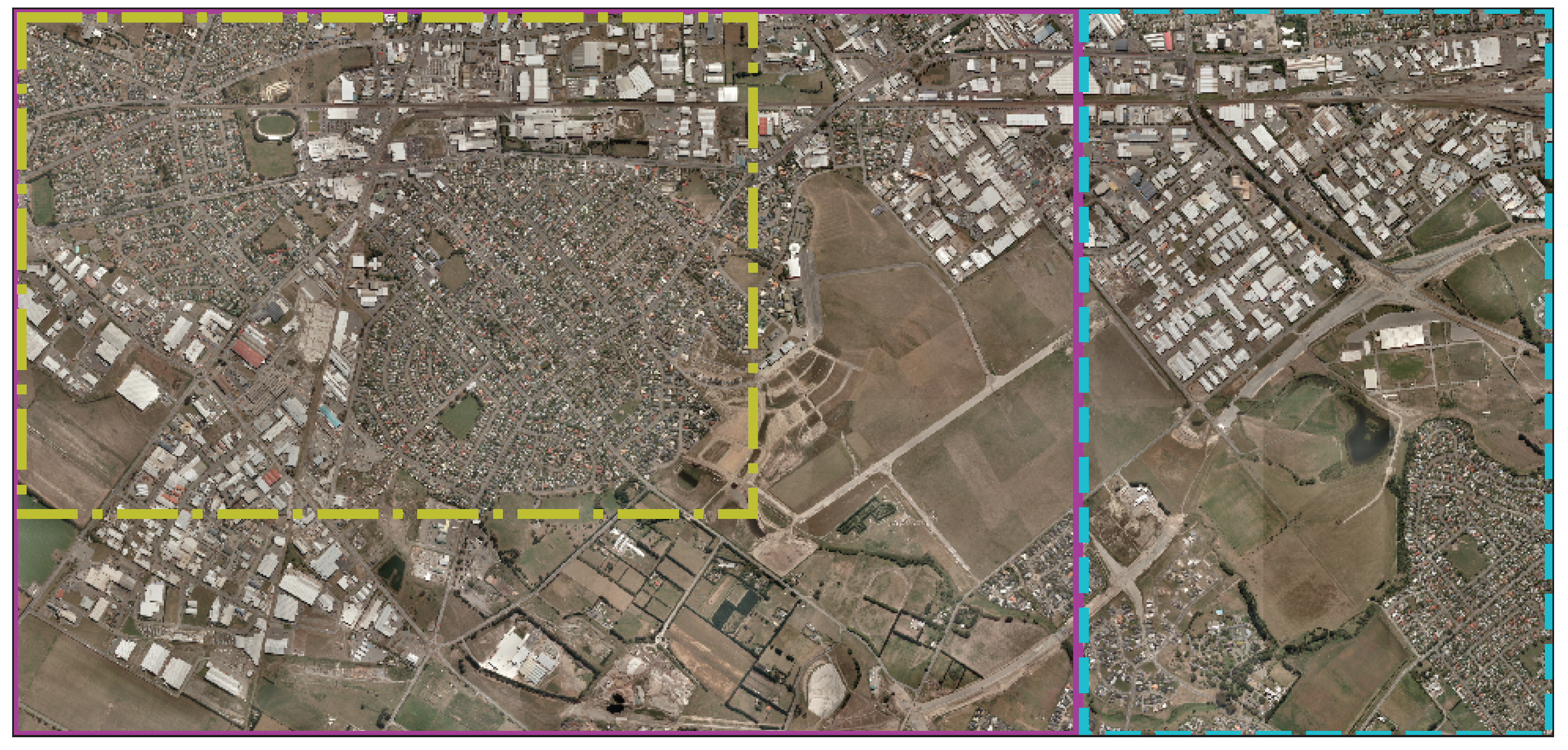
2.6.6. Inference on Large Rasters
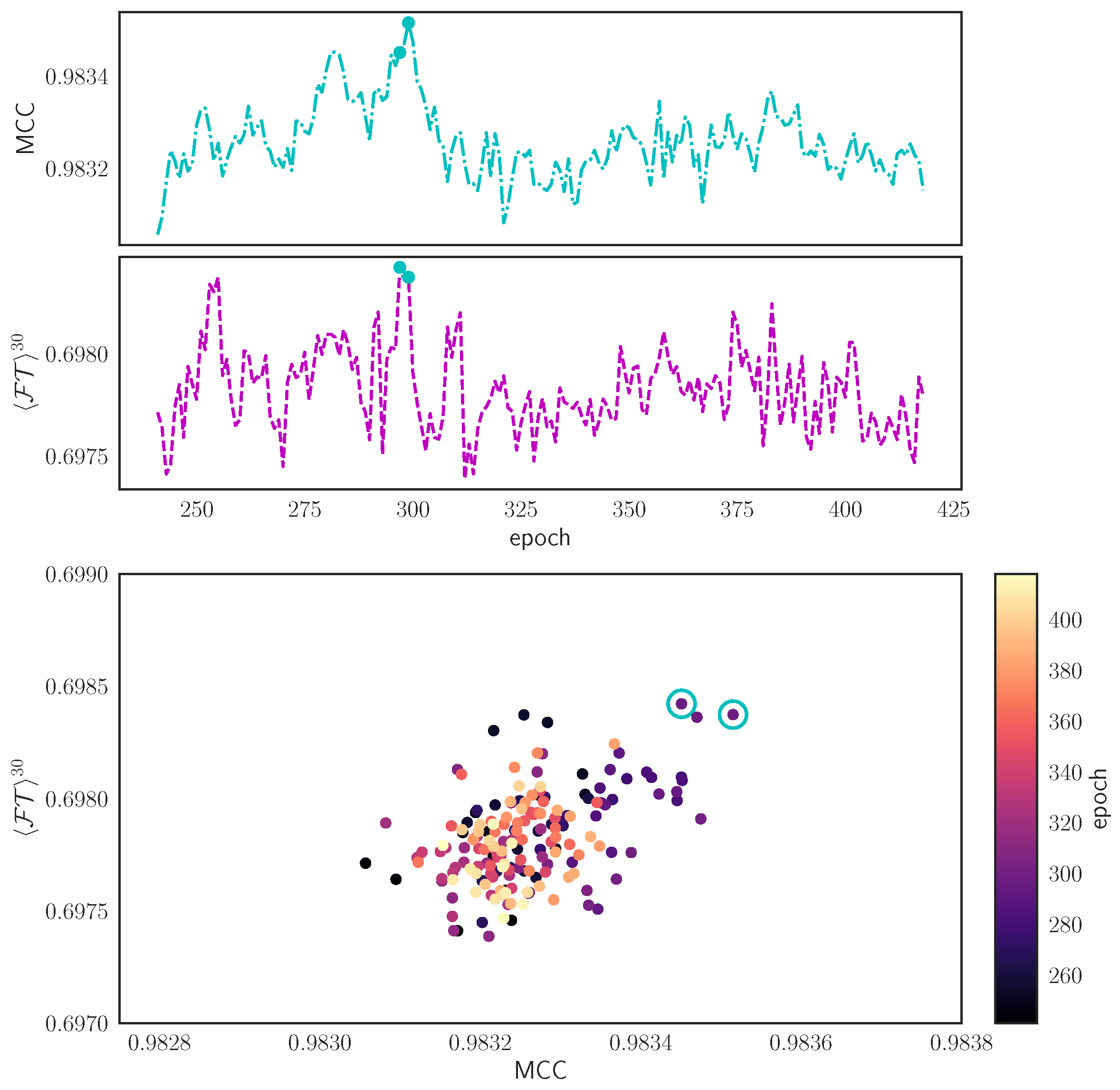
2.6.7. Model Selection Using Pareto Efficiency
3. Results
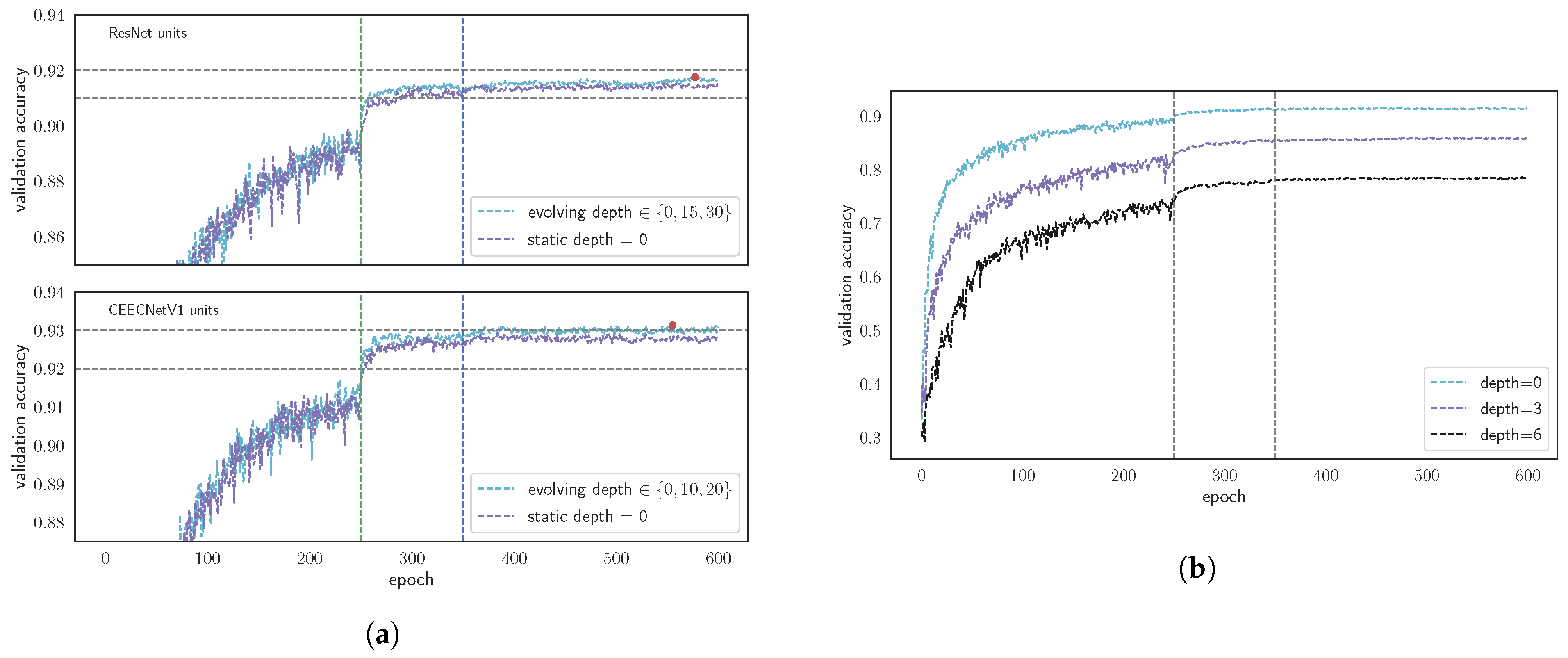
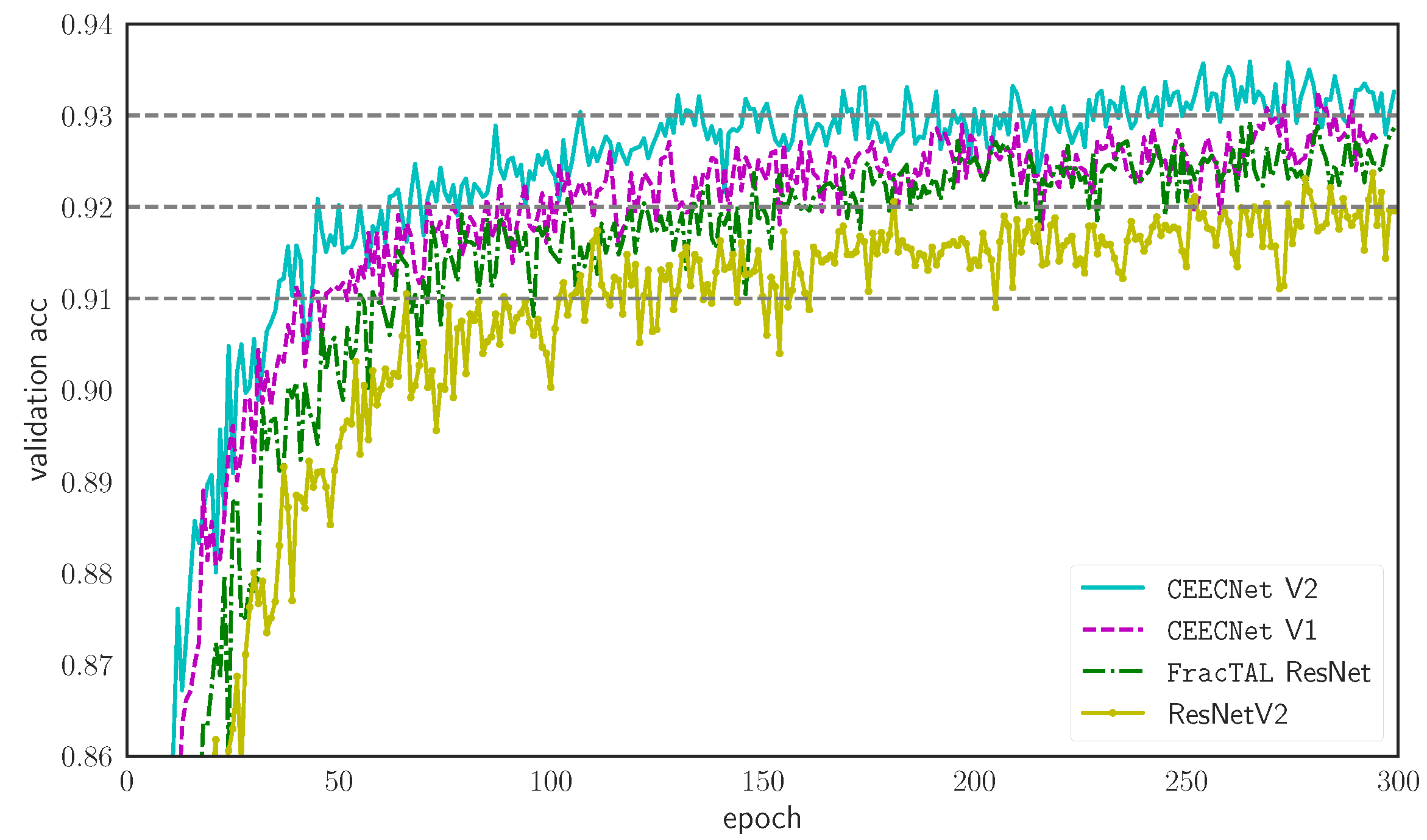
3.1. FracTALUnits and Evolving Loss Ablation Study
3.1.1. FracTALBuilding Blocks Performance
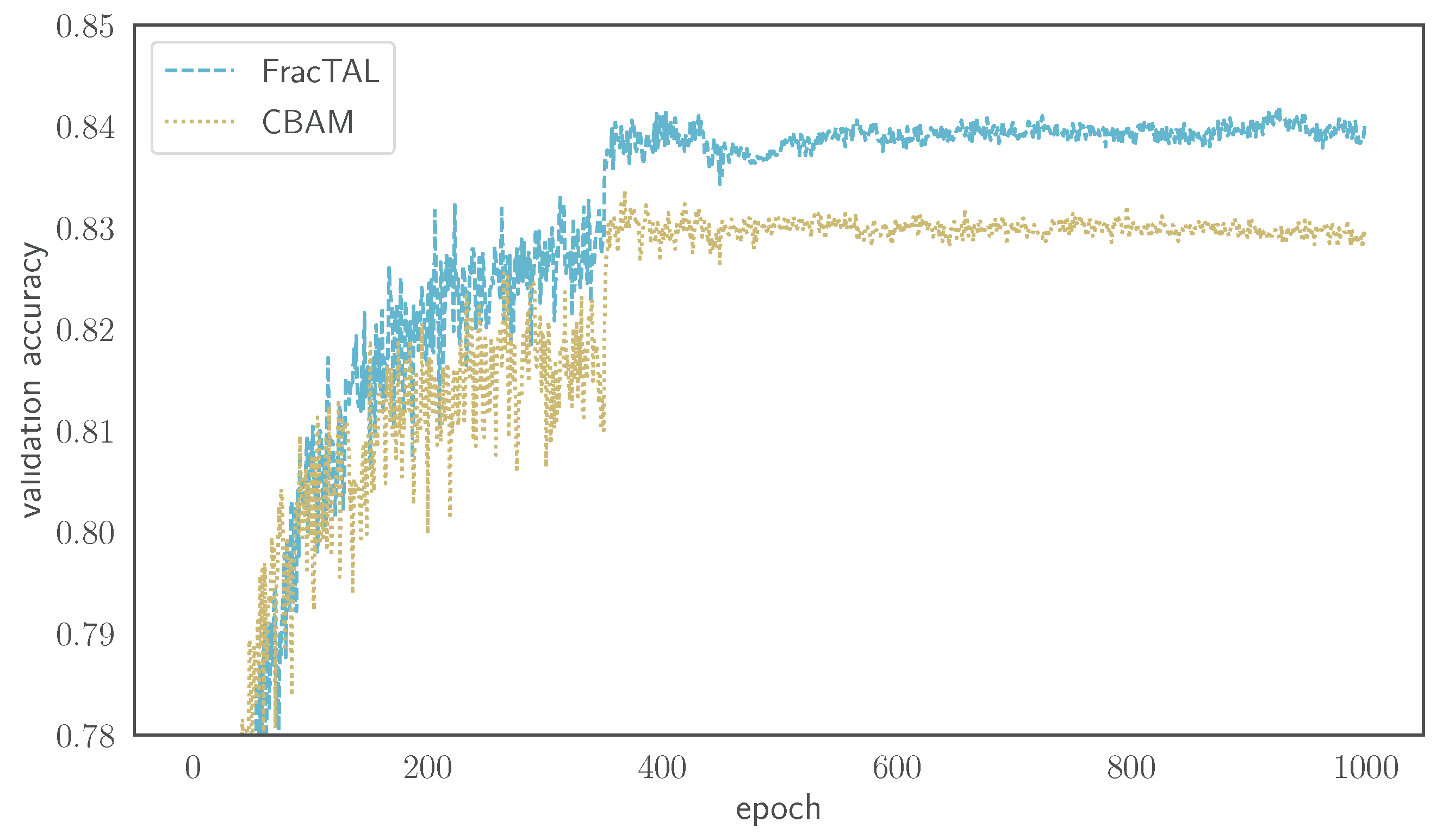
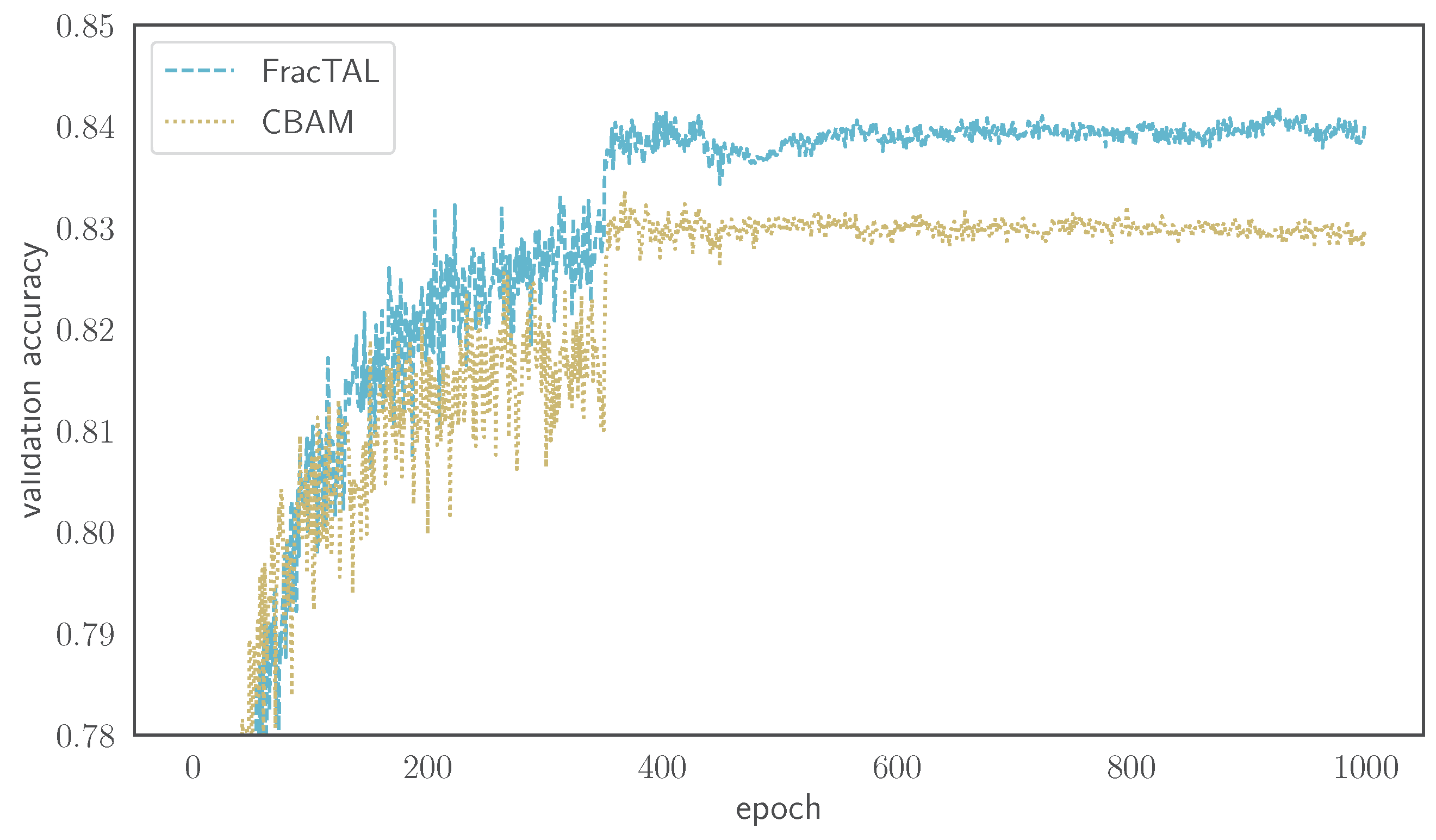
3.1.2. Comparing FracTALwith CBAM
3.1.3. Evolving Loss
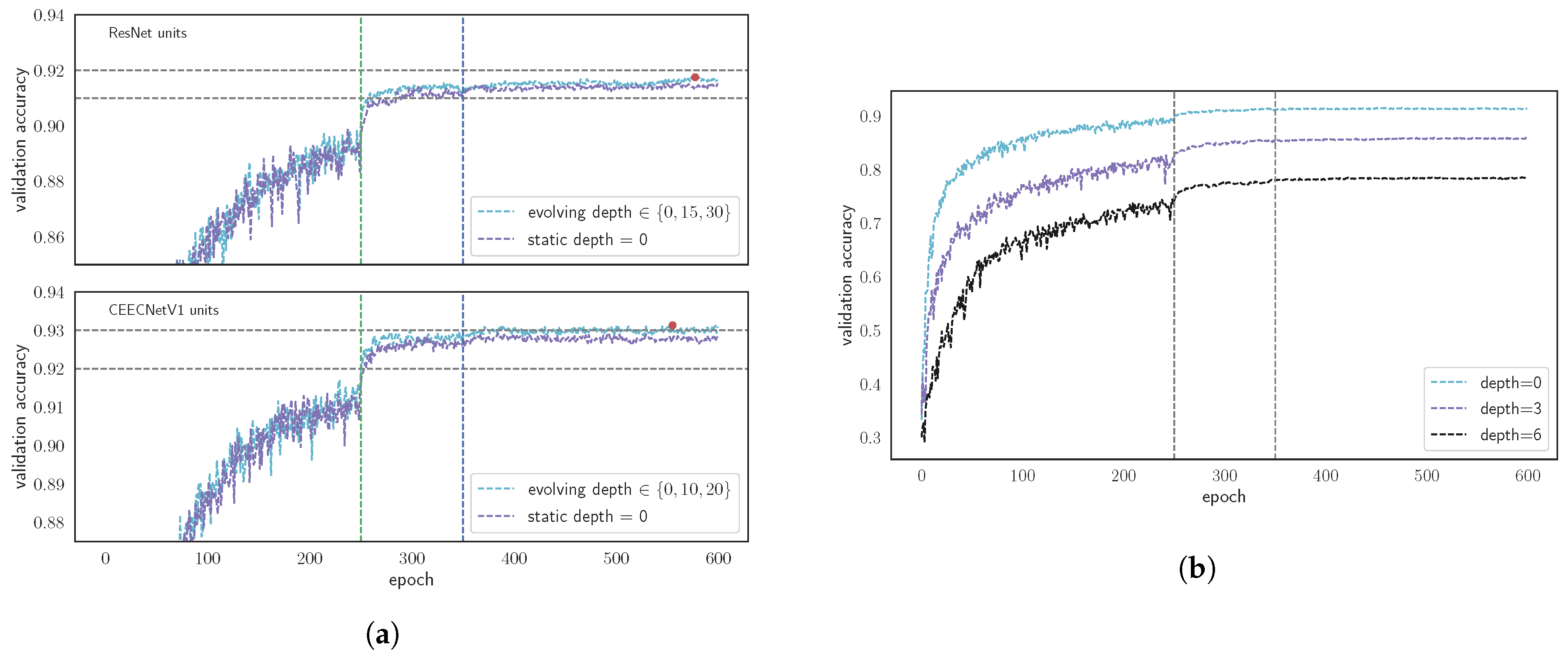
3.1.4. Performance Dependence on FracTALDepth
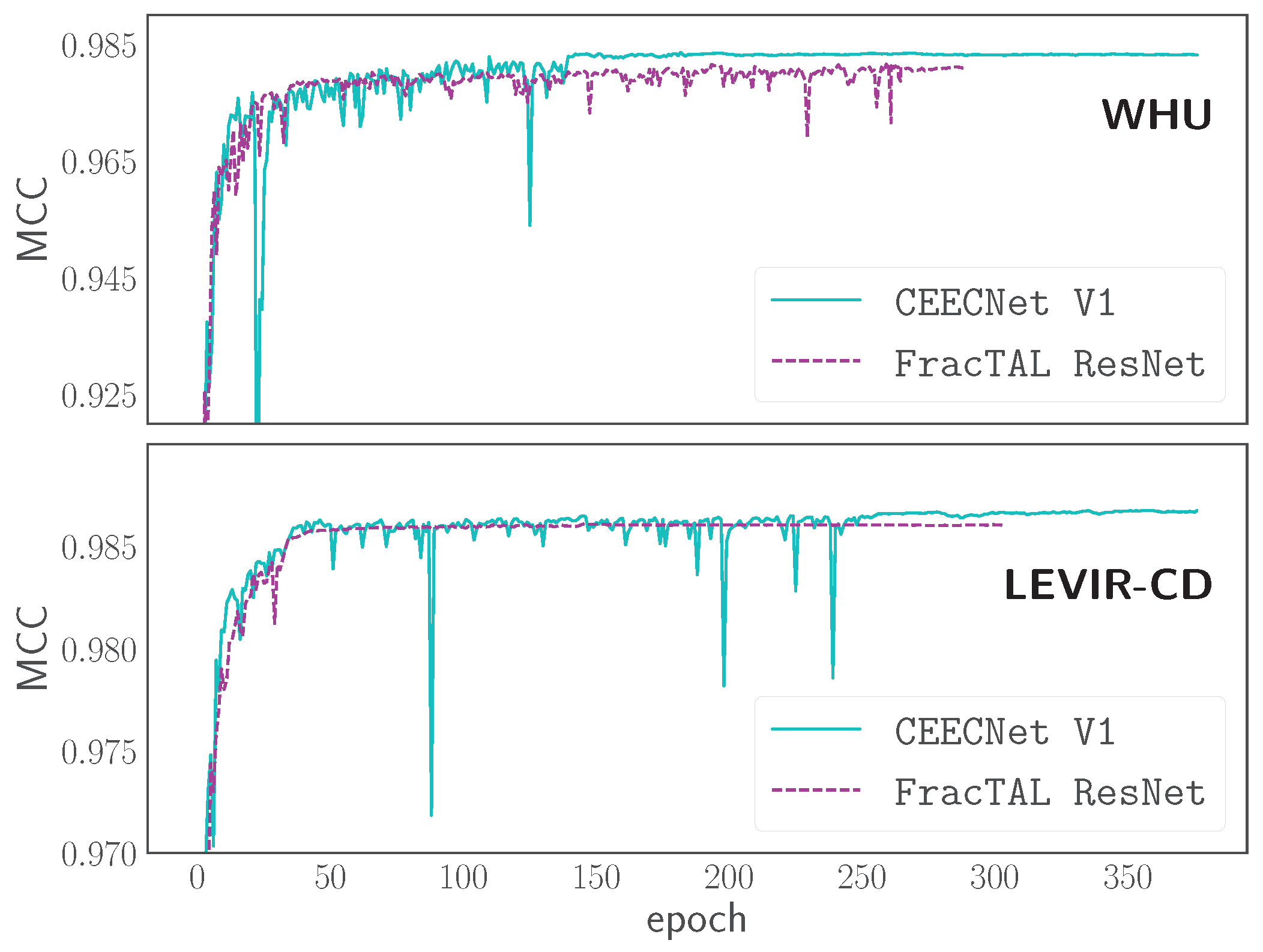
3.2. Change Detection Performance on LEVIRCD and WHU Datasets
3.2.1. Performance on LEVIRCD
3.2.2. Performance on WHU
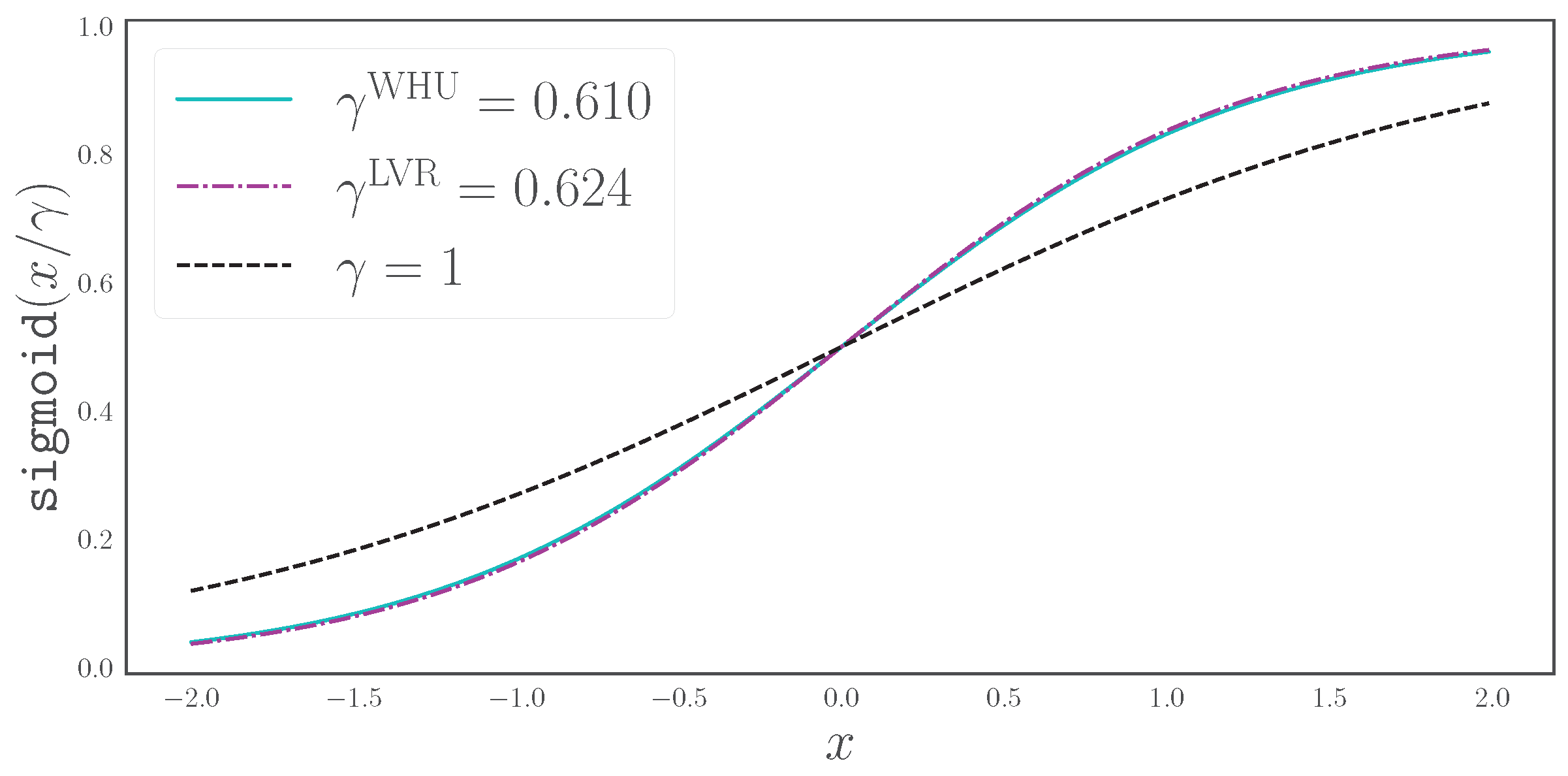
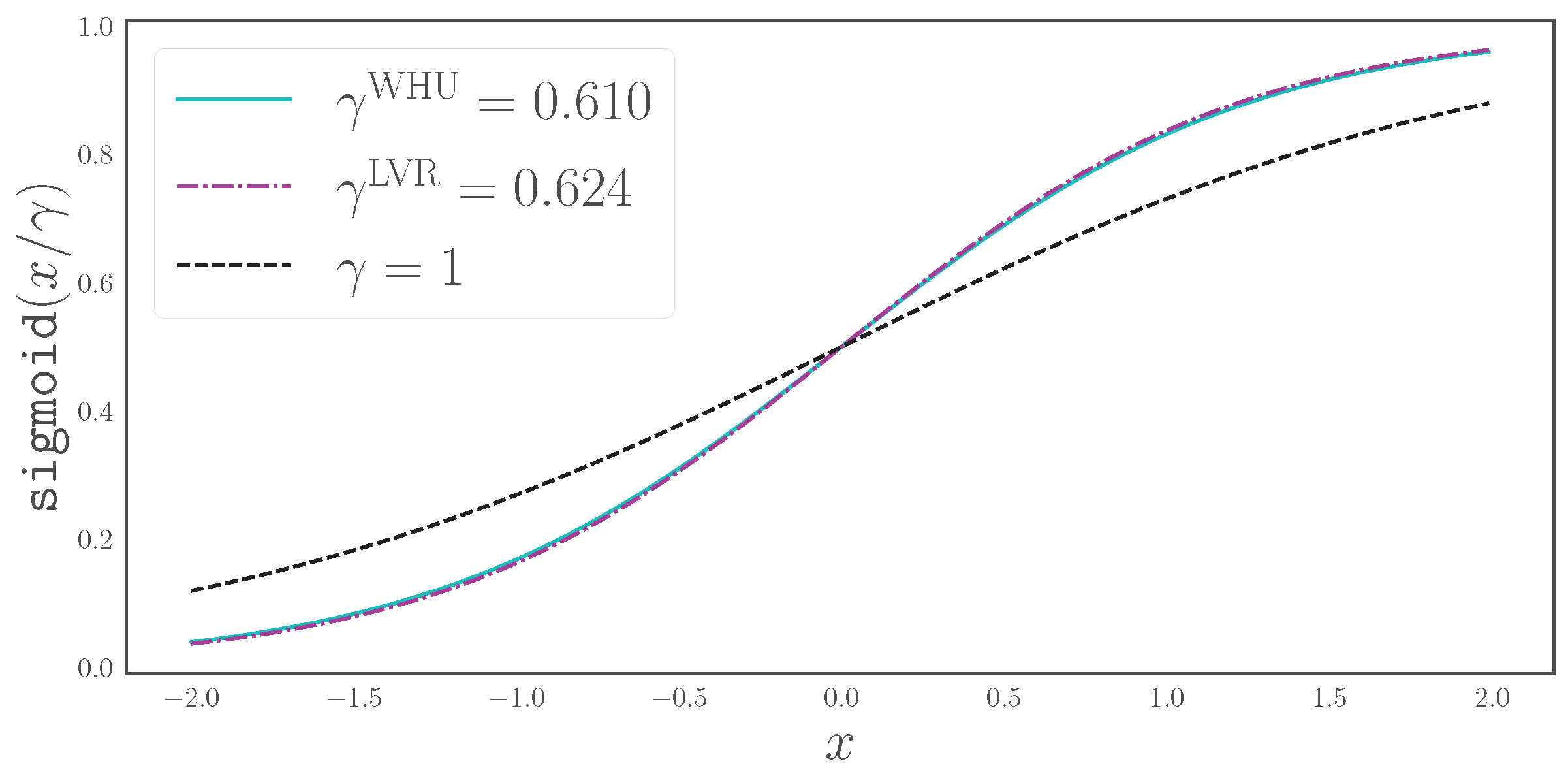
3.3. The Effect of Scaled Sigmoid on the Segmentation HEAD
4. Discussion
4.1. Qualitative CEECNet and FracTALPerformance
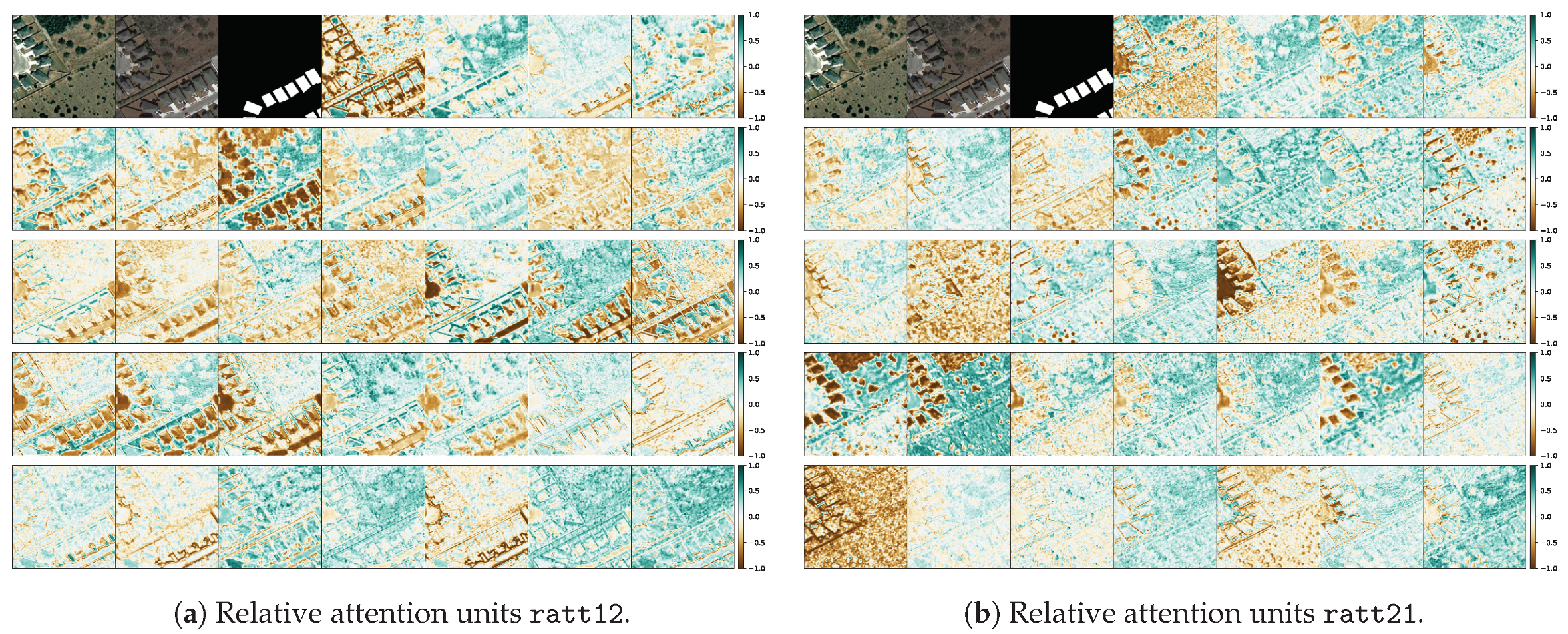
4.2. Qualitative Assesment of the Mantis Macro-Topology
5. Conclusions
- A novel set similarity coefficient, the fractal Tanimoto coefficient, that is derived from a variant of the Dice coefficient. This coefficient can provide finer detail of similarity at a desired level (up to a delta function), and this is regulated by a temperature-like hyperparameter, d (Figure 2).
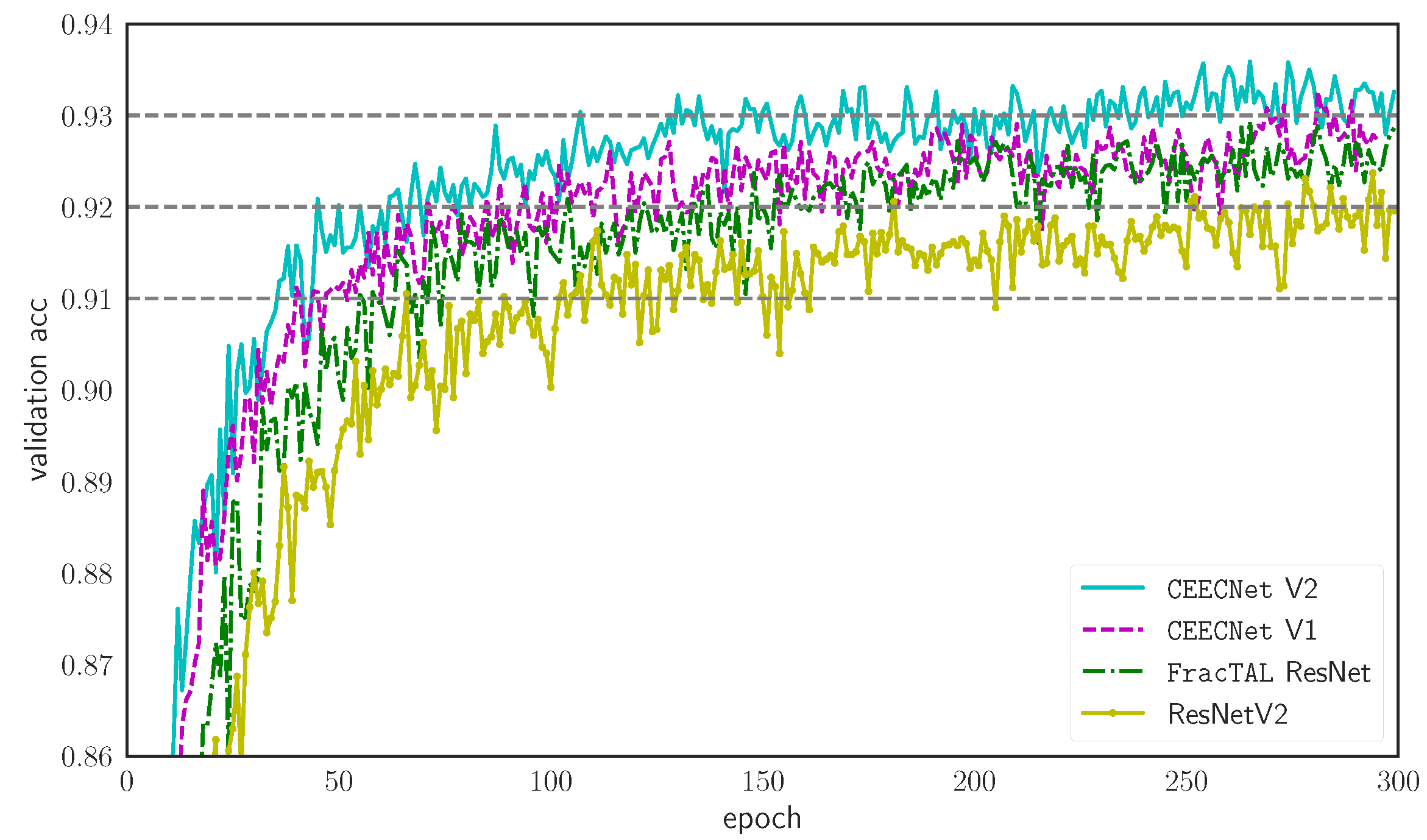
- A novel training loss scheme, where we use an evolving loss function, that changes according to learning rate reductions. This helps avoid overfitting and allows for a small increase in performance (Figure 11a,b). In particular, this scheme provided a ∼0.25% performance increase in validation accuracy on CIFAR10 tests, and performance increase of ∼0.9% on IoU and ∼0.5% on MCC on the LEVIRCD dataset.
- A novel spatial and channel attention layer, the fractal Tanimoto Attention Layer (FracTAL—see Listing A.2), that uses the fractal Tanimoto similarity coefficient as a means of quantifying the similarity between query and key entries. This layer is memory efficient and scales well with the size of input features.
- A novel building block, the FracTALResNet (Figure 4a), that has a small memory footprint and excellent convergent and performance properties that outperform standard ResNet building blocks.
- A corollary that follows from the introduced building blocks is a novel fusion methodology of layers and their corresponding attentions, both for self and relative attention, that improves performance (Figure 16). This methodology can be used as a direct replacement for concatenation in convolution neural networks.
- A novel macro-topology (backbone) architecture, the mantis topology (Figure 5), that combines the building blocks we developed and is able to consume images from two different dates and produce a single change detection layer. It should be noted that the same topology can be used in general segmentation problems, where we have two input images to a network that are somehow correlated and produce a semantic map. Moreover, it can be used for the fusion of features coming from different inputs (e.g., Digital Surface Maps and RGB images).
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. CIFAR10 Comparison Network Characteristics

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layers | Proposed Models | ResNet |
|---|---|---|
| Layer 1 | BBlock[nf = 64, nh = 8] | BBlock[nf = 64] |
| Layer 2 | BBlock[nf = 64, nh = 8 ] | BBlock[nf = 64] |
| Layer 3 | Conv2DN(nf = 128, s = 2) | Conv2DN(nf = 128, s = 2) |
| Layer 4 | BBlock[nf = 128, nh = 16] | BBlock[nf = 128] |
| Layer 5 | BBlock[nf = 128, nh = 16] | BBlock[nf = 128] |
| Layer 6 | Conv2DN(nf = 256, s = 2) | Conv2DN(nf = 256, s = 2) |
| Layer 7 | BBlock[ nf = 256, nh = 32] | BBlock[nf = 256] |
| Layer 8 | BBlock[ nf = 256, nh = 32] | BBlock[nf = 256] |
| Layer 9 | ReLU | ReLU |
| Layer 10 | DenseN(nf = 4096) | DenseN(nf = 4096) |
| Layer 11 | ReLU | ReLU |
| Layer 12 | DenseN(nf = 512) | DenseN(nf = 512) |
| Layer 13 | ReLU | ReLU |
| Layer 14 | DenseN(nf = 10) | DenseN(nf = 10) |
Appendix B. Inference across WHU Test Set

Appendix C. Algorithms
Appendix C.1. Fractal Tanimoto Attention 2D Module
| from mxnet.gluon import nn class FTanimoto(nn.Block): def __init__(self,depth=5, axis=[2,3],**kwards): super().__init__(**kwards) self.depth = depth self.axis=axis def inner_prod(self, prob, label): prdct = prob*label #dim:(B,C,H,W) prdct = prdct.sum(axis=self.axis,keepdims=True) return prdct #dim:(B,C,1,1) def forward(self, prob, label): a = 2.**self.depth b = -(2.*a-1.) tpl= self.inner_prod(prob,label) tpp= self.inner_prod(prob,prob) tll= self.inner_prod(label,label) denum = a*(tpp+tll)+b*tpl ftnmt = tpl/denum return ftnmt #dim:(B,C,1,1) |
| from mxnet import nd as F from mxnet.gluon import nn class FTAttention2D(nn.Block): def __init__(self, nchannels, nheads, **kwards): super().__init__(**kwards) self.q = Conv2DN(nchannels,groups=nheads) self.k = Conv2DN(nchannels,groups=nheads) self.v = Conv2DN(nchannels,groups=nheads) # spatial/channel similarity self.SpatialSim = FTanimoto(axis=[2,3]) self.ChannelSim = FTanimoto(axis=1) self.norm = nn.BatchNorm() def forward(self, qin, kin, vin): # query, key, value q = F.sigmoid(self.q(qin))#dim:(B,C,H,W) k = F.sigmoid(self.k(vin))#dim:(B,C,H,W) vs. = F.sigmoid(self.v(kin))#dim:(B,C,H,W) att_spat = self.ChannelSim(q,k)#dim:(B,1,H,W) v_spat = att_spat*v #dim:(B,C,H,W) att_chan = self.SpatialSim(q,k)#dim:(B,C,1,1) v_chan = att_chan*v #dim:(B,C,H,W) v_cspat = 0.5*(v_chan+v_spat) v_cspat = self.norm(v_cspat) return v_cspat #dim:(B,C,H,W) |
| import mxnet as mx from mxnet import nd as F class Fusion(nn.Block): def __init__(self, nchannels, nheads, **kwards): super().__init__(**kwards) self.fuse = Conv2DN(nchannels, kernel=3, padding=1, groups=nheads) self.att12 = FTAttention2D(nchannels,nheads) self.att21 = FTAttention2D(nchannels,nheads) self.gamma1 = self.params.get(’gamma1’, shape=(1,), init=mx.init.Zero()) self.gamma2 = self.params.get(’gamma2’, shape=(1,), init=mx.init.Zero()) def forward(self, input1,input2): ones = nd.ones_like(input1) # Attention on 1, for k,v from 2 qin = input1 kin = input2 vin = input2 att12 = self.att12(qin,kin,vin) out12 = input1*(ones+self.gamma1*att12) # Attention on 2, for k,v from 1 qin = input2 kin = input1 vin = input1 att21 = self.att21(qin,kin,vin) out21 = input2*(ones+self.gamma2*att21) out = nd.concat(out12,out21,dim=1) out = self.fuse(out) return out |
Appendix C.2. FracTALResNet
| import mxnet as mx from mxnet import nd as F class FTAttResUnit(nn.Block): def __init__(self, nchannels, nheads, **kwards): super().__init__(**kwards) # Residual Block: sequence of # (BN,ReLU,Conv,BN,ReLU,Conv) self.ResBlock = ResBlock(nchannels, kernel=3, padding=1) self.att = FTAttention2D(nchannels,nheads) self.gamma = self.params.get(’gamma’, shape=(1,), init=mx.init.Zero()) def forward(self, input): out = self.ResBlock(input)#dim:(B,C,H,W) qin = input vin = input kin = input att = self.attention(qin,vin,kin)#dim:(B,C,H,W) att = self.gamma * att out = (input + out)*(F.ones_like(out)+att) return out |
Appendix C.3. CEECNet Building Blocks
| import mxnet as mx from mxnet import nd as F class CEECNet_unit_V1(nn.Block): def __init__(self, nchannels, nheads, **kwards): super().__init__(**kwards) # Compress-Expand self.conv1= Conv2DN(nchannels/2) self.compr11= Conv2DN(nchannels,k=3,p=1,s=2) self.compr12= Conv2DN(nchannels,k=3,p=1,s=1) self.expand1= ExpandNComb(nchannels/2) # Expand Compress self.conv2= Conv2DN(nchannels/2) self.expand2= Expand(nchannels/4) self.compr21= Conv2DN(nchannels/2,k=3,p=1,s=2) self.compr22= Conv2DN(nchannels/2,k=3,p=1,s=1) self.collect= Conv2DN(nchannels,k=3,p=1,s=1) self.att= FTAttention2D(nchannels,nheads) self.ratt12= RelFTAttention2D(nchannels,nheads) self.ratt21= RelFTAttention2D(nchannels,nheads) self.gamma1 = self.params.get(’gamma1’, shape=(1,), init=mx.init.Zero()) self.gamma2 = self.params.get(’gamma2’, shape=(1,), init=mx.init.Zero()) self.gamma3 = self.params.get(’gamma3’, shape=(1,), init=mx.init.Zero()) def forward(self, input): # Compress-Expand out10 = self.conv1(input) out1 = self.compr11(out10) out1 = F.relu(out1) out1 = self.compr12(out1) out1 = F.relu(out1) out1 = self.expand1(out1,out10) out1 = F.relu(out1) # Expand-Compress out20 = self.conv2(input) out2 = self.expand2(out20) out2 = F.relu(out2) out2 = self.compr21(out2) out2 = F.relu(out2) out2 = F.concat([out2,out20],axis=1) out2 = self.compr22(out2) out2 = F.relu(out2) # attention att = self.gamma1*self.att(input) # relative attention 122 qin = out1 kin = out2 vin = out2 ratt12 = self.gamma2*self.ratt12(qin,kin,vin) # relative attention 211 qin = out2 kin = out1 vin = out1 ratt21 = self.gamma3*self.ratt21(qin,kin,vin) ones1 = F.ones_like(out10)# nchannels/2 out122= out1*(ones1+ratt12) out211= out2*(ones1+ratt21) out12 = F.concat([out122,out211],dim=1) out12 = self.collect(out12) out12 = F.relu(out12) # Final fusion ones2 = F.ones_like(input) out = (input+out12)*(ones2+att) return out |
| import mxnet as mx from mxnet import nd as F class Expand(nn.Block): def __init__(self, nchannels, nheads, **kwards): super().__init__(**kwards) self.conv1 = Conv2DN(nchannels,k=3, p=1, groups=nheads) self.conv2 = Conv2DN(nchannels,k=3, p=1, groups=nheads) def forward(self, input): out = F.BilinearResize2D(input, scale_height=2, scale_width=2) out = self.conv1(out) out = F.relu(out) out = self.conv2(out) out = F.relu(out) return out |
| import mxnet as mx from mxnet import nd as F class ExpandNCombine(nn.Block): def __init__(self, nchannels, nheads, **kwards): super().__init__(**kwards) self.conv1 = Conv2DN(nchannels,k=3, p=1, groups=nheads) self.conv2 = Conv2DN(nchannels,k=3, p=1, groups=nheads) def forward(self, input1,input2): # input1 has lower spatial dimensions out1 = F.BilinearResize2D(input1, scale_height=2, scale_width=2) out1 = self.conv1(out1) out1 = F.relu(out1) out2= F.concat([out1,input2],dim=1) out2 = self.conv2(out2) out2 = F.relu(out2) return out2 |
Appendix D. Software Implementation and Training Characteristics
References
- Chen, H.; Shi, Z. A Spatial-Temporal Attention-Based Method and a New Dataset for Remote Sensing Image Change Detection. Remote Sens. 2020, 12, 1662. [Google Scholar] [CrossRef]
- Giustarini, L.; Hostache, R.; Matgen, P.; Schumann, G.J.P.; Bates, P.D.; Mason, D.C. A change detection approach to flood mapping in urban areas using TerraSAR-X. IEEE Trans. Geosci. Remote Sens. 2012, 51, 2417–2430. [Google Scholar] [CrossRef] [Green Version]
- Morton, D.C.; DeFries, R.S.; Shimabukuro, Y.E.; Anderson, L.O.; Del Bon Espírito-Santo, F.; Hansen, M.; Carroll, M. Rapid assessment of annual deforestation in the Brazilian Amazon using MODIS data. Earth Interact. 2005, 9, 1–22. [Google Scholar] [CrossRef] [Green Version]
- Löw, F.; Prishchepov, A.V.; Waldner, F.; Dubovyk, O.; Akramkhanov, A.; Biradar, C.; Lamers, J. Mapping cropland abandonment in the Aral Sea Basin with MODIS time series. Remote Sens. 2018, 10, 159. [Google Scholar] [CrossRef] [Green Version]
- Caye Daudt, R.; Le Saux, B.; Boulch, A.; Gousseau, Y. Multitask learning for large-scale semantic change detection. Comput. Vis. Image Underst. 2019, 187, 102783. [Google Scholar] [CrossRef] [Green Version]
- Varghese, A.; Gubbi, J.; Ramaswamy, A.; Balamuralidhar, P. ChangeNet: A Deep Learning Architecture for Visual Change Detection. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Lu, D.; Mausel, P.; Brondizio, E.; Moran, E. Change detection techniques. Int. J. Remote Sens. 2004, 25, 2365–2401. [Google Scholar] [CrossRef]
- Coppin, P.; Jonckheere, I.; Nackaerts, K.; Muys, B.; Lambin, E. Review ArticleDigital change detection methods in ecosystem monitoring: A review. Int. J. Remote Sens. 2004, 25, 1565–1596. [Google Scholar] [CrossRef]
- Tewkesbury, A.P.; Comber, A.J.; Tate, N.J.; Lamb, A.; Fisher, P.F. A critical synthesis of remotely sensed optical image change detection techniques. Remote Sens. Environ. 2015, 160, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Hussain, M.; Chen, D.; Cheng, A.; Wei, H.; Stanley, D. Change detection from remotely sensed images: From pixel-based to object-based approaches. ISPRS J. Photogramm. Remote Sens. 2013, 80, 91–106. [Google Scholar] [CrossRef]
- Treisman, A.M.; Gelade, G. A feature-integration theory of attention. Cogn. Psychol. 1980, 12, 97–136. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Cho, K.; van Merrienboer, B.; Bahdanau, D.; Bengio, Y. On the Properties of Neural Machine Translation: Encoder-Decoder Approaches. arXiv 2014, arXiv:1409.1259. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. arXiv 2017, arXiv:1709.01507. [Google Scholar]
- Wang, X.; Girshick, R.B.; Gupta, A.; He, K. Non-local Neural Networks. arXiv 2017, arXiv:1711.07971. [Google Scholar]
- Chen, L.; Zhang, H.; Xiao, J.; Nie, L.; Shao, J.; Chua, T. SCA-CNN: Spatial and Channel-wise Attention in Convolutional Networks for Image Captioning. arXiv 2016, arXiv:1611.05594. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 3–19. [Google Scholar]
- Bello, I.; Zoph, B.; Vaswani, A.; Shlens, J.; Le, Q.V. Attention Augmented Convolutional Networks. arXiv 2019, arXiv:1904.09925. [Google Scholar]
- Katharopoulos, A.; Vyas, A.; Pappas, N.; Fleuret, F. Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention. arXiv 2020, arXiv:2006.16236. [Google Scholar]
- Li, R.; Su, J.; Duan, C.; Zheng, S. Multistage Attention ResU-Net for Semantic Segmentation of Fine-Resolution Remote Sensing Images. arXiv 2020, arXiv:2011.14302. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Sakurada, K.; Okatani, T. Change Detection from a Street Image Pair using CNN Features and Superpixel Segmentation. In Proceedings of the BMVC, Swansea, UK, 7–10 September 2015. [Google Scholar]
- Alcantarilla, P.F.; Stent, S.; Ros, G.; Arroyo, R.; Gherardi, R. Street-View Change Detection with Deconvolutional Networks. Robot. Sci. Syst. 2016. [Google Scholar] [CrossRef]
- Guo, E.; Fu, X.; Zhu, J.; Deng, M.; Liu, Y.; Zhu, Q.; Li, H. Learning to Measure Change: Fully Convolutional Siamese Metric Networks for Scene Change Detection. arXiv 2018, arXiv:1810.09111. [Google Scholar]
- Asokan, A.; Anitha, J. Change detection techniques for remote sensing applications: A survey. Earth Sci. Inform. 2019, 12, 143–160. [Google Scholar] [CrossRef]
- Shi, W.; Zhang, M.; Zhang, R.; Chen, S.; Zhan, Z. Change Detection Based on Artificial Intelligence: State-of-the-Art and Challenges. Remote Sens. 2020, 12, 1688. [Google Scholar] [CrossRef]
- Ji, S.; Shen, Y.; Lu, M.; Zhang, Y. Building Instance Change Detection from Large-Scale Aerial Images using Convolutional Neural Networks and Simulated Samples. Remote Sens. 2019, 11, 1343. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R.B. Mask R-CNN. arXiv 2017, arXiv:1703.06870. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- Chen, J.; Yuan, Z.; Peng, J.; Chen, L.; Huang, H.; Zhu, J.; Liu, Y.; Li, H. DASNet: Dual Attentive Fully Convolutional Siamese Networks for Change Detection in High-Resolution Satellite Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 1194–1206. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Jiang, H.; Hu, X.; Li, K.; Zhang, J.; Gong, J.; Zhang, M. PGA-SiamNet: Pyramid Feature-Based Attention-Guided Siamese Network for Remote Sensing Orthoimagery Building Change Detection. Remote Sens. 2020, 12, 484. [Google Scholar] [CrossRef] [Green Version]
- Lu, X.; Wang, W.; Ma, C.; Shen, J.; Shao, L.; Porikli, F. See More, Know More: Unsupervised Video Object Segmentation with Co-Attention Siamese Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P.; Wu, C. ResUNet-a: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS J. Photogramm. Remote Sens. 2020, 162, 94–114. [Google Scholar] [CrossRef] [Green Version]
- Ji, S.; Wei, S.; Lu, M. Fully Convolutional Networks for Multisource Building Extraction From an Open Aerial and Satellite Imagery Data Set. IEEE Trans. Geosci. Remote Sens. 2019, 57, 574–586. [Google Scholar] [CrossRef]
- Zhang, A.; Lipton, Z.C.; Li, M.; Smola, A.J. Dive into Deep Learning. 2020. Available online: https://d2l.ai (accessed on 1 January 2021).
- Kim, Y.; Denton, C.; Hoang, L.; Rush, A.M. Structured Attention Networks. arXiv 2017, arXiv:1702.00887. [Google Scholar]
- Zhang, H.; Goodfellow, I.; Metaxas, D.; Odena, A. Self-Attention Generative Adversarial Networks. arXiv 2018, arXiv:1805.08318. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity Mappings in Deep Residual Networks. arXiv 2016, arXiv:1603.05027. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked Hourglass Networks for Human Pose Estimation. arXiv 2016, arXiv:1603.06937. [Google Scholar]
- Liu, J.; Wang, S.; Hou, X.; Song, W. A deep residual learning serial segmentation network for extracting buildings from remote sensing imagery. Int. J. Remote Sens. 2020, 41, 5573–5587. [Google Scholar] [CrossRef]
- Qin, X.; Zhang, Z.; Huang, C.; Dehghan, M.; Zaiane, O.R.; Jagersand, M. U2-Net: Going deeper with nested U-structure for salient object detection. Pattern Recognit. 2020, 106, 107404. [Google Scholar] [CrossRef]
- Lindeberg, T. Scale-Space Theory in Computer Vision; Kluwer Academic Publishers: Norwell, MA, USA, 1994; ISBN 978-0-7923-9418-1. [Google Scholar]
- Wang, Z.; Chen, J.; Hoi, S.C.H. Deep Learning for Image Super-resolution: A Survey. arXiv 2019, arXiv:1902.06068. [Google Scholar] [CrossRef] [Green Version]
- Tschannen, M.; Bachem, O.; Lucic, M. Recent Advances in Autoencoder-Based Representation Learning. arXiv 2018, arXiv:1812.05069. [Google Scholar]
- Kingma, D.P.; Welling, M. An Introduction to Variational Autoencoders. arXiv 2019, arXiv:1906.02691. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the CVPR, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Waldner, F.; Diakogiannis, F.I. Deep learning on edge: Extracting field boundaries from satellite images with a convolutional neural network. Remote Sens. Environ. 2020, 245, 111741. [Google Scholar] [CrossRef]
- Wu, Y.; He, K. Group Normalization. arXiv 2018, arXiv:1803.08494. [Google Scholar]
- Haghighi, S.; Jasemi, M.; Hessabi, S.; Zolanvari, A. PyCM: Multiclass confusion matrix library in Python. J. Open Source Softw. 2018, 3, 729. [Google Scholar] [CrossRef] [Green Version]
- Matthews, B. Comparison of the predicted and observed secondary structure of T4 phage lysozyme. Biochim. Biophys. Acta (BBA) Protein Struct. 1975, 405, 442–451. [Google Scholar] [CrossRef]
- Emmerich, M.T.; Deutz, A.H. A Tutorial on Multiobjective Optimization: Fundamentals and Evolutionary Methods. Nat. Comput. Int. J. 2018, 17, 585–609. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images; Technical Report; Citeseer: Princeton, NJ, USA, 2009. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Cao, Z.; Wu, M.; Yan, R.; Zhang, F.; Wan, X. Detection of Small Changed Regions in Remote Sensing Imagery Using Convolutional Neural Network. IOP Conf. Ser. Earth Environ. Sci. 2020, 502, 012017. [Google Scholar] [CrossRef]
- Liu, Y.; Pang, C.; Zhan, Z.; Zhang, X.; Yang, X. Building Change Detection for Remote Sensing Images Using a Dual Task Constrained Deep Siamese Convolutional Network Model. arXiv 2019, arXiv:1909.07726. [Google Scholar]
- Waldner, F.; Diakogiannis, F.I.; Batchelor, K.; Ciccotosto-Camp, M.; Cooper-Williams, E.; Herrmann, C.; Mata, G.; Toovey, A. Detect, Consolidate, Delineate: Scalable Mapping of Field Boundaries Using Satellite Images. Remote Sens. 2021, 13, 2197. [Google Scholar] [CrossRef]
- Chen, T.; Li, M.; Li, Y.; Lin, M.; Wang, N.; Wang, M.; Xiao, T.; Xu, B.; Zhang, C.; Zhang, Z. Mxnet: A flexible and efficient machine learning library for heterogeneous distributed systems. arXiv 2015, arXiv:1512.01274. [Google Scholar]
- Sergeev, A.; Balso, M.D. Horovod: Fast and easy distributed deep learning in TensorFlow. arXiv 2018, arXiv:1802.05799. [Google Scholar]













| Model | FracTAL Depth | Loss Strategy | Precision | Recall | F1 | MCC | IoU | Model Params |
|---|---|---|---|---|---|---|---|---|
| Chen and Shi [1] | - | - | 83.80 | 91.00 | 87.30 | - | - | - |
| CEECNetV1 | sta, | 93.36 | 89.46 | 91.37 | 90.94 | 84.10 | 49.2 M | |
| CEECNetV1 | evo, | 93.73 | (89.93) | (91.79) | (91.38) | (84.82) | 49.2 M | |
| CEECNetV2 | evo, | 93.81 | 89.92 | 91.83 | 91.42 | 84.89 | 92.4 M | |
| FracTALResNet | evo, | 93.50 | 89.79 | 91.61 | 91.20 | 84.51 | 20.1 M | |
| FracTALResNet | evo, | 93.60 | 89.38 | 91.44 | 91.02 | 84.23 | 20.1 M | |
| FracTALResNet | evo, | (93.63) | 90.04 | 91.80 | 91.39 | 84.84 | 20.1 M |
| Model | FracTAL Depth | Loss Strategy | Precision | Recall | F1 | MCC | IoU |
|---|---|---|---|---|---|---|---|
| Ji et al. [28] M1 | - | - | 93.100 | 89.200 | (91.108) | - | (83.70) |
| Ji et al. [28] M2 | - | - | 93.800 | 87.800 | 90.700 | - | 83.00 |
| Chen et al. [31] | - | - | 89.2 | (90.5) | 89.80 | - | - |
| Cao et al. [57] | - | - | (94.00) | 79.37 | 86.07 | - | - |
| Liu et al. [58] | - | - | 90.15 | 89.35 | 89.75 | - | 81.40 |
| FracTALResNet | evo, | 95.350 | 90.873 | 93.058 | 92.892 | 87.02 | |
| CEECNetV1 | evo, | 95.571 | 92.043 | 93.774 | 93.616 | 88.23 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Diakogiannis, F.I.; Waldner, F.; Caccetta, P. Looking for Change? Roll the Dice and Demand Attention. Remote Sens. 2021, 13, 3707. https://doi.org/10.3390/rs13183707
Diakogiannis FI, Waldner F, Caccetta P. Looking for Change? Roll the Dice and Demand Attention. Remote Sensing. 2021; 13(18):3707. https://doi.org/10.3390/rs13183707
Chicago/Turabian StyleDiakogiannis, Foivos I., François Waldner, and Peter Caccetta. 2021. "Looking for Change? Roll the Dice and Demand Attention" Remote Sensing 13, no. 18: 3707. https://doi.org/10.3390/rs13183707
APA StyleDiakogiannis, F. I., Waldner, F., & Caccetta, P. (2021). Looking for Change? Roll the Dice and Demand Attention. Remote Sensing, 13(18), 3707. https://doi.org/10.3390/rs13183707