
Land Use Land Cover Classification with U-Net: Advantages of Combining Sentinel-1 and Sentinel-2 Imagery




Abstract
:
1. Introduction
2. Materials and Methods
2.1. Study Site
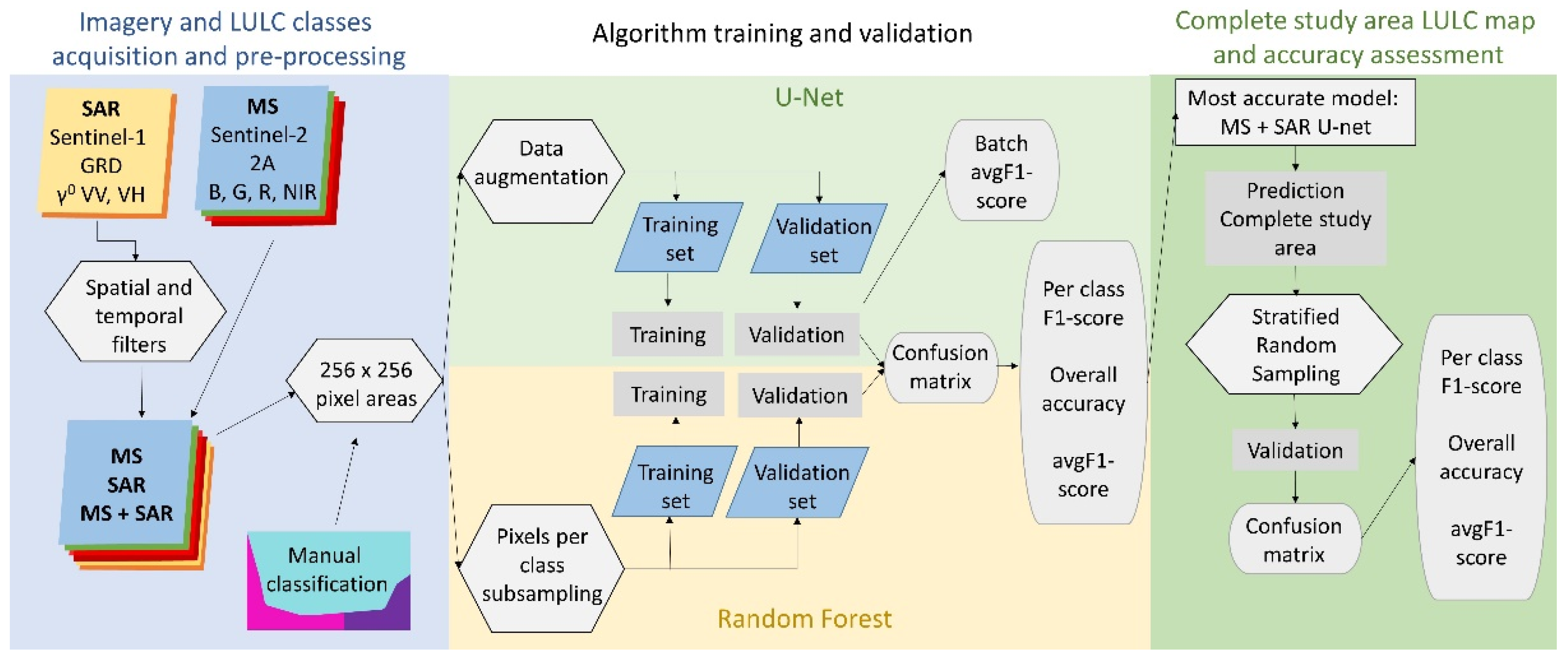
2.2. Imagery and LULC Classes Acquisition and Pre-Processing
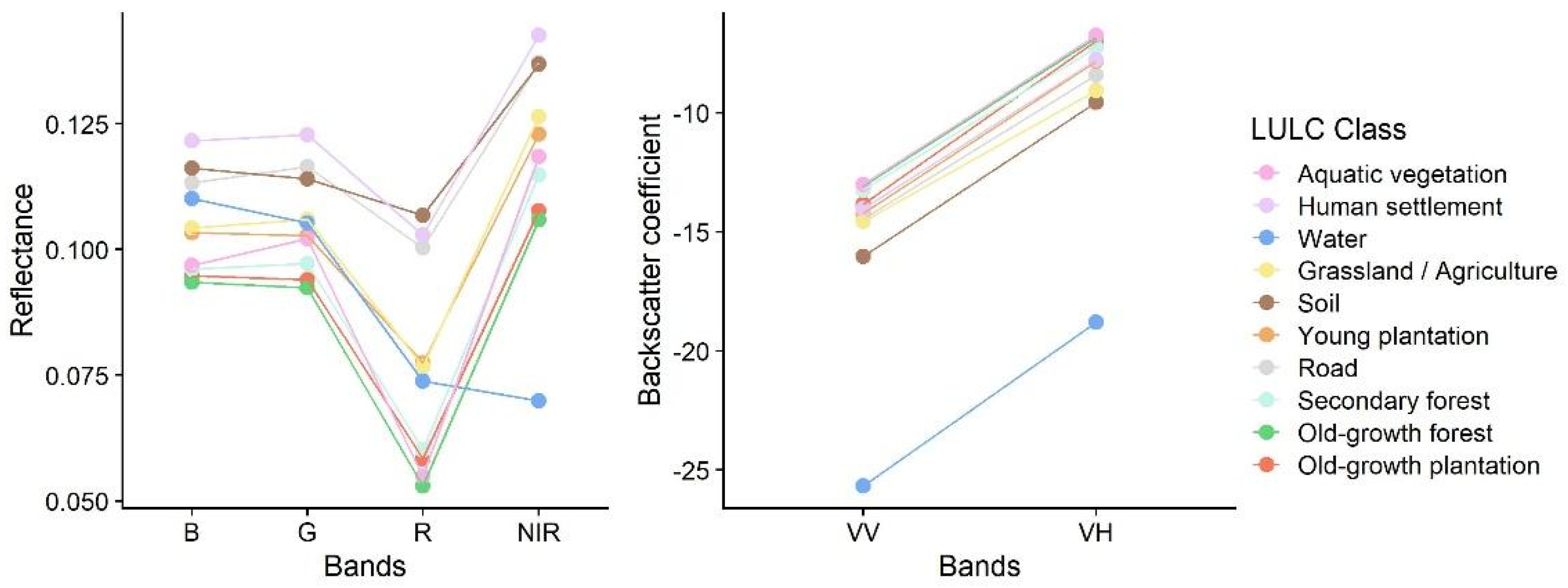
2.2.1. Remote Sensing Input Imagery
2.2.2. Acquisition of Training and Validation Data
2.3. Algorithm Training and Validation
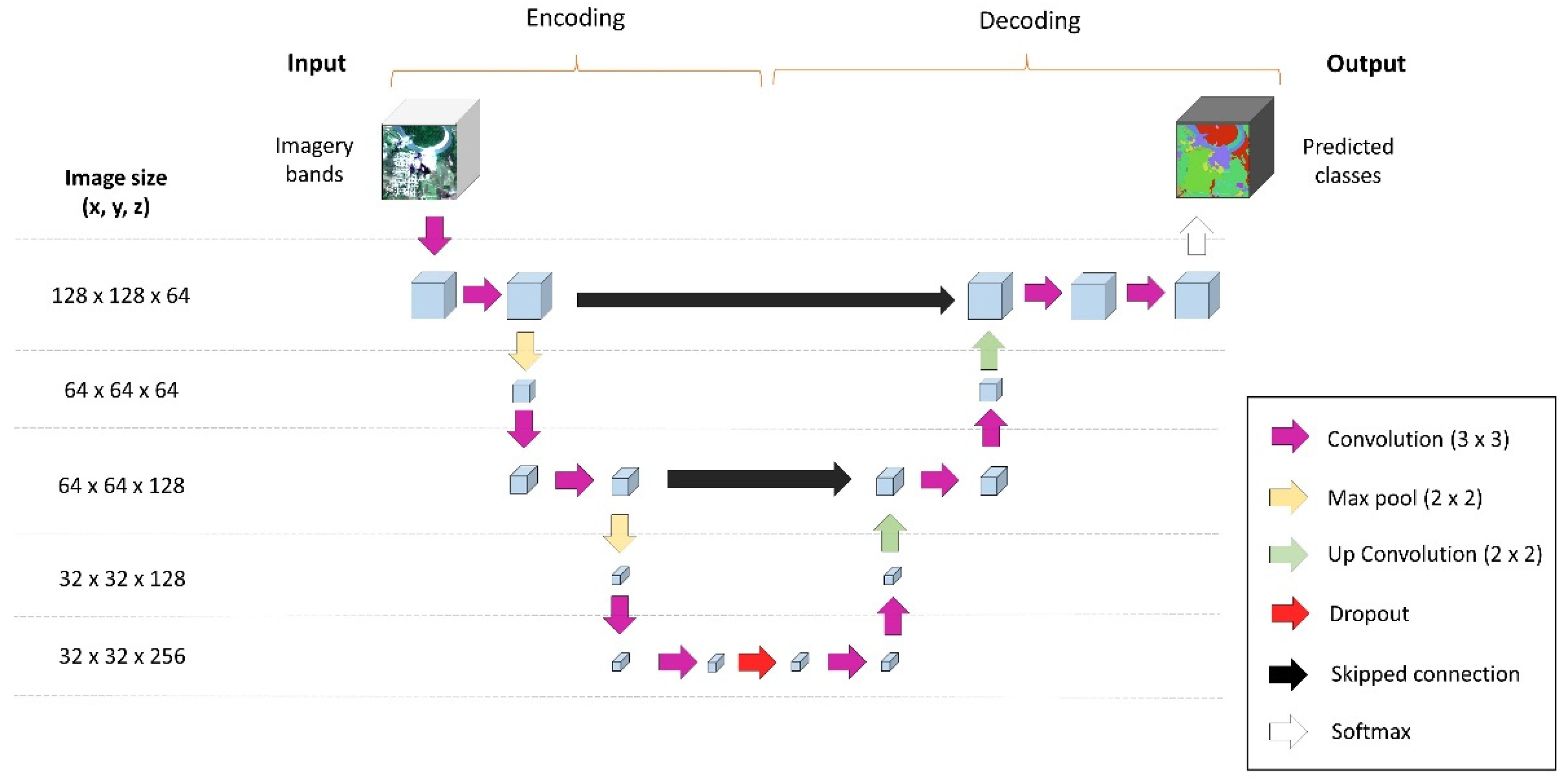
2.3.1. U-Net
2.3.2. Random Forests
2.4. Complete Study Area LULC Classification and Accuracy Assessment
3. Results
3.1. U-Net
3.1.1. Input Imagery and Hyperparameter Exploration
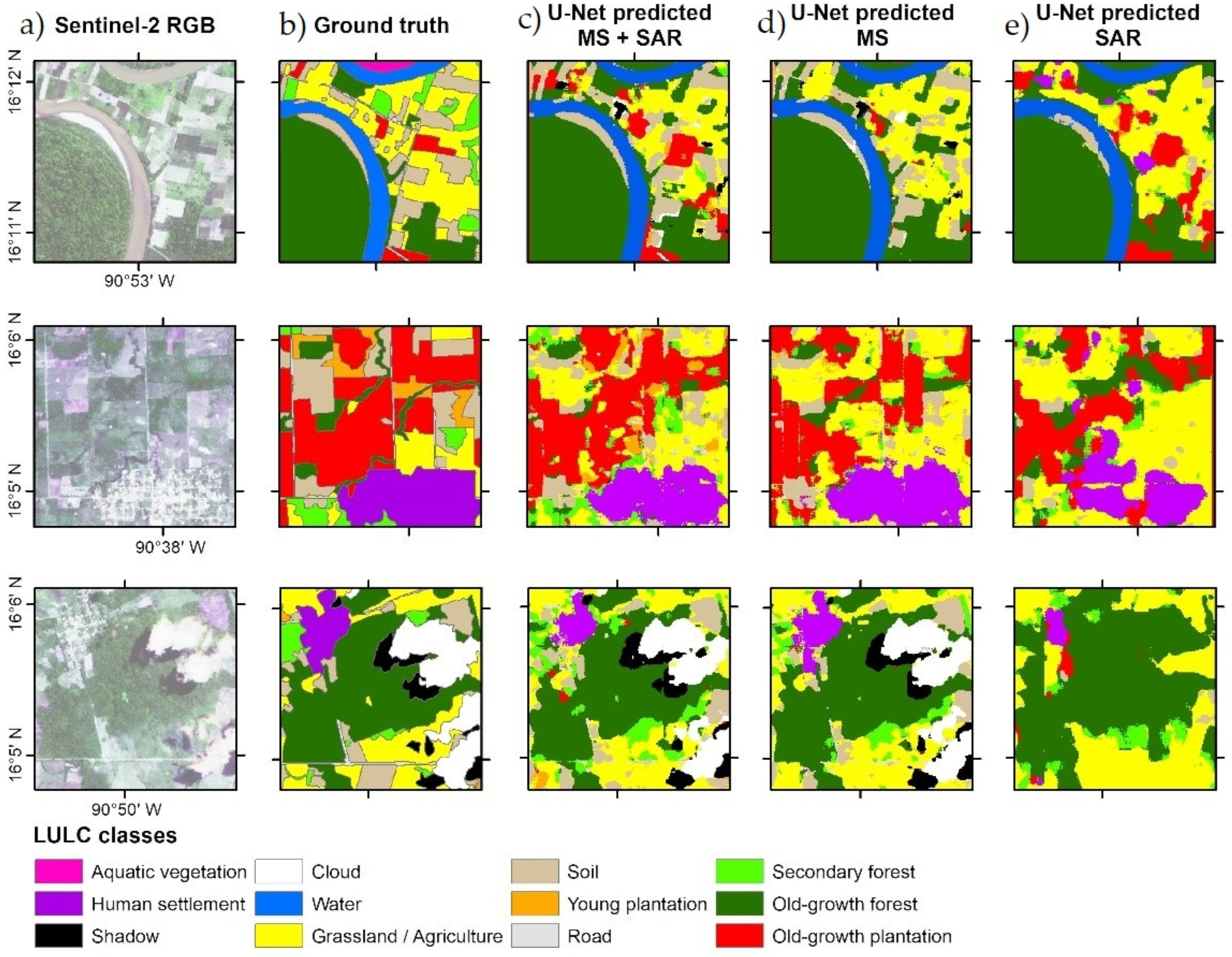
3.1.2. Image Input Comparison
3.2. Algorithm Comparison
3.3. Complete Study Area LULC Classification
4. Discussion
4.1. Algorithm Selection
4.2. U-Net: Imagery Input
4.2.1. Class Patterns
4.2.2. Hyperparameters Exploration
4.3. Error Analysis
4.4. Comparisons with Similar Studies
4.5. Methodological Highlights
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| AV | G/A | HS | OF | OP | R | SF | So | W | YP | User acc | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| AV | 594 | 115 | 0 | 240 | 0 | 0 | 0 | 0 | 0 | 0 | 0.63 |
| G/A | 0 | 902,138 | 11,583 | 35,162 | 25,472 | 23,834 | 64,813 | 88,484 | 322 | 22,190 | 0.76 |
| HS | 0 | 6917 | 159,892 | 627 | 1278 | 2810 | 2010 | 1926 | 0 | 13 | 0.91 |
| OF | 6001 | 55,782 | 5081 | 1,372,026 | 116,552 | 3245 | 68,833 | 3980 | 1595 | 3938 | 0.82 |
| OP | 0 | 22,157 | 238 | 26,673 | 246,789 | 3790 | 15,303 | 1667 | 128 | 26,695 | 0.72 |
| R | 0 | 8587 | 3488 | 895 | 2364 | 21,636 | 986 | 10,066 | 0 | 653 | 0.44 |
| SF | 0 | 67,145 | 8288 | 67,390 | 49,581 | 2463 | 143,531 | 1287 | 0 | 5531 | 0.41 |
| So | 21 | 48,149 | 1745 | 3046 | 1413 | 12,314 | 1363 | 181,030 | 1041 | 2280 | 0.69 |
| W | 170 | 855 | 1 | 775 | 44 | 0 | 9 | 272 | 59,215 | 0 | 0.97 |
| YP | 0 | 8338 | 197 | 164 | 12,528 | 927 | 1104 | 2668 | 0 | 5159 | 0.17 |
| Prod acc | 0.09 | 0.80 | 0.84 | 0.91 | 0.54 | 0.30 | 0.48 | 0.61 | 0.95 | 0.08 | |
| Overall accuracy | 0.76 | ||||||||||
| Batch avgF1-score | 0.72 | ||||||||||
| Overall avgF1-score | 0.58 | ||||||||||
| AV | G/A | HS | OF | OP | R | SF | So | W | YP | User Acc | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| AV | 397 | 327 | 0 | 25 | 8 | 0 | 62 | 0 | 0 | 0 | 0.48 |
| G/A | 109 | 945,076 | 12,870 | 38,984 | 58,029 | 24,740 | 105,371 | 103,450 | 45 | 33,760 | 0.71 |
| HS | 0 | 8727 | 171,136 | 1782 | 4255 | 5038 | 4903 | 5070 | 0 | 130 | 0.85 |
| OF | 5497 | 57,945 | 2401 | 1,386,121 | 136,575 | 3906 | 71,614 | 3827 | 324 | 14,346 | 0.81 |
| OP | 1 | 23,140 | 381 | 34,138 | 206,132 | 2072 | 23,195 | 1857 | 0 | 10,017 | 0.68 |
| R | 0 | 7045 | 1256 | 1393 | 1861 | 26,717 | 1382 | 11,403 | 0 | 561 | 0.52 |
| SF | 317 | 43,758 | 1888 | 43,919 | 45,045 | 870 | 89,761 | 338 | 1 | 5930 | 0.39 |
| So | 13 | 32,971 | 771 | 1631 | 899 | 8216 | 768 | 162,686 | 536 | 697 | 0.76 |
| W | 451 | 1104 | 0 | 916 | 82 | 0 | 38 | 409 | 61,225 | 0 | 0.95 |
| YP | 0 | 2316 | 1 | 171 | 3178 | 129 | 368 | 1180 | 0 | 1001 | 0.12 |
| Prod acc | 0.06 | 0.84 | 0.90 | 0.91 | 0.45 | 0.37 | 0.30 | 0.55 | 0.98 | 0.02 | |
| Overall accuracy | 0.76 | ||||||||||
| Batch avgF1-score | 0.72 | ||||||||||
| Overall avgF1-score | 0.55 | ||||||||||
| AV | G/A | HS | OF | OP | R | SF | So | W | YP | User Acc | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| AV | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.00 |
| G/A | 1 | 944,129 | 26,365 | 115,271 | 50,653 | 48,227 | 103,875 | 199,658 | 124 | 33,311 | 0.62 |
| HS | 0 | 14,585 | 79,076 | 19,238 | 23,998 | 2662 | 7312 | 5583 | 0 | 3997 | 0.51 |
| OF | 6561 | 150,845 | 70,460 | 1,512,101 | 183,508 | 13,216 | 138,688 | 24,125 | 1727 | 6467 | 0.72 |
| OP | 1 | 25,098 | 12,542 | 36,230 | 182,438 | 6766 | 14,267 | 12,689 | 64 | 17,395 | 0.59 |
| R | 0 | 103 | 16 | 1 | 32 | 7 | 1 | 30 | 0 | 6 | 0.04 |
| SF | 0 | 41,897 | 2610 | 50,157 | 18,848 | 2383 | 48959 | 2739 | 0 | 2351 | 0.29 |
| So | 1 | 16,572 | 514 | 2610 | 2725 | 1690 | 1030 | 60,535 | 552 | 2876 | 0.68 |
| W | 222 | 1014 | 0 | 1291 | 25 | 0 | 4 | 3088 | 59,834 | 0 | 0.91 |
| YP | 0 | 2382 | 150 | 77 | 2014 | 202 | 201 | 463 | 0 | 203 | 0.04 |
| Prod acc | 0.00 | 0.79 | 0.41 | 0.87 | 0.39 | 0.00 | 0.16 | 0.20 | 0.96 | 0.00 | |
| Overall accuracy | 0.65 | ||||||||||
| Batch avgF1-score | 0.57 | ||||||||||
| Overall avgF1-score | 0.39 | ||||||||||
| AV | G/A | HS | OF | OP | R | SF | So | W | YP | User Acc | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| AV | 551 | 3068 | 133 | 19,409 | 615 | 22 | 3474 | 6 | 0 | 174 | 0.02 |
| G/A | 16 | 93,773 | 2459 | 3373 | 1220 | 1385 | 5325 | 6354 | 12 | 1725 | 0.80 |
| HS | 2 | 10,147 | 9104 | 1760 | 539 | 1512 | 1185 | 2672 | 0 | 266 | 0.28 |
| OF | 296 | 1180 | 322 | 121,083 | 12,033 | 29 | 4389 | 10 | 0 | 411 | 0.85 |
| OP | 56 | 2552 | 1451 | 17,256 | 23,980 | 129 | 4370 | 126 | 1 | 2065 | 0.46 |
| R | 0 | 12,179 | 6247 | 525 | 620 | 5367 | 627 | 7774 | 3 | 229 | 0.15 |
| SF | 56 | 20,566 | 2804 | 37,231 | 13,487 | 470 | 24,686 | 288 | 0 | 2146 | 0.24 |
| So | 6 | 12,449 | 2015 | 322 | 244 | 1110 | 162 | 26,977 | 8 | 542 | 0.59 |
| W | 73 | 439 | 1 | 215 | 16 | 0 | 67 | 127 | 8542 | 4 | 0.90 |
| YP | 1 | 19,031 | 4343 | 3747 | 6912 | 933 | 3381 | 3575 | 0 | 3211 | 0.07 |
| Prod acc | 0.49 | 0.53 | 0.30 | 0.58 | 0.40 | 0.48 | 0.51 | 0.55 | 0.99 | 0.29 | |
| Overall accuracy | 0.53 | ||||||||||
| Batch avgF1-score | - | ||||||||||
| Overall avgF1-score | 0.43 | ||||||||||
| AV | G/A | HS | OF | OP | R | SF | So | W | YP | User Acc | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| AV | 15 | 0 | 0 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0.83 |
| G/A | 3 | 100 | 0 | 4 | 2 | 1 | 1 | 5 | 0 | 5 | 0.75 |
| HS | 0 | 0 | 22 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.00 |
| OF | 4 | 2 | 0 | 113 | 2 | 0 | 2 | 0 | 0 | 0 | 0.88 |
| OP | 0 | 1 | 0 | 4 | 18 | 1 | 3 | 0 | 0 | 9 | 0.46 |
| R | 0 | 0 | 1 | 0 | 1 | 12 | 0 | 0 | 0 | 0 | 0.80 |
| SF | 2 | 9 | 0 | 5 | 1 | 1 | 18 | 0 | 1 | 1 | 0.44 |
| So | 0 | 5 | 1 | 1 | 0 | 10 | 0 | 20 | 0 | 4 | 0.42 |
| W | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 23 | 0 | 1.00 |
| YP | 1 | 3 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 6 | 0.46 |
| Prod acc | 0.60 | 0.83 | 0.88 | 0.86 | 0.72 | 0.48 | 0.72 | 0.80 | 0.92 | 0.24 | |
| Overall accuracy | 0.77 | ||||||||||
| Batch avgF1-score | - | ||||||||||
| Overall avgF1-score | 0.68 | ||||||||||
References
- Aplin, P. Remote sensing: Land cover. Prog. Phys. Geogr. 2004, 28, 283–293. [Google Scholar] [CrossRef]
- Giri, C.P. Remote Sensing of Land Use and Land Cover. In Principles and Applications; CRC Press: Boca Raton, FL, USA, 2020; p. 477. [Google Scholar]
- Treitz, P.; Rogan, J. Remote sensing for mapping and monitoring land-cover and land-use change—An introduction. Prog. Plan. 2004, 61, 269–279. [Google Scholar] [CrossRef]
- Congalton, R.G.; Gu, J.; Yadav, K.; Thenkabail, P.; Ozdogan, M. Global land cover mapping: A review and uncertainty analysis. Remote Sens. 2014, 6, 12070–12093. [Google Scholar] [CrossRef] [Green Version]
- Gómez, C.; White, J.C.; Wulder, M.A. Optical remotely sensed time series data for land cover classification: A review. ISPRS J. Photogramm. Remote Sens. 2018, 10, 55–72. [Google Scholar] [CrossRef] [Green Version]
- Rogan, J.; Chen, D.M. Remote sensing technology for mapping and monitoring land-cover and land-use change. Prog. Plan. 2004, 61, 301–325. [Google Scholar] [CrossRef]
- Joshi, N.; Baumann, M.; Ehammer, A.; Fensholt, R.; Grogan, K.; Hostert, P.; Jepsen, M.R.; Kuemmerle, T.; Meyfroidt, P.; Mitchard, E.T.A.; et al. A review of the application of optical and radar remote sensing data fusion to land use mapping and monitoring. Remote Sens. 2016, 8, 70. [Google Scholar] [CrossRef] [Green Version]
- Gutiérrez-Vélez, V.H.; DeFries, R.; Pinedo-Vásquez, M.; Uriarte, M.; Padoch, C.; Baethgen, W.; Fernandes, K.; Lim, Y. High-yield oil palm expansion spares land at the expense of forests in the Peruvian Amazon. Environ. Res. Lett. 2011, 6, 44029. [Google Scholar] [CrossRef]
- Lee, J.S.H.; Wich, S.; Widayati, A.; Koh, L.P. Detecting industrial oil palm plantations on Landsat images with Google Earth Engine. Remote Sens. Appl. Soc. Environ. 2016, 4, 219–224. [Google Scholar] [CrossRef] [Green Version]
- Mercier, A.; Betbeder, J.; Rumiano, F.; Baudry, J.; Gond, V.; Blanc, L.; Bourgoin, C.; Cornu, G.; Ciudad, C.; Marchamalo, M.; et al. Evaluation of Sentinel-1 and 2 Time Series for Land Cover Classification of Forest-Agriculture Mosaics in Temperate and Tropical Landscapes. Remote Sens. 2019, 11, 979. [Google Scholar] [CrossRef] [Green Version]
- Poortinga, A.; Tenneson, K.; Shapiro, A.; Nquyen, Q.; Aung, K.S.; Chishtie, F.; Saah, D. Mapping plantations in Myanmar by fusing Landsat-8, Sentinel-2 and Sentinel-1 data along with systematic error quantification. Remote Sens. 2019, 11, 831. [Google Scholar] [CrossRef] [Green Version]
- Tropek, R.; Sedláček, O.; Beck, J.; Keil, P.; Musilová, Z.; Šímová, I.; Storch, D. Comment on “High-resolution global maps of 21st-century forest cover change”. Science 2014, 344, 981. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gibson, L.; Lee, T.M.; Koh, L.P.; Brook, B.W.; Gardner, T.A.; Barlow, J.; Peres, C.A.; Bradshaw, C.J.A.; Laurance, W.F.; Lovejoy, T.E.; et al. Primary forests are irreplaceable for sustaining tropical biodiversity. Nature 2011, 478, 378–381. [Google Scholar] [CrossRef] [PubMed]
- Singh, D.; Slik, J.W.F.; Jeon, Y.S.; Tomlinson, K.W.; Yang, X.; Wang, J.; Kerfahi, D.; Porazinska, D.L.; Adams, J.M. Tropical forest conversion to rubber plantation affects soil micro- & mesofaunal community & diversity. Sci. Rep. 2019, 9, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Wright, S.J. Tropical forests in a changing environment. Trends Ecol. Evol. 2005, 20, 553–560. [Google Scholar] [CrossRef] [PubMed]
- Zhang, D.; Stanturf, J. Forest plantations. In Encyclopedia of Ecology; Ecosystems; Jørgensen, S.E., Fath, B.D., Eds.; Academic Press: Oxford, UK, 2008; pp. 1673–1680. [Google Scholar]
- Carlson, K.M.; Curran, L.M.; Asner, G.P.; Pittman, A.M.D.; Trigg, S.N.; Marion Adeney, J. Carbon emissions from forest conversion by Kalimantan oil palm plantations. Nat. Clim. Chang. 2013, 3, 283–287. [Google Scholar] [CrossRef]
- Guo, L.B.; Gifford, R.M. Soil carbon stocks and land use change: A meta analysis. Glob. Chang. Biol. 2002, 8, 345–360. [Google Scholar] [CrossRef]
- Datcu, M.; Schwarz, G.; Dumitru, C.O. Deep Learning Training and Benchmarks for Earth Observation Images: Data Sets, Features, and Procedures. In Recent Trends in Artificial Neural Networks. From Training to Prediction; Sadollah, A., Ed.; InTech Open: London, UK, 2020. [Google Scholar]
- Hoeser, T.; Kuenzer, C. Object Detection and Image Segmentation with Deep Learning on Earth Observation Data: A Review-Part I: Evolution and Recent Trends. Remote Sens. 2020, 12, 1667. [Google Scholar] [CrossRef]
- Lary, D.J.; Alavi, A.H.; Gandomi, A.H.; Walker, A.L. Machine learning in geosciences and remote sensing. Geosci. Front. 2016, 7, 3–10. [Google Scholar] [CrossRef] [Green Version]
- Melesse, A.M.; Weng, Q.; Thenkabail, P.S.; Senay, G.B. Remote Sensing Sensors and Applications in Environmental Resources Mapping and Modelling. Sensors 2007, 7, 3209–3241. [Google Scholar] [CrossRef] [Green Version]
- Tang, X.; Bullock, E.L.; Olofsson, P.; Estel, S.; Woodcock, C.E. Near real-time monitoring of tropical forest disturbance: New algorithms and assessment framework. Remote Sens. Environ. 2019, 224, 202–218. [Google Scholar] [CrossRef]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Yuan, Q.; Shen, H.; Li, T.; Li, Z.; Li, S.; Jiang, Y.; Xu, H.; Tan, W.; Yang, Q.; Wang, J.; et al. Deep learning in environmental remote sensing: Achievements and challenges. Remote Sens. Environ. 2020, 241, 111716. [Google Scholar] [CrossRef]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep Learning in Remote Sensing: A Comprehensive Review and List of Resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef] [Green Version]
- Buduma, N. Fundamentals of Deep Learning; O’Reilly: Boston, MA, USA, 2017; p. 283. [Google Scholar]
- Chollet, F.; Allaire, J.J.; Planet Team. Deep Learning with R; Manning Publications Co.: Shelter Island, NY, USA, 2018; p. 335. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; p. 787. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Hoeser, T.; Bachofer, F.; Kuenzer, C. Object Detection and Image Segmentation with Deep Learning on Earth Observation Data: A Review—Part II: Applications. Remote Sens. 2020, 12, 3053. [Google Scholar] [CrossRef]
- Kattenborn, T.; Leitloff, J.; Schiefer, F.; Hinz, S. Review on Convolutional Neural Networks (CNN) in Vegetation Remote Sensing. ISPRS J. Photogramm. Remote Sens. 2021, 173, 24–49. [Google Scholar] [CrossRef]
- Liu, X.; Han, F.; Ghazali, K.; Mohamed, I.; Zhao, Y. A review of Convolutional Neural Networks in Remote Sensing Image. In Proceedings of the ICSCA 2019 8th International Conference on Software and Computer Applications, Penang, Malaysia, 19–21 February 2019; pp. 263–267. [Google Scholar]
- Luo, C.; Huang, H.; Wang, Y.; Wang, S. Utilization of Deep Convolutional Neural Networks for Remote Sensing Scenes Classification. In Advanced Remote Sensing Technology for Synthetic Aperture Radar Applications, Tsunami Disasters, and Infrastructure; Marghany, M., Ed.; IntechOpen: London, UK, 2019; pp. 1–18. [Google Scholar]
- Ball, J.E.; Anderson, D.T.; Chan, C.S. Comprehensive survey of deep learning in remote sensing: Theories, tools, and challenges for the community. J. Appl. Remote Sens. 2017, 11, 042609. [Google Scholar] [CrossRef] [Green Version]
- Pelletier, C.; Webb, G.I.; Petitjean, F. Temporal convolutional neural network for the classification of satellite image time series. Remote Sens. 2019, 11, 523. [Google Scholar] [CrossRef] [Green Version]
- Yuan, X.; Shi, J.; Gu, L. A review of deep learning methods for semantic segmentation of remote sensing imagery. Expert Syst. Appl. 2021, 169, 114417. [Google Scholar] [CrossRef]
- Zhang, C.; Sargent, I.; Pan, X.; Li, H.; Gardiner, A.; Hare, J.; Atkinson, P.M. Joint Deep Learning for land cover and land use classification. Remote Sens. Environ. 2019, 221, 173–187. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Zhang, L.; Du, B. Deep learning for remote sensing data: A technical tutorial on the state of the art. IEEE Geosci. Remote Sens. Mag. 2016, 4, 22–40. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. Lecture Notes in Computer Science In Medical Image Computing and Computer-Assisted Intervention, International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2015; Volume 9351, pp. 234–241. [Google Scholar] [CrossRef] [Green Version]
- Clark, A.; McKechnie, J. Detecting banana plantations in the wet tropics, Australia, using aerial photography and U-net. Appl. Sci. 2020, 10, 1–15. [Google Scholar] [CrossRef] [Green Version]
- Du, L.; McCarty, G.W.; Zhang, X.; Lang, M.W.; Vanderhoof, M.K.; Li, X.; Huang, C.; Lee, S.; Zou, Z. Mapping Forested Wetland Inundation in the Neural Networks. Remote Sens. 2020, 12, 644. [Google Scholar] [CrossRef] [Green Version]
- Flood, N.; Watson, F.; Collett, L. Using a U-net convolutional neural network to map woody vegetation extent from high resolution satellite imagery across Queensland, Australia. Int. J. Appl. Earth Obs. Geoinf. 2019, 82, 101897. [Google Scholar] [CrossRef]
- Isaienkov, K.; Yushchuk, M.; Khramtsov, V.; Seliverstov, O. Deep Learning for Regular Change Detection in Ukrainian Forest Ecosystem with Sentinel-2. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 14, 1–15. [Google Scholar] [CrossRef]
- Neves, A.K.; Körting, T.S.; Fonseca, L.M.G.; Neto, C.D.G.; Wittich, D.; Costa, G.A.O.P.; Heipke, C. Semantic segmentation of Brazilian savanna vegetation using high spatial resolution satellite data and U-net. In Proceedings of the 2020 XXIV ISPRS Congress (2020 Edition), Nice, France, 31 August–2 September 2020; pp. 505–511. [Google Scholar]
- Wagner, F.H.; Sanchez, A.; Aidar, M.P.M.; Rochelle, A.L.C.; Tarabalka, Y.; Fonseca, M.G.; Phillips, O.L.; Gloor, E.; Aragão, L.E.O.C. Mapping Atlantic rainforest degradation and regeneration history with indicator species using convolutional network. PLoS ONE 2020, 15, e0229448. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wagner, F.H.; Sanchez, A.; Tarabalka, Y.; Lotte, R.G.; Ferreira, M.P.; Aidar, M.P.M.; Gloor, E.; Phillips, O.L.; Aragão, L.E.O.C. Using the U-net convolutional network to map forest types and disturbance in the Atlantic rainforest with very high resolution images. Remote Sens. Ecol. Conserv. 2019, 5, 360–375. [Google Scholar] [CrossRef] [Green Version]
- Yi, Y.; Zhang, Z.; Zhang, W.; Zhang, C.; Li, W.; Zhao, T. Semantic Segmentation of Urban Buildings from VHR Remote Sensing Imagery Using a Deep Convolutional Neural Network. Remote Sens. 2019, 11, 1774. [Google Scholar] [CrossRef] [Green Version]
- Ulmas, P.; Liiv, I. Segmentation of satellite imagery using U-Net models for land cover classification. arXiv 2020, arXiv:2003.02899. [Google Scholar]
- Baek, J.; Kim, J.W.; Lim, G.J.; Lee, D.-C. Electromagnetic land surface classification through integration of optical and radar remote sensing data. IEEE Trans. Geosci. Remote Sens. 2011, 49, 1214–1222. [Google Scholar] [CrossRef]
- Gargiulo, M.; Dell’aglio, D.A.G.; Iodice, A.; Riccio, D.; Ruello, G. Integration of sentinel-1 and sentinel-2 data for land cover mapping using w-net. Sensors 2020, 20, 2969. [Google Scholar] [CrossRef] [PubMed]
- Heckel, K.; Urban, M.; Schratz, P.; Mahecha, M.D.; Schmullius, C. Predicting Forest Cover in Distinct Ecosystems: The Potential of Multi-Source Sentinel-1 and -2 Data Fusion. Remote Sens. 2020, 12, 302. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Ling, F.; Foody, G.M.; Ge, Y.; Boyd, D.S.; Li, X.; Du, Y.; Atkinson, P.M. Mapping annual forest cover by fusing PALSAR/PALSAR-2 and MODIS NDVI during 2007–2016. Remote Sens. Environ. 2019, 224, 74–91. [Google Scholar] [CrossRef] [Green Version]
- Morel, A.; Saatchi, S.; Malhi, Y.; Berry, N.; Banin, L.; Burslem, D.; Nilus, R.; Ong, R. Estimating aboveground biomass in forest and oil palm plantation in Sabah, Malaysian Borneo using ALOS PALSAR data. For. Ecol. Manag. 2011, 262, 1786–1798. [Google Scholar] [CrossRef]
- Malenovský, Z.; Rott, H.; Cihlar, J.; Schaepman, M.E.; García-Santos, G.; Fernandes, R.; Berger, M. Sentinels for science: Potential of Sentinel-1, -2, and -3 missions for scientific observations of ocean, cryosphere, and land. Remote Sens. Environ. 2012, 120, 91–101. [Google Scholar] [CrossRef]
- Carabias, J.; De la Maza, J.; Cadena, R. El escenario natural y social. In Conservación y Desarrollo Sustentable en la Selva Lacandona. 25 Años de Actividades y Experiencias; Carabias, J., De la Maza, J., Cadena, R., Eds.; Natura y Ecosistemas Mexicanos A.C: Mexico City, Mexico, 2015; pp. 16–18. [Google Scholar]
- Mendoza, E.; Dirzo, R. Deforestation in Lacandonia (Southeast Mexico): Evidence for the declaration of the northernmost tropical hot-spot. Biodivers. Conserv. 1999, 8, 1621–1641. [Google Scholar] [CrossRef]
- Castillo-Santiago, M.A.; Hellier, A.; Tipper, R.; De Jong, B.H.J. Carbon emissions from land-use change: An analysis of causal factors in Chiapas, Mexico. Mitig. Adapt. Strateg. Glob. Chang. 2007, 12, 1213–1235. [Google Scholar] [CrossRef]
- Fernández-Montes de Oca, A.I.; Gallardo-Cruz, A.; Ghilardi, A.; Kauffer, E.; Solórzano, J.V.; Sánchez-Cordero, V. An integrated framework for harmonizing definitions of deforestation. Environ. Sci. Policy 2021, 115, 71–78. [Google Scholar] [CrossRef]
- Vaca, R.A.; Golicher, D.J.; Cayuela, L.; Hewson, J.; Steininger, M. Evidence of incipient forest transition in Southern Mexico. PLoS ONE 2012, 7, e42309. [Google Scholar] [CrossRef] [PubMed]
- Cassol, H.L.; Shimabukuro, Y.E.; Beuchle, R.; Aragão, L.E.O.C. Sentinel-1 Time-Series Analysis for Detection of Forest Degradation By Selective Logging. In Proceedings of the Anais do XIX Simpósio Brasileiro de Sensoriamento Remoto, São José dos Campos, São José dos Campos, Brazil, 14–17 April 2019; pp. 1–4. [Google Scholar]
- Small, D. Flattening gamma: Radiometric terrain correction for SAR imagery. IEEE Trans. Geosci. Remote Sens. 2011, 49, 3081–3093. [Google Scholar] [CrossRef]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Planet Team. Planet Application Program Interface: In Space for Life on Earth; Planet Team: San Francisco, CA, USA, 2017; Available online: https://api.planet.com (accessed on 2 September 2021).
- Google. Google Satellite Images. 2021. Available online: http://www.google.cn/maps/vt?lyrs=s@189&gl=cn&x={x}&y={y}&z={z} (accessed on 7 September 2021).
- Yandex. Yandex Satellite Images. 2021. Available online: https://core-sat.maps.yandex.net/tiles?l=sat&v=3.564.0&x={x}&y={y}&z={z}&scale=1&lang=ru_RU (accessed on 7 September 2021).
- Bing. Bing Satellite Images. 2021. Available online: http://ecn.t3.tiles.virtualearth.net/tiles/a{q}.jpeg?g=0&dir=dir_n’ (accessed on 7 September 2021).
- QGIS Development Team. QGIS Geographic Information System 3.16; Open Source Geospatial Foundation. 2021. Available online: https://docs.qgis.org/3.16/en/docs/user_manual/ (accessed on 5 June 2021).
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2020. [Google Scholar]
- Hijmans, R.J. Raster: Geographic Data Analysis and Modeling. 2020. Available online: https://cran.r-project.org/web/packages/raster/index.html (accessed on 1 September 2021).
- Vaughan, D. Rray: Simple Arrays. 2020. Available online: https://github.com/r-lib/rray (accessed on 1 September 2021).
- Ushey, K.; Allaire, J.J.; Tang, Y. Reticulate: Interface to ‘Python’. 2020. Available online: https://cran.r-project.org/web/packages/reticulate/index.html (accessed on 1 September 2021).
- Hamdi, Z.M.; Brandmeier, M.; Straub, C. Forest Damage Assessment Using Deep Learning on High Resolution Remote Sensing Data. Remote Sens. 2019, 11, 1976. [Google Scholar] [CrossRef] [Green Version]
- Allaire, J.; Chollet, F. Keras: R Interface to ‘Keras’. 2018. Available online: https://cran.r-project.org/web/packages/keras/index.html (accessed on 1 September 2021).
- Falbel, D.; Zak, K. Unet: U-Net: Convolutional Networks for Biomedical Image Segmentation. 2020. Available online: https://github.com/r-tensorflow/unet (accessed on 1 September 2021).
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A System for Large-Scale Machine Learning. In Proceedings of the 12th USENIX Conference on Operating Systems Design and Implementation, Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–13, arXiv:1412.6980. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Goutte, C.; Gaussier, E. A Probabilistic Interpretation of Precision, Recall and F-Score, with Implication for Evaluation. Lect. Notes Comput. Sci. 2005, 3408, 345–359. [Google Scholar] [CrossRef]
- Allaire, J.J. Tfruns: Training Run Tools for ‘TensorFlow’. 2018. Available online: https://cran.r-project.org/web/packages/tfruns/index.html (accessed on 1 September 2021).
- Talukdar, S.; Singha, P.; Mahato, S.; Shahfahad, P.S.; Liou, Y.A.; Rahman, A. Land-use land-cover classification by machine learning classifiers for satellite observations. A review. Remote Sens. 2020, 12, 1135. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Sawangarreerak, S.; Thanathamathee, P. Random forest with sampling techniques for handling imbalanced prediction of university student depression. Information 2020, 11, 519. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. Classification and Regression by randomForest. 2002. Available online: https://cran.r-project.org/web/packages/randomForest/index.html (accessed on 1 September 2021).
- Cochran, W.G. Sampling Techniques, 3rd ed.; John Wiley & Sons: New York, NY, USA, 1977. [Google Scholar]
- Olofsson, P.; Foody, G.M.; Herold, M.; Stehman, S.V.; Woodcock, C.E.; Wulder, M.A. Good practices for estimating area and assessing accuracy of land change. Remote Sens. Environ. 2014, 148, 42–57. [Google Scholar] [CrossRef]
- Card, D.H. Using Known Map Category Marginal Frequencies to Improve Estimates of Thematic Map Accuracy. Photogramm. Eng. Remote Sens. 1982, 48, 431–439. [Google Scholar]
- FAO (Food and Agriculture Organization). Openforis Accuracy Assessment Tool. 2017. Available online: https://github.com/openforis/accuracy-assessment (accessed on 1 September 2021).
- De Bem, P.P.; de Carvalho, O.A.; Guimarães, R.F.; Gomes, R.A.T. Change detection of deforestation in the brazilian amazon using landsat data and convolutional neural networks. Remote Sens. 2020, 12, 901. [Google Scholar] [CrossRef] [Green Version]
- Giang, T.L.; Dang, K.B.; Le, Q.T.; Nguyen, V.G.; Tong, S.S.; Pham, V.-M. U-Net Convolutional Networks for Mining Land Cover Classification Based on High-Resolution UAV Imagery. IEEE Access 2020, 8, 186257–186273. [Google Scholar] [CrossRef]
- Ienco, D.; Interdonato, R.; Gaetano, R.; Ho Tong Minh, D. Combining Sentinel-1 and Sentinel-2 Satellite Image Time Series for land cover mapping via a multi-source deep learning architecture. ISPRS J. Photogramm. Remote Sens. 2019, 158, 11–22. [Google Scholar] [CrossRef]
- Kussul, N.; Lavreniuk, M.; Skakun, S.; Shelestov, A. Deep Learning Classification of Land Cover and Crop Types Using Remote Sensing Data. IEEE Geosci. Remote Sens. Lett. 2017, 14, 778–782. [Google Scholar] [CrossRef]
- Robinson, C.; Hou, L.; Malkin, K.; Soobitsky, R.; Czawlytko, J.; Dilkina, B.; Jojic, N. Large scale high-resolution land cover mapping with multi-resolution data. Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit. 2019, 2019, 12718–12727. [Google Scholar] [CrossRef]
- Stoian, A.; Poulain, V.; Inglada, J.; Poughon, V.; Derksen, D. Land cover maps production with high resolution satellite image time series and convolutional neural networks: Adaptations and limits for operational systems. Remote Sens. 2019, 11, 1986. [Google Scholar] [CrossRef] [Green Version]
- Hirschmugl, M.; Deutscher, J.; Sobe, C.; Bouvet, A.; Mermoz, S.; Schardt, M. Use of SAR and Optical Time Series for Tropical Forest Disturbance Mapping. Remote Sens. 2020, 12, 727. [Google Scholar] [CrossRef] [Green Version]
- Khan, A.; Govil, H.; Kumar, G.; Dave, R. Synergistic use of Sentinel-1 and Sentinel-2 for improved LULC mapping with special reference to bad land class: A case study for Yamuna River floodplain, India. Spat. Inf. Res. 2020, 28, 669–681. [Google Scholar] [CrossRef]
- Tavares, P.A.; Beltrão, N.E.S.; Guimarães, U.S.; Teodoro, A.C. Integration of sentinel-1 and sentinel-2 for classification and LULC mapping in the urban area of Belém, eastern Brazilian Amazon. Sensors 2019, 19, 1140. [Google Scholar] [CrossRef] [Green Version]
- Van Tricht, K.; Gobin, A.; Gilliams, S.; Piccard, I. Synergistic use of radar sentinel-1 and optical sentinel-2 imagery for crop mapping: A case study for Belgium. Remote Sens. 2018, 10, 1642. [Google Scholar] [CrossRef] [Green Version]
- Flores-Anderson, A.I.; Herndon, K.E.; Thapa, R.B.; Cherrington, E. The SAR Handbook. Comprehensive Methodologies for Forest Monitoring and Biomass Estimation; NASA: Huntsville, AL, USA, 2019. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, H.; Xue, X.; Jiang, Y.; Shen, Q. Deep learning for remote sensing image classification: A survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, 1–17. [Google Scholar] [CrossRef] [Green Version]
- Cheng, G.; Wang, Y.; Xu, S.; Wang, H.; Xiang, S.; Pan, C. Automatic Road Detection and Centerline Extraction via Cascaded End-to-End Convolutional Neural Network. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3322–3337. [Google Scholar] [CrossRef]
- McRoberts, R.E.; Stehman, S.V.; Liknes, G.C.; Næsset, E.; Sannier, C.; Walters, B.F. The effects of imperfect reference data on remote sensing-assisted estimators of land cover class proportions. ISPRS J. Photogramm. Remote Sens. 2018, 142, 292–300. [Google Scholar] [CrossRef]
- He, H.; Yang, D.; Wang, S.; Wang, S.; Li, Y. Road Extraction by Using Atrous Spatial Pyramid Pooling Integrated Encoder-Decoder Network and Structural Similarity Loss. Remote Sens. 2019, 11, 1015. [Google Scholar] [CrossRef] [Green Version]
- Huang, B.; Lu, K.; Audebert, N.; Khalel, A.; Tarabalka, Y.; Malof, J.; Boulch, A.; Saux, B.L.; Collins, L.; Bradbury, K.; et al. Large-scale semantic classification: Outcome of the first year of inria aerial image labeling benchmark. In Proceedings of the International Geoscience and Remote Sensing Symposium (IGARSS)—IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 1–4. [Google Scholar]
- Wagner, F.H.; Dalagnol, R.; Casapia, X.T.; Streher, A.S.; Phillips, O.L.; Gloor, E.; Aragão, L.E.O.C. Regional Mapping and Spatial Distribution Analysis of Canopy Palms in an Amazon Forest Using Deep Learning and VHR Images. Remote Sens. 2020, 23, 2225. [Google Scholar] [CrossRef]
- Zhang, P.; Ke, Y.; Zhang, Z.; Wang, M.; Li, P.; Zhang, S. Urban land use and land cover classification using novel deep learning models based on high spatial resolution satellite imagery. Sensors 2018, 18, 3717. [Google Scholar] [CrossRef] [Green Version]
- Alom, M.Z.; Taha, T.M.; Yakopcic, C.; Westberg, S.; Sidike, P.; Nasrin, M.S.; Hasan, M.; Van Essen, B.C.; Awwal, A.A.S.; Asari, V.K. A state-of-the-art survey on deep learning theory and architectures. Electronics 2019, 8, 292. [Google Scholar] [CrossRef] [Green Version]
- Zhao, H.; Liu, F.; Zhang, H.; Liang, Z. Convolutional neural network based heterogeneous transfer learning for remote-sensing scene classification. Int. J. Remote Sens. 2019, 40, 8506–8527. [Google Scholar] [CrossRef]
- Praticò, S.; Solano, F.; Di Fazio, S.; Modica, G. Machine learning classification of mediterranean forest habitats in google earth engine based on seasonal sentinel-2 time-series and input image composition optimisation. Remote Sens. 2021, 13, 586. [Google Scholar] [CrossRef]
- Chuvieco, E.; Ventura, G.; Martín, M.P. AVHRR multitemporal compositing techniques for burned land mapping. Int. J. Remote Sens. 2005, 26, 1013–1018. [Google Scholar] [CrossRef]

| Class | U-Net | RF | ||||||
|---|---|---|---|---|---|---|---|---|
| MS + SAR | MS | SAR | MS + SAR | |||||
| F1-Score | ΔF1-Score | F1-Score | ΔF1-Score | F1-Score | ΔF1-Score | F1-Score | ΔF1-Score | |
| Aquatic vegetation | 0.15 | 0 | 0.10 | 0.05 | 0 | 0.15 | 0.04 | 0.11 |
| Grassland/Agriculture | 0.78 | 0 | 0.77 | 0.01 | 0.69 | 0.09 | 0.63 | 0.15 |
| Human settlements | 0.87 | 0 | 0.87 | 0 | 0.45 | 0.42 | 0.29 | 0.58 |
| Old-growth forest | 0.86 | 0 | 0.86 | 0 | 0.79 | 0.07 | 0.69 | 0.17 |
| Old-growth plantations | 0.62 | 0 | 0.54 | 0.08 | 0.47 | 0.15 | 0.43 | 0.19 |
| Roads | 0.35 | 0.08 | 0.43 | 0 | 0 | 0.43 | 0.23 | 0.2 |
| Secondary forest | 0.45 | 0 | 0.34 | 0.11 | 0.20 | 0.25 | 0.33 | 0.12 |
| Soil | 0.65 | 0 | 0.64 | 0.01 | 0.30 | 0.35 | 0.57 | 0.08 |
| Water | 0.96 | 0.01 | 0.97 | 0 | 0.94 | 0.03 | 0.94 | 0.03 |
| Young plantations | 0.11 | 0 | 0.03 | 0.08 | 0.01 | 0.1 | 0.11 | 0 |
| Class | U-Net Study Area LULC Classification Accuracy Assessment | U-Net Validation Dataset | Area Estimates | |||
|---|---|---|---|---|---|---|
| Area (ha) | Proportion of Study Area (%) | F1-Score | F1-Score | Unbiased Area | 95% CI | |
| Aquatic vegetation | 467.06 | 0.21 | 0.70 | 0.15 | 6184.96 | 3848.47 |
| Grassland/Agriculture | 84,572.15 | 38.03 | 0.79 | 0.78 | 76282.87 | 6516.50 |
| Human settlements | 2494.09 | 1.12 | 0.94 | 0.87 | 3322.42 | 1082.37 |
| Old-growth forest | 93,341.09 | 41.97 | 0.87 | 0.86 | 90772.02 | 5449.89 |
| Old-growth plantations | 8076.54 | 3.63 | 0.56 | 0.62 | 7511.87 | 3233.03 |
| Roads | 806.18 | 0.36 | 0.60 | 0.35 | 6111.42 | 2790.73 |
| Secondary forest | 6195.65 | 2.79 | 0.54 | 0.45 | 5824.51 | 2793.85 |
| Soil | 17,769.69 | 7.99 | 0.55 | 0.65 | 12,162.86 | 4080.16 |
| Water | 4617.35 | 2.08 | 0.96 | 0.96 | 4780.39 | 319.57 |
| Young plantations | 4048.08 | 1.82 | 0.31 | 0.11 | 9434.56 | 3823.09 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Solórzano, J.V.; Mas, J.F.; Gao, Y.; Gallardo-Cruz, J.A. Land Use Land Cover Classification with U-Net: Advantages of Combining Sentinel-1 and Sentinel-2 Imagery. Remote Sens. 2021, 13, 3600. https://doi.org/10.3390/rs13183600
Solórzano JV, Mas JF, Gao Y, Gallardo-Cruz JA. Land Use Land Cover Classification with U-Net: Advantages of Combining Sentinel-1 and Sentinel-2 Imagery. Remote Sensing. 2021; 13(18):3600. https://doi.org/10.3390/rs13183600
Chicago/Turabian StyleSolórzano, Jonathan V., Jean François Mas, Yan Gao, and José Alberto Gallardo-Cruz. 2021. "Land Use Land Cover Classification with U-Net: Advantages of Combining Sentinel-1 and Sentinel-2 Imagery" Remote Sensing 13, no. 18: 3600. https://doi.org/10.3390/rs13183600
APA StyleSolórzano, J. V., Mas, J. F., Gao, Y., & Gallardo-Cruz, J. A. (2021). Land Use Land Cover Classification with U-Net: Advantages of Combining Sentinel-1 and Sentinel-2 Imagery. Remote Sensing, 13(18), 3600. https://doi.org/10.3390/rs13183600