
A Cross-Direction and Progressive Network for Pan-Sharpening




Abstract
:1. Introduction
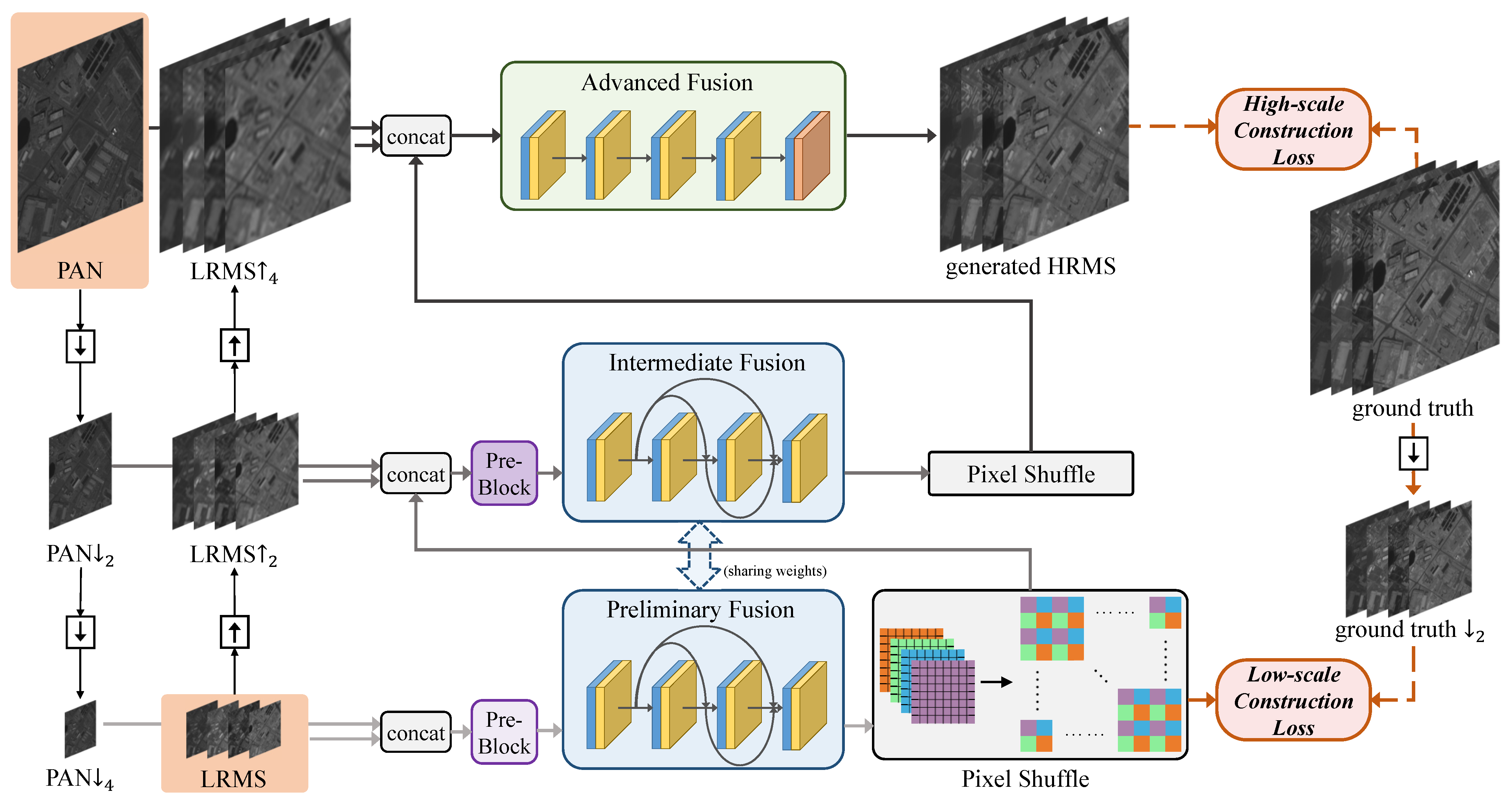
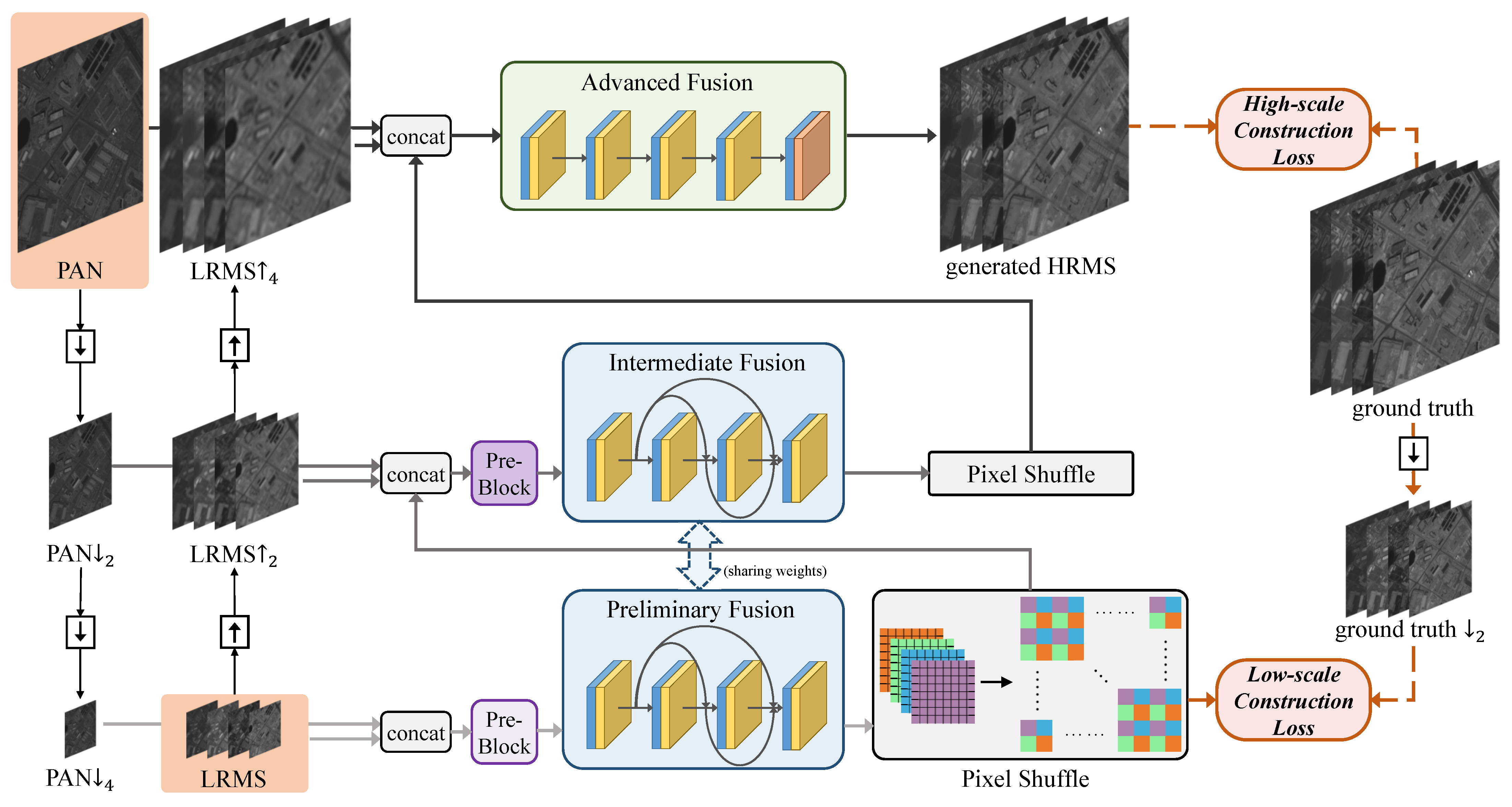
- Through the cross-direction processing of source images and the progressive reconstruction of the HRMS image, we propose a cross-direction and progressive network (CPNet) for pan-sharpening, which can fully process the source images’ information at different scales.
- The progressive reconstruction loss is designed in our model. It can boost the training in all aspects of the network to avoid the inactivation of partial networks. For another thing, it ensures a high degree of consistency between the fused image, i.e., the HRMS image, and the ground truth.
- Compared to the prior state-of-the-art works in great experiments, the proposed CPNet shows great superiority in both intuitive qualitative results and conventional quantitative metrics.
2. Related Work
2.1. Traditional Pan-Sharpening Methods
2.2. Deep Learning-Based Pan-Sharpening Methods
3. Proposed Method
3.1. Problem Formulation
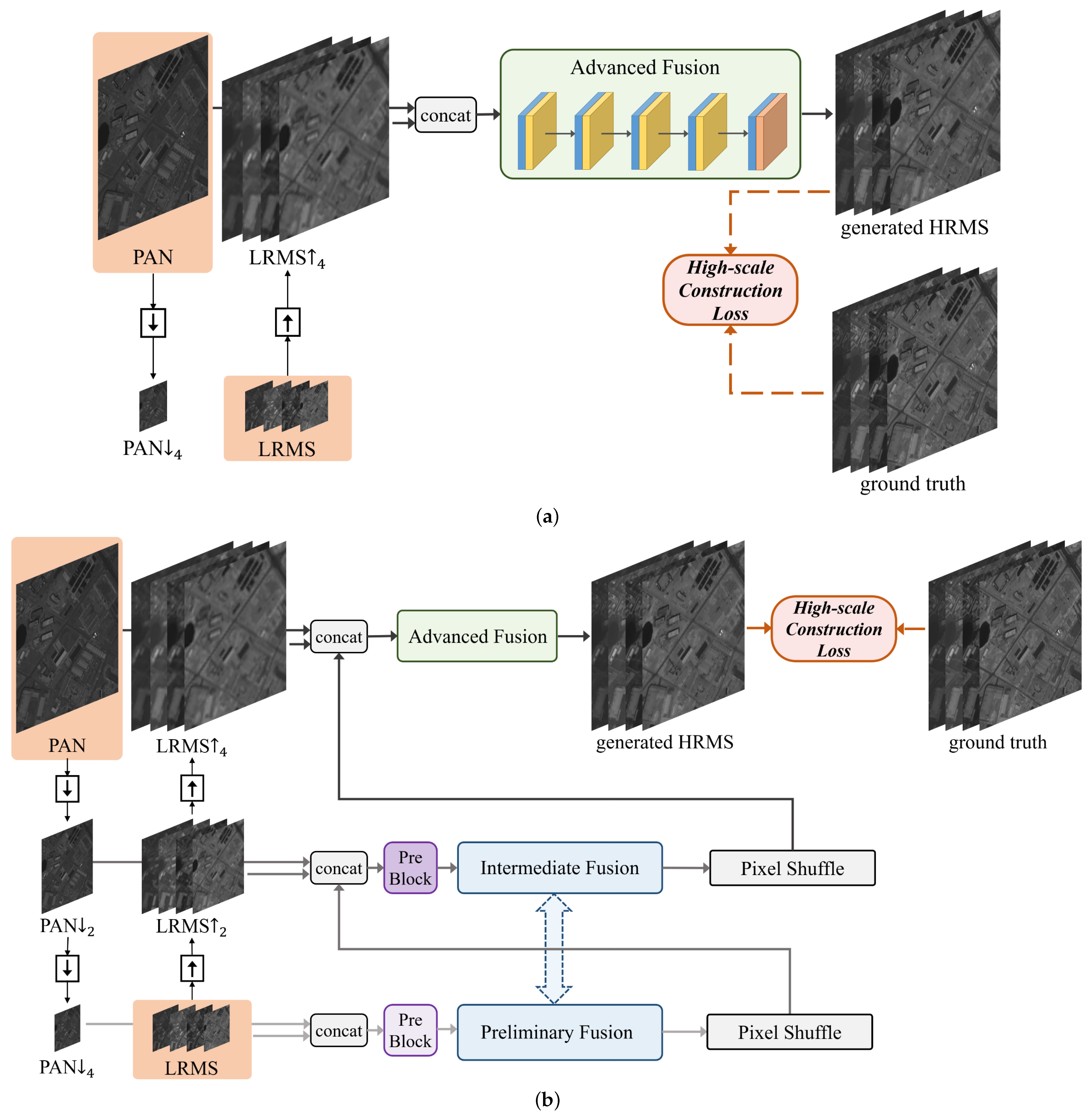
3.2. Network Architectures
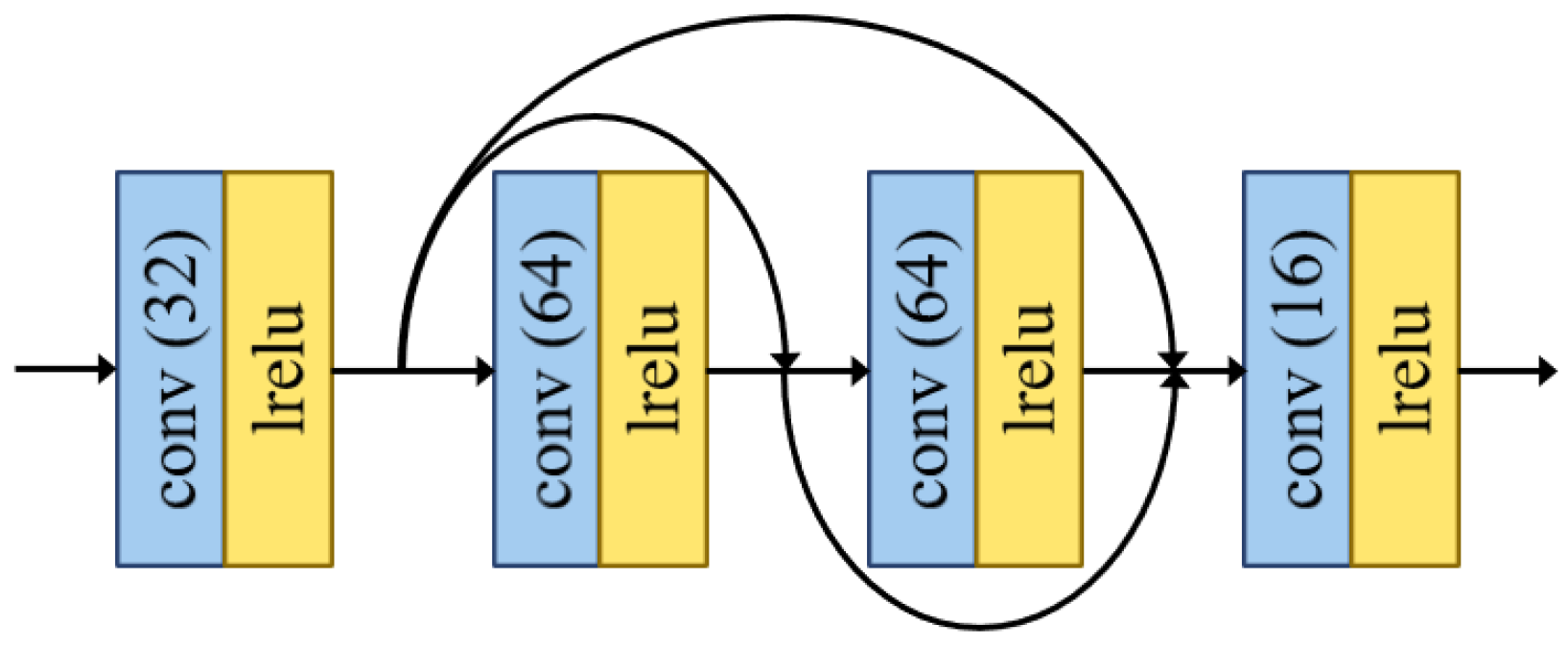
3.2.1. Network Architecture of the Pre-Block
3.2.2. Network Architecture of the Preliminary/Intermediate Fusion Module
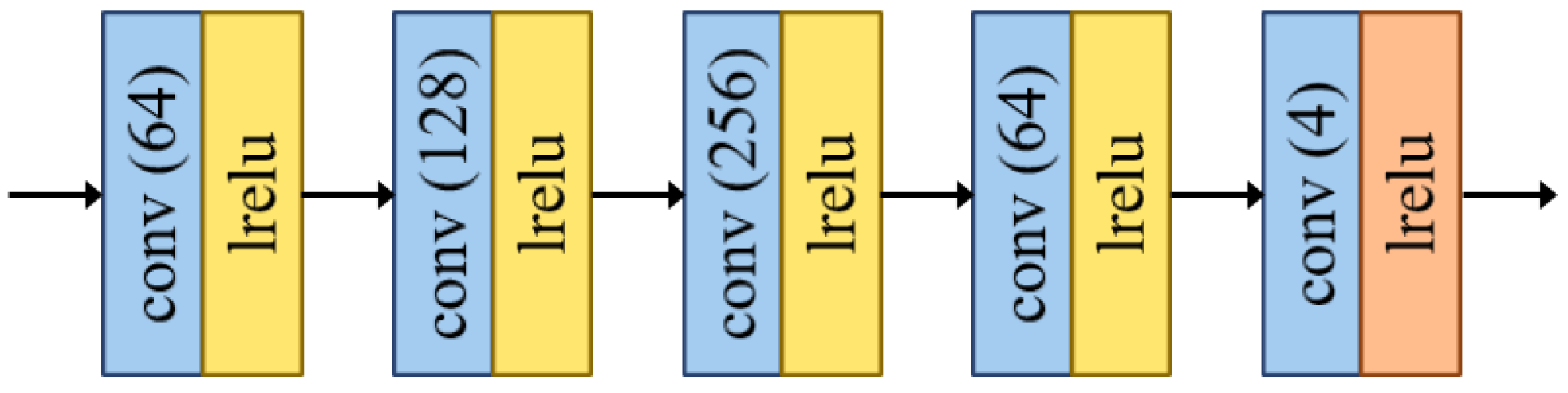
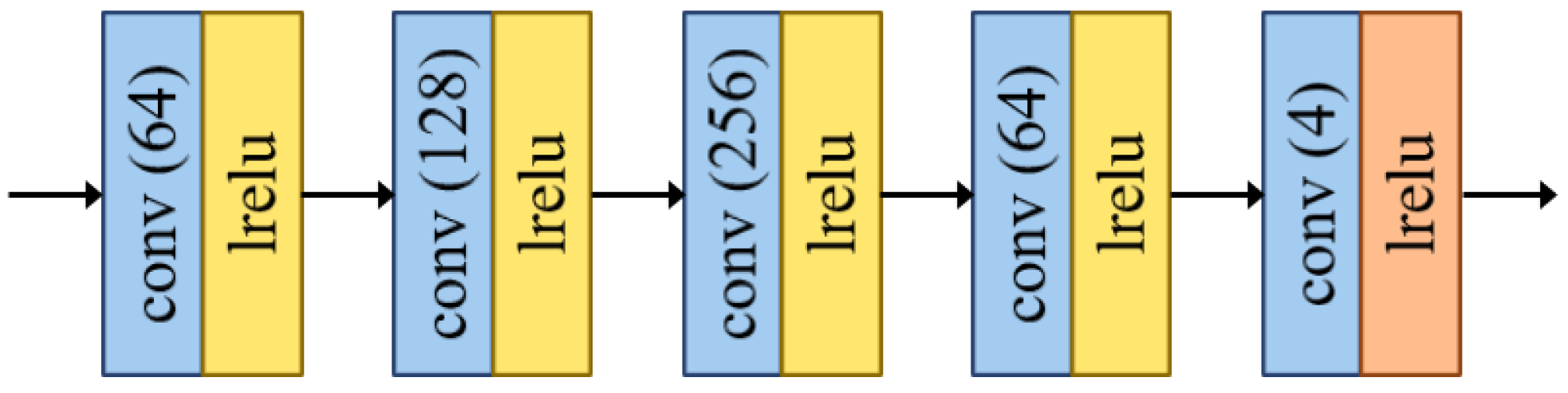
3.2.3. Network Architecture of the Advanced Fusion Module
3.3. Loss Function
4. Experiments and Analysis
4.1. Experimental Design
4.1.1. Data Set and Training Details
4.1.2. Comparison Methods
| Algorithm 1: Overall description of CPNet. |
|
4.1.3. Evaluation Metrics
- The ERGAS is used as a global metric, measuring the mean deviation and dynamic range change between the fused result and ground truth. Therefore, the smaller value of the ERGAS means that the fused image is closer to the ground truth. The ERGAS is mathematically defined as follows:where r is set as 4 in our work, expressing the spatial resolution ratio between the PAN image and LRMS image, and N is 4, denoting the number of the band of LRMS. We use the to compute the root mean square error between the fused result and ground truth, and the expresses the average of the ith band in the source LRMS image.
- The RMSE shows the difference between the fused result and ground truth through the change of pixel value. The smaller RMSE denotes that the pixel between the fusion image and the ground truth is closer. The RMSE is mathematically formulated as follows:where h and w indicate the height and weight of the LRMS image, respectively. The G and F are the ground truth and fused image.
- The SSIM is the metric measuring the structural similarity between the fused result and the ground truth. It evaluates the structural similarity in three different factors containing brightness, contrast, and structure. The higher the SSIM is, the more the fused image has higher structural similarity with the ground truth. The SSIM between the fused result F and the ground truth G is mathematically formalized as follows:where the g and f are, respectively, the image patches of the ground truth G and fused image F. The and are the mean value and standard deviation, respectively. The , and are the parameters stabilizing the metric.
- The SAM reflects the spectral quality of the fused result by calculating the angle between the fused result and ground truth, and the calculation is performed between each pixel vector in n-dimensional space and the endmember spectrum vector. The smaller SAM expresses that the fused image possesses a higher consistency with the ground truth in spectral information. The SAM is mathematically given by:
- The SCC embodies the correlation in spatial information between the fused result and the PAN image, and thus the ground truth is not needed as a reference. The larger value of SCC means that the fused image shows better performance in preserving spatial information.
4.2. Results of Reduced-Resolution Validation and Analysis
4.2.1. Qualitative Comparison
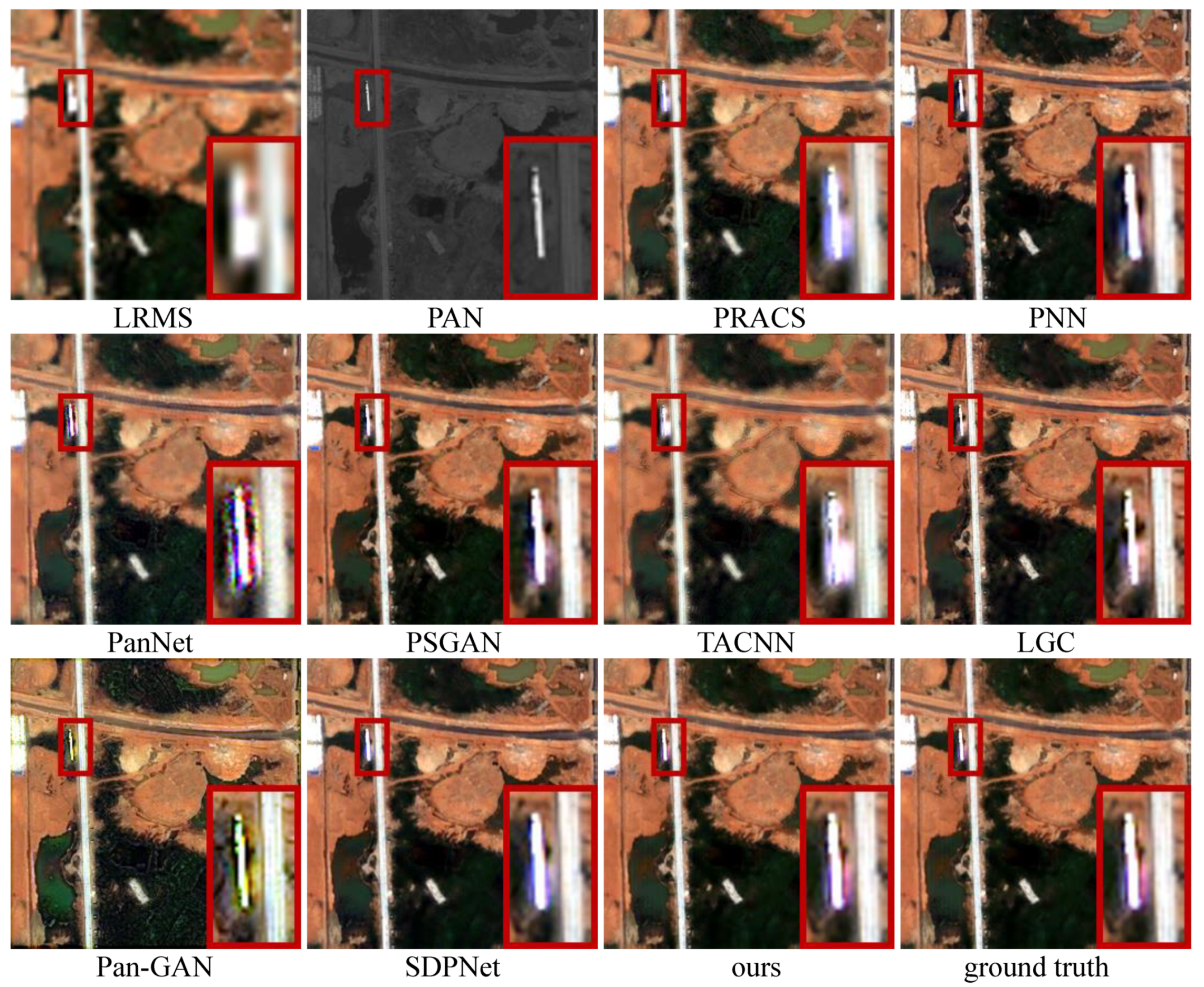
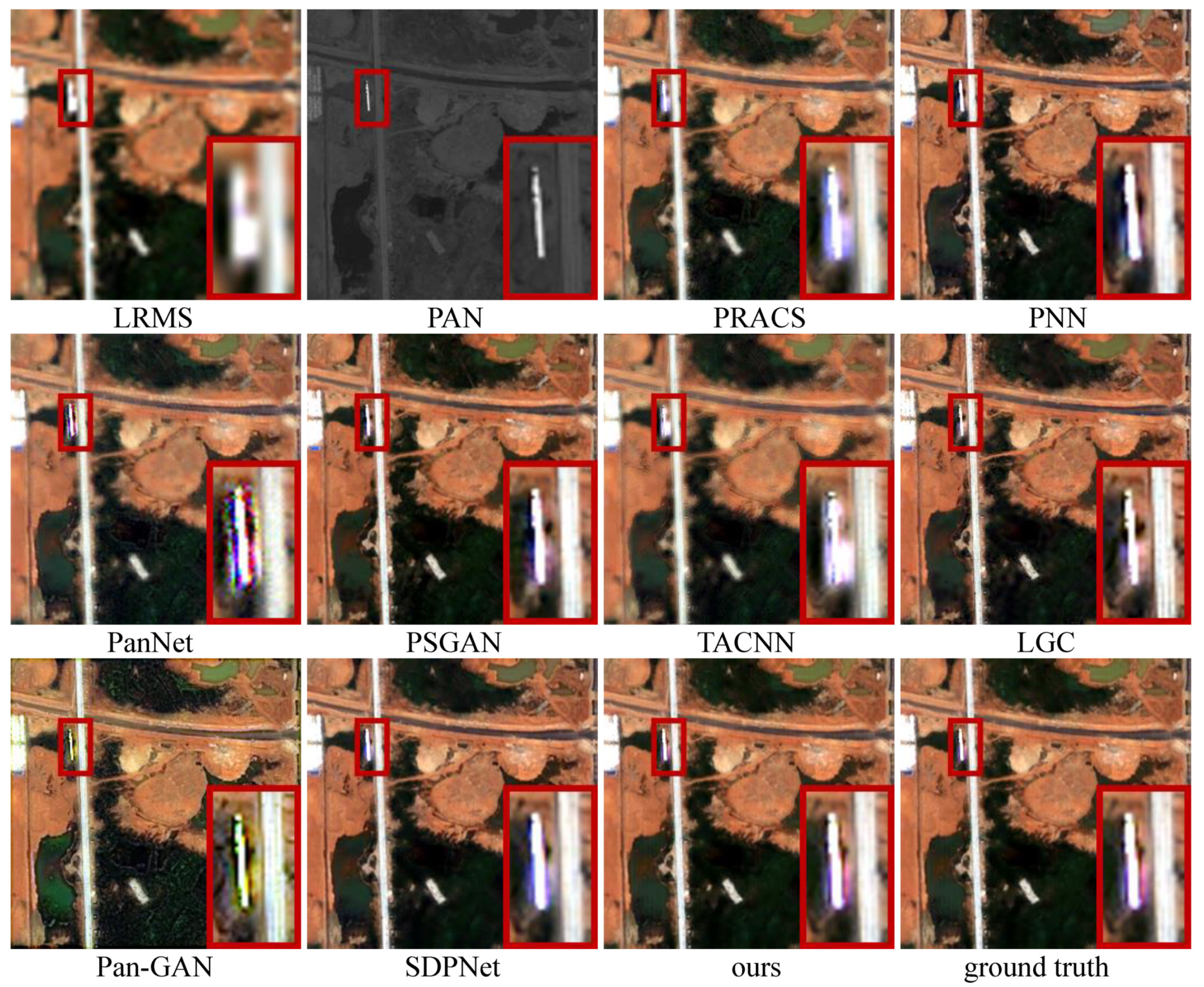
- Results. In qualitative comparison, to have better visualization and perception, we choose the first three bands (including the blue, green, and red bands) of the LRMS, generated HRMS images, and ground truth for presentation. The intuitive results on six typical satellite image pairs are illustrated in Figure 4, Figure 5, Figure 6, Figure 7, Figure 8 and Figure 9.
- Analysis. The fused results of each pan-sharpening method have approximately the same style in these six typical satellite image pairs. For PRACS, PNN, PanNet, and TACNN, on the one hand, the severe spatial distortion appears in all the six examples, shown as edge distortion or blurred texture details. On the other hand, they suffer from varying degrees of spectral distortion and show distinct differences in spectral information from the ground truth. In addition, the results of PanNet introduce significant noise.The Pan-GAN preserves the spatial and spectral information based on the constraints of the gradient and pixel intensity between the fused result and source images. Nevertheless, the excessive gradient constraint and the distinguishing between the fused result and the ground truth led to the most serious spectral distortion in these pan-sharpening methods in Figure 4, Figure 5, Figure 6, Figure 7, Figure 8 and Figure 9, as well as edge distortion, as shown in Figure 4.In PSGAN, LGC, and SDPNet, Although their fused results show approximately the same spectral information as the ground truth, their spatial information is still lacking compared to the ground truth, showing varying degrees of blurry texture details or edge distortion. The result of SDPNet in Figure 9 does not preserve the spectral information well. By comparison, the results of our CPNet do not undergo the questions as mentioned above and can better maintain the spatial and information simultaneously, showing the best qualitative results.
4.2.2. Quantitative Comparison
- Results. In order to have a more objective evaluation of the performances of these pan-sharpening methods, we further performed the quantitative comparison of our CPNet and the eight competitors on eighty satellite image pairs in the testing data. The statistical results are provided in Table 2.
- Analysis. As provided in the table, our CPNet achieved the best values in three out of five metrics, including the ERGAS, RMSE, and SSIM. In terms of the remaining two metrics, our CPNet can still reach the second-best value in SAM and the third value in SCC, respectively. To be more specific, the best value in ERGAS revealed that the mean deviation and dynamic range changes between the fused result and ground truth were the least, and the best value in RMSE indicates that the pixel change of our fused results was the smallest.The best value in SSIM demonstrates that the results of our CPNet showed the highest structural similarity with the ground truth. The second-best value in SAM also showed that our CPNet generated comparable results in preserving spectral information. Last, since the methods Pan-GAN and LGC both focus on imposing gradient constraints between the PAN image and the fused results, they preserved the spatial information well, which led to better results in SCC for PAN-GAN and LGC.However, they do not consider the preservation of the spectral information, and the transitional constraint on the gradient even caused edge distortion in some results. Therefore, with the comprehensive evaluation on all the five metrics, we concluded that our CPNet performed the best in preserving both spatial and spectral information in general.
4.2.3. Reliability and Stability Validation
4.3. Results of Full-Resolution Validation and Analysis
- Results. To verify the application of our CPNet on full-resolution data, we further performed qualitative experiments, whose source PAN and LRMS images were at the original scale, and hence there was no ground truth. The comparison results are presented in Figure 10, Figure 11, Figure 12 and Figure 13.
- Analysis. Equally, the results of our CPNet achieved outstanding performance. As shown in Figure 10, our fused result can describe the edge of the buildings most clearly, while the results of other methods have varying degrees of edge blur. The problem of spectral distortion still exists in the results of other methods. The result of PanNet also exposes the problem of noise introduction and the severest spectral distortion in the result of Pan-GAN.A similar situation also appears in other full-resolution satellite image pairs as displayed in Figure 11, Figure 12 and Figure 13. In conclusion, our CPNet also showed the best fusion performance in the full-resolution results, which is reflected in the spatial and spectral information preservation.
4.4. Ablation Study
4.5. Hyper-Parameter Analysis
4.6. Efficiency Comparison
4.7. Limitations and Future Works
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Palubinskas, G. Joint quality measure for evaluation of pansharpening accuracy. Remote Sens. 2015, 7, 9292–9310. [Google Scholar] [CrossRef] [Green Version]
- Blaschke, T.; Lang, S.; Lorup, E.; Strobl, J.; Zeil, P. Object-oriented image processing in an integrated GIS/remote sensing environment and perspectives for environmental applications. Environ. Inf. Plan. Politics Public 2000, 2, 555–570. [Google Scholar]
- Zhang, L.; Zhang, L.; Tao, D.; Huang, X.; Du, B. Hyperspectral remote sensing image subpixel target detection based on supervised metric learning. IEEE Trans. Geosci. Remote Sens. 2013, 52, 4955–4965. [Google Scholar] [CrossRef]
- Dian, R.; Li, S.; Kang, X. Regularizing hyperspectral and multispectral image fusion by CNN denoiser. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 1124–1135. [Google Scholar] [CrossRef] [PubMed]
- Ghassemian, H. A review of remote sensing image fusion methods. Inf. Fusion 2016, 32, 75–89. [Google Scholar] [CrossRef]
- Thomas, C.; Ranchin, T.; Wald, L.; Chanussot, J. Synthesis of multispectral images to high spatial resolution: A critical review of fusion methods based on remote sensing physics. IEEE Trans. Geosci. Remote Sens. 2008, 46, 1301–1312. [Google Scholar] [CrossRef] [Green Version]
- Zhang, H.; Xu, H.; Tian, X.; Jiang, J.; Ma, J. Image fusion meets deep learning: A survey and perspective. Inf. Fusion 2021, 76, 323–336. [Google Scholar] [CrossRef]
- Xie, B.; Zhang, H.K.; Huang, B. Revealing implicit assumptions of the component substitution pansharpening methods. Remote Sens. 2017, 9, 443. [Google Scholar] [CrossRef] [Green Version]
- Lillo-Saavedra, M.; Gonzalo-Martín, C.; García-Pedrero, A.; Lagos, O. Scale-aware pansharpening algorithm for agricultural fragmented landscapes. Remote Sens. 2016, 8, 870. [Google Scholar] [CrossRef] [Green Version]
- Wang, P.; Zhang, G.; Hao, S.; Wang, L. Improving remote sensing image super-resolution mapping based on the spatial attraction model by utilizing the pansharpening technique. Remote Sens. 2019, 11, 247. [Google Scholar] [CrossRef] [Green Version]
- Tian, X.; Chen, Y.; Yang, C.; Ma, J. Variational pansharpening by exploiting cartoon-texture similarities. IEEE Trans. Geosci. Remote Sens. 2021. [Google Scholar] [CrossRef]
- Choi, J.; Kim, G.; Park, N.; Park, H.; Choi, S. A hybrid pansharpening algorithm of VHR satellite images that employs injection gains based on NDVI to reduce computational costs. Remote Sens. 2017, 9, 976. [Google Scholar] [CrossRef] [Green Version]
- Xu, H.; Ma, J.; Shao, Z.; Zhang, H.; Jiang, J.; Guo, X. SDPNet: A Deep Network for Pan-Sharpening With Enhanced Information Representation. IEEE Trans. Geosci. Remote Sens. 2021, 59, 4120–4134. [Google Scholar] [CrossRef]
- Gastineau, A.; Aujol, J.F.; Berthoumieu, Y.; Germain, C. Generative Adversarial Network for Pansharpening with Spectral and Spatial Discriminators. IEEE Trans. Geosci. Remote Sens. 2021, in press. [Google Scholar] [CrossRef]
- Vitale, S.; Scarpa, G. A detail-preserving cross-scale learning strategy for CNN-based pansharpening. Remote Sens. 2020, 12, 348. [Google Scholar] [CrossRef] [Green Version]
- Liu, Q.; Han, L.; Tan, R.; Fan, H.; Li, W.; Zhu, H.; Du, B.; Liu, S. Hybrid Attention Based Residual Network for Pansharpening. Remote Sens. 2021, 13, 1962. [Google Scholar] [CrossRef]
- Zhang, H.; Ma, J. GTP-PNet: A residual learning network based on gradient transformation prior for pansharpening. ISPRS J. Photogramm. Remote Sens. 2021, 172, 223–239. [Google Scholar] [CrossRef]
- Zhang, H.; Xu, H.; Xiao, Y.; Guo, X.; Ma, J. Rethinking the image fusion: A fast unified image fusion network based on proportional maintenance of gradient and intensity. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 12797–12804. [Google Scholar]
- Vitale, S. A cnn-based pansharpening method with perceptual loss. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 3105–3108. [Google Scholar]
- Tu, T.M.; Su, S.C.; Shyu, H.C.; Huang, P.S. A new look at IHS-like image fusion methods. Inf. Fusion 2001, 2, 177–186. [Google Scholar] [CrossRef]
- Chavez, P.; Sides, S.C.; Anderson, J.A. Comparison of three different methods to merge multiresolution and multispectral data- Landsat TM and SPOT panchromatic. Photogramm. Eng. Remote Sens. 1991, 57, 295–303. [Google Scholar]
- Ghadjati, M.; Moussaoui, A.; Boukharouba, A. A novel iterative PCA–based pansharpening method. Remote Sens. Lett. 2019, 10, 264–273. [Google Scholar] [CrossRef]
- Shah, V.P.; Younan, N.H.; King, R.L. An efficient pan-sharpening method via a combined adaptive PCA approach and contourlets. IEEE Trans. Geosci. Remote Sens. 2008, 46, 1323–1335. [Google Scholar] [CrossRef]
- Shah, V.P.; Younan, N.H.; King, R. Pan-sharpening via the contourlet transform. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Barcelona, Spain, 23–28 July 2007; pp. 310–313. [Google Scholar]
- Yokoya, N.; Yairi, T.; Iwasaki, A. Coupled nonnegative matrix factorization unmixing for hyperspectral and multispectral data fusion. IEEE Trans. Geosci. Remote Sens. 2011, 50, 528–537. [Google Scholar] [CrossRef]
- Aiazzi, B.; Alparone, L.; Baronti, S.; Garzelli, A.; Selva, M. An MTF-based spectral distortion minimizing model for pan-sharpening of very high resolution multispectral images of urban areas. In Proceedings of the GRSS/ISPRS Joint Workshop on Remote Sensing and Data Fusion over Urban Areas, Berlin, Germany, 22–23 May 2003; pp. 90–94. [Google Scholar]
- Kaplan, N.H.; Erer, I. Bilateral pyramid based pansharpening of multispectral satellite images. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Munich, Germany, 22–27 July 2012; pp. 2376–2379. [Google Scholar]
- Ballester, C.; Caselles, V.; Igual, L.; Verdera, J.; Rougé, B. A variational model for P+ XS image fusion. Int. J. Comput. Vis. 2006, 69, 43–58. [Google Scholar] [CrossRef]
- Valizadeh, S.A.; Ghassemian, H. Remote sensing image fusion using combining IHS and Curvelet transform. In Proceedings of the International Symposium on Telecommunications, Tehran, Iran, 6–8 November 2012; pp. 1184–1189. [Google Scholar]
- Wang, D.; Li, Y.; Ma, L.; Bai, Z.; Chan, J.C.W. Going deeper with densely connected convolutional neural networks for multispectral pansharpening. Remote Sens. 2019, 11, 2608. [Google Scholar] [CrossRef] [Green Version]
- Hu, J.; He, Z.; Wu, J. Deep self-learning network for adaptive pansharpening. Remote Sens. 2019, 11, 2395. [Google Scholar] [CrossRef] [Green Version]
- O’Shea, K.; Nash, R. An introduction to convolutional neural networks. arXiv 2015, arXiv:1511.08458. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. arXiv 2014, arXiv:1406.2661. [Google Scholar] [CrossRef]
- Masi, G.; Cozzolino, D.; Verdoliva, L.; Scarpa, G. Pansharpening by convolutional neural networks. Remote Sens. 2016, 8, 594. [Google Scholar] [CrossRef] [Green Version]
- Yang, J.; Fu, X.; Hu, Y.; Huang, Y.; Ding, X.; Paisley, J. PanNet: A deep network architecture for pan-sharpening. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5449–5457. [Google Scholar]
- Zhong, J.; Yang, B.; Huang, G.; Zhong, F.; Chen, Z. Remote sensing image fusion with convolutional neural network. Sens. Imaging 2016, 17, 10. [Google Scholar] [CrossRef]
- Wei, Y.; Yuan, Q.; Shen, H.; Zhang, L. Boosting the accuracy of multispectral image pansharpening by learning a deep residual network. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1795–1799. [Google Scholar] [CrossRef] [Green Version]
- Wei, J.; Xu, Y.; Cai, W.; Wu, Z.; Chanussot, J.; Wei, Z. A Two-Stream Multiscale Deep Learning Architecture for Pan-Sharpening. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5455–5465. [Google Scholar] [CrossRef]
- Fu, S.; Meng, W.; Jeon, G.; Chehri, A.; Zhang, R.; Yang, X. Two-path network with feedback connections for pan-sharpening in remote sensing. Remote Sens. 2020, 12, 1674. [Google Scholar] [CrossRef]
- Zhou, C.; Zhang, J.; Liu, J.; Zhang, C.; Fei, R.; Xu, S. PercepPan: Towards unsupervised pan-sharpening based on perceptual loss. Remote Sens. 2020, 12, 2318. [Google Scholar] [CrossRef]
- Liu, Q.; Zhou, H.; Xu, Q.; Liu, X.; Wang, Y. Psgan: A generative adversarial network for remote sensing image pan-sharpening. IEEE Trans. Geosci. Remote Sens. 2020, in press. [Google Scholar] [CrossRef]
- Shao, Z.; Lu, Z.; Ran, M.; Fang, L.; Zhou, J.; Zhang, Y. Residual encoder–decoder conditional generative adversarial network for pansharpening. IEEE Geosci. Remote Sens. Lett. 2019, 17, 1573–1577. [Google Scholar] [CrossRef]
- Ma, J.; Yu, W.; Chen, C.; Liang, P.; Guo, X.; Jiang, J. Pan-GAN: An unsupervised pan-sharpening method for remote sensing image fusion. Inf. Fusion 2020, 62, 110–120. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.J. Densefuse: A fusion approach to infrared and visible images. IEEE Trans. Image Process. 2018, 28, 2614–2623. [Google Scholar] [CrossRef] [Green Version]
- Zhang, H.; Sindagi, V.; Patel, V.M. Multi-scale single image dehazing using perceptual pyramid deep network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 902–911. [Google Scholar]
- Wald, L.; Ranchin, T.; Mangolini, M. Fusion of satellite images of different spatial resolutions: Assessing the quality of resulting images. Photogramm. Eng. Remote Sens. 1997, 63, 691–699. [Google Scholar]
- Choi, J.; Yu, K.; Kim, Y. A new adaptive component-substitution-based satellite image fusion by using partial replacement. IEEE Trans. Geosci. Remote Sens. 2010, 49, 295–309. [Google Scholar] [CrossRef]
- Scarpa, G.; Vitale, S.; Cozzolino, D. Target-adaptive CNN-based pansharpening. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5443–5457. [Google Scholar] [CrossRef] [Green Version]
- Fu, X.; Lin, Z.; Huang, Y.; Ding, X. A variational pan-sharpening with local gradient constraints. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10265–10274. [Google Scholar]
- Alparone, L.; Wald, L.; Chanussot, J.; Thomas, C.; Gamba, P.; Bruce, L.M. Comparison of pansharpening algorithms: Outcome of the 2006 GRS-S data-fusion contest. IEEE Trans. Geosci. Remote Sens. 2007, 45, 3012–3021. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yuhas, R.H.; Goetz, A.F.; Boardman, J.W. Discrimination among semi-arid landscape endmembers using the spectral angle mapper (SAM) algorithm. In Proceedings of the 3rd Annual JPL Airborne Geosci. Workshop, Pasadena, CA, USA, 1–5 June 1992; pp. 147–149. [Google Scholar]
- Zhou, J.; Civco, D.; Silander, J. A wavelet transform method to merge Landsat TM and SPOT panchromatic data. Int. J. Remote Sens. 1998, 19, 743–757. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Spatial Resolutions | Spectral Bands | ||||||
|---|---|---|---|---|---|---|---|
| QuickBird | PAN | LRMS | PAN | Blue | Green | Red | Nir |
| 0.61 m GSD | 2.44 m GSD | 450–900 | 450–520 | 520–600 | 630–690 | 760–900 | |
| Methods | ERGAS↓ | RMSE↓ | SSIM↑ | SAM↓ | SCC↑ |
|---|---|---|---|---|---|
| PRACS [47] | 1.6048 ± 0.3730 | 3.7584 ± 0.9809 | 0.9185 ± 0.0315 | 2.1343 ± 0.5313 | 0.8656 ± 0.0468 |
| PNN [34] | 1.4129 ± 0.3432 | 3.2430 ± 0.9502 | 0.9412 ± 0.0260 | 1.8680 ± 0.3844 | 0.8432 ± 0.0297 |
| PanNet [35] | 1.7965 ± 0.3559 | 4.1060 ± 1.0516 | 0.9016 ± 0.0362 | 2.4372 ± 0.5441 | 0.7398 ± 0.0492 |
| PSGAN [41] | 1.3093 ± 0.3264 | 3.0488 ± 0.9325 | 0.9465 ± 0.0236 | 1.6386 ± 0.4209 | 0.8108 ± 0.0349 |
| TACNN [48] | 1.8509 ± 0.4022 | 4.3168 ± 1.1223 | 0.9054 ± 0.0366 | 2.1808 ± 0.5296 | 0.8467 ± 0.0350 |
| LGC [49] | 1.3161 ± 0.2952 | 3.0276 ± 0.8842 | 0.9437 ± 0.0240 | 1.7613 ± 0.5011 | 0.9059 ± 0.0284 |
| Pan-GAN [43] | 2.2084 ± 0.4698 | 5.0773 ± 1.4061 | 0.8992 ± 0.0381 | 2.7843 ± 0.7078 | 0.9304 ± 0.0287 |
| SDPNet [13] | 1.2757 ± 0.2960 | 3.0436 ± 0.8934 | 0.9449 ± 0.0240 | 1.8385 ± 0.4796 | 0.8662 ± 0.0223 |
| Ours | 1.2462 ± 0.2999 | 2.9854 ± 0.8861 | 0.9466 ± 0.0233 | 1.7556 ± 0.4558 | 0.8678 ± 0.0230 |
| Samples | ERGAS | RMSE | SSIM | SAM | |
|---|---|---|---|---|---|
| Training data | 72 | 1.2352 ± 0.2438 | 2.9011 ± 0.8471 | 0.9531 ± 0.0206 | 1.6232 ± 0.4194 |
| Test data | 80 | 1.2462 ± 0.2999 | 2.9854 ± 0.8861 | 0.9466 ± 0.0233 | 1.7556 ± 0.4558 |
| Calculated t-value | - | 0.2491 | 0.5994 | 1.8254 | 1.8650 |
| Critical t-value | - | 1.9679 | 1.9679 | 1.9679 | 1.9679 |
| Methods | ERGAS↓ | RMSE↓ | SSIM↑ | SAM↓ | SCC↑ |
|---|---|---|---|---|---|
| Advanced fusion | 1.3144 ± 0.2903 | 3.0794 ± 0.8762 | 0.9451 ± 0.0240 | 1.8120 ± 0.4511 | 0.8566 ± 0.0239 |
| High-scale loss () | 1.2729 ± 0.2993 | 3.0393 ± 0.8600 | 0.9459 ± 0.0238 | 1.7867 ± 0.4492 | 0.8639 ± 0.0250 |
| 1.4330 ± 0.2915 | 3.3146 ± 0.8555 | 0.9421 ± 0.0247 | 1.9944 ± 0.3983 | 0.8530 ± 0.0247 | |
| Ours () | 1.2462 ± 0.2999 | 2.9854 ± 0.8861 | 0.9466 ± 0.0233 | 1.7556 ± 0.4558 | 0.8678 ± 0.0230 |
| PRACS [47] | PNN [34] | PanNet [35] | PSGAN [41] | TACNN [48] | LGC [49] | Pan-GAN [43] | SDPNet [13] | Ours | |
|---|---|---|---|---|---|---|---|---|---|
| Reduced-resolution | 0.14 ± 0.16 | 0.03 ± 0.04 | 0.29 ± 0.09 | 0.04 ± 0.05 | 8.35 ± 0.73 | 14.86 ± 0.91 | 0.38 ± 0.10 | 0.15 ± 0.05 | 0.05 ± 0.01 |
| Full-resolution | 2.13 ± 0.17 | 0.23 ± 0.04 | 0.84 ± 0.15 | 0.28 ± 0.07 | 9.86 ± 0.08 | 552.47 ± 26.39 | 4.97 ± 0.08 | 0.56 ± 0.03 | 0.74 ± 0.02 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, H.; Le, Z.; Huang, J.; Ma, J. A Cross-Direction and Progressive Network for Pan-Sharpening. Remote Sens. 2021, 13, 3045. https://doi.org/10.3390/rs13153045
Xu H, Le Z, Huang J, Ma J. A Cross-Direction and Progressive Network for Pan-Sharpening. Remote Sensing. 2021; 13(15):3045. https://doi.org/10.3390/rs13153045
Chicago/Turabian StyleXu, Han, Zhuliang Le, Jun Huang, and Jiayi Ma. 2021. "A Cross-Direction and Progressive Network for Pan-Sharpening" Remote Sensing 13, no. 15: 3045. https://doi.org/10.3390/rs13153045
APA StyleXu, H., Le, Z., Huang, J., & Ma, J. (2021). A Cross-Direction and Progressive Network for Pan-Sharpening. Remote Sensing, 13(15), 3045. https://doi.org/10.3390/rs13153045