
Mapping Maize Area in Heterogeneous Agricultural Landscape with Multi-Temporal Sentinel-1 and Sentinel-2 Images Based on Random Forest




Abstract
:1. Introduction
2. Study Area and Data
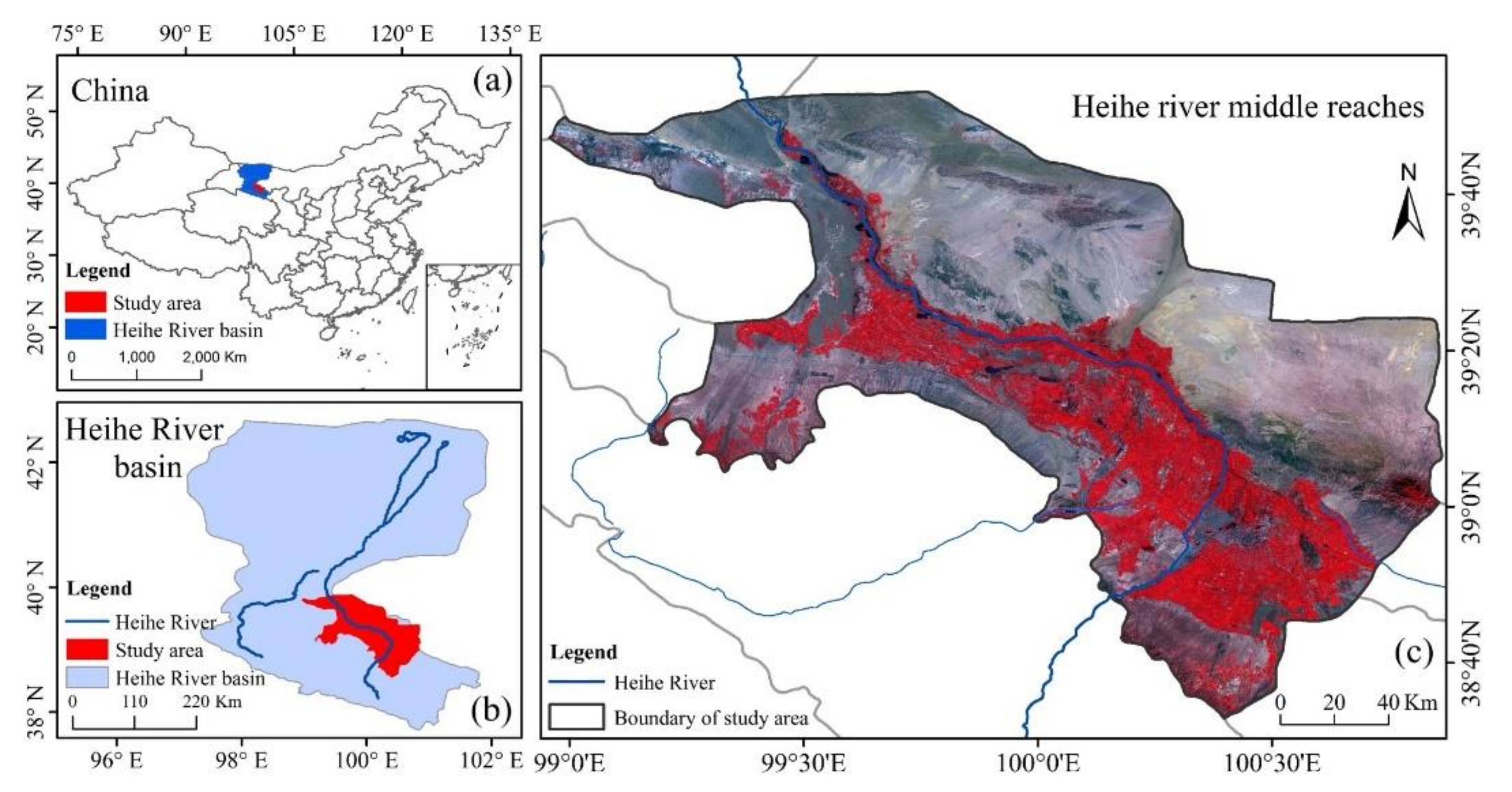
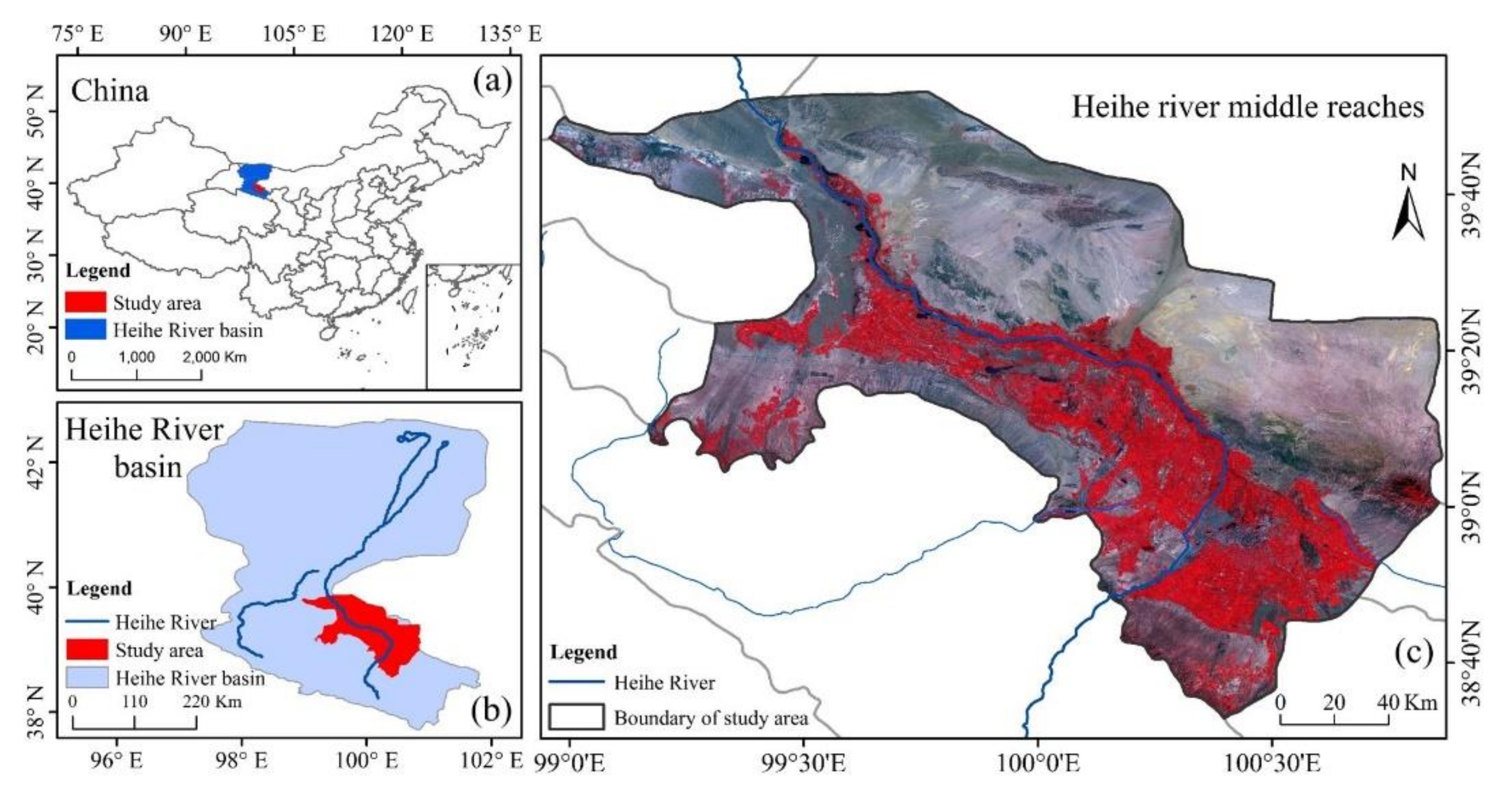
2.1. Study Area
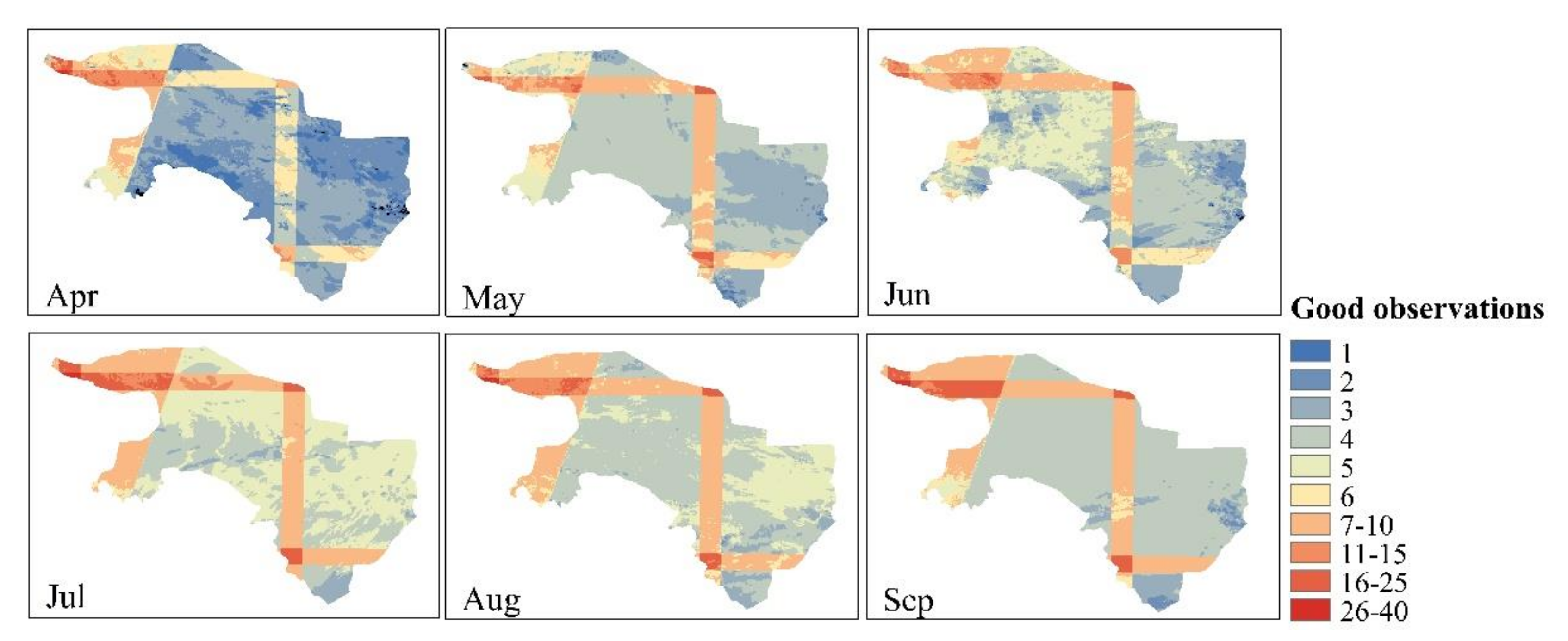
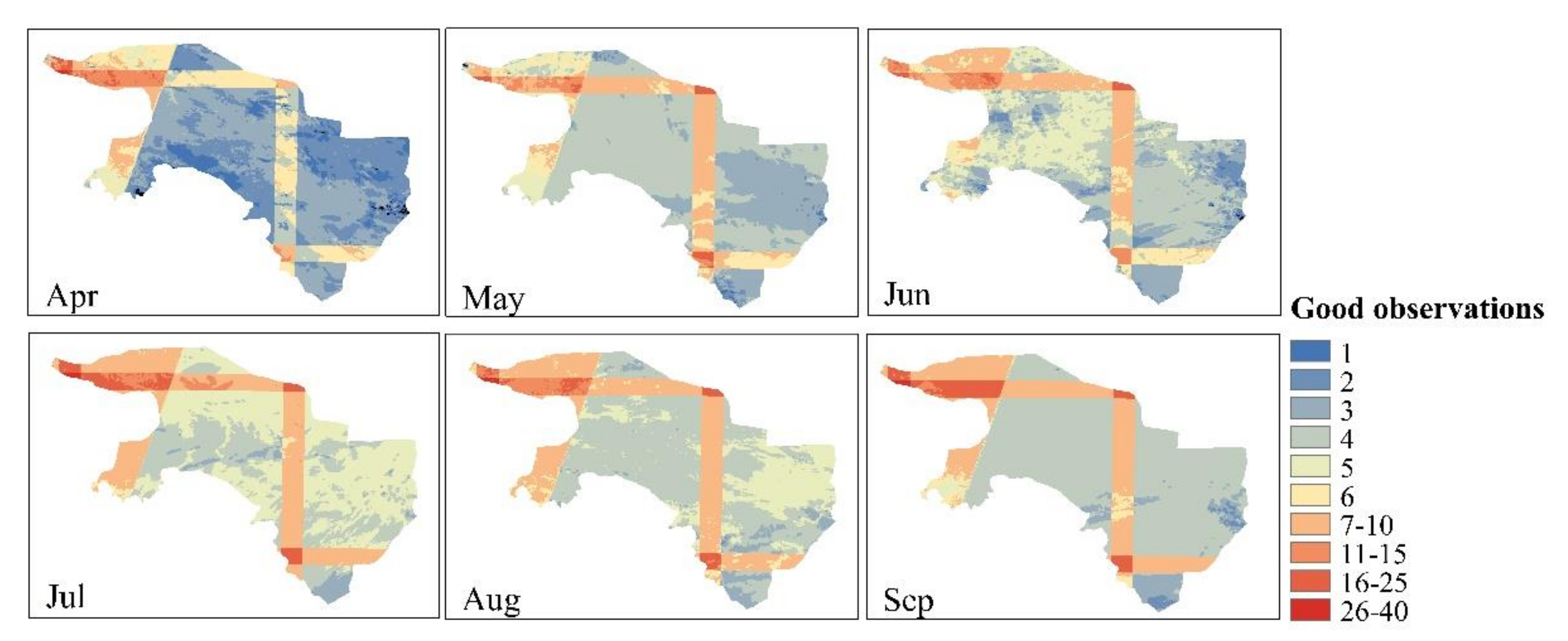
2.2. RS Images and Processing
2.2.1. Sentinel-1 Images
2.2.2. Sentinel-2 Images
2.3. Ground-Based Reference Dataset
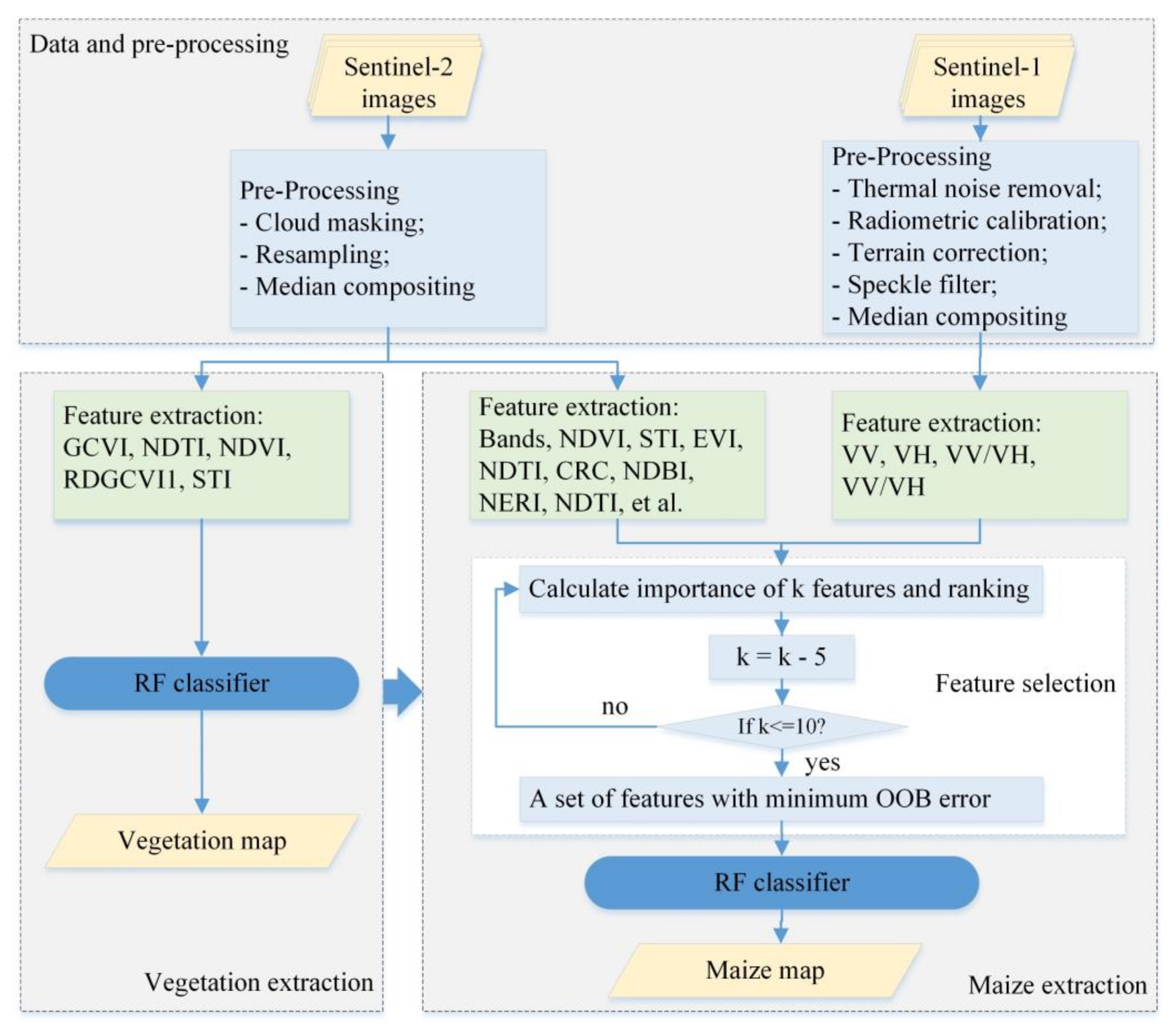
3. Method
3.1. Random Forest
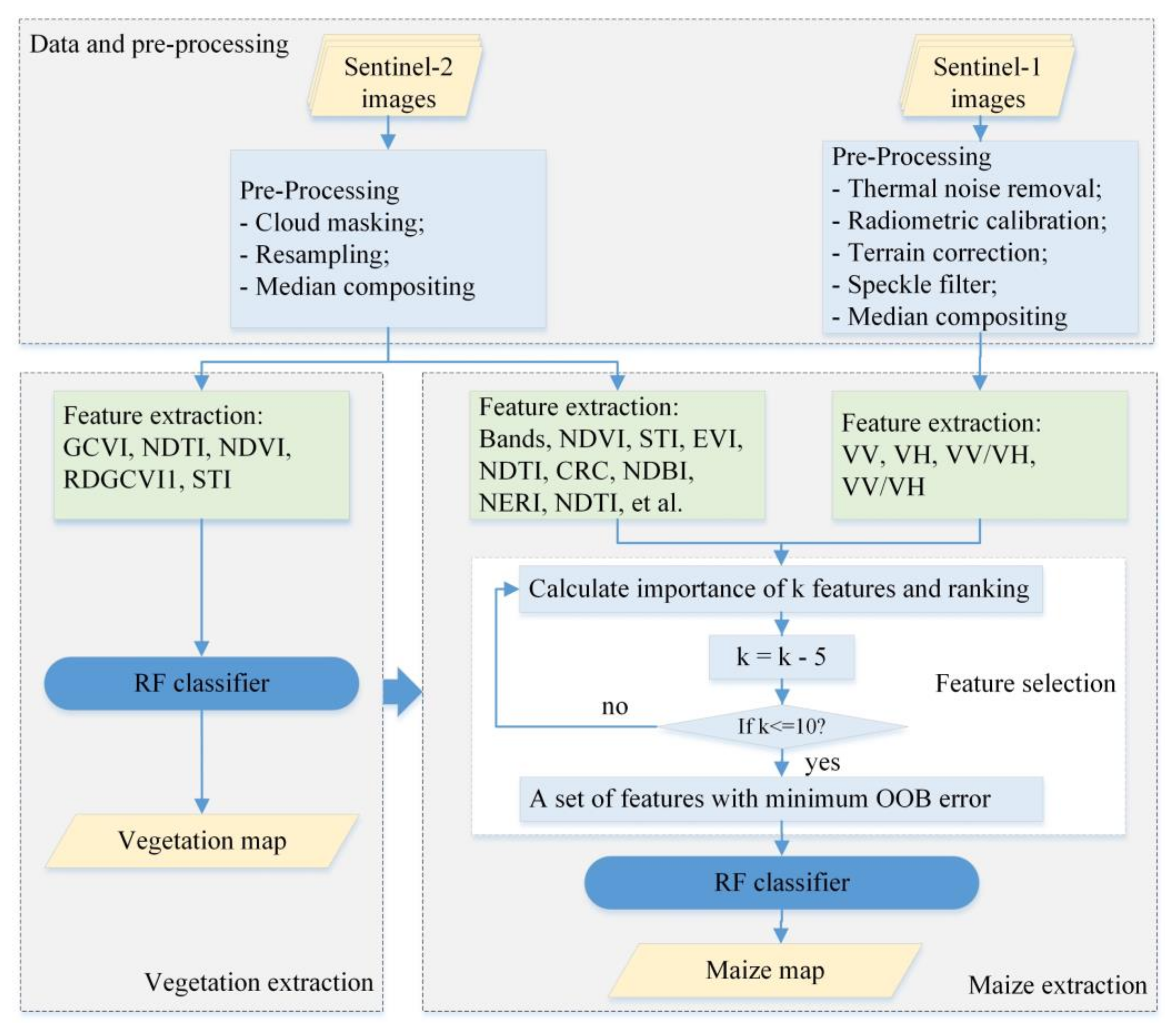
3.2. The Methodology of Maize Planting Area Extraction
3.3. Accuracy Assessment
4. Results
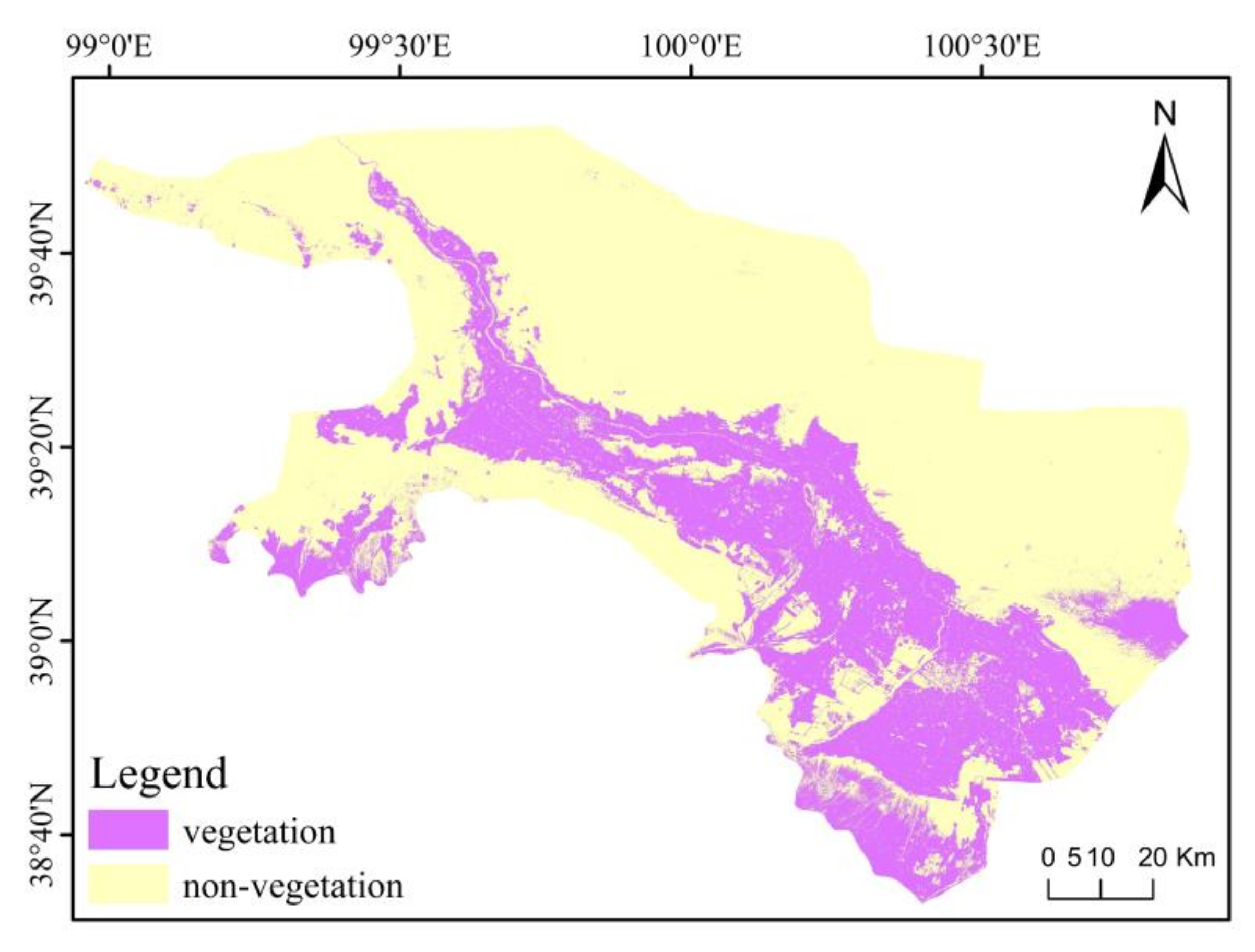
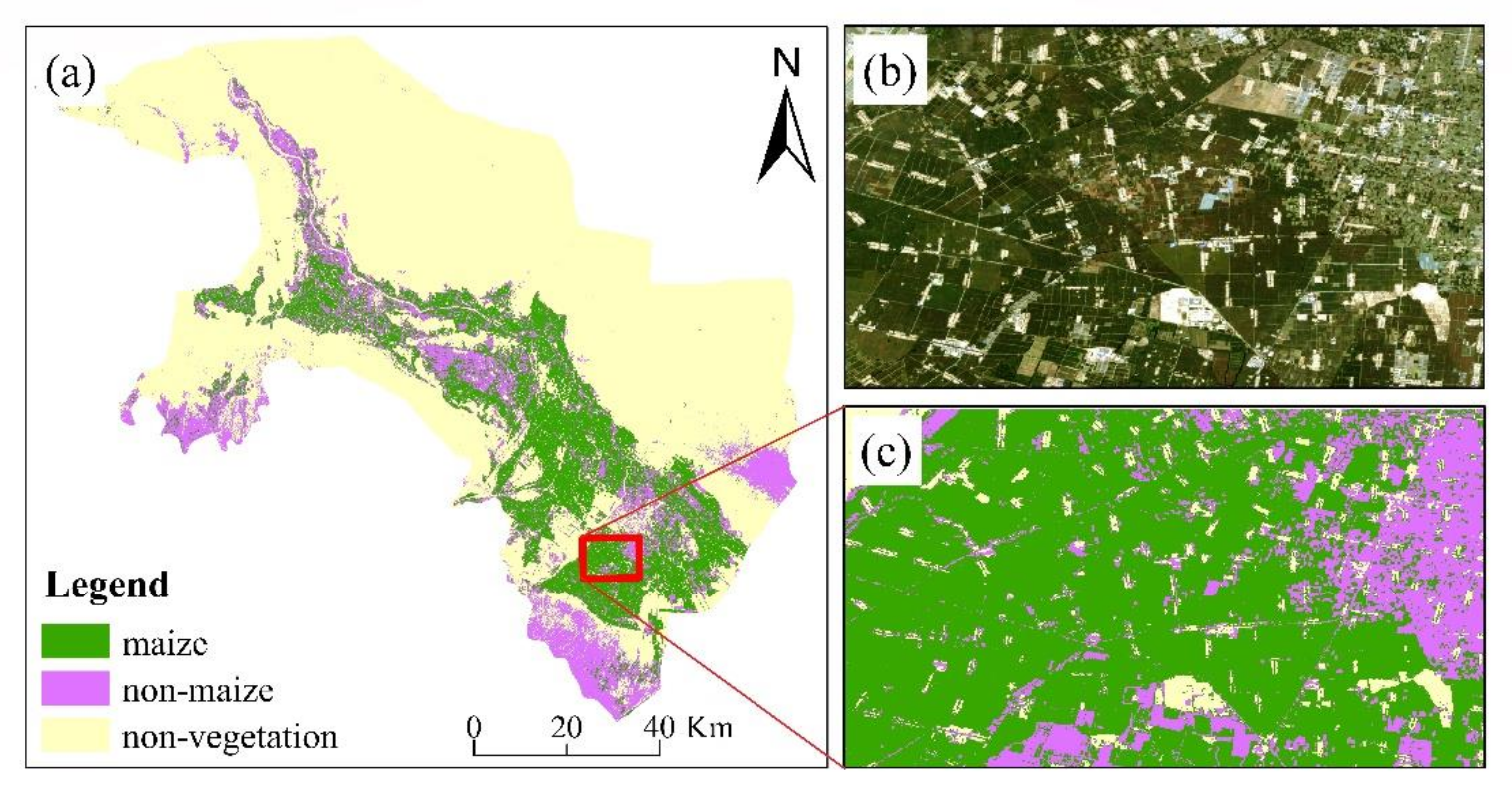
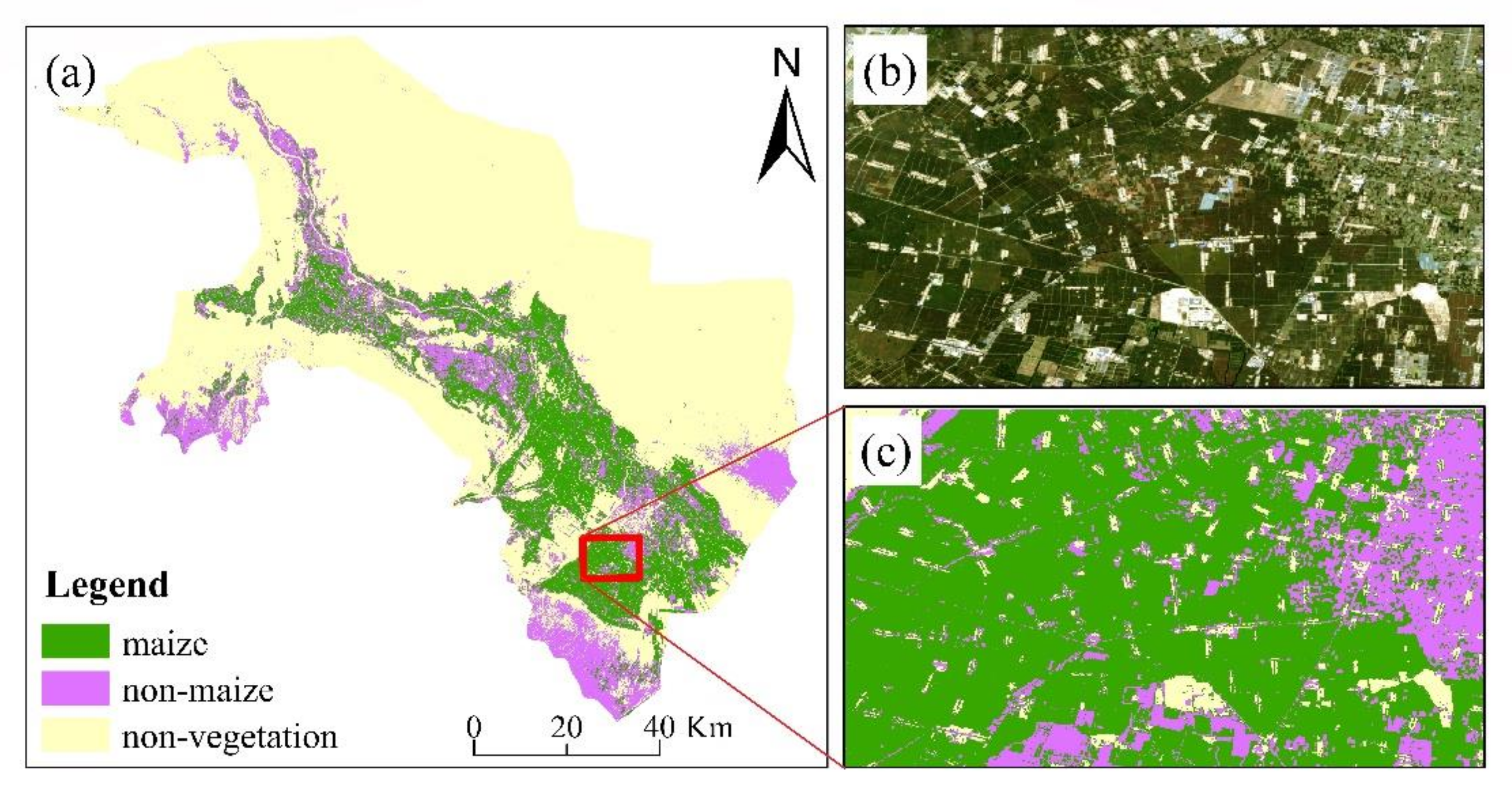
4.1. Vegetation Extraction Result
4.2. Maize Extraction Result
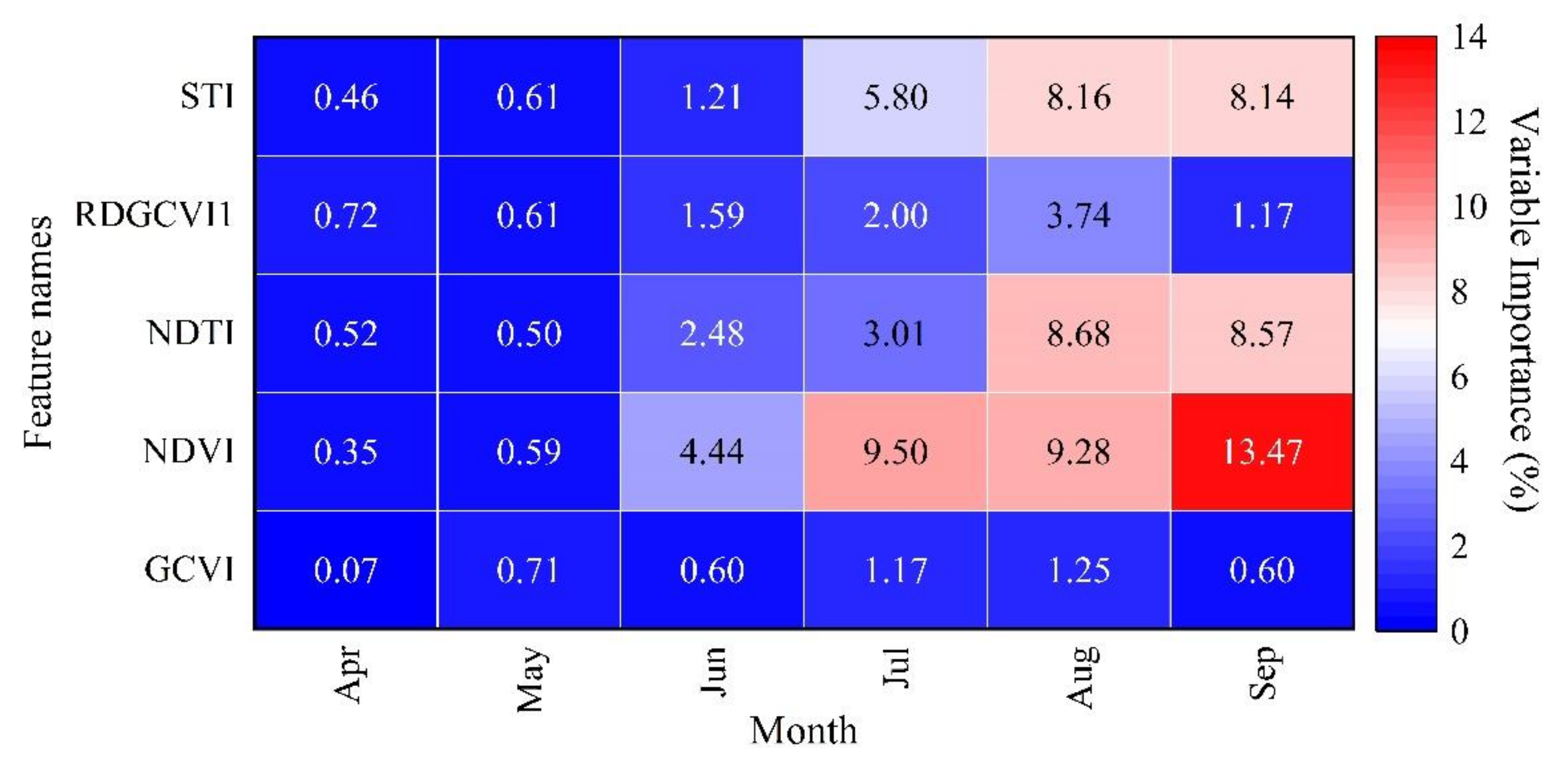
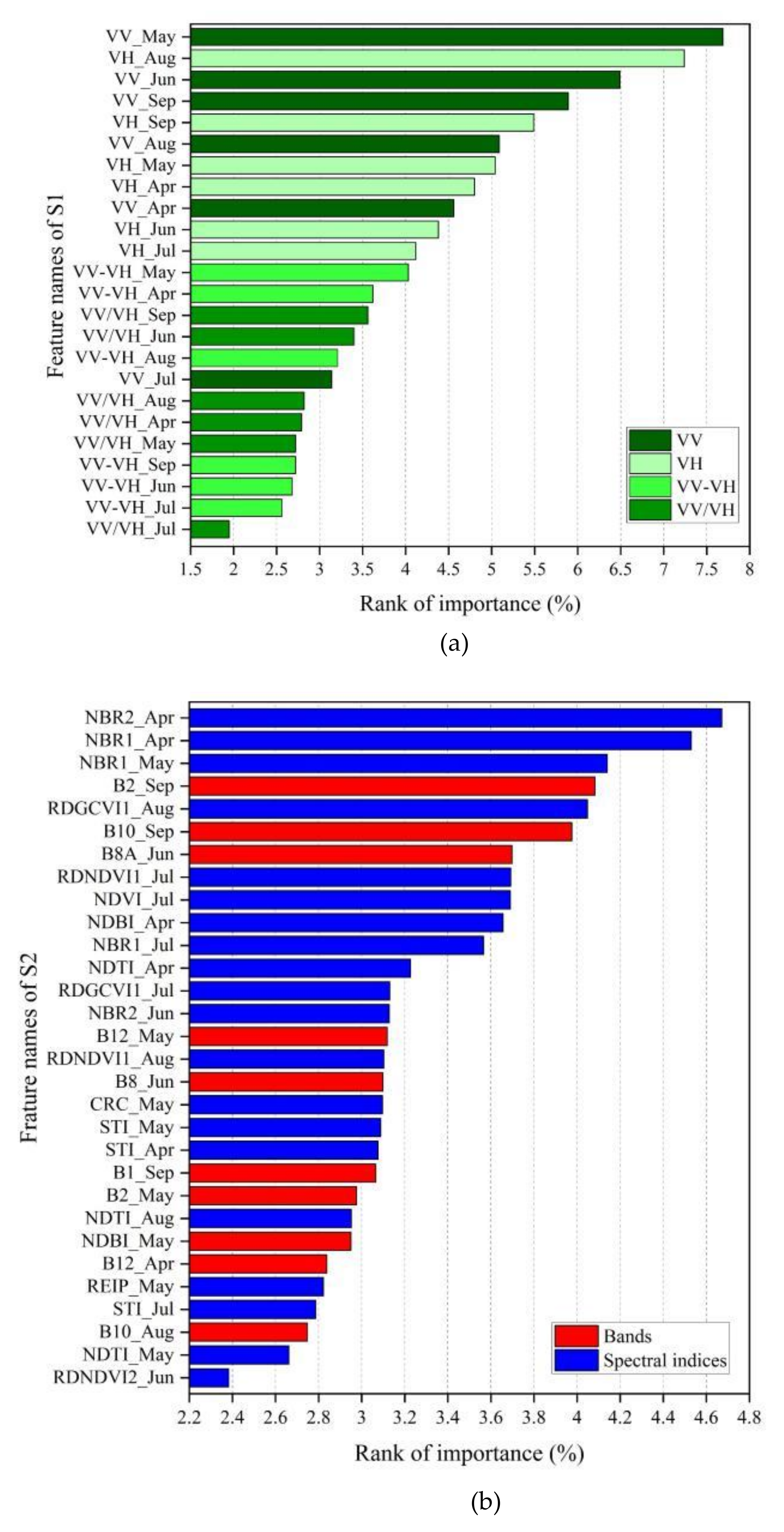
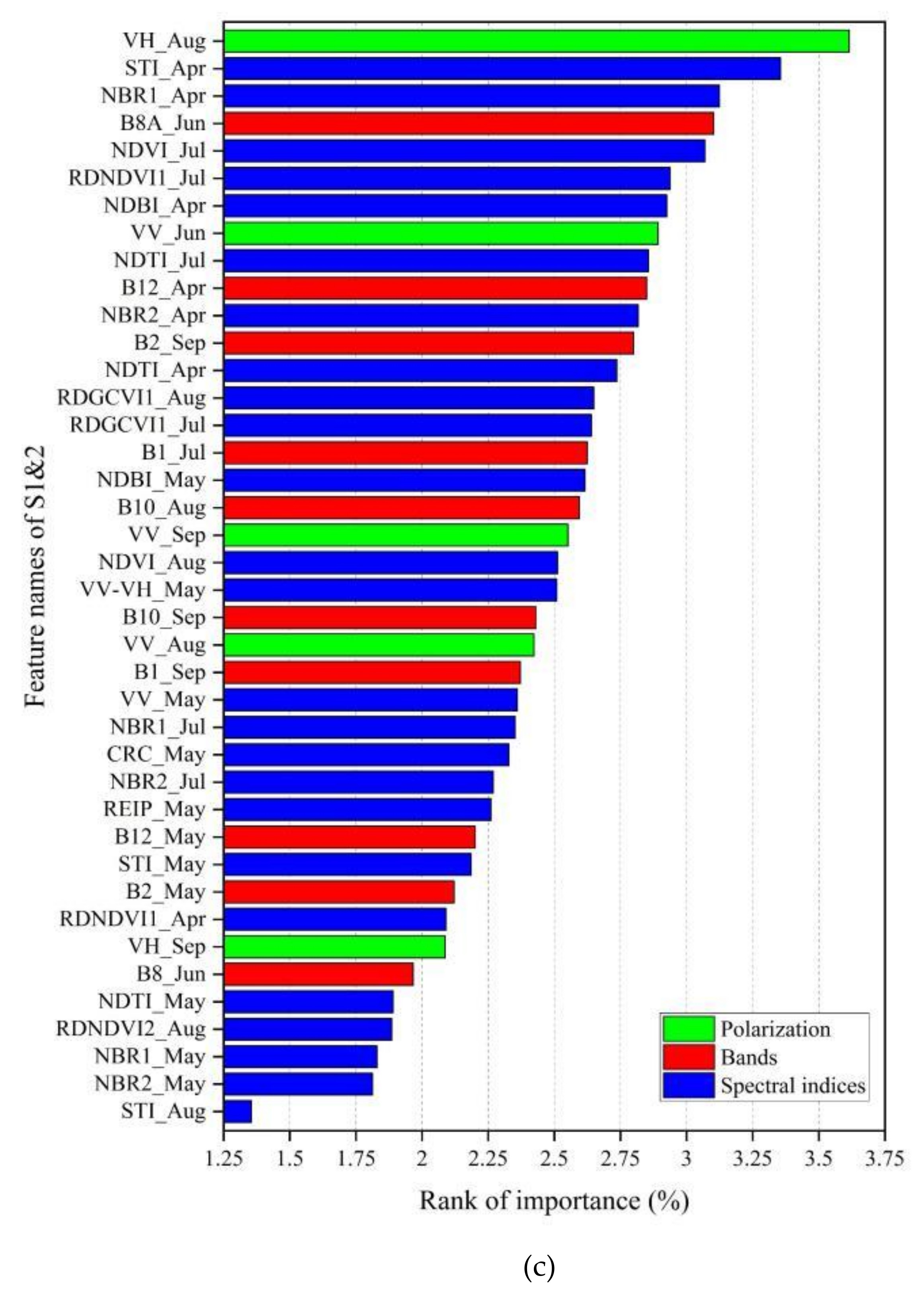
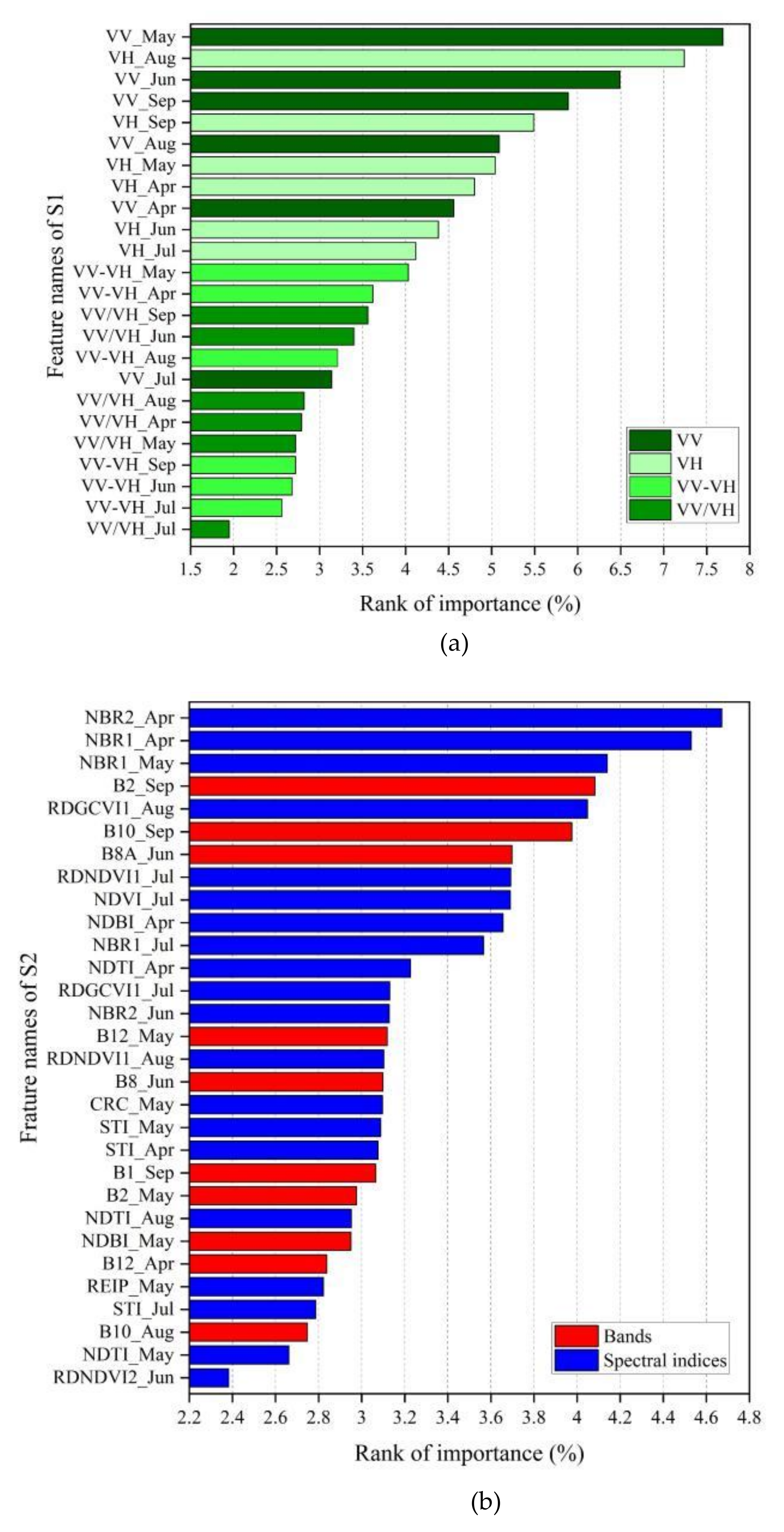
4.2.1. The Optimal Features
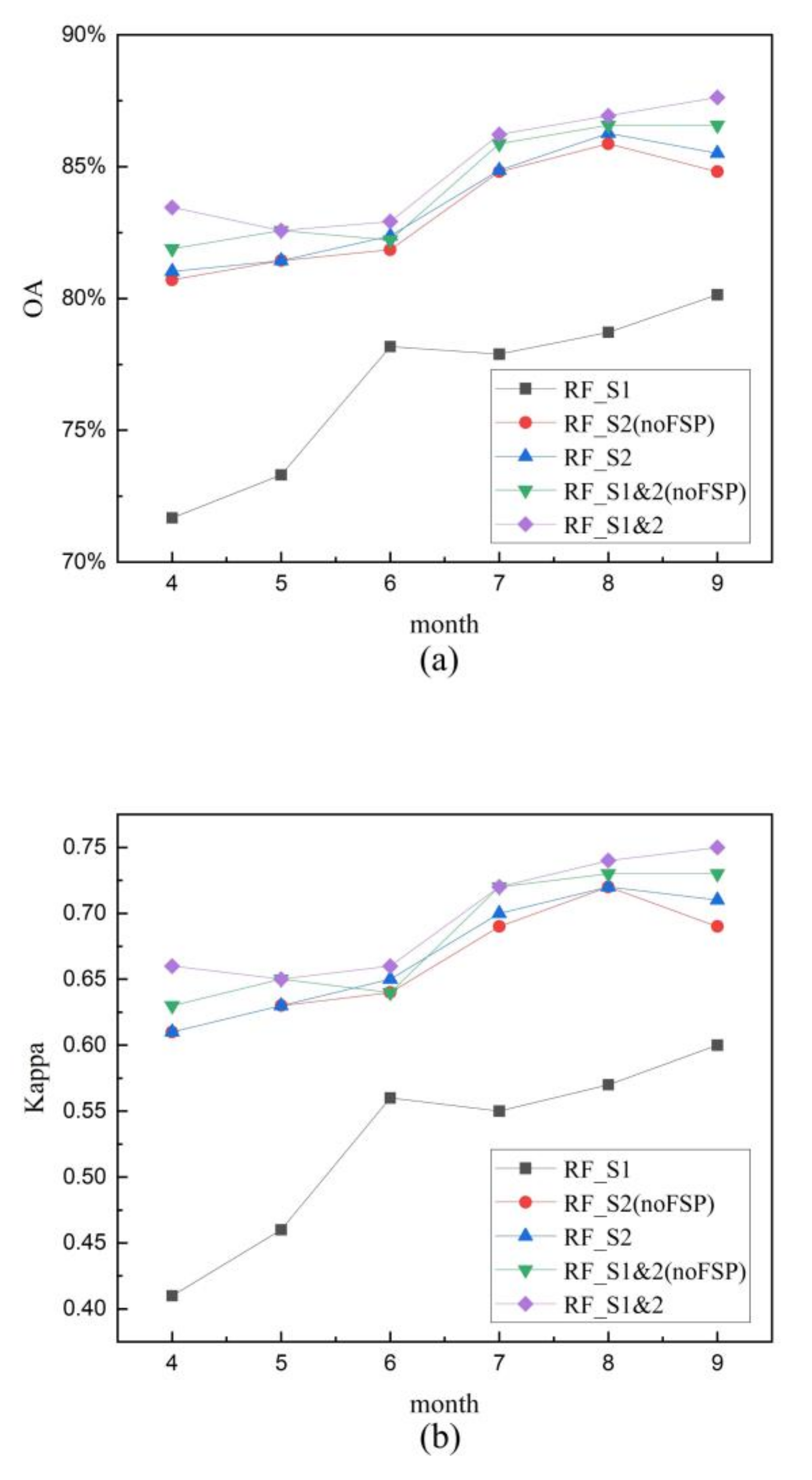
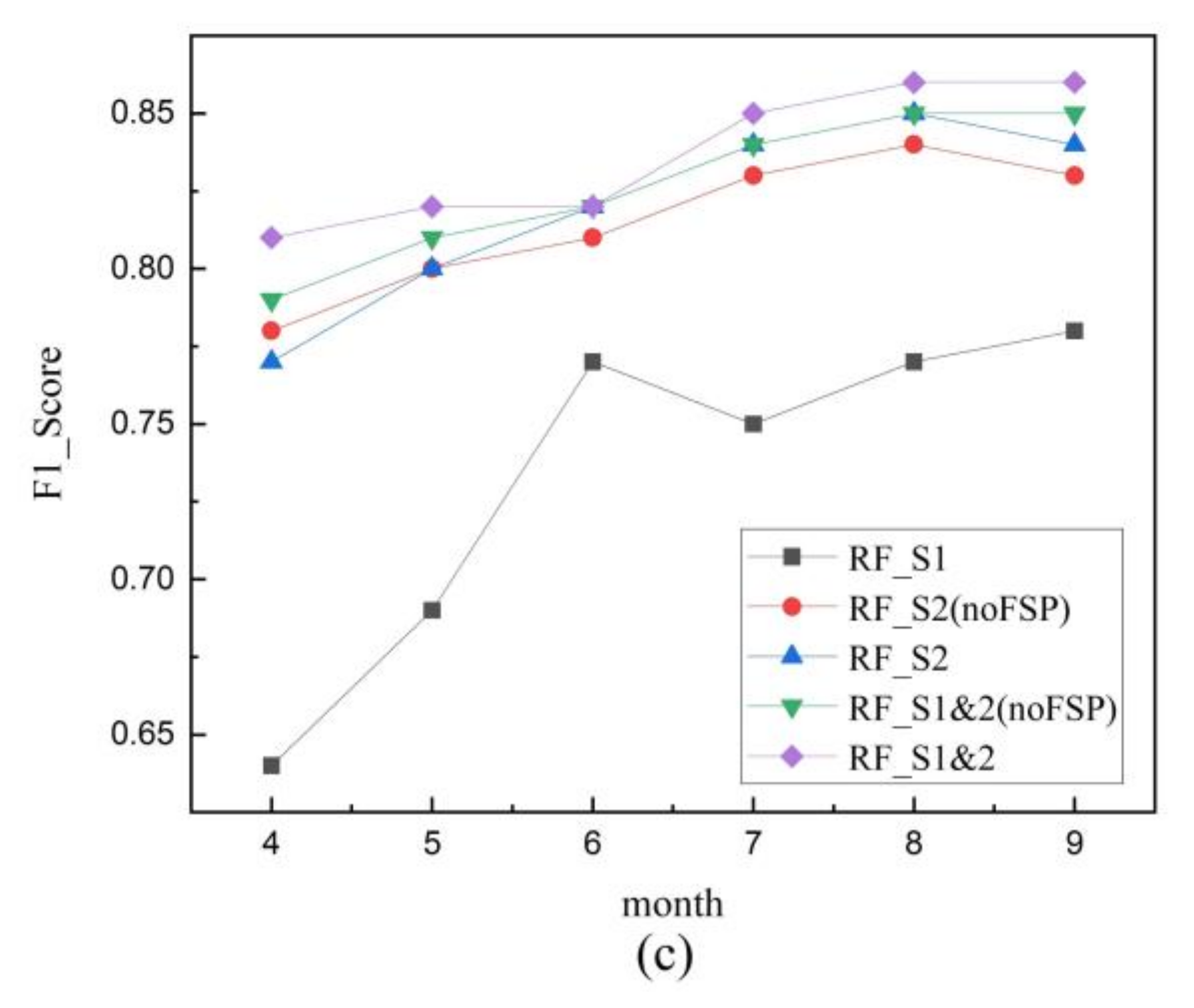
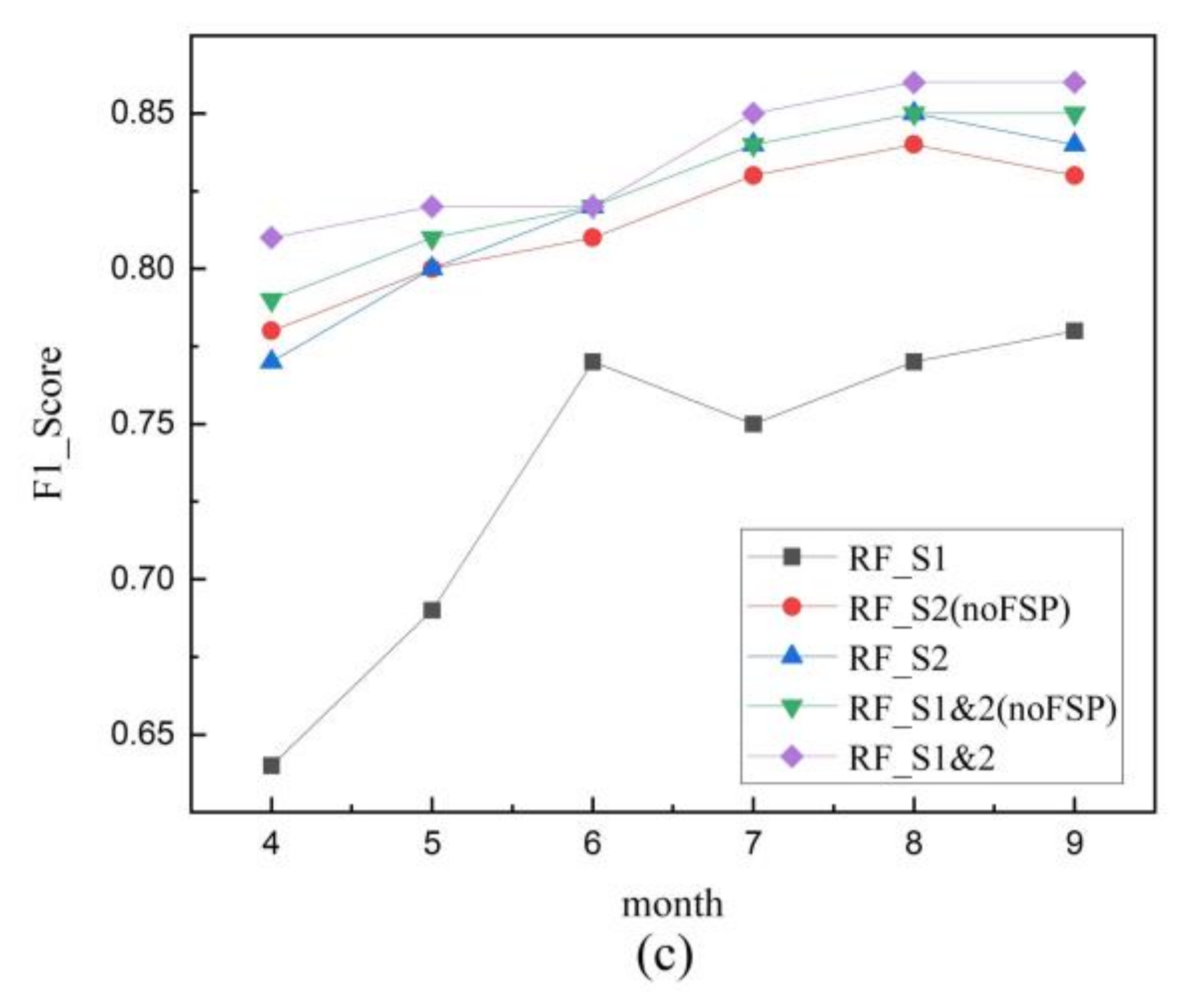
4.2.2. Comparison of Maize Extraction Results from Three RF Models
5. Discussion
5.1. Effects of Pre-processing on Maize Mapping
5.2. Effects of Multi-Temporal Images on Maize Mapping
5.3. Effects of Feature Selection Procedure on Maize Mapping
5.4. Uncertainty and Future Enhancement of Maize Mapping
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Peña-Barragán, J.M.; Ngugi, M.K.; Plant, R.E.; Six, J. Object-based crop identification using multiple vegetation indices, textural features and crop phenology. Remote Sens. Environ. 2011, 115, 1301–1316. [Google Scholar] [CrossRef]
- Song, Q.; Hu, Q.; Zhou, Q.; Hovis, C.; Xiang, M.; Tang, H.; Wu, W. In-Season Crop Mapping with GF-1/WFV Data by Combining Object-Based Image Analysis and Random Forest. Remote Sens. 2017, 9, 1184. [Google Scholar] [CrossRef] [Green Version]
- Muhammad, S.; Zhan, Y.; Wang, L.; Hao, P.; Niu, Z. Major crops classification using time series MODIS EVI with adjacent years of ground reference data in the US state of Kansas. Optik 2016, 127, 1071–1077. [Google Scholar] [CrossRef]
- Skakun, S.; Franch, B.; Vermote, E.; Roger, J.C.; Becker-Reshef, I.; Justice, C.; Kussul, N. Early season large-area winter crop mapping using MODIS NDVI data, growing degree days information and a Gaussian mixture model. Remote Sens. Environ. 2017, 195, 244–258. [Google Scholar] [CrossRef]
- Son, N.T.; Chen, C.F.; Chen, C.R.; Guo, H.Y. Classification of multitemporal Sentinel-2 data for field-level monitoring of rice cropping practices in Taiwan. Adv. Space Res. 2020, 65, 1910–1921. [Google Scholar] [CrossRef]
- Ajadi, O.A.; Barr, J.; Liang, S.Z.; Ferreira, R.; Kumpatla, S.P.; Patel, R.; Swatantran, A. Large-scale crop type and crop area mapping across Brazil using synthetic aperture radar and optical imagery. Int. J. Appl. Earth Obs. Geoinf. 2021, 97, 102294. [Google Scholar] [CrossRef]
- Minasny, B.; Shah, R.M.; Che Soh, N.; Arif, C.; Indra Setiawan, B. Automated Near-Real-Time Mapping and Monitoring of Rice Extent, Cropping Patterns, and Growth Stages in Southeast Asia Using Sentinel-1 Time Series on a Google Earth Engine Platform. Remote Sens. 2019, 11, 1666. [Google Scholar] [CrossRef] [Green Version]
- Mascolo, L.; Lopez-Sanchez, J.M.; Vicente-Guijalba, F.; Nunziata, F.; Migliaccio, M.; Mazzarella, G. A Complete Procedure for Crop Phenology Estimation With PolSAR Data Based on the Complex Wishart Classifier. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6505–6515. [Google Scholar] [CrossRef] [Green Version]
- Arias, M.; Campo-Bescós, M.Á.; Álvarez-Mozos, J. Crop Classification Based on Temporal Signatures of Sentinel-1 Observations over Navarre Province, Spain. Remote Sens. 2020, 12, 0278. [Google Scholar] [CrossRef] [Green Version]
- Erinjery, J.J.; Singh, M.; Kent, R. Mapping and assessment of vegetation types in the tropical rainforests of the Western Ghats using multispectral Sentinel-2 and SAR Sentinel-1 satellite imagery. Remote Sens. Environ. 2018, 216, 345–354. [Google Scholar] [CrossRef]
- Inglada, J.; Vincent, A.; Arias, M.; Marais-Sicre, C. Improved Early Crop Type Identification By Joint Use of High Temporal Resolution SAR And Optical Image Time Series. Remote Sens. 2016, 8, 362. [Google Scholar] [CrossRef] [Green Version]
- Cai, Y.; Lin, H.; Zhang, M. Mapping paddy rice by the object-based random forest method using time series Sentinel-1/Sentinel-2 data. Adv. Space Res. 2019, 64, 2233–2244. [Google Scholar] [CrossRef]
- Filella, I.; Penuelas, J. The red edge position and shape as indicators of plant chlorophyll content, biomass and hydric status. Int. J. Remote Sens. 1994, 15, 1459–1470. [Google Scholar] [CrossRef]
- Schlerf, M.; Atzberger, C.; Hill, J. Remote sensing of forest biophysical variables using HyMap imaging spectrometer data. Remote Sens. Environ. 2005, 95, 177–194. [Google Scholar] [CrossRef] [Green Version]
- Panda, S.S.; Ames, D.P.; Panigrahi, S. Application of vegetation indices for agricultural crop yield prediction using neural network techniques. Remote Sens. 2010, 2, 673–696. [Google Scholar] [CrossRef] [Green Version]
- Reed, B.C.; Brown, J.F.; VanderZee, D.; Loveland, T.R.; Merchant, J.W.; Ohlen, D.O. Measuring phenological variability from satellite imagery. J. Veg. Sci. 1994, 5, 703–714. [Google Scholar] [CrossRef]
- Huemmrich, K.F.; Privette, J.L.; Mukelabai, M.; Myneni, R.B.; Knyazikhin, Y. Time-series validation of MODIS land biophysical products in a Kalahari woodland, Africa. Int. J. Remote Sens. 2007, 26, 4381–4398. [Google Scholar] [CrossRef]
- Huete, A.; Liu, H.; Batchily, K.; Van Leeuwen, W. A comparison of vegetation indices over a global set of TM images for EOS-MODIS. Remote Sens. Environ. 1997, 59, 440–451. [Google Scholar] [CrossRef]
- Jeong, S.; Kang, S.; Jang, K.; Lee, H.; Hong, S.; Ko, D. Development of Variable Threshold Models for detection of irrigated paddy rice fields and irrigation timing in heterogeneous land cover. Agric. Water Manag. 2012, 115, 83–91. [Google Scholar] [CrossRef]
- Huete, A.; Didan, K.; Miura, T.; Rodriguez, E.P.; Gao, X.; Ferreira, L.G. Overview of the radiometric and biophysical performance of the MODIS vegetation indices. Remote Sens. Environ. 2002, 83, 195–213. [Google Scholar] [CrossRef]
- Van Deventer, A.; Ward, A.; Gowda, P.; Lyon, J. Using thematic mapper data to identify contrasting soil plains and tillage practices. Photogramm. Eng. Rem. S. 1997, 63, 87–93. [Google Scholar] [CrossRef]
- Roy, D.P.; Boschetti, L.; Trigg, S.N. Remote Sensing of Fire Severity: Assessing the Performance of the Normalized Burn Ratio. IEEE Geosci. Remote Sens. Lett. 2006, 3, 112–116. [Google Scholar] [CrossRef] [Green Version]
- Benbahria, Z.; Sebari, I.; Hajji, H.; Smiej, M.F. Automatic Mapping of Irrigated Areas in Mediteranean Context Using Landsat 8 Time Series Images and Random Forest Algorithm. In Proceedings of the IGARSS 2018-2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 7986–7989. [Google Scholar]
- Bannari, A.; Morin, D.; Bonn, F.; Huete, A. A review of vegetation indices. Remote Sens. 1995, 13, 95–120. [Google Scholar] [CrossRef]
- Jin, Z.; Azzari, G.; You, C.; Di Tommaso, S.; Aston, S.; Burke, M.; Lobell, D.B. Smallholder maize area and yield mapping at national scales with Google Earth Engine. Remote Sens. Environ. 2019, 228, 115–128. [Google Scholar] [CrossRef]
- Kishino, M.; Tanaka, A.; Ishizaka, J. Retrieval of Chlorophyll a, suspended solids, and colored dissolved organic matter in Tokyo Bay using ASTER data. Remote Sens. Environ. 2005, 99, 66–74. [Google Scholar] [CrossRef]
- Saeys, Y.; Inza, I.; Larrañaga, P. A review of feature selection techniques in bioinformatics. Bioinformatics 2007, 23, 2507–2517. [Google Scholar] [CrossRef] [Green Version]
- Li, Q.; Wang, C.; Zhang, B.; Lu, L. Object-Based Crop Classification with Landsat-MODIS Enhanced Time-Series Data. Remote Sens. 2015, 7, 16091–16107. [Google Scholar] [CrossRef] [Green Version]
- Hao, P.; Zhan, Y.; Wang, L.; Niu, Z.; Shakir, M. Feature Selection of Time Series MODIS Data for Early Crop Classification Using Random Forest: A Case Study in Kansas, USA. Remote Sens. 2015, 7, 5347–5369. [Google Scholar] [CrossRef] [Green Version]
- Demarez, V.; Helen, F.; Marais-Sicre, C.; Baup, F. In-Season Mapping of Irrigated Crops Using Landsat 8 and Sentinel-1 Time Series. Remote Sens. 2019, 11, 118. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Sun, Y.; Shang, K.; Zhang, L.; Wang, S. Crop Classification Based on Feature Band Set Construction and Object-Oriented Approach Using Hyperspectral Images. IEEE J-STARS. 2016, 9, 4117–4128. [Google Scholar] [CrossRef]
- Yin, L.; You, N.; Zhang, G.; Huang, J.; Dong, J. Optimizing Feature Selection of Individual Crop Types for Improved Crop Mapping. Remote Sens. 2020, 12, 0162. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.; Azzari, G.; Lobell, D.B. Crop type mapping without field-level labels: Random forest transfer and unsupervised clustering techniques. Remote Sens. Environ. 2019, 222, 303–317. [Google Scholar] [CrossRef]
- Basukala, A.K.; Oldenburg, C.; Schellberg, J.; Sultanov, M.; Dubovyk, O. Towards improved land use mapping of irrigated croplands: Performance assessment of different image classification algorithms and approaches. Eur. J. Remote Sens. 2017, 50, 187–201. [Google Scholar] [CrossRef] [Green Version]
- Moumni, A.; Lahrouni, A. Machine Learning-Based Classification for Crop-Type Mapping Using the Fusion of High-Resolution Satellite Imagery in a Semiarid Area. Scientifica 2021, 2021, 8810279. [Google Scholar] [CrossRef]
- Gilbertson, J.K.; Kemp, J.; van Niekerk, A. Effect of pan-sharpening multi-temporal Landsat 8 imagery for crop type differentiation using different classification techniques. Comput. Electron. Agric. 2017, 134, 151–159. [Google Scholar] [CrossRef] [Green Version]
- Zhang, H.; Kang, J.; Xu, X.; Zhang, L. Accessing the temporal and spectral features in crop type mapping using multi-temporal Sentinel-2 imagery: A case study of Yi’an County, Heilongjiang province, China. Comput. Electron. Agric. 2020, 176, 105618. [Google Scholar] [CrossRef]
- Sun, C.; Bian, Y.; Zhou, T.; Pan, J. Using of Multi-Source and Multi-Temporal Remote Sensing Data Improves Crop-Type Mapping in the Subtropical Agriculture Region. Sensors 2019, 19, 2401. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Biradar, C.M.; Thenkabail, P.S.; Noojipady, P.; Li, Y.; Dheeravath, V.; Turral, H.; Velpuri, M.; Gumma, M.K.; Gangalakunta, O.R.P.; Cai, X.L.; et al. A global map of rainfed cropland areas (GMRCA) at the end of last millennium using remote sensing. Int. J. Appl. Earth Obs. 2009, 11, 114–129. [Google Scholar] [CrossRef]
- Ragettli, S.; Herberz, T.; Siegfried, T. An Unsupervised Classification Algorithm for Multi-Temporal Irrigated Area Mapping in Central Asia. Remote Sens. 2018, 10, 1823. [Google Scholar] [CrossRef] [Green Version]
- Biggs, T.W.; Thenkabail, P.S.; Gumma, M.K.; Scott, C.A.; Parthasaradhi, G.R.; Turral, H.N. Irrigated area mapping in heterogeneous landscapes with MODIS time series, ground truth and census data, Krishna Basin, India. Int. J. Remote Sens. 2007, 27, 4245–4266. [Google Scholar] [CrossRef]
- Wardlow, B.D.; Egbert, S.L. Large-area crop mapping using time-series MODIS 250 m NDVI data: An assessment for the U.S. Central Great Plains. Remote Sens. Environ. 2008, 112, 1096–1116. [Google Scholar] [CrossRef]
- Chen, Y.; Lu, D.; Luo, L.; Pokhrel, Y.; Deb, K.; Huang, J.; Ran, Y. Detecting irrigation extent, frequency, and timing in a heterogeneous arid agricultural region using MODIS time series, Landsat imagery, and ancillary data. Remote Sens. Environ. 2018, 204, 197–211. [Google Scholar] [CrossRef]
- Lu, L.; Cheng, G.; Li, X. Landscape change in the middle reaches of Heihe River Basin. J. Appl. Ecol. 2001, 1, 68–74, PMID: 11813437. [Google Scholar]
- Wang, S.; Ma, C.; Zhao, Z.; Wei, L. Estimation of Soil Moisture of Agriculture Field in the Middle Reaches of the Heihe River Basin based on Sentinel-1 and Landsat 8 Imagery. Remote Sens. Technol. Appl. 2020, 35, 13–22. [Google Scholar]
- Jiao, Y.; Ma, M.; Xiao, D. Landscape Pattern of Zhangye Oasis in the Middle Reaches of Heihe River Basin. J. Glaciol. Geocryol. 2003, 25, 94–99. [Google Scholar] [CrossRef]
- Zheng, L.; Tan, M. Comparison of crop water use efficiency and direction of planting structure adjustment in the middle reaches of Heihe River. J. Geo Inf. Sci. 2016, 18, 977–986. [Google Scholar] [CrossRef]
- Veloso, A.; Mermoz, S.; Bouvet, A.; Le Toan, T.; Planells, M.; Dejoux, J.F.; Ceschia, E. Understanding the temporal behavior of crops using Sentinel-1 and Sentinel-2-like data for agricultural applications. Remote Sens. Environ. 2017, 199, 415–426. [Google Scholar] [CrossRef]
- Carrasco, L.; O’Neil, A.; Morton, R.; Rowland, C. Evaluating Combinations of Temporally Aggregated Sentinel-1, Sentinel-2 and Landsat 8 for Land Cover Mapping with Google Earth Engine. Remote Sens. 2019, 11, 0288. [Google Scholar] [CrossRef] [Green Version]
- Slagter, B.; Tsendbazar, N.E.; Vollrath, A.; Reiche, J. Mapping wetland characteristics using temporally dense Sentinel-1 and Sentinel-2 data: A case study in the St. Lucia wetlands, South Africa. Int. J. Earth Obs. 2020, 86, 102009. [Google Scholar] [CrossRef]
- Fauvel, M.; Lopes, M.; Dubo, T.; Rivers-Moore, J.; Frison, P.L.; Gross, N.; Ouin, A. Prediction of plant diversity in grasslands using Sentinel-1 and -2 satellite image time series. Remote Sens. Environ. 2020, 237, 111536. [Google Scholar] [CrossRef]
- You, N.; Dong, J. Examining earliest identifiable timing of crops using all available Sentinel 1/2 imagery and Google Earth Engine. ISPRS J. Photogramm. 2020, 161, 109–123. [Google Scholar] [CrossRef]
- Gatti, A.; Bertolini, A. Sentinel-2 Products Specification Document. Available online: https://earth.esa.int/documents/247904/685211/Sentinel-2-Products-Specification-Document (accessed on 23 February 2015).
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Belgiu, M.; Drăguţ, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Pelletier, C.; Valero, S.; Inglada, J.; Champion, N.; Dedieu, G. Assessing the robustness of Random Forests to map land cover with high resolution satellite image time series over large areas. Remote Sens. Environ. 2016, 187, 156–168. [Google Scholar] [CrossRef]
- Teluguntla, P.; Thenkabail, P.S.; Oliphant, A.; Xiong, J.; Gumma, M.K.; Congalton, R.G.; Yadav, K.; Huete, A. A 30-m landsat-derived cropland extent product of Australia and China using random forest machine learning algorithm on Google Earth Engine cloud computing platform. ISPRS J. Photogramm. 2018, 144, 325–340. [Google Scholar] [CrossRef]
- Chen, Z. Mapping plastic-mulched farmland with multi-temporal Landsat-8 data. Remote Sens. 2017, 9, 557. [Google Scholar] [CrossRef] [Green Version]
- Rodriguez-Galiano, V.F.; Ghimire, B.; Rogan, J.; Chica-Olmo, M.; Rigol-Sanchez, J.P. An assessment of the effectiveness of a random forest classifier for land-cover classification. ISPRS J. Photogramm. 2012, 67, 93–104. [Google Scholar] [CrossRef]
- Díaz-Uriarte, R.; Alvarez de Andrés, S. Gene selection and classification of microarray data using random forest. BMC Bioinform. 2006, 7, 3. [Google Scholar] [CrossRef] [Green Version]
- Genuer, R.; Poggi, J.M.; Tuleau-Malot, C. Variable selection using random forests. Pattern Recognit. Lett. 2010, 31, 2225–2236. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Huang, C.; Hou, J.; Han, W.; Feng, Y.; Li, X.; Wang, J. Extraction of Maize Planting Area based on Multi-temporal Sentinel-2 Imagery in the Middle Reaches of Heihe River. Remote Sens. Technol. Appl. 2021, 36, 340–347. [Google Scholar] [CrossRef]
- Guyon, I.; Weston, J.; Barnhill, S.; Vapnik, V. Gene Selection for Cancer Classification using Support Vector Machines. Mach. Learn. 2002, 46, 389–422. [Google Scholar] [CrossRef]
- Zhao, H.; Chen, Z.; Jiang, H.; Jing, W.; Sun, L.; Feng, M. Evaluation of Three Deep Learning Models for Early Crop Classification Using Sentinel-1A Imagery Time Series—A Case Study in Zhanjiang, China. Remote Sens. 2019, 11, 2673. [Google Scholar] [CrossRef] [Green Version]
- Thanh Noi, P.; Kappas, M. Comparison of random forest, k-nearest neighbor, and support vector machine classifiers for land cover classification using Sentinel-2 imagery. Sensors 2018, 18, 18. [Google Scholar] [CrossRef] [Green Version]
- Minh, H.V.T.; Avtar, R.; Mohan, G.; Misra, P.; Kurasaki, M. Monitoring and Mapping of Rice Cropping Pattern in Flooding Area in the Vietnamese Mekong Delta Using Sentinel-1A Data: A Case of An Giang Province. ISPRS Int. J. Geoinf. 2019, 8, 0211. [Google Scholar] [CrossRef] [Green Version]
- Shamsoddini, A.; Trinder, J.C. Edge-detection-based filter for SAR speckle noise reduction. Int. J. Remote Sens. 2012, 33, 2296–2320. [Google Scholar] [CrossRef]
- Vuolo, F.; Neuwirth, M.; Immitzer, M.; Atzberger, C.; Ng, W.T. How much does multi-temporal Sentinel-2 data improve crop type classification? Int. J. Appl. Earth Obs. 2018, 72, 122–130. [Google Scholar] [CrossRef]
- Mercier, A.; Betbeder, J.; Rumiano, F.; Baudry, J.; Gond, V.; Blanc, L.; Bourgoin, C.; Cornu, G.; Ciudad, C.; Marchamalo, M.; et al. Evaluation of Sentinel-1 and 2 Time Series for Land Cover Classification of Forest–Agriculture Mosaics in Temperate and Tropical Landscapes. Remote Sens. 2019, 11, 0979. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, D.B.; Wagner, W. European Rice Cropland Mapping with Sentinel-1 Data: The Mediterranean Region Case Study. Water 2017, 9, 0392. [Google Scholar] [CrossRef]
- Bargiel, D. A new method for crop classification combining time series of radar images and crop phenology infor-mation. Remote Sen. Environ. 2017, 198, 369–383. [Google Scholar] [CrossRef]
- Marais Sicre, C.; Inglada, J.; Fieuzal, R.; Baup, F.; Valero, S.; Cros, J.; Huc, M.; Demarez, V. Early Detection of Summer Crops Using High Spatial Resolution Optical Image Time Series. Remote Sen. 2016, 8, 0591. [Google Scholar] [CrossRef] [Green Version]
- Mercier, A.; Betbeder, J.; Baudry, J.; Le Roux, V.; Spicher, F.; Lacoux, J.; Roger, D.; Hubert-Moy, L. Evaluation of Sentinel-1 & 2 time series for predicting wheat and rapeseed phenological stages. ISPRS J. Photogramm. 2020, 163, 231–256. [Google Scholar] [CrossRef]
- Kussul, N.; Lavreniuk, M.; Skakun, S.; Shelestov, A. Deep Learning Classification of Land Cover and Crop Types Using Remote Sensing Data. IEEE Geosci. Remote Sens. Lett. 2017, 14, 778–782. [Google Scholar] [CrossRef]
- Interdonato, R.; Ienco, D.; Gaetano, R.; Ose, K. DuPLO: A DUal view Point deep Learning architecture for time series classification. ISPRS J. Photogramm. 2019, 149, 91–104. [Google Scholar] [CrossRef] [Green Version]
- Ren, T.; Liu, Z.; Zhang, L.; Liu, D.; Xi, X.; Kang, Y.; Zhao, Y.; Zhang, C.; Li, S.; Zhang, X. Early Identification of Seed Maize and Common Maize Production Fields Using Sentinel-2 Images. Remote Sens. 2020, 12, 2140. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Band or Index | Central Wavelength/Index Formula | Satellite | |
|---|---|---|---|
| 1 | VV | S1 | |
| 2 | VH | S1 | |
| 3 | VV-VH | VV-VH | S1 |
| 4 | VV/VH | VV/VH | S1 |
| 5 | B1 | 443.9 nm(S2A)/442.3 nm(S2B) | S2 |
| 6 | B2 | 496.6 nm(S2A)/492.1 nm(S2B) | S2 |
| 7 | B3 | 560 nm(S2A)/559 nm(S2B) | S2 |
| 8 | B4 | 664.5 nm(S2A)/665 nm(S2B) | S2 |
| 9 | B5 | 703.9 nm(S2A)/703.8 nm(S2B) | S2 |
| 10 | B6 | 740.2 nm(S2A)/739.1 nm(S2B) | S2 |
| 11 | B7 | 782.5 nm(S2A)/779.7 nm(S2B) | S2 |
| 12 | B8 | 835.1 nm(S2A)/833 nm(S2B) | S2 |
| 13 | B8A | 864.8 nm(S2A)/864 nm(S2B) | S2 |
| 14 | B9 | 945 nm(S2A)/943.2 nm(S2B) | S2 |
| 15 | B10 | 1373.5 nm(S2A)/1376.9 nm(S2B) | S2 |
| 16 | B11 | 1613.7 nm(S2A)/1610.4 nm(S2B) | S2 |
| 17 | B12 | 2202.4 nm(S2A)/2185.7 nm(S2B) | S2 |
| 18 | NDVI | (B8 − B4)/(B8 + B4) | S2 |
| 19 | RDNDVI1 | (B8 − B5)/(B8 + B5) | S2 |
| 20 | RDNDVI2 | (B8 − B6)/(B8 + B6) | S2 |
| 21 | GCVI | (B8/B3) − 1 | S2 |
| 22 | RDGCVI1 | (B8/B5) − 1 | S2 |
| 23 | RDGCVI2 | (B8/B6) − 1 | S2 |
| 24 | REIP | 700 + 40 × ((B4 + B7)/2 − B5)/(B7 − B5) | S2 |
| 25 | NBR1 | (B8 − B11)/(B8 + B11) | S2 |
| 26 | NBR2 | (B8 − B12)/(B8 + B12) | S2 |
| 27 | NDTI | (B11 − B12)/(B11 + B12) | S2 |
| 28 | CRC | (B11 − B3)/(B11 + B3) | S2 |
| 29 | STI | B11/B12 | S2 |
| 30 | NDBI | (B12 − B4)/(B12 + B4) | S2 |
| 31 | NDWI | (B3 − B4)/(B3 + B4) | S2 |
| 32 | LSWI | (B4 − B11)/(B4 + B11) | S2 |
| 33 | EVI | 2.5 × (B8 − B4)/(B8 + 6 × B4 − 7.5 × B2 + 1) | S2 |
| 34 | REP | 705 + 35 × (0.5 × (B7 + B4) − B5)/(B6 − B5) | S2 |
| Confusion Matrix | Predictive Value | R | P | OA | KAPPA | F1_Score | ||
|---|---|---|---|---|---|---|---|---|
| Maize | Non-Maize | |||||||
| actual value (training set) | RF_S1 | |||||||
| maize | 386 | 68 | 0.84 | 0.85 | 86.42% | 0.72 | 0.84 | |
| non-maize | 72 | 505 | 0.88 | 0.88 | ||||
| RF_S2 | ||||||||
| maize | 404 | 52 | 0.86 | 0.89 | 88.39% | 0.76 | 0.87 | |
| non-maize | 68 | 510 | 0.91 | 0.88 | ||||
| RF_S1&S2 | ||||||||
| maize | 412 | 44 | 0.9 | 0.9 | 89.46% | 0.79 | 0.90 | |
| non-maize | 65 | 513 | 0.89 | 0.89 | ||||
| actual value (test set) | RF_S1 | |||||||
| maize | 103 | 24 | 0.76 | 0.81 | 80.14% | 0.6 | 0.78 | |
| non-maize | 32 | 123 | 0.84 | 0.79 | ||||
| RF_S2 | ||||||||
| maize | 110 | 17 | 0.82 | 0.87 | 85.51% | 0.71 | 0.84 | |
| non-maize | 24 | 132 | 0.89 | 0.85 | ||||
| RF_S1&S2 | ||||||||
| maize | 113 | 14 | 0.84 | 0.89 | 87.63% | 0.75 | 0.86 | |
| non-maize | 21 | 135 | 0.91 | 0.87 | ||||
| S2-Moving Median Processing | S1-7 × 7 Refined Lee Speckle Filter | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| month | OA | KAPPA | F1_Score | OA | KAPPA | F1_Score | ||||||
| before | after | before | after | before | after | before | after | before | after | before | after | |
| 4 | 80.18% | 80.71% | 0.58 | 0.61 | 0.73 | 0.78 | 69.26% | 71.68% | 0.34 | 0.41 | 0.59 | 0.64 |
| 5 | 79.77% | 79.46% | 0.59 | 0.59 | 0.76 | 0.77 | 71.21% | 73.05% | 0.42 | 0.45 | 0.67 | 0.69 |
| 6 | 74.91% | 77.46% | 0.49 | 0.54 | 0.71 | 0.74 | 69.89% | 69.06% | 0.40 | 0.38 | 0.68 | 0.68 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Hou, J.; Huang, C.; Zhang, Y.; Li, X. Mapping Maize Area in Heterogeneous Agricultural Landscape with Multi-Temporal Sentinel-1 and Sentinel-2 Images Based on Random Forest. Remote Sens. 2021, 13, 2988. https://doi.org/10.3390/rs13152988
Chen Y, Hou J, Huang C, Zhang Y, Li X. Mapping Maize Area in Heterogeneous Agricultural Landscape with Multi-Temporal Sentinel-1 and Sentinel-2 Images Based on Random Forest. Remote Sensing. 2021; 13(15):2988. https://doi.org/10.3390/rs13152988
Chicago/Turabian StyleChen, Yansi, Jinliang Hou, Chunlin Huang, Ying Zhang, and Xianghua Li. 2021. "Mapping Maize Area in Heterogeneous Agricultural Landscape with Multi-Temporal Sentinel-1 and Sentinel-2 Images Based on Random Forest" Remote Sensing 13, no. 15: 2988. https://doi.org/10.3390/rs13152988
APA StyleChen, Y., Hou, J., Huang, C., Zhang, Y., & Li, X. (2021). Mapping Maize Area in Heterogeneous Agricultural Landscape with Multi-Temporal Sentinel-1 and Sentinel-2 Images Based on Random Forest. Remote Sensing, 13(15), 2988. https://doi.org/10.3390/rs13152988