2.1. Manual Crowd Estimation
In 1967, Herbert Jacobs [
1], a professor at the University of California, Berkeley, proposed a simple method of dealing with scenarios where estimating the crowd size is not as easy as counting the number of tickets sold. His office looked out onto the plaza where students assembled to protest the Vietnam War. The concrete on this plaza was divided into grids. Jacobs used the layout to develop his method for estimating crowd size based on area times density. As he observed numerous demonstrations, Jacobs gathered plenty of information that led him to come up with a few basic rules of thumb, which are still used today. According to Jacobs, in a loose crowd, where the distance between each person is about one arm’s length, one person would occupy 10 square feet of space. People occupy 4.5 square feet for a dense crowd, and 2.5 square feet for a mosh-pit density crowd.
In other words, if you knew the area that the crowd was covering and you applied Jacob’s rule of thumb for the density of the crowd, you could easily estimate the size of the crowd by multiplying the area by density. In practice, however, it is not always easy to determine the specific area crowds cover, and densities may vary across a crowd. Suppose a crowd has gathered to hear a speaker up on a stage. We might predict that the crowd would be denser up front and less dense during the back and around the edges. To address these problems, it may be helpful to divide the crowds into low, medium, and high density zones and collect samples from each. The sample method would allow us to obtain a more reliable representation of the crowd area and density along with an estimate of standard error for both. We can use the delta rule to find the relative standard error for our estimation of the crowd size, if we have the standard errors for area and density and assume they are at least roughly independent.
Manually detecting the development and movement of a crowd around the clock, or manually counting persons in exceptionally dense crowds, is a time-consuming process. When it comes to static linear and static nonlinear events, where the entire crowd is present at the same time in a single-session event, such as a Christmas Parade or a Pride Parade, there is a higher chance of getting a false estimate due to a shift in the crowd and counting the same person multiple times. Manual crowd estimating techniques like Jacob’s Crowd Formula (JCF) are inefficient in dealing with such a large flow of crowd, these methods are confined to finding the average of the overlapped or shifting crowd sizes. Thus, it is very likely to estimate a larger crowd size than expected that would result in a crowd count with an unknown error rate. Considering the challenging situations such as dynamic linear or dynamic nonlinear events, it is extremely difficult to count and maintain an accurate estimate as these events often have free-flowing crowds with various entry points and can be stretched across several sessions or days. These methods are suitable for estimating the maximum crowd capacity in an area, but when it comes to accurate estimation, there is a need to develop automatic crowd estimation methods.
2.2. Computer Vision for Crowd Estimation and Analysis
Computer vision-based crowd estimation has gained considerable attention in various aspects of crowd analysis. In 2017, Marsden et al. [
2] described that crowd analysis focuses on developing task-specific systems that perform a single analysis task such as crowd counting, crowd behavior recognition, crowd density level classification and crowd behavior anomaly detection. For crowd estimation purposes, crowd counting approaches may vary based on factors like estimating the crowd from an image or from a real-time video. Loy et al. [
3] classified the crowd counting approaches into three different categories known as detection-based [
4,
5], regression-based [
6,
7] and density-based estimation [
8]. The evolving interest of researchers in the last five years has contributed to new developments and rapid expansion in the crowd counting domain, where the researches have mainly concentrated on crowd tracking, pedestrian counting and crowd behavior analysis, among other tasks.
Idrees et al. [
9] performed dense crowd estimation using a locally consistent scale to capture the similarity between local neighbourhoods and its smooth variation using images. The high crowd density and challenging nature of the data set led to several failure cases. A high-confidence detection in the first iteration often made the method over-sensitive to detection hypotheses occurring at the desired scale in neighboring areas. Similarly, at early iterations, high confidence nonhuman detection drastically degraded the prior scale, because they provided incorrect scale information. It led to misdetections in the surrounding areas that later papers tried to address.
Zhang et al. [
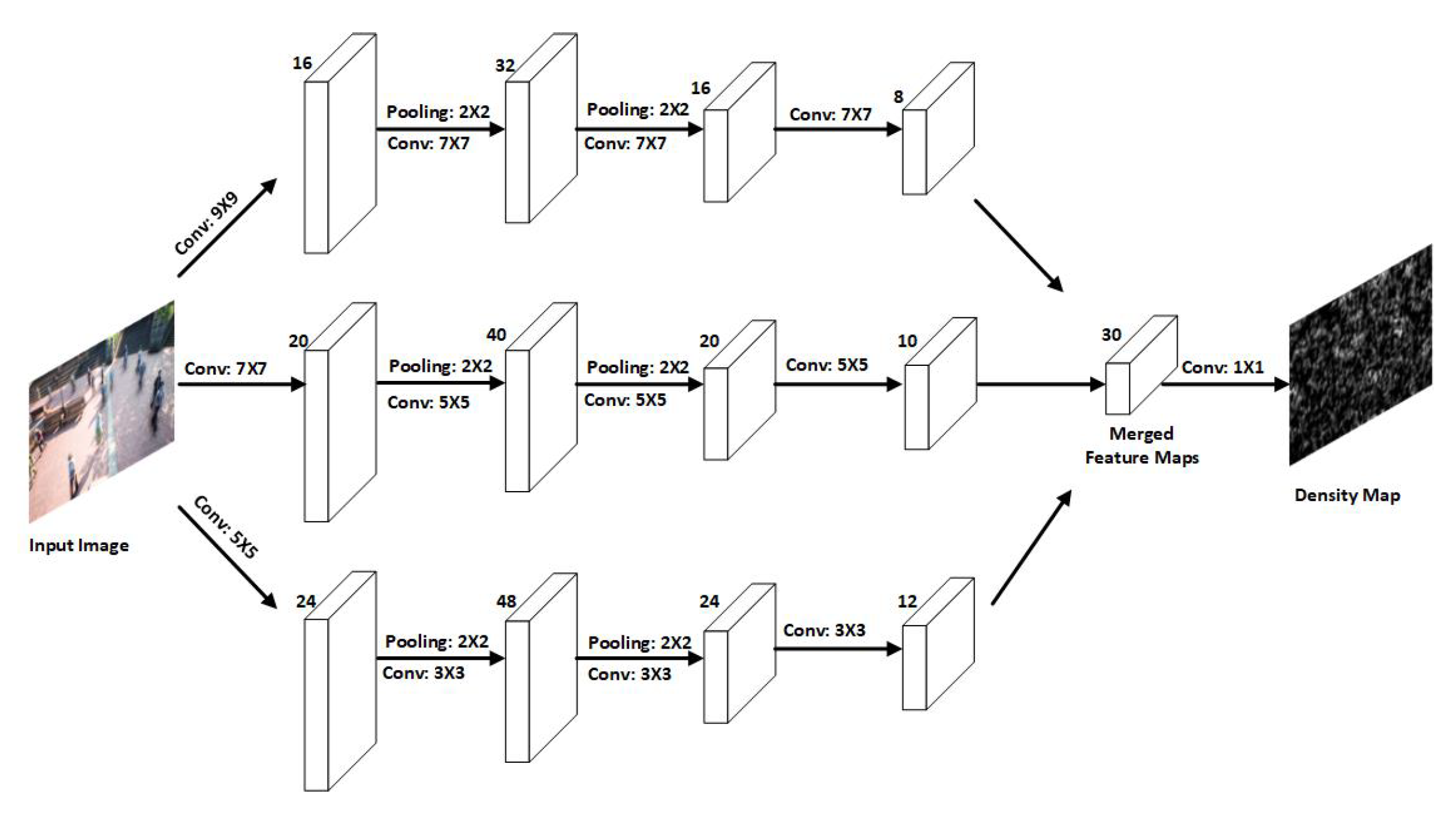
10] proposed a multicolumn convolutional neural network architecture (MCNN) which could estimate the number of people in a single image. By creating a network comprising of three columns corresponding to filters with receptive fields of varying sizes, the proposed approach offers resistance to huge variations in object scales (large, medium, small). The three columns were created to accommodate various object scales in the images. In addition, it offered a novel method to generate ground truth crowd density maps. In contrast to the existing methods that either summed up Gaussian kernels with a fixed variance or perspective maps, Zhang et al. also proposed that perspective distortion should be taken into consideration by estimating the spread parameter of the Gaussian kernel based on the size of each person’s head within the image. However, using density maps to determine head sizes and their underlying relationships is impractical. Instead, the authors employed a key feature noticed in high-density crowd images: the relationship between head size and distance between the centres of two neighbouring people. Each person’s spread parameter was calculated using data-adaptive methods based on their average distance from their neighbours. It is worth noting that the ground truth density maps generated using this method included distortion information without employing perspective maps.
Zhang et al. [
11] recently introduced a multiview crowd counting method using 3D features fused with 3D scene-level density maps. The deep neural network-based (DNN) 3D multiview counting method was integrated with camera views to estimate the 3D scene-level density maps. This method used 3D projection and fusion, which could address situations where people were not all at the same height (e.g., people standing on a staircase) and provided a way to tackle the scale variation issue in 3D space without a scale selection operation. However, increasing the height resolution did not contribute to the body’s information, but could introduce more noise (other people’s features) along the z-dimension, resulting in poor performance.
Zhao et al. [
12] introduced crowd counting with limited supervision. Initially, it labeled the most informative images and later introduced a classifier to align the data and then performed estimation based on density. The number of labeled individuals varied over the course of trials and cycles. However, the ground truth was unknown, so it was difficult to determine the exact number of people, which led to a higher or lower detection rate. A ground truth verification is necessary to overcome the problem or justify the introduced method since labeling more or fewer heads does not imply a better or worse performance.
Recently, Wang et al. [
13] developed a new Scale Tree Network (STNet) for crowd counting that aimed to improve scale variety and pixel-wise background recognition. The STNet network consistently met the challenges of drastic scale variations, density changes, and complex backgrounds. A tree-based scale enhancer dealt with scale variations and a multilevel auxiliator filtered pixels from complex backgrounds and adjusted them to density changes. STNet proved to be superior to the state-of-the-art approaches on four popular crowd counting data sets, while employing fewer parameters at the same time. They also proposed a method for addressing the crowd and background imbalance problem using pure background images. This concept could be easily incorporated in other crowd counting algorithms to further improve accuracy.
Ranjan et al. [
14] recently published a crowd counting method based on images with imprecise estimation. The majority of the presented work focused on estimating crowd density and using a random sample selection technique to eliminate the need for labeled data. They provided results that showed improved performance based on selecting only 17% of the training samples previously used.
Mustapha et al. [
15] presented a study that used CNN and Support Vector Machines (SVM) with sensor data adapted from both structure sensors and accelerometers of wearable devices to study crowd flows and bridge loads. A classification was used to determine crowd flow classification either as a binary choice of motion speed being fast or slow or as a multiclass decision based on high, medium, low, heavy, and light crowd loads, with heavy and light corresponding to crowd load designation. The load estimate of the crowd on the structure was calculated using regression to obtain the overall weight in kilograms. However, the regression results revealed inconsistency in fusion performance and a huge percentage of errors, when using the raw signal for SVM. Additionally, the study was conducted on a small scale. While considering the size of the crowd, however, any size can be considered in the future. That said, a large-scale crowd flow study is required to establish and comprehend the relationship between crowd flow and bridge load.
Almeida et al. [
16] recently proposed a crowd flow filtering method to analyze crowd flow behavior. It converted the input for the optical flow from an image plane into world coordinates to perform a local motion analysis, while exploring the Social Forces Model. The filtered flow was then returned to the image plane. The method was evaluated using an image plane and needs to be expanded for the image’s analysis to world coordinates. However, the work was confined to static cameras and could monitor behavior in a limited area. In addition, there is a pressing need to implement the proposed filtering approach on GPUs to achieve even faster execution times. However, the possibility for substantial speedups must be assessed.
Choi et al. [
17] recently presented 3DCrowdNet, a 2D human pose-guided 3D crowd pose and shape estimation system for in-the-wild scenes. The 2D human pose estimation methods provide relatively robust outputs on crowd scenes than 3D human pose estimation methods. After all, they can exploit in-the-wild multiperson 2D data sets. Nevertheless, the challenge remains in recovering accurate 3D poses from images with close interaction. Extreme instances frequently entail difficult poses and substantial interperson occlusion, which are both uncommon in the existing trained data.
Fahad et al. [
18] attempted to address the issue of public venues by using static camera positions that only record the top view of the images. To deal with events like strikes and riots, the proposed approach captured both the top and front view of the photos. The congested scene recognition (CSRNet) model assessed in this study utilized two separate test cases, one with only top view photos and the other with only front view images. However, the mean absolute error (MAE) and mean squared error (MSE) values of the front view images were higher than the top view images which needs to be reconsidered using other state-of-the-art networks. The gradient adversarial neural network (GANN) network could be effective in resolving the problem of projecting images from multiple viewpoints.
2.3. Previous Reviews and Surveys
Zhan et al. [
19] presented the first assessment of crowd analysis approaches used in computer vision research and discussed how diverse research disciplines can assist computer vision approach. Later on, Junior et al. [
20] provided a survey on crowd analysis using computer vision techniques, which covered topics including people monitoring, crowd density estimation, event detection, validation, and simulation. The research focused on three key issues in crowd analysis: density estimation, tracking in crowded settings, and analysing crowd behavior at a higher level, such as temporal evolution, primary directions, velocity predictions, and detection of unexpected situations. In terms of crowd synthesis, the review mostly focused on crowd models that either used computer vision algorithms to extract real-world data to improve simulation realism or were used to train and test computer vision techniques.
Teixeira et al. [
21] presented the first human sensing survey offering a comprehensive analysis of the presence, count, location, and track of a crowd. It focused on five commonly encountered spatio-temporal properties: identity, presence, count, location, and track. The survey provided an inherently multidisciplinary literature of human-sensing, focusing mainly on the extraction of five commonly needed spatio-temporal properties: namely presence, count, location, track and identity. It also covered a new taxonomy of observable human attributes and physical characteristics, as well as the sensing technologies that may be utilized to extract them. In addition, it compared active and passive sensors, sensor fusion techniques, and instrumented and uninstrumented settings.
Loy et al. [
3] discussed and evaluated state-of-the-art approaches for crowd counting based on video images as well as a systematic comparison of different methodologies using the same procedure. The review concluded that regression models capable of dealing with multicollinearity among features, such as Kernel ridge regression (KRR), Partial least-squares regression (PLSR), and Least-squares support vector regression (LSSVR), perform better than linear regression (LR) and random forest regression (RFR). The findings also revealed that depending on the crowd structure and density, certain features may be more useful. In sparse settings, foreground segment-based features could give all of the information required to estimate crowd density. Edge-based features and texture-based features, on the other hand, became increasingly important when a scene becomes packed with frequent interobject occlusions. Depending on the data set and regression model used, the final results affirmed that combining all attributes does not always help.
In 2014, Ferryman et al. [
22] presented a PETS2009 crowd analysis data set and highlighted performance in detection and tracking. It first published a performance review of state-of-the-art crowd image analysis visual surveillance technologies, using defined metrics to objectively evaluate their detection and tracking algorithms. Comparing results with others, whether anonymous or not, was a practical and encouraging research strategy for advanced, robust, real-time visual systems. Furthermore, the latest findings highlighted the requirement for ground truth data sets, which may be used to showcase the different systems capabilities, such as accuracy, precision, and robustness.
Li et al. [
23] examined the state-of-the-art techniques for crowded scene analysis in three major areas: motion pattern segmentation, crowd behavior recognition, and anomaly detection, using various methods such as crowd motion pattern learning, crowd behavior, activity analysis, and anomaly detection in crowds. The survey concluded that crowded settings frequently involve extreme clutter and object occlusions, making current visual-based techniques difficult to use. Fusion of data from several sensors is a proven tool to eliminate confusion and enhance accuracy [
24]. Another finding revealed that many existing video analysis systems track, learn, and detect by integrating the functional modules, without taking into account the interactions between them. It was preferable for crowded scene analysis systems to execute tracking, model learning, and behavior recognition in a completely online and unified manner to effectively utilise the hierarchical contextual information. Despite the development of several approaches for feature extraction and model learning in crowded scene analysis, there is no widely acknowledged crowded scene representation.
Ryan et al. [
25] offered a comparison of holistic, local, and histogram-based approaches as well as numerous picture characteristics and regression models, across multiple data sets. The performance of five public data sets was evaluated using a
K-fold cross-validation protocol: the UCSD [
26], PETS 2009 [
27], Fudan [
28], Mall [
29], and Grand Central [
30] data sets. The survey of the various methods concluded that the usage of local features consistently surpassed holistic and histogram features. Despite their extensive use in literature, edge and texture traits did not deliver ideal performance for a holistic approach. As a result, further data sets must be examined to corroborate these findings and to see if other feature sets or regression models might boost performance.
Later, Saleh et al. [
31] considered crowd density and visual surveillance to be the most significant aspects in the computer vision research context. The survey focused on two approaches: direct (i.e., object-based target detection) and indirect (e.g., pixel-based, texture-based, and corner points based analysis). As long as people were adequately segregated, direct approaches tracked and counted people simultaneously. The indirect technique, on the other hand, used a collection of measuring features and crowd learning algorithms to conduct the counting and estimating processes. While concluding the direct crowd estimating approach, the survey highlights that in lower-density groups, recognising individuals is easier. When detecting people in large groups or in the presence of occlusions, however, this process became more challenging and complex. That’s why despite recent breakthroughs in computer vision and pattern recognition algorithms, many recent studies have avoided the task of detecting individuals to save processing time. Instead, majority of the research has focused on indirect crowd estimation approaches based on a learning mapping between a set of observable variables and the number of people.
Zitouni et al. [
32] attempted to provide an explanation of such challenges by extrapolating relevant statistical evidence from the literature and making recommendations for focusing on the general elements of approaches rather than any specific algorithm. The study focused on existing crowd modeling approaches from the literature, concluding that the methods are still density dependent. In addition, real-world applications in surveillance, behavioral understanding, and other areas necessitate that crowd analysis that begins at the macro-level and branches into the micro-level. Let us consider the case of a crowd splitting due to an individual target crossing. Although macro-analysis (in this case, splitting) could detect changes in crowd behavior, micro-analysis (individual target crossing) is required to understand the cause of the behavior. To meet such realistic expectations, crowd representation and inference must concentrate on development at both macro and micro levels as well as in the middle. Most techniques, according to the study, operate under strong and restrictive assumptions such as camera perspective, environmental conditions, density, background and occlusion which must be addressed in the future.
Grant et al. [
33] investigated crowd analysis in relation to two main research areas: crowd statistics and behavior analysis. To address the challenge of measuring large crowds with high densities, the survey determined that good data including photographs collected at a variety of standoffs, angles, and resolutions as well as ground-truth labels for comparisons, is essential. It also shed light on the intriguing topic of detecting crowd demographics, where knowing demographics like gender, ethnicity, and age could be beneficial for event planning and marketing. The study also indicated that combining behavior recognition could help determine factors like the quantity of persons walking versus sprinting in a scene. It was strongly stated that synthetic crowd videos filled many gaps, and that these videos were useful in generating important ground-truth information for evaluating and comparing algorithms as well as providing scenes of situations that are too dangerous to re-enact. Plus, it justified the need to generate synthetic crowd data set in the future to avoid such scenarios.
Sindagi et al. [
34] compared and contrasted several single-image crowd counting pioneering methodologies and density estimation methods that used hand-crafted representations, with a strong emphasis on newer CNN-based approaches. Across all the data sets, the most recent CNN-based algorithms outperformed the traditional approaches, according to the study. While CNN-based methods performed well in high-density crowds with a variety of scene conditions, traditional approaches had substantial error rates in these situations. Additionally, the multicolumn CNN architecture [
10] was tested on three diverse data sets such as UCSD, WorldExpo ’10, and ShanghaiTech and the method attained state-of-the-art results on all the three data sets. The CNN-boosting approach by Walach and Wolf [
35] achieved the best results on the Mall data set. Optimum results on the UCF_CC_50 data set were achieved by joint local and global count approach [
36] and Hydra-CNN [
37].
Kang et al. [
38] examined crowd density maps created using various methodologies on a variety of crowd analysis tasks, such as counting, detection, and tracking. While fully-convolutional neural networks (e.g., MCNN) produce reduced-resolution density maps performed well at counting, their accuracy decreased at localisation tasks due to the loss of spatial resolution, which cannot be entirely recovered using upsampling and skip connections. It was also recommended that dense pixel-prediction of a full resolution density map using CNN-pixel generated the best density map for localisation tasks, with a minor decrease in counting tasks. Dense prediction, on the other hand, had a larger computational complexity than fully-convolutional networks.
Tripathi et al. [
39] offered a thorough overview of contemporary convolution neural network (CNN)-based crowd behavior analysis approaches. The goal of the approaches that were examined was to give law enforcement agencies a real-time and accurate visual monitoring of a busy area. The study identified a shortage of training data sets as a major difficulty when utilising CNN to analyze distinct population types. A list of numerous data sets was offered in this survey. These data sets, however, only comprised a few hundred training examples that were insufficient to train a CNN. CNN-based methods require a large pool of labeled training data sets and major manual interventions that were both complex and time-consuming. Another study found that CNN-based approaches require specialized hardware for training, such as GPUs, because training a CNN is a computationally expensive proposition. To overcome this issue, it would be interesting to look into transfer learning approaches that used previously taught models rather than having to train the model from scratch. Because a shortage of training examples for various types of crowd can impair the system’s performance, online CNN training could become an exciting research domain.
Most recently, Gao et al. [
40] presented a review of over 220 methods that looked at crowd counting models, primarily CNN-based density map estimates from a variety of angles, including network design and learning paradigms. It tested various state-of-the-art approaches and benchmarked crowd counting algorithms against several crowd data sets such as the National Forum for Urban Research, UCSD, Mall, WorldExpo’10, SHA and UCF-QNRF. The study suggested that PGCNet [
41], S-DCNet [
42] and PaDnet [
43] methods outperformed on Shanghai Tech data set with a MAE of 57.0%, 58.3% and 59.2%, respectively. The study demonstrated, however, that mainstream models were intended for domain-specific applications. Furthermore, supervised learning necessitates precise annotations could be time-consuming to manually label data, especially in highly congested scenarios. Given the unanticipated domain gap, generalising the training model to unseen scenarios might provide sub-optimal outcomes. The study also found that MCNN’s [
10] head size is proportional to the distance between two people. This notion prompted the creation of a geometry-adaptive kernel-based density map creation method, which has inspired many crowd estimation works to use this tool to prepare training data.
The studies [
34,
38,
39,
40] found that CNN methods are successful and outperform traditional approaches in high-density crowds with a variety of scene variables, whereas traditional approaches suffer from high-error margins in such settings. Sindagi et al. [
34] compared different methods for single-image crowd counts and density estimation, the multicolumn CNN architecture [
10] performed best on the data sets from UCSD, WorldExpo 10, and ShanghaiTech. Another study from Kang et al. [
38] found that MCNN-generated reduced-resolution density maps performed well in crowd counting. Tripathi et al. [
39] highlighted a shortage of training data sets as a major issue in utilising CNN to analyze diverse crowd types. It indicated that the existing data sets only had a limited amount of training examples, which were insufficient to train a CNN. Hence, it validated the need to create more training data. After examining more than 220 works, which primarily included CNN-based density map estimation methods, the most recent study from Gao et al. [
40] highlighted that MCNN [
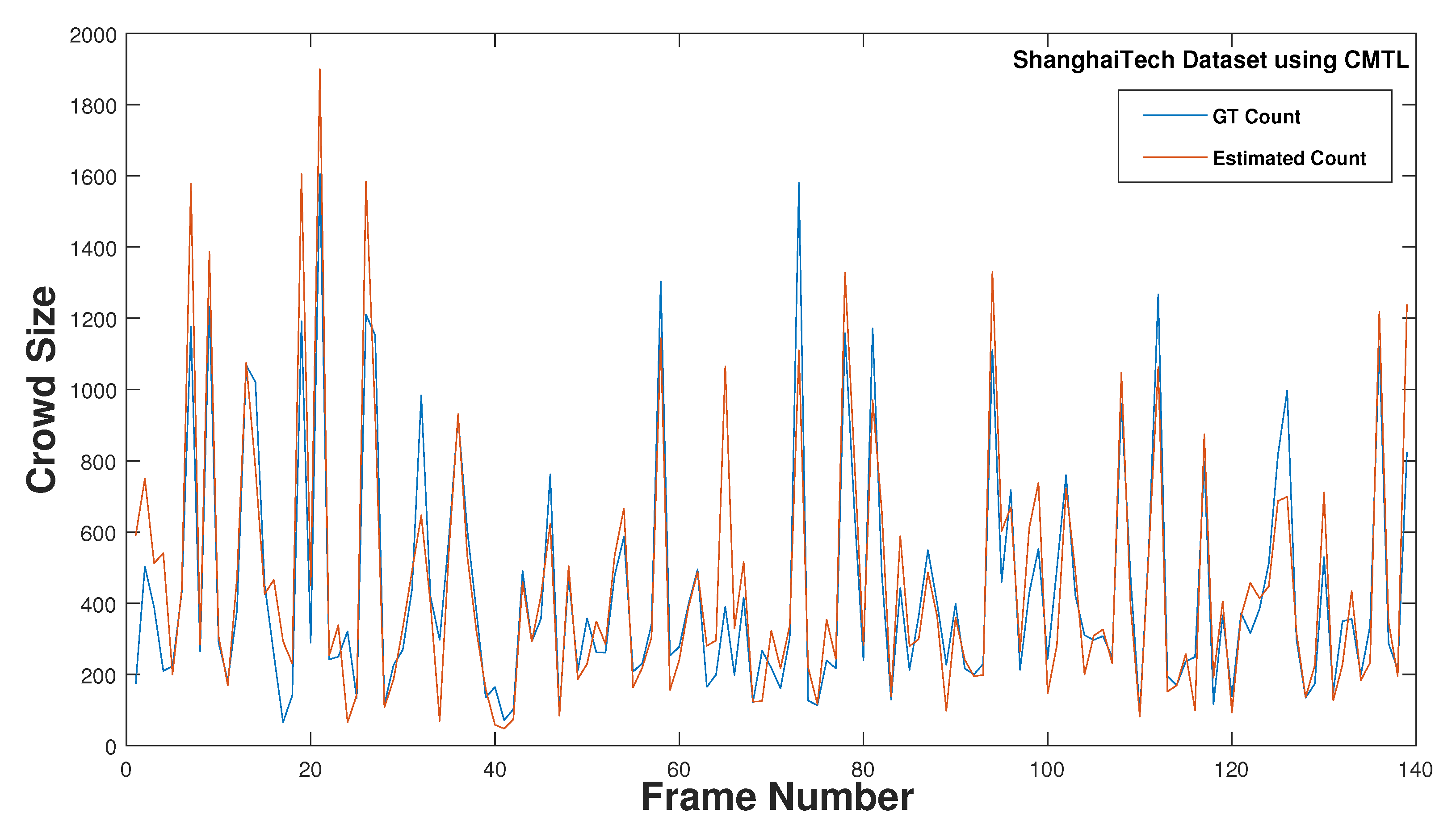
10] performed well in dense crowd scenes. Considering the suggestions from the most recent studies, we have applied the MCNN and used ShanghaiTech data set to train, test, and validate the simulation system against real-crowd data and have discussed it further in
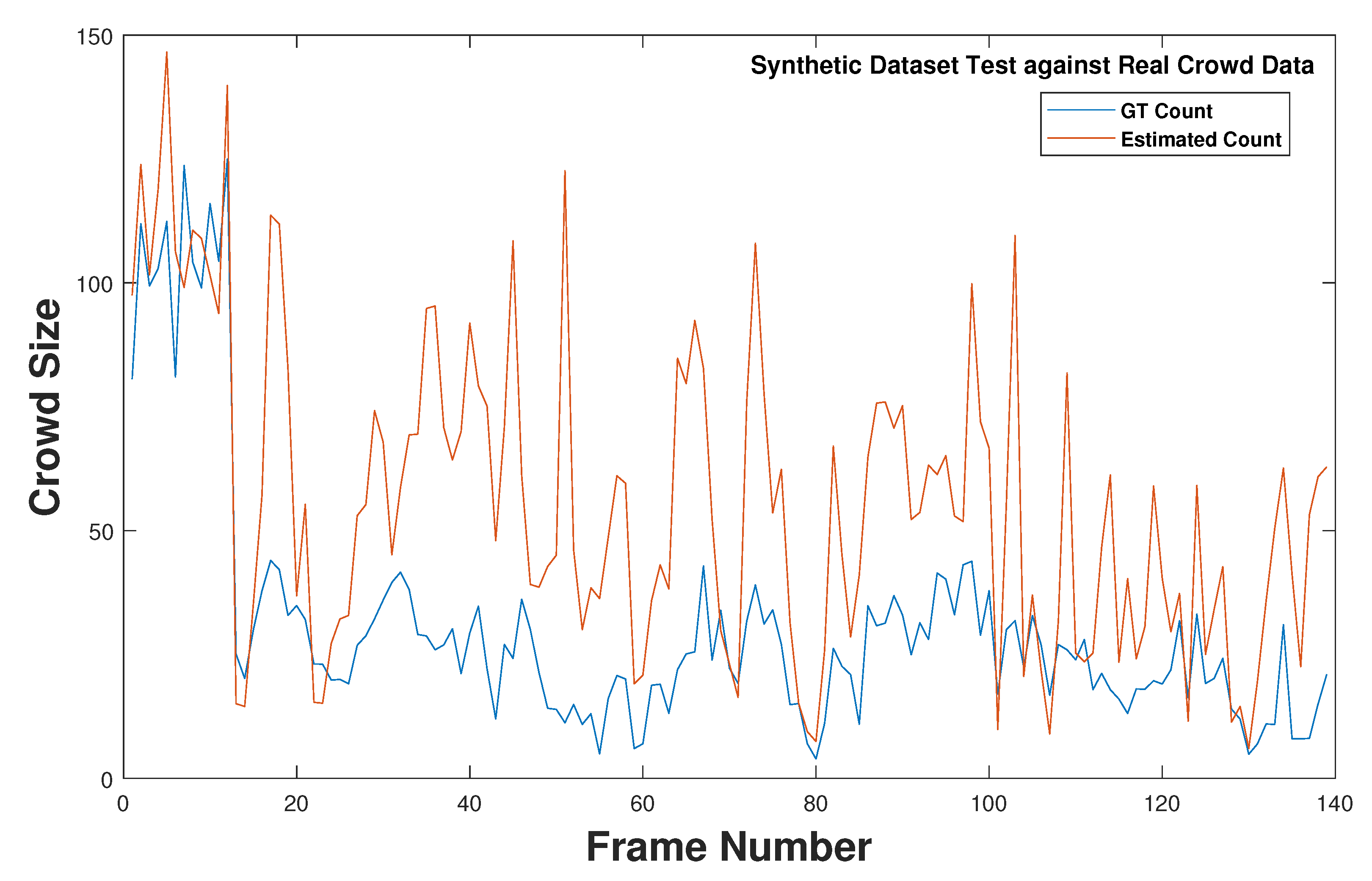
Section 3.4.
2.4. Related Open Source Crowd Simulator
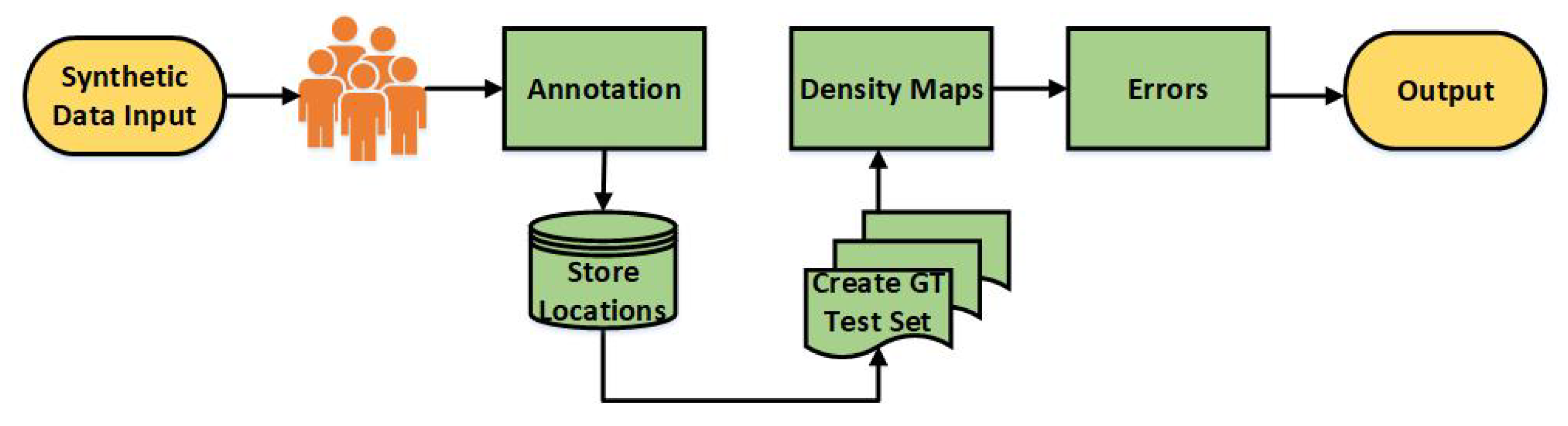
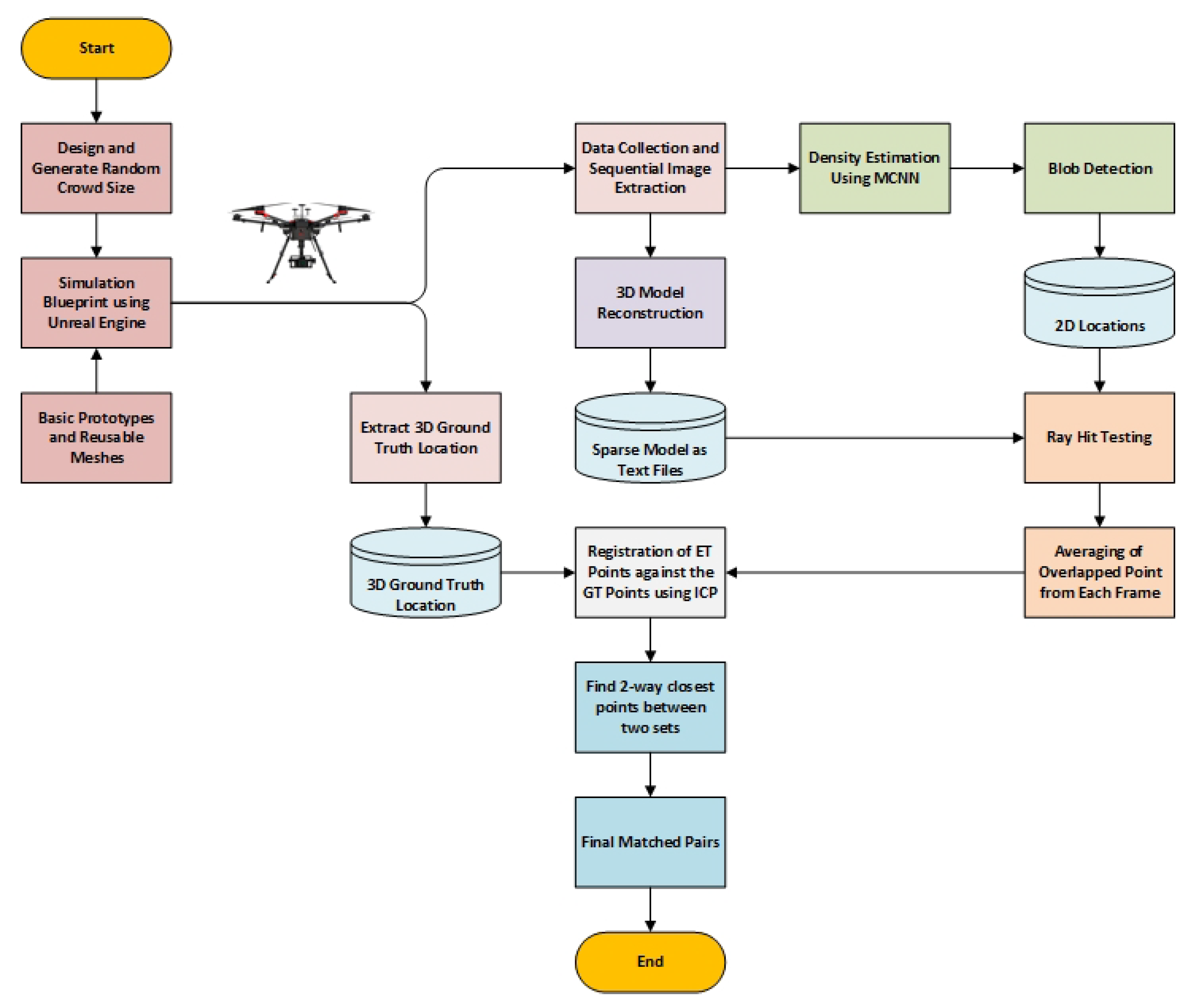
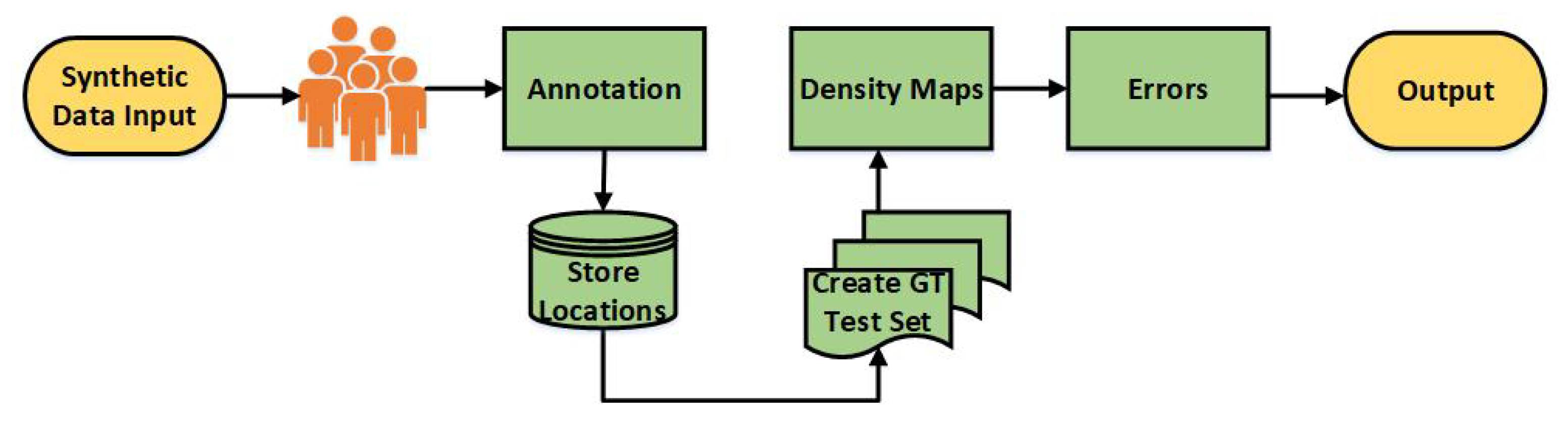
Considering the recent growth in crowd estimation, testbed for generating crowd training and testing data is a major issue. Capturing the crowd has never been easy and ethical issues don’t allow to capture the crowd in most countries. Furthermore, the process of capturing the crowd is expensive and can backfire. Simulators are the best solution to overcome the testbed issue because they are cost-effective and can easily produce data for training and testing. To resolve the issue, we have reviewed the existing crowd simulators, determined its limitations, and demonstrated why a new 3D crowd simulation system with an integrated UAV simulator is required.
Kleinmeier et al. [
44] introduced Vadere, a framework for simulation of crowd dynamics. It consists of features that allowed interaction with the microscopic pedestrian. As a result, it has contributed to many simulation models and comprises of models like the gradient navigation model and social force model for further research purposes, which are restricted to 2D simulations. Maury et al. [
45] introduced Cromosim, a library specifically designed for Python that was mainly used to model crowd movements. It is simple to set up, and there are some examples models available to monitor the trend, such as follow-the-leader and social powers. However, its use is limited in other respects, such as crowd motion tracking. Curtis et al. [
46] developed Menge, a full-featured 3D crowd simulator designed for crowd simulation and dynamics that compared two different models. Since the crowd and its aspects do not appear to be real, it could only be used for tracking purposes within the developed environment.
Crowd Dynamics is another 2D simulation system intended to develop for crowd movement. However, the system is still in the early stages of development. PEDSIM is a microscopic pedestrian crowd library with limited application. Consequently, the documents simply mention the use of PEDSIM to implement several models such as cellular automata and social force, but nothing else is specified. Wagoum et al. [
47] presented JUPEDSIM framework to map crowd dynamics. The framework is an open source one and can be used for research purposes such as mapping and measuring crowd dynamics, data visualization etc. Mesa [
48] is a python library limited to modeling functions and can’t be used for simulation. There isn’t enough data available for RVO2 [
49], Fire Dynamics [
50] and AgentJL. These frameworks have been developed specifically for crowd dynamics navigation and haven’t been updated in a long while. Other licensed and paid crowd simulators such as CrowdSim3D and Urho3D are also available with built-in tracking and mapping features, but their use is limited and they are expensive.
To summarise, except for Menge, most open-source simulators are limited to 2D and are specifically designed to track the crowd dynamics and motion. A detailed review of the available open-source simulators summarised in
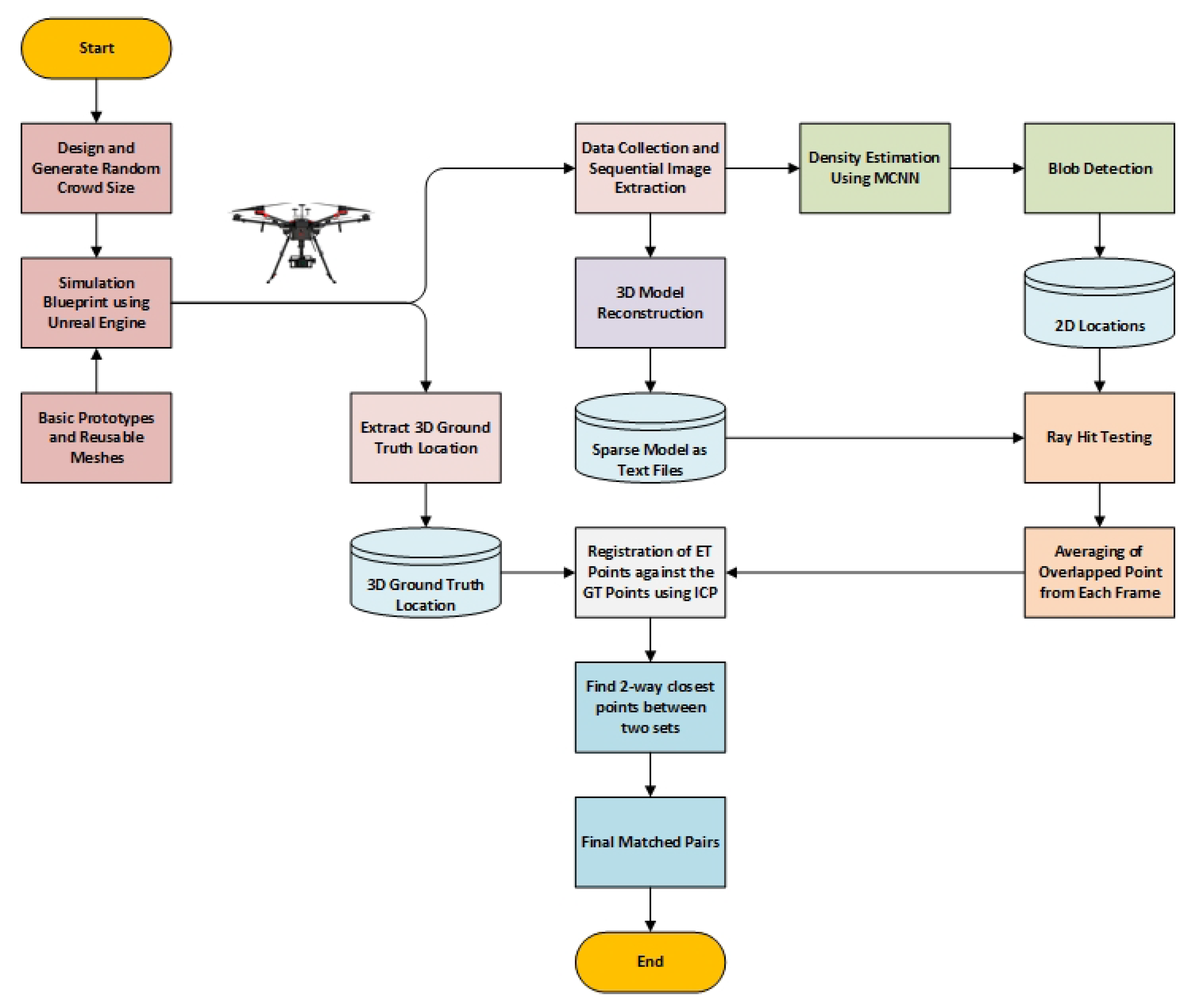
Table 1 has revealed that most simulators are designed for specific tasks such as crowd dynamics or fire dynamics study in 2D and are not efficient enough to generate 3D synthetic data and avatars to mimic real-world conditions. Considering the available 3D simulator ’Menge’, it consists of repeated characters and encounters problems in distinguishing various features of individuals such as gender, age, weight, height, ethnicity, proportion, outfit, pose, color, and geometry. As a result, this 3D simulator cannot be used to envision any scenario that mimics real-world settings. Furthermore, various geometric shapes and topologies for each individual’s eyes, hair, teeth, eyebrows, eyelashes, and other features are necessary to produce a realistic prototype. Menge does not provide this functionality. All these factors validate the need for developing a new 3D crowd simulator that can generate reams of data in any scenario, visualise a realistic 3D world, as well as relative locations for crowd estimation.
2.5. Crowd Data Sets
Traditional surveillance systems for crowd estimation are effective when dealing with small crowd sizes. Nevertheless, the traditional approach has some design issues including slow frame processing speeds, resulting in a major breakdown in the process because it cannot handle high-density crowds. Most of the methods have been developed and tested for single images or videos, with majority of the approaches perform crowd testing with low-density crowds [
2]. This study analyzes crowd data sets and subclassifies them into free, surveillance and drone-view crowds. The data sets have been categorized based on release year, attribute, number of samples, and average count per image. The primary objective of this study is to identify why existing drone view data sets cannot be used for the estimation of crowds using UAV, and why synthetic data is required.
The first free-view data sets UCF_CC_50 [
51] were released in 2013 with a sample size of 50 and 63,974 instances. UCF_CC_50 is the only available large density crowd data set as shown in
Table 2. ShanghaiTech Part A [
10] is another congested attributed data set containing 241,677 instances with an average count of 501 people. Sindagi et al. [
52] discussed available data sets for crowd surveillance and estimations. Some of the popular and easily accessible data sets include UCSD [
26] which consists of 2000 frames of size 238 × 158, and the Mall data set [
29] containing 2000 frames of size 320 × 240 with 6000 instances and large number of labeled pedestrians. The ShanghaiTech crowd data set [
10] discussed in
Table 3 includes both part A and part B of the dataset. It consists of 1198 images with a large number of 330,000 annotated heads.
Bahmanyar et al. [
66] presented the first drone-view crowd data set in 2019 for crowd estimation known as DLR’s Aerial Crowd Data Set. The images were captured through a helicopter providing 33 aerial images from 16 different fights of a slowly moving crowd. Zhu et al. [
67] presented the second aerial data set of the crowd. As shown in
Table 4, this data set comprised of 112 video clips collected from 70 different scenarios.
According to the pattern since 2008, when UCSD’s first crowd data set was released, the majority of publicly available crowd data sets have been captured with static cameras [
34] and have been limited to 2D. The first aerial crowd data set was released in 2019 with a sample size of 33. That said, the data set is inaccessible and has no annotations. In fact, most aerial crowd data sets are not widely available for study. Previous studies [
39] evidenced and highlighted the shortage of training examples for various crowd types. Ref. [
20] focused primarily on simulation realism and highlighted the importance of virtual data sets that will address the issue in the near future. Our study also concluded that gathering and manually annotating crowd data sets are both expensive and time-consuming. Considering the current laws and ethical issues, there is a justified need of a testbed that can generate virtual crowd data set and contain in-depth information of both 2D and 3D images.
The study of various traditional and most recent 2D crowd estimation approaches discussed in
Section 2.2 and
Section 2.3 highlighted the inherent limitations of 2D approaches which include static camera monitoring that can monitor a specific area with a high possibility of counting the same individual multiple times, nonhuman or false detections, and lack of information and inconsistency in performance, which leads to a high percentage of errors, among others. Extensive work has been done for different segments of 2D crowd estimation and received a lot of attention, but work related to 3D crowd estimation is limited. Recently, promising research has been conducted on density estimation [
69,
70,
71,
72] and advances have been made in 3D pose estimation from 2D [
11,
73,
74,
75,
76,
77,
78,
79,
80] but the work related to 3D crowd estimation using UAV is not prevalent. Interestingly, UAVs have immense potential to estimate the crowd spread over a huge geographical area in a shorter duration. Recent advances in optical instrumentation and computer vision techniques have facilitated the use of 3D models to explore in-depth information. In contrast, very little research has been done regarding 3D crowd estimations with UAVs. This fact alone underscores the necessity to devise a new way to overcome the traditional and inherent limitations. It also demonstrates how our 3D work varies from existing and conventional 2D crowd estimation methodologies. To summarise, taking into account the existing shortcomings, we have presented a 3D crowd simulator in
Section 3.3, trained, tested and validated the simulation system against real-crowd data in
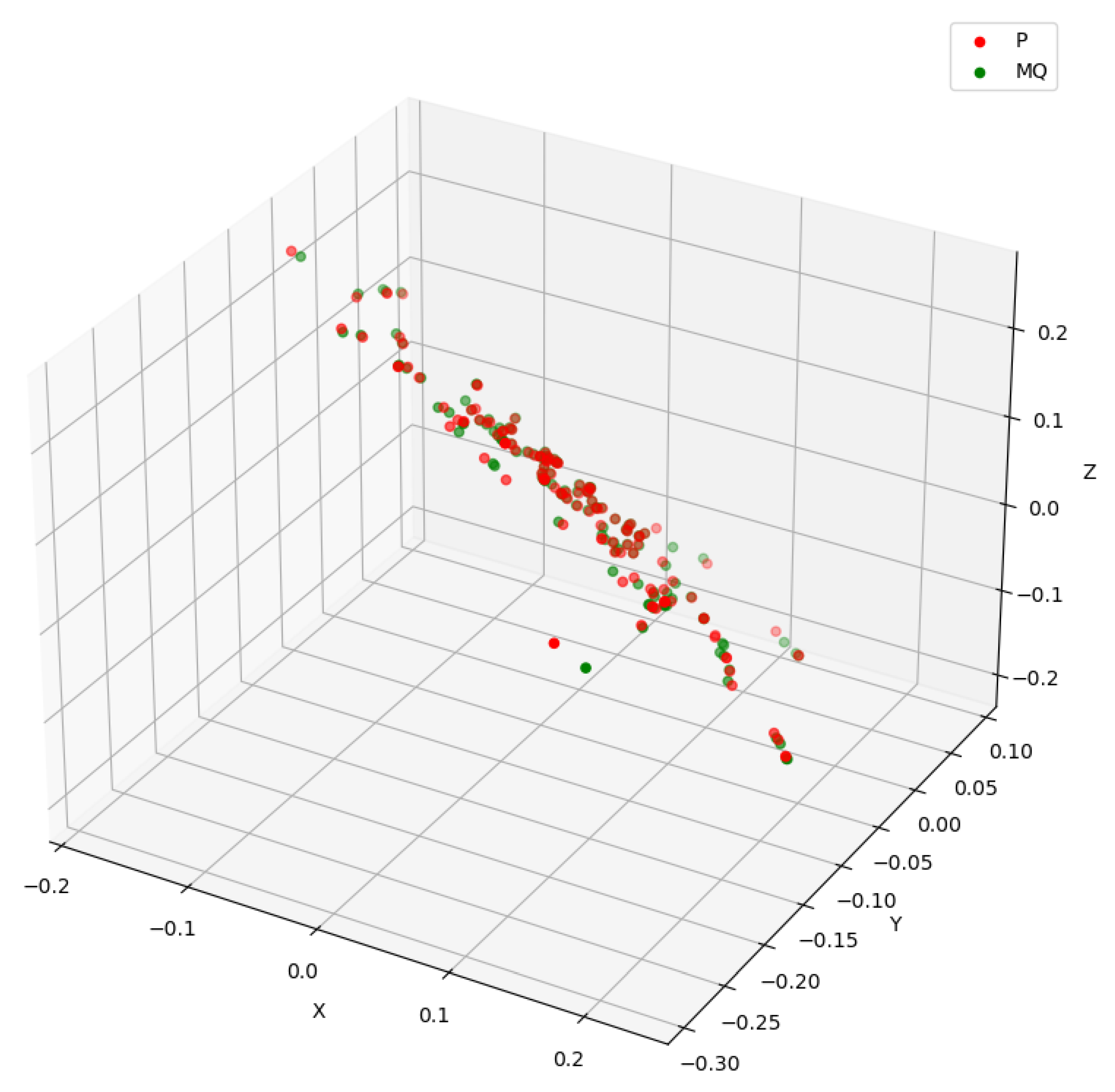
Section 3.4. In addition, we have introduced a novel 3D crowd estimation technique using UAV for a robust and accurate estimation of a crowd spread over a large geographical area in the subsequent sections.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}