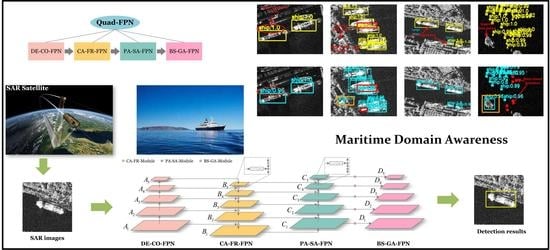
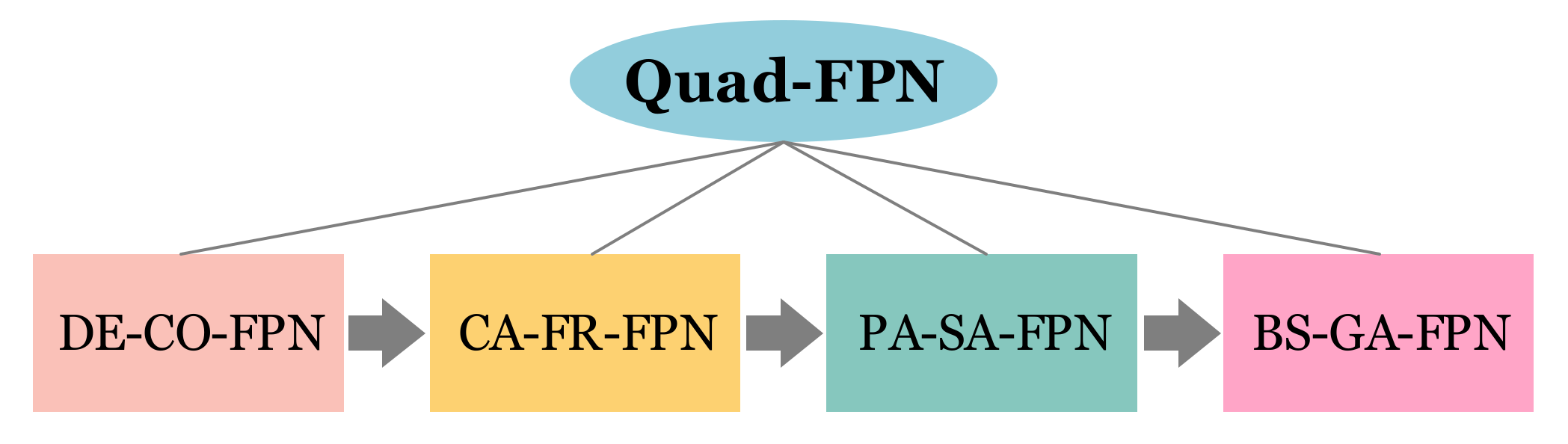
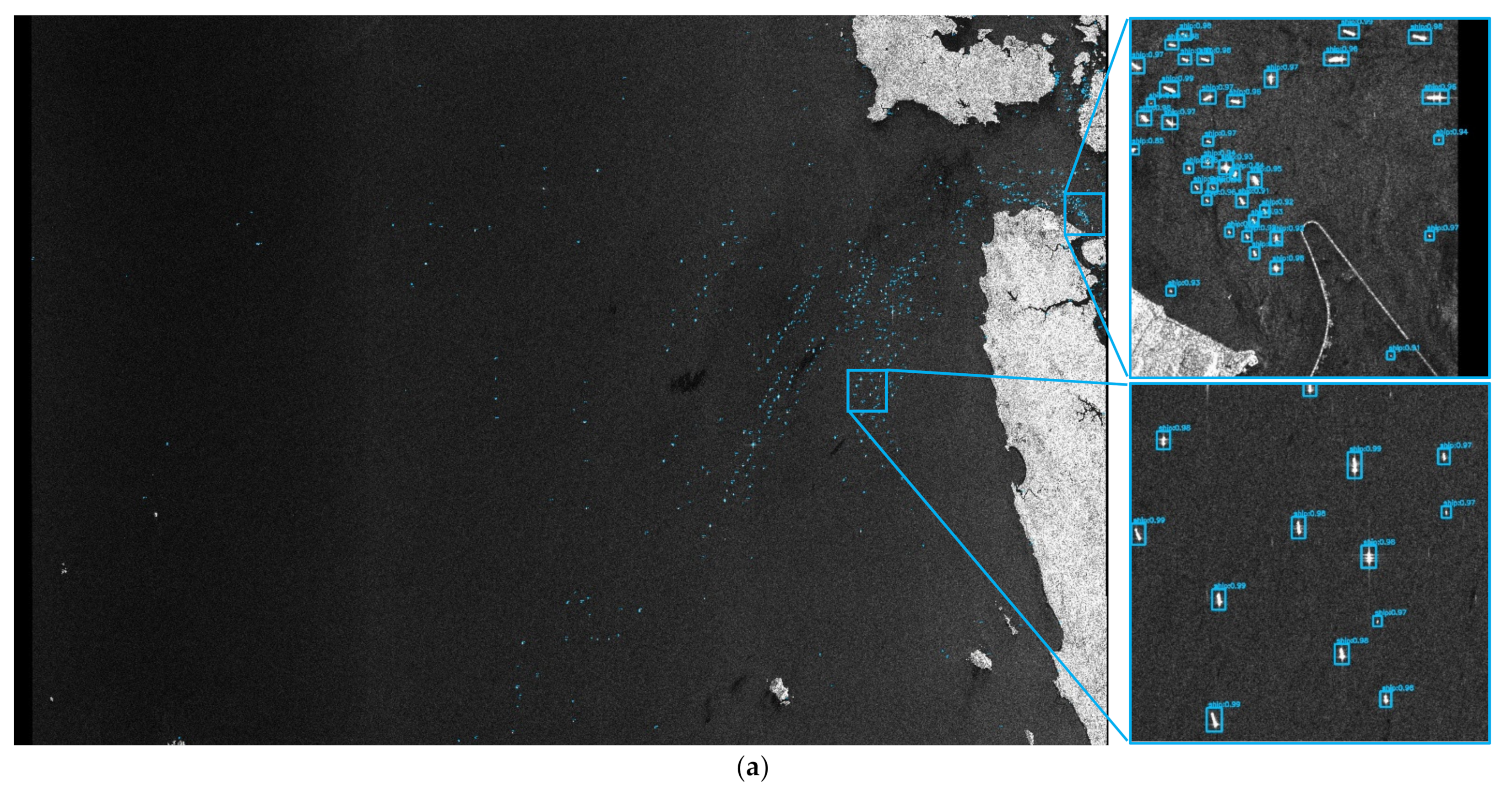
The overall design idea of Quad-FPN is as follows.
2.1. DEformable COnvolutional FPN (DE-CO-FPN)
The core idea of DE-CO-FPN is that we use the deformable convolution [
24] to extract ship features. It contains more useful ship shape information, meanwhile alleviating complex background interferences. Previous work [
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15] mostly adopted the standard or dilated convolutions [
25] to extract features. However, the two have limited geometric modeling ability due to their regular kernels. This means that their ability to extract the shape features of multi-scale ships is bound to become poor, causing poor multi-scale detection performance. For inshore ships, the standard and dilated convolutions cannot restrain interferences of port facilities; for ships side-by-side parking at ports, they also cannot eliminate interferences from the nearby ship hull. Thus, to solve this problem, the deformable convolution is used to establish DE-CO-FPN.
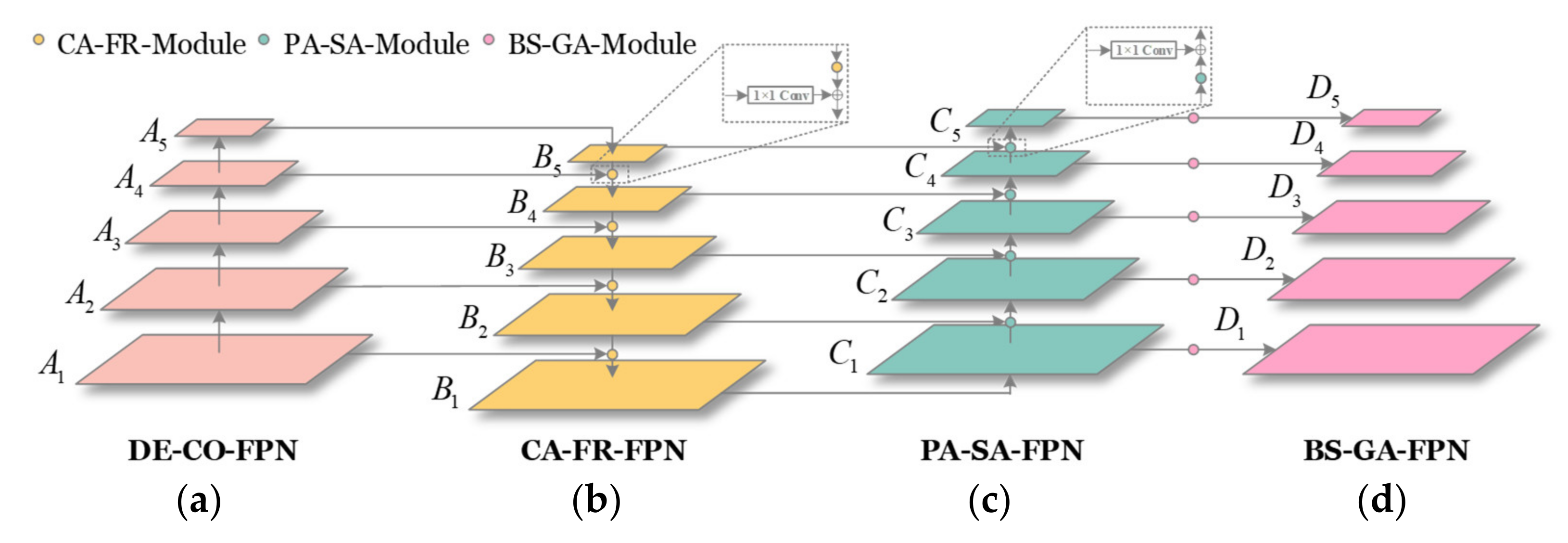
Figure 3 shows their intuitive comparison. From
Figure 3, it is obvious that the deformable convolution can extract ship shape features more effectively; it can suppress the interference of complex backgrounds, especially for more complex inshore scenes. Finally, ships are likely to be separated successfully from complex backgrounds. Thus, this deformable convolution process can be regarded as an extraction of salient objects in various scenes, which plays a role of spatial attention.
In the deformable convolution, the standard convolution kernel is augmented with offsets ∆
pn that are adaptively learned in training to model targets’ shape features, i.e.,
where
p0 denotes each location, ℜ denotes the convolution region,
w denotes the weight parameters,
x denotes the input,
y denotes the output, and ∆
pn denotes the learned offsets at the
n-th location. It should be noted that compared with standard convolutions, deformable ones’ training is in fact time-consuming; it needs more GPU memory. This is because the learned offsets add extra network parameters, increasing networks’ complexity. A reasonable fitting of these offsets must be time-consuming. Yet, in this paper, to obtain better accuracy of ships with various shapes, we have not studied this issue deeply for the time being. This problem will be considered with due attention in our future work.
In Equation (1), ∆
pn is typically fractional. Thus, we use the bilinear interpolation to ensure the smooth implementation of convolutions, i.e.,
where
p denotes the fraction location to be interpolated,
q denotes all integral spatial locations in the feature map
x, and
G( ) denotes the bilinear interpolation kernel defined by
In experiments, we add another one convolution layer to learn the offsets ∆
pn. Then, the standard convolution combining ∆
pn is performed on the input feature maps. Finally, ship features with rich shape information (
A1,
A2,
A3,
A4, and
A5 in
Figure 2a) will be transferred to subsequent FPNs for more operations.
2.2. Content-Aware Feature Reassembly (CA-FR-FPN)
The core idea of CA-FR-FPN is that we design a CA-FR-Module (marked by circle in
Figure 2b) to enhance feature transmission benefits when performing the up-sampling multi-level feature fusion. Previous work [
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15] added a feature fusion branch from top to bottom to via feature up-sampling. This feature up-sampling is often completed by the nearest neighbor or bilinear interpolations, but the two means merely consider sub-pixel neighborhoods, which cannot effectively capture the rich semantic information required by dense detection tasks [
26], especially for densely distributed small ships. That is, features of small ships are easily diluted because of their poor conspicuousness, leading to feature loss. Thus, to solve this problem, we propose a CA-FR-Module in the up-sampling feature fusion branch from top to bottom to achieve a feature reassembly. It can be aware of important contents in feature maps, and attach importance to key small ship features, thereby improving feature transmission benefits.
Figure 2b shows the network architecture of CA-FR-FPN. From
Figure 2b, for five-scale levels (
B1,
B2,
B3,
B4, and
B5), four CA-FR-Modules are used for feature reassembly. In practice, CA-FR-Module will complete the task that is similar to the 2× up-sampling operation in essence.
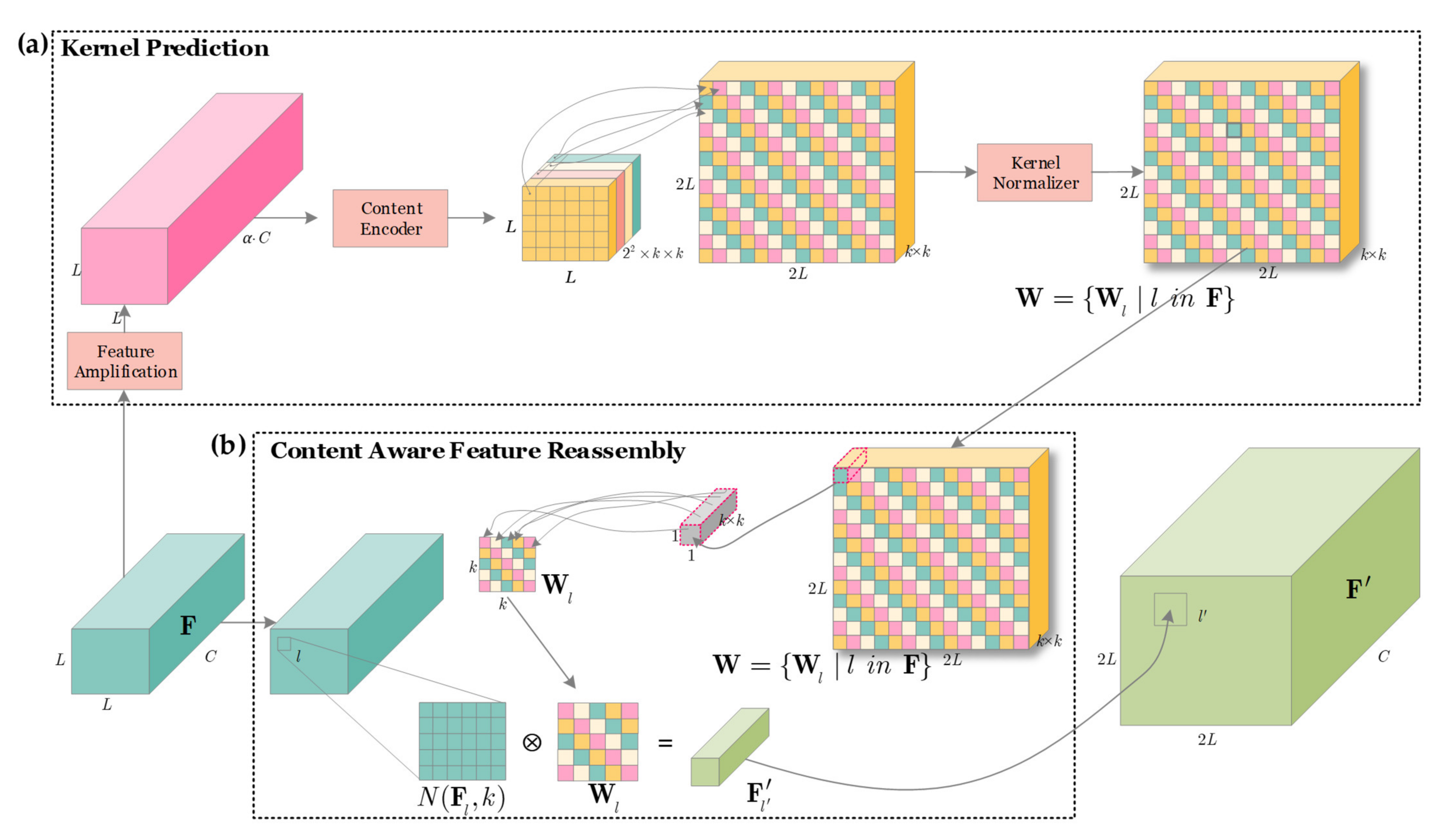
Figure 4 shows the implementation process of CA-FR-Module. From
Figure 4, there are two basic steps in CA-FR-Module: (1) kernel prediction, and (2) content-aware feature reassembly.
Step 1: Kernel Prediction
Figure 4a shows the implementation process of the kernel prediction. In
Figure 4, the feature maps
F’s dimension is
L ×
L ×
C, where
L denotes its size and
C denotes its channel width. Overall, the process of the kernel prediction (denoted by
ψ) is responsible for generating adaptive feature reassembly kernels
Wl at the original location
l, according to the
k ×
k neighbors of feature maps
Fl through a content-aware manner, i.e.,
where
N(·) means the neighbors and
Wl denotes the reassembly kernel.
To enhance the content-aware benefits of the kernel prediction, we first design a convolution layer to amplify the inputted feature maps
F by α times (from
C to α∙
C). This convolution layer’s kernel number is set to α∙
C, where α is an experimental hyper-parameter that will be studied in
Section 5.2.2. Then, we adopt another convolution layer to encode the content of input features so as to obtain reassembly kernels. Here, we set the kernel width as 2
2 ×
k ×
k where 2 is from the requirement of the 2× up-sampling operation. The purpose is to enlarge the size of feature maps to 2
L. Moreover,
k ×
k is from the
k ×
k neighbors of feature maps
Fl. Afterwards, the content encoded features are reshaped to a 2
L × 2
L × (
k ×
k) dimension via the pixel shuffle means [
27]. Finally, each reassembly kernel is normalized by a soft-max function spatially to reflect the weight of each sub-content.
In summary, the above operations can be described by:
where
famplify denotes the feature amplification operation,
fencode denotes the content encode operation,
shuffle denotes the pixel shuffle means,
soft-max denotes the soft-max function defined by
, and
Wl denotes the generated reassembly kernel.
Step 2: Content-Aware Feature Reassembly
Figure 4b shows the implementation process of the content-aware feature reassembly. Overall, the process of the content-aware feature reassembly (denoted by
ϕ) is responsible for generating the final up-sampling feature maps
F′
l′, i.e.,
where
k denotes the
k ×
k neighbors and
Wl denotes the reassembly kernel in Equation (4) that corresponds to the
l’ location of feature maps after up-sampling from the original
l location. For each reassembly kernel
Wl, this step will reassemble the features within a local region via the function
ϕ in Equation (6). Similar to the standard convolution operation,
ϕ can be implemented by a weighted sum. Thus, for a target location
l’ and the corresponding square region
N(
Fl,
k) centered at
l = (
i,
j), the reassembly output is described by
where ℜ denotes the corresponding square region
N(
Fl,
k). Moreover,
k is set to 5 in our work that is an optimal value followed by [
26].
With the reassembly kernel Wl, each pixel in the region ℜ of the original location l contributes to the up-sampled pixel l′ differently, based on the content of features rather than location distance. Semantic features from the pyramid top will be transferred into the bottom, bringing better transmission benefits. Finally, the pyramid top’s features will be fused into the bottom to enhance the feature expression ability of small ships.
2.3. Path Aggregation Space Attention FPN (PA-SA-FPN)
The core idea of PA-SA-FPN is that we add an extra path aggregation branch with a space attention module (PA-SA-Module) (marked by circle in
Figure 2c) from the pyramid bottom to the top. Previous work [
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15] often transmitted high-level strong semantic features to the bottom to improve the whole pyramid expressiveness. Yet, the low-level location information from the pyramid bottom was not considered to be transmitted to the top. This can lead to inaccurate positionings of large ship bounding boxes, so the detection performance of large ships is reduced. Thus, we add an extra path aggregation branch (bottom-to-top) to handle this problem. Moreover, to further improve path aggregation benefits, we design a PA-SA-Module to concentrate on important spatial information to avoid interferences of complex port facilities.
Figure 2c shows PA-SA-FPN’s architecture. From
Figure 2c, the location information of the pyramid bottom is transmitted to the top (
C1 →
C2 →
C3 →
C4 →
C5) by the feature down-sampling. In this way, the top semantic features will be enriched with more ship spatial information. This can improve feature expression ability of large ships. Moreover, before the down-sampling, the low-level feature maps are refined by a PA-SA-Module to improve path aggregation benefits [
28].
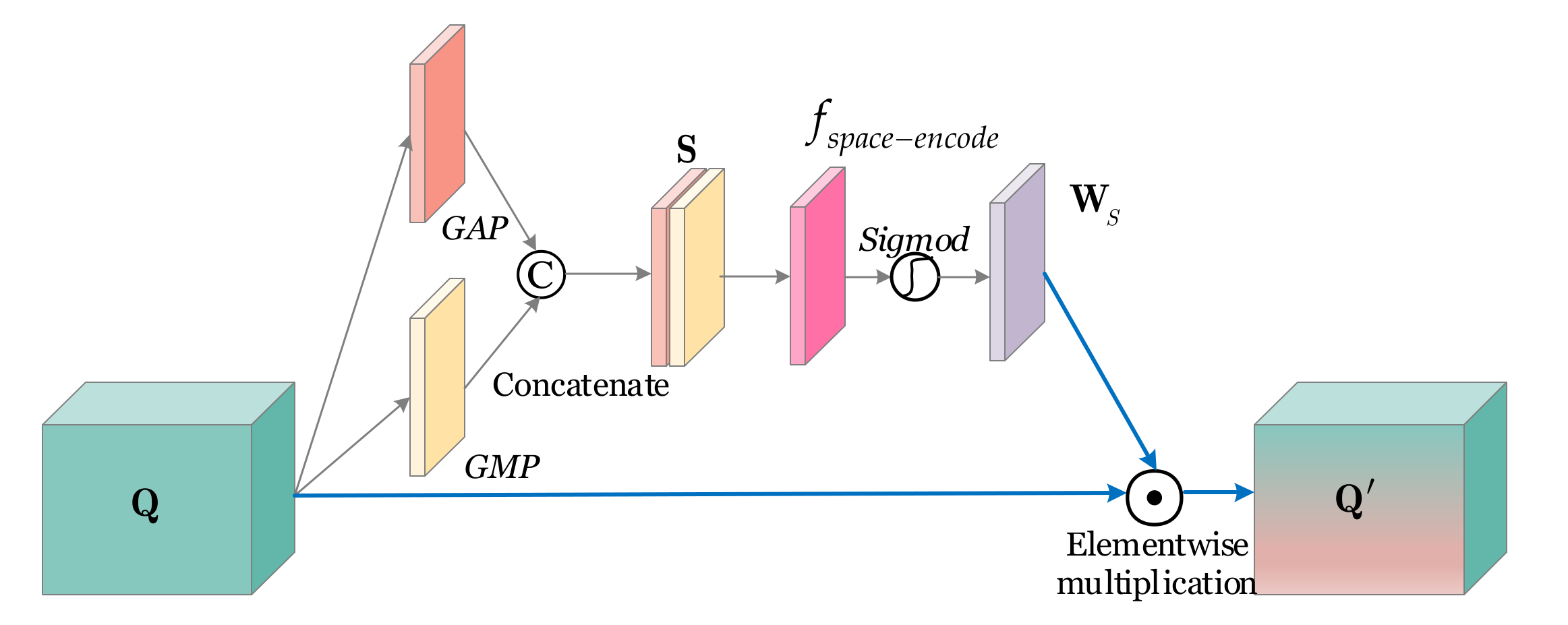
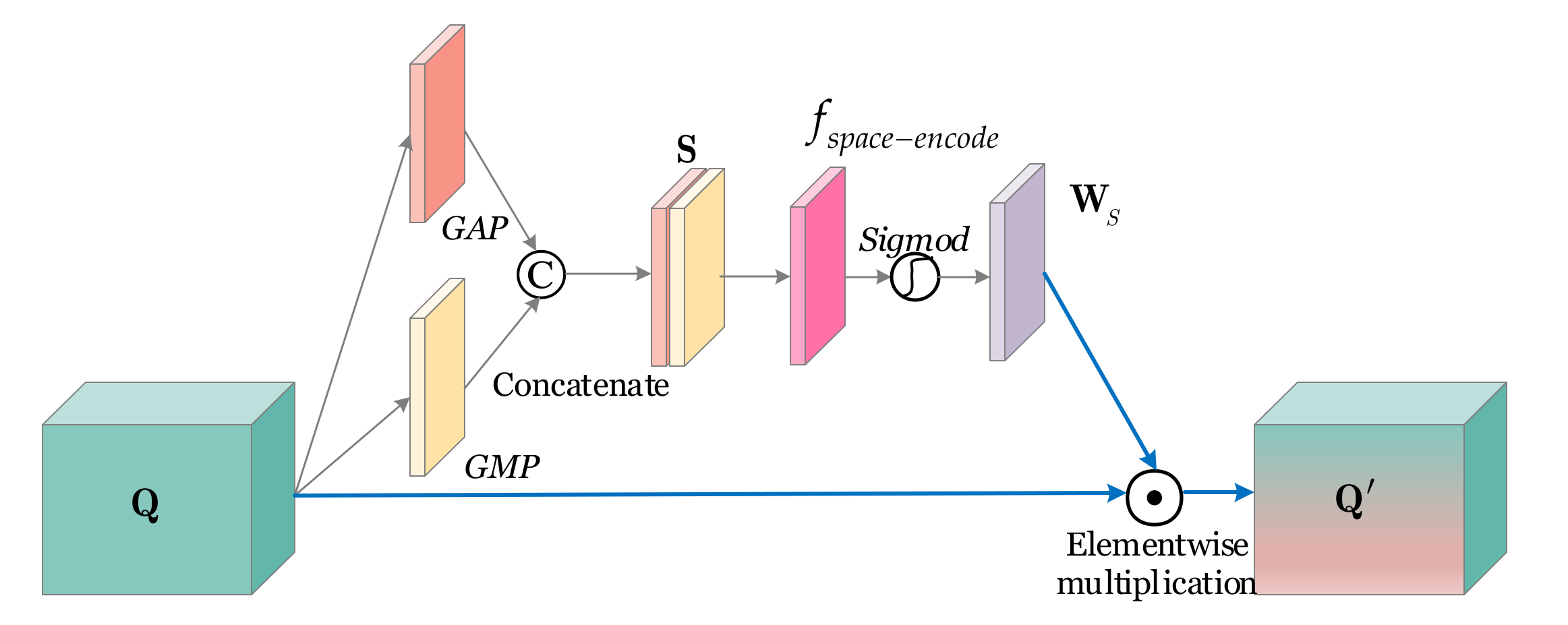
Figure 5 shows the implementation process of PA-SA-Module. In
Figure 5, the input feature maps are denoted by
Q and the output ones are denoted by
Q’. First, a global average pooling (GAP) [
29] is used to obtain the average response in space; a global max pooling (GMP) [
29] is used to obtain the maximum response in space. Then, their implementation results are concatenated as the synthetic feature maps, denoted by
S. Unlike the previous convolutional block attention module [
28], we design a space encoder
fspace-encode to encode the space information. It is used to represent the spatial correlation. This can improve spatial attention gains because features in the coding space are more concentrated. Then, the output of
fspace-encode is activated by a
sigmod function to represent each pixel’s importance-level in the original space, i.e., an importance-level weight matrix
WS. Finally, an elementwise multiplication is conducted between the original feature maps
Q and the importance-level weight matrix
WS to obtain the output
Q′.
In short, the above can be described by
where
Q denotes the input feature maps,
Q′ denotes the output feature maps, ⊙ denotes the elementwise multiplication, and
WS denotes the importance-level weight matrix, i.e.,
where
GAP denotes the global average-pooling,
GMP denotes the global max-pooling,
fspace-encode denotes the space encoder, © denotes the concatenation operation, and
sigmod is an activation function defined by 1/(1 +
e−x).
Finally, the feature pyramid will be stronger when possessing both the top-to-bottom branch and bottom-to-top branch. Each level has rich spatial location information and abundant semantic information, which help improve large ships’ detection performance.
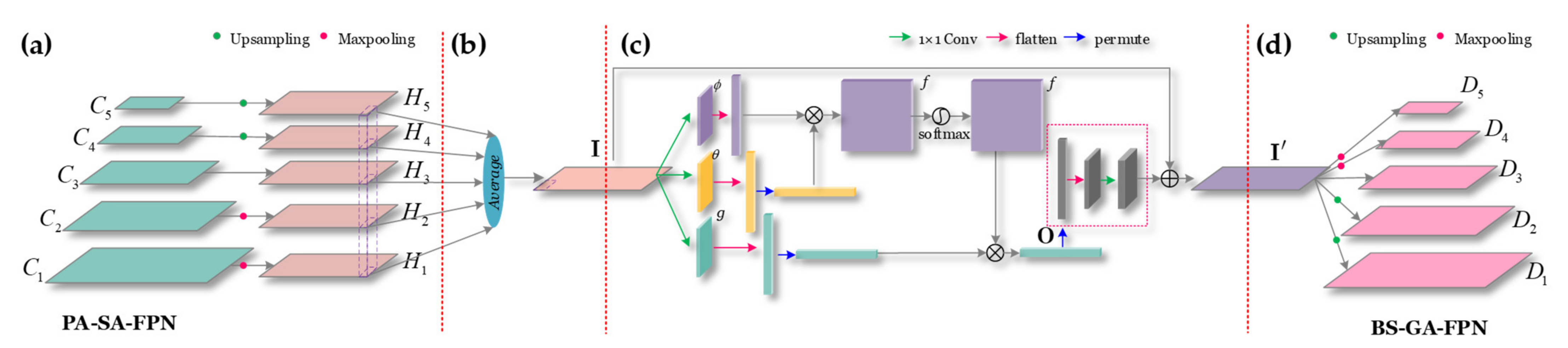
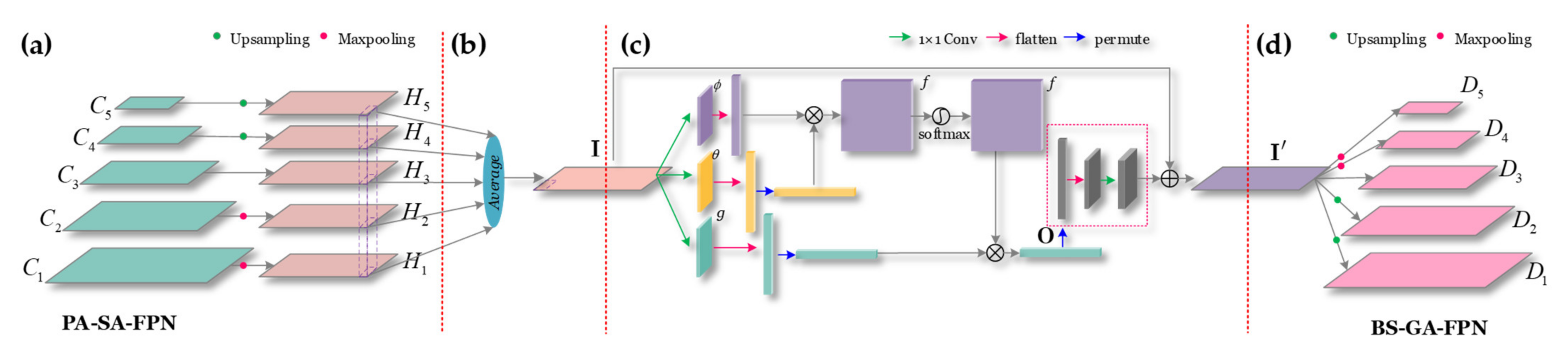
2.4. Balance Scale Global Attention FPN (BS-GA-FPN)
The core idea of BS-GA-FPN is that we further refine features from each feature level in the pyramid, to address the feature level imbalance of different scale ships. SAR ships often present different characteristics at different levels in the pyramid, i.e., the existence of multi-scale ship feature differences. Due to the difference of resolutions, the difference of satellite shooting distances, and different slicing methods, there are many scales of ships in the existing SAR ship datasets. E.g., for SSDD, the smallest ship pixel size is 7 × 7 while the biggest one is 211 × 298. Such huge size gap results in large ship feature differences, which makes it very difficult to detect them. In the computer vision community, Pang et al. [
30] found that such feature level imbalance may weaken the feature expression capacity of FPN, but previous work [
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15] in the SAR ship detection community was not aware of this problem. Thus, to handle this problem, we design a BS-GA-Module to further process pyramid features to recover a balanced BS-GA-FPN. Implementation process of BS-GA-Module consists of four steps: (1) feature pyramid resizing, (2) balanced multi-scale feature fusion, (3) global attention (GA) refinement, and (4) feature pyramid recovery, as in
Figure 6.
Step 1: Feature Pyramid Resizing
Figure 6a shows the graphical description of the feature pyramid resizing. In
Figure 6a, in the PA-SA-FPN, features maps at different levels are denoted by
C1,
C2,
C3,
C4, and
C5. To facilitate the fusion of balanced features to preserve their semantic hierarchy at the same time, we resize each detection scale (
C1,
C2,
C3,
C4, and
C5) to a unified resolution, by a max-pooling or up-sampling. Here,
C3 is selected as this unified resolution level because it locates in the middle of the pyramid. It can maintain a trade-off between top semantic information and bottom spatial information. Finally, the above can be described by
where
H1,
H2,
H3,
H4, and
H5 are the resized feature maps from the original ones,
UpSamplingn× denotes the
n times up-sampling, and
MaxPooln× denotes the
n times max-pooling.
Step 2: Balanced Multi-Scale Feature Fusion
Figure 6b shows the graphical description of the balanced multi-scale feature fusion. After obtaining feature maps with the same unified resolution, the balanced multi-scale feature fusion is executed by
where
k denotes the
k-th detection level, (
i, j) denotes the spatial location of feature maps, and
I denotes the output integrated features. From Equation (11), the features from each scale (
H1,
H2,
H3,
H4, and
H5) are uniformly fused as the output
I (a mean operation). Here, the average operation fully reflects the balanced idea of SAR ship scale feature fusion.
Finally, the output I with condensed multi-scale information will contain balanced semantic features of various resolutions. In this way, big ship features and small ones can complement each other to facilitate the information flow.
Step 3: GA Refinement
To make features from different scales become more discriminative, we also propose a GA refinement mechanism to further refine balanced features in Equation (11). This can enhance their global response ability. That is, the network will pay more attention to important spatial global information (feature self-attention), as in
Figure 6c.
The GA refinement can be described by
where
Ii denotes the input at the
i-th location,
Oi denotes the output at the
i-th location,
f(·) is a function used to calculate the similarity between the location
Ii and
Ij,
g(·) is a function to characterize the feature representation at the
j-th location, and
ξ(·) denotes a normalized coefficient (the input overall response). The
i-th location information denotes the current location’s response, and the
j-th location information denotes the global response.
In Equation (12),
g(·) can be regarded as a linear embedding,
where
Wg is a weight matrix to be learned, and we use a 1 × 1 convolutional layer to obtain this weight matrix during training.
Furthermore, one simple extension of the Gaussian function is to compute similarity
f(·) in an embedding space,
where
θ(
Ii) =
WθIi and
ϕ(
Ij) =
WϕIj are two embeddings.
Wθ and
Wϕ are the weight matrixes to be learned that are both achieved by other two 1 × 1 convolutional layers.
As above, the normalized coefficient
ξ(·) is set to
Finally, the whole GA refinement is instantiated as:
where
can be achieved by a soft-max function.
Figure 6c shows the graphical description of the above GA refinement. From
Figure 6c, two 1 × 1 convolutional layers are used to compute
ϕ and
θ. Then, by the matrix multiplication
θTϕ, the similarity
f is obtained. One 1 × 1 convolutional layer is used to characterize the representation of the features
g. Finally,
f with a soft-max function multiplies by
g to obtain the feature self-attention output
O = {
Oi | i in
I}. Finally, the feature self-attention output
O is further processed by one 1 × 1 convolutional layer (marked in a dotted box). The purpose is to make
O match the dimension of the original input
I to facilitate follow-up element-wise adding. This is similar to the residual/skip connections of ResNet. Consequently, the refined features
I′ combining the feature self-attention information are achieved, which will be further processed in the subsequent steps, i.e.,
where
WO is also a weight matrix to be learned, and another 1 × 1 convolutional layer can be used to obtain it during training.
In essence, the GA refinement can directly capture long-range dependence of each location (global response) by calculating the interaction between two different arbitrary positions. It is equivalent to constructing a convolutional kernel with the same size as the feature map
I, to maintain more useful ship information, making feature maps more discriminative. More detailed theories about this global attention can be found in [
31].
Step 4: Feature Pyramid Recovery
Figure 6d shows the graphical description of the feature pyramid recovery. From
Figure 6d, the refined features
I′ are resized again through using the similar but reverse procedure of Equation (10) to recover a balanced feature pyramid, i.e.,
where
D1,
D2,
D3,
D4, and
D5 denote the recovered feature maps at different levels after ship scale balance operations. They reconstruct the final network architecture of BS-GA-FPN. Ultimately,
D1,
D2,
D3,
D4, and
D5 in BS-GA-FPN will possess more multi-scale balanced features that will be used to be responsible for the final ship detection.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}