2.3. Proposed Methods
In these investigations, the designed hyperspectral unmixing methods aim towards modeling the mixing function defined by Equation (3). The variables involved in the considered unmixing methods consist of two matrices
and
, which respectively aim at estimating
and
. The rows of the matrix
are used to decompose the row vectors of the matrix
, while the matrix
contains the linear and second-order abundance fraction coefficients of this decomposition. Moreover, it should be noted here that the matrix
is constrained as described in Equations (8)–(11), whereas only the top
rows of
, which contain the estimated endmember spectra, are free; all the rows that follow are element-wise products of the above master
rows [
62], making them slave rows. The proposed approaches minimize the following cost function:
where
denotes the Frobenius norm. As explained above, since only the elements of the first
row vectors of the matrix
are considered as master variables, they are freely tuned, while all slave subsequent row vectors of this matrix are updated by using element-wise products together with the above top
row vectors. Furthermore, the matrix
is considered as a slave variable and it is defined by its optimum least square solution, which minimizes the cost function
for a considered value of
(assumed to have full row rank). Thus, the matrix
is predetermined as follows:
where
denotes the matrix inverse. Replacing the matrix
by its optimal value
in Equation (12), the cost function to be optimized becomes:
In the latter equation,
and the considered cost function
are defined by a closed-form expression, which permits the calculation of the gradient expression of
with respect to the master part of matrix
. After deriving this expression for each mixing model, this gradient is used in the endmember spectra extraction step of the proposed methods. To simplify the calculation of the gradient expression of the considered cost function, this function is rewritten by using standard matrix and Frobenius norm properties as:
where
denotes the matrix trace. By considering the case when the matrix
has more columns than rows,
is replaced by
(the Moore–Penrose pseudo-inverse matrix of
) in (15). This yields the following new expression for
that is used, hereafter, in the endmember spectra extraction step:
As detailed in [
60,
61], using Equation (16), the gradient expression of
with respect to an element
of row
among the
master rows of the matrix
can be expressed as:
The above expression contains two derivative terms. The first one is:
where
denotes the identity matrix with the appropriate dimension. The second derivative term is:
Thus, the gradient expression of
with respect to
is given as follows:
Consequently, the final form of Equation (20) can be calculated by deriving the expression of
, which depends on the considered mixing model, among the bilinear [
60] and LQ [
61] ones. For both models, the same
symmetric matrix
, whose main diagonal is unused and whose upper part is organized as follows, is introduced. Each element
, corresponding to position
with
in
, concerns the cross-pseudo-endmember
and is equal to the index of the row, within
, which contains that cross-pseudo-endmember. Due to the structure Equation (9) of that matrix, these values
, stored from left to right and top to bottom in the upper part of
, are integers in increasing order, that is 1 to
on the first row,
to
on the second row, and so on. These values can be expressed as follows (for
):
When considering the bilinear mixing model, the values of
form a matrix with
rows and
L columns. The value of an element
of this matrix in the position
is equal to:
Similarly, for the LQ mixing model,
yields a matrix with dimensions
and
L, and the value of the element
in that matrix is equal to:
The first designed approach, in the endmember spectra extraction step, uses the projected-gradient descent algorithm, with a fixed positive scalar learning rate
. Thus, for this first approach, two algorithms are proposed for the considered mixing models. The first algorithm, called Grd-NS-LS-BMF for “gradient-based non-negative spectra least squares bilinear matrix factorization” [
60], is designed for the bilinear mixing model. The second algorithm, which is designed for the LQ mixing model, is called Grd-NS-LS-LQMF for “gradient-based non-negative spectra least squares linear-quadratic matrix factorization” [
61]. Therefore, for both gradient-based algorithms, the final form Equation (20) yields, for the master elements
of the top
rows of
, the following preliminary iterative update rule:
This update rule does not ensure non-negativity and, therefore, it is not sufficient. To guarantee this constraint, an iterative projected-gradient update rule, derived from the one above, is considered. This rule consists of projecting the value obtained from Equation (24) onto the non-negative real number subspace
. This projection, denoted
, can be achieved by replacing
, if it is negative, by zero, or in practice, by a small positive number
, in order to avoid numerical instabilities. Thus, the projection becomes
, and the final iterative projected-gradient update rule reads:
It is important to mention here that, unlike with the update rule (24), there is no theoretical convergence guarantee with the above final iterative projected-gradient update rule Equation (25). However, this rule Equation (25), like those used in standard NMF methods, minimizes, practically and globally, the considered cost function throughout iterations.
For the second designed approach, still in the endmember spectra extraction step, and unlike the work done in [
60,
61], an iterative, multiplicative and projective update rule derived from the gradient-based update rule Equation (24) is proposed in the present paper for the two considered mixing models. To this end, this approach first uses the procedure which has been proposed in the literature for developing “standard” (i.e., nonprojective) multiplicative versions of various algorithms. This procedure is, e.g., detailed in [
3] for another type of algorithm, and may be transposed as follows to the present context. First, the above fixed scalar learning rate
is replaced by a matrix, whose terms
are used as learning rates, respectively, for each of the considered adaptive scalar variables
. Then, the gradient expression of
with respect to
is rewritten as the difference of two functions such that:
where the function
is obtained by keeping the terms of (20) preceded by a plus sign, whereas
is obtained by keeping the terms preceded by a minus sign. Each learning rate
is then set to:
Thus, the update rule Equation (24) becomes:
where
is a very small and positive value that is added to the denominator of the above multiplicative update rule to prevent possible division by zero. For the methods reported in the literature, this procedure is relevant because the counterparts of
and
in those methods are non-negative (since they are elements of products and sums of non-negative matrices), so that the counterparts of the learning rates
and the new value assigned to the counterparts of
, as in the right-hand term of Equation (28), are also non-negative, provided all these counterparts of
are initialized to non-negative values. In contrast, when applying this general procedure here, the expressions of
and
contain one matrix which is not necessarily non-negative, namely the Moore–Penrose pseudo-inverse matrix
, which appears in Equation (20). Therefore, to take advantage of the preliminary, purely multiplicative rule Equation (28), while ensuring that
remains non-negative, here, heuristic algorithms are introduced by replacing the quantities
and
in Equation (28) by modified versions that are guaranteed to be non-negative. This may be achieved in various ways. The first version is obtained by first projecting the complete expressions
and
onto
, as in Equation (25), and then using these completely projected quantities in Equation (28), instead of the original ones. Other versions are derived by analyzing the structure of the expressions
and
so as to separately project some of their terms that may be negative, thus using “partly projected functions”. The first approach based on such partial projections (denoted
hereafter) operates as follows. Equation (20) shows that
and
are matrix traces. One, therefore, modifies these derivatives by first projecting each of the considered matrix elements onto
. This yields (taking into account that
):
The rule Equation (28) is then replaced by:
The second approach based on partial projections (denoted
hereafter) is obtained by only replacing
by its projection [
in the quantities
and
, because this is sufficient for making them non-negative. Equation (20) shows that this second type of partly projected functions, denoted as
and
, reads:
The corresponding multiplicative projective adaptation rule reads:
Here also, and as mentioned above, there is no theoretical convergence guarantee with the above-defined completely/partly projected multiplicative adaptation rules. Nevertheless, these rules, like those used in standard multiplicative NMF algorithms, also practically and globally optimize the used cost function throughout iterations.
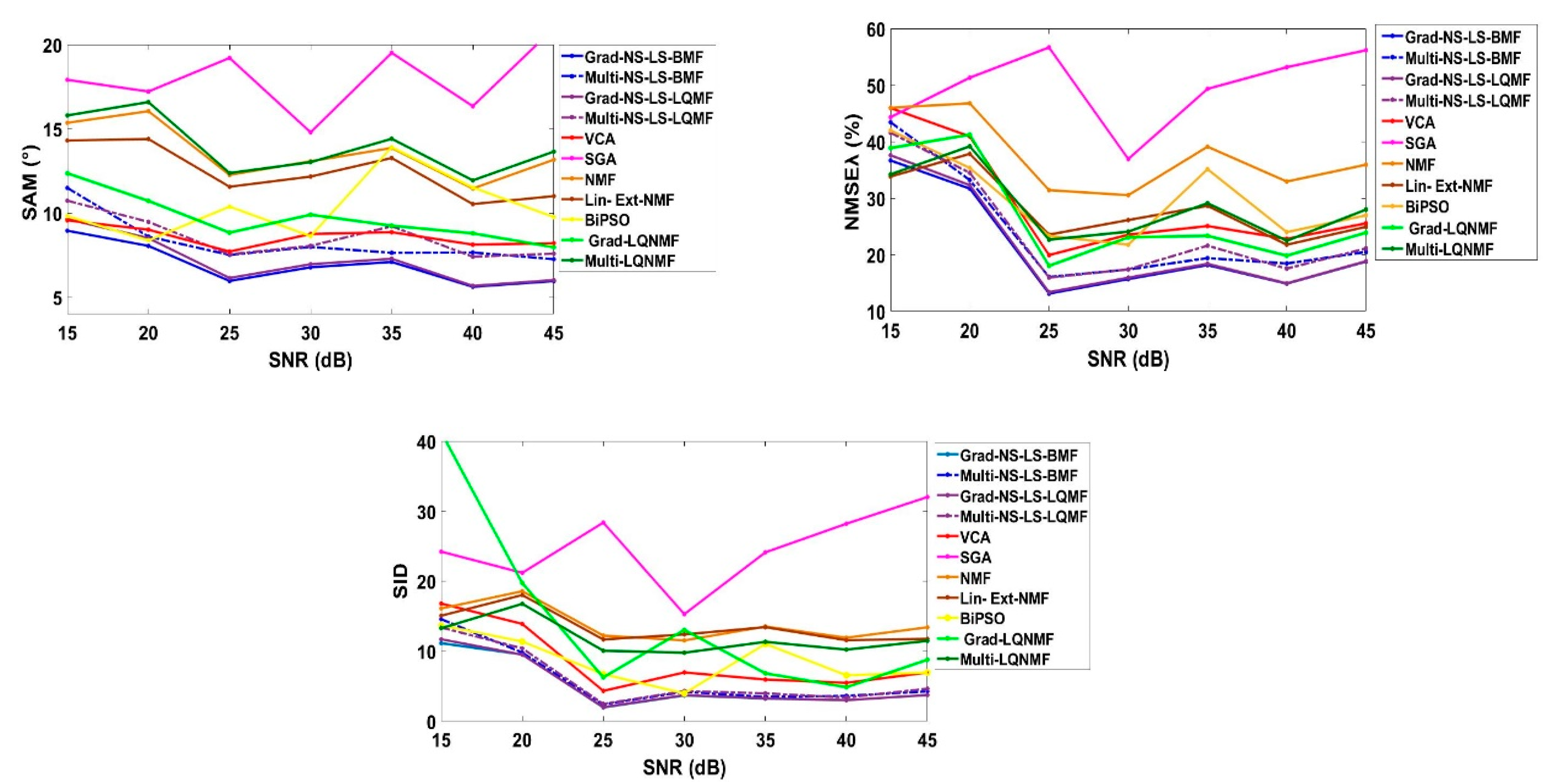
In the conducted tests (described hereafter), the rule Equation (31) resulted in better performance than the rule Equation (34), as well as the first version, based on completely projected functions. Therefore, hereafter, only the rule Equation (31) is considered. Thus, for this multiplicative approach (which is also projective; this is implicit in the names of the methods below), and for the considered bilinear and LQ mixing models, two algorithms are also proposed. The first one, called Multi-NS-LS-BMF for “multiplicative non-negative spectra least squares bilinear matrix factorization”, is designed for the bilinear mixing model. The second algorithm, proposed for the LQ mixing model, is called Multi-NS-LS-LQMF for “multiplicative non-negative spectra least squares linear-quadratic matrix factorization”.
Moreover, in all of the above four proposed algorithms, the slave variables of
are updated together with the master ones. When considering the bilinear mixing model, cross-pseudo-endmember slave elements
are updated as follows:
When considering the LQ mixing model, and in addition to updating cross-pseudo-endmember slave elements
by using the update rule (35), auto-pseudo-endmember slave elements
are also updated as follows:
In this endmember spectra extraction step, the master variables (i.e., the hyperspectral endmember spectra) may be initialized by one of the standard linear methods. Indeed, although these methods are designed for linear mixtures, their estimation results may be considered as first approximations to be injected as an initialization of nonlinear methods. After a number of tests (described below in the experimental results section) by using three techniques in this step, the linear VCA method [
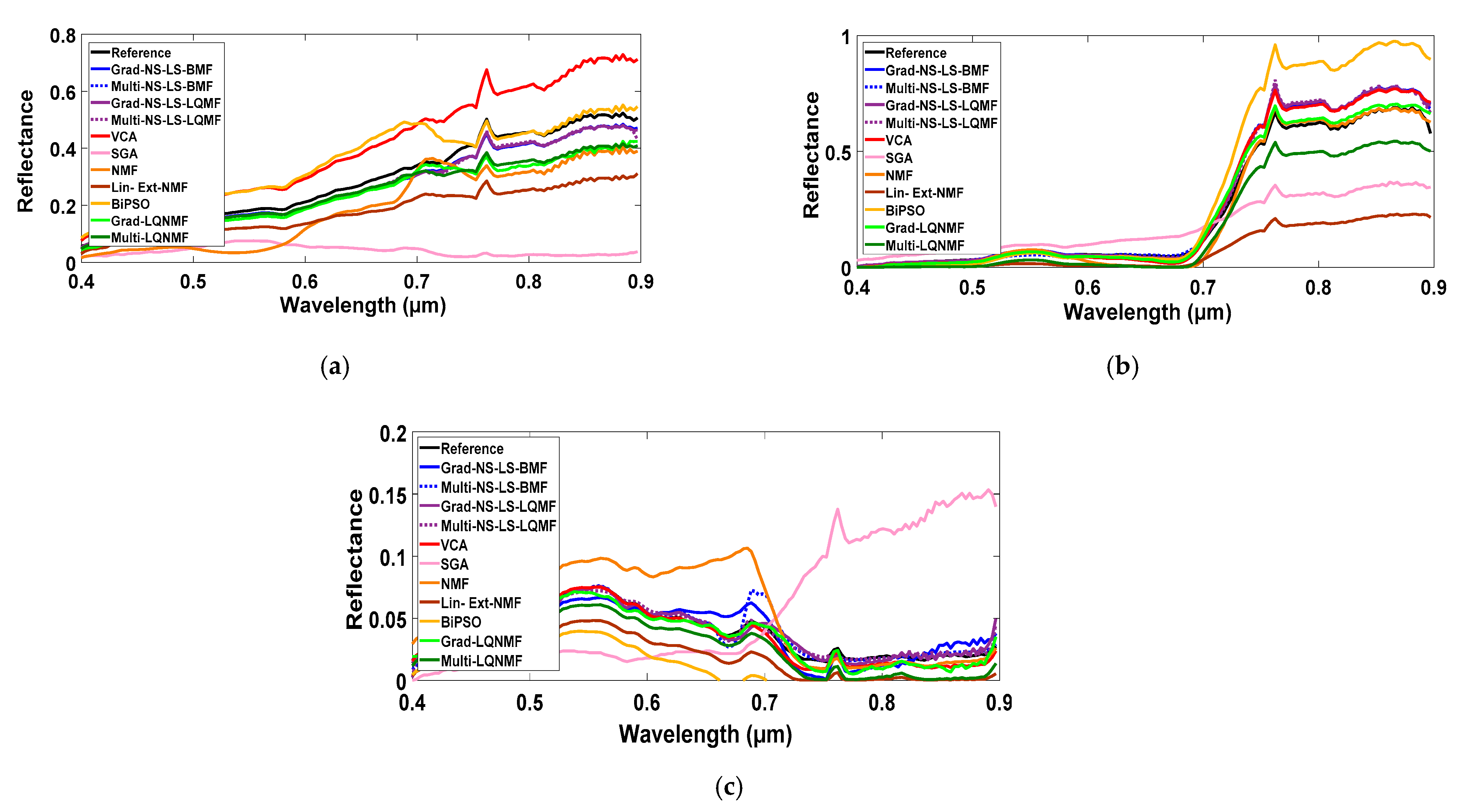
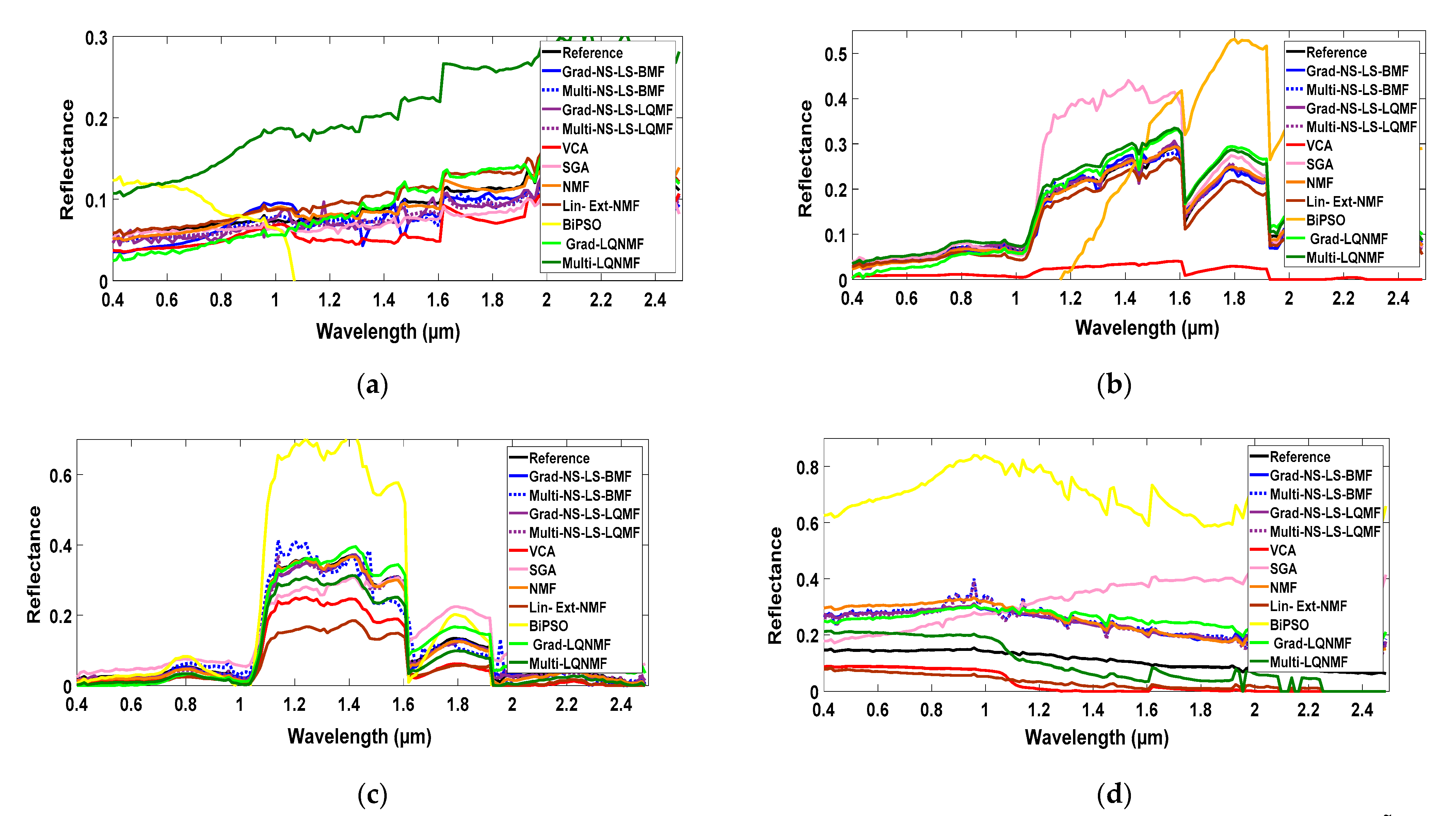
29] is chosen for initializing the master variables. Moreover, still in this endmember spectra extraction step, the slave variables (i.e., the hyperspectral cross/auto-pseudo-endmember spectra) are initialized from the initial master variables by using only Equation (35) when considering the bilinear mixing model, or Equations (35) and (36) when considering the linear-quadratic one.
The adaptation of all master and slave variables is stopped when the number of iterations reaches a predefined maximum value, or when the relative modification of the criterion
takes a value below a predefined threshold as follows:
where
corresponds to an iteration.
Furthermore, and as mentioned in
Section 2, in the present paper and contrary to the works reported in [
60,
61], the estimation of endmember abundance fractions is also considered. Indeed, in this work, three alternative approaches are proposed for estimating the endmember abundance fractions. In the first approach, the matrix
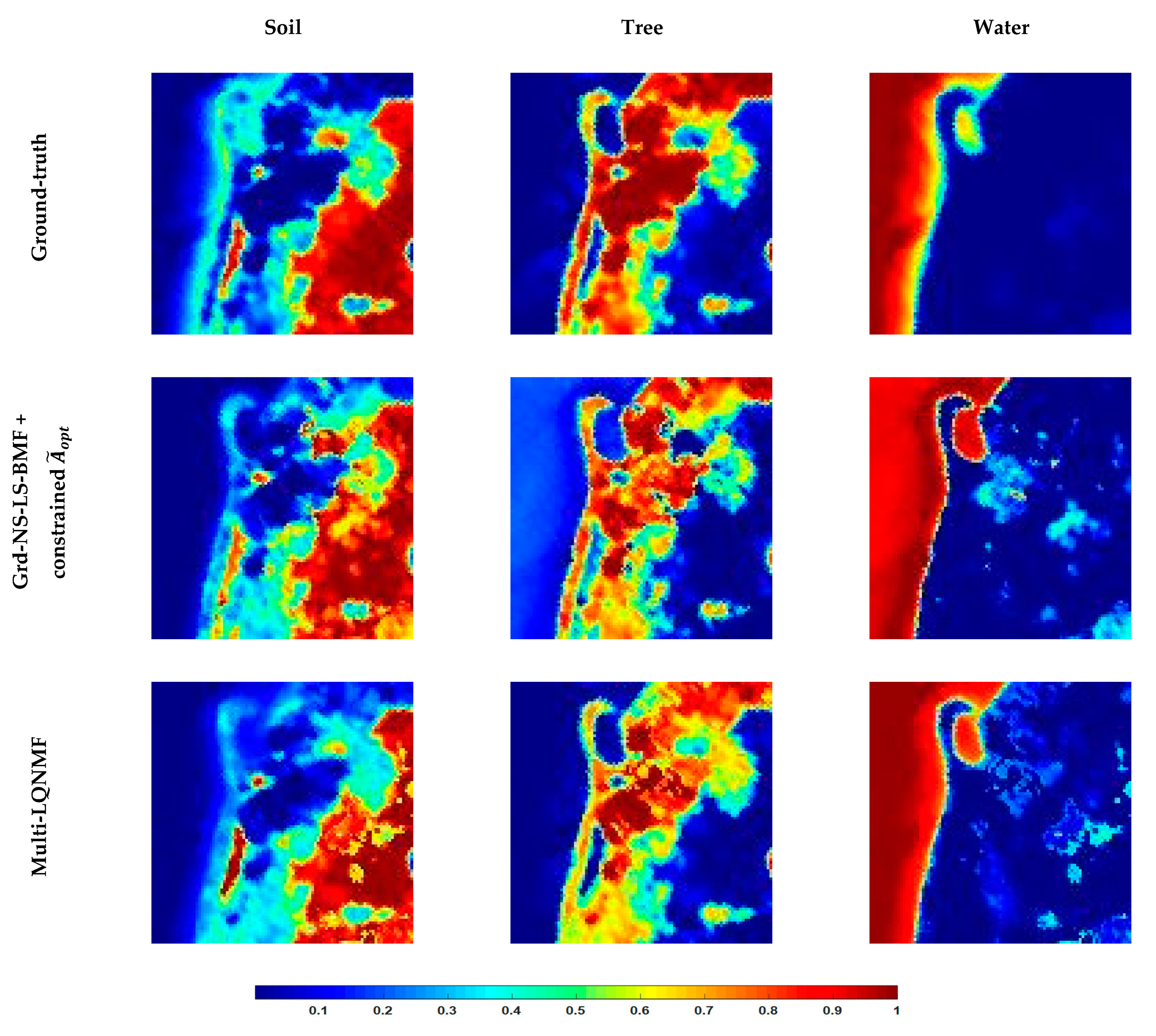
, defined by Equation (13) and containing linear and second-order abundance fractions, is constrained and used to obtain the considered coefficients (the corresponding four complete unmixing methods are, therefore, called “Grd-NS-LS-BMF + constrained
”, and so on). The constraints, defined hereafter, imposed on this matrix are those related to the non-negativity of variables obtained by using the projection approach, the sum-to-one property of linear coefficients, and the upper bounding of second-order coefficients, as defined in Equation (1). These constraints respectively read:
The second approach for estimating endmember linear and second-order abundance fractions consists of running a modified version of the iterative multiplicative LQNMF (Multi-LQNMF) method of [
47], restricted to the bilinear mixing model when this one is considered, or fully used when the LQ mixing model is considered. This technique, which jointly estimates spectra and abundance fractions, is initialized by (i) the endmember and pseudo-endmember spectra contained in the matrix
, obtained by using one of the above four proposed algorithms, and (ii) the constrained
matrix obtained by using Equations (13), (38) and (39). Unlike in [
47], only linear and second-order abundance fractions are here updated with this Multi-LQNMF algorithm that also contains the constraints defined by (39) and (40), whereas endmember and pseudo-endmember spectra are not updated here. The corresponding four complete unmixing methods, hereafter called “Grd-NS-LS-BMF + post-Multi-LQNMF1” and so on, therefore yield exactly the same estimated spectra as the associated above-defined methods “Grd-NS-LS-BMF + constrained
” and so on, but they result in different estimated abundance fractions.
The third and last approach, which leads to the four methods called “Grd-NS-LS-BMF + post-Multi-LQNMF2” and so on, is similar to the second one, but it jointly updates spectra and abundance fractions using the iterative Multi-LQNMF algorithm, again restricted to the bilinear mixing model when this model is considered, or fully used when the LQ mixing model is considered.
In the above second and third approaches, the adaptation of the considered variables is stopped when the number of iterations reaches a predefined maximum value.
The complete pseudo-code of the proposed algorithms is provided below.
| Pseudo-code: hyperspectral unmixing methods based on constrained bilinear or linear-quadratic matrix factorization. |
| Input: hyperspectral image X. |
- 1.
Endmember spectra extraction step - 1.1.
Initialization stage - 1.1.1.
Initialize master variables of from X by means of the VCA method. - 1.1.2.
Initialize slave variables of from the initial master variables by using only Equation (35) when considering the bilinear mixing model, or Equation (35) and Equation (36) when considering the linear-quadratic one.
- 1.2.
Optimization stage (until convergence)
- 1.2.1.
Update master variables of by using Equation (25) for the gradient-based methods, or Equation (31) for the multiplicative ones (using the appropriate formula when calculating in according to the considered mixing model: bilinear or linear-quadratic). - 1.2.2.
Update slave variables of from the updated master variables by using only Equation (35) when considering the bilinear mixing model, or Equations (35) and (36) when considering the linear-quadratic one.
- 2.
Abundance fractions estimation step - 2.1.
Initialization stage: initialize linear and second-order abundance fractions by using Equation (13), and considering the above extracted endmember spectra. - 2.2.
Optimization stage (until convergence): update only abundance fractions by using Equations (38)–(40) for the first approach, or update only abundance fractions by using the Multi-LQNMF algorithm for the second approach, or jointly update endmember spectra and abundance fractions by using the Multi-LQNMF algorithm.
|
| Output: endmember and cross/auto-pseudo endmember spectra, and their associated linear and second-order abundance fractions. |


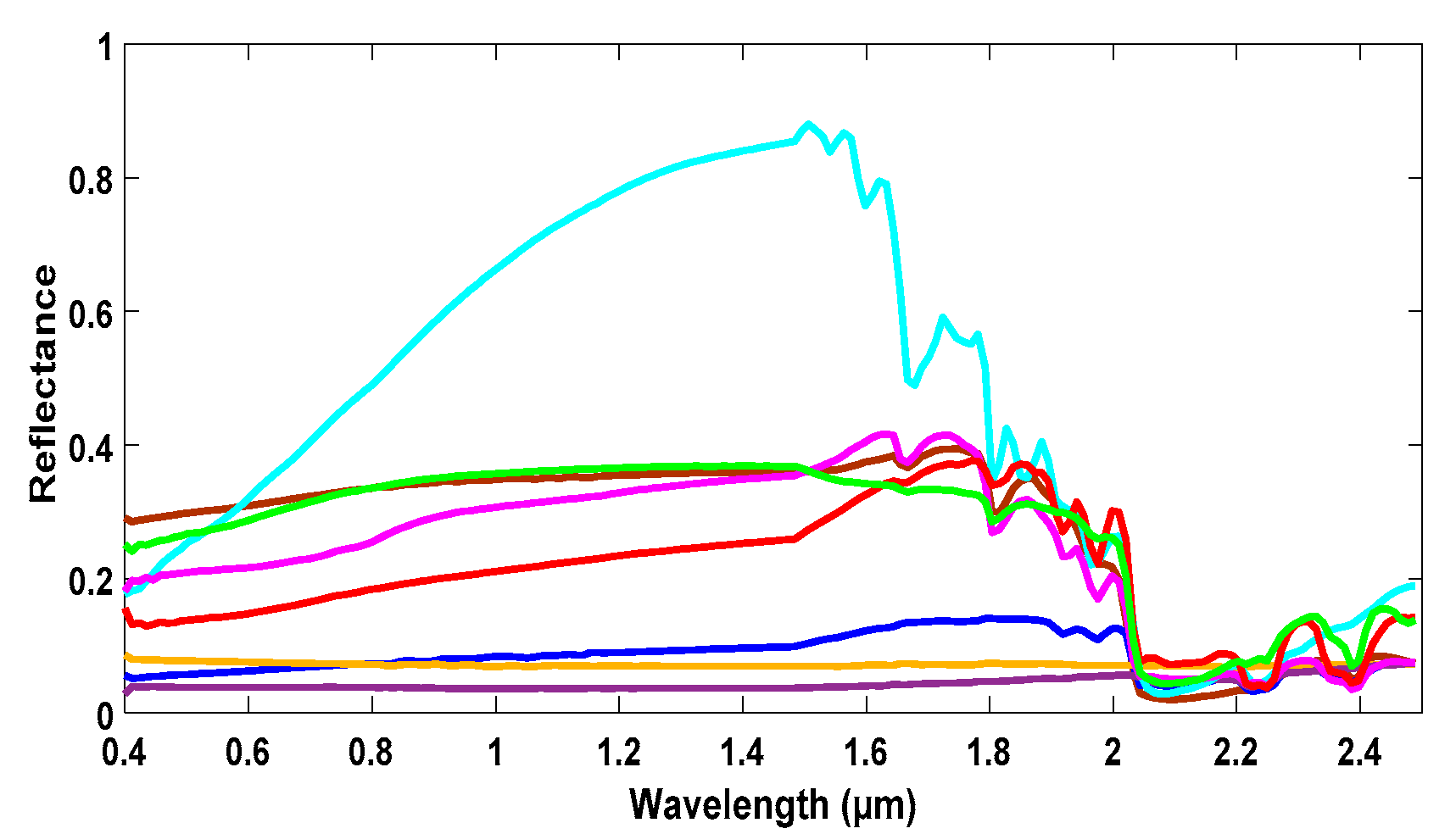
 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}