Visual-Inertial Odometry of Smartphone under Manhattan World


Abstract
1. Introduction
- A fast structural feature extraction method that can run in real-time on the mobile phone is proposed. We adopt the method of exhausting VP hypotheses to obtain the optimal global solution.
- We propose to directly parameterize the three VPs into an orthogonal basis and define the orthogonal basis as a structural feature. In mathematics, we use Hamilton quaternion to represent this orthogonal basis to avoid singularity. At the same time, we use the tangent space of the rotating manifold to update the structural feature. The orthogonality of the structural feature is considered in this updating method.
- We propose a tightly-coupled, optimization-based monocular visual-inertial odometry where IMU measurements, point features, and structural features are used as observation information. As far as we know, this is the first to add structural regularity constraint to VIO in the form of an orthogonal basis. Moreover, it can run in real-time on an Android phone with Kirin 990 5G processor at an average processing speed of 28.1 ms for a single frame.
2. Related Work
2.1. VI-SLAM and VIO
2.2. Vanishing Point Extraction
2.3. Structural Regularity
3. Preliminaries
4. Monocular Visual Inertial Odometry Based on Point and Structural Features
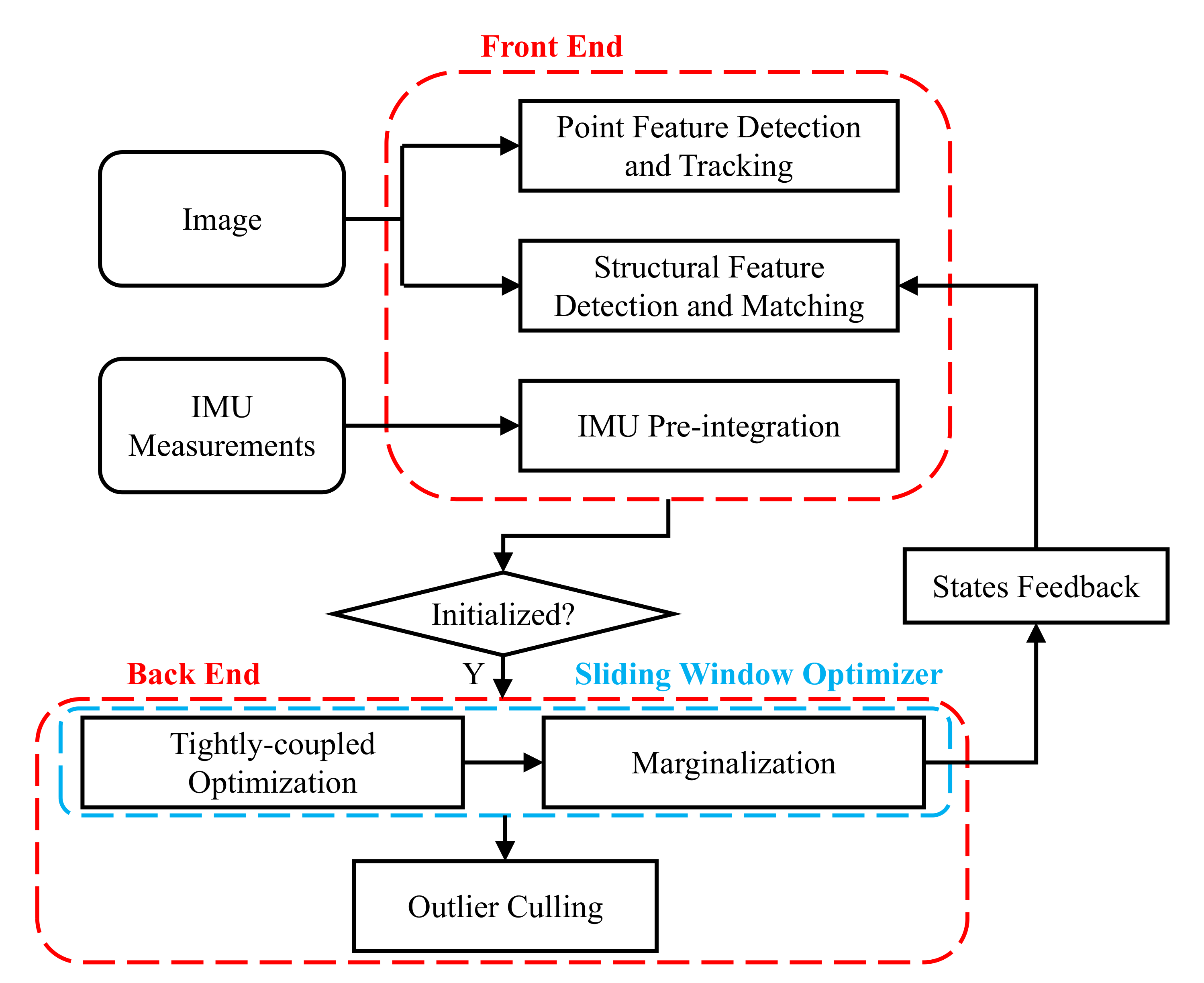
4.1. System Overview
- There are many newly observed landmarks.
- There are many untracked landmarks.
- The average parallax between point features matched between successive frames is large.
4.2. Front End
4.2.1. IMU Pre-Integration
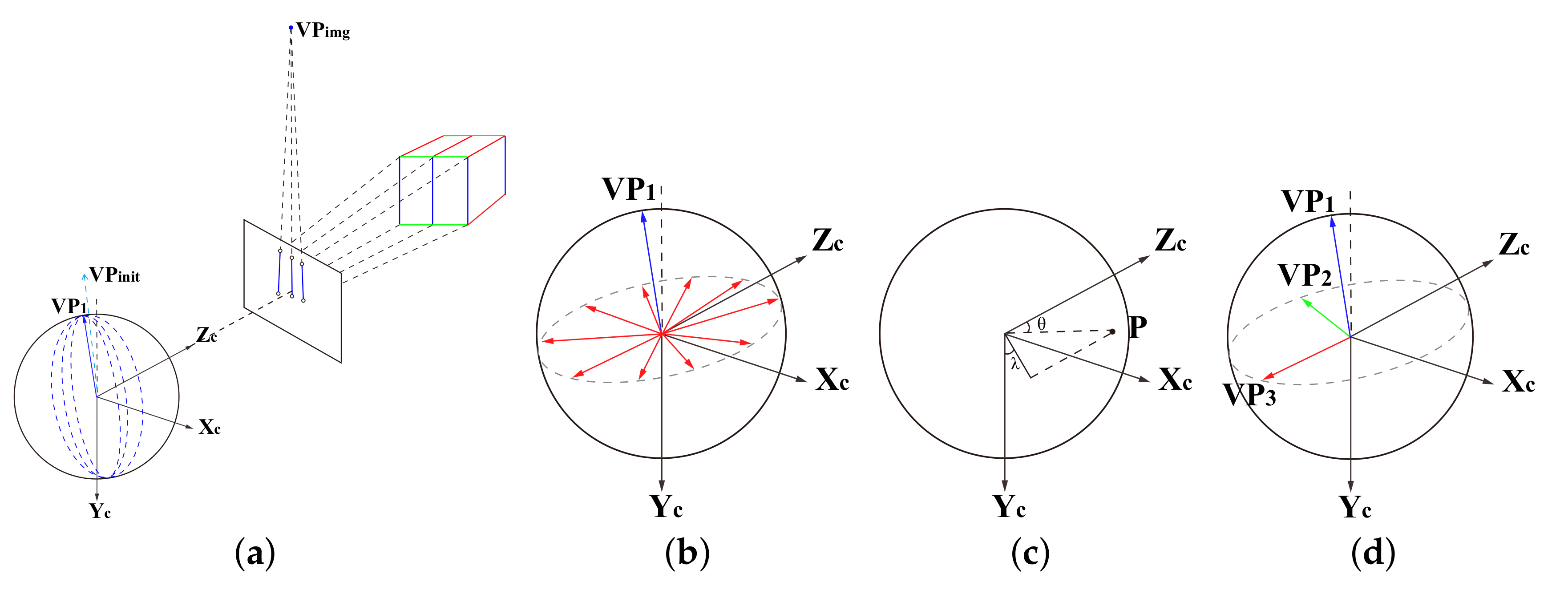
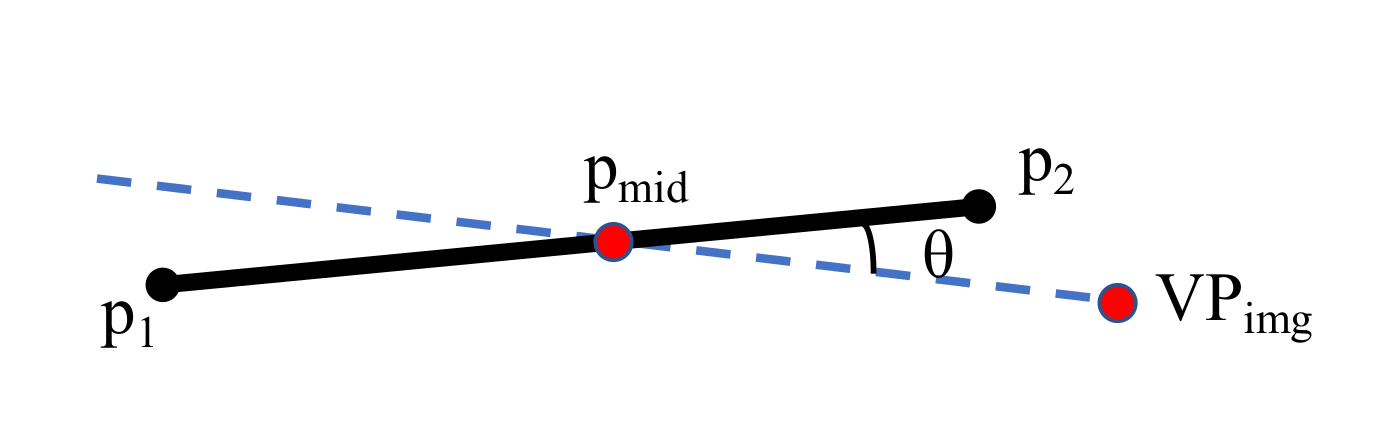
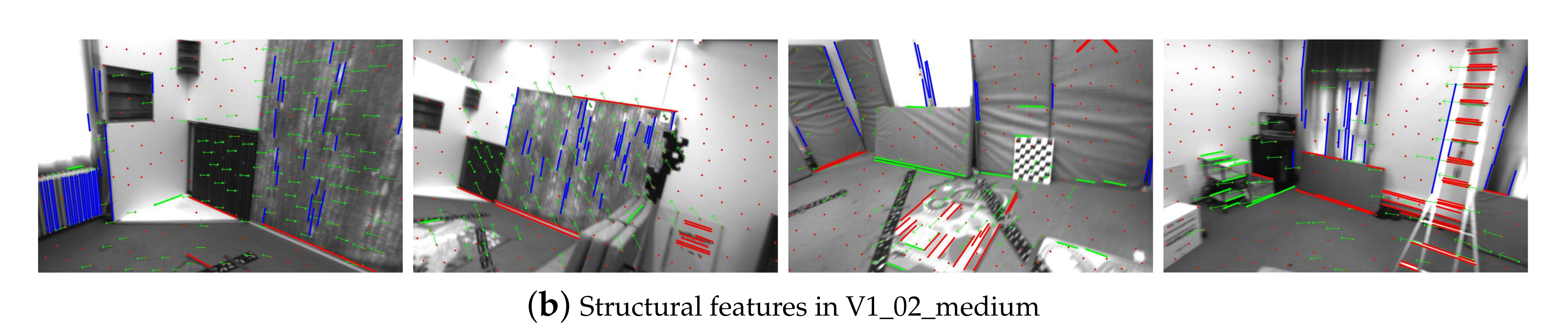
4.2.2. Structural Feature Detection and Matching
4.3. Back End
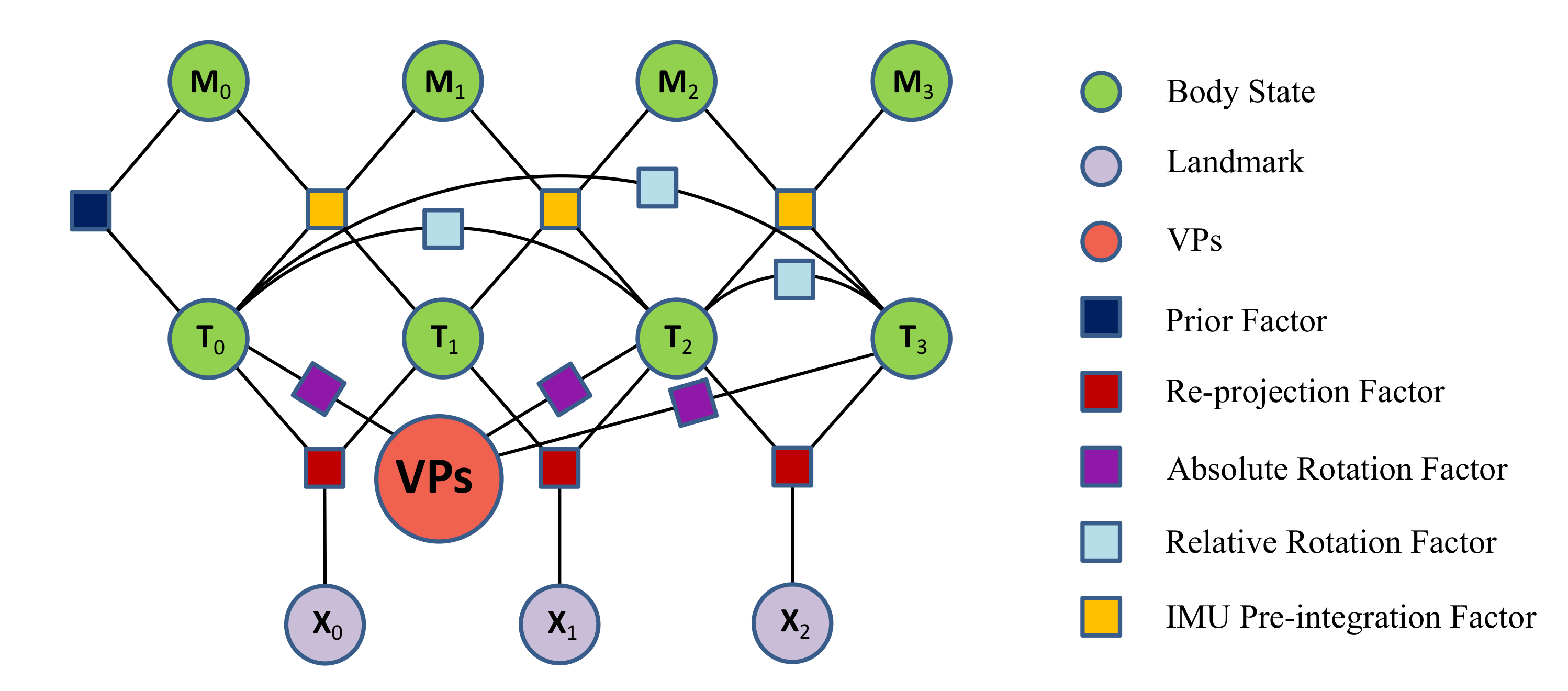
4.3.1. Tightly-Coupled Nonlinear Optimization
4.3.2. Point Feature Measurement Factor
4.3.3. Structural Feature Measurement Factor
4.3.4. IMU Measurement Factor
5. Experimental Results
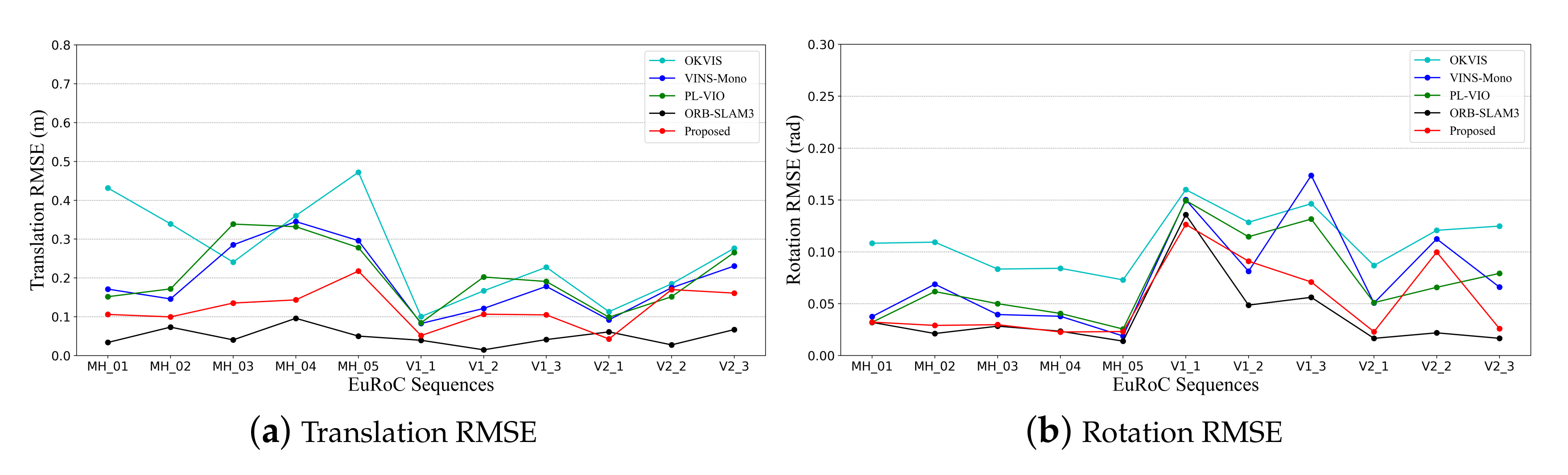
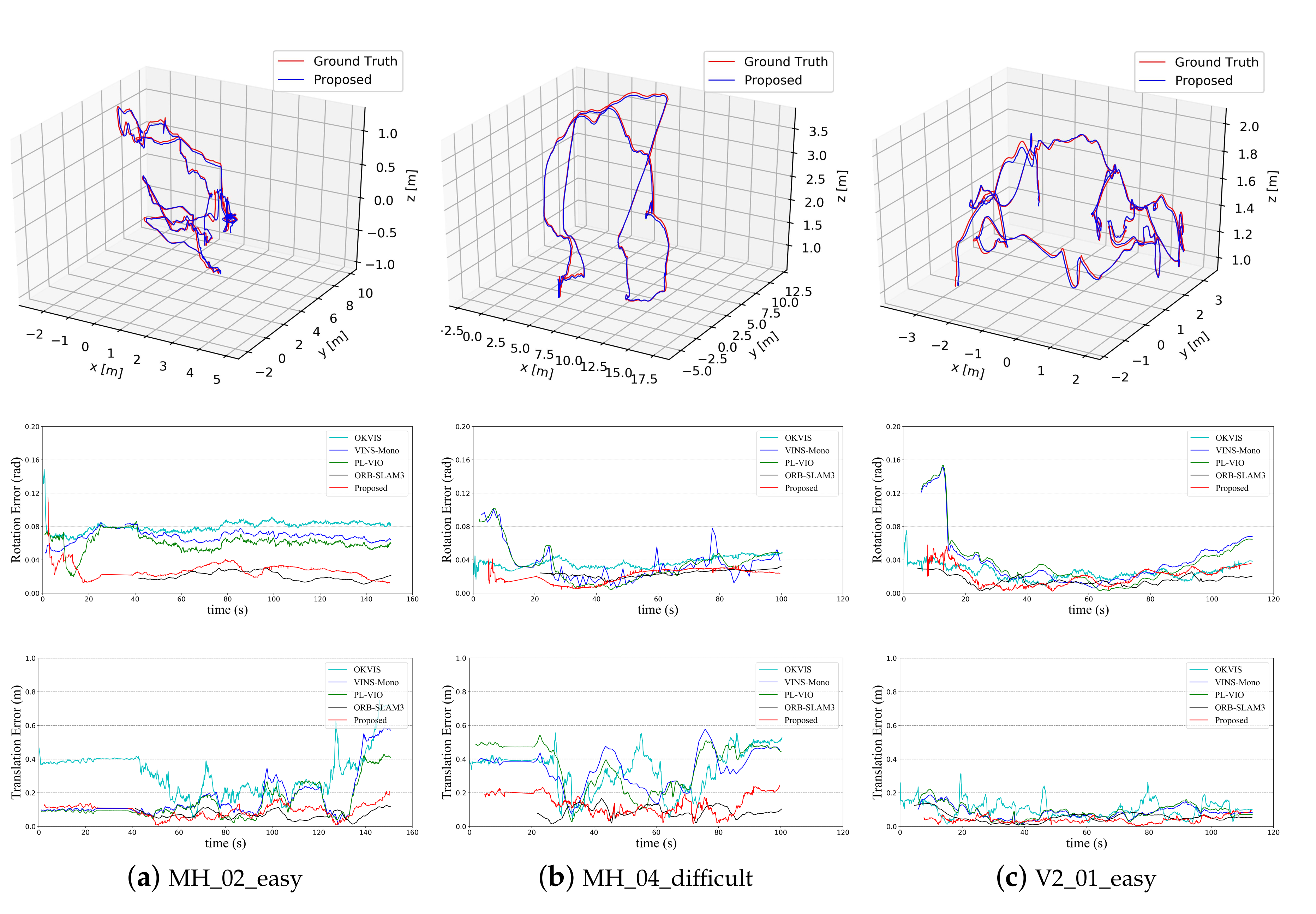
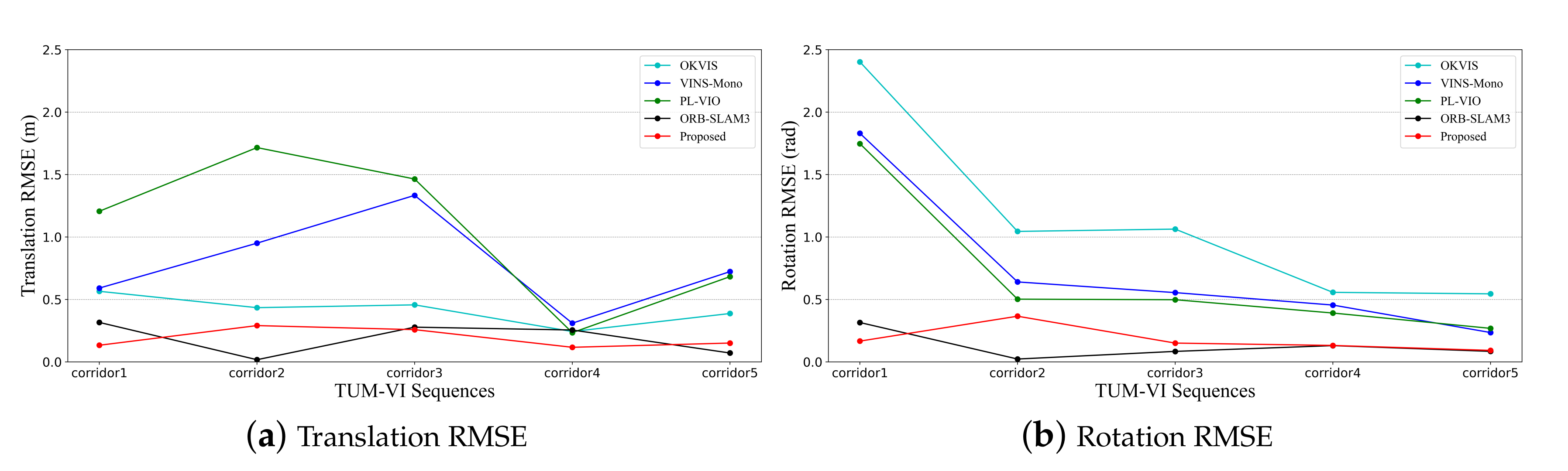
5.1. Dataset Comparison
5.1.1. EuRoC Dataset
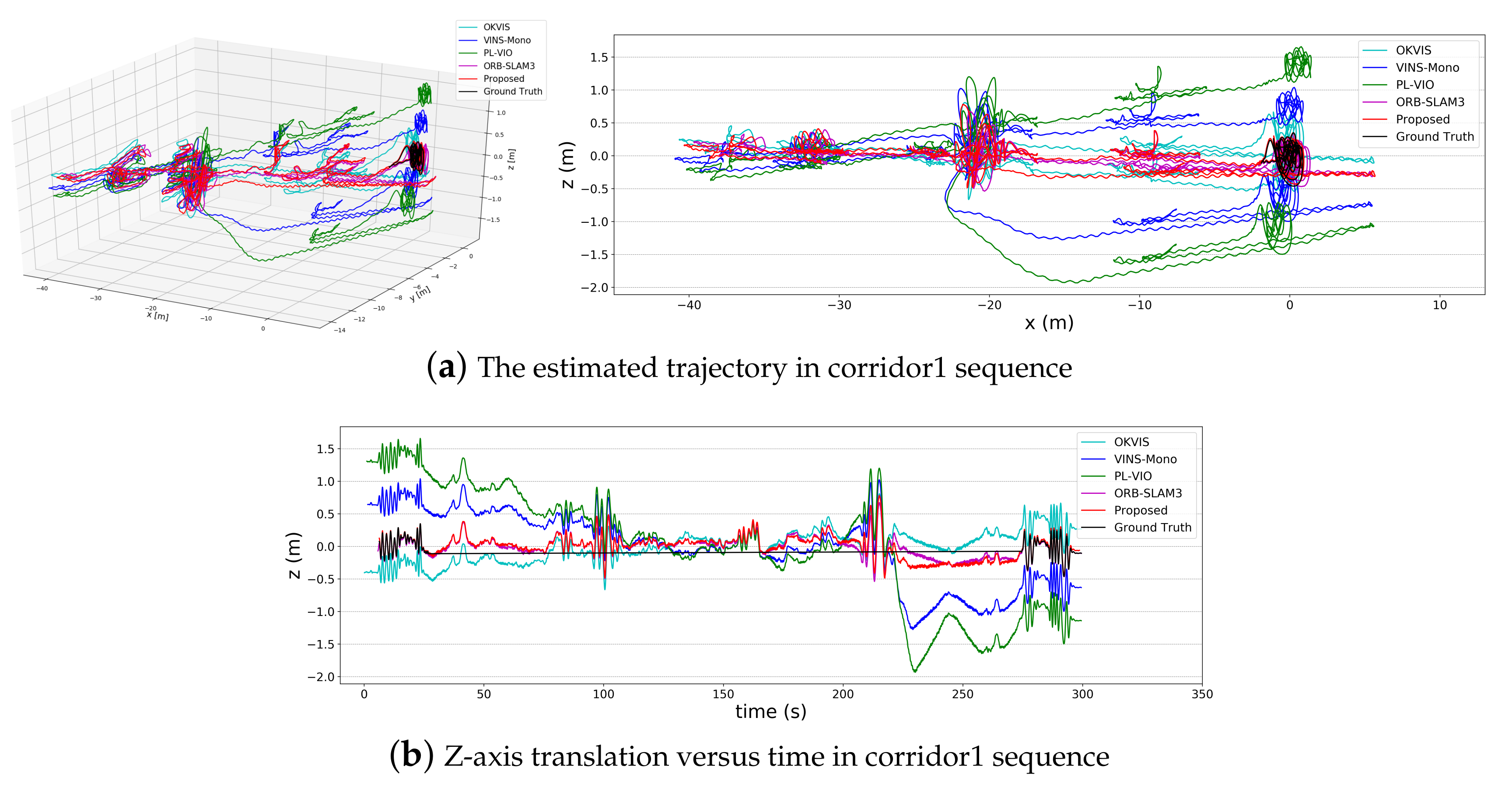
5.1.2. TUM-VI Dataset
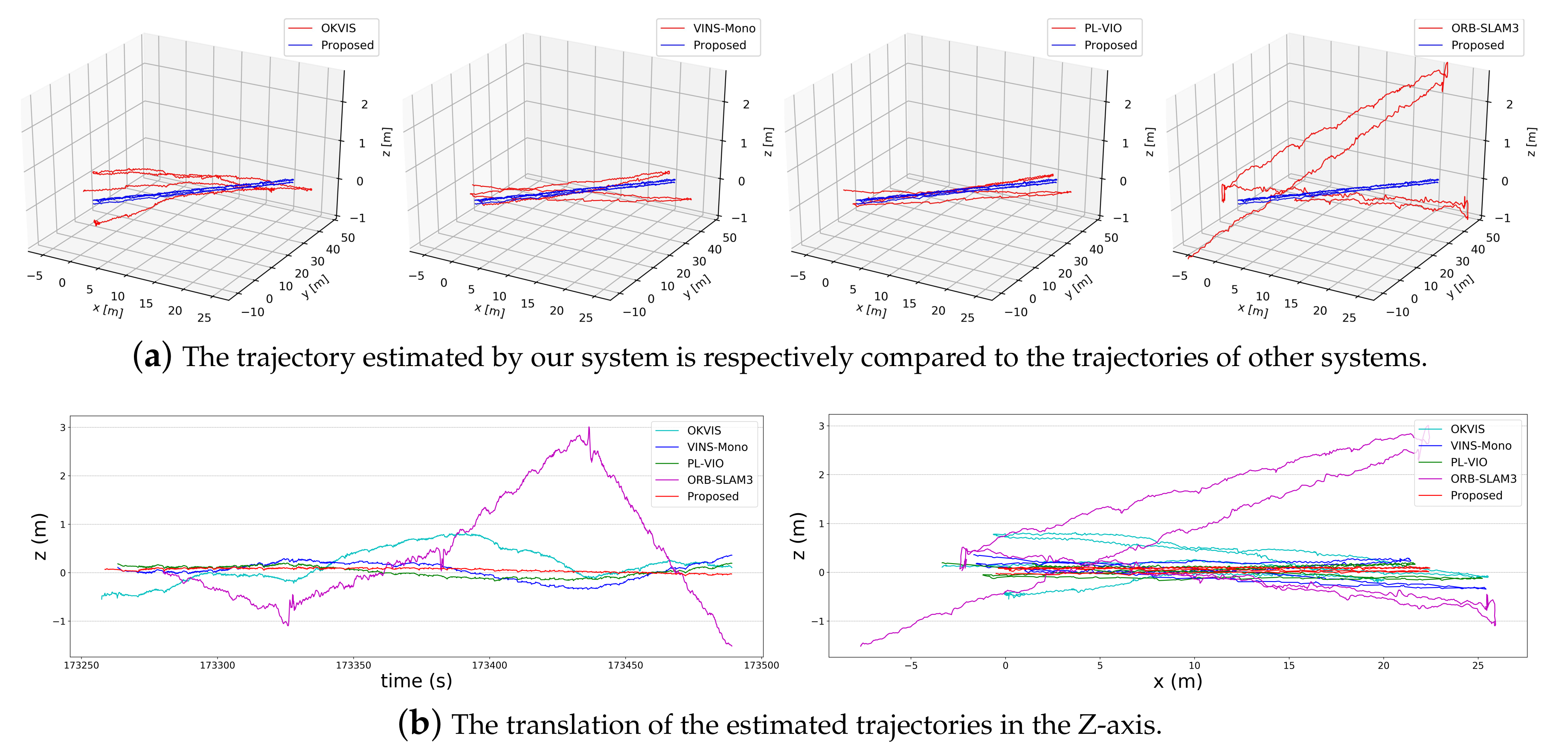
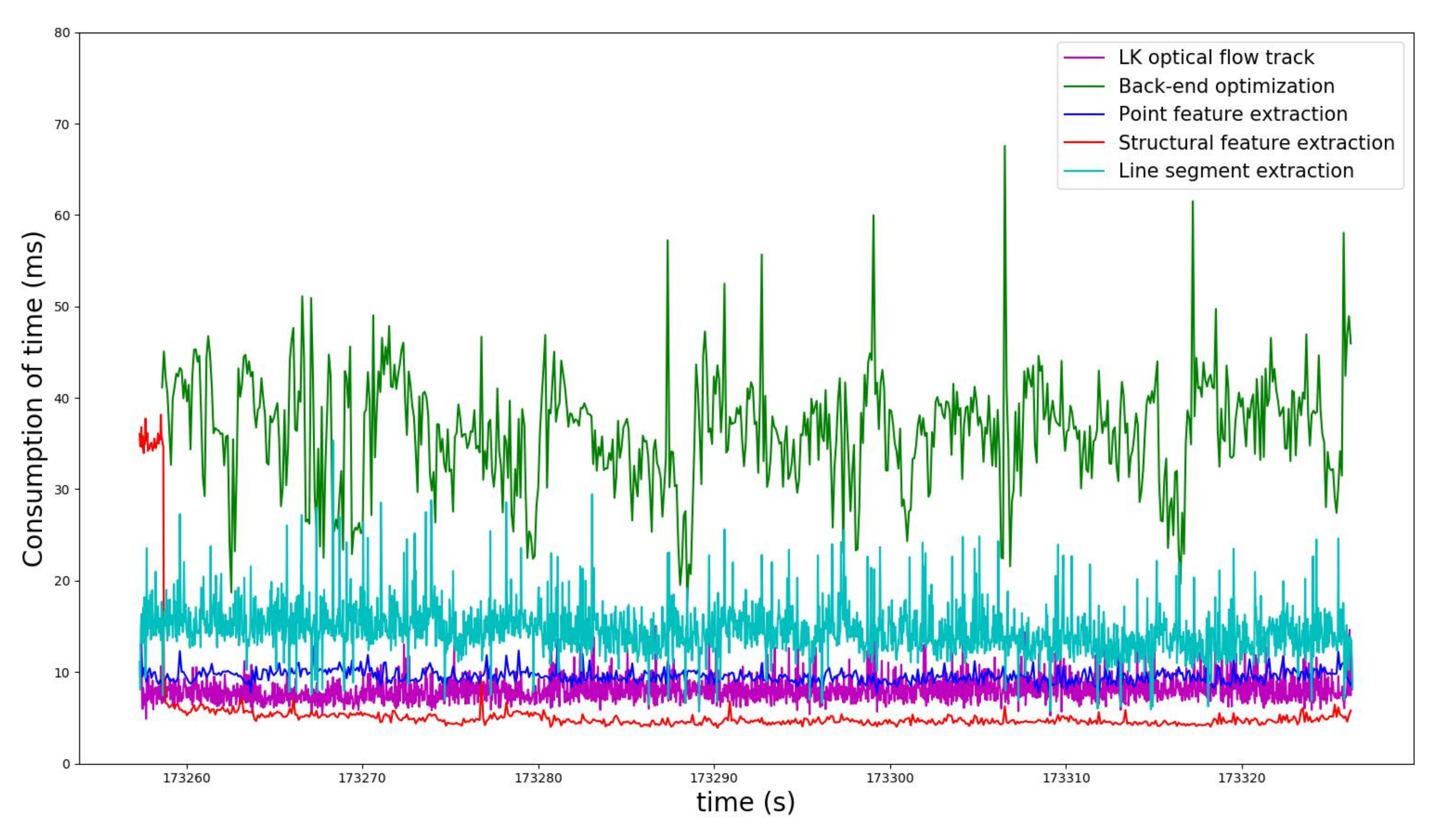
5.2. Field Test
6. Conclusions and Future Works
Author Contributions
Funding
Conflicts of Interest
References
- Groves, P.D. Principles of GNSS, inertial, and multisensor integrated navigation systems, [Book review]. IEEE Aerosp. Electron. Syst. Mag. 2015, 30, 26–27. [Google Scholar] [CrossRef]
- Hess, W.; Kohler, D.; Rapp, H.; Andor, D. Real-time loop closure in 2D LIDAR SLAM. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 1271–1278. [Google Scholar]
- Heng, L.; Choi, B.; Cui, Z.; Geppert, M.; Hu, S.; Kuan, B.; Liu, P.; Nguyen, R.; Yeo, Y.C.; Geiger, A.; et al. Project AutoVision: Localization and 3D Scene Perception for an Autonomous Vehicle with a Multi-Camera System. In Proceedings of the International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 4695–4702. [Google Scholar]
- Sun, K.; Mohta, K.; Pfrommer, B.; Watterson, M.; Liu, S.; Mulgaonkar, Y.; Taylor, C.J.; Kumar, V. Robust Stereo Visual Inertial Odometry for Fast Autonomous Flight. IEEE Robot. Autom. Lett. 2018, 3, 965–972. [Google Scholar] [CrossRef]
- Qin, T.; Pan, J.; Cao, S.; Shen, S. A General Optimization-based Framework for Local Odometry Estimation with Multiple Sensors. arXiv 2019, arXiv:1901.03638. [Google Scholar]
- Chen, L.; Thevenon, P.; Seco-Granados, G.; Julien, O.; Kuusniemi, H. Analysis on the TOA tracking with DVB-T signals for positioning. IEEE Trans. Broadcast. 2016, 62, 957–961. [Google Scholar] [CrossRef]
- Chen, L.; Yang, L.L.; Yan, J.; Chen, R. Joint wireless positioning and emitter identification in DVB-T single frequency networks. IEEE Trans. Broadcast. 2017, 63, 577–582. [Google Scholar] [CrossRef]
- Chen, L.; Thombre, S.; Järvinen, K.; Lohan, E.S.; Alén-Savikko, A.; Leppäkoski, H.; Bhuiyan, M.Z.H.; Bu-Pasha, S.; Ferrara, G.N.; Honkala, S.; et al. Robustness, security and privacy in location-based services for future IoT: A survey. IEEE Access 2017, 5, 8956–8977. [Google Scholar] [CrossRef]
- Zhou, X.; Chen, L.; Yan, J.; Chen, R. Accurate DOA Estimation With Adjacent Angle Power Difference for Indoor Localization. IEEE Access 2020, 8, 44702–44713. [Google Scholar] [CrossRef]
- Meilland, M.; Drummond, T.; Comport, A.I. A Unified Rolling Shutter and Motion Blur Model for 3D Visual Registration. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Sydney, Australia, 1–8 December 2013; pp. 2016–2023. [Google Scholar]
- Liu, H.; Zhang, G.; Bao, H. Robust Keyframe-based Monocular SLAM for Augmented Reality. In Proceedings of the IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Merida, Mexico, 19–23 September 2016; pp. 1–10. [Google Scholar]
- Piao, J.C.; Kim, S. Adaptive Monocular Visual–Inertial SLAM for Real-Time Augmented Reality Applications in Mobile Devices. Sensors 2017, 17, 2567. [Google Scholar] [CrossRef]
- Li, P.; Qin, T.; Hu, B.; Zhu, F.; Shen, S. Monocular Visual-Inertial State Estimation for Mobile Augmented Reality. In Proceedings of the IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Nantes, France, 9–13 October 2017; pp. 11–21. [Google Scholar]
- Mourikis, A.I.; Roumeliotis, S.I. A Multi-State Constraint Kalman Filter for Vision-aided Inertial Navigation. In Proceedings of the International Conference on Robotics and Automation (ICRA), Roma, Italy, 10–14 April 2007; pp. 3565–3572. [Google Scholar]
- Murartal, R.; Montiel, J.M.M.; Tardos, J.D. ORB-SLAM: A Versatile and Accurate Monocular SLAM System. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef]
- Qin, T.; Li, P.; Shen, S. VINS-Mono: A Robust and Versatile Monocular Visual-Inertial State Estimator. IEEE Trans. Robot. 2018, 34, 1004–1020. [Google Scholar] [CrossRef]
- Pumarola, A.; Vakhitov, A.; Agudo, A.; Sanfeliu, A.; Morenonoguer, F. PL-SLAM: Real-time monocular visual SLAM with points and lines. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 4503–4508. [Google Scholar]
- Gomez-Ojeda, R.; Zuiga-Nol, D.; Moreno, F.A.; Scaramuzza, D.; Gonzalez-Jimenez, J. PL-SLAM: A Stereo SLAM System through the Combination of Points and Line Segments. IEEE Trans. Robot. 2017, 35, 734–746. [Google Scholar] [CrossRef]
- Yijia, H.; Zhao, J.; Guo, Y.; He, W.; Yuan, K. PL-VIO: Tightly-Coupled Monocular Visual-Inertial Odometry Using Point and Line Features. Sensors 2018, 18, 1159. [Google Scholar]
- Coughlan, J.; Yuille, A.L. Manhattan World: Compass direction from a single image by Bayesian inference. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Kerkyra, Greece, 20–27 September 1999; 2, pp. 941–947. [Google Scholar]
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Camposeco, F.; Pollefeys, M. Using vanishing points to improve visual-inertial odometry. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 5219–5225. [Google Scholar]
- Zhou, H.; Zou, D.; Pei, L.; Ying, R.; Liu, P.; Yu, W. StructSLAM: Visual SLAM With Building Structure Lines. IEEE Trans. Veh. Technol. 2015, 64, 1364–1375. [Google Scholar] [CrossRef]
- Li, H.; Yao, J.; Bazin, J.; Lu, X.; Xing, Y.; Liu, K. A Monocular SLAM System Leveraging Structural Regularity in Manhattan World. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 2518–2525. [Google Scholar]
- Li, Y.; Brasch, N.; Wang, Y.; Navab, N.; Tombari, F. Structure-SLAM: Low-Drift Monocular SLAM in Indoor Environments. IEEE Robot. Autom. Lett. 2020, 5, 6583–6590. [Google Scholar] [CrossRef]
- Liu, J.; Meng, Z. Visual SLAM With Drift-Free Rotation Estimation in Manhattan World. IEEE Robot. Autom. Lett. 2020, 5, 6512–6519. [Google Scholar] [CrossRef]
- Kim, P.; Coltin, B.; Kim, H.J. Low-drift visual odometry in structured environments by decoupling rotational and translational motion. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 7247–7253. [Google Scholar]
- Guo, R.; Peng, K.; Zhou, D.; Liu, Y. Robust visual compass using hybrid features for indoor environments. Electronics 2019, 8, 220. [Google Scholar] [CrossRef]
- Zhou, Y.; Kneip, L.; Rodriguez, C.; Li, H. Divide and conquer: Efficient density-based tracking of 3D sensors in Manhattan worlds. In Proceedings of the Asian Conference on Computer Vision (ACCV), Taipei, Taiwan, 20–24 November 2016; pp. 3–19. [Google Scholar]
- Bloesch, M.; Omari, S.; Hutter, M.; Siegwart, R. Robust visual inertial odometry using a direct EKF-based approach. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 298–304. [Google Scholar]
- Murartal, R.; Tardos, J.D. Visual-Inertial Monocular SLAM With Map Reuse. IEEE Robot. Autom. Lett. 2017, 2, 796–803. [Google Scholar] [CrossRef]
- Leutenegger, S.; Lynen, S.; Bosse, M.; Siegwart, R.; Furgale, P. Keyframe-based visual-inertial odometry using nonlinear optimization. Int. J. Robot. Res. 2015, 34, 314–334. [Google Scholar] [CrossRef]
- Campos, C.; Elvira, R.; Rodríguez, J.J.G.; Montiel, J.M.; Tardós, J.D. ORB-SLAM3: An accurate open-source library for visual, visual-inertial and multi-map SLAM. arXiv 2020, arXiv:2007.11898. [Google Scholar]
- Lu, X.; Yaoy, J.; Li, H.; Liu, Y. 2-Line Exhaustive Searching for Real-Time Vanishing Point Estimation in Manhattan World. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 345–353. [Google Scholar]
- Aguilera, D.; Lahoz, J.G.; Codes, J.F. A new method for vanishing points detection in 3D reconstruction from a single view. In Proceedings of the ISPRS Comission, Vienna, Austria, 29–30 August 2005. [Google Scholar]
- Tardif, J. Non-iterative approach for fast and accurate vanishing point detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Kyoto, Japan, 29 September–2 October 2009; pp. 1250–1257. [Google Scholar]
- Bazin, J.; Pollefeys, M. 3-line RANSAC for orthogonal vanishing point detection. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vilamoura, Portugal, 7–12 October 2012; pp. 4282–4287. [Google Scholar]
- Chatterjee, A.; Govindu, V.M. Efficient and Robust Large-Scale Rotation Averaging. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Tokyo, Japan, 3–7 November 2013; pp. 521–528. [Google Scholar]
- Furgale, P.; Rehder, J.; Siegwart, R. Unified temporal and spatial calibration for multi-sensor systems. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Sydney, Australia, 1–8 December 2013; pp. 1280–1286. [Google Scholar]
- Sola, J. Quaternion kinematics for the error-state Kalman filter. arXiv 2017, arXiv:1711.02508. [Google Scholar]
- Lucas, B.D.; Kanade, T. An iterative image registration technique with an application to stereo vision. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), Vancouver, BC, Canada, 24–28 August 1981; pp. 674–679. [Google Scholar]
- Rosten, E.; Porter, R.; Drummond, T. Faster and better: A machine learning approach to corner detection. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 32, 105–119. [Google Scholar] [CrossRef] [PubMed]
- Akinlar, C.; Topal, C. EDLines: A real-time line segment detector with a false detection control. Pattern Recognit. Lett. 2011, 32, 1633–1642. [Google Scholar] [CrossRef]
- Burri, M.; Nikolic, J.; Gohl, P.; Schneider, T.; Rehder, J.; Omari, S.; Achtelik, M.W.; Siegwart, R. The EuRoC micro aerial vehicle datasets. Int. J. Robot. Res. 2016, 35, 1157–1163. [Google Scholar] [CrossRef]
- Schubert, D.; Goll, T.; Demmel, N.; Usenko, V.; Stückler, J.; Cremers, D. The TUM VI benchmark for evaluating visual-inertial odometry. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1680–1687. [Google Scholar]
- Schindler, G.; Dellaert, F. Atlanta world: An expectation maximization framework for simultaneous low-level edge grouping and camera calibration in complex man-made environments. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Washington, DC, USA, 27 June–2 July 2004; p. I. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Seq. | OKVIS | VINS-Mono | PL-VIO | ORB-SLAM3 | Proposed | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Trans. | Rot. | Trans. | Rot. | Trans. | Rot. | Trans. | Rot. | Trans. | Rot. | ||
| MH_01_easy | 0.432 | 0.108 | 0.171 | 0.038 | 0.152 | 0.032 | 0.034 | 0.032 | 0.106 | 0.032 | |
| MH_02_easy | 0.339 | 0.109 | 0.146 | 0.069 | 0.172 | 0.062 | 0.073 | 0.021 | 0.100 | 0.029 | |
| MH_03_medium | 0.241 | 0.083 | 0.285 | 0.039 | 0.339 | 0.050 | 0.040 | 0.028 | 0.135 | 0.030 | |
| MH_04_difficult | 0.360 | 0.084 | 0.345 | 0.038 | 0.332 | 0.041 | 0.096 | 0.023 | 0.143 | 0.023 | |
| MH_05_difficult | 0.472 | 0.073 | 0.296 | 0.019 | 0.278 | 0.026 | 0.050 | 0.014 | 0.218 | 0.023 | |
| V1_01_easy | 0.100 | 0.160 | 0.083 | 0.150 | 0.084 | 0.149 | 0.039 | 0.136 | 0.052 | 0.126 | |
| V1_02_medium | 0.167 | 0.128 | 0.121 | 0.081 | 0.202 | 0.115 | 0.015 | 0.049 | 0.107 | 0.091 | |
| V1_03_difficult | 0.227 | 0.146 | 0.178 | 0.174 | 0.191 | 0.132 | 0.041 | 0.056 | 0.105 | 0.071 | |
| V2_01_easy | 0.113 | 0.087 | 0.092 | 0.051 | 0.099 | 0.051 | 0.061 | 0.017 | 0.043 | 0.023 | |
| V2_02_medium | 0.185 | 0.121 | 0.175 | 0.112 | 0.152 | 0.066 | 0.028 | 0.022 | 0.170 | 0.100 | |
| V2_03_difficult | 0.276 | 0.125 | 0.231 | 0.066 | 0.265 | 0.079 | 0.067 | 0.017 | 0.161 | 0.026 | |
| Seq. | OKVIS | VINS-Mono | PL-VIO | ORB-SLAM3 | Proposed | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Trans. | Rot. | Trans. | Rot. | Trans. | Rot. | Trans. | Rot. | Trans. | Rot. | ||
| corridor1 | 0.565 | 2.403 | 0.591 | 1.831 | 1.206 | 1.748 | 0.316 | 0.315 | 0.133 | 0.166 | |
| corridor2 | 0.434 | 1.045 | 0.951 | 0.640 | 1.716 | 0.502 | 0.017 | 0.023 | 0.291 | 0.366 | |
| corridor3 | 0.457 | 1.063 | 1.334 | 0.555 | 1.465 | 0.498 | 0.278 | 0.084 | 0.258 | 0.150 | |
| corridor4 | 0.234 | 0.557 | 0.310 | 0.455 | 0.234 | 0.391 | 0.255 | 0.130 | 0.117 | 0.131 | |
| corridor5 | 0.387 | 0.545 | 0.723 | 0.235 | 0.682 | 0.268 | 0.071 | 0.084 | 0.151 | 0.092 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Chen, L.; Wei, P.; Lu, X. Visual-Inertial Odometry of Smartphone under Manhattan World. Remote Sens. 2020, 12, 3818. https://doi.org/10.3390/rs12223818
Wang Y, Chen L, Wei P, Lu X. Visual-Inertial Odometry of Smartphone under Manhattan World. Remote Sensing. 2020; 12(22):3818. https://doi.org/10.3390/rs12223818
Chicago/Turabian StyleWang, YuAn, Liang Chen, Peng Wei, and XiangChen Lu. 2020. "Visual-Inertial Odometry of Smartphone under Manhattan World" Remote Sensing 12, no. 22: 3818. https://doi.org/10.3390/rs12223818
APA StyleWang, Y., Chen, L., Wei, P., & Lu, X. (2020). Visual-Inertial Odometry of Smartphone under Manhattan World. Remote Sensing, 12(22), 3818. https://doi.org/10.3390/rs12223818