Technical Solution Discussion for Key Challenges of Operational Convolutional Neural Network-Based Building-Damage Assessment from Satellite Imagery: Perspective from Benchmark xBD Dataset

 , ,
, ,  and
and
Abstract
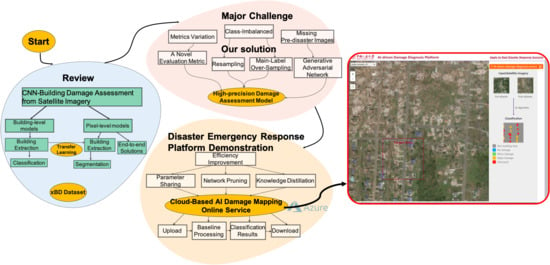
1. Introduction
1.1. Motivation and Problem Statement
1.2. xBD Benchmark Dataset
1.3. The Structure of the Article
2. State-of-The-Art Review of Convolutional Neural Network-Based Building-Damage Assessment from Satellite Imagery
2.1. The Approaches of Damage Assessment at Building Level
2.2. The Approaches of Damage Assessment at Pixel Level
2.2.1. The Idea of Pixel-Level Approach: Semantic Segmentation
2.2.2. Innovative Solution: End-to-End Network
2.2.3. Innovative Solution: Integration of Transfer Learning Ideas
3. Major Challenges and Our Solutions
3.1. Challenge 1: How Do We Objectively Compare the Accuracy of Various Methods in Case Evaluation Metrics Are Not Uniform?
3.1.1. Solution 1: Conversion Between Two Metrics
3.1.2. Solution 2: Introduce a Novel Evaluation Metric
3.2. Challenge 2: How Do We Conduct Building-Damage Assessment in the Absence of Pre-Disaster Satellite Imagery?
3.2.1. Solution 1: Development of Building-Damage Assessment Methods Based on Only Post-Disaster Satellite Imagery
3.2.2. Solution 2: Use of Generative Adversarial Network to Generate a Pre-disaster Image
3.3. Challenge 3: How Do We Train a Robust Prediction Model Based on Disaster Data with Unbalanced Categories?
3.3.1. Solution 1: Data Resampling Strategies
- Main-Label Over-Sampling (MLOS)
- Discrimination After Cropping (DAC)
- Dilation of Area with Minority (DAM)
- Synthetic Minority Over-Sampling Technique (SMOTE)
3.3.2. Solution 2: Cost-Sensitive Re-Weighting Schemes
3.3.3. Rethinking: Continuous Label Problems about Data
3.4. Challenge 4: Which Technical Solutions Should Be Adopted to Improve the Efficiency of Building-Damage Evaluation Models?
3.4.1. Solution 1: Feature-Map Subtraction
3.4.2. Solution 2: Parameter Sharing
3.4.3. Solution 3: Knowledge Distillation
| Algorithm 1: Knowledge Distillation for Satellite Image Segmentation |
 |
3.4.4. Solution 4: Network Pruning
4. Results: Disaster Emergency Response Platform Building Challenges: Cloud-Based AI Damage-Mapping Online Service
4.1. Challenge 1: How to Continuously Give State-of-the-Art Prediction?
4.1.1. Splitting the Whole Procedure into Several Minima Execute Units
4.1.2. Making the Prediction Unit a Highly Changeable Box
4.2. Challenge 2: How to Meet the Need for Both the Visitors and the Real Demand Side?
4.2.1. Demo Image and Friendly Interface Design for the Visitors
4.2.2. Image Upload and Download API for the Real Demand Side
4.3. Challenge 3: How to Solve the Concurrent Access Problem?
4.3.1. Control the GPU Usage: Release Resources and Maintain a Thread Queue
- Considering the limited GPU resources of our device, we have adopted some optimization upon the Pytorch framework. First, we minimize the unnecessary intermediate variables in our code. As an instance, using “a = 2a” instead of creating a new variable with “b = 2a” will save quite a lot of space. Moreover, releasing the image memory promptly and deleting the used image storage helps a lot in reducing the burden of GPU.
- To handle frequent and multiple requests, we maintain a task queue collecting tasks in chronological order. Instead of performing tasks serially, we turn on a multithreaded structure. Once a single request is started in a thread, the user will get a notification. Meanwhile, the web will frequently make inquiries about the server until the classified images are output.
4.3.2. Improve the Waiting Experience: Asynchronous Rendering and Polling by the JavaScript
4.4. Challenge 4: How to Design an AI Platform Easy for Data Scientists to Iterate the Algorithm?
4.4.1. Platform Structure Based on the Technology Stacks of the Python Family
4.4.2. Pipeline Design Specifically for Building-Damage Detection
5. Conclusions
- Different metrics for the building-level and pixel-level put an obstacle in comparison. This paper puts forward the conversion method and a novel metric for comparison of the performance of different levels.
- The UAV is the most efficient device to get images after disasters, although it only captures the post-disaster image. This paper gives two solutions—one is naïve, and the other needs to use the GAN trained on the dataset with both pre- and post-disaster images.
- Disasters that can explicitly destroy a building happen infrequently, and severely destroyed buildings are relatively rare in the current open-source benchmark. This paper gives solutions from the perspective of both the data processing and the loss function.
- Real-time rescue demands faster inference of the damage situation with less computing resource in the industry environment. Feature-map subtraction, parameter sharing, knowledge distillation, and network pruning are discussed and studied by cases.
6. Discussions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| IoU | Intersection over Union |
| MLOS | Main-Label Over-Sampling |
| DAC | Discrimination After Cropping |
| DAM | Dilation of11Area with Minority |
| SMOTE | Synthetic Minority Over-Sampling Technique |
| ADDP | AI-driven Damage Diagnose Platform |
| GCN | Graph Convolutional Network |
| ABCD | AIST Building Change Detection |
| FPN | Feature Pyramid Networks |
| R-CNN | Regions with CNN features |
| GAN | Generative Adversarial Network |
| CNN | Convolution Neural Network |
| RUS | Random Under-sampling |
References
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 20 2009; pp. 248–255. [Google Scholar]
- Koshimura, S.; Shuto, N. Response to the 2011 great East Japan earthquake and tsunami disaster. Philos. Trans. Math. Phys. Eng. Sci. 2015, 373, 20140373. [Google Scholar] [CrossRef]
- Mas, E.; Bricker, J.; Kure, S.; Adriano, B.; Yi, C.; Suppasri, A.; Koshimura, S. Field survey report and satellite image interpretation of the 2013 Super Typhoon Haiyan in the Philippines. Nat. Hazards Earth Syst. Sci. 2015, 15, 805–816. [Google Scholar] [CrossRef]
- Suppasri, A.; Koshimura, S.; Matsuoka, M.; Gokon, H.; Kamthonkiat, D. Remote Sensing: Application of remote sensing for tsunami disaster. Remote Sens. Planet Earth 2012, 143–168. [Google Scholar] [CrossRef]
- Gokon, H.; Koshimura, S. Mapping of building damage of the 2011 Tohoku earthquake tsunami in Miyagi Prefecture. Coast. Eng. J. 2012, 54, 1250006. [Google Scholar] [CrossRef]
- Mori, N.; Takahashi, T. Nationwide post event survey and analysis of the 2011 Tohoku earthquake tsunami. Coast. Eng. J. 2012, 54, 1250001-1–1250001-27. [Google Scholar] [CrossRef]
- Gupta, R.; Hosfelt, R.; Sajeev, S.; Patel, N.; Goodman, B.; Doshi, J.; Heim, E.; Choset, H.; Gaston, M. xbd: A dataset for assessing building damage from satellite imagery. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Bromley, J.; Guyon, I.; LeCun, Y.; Säckinger, E.; Shah, R. Signature verification using a “siamese” time delay neural network. In Proceedings of the Advances in Neural Information Processing Systems 6, Denver, CO, USA, 29 November–2 December 1993; pp. 737–744. [Google Scholar]
- Wheeler, B.J.; Karimi, H.A. Deep Learning-Enabled Semantic Inference of Individual Building Damage Magnitude from Satellite Images. Algorithms 2020, 13, 195. [Google Scholar] [CrossRef]
- Trevino, R.; Sawal, V.; Yang, K. GIN & TONIC: Graph Infused Networks with Topological Neurons for Inference & Classification. 2020. Available online: http://cs230.stanford.edu/projects_winter_2020/reports/32621646.pdf (accessed on 20 November 2020).
- Fujita, A.; Sakurada, K.; Imaizumi, T.; Ito, R.; Hikosaka, S.; Nakamura, R. Damage detection from aerial images via convolutional neural networks. In Proceedings of the Fifteenth IAPR International Conference on Machine Vision Applications (MVA), Nagoya, Japan, 8–12 May 2017; pp. 8–12. [Google Scholar]
- Xu, J.Z.; Lu, W.; Li, Z.; Khaitan, P.; Zaytseva, V. Building damage detection in satellite imagery using convolutional neural networks. 2020. Available online: https://arxiv.org/pdf/1910.06444.pdf (accessed on 16 November 2020).
- Huang, F.; Chen, L.; Yin, K.; Huang, J.; Gui, L. Object-oriented change detection and damage assessment using high-resolution remote sensing images, Tangjiao Landslide, Three Gorges Reservoir, China. Environ. Earth Sci. 2018, 77, 183. [Google Scholar] [CrossRef]
- Nex, F.C.; Duarte, D.; Tonolo, F.G.; Kerle, N. Structural Building Damage Detection with Deep Learning: Assessment of a State-of-the-Art CNN in Operational Conditions. Remote Sens. 2019, 11, 2765. [Google Scholar] [CrossRef]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Caye Daudt, R.; Le Saux, B.; Boulch, A.; Gousseau, Y. Guided Anisotropic Diffusion and Iterative Learning for Weakly Supervised Change Detection. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Nia, K.R.; Mori, G. Building Damage Assessment Using Deep Learning and Ground-Level Image Data. In Proceedings of the 2017 14th Conference on Computer and Robot Vision (CRV), Edmonton, AB, Canada, 16–19 May 2017; pp. 95–102. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Humanitarian Data Exchange. Available online: https://data.humdata.org (accessed on 1 September 2019).
- Cooner, A.J.; Shao, Y.; Campbell, J.B. Detection of Urban Damage Using Remote Sensing and Machine Learning Algorithms: Revisiting the 2010 Haiti Earthquake. Remote Sens. 2016, 8, 868. [Google Scholar] [CrossRef]
- Ji, M.; Liu, L.; Buchroithner, M. Identifying Collapsed Buildings Using Post-Earthquake Satellite Imagery and Convolutional Neural Networks: A Case Study of the 2010 Haiti Earthquake. Remote Sens. 2018, 10, 1689. [Google Scholar] [CrossRef]
- Hao, H.; Baireddy, S.; Bartusiak, E.R.; Konz, L.; LaTourette, K.; Gribbons, M.; Chan, M.; Comer, M.L.; Delp, E.J. An Attention-Based System for Damage Assessment Using Satellite Imagery. arXiv 2020, arXiv:2004.06643. [Google Scholar]
- Weber, E.; Kané, H. Building Disaster Damage Assessment in Satellite Imagery with Multi-Temporal Fusion. arXiv 2020, arXiv:2004.05525. [Google Scholar]
- Shao, L.; Zhu, F.; Li, X. Transfer Learning for Visual Categorization: A Survey. IEEE Trans. Neural Netw. Learn. Syst. 2015, 26, 1019–1034. [Google Scholar] [CrossRef]
- Gupta, R.; Shah, M. RescueNet: Joint Building Segmentation and Damage Assessment from Satellite Imagery. arXiv 2020, arXiv:2004.07312. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 1–15. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2014), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 13–16 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, ON, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Ali, A.; Shamsuddin, S.M.; Ralescu, A.L. Classification with class imbalance problem: A review. Int. J. Adv. Soft Comput. Its Appl. 2015, 7, 176–204. [Google Scholar]
- Leevy, J.L.; Khoshgoftaar, T.M.; Bauder, R.A.; Seliya, N. A survey on addressing high-class imbalance in big data. J. Big Data 2018, 5, 42. [Google Scholar] [CrossRef]
- Chawla, N.V.; Lazarevic, A.; Hall, L.O.; Bowyer, K.W. SMOTEBoost: Improving Prediction of the Minority Class in Boosting. In Knowledge Discovery in Databases: PKDD 2003; Springer: Berlin/Heidelberg, Germany, 2003; pp. 107–119. [Google Scholar]
- Cao, P.; Zhao, D.; Zaiane, O. An Optimized Cost-Sensitive SVM for Imbalanced Data Learning. In Advances in Knowledge Discovery and Data Mining; Springer: Berlin/Heidelberg, Germany, 2013; pp. 280–292. [Google Scholar]
- Hinton, G.E.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. Comput. Sci. 2015, 14, 38–39. [Google Scholar]
- Liu, Y.; Cao, J.; Li, B.; Yuan, C.; Hu, W.; Li, Y.; Duan, Y. Knowledge distillation via instance relationship graph. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 7096–7104. [Google Scholar]
- Zhao, B.; Tang, S.; Chen, D.; Bilen, H.; Zhao, R. Continual Representation Learning for Biometric Identification. arXiv 2020, arXiv:2006.04455. [Google Scholar]
- Li, Q.; Jin, S.; Yan, J. Mimicking Very Efficient Network for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Liu, Y.; Chen, K.; Liu, C.; Qin, Z.; Luo, Z.; Wang, J. Structured knowledge distillation for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 2604–2613. [Google Scholar]
- Geng, K.; Sun, X.; Yan, Z.; Diao, W.; Gao, X. Topological Space Knowledge Distillation for Compact Road Extraction in Optical Remote Sensing Images. Remote Sens. 2020, 12, 3157. [Google Scholar] [CrossRef]
- Liu, Z.; Sun, M.; Zhou, T.; Huang, G.; Darrell, T. Rethinking the Value of Network Pruning. In Proceedings of the International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metrics | Definition |
|---|---|
| Mean score at IoU = 0.50:0.05:0.95 | |
| score at IoU = 0.50 (normal object-level metrics) | |
| score at IoU = 0.75 (strict metric) |
| Non-Building | No Damage | Minor Damage | Major Damage | Destroyed |
|---|---|---|---|---|
| 96.97% | 2.33% | 0.24% | 0.27% | 0.18% |
| Methods | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Naïve PPM-SSNet | 90.81 | 94.12 | 92.43 | 15.75 | 32.01 | 21.12 | 30.23 | 37.54 | 33.43 | 72.41 | 31.23 | 43.61 | 36.01 |
| + Data Resampling | 96.04 | 67.93 | 79.51 | 20.69 | 73.64 | 32.28 | 58.28 | 70.12 | 63.69 | 80.49 | 74.17 | 77.25 | 55.41 |
| 0.75,0.75,0.75 + Data Resampling + Weighted Loss | 90.64 | 89.07 | 89.85 | 35.51 | 49.50 | 41.36 | 65.80 | 64.93 | 65.36 | 87.08 | 57.89 | 69.55 | 61.55 |
| Models | IoU for Building Localization | Overall F1 Score for xView2 Challenge |
|---|---|---|
| Teacher (xView2 1st place model) | 0.84 | 0.79 |
| Student (about half parameters of Teacher) | 0.82 | 0.72 |
| API | Request Type | Usage | Parameter | Result |
|---|---|---|---|---|
| get-sub-image | post | cut and get the region | id (image number) x (left-top x coordinate) y (left-top y coordinate) | id pre_cut (cut pre- image), post_cut (cut post- image) |
| get-cls-image | get | get the classification result | id | img (classification result) |
| upload | post | upload image | file type (pre- or post-damage), fileName (filename uploaded) | fileName (uploaded file name) |
| download | get | download image | fileName | file |
| cls-for-upload | post | managing pre-and-post images | preName, postName | fileName (the result file name) |
| check download result | get | check if the manage process is done | fileName | is Finish (false/true) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Su, J.; Bai, Y.; Wang, X.; Lu, D.; Zhao, B.; Yang, H.; Mas, E.; Koshimura, S. Technical Solution Discussion for Key Challenges of Operational Convolutional Neural Network-Based Building-Damage Assessment from Satellite Imagery: Perspective from Benchmark xBD Dataset. Remote Sens. 2020, 12, 3808. https://doi.org/10.3390/rs12223808
Su J, Bai Y, Wang X, Lu D, Zhao B, Yang H, Mas E, Koshimura S. Technical Solution Discussion for Key Challenges of Operational Convolutional Neural Network-Based Building-Damage Assessment from Satellite Imagery: Perspective from Benchmark xBD Dataset. Remote Sensing. 2020; 12(22):3808. https://doi.org/10.3390/rs12223808
Chicago/Turabian StyleSu, Jinhua, Yanbing Bai, Xingrui Wang, Dong Lu, Bo Zhao, Hanfang Yang, Erick Mas, and Shunichi Koshimura. 2020. "Technical Solution Discussion for Key Challenges of Operational Convolutional Neural Network-Based Building-Damage Assessment from Satellite Imagery: Perspective from Benchmark xBD Dataset" Remote Sensing 12, no. 22: 3808. https://doi.org/10.3390/rs12223808
APA StyleSu, J., Bai, Y., Wang, X., Lu, D., Zhao, B., Yang, H., Mas, E., & Koshimura, S. (2020). Technical Solution Discussion for Key Challenges of Operational Convolutional Neural Network-Based Building-Damage Assessment from Satellite Imagery: Perspective from Benchmark xBD Dataset. Remote Sensing, 12(22), 3808. https://doi.org/10.3390/rs12223808