Flash Flood Susceptibility Modeling Using New Approaches of Hybrid and Ensemble Tree-Based Machine Learning Algorithms
 ,
,  , ,
, ,  ,
,  and
and 
Abstract
1. Introduction
2. Materials and Methods
2.1. Description of the Study Area
2.2. Methodology
- I.
- A total of 256 flash flood susceptibility points were recognized based on field visits and information of the Department of Regional Water of Markazi Province.
- II.
- Thirteen flash flood susceptibility conditioning factors were chosen for modeling FSM.
- III.
- The multi-collinearity analysis was done among the flash flood susceptibility conditioning factors using the variance inflation factor (VIF) and tolerance (TOL) techniques.
- IV.
- Random forest model hybrid with two algorithmic regularizations and parallel for flash flood modeling was used.
- V.
- Extremely randomized trees such as an ensemble of a decision tree were used for flash flood modeling.
- VI.
- Flash flood susceptibility maps were prepared using BRT, RF, parallel and regularization methods on random forest and ensemble for extremely randomized trees (ERT).
- VII.
- Different flash flood susceptibility models’ performances were validated through statistical indices along with receiver operating characteristic (ROC)-AUC analysis.
2.3. Dataset Preparation for Spatial Modeling
2.4. Multi-Collinearity Analysis
2.5. Machine Learning Method Used in Flash Flood Susceptibility Modeling
2.5.1. Boosted Regression Tree (BRT)
2.5.2. Random Forest (RF)
2.5.3. Parallel Random Forest (PRF)
2.5.4. Regularized Random Forest (RRF)
2.5.5. Extremely Randomized Trees (ERT)
2.6. Methods of Validation and Accuracy Assessment
3. Results
3.1. Multi-Collinearity Analysis
3.2. Flash Flood Susceptibility Modeling
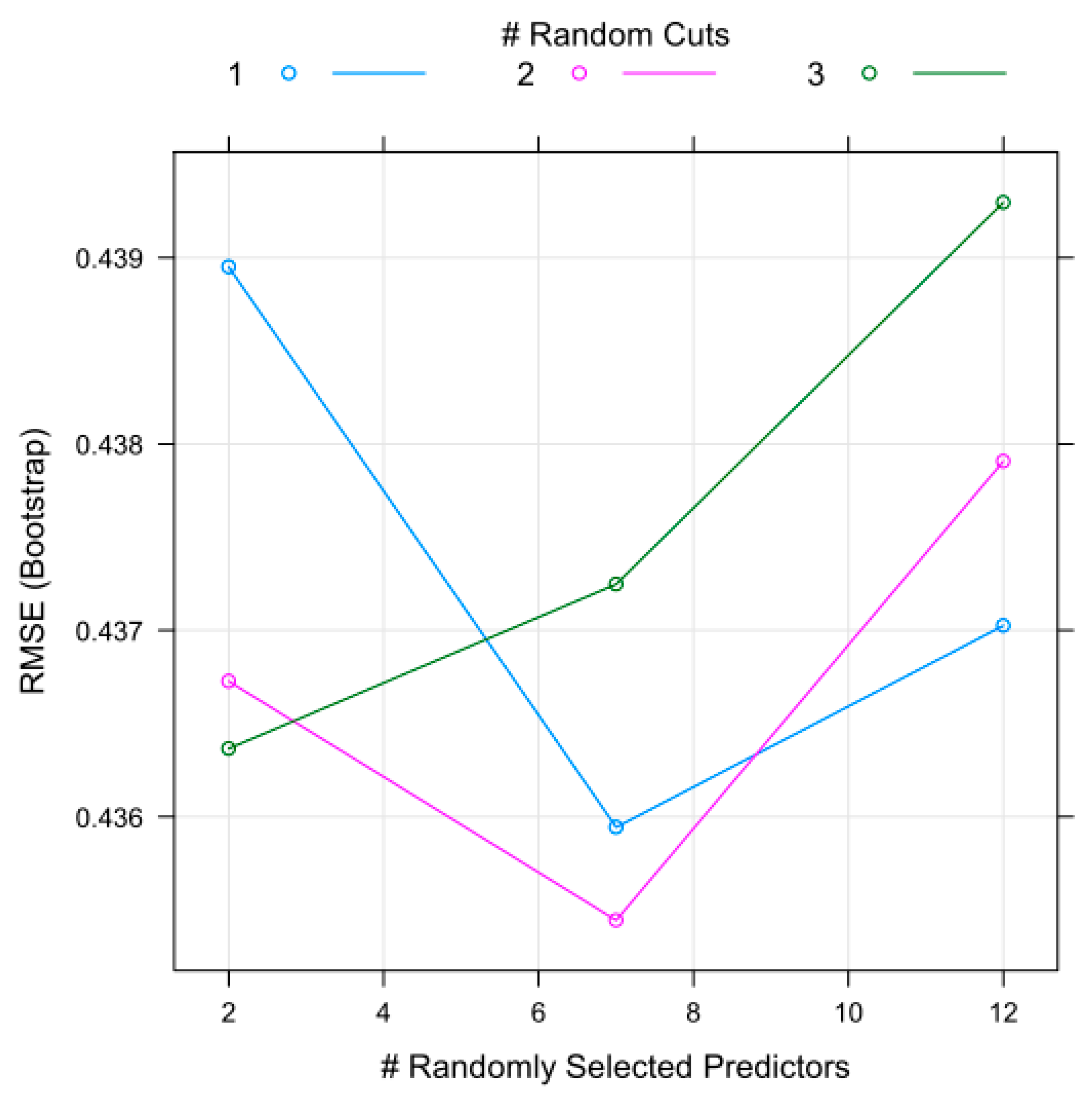
3.3. Evaluation of Parameters
3.4. Validation of the Models
3.5. Importance Value
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Shen, G.; Hwang, S.N. Spatial—Temporal snapshots of global natural disaster impacts Revealed from EM-DAT for 1900–2015. Geomat. Nat. Hazards Risk 2019, 10, 912–934. [Google Scholar] [CrossRef]
- Chapi, K.; Singh, V.P.; Shirzadi, A.; Shahabi, H.; Bui, D.T.; Pham, B.T.; Khosravi, K. A novel hybrid artificial intelligence approach for flood susceptibility assessment. Environ. Model. Softw. 2017, 95, 229–245. [Google Scholar] [CrossRef]
- Roy, P.; Pal, S.C.; Chakrabortty, R.; Chowdhuri, I.; Malik, S.; Das, B. Threats of climate and land use change on future flood susceptibility. J. Clean. Prod. 2020, 272, 122757. [Google Scholar] [CrossRef]
- Khosravi, K.; Pourghasemi, H.R.; Chapi, K.; Bahri, M. Flash flood susceptibility analysis and its mapping using different bivariate models in Iran: A comparison between Shannon’s entropy, statistical index, and weighting factor models. Environ. Monit. Assess. 2016, 188, 656. [Google Scholar] [CrossRef] [PubMed]
- Yariyan, P.; Janizadeh, S.; Van Phong, T.; Nguyen, H.D.; Costache, R.; Van Le, H.; Pham, B.T.; Pradhan, B.; Tiefenbacher, J.P. Improvement of Best First Decision Trees Using Bagging and Dagging Ensembles for Flood Probability Mapping. Water Resour. Manag. 2020, 34, 3037–3053. [Google Scholar] [CrossRef]
- Janizadeh, S.; Avand, M.; Jaafari, A.; Phong, T.V.; Bayat, M.; Ahmadisharaf, E.; Prakash, I.; Pham, B.T.; Lee, S. Prediction Success of Machine Learning Methods for Flash Flood Susceptibility Mapping in the Tafresh Watershed, Iran. Sustainability 2019, 11, 5426. [Google Scholar] [CrossRef]
- Ferreira, S.; Hamilton, K.; Vincent, J.R. Nature, Socioeconomics and Adaptation to Natural Disasters: New Evidence from Floods; World Bank Group: Washington, DC, USA, 2011. [Google Scholar]
- Chowdary, V.M.; Chakraborthy, D.; Jeyaram, A.; Murthy, Y.V.N.K.; Sharma, J.R.; Dadhwal, V.K. Multi-criteria decision making approach for watershed prioritization using analytic hierarchy process technique and GIS. Water Resour. Manag. 2013, 27, 3555–3571. [Google Scholar] [CrossRef]
- Pham, B.T.; Avand, M.; Janizadeh, S.; Phong, T.V.; Al-Ansari, N.; Ho, L.S.; Das, S.; Le, H.V.; Amini, A.; Bozchaloei, S.K.; et al. GIS Based Hybrid Computational Approaches for Flash Flood Susceptibility Assessment. Water 2020, 12, 683. [Google Scholar] [CrossRef]
- Dano, U.L.; Balogun, A.-L.; Matori, A.-N.; Wan Yusouf, K.; Abubakar, I.R.; Said Mohamed, M.A.; Aina, Y.A.; Pradhan, B. Flood susceptibility mapping using GIS-based analytic network process: A case study of Perlis, Malaysia. Water 2019, 11, 615. [Google Scholar] [CrossRef]
- Khan, A.N. Analysis of flood causes and associated socio-economic damages in the Hindukush region. Nat. Hazards 2011, 59, 1239. [Google Scholar]
- Khosravi, K.; Nohani, E.; Maroufinia, E.; Pourghasemi, H.R. A GIS-based flood susceptibility assessment and its mapping in Iran: A comparison between frequency ratio and weights-of-evidence bivariate statistical models with multi-criteria decision-making technique. Nat. Hazards 2016, 83, 947–987. [Google Scholar] [CrossRef]
- Das, B.; Pal, S.C.; Malik, S. Assessment of flood hazard in a riverine tract between Damodar and Dwarkeswar River, Hugli District, West Bengal, India. Spat. Inf. Res. 2018, 26, 91–101. [Google Scholar] [CrossRef]
- Ali, S.A.; Khatun, R.; Ahmad, A.; Ahmad, S.N. Application of GIS-based analytic hierarchy process and frequency ratio model to flood vulnerable mapping and risk area estimation at Sundarban region, India. Model. Earth Syst. Environ. 2019, 5, 1083–1102. [Google Scholar] [CrossRef]
- Ali, S.A.; Parvin, F.; Pham, Q.B.; Vojtek, M.; Vojteková, J.; Costache, R.; Linh, N.T.T.; Nguyen, H.Q.; Ahmad, A.; Ghorbani, M.A. GIS-based comparative assessment of flood susceptibility mapping using hybrid multi-criteria decision-making approach, na{\″\i}ve Bayes tree, bivariate statistics and logistic regression: A case of Topl’a basin, Slovakia. Ecol. Indic. 2020, 117, 106620. [Google Scholar] [CrossRef]
- Bui, D.T.; Tsangaratos, P.; Ngo, P.-T.T.; Pham, T.D.; Pham, B.T. Flash flood susceptibility modeling using an optimized fuzzy rule based feature selection technique and tree based ensemble methods. Sci. Total Environ. 2019, 668, 1038–1054. [Google Scholar] [CrossRef] [PubMed]
- Brunner, G.W. HEC-RAS River Analysis System. Hydraulic Reference Manual. Version 1.0.; Hydrologic Engineering Center: Davis, CA, USA, 1995. [Google Scholar]
- Malik, S.; Pal, S.C. Application of 2D numerical simulation for rating curve development and inundation area mapping: A case study of monsoon dominated Dwarkeswar River. Int. J. River Basin Manag. 2020, 18, 1–11. [Google Scholar] [CrossRef]
- Zhou, Q.; Mikkelsen, P.S.; Halsnæs, K.; Arnbjerg-Nielsen, K. Framework for economic pluvial flood risk assessment considering climate change effects and adaptation benefits. J. Hydrol. 2012, 414, 539–549. [Google Scholar] [CrossRef]
- Biswajeet, P.; Mardiana, S. Flood hazrad assessment for cloud prone rainy areas in a typical tropical environment. Disaster Adv. 2009, 2, 7–15. [Google Scholar]
- Costache, R.; Bui, D.T. Identification of areas prone to flash-flood phenomena using multiple-criteria decision-making, bivariate statistics, machine learning and their ensembles. Sci. Total Environ. 2020, 712, 136492. [Google Scholar] [CrossRef]
- Chowdhuri, I.; Pal, S.C.; Chakrabortty, R. Flood susceptibility mapping by ensemble evidential belief function and binomial logistic regression model on river basin of eastern India. Adv. Sp. Res. 2020, 65, 1466–1489. [Google Scholar] [CrossRef]
- Shafizadeh-Moghadam, H.; Valavi, R.; Shahabi, H.; Chapi, K.; Shirzadi, A. Novel forecasting approaches using combination of machine learning and statistical models for flood susceptibility mapping. J. Environ. Manag. 2018, 217, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Choubin, B.; Moradi, E.; Golshan, M.; Adamowski, J.; Sajedi-Hosseini, F.; Mosavi, A. An ensemble prediction of flood susceptibility using multivariate discriminant analysis, classification and regression trees, and support vector machines. Sci. Total Environ. 2019, 651, 2087–2096. [Google Scholar] [CrossRef]
- Hosseini, F.S.; Choubin, B.; Mosavi, A.; Nabipour, N.; Shamshirband, S.; Darabi, H.; Haghighi, A.T. Flash-flood hazard assessment using ensembles and Bayesian-based machine learning models: Application of the simulated annealing feature selection method. Sci. Total Environ. 2020, 711, 135161. [Google Scholar] [CrossRef] [PubMed]
- Dodangeh, E.; Choubin, B.; Eigdir, A.N.; Nabipour, N.; Panahi, M.; Shamshirband, S.; Mosavi, A. Integrated machine learning methods with resampling algorithms for flood susceptibility prediction. Sci. Total Environ. 2020, 705, 135983. [Google Scholar] [CrossRef]
- Fan, J.; Wang, X.; Wu, L.; Zhou, H.; Zhang, F.; Yu, X.; Lu, X.; Xiang, Y. Comparison of Support Vector Machine and Extreme Gradient Boosting for predicting daily global solar radiation using temperature and precipitation in humid subtropical climates: A case study in China. Energy Convers. Manag. 2018, 164, 102–111. [Google Scholar] [CrossRef]
- Fernández, D.S.; Lutz, M.A. Urban flood hazard zoning in Tucumán Province, Argentina, using GIS and multicriteria decision analysis. Eng. Geol. 2010, 111, 90–98. [Google Scholar] [CrossRef]
- Shafapour Tehrany, M.; Shabani, F.; Neamah Jebur, M.; Hong, H.; Chen, W.; Xie, X. GIS-based spatial prediction of flood prone areas using standalone frequency ratio, logistic regression, weight of evidence and their ensemble techniques. Geomat. Nat. Hazards Risk 2017, 8, 1538–1561. [Google Scholar] [CrossRef]
- Moore, I.D.; Wilson, J.P. Length-slope factors for the Revised Universal Soil Loss Equation: Simplified method of estimation. J. Soil Water Conserv. 1992, 47, 423–428. [Google Scholar]
- Mandal, S.; Mondal, S. Machine Learning Models and Spatial Distribution of Landslide Susceptibility. In Geoinformatics and Modelling of Landslide Susceptibility and Risk; Springer: Berlin/Heidelberg, Germany, 2019; pp. 165–175. [Google Scholar]
- Sörensen, R.; Zinko, U.; Seibert, J. On the Calculation of the Topographic Wetness Index: Evaluation of Different Methods Based on Field Observations. Hydrol. Earth Syst. Sci. 2006, 10, 101–112. [Google Scholar]
- Arabameri, A.; Rezaei, K.; Pourghasemi, H.R.; Lee, S.; Yamani, M. GIS-based gully erosion susceptibility mapping: A comparison among three data-driven models and AHP knowledge-based technique. Environ. Earth Sci. 2018, 77, 1–22. [Google Scholar] [CrossRef]
- Wang, G.; Chen, X.; Chen, W. Spatial Prediction of Landslide Susceptibility Based on GIS and Discriminant Functions. ISPRS Int. J. Geo-Inf. 2020, 9, 144. [Google Scholar] [CrossRef]
- Kutner, M.H.; Nachtsheim, C.J.; Neter, J.; Li, W. Applied Linear Statistical Models; McGraw-Hill Irwin: New York, NY, USA, 2005; Volume 5. [Google Scholar]
- Roy, P.; Chakrabortty, R.; Chowdhuri, I.; Malik, S.; Das, B.; Pal, S.C. Development of Different Machine Learning Ensemble Classifier for Gully Erosion Susceptibility in Gandheswari Watershed of West Bengal, India. In Machine Learning for Intelligent Decision Science; Springer: Berlin/Heidelberg, Germany, 2020; pp. 1–26. [Google Scholar]
- Robinzonov, N. Advances in Boosting of Temporal and Spatial Models, Lmu; University of Zurich: Zürich, Switzerland, 2013. [Google Scholar]
- Aertsen, W.; Kint, V.; Van Orshoven, J.; Muys, B. Evaluation of modelling techniques for forest site productivity prediction in contrasting ecoregions using stochastic multicriteria acceptability analysis (SMAA). Environ. Model. Softw. 2011, 26, 929–937. [Google Scholar] [CrossRef]
- Rahmati, O.; Naghibi, S.A.; Shahabi, H.; Bui, D.T.; Pradhan, B.; Azareh, A.; Rafiei-Sardooi, E.; Samani, A.N.; Melesse, A.M. Groundwater spring potential modelling: Comprising the capability and robustness of three different modeling approaches. J. Hydrol. 2018, 565, 248–261. [Google Scholar] [CrossRef]
- Naghibi, S.A.; Pourghasemi, H.R.; Abbaspour, K. A comparison between ten advanced and soft computing models for groundwater qanat potential assessment in Iran using R and GIS. Theor. Appl. Climatol. 2018, 131, 967–984. [Google Scholar] [CrossRef]
- Kuhn, M.; Johnson, K. A Short Tour of the Predictive Modeling Process. In Applied Predictive Modeling; Springer: Berlin/Heidelberg, Germany, 2013; pp. 19–26. [Google Scholar]
- Leathwick, J.R.; Elith, J.; Francis, M.P.; Hastie, T.; Taylor, P. Variation in demersal fish species richness in the oceans surrounding New Zealand: An analysis using boosted regression trees. Mar. Ecol. Prog. Ser. 2006, 321, 267–281. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests Machine Learning; Springer: Berlin/Heidelberg, Germany, 2001; Volume 45, pp. 5–32. [Google Scholar]
- Goetz, J.N.; Brenning, A.; Petschko, H.; Leopold, P. Evaluating machine learning and statistical prediction techniques for landslide susceptibility modeling. Comput. Geosci. 2015, 81, 1–11. [Google Scholar] [CrossRef]
- Catani, F.; Lagomarsino, D.; Segoni, S.; Tofani, V. Landslide susceptibility estimation by random forests technique: Sensitivity and scaling issues. Nat. Hazards Earth Syst. Sci. 2013, 13, 2815. [Google Scholar] [CrossRef]
- Olden, J.D.; Kennard, M.J.; Pusey, B.J. Species invasions and the changing biogeography of Australian freshwater fishes. Glob. Ecol. Biogeogr. 2008, 17, 25–37. [Google Scholar] [CrossRef]
- Yang, R.-M.; Zhang, G.-L.; Liu, F.; Lu, Y.-Y.; Yang, F.; Yang, F.; Yang, M.; Zhao, Y.-G.; Li, D.-C. Comparison of boosted regression tree and random forest models for mapping topsoil organic carbon concentration in an alpine ecosystem. Ecol. Indic. 2016, 60, 870–878. [Google Scholar] [CrossRef]
- Masetic, Z.; Subasi, A. Congestive heart failure detection using random forest classifier. Comput. Methods Programs Biomed. 2016, 130, 54–64. [Google Scholar] [CrossRef] [PubMed]
- Natarajan, V.A.; Kumari, N.S. Wind Power Forecasting Using Parallel Random Forest Algorithm. In Soft Computing for Problem Solving; Springer: Berlin/Heidelberg, Germany, 2020; pp. 209–224. [Google Scholar]
- Kullarni, V.Y.; Sinha, P.K. Random Forest classifier: A survey and future research directions. Int. J. Adv. Comput. 2013, 36, 1144–1156. [Google Scholar]
- Yang, X.; Wu, W.; Yan, B.; Wang, H.; Zhou, K.; Liu, K. Infrared image super-resolution with parallel random Forest. Int. J. Parallel Program. 2018, 46, 838–858. [Google Scholar] [CrossRef]
- Deng, H.; Runger, G. Feature selection via regularized trees. In Proceedings of the the 2012 International Joint Conference on Neural Networks (IJCNN), Brisbane, Australia, 10–15 June 2012; pp. 1–8. [Google Scholar]
- Tuv, E.; Borisov, A.; Runger, G.; Torkkola, K. Feature selection with ensembles, artificial variables, and redundancy elimination. J. Mach. Learn. Res. 2009, 10, 1341–1366. [Google Scholar]
- Deng, H.; Runger, G. Gene selection with guided regularized random forest. Pattern Recognit. 2013, 46, 3483–3489. [Google Scholar] [CrossRef]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef]
- Yarveicy, H.; Ghiasi, M.M. Modeling of gas hydrate phase equilibria: Extremely randomized trees and LSSVM approaches. J. Mol. Liq. 2017, 243, 533–541. [Google Scholar] [CrossRef]
- Goetz, M.; Weber, C.; Bloecher, J.; Stieltjes, B.; Meinzer, H.-P.; Maier-Hein, K. Extremely randomized trees based brain tumor segmentation. Proc. BRATS Chall. MICCAI 2014, 4, 6–11. [Google Scholar]
- Paul, A.; Furmanchuk, A.; Liao, W.; Choudhary, A.; Agrawal, A. Property prediction of organic donor molecules for photovoltaic applications using extremely randomized trees. Mol. Inform. 2019, 38, 1900038. [Google Scholar] [CrossRef]
- Khosravi, K.; Shahabi, H.; Pham, B.T.; Adamowski, J.; Shirzadi, A.; Pradhan, B.; Dou, J.; Ly, H.-B.; Gróf, G.; Ho, H.L.; et al. A comparative assessment of flood susceptibility modeling using Multi-Criteria Decision-Making Analysis and Machine Learning Methods. J. Hydrol. 2019, 573, 311–323. [Google Scholar] [CrossRef]
- Pham, B.T.; Prakash, I. Evaluation and comparison of LogitBoost Ensemble, Fisher’s Linear Discriminant Analysis, logistic regression and support vector machines methods for landslide susceptibility mapping. Geocarto Int. 2019, 34, 316–333. [Google Scholar] [CrossRef]
- Zhou, X.; Pang, J.; Liang, G. Image classification for malware detection using extremely randomized trees. In Proceedings of the 2017 11th IEEE International Conference on Anti-Counterfeiting, Security, and Identification (ASID), Guangzhou, China, 27–29 October 2017; pp. 54–59. [Google Scholar]
- Eslami, E.; Salman, A.K.; Choi, Y.; Sayeed, A.; Lops, Y. A data ensemble approach for real-time air quality forecasting using extremely randomized trees and deep neural networks. Neural Comput. Appl. 2019, 32, 7563–7579. [Google Scholar] [CrossRef]
- Zafari, A.; Zurita-Milla, R.; Izquierdo-Verdiguier, E. Land cover classification using extremely randomized trees: A kernel perspective. IEEE Geosci. Remote Sens. Lett. 2019, 17, 1702–1706. [Google Scholar] [CrossRef]
- Heddam, S.; Ptak, M.; Zhu, S. Modelling of Daily Lake Surface Water Temperature from Air Temperature: Extremely Randomized Trees (ERT) versus Air2Water, MARS, M5Tree, RF and MLPNN. J. Hydrol. 2020, 588, 125130. [Google Scholar] [CrossRef]
- Hong, H.; Panahi, M.; Shirzadi, A.; Ma, T.; Liu, J.; Zhu, A.-X.; Chen, W.; Kougias, I.; Kazakis, N. Flood susceptibility assessment in Hengfeng area coupling adaptive neuro-fuzzy inference system with genetic algorithm and differential evolution. Sci. Total Environ. 2018, 621, 1124–1141. [Google Scholar] [CrossRef]
- Hong, H.; Tsangaratos, P.; Ilia, I.; Liu, J.; Zhu, A.-X.; Chen, W. Application of fuzzy weight of evidence and data mining techniques in construction of flood susceptibility map of Poyang County, China. Sci. Total Environ. 2018, 625, 575–588. [Google Scholar] [CrossRef] [PubMed]
- Arabameri, A.; Saha, S.; Chen, W.; Roy, J.; Pradhan, B.; Bui, D.T. Flash flood susceptibility modelling using functional tree and hybrid ensemble techniques. J. Hydrol. 2020, 587, 125007. [Google Scholar] [CrossRef]
- Predick, K.I.; Turner, M.G. Landscape configuration and flood frequency influence invasive shrubs in floodplain forests of the Wisconsin River (USA). J. Ecol. 2008, 96, 91–102. [Google Scholar] [CrossRef]
- Darabi, H.; Choubin, B.; Rahmati, O.; Haghighi, A.T.; Pradhan, B.; Kløve, B. Urban flood risk mapping using the GARP and QUEST models: A comparative study of machine learning techniques. J. Hydrol. 2019, 569, 142–154. [Google Scholar] [CrossRef]
- Tehrany, M.S.; Pradhan, B.; Mansor, S.; Ahmad, N. Flood susceptibility assessment using GIS-based support vector machine model with different kernel types. Catena 2015, 125, 91–101. [Google Scholar] [CrossRef]
- Costache, R.; Pravalie, R.; Mitof, I.; Popescu, C. Flood vulnerability assessment in the low sector of Saratel Catchment. Case study: Joseni Village. Carpathian J. Earth Environ. Sci. 2015, 10, 161–169. [Google Scholar]
- Termeh, S.V.R.; Kornejady, A.; Pourghasemi, H.R.; Keesstra, S. Flood susceptibility mapping using novel ensembles of adaptive neuro fuzzy inference system and metaheuristic algorithms. Sci. Total Environ. 2018, 615, 438–451. [Google Scholar] [CrossRef] [PubMed]
- Costache, R. Flash-flood Potential Index mapping using weights of evidence, decision Trees models and their novel hybrid integration. Stoch. Environ. Res. Risk Assess. 2019, 33, 1375–1402. [Google Scholar] [CrossRef]
- Al-Juaidi, A.E.M.; Nassar, A.M.; Al-Juaidi, O.E.M. Evaluation of flood susceptibility mapping using logistic regression and GIS conditioning factors. Arab. J. Geosci. 2018, 11, 765. [Google Scholar] [CrossRef]
- Tehrany, M.S.; Kumar, L.; Shabani, F. A novel GIS-based ensemble technique for flood susceptibility mapping using evidential belief function and support vector machine: Brisbane, Australia. PeerJ 2019, 7, e7653. [Google Scholar] [CrossRef]
- Hooijer, A.; Klijn, F.; Pedroli, G.B.M.; Van Os, A.G. Towards sustainable flood risk management in the Rhine and Meuse river basins: Synopsis of the findings of IRMA-SPONGE. River Res. Appl. 2004, 20, 343–357. [Google Scholar] [CrossRef]
- Kourgialas, N.N.; Karatzas, G.P. Flood management and a GIS modelling method to assess flood-hazard areas—A case study. Hydrol. Sci. J. J. Sci. Hydrol. 2011, 56, 212–225. [Google Scholar] [CrossRef]
- Sanyal, J.; Lu, X.X. Application of remote sensing in flood management with special reference to monsoon Asia: A review. Nat. Hazards 2004, 33, 283–301. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variables | VIF | Tolerance |
|---|---|---|
| Altitude | 2.07 | 0.48 |
| Slope | 2.44 | 0.41 |
| Aspect | 1.07 | 0.93 |
| Plan curvature | 1.57 | 0.64 |
| Profile curvature | 1.44 | 0.69 |
| Distance from river | 1.46 | 0.68 |
| Distance from road | 1.38 | 0.72 |
| Rainfall | 1.47 | 0.68 |
| Land use | 1.54 | 0.65 |
| Lithology | 2.03 | 0.49 |
| Soil type | 1.49 | 0.67 |
| SPI | 1.28 | 0.78 |
| TWI | 1.67 | 0.60 |
| Models | Area | Susceptibility Class | ||||
|---|---|---|---|---|---|---|
| Very Low | Low | Moderate | High | Very High | ||
| BRT | Km2 | 100.7 | 404.28 | 442.73 | 683.91 | 425.13 |
| % | 4.90 | 19.66 | 21.52 | 33.25 | 20.67 | |
| RF | Km2 | 618.49 | 388.53 | 440.21 | 384.4 | 225.12 |
| % | 30.07 | 18.99 | 21.56 | 18.79 | 10.95 | |
| PRF | Km2 | 518.23 | 440.96 | 461.12 | 396.72 | 239.72 |
| % | 25.20 | 21.44 | 22.42 | 19.29 | 11.65 | |
| RRF | Km2 | 608.89 | 359.57 | 466.56 | 373.75 | 247.98 |
| % | 29.60 | 17.48 | 22.68 | 18.18 | 12.06 | |
| ERT | Km2 | 651.54 | 431.14 | 391.51 | 332.72 | 249.84 |
| % | 31.68 | 20.96 | 19.03 | 16.18 | 12.15 | |
| Models | Stage | Parameters | ||||
|---|---|---|---|---|---|---|
| Sensitivity | Specificity | PPV | NPV | AUC | ||
| BRT | Train | 0.86 | 0.62 | 0.69 | 0.81 | 0.83 |
| Validation | 0.83 | 0.52 | 0.60 | 0.78 | 0.75 | |
| RF | Train | 0.84 | 0.78 | 0.82 | 0.80 | 0.89 |
| Validation | 0.83 | 0.57 | 0.63 | 0.79 | 0.78 | |
| PRF | Train | 0.93 | 0.72 | 0.80 | 0.89 | 0.88 |
| Validation | 0.82 | 0.59 | 0.64 | 0.79 | 0.79 | |
| RRF | Train | 0.77 | 0.80 | 0.82 | 0.74 | 0.87 |
| Validation | 0.82 | 0.61 | 0.65 | 0.79 | 0.80 | |
| ERT | Train | 0.88 | 0.86 | 0.88 | 0.86 | 0.91 |
| Validation | 0.81 | 0.66 | 0.67 | 0.79 | 0.82 | |
| Variables | BRT | RF | PRF | RRF | ERT |
|---|---|---|---|---|---|
| Altitude | 87.36 | 81.89 | 79.53 | 36.95 | 87.36 |
| Slope | 86.22 | 26.95 | 26.93 | 36.15 | 86.22 |
| Aspect | 18.21 | 12.32 | 8.11 | 2.34 | 14.79 |
| Plan curvature | 22.37 | 0 | 5.72 | 0 | 22.37 |
| Profile curvature | 29.52 | 9.11 | 1.63 | 5.32 | 29.52 |
| Distance from river | 100 | 75.03 | 74.81 | 94.21 | 100 |
| Distance from road | 51.28 | 39.13 | 23.51 | 24.75 | 51.28 |
| Rainfall | 94.97 | 100 | 100 | 100 | 94.97 |
| Land use | 14.88 | 10.74 | 0 | 5.42 | 14.88 |
| Lithology | 63.22 | 40.72 | 37.62 | 47.21 | 63.22 |
| Soil type | 14.41 | 14.64 | 2.93 | 8.34 | 14.41 |
| SPI | 0 | 36.91 | 30.75 | 12.9 | 0 |
| TWI | 69.09 | 25.92 | 17.63 | 34.34 | 69.09 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Band, S.S.; Janizadeh, S.; Chandra Pal, S.; Saha, A.; Chakrabortty, R.; Melesse, A.M.; Mosavi, A. Flash Flood Susceptibility Modeling Using New Approaches of Hybrid and Ensemble Tree-Based Machine Learning Algorithms. Remote Sens. 2020, 12, 3568. https://doi.org/10.3390/rs12213568
Band SS, Janizadeh S, Chandra Pal S, Saha A, Chakrabortty R, Melesse AM, Mosavi A. Flash Flood Susceptibility Modeling Using New Approaches of Hybrid and Ensemble Tree-Based Machine Learning Algorithms. Remote Sensing. 2020; 12(21):3568. https://doi.org/10.3390/rs12213568
Chicago/Turabian StyleBand, Shahab S., Saeid Janizadeh, Subodh Chandra Pal, Asish Saha, Rabin Chakrabortty, Assefa M. Melesse, and Amirhosein Mosavi. 2020. "Flash Flood Susceptibility Modeling Using New Approaches of Hybrid and Ensemble Tree-Based Machine Learning Algorithms" Remote Sensing 12, no. 21: 3568. https://doi.org/10.3390/rs12213568
APA StyleBand, S. S., Janizadeh, S., Chandra Pal, S., Saha, A., Chakrabortty, R., Melesse, A. M., & Mosavi, A. (2020). Flash Flood Susceptibility Modeling Using New Approaches of Hybrid and Ensemble Tree-Based Machine Learning Algorithms. Remote Sensing, 12(21), 3568. https://doi.org/10.3390/rs12213568