1. Introduction
Hyperspectral image (HSI) collects as many as hundreds of spectral bands of a scene, and has been widely used in the area of remote sensing. Taking advantage of its abundant spectral profiles, HSIs have been applied to earth monitoring [
1], mineral exploration [
2,
3] and agriculture characterizing [
4,
5], to name a few. Given that the spectral and spatial information in HSI can provide discriminative features in identifying material characteristics, utilizing this information to classify HSIs has become an active topic in the hyperspectral community.
HSI classification often identifies the category of the material at each pixel instead of the full image, where the high-dimensional spectral vector is supposed to provide sufficient characteristics and can be easily distinguished by classifiers. However, due to the limited number of labeled training samples, some approaches are largely affected by the
curse of dimensionality [
6], which may lead to a drop in classification accuracy. The trade-off between classification accuracy and number of dimensions has been known as the Hughes effect [
7]. In order to reduce the Hughes effect when classifying HSIs, dimensionality reduction operation is often utilized to simplify the original high-dimensional data. Most HSI classification methods focus on transforming the high-dimensional HSI samples into lower ones, while maintaining the intrinsic and most discriminative features. This kind of dimensionality reduction method can be called feature extraction. The goal of feature extraction is to derive an effective representation of the original HSI in a certain feature space, and reduce redundant information within HSIs.
During the early research on HSI classification, some methods directly exploit spectral features. For example, PCA [
8], DBN [
9], and SAE [
10] simply exploit the linear feature representation of HSIs in the spectral domain. Considering the limited representation ability of linear models, some nonlinear methods are presented to extract spectral features. Li et al. [
11] used pixel-pair features extracted by the convolutional neural network (CNN) to explore the correlation between hyperspectral pixels in spectral domain. Hu et al. [
12] utilized 1D-CNN to convolve the high dimensional vector of each pixel to form a low-dimensional feature for HSI classification. Spectral feature-extraction-based methods have a small computational cost, but the accuracy is limited, for they do not explore the neighboring information.
Recently, more approaches have begun to extract features with both spectral and spatial information. Since deep-learning-based methods are convenient tools to exploit spatial correlation while extracting features, spectral–spatial feature-based classification is becoming increasingly popular. Zhang et al. [
13] fused the features extracted by multi-scale kernels to obtain features from different spatial neighbors. Zhang et al. [
14] learned a mapping between two patches to find the hidden spectral–spatial feature. 3D-CNN [
15,
16] directly extracted spectral and spatial features simultaneously. A recent trend is to incorporate attention mechanism [
17,
18,
19] during deep feature extraction, as the importance of different spectral bands varies. Although these methods have achieved promising results, they rely on high-dimensional HSIs and collecting them is costly.
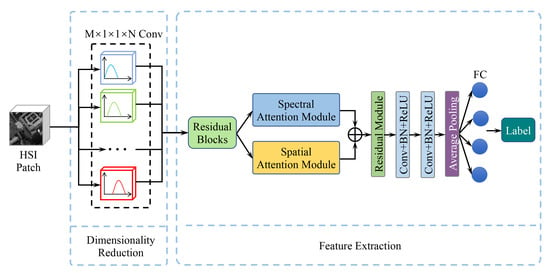
To solve these HSI classification problems, we present a CNN architecture, i.e., the camera spectral response network (CSR-Net), which can achieve the optimal camera spectral response (CSR) functions for HSI classification. More importantly, the learned CSR can be directly used to reduce data dimensions when capturing images as well as guarantee the classification accuracy. In CSR-Net, we design a specialized convolutional layer to simulate the capturing process of cameras, and the optimal CSR is learned in this layer under smooth and non-negative constraints. The learned CSR can be regarded as a practical dimensionality reduction method for HSIs, and the obtained low-dimensional features are further classified by an attention-based feature extractor which draws global context to enhance feature extraction ability.
The main contributions of this work are summarized as follows:
The physical process of CSR is modeled via a specific convolutional layer and the optimal CSR is learned automatically along with the entire classification model, which can reduce the dimensionality of spectral data in the image capturing process;
In CSR-subspace, the spectral attention module and spatial attention module are further designed to effectively exploit the spectral–spatial correlation and enhance feature extraction ability.
The remainder of this paper is organized as follows.
Section 2 reviews previous studies relevant to this paper.
Section 3 describes the proposed CSR-Net in detail.
Section 4 shows the experimental results and some analysis on our work. Finally,
Section 5 concludes this paper and points out future work.
2. Related Work
In this section, we review the most relevant studies on CSR optimization, traditional dimensionality reduction methods, and state-of-the-art deep feature extraction methods for HSI classification.
2.1. Learned Spectral Filters
When capturing the same scene using different cameras, the obtained image may look different in color due to different CSRs, and the amount of information contained in these images is also different. Some previous works [
20,
21,
22] have investigated the influence of the CSR on several HSI tasks. Arad et al. [
20] estimated HSIs from a single RGB image, and found out that the quality of recovered images was sensitive to the camera sensitivity filters. Fu et al. [
21] modeled optimal CSR selection as a convolutional layer and recovered the HSI from a single RGB image under the selected best filters. In HSI super-resolution, the study in [
22] used CNN to select the proper CSR, or directly learned a CSR function under some physical restrictions to improve the results.
These methods have proved that CSR optimization is a possible solution for improving the accuracy of different hyperspectral tasks. Furthermore, we observe that, different from these methods, which aim to improve accuracy, CSR optimization can be practically beneficial for HSI classification, since the capturing process of cameras is akin to the dimensionality reduction in HSIs. Therefore, we attempt to learn the optimal CSR that can retain the most significant features for HSI classification, and ease the process of data acquisition as well.
2.2. Traditional Dimensionality Reduction for HSI
The high spectral resolution of HSI implies abundant spectral information within HSI data, but it may also cause Hughes effect and severe overfitting for HSI classifiers. Therefore, it is significant to find out a proper dimensionality reduction method to map high-dimensional HSI samples into lower ones. An effective dimensionality reduction method is supposed to eliminate the redundant information of HSI, avoid the curse of dimensionality, and maintain most discriminative information of the original HSI using a small number of feature channels.
Previous works usually use traditional linear machine-learning methods to learn the mapping between the original images and the corresponding feature maps. Licciardi et al. [
23] used principal component analysis (PCA) to learn the subspace of HSI data by minimizing data variation. Independent component analysis (ICA) [
24] separated each subcomponent by maximizing the statistical independence. Local linear embedding (LLE) [
25] encoded the high-dimensional spectral vectors by a low-dimensional mapping to reduce redundancy among the pixels. Nonparametric-weighted feature extraction (NWFE) [
26] defined nonparametric scatter matrices by setting greater weights near the decision boundary. Linear discriminative analysis (LDA)-based methods [
27] explored the best subspace which maximized the interclass distance and minimized the intraclass distance simultaneously in a supervised manner.
Different from most dimensionality reduction methods, which have strict hand-crafted parameters, our CSR-Net uses a simple convolution kernel to reduce dimensions, which simulates the image-sensing process, and the parameters of our method are automatically learned along with the entire framework.
2.3. Deep Feature Extraction for HSI
Recently, deep-learning-based methods have been introduced to HSI classification, and are a breakthrough technology for this area. As we know, deep learning has strong abilities regarding representation, and learns complex features without specific model assumption. Besides, as the parameters can be automatically obtained through back propagation, deep-learning-based methods are easy to train without hand-crafted parameters. Mou et al. [
28] regarded HSIs as continuous spectral bands, and used recurrent neural networks (RNN) for per-pixel HSI classification. Zhu et al. [
29] used a conditional generative adversarial network with an auxiliary multi-class classifier to identify HSIs. Some works [
30,
31] followed the idea of capsule networks [
32] and employed neural capsules to replace neurons and learned spectral–spatial features. He et al. [
33] modified BERT architecture [
34] that was originally used in the natural language processing field, and proposed HSI-BERT for HSI classification.
As CNN is well-known and widely applied in image classification, a large number of approaches designed CNN-based architectures to extract features of HSIs. Some methods [
15,
35] simply employed 3D-CNN, for 3D kernels were able to slide in both the spatial domain and long spectral bands. Besides, some famous CNN architectures for RGB image classification have been used for HSI classification, e.g., ResNet [
36,
37], DenseNet [
38], and PyramidNet [
39]. Inspired by the attention mechanism, Mou et al. [
17] added an attention module in front of feature-extraction networks to recalibrate the input, thus important bands were emphasized. Haut et al. [
18] designed a two-branch network to learn features and a weighted mask when extracting features. Fusion-based methods were another way to increase accuracy; they fused features from different sources [
40,
41,
42], different neighbors [
13], or different hierarchies [
14,
43].
In our method, we also take advantage of CNN to learn feature representations of the scene. We use residual networks as a backbone network, followed by two attention modules, i.e., the spectral attention module and the spatial attention module. The spectral attention module is responsible for learning the correlation among spectral bands, and the spatial attention module considers the interdependencies between any two spatial pixels. Therefore, our model can effectively exploit both spectral and spatial features.
3. The Proposed Method
In this section, we first formulate the problem and introduce the motivation for our proposed method. Then, we describe our CSR optimization network and the feature extractor we use. Finally, learning details are provided. The overall framework of the proposed CSR-Net is illustrated in
Figure 1.
3.1. Formulation and Motivation
Assuming that a hyperspectral camera is able to capture spectral images with
M channels and
N pixels, the obtained HSI
H at the spatial position
n for the
m-th band can be described as
where
denotes the CSR function along wavelength
for the
m-th band.
is the radiance of scene point at position
n and wavelength
, which is the compound of spectral reflectance and the illumination condition. Instead of using the continuous spectral bands, it is usually discretely described along spectra in practice, i.e.,
, where
and
B is the number of spectral bands. Thus, Equation (
1) can be rewritten as
and it can be simplified in the matrix form as
where
denotes the matrix form of
,
and
represent CSR and scene radiance, respectively. According to Equation (
3), the captured hyperspectral data are determined by two factors, i.e., the CSR function
and the radiance of the scene
.
is consistent for each scene when capturing outdoors or remotely sensed images. Since the spectral distribution of CSR depends on the type of camera, we could choose a proper
to influence the formation of
so as to retain more scene information for HSI classification.
Previous works on HSI recovery from a single RGB image [
20,
21] and HSI super-resolution [
22] inferred that the abundant information of HSIs can be effectively kept in lower-dimensional data by using the optimal CSR. Here, we design a CNN architecture, i.e., CSR-Net, to learn the optimal CSR for the pixel-wise classification of HSI. Using the learned optimal CSR, we can capture images with much lower dimensions and the capturing process becomes convenient. The overview of our CSR-Net is shown in
Figure 1. The CSR optimization layer and attention-based spectral–spatial feature extractor are described in the following sections.
3.2. CSR Optimization for Dimensionality Reduction
Existing CSR optimization methods [
20,
21,
22] have proven that the optimal CSR function significantly improves the results of different HSI tasks. In this work, we aim to find the optimal CSR, which can be used to reduce data dimensions during the image acquisition process, and make the captured low-dimensional data contain sufficient spectral and spatial information for HSI classification tasks.
In the field of HSI classification, most previous works utilize hundreds of spectral bands as the model input. Due to the
curse of dimensionality, dimensional reduction methods are presented to represent the complex HSIs by lower dimensional data. For example, Chen et al. [
44] performed PCA on the input HSI before sending to a CNN, and Zhao et al. [
45] proposed a balanced local discriminant embedding algorithm to extract features from high-dimensional HSIs. All these methods capture the full spectral bands and reduce their dimensions in the post-processing, and the main drawback is that the acquisition process is costly.
In this work, we present an approach to reduce the acquired image dimensions by optimizing CSR functions as well as guaranteeing the classification accuracy. Specifically, we propose a CSR optimization layer to create new CSR functions, so that data with lower dimensions are required and the classification accuracy is also kept in practice.
It can be observed from Equation (
3) that each row of
is performing an exact convolution operation with
along spectral bands. Thus, it can be regarded as a
convolutional layer. As illustrated on the left side of
Figure 1,
can be replaced by
convolution kernels with
M output channels. Letting
denote the corresponding convolutional layer, the process of capturing the
t-th scene can be expressed as
where
is the radiance for the
t-th scene.
Due to the limitation of CSR implementation technology, the designed CSR function should be smooth along the spectral dimension and all parameters in
should be non-negative, for the camera always responds with a non-negative value. Thus,
can be optimized through minimizing the empirical loss under smooth and non-negative constraints
where
denotes the corresponding ground truth for
, and is the low dimensional data under the optimal CSR.
is the predefined parameter, and
G denotes the first derivative matrix for the penalty of non-smoothness.
In the training stage, the CSR optimization layer can simulate the capturing process of cameras and generate low-dimensional data. Then, the low-dimensional data are directly fed to the feature extractor (more details in
Section 3.3). By optimizing the whole model, the optimal CSR for HSI classification is obtained. In the testing stage, thanks to the advanced filter technology, the learned CSR can be realized physically by optical filters. Our model makes it possible to capture fewer image bands in the data acquisition process and reduce the collection expenses to a great extent. As the learned CSR function contains prior knowledge of HSI classification, the captured low-dimensional data are sufficient for HSI classification. To better visualize the effect of our optimal CSR, we utilize a technique called t-SNE [
46] to show the two-dimensional feature distributions from both the full HSI and the dimensionality-reduced image, which is captured under our optimal CSR, as shown in
Figure 2. It can be observed that samples of different categories overlap a lot for the image without dimensionality reduction, while those samples become separable for the reduced image.
3.3. Deep Feature Extraction
To effectively extract the spatial and spectral features of the low dimensional images obtained by the optimal CSR, we employ the spectral attention module and spatial attention module to draw a global context over local features. Applying this architecture to pixel-wise HSI classification can help in the exploitation of spatial and spectral features, because the spectral attention module investigates the interdependencies between any two spectral maps and the spatial attention module exploits the global correlation between spatial pixel pairs.
The overview of the deep feature extraction network is shown on the right of
Figure 1. We utilize an ordinary residual network as a backbone network. Specifically, a convolutional layer is performed to produce feature maps with
P channels, and followed by
K residual modules. In our experiment, we set
and
. Each residual module has three convolutional layers, and the number of input and output channels are set as
, while the depth of the middle layer
, as shown in
Table 1. Thus, the output of the
k-th residual module
can be expressed as
where
denotes the
k-th residual module, and
is the input for the first residual block. After
K residual modules, a feature map
is obtained.
The number of feature channels remains consistent through the residual blocks, and the output features still contain spatial and spectral correlation. The output of the K-th residual block directly flows to two attention modules, i.e., the spectral attention module and spatial attention module, to exploit more global spectral and spatial correlation.
The spectral attention module is illustrated in
Figure 3a. It learns a
attention map
along channels to improve the feature representation of spectral semantics, and the steps for obtaining spectral attention map are described as follows. First, we perform a matrix multiplication of
and the transpose of
to obtain a
tensor, which represents the interdependencies between every two feature channels. Then, a softmax layer is employed to rescale the spectral attention map between 0 and 1, the spectral attention map can be described as
Then, by multiplying
and the original feature
and adding a skip connection, the correlations between every two feature channels are added to the original feature map, and we obtain features with more global semantics
where
is a learnable variable.
Similar to the spectral attention module, as illustrated in
Figure 3b, the spatial attention module obtains an attention map by performing a matrix multiplication of the transpose of
and
and the map size is
. It measures the mutual influence of any two spatial points. Thus, the output of the spatial attention module can be expressed as
where
is learned with the whole architecture.
Then, the features from two attention modules are simply summed up and sent to a feature fusion residual block. We perform downsampling by two convolutional layers with a stride of 2, followed by batch normalization and ReLU [
47], as well as an average pooling layer. Finally, the fused features are fed to a fully connected layer, which is the classifier of our model and outputs a category prediction. Since the final feature map considers both spectral and spatial correlation, it contains more discriminative features that are useful for HSI classification.
3.4. Learning Details
The learning framework mainly consists of two parts, i.e., a CSR optimization layer and a deep feature extractor. The output of the former part is directly fed to the latter part, and both parts are learned simultaneously.
Letting
denote the parameter for our deep feature extraction network, the loss function for classification can be described as
where
and
g represent the predicted label and ground truth label for the
t-th scene, and
H is the cross entropy loss to evaluate the classification accuracy.
When our model is trained, the loss for both the CSR layer and feature extractor are minimized simultaneously
where
is a predefined parameter.
In the experiment, through trial and error, we set
and
in Equations (
5) and (
12). Our network is optimized by the Stochastic Gradient Descent (SGD) [
48] optimizer; the learning rate is initially set to
and finally decays to
. The CSR optimization layer is initialized with random positive weights, and the feature extraction network is initialized by Kaiming initialization [
49].
4. Experimental Results and Analysis
In this section, we first introduce four public HSI datasets used in our experiment and describe our experimental setting. Then, we present some analysis on CSR optimization. Finally, we compare our method with the state-of-the-art dimensionality reduction-based methods and feature-extraction methods.
4.1. Hyperspectral Datasets
In our experiment, four public remote-sensing datasets are used to evaluate all methods, i.e., the Indian Pines dataset, the University of Pavia dataset, the Salinas Valley dataset, and the Kennedy Space Center dataset.
Here, we provide more details of the datasets.
The University of Pavia dataset is captured by the ROSIS sensor in Pavia, Northern Italy. The whole image of the University of Pavia dataset contains
pixels, with 103 spectral bands ranging from 430 to 860 nm, and the spatial resolution is
m per pixel. As some part of this image is corrupted and contains no useful information, these parts are discarded and the size remains
in practice. Each pixel in the University of Pavia dataset is labeled in 9 classes, and the sample numbers for each class is presented in
Table 2.
The Indian Pines dataset is collected in north-western Indiana by the AVRIS sensor, and mainly consists of crops, forests and other natural perennial vegetation. The spatial size of the Indian Pines dataset is
, and it has 224 spectral bands ranging from 400 to 2500 nm. In our experiments, we use the corrected version of the dataset, which removes 24 bands over the region of water absorption. The ground truth is divided into 16 classes, and more details are shown in
Table 3.
The Salinas Valley dataset is also captured by AVRIS sensor, over Salinas Valley, which is the most productive agricultural region in California. The image size is
, with a high spatial resolution of
m per pixel. The total number of spectral bands is 204 after removing 20 water absorption bands. The ground truth of the Salinas Valley dataset contains 16 classes, which is presented in
Table 4.
The Kennedy Space Center dataset is acquired over the Kennedy Space Center, Florida, using the AVIRIS sensor. This dataset has a spatial resolution of 18 m per pixel, and consists of
pixels in total. After removing some noisy and low-SNR bands, 176 bands are used in the experiments. The ground truth consists of 13 classes, and more details are provided in
Table 5.
4.2. Experimental Settings
For all four public remote-sensing datasets, we randomly select
pixels as training samples, and the remained pixels are served as testing samples. For spectral-feature-extraction-based dimensionality reduction methods, the input is each
pixel. As for spatial spectral-feature-extraction-based methods, the spatial size of the input patch infers the amount of neighboring information, and may influence the classification results. Therefore, we investigate the relationship between patch size and classification results. The classification results of our method using the patch size of
,
,
and
on these four datasets are provided in
Table 6, and it can be observed that the accuracy becomes stable when the patch size is larger than
. Considering both the classification accuracy and computational cost, we choose a spatial size of
for all spectral–spatial feature extraction methods.
In our experiments, all methods are evaluated by three widely used metrics, i.e., overall accuracy (OA), average accuracy (AA), and Kappa coefficient. Our experiments are run on an NVIDIA GTX 1080Ti GPU with the deep-learning framework PyTorch.
4.3. CSR Analysis
4.3.1. The Optimal CSR
To empirically analyze how our CSR optimization layer works, we present the spectral power distribution of the learned CSR under 10 spectral bands in
Figure 4a. It can be seen that the combination of all spectra nearly cover the whole spectral bands, and some spectral bands with large weights can be considered as significant bands for HSI classification. This observation can be intuitively understood, since, for each component, capturing information independently could improve the utilization of feature channels. Covering all spectral bands retains the integral information of the scene. Some spectral bands contain more useful information for HSI classification, and these bands turn out to have larger weights. To further explain the optimal CSR, we compute the singular values for our optimal CSR function, and the result is shown in
Figure 4b.
Figure 4b further indicates the low linear correlation in optimal CSR.
4.3.2. The Curse of Dimensionality
It is known that the curse of dimensionality widely exists in HSI classification, and some classifiers show an apparent performance degradation as data dimensions become higher. Thus, it is significant for HSI classification methods to extract lower dimensional data before sending to the classifier. Besides, choosing a balanced number of dimensions is important, because high dimensions may cause the curse of dimensionality and images with too low dimensions (like RGB images) apparently contain less information. Thus, dimensionality reduction is introduced.
Since our CSR-based dimensionality reduction method reduces data dimensions in the spectral domain, we use spectral-feature-based HSI classification methods including SVM and 1D-CNN to verify the effectiveness of our optimal CSR on dimensionality reduction ability. We consider the spectral information for each pixel, and the spatial
tensor is regarded as the model input. The results that use our CSR-based dimensionality reduction are denoted as CSR-SVM and CSR-1DCNN, and the OA and Kappa performances are shown in
Table 7. It can be seen that by using the low dimensional data that are captured by the optimal CSR, both methods achieve better classification results than when using the HSIs with full spectral bands. The reason for this is that the results using entire HSI as input suffer from the
curse of dimensionality, and our CSR-optimization-based dimensionality reduction effectively avoids this phenomenon.
4.4. Compared with the State-of-the-Arts
4.4.1. Comparisons with Dimensionality Reduction Methods
First, we evaluate the effectiveness of our learned optimal CSR, compared with several famous dimensionality reduction methods, including Principle Component Analysis (PCA) [
8], Locally Linear Embedding (LLE) [
25], and Independent Component Analysis (ICA) [
24]. Our dimensionality reduction method based on CSR optimization is denoted as CSR-Opt.
In the compared methods, PCA learns an orthogonal transformation to map the redundant data into a lower dimension space by maximizing the data variance. LLE is a manifold learning-based method that learns the compact representation of the high-dimensional data. ICA separates the data into additive non-Gaussian subcomponents. Our CSR-Opt attempts to find the best CSR by simulating camera sensors that could capture more informative images. To evaluate the dimensionality reduction ability, for CSR-Opt, the outputs of the CSR optimization layer are directly fed to the classifier without passing through the feature-extraction network.
We employ support vector machines (SVM) with RBF kernel to classify the low-dimensional features generated by the aforementioned methods, and the number of reduced dimensions are set from 10 to 50, at the interval of 10, for each method. Experiments are conducted on all four datasets mentioned in
Section 4.1, and the corresponding OA and Kappa coefficients are shown in
Table 8,
Table 9,
Table 10 and
Table 11. To better visualize this, we show the OA performances of all methods along feature numbers (ranging from 1 to 50) in
Figure 5. It can be seen that PCA performs better than other traditional reduction methods. The reason for this is that PCA extracts more discriminative features, which help the classifier to make predictions. Our CSR-Opt shows better classification accuracy, compared to these traditional methods, and this verifies the effectiveness of our CSR optimization method for dimensional reduction. Moreover, from
Table 8,
Table 9,
Table 10 and
Table 11 and
Figure 5, we can observe that the classification accuracy of our dimensionality reduction method improves significantly when we increase the number of dimensions from 1 to 10, while OA results are almost fixed using dimensions greater than 10. Other methods seem to require more dimensions to reach the saturated accuracy, e.g., 20 dimensions for PCA. In addition, our CSR optimization networks are simply implemented by convolutional layers, and the learned CSR can be further physically implemented to capture low-dimensional data in the acquisition process.
4.4.2. Comparisons with Feature Extraction Methods
We compare our feature extraction network with the optimal CSR to several feature extraction methods. The compared methods include Decision Tree (DT) [
50], Logistic Regression (LR) [
51], K-Nearest Neighbors (KNN) [
52], 1D-CNN [
12], 2D-CNN [
44], 3D-CNN [
44], as well as state-of-the-art deep-learning-based methods, i.e., VAD [
18]. VAD proposes a two-branch visual attention-driven architecture to learn the mapping from input images to feature map. From
Figure 5, we can observe that, as the number of dimensions increases from 1 to 10, the overall classification accuracy of our dimensionality reduction method improves remarkably. However, the accuracy becomes stable when the number of dimensions is more than 10, and using more dimensions could not achieve better results. In other words, 10 dimensions have kept enough information for HSI classification. Thus, we set the number of reduced dimensions to 10 for our CSR-Net.
We have conducted experiments on all datasets, and the average accuracy for each class, OA, AA and Kappa coefficients are shown in
Table 12,
Table 13,
Table 14 and
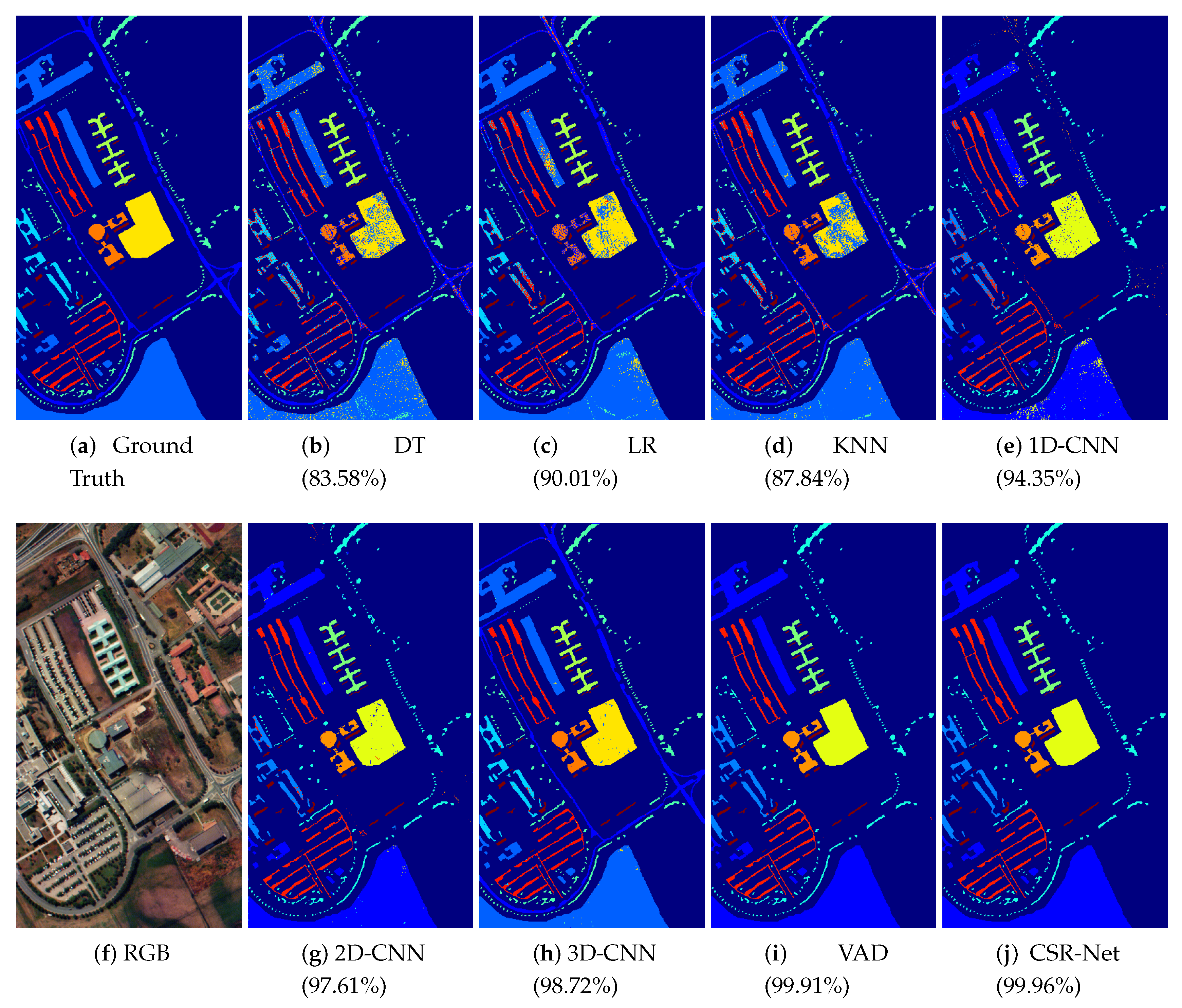
Table 15. It can be observed that traditional feature extraction methods like DT, LR and KNN can only provide limited classification accuracy. Among those deep-learning-based methods, deeper networks (VAD and Ours) tend to perform better than other architectures; this is because VAD and our method designed customized neural networks for hyperspetral images to consider both spatial and spectral correlation. Thus, the spatial and spectral correlation can be better utilized, and leads to better classification results. It can be noticed that our model outperforms all compared methods. Although VAD provides a close performance to our CSR-Net, our model does not need the full bands of HSI like VAD does, which are acquired by advanced and extremely expensive hyperspectral sensors. In the prediction process, instead of densely capturing the spectral information across full wavelength bands using costly devices, we only need to capture the low-dimensional data under the optimal CSR function. Our model can classify HSIs as accurately as other state-of-the-art architectures like VAD, with fewer input image bands.
Figure 6,
Figure 7,
Figure 8 and
Figure 9 show the classification map for all methods on the University of Pavia dataset, the Indian Pines dataset, the Salinas Valley dataset and the Kennedy Space Center dataset, respectively. It can be seen that the visual results of our methods are close to the ground truth, and the neighboring pixels are typically classified in the same class.
5. Conclusions
In this paper, we present a novel HSI classification method named the CSR-Net, which effectively investigates the optimal CSR and makes it possible to reach high classification accuracy with only limited number of image bands. Specifically, we design a special convolutional layer to simulate the camera-capturing process, which can guarantee the classification accuracy and effectively reduce the spectral dimensions of the captured data. Then, the reduced data are sent to spectral attention and spatial attention-based networks to extract the spectral–spatial correlation. Our CSR-Net can use far fewer bands than ordinary HSIs without sacrificing the classification accuracy, which makes it possible to simplify the data acquisition process, and provides insight into the design of simpler sensors to solve remote sensing problems. The experimental results of four HSI datasets verify the effectiveness of our method, and prove that the proposed method for low-dimensional data-capturing is sufficient for keeping enough information for HSI classification.
Our CSR optimization-based dimensionality reduction method sheds light on designing task-specific optical filters for different tasks, and can achieve promising results without capturing the redundant high-dimensional data. Therefore, the proposed optimal CSR-based method can further be applied to various practical situations. For example, in tje medical field, our CSR optimization model can be used for automatically finding the most suitable CSR, which can retain much diagnostic information with a limited number of data dimensions, which is meaningful for disease diagnosis and medical surgery. Applying our model in order to solve more practical problems remains one of our important future works.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





















































