1. Introduction
Blind source separation (BSS) methods, also known as unsupervised unmixing methods in the field of “remote sensing” (Earth observation), aim at estimating a set of unknown source signals, called abundance fractions, and their corresponding endmember spectra, by using only a set of known observed signals (observed pixel spectra), obtained by combining these source signals by means of an almost unknown mixing function. Several algorithms have been proposed in the literature to this end.
These unmixing methods are based on a predefined mixing model. For some cases, depending on the application and/or the content of the used data, it can be linear or nonlinear. The linear model is the one that has most been used in the literature; therefore, we will focus on the methods based on this model which, in addition to its ease of use, is considered in some situations to represent a good approximation of the real environment [
1]. Indeed, this model is adequate when considering large sets of land use presenting a more or less flat landscape (for example agricultural areas) and illuminated in a homogeneous way. Moreover, these methods use the assumptions related to the presence or absence of pure pixels in the considered image, or even according to the supervised nature or not, of the considered method. Based on works reported in [
1,
2], we present a classification of this type of method according to the presence or absence of pure pixels.
For the methods using the hypothesis of presence of pure pixels, the main assumption retained consists in assuming the existence of at least one pure pixel per distinct material contained in the considered image. Therefore, the natural adopted approach consists in finding the purest image pixels that are assumed to be located on the vertices of the simplex containing the observed data. Several strategies have been used to identify, as a first step, endmember spectra. To have a very precise idea of the most mentioned methods in the literature or other existing methods in this category (not cited in this paper), it is possible to consult, for example, with the works in [
1,
2,
3,
4] (and the associated references).
Despite the effectiveness of this type of method in the situation where there exist pure pixels, it does not give good results when applied to images that do not contain pure pixels [
2]. Indeed, the hypothesis on which these methods are based is unfortunately not applicable to some remote sensing images whose spatial resolution is too low, for example, for them to be able to contain pure pixels. In this specific case, other geometrical approaches have been proposed which do not use this assumption. The majority of the methods developed in this category seek to generate virtual endmembers (which are not available in the considered image). In other words, this approach consists in minimizing the volume of the simplex containing the data. The approach adopted by these methods is considered to be a non-convex optimization problem, and is thus more difficult to solve in comparison with the approaches using pure pixels. To do this, here also, each of these methods has its own strategy. As for the previous category, more details concerning these methods, or other methods of the same category (not cited in this paper), are presented in [
1,
2,
3,
4] (and the associated references).
It is also possible to find in the literature other BSS-based approaches, namely, Independent Component Analysis, Non-negative Matrix Factorization, or Sparse Component Analysis. In particular, various BSS methods based on source sparsity may be found in the literature. They were developed for temporal, time-frequency, or even time-scale signal representations (for more details see in [
5,
6,
7,
8], and in particular in [
9,
10,
11]). In [
12], the same types of approaches as in [
9] were applied to multispectral satellite images. As detailed in [
12], the authors divide the observed data into small two-dimensional spatial zones, called “analysis zones”, consisting of adjacent pixels. These zones can be of any shape and are hereafter denoted as
. The main hypothesis underlying these methods is related to the existence, in the considered image, of analysis zones containing only one “active” source, which means that each such analysis zone corresponds to a region of the Earth surface where only one pure material is present. Such a zone is called a “single-source zone” and each of its pixels is stated to be “pure”.
The advantage of such methods is that they require only a low sparsity hypothesis. However, the specific sparsity hypothesis underlying the approaches based on single-source zones is, as mentioned above, unfortunately not applicable to some images, whose spatial resolution is too low for them to contain pure pixels and therefore single-source zones. In this study, pure pixels are therefore ignored, which either means that they do not exist or that single-source zones are detected using, for example, the method proposed in [
12], and the corresponding spectra are thus estimated by the latter method.
The above limitation led us to work with a less restrictive sparsity hypothesis than that presented above, and which consists in assuming the presence of “two-source zones”, i.e., zones containing only two pure materials. This assumption is quite realistic because we do not need pure pixels in the considered image. Furthermore, our unsupervised method estimates the endmember spectra without using a spectral library, which cannot be done for some semisupervised sparse based approaches reported in [
1] (and the associated references).
To this end, we hereafter propose a new unsupervised unmixing approach, called “BiS-Corr”, for Bi-Source Correlation-based BSS method.
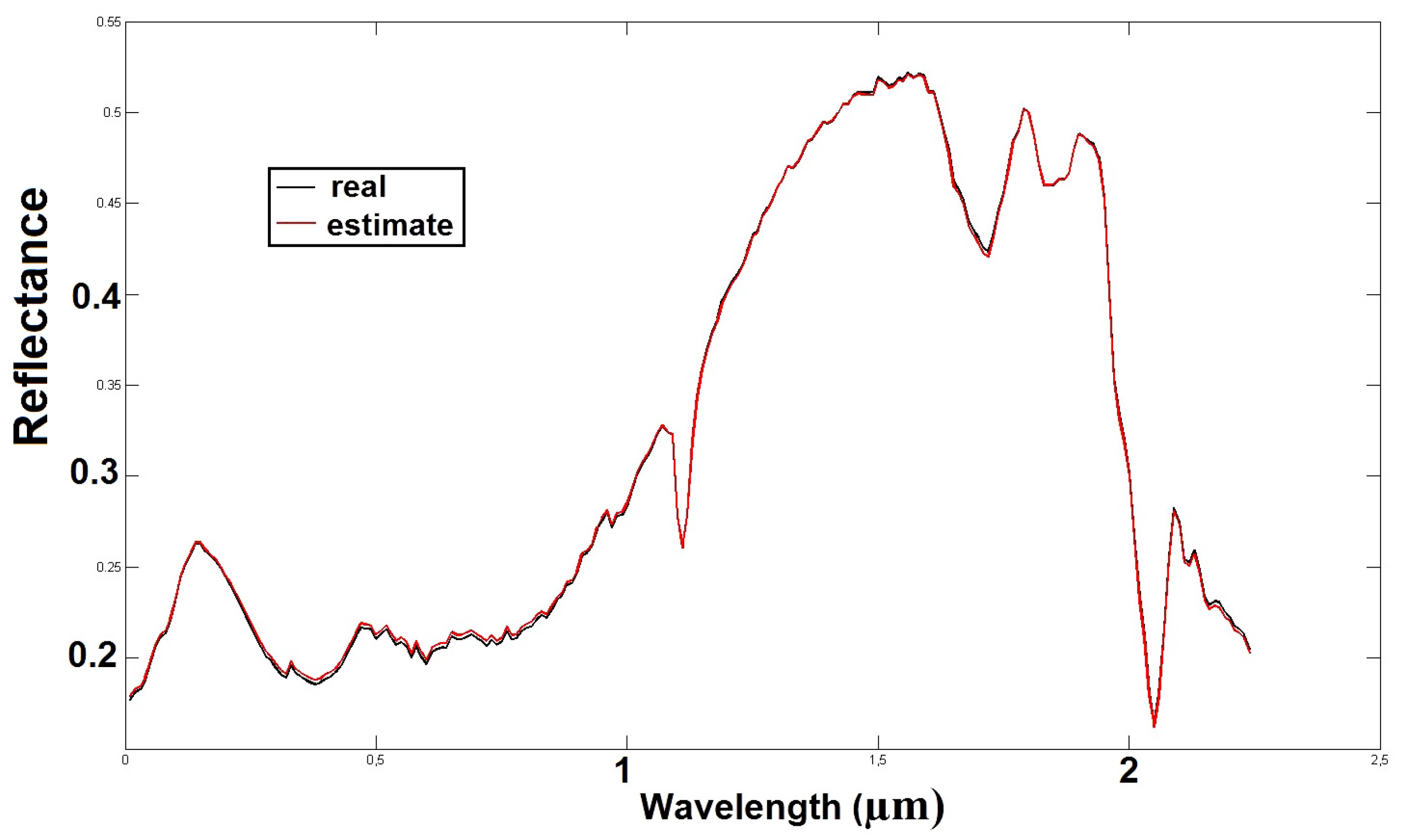
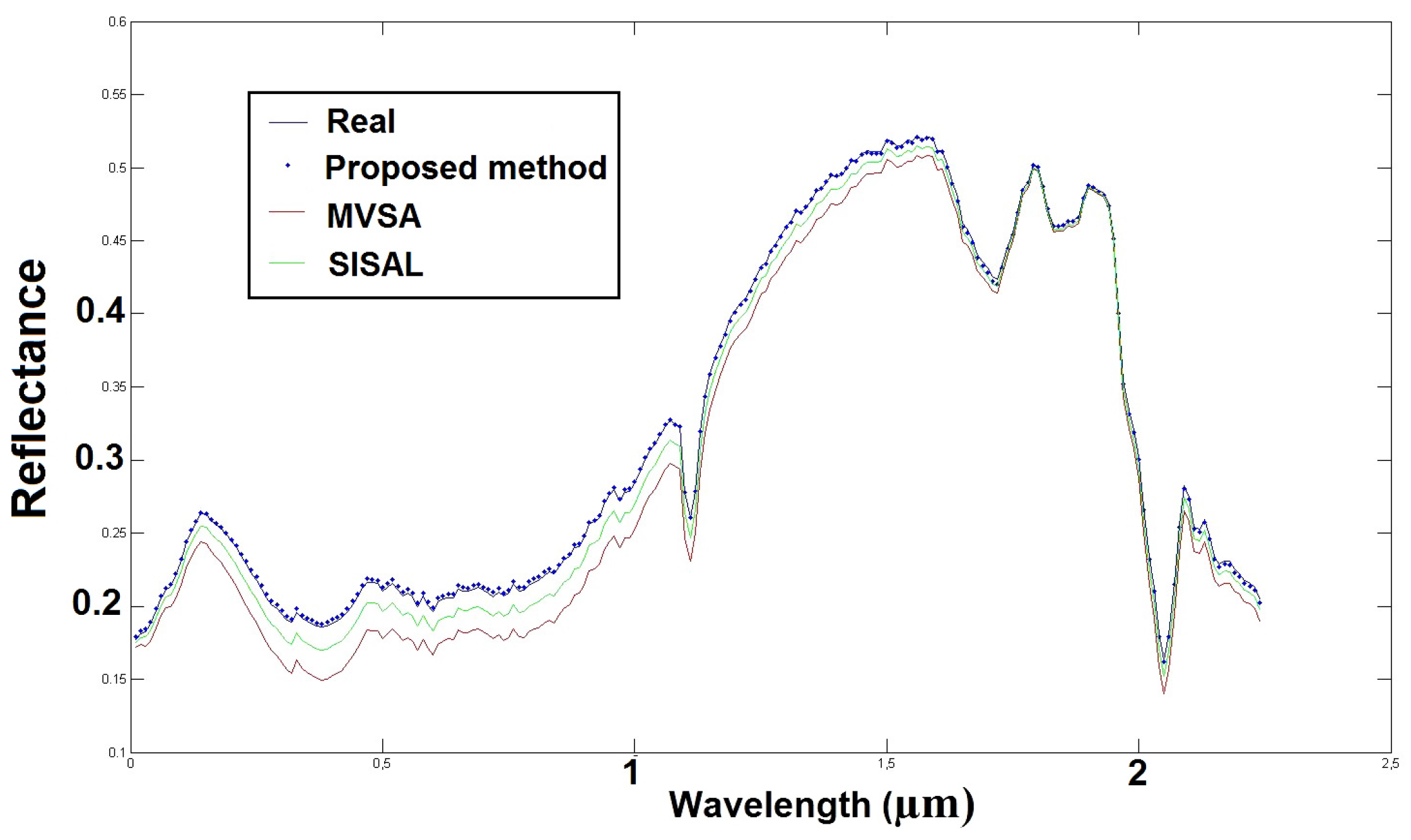
This method combines sparsity and geometrical properties. First, it consists of finding analysis zones containing only two sources, by using a criterion based on correlation. This step is followed by an identification step, where our method estimates the spectra of the pure materials contained in the considered image, thanks to geometrical properties. In the last step, our method estimates the abundance fractions of the pure materials by using a least squares method with non-negativity and sum-to-one constraints. The results obtained for realistic numerical mixtures of realistic sources prove the good performance of our method as compared with other methods from the literature.
The remainder of this paper is therefore organized as follows. We first define the standard linear mixing model for hyperspectral remote sensing images (
Section 2). We then present some properties that facilitate the introduction of the hypotheses considered in the proposed BSS method (
Section 3). This method is detailed in
Section 4, and we provide details about the data used in our experiments (
Section 5), test results in
Section 6, and finally a discussion of the obtained results in
Section 7, before a conclusion.
2. Data Model
In this paper, the considered hyperspectral remote sensing image is represented by using the standard linear mixing model. This model is here presented in the same way as in [
1,
13]. After vectorizing the spatial dimensions, one can express the non-negative reflectance observed in the
ℓth spectral band of the image, for a given pixel
n, as follows,
where
represents the
ℓth spectral component (reflectance) of the
mth pure material.
represents the abundance fraction of the
mth pure material in the
nth pixel.
M is the number of pure materials in the considered image,
N is its number of pixels, and
L is its number of spectral bands.
The complete observed image is defined as
with
where
stands for transpose. Using (
1), this image reads
where the columns of the mixing matrix
R contain the (non-negative) spectra of the pure materials, that is
with
Moreover, each column of the source matrix
F contains the abundance fractions of all the pure materials in the considered pixel. It is thus organized as follows,
with
Besides, these data meet the following non-negativity and sum-to-one constraints,
3. Properties of Two-Source Analysis Zones
In the proposed approach, we first focus on the pixels containing only two sources of indices
i and
j (with
) among the
M sources taken into account in the considered data. Each such pixel is hereafter referred to as a “two-source pixel”. Due to (
1), such a pixel yields
Considering (
11), and taking into account the constraint (
10),which induces
,
we obtain
If we now use two spectral bands of indices
ℓ and
p (with
), for each pixel
n we obtain a couple of values (
,
) defining a point in the (
,
) plane. The totality of the two-source pixels containing the selected sources
i and
j defines a scatter plot in this plane, and we want to analyze the shape of this scatter plot. Taking (
12) and its counterpart for band
p into account, we have
which yields
Assume that only two sources
and
are non-null everywhere in an analysis zone (hereafter called a “two-source zone”) composed of adjacent pixels. In this case, Equation (
15) yields the following expression for the second coordinate of the (
,
) point with respect to the first one,
with
assuming
Thus, all the corresponding points (
,
) belong to the above-defined line (
16). On the contrary, if more than two sources are non-zero and vary arbitrarily in an analysis zone, the corresponding points are not on a line.
More precisely, the two-source points only belong to a segment of the above line, as . The bounds of this segment are therefore defined by
- (i)
:
In this case, Equations (
13) and (
14) yield
and
, respectively. This is normal, because only source
j is non-zero, and it is its spectrum that is observed in such a pixel.
- (ii)
:
In this case, and , which is interpreted in the same way as above.
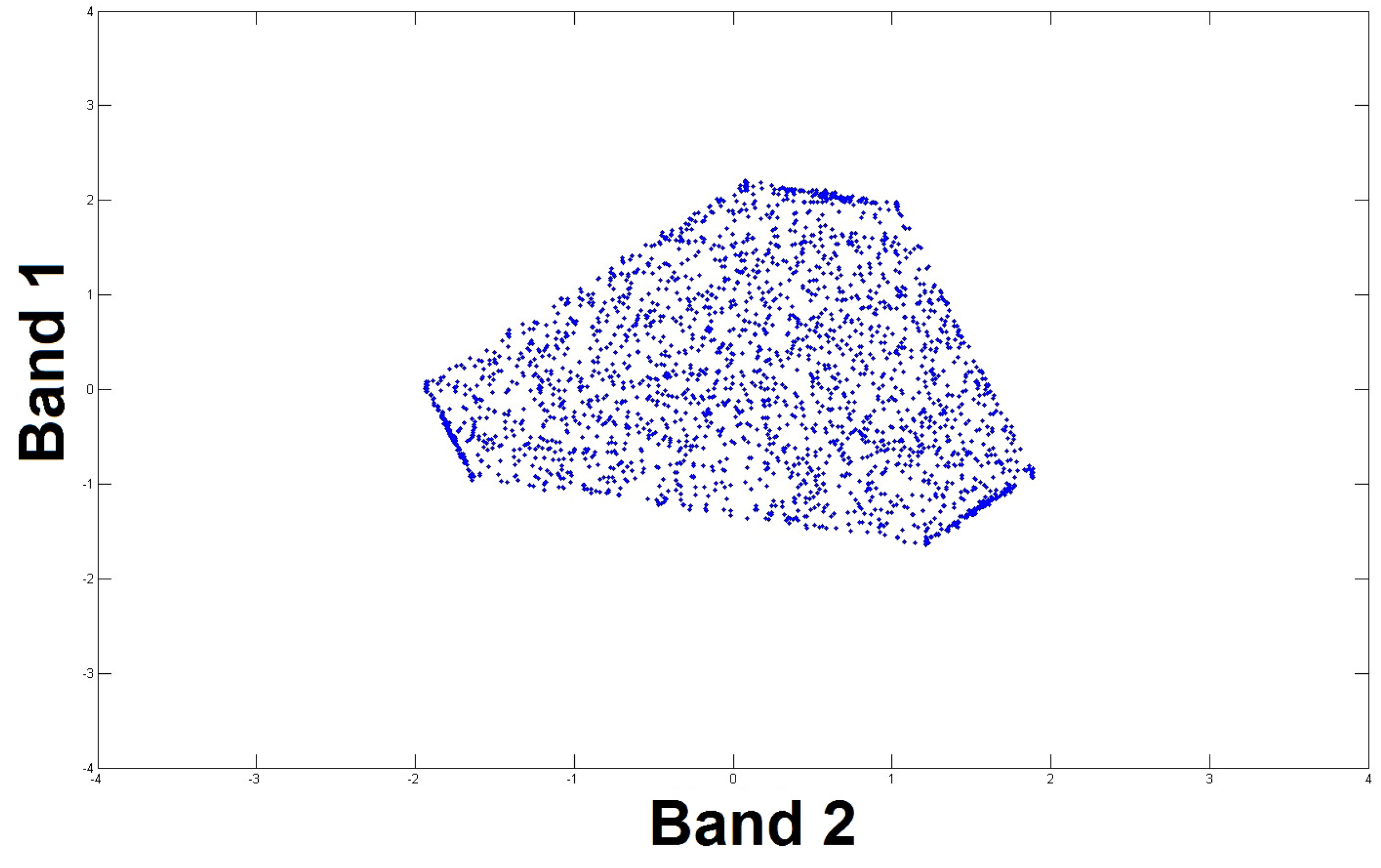
If we now assume that the considered image contains at least one two-source analysis zone for each pair of sources, among the M sources in that image, then a line segment is obtained for each possible pair of sources. We then have a total of possible line segments. These segments have common extremities corresponding to the M sources. As shown above, each of these extreme points has the following coordinates, with .
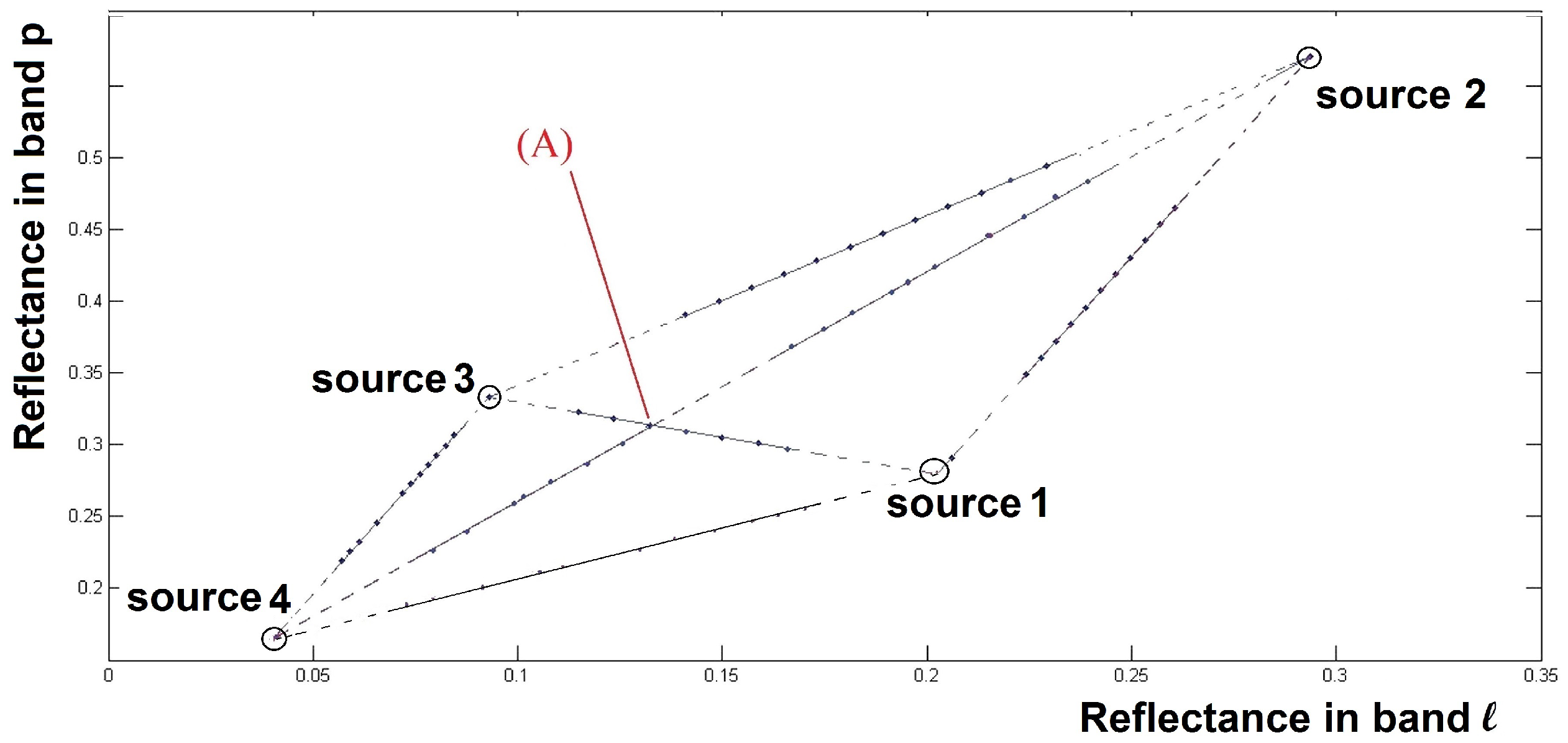
Figure 1 shows a scatter plot obtained for pixels corresponding to all the pairs of sources selected from an overall set of
artificial sources inducing, as mentioned above,
possible lines.
The most difficult case, which is therefore investigated in this paper, is when the available data points that are associated with each pair of sources do not include the bounds of each possible segment. These segment bounds correspond to pure pixels, and are illustrated by small circles in
Figure 1.
In the case when there are no pure pixels, assume we managed to estimate two lines corresponding to two pairs of sources, with indices for the first pair and for the second (with ). This means that we estimated the slopes and intercepts of both lines. Assuming that these lines are not identical for the considered two spectral bands, this allows us to deduce their intersection point and thus obtain the coordinates (), corresponding to spectral bands l and p of the pure material.
The above detailed analysis, which considers only two spectral bands, is useful to understand the preliminary version of our approach. However, the use of only two bands does not allow us to completely solve the considered problem. This is first because the obtained intersection points for all the pairs of sources only give us a part of the spectra that corresponds to two spectral bands (among the
L bands considered in the image); second, this 2D scatter plot also contains spurious intersections, or intersections between line segments associated with pairs of sources
and
which share no source: such intersections do not correspond to any actual pure material. This case is represented by point (A) of
Figure 1. Blind determination of all the intersections of two-source segments would therefore lead to spurious pure materials. This problem results from the fact that two (non-parallel) lines always intersect in a 2D space.
To solve the above problem, we now extend our approach to more than two spectral bands. To this end, we first estimate the parameters of the lines associated with each two-source zone, we then classify these parameters, we determine the intersection points which provide pure spectra estimates, and finally we estimate the abundance fractions. This yields the complete version of our BSS method, which is more formally presented in the next section.
4. Proposed BSS Method (BiS-Corr)
Using the properties introduced above, we hereafter define a new BSS method (called BiS-Corr) based on sparsity and applied to hyperspectral remote sensing images. In this approach, we use some notations, definitions, and assumptions that are related to the sought sources (abundance fractions) and mixing matrix (reflectance spectra of pure materials). These items are detailed below.
Notations:
The zero-mean versions of
and
are respectively denoted as follows,
where
and
, respectively, represent the means of
and
over the considered analysis zone
.
The vector is formed of all with , when considering as a set of indices of the associated pixels.
The vector is formed of all with .
The zero-mean versions of the vectors and are, respectively, denoted as and .
Definition 1. A pure material, with an index i among the M considered pure materials, is “active“ in an analysis zone Ω if it yields a non-zero vector .
Definition 2. A pair of pure materials is “isolated” in an analysis zone if only these two pure materials are active in this analysis zone. This zone is then called a “two-source zone”.
Definition 3. A pair of pure materials is said to be “accessible” in the spatial domain if there exists at least one analysis zone wherein this pair of materials is isolated.
Assumption 1. If a pure material, with an index i among the M considered pure materials, is active in an analysis zone Ω, then its abundance fraction is not constant over all that zone (so that ).
Assumption 2. For each pure material of index j, among the M considered pure materials, there are at least two pairs of materials with indices and (with ), sharing this material, which are accessible.
Using the sum-to-one constraint (
10), we can write one of the sources (among the
M sources considered in the mixture) with respect to the others. The index of this arbitrary source is denoted as
, and we denote as
the set of indices of all the other sources:
Equation (
10) thus yields
By inserting (
20) in (
1), we obtain
with
representing the term related to source
that we wish to remove, so as to consider only the sources contained in
. Equation (
21) thus yields
Using the above-defined notations, the centered and vectorized version of (
22) reads
Similarly, as regards the spectral band
p, we obtain
In the case when more than two pure materials are active in the considered analysis zone , the set contains at least two active pure materials. To handle this configuration, we also add the following assumptions, where is the number of pure materials that are active in zone :
Assumption 3. In each analysis zone Ω where is greater than or equal to three, when considering up to non-zero vectors , they are always linearly independent.
Assumption 4. In each analysis zone Ω, the “matrix of reflectance differences” has full column rank, where this matrix is defined as follows. Each of its columns corresponds to a value such that is non-zero. This column contains the values corresponding to all spectral bands ℓ.
Assumption 5. The mixing model is locally (over)determined, in any analysis zone Ω (see [12] for more details). Taking into account these assumptions and definitions, we now present the general structure of the proposed approach. It consists of the following three steps.
Detection of all the two-source analysis zones that are available in the observed image.
Identification of the mixing matrix.
Extraction of the sought sources, taking the non-negativity constraint into account.
Each of these steps is detailed below.
4.1. Two-Source Zone Detection Step (Step 1)
The observed data are first divided into small two-dimensional spatial zones (analysis zones), consisting of adjacent pixels. The spatial domain is then explored using these analysis zones, which are adjacent or overlapping. The purpose of this step is to determine the analysis zones of the image where only two pure materials are active. These represent the sought two-source zones.
In any two-source zone, using the zero-mean versions of the observed data in bands
ℓ and
p, (
13) and () yield
Equations (
25) and (
26) show that
and
vary proportionally over the two-source zones. For each analysis zone
, we detect this proportionality through the calculation of the cross-correlation coefficients
, between the (centered) observed signals, which are defined as follows,
where
and
, respectively, represent the 2-norm of
x and inner product of
x and
y.
Applying the Cauchy–Schwarz inequality to (
27), shows that
with equality if and only if
and
are linearly dependent. Thus, a necessary condition for a pair of materials to be isolated in an analysis zone
is
because if, in the considered zone, the number of active pure materials is
equal to two, Equations (
25) and (
26) show that
and
are linearly dependent, and therefore the values of
reach their maximum, equal to one. Furthermore, under Assumptions 3 and 4, condition (
29) is a sufficient condition for the considered analysis zone to be two-source, as shown in the
Appendix A.
In practice, for each zone, to check if (
29) is met, we compute the minimum among all
for any
ℓ,
p with
. If this measure is greater than a threshold set to a value somewhat lower than one, we consider this zone as a two-source zone.
4.2. Identification Step (Step 2)
This step consists in estimating the columns of the mixing matrix. To this end, we first estimate the parameters of each line associated with a two-source zone, supposedly present in the considered data (Part 1). The vectors of parameters thus obtained are then clustered, so as to derive a single line for each considered pair of sources (Part 2). Finally, the minimum distance between lines is calculated for each pair of these lines, so as to then derive the coordinates of the sought pure material spectra (or endmember spectra).
4.2.1. Line Parameter Estimation (Part 1)
In the
L-dimensional space associated with each data point defined by a pixel spectrum of the observed hyperspectral image, a line
D may be represented by the parametric equation [
14,
15,
16]
where
,
, and
are
L-dimensional column vectors and
s is a scalar. In an ideal two-source zone containing sources
i and
j, all points corresponding to observed spectra belong to such a line: their spectra read as
in (
30), where the
ℓth components of
and
are, respectively, equal to
and
, and where
s is equal to
. In practice, two-source zones are only nearly ideal, and the data points associated with such a zone are only nearly aligned. In this Part 1, we therefore aim at estimating the direction vector
and the point represented by the vector
of the line
D, which minimizes the mean-squared error between the data points of the considered zone and this line.
Each analysis zone
provides a matrix
containing the pixel values
of the considered zone, in its column
ℓ (with
). One of the possible solutions to fitting a line to data points is to determine the first principal axis of these data [
14,
15]. This is achieved as follows.
However, when fitting a model to data, it is important that the model is identifiable. Otherwise, the solution of the fitting procedure is not unique. In (
30), the line is defined by
parameters: the components of
u and
d. However, in an
L-dimensional space, a line can be characterized as follows with only
parameters (This is easier to understand if we apply our reasoning in a 2 dimensional space (
). Indeed, although in this case the line (
30) is defined by
(
) parameters, in reality there are only
(
) degrees of freedom (slope and intercept).), provided it is not orthogonal to the first axis, i.e., provided the first component
of
u is different from zero. The 1st and
ℓth elements of (
30) read
Thus, if
, we obtain
which yields
that is
where the
normalized parameters are defined as follows,
Equations (
31) and (
32) also apply to
, by introducing
and
. Gathering all the
L components
(respectively,
) in a vector
(respectively,
), Equation (
31) defining the considered line reads in vector form
For the sake of readability, is replaced by s hereafter (particularly in Part 3).
4.2.2. Classification of the Line Parameters (Part 2)
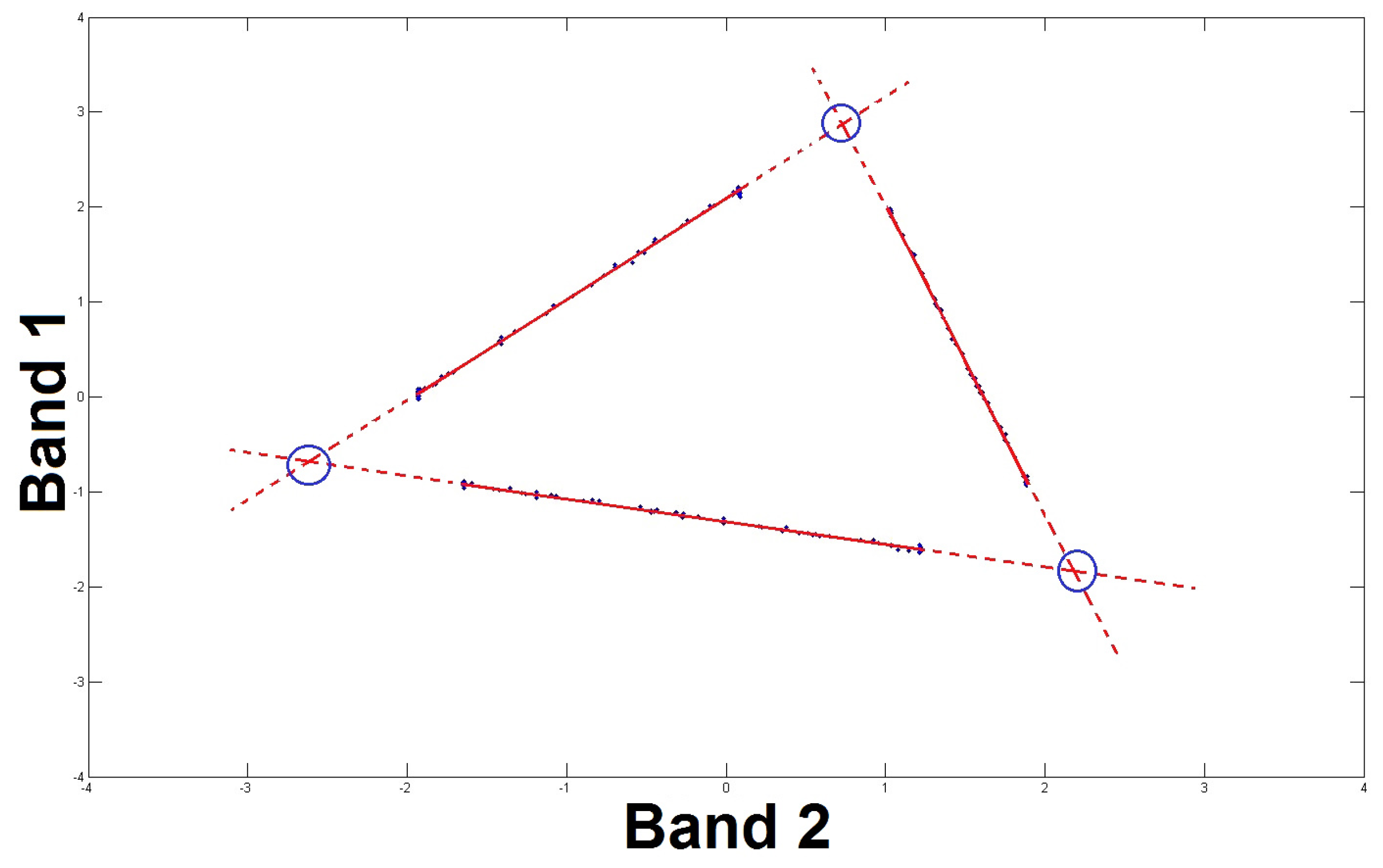
For each pair of sources, the above Part 1 allows one to define several couples of vectors and , i.e., one couple for each two-source zone containing these sources. We then aim at deriving a single couple for each pair of sources. In other words, the current Part 2 consists in classifying the different two-source zones that were previously determined, taking into account the parameters of the corresponding lines, thereby permitting the identification of a unique line associated with each pair of sources. To this end, we rearrange each estimated couple as an overall vector and we classify these vectors by successively using each of them as follows.
After setting the first vector to a first class denoted as “class-1”, each vector is compared to that attributed to this class by computing the distance between them (the 2-norm of their difference). Whenever this distance is less than a threshold, we assign the tested vector to this first class. Otherwise, a new class is created (“class-2”), and we assign this vector to it. Then, we compare the subsequent vectors to the first vector of each of the existing classes. Each tested vector is either assigned to the closest class in terms of distance, or if its distance to all existing classes is greater than the fixed threshold, it defines a new class, and so on for all other vectors.
After thus assigning a class to each vector, we estimate a unique line for each class, by repeating the line parameter estimation procedure described in Part 1, the only difference being the use of a new matrix containing the pixel values corresponding to all two-source zones detected for the considered class, to increase accuracy.
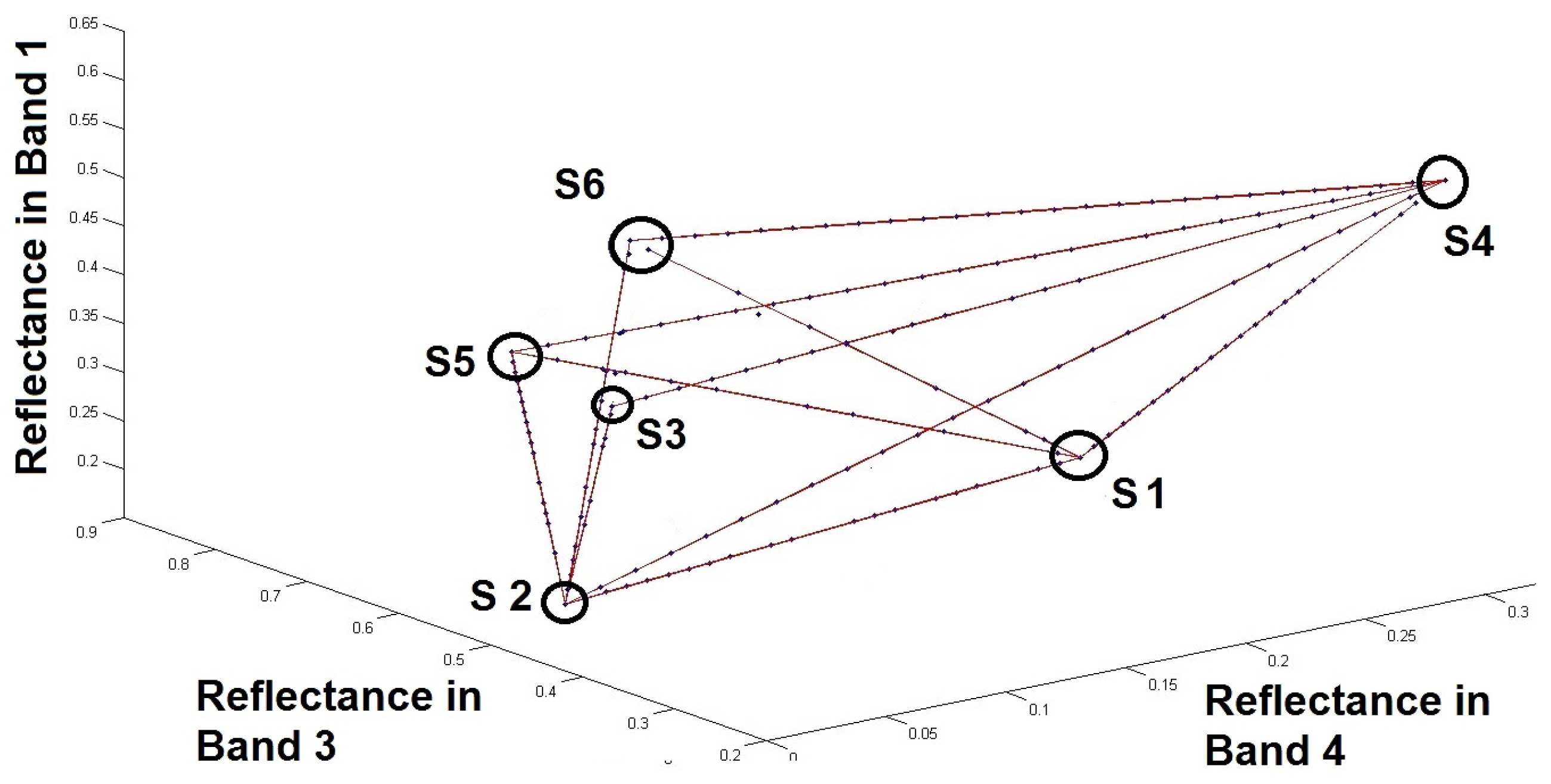
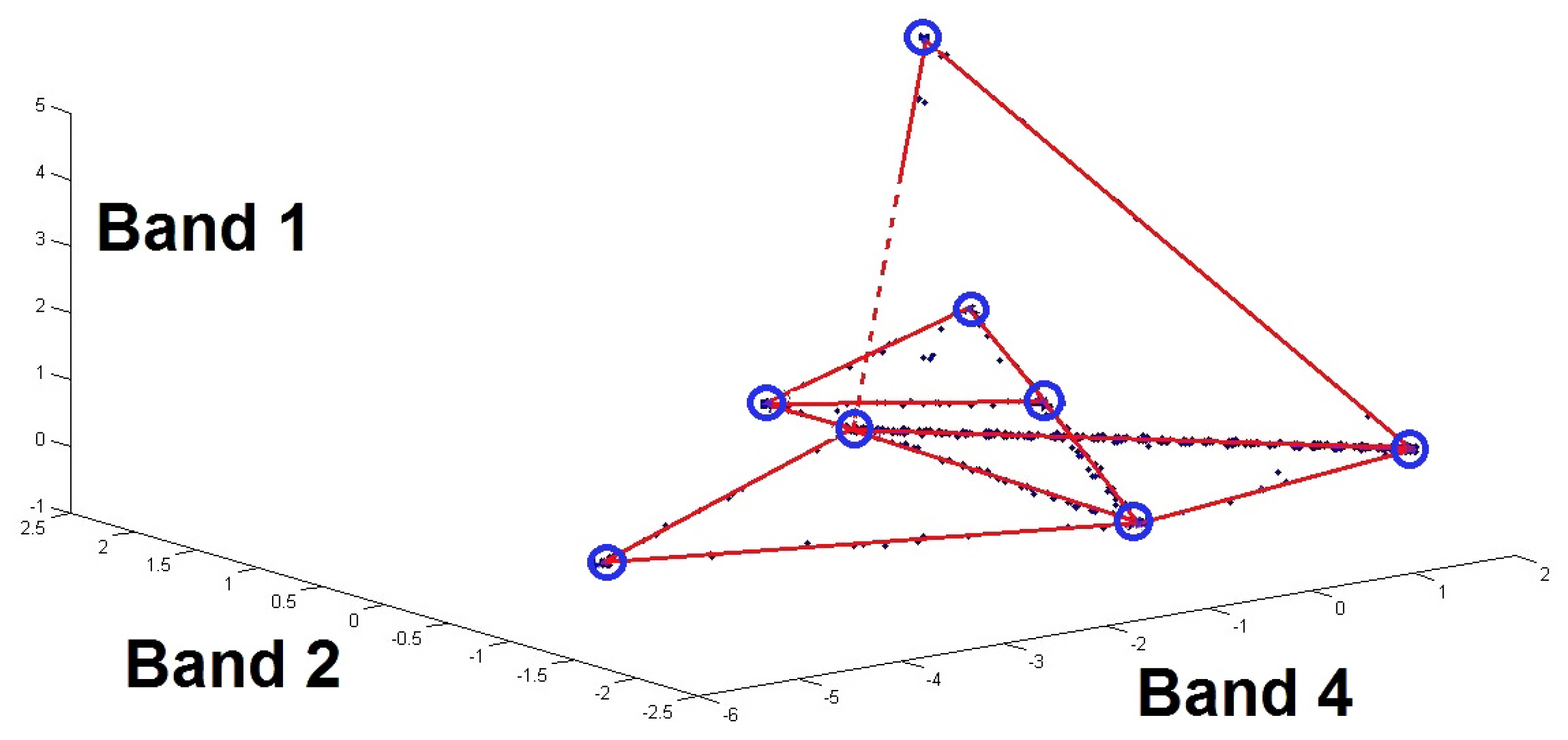
Figure 2 shows an illustration of several lines corresponding to different classes. These lines were defined from a simulated image containing 6 artificial sources. As mentioned earlier in
Section 3, the number of possible lines is 15 (calculated from
).
The number of lines corresponding to the determined pairs of sources (Although the number of lines determined by the procedure detailed above is less than the number of possible lines given the number of sources used in this example, it is still possible, with the assumptions listed above, to find the sought sources. As an example, even if the method could not detect the line “
” because the considered image does not contain two-source zones for sources
and
, source
can be identified, as shown in
Figure 2, from the (detected) lines “
” and “
”.) in this example is 11.
As illustrated in
Figure 2, at this stage of the proposed method, we are able to represent each line containing the points associated with each class, and thus to estimate the points of intersection between different pairs of lines (the small circles in
Figure 2). This is detailed below.
4.2.3. Computing the Minimum-Distance Points between Lines (Part 3)
In this last part of the identification step, the coordinates of each endmember spectrum (column of the mixing matrix R) are derived by estimating the intersection points, successively for different pairs of lines corresponding to two pairs of sources. In theory, such points exist if and only if the considered two pairs of sources share one source, under the following assumption (which is not very restrictive in our applications).
Assumption 6. If two pairs of pure materials do not contain a common pure material, the two lines, respectively defined by each of these pairs on their two-source zones, do not have any intersection point.
However, in practice, two lines estimated for two pairs of pure materials containing a common material may not exactly intersect (for example, due to data noise). In this case, the endmember spectra coordinates may be estimated by computing the closest point, i.e., the minimum-distance one, between the associated two lines. We hereafter detail the resulting procedure for first estimating these minimum distances between lines and then deriving the sought spectra thanks to the parametric equations of the lines.
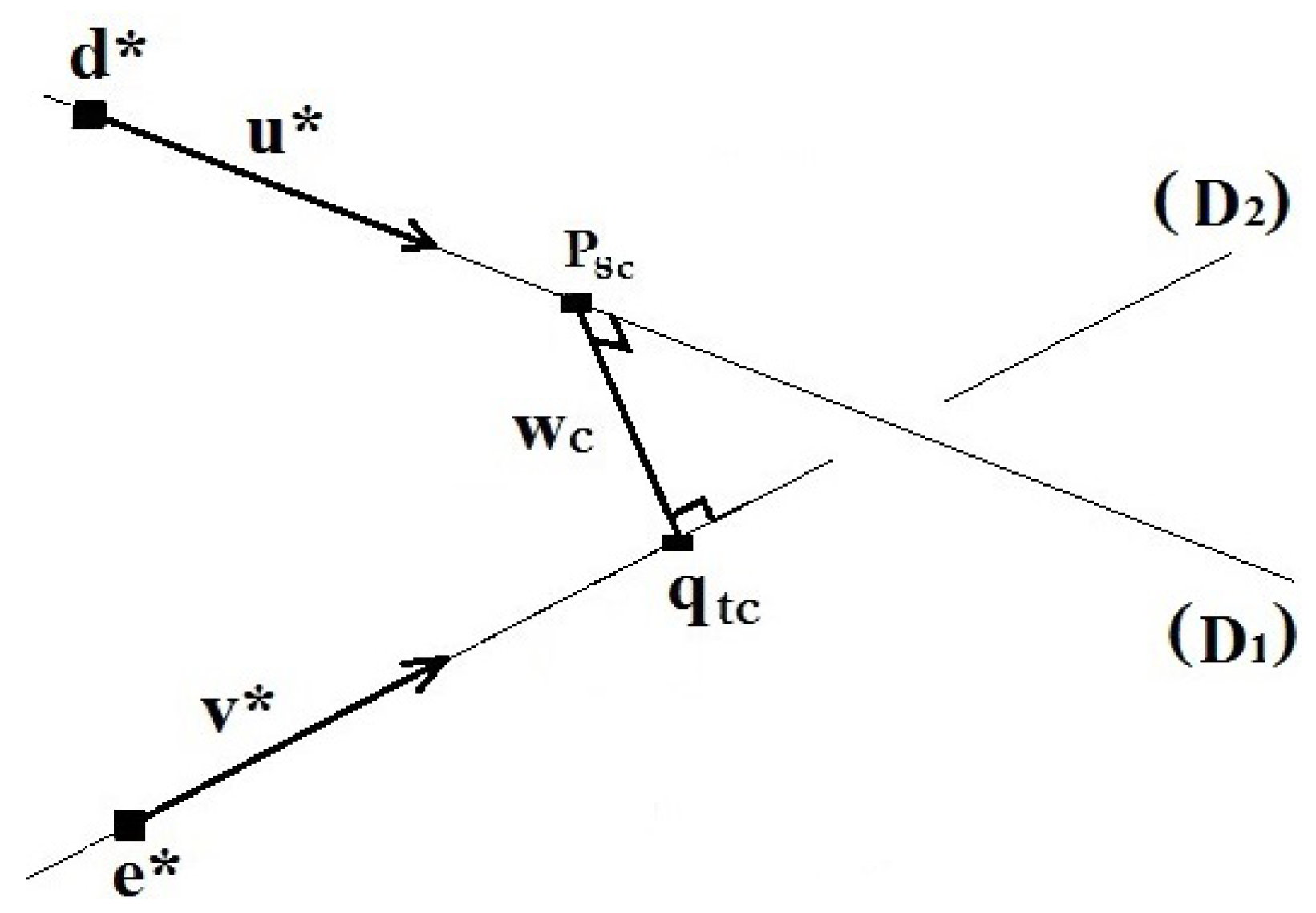
The estimation of the minimum distance between two lines in the considered
L-dimensional space is achieved by finding two points, respectively,
on one of the lines (denoted
) and
on the other line (denoted
), where this minimum occurs [
16].
and
are, respectively, defined by the following parametric equations,
is the vector defined by two arbitrary points on the two lines. Our goal is to find
w(
) (hereafter denoted
w) that has the minimum length among all the
s and
t. To this end, we have to find the line segment (
) joining these points and which is simultaneously perpendicular to the two lines
and
[
16], as shown in
Figure 3.
In other words, the vector w is perpendicular to the direction vectors and , and this is equivalent to meeting the two conditions and .
We can easily solve this couple of equations by replacing
w by (
) and using (
33). Denoting
, this yields
Then, by denoting
,
,
,
, and
, we obtain
From Equation (
33), by replacing
s and
t by
and
, we can thus estimate the points
and
on the two lines
and
, where they are the closest to each other.
In practice, if the minimum distance between the two lines, denoted
is less than a threshold, the mean of the coordinates of
and
is retained as being the point of intersection of these lines, and therefore one of the columns of the sought mixing matrix
R. Otherwise, we conclude that the considered two lines do not share a common source. This is repeated for all the other pairs of lines.
Taking advantage of the above analysis, one may instead estimate the minimum-distance points of two lines by using the least squares method. Indeed, considering the parametric equations of the lines (
33), we can proceed as follows,
By using the following notations,
we seek to estimate
such that
We can solve this problem by applying the least squares method, whose solution is (for a full-column-rank matrix
A):
As in the first method detailed above, if the minimum distance between the two lines is less than a threshold, the mean of the coordinates of
and
, obtained from Equation (
33), is retained as being one of the columns of the sought mixing matrix. The above least squares method was used in the simulations reported in
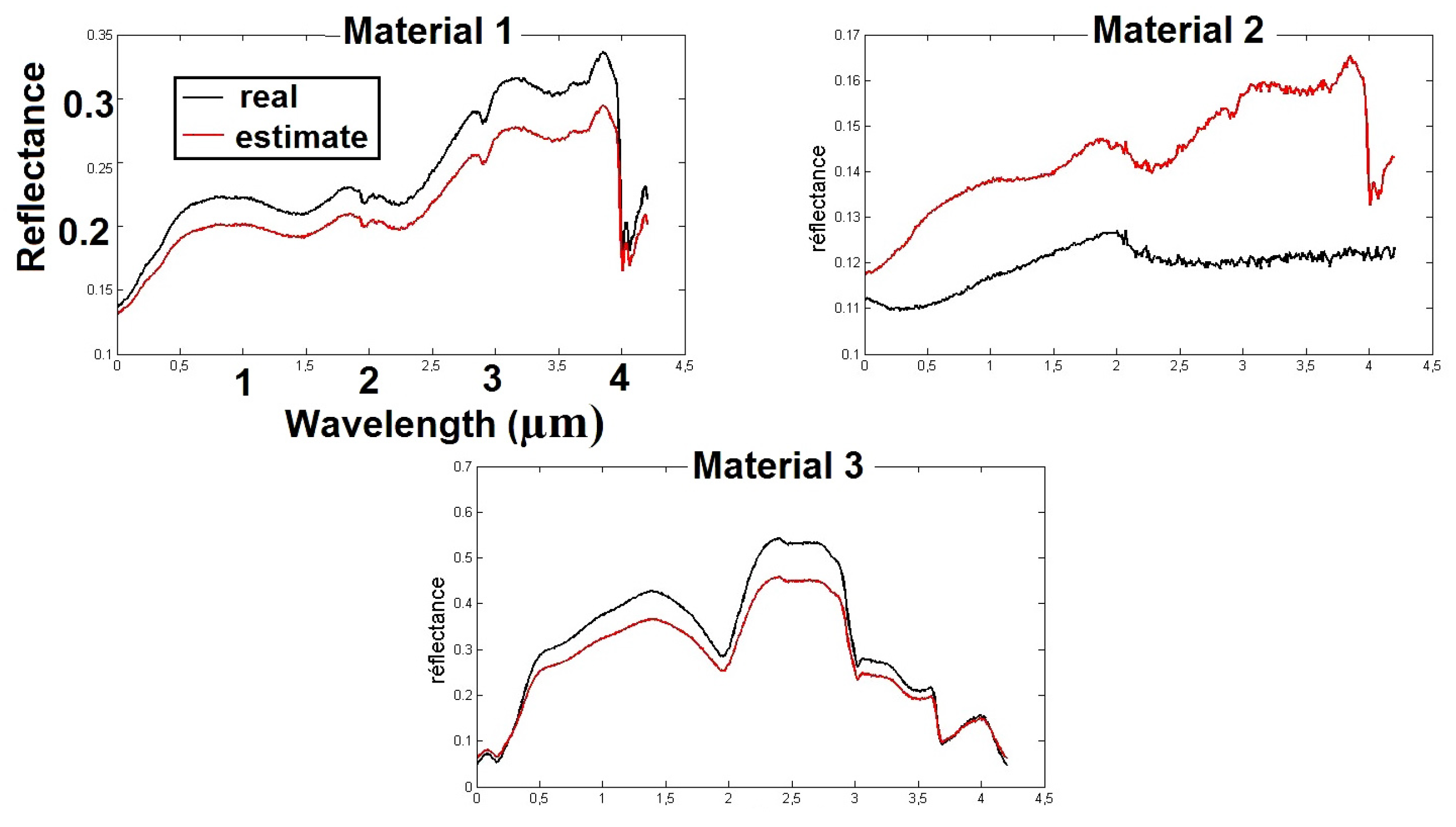
Section 6.
4.3. Extraction Step (Step 3)
After estimating the spectrum of each pure material, the last step of the proposed approach consists in extracting the
M abundance maps (sources) that are present in the considered data. To this end, we apply a least squares method with non-negativity constraint (“Non-negative Least Squares” (NLS)) [
17] to each pixel of the considered image. This is achieved as follows,
This method requires the number of non-zero elements in the estimated vector
to be at most equal to the number of elements in the vector
. This is verified thanks to Assumption 5. Furthermore, to handle the imposed sum-to-one constraints (
10), we add a row consisting of the same positive constant value to the mixing matrix
R and to the observation matrix
X [
18].
It should be noted that the above first two steps of BiS-Corr are directly applicable to multispectral and hyperspectral images (whereas the above-mentioned constraint in the third step of BiS-Corr may not be met for images which have a very low number of bands). Moreover, tests performed with simulated data especially showed for hyperspectral images that the number of two-source zones detected in Step 1 was lower when adding white noise to the images, with a signal to noise ratio varying between 60 and 40 dB, as compared with the number of zones detected with the noise-free version of the same image (for the same threshold value in the detection criterion). This reduction of the number of detected zones then led to the reduction of the number of associated identified lines, which are necessary for the next stages of the proposed approach (Parts 2 and 3 of Step 2). This problem was solved by adding a preliminary step into the BiS-Corr method, before the above-defined Step 1. This preliminary step achieves dimensionality reduction by performing Principal Component Analysis (PCA): it creates
K new spectral bands, equal to the
K first components of the considered data, here with
where
M is the number of sources selected for the performed simulations. This preliminary step not only decreases the complexity of the endmember spectra extraction but also reduces the noise possibly contained in the considered data [
1]. The proposed BiS-Corr method thus first extracts the representation of the unmixed data in the PCA-based
K-dimensional subspace, ideally without loss of information, as the noise-free original data are in that subspace. Then, using the full-dimensional (dimension equal to
L) inverse PCA basis-to-basis transform, the unmixed spectra are finally transformed back to the original data representation space, so as to extract the
L-component pure material spectra.
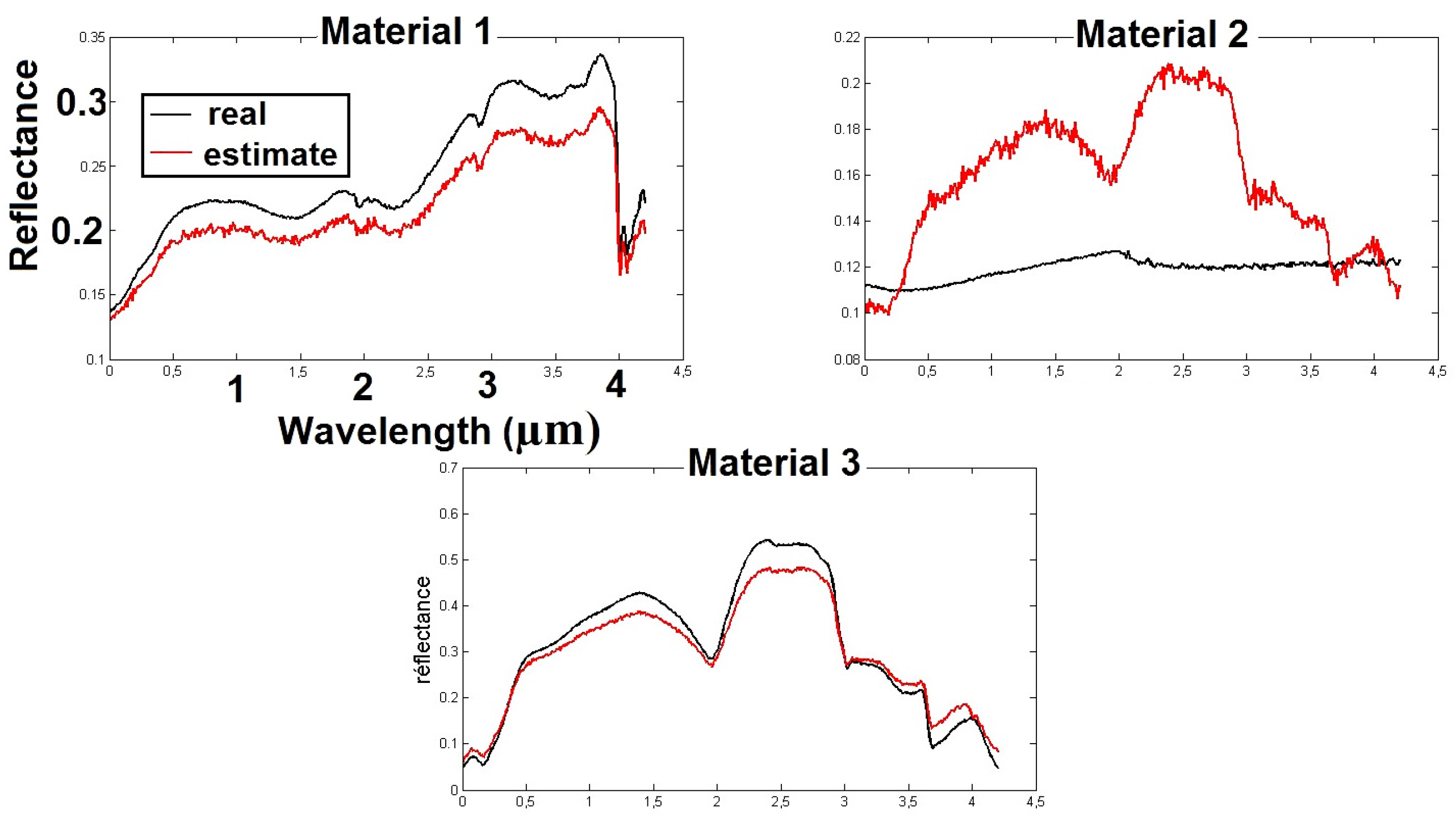
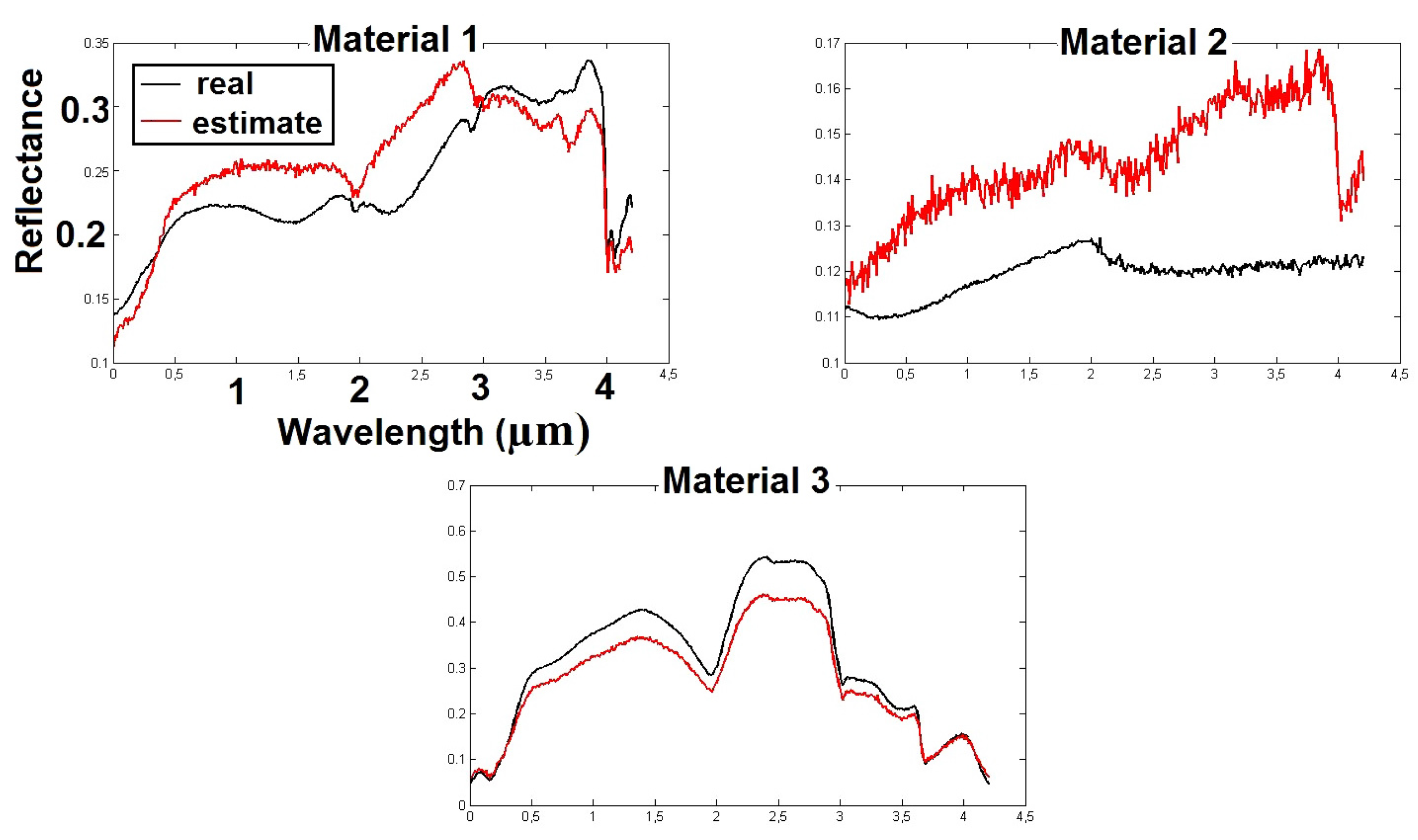
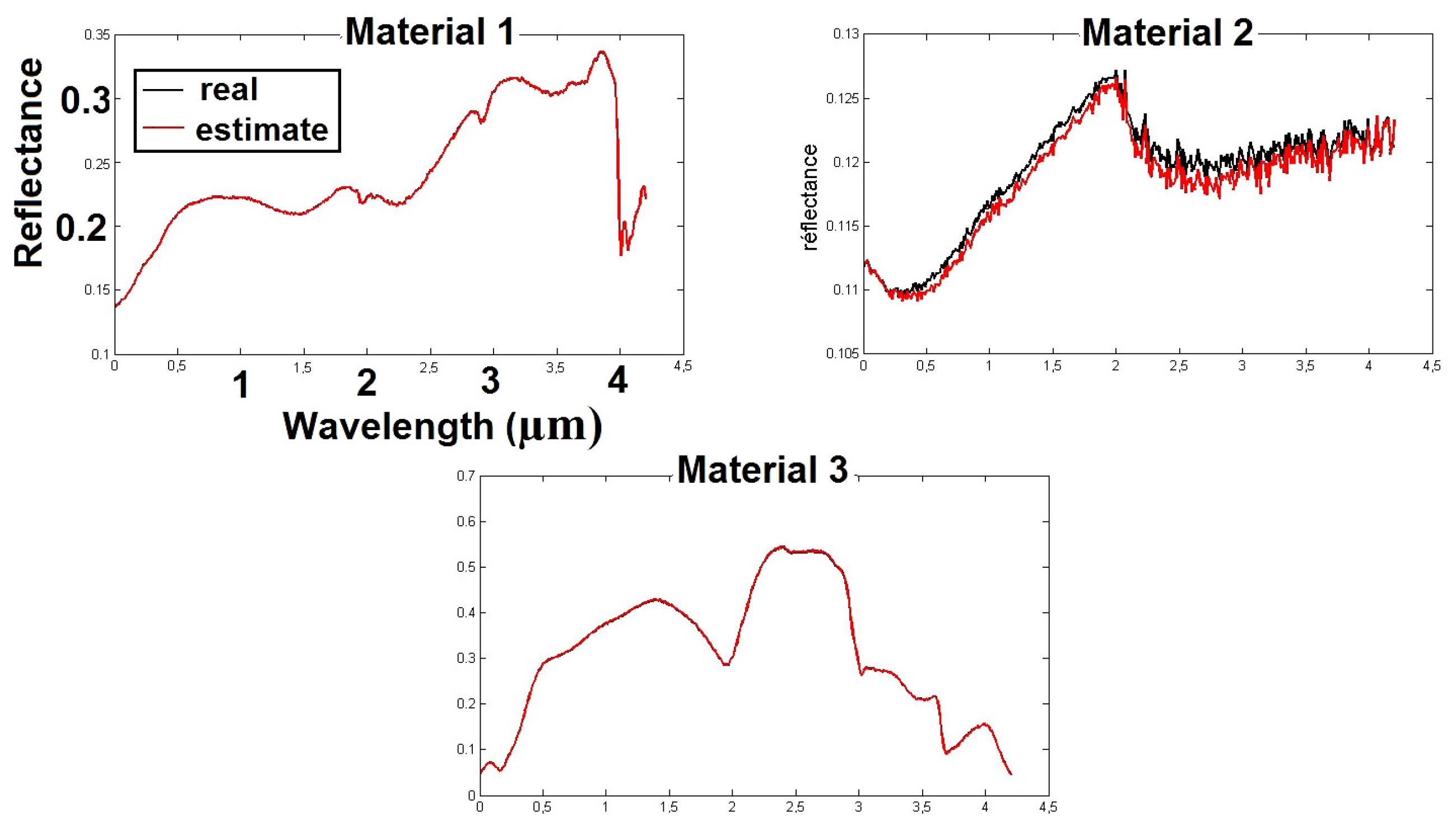
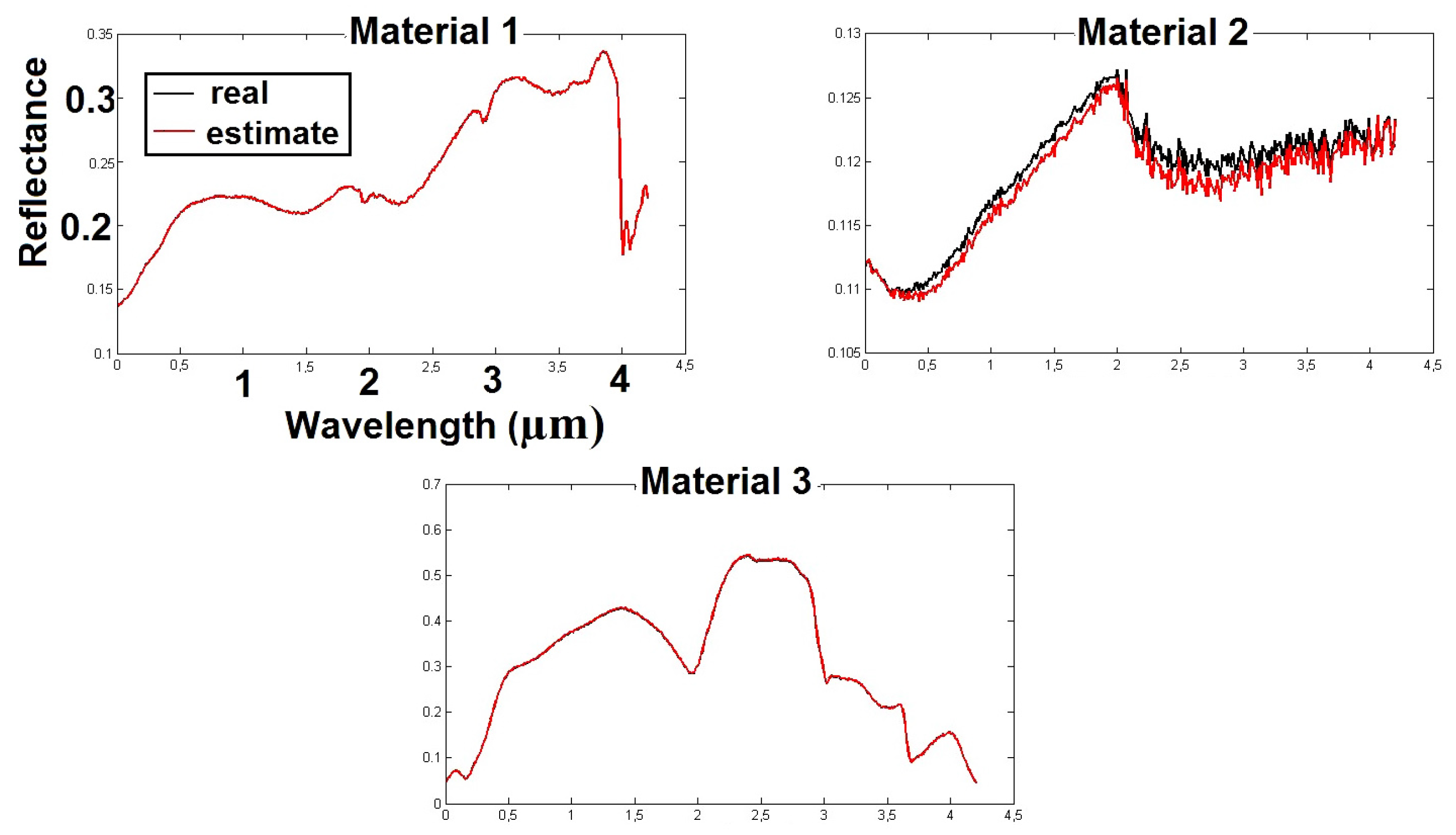
The pseudo-code of the BiS-Corr method is provided in Algorithm 1.
| Algorithm 1: BiS-Corr method. |
 |






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}