Multi-Temporal Sentinel-2 Data in Classification of Mountain Vegetation



Abstract
:
1. Introduction
2. Materials and Methods
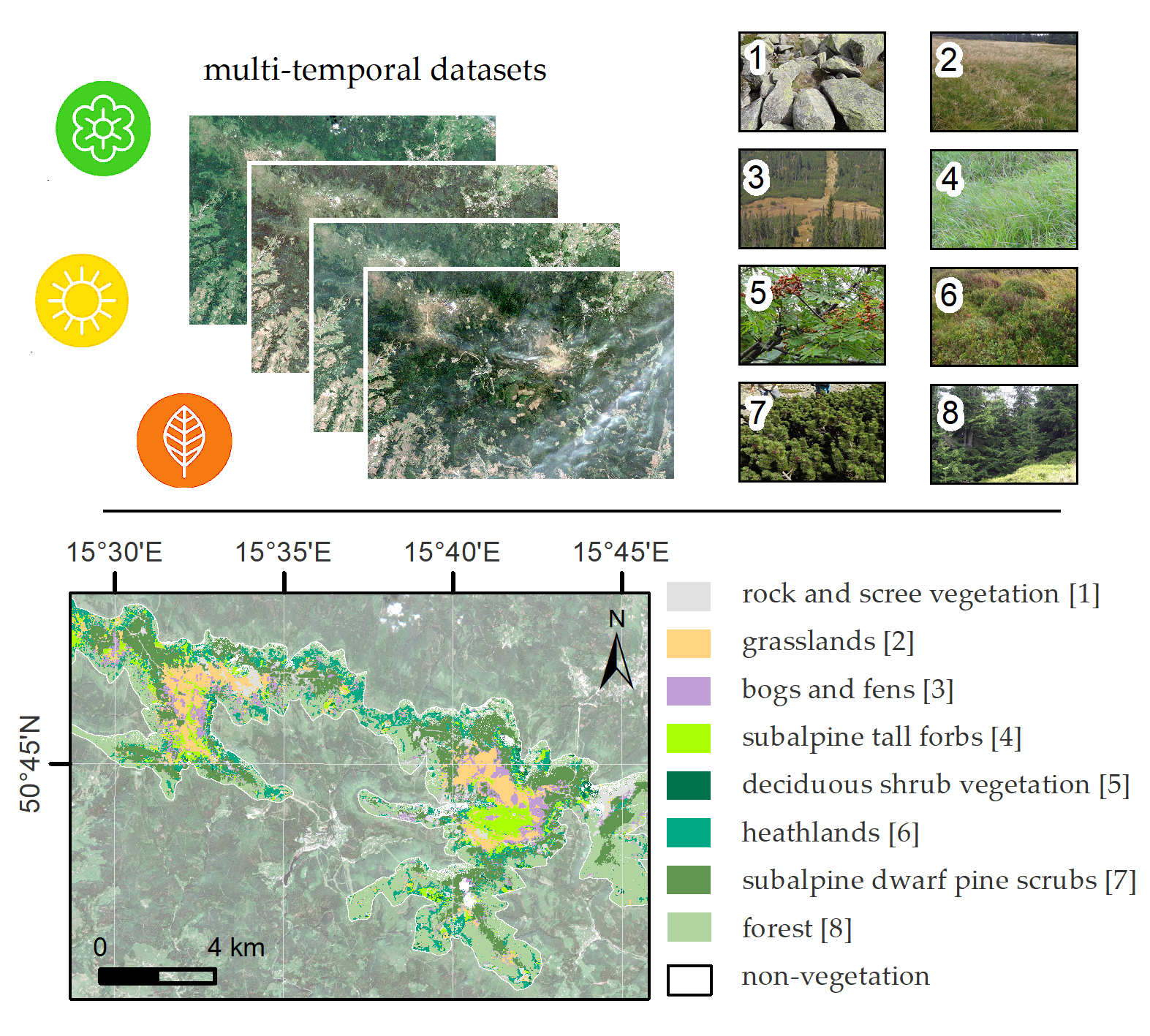
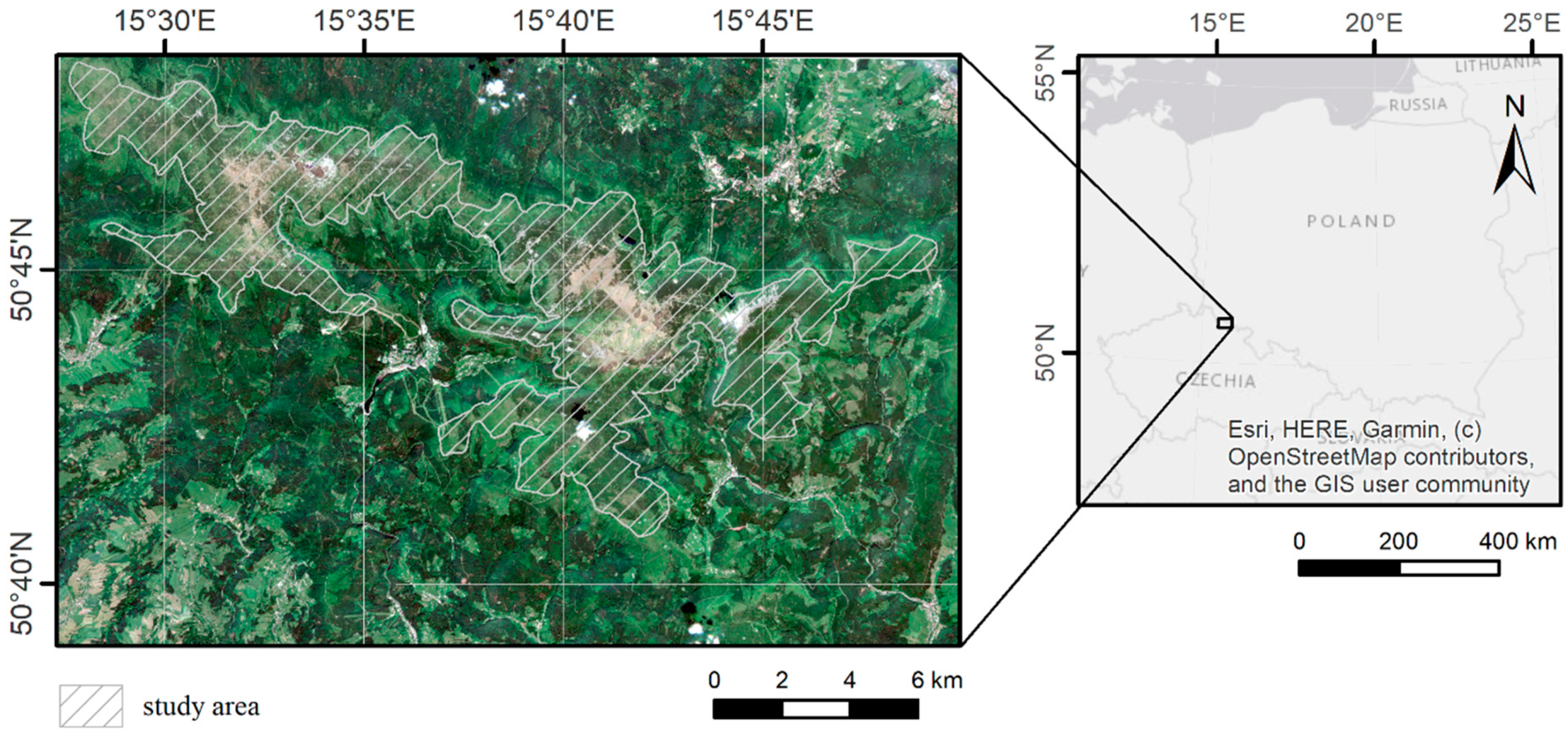
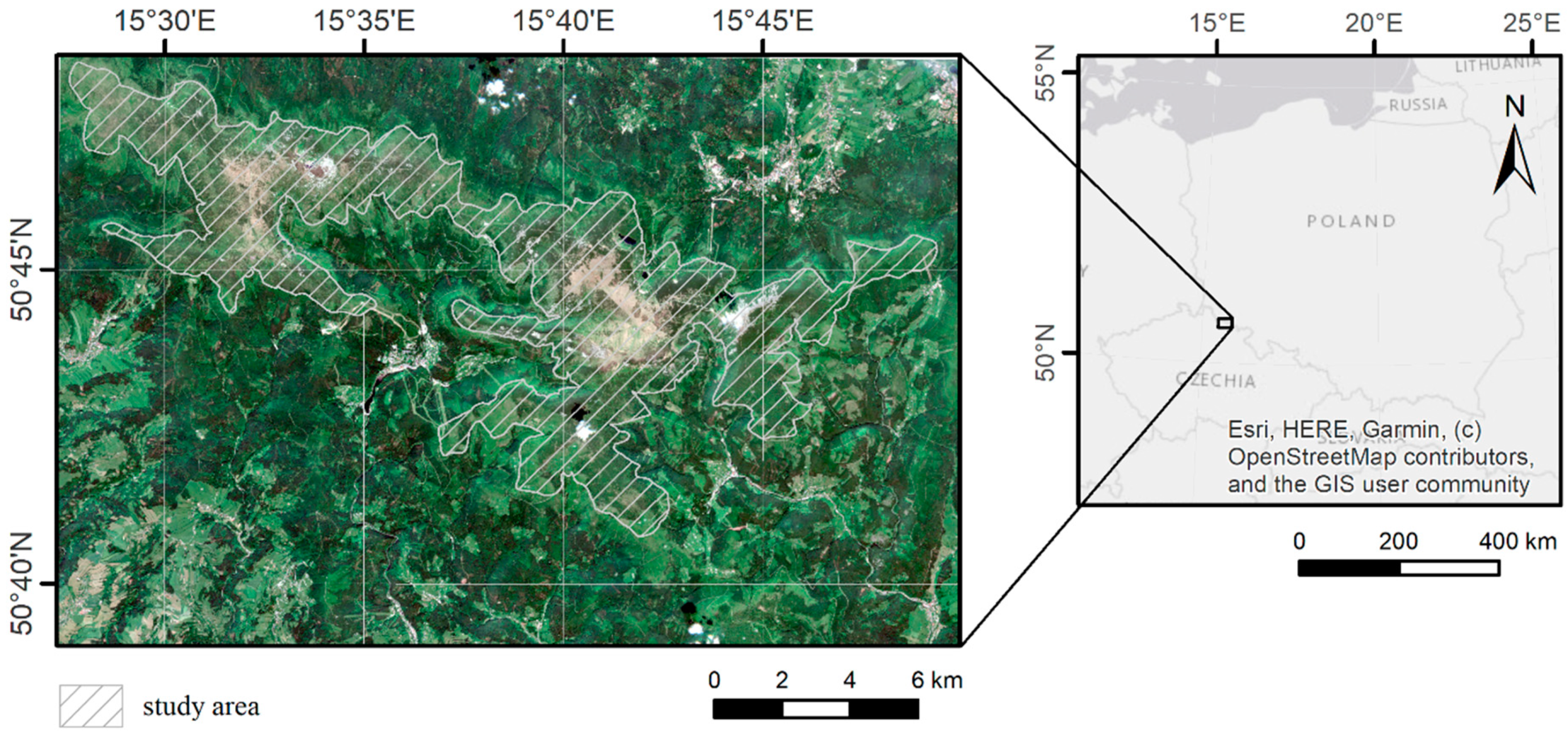
2.1. Study Area and Object of the Study
2.2. Sentinel-2 Satellite Data
2.2.1. Additional Variables Calculation
2.2.2. Multi-Temporal Datasets Creation
2.3. Reference Data
2.4. Classification with Iterative Accuracy Assessment
3. Results
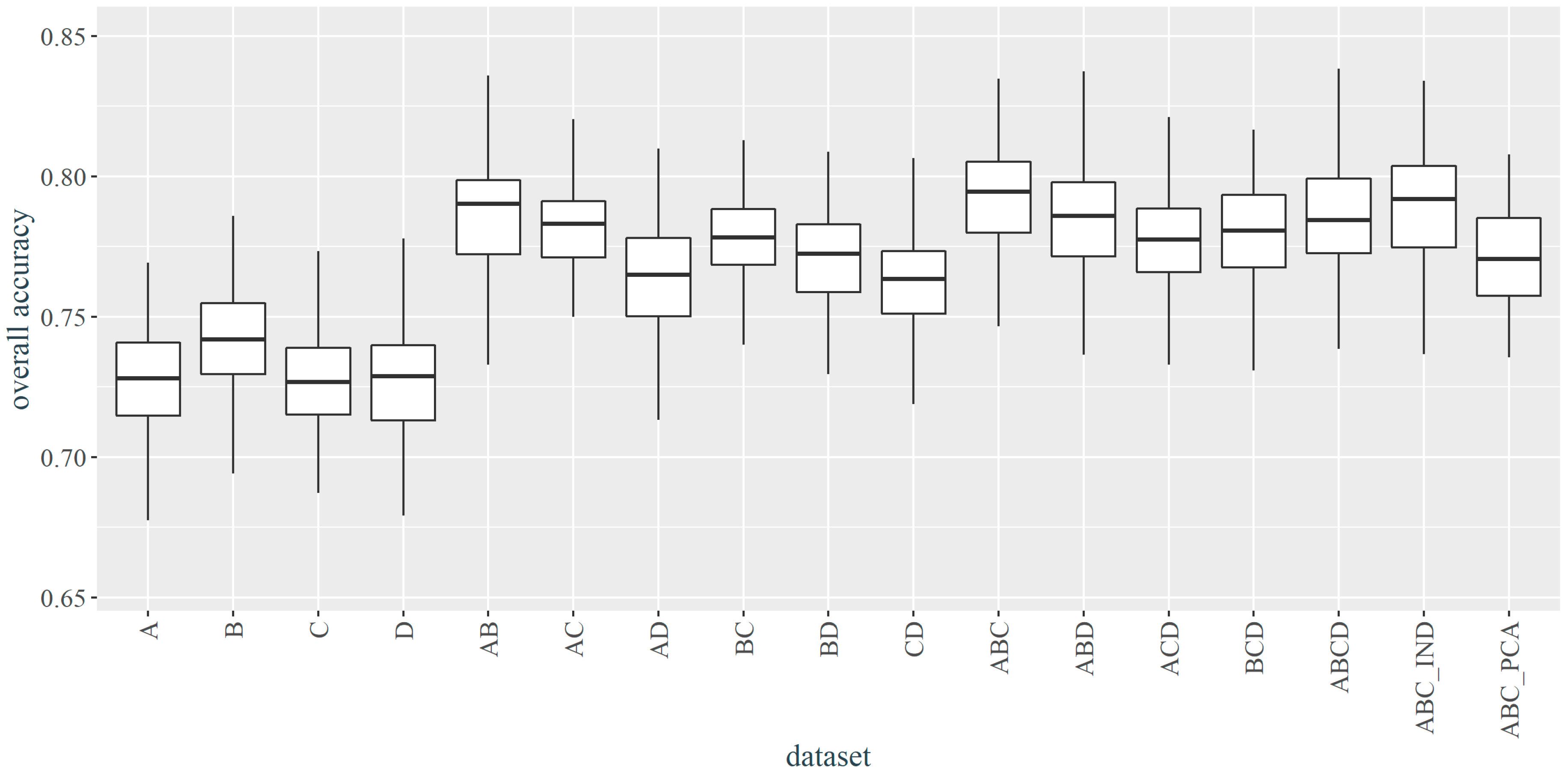
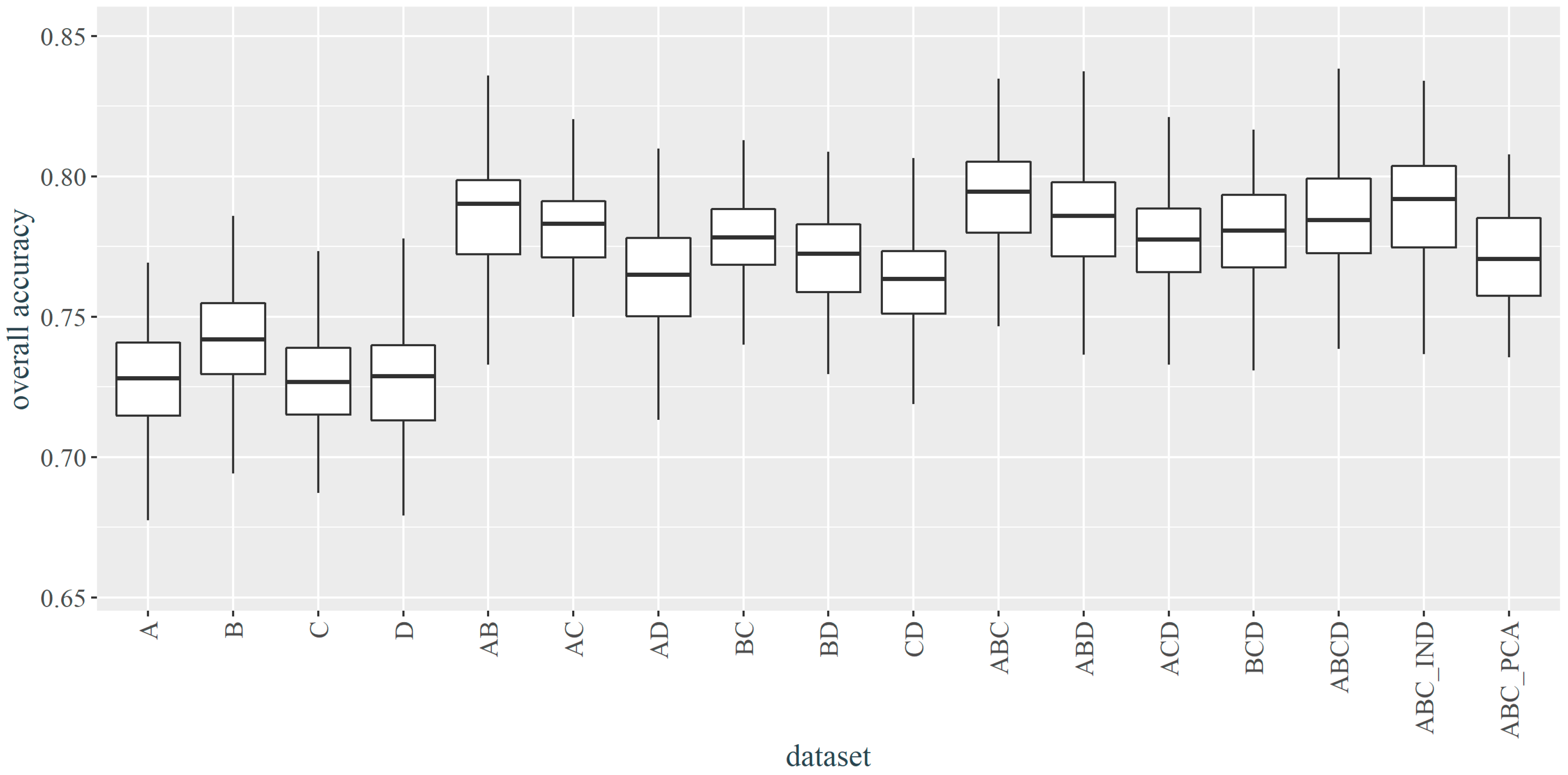
3.1. Selection of the best Parameters and Dataset
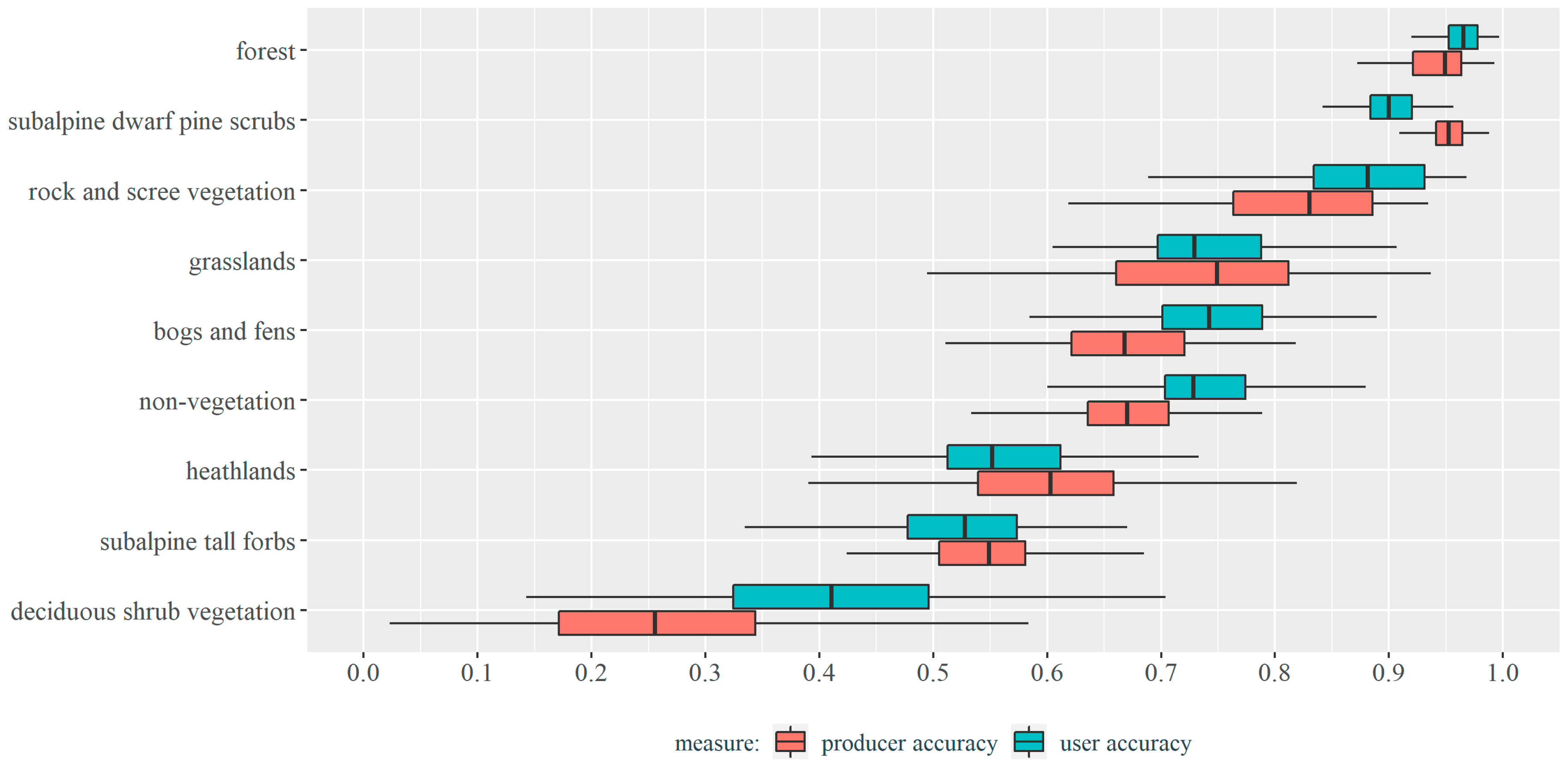
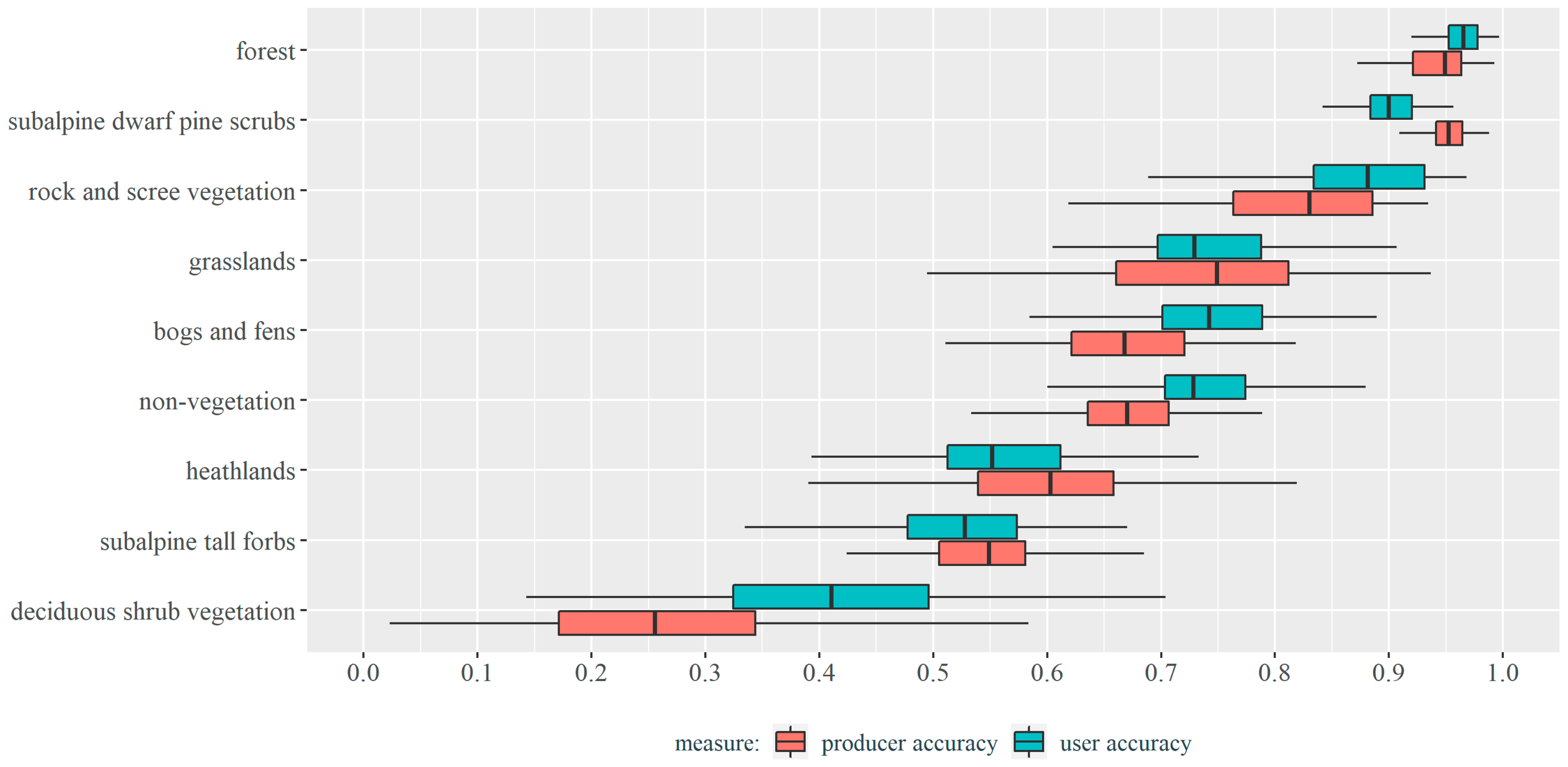
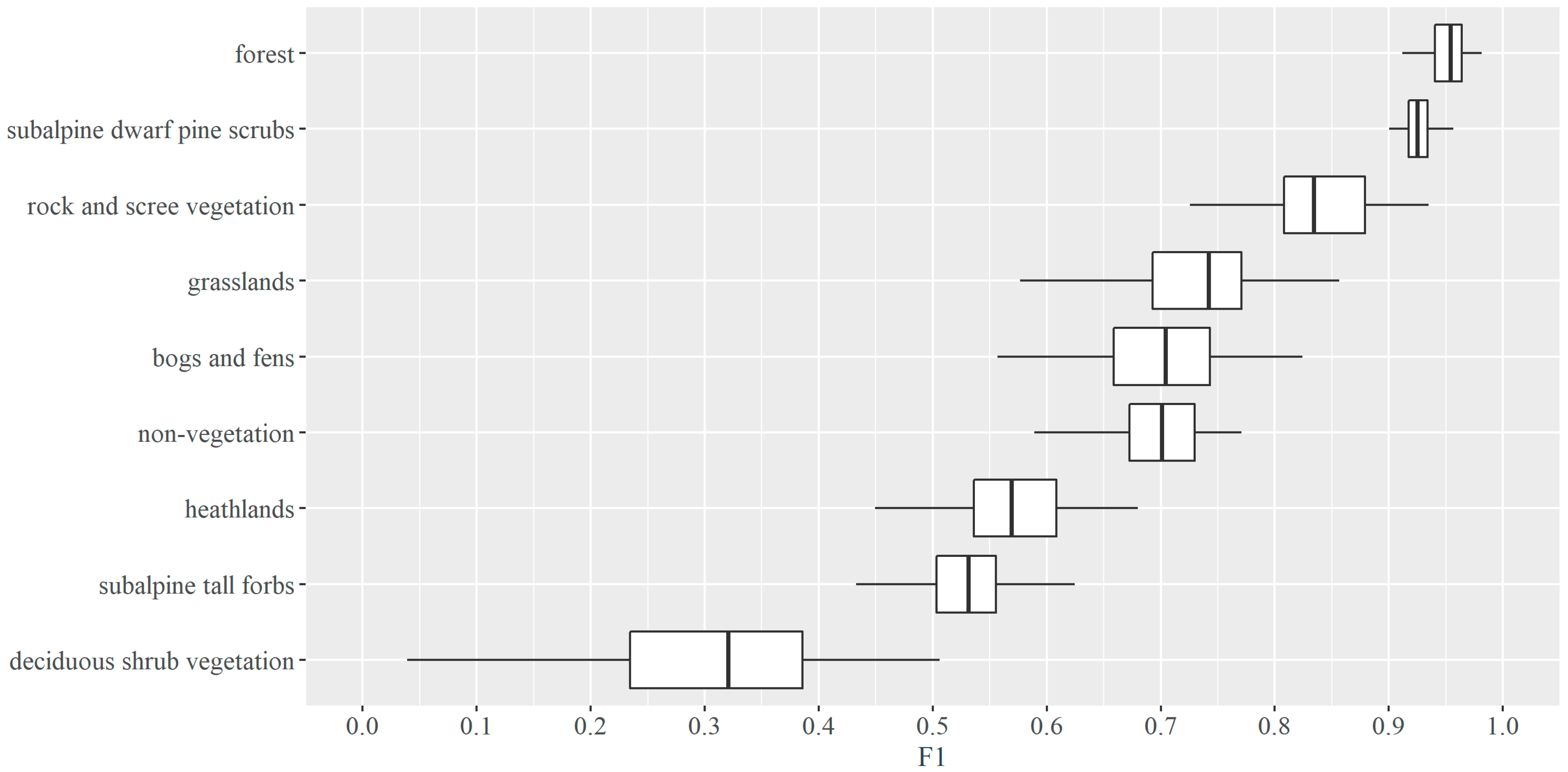
3.2. Vegetation Types Classification Results
4. Discussion
4.1. Mountain Vegetation Classification
4.2. Multi-Temporal Classification
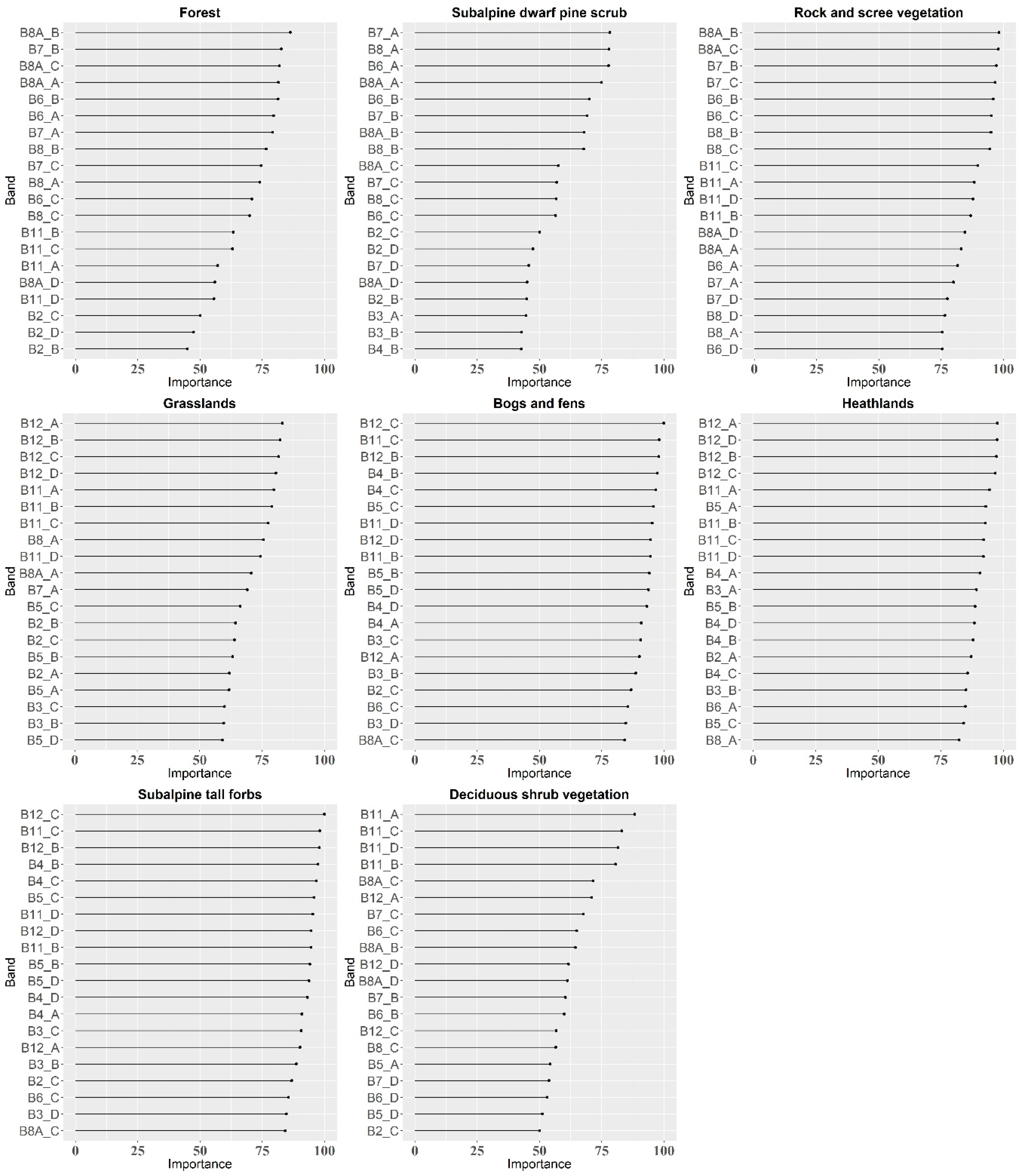
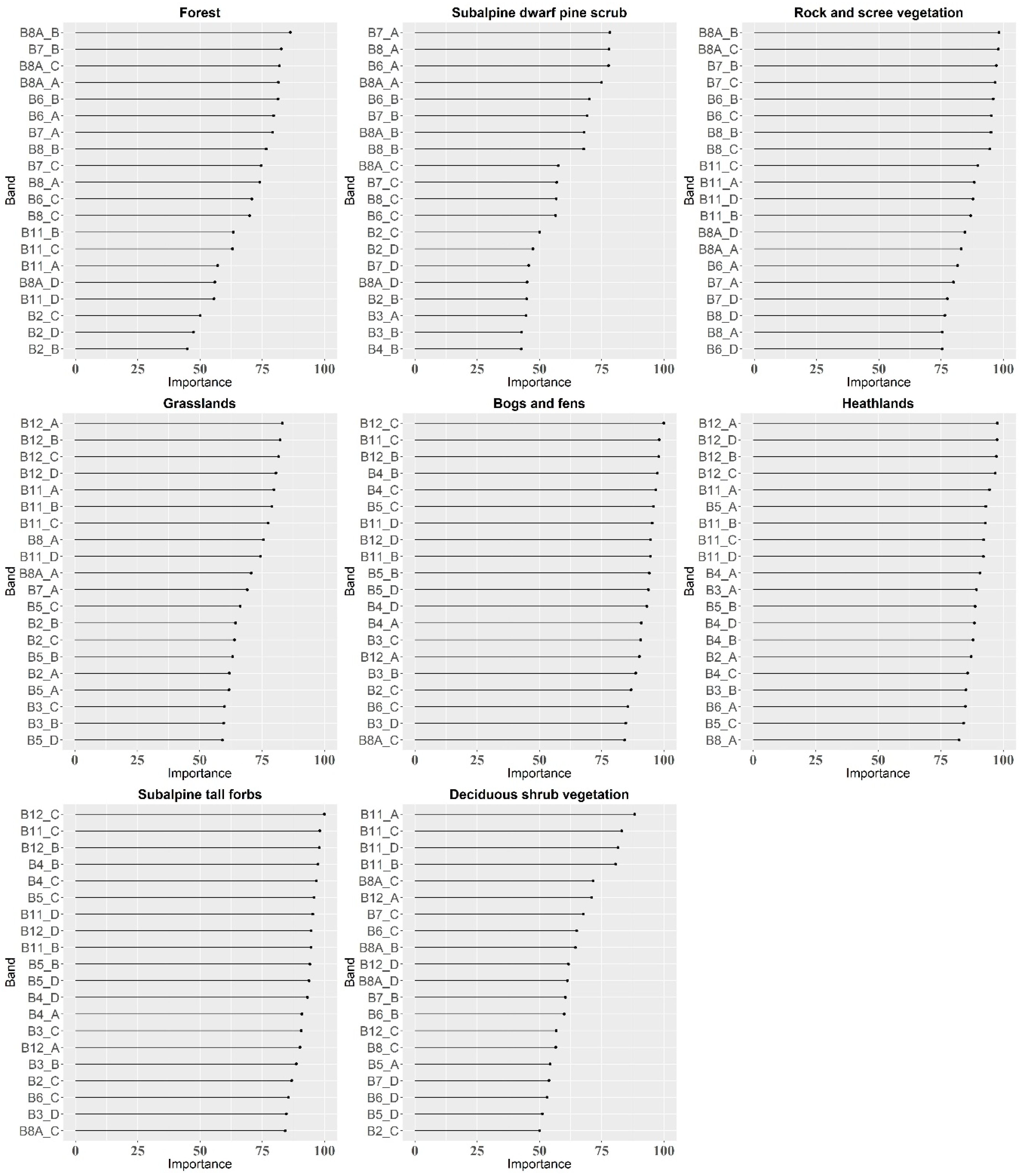
4.3. Additional Variables
5. Conclusions
- Sentinel-2 multispectral data allow us to classify high-mountain vegetation at a satisfactory level of accuracy, assuming the right level of generalization of the legend, the selection of a classification algorithm adequate to the character of the data, and the use of the advantages associated with high temporal resolution—classification based on multi-temporal compositions allows achieving better results compared to the results generated based on single-date data. Contrary to high-accuracy hyperspectral data not fully available at this moment even for single-date collection and limited for use in local-scale analysis, Sentinel-2 data can be assessed as more applicable.
- The quality of the temporal composition, in addition to the number of images, is primarily due to the date of acquisition—compositions containing contrasting spring and autumn, i.e., the time of intensified discoloration associated with flowering and senescence vegetation, were considered to be the most informative. Lower OA of a single image does not exclude it as a valuable component of the multi-temporal composition, as after adding an image from late August gave better accuracies than the two preceding images from the beginning of August and the end of May.
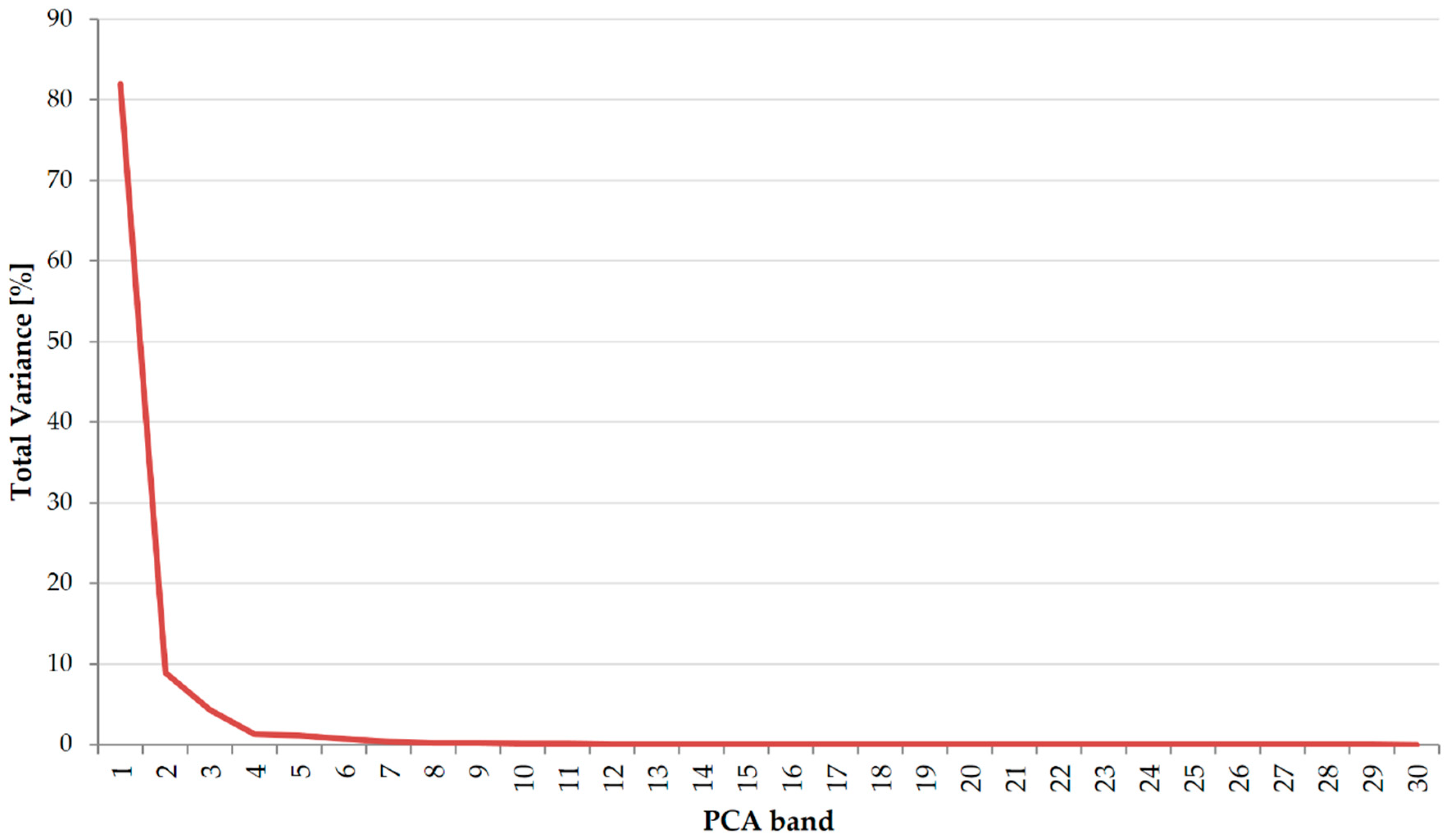
- The additional variables (vegetation indices and PCA transformation bands) tested on the best-classified dataset did not contribute to the increase in OA, which suggests that in the case of the classification of multi-temporal Sentinel-2 data, the most important variables for a satisfactory result are the images themselves (number and dates of acquisition), not their additional processing; however, the inclusion of vegetation indices can be investigated more deeply, taking into account the most influential indices for particular vegetation types classification to build the models based on only the most informative features.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Abbreviation | Name | Formula for Sentinel-2 data |
|---|---|---|---|
| 1 | EVI | Enhanced Vegetation Index | EVI = 2.5 × (8 − 5)/(8 + 6 × 5 − 7.5 × 2) + 1 |
| 2 | GDVI | Green Difference Vegetation Index | GDVI = 8 − 3 |
| 3 | GNDVI | Green Normalized Difference Vegetation Index | GNDVI = 8 − 3/9 + 3 |
| 4 | GRVI | Green Ratio Vegetation Index | GRVI = 8/3 |
| 5 | MSI | Moisture Stress Index | MSI = 11/8 |
| 6 | MTVI1 | Modified Triangular Vegetation Index | MTVI1 = 1.2 (1.2 (8 − 3) − 2.5 (4 − 3)) |
| 7 | MTVI2 | Modified Triangular Vegetation Index - Improved | MTVI2 = 1.5 (1.2 (8 − 3) − 2.5 (4 − 3))(√(2 × 8 + 1)2 − (6 × 8 − 5√4) − 0.5) |
| 8 | NDRESWIR | Normalized Difference Red-Edge and SWIR2 | NDRESWIR = 6 − 12/6 + 12 |
| 9 | NDVI | Normalized Difference Vegetation Index | NDVI = 8 − 4/8 + 4 |
| 10 | NDWI1 | Normalized Difference Water Index 1 | NDWI1 = 8 − 11/8 + 11 |
| 11 | NDWI2 | Normalized Difference Water Index 2 | NDWI2 = 8 − 12/8 + 12 |
| 12 | OSAVI | Optimized Soil Adjusted Vegetation Index | OSAVI = (1 + 0.16) 8 − 4/8 + 4 + 0.16 |
| 13 | reNDVI | Red Edge Normalized Difference Vegetation Index | NDVI 705 = 8 − 5/8 + 5 |
| 14 | RGRI | Red Green Ratio Index | RGRI = 5/3 |
| 15 | DIRESWIR | Red SWIR1 Difference | DIRESWIR = 4 − 11 |
| 16 | SAVI | Soil Adjusted Vegetation Index | SAVI = 1.5 (8 − 4) 8 + 4 + 0.5 |
| 17 | SR | Simple Ratio | SR = 8/4 |
| 18 | VARI | Visible Atmospherically Resistant Index | VARI = 3 − 4/3 + 4 − 2 |
| Band | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 0.9 | 0.9 | 0.8 | 0.4 | 0.3 | 0.3 | 0.3 | 0.6 | 0.8 | 0.8 | 0.7 | 0.7 | 0.6 | 0.4 | 0.3 | 0.3 | 0.3 | 0.5 | 0.6 | 0.7 | 0.7 | 0.7 | 0.6 | 0.4 | 0.3 | 0.3 | 0.3 | 0.5 | 0.5 |
| 2 | 0.9 | 1 | 0.9 | 0.9 | 0.6 | 0.5 | 0.5 | 0.5 | 0.8 | 0.8 | 0.8 | 0.8 | 0.7 | 0.8 | 0.6 | 0.5 | 0.6 | 0.5 | 0.7 | 0.7 | 0.8 | 0.8 | 0.7 | 0.8 | 0.6 | 0.5 | 0.5 | 0.5 | 0.6 | 0.7 |
| 3 | 0.9 | 0.9 | 1 | 0.8 | 0.3 | 0.2 | 0.2 | 0.2 | 0.7 | 0.8 | 0.8 | 0.7 | 0.7 | 0.7 | 0.4 | 0.3 | 0.3 | 0.3 | 0.5 | 0.6 | 0.7 | 0.7 | 0.7 | 0.6 | 0.4 | 0.3 | 0.3 | 0.3 | 0.5 | 0.6 |
| 4 | 0.8 | 0.9 | 0.8 | 1 | 0.7 | 0.6 | 0.6 | 0.6 | 0.9 | 0.9 | 0.7 | 0.8 | 0.7 | 0.9 | 0.7 | 0.7 | 0.6 | 0.7 | 0.8 | 0.8 | 0.7 | 0.8 | 0.7 | 0.9 | 0.7 | 0.6 | 0.6 | 0.6 | 0.8 | 0.8 |
| 5 | 0.4 | 0.6 | 0.3 | 0.7 | 1 | 1 | 1 | 1 | 0.8 | 0.6 | 0.5 | 0.6 | 0.5 | 0.7 | 0.9 | 0.9 | 0.9 | 0.9 | 0.8 | 0.7 | 0.5 | 0.6 | 0.5 | 0.7 | 0.9 | 0.9 | 0.8 | 0.9 | 0.8 | 0.7 |
| 6 | 0.3 | 0.5 | 0.2 | 0.6 | 1 | 1 | 1 | 1 | 0.7 | 0.5 | 0.4 | 0.6 | 0.5 | 0.7 | 0.9 | 0.9 | 0.9 | 0.9 | 0.8 | 0.7 | 0.4 | 0.6 | 0.5 | 0.7 | 0.9 | 0.8 | 0.8 | 0.9 | 0.8 | 0.7 |
| 7 | 0.3 | 0.5 | 0.2 | 0.6 | 1 | 1 | 1 | 1 | 0.7 | 0.5 | 0.4 | 0.6 | 0.5 | 0.7 | 0.9 | 0.9 | 0.9 | 0.9 | 0.8 | 0.6 | 0.4 | 0.6 | 0.5 | 0.7 | 0.8 | 0.8 | 0.8 | 0.8 | 0.7 | 0.6 |
| 8 | 0.3 | 0.5 | 0.2 | 0.6 | 1 | 1 | 1 | 1 | 0.8 | 0.6 | 0.4 | 0.6 | 0.5 | 0.7 | 0.9 | 0.9 | 0.9 | 0.9 | 0.8 | 0.7 | 0.4 | 0.6 | 0.5 | 0.7 | 0.9 | 0.9 | 0.8 | 0.9 | 0.8 | 0.7 |
| 9 | 0.6 | 0.8 | 0.7 | 0.9 | 0.8 | 0.7 | 0.7 | 0.8 | 1 | 1 | 0.7 | 0.8 | 0.7 | 0.9 | 0.8 | 0.8 | 0.7 | 0.8 | 0.9 | 0.9 | 0.7 | 0.8 | 0.7 | 0.9 | 0.8 | 0.7 | 0.7 | 0.7 | 0.9 | 0.9 |
| 10 | 0.8 | 0.8 | 0.8 | 0.9 | 0.6 | 0.5 | 0.5 | 0.6 | 1 | 1 | 0.7 | 0.8 | 0.8 | 0.8 | 0.7 | 0.6 | 0.6 | 0.6 | 0.8 | 0.8 | 0.7 | 0.8 | 0.8 | 0.8 | 0.6 | 0.6 | 0.5 | 0.6 | 0.8 | 0.8 |
| 11 | 0.8 | 0.8 | 0.8 | 0.7 | 0.5 | 0.4 | 0.4 | 0.4 | 0.7 | 0.7 | 1 | 1 | 1 | 0.8 | 0.5 | 0.4 | 0.4 | 0.4 | 0.7 | 0.8 | 0.9 | 0.9 | 0.9 | 0.8 | 0.5 | 0.4 | 0.4 | 0.4 | 0.7 | 0.8 |
| 12 | 0.7 | 0.8 | 0.7 | 0.8 | 0.6 | 0.6 | 0.6 | 0.6 | 0.8 | 0.8 | 1 | 1 | 0.9 | 0.9 | 0.7 | 0.6 | 0.6 | 0.6 | 0.8 | 0.9 | 0.9 | 1 | 0.9 | 0.9 | 0.7 | 0.6 | 0.6 | 0.6 | 0.8 | 0.9 |
| 13 | 0.7 | 0.7 | 0.7 | 0.7 | 0.5 | 0.5 | 0.5 | 0.5 | 0.7 | 0.8 | 1 | 0.9 | 1 | 0.9 | 0.5 | 0.4 | 0.4 | 0.4 | 0.8 | 0.9 | 0.9 | 0.9 | 1 | 0.9 | 0.5 | 0.4 | 0.4 | 0.4 | 0.8 | 0.9 |
| 14 | 0.6 | 0.8 | 0.7 | 0.9 | 0.7 | 0.7 | 0.7 | 0.7 | 0.9 | 0.8 | 0.8 | 0.9 | 0.9 | 1 | 0.8 | 0.7 | 0.7 | 0.7 | 0.9 | 0.9 | 0.8 | 0.9 | 0.9 | 1 | 0.7 | 0.7 | 0.6 | 0.7 | 0.9 | 0.9 |
| 15 | 0.4 | 0.6 | 0.4 | 0.7 | 0.9 | 0.9 | 0.9 | 0.9 | 0.8 | 0.7 | 0.5 | 0.7 | 0.5 | 0.8 | 1 | 1 | 0.9 | 1 | 0.8 | 0.7 | 0.5 | 0.7 | 0.5 | 0.8 | 1 | 1 | 0.9 | 1 | 0.8 | 0.7 |
| 16 | 0.3 | 0.5 | 0.3 | 0.7 | 0.9 | 0.9 | 0.9 | 0.9 | 0.8 | 0.6 | 0.4 | 0.6 | 0.4 | 0.7 | 1 | 1 | 1 | 1 | 0.7 | 0.6 | 0.4 | 0.6 | 0.5 | 0.7 | 1 | 1 | 0.9 | 1 | 0.7 | 0.6 |
| 17 | 0.3 | 0.6 | 0.3 | 0.6 | 0.9 | 0.9 | 0.9 | 0.9 | 0.7 | 0.6 | 0.4 | 0.6 | 0.4 | 0.7 | 0.9 | 1 | 1 | 1 | 0.7 | 0.6 | 0.4 | 0.6 | 0.5 | 0.7 | 0.9 | 0.9 | 1 | 0.9 | 0.7 | 0.6 |
| 18 | 0.3 | 0.5 | 0.3 | 0.7 | 0.9 | 0.9 | 0.9 | 0.9 | 0.8 | 0.6 | 0.4 | 0.6 | 0.4 | 0.7 | 1 | 1 | 1 | 1 | 0.8 | 0.6 | 0.4 | 0.6 | 0.5 | 0.7 | 1 | 1 | 0.9 | 1 | 0.7 | 0.6 |
| 19 | 0.5 | 0.7 | 0.5 | 0.8 | 0.8 | 0.8 | 0.8 | 0.8 | 0.9 | 0.8 | 0.7 | 0.8 | 0.8 | 0.9 | 0.8 | 0.7 | 0.7 | 0.8 | 1 | 1 | 0.7 | 0.8 | 0.8 | 0.9 | 0.8 | 0.7 | 0.7 | 0.7 | 1 | 1 |
| 20 | 0.6 | 0.7 | 0.6 | 0.8 | 0.7 | 0.7 | 0.6 | 0.7 | 0.9 | 0.8 | 0.8 | 0.9 | 0.9 | 0.9 | 0.7 | 0.6 | 0.6 | 0.6 | 1 | 1 | 0.8 | 0.9 | 0.9 | 0.9 | 0.6 | 0.6 | 0.5 | 0.6 | 1 | 1 |
| 21 | 0.7 | 0.8 | 0.7 | 0.7 | 0.5 | 0.4 | 0.4 | 0.4 | 0.7 | 0.7 | 0.9 | 0.9 | 0.9 | 0.8 | 0.5 | 0.4 | 0.4 | 0.4 | 0.7 | 0.8 | 1 | 1 | 1 | 0.8 | 0.5 | 0.4 | 0.4 | 0.4 | 0.7 | 0.8 |
| 22 | 0.7 | 0.8 | 0.7 | 0.8 | 0.6 | 0.6 | 0.6 | 0.6 | 0.8 | 0.8 | 0.9 | 1 | 0.9 | 0.9 | 0.7 | 0.6 | 0.6 | 0.6 | 0.8 | 0.9 | 1 | 1 | 1 | 0.9 | 0.7 | 0.6 | 0.6 | 0.6 | 0.8 | 0.9 |
| 23 | 0.7 | 0.7 | 0.7 | 0.7 | 0.5 | 0.5 | 0.5 | 0.5 | 0.7 | 0.8 | 0.9 | 0.9 | 1 | 0.9 | 0.5 | 0.5 | 0.5 | 0.5 | 0.8 | 0.9 | 1 | 1 | 1 | 0.9 | 0.5 | 0.4 | 0.4 | 0.4 | 0.8 | 0.9 |
| 24 | 0.6 | 0.8 | 0.6 | 0.9 | 0.7 | 0.7 | 0.7 | 0.7 | 0.9 | 0.8 | 0.8 | 0.9 | 0.9 | 1 | 0.8 | 0.7 | 0.7 | 0.7 | 0.9 | 0.9 | 0.8 | 0.9 | 0.9 | 1 | 0.8 | 0.7 | 0.7 | 0.7 | 0.9 | 0.9 |
| 25 | 0.4 | 0.6 | 0.4 | 0.7 | 0.9 | 0.9 | 0.8 | 0.9 | 0.8 | 0.6 | 0.5 | 0.7 | 0.5 | 0.7 | 1 | 1 | 0.9 | 1 | 0.8 | 0.6 | 0.5 | 0.7 | 0.5 | 0.8 | 1 | 1 | 0.9 | 1 | 0.7 | 0.6 |
| 26 | 0.3 | 0.5 | 0.3 | 0.6 | 0.9 | 0.8 | 0.8 | 0.9 | 0.7 | 0.6 | 0.4 | 0.6 | 0.4 | 0.7 | 1 | 1 | 0.9 | 1 | 0.7 | 0.6 | 0.4 | 0.6 | 0.4 | 0.7 | 1 | 1 | 0.9 | 1 | 0.7 | 0.6 |
| 27 | 0.3 | 0.5 | 0.3 | 0.6 | 0.8 | 0.8 | 0.8 | 0.8 | 0.7 | 0.5 | 0.4 | 0.6 | 0.4 | 0.6 | 0.9 | 0.9 | 1 | 0.9 | 0.7 | 0.5 | 0.4 | 0.6 | 0.4 | 0.7 | 0.9 | 0.9 | 1 | 0.9 | 0.7 | 0.5 |
| 28 | 0.3 | 0.5 | 0.3 | 0.6 | 0.9 | 0.9 | 0.8 | 0.9 | 0.7 | 0.6 | 0.4 | 0.6 | 0.4 | 0.7 | 1 | 1 | 0.9 | 1 | 0.7 | 0.6 | 0.4 | 0.6 | 0.4 | 0.7 | 1 | 1 | 0.9 | 1 | 0.7 | 0.6 |
| 29 | 0.5 | 0.6 | 0.5 | 0.8 | 0.8 | 0.8 | 0.7 | 0.8 | 0.9 | 0.8 | 0.7 | 0.8 | 0.8 | 0.9 | 0.8 | 0.7 | 0.7 | 0.7 | 1 | 1 | 0.7 | 0.8 | 0.8 | 0.9 | 0.7 | 0.7 | 0.7 | 0.7 | 1 | 1 |
| 30 | 0.5 | 0.7 | 0.6 | 0.8 | 0.7 | 0.7 | 0.6 | 0.7 | 0.9 | 0.8 | 0.8 | 0.9 | 0.9 | 0.9 | 0.7 | 0.6 | 0.6 | 0.6 | 1 | 1 | 0.8 | 0.9 | 0.9 | 0.9 | 0.6 | 0.6 | 0.5 | 0.6 | 1 | 1 |



References
- Reese, H.; Nordkvist, K.; Nyström, M.; Bohlin, J.; Olsson, H. Combining point clouds from image matching with SPOT 5 multispectral data for mountain vegetation classification. Int. J. Remote Sens. 2015. [Google Scholar] [CrossRef]
- Żołnierz, L.; Wojtuń, B.; Przewoźnik, L. Ekosystemy Nieleśne Karkonoskiego Parku Narodowego; Karkonoski Park Narodowy: Jelenia Góra, Poland, 2012. [Google Scholar]
- Xie, Y.; Sha, Z.; Yu, M. Remote sensing imagery in vegetation mapping: A review. J. Plant Ecol. 2008, 1, 9–23. [Google Scholar] [CrossRef]
- Osińska-Skotak, K.; Radecka, A.; Piórkowski, H.; Michalska-Hejduk, D.; Kopeć, D.; Tokarska-Guzik, B.; Ostrowski, W.; Kania, A.; Niedzielko, J. Mapping Succession in Non-Forest Habitats by Means of Remote Sensing: Is the Data Acquisition Time Critical for Species Discrimination? Remote Sens. 2019, 11, 2629. [Google Scholar] [CrossRef] [Green Version]
- Sławik, Ł.; Niedzielko, J.; Kania, A.; Piórkowski, H.; Kopeć, D. Multiple flights or single flight instrument fusion of hyperspectral and ALS data? A comparison of their performance for vegetation mapping. Remote Sens. 2019, 11, 913. [Google Scholar] [CrossRef] [Green Version]
- Macintyre, P.; van Niekerk, A.; Mucina, L. Efficacy of multi-season Sentinel-2 imagery for compositional vegetation classification. Int. J. Appl. Earth Obs. Geoinf. 2020, 85, 101980. [Google Scholar] [CrossRef]
- Kupková, L.; Červená, L.; Suchá, R.; Jakešová, L.; Zagajewski, B.; Březina, S.; Albrechtová, J. Classification of tundra vegetation in the Krkonoše Mts. National park using APEX, AISA dual and sentinel-2A data. Eur. J. Remote Sens. 2017, 50, 29–46. [Google Scholar] [CrossRef]
- Sabat-Tomala, A.; Raczko, E.; Zagajewski, B. Comparison of support vector machine and random forest algorithms for invasive and expansive species classification using airborne hyperspectral data. Remote Sens. 2020, 12, 516. [Google Scholar] [CrossRef] [Green Version]
- Burai, P.; Deák, B.; Valkó, O.; Tomor, T. Classification of herbaceous vegetation using airborne hyperspectral imagery. Remote Sens. 2015, 7, 2046–2066. [Google Scholar] [CrossRef] [Green Version]
- Adagbasa, E.G.; Adelabu, S.A.; Okello, T.W. Application of deep learning with stratified K-fold for vegetation species discrimation in a protected mountainous region using Sentinel-2 image. Geocarto Int. 2019. [Google Scholar] [CrossRef]
- Vapnik, V.N. An overview of statistical learning theory. IEEE Trans. Neural Networks 1999, 10, 988–999. [Google Scholar] [CrossRef] [Green Version]
- Foody, G.M.; Mathur, A. Toward intelligent training of supervised image classifications: Directing training data acquisition for SVM classification. Remote Sens. Environ. 2004, 93, 107–117. [Google Scholar] [CrossRef]
- Waske, B.; van der Linden, S.; Benediktsson, J.A.; Rabe, A.; Hostert, P. Sensitivity of Support Vector Machines to Random Feature Selection in Classification of Hyperspectral Data. IEEE Trans. Geosci. Remote Sens. 2010, 48, 2880–2889. [Google Scholar] [CrossRef] [Green Version]
- Demarchi, L.; Canters, F.; Cariou, C.; Licciardi, G.; Chan, J.C.-W. Assessing the performance of two unsupervised dimensionality reduction techniques on hyperspectral APEX data for high resolution urban land-cover mapping. ISPRS J. Photogramm. Remote Sens. 2014, 87, 166–179. [Google Scholar] [CrossRef]
- Marcinkowska-Ochtyra, A.; Zagajewski, B.; Raczko, E.; Ochtyra, A.; Jarocińska, A. Classification of high-mountain vegetation communities within a diverse Giant Mountains ecosystem using airborne APEX hyperspectral imagery. Remote Sens. 2018, 10, 570. [Google Scholar] [CrossRef] [Green Version]
- Akbani, R.; Kwek, S.; Japkowicz, N. Applying Support Vector Machines to Imbalanced Datasets. In Lecture Notes in Artificial Intelligence (Subseries of Lecture Notes in Computer Science); Springer: Berlin/Heidelberg, Germany, 2004; pp. 39–50. [Google Scholar]
- Thanh Noi, P.; Kappas, M. Comparison of Random Forest, k-Nearest Neighbor, and Support Vector Machine Classifiers for Land Cover Classification Using Sentinel-2 Imagery. Sensors 2017, 18, 18. [Google Scholar] [CrossRef] [Green Version]
- Jędrych, M.; Zagajewski, B.; Marcinkowska-Ochtyra, A. Application of Sentinel-2 and EnMAP new satellite data to the mapping of alpine vegetation of the Karkonosze Mountains. Pol. Cartogr. Rev. 2017, 49, 107–119. [Google Scholar] [CrossRef] [Green Version]
- Kokaly, R.F.; Despain, D.G.; Clark, R.N.; Livo, K.E. Mapping vegetation in Yellowstone National Park using spectral feature analysis of AVIRIS data. Remote Sens. Environ. 2003, 84, 437–456. [Google Scholar] [CrossRef] [Green Version]
- Chan, J.C.W.; Paelinckx, D. Evaluation of Random Forest and Adaboost tree-based ensemble classification and spectral band selection for ecotope mapping using airborne hyperspectral imagery. Remote Sens. Environ. 2008. [Google Scholar] [CrossRef]
- Raczko, E.; Zagajewski, B. Tree species classification of the UNESCO man and the biosphere Karkonoski National Park (Poland) using artificial neural networks and APEX hyperspectral images. Remote Sens. 2018, 10, 1111. [Google Scholar] [CrossRef] [Green Version]
- Dehaan, R.; Louis, J.; Wilson, A.; Hall, A.; Rumbachs, R. Discrimination of blackberry (Rubus fruticosus sp. agg.) using hyperspectral imagery in Kosciuszko National Park, NSW, Australia. ISPRS J. Photogramm. Remote Sens. 2007. [Google Scholar] [CrossRef]
- Cingolani, A.M.; Renison, D.; Zak, M.R.; Cabido, M.R. Mapping vegetation in a heterogeneous mountain rangeland using landsat data: An alternative method to define and classify land-cover units. Remote Sens. Environ. 2004. [Google Scholar] [CrossRef]
- Kopeć, D.; Zakrzewska, A.; Halladin-Dąbrowska, A.; Wylazłowska, J.; Kania, A.; Niedzielko, J. Using Airborne Hyperspectral Imaging Spectroscopy to Accurately Monitor Invasive and Expansive Herb Plants: Limitations and Requirements of the Method. Sensors 2019, 19, 2871. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rapinel, S.; Bouzillé, J.B.; Oszwald, J.; Bonis, A. Use of bi-Seasonal Landsat-8 Imagery for Mapping Marshland Plant Community Combinations at the Regional Scale. Wetlands 2015. [Google Scholar] [CrossRef]
- Díaz Varela, R.A.; Ramil Rego, P.; Calvo Iglesias, S.; Muñoz Sobrino, C. Automatic habitat classification methods based on satellite images: A practical assessment in the NW Iberia coastal mountains. Environ. Monit. Assess. 2008. [Google Scholar] [CrossRef] [PubMed]
- Rapinel, S.; Mony, C.; Lecoq, L.; Clément, B.; Thomas, A.; Hubert-Moy, L. Evaluation of Sentinel-2 time-series for mapping floodplain grassland plant communities. Remote Sens. Environ. 2019. [Google Scholar] [CrossRef]
- Persson, M.; Lindberg, E.; Reese, H. Tree Species Classification with Multi-Temporal Sentinel-2 Data. Remote Sens. 2018, 10, 1794. [Google Scholar] [CrossRef] [Green Version]
- Grabska, E.; Hostert, P.; Pflugmacher, D.; Ostapowicz, K. Forest stand species mapping using the sentinel-2 time series. Remote Sens. 2019, 11, 1197. [Google Scholar] [CrossRef] [Green Version]
- Immitzer, M.; Neuwirth, M.; Böck, S.; Brenner, H.; Vuolo, F.; Atzberger, C. Optimal Input Features for Tree Species Classification in Central Europe Based on Multi-Temporal Sentinel-2 Data. Remote Sens. 2019, 11, 2599. [Google Scholar] [CrossRef] [Green Version]
- Hościło, A.; Lewandowska, A. Mapping Forest Type and Tree Species on a Regional Scale Using Multi-Temporal Sentinel-2 Data. Remote Sens. 2019, 11, 929. [Google Scholar] [CrossRef] [Green Version]
- Puletti, N.; Chianucci, F.; Castaldi, C. Use of Sentinel-2 for forest classification in Mediterranean environments. Ann. Silvic. Res. 2018. [Google Scholar] [CrossRef]
- Hunter, F.D.L.; Mitchard, E.T.A.; Tyrrell, P.; Russell, S. Inter-seasonal time series imagery enhances classification accuracy of grazing resource and land degradation maps in a savanna ecosystem. Remote Sens. 2020, 12, 198. [Google Scholar] [CrossRef] [Green Version]
- Oldeland, J.; Dorigo, W.; Lieckfeld, L.; Lucieer, A.; Jürgens, N. Combining vegetation indices, constrained ordination and fuzzy classification for mapping semi-natural vegetation units from hyperspectral imagery. Remote Sens. Environ. 2010, 114, 1155–1166. [Google Scholar] [CrossRef]
- Hotelling, H. Analysis of a complex of statistical variables into principal components. J. Educ. Psychol. 1933. [Google Scholar] [CrossRef]
- Kauth, R.J.; Thomas, G.S. The tasseled cap-A graphic description of the spectral-temporal development of agricultural crops as seen by Landsat. In Proceedings of the Symposium on Machine Processing of Remotely Sensed Data, West Lafayette, IN, USA, 29 June–1 July 1976. [Google Scholar]
- Rouse, J.W.; Haas, R.H.; Schell, J.A.; Deering, D.W. Monitoring the vernal advancement and retrogradation (green wave effect) of natural vegetation. Prog. Rep. 1973. RSC 1978-4. [Google Scholar]
- Schuster, C.; Schmidt, T.; Conrad, C.; Kleinschmit, B.; Förster, M. Grassland habitat mapping by intra-annual time series analysis—Comparison of RapidEye and TerraSAR-X satellite data. Int. J. Appl. Earth Obs. Geoinf. 2015, 34, 25–34. [Google Scholar] [CrossRef]
- Demarchi, L.; Kania, A.; Ciezkowski, W.; Piórkowski, H.; Oświecimska-Piasko, Z.; Chormański, J. Recursive feature elimination and random forest classification of natura 2000 grasslands in lowland river valleys of poland based on airborne hyperspectral and LiDAR data fusion. Remote Sens. 2020, 12, 1842. [Google Scholar] [CrossRef]
- Marcinkowska-Ochtyra, A.; Jarocińska, A.; Bzdȩga, K.; Tokarska-Guzik, B. Classification of expansive grassland species in different growth stages based on hyperspectral and LiDAR data. Remote Sens. 2018, 10, 2019. [Google Scholar] [CrossRef] [Green Version]
- Shoko, C.; Mutanga, O. Examining the strength of the newly-launched Sentinel 2 MSI sensor in detecting and discriminating subtle differences between C3 and C4 grass species. ISPRS J. Photogramm. Remote Sens. 2017. [Google Scholar] [CrossRef]
- Marcinkowska-Ochtyra, A.; Gryguc, K.; Ochtyra, A.; Kopeć, D.; Jarocińska, A.; Sławik, Ł. Multitemporal hyperspectral data fusion with topographic indices’improving classification of natura 2000 grassland habitats. Remote Sens. 2019, 11, 2264. [Google Scholar] [CrossRef] [Green Version]
- Oeser, J.; Pflugmacher, D.; Senf, C.; Heurich, M.; Hostert, P. Using intra-annual Landsat time series for attributing forest disturbance agents in Central Europe. Forests 2017, 8, 251. [Google Scholar] [CrossRef]
- Ochtyra, A. Forest disturbances in Polish Tatra Mountains for 1985-2016 in relation to topography, stand features, and protection zone. Forests 2020, 11, 579. [Google Scholar] [CrossRef]
- Suchá, R.; Jakešová, L.; Kupková, L.; Červená, L. Classification of vegetation above the tree line in the krkonoše mts. national park using remote sensing multispectral data. Acta Univ. Carol. Geogr. 2016. [Google Scholar] [CrossRef] [Green Version]
- Marcinkowska-Ochtyra, A.; Zagajewski, B.; Ochtyra, A.; Jarocińska, A.; Wojtuń, B.; Rogass, C.; Mielke, C.; Lavender, S. Subalpine and alpine vegetation classification based on hyperspectral APEX and simulated EnMAP images. Int. J. Remote Sens. 2017, 38, 1839–1864. [Google Scholar] [CrossRef] [Green Version]
- Wojtuń, B.; Żołnierz, L. Plan ochrony ekosystemów nieleśnych—inwentaryzacja zbiorowisk. In Plan Ochrony Karkonoskiego Parku Narodowego; Bureau for Forest Management and Geodesy: Brzeg, Poland, 2002; p. 67. [Google Scholar]
- Przewoźnik, L. Rośliny Karkonoskiego Parku Narodowego; Karkonoski Park Narodowy: Jelenia Góra, Poland, 2008. [Google Scholar]
- Jarocińska, A.; Zagajewski, B.; Ochtyra, A.; Marcinkowska-Ochtyra, A.; Kycko, M.; Pabjanek, P. Przebieg klęski ekologicznej w Karkonoszach i Górach Izerskich na podstawie analizy zdjęć satelitarnych Landsat. In Konferencja Naukowa z Okazji 55-Lecia Karkonoskiego Parku Narodowego: 25 lat po Klęsce Ekologicznej w Karkonoszach i Górach Izerskich—Obawy a Rzeczywistość; Knapik, R., Ed.; Karkonoski Park Narodowy: Jelenia Góra, Poland, 2014; pp. 47–62. [Google Scholar]
- Hejcman, M.; Češková, M.; Pavlů, V. Control of Molinia caerulea by cutting management on sub-alpine grassland. Flora Morphol. Distrib. Funct. Ecol. Plants 2010, 205, 577–582. [Google Scholar] [CrossRef]
- Marcinkowska-Ochtyra, A. Assessment of APEX Hyperspectral Images and Support Vector Machines for Karkonosze Subalpine and Alpine Vegetation Classification. Ph.D. Thesis, University of Warsaw, Warsaw, Poland, 2016. [Google Scholar]
- Bannari, A.; Morin, D.; Bonn, F.; Huete, A.R. A review of vegetation indices—Remote Sensing Reviews. Remote Sens. Rev. 1995. [Google Scholar] [CrossRef]
- Meyer, D.; Dimitriadou, E.; Hornik, K.; Weingessel, A.; Leisch, F.; Chang, C.-C.; Lin, C.-C. Misc Functions of the Department of Statistics, Probability Theory Group (Formerly: E1071); TU Wien: Vienna, Austria, 2019; ISBN 0805331700. [Google Scholar]
- R Core Team A Language and Environment for Statistical Computing; R Found. Stat. Comput.: Vienna, Austria, 2018.
- Gualtieri, J.A.; Cromp, R.F. Support vector machines for hyperspectral remote sensing classification. In Proceedings of the 27th AIPR Workshop: Advances in Computer Assisted Recognition, Washington, DC, USA, 14–16 October 1998; SPIE: Bellingham, WA, USA, 1999; pp. 221–232. [Google Scholar]
- Ghosh, A.; Fassnacht, F.E.; Joshi, P.K.; Koch, B. A framework for mapping tree species combining hyperspectral and LiDAR data: Role of selected classifiers and sensor across three spatial scales. Int. J. Appl. Earth Obs. Geoinf. 2014. [Google Scholar] [CrossRef]
- Congalton, R.G. A review of assessing the accuracy of classifications of remotely sensed data. Remote Sens. Environ. 1991, 37, 35–46. [Google Scholar] [CrossRef]
- Van Rijsbergen, C.J. Information Retrieval, 2nd ed.; Butterworths: Oxford, UK, 1979. [Google Scholar]
- Kuhn, M. Package ‘caret’, Classification and Regression Training. J. Stat. Softw. 2008, 28, 1–26. [Google Scholar]
- Karasiak, N.; Sheeren, D.; Fauvel, M.; Willm, J.; Dejoux, J.F.; Monteil, C. Mapping tree species of forests in southwest France using Sentinel-2 image time series. In Proceedings of the 2017 9th International Workshop on the Analysis of Multitemporal Remote Sensing Images, MultiTemp 2017, Brugge, Belgium, 27–29 June 2017. [Google Scholar]
- Sitokonstantinou, V.; Papoutsis, I.; Kontoes, C.; Arnal, A.L.; Andrés, A.P.A.; Zurbano, J.A.G. Scalable parcel-based crop identification scheme using Sentinel-2 data time-series for the monitoring of the common agricultural policy. Remote Sens. 2018, 10, 911. [Google Scholar] [CrossRef] [Green Version]
- Brown De Colstoun, E.C.; Story, M.H.; Thompson, C.; Commisso, K.; Smith, T.G.; Irons, J.R. National Park vegetation mapping using multitemporal Landsat 7 data and a decision tree classifier. Remote Sens. Environ. 2003. [Google Scholar] [CrossRef]
- Guerschman, J.P.; Paruelo, J.M.; Di Bella, C.; Giallorenzi, M.C.; Pacin, F. Land cover classification in the Argentine Pampas using multi-temporal Landsat TM data. Int. J. Remote Sens. 2003. [Google Scholar] [CrossRef]
- Immitzer, M.; Vuolo, F.; Atzberger, C. First experience with Sentinel-2 data for crop and tree species classifications in central Europe. Remote Sens. 2016, 8, 166. [Google Scholar] [CrossRef]

| Dataset No. | Type | Date | Dataset | Bands |
|---|---|---|---|---|
| 1 | single-date | 31 May 2018 1 | A | 10 |
| 2 | 07 August 2018 2 | B | 10 | |
| 3 | 27 August 2018 3 | C | 10 | |
| 4 | 18 September 2018 4 | D | 10 | |
| 5 | multi-temporal | 31 May 2018/07 August 2018 | AB | 10/10 |
| 6 | 31 May 2018/27 August 2018 | AC | 10/10 | |
| 7 | 31 May 2018/18 September 2018 | AD | 10/10 | |
| 8 | 07 August 2018/27 August 2018 | BC | 10/10 | |
| 9 | 07 August 2018/18 September 2018 | BD | 10/10 | |
| 10 | 27 August 2018/18 September 2018 | CD | 10/10 | |
| 11 | 31 May 2018/07 August 2018/27 August 2018 | ABC | 10/10/10 | |
| 12 | 31 May 2018/07 August 2018/18 September 2018 | ABD | 10/10/10 | |
| 13 | 31 May 2018/27 August 2018/18 September 2018 | ACD | 10/10/10 | |
| 14 | 07 August 2018/27 August 2018/18 September 2018 | BCD | 10/10/10 | |
| 15 | 31 May 2018/07 August 2018/27 August 2018/18 September 2018 | ABCD | 10/10/10/10 | |
| 16 | - | the_best_IND | X + Y × 18 | |
| 17 | - | the_best_PCA_ | X + Z |
| Vegetation Type | Number of Polygons | Area [m2] |
|---|---|---|
| subalpine dwarf pine scrub | 102 | 255,600 |
| grasslands | 67 | 102,000 |
| forest | 33 | 95,600 |
| heathlands | 70 | 69,200 |
| bogs and fens | 50 | 67,600 |
| subalpine tall forbs | 59 | 51,200 |
| non-vegetation | 63 | 47,600 |
| rock and scree vegetation | 39 | 44,000 |
| deciduous shrub vegetation | 19 | 16,800 |
| Sum | 502 | 749,600 |
| Number | Date | Dataset | Overall Accuracy (%) | |
|---|---|---|---|---|
| Default 1 | Optimized 2 | |||
| 1 | 31.05 | A | 71.30 | 72.80 |
| 2 | 07.08 | B | 72.29 | 74.19 |
| 3 | 27.08 | C | 70.77 | 72.67 |
| 4 | 18.09 | D | 71.64 | 72.89 |
| Reference Data | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| SDPS | F | G | NV | BF | RSV | DSV | STF | H | |||
| Classified data | SDPS | 827 | 6 | 6 | 18 | 34 | 28 | 0 | 0 | 3 | 922 |
| F | 6 | 321 | 0 | 4 | 0 | 0 | 0 | 0 | 2 | 333 | |
| G | 1 | 0 | 311 | 1 | 11 | 2 | 0 | 40 | 25 | 391 | |
| NV | 1 | 11 | 31 | 132 | 1 | 3 | 1 | 0 | 14 | 194 | |
| BF | 4 | 0 | 27 | 3 | 118 | 0 | 0 | 7 | 3 | 162 | |
| RSV | 0 | 0 | 3 | 6 | 0 | 127 | 2 | 3 | 2 | 143 | |
| DSV | 2 | 9 | 0 | 1 | 0 | 1 | 27 | 1 | 24 | 65 | |
| STF | 0 | 1 | 14 | 9 | 16 | 4 | 12 | 115 | 41 | 212 | |
| H | 7 | 8 | 28 | 2 | 16 | 3 | 18 | 26 | 158 | 266 | |
| 848 | 356 | 420 | 176 | 196 | 168 | 60 | 192 | 272 | 2416 | ||
| Ref. | Obj. | Sens. | Multi-Temporal Composition | Method | OA (%) | ||
|---|---|---|---|---|---|---|---|
| No. of Images | Dates of Acquisition | No. of Classes | Alg. | ||||
| [62] | land cover | Landsat-7 | 1 | all possible single images | 11 | DT | 70.0–72.0 |
| 2 | composition of two images | 82.0 | |||||
| 23 September 1999 (early autumn) 29 January 2000 (winter) | |||||||
| [63] | land cover | Landsat-5 | 1 | all possible single images | 6 | ML | 49.7–65.9 |
| 2 | all possible compositions of two images | 62.2–77.0 | |||||
| 3 | all possible compositions of three images | 70.8–79.4 | |||||
| 4 | composition of four images | 80.8 | |||||
| 5 October 1996 (spring) 24 December 1996 (early summer) 10 February 1997 (late summer) 30 March 1997(early autumn) | |||||||
| [25] | swamp communities | Landsat-8 | 1 | all possible single images | 12 | ML | 63.1–76.1 |
| 2 | composition of two images | 85.9 | |||||
| 3 September 2013 (late summer) 8 December 2013 (late autumn) | |||||||
| [28] | tree species | Sentinel-2 | 1 | all possible single images | 5 | RF | 72.4–80.5 |
| 2 | all possible compositions of two images | 78.3–85.0 | |||||
| 3 | all possible compositions of three images | 85.1–87.4 | |||||
| 4 | composition of four images | 88.2 | |||||
| 7 April 2017 (early spring) 27 May 2017 (spring) 9 July 2017 (early summer) 19 October 2017 (early autumn) | |||||||
| [27] | grassy communities | Sentinel-2 | 1 | all possible single images | 7 | SVM | 33.0–67.0 |
| 12 | composition of twelve images | 78.0 | |||||
| 3, 30 November 2016 (late autumn) 19 January; 18 February 2017 (winter) 18, 30 March; 9 April 2017(early spring) 9, 22 May 2017 (spring) 21 June; 6 July; 27 August 2017(summer) | |||||||
| [30] | tree species | Sentinel-2 | 1 | all possible single images | 12 | RF | 48.1–78.6 |
| 2-17 | all possible compositions of at least two and maximum of seventeen out of eighteen images | 72.9–95.3 | |||||
| 18 | composition of eighteen images | 96.2 | |||||
| 27 March; 13 April 2016; 1 April 2017 (early spring) 28 May 2017 (spring) 30 August 2015; 31 August 2016; 20 June; 1, 8 August 2017 (summer) 13, 30 September 2016; 8, 28, 30 September 2017 (autumn) 15 October 2017 (late autumn) 25 December 2015; 11 January 2017 (winter) | |||||||
| [29] | tree species | Sentinel-2 | 1 | all possible single images | 9 | RF | ~72.0–87.4 |
| 2 | all possible compositions of two images | ~79.9–90.2 | |||||
| 3 | all possible compositions of three images | ~89.9–91.8 | |||||
| 4 | all possible compositions of four images | ~91.0–92.1 | |||||
| 5 | composition of five images | 92.4 | |||||
| 18 | composition of eighteen images | 92.1 | |||||
| 5, 12, 20, 30 April 2018 (early spring) 2, 5, 7, 12 May 2018 (spring) 6 June 2018 (spring) 20, 30 August 2018 (summer) 12, 19 September; 9, 14, 17 October 2018 (autumn) 6, 8 November 2018 (late autumn) | |||||||
| [33] | grassy and woody vegetation of savanna | Sentinel-2 | 1 | single image | 9 | SVM | 68.0 |
| 2 | composition of two images | 74.0 | |||||
| 5 | composition of five images | 82.2 | |||||
| May 2018 (×2; wet season) June 2018 (dry season) August 2018 (dry season) October 2018 (dry season) | |||||||
| [6] | hardwood shrub communities | Sentinel-2 | 1 | all possible single images | 24 | SVM | 4.0–53.0 |
| 2 | all possible compositions of two images | 3.0–68.0 | |||||
| 3 | all possible compositions of three images | 5.0 | |||||
| 4 | composition of four images | 12.0 | |||||
| 7 January 2017 (summer) 17 May 2017 (autumn) 26 June 2017 (winter) 4 October 2017 (spring) | |||||||
| this study | high-mountain vegetation | Sentinel-2 | 1 | all possible single images | 9 | SVM | 72.7–74.2 |
| 2 | all possible compositions of two images | 76.3–79.0 | |||||
| 3 | all possible compositions of three images | 77.8–79.5 | |||||
| 4 | composition of four images | 78.5 | |||||
| 31 May 2018 (spring) 7 August 2018 (summer) 27 August 2018 (summer) 18 September 2018 (early autumn) | |||||||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wakulińska, M.; Marcinkowska-Ochtyra, A. Multi-Temporal Sentinel-2 Data in Classification of Mountain Vegetation. Remote Sens. 2020, 12, 2696. https://doi.org/10.3390/rs12172696
Wakulińska M, Marcinkowska-Ochtyra A. Multi-Temporal Sentinel-2 Data in Classification of Mountain Vegetation. Remote Sensing. 2020; 12(17):2696. https://doi.org/10.3390/rs12172696
Chicago/Turabian StyleWakulińska, Martyna, and Adriana Marcinkowska-Ochtyra. 2020. "Multi-Temporal Sentinel-2 Data in Classification of Mountain Vegetation" Remote Sensing 12, no. 17: 2696. https://doi.org/10.3390/rs12172696
APA StyleWakulińska, M., & Marcinkowska-Ochtyra, A. (2020). Multi-Temporal Sentinel-2 Data in Classification of Mountain Vegetation. Remote Sensing, 12(17), 2696. https://doi.org/10.3390/rs12172696