Prediction of Sea Surface Temperature in the China Seas Based on Long Short-Term Memory Neural Networks


Abstract
1. Introduction
2. Materials and Methods
2.1. Study Area
2.2. Data
2.3. Proposed Method
2.3.1. Classification
- Choose small random values for the initial weight vectors , , where is the number of neurons, which is the classified number chosen by the designer, and is different in .
- Select an input vector randomly in the training data set.
- Find the best-matching (winning) neuron at time-step using the minimum-distance criterion:
- Adjust the synaptic weight vectors of all excited neurons using the update formula:
2.3.2. Deep Neural Networks Models
- In the first step, the LSTM determines what information is removed from the previous cell state . The input vector , the outputs of the memory cells in the previous step, and the forget gate bias are calculated in the forget gate unit:The range of is scaled by the sigmoid function , which is between 0 (completely remove) and 1 (completely keep).
- In the next step, the LSTM determines what new information is stored in the cell state . This includes adding a new candidate value to the cell state and updating information through the input gate. The computation is as follows:
- The third step updates the cell state based on the above output values.
- Finally, the LSTM determines output :
2.3.3. Ensemble Predicting Results
3. Results
3.1. Comparison between the Model Trained with and without Class Labels
3.2. SST Prediction with Different Lead Times from 2015 to 2018
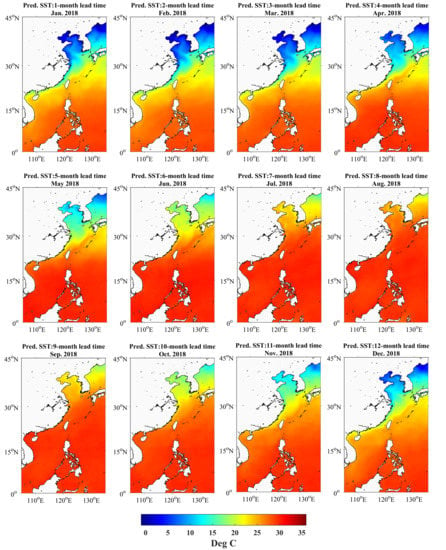
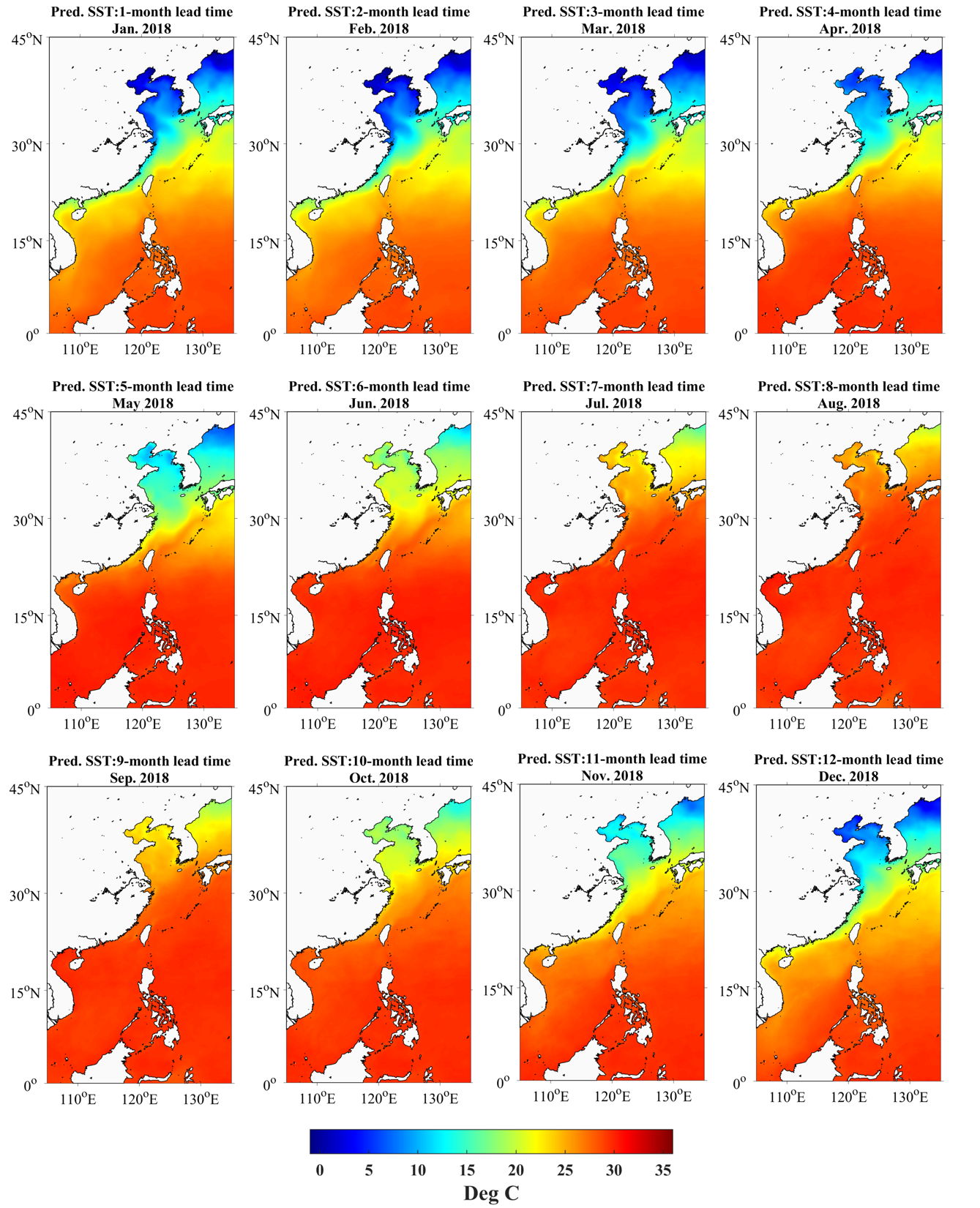
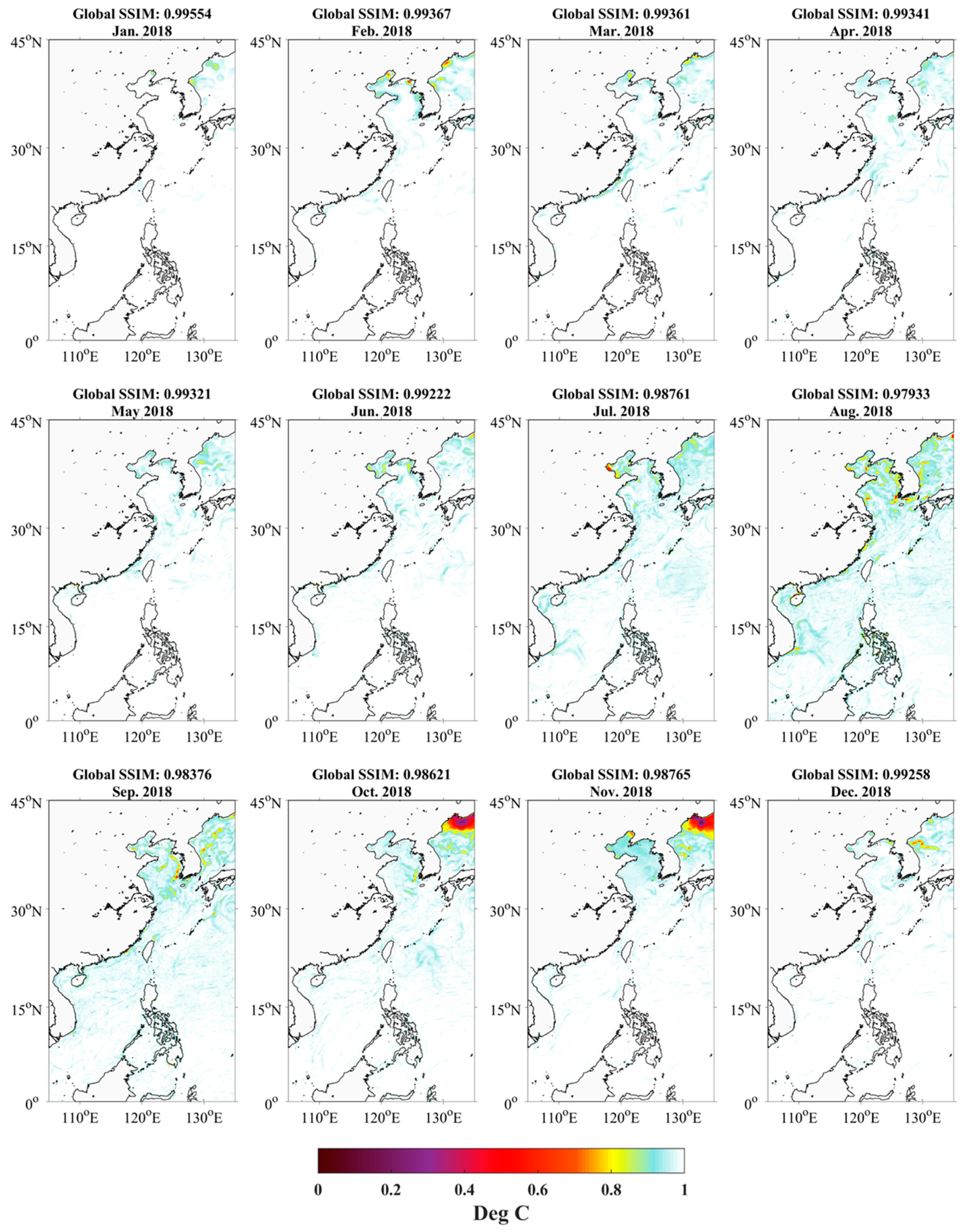
3.3. Predicted SST Distribution in Space
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Deser, C.; Phillips, A.S.; Alexander, M.A. Twentieth century tropical sea surface temperature trends revisited. Geophys. Res. Lett. 2010, 37. [Google Scholar] [CrossRef]
- Alexander, M.A.; Scott, J.D.; Friedland, K.D.; Mills, K.E.; Nye, J.A.; Pershing, A.; Thomas, A.C. Projected sea surface temperatures over the 21st century: Changes in the mean, variability and extremes for large marine ecosystem regions of Northern Oceans. Elem. Sci. Anth. 2018, 6, 9. [Google Scholar] [CrossRef]
- Tan, H.; Cai, R.; Huang, R. Enhanced Responses of Sea Surface Temperature over Offshore China to Global Warming and Hiatus. Clim. Chang. Res. 2016, 12, 500–507. [Google Scholar]
- Wang, Q.; Li, Y.; Li, Q.; Liu, Y.; Wang, Y.-N. Changes in Means and Extreme Events of Sea Surface Temperature in the East China Seas Based on Satellite Data from 1982 to 2017. Atmosphere 2019, 10, 140. [Google Scholar] [CrossRef]
- Cai, R.; Tan, H.; Kontoyiannis, H. Robust Surface Warming in Offshore China Seas and Its Relationship to the East Asian Monsoon Wind Field and Ocean Forcing on Interdecadal Time Scales. J. Clim. 2017, 30, 8987–9005. [Google Scholar] [CrossRef]
- Liang, C.; Xian, W.; Pauly, D. Impacts of Ocean Warming on China’s Fisheries Catches: An Application of “Mean Temperature of the Catch” Concept. Front. Mar. Sci. 2018, 5, 5. [Google Scholar] [CrossRef]
- Xu, G.; Lin, C. Relationship between the Variation of the Sea Surface Temperature over the South China Sea and the Rainfalls over the Middle and Lower Reaches of the Yangtze River in Jun. Sci. Meteorol. Sin. 1990, 10, 174–181. [Google Scholar]
- McTaggart-Cowan, R.; Davies, E.L.; Fairman, J.G., Jr.; Galarneau, T.J., Jr.; Schultz, D.M. Revisiting the 26.5 °C sea surface temperature threshold for tropical cyclone development. Bull. Am. Meteorol. Soc. 2015, 96, 1929–1943. [Google Scholar] [CrossRef]
- Ha, Y.; Zhong, Z.; Zhang, Y.; Ding, J.; Yang, X. Relationship between interannual changes of summer rainfall over Yangtze River Valley and South China Sea–Philippine Sea: Possible impact of tropical zonal sea surface temperature gradient. Int. J. Clim. 2019, 39, 5522–5538. [Google Scholar] [CrossRef]
- Qiong, Z.; Ping, L.; Guoxiong, W. The relationship between the flood and drought over the lower reach of the Yangtze River valley and the SST over the Indian ocean and the South China Sea. Chin. J. Atmos. Sci. 2003, 27, 992–1006. [Google Scholar]
- Liu, J.Y. Status of Marine Biodiversity of the China Seas. PLoS ONE 2013, 8, e50719. [Google Scholar] [CrossRef] [PubMed]
- Thakur, K.; Vanderstichel, R.; Barrell, J.; Stryhn, H.; Patanasatienkul, T.; Revie, C.W. Comparison of Remotely-Sensed Sea Surface Temperature and Salinity Products With in Situ Measurements From British Columbia, Canada. Front. Mar. Sci. 2018, 5, 5. [Google Scholar] [CrossRef]
- Fablet, R.; Viet, P.H.; Lguensat, R. Data-Driven Models for the Spatio-Temporal Interpolation of Satellite-Derived SST Fields. IEEE Trans. Comput. Imaging 2017, 3, 647–657. [Google Scholar] [CrossRef]
- Tangang, F.T.; Hsieh, W.W.; Tang, B. Forecasting the equatorial Pacific sea surface temperatures by neural network models. Clim. Dyn. 1997, 13, 135–147. [Google Scholar] [CrossRef]
- Tangang, F.T.; Hsieh, W.W.; Tang, B. Forecasting regional sea surface temperatures in the tropical Pacific by neural network models, with wind stress and sea level pressure as predictors. J. Geophys. Res. Space Phys. 1998, 103, 7511–7522. [Google Scholar] [CrossRef]
- Tangang, F.T.; Tang, B.; Monahan, A.H.; Hsieh, W.W. Forecasting ENSO Events: A Neural Network–Extended EOF Approach. J. Clim. 1998, 11, 29–41. [Google Scholar] [CrossRef]
- Wu, A.; Hsieh, W.W.; Tang, B. Neural network forecasts of the tropical Pacific sea surface temperatures. Neural Netw. 2006, 19, 145–154. [Google Scholar] [CrossRef]
- Ali, M.M.; Weller, R.A.; Swain, D. Estimation of ocean subsurface thermal structure from surface parameters: A neural network approach. Geophys. Res. Lett. 2004, 31. [Google Scholar] [CrossRef]
- Barrows, T.T.; Juggins, S. Sea-surface temperatures around the Australian margin and Indian Ocean during the Last Glacial Maximum. Quat. Sci. Rev. 2005, 24, 1017–1047. [Google Scholar] [CrossRef]
- Hayes, A.; Kucera, M.; Kallel, N.; Sbaffi, L.; Rohling, E.J. Glacial Mediterranean sea surface temperatures based on planktonic foraminiferal assemblages. Quat. Sci. Rev. 2005, 24, 999–1016. [Google Scholar] [CrossRef]
- Garcia-Gorriz, E.; Garcia-Sanchez, J. Prediction of sea surface temperatures in the western Mediterranean Sea by neural networks using satellite observations. Geophys. Res. Lett. 2007, 34. [Google Scholar] [CrossRef]
- Patil, K.; Deo, M.C. Prediction of daily sea surface temperature using efficient neural networks. Ocean Dyn. 2017, 67, 357–368. [Google Scholar] [CrossRef]
- Mahongo, S.B.; Deo, M.C. Using Artificial Neural Networks to Forecast Monthly and Seasonal Sea Surface Temperature Anomalies in the Western Indian Ocean. Int. J. Ocean Clim. Syst. 2013, 4, 133–150. [Google Scholar] [CrossRef]
- Patil, K.; Deo, M.C.; Ravichandran, M. Prediction of Sea Surface Temperature by Combining Numerical and Neural Techniques. J. Atmos. Ocean. Technol. 2016, 33, 1715–1726. [Google Scholar] [CrossRef]
- Wei, L.; Guan, L.; Qu, L. Prediction of Sea Surface Temperature in the South China Sea by Artificial Neural Networks. IEEE Geosci. Remote Sens. Lett. 2019, 17, 558–562. [Google Scholar] [CrossRef]
- Zhang, Q.; Wang, H.; Dong, J.; Zhong, G.; Sun, X. Prediction of Sea Surface Temperature Using Long Short-Term Memory. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1745–1749. [Google Scholar] [CrossRef]
- Yang, Y.; Dong, J.; Sun, X.; Lima, E.; Mu, Q.; Wang, X. A CFCC-LSTM Model for Sea Surface Temperature Prediction. IEEE Geosci. Remote Sens. Lett. 2018, 15, 207–211. [Google Scholar] [CrossRef]
- Patil, K.; Deo, M.C. Basin-Scale Prediction of Sea Surface Temperature with Artificial Neural Networks. J. Atmos. Ocean. Technol. 2018, 35, 1441–1455. [Google Scholar] [CrossRef]
- Gong, S.; Wong, K. Spatio-Temporal Analysis of Sea Surface Temperature in the East China Sea Using TERRA/MODIS Products Data. In Sea Level Rise and Coastal Infrastructure; IntechOpen: London, UK, 2018. [Google Scholar]
- Ouyang, L.; Hui, F.; Zhu, L.; Cheng, X.; Cheng, B.; Shokr, M.; Zhao, J.; Ding, M.; Zeng, T. The spatiotemporal patterns of sea ice in the Bohai Sea during the winter seasons of 2000–2016. Int. J. Digit. Earth 2019, 12, 893–909. [Google Scholar] [CrossRef]
- Nihashi, S.; Ohshima, K.I.; Saitoh, S.-I. Sea-ice production in the northern Japan Sea. Deep. Sea Res. Part I Oceanogr. Res. Pap. 2017, 127, 65–76. [Google Scholar] [CrossRef]
- Roberts-Jones, J.; Fiedler, E.K.; Martin, M.J. Daily, Global, High-Resolution SST and Sea Ice Reanalysis for 1985-2007 Using the Ostia System. J. Clim. 2012, 25, 6215–6231. [Google Scholar] [CrossRef]
- McLaren, A.; Fiedler, E.; Roberts-Jones, J.; Martin, M.; Mao, C.; Good, S. Quality Information Document: Global Ocean OSTIA Near Real Time Level 4 Sea Surface Temperature Product. Available online: https://resources.marine.copernicus.eu/documents/QUID/CMEMS-OSI-QUID-010-001.pdf (accessed on 20 August 2020).
- Kohonen, T.; Mäkisara, K. The self-organizing feature maps. Phys. Scr. 1989, 39, 168–172. [Google Scholar] [CrossRef]
- Haykin, S. Neural Networks and Learning Machines; 3rd ed.; Pearson Education: Upper Saddle River, NJ, USA, 2009. [Google Scholar]
- Oyana, T.J.; Achenie, L.E.; Cuadros-Vargas, E.; Rivers, P.A.; Scott, K.E. A Mathematical Improvement of the Self-Organizing Map Algorithm. In Proceedings from the International Conference on Advances in Engineering and Technology; Elsevier BV: Amsterdam, The Netherlands, 2006; pp. 522–531. [Google Scholar]
- Hu, J.; Wang, X.H. Progress on upwelling studies in the China seas. Rev. Geophys. 2016, 54, 653–673. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Fischer, T.; Krauss, C. Deep learning with long short-term memory networks for financial market predictions. Eur. J. Oper. Res. 2018, 270, 654–669. [Google Scholar] [CrossRef]
- Olah, C. Understanding LSTM Networks. Available online: http://colah.github.io/posts/2015-08-Understanding-LSTMs/ (accessed on 8 March 2020).
- Bengio, Y. Practical Recommendations for Gradient-Based Training of Neural Networks: Tricks of the Trade; Springer: Heidelberg, Germany, 2012; pp. 437–478. [Google Scholar]
- Bergstra, J.; Bengio, Y. Random Search for Hyper-Parameter Optimization. J. Mach. Learn Res. 2012, 13, 281–305. [Google Scholar]
- Bishop, C.M. Neural Networks for Pattern Recognition; Oxford University Press: New York, NY, USA, 1995. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- China Offshore Ocean Climate Monitoring Bulletin. Available online: http://www.nmefc.cn/chanpin/hyqh/qhjc/bulletin_201608.pdf (accessed on 1 July 2020).
- Tan, H.; Cai, R. What caused the record-breaking warming in East China Seas during August 2016? Atmos. Sci. Lett. 2018, 19, e853. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 2018 | Jan. | Feb. | Mar. | Apr. | May | Jun. | Jul. | Aug. | Sep. | Oct. | Nov. | Dec. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Bias (°C) | 0.05 | 0.28 | 0.06 | 0.26 | −0.17 | 0.04 | 0.3 | 0.21 | 0.35 | 0.28 | 0.11 | −0.29 |
| SD (°C) | 0.39 | 0.66 | 0.56 | 0.60 | 0.50 | 0.42 | 0.68 | 0.72 | 0.51 | 0.56 | 0.49 | 0.60 |
| RMSE (°C) | 0.39 | 0.71 | 0.56 | 0.65 | 0.53 | 0.42 | 0.74 | 0.75 | 0.62 | 0.63 | 0.50 | 0.67 |
| P (±0.5 °C) % | 84.09 | 55.06 | 68.93 | 58.5 | 75.78 | 81.23 | 57.53 | 48.56 | 55.74 | 66.52 | 72.82 | 57.30 |
| P (±1 °C) % | 98.19 | 87.53 | 93.47 | 86.86 | 93.36 | 96.92 | 85.17 | 85.46 | 88.63 | 90.57 | 95.53 | 85.95 |
| P (±1.5 °C) % | 99.59 | 96.34 | 98.3 | 98.07 | 97.72 | 99.60 | 94.00 | 95.03 | 99.35 | 96.87 | 98.84 | 97.68 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, L.; Guan, L.; Qu, L.; Guo, D. Prediction of Sea Surface Temperature in the China Seas Based on Long Short-Term Memory Neural Networks. Remote Sens. 2020, 12, 2697. https://doi.org/10.3390/rs12172697
Wei L, Guan L, Qu L, Guo D. Prediction of Sea Surface Temperature in the China Seas Based on Long Short-Term Memory Neural Networks. Remote Sensing. 2020; 12(17):2697. https://doi.org/10.3390/rs12172697
Chicago/Turabian StyleWei, Li, Lei Guan, Liqin Qu, and Dongsheng Guo. 2020. "Prediction of Sea Surface Temperature in the China Seas Based on Long Short-Term Memory Neural Networks" Remote Sensing 12, no. 17: 2697. https://doi.org/10.3390/rs12172697
APA StyleWei, L., Guan, L., Qu, L., & Guo, D. (2020). Prediction of Sea Surface Temperature in the China Seas Based on Long Short-Term Memory Neural Networks. Remote Sensing, 12(17), 2697. https://doi.org/10.3390/rs12172697