Review of Remote Sensing Methods to Map Coffee Production Systems


 , , ,
, , ,  ,
, 
Abstract
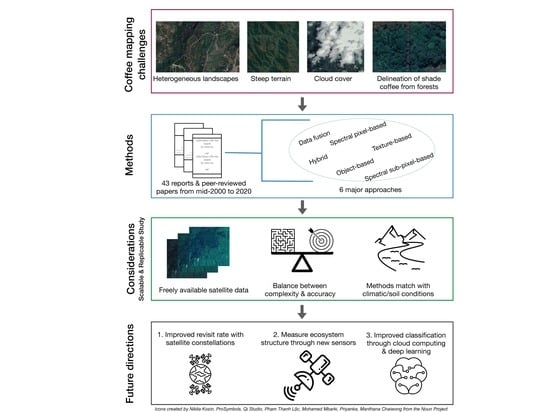
:
1. Introduction
1.1. Review of Coffee Characteristics and Systems
1.2. Using Remote Sensing to Map Coffee
2. Methods
2.1. Planning the Review
2.2. Conducting the Review
2.3. Reporting Results
3. Results
3.1. Spectral Pixel-Based Approaches
3.2. Spectral Sub-Pixel Approaches
3.3. Texture-Based Approaches
3.4. Data Fusion Approaches
3.5. Object-Based Approaches
3.6. Hybrid Approaches
3.7. Accuracy Assessment
4. Discussion
4.1. Approaches to Overcome Coffee Mapping Challenges
4.2. Considerations for Choosing the Best Method
- Budget for imagery, software licensing, and validation data.
- Complexity of approach (i.e., processing requirements, replicability).
- Methods tested in similar geography and for target coffee system(s).
- Accuracy assessment plan.
4.3. Future Research Directions
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Goldschein, E. 11 incredible facts about the global coffee industry. Bus. Insider 2011. Available online: https://www.businessinsider.com/facts-about-the-coffee-industry-2011-11 (accessed on 6 June 2020).
- Illy, E. The complexity of coffee. Sci. Am. 2002, 286, 86–91. [Google Scholar] [CrossRef] [PubMed]
- International Trade Centre UNCTAD/WTO. The Coffee Exporter’s Guide, 3rd ed.; International Trade Centre UNCTAD/WTO: Geneva, Switzerland, 2011. [Google Scholar]
- Sustainable Coffee Challenge. Resources. Available online: https://www.sustaincoffee.org/resources/ (accessed on 6 June 2020).
- Consumer Goods Forum. Commitments & Achievements. Available online: https://www.theconsumergoodsforum.com/initiatives/environmental-sustainability/about/our-commitments+and+achievements (accessed on 6 June 2020).
- New York Declaration on Forests; UN Climate Summit, United Nations Headquarters: New York, NY, USA, 2014.
- Schmitt-Harsh, M. Landscape change in Guatemala: Driving forces of forest and coffee agroforest expansion and contraction from 1990 to 2010. Appl. Geogr. 2013, 40, 40–50. [Google Scholar] [CrossRef]
- Bray, D. Forest cover dynamics and forest transitions in Mexico and Central America: Towards a “Great Restoration”? In Reforesting Landscapes; Springer: Dordrecht, The Netherlands, 2009; Volume 10, pp. 85–120. ISBN 978-1-4020-9656-3. [Google Scholar]
- Soto-Pinto, L.; Anzueto, M.; Mendoza, J.; Ferrer, G.J.; de Jong, B. Carbon sequestration through agroforestry in indigenous communities of Chiapas, Mexico. Agrofor. Syst. 2009, 78, 39–51. [Google Scholar] [CrossRef]
- Van Noordwijk, M.; Rahayu, S.; Hairiah, K.; Wulan, Y.; Farida, A.; Verbist, B. Carbon stock assessment for a forest-to-coffee conversion landscape in Sumber-Jaya (Lampung, Indonesia): From allometric equations to land use change analysis. Sci. China 2002, 45, 75–86. [Google Scholar]
- Bliss, S. Coffee biomes. Geogr. Bull. 2017, 49, 29. [Google Scholar]
- Bunn, C.; Laderach, P.; Ovalle Rivera, O.; Kirschke, D. A bitter cup: Climate change profile of global production of Arabica and Robusta coffee. Clim. Chang. 2014, 129. [Google Scholar] [CrossRef] [Green Version]
- Vaast, P.; Harmand, J.-M.; Rapidel, B.; Jagoret, P.; Deheuvels, O. Coffee and cocoa production in agroforestry—A climate-smart agriculture model. In Climate Change and Agriculture Worldwide; Torquebiau, E., Ed.; Springer: Dordrecht, The Netherlands, 2016; pp. 209–224. ISBN 978-94-017-7462-8. [Google Scholar]
- Jha, S.; Bacon, C.M.; Philpott, S.M.; Rice, R.A.; Méndez, V.E.; Läderach, P. A review of ecosystem services, farmer livelihoods, and value chains in shade coffee agroecosystems. In Integrating Agriculture, Conservation and Ecotourism: Examples from the Field; Issues in Agroecology–Present Status and Future Prospectus; Campbell, W.B., Lopez Ortiz, S., Eds.; Springer: Dordrecht, The Netherlands, 2011; pp. 141–208. ISBN 978-94-007-1309-3. [Google Scholar]
- Vignola, R.; Harvey, C.A.; Bautista-Solis, P.; Avelino, J.; Rapidel, B.; Donatti, C.; Martinez, R. Ecosystem-based adaptation for smallholder farmers: Definitions, opportunities and constraints. Agric. Ecosyst. Environ. 2015, 211, 126–132. [Google Scholar] [CrossRef] [Green Version]
- Food and Agriculture Organization of the United Nations. FAOSTAT Statistical Database. Available online: http://www.fao.org/faostat/en/#data (accessed on 6 June 2020).
- DaMatta, F.M.; Ronchi, C.P.; Maestri, M.; Barros, R.S. Ecophysiology of coffee growth and production. Braz. J. Plant Physiol. 2007, 19, 485–510. [Google Scholar] [CrossRef] [Green Version]
- Waller, J.M.; Bigger, M.; Hillocks, R.J. Coffee Pests, Diseases and Their Management, 1st ed.; CABI: Wallingford, UK; Cambridge, MA, USA, 2007; ISBN 978-1-84593-129-2. [Google Scholar]
- Philpott, S.M.; Arendt, W.J.; Armbrecht, I.; Bichier, P.; Diestch, T.V.; Gordon, C.; Greenberg, R.; Perfecto, I.; Reynoso-Santos, R.; Soto-Pinto, L.; et al. Biodiversity loss in Latin American coffee landscapes: Review of the evidence on ants, birds, and trees. Conserv. Biol. 2008, 22, 1093–1105. [Google Scholar] [CrossRef]
- Kremen, C.; Iles, A.; Bacon, C. Diversified farming systems: An agroecological, systems-based alternative to modern industrial agriculture. Ecol. Soc. 2012, 17. [Google Scholar] [CrossRef]
- Perfecto, I.; Mas, A.; Dietsch, T.; Vandermeer, J. Conservation of biodiversity in coffee agroecosystems: A tri-taxa comparison in southern Mexico. Biodivers. Conserv. 2003, 12, 1239–1252. [Google Scholar] [CrossRef]
- Perfecto, I.; Vandermeer, J.; Mas, A.; Pinto, L.S. Biodiversity, yield, and shade coffee certification. Ecol. Econ. 2005, 54, 435–446. [Google Scholar] [CrossRef]
- Schmitt-Harsh, M.; Evans, T.P.; Castellanos, E.; Randolph, J.C. Carbon stocks in coffee agroforests and mixed dry tropical forests in the western highlands of Guatemala. Agrofor. Syst. 2012, 86, 141–157. [Google Scholar] [CrossRef]
- Sekercioglu, C.H.; Loarie, S.R.; Oviedo Brenes, F.; Ehrlich, P.R.; Daily, G.C. Persistence of forest birds in the Costa Rican agricultural countryside. Conserv. Biol. 2007, 21, 482–494. [Google Scholar] [CrossRef]
- Vandermeer, J.; Perfecto, I.; Philpott, S. Ecological complexity and pest control in organic coffee production: Uncovering an autonomous ecosystem service. BioScience 2010, 60, 527–537. [Google Scholar] [CrossRef] [Green Version]
- Karp, D.S.; Mendenhall, C.D.; Sandí, R.F.; Chaumont, N.; Ehrlich, P.R.; Hadly, E.A.; Daily, G.C. Forest bolsters bird abundance, pest control and coffee yield. Ecol. Lett. 2013, 16, 1339–1347. [Google Scholar] [CrossRef]
- Jha, S.; Bacon, C.M.; Philpott, S.M.; Ernesto Méndez, V.; Läderach, P.; Rice, R.A. Shade coffee: Update on a disappearing refuge for biodiversity. BioScience 2014, 64, 416–428. [Google Scholar] [CrossRef] [Green Version]
- Gobbi, J.A. Is biodiversity-friendly coffee financially viable? An analysis of five different coffee production systems in western El Salvador. Ecol. Econ. 2000, 33, 267–281. [Google Scholar] [CrossRef]
- Philpott, S.M.; Dietsch, T. Coffee and conservation: A global context and the value of farmer involvement. Conserv. Biol. 2003, 17, 1844–1846. [Google Scholar] [CrossRef] [Green Version]
- Richards, M.B.; Méndez, V.E. Interactions between carbon sequestration and shade tree diversity in a smallholder coffee cooperative in El Salvador. Conserv. Biol. 2014, 28, 489–497. [Google Scholar] [CrossRef] [PubMed]
- Lin, B.B. Resilience in agriculture through crop diversification: Adaptive management for environmental change. BioScience 2011, 61, 183–193. [Google Scholar] [CrossRef] [Green Version]
- Borkhataria, R.; Collazo, J.A.; Groom, M.J.; Jordan-Garcia, A. Shade-grown coffee in Puerto Rico: Opportunities to preserve biodiversity while reinvigorating a struggling agricultural commodity. Agric. Ecosyst. Environ. 2012, 149, 164–170. [Google Scholar] [CrossRef]
- Perfecto, I.; Rice, R.A.; Greenberg, R.; Van der Voort, M.E. Shade coffee: A disappearing refuge for biodiversity. BioScience 1996, 46, 598–608. [Google Scholar] [CrossRef] [Green Version]
- Moguel, P.; Toledo, V.M. Biodiversity conservation in traditional coffee systems of Mexico. Conserv. Biol. 1999, 13, 11–21. [Google Scholar] [CrossRef]
- Faminow, M.D. Biodiversity of Flora and Fauna in Shaded Coffee Systems; International Centre for Research in Agroforestry Latin American Regional Office: Lima, Peru, 2001; p. 43. [Google Scholar]
- Moreira, M.A.; Rudorff, B.F.T.; Barros, M.A.; de Faria, V.G.C.; Adami, M. Geotecnologias para mapear lavouras de café nos estados de Minas Gerais e São Paulo. Eng. Agríc. 2010, 30, 1123–1135. [Google Scholar] [CrossRef] [Green Version]
- Jaffee, D. Brewing Justice: Fair Trade Coffee, Sustainability, and Survival, 1st ed.; University of California Press: Oakland, CA, USA, 2007; ISBN 978-0-520-24958-5. [Google Scholar]
- Somarriba, E.; Harvey, C.; Samper, M.; Anthony, F.; Gonzalez, J.; Staver, C.; Rice, R. Biodiversity conservation in neotropical coffee (Coffea arabica) plantations. In Agroforestry and Biodiversity Conservation in Tropical Landscapes; Springer: Dordrecht, The Netherlands, 2004; pp. 198–226. [Google Scholar]
- Soto-Pinto, L.; Villalvazo-López, V.; Jiménez-Ferrer, G.; Ramírez-Marcial, N.; Montoya, G.; Sinclair, F.L. The role of local knowledge in determining shade composition of multistrata coffee systems in Chiapas, Mexico. Biodivers. Conserv. 2007, 16, 419–436. [Google Scholar] [CrossRef]
- Tabor, K.; Hewson, J. The evolution of remote sensing applications vital to effective biodiversity conservation and sustainable development. In Satellite Remote Sensing for Conservation Action: Case Studies from Aquatic and Terrestrial Ecosystems; Leidner, A.K., Buchanan, G.M., Eds.; Cambridge University Press: Cambridge, UK, 2018; pp. 274–300. ISBN 978-1-316-51386-6. [Google Scholar]
- Woodcock, C.E.; Allen, R.; Anderson, M.; Belward, A.; Bindschadler, R.; Cohen, W.; Gao, F.; Goward, S.N.; Helder, D.; Helmer, E.; et al. Free access to Landsat imagery. Science 2008, 320, 1011. [Google Scholar] [CrossRef]
- Wulder, M.A.; Loveland, T.R.; Roy, D.P.; Crawford, C.J.; Masek, J.G.; Woodcock, C.E.; Allen, R.G.; Anderson, M.C.; Belward, A.S.; Cohen, W.B.; et al. Current status of Landsat program, science, and applications. Remote Sens. Environ. 2019, 225, 127–147. [Google Scholar] [CrossRef]
- Langford, M.; Bell, W. Land cover mapping in a tropical hillsides environment: A case study in the Cauca region of Colombia. Int. J. Remote Sens. 1997, 18, 1289–1306. [Google Scholar] [CrossRef]
- Bernardes, T.; Moreira, M.A.; Adami, M.; Giarolla, A.; Rudorff, B.F.T. Monitoring biennial bearing effect on coffee yield using MODIS remote sensing imagery. Remote Sens. 2012, 4, 2492–2509. [Google Scholar] [CrossRef] [Green Version]
- Cordero-Sancho, S.; Sader, S.A. Spectral analysis and classification accuracy of coffee crops using Landsat and a topographic-environmental model. Int. J. Remote Sens. 2007, 28, 1577–1593. [Google Scholar] [CrossRef]
- Lu, D.; Batistella, M.; de Miranda, E.E.; Moran, E. A comparative study of Landsat TM and SPOT HRG images for vegetation classification in the Brazilian Amazon. Photogramm. Eng. Remote Sens. 2008, 74, 311–321. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bolanos, S. Using Image Analysis and GIS for Coffee Mapping; Department of Geography, McGill University: Montréal, QC, Canada, 2007. [Google Scholar]
- Kushalappa, A.C.; Eskes, A.B. Coffee Rust: Epidemiology, Resistance, and Management; CRC Press: Boca Raton, FL, USA, 1989; ISBN 978-0-8493-6899-8. [Google Scholar]
- Finer, M.; Novoa, S.; Weisse, M.J.; Petersen, R.; Mascaro, J.; Souto, T.; Stearns, F.; Martinez, R.G. Combating deforestation: From satellite to intervention. Science 2018, 360, 1303–1305. [Google Scholar] [CrossRef]
- Reiche, J.; Lucas, R.; Mitchell, A.L.; Verbesselt, J.; Hoekman, D.H.; Haarpaintner, J.; Kellndorfer, J.M.; Rosenqvist, A.; Lehmann, E.A.; Woodcock, C.E.; et al. Combining satellite data for better tropical forest monitoring. Nat. Clim. Chang. 2016, 6, 120–122. [Google Scholar] [CrossRef]
- Planet Our Constellations. Available online: https://storage.googleapis.com/planet-ditl/day-in-the-life/index.html (accessed on 6 June 2020).
- Li, J.; Roy, D.P. A global analysis of Sentinel-2A, Sentinel-2B and Landsat-8 data revisit intervals and implications for terrestrial monitoring. Remote Sens. 2017, 9, 902. [Google Scholar] [CrossRef] [Green Version]
- Pullin, A.S.; Stewart, G.B. Guidelines for systematic review in conservation and environmental management. Conserv. Biol. 2006, 20, 1647–1656. [Google Scholar] [CrossRef]
- Maurice, N.E.; Davis, J. Unraveling the Underlying Causes of Price Volatility in World Coffee and Cocoa Commodity Markets; Erasmus University: Rotterdam, The Netherlands, 2011. [Google Scholar]
- Ortega-Huerta, M.A.; Komar, O.; Price, K.P.; Ventura, H.J. Mapping coffee plantations with Landsat imagery: An example from El Salvador. Int. J. Remote Sens. 2012, 33, 220–242. [Google Scholar] [CrossRef]
- Martínez-Verduzco, G.C.; Galeana-Pizaña, J.M.; Cruz-Bello, G.M. Coupling community mapping and supervised classification to discriminate shade coffee from natural vegetation. Appl. Geogr. 2012, 34, 1–9. [Google Scholar] [CrossRef]
- Tutu Benefoh, D.; Villamor, G.B.; van Noordwijk, M.; Borgemeister, C.; Asante, W.A.; Asubonteng, K.O. Assessing land-use typologies and change intensities in a structurally complex Ghanaian cocoa landscape. Appl. Geogr. 2018, 99, 109–119. [Google Scholar] [CrossRef]
- Bourgoin, C.; Oszwald, J.; Bourgoin, J.; Gond, V.; Blanc, L.; Dessard, H.; Phan, T.V.; Sist, P.; Läderach, P.; Reymondin, L. Assessing the ecological vulnerability of forest landscape to agricultural frontier expansion in the Central Highlands of Vietnam. Int. J. Appl. Earth Obs. Geoinf. 2020, 84, 101958. [Google Scholar] [CrossRef]
- Chemura, A.; Mutanga, O. Developing detailed age-specific thematic maps for coffee (Coffea arabica L.) in heterogeneous agricultural landscapes using random forests applied on Landsat 8 multispectral sensor. Geocarto Int. 2017, 32, 759–776. [Google Scholar] [CrossRef]
- Kelley, L.C.; Pitcher, L.; Bacon, C. Using Google Earth Engine to map complex shade-grown coffee landscapes in northern Nicaragua. Remote Sens. 2018, 10, 952. [Google Scholar] [CrossRef] [Green Version]
- Baeta, R.; Nogueira, K.; Menotti, D.; dos Santos, J.A. Learning deep features on multiple scales for coffee crop recognition. In Proceedings of the 2017 30th SIBGRAPI Conference on Graphics, Patterns and Images (SIBGRAPI), Niteroi, Brazil, 17–20 October 2017; pp. 262–268. [Google Scholar]
- Ramirez, G.M.; Zullo Junior, J.; Assad, E.D.; Pinto, H.S. Comparação de dados dos satélites Ikonos-II e Landsat/ETM+ no estudo de áreas cafeeiras [Comparison between Ikonos-II and Landsat/ETM+ satellites data in the study of coffee areas]. Pesq. Agropec. Bras. 2006, 41, 661–666. [Google Scholar] [CrossRef] [Green Version]
- Sánchez-Méndez, A.G.; Arguijo-Hernández, S.P. Análisis de imágenes multiespectrales para la detección de cultivos y detección de plagas y enfermedades en la producción de café [Analysis of multispectral images for the detection of crops and detection of pests and diseases in coffee production]. RCS 2018, 147, 309–317. [Google Scholar] [CrossRef]
- Moreira, M.A.; Adami, M.; Rudorff, B.F.T. Análise espectral e temporal da cultura do café em imagens Landsat [Spectral and temporal behavior analysis of coffee crop in Landsat images]. Pesqui. Agropecu. Bras. 2004, 39, 223–231. [Google Scholar] [CrossRef]
- Chemura, A.; Mutanga, O.; Dube, T. Integrating age in the detection and mapping of incongruous patches in coffee (Coffea arabica) plantations using multi-temporal Landsat 8 NDVI anomalies. Int. J. Appl. Earth Obs. Geoinf. 2017, 57, 1–13. [Google Scholar] [CrossRef]
- González, F.A.; Gómez, J.J.; Amaya, D.F. Multispectral image processing in coffee and cocoa crops. Rev. CINTEX 2017, 22, 51–67. [Google Scholar] [CrossRef]
- Johl, R.; Henke, S.; Schweikart, J. Acquiring geodata for coffee mapping using remote sensing data based on a pilot study in the Mbinga district Tanzania. Zent. für Geol. Paläontologie Teil I 2014, 2014, 211–225. [Google Scholar] [CrossRef]
- Kawakubo, F.S.; Machado, R.P.P. Mapping coffee crops in southeastern Brazil using spectral mixture analysis and data mining classification. Int. J. Remote Sens. 2016, 37, 3414–3436. [Google Scholar] [CrossRef]
- Schmitt-Harsh, M.; Sweeney, S.P.; Evans, T. Classification of Coffee-Forest Landscapes Using Landsat TM Imagery and Spectral Mixture Analysis. Photogramm. Eng. Remote. Sens. 2013, 79, 457–468. [Google Scholar] [CrossRef]
- Bispo, R.C.; Lamparelli, R.A.C.; Rocha, J.V. Using fraction images derived from modis data for coffee crop mapping. Eng. Agríc. 2014, 34, 102–111. [Google Scholar] [CrossRef] [Green Version]
- Lu, D.; Moran, E.; Batistella, M. Linear mixture model applied to Amazonian vegetation classification. Remote Sens. Environ. 2003, 87, 456–469. [Google Scholar] [CrossRef] [Green Version]
- Lu, D.; Batistella, M.; Moran, E.; Mausel, P. Application of spectral mixture analysis to Amazonian land-use and land-cover classification. Int. J. Remote Sens. 2004, 25, 5345–5358. [Google Scholar] [CrossRef]
- Souza, J.; Siqueira, J.V.; Sales, M.H.; Fonseca, A.V.; Ribeiro, J.G.; Numata, I.; Cochrane, M.A.; Barber, C.P.; Roberts, D.A.; Barlow, J. Ten-Year Landsat classification of deforestation and forest degradation in the Brazilian Amazon. Remote Sens. 2013, 5, 5493–5513. [Google Scholar] [CrossRef] [Green Version]
- Lelong, C.C.D.; Thong-Chane, A. Application of textural analysis on very high resolution panchromatic images to map coffee orchards in Uganda. In Proceedings of the IGARSS 2003. 2003 IEEE International Geoscience and Remote Sensing Symposium. Proceedings (IEEE Cat. No.03CH37477), Toulouse, France, 21–25 July 2003; Volume 2, pp. 1007–1009. [Google Scholar]
- Dostálová, A.; Hollaus, M.; Milenković, M.; Wagner, W. Forest area derivation from Sentinel-1 data. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, III–7, 227–233. [Google Scholar] [CrossRef]
- Silva, W.F.; Rudorff, B.F.T.; Formaggio, A.R.; Paradella, W.R.; Mura, J.C. Discrimination of agricultural crops in a tropical semi-arid region of Brazil based on L-band polarimetric airborne SAR data. ISPRS J. Photogramm. Remote Sens. 2009, 64, 458–463. [Google Scholar] [CrossRef]
- Otsu, N. A threshold selection method from gray-level histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef] [Green Version]
- Hartigan, J.A.; Wong, M.A. Algorithm AS 136: A k-means clustering algorithm. J. R. Stat. Soc. Ser. C (Appl. Stat.) 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Zhou, T.; Pan, J.; Zhang, P.; Wei, S.; Han, T. Mapping winter wheat with multi-temporal SAR and optical images in an urban agricultural region. Sensors 2017, 17, 1210. [Google Scholar] [CrossRef]
- Lu, D.; Batistella, M.; Moran, E. Land-cover classification in the Brazilian Amazon with the integration of Landsat ETM+ and Radarsat data. Int. J. Remote Sens. 2007, 28, 5447–5459. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Gong, W.; Hu, X.; Gong, J. Forest type identification with random forest using Sentinel-1A, Sentinel-2A, multi-temporal Landsat-8 and DEM data. Remote Sens. 2018, 10, 946. [Google Scholar] [CrossRef] [Green Version]
- Numbisi, F.N.; Van Coillie, F.M.B.; De Wulf, R. Delineation of cocoa agroforests using multiseason Sentinel-1 SAR images: A low grey level range reduces uncertainties in GLCM texture-based mapping. ISPRS Int. J. Geo-Inf. 2019, 8, 179. [Google Scholar] [CrossRef] [Green Version]
- Fagan, M.E.; DeFries, R.S.; Sesnie, S.E.; Arroyo-Mora, J.P.; Soto, C.; Singh, A.; Townsend, P.A.; Chazdon, R.L. Mapping species composition of forests and tree plantations in northeastern Costa Rica with an integration of hyperspectral and multitemporal Landsat imagery. Remote Sens. 2015, 7, 5660–5696. [Google Scholar] [CrossRef] [Green Version]
- Lelong, C. Very High Resolution Satellite-Imagery-Based Agrosystems Mapping: To Help Defining Geographic Indications for the Arabica Coffee in the Kintamani Country of Bali; CIRAD-AMIS: Montpellier, France, 2005. [Google Scholar]
- Vieira, T.G.C.; Alves, H.M.R.; Bertoldo, M.A.; Souza, V.C.O. de Geotecnologias na avaliação das mudanças no uso da terra de regiões cafeeiras do estado de Minas Gerais, Brasil [Geotechnologies in the assessment of land use changes in coffee regions of the state of Minas Gerais in Brazil]. Coffee Sci. 2007, 2, 142–149. [Google Scholar] [CrossRef]
- Dos Santos, J.A.; Gosselin, P.-H.; Philipp-Foliguet, S.; Da Silva Torres, R.; Falcao, A.X. Multiscale classification of remote sensing images. IEEE Trans. Geosci. Remote Sens. 2012, 50, 3764–3775. [Google Scholar] [CrossRef]
- Schapire, R.E. A brief introduction to boosting. In Proceedings of the Sixteenth International Joint Conference on Artificial Intelligence; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1999; Volume 2, pp. 1401–1406. [Google Scholar]
- Gaertner, J.; Genovese, V.B.; Potter, C.; Sewake, K.; Manoukis, N.C. Vegetation classification of Coffea on Hawaii Island using WorldView-2 satellite imagery. JARS 2017, 11, 046005. [Google Scholar] [CrossRef] [Green Version]
- Mukashema, A.; Veldkamp, A.; Vrieling, A. Automated high resolution mapping of coffee in Rwanda using an expert Bayesian network. Int. J. Appl. Earth Obs. Geoinf. 2014, 33, 331–340. [Google Scholar] [CrossRef]
- Alves, H.M.R.; Vieira, T.G.C.; Volpato, M.M.L.; Lacerda, M.P.C.; Borém, F.M. Geotechnologies for the characterization of specialty coffee environments of Mantiqueira de Minas In Brazil. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, XLI-B8, 797–799. [Google Scholar] [CrossRef]
- Gomez, C.; Mangeas, M.; Petit, M.; Corbane, C.; Hamon, P.; Hamon, S.; De Kochko, A.; Pierres, D.; Poncet, V.; Despinoy, M. Use of high-resolution satellite imagery in an integrated model to predict the distribution of shade coffee tree hybrid zones. Remote Sens. Environ. 2010, 114, 2731–2744. [Google Scholar] [CrossRef]
- Widayati, A.; Verbist, B.; Meijerink, A. Application of Combined Pixel-Based and Spatial-Based Approaches for Improved Mixed Vegetation. 2003. Available online: https://www.researchgate.net/publication/2552065_Application_Of_Combined_Pixel-Based_And_Spatial-Based_Approaches_For_Improved_Mixed_Vegetation (accessed on 6 June 2020).
- Xiong, J.; Thenkabail, P.S.; Tilton, J.C.; Gumma, M.K.; Teluguntla, P.; Oliphant, A.; Congalton, R.G.; Yadav, K.; Gorelick, N. Nominal 30-m cropland extent map of continental Africa by integrating pixel-based and object-based algorithms using Sentinel-2 and Landsat-8 data on Google Earth Engine. Remote Sens. 2017, 9, 1065. [Google Scholar] [CrossRef] [Green Version]
- Dos Santos, J.A.; Faria, F.; Calumby, R.; Torres, R.D.S.; Lamparelli, R.A.C. A Genetic Programming approach for coffee crop recognition. In Proceedings of the 2010 IEEE International Geoscience and Remote Sensing Symposium, Honolulu, HI, USA, 25–30 July 2010; pp. 3418–3421. [Google Scholar]
- Olofsson, P.; Foody, G.M.; Herold, M.; Stehman, S.V.; Woodcock, C.E.; Wulder, M.A. Good practices for estimating area and assessing accuracy of land change. Remote Sens. Environ. 2014, 148, 42–57. [Google Scholar] [CrossRef]
- Cohen, J. A Coefficient of Agreement for Nominal Scales. Educ. Psychol. Meas. 2016. [Google Scholar] [CrossRef]
- Fawcett, T. Introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Chemura, A.; Mutanga, O.; Dube, T. Separability of coffee leaf rust infection levels with machine learning methods at Sentinel-2 MSI spectral resolutions. Precis. Agric. 2017, 18, 859–881. [Google Scholar] [CrossRef]
- Chemura, A.; Mutanga, O.; Odindi, J.; Kutywayo, D. Mapping spatial variability of foliar nitrogen in coffee (Coffea arabica L.) plantations with multispectral Sentinel-2 MSI data. ISPRS J. Photogramm. Remote Sens. 2018, 138. [Google Scholar] [CrossRef]
- Belgiu, M.; Csillik, O. Sentinel-2 cropland mapping using pixel-based and object-based time-weighted dynamic time warping analysis. Remote Sens. Environ. 2018, 204, 509–523. [Google Scholar] [CrossRef]
- Radoux, J.; Chomé, G.; Jacques, D.C.; Waldner, F.; Bellemans, N.; Matton, N.; Lamarche, C.; D’Andrimont, R.; Defourny, P. Sentinel-2′s Potential for Sub-Pixel Landscape Feature Detection. Remote Sens. 2016, 8, 488. [Google Scholar] [CrossRef] [Green Version]
- Claverie, M.; Ju, J.; Masek, J.G.; Dungan, J.L.; Vermote, E.F.; Roger, J.-C.; Skakun, S.V.; Justice, C. The Harmonized Landsat and Sentinel-2 surface reflectance data set. Remote Sens. Environ. 2018, 219, 145–161. [Google Scholar] [CrossRef]
- Lillesand, T.; Kiefer, R.W.; Chipman, J. Remote Sensing and Image Interpretation, 7th ed.; Wiley: Hoboken, NJ, USA, 2015. [Google Scholar]
- Ovalle-Rivera, O.; Läderach, P.; Bunn, C.; Obersteiner, M.; Schroth, G. Projected shifts in Coffea arabica suitability among major global producing regions due to climate change. PLoS ONE 2015, 10, e0124155. [Google Scholar] [CrossRef] [Green Version]
- Joshi, N.; Baumann, M.; Ehammer, A.; Fensholt, R.; Grogan, K.; Hostert, P.; Jepsen, M.R.; Kuemmerle, T.; Meyfroidt, P.; Mitchard, E.T.A.; et al. A review of the application of optical and radar remote sensing data fusion to land use mapping and monitoring. Remote Sens. 2016, 8, 70. [Google Scholar] [CrossRef] [Green Version]
- Campbell, M.J.; Dennison, P.E.; Hudak, A.T.; Parham, L.M.; Butler, B.W. Quantifying understory vegetation density using small-footprint airborne lidar. Remote Sens. Environ. 2018, 215, 330–342. [Google Scholar] [CrossRef]
- Jubanski, J.; Ballhorn, U.; Kronseder, K.; Franke, J.; Siegert, F. Detection of large above-ground biomass variability in lowland forest ecosystems by airborne LiDAR. Biogeosciences 2013, 10, 3917–3930. [Google Scholar] [CrossRef] [Green Version]
- Bey, A.; Sánchez-Paus Díaz, A.; Maniatis, D.; Marchi, G.; Mollicone, D.; Ricci, S.; Bastin, J.-F.; Moore, R.; Federici, S.; Rezende, M.; et al. Collect Earth: Land use and land cover assessment through augmented visual interpretation. Remote Sens. 2016, 8, 807. [Google Scholar] [CrossRef] [Green Version]
- Duncanson, L.; Armston, J.; Disney, M.; Avitabile, V.; Barbier, N.; Calders, K.; Carter, S.; Chave, J.; Herold, M.; Crowther, T.W.; et al. The Importance of Consistent Global Forest Aboveground Biomass Product Validation. Surv. Geophys. 2019, 40, 979–999. [Google Scholar] [CrossRef] [Green Version]
- Cheng, G.; Yang, C.; Yao, X.; Guo, L.; Han, J. When Deep Learning Meets Metric Learning: Remote Sensing Image Scene Classification via Learning Discriminative CNNs. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2811–2821. [Google Scholar] [CrossRef]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
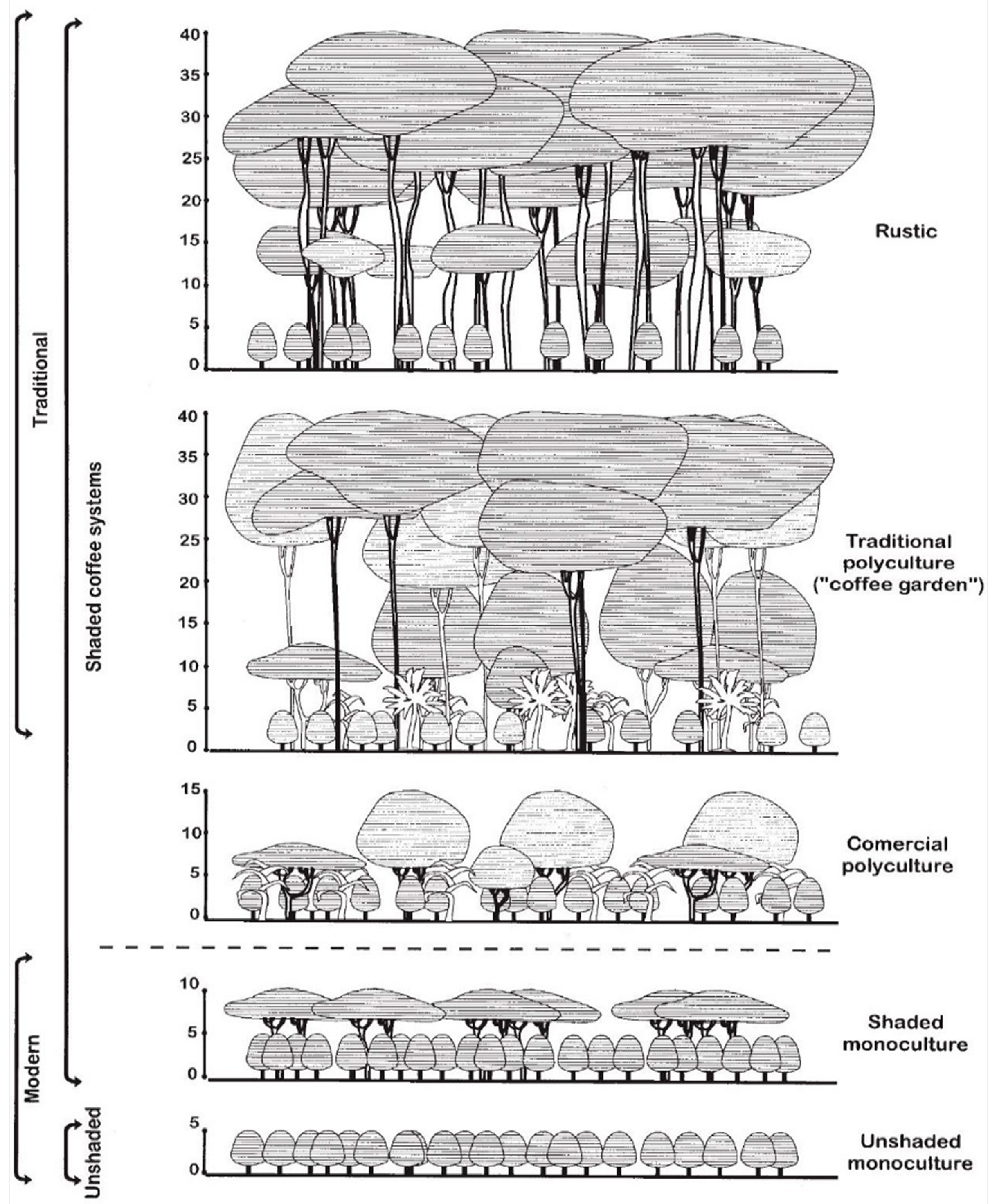

{kind=link}
{kind=link}
| Rank | Country | Coffee Production 2017 (tons) | Area Harvested 2017 (ha) | Export Value of Coffee Products, 2017 | Percent of Crop and Livestock Product Exports by Value, 2017 |
|---|---|---|---|---|---|
| 1 | Brazil | 2,684,508 | 1,802,417 | $5.27 billion | 6.62% |
| 2 | Vietnam | 1,542,398 | 605,178 | $3.50 billion | 15.9% |
| 3 | Colombia | 760,209 | 799,046 | $2.81 billion | 39.5% |
| 4 | Indonesia | 668,677 | 1,253,796 | $1.66 billion | 4.22% |
| 5 | Honduras | 473,718 | 434,312 | $1.29 billion | 48.8% |
| 6 | Ethiopia | 467,679 | 694,179 | $955 million | 44.0% |
| 7 | Peru | 337,330 | 424,129 | $710 million | 13.5% |
| 8 | India | 312,000 | 449,357 | $968 million | 2.86% |
| 9 | Guatemala | 246,319 | 281,841 | $749 million | 14.1% |
| 10 | Uganda | 209,421 | 379,108 | $555 million | 34.8% |
| Coffee | Remote Sensing | Geography |
|---|---|---|
| coffee | remote sensing | mapping |
| agroforestry | satellite | tropics |
| shade-coffee | Sentinel-1 | global |
| sun-coffee | Sentinel-2 | Indonesia |
| polyculture | MODIS | Colombia |
| monoculture | SAR | Brazil |
| Arabica | Landsat | Vietnam |
| Robusta | optical | Ethiopia |
| high resolution |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hunt, D.A.; Tabor, K.; Hewson, J.H.; Wood, M.A.; Reymondin, L.; Koenig, K.; Schmitt-Harsh, M.; Follett, F. Review of Remote Sensing Methods to Map Coffee Production Systems. Remote Sens. 2020, 12, 2041. https://doi.org/10.3390/rs12122041
Hunt DA, Tabor K, Hewson JH, Wood MA, Reymondin L, Koenig K, Schmitt-Harsh M, Follett F. Review of Remote Sensing Methods to Map Coffee Production Systems. Remote Sensing. 2020; 12(12):2041. https://doi.org/10.3390/rs12122041
Chicago/Turabian StyleHunt, David A., Karyn Tabor, Jennifer H. Hewson, Margot A. Wood, Louis Reymondin, Kellee Koenig, Mikaela Schmitt-Harsh, and Forrest Follett. 2020. "Review of Remote Sensing Methods to Map Coffee Production Systems" Remote Sensing 12, no. 12: 2041. https://doi.org/10.3390/rs12122041
APA StyleHunt, D. A., Tabor, K., Hewson, J. H., Wood, M. A., Reymondin, L., Koenig, K., Schmitt-Harsh, M., & Follett, F. (2020). Review of Remote Sensing Methods to Map Coffee Production Systems. Remote Sensing, 12(12), 2041. https://doi.org/10.3390/rs12122041