Precise and Robust Ship Detection for High-Resolution SAR Imagery Based on HR-SDNet


Abstract
1. Introduction
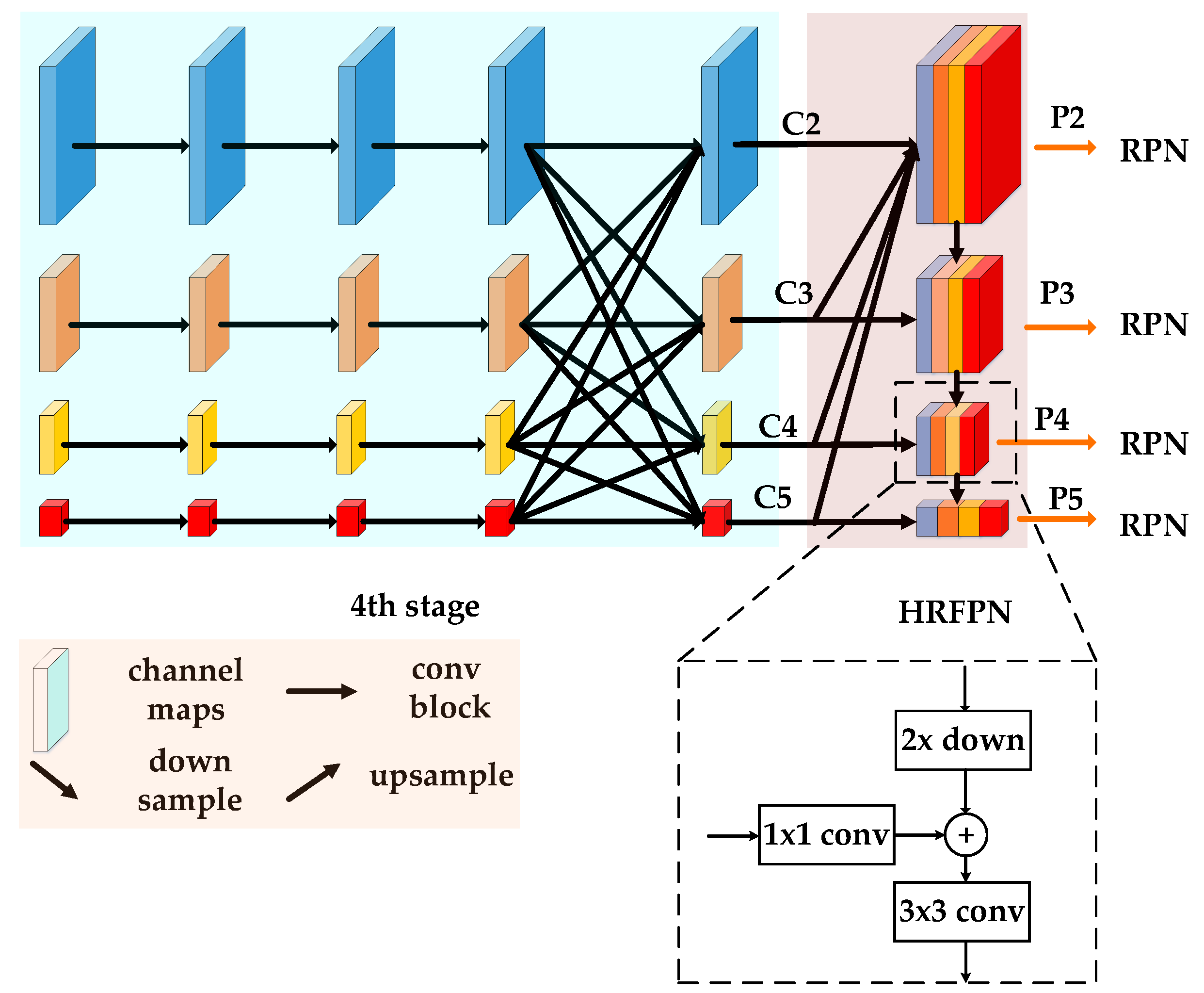
- The HRFPN takes full advantage of the feature maps of high-resolution and low-resolution convolutions for SAR image ship detection. Furthermore, the HRFPN connects high-to-low resolution subnetworks in parallel and can maintain the high resolution. Accordingly, the predicted results are more precise in space compared with FPN, especially inshore and offshore scenes.
- Our proposed framework HR-SDNet is more accurate and robust than the existing algorithms for ship detection in high-resolution SAR imagery, especially inshore and offshore scenes.
- The Soft-NMS is used to improve the performance of the NMS. It uses the linear penalty function to reduce the detection scores of all other neighbors, thereby improving the detection performance of the dense ships.
- We introduce COCO evaluation metrics to precisely evaluate the detection performance of our method. It contains not only the higher quality evaluation metrics AP but also the evaluation metrics for small, medium, and large targets.
- We analyze the effect of image preprocessing on the robust performance of our detector by the clipping function of the displayed image.
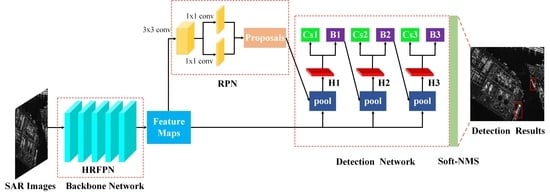
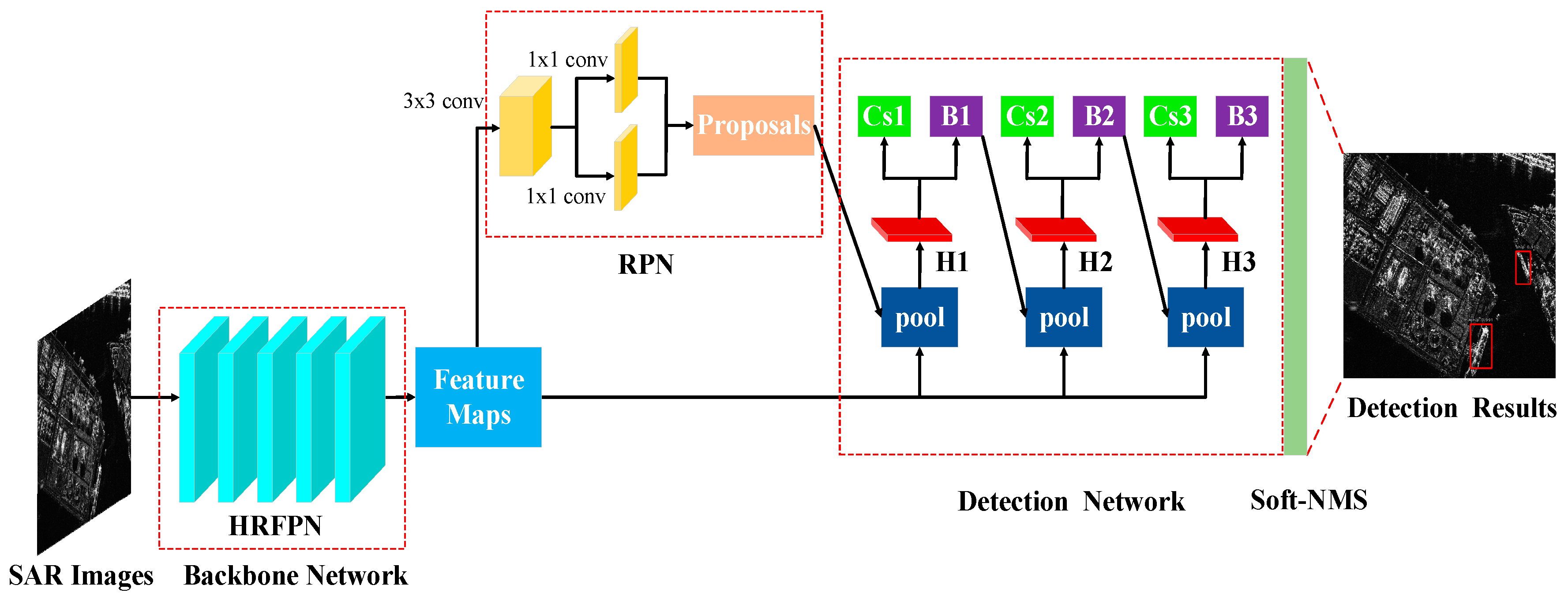
2. The Methods
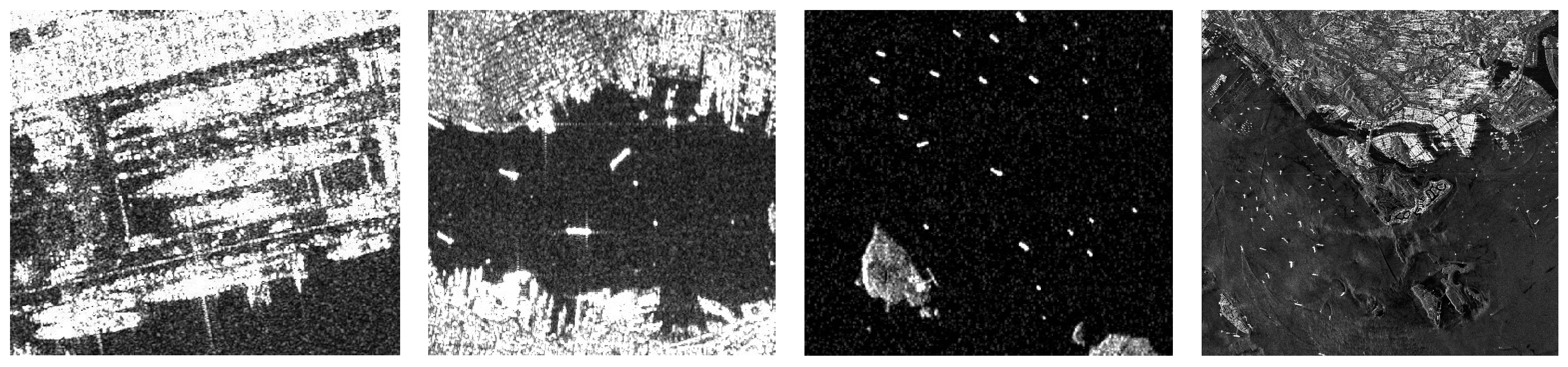
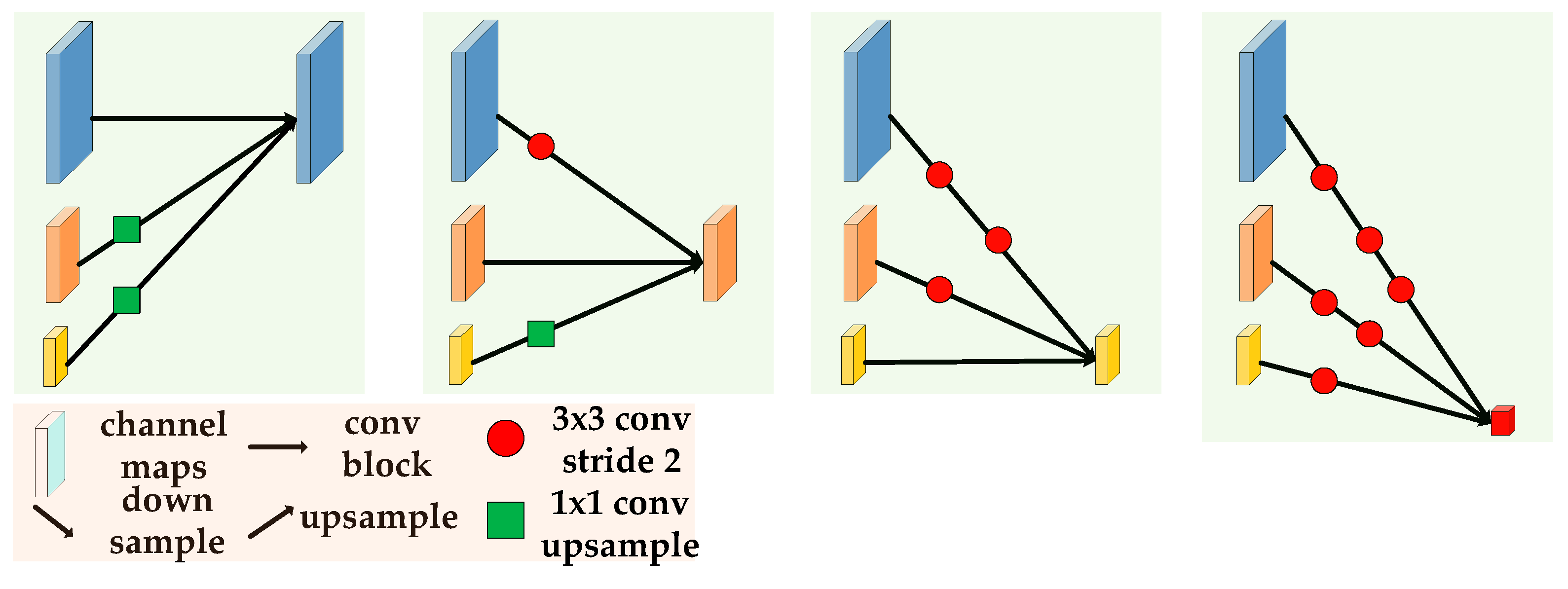
2.1. The Background of HRNet
2.2. Detailed Description of the Network Architecture
2.2.1. Backbone Network
2.2.2. Region Proposal Network (RPN)
2.2.3. Detection Network
2.2.4. Soft-NMS
2.3. Loss Function
3. Experiments and Results
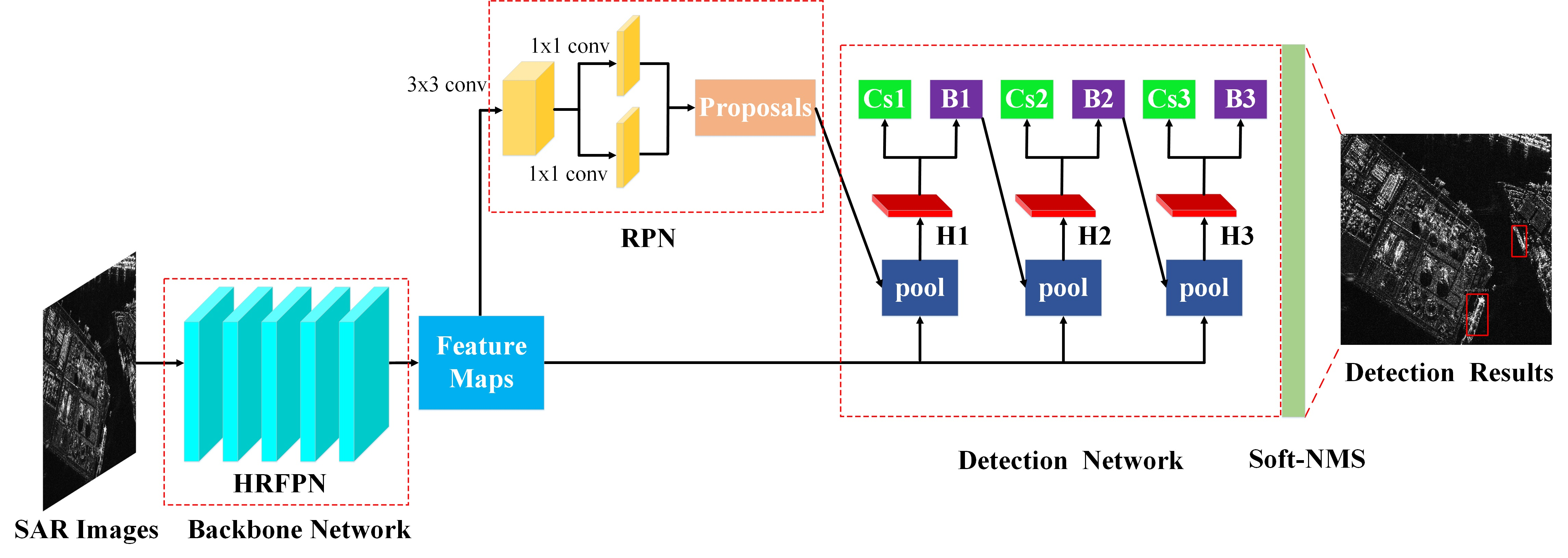
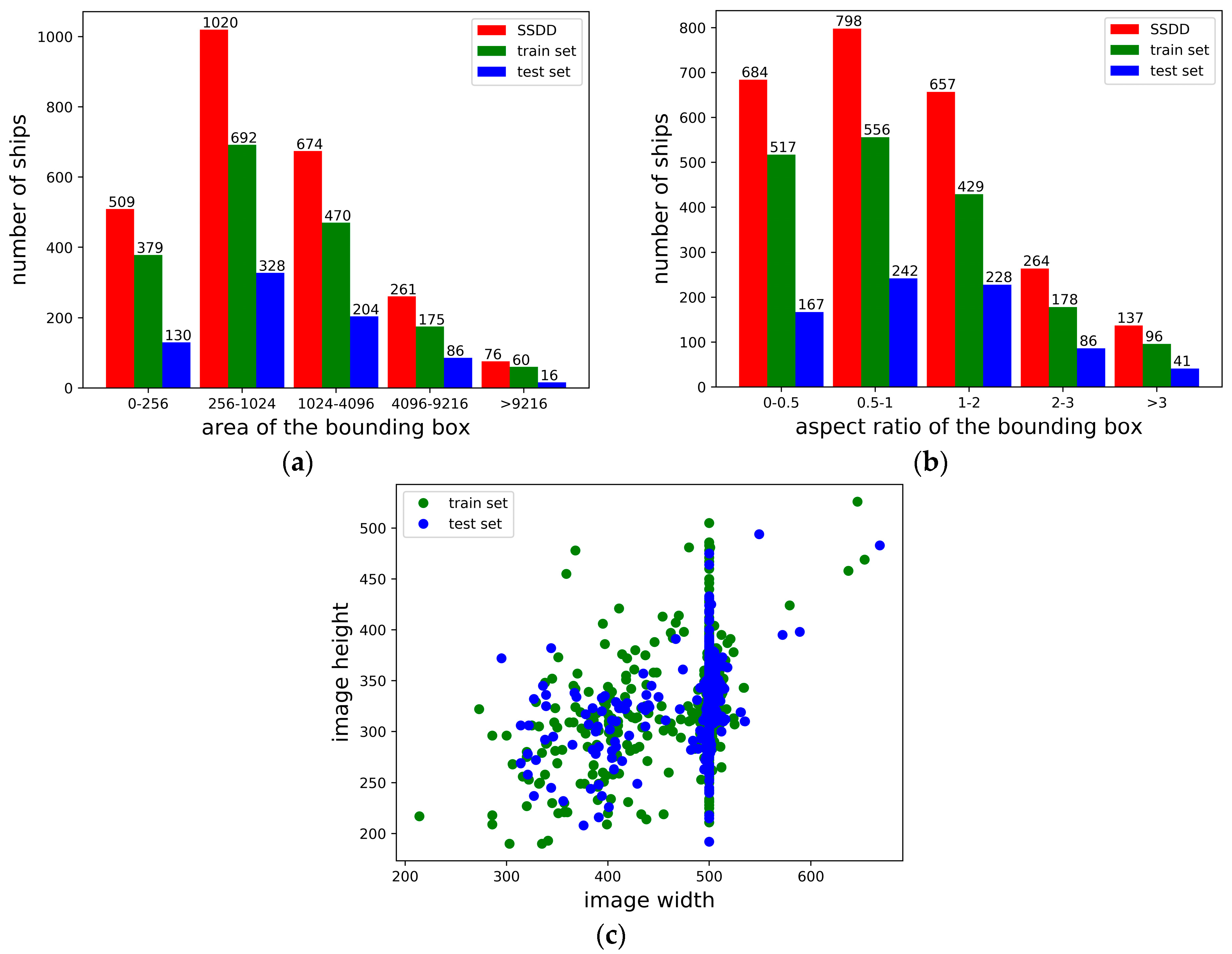
3.1. Dataset Description
3.2. Evaluation Metrics
3.3. Implementation Details
3.3.1. Implementation Details of HR-SDNet
3.3.2. Compared Approaches
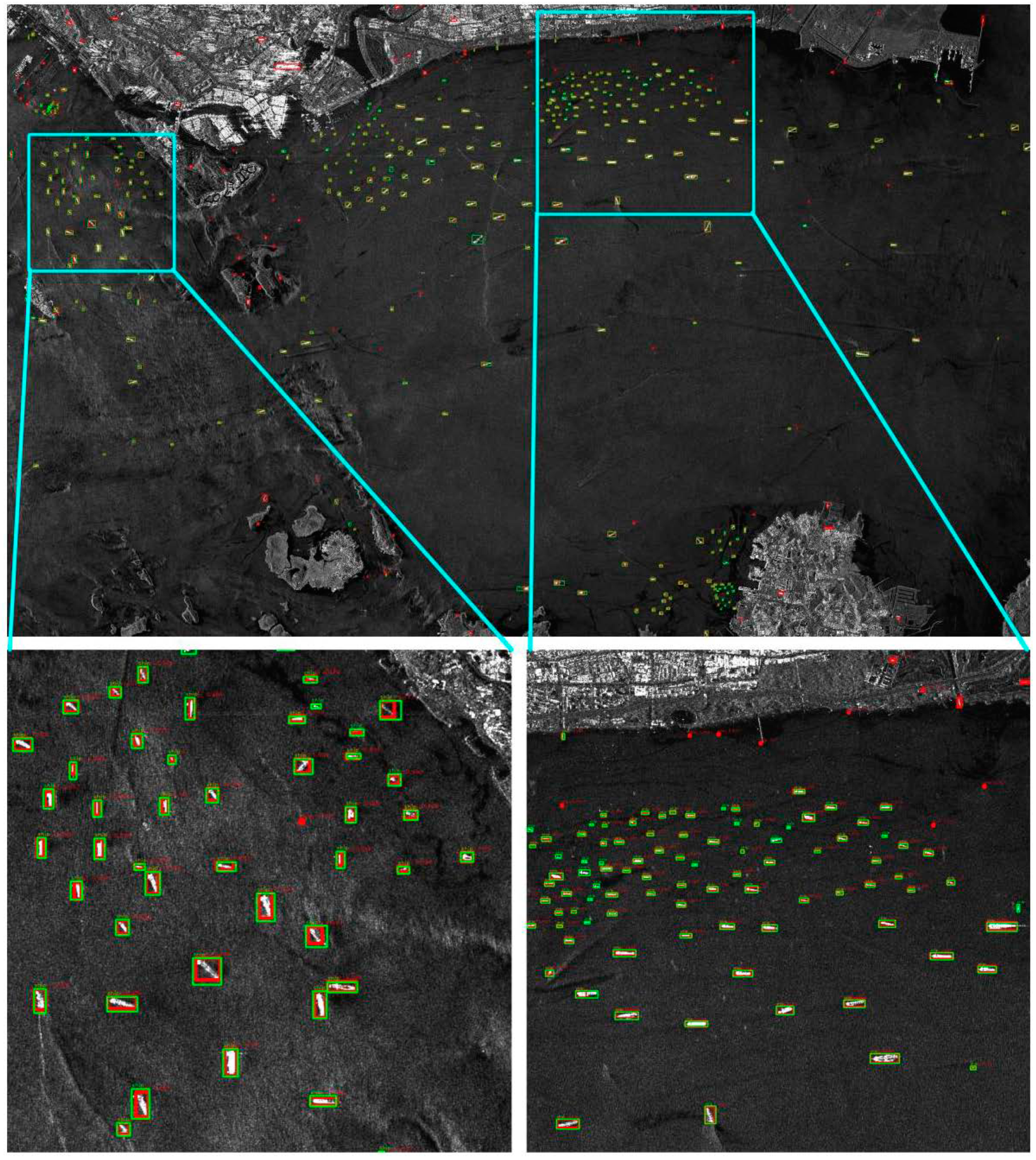
3.4. Experimental Results and Analysis of HR-SDNet
3.4.1. Effect of the HRFPN
3.4.2. Results of the HR-SDNet
3.5. Comparison with the State-of-the-Art
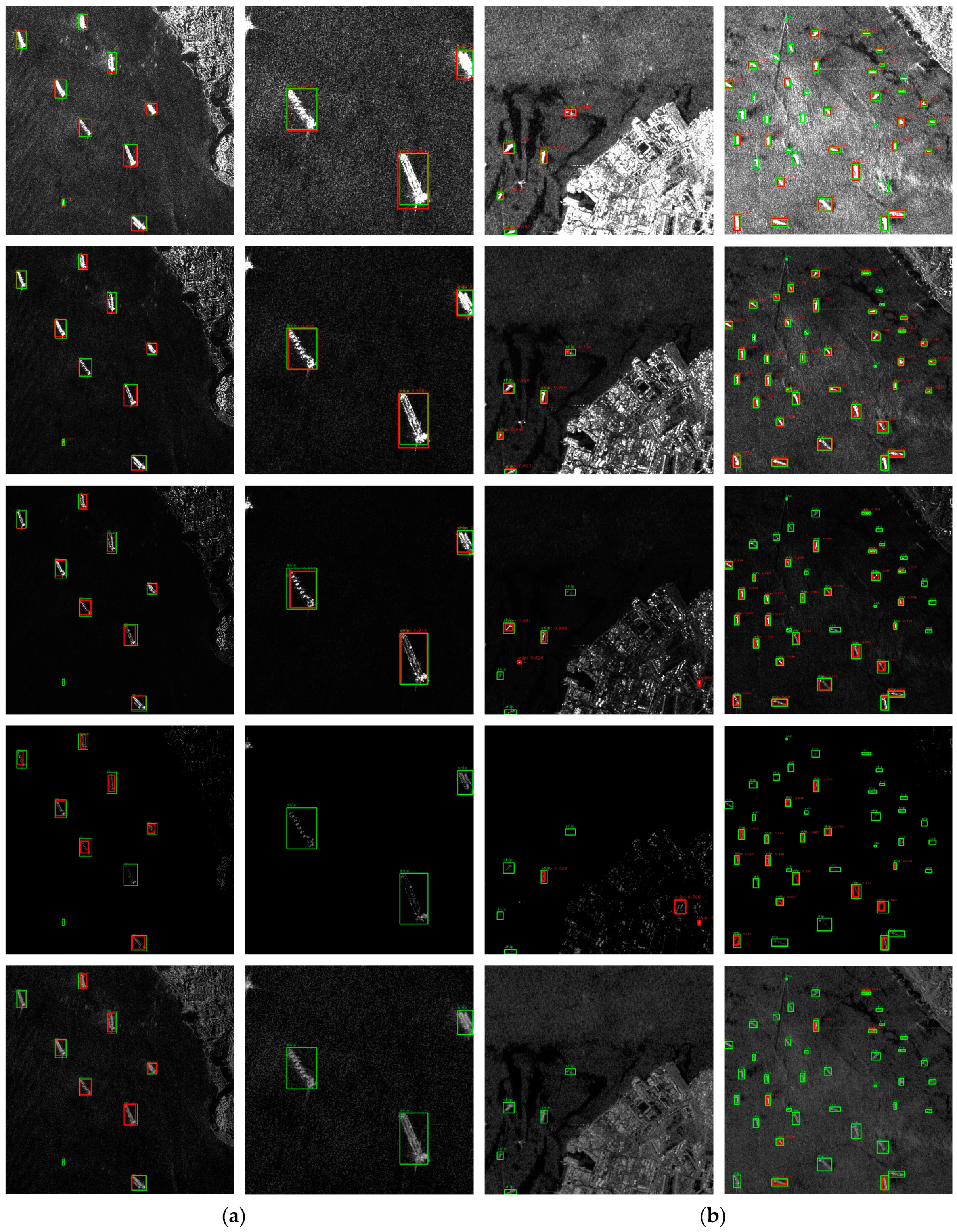
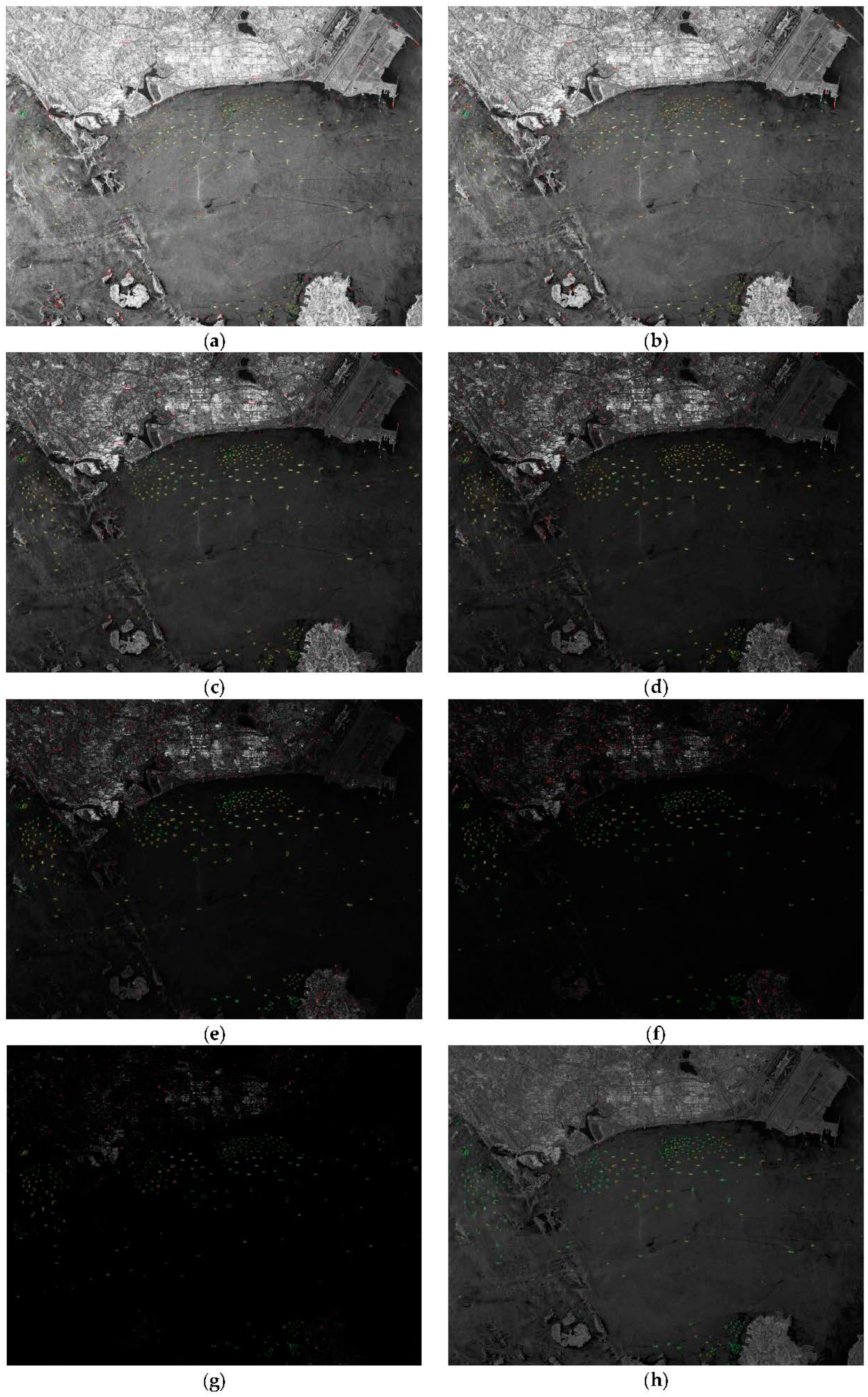
3.6. Robustness Analysis
4. Discussion
4.1. Choice of Contrasting Backbone Networks
4.2. Further Robustness Analysis and Choice of Threshold
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Cui, Z.; Li, Q.; Cao, Z.; Liu, N. Dense Attention Pyramid Networks for Multi-Scale Ship Detection in SAR Images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8983–8997. [Google Scholar] [CrossRef]
- Pei, J.; Huang, Y.; Huo, W.; Zhang, Y.; Yang, J.; Yeo, T.S. SAR automatic target recognition based on multiview deep learning framework. IEEE Trans. Geosci. Remote Sens. 2017, 56, 2196–2210. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, C.; Zhang, H.; Dong, Y.; Wei, S. Automatic Ship Detection Based on RetinaNet Using Multi-Resolution Gaofen-3 Imagery. Remote Sens. 2019, 11, 531. [Google Scholar] [CrossRef]
- Deng, Z.; Sun, H.; Zhou, S.; Zhao, J.; Lei, L.; Zou, H. Multi-scale object detection in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2018, 145, 3–22. [Google Scholar] [CrossRef]
- Liu, N.; Cao, Z.; Cui, Z.; Pi, Y.; Dang, S. Multi-Scale Proposal Generation for Ship Detection in SAR Images. Remote Sens. 2019, 11, 526. [Google Scholar] [CrossRef]
- Gao, G.; Liu, L.; Zhao, L.; Shi, G.; Kuang, G. An adaptive and fast CFAR algorithm based on automatic censoring for target detection in high-resolution SAR images. IEEE Trans. Geosci. Remote Sens. 2008, 47, 1685–1697. [Google Scholar] [CrossRef]
- Farrouki, A.; Barkat, M. Automatic censoring CFAR detector based on ordered data variability for nonhomogeneous environments. IEE Proc.-Radar Sonar Navig. 2005, 152, 43–51. [Google Scholar] [CrossRef]
- El-Darymli, K.; Gill, E.W.; McGuire, P.; Power, D.; Moloney, C. Automatic target recognition in synthetic aperture radar imagery: A state-of-the-art review. IEEE Access 2016, 4, 6014–6058. [Google Scholar] [CrossRef]
- Huang, X.; Yang, W.; Zhang, H.; Xia, G.S. Automatic ship detection in SAR images using multi-scale heterogeneities and an a contrario decision. Remote Sens. 2015, 7, 7695–7711. [Google Scholar] [CrossRef]
- Souyris, J.C.; Henry, C.; Adragna, F. On the use of complex SAR image spectral analysis for target detection: Assessment of polarimetry. IEEE Trans. Geosci. Remote Sens. 2003, 41, 2725–2734. [Google Scholar] [CrossRef]
- Souyris, J.C.; Henry, C.; Adragna, F. Ship detection based on coherence images derived from cross correlation of multilook SAR images. IEEE Geosci. Remote Sens. Lett. 2004, 1, 184–187. [Google Scholar]
- Kaplan, L.M. Improved SAR target detection via extended fractal features. IEEE Trans. Aerosp. Electron. Syst. 2001, 37, 436–451. [Google Scholar] [CrossRef]
- Schwegmann, C.P.; Kleynhans, W.; Salmon, B.P.; Mdakane, L.W.; Meyer, R.G. Very deep learning for ship discrimination in synthetic aperture radar imagery. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 104–107. [Google Scholar]
- Zhao, J.; Guo, W.; Zhang, Z.; Yu, W. A coupled convolutional neural network for small and densely clustered ship detection in SAR images. Sci. China Inf. Sci. 2019, 62, 42301. [Google Scholar] [CrossRef]
- El-Darymli, K.; McGuire, P.; Power, D.; Moloney, C.R. Target detection in synthetic aperture radar imagery: A state-of-the-art survey. J. Appl. Remote Sens. 2013, 7, 071598. [Google Scholar] [CrossRef]
- Li, T.; Liu, Z.; Xie, R.; Ran, L. An improved superpixel-level CFAR detection method for ship targets in high-resolution SAR images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 11, 184–194. [Google Scholar] [CrossRef]
- He, J.; Wang, Y.; Liu, H.; Wang, N.; Wang, J. A Novel Automatic PolSAR Ship Detection Method Based on Superpixel-Level Local Information Measurement. IEEE Geosci. Remote Sens. Lett. 2018, 15, 384–388. [Google Scholar] [CrossRef]
- Lin, H.; Chen, H.; Jin, K.; Zeng, L.; Yang, J. Ship Detection With Superpixel-Level Fisher Vector in High-Resolution SAR Images. IEEE Geosci. Remote Sens. Lett. 2019. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2015; pp. 91–99. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Fu, C.Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. Dssd: Deconvolutional single shot detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Li, Z.; Zhou, F. FSSD: Feature fusion single shot multibox detector. arXiv 2017, arXiv:1712.00960. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Liu, Y.; Zhang, M.H.; Xu, P.; Guo, Z.W. SAR ship detection using sea-land segmentation-based convolutional neural network. In Proceedings of the 2017 International Workshop on Remote Sensing with Intelligent Processing (RSIP), Shanghai, China, 18–21 May 2017; pp. 1–4. [Google Scholar]
- Kang, M.; Ji, K.; Leng, X.; Lin, Z. Contextual region-based convolutional neural network with multilayer fusion for SAR ship detection. Remote Sens. 2017, 9, 860. [Google Scholar] [CrossRef]
- Kang, M.; Leng, X.; Lin, Z.; Ji, K. A modified faster R-CNN based on CFAR algorithm for SAR ship detection. In Proceedings of the 2017 International Workshop on Remote Sensing with Intelligent Processing (RSIP), Shanghai, China, 18–21 May 2017; pp. 1–4. [Google Scholar]
- Li, J.; Qu, C.; Shao, J. Ship detection in SAR images based on an improved faster R-CNN. In Proceedings of the 2017 SAR in Big Data Era: Models, Methods and Applications (BIGSARDATA), Beijing, China, 13–14 November 2017; pp. 1–6. [Google Scholar]
- Wang, Y.; Wang, C.; Zhang, H. Combining a single shot multibox detector with transfer learning for ship detection using sentinel-1 SAR images. Remote Sens. Lett. 2018, 9, 780–788. [Google Scholar] [CrossRef]
- Chang, Y.L.; Anagaw, A.; Chang, L.; Wang, Y.C.; Hsiao, C.Y.; Lee, W.H. Ship Detection Based on YOLOv2 for SAR Imagery. Remote Sens. 2019, 11, 786. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X. High-Speed Ship Detection in SAR Images Based on a Grid Convolutional Neural Network. Remote Sens. 2019, 11, 1206. [Google Scholar] [CrossRef]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: High Quality Object Detection and Instance Segmentation. arXiv 2019, arXiv:1906.09756. [Google Scholar] [CrossRef]
- Chen, K.; Pang, J.; Wang, J.; Xiong, Y.; Li, X.; Sun, S.; Loy, C.C. Hybrid task cascade for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4974–4983. [Google Scholar]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS—Improving Object Detection with One Line of Code. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5561–5569. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Curlander, J.C.; McDonough, R.N. Synthetic Aperture Radar—Systems and Signal Processing; John Wiley & Sons, Inc: New York, NY, USA, 1991. [Google Scholar]
- Pitz, W.; Miller, D. The TerraSAR-X satellite. IEEE Trans. Geosci. Remote Sens. 2010, 48, 615–622. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked hourglass networks for human pose estimation. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016; pp. 483–499. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. arXiv Prepr. 2019, arXiv:1902.09212. [Google Scholar]
- Sun, K.; Zhao, Y.; Jiang, B.; Cheng, T.; Xiao, B.; Liu, D.; Wang, J. High-Resolution Representations for Labeling Pixels and Regions. arXiv 2019, arXiv:1904.04514. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Zhuang, S.; Wang, P.; Jiang, B.; Wang, G.; Wang, C. A Single Shot Framework with Multi-Scale Feature Fusion for Geospatial Object Detection. Remote Sens. 2019, 11, 594. [Google Scholar] [CrossRef]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Zhang, Z. MMDetection: Open MMLab Detection Toolbox and Benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Wang, C.; Shi, J.; Yang, X.; Zhou, Y.; Wei, S.; Li, L.; Zhang, X. Geospatial Object Detection via Deconvolutional Region Proposal Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 3014–3027. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016; pp. 630–645. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable convnets v2: More deformable, better results. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 9308–9316. [Google Scholar]
- Wada, K. labelme: Image Polygonal Annotation with Python. 2016. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
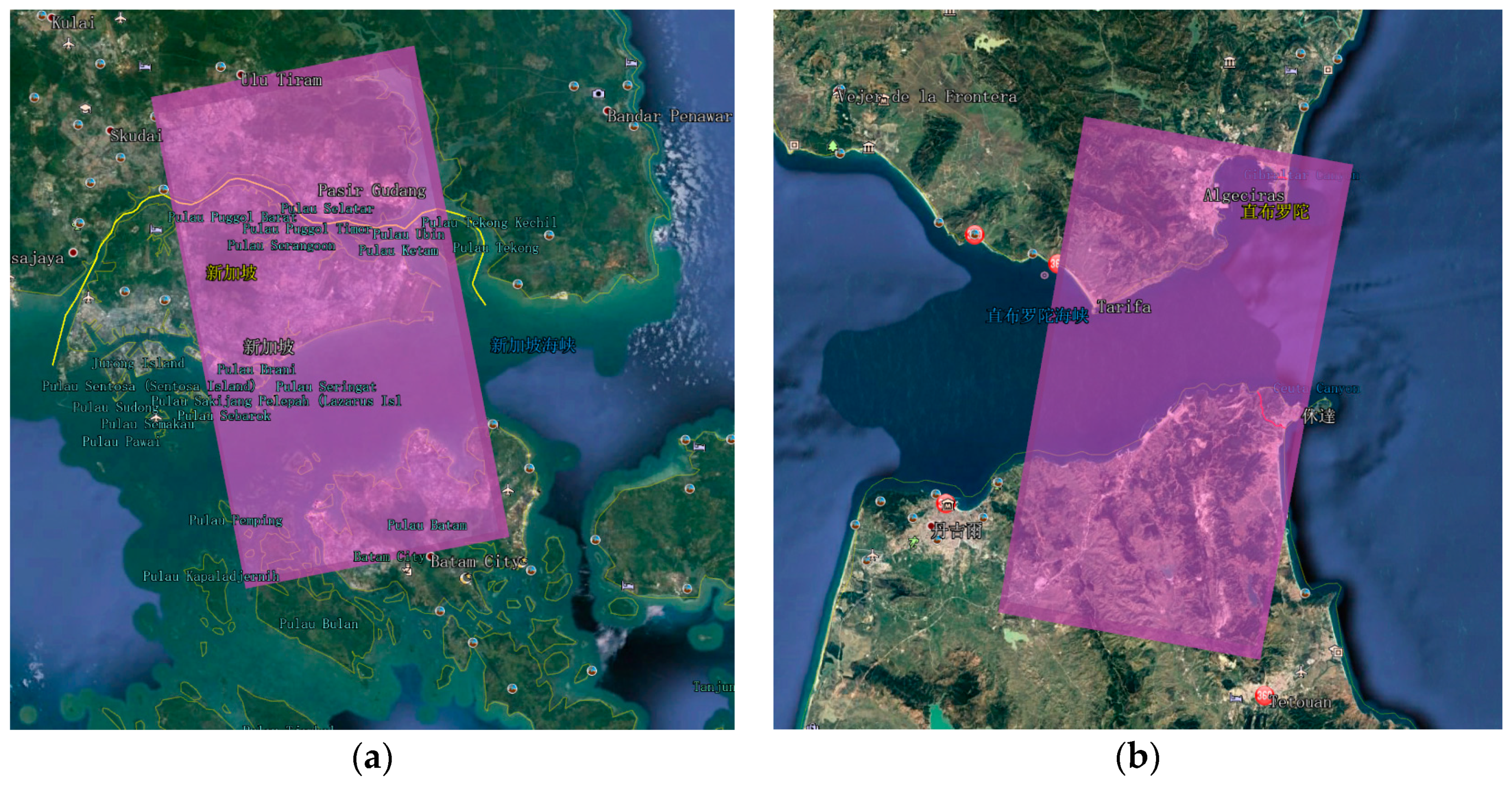
| Satellite | Waveband | Polarization | Resolution | Time | Position | Imaging Mode |
|---|---|---|---|---|---|---|
| TerraSAR | X | HH | 3 m | 2010-05-17 | Strait of Singapore | Strip Map |
| TerraSAR | X | HH | 3 m | 2008-05-12 | Strait of Gibraltar | Strip Map |
| Metrics | Metrics Meaning |
|---|---|
| AP | AP at IoU = 0.50: 0.05: 0.95 |
| AP50 | AP at IoU = 0.50 |
| AP75 | AP at IoU = 0.75 |
| APS | AP for small objects: area < 322 |
| APM | AP for medium objects: 322 < area < 962 |
| APL | AP for large objects: area > 962 |
| Backbone | Param (M) | Test Speed | Scenes | AP | AP50 | AP75 | APS | APM | APL |
|---|---|---|---|---|---|---|---|---|---|
| ResNet-50+FPN | 552.6 | 0.099s | Inshore | 46.7 | 80.6 | 48.4 | 40.1 | 53.5 | 51.3 |
| Offshore | 64.8 | 98.6 | 76.0 | 59.2 | 74.2 | 63.4 | |||
| ResNet-101+FPN | 704.8 | 0.112s | Inshore | 47.9 | 83.8 | 46.7 | 40.1 | 53.5 | 51.3 |
| Offshore | 64.7 | 98.7 | 76.4 | 59.4 | 73.4 | 60.1 | |||
| ResNext-101+64x4d+FPN | 1024.0 | 0.164s | Inshore | 49.3 | 85.1 | 48.7 | 41.3 | 56.4 | 60.2 |
| Offshore | 65.8 | 98.4 | 75.7 | 60.1 | 74.7 | 63.5 | |||
| HRFPN-W18 | 439.7 | 0.083s | Inshore | 50.7 | 84.7 | 54.2 | 42.6 | 57.8 | 66.3 |
| Offshore | 66.1 | 98.7 | 76.7 | 60.2 | 75.8 | 60.1 | |||
| HRFPN-W32 | 598.1 | 0.095s | Inshore | 51.0 | 84.6 | 54.0 | 42.5 | 57.5 | 67.3 |
| Offshore | 66.4 | 98.7 | 79.0 | 60.6 | 75.1 | 63.4 | |||
| HRFPN-W40 | 728.2 | 0.103s | Inshore | 53.6 | 88.7 | 56.9 | 46.1 | 59.6 | 74.8 |
| Offshore | 66.6 | 98.8 | 79.5 | 60.5 | 75.0 | 60.6 |
| Backbone | Method | AP | AP50 | AP75 | APS | APM | APL |
|---|---|---|---|---|---|---|---|
| ResNet-50+FPN | NMS | 61.3 | 95.6 | 70.7 | 56.5 | 69.0 | 53.0 |
| Soft-NMS | 62.7 | 96.2 | 73.4 | 57.6 | 70.5 | 56.9 | |
| ResNet-101+FPN | NMS | 61.4 | 96.0 | 70.4 | 56.7 | 68.1 | 68.3 |
| Soft-NMS | 62.7 | 96.7 | 71.9 | 57.7 | 69.6 | 70.0 | |
| ResNext-101+64x4d+FPN | NMS | 62.8 | 96.5 | 70.3 | 57.3 | 70.3 | 61.6 |
| Soft-NMS | 63.9 | 96.5 | 72.9 | 58.4 | 71.6 | 64.1 | |
| HRFPN-W18 | NMS | 63.0 | 96.1 | 72.1 | 57.3 | 71.4 | 63.0 |
| Soft-NMS | 63.9 | 96.8 | 73.1 | 58.2 | 72.3 | 65.0 | |
| HRFPN-W32 | NMS | 63.5 | 96.3 | 74.3 | 58.0 | 71.0 | 66.1 |
| Soft-NMS | 64.5 | 97.0 | 76.0 | 58.8 | 72.0 | 67.7 | |
| HRFPN-W40 | NMS | 63.7 | 97.3 | 74.3 | 58.3 | 71.2 | 70.6 |
| Soft-NMS | 64.6 | 97.9 | 75.9 | 59.0 | 72.3 | 72.0 |
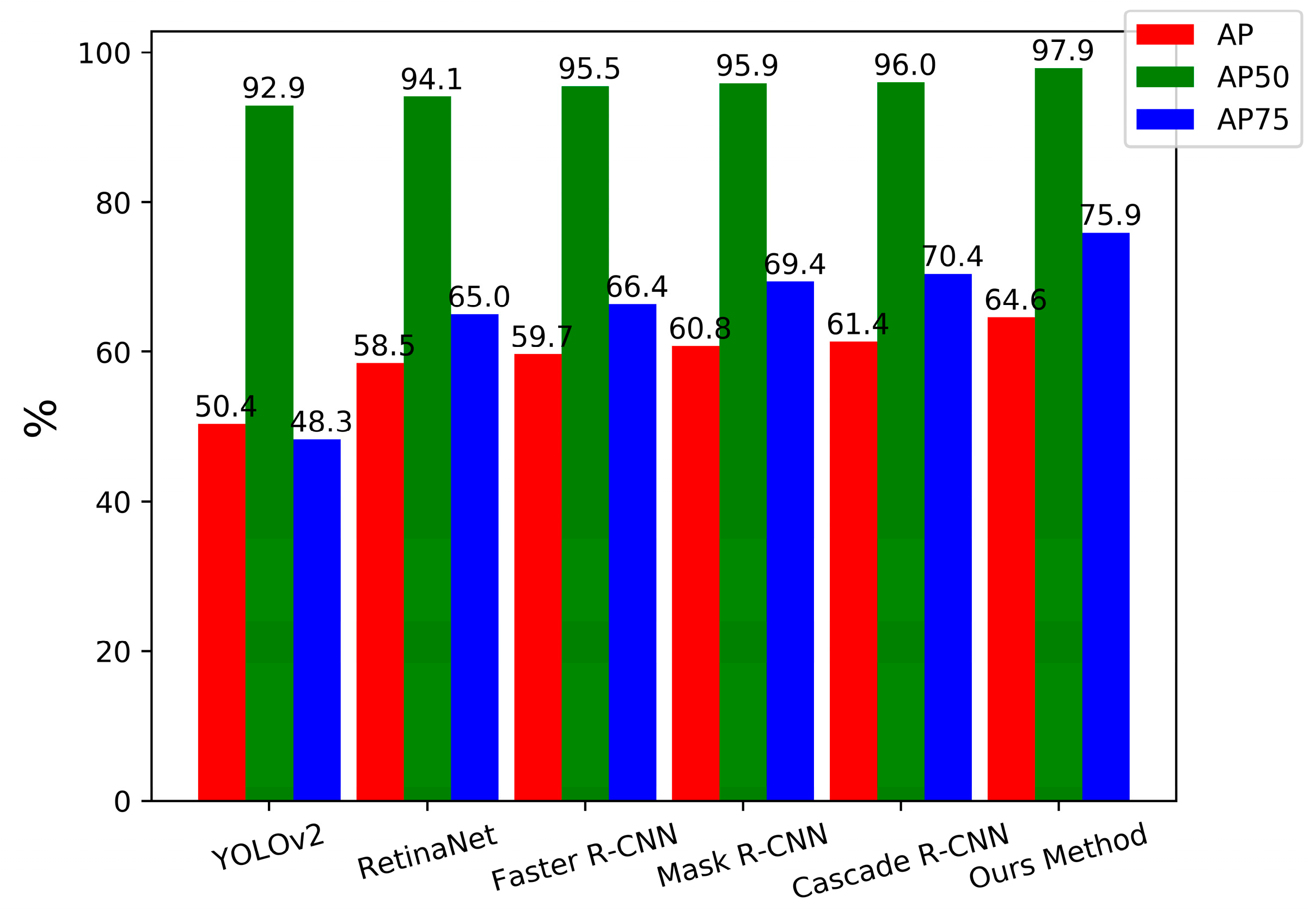
| Model | Backbone | Param (M) | Test Speed | AP | AP50 | AP75 | APS | APM | APL |
|---|---|---|---|---|---|---|---|---|---|
| YOLOv2 | Darknet-19 | 197.0 | 0.020s | 50.4 | 92.9 | 48.3 | 52.4 | 52.5 | 54.9 |
| RetinaNet | ResNet-50+FPN | 290.0 | 0.075s | 58.5 | 94.1 | 65.0 | 54.2 | 65.8 | 52.0 |
| RetinaNet | ResNet-101+FPN | 442.3 | 0.078s | 58.3 | 93.8 | 65.5 | 54.0 | 65.5 | 55.0 |
| Faster R-CNN | ResNet-50+FPN | 330.2 | 0.063s | 59.5 | 96.2 | 67.0 | 55.5 | 66.3 | 46.9 |
| Faster R-CNN | ResNet-101+FPN | 482.4 | 0.075s | 59.7 | 95.5 | 66.4 | 55.3 | 66.3 | 48.1 |
| Mask R-CNN | ResNet-50+FPN | 351.2 | 0.069s | 60.5 | 96.3 | 70.0 | 56.7 | 67.4 | 47.9 |
| Mask R-CNN | ResNet-101+FPN | 503.4 | 0.080s | 60.8 | 95.9 | 69.4 | 56.0 | 68.6 | 49.0 |
| Cascade R-CNN | ResNet-50+FPN | 552.6 | 0.099s | 61.3 | 95.6 | 70.7 | 56.5 | 69.0 | 53.0 |
| Cascade R-CNN | ResNet-101+FPN | 704.8 | 0.112s | 61.4 | 96.0 | 70.4 | 56.7 | 68.1 | 68.3 |
| HR-SDNet | HRFPN-W18 | 439.7 | 0.083s | 63.9 | 96.8 | 73.1 | 58.2 | 72.3 | 65.0 |
| HR-SDNet | HRFPN-W32 | 598.1 | 0.095s | 64.5 | 97.0 | 76.0 | 58.8 | 72.0 | 67.7 |
| HR-SDNet | HRFPN-W40 | 728.2 | 0.103s | 64.6 | 97.9 | 75.9 | 59.0 | 72.3 | 72.0 |
| Model | Backbone | Scenes | AP | AP50 | AP75 | APS | APM | APL |
|---|---|---|---|---|---|---|---|---|
| Faster R-CNN | ResNet-50+FPN | Inshore | 43.2 | 79.0 | 42.1 | 36.6 | 51.8 | 43.2 |
| Offshore | 63.1 | 98.6 | 73.3 | 58.4 | 70.9 | 60.0 | ||
| ResNet-101+FPN | Inshore | 44.5 | 79.8 | 42.0 | 37.8 | 51.6 | 47.9 | |
| Offshore | 63.0 | 97.7 | 72.5 | 58.1 | 71.1 | 55.0 | ||
| Mask R-CNN | ResNet-50+FPN | Inshore | 45.0 | 79.8 | 43.7 | 37.8 | 53.7 | 44.8 |
| Offshore | 63.9 | 98.7 | 76.3 | 59.7 | 71.5 | 60.1 | ||
| ResNet-101+FPN | Inshore | 44.6 | 77.6 | 45.4 | 38.8 | 50.7 | 45.3 | |
| Offshore | 64.3 | 98.5 | 74.8 | 58.6 | 73.6 | 60.1 | ||
| Cascade R-CNN | ResNet-50+FPN | Inshore | 46.7 | 80.6 | 48.4 | 40.1 | 53.5 | 51.3 |
| Offshore | 64.8 | 98.6 | 76.0 | 59.2 | 74.2 | 63.4 | ||
| ResNet-101+FPN | Inshore | 47.9 | 83.8 | 46.7 | 40.1 | 53.5 | 51.3 | |
| Offshore | 64.7 | 98.7 | 76.4 | 59.4 | 73.4 | 60.1 | ||
| DAPN [1] | DFPN-CON | Inshore | - | 67.5 | - | - | - | - |
| Inshore | - | 95.9 | - | - | - | - | ||
| HR-SDNet | HRFPN-W18 | Inshore | 50.7 | 84.7 | 54.2 | 42.6 | 57.8 | 66.3 |
| Offshore | 66.1 | 98.7 | 76.7 | 60.2 | 75.8 | 60.1 | ||
| HRFPN-W32 | Inshore | 51.0 | 84.6 | 54.0 | 42.5 | 57.5 | 67.3 | |
| Offshore | 66.4 | 98.7 | 79.0 | 60.6 | 75.1 | 63.4 | ||
| HRFPN-W40 | Inshore | 53.6 | 88.7 | 56.9 | 46.1 | 59.6 | 74.8 | |
| Offshore | 66.6 | 98.8 | 79.5 | 60.5 | 75.0 | 60.6 |
| Threshold | Ground Truth | TP | FN | FP | Recall | Precision |
|---|---|---|---|---|---|---|
| 0.008 | 58 | 44 | 14 | 0 | 75.86% | 100% |
| 0.02 | 58 | 52 | 6 | 0 | 89.66% | 100% |
| 0.05 | 58 | 39 | 19 | 2 | 67.24% | 95.12% |
| −20dB | 58 | 22 | 36 | 2 | 37.93% | 71.67% |
| −30dB | 58 | 15 | 43 | 0 | 25.86% | 100% |
| Backbone | Param (M) | Test-Speed | AP | AP50 | AP75 | APS | APM | APL |
|---|---|---|---|---|---|---|---|---|
| ResNet-50+C4 | 263.7 | 0.625 s | 59.9 | 93.8 | 68.5 | 55.2 | 67.0 | 64.6 |
| ResNet-50+FPN | 552.6 | 0.099 s | 61.3 | 95.6 | 70.7 | 56.5 | 69.0 | 53.0 |
| ResNet-50+FPN+DCN2 | 557.3 | 0.097 s | 61.8 | 96.6 | 70.3 | 56.8 | 69.1 | 55.7 |
| ResNext-50+32x4d+FPN | 548.5 | 0.109 s | 61.5 | 95.6 | 71.6 | 56.9 | 69.2 | 52.0 |
| ResNet-101+FPN | 704.8 | 0.112 s | 61.4 | 96.0 | 70.4 | 56.7 | 68.1 | 68.3 |
| ResNet-101+FPN+DCN2 | 715.1 | 0.123 s | 62.1 | 95.7 | 70.2 | 56.3 | 70.5 | 62.6 |
| ResNext-101+32x4d+FPN | 702.0 | 0.129 s | 62.9 | 96.7 | 72.5 | 57.9 | 70.6 | 56.4 |
| ResNext-101+64x4d+FPN | 1024.0 | 0.164 s | 62.8 | 96.5 | 70.3 | 57.3 | 70.3 | 61.6 |
| HRFPN-W18 | 439.7 | 0.083 s | 63.0 | 96.1 | 72.1 | 57.3 | 71.4 | 63.0 |
| HRFPN-W32 | 598.1 | 0.095 s | 63.5 | 96.3 | 74.3 | 58.0 | 71.0 | 66.1 |
| HRFPN-W40 | 728.2 | 0.103 s | 63.7 | 97.3 | 74.3 | 58.3 | 71.2 | 70.6 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, S.; Su, H.; Ming, J.; Wang, C.; Yan, M.; Kumar, D.; Shi, J.; Zhang, X. Precise and Robust Ship Detection for High-Resolution SAR Imagery Based on HR-SDNet. Remote Sens. 2020, 12, 167. https://doi.org/10.3390/rs12010167
Wei S, Su H, Ming J, Wang C, Yan M, Kumar D, Shi J, Zhang X. Precise and Robust Ship Detection for High-Resolution SAR Imagery Based on HR-SDNet. Remote Sensing. 2020; 12(1):167. https://doi.org/10.3390/rs12010167
Chicago/Turabian StyleWei, Shunjun, Hao Su, Jing Ming, Chen Wang, Min Yan, Durga Kumar, Jun Shi, and Xiaoling Zhang. 2020. "Precise and Robust Ship Detection for High-Resolution SAR Imagery Based on HR-SDNet" Remote Sensing 12, no. 1: 167. https://doi.org/10.3390/rs12010167
APA StyleWei, S., Su, H., Ming, J., Wang, C., Yan, M., Kumar, D., Shi, J., & Zhang, X. (2020). Precise and Robust Ship Detection for High-Resolution SAR Imagery Based on HR-SDNet. Remote Sensing, 12(1), 167. https://doi.org/10.3390/rs12010167