1. Introduction
Synthetic aperture radar (SAR), an active microwave remote sensing imaging radar capable of observing the earth’s surface all-day and all-weather, has a wide range of applications in military, agriculture, geology, ecology, oceanography, etc. In particular, since the United States launched the first civil SAR satellite to carry out ocean exploration in 1978 [
1], SAR has begun to be constantly used in the marine field, such as fishery management [
2], traffic control [
3], sea-ice monitoring [
4], marine environmental protection [
5], ship surveillance [
6,
7], etc. Among them, in recent years, ship detection in SAR images has become a research hotspot for its broad application prospects [
8,
9]. On the military side, it is conducive for tactical deployment and ocean defense early warning. On the civil side, it is also beneficial for maritime transport management and maritime distress rescue. However, despite of the wide practical value in the military and civil side, up to now, SAR ship detection technology is still lagging behind optical images due to their different imaging mechanisms [
10].
Therefore, many constructive methods are emerging to solve this problem, which promote the development of SAR interpretation technology persistently. According to our investigation, these multifarious methods can be mainly divided into two categories: (1) Traditional feature extraction methods; (2) modern deep learning (DL) methods.
The most noteworthy characteristic of the traditional feature extraction methods is the manual feature extraction. In these ways, ships can be distinguished from ports, islands, etc., through gray level, texture, contrast ratio, geometric size, scattering characteristics, the scale-invariant feature transform (SIFT) [
11], haar-like (Haar) [
12], histogram of oriented gradient (HOG) [
13], etc. Among them, the constant false alarm rate (CFAR) is one of the typical algorithms. When performing ship detection, CFAR detectors provide a threshold, which needs to avoid noise background clutter and interference as far as possible, to detect the existence of ships. Therefore, it is essential to establish an accurate clutter statistical model for CFAR detectors. Among them, some frequently-used clutter statistical models are based on Gauss-distribution [
14], Rayleigh-distribution [
15],
k-distribution [
16], and Weibull-distribution [
17]. However, for these CFAR detectors, there are still two drawbacks hindering its development and application. On the one hand, it is bitterly challenging to build an accurate clutter model. On the other hand, these established models are inevitably vulnerable to sea clutter and ocean currents. Therefore, the application scenarios are limited and the migration capacity is also weak. Even worse, in the practical applications, it takes a lot of time to solve lots of parameters of the above distribution equations, leading to a slower detection speed. Another common traditional method is the template-based detection [
18,
19]. This method considers both the characteristics of specific targets and that of backgrounds, which has achieved good detection performance. However, these detection templates are frequently dependent on the expert experience and deficient in mature theories, which may lead to their poor migration ability. In addition, the template matching in wide-region SAR images is also time-consuming, which undoubtedly declines the detection speed. In summary, these traditional feature extraction methods are complex in computation, weak in generalization, and troublesome in manual feature extraction. Most importantly, the detection speed of these methods is too slow to satisfy real-time ship detection in the practical application occasion.
The most noteworthy characteristic of the modern DL methods is the automatic feature extraction [
20]. By this means, it is unnecessary to design features via manual participation, simply and efficiently. As long as given a labeled dataset, computers can train and learn like human brains to accomplish accurate object detection tasks. For this reason, nowadays, more and more scholars are following the path of artificial intelligence (AI) to achieve SAR ship detection. Generally, there are two main types of object detectors in the DL field [
21]: (1) Two-stage detectors; (2) one-stage detectors.
Two-stage detectors usually assign detection tasks into two stages: acquisition of region of interest (ROI) and classification of ROI. Region-convolutional neural network (R-CNN) [
22] is the first one to realize object detection via DL methods. R-CNN used the selective search [
23] to generate ROIs, then extracted the features of ROIs by CNNs, and finally, classified ROIs by support vector machine (SVM) [
24]. It made the mean average precision (mAP) on the Pascal VOC dataset [
25] a great increment compared with previous traditional methods. However, due to its huge amount of calculation, the detection speed of R-CNN is notoriously slow, leading to impracticability in industry. To improve the detection speed, a fast region-convolutional neural network (Fast R-CNN) was proposed by Girshick et al. [
26], which draws some experience from spatial pyramid pooling network (SPP-net) [
27]. Fast R-CNN added an ROI pooling layer and realized feature sharing, as a result, its speed is 213 times faster than R-CNN [
26]. However, the ROI extraction process still takes up most of the detection time, reducing its detection efficiency. Therefore, faster region-convolutional neural network (Faster R-CNN) [
28] was proposed to simplify this process by a region proposal network (RPN), as a result, its speed is 10 times faster than Fast R-CNN [
28]. So far, Faster R-CNN is still one of the mainstream object detection methods in the DL field [
29]. From these emerged methods, we can summarize that the development tendency of two-stage detectors is to improve the detection speed. Nevertheless, two-stage detectors inherently need to obtain region recommendation boxes in advance, leading to their heavy computation. Therefore, there are some intrinsic technical bottlenecks in improving detection speed, so they scarcely meet the real-time requirement. Hence, one-stage detectors emerged to simplify the detection process.
One-stage detectors achieve detection tasks directly based on position regression. Redmon et al. [
30] proposed the first one-stage detector, called you only look once (YOLO), which processes the input image only once. In this way, the amount of calculation gets decreased further and the detection speed gets improved further, compared with two-stage detectors. However, its detection performance on neighboring targets and small ones is not ideal, because each grid is responsible for predicting only one target. Therefore, they also proposed an improved version called YOLOv2 [
31] based on anchor box mechanism and feature fusion. In YOLOv2, a more robust backbone network Darknet-19 [
31] was proposed to improve the detection accuracy. However, the accuracy of YOLOv2 is still far inferior to two-stage detectors. Finally, YOLOv3 [
32] was proposed to increase the detection accuracy further, by using Darknet-53 [
32] and multiscale mechanism. In addition, another two common one-stage detectors are single shot multi-box detector (SSD) proposed by Liu et al. [
33] and RetinaNet proposed by Lin et al. [
34]. SSD combined the advantages of YOLO and Faster R-CNN to achieve a balance between accuracy and speed. RetinaNet proposed a focal loss to solve the extreme imbalance between positive and negative sample regions, which can improve accuracy. However, their detection speed is inferior to YOLO. From these emerged methods, we can summarize that the development tendency of one-stage detectors is to improve the detection accuracy.
From the comparison of two-stage detectors and one-stage detectors, both accuracy and speed are extremely significant for object detection. However, nowadays, in the SAR ship detection field, many types of researches are focusing on improving the ship detection accuracy. Unfortunately, there are few studies on improving the ship detection speed. However, it definitely cannot be ignored as high-speed SAR ship detection is of great practical value, especially in the cases of maritime distress rescue and war emergency scenarios.
Therefore, in order to address this problem, in this paper, a novel high-speed SAR ship detection approach was proposed by mainly using depthwise separable convolution neural network (DS-CNN). A DS-CNN is composed of a depthwise convolution (D-Conv2D) and a pointwise convolution (P-Conv2D), which substitute for the conventional convolution neural network (C-CNN), by which the number of network parameters get greatly decreased. Consequently, the detection speed gets dramatically improved. Particularly, a brand-new light-weight network architecture, which integrates multi-scale detection mechanism, concatenation mechanism and anchor box mechanism, was exclusively established for the high-speed SAR ship detection. We experimented on an open SAR ship detection dataset (SSDD) [
35] to verify the correctness and feasibility of the proposed method. In addition, we also carried out actual ship detection on a wide-region large-size Sentinel-1 SAR image to verify the strong migration ability of the proposed method. Finally, the experimental results indicated that our method can achieve high-speed SAR ship detection, authentically. On the SSDD dataset, it only takes 9.03 ms per SAR image for ship detection (111 images can be detected per second). The detection speed of the proposed method is faster than other methods, such as Faster R-CNN, RetinaNet, SSD, and YOLO, under the same hardware platform with NVIDIA RTX2080Ti GPU. Our method accelerated SAR ship detection by many times with only a slight accuracy sacrifice compared with the state-of-art object detectors, which is of great application value in real-time maritime disaster rescue and emergency military planning.
To be clear, in this paper, we did not consider the time of SAR imaging process (most often, decades of minutes up to hours for a wide region) because SAR images to be detected have been acquired previously. Therefore, only the time of SAR image interpretation, namely ship detection, was considered. Another point to note is that the adjective “high-speed” is used to describe the detection speed by a detector, instead of the moving speed of ship.
The main contributions of our work are as follows:
A brand-new light-weight network architecture for the high-speed SAR ship detection was established by mainly using DS-CNN;
Multi-scale detection mechanism, concatenation mechanism and anchor box mechanism were integrated into our method to improve the detection accuracy;
The ship detection speed of our proposed method is faster than the current other object detectors, with only a slight accuracy sacrifice compared with the state-of-art object detectors.
The rest of this paper is organized as follows.
Section 2 introduces C-CNN and DS-CNN.
Section 3 introduces our network architecture.
Section 4 introduces our ship detection model.
Section 5 introduces our experiments.
Section 6 presents the results of SAR ship detection. Finally, a summary is made in
Section 7.
5. Experiments
In this section, firstly, we will introduce the SSDD dataset used in this paper. Then, we will introduce the loss function. Afterwards, we will introduce our training strategies. Finally, we will introduce the establishment process of the SAR ship detection model through five types of researches.
Our experimental hardware platform is a personal computer (PC) with the hardware configuration of Intel(R) i9-9900K CPU @3.60GHz, NVIDIA RTX2080Ti GPU, and 32G memory. Our experiments are performed on PyCharm [
51] software platform, with Python 3.5 language. Our programs are written based on the Keras framework [
52], a Python-based deep learning library with TensorFlow [
53] as backend. In addition, we call GPU through CUDA 10.0 and cuDNN 7.6 for training acceleration.
In our experiments, to achieve better detection accuracy, we set IoU = 0.5 and score = 0.5 as detection thresholds, which means that if the probability of a bounding box containing a ship is greater than or equal to 50%, it is retained. In fact, these two detection thresholds can be dynamically adjusted as a good tradeoff between false alarm and missed detection according to the actual detection results.
5.1. Dataset
In the DL field, a dataset that has been correctly labeled is a momentous prerequisite for research. Therefore, we chose an open SSDD dataset [
35] to verify the correctness and feasibility of our proposed method.
Table 2 shows the detailed descriptions of SSDD. From
Table 2, there are 1160 SAR images in SSDD dataset coming from three different sensors and there are 2358 ships in these images, with 2.03 ships in one image on average. These 1160 SAR images are labeled by Li et al. [
35] by using LabelImg [
54], an image annotation software. SAR images in this dataset possess different satellite sensors, various polarization modes, multiple resolutions, different scenes, and abundant ship sizes, so it can verify the robustness of methods. Therefore, many scholars [
10,
21,
35,
55,
56,
57,
58,
59,
60,
61,
62,
63] conducted research based on it for a better comparison.
5.2. Loss Function
The task of ship detection is to provide five parameters (x, y, w, h, score) of a prediction box. Therefore, our loss function is mainly composed of the errors of these five parameters.
Loss function of the predictive coordinates (
x,
y) is defined by:
where (
xi,
yi) is the coordinate of the
i-th ship’s ground truth box, (
i,j,
i,j) is the coordinate of the
i-th ship’s prediction box of the
j-th grid cell.
Loss function of the predictive width and height (
w, h) is defined by:
where (
wi,
hi) is the width and height of the
i-th ship’s ground truth box, (
i,j,
i,j) is the width and height of the
i-th ship’s prediction box of the
j-th grid cell.
Loss function of the predictive confidence (
score) is defined by:
where
i,j is the score of the
i-th ship’s prediction box of the
j-th grid cell, and
γ is a weight coefficient.
Therefore, the total loss function is:
where
α,
β and
γ are the weight coefficients, which indicate the weight of various types of loss in the total loss. In particular, here,
γ is the same as that in Equation (24), inspired from the experience of reference [
30].
In our ship detection model, we set
α = β = 5 and
γ = 0.5, inspired by the experience of YOLO [
30]. By using Equation (25), our model will have a good convergence in training process, which is a critical premise for our work. The good convergence in training process will be presented in
Figure 10 of
Section 5.3.
5.3. Training Strategies
We randomly divided the dataset into a training set, a validation set and a test set according to the ratio of 7:2:1. The training set is used to train the model, the verification set is used to adjust the model to avoid over-fitting, and the test set is used to evaluate the performance of the model.
We used adaptive moment estimation (Adam) algorithm [
64] to realize the iteration of network parameters. We trained the network for 100 epochs with batch size = 8, which means that every eight samples complete a parameter update. For the first 50 epochs, the learning rate was set to 0.001; for the last 50 epochs, the learning rate was changed to 0.0001 in order to further reduce the loss. In the last 50 epochs, if the loss of verification set does not decrease for three consecutive times, the learning rate will automatically decrease.
For the deeper layers of our backbone network, we adopted dropout mechanism [
65] to accelerate the learning speed of the network and avoid over-fitting, by which each neuron loses its activity at a 0.1% probability. In addition, in order to further avoid over-fitting of the whole network, we also adopted early stopping mechanism [
66], by which if the loss of the verification set does not decrease for 10 consecutive times, the network is forced to stop training.
Especially, in order to reduce the number of iterations and avoid falling into local optimum, we first pre-trained our network on ImageNet dataset [
40]. In the DL field, ImageNet pre-training [
67] is a normal practice, which has adopted by many other object detectors. Certainly, we can also start training from scratch [
68], but it reduces the accuracy by 4% in our experiments. Detailed research of pre-training will be introduced in
Section 5.4.2.
We also used TensorBoard [
53], a visualization tool of TensorFlow, to facilitate the monitor of the training process. In our experiments, we saved the model only when the loss of the verification set of the current epoch is better than that of the previous epoch. Finally, the optimal SAR ship detection model was retained and others were deleted.
Figure 10 shows the loss curves of the training set and the validation set. From
Figure 10, for one thing, the loss can be reduced rapidly, which shows that the loss function we set in
Section 5.2 is effective (only need 10 epochs from 3500 loss to 45 loss, a good convergence). For another thing, the gap between the loss of the validation set and the training set is very narrow, which indicates that there is not an over-fitting phenomenon in our network, so our training strategies are effective and feasible. In particular, in
Figure 10, this network trained only 77 epochs due to the early stopping mechanism. In fact, in our experiments, almost every training was forced to stop (<100 epochs), which reflected the powerful and effective role of early stopping mechanism.
5.4. Establishment of Model
Next, we will establish the most suitable high-speed SAR ship detection model through the following five types of researches.
5.4.1. Research on Image Size
From
Figure 8, the images to be detected are resized into
L ×
L by resampling. Then, we need to determine the final exact value of
L to obtain a better detection performance. Therefore, we studied the influence of different values of
L on detection performance. In particular, since our network can be regarded as 32 times down-sampling (Input:
L; Detection network-1:
L/32),
L must be a multiple of 32.
Thus, we set:
to conduct comparative experiments.
In addition, these ten groups of experiments were conducted under the following same conditions:
- (a)
Pretraining;
- (b)
Two concatenations;
- (c)
Three detection scales;
- (d)
Nine anchor boxes.
Table 3 shows the evaluation indexes of research on image size.
Figure 11a shows the precision-recall (P-R) curves and
Figure 11b is the bar graph of mAP (accuracy) and FPS (speed).
- (1)
The detection accuracy becomes higher with the increase of
L when
L < 160 (marked in green in
Figure 11b). The detection accuracy is the highest when
L = 160. The detection accuracy does not increase any more, but fluctuates slightly when
L > 160;
- (2)
The detection speed becomes lower with the increase of
L (marked in pink in
Figure 11b). This phenomenon is in line with common sense because large-size images have more pixels, leading to more computation.
Finally, we chose L = 160 as a tradeoff between accuracy and speed in our final model. For one thing, it has relatively high accuracy (94.13% mAP). For another thing, its detection speed does not decrease too much, compared with L = 32 (from 124 FPS to 111 FPS).
5.4.2. Research on Pretraining
In the DL field, in recent years, a common practice is to pre-train the model on some large-scale datasets (such as ImageNet dataset) and then fine-tune the model on other target tasks with less training data [
67]. Compared with 1.26 million images in ImageNet, the number of SAR images in SSDD dataset is very small (only 1160 images). Therefore, we studied the effect of pretraining on ImageNet on detection performance.
We arranged two groups of experiments, one for pretraining on ImageNet and the other for non-pretraining on ImageNet, and these two groups of experiments were conducted under the following same conditions:
- (a)
L = 160;
- (b)
Two concatenations;
- (c)
Three detection scales;
- (d)
Nine anchor boxes.
Table 4 shows the evaluation indexes of research on pretraining.
Figure 12a shows the precision-recall (P-R) curves and
Figure 12b is the bar graph of mAP (accuracy) and FPS (speed).
- (1)
The detection accuracy of pretraining on ImageNet is superior to that of non-pretraining. This phenomenon shows that pretraining is an effective way to improve the detection accuracy;
- (2)
The detection speed of pretraining and non-pretraining is similar (110 FPS and 111 FPS) because the pre-training is only carried out in the training process, it does not affect the subsequent actual detection.
Although pretraining on ImageNet is time-consuming before establishing the model, it can improve the accuracy considerably. Therefore, finally, we still chose pretraining on ImageNet in our final model.
5.4.3. Research on Multi-Scale Detection Mechanism
In our network, we set three different detection networks (detection network-1, detection network-2, and detection network-3) to detect ships with different sizes (
L/32,
L/16, and
L/8), as is shown in
Figure 6. Therefore, we made a further research on multi-scale detection to confirm that it can indeed improve the detection accuracy.
We arranged seven groups of comparative experiments under the following same conditions:
- (a)
L = 160;
- (b)
Pretraining;
- (c)
Two concatenations;
- (d)
Nine anchor boxes.
Table 5 shows the evaluation indexes of research on multi-scale detection mechanism.
Figure 13a shows the precision-recall (P-R) curves and
Figure 13b is the bar graph of mAP (accuracy) and FPS (speed).
- (1)
The detection accuracy shows a upward trend with the increase of the number of detection scales. If using only one scale, the detection accuracy is the lowest. If using two scales, the detection accuracy is better than that of one scale. However, it is still too poor to meet the actual needs (mAP < 90%). If using all three scales, the detection accuracy is the highest (mAP = 94.13%). This phenomenon shows that multi-scale detection mechanism can indeed improve detection accuracy;
- (2)
The detection speed shows a downward trend with the increase of the number of detection scales. This phenomenon is in line with common sense because the size of the network has increased.
In addition, in the SSDD dataset, the smallest size of ship is 4 × 7 and the biggest size of ship is 211 × 298. Ships from the smallest to the biggest can all be detected successfully by these three different detection scales. In other words, three different detection scales are sufficient. Certainly, if more detection scales are used, the detection accuracy may be higher while the detection speed is bound to decline.
Therefore, finally, we chose three detection scales in our final model, which can achieve the best detection accuracy.
5.4.4. Research on Concatenation Mechanism
In our detection network, we set two concatenations to achieve feature fusion, as is shown in
Figure 4. Therefore, we studied the effect of concatenation and non-concatenation.
We arranged two groups of comparative experiments under the following same conditions:
- (a)
L = 160;
- (b)
Pretraining;
- (c)
Three detection scales;
- (d)
Nine anchor boxes.
Table 6 shows the evaluation indexes of research on concatenation mechanism.
Figure 14a shows the precision-recall (P-R) curves and
Figure 14b is the bar graph of mAP (accuracy) and FPS (speed).
- (1)
The detection accuracy of concatenation is superior to that of non-concatenation (94.13% mAP > 92.43% mAP). This phenomenon shows that concatenation mechanism can indeed improve detection accuracy because the shallow features and deep features have been fully integrated;
- (2)
The detection speed of concatenation and non-concatenation is almost equal (112 FPS and 111 FPS), because only two concatenations does not increase network parameters too much.
Finally, in order to obtain better detection accuracy, we adopted the concatenation mechanism in our final model.
5.4.5. Research on Anchor Box Mechanism
Finally, we also studied the influence of the number of anchor boxes on the detection performance. Therefore, we arranged three groups of experiments, and the number of their anchor boxes were 3, 6, and 9, respectively. If there are 3 anchor boxes, then each detection scale generates only one bounding box. If there are 6 anchor boxes, then each detection scale generates two bounding boxes. If there are 9 anchor boxes, then each detection scale generates three bounding boxes. Besides, 9 anchor boxes are sufficient, because, in the SSDD dataset, a grid cell contains less than 9 ships. However, for other dataset, the maximum number of anchor boxes may be different.
In addition, the three groups of experiments were conducted under the following same conditions:
- (a)
L = 160;
- (b)
Pretraining;
- (c)
Two concatenations;
- (d)
Three detection scales.
Table 7 shows the evaluation indexes of research on anchor box mechanism.
Figure 15a shows the precision-recall (P-R) curves and
Figure 15b is the bar graph of mAP (accuracy) and FPS (speed).
- (1)
The detection accuracy becomes higher with the increase of the number of anchor boxes. One possible reason is that more anchor boxes can improve the detection accuracy of densely distributed small ships;
- (2)
The detection speed is not greatly affected by the number of anchor boxes, because the number of the network parameters are invariable for these three cases and only a small amount of follow-up processing is added with the increase of the number of anchor boxes.
In addition, for these three cases, we also compared the detection results of some small ships with the dense distribution.
Figure 16 shows the ship detection results of a SAR image with densely distributed small ships. In
Figure 16a, there are 27 real ships in the image. In
Figure 16b, for 3 anchor boxes, 15 ships are detected successfully and 12 ships are missed detected. In
Figure 16c, for 6 anchor boxes, 21 ships are detected successfully and 6 ships are missed detected. In
Figure 16d, for 9 anchor boxes, 25 ships are detected successfully and 1 ship is missed detected, meanwhile a false alarm case appears. In brief, if there are more anchor boxes, our model has a lower missed detection rate for those small and densely distributed ships.
Therefore, finally, we chose 9 anchor boxes in our final model, which can improve the accuracy of small ships.
5.5. Visualization of Feature Maps
Through the above five types of researches in
Section 5.4, we determined our final high-speed SAR ship detection model, and the specific parameters are as follows:
- (a)
L = 160;
- (b)
Pretraining;
- (c)
Two concatenations;
- (d)
Three scales detection;
- (e)
Nine anchor boxes.
After building the model, in order to more vividly present the processing of the input image by deep neural networks, we visualized some important feature maps of our network (input, output of the 1st layer, output of backbone network, output of detection network-1, output of detection network-2, and output of detection network-3). Besides, the visualization of feature maps is also convenient to understand the process of feature extraction by deep neural networks.
Figure 17 shows the visualization of some important feature maps. In
Figure 17a, the image is resized into 160 × 160, and the number of channels is 3. In
Figure 17b, after the convolution operation of the 1
st layer (Conv2D_1 in
Figure 4), the size of all feature maps is 80 × 80 × 32, where 80 is the number of width pixels and height pixels and 32 is the number of channels. From
Figure 17b, the features extracted from deep networks are abstract and difficult to explain (maybe texture, edge, shape, etc.), which is a consensus in the DL field [
20,
69]. Even this, computers can surprisingly accurately detect objects based on these abstract features, which subverts the feature extraction theory of traditional methods. In
Figure 17c, after processing of the backbone network, the outputs consist of 1024 feature maps with the size of 5 × 5 (P-Conv2D_13 in
Figure 4). Then, these 1024 feature maps are inputted into three detection networks for ship detection. In
Figure 17d, there are 18 feature maps with the size of 5 × 5 (
L/32) for detecting big size ships. In
Figure 17e, there are 18 feature maps with the size of 10 × 10 (
L/16) for detecting medium size ships. In
Figure 17f, there are 18 feature maps with the size of 20 × 20 (
L/8) for detecting small size ships. Finally, our model will generate prediction boxes based on the feature maps of
Figure 17d–f. More details about the visualization of feature maps can be found in reference [
69].
6. Results
In this section, firstly, we will carry out actual ship detection on the test set of SSDD dataset. Then, to verify the migration capability of the model, we will also carry out actual ship detection in a wide-region large-size Sentinel-1 SAR image. Finally, we will make a performance comparison between our method and other methods on the SSDD dataset. In addition, we did not show the performance comparison results on the Sentinel-1 SAR image, because of: (1) the similar conclusions to that on the SSDD dataset; (2) page limit.
6.1. Results of Ship Detection on Test Set
Figure 18 shows the SAR ship detection results of some sample images in the SSDD dataset. From
Figure 18, real ships in various backgrounds can almost be detected correctly, which shows that our ship detection system has strong robustness. In addition, there are also some false alarm and missed detection cases. For the former, one possible reason is the high similarity between other port facilities and ships. For the latter, one possible reason is that these ships are densely distributed and too small, which bring some obstacles to the system for their lower
IoU scores. In a word, from a subjective point of view in
Figure 18, our model achieves satisfactory ship detection results.
Then, we objectively evaluated our model on the test set of SSDD.
Table 8 shows the evaluation indexes of the test set of SSDD.
Figure 19a shows the precision-recall (P-R) curves and
Figure 19b is the bar graph of mAP (accuracy) and FPS (speed).
- (1)
The detection accuracy of our method is 94.13% mAP, which can meet the requirement of SAR ship detection;
- (2)
The detection speed of our method is 111 FPS, which can detect 111 SAR images in the SSDD dataset per second. The number of SAR images in the test set of the SSDD dataset is 116 (10% of 1160), and DS-CNN averagely takes 9.03 ms to complete the ship detection of one image. Therefore, DS-CNN takes 1047.48 ms (116 × 9.03 ms) to complete the ship detection of the whole test set. Moreover, there are 182 ships in the test set of the SSDD dataset, then the detection average speed is 5.76 ms/ship (1047.48 ms/182).
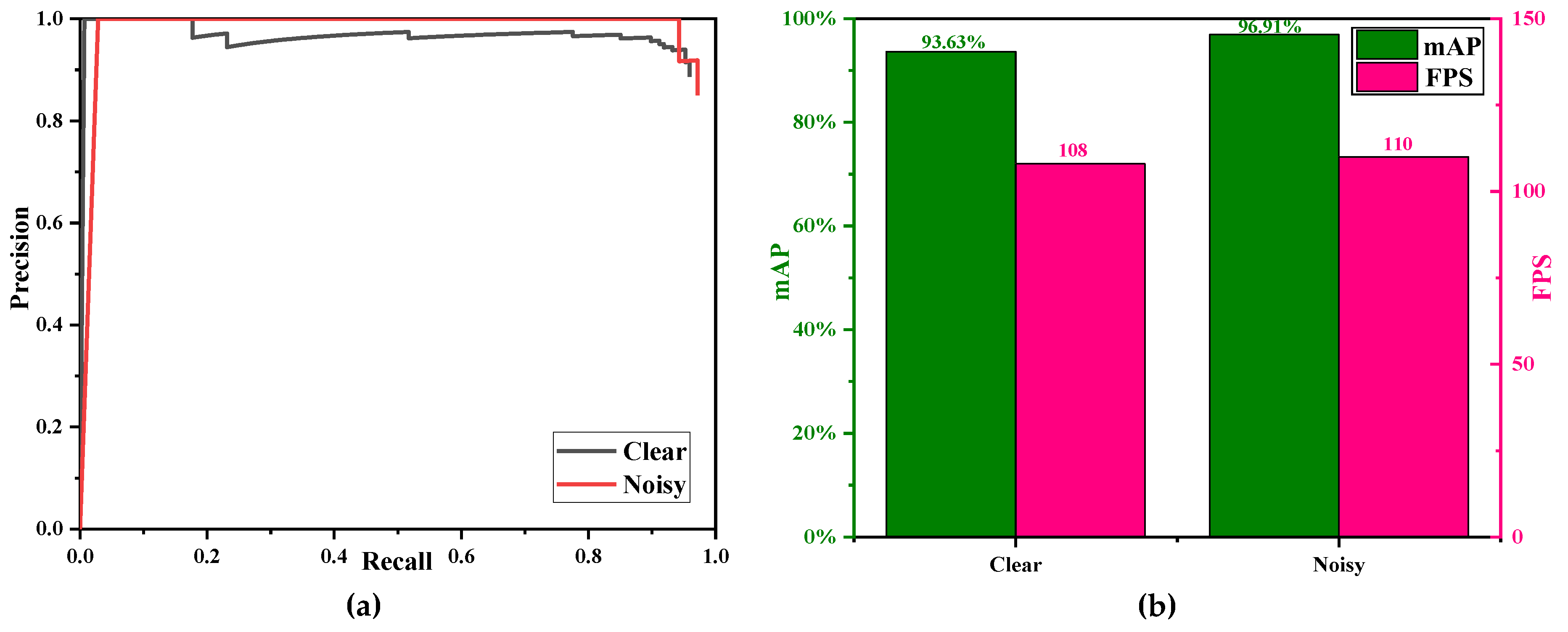
Finally, we also compared the detection results of images with severe speckle noise and clear images.
Table 9 shows the ship detection evaluation indexes of images with severe speckle noise and clear images.
Figure 20a shows the precision-recall (P-R) curves and
Figure 20b is the bar graph of mAP (accuracy) and FPS (speed).
Figure 21 shows the ship detection results of images with severe speckle noise and clear images.
- (1)
The detection accuracy of the nosiy images is superior to that of the clear images (96.91% mAP > 93.63% mAP). This phenomenon seems to be out of line with common sense, because usually, clear images should have higher accuracy than noisy ones. In fact, the possible reasons for this phenomenon are that (1) in the test set of the SSDD dataset (1160 × 10% = 116), the number of moisy images is less than that of clear images (28 of 116 < 88 of 116), which may lead to greater accuracy randomness; (2) noisy images have a single background and contain offshore ships (See
Figure 21a) while clear images have more complex backgrounds and contain onshore ships (See
Figure 21b), and evidently, it is more difficulty to detect the onshore ships than the offshore ships;
- (2)
The detection speed of the clear images is similar to that of the nosiy images, because the size of images is the same.
6.2. Results of Ship Detection on Sentinel-1
In order to verify that our ship detection model has strong migration ability, we carried out actual ship detection on a wide-region large-size Sentinel-1 SAR image with multiple targets and complex backgrounds. We obtained this SAR image from the website of reference [
70], and obtained the ground truth information from the Association for Information Systems (AIS) [
71,
72].
Table 10 shows the descriptions of the Sentinel-1 SAR image to be detected.
We directly divided the original wide-region large-size SAR image (6333 × 4185) into 900 sub-images on average, with 211 × 140 size for each sub-image, and then resized these 900 sub-images into 160 × 160. Finally, these sub-images were inputted into our high-speed SAR ship detection system to carry out the actual ship detection.
Figure 22 shows the ship detection results of the Sentinel-1 SAR image. From
Figure 22, our method can detect almost all ships (marked in blue). There are some false alarm cases on land (marked in yellow), which is due to the high similarity between these land facilities and real ships. Besides, there are some missed detection cases (marked in red), which may be due to the dense distribution or parallel parking of ships, causing certain difficulties for detection. In short, our method has strong migration ability which can be applied in practical SAR ship detection.
Then, we evaluated our model on the Sentinel-1 SAR image.
Table 11 shows the evaluation indexes of the Sentinel-1 SAR image.
Figure 23a shows the precision-recall (P-R) curves and
Figure 23b is the bar graph of mAP (accuracy) and FPS (speed).
From
Table 11 and
Figure 23, our method has high accuracy with 90.36% mAP, which can meet the practical application requirements. The time to divide the wide-region large-size SAR image into small-size sub-images (time of preprocessing) is 54.85 × 10
−3 s by using Python Imaging Library (PIL), an image preprocessing tool. Additionally, our method takes only 8.92 × 10
−3 s for one sub-image (160 × 160) similar to the detection time in SSDD dataset (9.03 × 10
−3 s), and takes only 8.09 s (8.92 × 10
−3 s × 900 + 54.85 × 10
−3 s = 8.09 s) to complete the whole wide-region large-size SAR image detection (6333 × 4185). Therefore, our method is of value in practical application from the above detection results.
6.3. Compared with C-CNN
From
Figure 4, there are 13 DS-CNNs in our backbone network, which are used to extract ships’ features. To confirm that DS-CNN can really speed up ship detection and sacrifice little accuracy, we replaced these 13 DS-CNNs in
Figure 4 with 13 C-CNNs to carry out further research, as is shown in
Figure 24.
In addition, in order to ensure the rationality of the study, we arranged the following two groups of experiments under the following same conditions:
- (a)
L = 160;
- (b)
Pretraining;
- (c)
Two concatenations;
- (d)
Three scales detection;
- (e)
Nine anchor boxes.
In particular, we only compared the detection speed of small-size sub-images in the test set of the SSDD dataset, because the faster detection speed of small-size sub-images will naturally bring about the increase of detection speed of wide-region large-size images.
Table 12 shows the evaluation indexes of C-CNN and DS-CNN.
Figure 25a shows the precision-recall (P-R) curves and
Figure 25b is the bar graph of mAP (accuracy) and FPS (speed).
- (1)
The detection accuracy of DS-CNN is slightly lower than C-CNN (94.13% mAP < 94.39% mAP). This phenomenon shows that using DS-CNN to build a network is feasible and does not decline the detection accuracy too much;
- (2)
The detection speed of DS-CNN is 2.7 times than C-CNN (111 FPS > 41 FPS). This phenomenon shows that DS-CNN can indeed improve the detection speed by using D-Conv2D and P-Conv2D to replace C-CNN.
Especially, it is meaningful to increase the detection speed from 41 FPS to 111 FPS for 160 × 160 images. For example, DS-CNN only takes 10.45 s to complete the ship detection task of 1160 SAR images in the SSDD dataset, while C-CNN needs 28.2 s. In general, even millisecond level time saving is meaningful and valuable in the field of image processing. In addition, for the wide-region large-size SAR image (6333 × 4185) in
Figure 22, the detection time of DS-CNN is 8.09 s, while that of C-CNN is 21.8 s. From the perspective of image processing, such much time saving is remarkable, which can facilitate subsequent reprocessing (such as ship classification) and improve efficiency of full-link SAR application. Most noteworthy, generally, the size of SAR images acquired from spaceborne SAR satellites is often larger (tens of thousands of pixels × tens of thousands of pixels), so in this case, the advantages of DS-CNN will be better reflected.
We also compared the network sizes of C-CNN and DS-CNN. In the DL field, the number of network parameters, model file size, and weight file size are often used to measure the size of the network. Therefore, we made a comparison from the above three perspectives to illustrate the lightweight nature of our network.
Table 13 shows the network sizes of C-CNN and DS-CNN.
From
Table 13, the number of network parameters of our proposed DS-CNN is only 3,299,862, which is about one-ninth of the C-CNN’s (28,352,054). Similarly, the model file size and weight file size are nearly one-tenth of the C-CNN’s. Therefore, our network is lighter, leading to higher training efficiency and faster detection speed, which accords with the theoretical analysis before in
Section 2.3.
Figure 26 shows the ship detection results of C-CNN and DS-CNN. From
Figure 26, both C-CNN and DS-CNN can detect almost all ships successfully, with similar accuracy. In addition, for the second image in
Figure 26, DS-CNN generates more missed detection cases (the number of missed detection is (3) than C-CNN (the number of missed detection is (1). One possible reason is that DS-CNN does not adequately extract features from the inshore ships.
Therefore, our method is effective and brilliant. Despite of the slight sacrifice of accuracy for the inshore ships, the detection speed has got largely improved.
6.4. Compared with Other Object Detectors
In order to prove that our method can authentically achieve high-speed ship detection, we also compared the performance with other object detectors, such as Faster R-CNN, RetinaNet, SSD, YOLOv1, YOLOv2, YOLOv2-tiny, YOLOv3, and YOLOv3-tiny. Here, YOLOv2-tiny and YOLOv3-tiny are two lightweight networks that improve YOLOv2 and YOLOv3 respectively, proposed by Redmon et al. [
31,
32]. Moreover, in order to ensure the rationality of experiments, these other object detectors are implemented on the same platform, and the training mechanism is basically consistent.
Especially, the detection speed of the traditional feature extraction methods is quite slow, whose detection time reaches several seconds or more per image, while the modern DL methods only need tens or hundreds of milliseconds per image. Therefore, we ignored the comparison with the traditional feature extraction methods.
Table 14 shows the evaluation indexes of different object detectors.
Figure 27 shows the precision-recall (P-R) curves and
Figure 28 is the bar graph of mAP (accuracy) and FPS (speed).
- (1)
The detection accuracy of our method is slightly lower than RetinaNet (94.13% mAP < 95.68% mAP). However, our detection speed is almost 37 times faster than RetinaNet. Therefore, it is of far-reaching significance that a little sacrifice of accuracy brings about a multiplier increase in speed;
- (2)
The detection accuracy of our method is also slightly lower than YOLOv3 (94.13% mAP < 95.34% mAP). However, our detection speed is 2.47 times faster than YOLOv3. Therefore, our approach is still excellent because we traded 2.1% accuracy for a 147% speed increase;
- (3)
The detection accuracy and speed of our method are all superior to Faster R-CNN, SSD, YOLOv1, YOLOv2, and YOLOv3-tiny;
- (4)
The detection speed of our method is slightly faster than YOLOv2-tiny (111 FPS > 107 FPS). However, the detection accuracy of YOLOv2-tiny is too poor to meet the actual detection requirements at all (44.40% mAP), which is far lower than that of our method (94.13% mAP);
- (5)
The detection speed of our method is superior to all other methods (9.03 ms per image and 111 FPS);
- (6)
Our method has not only the fastest detection speed but also satisfactory accuracy (Both mAP and FPS are high in
Figure 28), while other methods cannot maintain a good balance between accuracy and speed.
Figure 29 shows the ship detection results of some sample images of different object detectors. From
Figure 29, we can draw the following conclusions:
- (1)
All methods can successfully detect ships in simple sample images, except YOLOv3-tiny and YOLOv2-tiny;
- (2)
YOLOv3-tiny and YOLOv2-tiny generate more missed detection cases;
- (3)
RetinaNet and YOLOv2 have a better detection performance for small ships with dense distribution, with only one missed detection case;
- (4)
Compared with RetinaNet and YOLOv2, YOLOv3 have similar detection performance for small ships with dense distribution, with only one missed detection case and only one false alarm case;
- (5)
Compared with all other methods, from a subjective point of view in
Figure 29, our method has obtained satisfactory ship detection results, although not the best.
We also compared the network sizes of other object detectors.
Table 15 shows the network sizes of different object detectors. From
Table 15, our model has the fewest network parameters only 3,299,862, while the numbers of network parameters of other methods are several or even tens of times than that of our method. Moreover, the model file size and the weight file size are also minimal compared with other methods. Therefore, our network is lighter, leading to higher training efficiency and faster detection speed, which also accords with the theoretical analysis before in
Section 2.3.
In summary, by comparing the actual network size, it further more forcefully indicated that our method can achieve high-speed SAR ship detection.
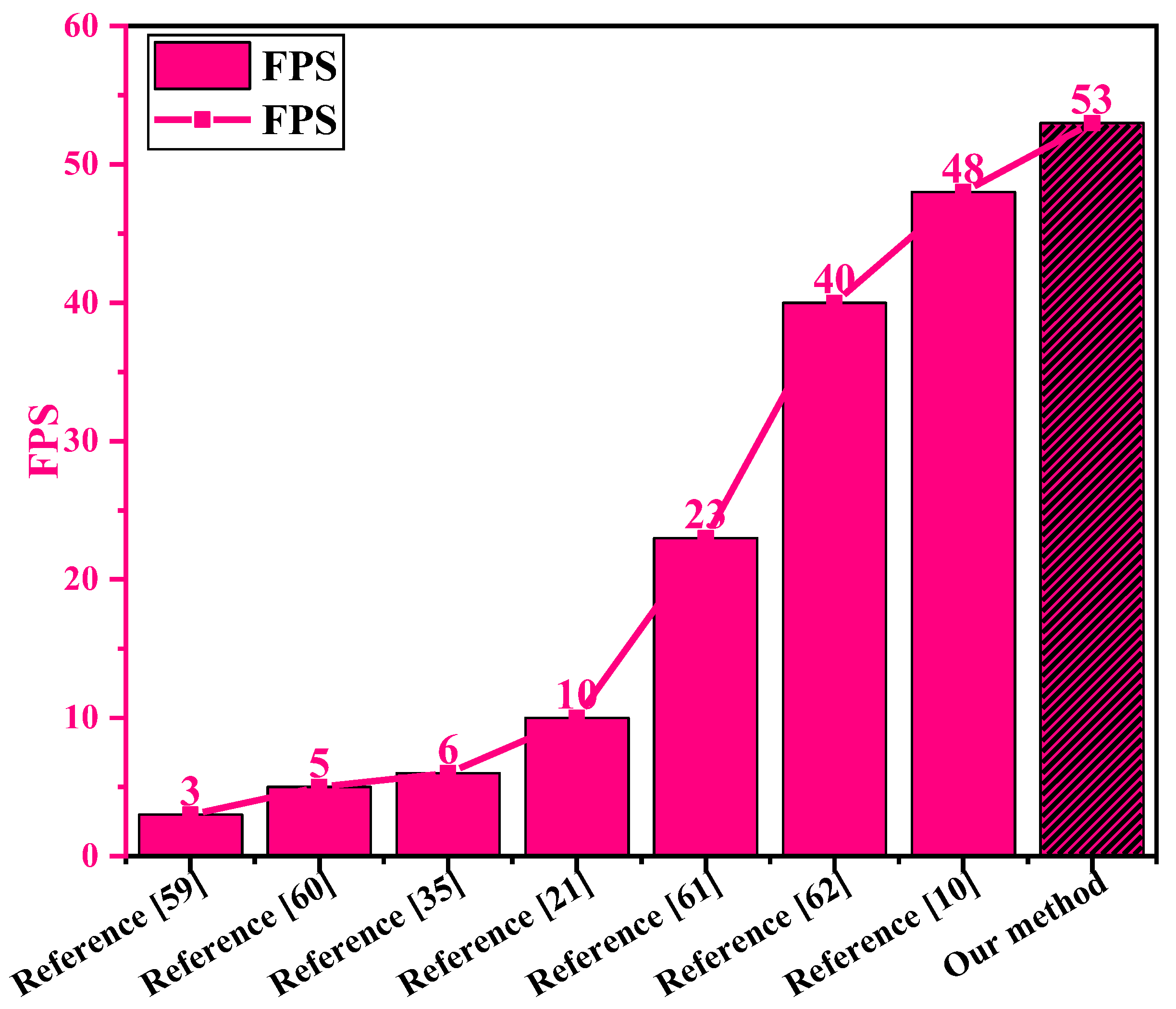
6.5. Compared with References
We also compared our methods with some previous open studies which use the same SSDD dataset. To be clear, here, we replaced NVIDIA RTX2080Ti GPU with NVIDIA GTX1080 GPU to keep the hardware environment basically the same as previous other open studies (References [
10,
21,
35,
59,
60,
61,
62] used NVIDIA GTX1080 GPU.). For different performances of different types of GPUs, we have to make such a replacement in order to consider the rationality of the comparison experiment.
Figure 30 shows the contrast results of ship detection speed (FPS, Frames Per Second) between our method and previous other open studies.
From
Figure 30, the ship detection speed of our method is 53 FPS under the NVIDIA GTX1080 GPU, which is the half of that under the NVIDIA RTX2080Ti GPU (111 FPS introduced before). This phenomenon is in line with common sense, because the performance of RTX2080Ti GPU is superior to that of GTX1080 GPU. In
Figure 30, our method has the fastest detection speed compared with the other references under the similar hardware environment with NVIDIA GTX1080 GPU. Most noteworthy, the detection speed of reference [
10] is 48 FPS, which is close to that of the method in this paper (53 FPS). However, the accuracy of reference [
10] is lower than ours (Reference [
10]: 90.16% mAP; Ours: 94.13% mAP).
Therefore, our method can reliably realize high-speed SAR ship detection. In addition, due to the lacking of specific type GPUs, we cannot make full comparisons between our method and the remaining studies using the same SSDD dataset.


































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}