Sensitivity Analysis of Machine Learning Models for the Mass Appraisal of Real Estate. Case Study of Residential Units in Nicosia, Cyprus



Abstract
1. Introduction
1.1. Background of the Study
1.2. State of the Art
2. Comparable Evidence and Methods
2.1. Database, Pre-Processing, Methods and Performance Metrics
- Unit Enclosed extent, which is the Internal Area in m (IntArea).
- The Unit covered extent, which is the Area of covered verandahs in m (CovVer).
- The Unit uncovered extent, which is the Area of uncovered verandahs in m (UnCovVer).
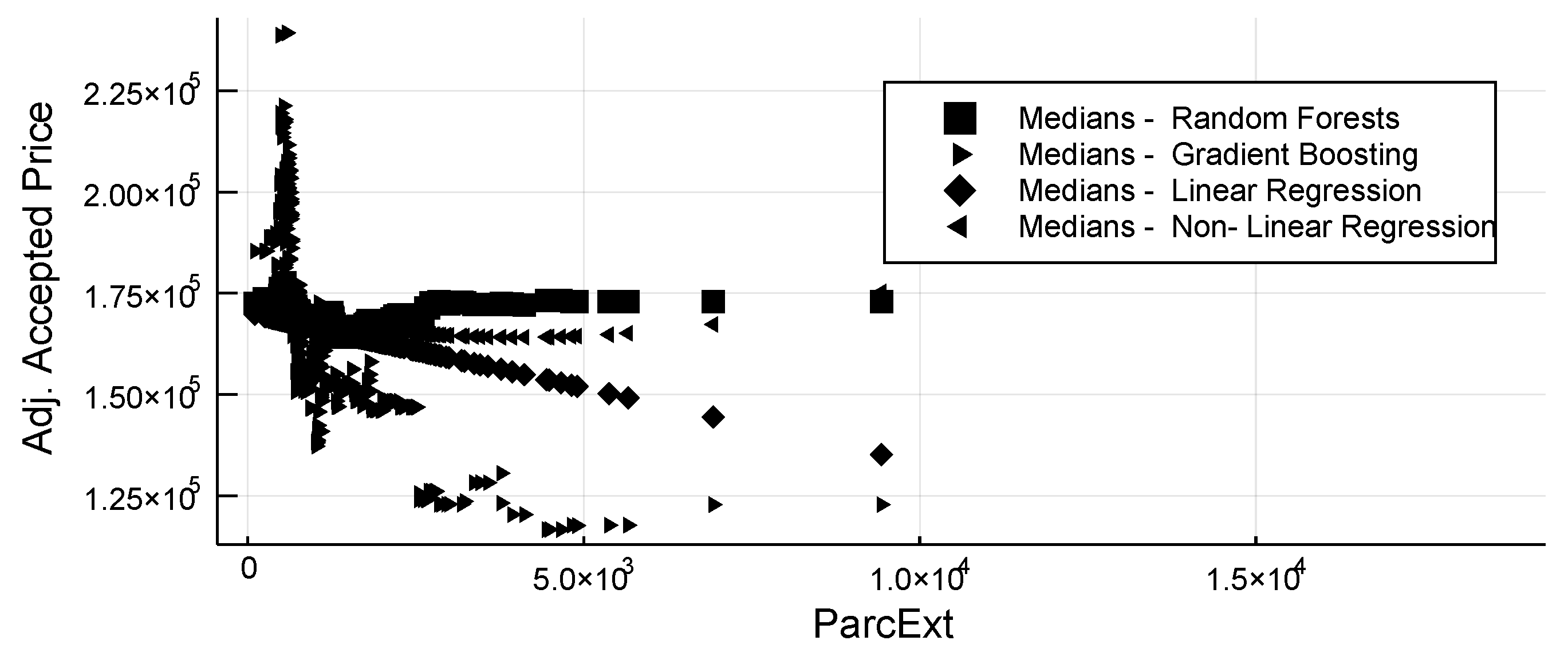
- Parcel extent, that is the Area of parcel (or plot) in m (ParcExt).
- The Built Years, calculated as the difference among the date the transaction happened and the date the building was constructed, in years (BuiltYrs).
- The Unit condition code (Cond), that denotes the condition of the building, and takes values from 1 (best condition) to 4 (worst condition).
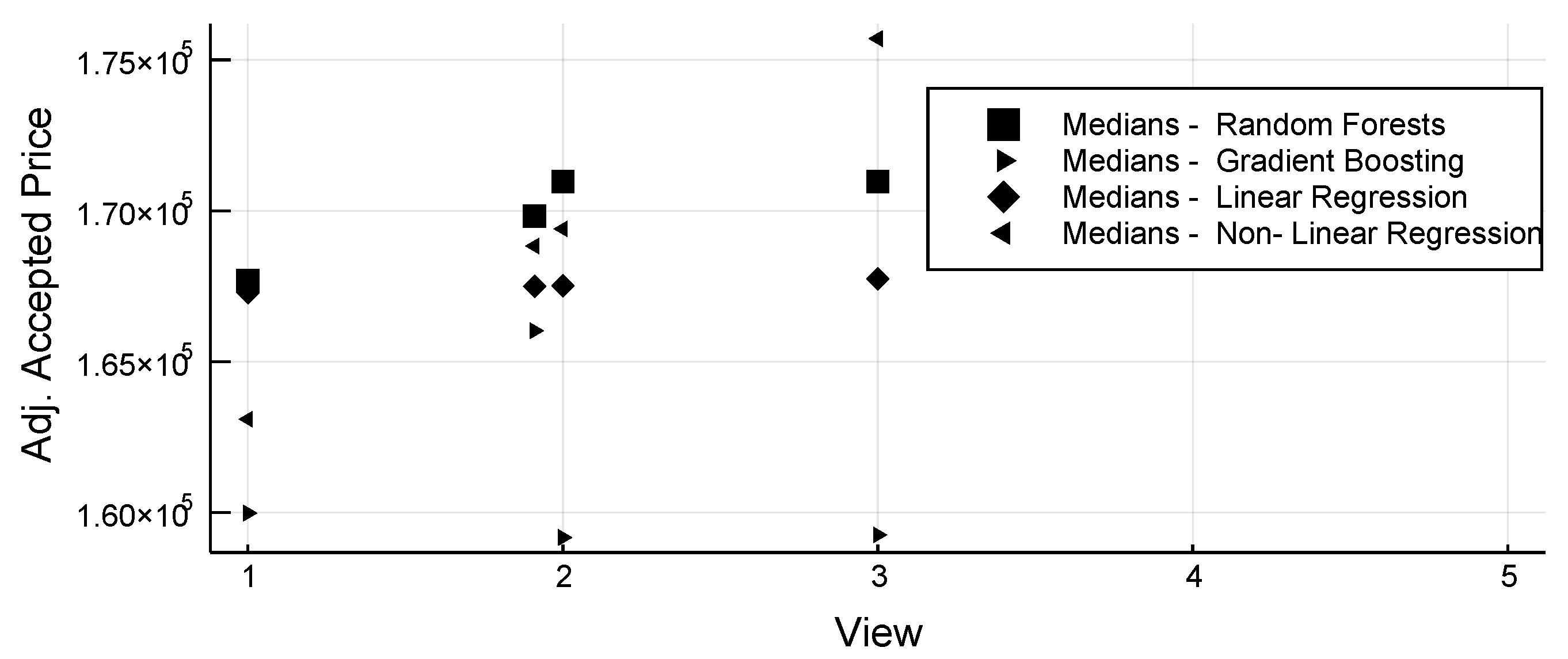
- The Unit’s view code (View), which denotes the view of the unit, with values from 1 (best view) to 4 (worst view).
- The Unit’s class code (Class), denoting the class of the building. It takes Values from 1 (best class) to 4 (worst class).
- Density (Dens), as the maximum allowed density (built m, over plots m) of the specific district.
2.2. Error Metrics
2.3. Anomaly Detection
| Algorithm 1:Anomaly Detection |
 |
2.4. Machine Learning Methods
| Algorithm 2:Step-wise, Higher Order Regression |
 |
3. Results
3.1. Regression Analysis
3.2. Sensitivity Analysis
3.3. How Much Data Is Big Enough?
3.4. Prediction Formula
4. Discussion
Remote Sensing Integration in Mass Appraisals
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A
Appendix A.1. Prediction Formula with 100 terms (MAE = 19694€)







References
- Makridakis, S.; Bakas, N. Forecasting and uncertainty: A survey. Risk Decis. Anal. 2016, 6, 37–64. [Google Scholar] [CrossRef]
- Bakas, N.P. Numerical Solution for the Extrapolation Problem of Analytic Functions. Res. 2019, 2019, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Jiang, F.; Jiang, Y.; Zhi, H.; Dong, Y.; Li, H.; Ma, S.; Wang, Y.; Dong, Q.; Shen, H.; Wang, Y. Artificial intelligence in healthcare: past, present and future. Stroke Vasc. Neurol. 2017, 2, 230–243. [Google Scholar] [CrossRef] [PubMed]
- Pozna, C.; Antonya, C. Issues about autonomous cars. In Proceedings of the 2016 IEEE 11th International Symposium on Applied Computational Intelligence and Informatics (SACI), Timisoara, Romania, 12–14 May 2016; pp. 13–18. [Google Scholar]
- Gupta, S.; Sharma, A.; Abubakar, A. Artificial intelligence–driven asset optimizer. In Proceedings of the SPE Annual Technical Conference and Exhibition, Dallas, TX, USA, 24–26 September 2018. [Google Scholar]
- De Swarte, T.; Boufous, O.; Escalle, P. Artificial intelligence, ethics and human values: The cases of military drones and companion robots. Artif. Life Robot. 2019, 24, 291–296. [Google Scholar] [CrossRef]
- Olson, C.; Levy, J. Transforming marketing with artificial intelligence. Appl. Mark. Anal. 2018, 3, 291–297. [Google Scholar]
- Zadeh, L.A.; Tadayon, S.; Tadayon, B. System and Method for Extremely Efficient Image and Pattern Recognition and Artificial Intelligence Platform. U.S. Patent App. 15/919,170, 3 December 2018. [Google Scholar]
- Cave, S.; Dihal, K. Ancient dreams of intelligent machines: 3,000 years of robots. Nature 2018, 559, 473–475. [Google Scholar] [CrossRef]
- MAYOR, A. Gods and Robotss: Myths, Machines, and Ancient Dreams of Technology; Princeton University Press: Princeton, NJ, USA, 2018. [Google Scholar] [CrossRef]
- Dimopoulos, T.; Bakas, N. An artificial intelligence algorithm analyzing 30 years of research in mass appraisals. Reland Int. J. Real Estate & Land Plan. 2019, 2, 10–27. [Google Scholar]
- Dimopoulos, T.; Tyralis, H.; Bakas, N.P.; Hadjimitsis, D. Accuracy measurement of Random Forests and Linear Regression for mass appraisal models that estimate the prices of residential apartments in Nicosia, Cyprus. Adv. Geosci. 2018, 45, 377–382. [Google Scholar] [CrossRef]
- Merriam Webster; Merriam Webster: Miami, FL, USA, 2016.
- Worzala, E.; Lenk, M.; Silva, A. An exploration of neural networks and its application to real estate valuation. J. Real Estate Res. 1995, 10, 185–201. [Google Scholar]
- Brynjolfsson, E.; Mitchell, T.; Rock, D. What Can Machines Learn, and What Does It Mean for Occupations and the Economy? Aea Pap. Proc. 2018, 108, 43–47. [Google Scholar] [CrossRef]
- Pagano, D. Machine Learning Will Replace Tasks, Not Jobs, Say MIT Researchers. MIT News, 26 June 2018. [Google Scholar]
- Bryson, J.J. Robots should be slaves. In Close Engagements with Artificial Companions: Key Social, Psychological, Ethical and Design Issues; University of Bath: Bath, UK, 2010; pp. 63–74. [Google Scholar]
- Agrawal, S.; Agrawal, J. Survey on anomaly detection using data mining techniques. Procedia Comput. Sci. 2015, 60, 708–713. [Google Scholar] [CrossRef]
- Dimopoulos, T.; Moulas, A. A proposal of a mass appraisal system in Greece with CAMA system: Evaluating GWR and MRA techniques in Thessaloniki Municipality. Open Geosci. 2016, 8, 675–693. [Google Scholar] [CrossRef]
- Chan, A.P.; Abidoye, R.B. Advanced property valuation techniques and valuation accuracy: Deciphering the artificial neural network technique. Reland Int. J. Real Estate & Land Plan. 2019, 2, 1–9. [Google Scholar]
- Arribas, I.; García, F.; Guijarro, F.; Oliver, J.; Tamošiūnienė, R. Mass appraisal of residential real estate using multilevel modelling. Int. J. Strateg. Prop. Manag. 2016, 20, 77–87. [Google Scholar] [CrossRef]
- Ciuna, M.; Milazzo, L.; Salvo, F. A mass appraisal model based on market segment parameters. Building 2017, 7, 34. [Google Scholar] [CrossRef]
- Chica-Olmo, J.; Cano-Guervos, R.; Chica-Rivas, M. Estimation of housing price variations using spatio-temporal data. Sustainability 2019, 11, 1551. [Google Scholar] [CrossRef]
- Cyprus New General Valuation 2013. 2013. Available online: https://portal.dls.moi.gov.cy/en-us/Pages/New-General-Valuation-as-at-1-1-2013.aspx (accessed on 1 June 2019).
- Lelo, K.; Tomassi, S.M.F. Urban inequalities in Italy: A comparison between Rome, Milan and Naples. Entrep. Sustain. Issues 2018, 6, 939–957. [Google Scholar] [CrossRef]
- NCSS Statistical Software. Appraisal Ratio Studies; NCSS: Kaysville, UT, USA, 2015. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Sadeghi, B. DecisionTree.jl. 2013. Available online: https://github.com/bensadeghi/DecisionTree.jl (accessed on 1 June 2019).
- Xu, B.; Chen, T. XGBoost.jl. 2014. Available online: https://arxiv.org/abs/1603.02754 (accessed on 1 June 2019).
- Bezanson, J.; Edelman, A.; Karpinski, S.; Shah, V.B. Julia: A fresh approach to numerical computing. Siam Rev. 2017, 59, 65–98. [Google Scholar] [CrossRef]
- Gevrey, M.; Dimopoulos, I.; Lek, S. Review and comparison of methods to study the contribution of variables in artificial neural network models. Ecol. Model. 2003. [Google Scholar] [CrossRef]
- Olden, J.D.; Jackson, D.A. Illuminating the “black box”: A randomization approach for understanding variable contributions in artificial neural networks. Ecol. Model. 2002. [Google Scholar] [CrossRef]
- Sagi, O.; Rokach, L. Ensemble learning: A survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1249. [Google Scholar] [CrossRef]
- Oreskes, N.; Shrader-Frechette, K.; Belitz, K. Verification, validation, and confirmation of numerical models in the earth sciences. Science 1994. [Google Scholar] [CrossRef] [PubMed]
- Lybeck, E. The black swan: The impact of the highly improbable. arXiv 2017, arXiv:1011.1669v3. [Google Scholar]
- Bird, R.; Slack, E.; Guevara, M. Real Property Taxation in the Philippines. In International Handbook of Land and Property Taxation; Edward Elgar Publishing: Cheltenham, UK, 2013. [Google Scholar] [CrossRef]
- Autor, D.H. Why Are There Still So Many Jobs? The History and Future of Workplace Automation. J. Econ. Perspect. 2015. [Google Scholar] [CrossRef]
- Ismail, S.; Buyong, T. Residential Property Valuation Using Geographic Information System; Bulgarian Geoinformation Company: Ovcha Kupel, Bulgaria, 1998. [Google Scholar]
- Frey, C.B.; Osborne, M.A. The future of employment: How susceptible are jobs to computerisation? Technol. Forecast. Soc. Chang. 2017. [Google Scholar] [CrossRef]
- Dimopoulos, T.; Labropoulos, T.; Hadjimitsis, D.G. Comparative analysis of property taxation policies within Greece and Cyprus evaluating the use of GIS, CAMA, and remote sensing techniques. Proc. SPIE Int. Soc. Opt. Eng. 2014, 9229, 92290O. [Google Scholar]
- Nayak, S.; Zlatanova, S. Remote Sensing and GIS Technologies for Monitoring and Prediction of Disasters; Springer: Berlin, Germnay, 2008. [Google Scholar]
- LIU, X.S.; Zhe, D.; WANG, T.L. Real estate appraisal system based on GIS and BP neural network. Trans. Nonferrous Met. Soc. China 2011, 21, s626–s630. [Google Scholar] [CrossRef]
- Lindgren, D. Land Use Planning and Remote Sensing; Taylor & Francis: New York, NY, USA, 1984; Volume 2. [Google Scholar]
Sample Availability: The dataset was provided from the Department of Lands and Surveys. |





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | MAE | RMSE | MAPE | MAXAPE | SR | COD | ||
|---|---|---|---|---|---|---|---|---|
| Train Set | ||||||||
| Random Forests | 0.914 | 17931.100 | 28854.237 | 0.111 | 1.307 | 1.031 | 0.739 | 10.778 |
| Gradient Boosting | 0.992 | 2630.784 | 8923.668 | 0.016 | 0.441 | 1.002 | 0.983 | 1.753 |
| Linear Regression | 0.863 | 24546.300 | 34745.422 | 0.151 | 0.550 | 1.027 | 0.746 | 14.703 |
| Non-Linear Regression | 0.880 | 23520.570 | 32700.793 | 0.146 | 1.100 | 1.032 | 0.775 | 14.197 |
| Test Set | ||||||||
| Random Forests | 0.877 | 20817.165 | 27950.722 | 0.134 | 0.802 | 1.040 | 0.753 | 12.950 |
| Gradient Boosting | 0.803 | 24485.519 | 35946.437 | 0.151 | 1.092 | 1.009 | 0.776 | 15.017 |
| Linear Regression | 0.858 | 22977.825 | 30047.707 | 0.146 | 0.506 | 1.025 | 0.789 | 14.279 |
| Non-Linear Regression | 0.862 | 22525.779 | 29500.974 | 0.144 | 0.552 | 1.032 | 0.761 | 13.984 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dimopoulos, T.; Bakas, N. Sensitivity Analysis of Machine Learning Models for the Mass Appraisal of Real Estate. Case Study of Residential Units in Nicosia, Cyprus. Remote Sens. 2019, 11, 3047. https://doi.org/10.3390/rs11243047
Dimopoulos T, Bakas N. Sensitivity Analysis of Machine Learning Models for the Mass Appraisal of Real Estate. Case Study of Residential Units in Nicosia, Cyprus. Remote Sensing. 2019; 11(24):3047. https://doi.org/10.3390/rs11243047
Chicago/Turabian StyleDimopoulos, Thomas, and Nikolaos Bakas. 2019. "Sensitivity Analysis of Machine Learning Models for the Mass Appraisal of Real Estate. Case Study of Residential Units in Nicosia, Cyprus" Remote Sensing 11, no. 24: 3047. https://doi.org/10.3390/rs11243047
APA StyleDimopoulos, T., & Bakas, N. (2019). Sensitivity Analysis of Machine Learning Models for the Mass Appraisal of Real Estate. Case Study of Residential Units in Nicosia, Cyprus. Remote Sensing, 11(24), 3047. https://doi.org/10.3390/rs11243047