1. Introduction
Energy security is considered an important challenge in numerous countries to maintaining sustainable economic development in the world. The construction and building sectors consume the most energy globally. Moreover, recent public statistics related to energy consumption around the world cite that 22% of total energy consumption is consumed by residential buildings distributed in different residential end uses (i.e., HVAC, lighting, water heating, cooking, and other appliances) [
1]. In fact, the growth of energy demand gives rise to power degradation. Furthermore, the excessive use of fossil fuels can lead to extensive environmental impact. Therefore, developing new strategies to manage energy use and integrating renewable energy sources are a major focus for researchers worldwide.
Most governments around the world investigate the development of new strategies for optimizing energy use and protecting the environment. For example, the Moroccan government aims to achieve 20% of energy-saving potential by 2030 [
2]. Accordingly, modern residential and commercial buildings integrate building energy management systems (BEMSs) as advanced methods for controlling different building services, with the aim of optimizing energy consumption and maintaining the occupants’ comfort. BEMSs integrate different services, such as lighting, shading, and HVAC. Moreover, advanced controllers, such as MPC and GPC, can provide significant indoor air quality with potential energy savings in a specific area [
3]. Several control methods can merge thermal data to efficiently control HVAC and ventilation systems [
4]. Moreover, the integration of renewable sources into the existing grid poses a big challenge to controlling approaches and storage instrumentation. Therefore, many investigators have proposed different smart grid ideas with the intention of securing electricity for consumers and exploiting generated electricity efficiently [
5]. In fact, badly managing building’s active systems may considerably increase the wasted energy. Therefore, BEMSs have been proposed by numerous studies in order to facilitate the control and management of energy use in buildings, where weather information and occupant impact are considered key parameters [
6,
7,
8,
9]. In addition, building information models play an important role in BEMSs, where different information could be integrated and considered (i.e., such as geometric information, physical properties, and component information) for optimal computing and calculating essential building services such as thermal efficiency and lighting intensity. The main aim of smart buildings is to integrate physical and computational components to create an environment where the energy is well exploited, and the occupants’ comfort is preserved. Each building has a unique characteristic. Therefore, emerging real-time and adaptive approaches to environmental settings are a big challenge enabled by the development of smart buildings. Dealing with this issue requires the integration of new adaptive techniques and deep insight into control modeling. With recent advances in data processing sensing networks, many industries and researchers have confirmed the potential of IoT as an enabler in the development of intelligent and context-aware services and applications [
10,
11]. Most studies demonstrate that building services require the integration of recent IoT and big-data technologies due to the complexity of large amounts of data that can be monitored and exploited [
12,
13,
14,
15]. These services can dynamically react to the changes in the environment and users’ preferences. Their main objective is to create a comfortable environment for occupants depending on their location and ongoing activities.
Typically, a complex sensing network connects home appliances. Therefore, monitoring and controlling home appliances and active systems with high performance require the integration of IoT and big data technologies in order to deal with large amounts of non-structured data that are generated from objects in smart buildings, such as smart meters and other deployed sensors [
16,
17]. In fact, IoT refers to a network of interconnected devices capable of collecting and exchanging data. Big data refers to the vast and intricate datasets that originate from a variety of sources, including IoT devices. They are characterized by high volume, velocity, and variety, requiring advanced tools for processing and analysis [
18,
19,
20]. The multiple sources of data that are generated from deployed sensors involve the integration of recent big data techniques such as artificial intelligence algorithms and distributed ledger technology. Additionally, data generated from buildings are mostly asynchronous, heterogeneous, and stored in different formats. Therefore, in order to manage building data clearly, big data approaches are required to be integrated for processing large amounts of both historical and stream data to extract appropriate knowledge for making data-driven instructions [
21].
In summary, the large-volume and complex data generated from smart objects in buildings necessitates the implementation of effective IoT architecture to efficiently collect data and communicate between building appliances via the integration of recent big data technologies for the processing already-stored or real-time stream data. Accordingly, the main purpose of this study is to illustrate the right path and propose optimal architecture for managing building services with high performance. Furthermore, this study presents and discusses a high level of data-driven approaches for data exchange, building data management, and real-time stream data processing. Further, existing works related to IoT and big data technologies are provided and compared in terms of their characteristics and performances.
The remainder of this paper is organized as follows:
Section 2 introduces the methodology followed for collecting and analyzing studies related to data sensing and processing approaches for smart building applications.
Section 3 presents an overview of the sensing technologies used for smart building applications.
Section 4 sheds more light on different big data technologies, including batch-based and stream-based techniques that can be integrated into building management systems. The discussion of and comparison criteria between stream processing techniques and the proposition of a global IoT and big data architecture platform are presented in
Section 5.
2. Materials and Methods
This section provides the methodology used for collecting, selecting, and analyzing studies related to the sensing and data processing approaches that can be integrated for improving smart building services management. The main objective of this work is to share efficient and novel technologies in order to help developers and researchers design an optimal IoT architecture to enhance the infrastructure deployment of new building management systems. This section presents a detailed review methodology.
2.1. Narrative Review Method
The use of IoT and big data technologies in smart buildings can help improve the building management system in order to reduce the energy consumption and maintain the occupants’ comfort. However, selecting the most relevant technologies for setting up an optimal architecture has still proven challenging in many studies related to smart buildings. This study follows a narrative literature review approach to provide a comprehensive overview of IoT and big data technologies that can be applied to smart building applications.
2.2. Data Collection Method
In order to perform this review, we collected relevant scientific articles, technical reports, and international standards from well-known databases such as IEEE Xplore, ScienceDirect, and Google Scholar. The selection criteria focused mostly on recent publications (from 2015 to 2024) related to energy performance, comfort indicators, and smart building technologies.
Several keywords have been used for this study, including “occupancy detection”, “buildings active services”, “buildings management systems”, and “IoT and big data for smart buildings”. The first search in Scopus yielded 1416 documents. Furthermore, another search was made using secondary keywords for extracting IoT and data processing approaches that can be integrated into building management systems.
2.3. Data Analysis Method
The data collected in this work were analyzed using qualitative research content analysis by systematically examining textual information in order to explore how IoT and big data technologies are applied to enable and improve smart building services. This method involved an in-depth examination of the selected literature to categorize the technological methods of enhancing key performance metrics and to highlight their relevance and applications across various smart buildings services (i.e., energy management, occupancy detection, and indoor air quality).
Qualitative content analysis was chosen due to its effectiveness in synthesizing diverse and interdisciplinary sources, especially in studies related to smart buildings. It allowed for the extraction of both explicit outcomes (e.g., energy savings, latency, and data accuracy) and implicit patterns (e.g., integration challenges, privacy concerns, and scalability issues). By clustering findings into thematic categories (i.e., sensor networks, data analytics techniques, system interoperability, and real-time decision-making), the review introduces a comprehensive overview of the current landscape. Despite this approach’s added value, it is important to identify numerous challenges. Like several literature-based studies, the analysis is constrained by the reporting quality of existing studies. Many innovations may have been excluded if they were not presented and published in an accessible academic source.
Based on most of the research work presented in this review, at the end of this work, an architecture is presented, as general as possible, with detailed descriptions of different components that can be integrated in smart building applications. Furthermore, a detailed prototype platform of one of the important services in smart buildings, namely, occupancy detection, is presented by illustrating significant hardware/software settings in order to facilitate the deployment design of the IoT infrastructure for improving smart building services.
3. Sensing Technologies Used in Smart Building Services
New generations of buildings, or smart buildings, aim at integrating various methos of ensuring the comfort of building occupants while also ensuring that the energy is well exploited. In fact, large amounts of data are generated daily from smart building-connected devices. Therefore, IoT, big data analytics, machine learning, and sensing techniques are cost-effective technologies that can be integrated into smart buildings with minimum infrastructure in order to facilitate the use of large amounts of data generated from building objects and to create an optimal decision to well manage building services [
5]. Different types of sensors can be integrated for analyzing occupants’ behavior in buildings and, therefore, for studying the occupants’ preferences (i.e., visual and thermal) in order to introduce building automation and establish better control of active building systems [
22]. Various studies related to energy management in buildings have investigated the integration of IoT and big data technologies with the aim of managing the trade-off between energy consumption and occupants’ comfort. This section presents an overview of IoT integration into smart buildings, evaluating it based on diverse characteristics.
Indoor air quality is an important feature related to the comfort and well-being of building occupants. For example, the authors of [
23] proposed a general architecture prototype for real-time monitoring and processing; the aim of this work is to monitor and analyze the influence of CO
2 on and the SPO2 of building occupants. In fact, IoT platforms can help gather environmental data and act on building equipment in order to make building occupants more comfortable. The authors of [
24] present the usefulness of integrating IoT technology for regulating HVAC and determine the opening/closing patterns for windows based on indoor air quality data in order to improve the performance of students learning in a classroom. Moreover, advanced indoor air quality monitoring systems are presented in [
25] by integrating an open-source IoT web server platform named Emoncms for long-term monitoring and the storing of useful environmental data. Furthermore, the authors of [
26] integrated IoT techniques for monitoring indoor air quality data, including CO, NH
3, CH
4, NO
2, CO
2, and machine learning for predicting different pollutant concentrations. In setting up a low-cost solution for monitoring indoor air quality data, CO
2 is easy to measure and can be influenced by the building occupants. The authors of [
27] propose an IoT-based solution for monitoring real-time CO
2 concentration in the closed area. An ESP8266 microcontroller, which comprises a Wi-Fi module, was integrated as a communication unit. Furthermore, the work presented in [
28] proposes a cloud-based IoT platform using a Lora gateway for gathering indoor air quality data, such as PM
2.5/PM10, CO, SO
2, NO
x, and O
3 pollutants. Support vector machine regression (SVMR) and neural network algorithms were integrated and evaluated for predictive analysis. Moreover, different algorithms can be proposed for controlling building active systems based on different parameters such as occupancy information, air quality, and thermal parameters. For example, the authors of [
29] present a fuzzy control for adjusting the working interval of the exhaust fan with the use of an IoT platform for monitoring the CO
2 level and conducting the control remotely. The work presented in [
30] concerns a simple approach for real-time controlling HVAC systems and achieving building occupants’ comfort. IoT technologies have been integrated to collect environmental thermal data. The authors of [
31] introduce an advanced approach in order to choose a suitable control strategy for ventilation systems. IoT devices and big data techniques were integrated for real-time data monitoring and processing. Moreover, the work presented in [
32] presents a smart home application for controlling HVAC and lighting equipment using the ESP8266 microcontroller and Blynk platform.
Several works related to energy management systems have demonstrated the importance of integrating IoT to enhance many building services, such as occupancy detection [
33,
34].
Table 1 presents the studies showing the importance of IoT and sensing technologies for improving building services by introducing different communication technologies that can be integrated into building equipment control. For example, the authors of [
35] present an occupancy detection algorithm using an IoT platform for collecting four environmental sensors (i.e., temperature, humidity, and CO
2) to determine wasted spaces in the building. An IoT-based prototype has been proposed by the authors of [
36] for gathering occupancy information in the framework of energy building management. Lattice iCE40-HX1K stick FPGA boards and Raspberry Pi are the main elements integrated for counting people walking through the door. Further, the authors of [
37] present an IoT platform for collecting and processing environmental data to create a low-cost and accurate occupancy detection model. Moreover, the authors of [
38] propose a mobile air quality monitoring system (i.e., named e-nose) of different environmental parameters such as CO, CO
2, NO
2, PM10, humidity, and temperature in order to evaluate the impact of human activities on the indoor environment with the integration of different sensing techniques and cloud services.
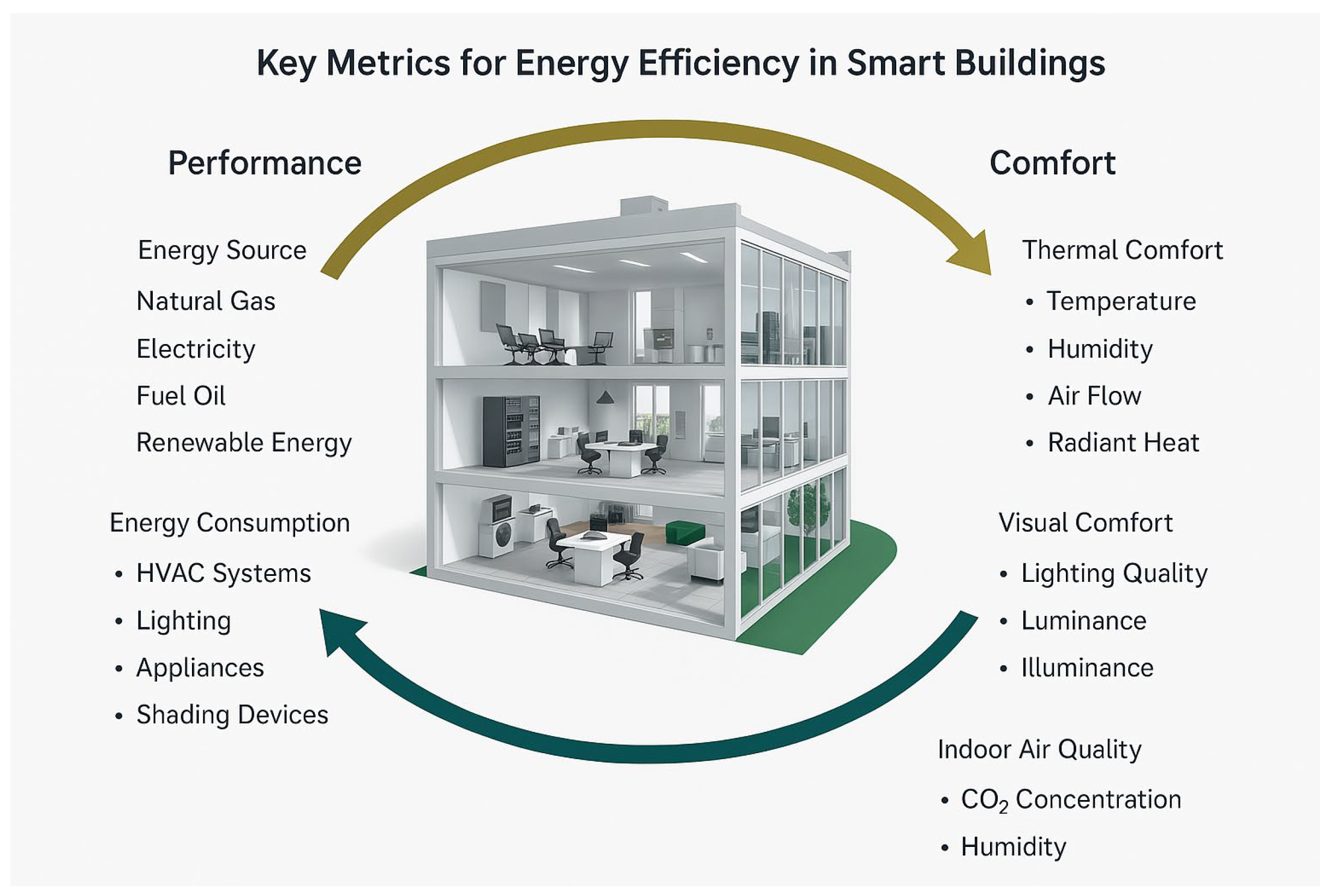
Smart buildings are considered as sociotechnical systems including various heterogeneous entities (e.g., lighting, HVAC, RES) to balance between energy use and user comfort [
39]. Making living in buildings more comfortable requires the integration of advanced techniques allowing for the interaction of different building entities in order to perform appropriate actions (e.g., well-controlling HVAC and lighting), as depicted in
Figure 1. For example, occupancy detection and information can help control the building’s active systems [
40,
41,
42]. Different studies have investigated the development of advanced and intelligent strategies for making occupants’ lives more comfortable and therefore efficiently managing energy consumption. The main purpose of smart or intelligent buildings is the responsiveness to users’ preference needs. Integrating recent technologies is the main challenge of developing advanced building services in terms of reliability and performance [
10]. Several definitions are proposed for smart buildings due to the evolution of technology. The integration of IoT and big data become important in order to evolve the smart approaches of building services [
39,
43]. The main purpose of building an efficient institute is to provide a comfortable environment and optimize energy use and gas emission. As depicted in
Figure 1, different services (i.e., such as lighting control, air conditioning, solar energy generators, temperature/humidity monitoring, energy use monitoring, and cameras) can be integrated into smart buildings in order to establish the trade-off between occupants’ comfort and energy consumption [
16,
44,
45]. Intelligent approaches and smart control strategies (e.g., automotive control, machine learning, and q-learning) of such building appliances (i.e., such as lighting, HVAC, and windows opening) can assist in ensuring efficient energy use [
4,
46].
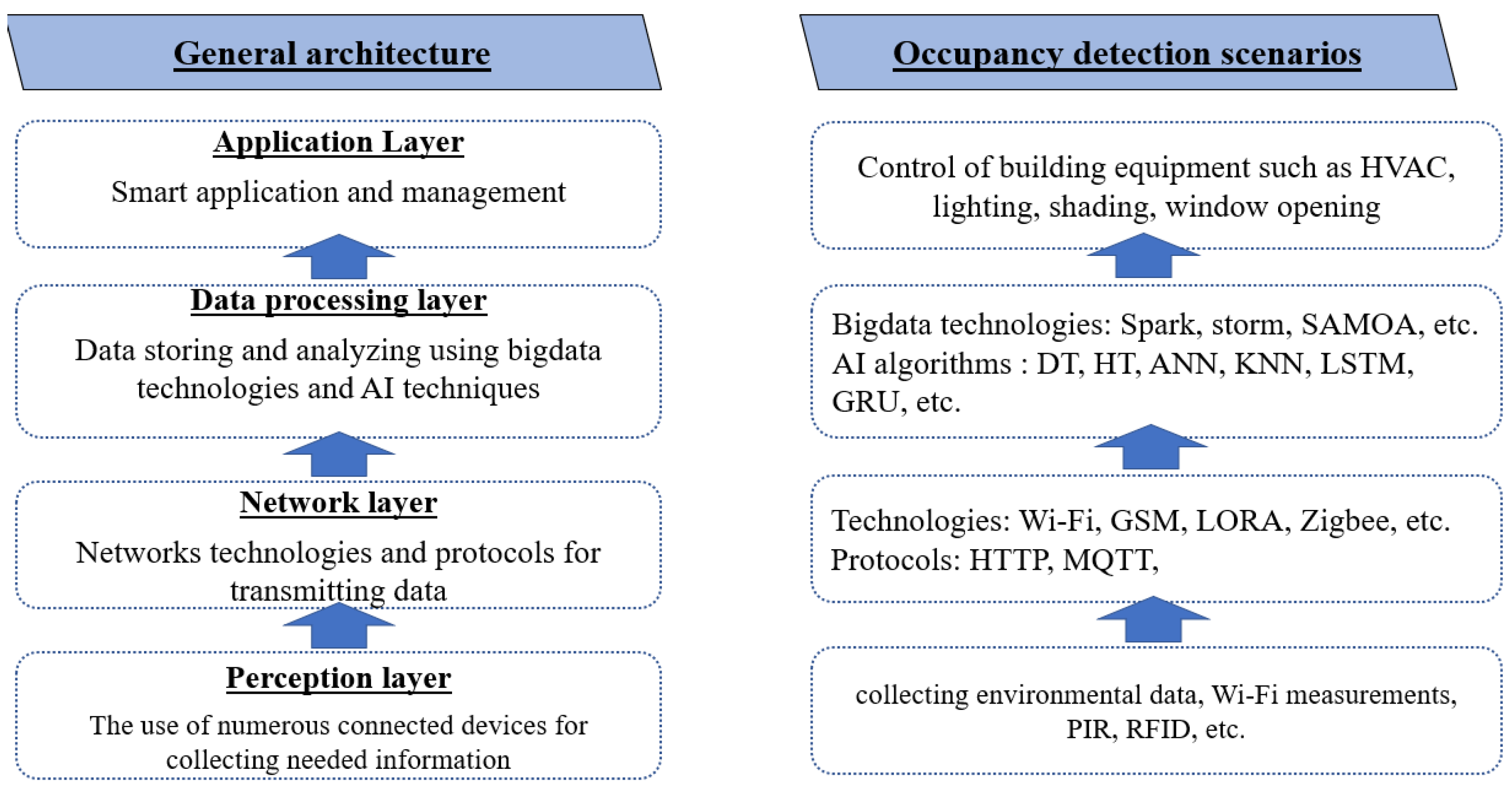
IoT technology is the main concept employed to enable building entities to collect data, run commands, and control equipment. Therefore, the introduction of IoT can be considered an opportunity for developing products that save energy costs and increase user comfort and work efficiency. This subsection presents, as generally as possible, the architecture and detailed layers adopted by industries and researchers. Generally, there is no standard IoT architecture. Diverse architectures have been proposed by different studies. The most adopted IoT architecture consists of four main layers, namely, the perception, network, data processing, and application layers, as shown in
Figure 2.
Deploying recent occupancy detection techniques requires the integration of advanced IoT architecture in order to deal with various numbers of connected devices deployed in distributed areas (e.g., offices, conference rooms, etc.) [
37,
41,
47]. As illustrated in
Figure 2, four main layers must be implemented in order to facilitate the deployment of advanced occupancy detection scenarios.
Perception layer: The perception layer (i.e., physical layer) consists mainly of sensing techniques. Various types of sensors can be deployed simply or are already installed in the building. Recent studies have revealed an interest in using environmental sensors (i.e., such as CO2, temperature, humidity, light intensity, etc.) in order to fit the user privacy requirement contrary to camera sensors.
Network layer: The network layer is responsible for connecting all smart things and servers. As presented in
Figure 2, different protocols (i.e., such as HTTP, MQTT, etc.) and techniques can be integrated for transmitting and processing sensor data.
Data processing layer: To set up smart building services using big data, traditional methods are not sufficient (i.e., due to latency and fault tolerance). The integration of big data techniques becomes a necessity for collecting and analyzing the numerous building data generated. Sophisticated IoT platforms such as Kaa and Thingsboard can provide advanced services such as the managing and integrating of various IoT devices, and they are horizontally scalable and fault tolerant. Big data tools such as Spark and Apache Storm can process real-time big data streams in a distributed manner [
48].
Application layer: In order to efficiently use building systems such as HVAC, lighting, and ventilation, different control strategies have been developed for managing the use of these systems. For instance, building platforms could integrate MPC, GPC, and PID to efficiently control active equipment using environmental data and occupancy information [
44].
In order to set up and integrate occupancy detection systems in the building, integrating IoT technologies becomes important to facilitate the collection and processing of data and therefore to make action efficient. Moreover, some works add more layers to their architecture due to a lack of certain features, such as security and business layers [
49]. The aim is to facilitate the process of collecting and analyzing data in order to enable more efficient actions with the aim of reducing energy consumption and increasing the users’ comfort.
4. Data Processing Technologies for Smart Building Services
Most modern buildings include a diversity of sensors, actuators, and advanced connectivity techniques. Further, these buildings generate a huge amount of data every second. In fact, it is difficult to organize, analyze, and store such a large amount of data. Therefore, large-scale data processing techniques have become increasingly important for efficiently analyzing building data and generating decisions in order to better control active equipment. The aim is to process a myriad of generated data in an intelligent manner with high-performance computing [
39]. In the past, data storage was limited to spreadsheets and roles in database management systems. The information that could be structured in different row–column formats was disregarded [
50]. Big data technologies are designed for analyzing different types of data and predicting accurate results in a short period of time. Big data techniques include five main characteristics, named the five Vs (i.e., volume, variety, velocity, value, veracity), in order to deal efficiently with different kinds of generated data.
Volume: Storing and analyzing a large amount of data is the main challenge of big data technologies. In fact, developing big data solutions means no longer dealing only with gigabytes; the current challenge is dealing with zettabytes.
Variety: The data can be categorized into different types (i.e., structured, unstructured, or structured). In fact, traditional database management tools are not sufficient to store and process a large amount of data of different types, and the data can be formed as documents, images, audio, logs, text, emails, or others.
Generally, processing big data consumes substantial resources and time. The aim is to ensure the processing of data streams in a short time with high performance and continuity. In fact, most research work related to big data development refers to the velocity of data streaming collected from websites, sensors, and video streams.
Value: The value refers to how the data can be beneficial in decision-making. For example, the work related to energy efficiency in buildings requires the implementation of big data technologies for managing energy use and increasing human comfort [
31,
51].
Veracity: This refers to data (i.e., accuracy and noise) and availability. This factor can affect the analysis methods, the time needed, and data dependency.
According to several studies and norms related to big data development, the above-mentioned characteristics do not comprise definitive rule. Several other characteristics can be taken into consideration such as variability (changeability in data flow), viscosity (degree of correlation or complexity), viability (ability to be active), volatility (how long-time data are valid and how long they should be stored (i.e., durability)), and validity (understandable in order to find the hidden relationships) [
52].
Combining wireless communication technologies and electronic devices (i.e., smartphones, tablets, sensors, and house appliances) led to the emergence of the concept of the IoT. While the development of IoT infrastructure is growing, the need for platforms for managing data generated by large numbers of devices has become more important. This phenomenon has resulted in the generation of copious amounts of data from diverse sources.
Big data technology is the best solution to the problem of valuing and exploiting the huge data generated from IoT. Furthermore, industries and organizations should take advantage of the massive amount of data collected. The quick growth of information technologies, such as smartphones, social applications, and machine-to-machine communication, has led to the development of big data technologies [
53]. Several studies have investigated the integration of IoT and big data for ensuring the development and implementation of different services such as energy building management, healthcare, and electrical vehicles. For example, in the healthcare field, some solutions have been proposed using IoT for remotely monitoring patients and analyzing the data collected from the embedded connected devices such as glycosometers and tension meters [
54]. Further, in the building sector, for the successful management of the active equipment, the integration of IoT and data analytics techniques is greatly needed due to the big data generated from sensors deployed in different areas in residentials or industrial buildings [
31,
47]. Recently, car companies have invested in the development of new strategies in order to manage the reduction in energy consumption of vehicle components (i.e., HVAC) and the deployment of recharge stations using the IoT to collect data and to employ big data tools for analyzing the behavior of vehicles and drivers in order to provide efficient action and control [
55,
56].
In fact, the IoT and big data development necessitate the integration of different technologies and frameworks in order to transfer and gather the generated data to be processed. The following technologies have been presented in many research projects and are used by different companies to deploy their own solutions.
- (1)
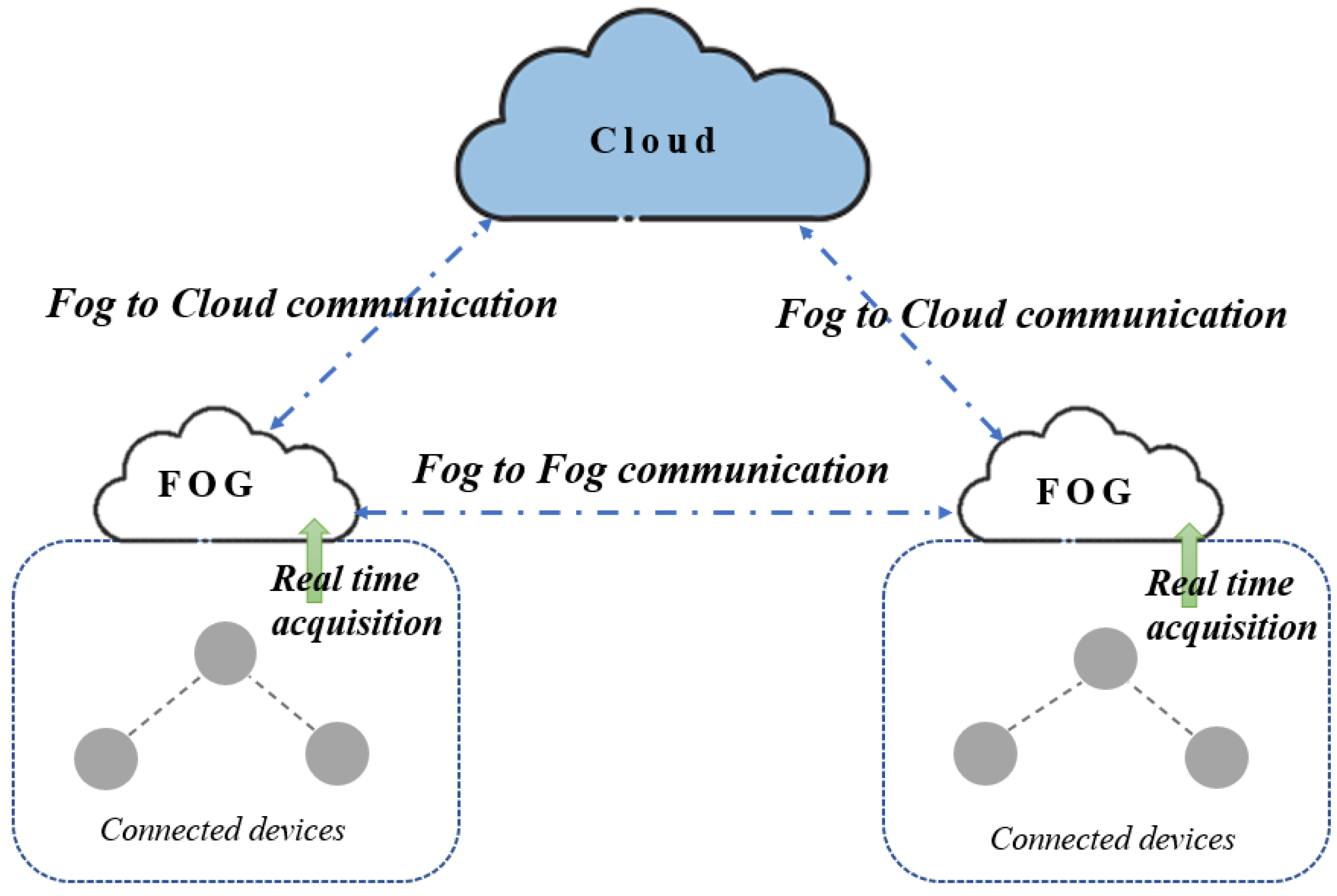
Fog computing techniques: Fog computing is an extension of cloud computing. It can be considered a mini data center integrated between cloud computing and the edge of the network. Moreover, it is a highly virtualized platform that offers storage, processing, and networking services between edge and traditional cloud servers. Furthermore, depending on much research work, fog computing is described as a bringer that makes cloud computing closer to IoT devices. Any computing device with data processing and storage ability can be considered a fog node [
57]. Among the advantages of fog nodes is their ability to reduce the amount of data transferred to the cloud server, as presented in
Figure 3.
- (2)
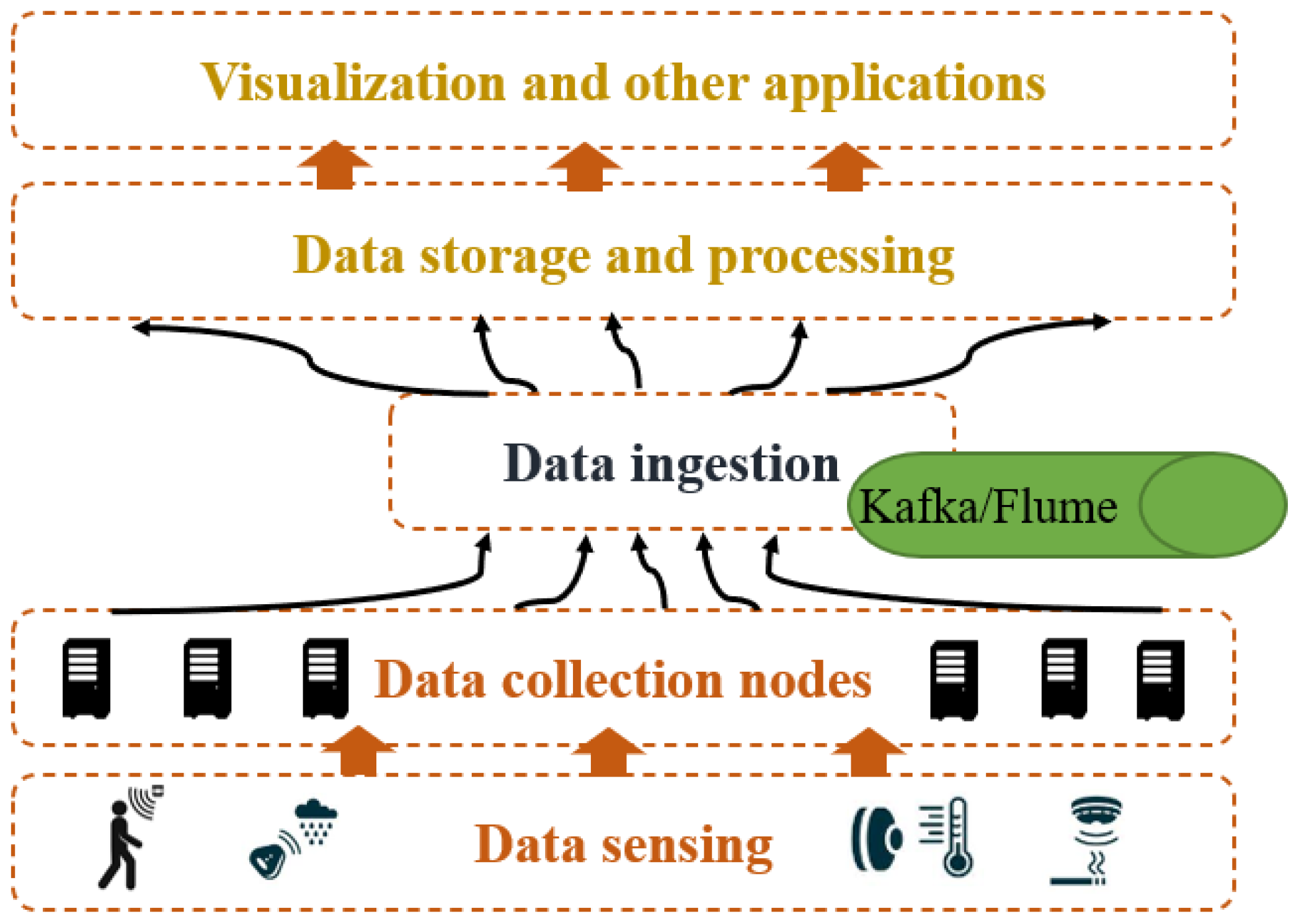
Data aggregation and ingestion. In order to link IoT devices to the processing unit (i.e., such as Spark and Apache Storm), different linker techniques can be deployed and implemented in order to enable the connection between big data processing elements and the data collected from different sources such as IoT devices and SaaS apps, ending up in different target environments. Data ingestion is an important technology that can help make sense of the increasing volume and data complexity. In fact, two main methods can be adopted for data ingestion, namely, batches and real-time. Real-time data ingestion refers to a process of collecting and transferring data to be processed directly from sources (i.e., see
Figure 4). Real-time ingesting is an important technique for applications that are time-sensitive, i.e., when organizations need to rapidly react to new information (i.e., such as stock market trading, power grid monitoring, etc.). Also, the high-performance data pipeline refers to a crucial technique employed in order to help improve real-time data processing when systems are used to make rapid operational decisions and act on new insights. However, batches ingestion is designed for transferring data as batches depending on the interval of time. The ingestion, in this case, is useful when the user needs to gather a specific set of data already stored on a daily basis and not for real-time decision-making.
Several techniques have been developed for data ingestion into different big data technologies (i.e., such as Spark, Storm, Samza, S4, etc.):
Apache Flume (
https://flume.apache.org/): This is a reliable and distributed service for efficiently collecting and transferring large amounts of streaming data and log data into the big data technologies employed such as the Hadoop distributed file system (HDFS). It is robust, scales horizontally, and is fault tolerant, with tunable reliability mechanisms. It integrates an extensive data model to enable online data processing techniques.
Apache Kafka (
https://kafka.apache.org/): This is component of a data stream platform used for collecting, processing, storing, and integrating data at scale. It has many use cases, including real-time pub/sub messaging, stream processing, and distributed streaming.
Different technologies have been developed in order to improve the management of a large amount of data needing to be stored or processed. Data ingestion is more important in order to ensure the transmission of well-structured data into a processing platform, whether stream (i.e., near real-time) or batch processing.
4.1. Batches-Based Processing Techniques
Batch setting, or batch-based processing, involves procedures and operations pertaining to a big and static dataset. Moreover, the results can be returned at a later time when processing is definitively completed. In fact, batch processing is when the set of data is already stored over a period of time in the server, and a big set of data can be totally analyzed and processed using different batch-based techniques such as Hadoop and Spark. For instance, weekly or monthly processing is required for billing systems and payrolls. Hadoop ecosystems and Apache Spark are the most popular technologies adopted to store, process, and analyze data in batches [
59].
Hadoop MapReduce: This is the main programming model and execution engine for analyzing massive data in Hadoop framework is MapReduce. As a programming model, MapReduce includes two main functions, namely, the Map (Ki, Vi) and the reduce (Kj, list (Vj)). Each map function of input key-value (Ki, Vi) is used to output different intermediate key values (Kj, Vj). The intermediate values Vj should be grouped in order to generate the pairs Kj, list (Vj). The reduce function of the Kj list (Vj) summarizes the entire dataset into pairs (i.e., Kk, Vk) after the shuffling phase [
59,
60,
61].
Apache Spark: This is popular for simplifying the development of applications that can be executed in parallel and in a distributed cluster in a fault-tolerant way. The most common programming support for Spark is Scala. The implementations of the tasks are based on the resilient distributed dataset (RDD) as a multiset of objects with the “read-only” feature propagating over a cluster with the fault-tolerant system [
59]. In fact, the whole architecture components include Spark Core and a set of libraries. Most of the functionalities provided by Apache Spark are built on top of Spark Core. Moreover, it is considered to be the basis of the distributed and parallel processing of large amounts of data. It contains Spark Core at its top layer, including Spark SQL, Spark streaming, Mlib, and Spark GraphX, which are utilized for data monitoring and processing [
62].
The above-mentioned techniques (i.e., the batches processing techniques) can be integrated for setting up different scenarios related to energy management in buildings. Using data already stored in the past can help create the best approaches and methods for increasing profit and decreasing costs. As an example, several works have investigated the integration of batch processing techniques in order to forecast the behavior of building occupants using historical data from previous years in order to develop the best planning and schedules of the occupancy in a specific area (i.e., such as offices, floor, buildings, and conference rooms). The main purpose of such studies is to efficiently control the active equipment of buildings (i.e., turn on/off HVAC, and lighting systems) in order to reduce the wasted energy in buildings.
Better control of building services requires real-time action. Several works investigate the use of environmental data in order to manage the use of most energy-consuming equipment [
3,
4]. Analyzing all generated data from IoT and acting directly on this equipment necessitate the integration of stream data processing techniques in order to analyze continuously generated data with high performance (i.e., latency and accuracy) [
63].
4.2. Stream-Based Processing Techniques
Processing a myriad of generated data in batch is not sufficient when a new instance of data should be processed rapidly in order to ensure a fast reaction. Specifically, the stream processing paradigm online enables the analysis of continuous and dynamic data. Therefore, stream data processing techniques have become more important to industries and researchers who are working on real-time services such as building energy management systems [
5]. The common streaming engines that have a large-scale adoption are Apache Spark Streaming (
https://spark.apache.org/), Apache Flink (
https://flink.apache.org/), and Apache Storm (
https://storm.apache.org/). In fact, several applications necessitate the integration of these data stream processing tools. For example, the purchases of tasks for some applications, such as online video games that are downloaded from different sources, must analyze the users’ actions.
Apache Storm: This is a distributed real-time processing system. It is easy to process and consumes a large amount of stream data in order to ensure real-time processing. It includes several processing techniques, such as API and SQL stream processing. The architecture of the Storm is composed of three essential elements: spouts as a source unit, and bolts and topologies as processing units. A spout is considered a source of streams. It consumes data from different sources, such as message queues and databases, and then transfers the tuples into the bolts in the topology without any processing tasks. Moreover, bolts consume the tuple from the spout, apply some tasks, such as aggregation, joining operations, or filtering, and then emit the new tuples to its output streams. The topology of a Storm application covers the multi-stage stream communication and computation of spouts and bolts, which are connected to stream grouping [
64].
Apache Spark streaming: Spark streaming enables real-time data processing of data coming from different sources such as Flume, Kafka, and Amazon Kinesis. In fact, these processed data can be emitted to file systems and live dashboards. It is considered a micro batch generic-purpose data stream processing engine, an extension of the Spark Core API. The main data abstraction in Spark is called the resilient distributed dataset (RDD). Furthermore, Spark streaming offers the concept of discretized stream (DStream) in order to process a continuous stream of data, represented as a sequence of RDDs [
65].
Apache Flink: This is designed for the distributed processing and stateful computation of continuous data streams (i.e., unbounded or bounded data streams). It is also considered a generic-purpose data stream processing engine. Each dataflow or instance in Flink starts with one or several sources and ends in multiple sinks in order to submit data to different outputs such as file systems or databases [
66,
67]. Apache Flink can be integrated into different cluster resource managers such as Hadoop and Kubernetes, and it can also be set up to be executed as a stand-alone cluster.
4.3. Big Data and Machine Leaning
Industry parts need to gather useful information from data streams (i.e., such as social media, credit card transactions, deployed sensors, etc.). Data collected from high-speed streams are more and more common in modern data ecosystems [
68]. The real-time processing of a huge amount of data is not easy. For example, web companies must integrate systems that are able to process each instance of incoming data, demonstrating high performance in terms of time of execution and memory use [
69]. Furthermore, Machine learning approaches have has an impact on many types of applications and systems, such as speech processing, natural language, computer vision, etc. Batch-based learning techniques require the training phase on the data already stored in file systems or databases. Different frameworks are designed and developed for applying machine learning algorithms on big data as one batch. Distributed machine learning frameworks (i.e., MLBase and Mahout) have demonstrated their effectiveness in terms of variety and volume [
70]. However, different frameworks have been developed in order to address the issue of applying machine learning techniques on data coming from different sources (e.g., social media, building sensors, internet traffic data) as a data stream. In fact, streaming machine learning frameworks (i.e., such as massive online analysis (MOA)) also address the dimensions of variety and velocity [
69,
70].
Batch-based machine learning integration (Apache Mahout): Most of the work related to building energy management, such as via occupancy detection systems, has investigated the integration of batch machine learning techniques. This means that the data should be already available in a specific database or file system in order to build a model by training it on this data and building an efficient model. In this case, the model cannot be updated or improved using stream data. Further, Apache Mahout is an open-source framework that offers the free implementation of scalable and distributed machine learning algorithms, including several approaches such as classification, clustering, and recommender engine. The authors of [
71] present the Hadoop ecosystems architecture, which includes several libraries, including the Mahout library, which is suitable for applications necessitating the scale of large amount of data executed on top of the Apache Hadoop.
Figure 5 presents the global architecture of Hadoop ecosystems presented by [
71], including the Mahout Library. In summary, the main purpose of Apache Mahout is to execute and apply machine learning algorithms on data already stored in HDFS.
In fact, batch machine learning is extremely important in order to improve the different services that need to process historical data in order to make efficient decisions and to plan for the present or the future. However, many issues cannot deal with batch-based methods because of the environment change, and the static model will be unserviceable over time.
4.4. Online and Real-Time Machine Learning Techniques
Most developed solutions and frameworks related to machine learning techniques address just two out of three dimensions (i.e., variety and volume). In fact, some solutions have emerged for the three most popular dimensions (i.e., variety, volume, and velocity) in order to perform the stream mining of big data [
72]. The main idea of stream machine learning or online machine learning is to update the model continuously and improve performance when each instance arrives at the processing unit in real or near real time. In fact, batch-based machine learning algorithms are static. These algorithms should exploit a large dataset to train and identify the model results before moving it to production. In contrast, online learning algorithms are processed incrementally when new data become available. Actually, stream learning is still developing its philosophy, and the documentation of its general properties is not yet comprehensive, as in batch learning. In this subsection, we discuss the two main frameworks that involve machine learning for the data stream: Apache Samoa, developed by Apache [
69], and StreamDM, by Huawei [
68].
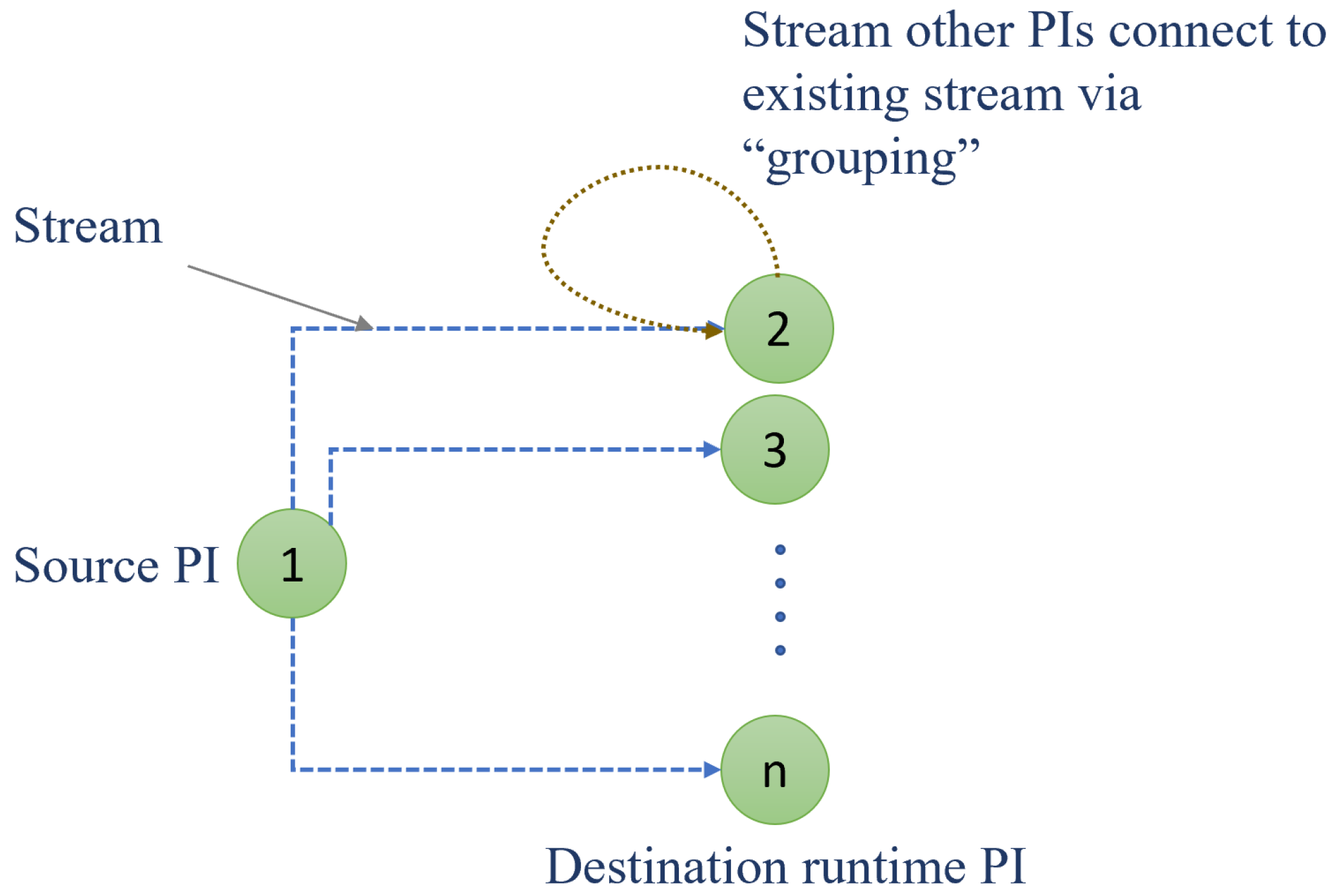
Apache SAMOA (scalable advanced massive online analysis) is a distributed system for applying and programming streaming algorithms in order to develop new ML algorithms by avoiding the complication of streaming processing engines (SPEs), and developers can integrate new platforms using SAMOA APIs. The SAMOA project is divided into two main elements: SAMOA-Platform and SAMOA-API. The SAMOA-API can be integrated with different SPEs without any restriction. If new SPEs are being released, a new SAMOA platform module can be included. In order to perform ML algorithm development in SAMOA, five components are included in the global architecture: processing items, content event, stream, topology, and task. Processors are computational units in SAMOA use for executing algorithms separately on a defined SPE. In fact, these processing items (PIs) refer to the particular implementation of processors in different SPEs, such as Bolt in Storm. Two different PIs type are presented by the SAMOA community, namely, the entrance PI and the normal PI. The entrance PI consumes events from external sources or generates new events and transfers them to the normal PI to be processed and exploited for ML algorithms. The normal PI can send the processed event or new event to the outgoing streams. The SAMOA framework facilitates the implementation of ML algorithms in a parallel way by specifying the parallelism hint (i.e., the PI runtime during the task execution), as presented in
Figure 6. Also, the stream can be considered as a communication tool between PIs (source PI and destination PI), as shown in
Figure 6. The content event handles the data transferred from one PI to another via a stream. The source Pi sends an event to the destination PI via a stream, while the destination PI consumes the event coming from source PI. In fact, in order to consume the content event coming from source PI, the destination PI should integrate different “grouping” mechanisms, which define the stream route of content events. Three grouping mechanisms in SAMOA can be recognized, namely, shuffle grouping, all grouping, and key grouping. Moreover, the topology is a set of connected PIs and streams. The distributed streaming ML algorithms can be integrated into the SAMOA architecture. Tasks are related to ML integration. It is often used for evaluating the performance of algorithms. For example, the prequential evaluation task is the most popular task in the SAMOA architecture. It is used for testing the performance of models and for exploiting the current instance to train and update the model [
69].
StreamDM is an open-source framework for applying machine learning algorithms on data streams. It has emerged on top of Spark streaming. The main goal is to connect the Spark framework using the Spark streaming library and online machine learning algorithms in a distributed system. The Spark environment already includes machine learning libraries such as MLlib and spark.ml. The aim of StreamDM is to develop advanced methods of data mining and machine learning in order to apply them to large-scale data streams. In fact, StreamDM has been developed for practical users, only using algorithms that are already presented by the framework, i.e., without the need to develop new algorithms, and researchers and developers can implement new algorithms in StreamDM. The Spark streaming is the main provider of data streams in StreamDM. In fact, it is not an instance-by-instance setting of streams. The idea is to process mini batches of data. Therefore, the latency of data needs more time. Further, StreamDM is mostly based on tasks that describe its functionality in mining data streams.
Figure 7 describes as generally as possible the workflow of an example of a StreamDM task named “EvaluatePrequential”. The task processes contain four main classes. First, the Reader class reads data streams from discretized streams. In addition, the testing and training data streams are consumed by the Learner class, which contains machine learning algorithms. Further, the predicted data are transmitted to the Evaluator class in order to evaluate the performance of the applied algorithm. Then, the results are sent by the Output Writer class into other data stream consumers such as file systems, consoles, or other tasks.
5. Discussion
Most digital solutions exploit a huge amount of data generated every millisecond. The main aim is to process these data quickly with high performance. Furthermore, many applications and systems require the near-real-time processing of large amounts of data streams and the real-time acting and controlling of a myriad of deployed devices simultaneously, such as building energy management systems. Numerous open-source frameworks and systems have been designed and developed for processing data streams. In fact, generating significant knowledge from unbounded data in time has become more difficult. The various number of developed frameworks and systems presents a substantial challenge for researchers and developers in choosing the best elements and determining which framework is suitable for their use cases. There are many features for processing data streams that should be taken into account in order to make the right design and develop an appropriate approach.
The benchmarking of some services is an important tool that can be used for evaluating the performance of big data technologies, especially stream processing frameworks [
73]. Latency and fault tolerance are the main parameters that can help researchers and industries to choose an appropriate framework for their use cases. Several works have evaluated the performance of different stream processing frameworks. The aim is to choose a suitable system that can help facilitate the implementation of desirable solutions. Most works related to big data stream technologies focus on evaluating three popular data stream processing systems, namely, Apache Storm, Apache Spark, and Apache Flink. These systems can be integrated in order to process data streams with high performance. For example, the authors of [
74] set up a benchmarking method for testing and evaluating the performance of Apache Storm, Spark streaming, and Flink in terms of throughput and latency. The results show that Apache Flink and Strom are close in terms of latency; however, Apache Spark has the biggest latency. Moreover, the work presented in [
75] shows the potential of Apache Storm in terms of latency and node failure. The results of the experiment showed that Storm has better performance (i.e., by at least 50%) than Apache Flink and Apache Spark.
Table 2 presents the comparison criteria of the two most popular big data stream processing systems.
The main objective of this work is to design and choose the best elements in order to set up occupancy detection systems using environmental data generated from sensors deployed in buildings. Most building services require control of active equipment in time; this is why the integration of real-time monitoring and processing large amounts of environmental data have become more important in order to set up effective control of building active equipment. In fact, occupancy information is considered the main input for applying different control approaches such as PID, MPC, and GPC on HVAC, ventilation, or lighting systems in order to save energy and maintain the users’ comfort.
Machine learning (ML) algorithms are the most popular solution that can help researchers and developers to use environmental data for detecting indoor building occupancy, i.e., either the presence of an occupant or the number thereof. Most of the works related to occupancy detection systems use the traditional ML algorithm. This means that the environmental data should already be collected and stored for exploitation in order to build the model using many ML algorithms (i.e., such as SVM, ANN, DT, etc.). However, dealing with environmental data is not easy because it is not stationary and changes over time. The main purpose of this paper is to design and develop an appropriate architecture platform using recent big data stream processing technologies, which can involve the integration of machine learning algorithms that can deal with data streams and non-stationary data. Based on the results presented in the literature review of works that address the evaluation of stream processing techniques, Storm is still the best framework for implementing occupancy detection systems in terms of latency and fault tolerance. In this work, the objective is to present a general architecture that can be integrated into a smart building for detecting occupancy based on environmental data using recent IoT and big data technologies. The idea is to use valuable tools in terms of performance in order to provide efficient building services.
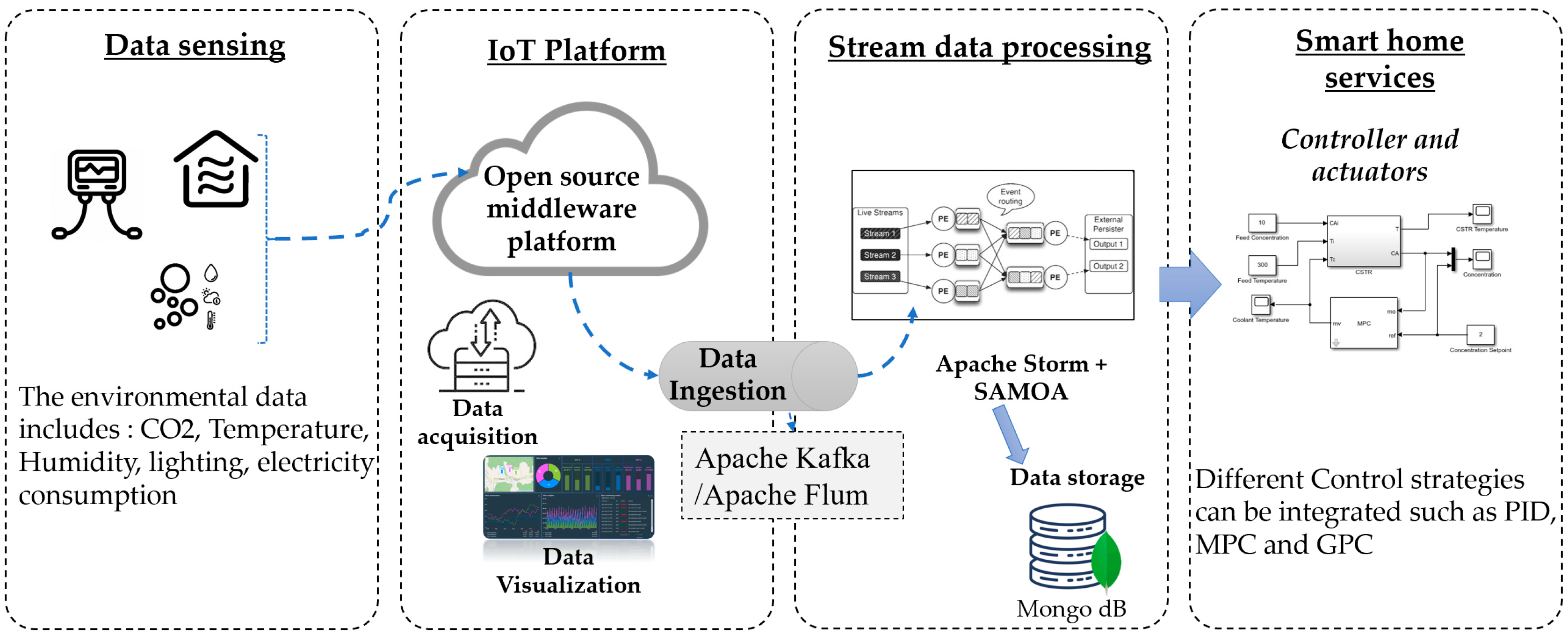
Figure 8 illustrates the adopted architecture that can improve the performance of occupancy detection using IoT and big data technologies. The architecture includes four main layers.
Data sensing: Many types of sensors can be included in the proposed architecture. As an example, for collecting CO2 data, there are different embedded technologies that can help in collecting data from sensors in the environment. The main types of environmental data that can be used for detecting occupancy include CO2, temperature, humidity, lighting, and electricity consumption. Furthermore, infrared or camera sensors can be exploited to gather the true occupancy information, which can help to train the model (it is named the label).
IoT platform middleware: An IoT platform is a set of elements that enable developers to collect data from multiple sensors remotely while ensuring secure connectivity. The aim of each deployed IoT platform is fast communication between different connected devices and the cloud, using advanced networking protocols such as MQTT and HTTPs. Different IoT platforms provide a free service for data acquisition and visualization. In fact, these platforms can be implemented in the cluster. For example, Kaa and Thingsboard are the most popular open-source IoT platforms that include multiple services related to data management.
Stream data processing techniques: In the proposed architecture, Storm is the most suitable due to its effectiveness in terms of fault tolerance and latency. Moreover, it is a distributed system and can support an advanced Machine learning framework, such as Apache SAMOA.
Smart home services: Different applications can be developed for controlling active equipment in buildings. The aim is to manage building services such as HVAC and lighting systems in order to reduce energy consumption and maintain the occupants’ comfort. Different approaches proposed in the literature aim at building control devices efficiently [
29,
30,
31].
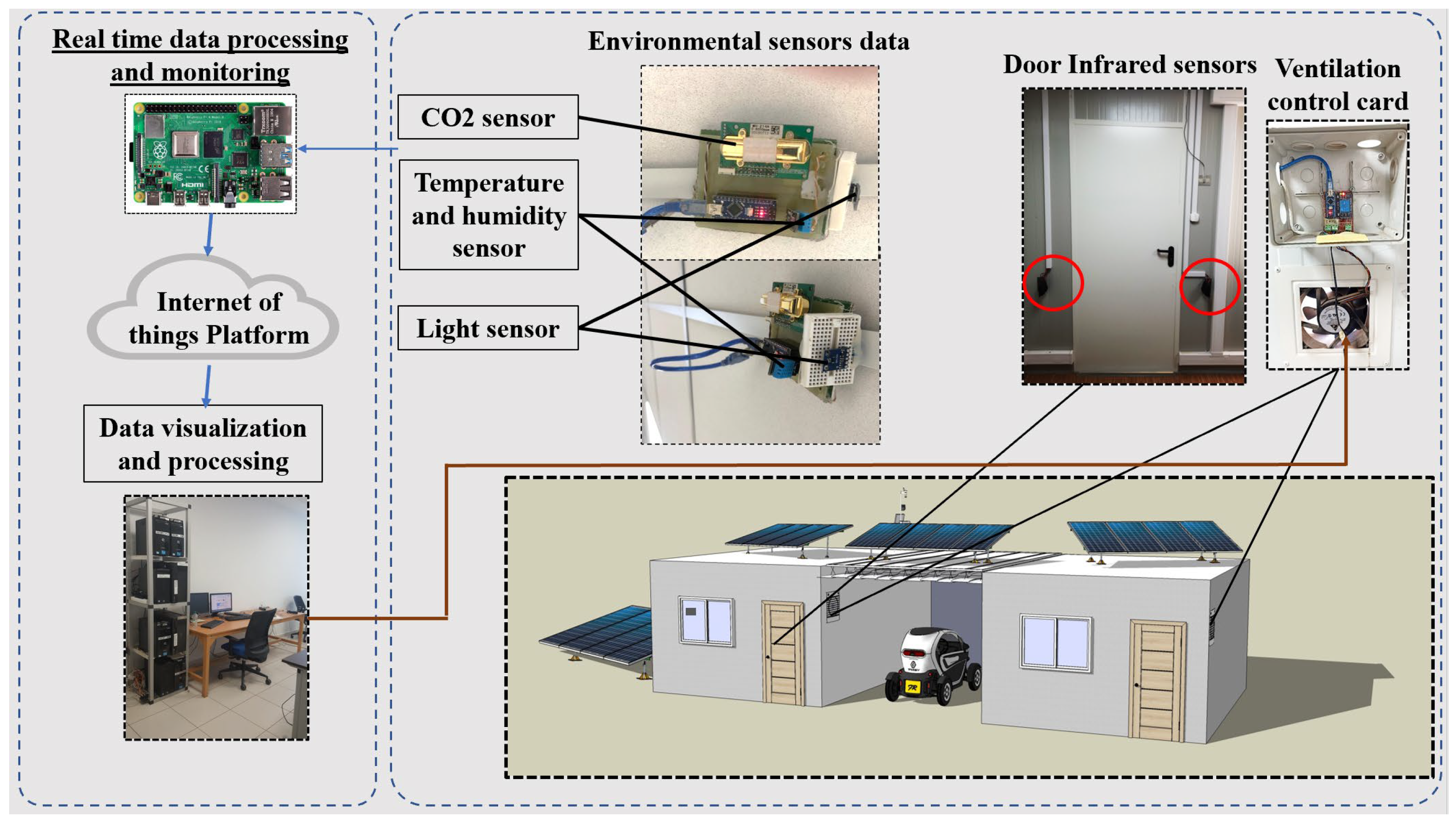
Furthermore, a prototype platform was deployed in the laboratory in order to set up the occupancy detection use case by integrating the above-mentioned technologies for ensuring the real-time stream processing of data coming from deployed sensors.
Figure 9 illustrates different elements and components that are integrated into the platform in order to set up an occupancy detection system. In the proposed scenario, multiple types of sensors and microcontrollers have been exploited as hardware parts for collecting, gathering, and sending data to the remote server. In fact, the main hardware modules that have been deployed for data acquisition and monitoring in EEBLab are as follows.
MH Z14A is an infrared CO2 meter that could be integrated using either UART or I2C protocols. DHT22 is used in thermal comfort by measuring indoor/outdoor temperature and relative humidity in a given area. One wire communication protocol was used for gathering data. Further, Raspberry PI 3 is considered a bridge or edge of the deployed platform. The main task of Raspberry is to gather data using the UART protocol and to filter/reorganize sensors’ data to be transmitted to the server.
NodeMCU is a low-cost Wi-Fi module with an 802.1 Wi-Fi direct protocol and a soft-AP-integrated TCP/IP protocol stack, Fan module (12 V) is used to control air quality in the room, and PZEM 004T current sensor is deployed for measuring the consumption of different building appliances and machines (e.g., ventilation, HVAC, lighting).
Regarding data transfer, communication techniques are required. The MQTT (message queue telemetry transport) protocol is deployed in the Ubuntu server. It is mainly used to transmit data from the monitoring prototype to the gateway actor. It is worth noting that MQTT protocol is a machine-to-machine connectivity protocol, and it was designed as an extremely lightweight publish/subscribe messaging transport. In fact, the sensing node starts sampling sensors’ data and sends them via MQTT to the gateway, which transports them to the server using HTTP transport protocols. The deployed cluster includes the Apache Storm setup as a data stream engine for processing data coming directly from sensors without storing them and then resending the decision results for the ventilation system control.
6. Conclusions and Perspectives
The integration of IoT and big data is a crucial solution for improving building services. For example, managing building equipment requires the efficient manipulation of the large amount of data generated from connected devices. In this work, we provide an overview highlighting the transformative role of IoT and big data technologies in smart building applications in order to improve operational efficiency, energy management, and occupant comfort. Many technologies have been presented and discussed: both batch-based and stream-based techniques for developing the optimal architecture for processing building data and setting up active services. The key findings demonstrate that IoT devices, integrated with big data analytics, enable the real-time monitoring and optimization of building systems, leading to significant energy savings and improved sustainability. In fact, stream processing technologies are the most suitable for processing building environmental data.
For example, Storm is classified by various studies as the best framework that can be integrated for processing data streams in terms of latency and fault tolerance. The main objective of this study was to design an effective architecture, including the best tools for processing large amounts of environmental data, in order to implement efficient management building systems so as to improve building services with the aim of reducing energy and maintaining the occupants’ comfort. The technologies and platforms studied are the main means for researchers to improve the deployment of next-generation approaches, such as digital twin, for critical environment monitoring and anomaly detection. Future research should focus on addressing these issues by developing robust data security frameworks, improving interoperability between IoT devices, and exploring advanced data processing techniques like edge computing. Overall, the continued development of IoT and big data technologies holds great promise for the evolution of smart buildings, fostering more intelligent, energy-efficient, and responsive environments.




 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}