
Forecasting Maximum Temperature Trends with SARIMAX: A Case Study from Ahmedabad, India


 , ,
, , 

Abstract
1. Introduction
2. Related Work
3. Proposed Methodology
3.1. Data Selection
3.2. Data Preprocessing
3.2.1. Data Cleaning and Transformation
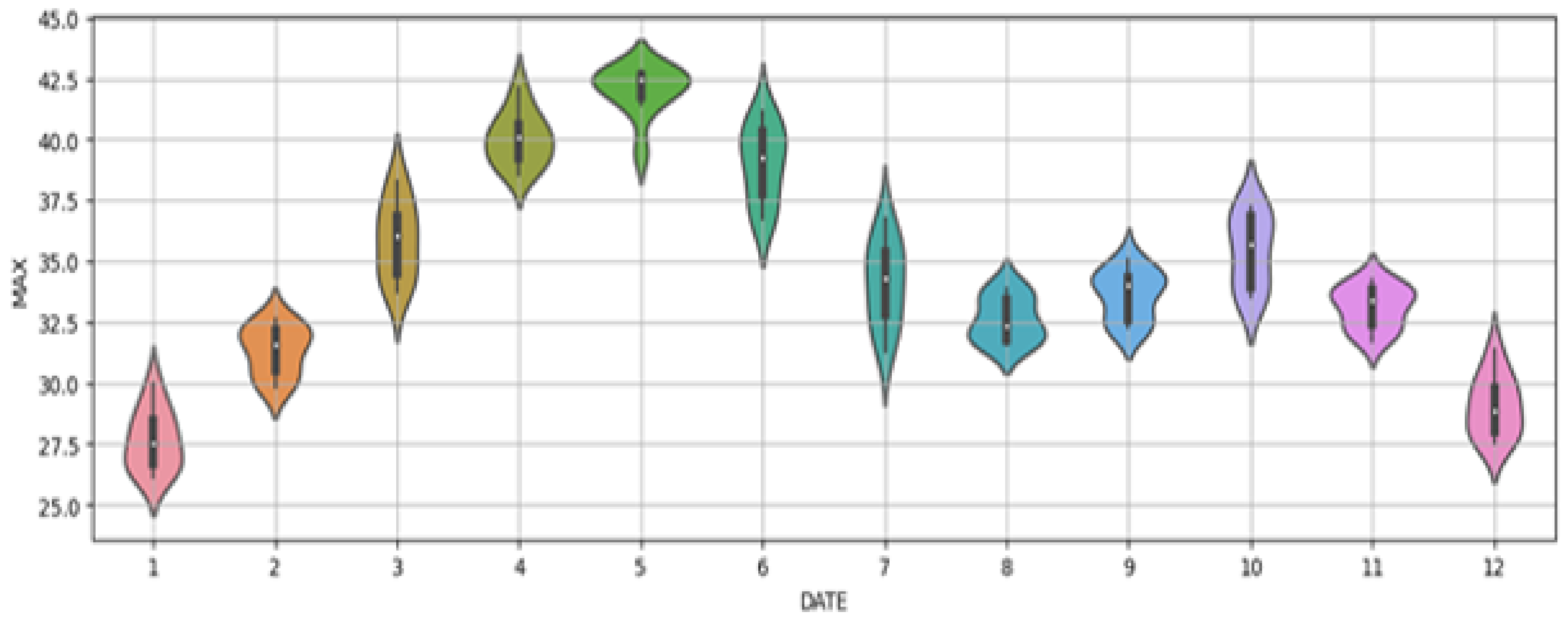
3.2.2. Observing the Trend
3.2.3. Stationarity Check Using Augmented Dickey–Fuller Test
3.3. Temperature Forecasting Using SARIMAX
- p, d, and q represent the non-seasonal components of the model, indicating the order of autoregressive terms, the degree of differencing, and the order of moving average terms, respectively.
- P, D, and Q detail the seasonal elements, specifying the order of seasonal autoregressive terms, the degree of seasonal differencing, and the order of seasonal moving average terms.
- s denotes the seasonal periodicity, defining the cycle’s length within the time-series data.
3.3.1. SARIMAX
- Autoregressive (AR) Component: This encapsulates the influence of the preceding values on the current value, denoted as , where p is the number of lag observations included in the model. The AR part is formulated as
- Integrated (I) Component: This facilitates the stationarity in the series by differencing the data, represented as , with d indicating the degree of differencing required.
- Moving Average (MA) Component: This models the error of the time series as a linear combination of error terms from previous forecasts, expressed as , where q is the order of the moving average term [28].
- Seasonal Components: These include Seasonal and Seasonal terms, adding layers to capture seasonal effects within the data.
- Exogenous Variables (): These represent external variables influencing the time series, incorporated as additional predictors to enhance the model’s accuracy [29].
- Parameter settings: , , for the non-seasonal components, and , , , for the seasonal components, tailored to capture the annual cycle evident in temperature data.
- Exogenous variables (): To enhance the predictive power of the SARIMAX model, we included specific climatic and economic indicators known to affect temperature variations. These exogenous variables were selected based on their relevance and data availability:
- −
- Pollution indices: Local air quality measurements such as PM2.5 and NO2 concentrations were included, which have been shown to correlate with temperature anomalies due to their impact on atmospheric composition and heat retention.
- −
- Urban development rates: Quantified through changes in land use patterns, population density, and construction activity within the region. These metrics were sourced from municipal urban development reports and satellite imagery analysis, reflecting the urban heat island effect, which significantly impacts local temperature patterns.
- −
- Vegetation indexes: Utilizing NDVI (normalized difference vegetation index) data derived from satellite images to account for changes in land cover and their effects on the local climate. Vegetation affects local temperature through evapotranspiration and provides cooling, which can be a critical variable in urban settings.
- −
- Economic indicators: Economic growth rates and industrial activity levels, obtained from government economic reports, which indirectly affect temperature through energy consumption patterns and the resultant heat emissions.
- : These autoregressive coefficients quantify the influence of prior values within the series on the current value, embedding the model’s memory of past observations.
- : Moving average coefficients model the impact of past errors (or shocks) on the current observation, allowing the model to adjust for anomalies or unexpected changes in the time series.
- : Represents the actual value of the series at time t, serving as both the target for prediction and a component of the model’s calculations.
- : The error term at time t captures the difference between the observed values and those predicted by the model, representing the unexplained variance.
- : Denotes the value of the series at a time lagged by d periods, essential for the model’s differencing process, aimed at achieving stationarity.
- : Refers to the seasonal ARMA components, which are crucial for capturing and modeling the cyclical patterns inherent in the data, ensuring that the model accurately reflects seasonal variations.
- : Exogenous (or external) variables are included as additional predictors to account for the influence of outside factors on the time series. These variables can significantly enhance the model’s accuracy by integrating relevant external information, such as economic indicators or environmental factors, that may impact the series.
3.3.2. Advantages and Disadvantages of SARIMAX
3.3.3. Seasonal Hyperparameter Tuning Using AIC
3.4. Proposed Algorithm
| Algorithm 1 Forecasting monthly average maximum temperature using SARIMAX |
|
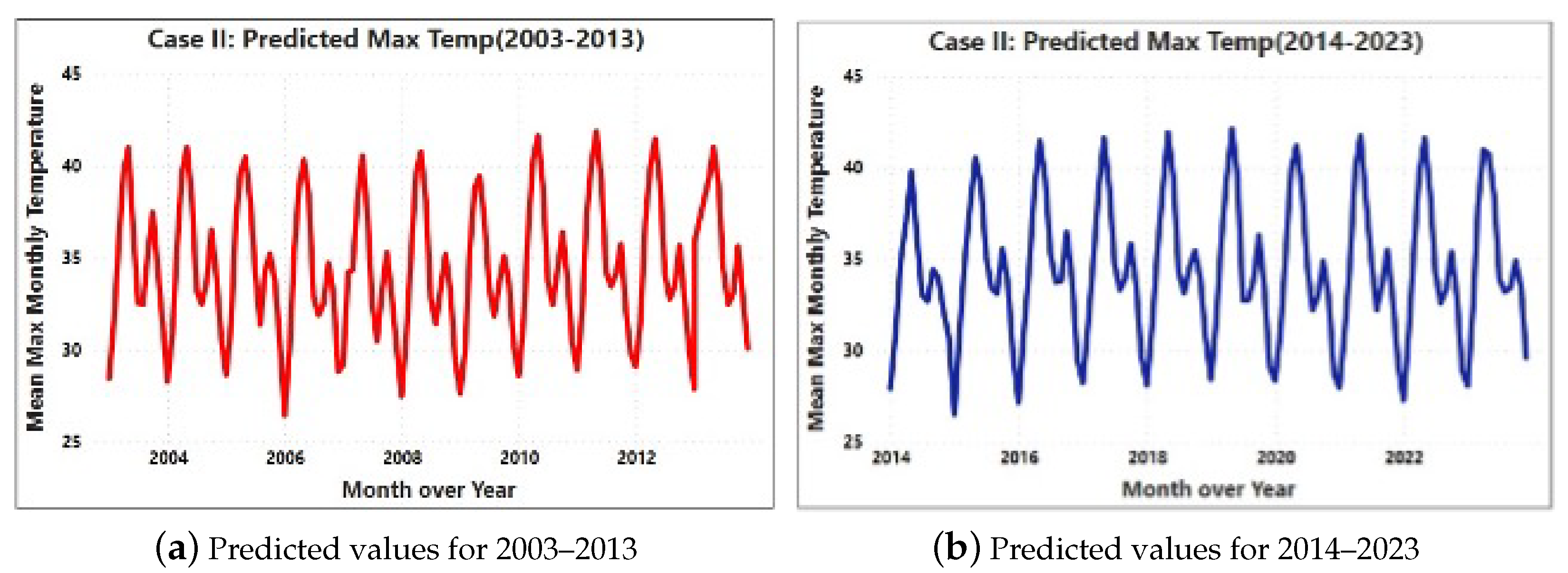
3.4.1. Case 1: Initial Forecasting Approach
3.4.2. Case 2: Dynamic Forecasting Strategy
3.4.3. Comparative Analysis of Case 1 and Case 2
4. Experimental Evaluation
4.1. Results
4.2. Comparative Performance Analysis of Forecasting Models
4.3. Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- National Oceanic and Atmospheric Administration: Excessive Heat, a `Silent Killer’. Available online: https://www.noaa.gov/stories/excessive-heat-silent-killer (accessed on 16 July 2024).
- Gustin, M.; McLeod, R.S.; Lomas, K.J. Forecasting Indoor Temperatures during Heatwaves using Time Series Models. Build. Environ. 2018, 143, 727–739. [Google Scholar] [CrossRef]
- The Intergovernmental Panel on Climate Change (IPCC). Available online: https://www.ipcc.ch/report/ar6/wg1/downloads/report/IPCC_AR6_WGI_SPM_final.pdf (accessed on 16 July 2024).
- Data Dive: Land Lost to Forest Fires in India Increases by 122% in 5 Years. Available online: https://www.factchecker.in/data-dive/data-dive-land-lost-to-forest-fires-in-india-increases-by-122-in-5-years-815025 (accessed on 16 July 2024).
- The Climate Action Button. Available online: https://climatebutton.ucsusa.org/ (accessed on 16 July 2024).
- Kreuzer, D.; Munz, M.; Schlüter, S. Short-Term Temperature Forecasts using a Convolutional Neural Network—An application to Different Weather Stations in Germany. Mach. Learn. Appl. 2020, 2, 100007. [Google Scholar] [CrossRef]
- Sustainable Development Goals: 17 Goals to Transform Our World—Ensure Access to Affordable, Reliable, Sustainable and Modern Energy. Available online: https://www.un.org/sustainabledevelopment/energy/ (accessed on 16 July 2024).
- Veeramsetty, V.; Kiran, P.; Sushma, M.; Salkuti, S.R. Weather Forecasting Using Radial Basis Function Neural Network in Warangal, India. Urban Sci. 2023, 7, 68. [Google Scholar] [CrossRef]
- Kaur, B.; Kaur, N.; Gill, K.K.; Singh, J.; Bhan, S.C.; Saha, S. Forecasting Mean Monthly Maximum and Minimum Air Temperature of Jalandhar District of Punjab, India using Seasonal ARIMA Model. J. Agrometeorol. 2022, 24, 42–49. [Google Scholar]
- Brown, G.D.; Largey, A.; McMullan, C.; Reilly, N.; Sahdev, M. Weathering the Storm: Developing a User-centric Weather Forecast and Warning System for Ireland. Int. J. Disaster Risk Reduct. 2023, 91, 103687. [Google Scholar] [CrossRef]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting. In Proceedings of the 35th AAAI Conference on Artificial Intelligence (AAAI), Virtually, 2–9 February 2021; AAAI Press: Washington, DC, USA, 2021; pp. 11106–11115. [Google Scholar]
- Roy, D.S. Forecasting The Air Temperature at a Weather Station Using Deep Neural Networks. Procedia Comput. Sci. 2020, 178, 38–46. [Google Scholar] [CrossRef]
- Elshewey, A.M.; Shams, M.Y.; Elhady, A.M.; Shohieb, S.M.; Abdelhamid, A.A.; Ibrahim, A.; Tarek, Z. A Novel WD-SARIMAX Model for Temperature Forecasting Using Daily Delhi Climate Dataset. Sustainability 2022, 15, 757. [Google Scholar] [CrossRef]
- Cadenas, E.; Rivera, W.; Campos-Amezcua, R.; Heard, C. Wind Speed Prediction Using a Univariate ARIMA Model and a Multivariate NARX Model. Energies 2016, 9, 109. [Google Scholar] [CrossRef]
- Hewage, P.; Trovati, M.; Pereira, E.; Behera, A. Deep Learning-based Effective Fine-grained Weather Forecasting Model. Pattern Anal. Appl. 2021, 24, 343–366. [Google Scholar] [CrossRef]
- Zenkner, G.; Navarro-Martinez, S. A Flexible and Lightweight Deep Learning Weather Forecasting Model. Appl. Intell. 2023, 53, 24991–25002. [Google Scholar] [CrossRef]
- Thakur, N.; Karmakar, S.; Soni, S. Time Series Forecasting for Uni-variant Data using Hybrid GA-OLSTM Model and Performance Evaluations. Int. J. Inf. Technol. 2022, 14, 1961–1966. [Google Scholar] [CrossRef]
- Biswas, M.; Dhoom, T.; Barua, S. Weather Forecast Prediction: An Integrated Approach for Analyzing and Measuring Weather Data. Int. J. Comput. Appl. 2018, 182, 20–24. [Google Scholar] [CrossRef]
- U, J.K.; Kovoor, B.C. Deterministic Weather Forecasting Models based on Intelligent Predictors: A Survey. J. King Saud Univ.—Comput. Inf. Sci. 2022, 34, 3393–3412. [Google Scholar]
- Aslam, M. Time Series Data Analysis under Indeterminacy. J. Big Data 2023, 10, 126. [Google Scholar] [CrossRef]
- Al-Duais, F.S.; Al-Sharpi, R.S. A Unique Markov Chain Monte Carlo Method for Forecasting Wind Power Utilizing Time Series Model. Alex. Eng. J. 2023, 74, 51–63. [Google Scholar] [CrossRef]
- Ampountolas, A. Modeling and Forecasting Daily Hotel Demand: A Comparison Based on SARIMAX, Neural Networks, and GARCH Models. Forecasting 2021, 3, 580–595. [Google Scholar] [CrossRef]
- Hamed, K.H.; Rao, A.R. A Modified Mann-Kendall Trend Test for Autocorrelated Data. J. Hydrol. 1998, 204, 182–196. [Google Scholar] [CrossRef]
- Abhishek, K.; Singh, M.; Ghosh, S.; Anand, A. Weather Forecasting Model using Artificial Neural Network. Procedia Technol. 2012, 4, 311–318. [Google Scholar] [CrossRef]
- Ajewole, K.P.; Adejuwon, S.O.; Jemilohun, V.G. Test for Stationarity on Inflation Rates in Nigeria using Augmented Dickey Fuller Test and Phillips-Persons Test. IOSR J. Math. 2020, 16, 11–14. [Google Scholar]
- Zhang, Z.; Dong, Y. Temperature Forecasting via Convolutional Recurrent Neural Networks Based on Time-Series Data. Complexity 2020, 2020, 3536572:1–3536572:8. [Google Scholar] [CrossRef]
- Yang, B.; Ma, T.; Huang, X. ATFSAD: Enhancing Long Sequence Time-Series Forecasting on Air Temperature Prediction. IEEE Access 2023, 11, 92080–92091. [Google Scholar] [CrossRef]
- Lynch, P. The Origins of Computer Weather Prediction and Climate Modeling. J. Comput. Phys. 2008, 227, 3431–3444. [Google Scholar] [CrossRef]
- Scher, S.; Messori, G. Predicting Weather Forecast Uncertainty with Machine Learning. Q. J. R. Meteorol. Soc. 2018, 144, 2830–2841. [Google Scholar] [CrossRef]
- Chai, T.; Draxler, R.R. Root Mean Square Error (RMSE) or Mean Absolute Error (MAE)?–Arguments against Avoiding RMSE in the Literature. Geosci. Model Dev. 2014, 7, 1247–1250. [Google Scholar] [CrossRef]
- Merabet, K.; Heddam, S. Improving the Accuracy of Air Relative Humidity Prediction using Hybrid Machine Learning based on Empirical Mode Decomposition: A Comparative Study. Environ. Sci. Pollut. Res. 2023, 30, 60868–60889. [Google Scholar] [CrossRef] [PubMed]
- Tao, H.; Awadh, S.M.; Salih, S.Q.; Shafik, S.S.; Yaseen, Z.M. Integration of Extreme Gradient Boosting Feature Selection Approach with Machine Learning Models: Application of Weather Relative Humidity Prediction. Neural Comput. Appl. 2022, 34, 515–533. [Google Scholar] [CrossRef]
- Swain, D.; Vijeta; Manjare, S.; Kulawade, S.; Sharma, T. Stock Market Prediction Using Long Short-Term Memory Model. In Proceedings of the Machine Learning and Information Processing ; Springer: Cham, Switzerland, 2021; pp. 83–90. [Google Scholar]
- Amnuaylojaroen, T. Advancements in Downscaling Global Climate Model Temperature Data in Southeast Asia: A Machine Learning Approach. Forecasting 2023, 6, 1–17. [Google Scholar] [CrossRef]
- Shrivastav, L.K.; Jha, S.K. A Gradient Boosting Machine Learning Approach in Modeling the Impact of Temperature and Humidity on the Transmission Rate of COVID-19 in India. Appl. Intell. 2021, 51, 2727–2739. [Google Scholar] [CrossRef]
- Zohdi, M.; Rafiee, M.; Kayvanfar, V.; Salamiraad, A. Demand Forecasting based Machine Learning Algorithms on Customer Information: An Applied Approach. Int. J. Inf. Technol. 2022, 14, 1937–1947. [Google Scholar] [CrossRef]
- Bojer, C.S. Understanding Machine Learning-based Forecasting Methods: A Decomposition Framework and Research Opportunities. Int. J. Forecast. 2022, 38, 1555–1561. [Google Scholar] [CrossRef]
- Kanavos, A.; Trigka, M.; Dritsas, E.; Vonitsanos, G.; Mylonas, P. A Regularization-Based Big Data Framework for Winter Precipitation Forecasting on Streaming Data. Electronics 2021, 10, 1872. [Google Scholar] [CrossRef]
- Kanavos, A.; Panagiotakopoulos, T.; Vonitsanos, G.; Maragoudakis, M.; Kiouvrekis, Y. Forecasting Winter Precipitation based on Weather Sensors Data in Apache Spark. In Proceedings of the 12th International Conference on Information, Intelligence, Systems & Applications (IISA), Chania, Greece, 12–14 July 2021; pp. 1–6. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
| Feature | Description |
|---|---|
| INDEX | City Identifier |
| YEAR | Year of Record |
| MN | Month |
| MAX | Maximum Temperature (℃) |
| Mean | Standard Deviation | Min | Max | |
|---|---|---|---|---|
| Max Temperature | 34.42 | 4.18 | 26.10 | 43.80 |
| Year Used for Training | Predicted Year | RMSE |
|---|---|---|
| 1992–2002 | 2003 | 1.4185 |
| 1993–2003 | 2004 | 1.5347 |
| 1994–2004 | 2005 | 1.4740 |
| 1995–2005 | 2006 | 1.5436 |
| 1996–2006 | 2007 | 1.3115 |
| 1997–2007 | 2008 | 1.0265 |
| 1998–2008 | 2009 | 1.7331 |
| 1999–2009 | 2010 | 1.4287 |
| 2000–2010 | 2011 | 1.1369 |
| 2001–2011 | 2012 | 1.1474 |
| 2002–2012 | 2013 | 1.3161 |
| Paper | Methodology | RMSE |
|---|---|---|
| [13] | WD-SARIMAX for Temperature Prediction | 1.67 |
| [16] | Bi-directional LSTM for Temperature Forecasting | 1.74 |
| [21] | Wind Energy Analysis with SARIMA and MCMC | 14.66 |
| [22] | Demand Forecasting with SARIMAX | 10.365 |
| [9] | Temperature Forecasting with Mann-Kendall and ARIMA | 1.40 |
| [24] | Weather Forecasting using Artificial Neural Network | 2.55 |
| Proposed SARIMAX Methodology | 1.026 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shah, V.; Patel, N.; Shah, D.; Swain, D.; Mohanty, M.; Acharya, B.; Gerogiannis, V.C.; Kanavos, A. Forecasting Maximum Temperature Trends with SARIMAX: A Case Study from Ahmedabad, India. Sustainability 2024, 16, 7183. https://doi.org/10.3390/su16167183
Shah V, Patel N, Shah D, Swain D, Mohanty M, Acharya B, Gerogiannis VC, Kanavos A. Forecasting Maximum Temperature Trends with SARIMAX: A Case Study from Ahmedabad, India. Sustainability. 2024; 16(16):7183. https://doi.org/10.3390/su16167183
Chicago/Turabian StyleShah, Vyom, Nishil Patel, Dhruvin Shah, Debabrata Swain, Manorama Mohanty, Biswaranjan Acharya, Vassilis C. Gerogiannis, and Andreas Kanavos. 2024. "Forecasting Maximum Temperature Trends with SARIMAX: A Case Study from Ahmedabad, India" Sustainability 16, no. 16: 7183. https://doi.org/10.3390/su16167183
APA StyleShah, V., Patel, N., Shah, D., Swain, D., Mohanty, M., Acharya, B., Gerogiannis, V. C., & Kanavos, A. (2024). Forecasting Maximum Temperature Trends with SARIMAX: A Case Study from Ahmedabad, India. Sustainability, 16(16), 7183. https://doi.org/10.3390/su16167183