

Artificial Intelligence Classification Model for Modern Chinese Poetry in Education
Abstract
1. Introduction
- The Modern Chinese Poetry based on eXtreme Gradient Boosting (XGBoost-MCP) model is built in this paper, which makes poetry classification more accurate, objective, and efficient. It also resolves the defects in traditional poetry education.
- After labeling, word segmentation, and the removal of stopwords from the text data of modern Chinese poetry, the XGBoost-MCP model was iteratively trained using Doc2Vec and XGBoost algorithms, and, finally, we obtained the optimal model.
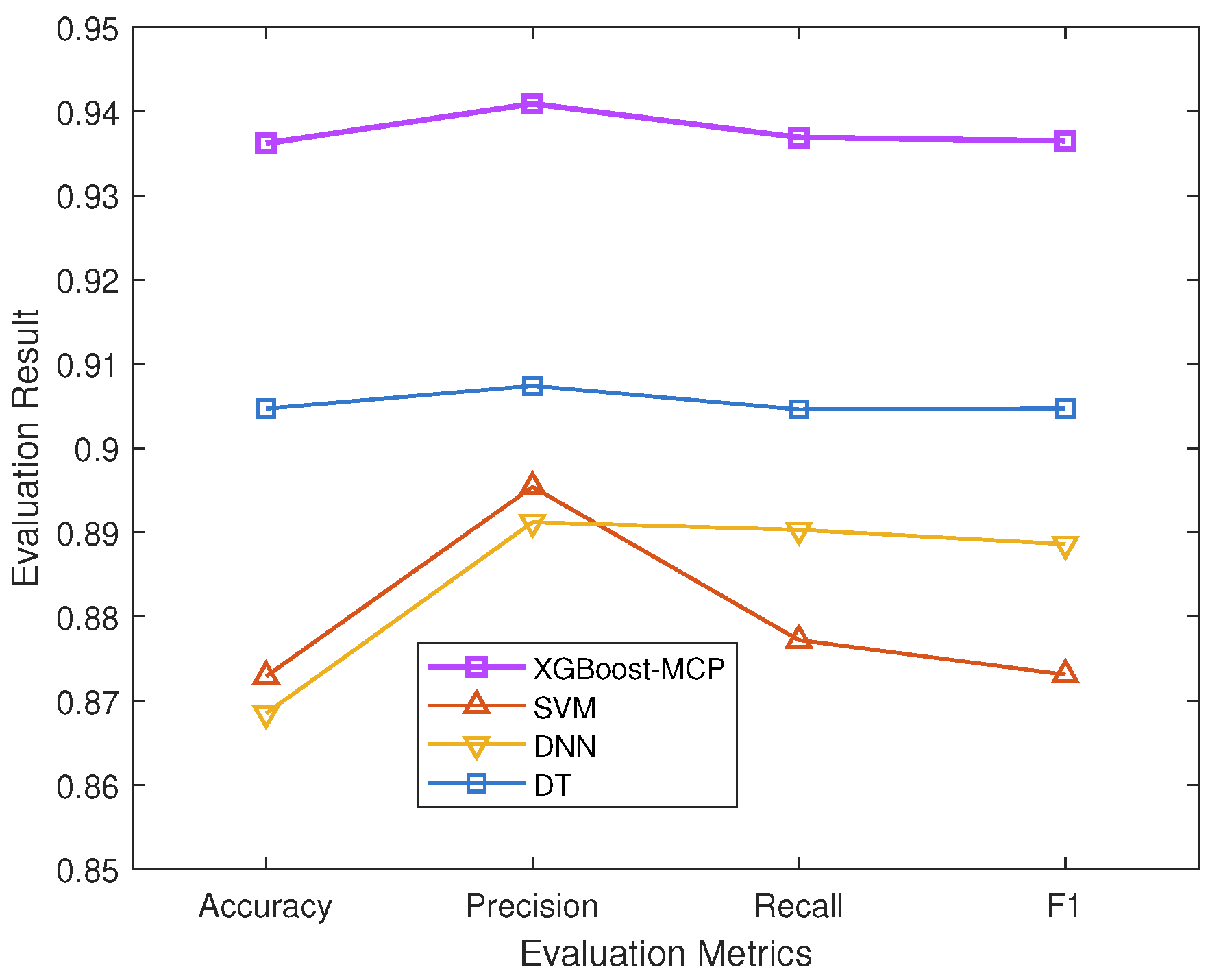
- Experiments on real datasets show that the XGBoost-MCP model is obviously superior to the Support Vector Machine (SVM), Deep Neural Network (DNN), and Decision Tree (DT) models, has certain accuracy and objectivity, and provides convenient auxiliary tools for poetry learners and researchers, which can promote sustainable poetry education.
2. Related Works
2.1. Classification of Short Text and Literary Text
2.2. Classification Methods
2.3. Automatic Classification of Poems
- English: Hayward contended that the metrical choice of poets demonstrates distinction and personality. This is an early study of poetry classification. Hayward used a connectionist model to successfully discover substantive differences among the ten surveyed poets [5]. Subsequently, research on the classification of English poetry continued. Kaplan and Blei proposed automatically recognizing poetry style through computers. Their experiment used a quantitative method to evaluate the style of American poetry and PCA to describe the relationship between poetry collections [6]. Kao and Jurafsky compared the styles of award-winning poets and amateur poets according to quantitative characteristics and revealed the aesthetics of linguistic art using computer technology [7]. Lou et al. concentrated on how the lexicon of a poem determines its theme. They used tf-idf and latent Dirichlet allocation for the feature extraction of English poems and SVM for classification [8].
- Persian: Hamidi et al. used SVM to classify spoken-word Persian poems based on a syllable system [9].
- Ottoman: Can et al. used SVM and NB as classification algorithms to classify the poets and ages of Ottoman poetry. The results showed that SVM is a more accurate classifier than NB [10].
- Malaysian: Jamal et al. tried to classify Malaysian poetry by theme, poetry and nonpoetry. The results proved SVM’s ability to classify poems [11].
- Spanish: Barros et al. used DT to classify Francisco Quivedo’s poems. Manuel Blecua’s classification of Francisco Quevedo’s poetry’s emotion was used as a reference classification. The experimental results showed that the classification model that they established could automatically classify poetry emotion with an accuracy of 56.22%. After filtering, the accuracy was increased to 75.13% [12].
- Arabic: Alsharif et al. built an Arabic poetry corpus with emotional annotation to examine and evaluate the impact of different levels of language preprocessing settings, feature vector dimensions, and machine learning methods on emotion classification, and studied and compared four machine learning algorithms. Hyperpipes was shown to have the highest accuracy at 79% [13].
- Bengali: Rakshit used semantic features to classify the themes of Bengali poetry. They used SVM to divide Tagore’s poetry into four categories. They also found the most useful lexical features in each category. The accuracy of the classifier was 56.8%. The experiment also used the SVM classifier to identify the four poets, with an accuracy of 92.3% [14].
- Punjabi: Kaur and Saini conducted a lexical and content-based categorization of Punjabi poetry, evaluating the classification accuracy of eleven machine algorithms. According to the classification results, Hyperpipes, KNN, NB, and SVM had efficiencies ranging from 50.63% to 52.92% and 52.75% to 58.79%, respectively, surpassing the performance of all other tested machine learning algorithms [15].
- Chinese: Li et al. explained the feasibility of a poetry style evaluation method based on term connection and used this method to determine poetry style [16]. Yi et al. classified song lyrics into two artistic categories, the Magnificent School and the Euphemistic School, using NB. An accuracy rate of 88.5% was achieved [17]. Fang et al. studied the problem of computer-aided understanding and analysis of Chinese classical poetry and built a syntactic parser that could automatically identify poetry images [18]. Voigt and Jurafsky utilized computer-assisted analysis for feature extraction to examine the link between new Chinese poetry and classical Chinese poetry [19].
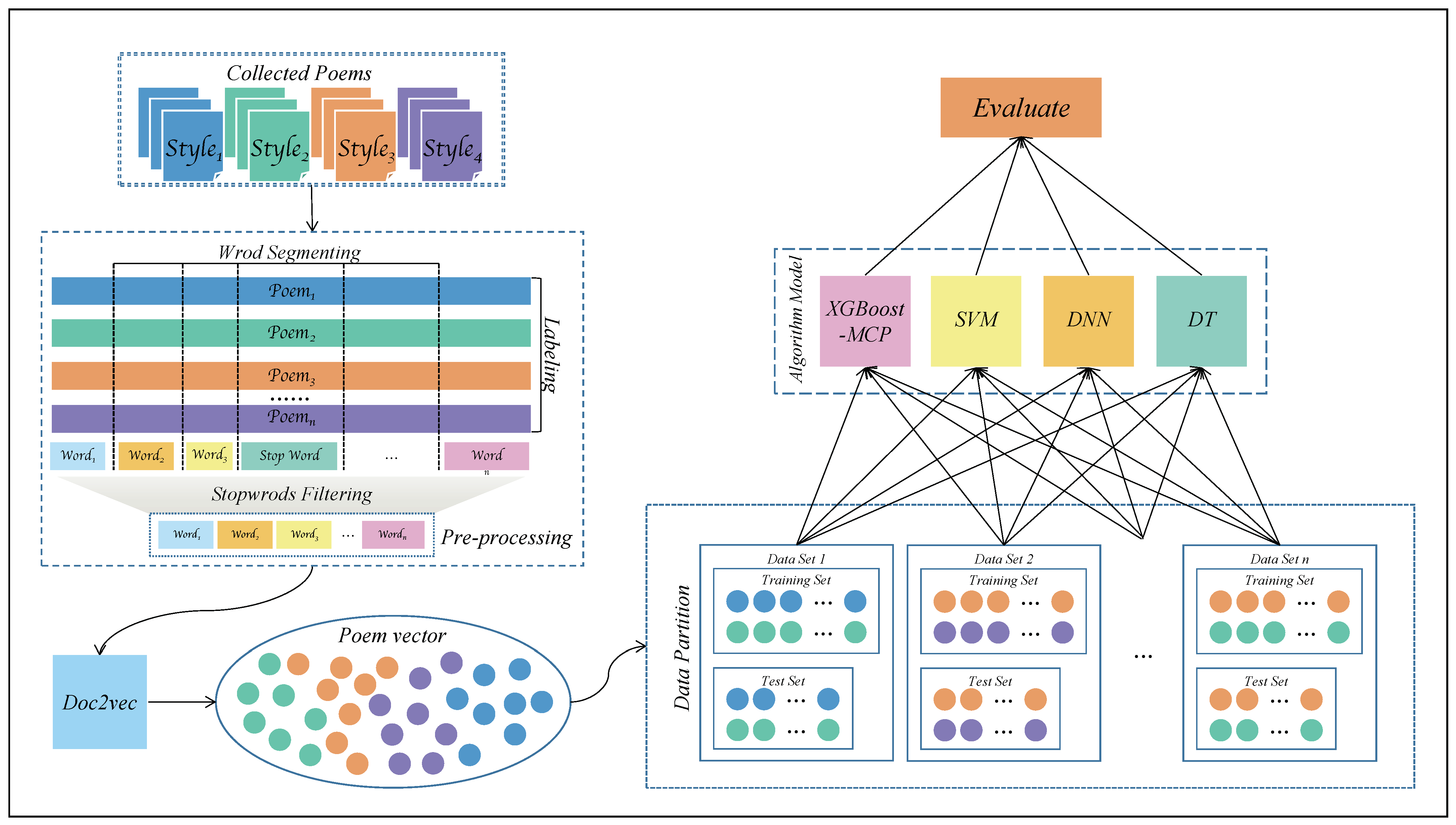
3. Modern Chinese Poetry Prediction Framework
3.1. Data Preprocessing
- Labeling: Based on the supervised learning approach, the style to which each poem belongs is manually labeled to facilitate the following classification.
- Word segmenting: Word segmenting is an important step in natural language processing. This is a process that regroups the sentences formed by character sequences into a set of words according to certain rules. Chinese word segmentation is much more complicated than English word segmentation. Jieba is a widely used Chinese word-splitting tool with a good word-splitting effect.
- Stopword filtering: The accuracy of stopword filtering directly affects the results of text analysis. Words without practical meaning, such as auxiliary words, interfere with the accuracy of the word-splitting results.
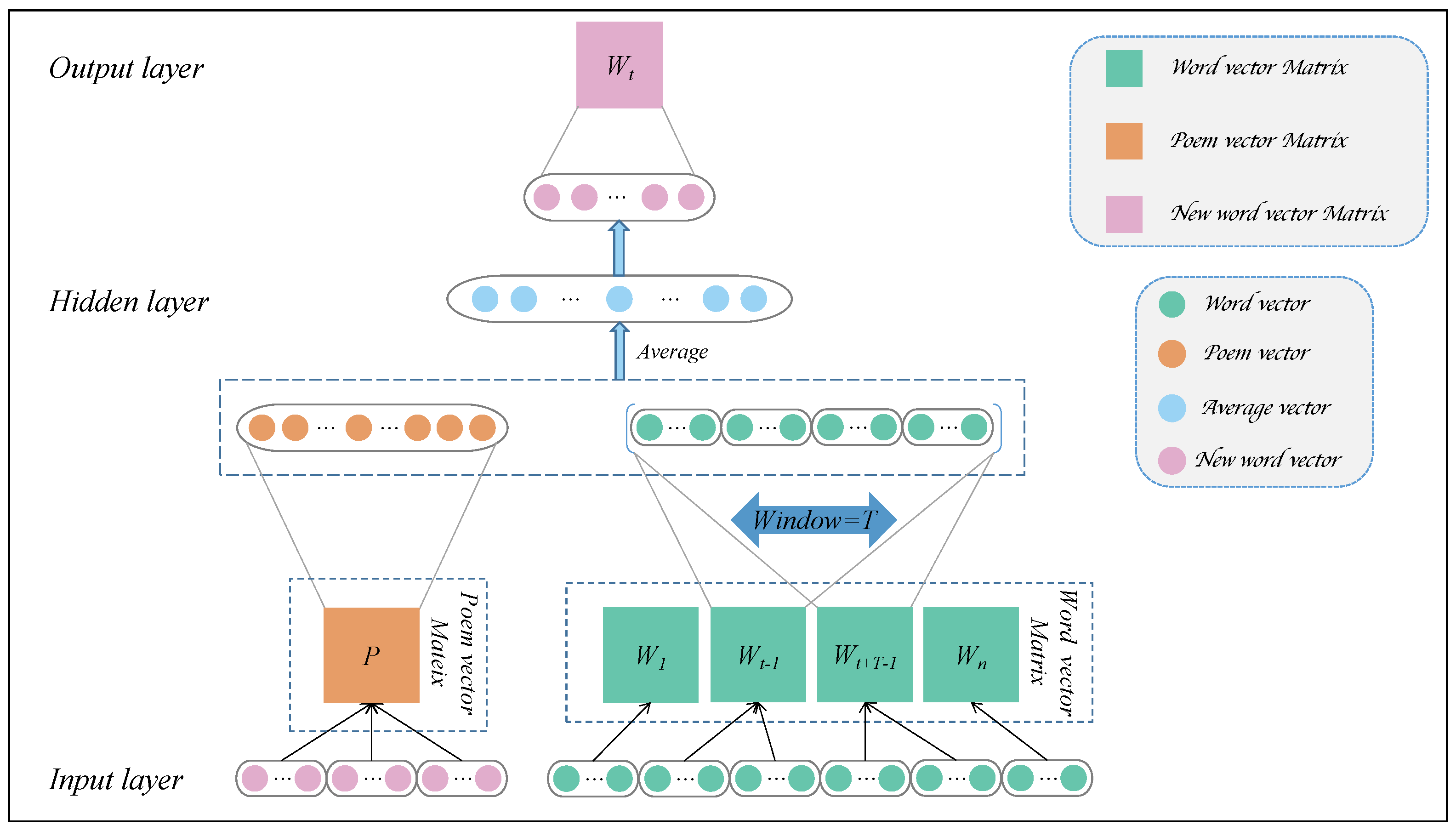
3.2. Feature Extraction
3.3. Introduction of the XGBoost-MCP Algorithm
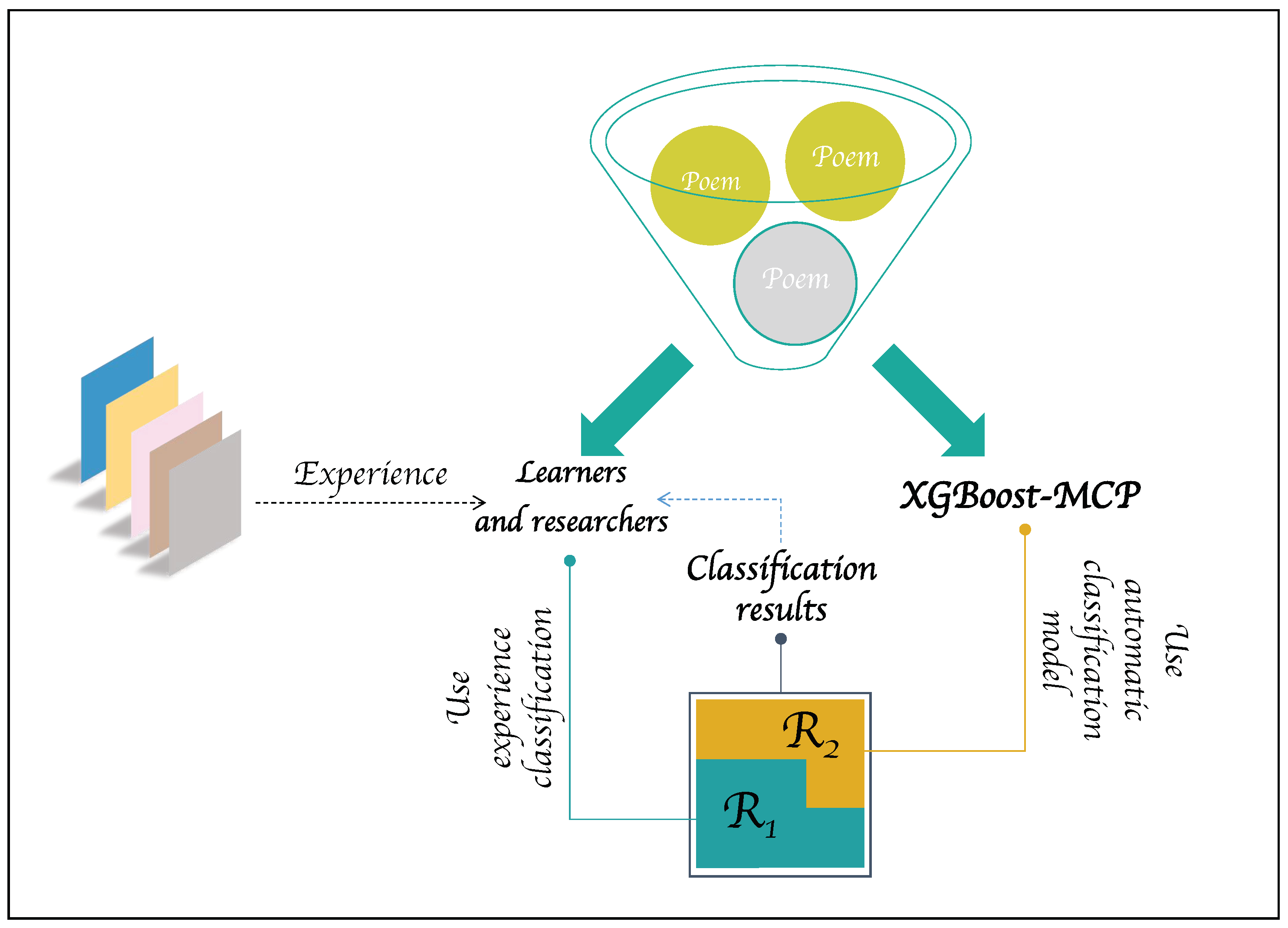
3.4. Application in Education
4. Experiment
4.1. Datasets
4.2. Evaluation Method
4.3. Parameter Setting of the Doc2Vec Model
4.4. Training and Testing Design
4.5. Parameter Setting of the Classifier
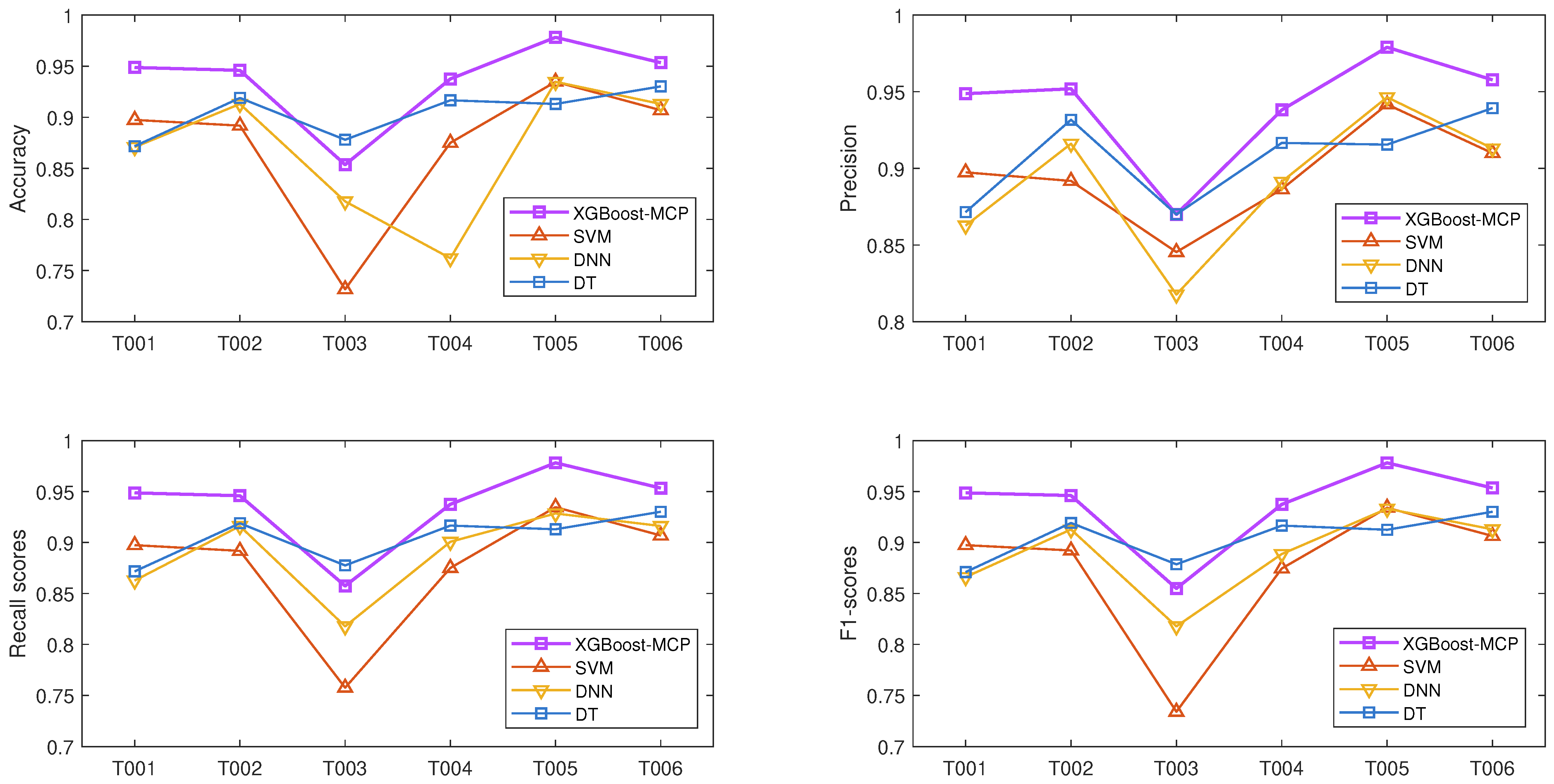
4.6. Analysis of the Results
5. Conclusions and Prospects
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Christou, D.; Tsoumakas, G. Extracting semantic relationships in Greek literary texts. Sustainability 2021, 13, 9391. [Google Scholar] [CrossRef]
- Zeng, Z.; Cai, Y.; Wang, F.L.; Xie, H.; Chen, J. Weighted N-grams CNN for Text Classification. In Proceedings of the Information Retrieval Technology: 15th Asia Information Retrieval Societies Conference, AIRS 2019, Hong Kong, China, 7–9 November 2019; Springer: Cham, Switzerland, 2020; pp. 158–169. [Google Scholar]
- Wang, T.; Cai, Y.; Leung, H.f.; Lau, R.Y.; Xie, H.; Li, Q. On entropy-based term weighting schemes for text categorization. Knowl. Inf. Syst. 2021, 63, 2313–2346. [Google Scholar] [CrossRef]
- Wang, J.; Xie, H.; Wang, F.L.; Lee, L.K. Improving text classification via a soft dynamical label strategy. Int. J. Mach. Learn. Cybern. 2023, 1–11. [Google Scholar] [CrossRef]
- Hayward, M. Analysis of a corpus of poetry by a connectionist model of poetic meter. Poetics 1996, 24, 1–11. [Google Scholar] [CrossRef]
- Kaplan, D.M.; Blei, D.M. A computational approach to style in American poetry. In Proceedings of the Seventh IEEE International Conference on Data Mining (ICDM 2007), Omaha, NE, USA, 28–31 October 2007; pp. 553–558. [Google Scholar]
- Kao, J.; Jurafsky, D. A computational analysis of style, affect, and imagery in contemporary poetry. In Proceedings of the NAACL-HLT 2012 Workshop on Computational Linguistics for Literature, Montréal, QC, Canada, 8 June 2012; pp. 8–17. [Google Scholar]
- Lou, A.; Inkpen, D.; Tanasescu, C. Multilabel subject-based classification of poetry. In Proceedings of the Twenty-Eighth International Flairs Conference, Hollywood, FL, USA, 18–20 May 2015. [Google Scholar]
- Hamidi, S.; Razzazi, F.; Ghaemmaghami, M.P. Automatic meter classification in Persian poetries using support vector machines. In Proceedings of the 2009 IEEE International Symposium on Signal Processing and Information Technology (ISSPIT), IEEE, Ajman, United Arab Emirates, 14–17 December 2009; pp. 563–567. [Google Scholar]
- Can, E.F.; Can, F.; Duygulu, P.; Kalpakli, M. Automatic categorization of ottoman literary texts by poet and time period. In Computer and Information Sciences II; Springer: London, UK, 2011; pp. 51–57. [Google Scholar]
- Jamal, N.; Mohd, M.; Noah, S.A. Poetry classification using support vector machines. J. Comput. Sci. 2012, 8, 1441. [Google Scholar]
- Barros, L.; Rodriguez, P.; Ortigosa, A. Automatic Classification of Literature Pieces by Emotion Detection: A Study on Quevedo’s Poetry. In Proceedings of the 2013 Humaine Association Conference on Affective Computing and Intelligent Interaction, IEEE, Geneva, Switzerland, 2–5 September 2013; pp. 141–146. [Google Scholar]
- Alsharif, O.; Alshamaa, D.; Ghneim, N. Emotion classification in Arabic poetry using machine learning. Int. J. Comput. Appl. 2013, 65, 16. [Google Scholar]
- Rakshit, G.; Ghosh, A.; Bhattacharyya, P.; Haffari, G. Automated analysis of bangla poetry for classification and poet identification. In Proceedings of the 12th International Conference on Natural Language Processing, Trivandrum, India, 11–14 December 2015; pp. 247–253. [Google Scholar]
- Kaur, J.; Saini, J.R. Punjabi poetry classification: The test of 10 machine learning algorithms. In Proceedings of the 9th International Conference on Machine Learning and Computing, Singapore, 24–26 February 2017; pp. 1–5. [Google Scholar]
- Li, L.Y.; He, Z.S.; Yi, Y. Poetry stylistic analysis technique based on term connections. In Proceedings of the 2004 International Conference on Machine Learning and Cybernetics (IEEE Cat. No. 04EX826), IEEE, Shanghai, China, 26–29 August 2004; Volume 5, pp. 2713–2718. [Google Scholar]
- Yong, Y.I.; Zhong-Shi, H.E.; Liang-Yan, L.I.; Zhou, J.Y. A Traditional Chinese Poetry Style Identification Calculation Improvement Model. Comput. Sci. 2005, 32, 156–158. [Google Scholar]
- Fang, A.C.; Lo, F.J.; Chinn, C.K. Adapting nlp and corpus analysis techniques to structured imagery analysis in classical chinese poetry. In Proceedings of the Workshop on Adaptation of Language Resources and Technology to New Domains, Borovets, Bulgaria, 17 September 2009; pp. 27–34. [Google Scholar]
- Voigt, R.; Jurafsky, D. Tradition and modernity in 20th century Chinese poetry. In Proceedings of the Workshop on Computational Linguistics for Literature, Atlanta, GA, USA, June 2013; pp. 17–22. [Google Scholar]
- Chen, X.; Xie, H.; Hwang, G.J. A multi-perspective study on artificial intelligence in education: Grants, conferences, journals, software tools, institutions, and researchers. Comput. Educ. Artif. Intell. 2020, 1, 100005. [Google Scholar] [CrossRef]
- Hwang, G.J.; Xie, H.; Wah, B.W.; Gašević, D. Vision, challenges, roles and research issues of Artificial Intelligence in Education. Comput. Educ. Artif. Intell. 2020, 1, 100001. [Google Scholar] [CrossRef]
- Hwang, G.J.; Tu, Y.F. Roles and research trends of artificial intelligence in mathematics education: A bibliometric mapping analysis and systematic review. Mathematics 2021, 9, 584. [Google Scholar] [CrossRef]
- Chang, I.C.; Yu, T.K.; Chang, Y.J.; Yu, T.Y. Applying text mining, clustering analysis, and latent dirichlet allocation techniques for topic classification of environmental education journals. Sustainability 2021, 13, 10856. [Google Scholar] [CrossRef]
- Renfen, H.; Yuchen, Z. Automatic classification of tang poetry themes. Acta Sci. Nat. Univ. Pekin. 2015, 2, 262–268. [Google Scholar]
- Ahmed, M.A.; Hasan, R.A.; Ali, A.H.; Mohammed, M.A. The classification of the modern arabic poetry using machine learning. TELKOMNIKA (Telecommun. Comput. Electron. Control) 2019, 17, 2667–2674. [Google Scholar] [CrossRef]
- Abdulfattah, O. Identifying themes in fiction: A centroid-based lexical clustering approach. J. Lang. Linguist. Stud. 2021, 17, 580–594. [Google Scholar]
- Promrit, N.; Waijanya, S. Convolutional neural networks for thai poem classification. In International Symposium on Neural Networks; Springer: Cham, Switzerland, 2017; pp. 449–456. [Google Scholar]
- Ahmad, S.; Asghar, M.Z.; Alotaibi, F.M.; Khan, S. Classification of Poetry Text Into the Emotional States Using Deep Learning Technique. IEEE Access 2020, 8, 73865–73878. [Google Scholar] [CrossRef]
- Li, X.; Pang, J.; Mo, B.; Rao, Y.; Wang, F.L. Deep neural network for short-text sentiment classification. In Database Systems for Advanced Applications, Proceedings of the DASFAA 2016 International Workshops: BDMS, BDQM, MoI, and SeCoP, Dallas, TX, USA, 16–19 April 2016; Springer: Cham, Switzerland, 2016; pp. 168–175. [Google Scholar]
- Rao, Y.; Xie, H.; Li, J.; Jin, F.; Wang, F.L.; Li, Q. Social emotion classification of short text via topic-level maximum entropy model. Inf. Manag. 2016, 53, 978–986. [Google Scholar] [CrossRef]
- Zheng, W.; Xu, Z.; Rao, Y.; Xie, H.; Wang, F.L.; Kwan, R. Sentiment classification of short text using sentimental context. In Proceedings of the 2017 International Conference on Behavioral, Economic, Socio-Cultural Computing (BESC), IEEE, Krakow, Poland, 16–18 October 2017; pp. 1–6. [Google Scholar]
- Liang, W.; Xie, H.; Rao, Y.; Lau, R.Y.; Wang, F.L. Universal affective model for readers’ emotion classification over short texts. Expert Syst. Appl. 2018, 114, 322–333. [Google Scholar] [CrossRef]
- Chen, X.; Rao, Y.; Xie, H.; Wang, F.L.; Zhao, Y.; Yin, J. Sentiment classification using negative and intensive sentiment supplement information. Data Sci. Eng. 2019, 4, 109–118. [Google Scholar] [CrossRef]
- Mosteller, F.; Wallace, D.L. Inference in an authorship problem: A comparative study of discrimination methods applied to the authorship of the disputed Federalist Papers. J. Am. Stat. Assoc. 1963, 58, 275–309. [Google Scholar]
- Holmes, D.I. Authorship attribution. Comput. Humanit. 1994, 28, 87–106. [Google Scholar] [CrossRef]
- Forsyth, R.S.; Holmes, D.I. Feature-finding for text classification. Lit. Linguist. Comput. 1996, 11, 163–174. [Google Scholar] [CrossRef]
- Argamon, S.; Whitelaw, C.; Chase, P.; Hota, S.R.; Garg, N.; Levitan, S. Stylistic text classification using functional lexical features. J. Am. Soc. Inf. Sci. Technol. 2007, 58, 802–822. [Google Scholar] [CrossRef]
- Koppel, M.; Argamon, S.; Shimoni, A.R. Automatically categorizing written texts by author gender. Lit. Linguist. Comput. 2002, 17, 401–412. [Google Scholar] [CrossRef]
- Argamon, S.; Koppel, M.; Fine, J.; Shimoni, A.R. Gender, genre, and writing style in formal written texts. Text Talk 2003, 23, 321–346. [Google Scholar] [CrossRef]
- Walkowiak, T.; Piasecki, M. Stylometry analysis of literary texts in Polish. In International Conference on Artificial Intelligence and Soft Computing; Springer: Cham, Switzerland, 2018; pp. 777–787. [Google Scholar]
- Burrows, J.F. Word-Patterns and Story-Shapes: The Statistical Analysis of Narrative Style. Lit Linguist. Comput. 1987, 2, 61–70. [Google Scholar] [CrossRef]
- Ledger, G.; Merriam, T. Shakespeare, Fletcher, and the Two Noble Kinsmen. Lit Linguist. Comput. 1994, 9, 235–248. [Google Scholar] [CrossRef]
- Craig, H. Authorial attribution and computational stylistics: If you can tell authors apart, have you learned anything about them? Lit. Linguist. Comput. 1999, 14, 103–113. [Google Scholar] [CrossRef]
- Diederich, J.; Kindermann, J.; Leopold, E.; Paass, G. Authorship Attribution with Support Vector Machines. Appl. Intell. 2003, 19, 109–123. [Google Scholar] [CrossRef]
- De Vel, O.; Anderson, A.; Corney, M.; Mohay, G. Mining e-mail content for author identification forensics. ACM Sigmod Rec. 2001, 30, 55–64. [Google Scholar] [CrossRef]
- Zheng, R.; Li, J.; Chen, H.; Huang, Z. A framework for authorship identification of online messages: Writing-style features and classification techniques. J. Am. Soc. Inf. Sci. Technol. 2006, 57, 378–393. [Google Scholar] [CrossRef]
- Yu, B. An evaluation of text classification methods for literary study. Lit. Linguist. Comput. 2008, 23, 327–343. [Google Scholar] [CrossRef]
- Mu, Y. Using keyword features to automatically classify genre of Song Ci poem. In Proceedings of the Workshop on Chinese Lexical Semantics, Leshan, China, 18–20 May 2015; Springer: Cham, Switzerland, 2015; pp. 478–485. [Google Scholar]
- Pal, K.; Patel, B.V. Automatic multiclass document classification of hindi poems using machine learning techniques. In Proceedings of the 2020 International Conference for Emerging Technology (INCET), IEEE, Belgaum, India, 5–7 June 2020; pp. 1–5. [Google Scholar]
- Kalcheva, N.; Karova, M.; Penev, I. Comparison of the accuracy and the execution time of classification algorithms for Bulgarian literary works. In Proceedings of the 2020 International Conference Automatics and Informatics (ICAI), IEEE, Varna, Bulgaria, 1–3 October 2020; pp. 1–5. [Google Scholar]
- Wei, S.; Hou, H.; Sun, H.; Li, W.; Song, W. The Classification System of Literary Works Based on K-Means Clustering. J. Interconnect. Netw. 2022, 22, 2141001. [Google Scholar] [CrossRef]
- Khattak, A.; Asghar, M.Z.; Khalid, H.A.; Ahmad, H. Emotion classification in poetry text using deep neural network. Multimed. Tools Appl. 2022, 81, 26223–26244. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Shwartz-Ziv, R.; Armon, A. Tabular data: Deep learning is not all you need. Inf. Fusion 2022, 81, 84–90. [Google Scholar] [CrossRef]
- Kowsari, K.; Jafari Meimandi, K.; Heidarysafa, M.; Mendu, S.; Barnes, L.; Brown, D. Text classification algorithms: A survey. Information 2019, 10, 150. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Explanation |
|---|---|
| f | A tree structure model |
| T | The number of nodes |
| The weight matrix of the T dimension | |
| m | The number of features |
| q | Mapping data x from the m dimension to a node |
| L | The loss function |
| C | Constant |
| The true value of the i-th data point | |
| The predicted value of the i-th data point of the current tree | |
| The predicted value of the i-th data point of the previous tree | |
| The output of the current tree model | |
| The regularization term | |
| The complexity cost introduced by adding new leaf nodes T | |
| The coefficient of the regular term | |
| The cumulative loss value of the prediction result of the previous tree | |
| The first order derivative of | |
| The second order derivative of | |
| j | Leaf node |
| The sample set allocated to j | |
| The sum of the first order derivatives in the set of samples of the current j | |
| The sum of the second order derivatives in the set of samples of the current j | |
| L | The left subtree node |
| R | The right subtree node |
| The value of the node before it is split | |
| The value of the left leaf node | |
| The value of the right leaf node |
| The Case Category | Training Sets | Test Sets |
|---|---|---|
| Crescent School | 201 | 22 |
| Symbolism School | 223 | 25 |
| Modernism School | 183 | 20 |
| Nine Leaves School | 146 | 16 |
| Datasets | The Case Category | Size |
|---|---|---|
| T001 | Nine Leaves School and Crescent School | 385 |
| T002 | Nine Leaves School and Symbolism School | 410 |
| T003 | Modernism School and Nine Leaves School | 365 |
| T004 | Modernism School and Crescent School | 426 |
| T005 | Modernism School and Symbolism School | 451 |
| T006 | Crescent School and Symbolism School | 471 |
| Data Sets | T001 | T002 | T003 | T004 | T005 | T006 | Average | |
|---|---|---|---|---|---|---|---|---|
| Model | ||||||||
| XGBoost-MCP | 0.9487 | 0.9459 | 0.8536 | 0.9375 | 0.9782 | 0.9534 | 0.9362 | |
| SVM | 0.8974 | 0.8918 | 0.7317 | 0.8750 | 0.9347 | 0.9069 | 0.8729 | |
| DNN | 0.8708 | 0.9130 | 0.8177 | 0.7621 | 0.9347 | 0.9130 | 0.8685 | |
| DT | 0.8717 | 0.9189 | 0.8780 | 0.9166 | 0.9130 | 0.9302 | 0.9047 | |
| Data Sets | T001 | T002 | T003 | T004 | T005 | T006 | Average | |
|---|---|---|---|---|---|---|---|---|
| Model | ||||||||
| XGBoost-MCP | 0.9487 | 0.9519 | 0.8700 | 0.9381 | 0.9790 | 0.9577 | 0.9409 | |
| SVM | 0.8974 | 0.8918 | 0.8454 | 0.8864 | 0.9417 | 0.9099 | 0.8954 | |
| DNN | 0.8627 | 0.9161 | 0.8177 | 0.8913 | 0.9464 | 0.9130 | 0.8912 | |
| DT | 0.8715 | 0.9317 | 0.8700 | 0.9166 | 0.9155 | 0.9393 | 0.9074 | |
| Data Sets | T001 | T002 | T003 | T004 | T005 | T006 | Average | |
|---|---|---|---|---|---|---|---|---|
| Model | ||||||||
| XGBoost-MCP | 0.9487 | 0.9459 | 0.8574 | 0.9375 | 0.9782 | 0.9534 | 0.9369 | |
| SVM | 0.8974 | 0.8918 | 0.7575 | 0.8750 | 0.9347 | 0.9069 | 0.8772 | |
| DNN | 0.8627 | 0.9161 | 0.8177 | 0.9007 | 0.9285 | 0.9162 | 0.8903 | |
| DT | 0.8717 | 0.9189 | 0.8775 | 0.9166 | 0.9130 | 0.9302 | 0.9046 | |
| Data Sets | T001 | T002 | T003 | T004 | T005 | T006 | Average | |
|---|---|---|---|---|---|---|---|---|
| Model | ||||||||
| XGBoost-MCP | 0.9487 | 0.9461 | 0.8549 | 0.9374 | 0.9782 | 0.9535 | 0.9365 | |
| SVM | 0.8974 | 0.8922 | 0.7339 | 0.8745 | 0.9341 | 0.9064 | 0.8731 | |
| DNN | 0.8661 | 0.9128 | 0.8177 | 0.8887 | 0.9332 | 0.9129 | 0.8886 | |
| DT | 0.8710 | 0.9192 | 0.8786 | 0.9166 | 0.9125 | 0.9302 | 0.9047 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, M.; Wang, G.; Li, C.; Wang, H.; Zhang, B. Artificial Intelligence Classification Model for Modern Chinese Poetry in Education. Sustainability 2023, 15, 5265. https://doi.org/10.3390/su15065265
Zhu M, Wang G, Li C, Wang H, Zhang B. Artificial Intelligence Classification Model for Modern Chinese Poetry in Education. Sustainability. 2023; 15(6):5265. https://doi.org/10.3390/su15065265
Chicago/Turabian StyleZhu, Mini, Gang Wang, Chaoping Li, Hongjun Wang, and Bin Zhang. 2023. "Artificial Intelligence Classification Model for Modern Chinese Poetry in Education" Sustainability 15, no. 6: 5265. https://doi.org/10.3390/su15065265
APA StyleZhu, M., Wang, G., Li, C., Wang, H., & Zhang, B. (2023). Artificial Intelligence Classification Model for Modern Chinese Poetry in Education. Sustainability, 15(6), 5265. https://doi.org/10.3390/su15065265