4.1. B Impact Assessment Global Scores
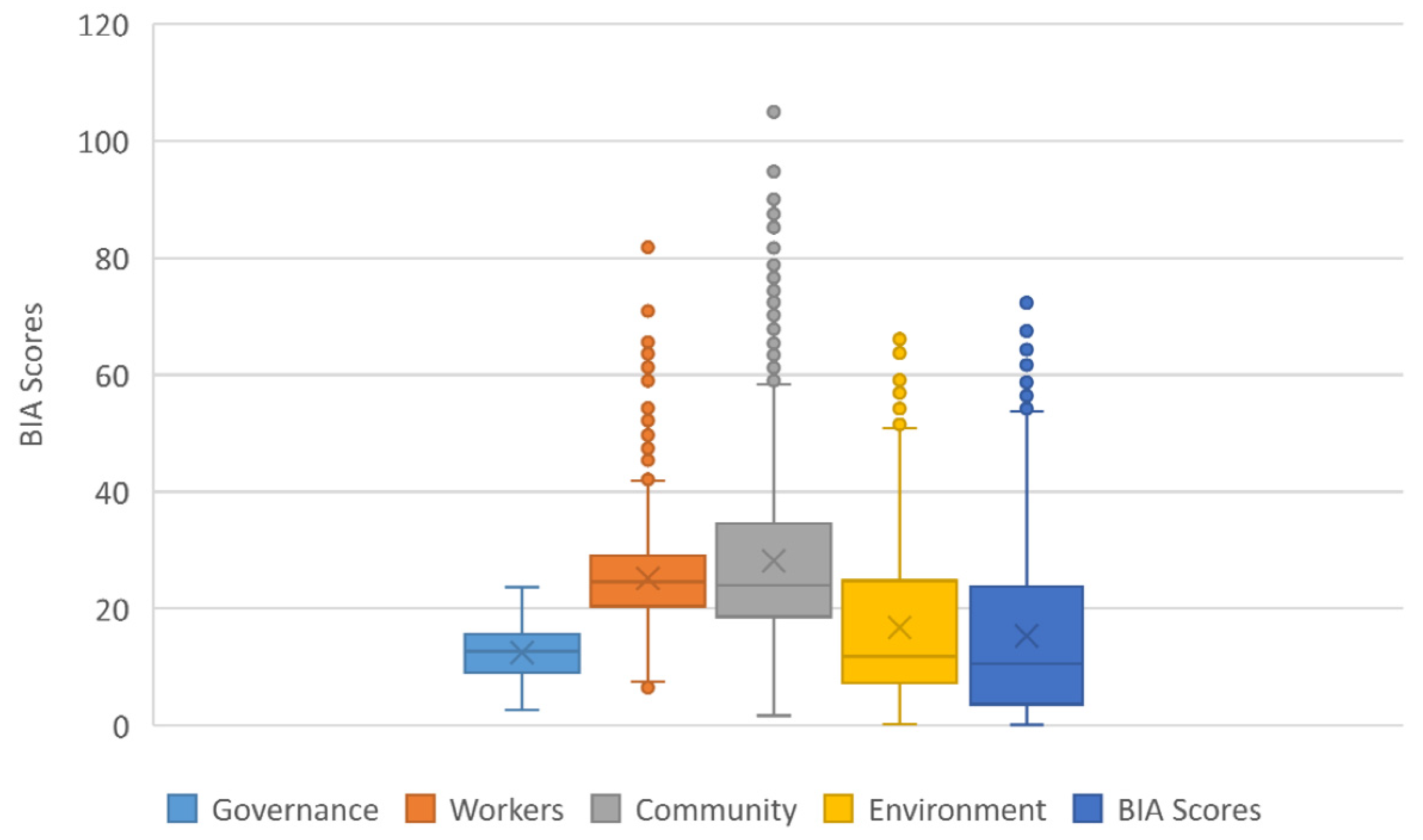
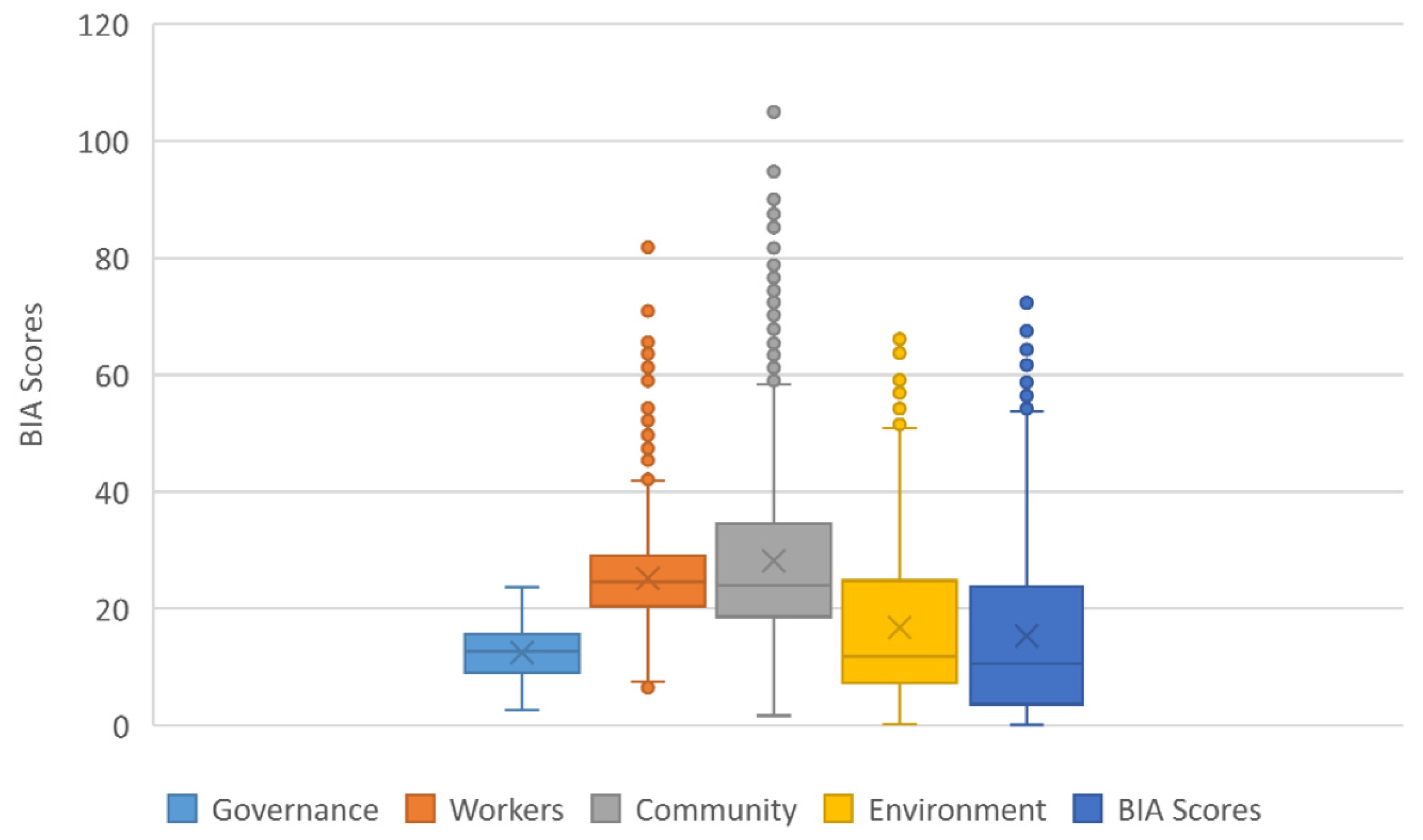
The BIA indicators have different dispersions that result from the indicators’ use of different scales (see
Figure 2). For example, the workers indicator presents the highest median value and the community indicator the highest score. In general, all the BIA indicators present a significant dispersion of the data, except for the governance indicator, which exhibits a higher concentration of the data.
Community is the evaluation B indicator with the highest number of discrepant values, followed by employees, customers, and the environment. Although there is a minimum final value for companies to obtain certification, it appears from the data analyzed that B Corp does not define an evaluation scale for its auditing process.
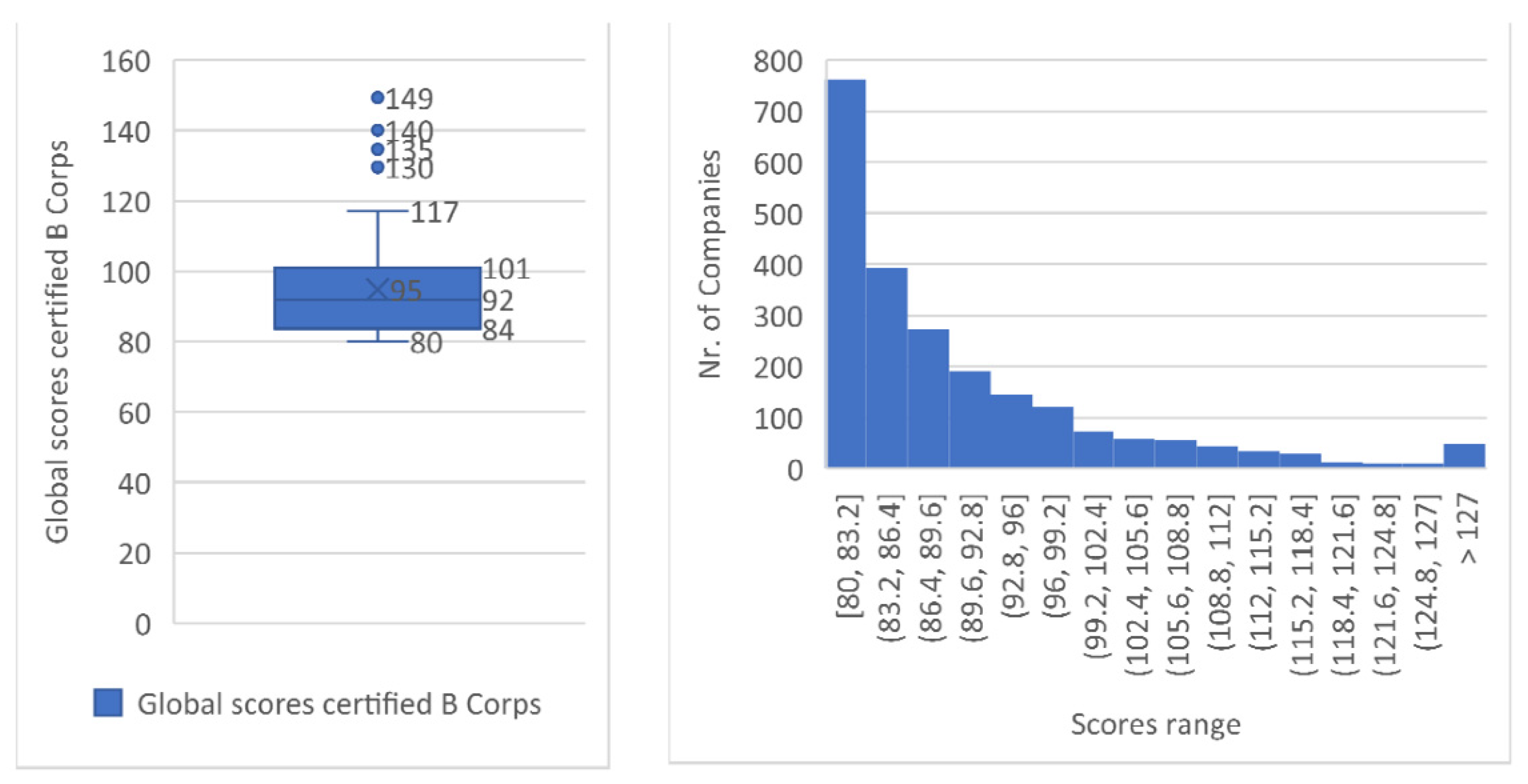
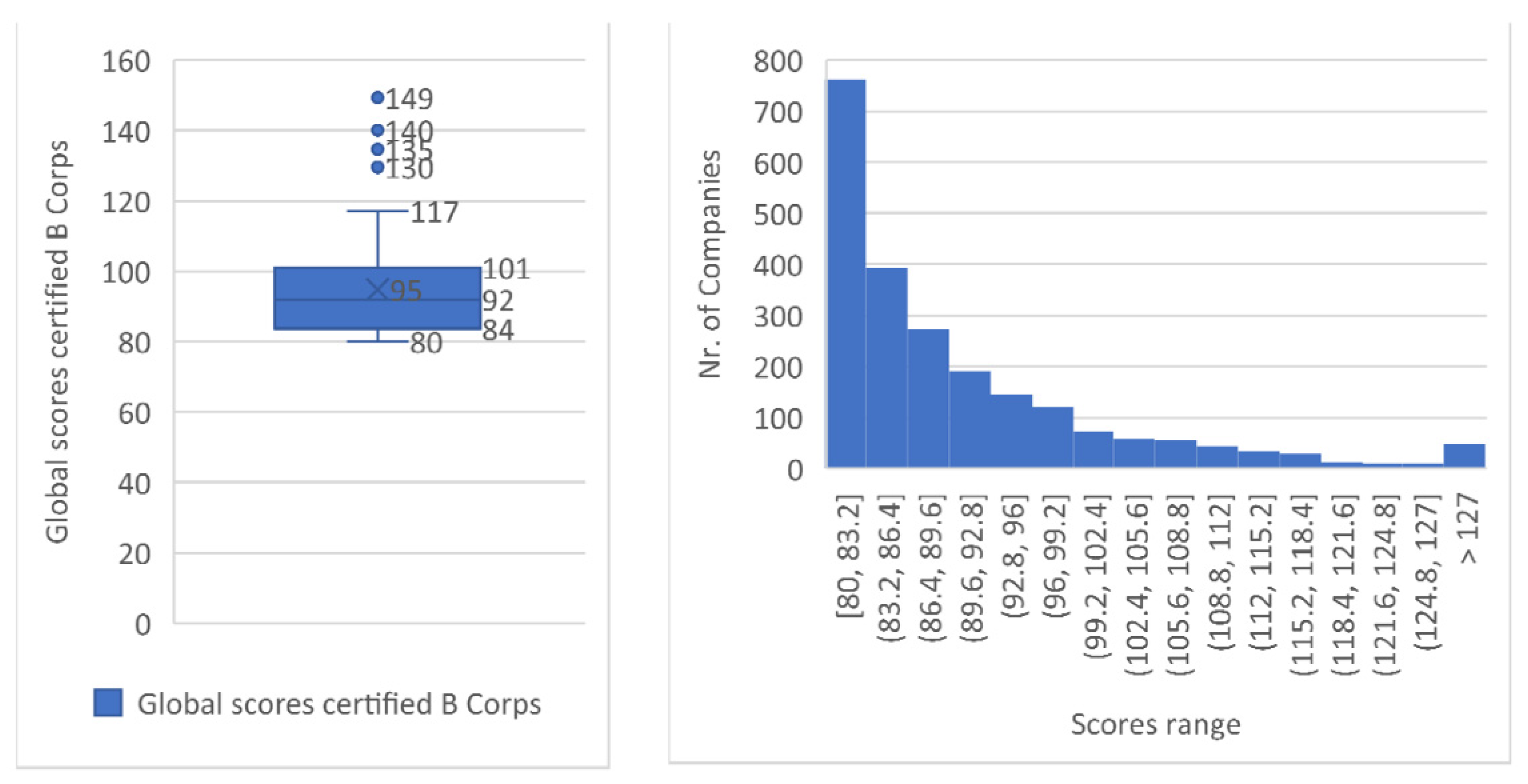
The data analyzed also allows us to generally verify the distribution of the final scores of the certified B companies (see
Figure 3).
As represented in the BIA final score chart above, all companies in our sample meet the minimum requirement of 80 points for B Corp certification, and most companies achieve a score between (80–83).
The countries with the highest number of certifications during our sample period are the United States with 681 companies, followed by the United Kingdom with 303 certified companies. Australia and Canada had 171 certifications during the same period. In Europe, besides the United Kingdom as mentioned above, France and Italy stand out with 87 certifications each. Portugal had 10 certifications during the period under observation.
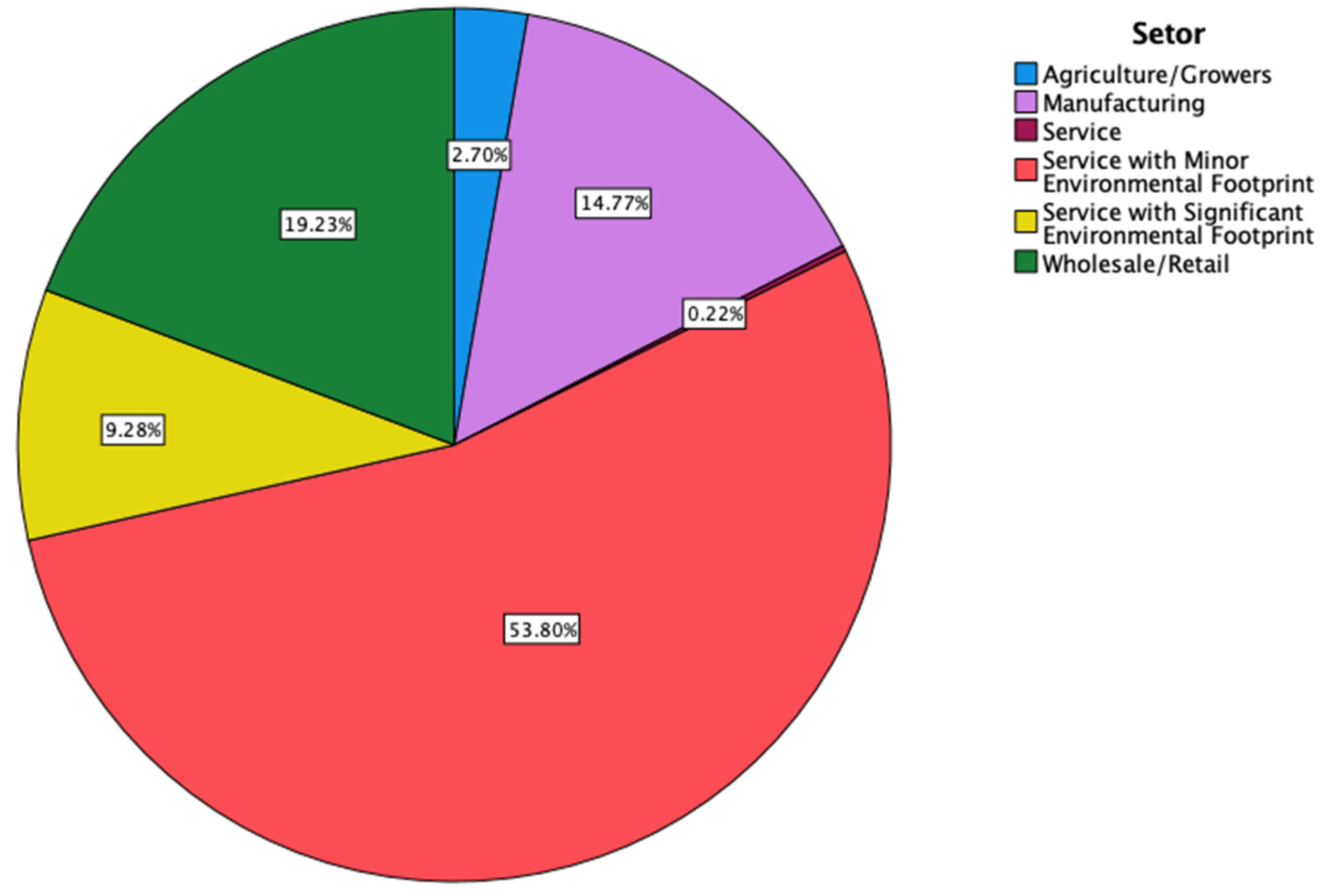
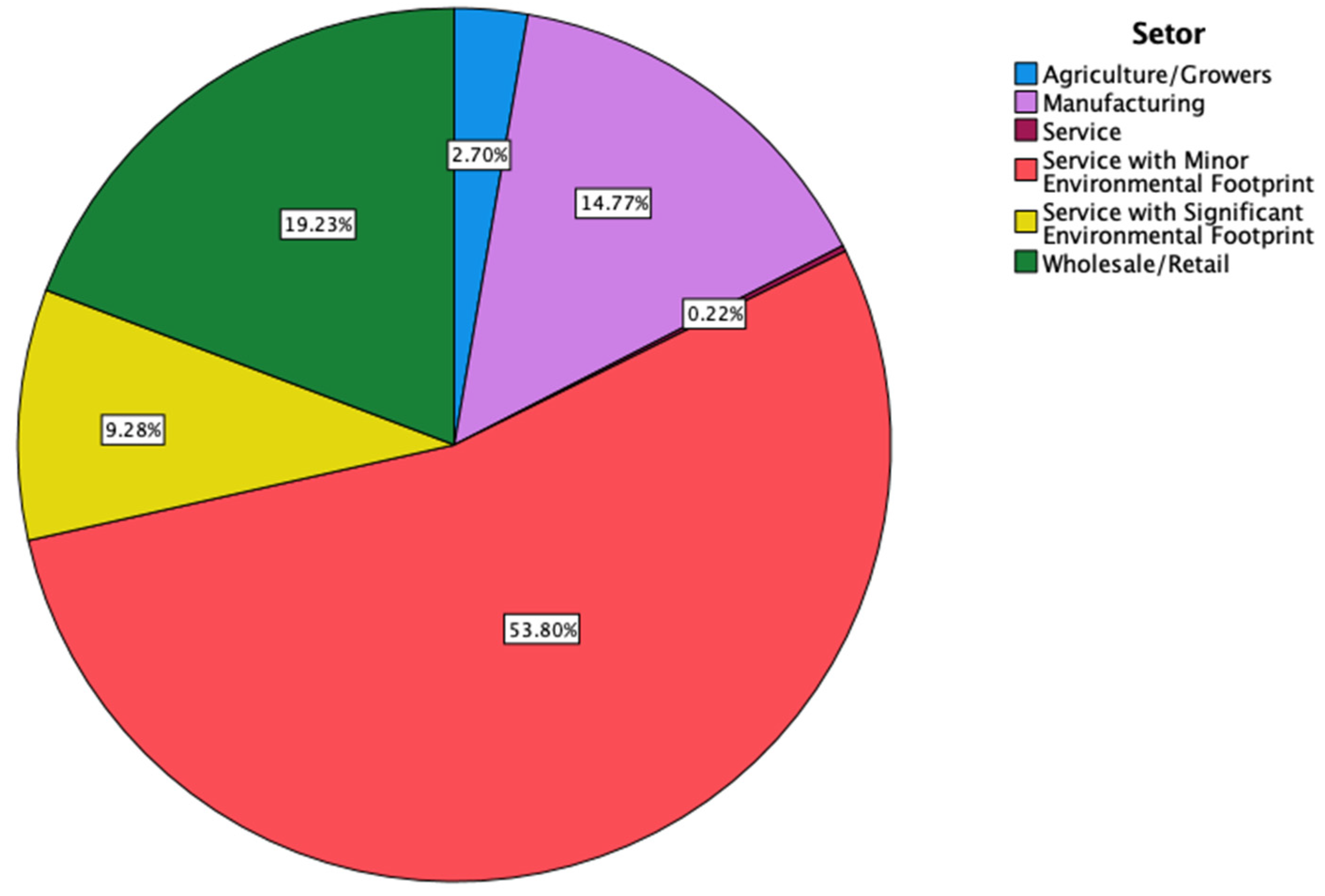
In terms of the activity sector, organizations in the services sector with a minor ecological footprint predominate. The sectoral distribution of the B Corporation can be seen in
Figure 4.
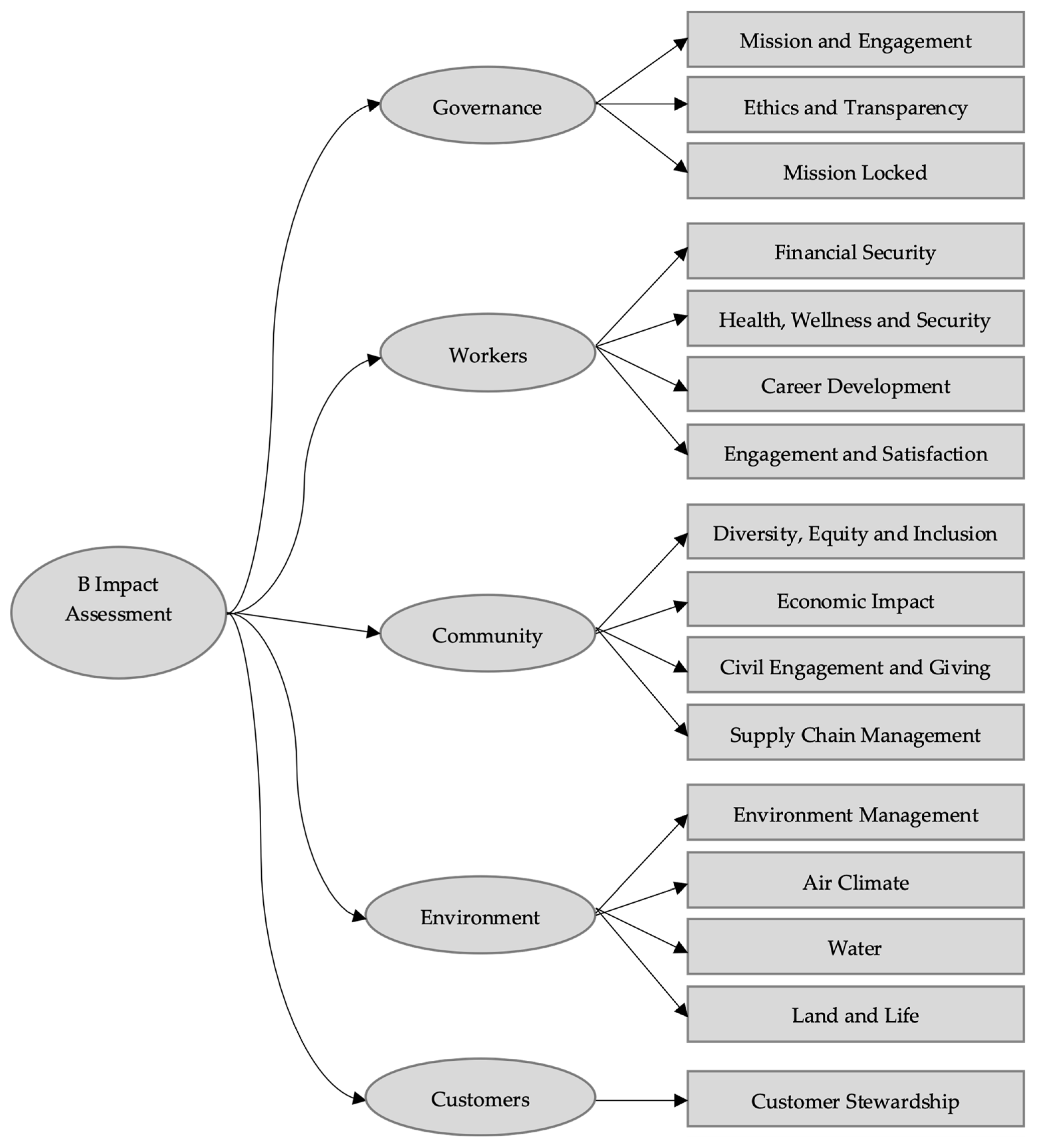
4.2. B Impact Assessment—Measurement Model Validation
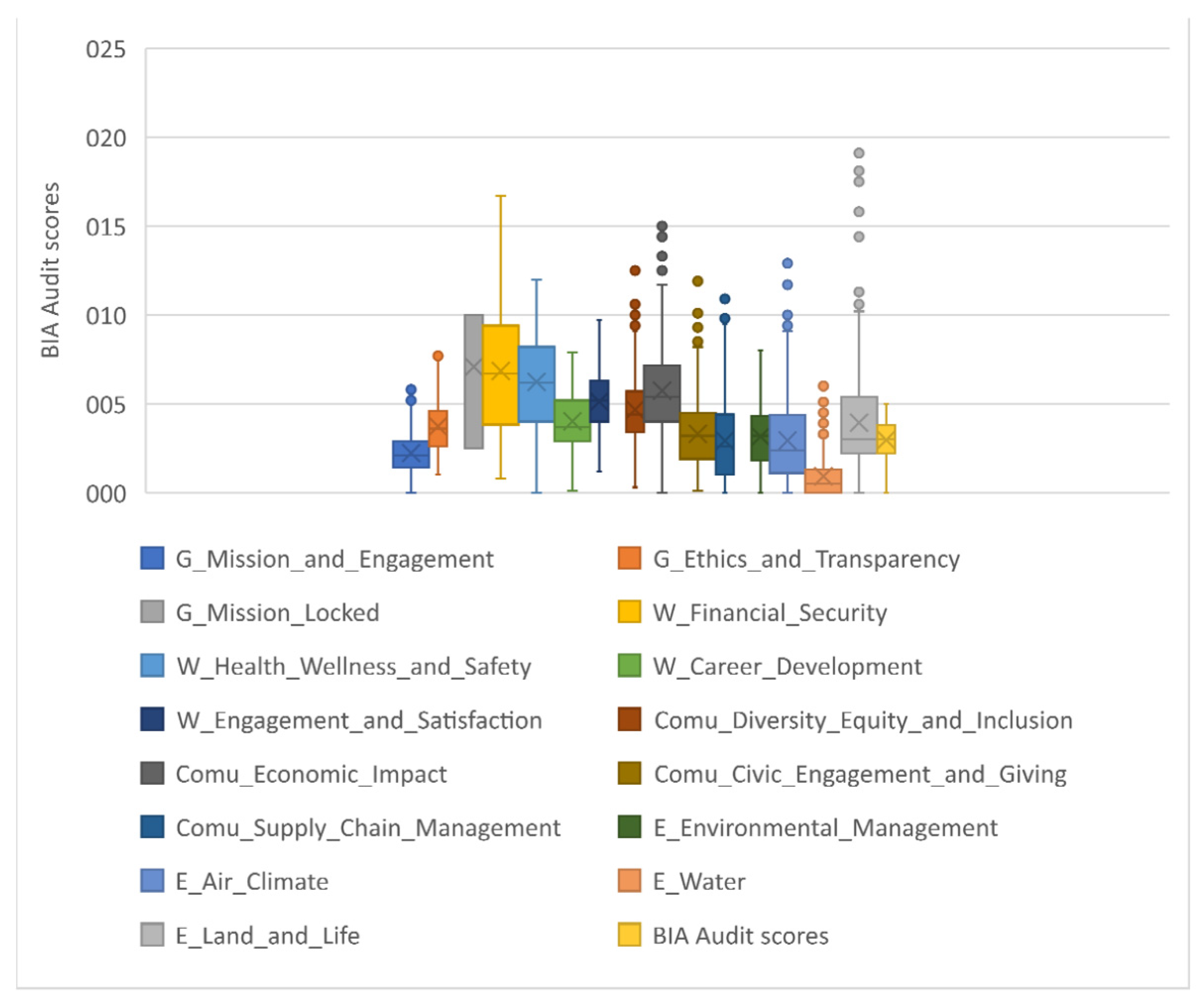
As mentioned above, for reasons of data consistency and elimination of missing values, we reduced the initial sample to 556 cases, corresponding to companies certified in the period from January 2020 to March 2021. In
Figure 5, we analyze the dispersion and median values of the observed variables present in this reduced sample.
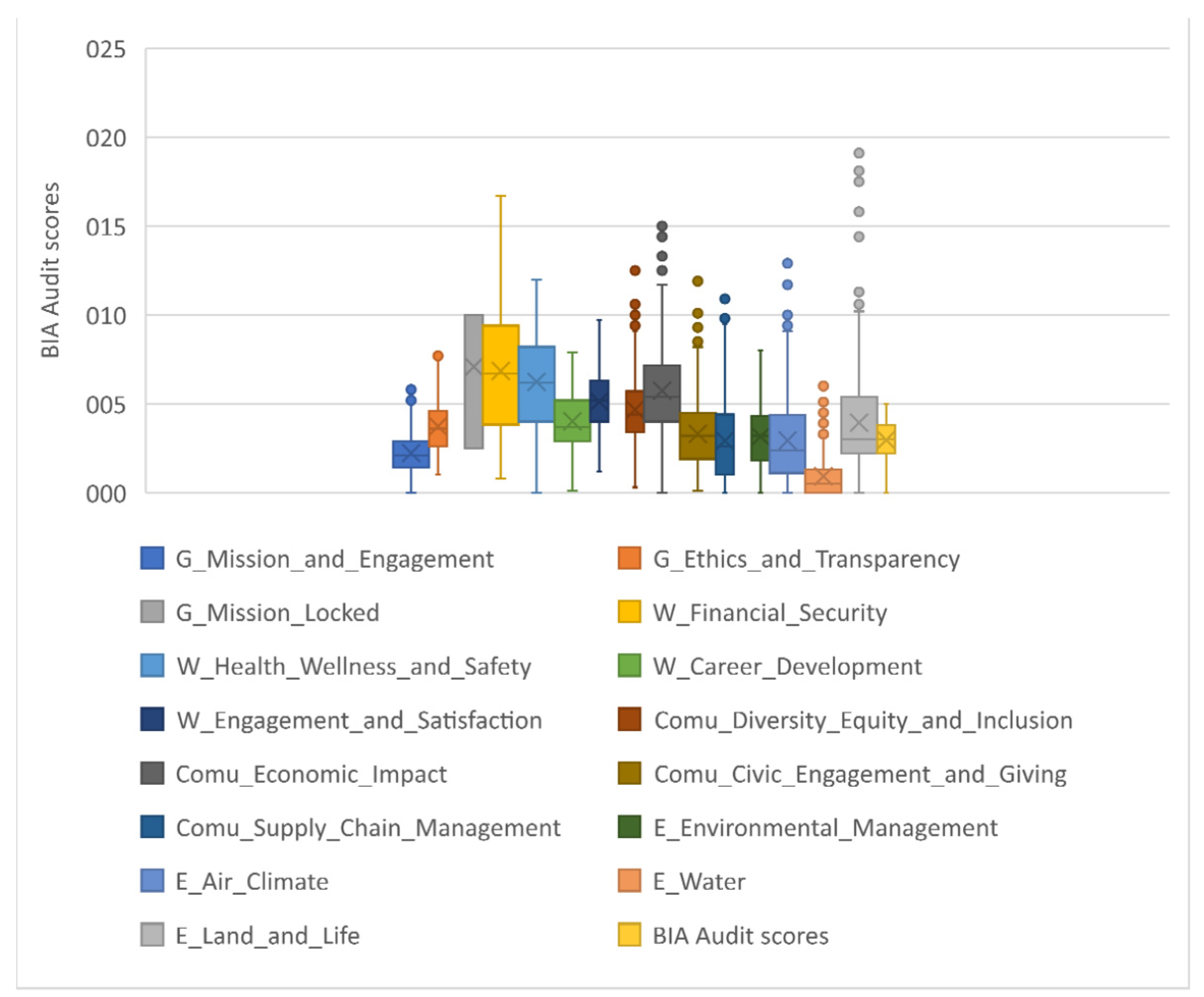
The variable with the highest data dispersion is “Land and Life” from the environment indicator. The graph below shows that the audit B variables with a greater range of values are from community and environment indicators. The analysis of the “Mission locked” variable leads us to assume that a fixed rating scale with constant values is used to evaluate this item.
Since
Figure 5 shows a high dispersion of the data, an analysis of extreme values was performed. Extreme values are “observations with a unique combination of characteristics identifiable as distinctly different from other observations” [
43] (p. 64). Usually, an extreme value is an observation that presents an unusually high or low value.
To determine extreme values, we use univariate and multivariate detection methods:
(i) In terms of univariate analysis, we consider as an extreme value any observation with a value higher than Q3 + 1.5 × (Q3 − Q1) or lower than Q1 − 1.5 × (Q3 − Q1), where Q3 and Q1 represent quartiles 3 and 1, respectively [
44]. When this proportion exceeds 5%, the impact on descriptive statistics is analyzed.
(ii) Concerning multivariate analysis, we used the Mahalanobis distance (D
2), which performs a multivariate assessment of each observation across a set of variables [
43,
44]. For large samples, an observation with a value greater than three when dividing the Mahalanobis distance (D
2) by the degrees of freedom (df) is considered a possible multidimensional extreme value [
43].
Table 3 presents univariate extreme values analysis.
The variable water presents a percentage of extreme values higher than 5%. After analyzing the descriptive measures with and without extreme values (see
Table 4), the 34 observations were removed, since the differences are significant.
Subsequently, the Mahalanobis distance (D
2) was calculated considering 15 degrees of freedom (16 observed variables minus 1). As can be seen in
Table 5, there are two multivariate extreme values in the database.
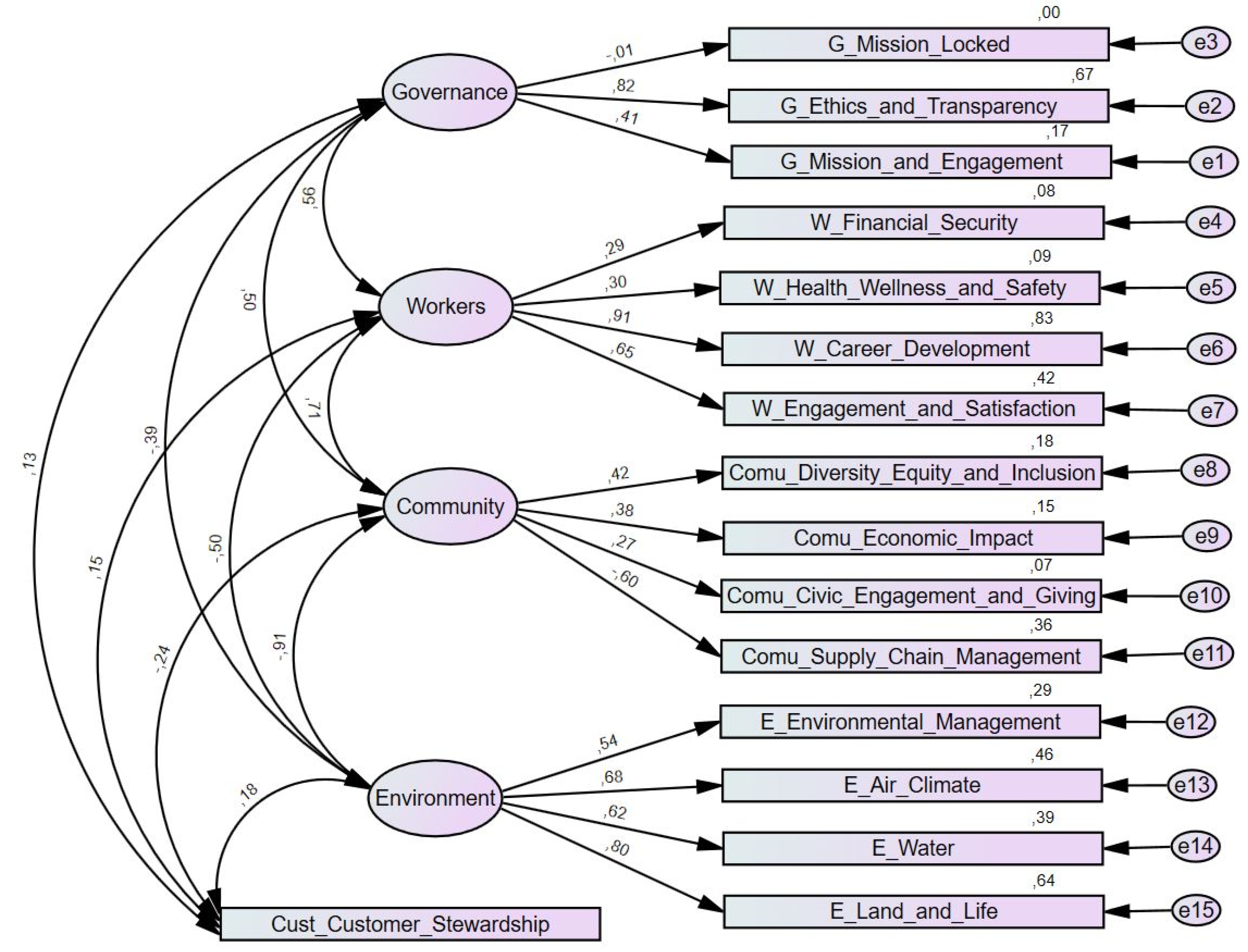
For the validation of the measurement model, composed of four latent variables (governance, workers, community, and environment) and one observed variable (customer stewardship), a database of 520 companies was considered.
The five variables of the measurement model are intercorrelated. The four latent variables are measured through fifteen observed variables, and errors of measurement associated with each observed variable (e1–e15) are uncorrelated. Since latent variables are unobserved, their metric scale must be guaranteed by observed variables by setting at least one path coefficient of an observed variable or by setting the variance of the latent variable [
43]. We have chosen to standardize the latent variables, setting their variance at 1.
There are several methods for adjusting measurement models. In this research, the maximum likelihood method was chosen. This method provides centered and consistent estimates and is assumed to be robust when the violation of the multivariate normality assumption of the manifest variables occurs [
43].
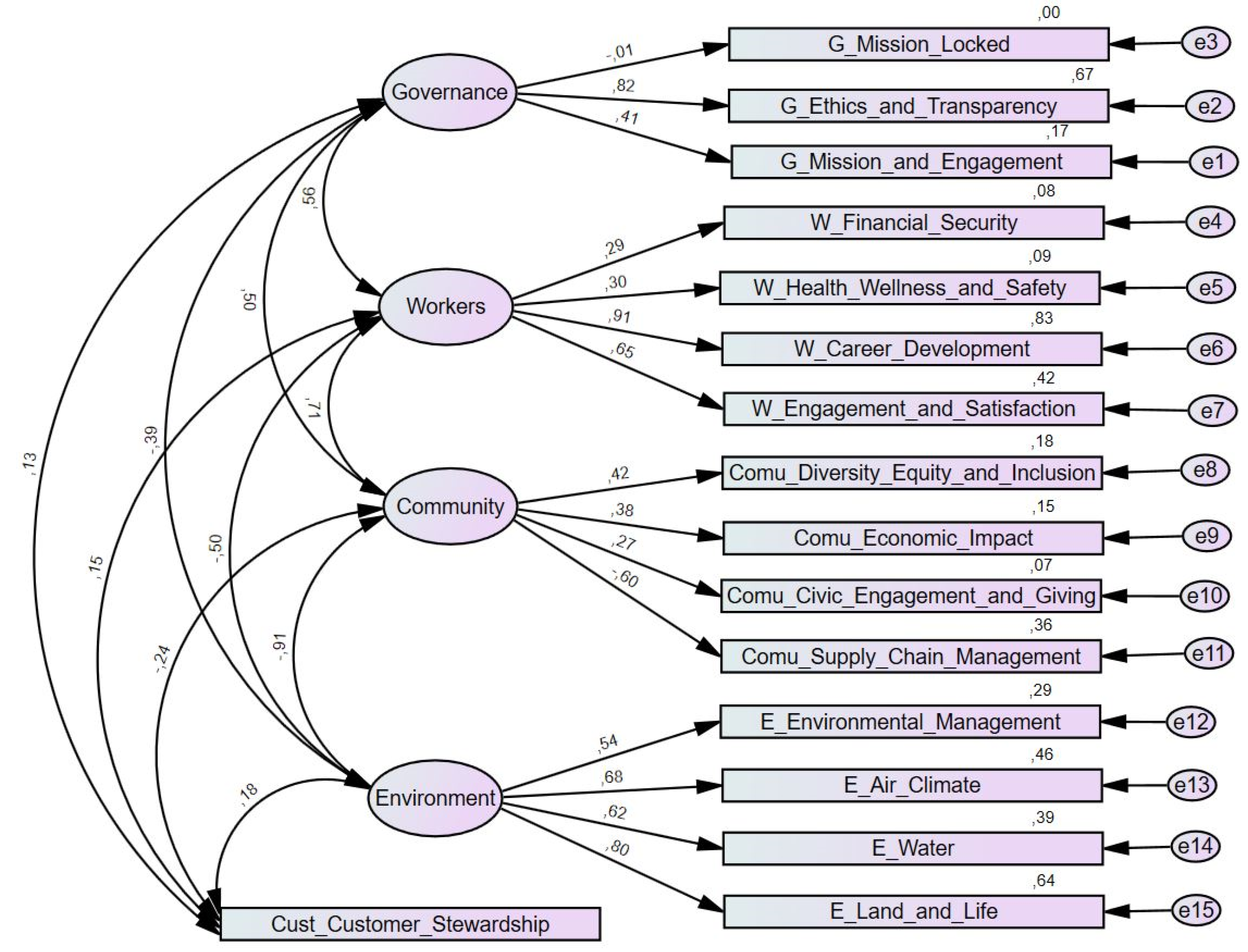
Figure 6 presents the measurement model adjusted to a sample of 520 firms, including the values of the standardized factor weights and the individual reliability of each of the observed variables.
A summary table of regression weights with standardized coefficients and statistic tests for each of the observed variables of the B Impact Assessment is presented in
Table 6.
Of all the variables observed, those that do not seem to contribute positively to the model due to the standardized factor weights are “mission locked” from the governance indicator and “supply chain management” from the community indicator. The negative standard coefficient shown in the model (see
Figure 6 and
Table 6) suggests that as the observed variable increases, the latent variable tends to decrease. All standardized estimates calculated are below 1.0. The governance indicator is reflected essentially in the observed variable “ethics and transparency,” the workers indicator in the variable “career development,” the community indicator in the variable “diversity equity and inclusion” and, finally, the environment indicator in the variable “land and life.”
We then proceeded to evaluate the measurement model as a whole, using the adjustment indices (see
Table 7). This analysis determines the goodness-of-fit between the hypothesized model and the sample data. The chi-square statistic with the respective degrees of freedom and the CFI and RMSEA indices are the most reported in the literature [
46]. Additionally, the TLI index also stands out among other indices, with some incidence.
The CMIN/DF (chi-square/degree of freedom) is an absolute index that evaluates the quality of the model per se, without comparison with other models [
44]. The CFI and TLI are relative indices of fit, since they assess the quality of the model relative to the model with the worst possible fit (independence model, in which there are no relationships between the observed variables) and/or the model with the best possible fit (saturated model, in which all the observed variables are correlated) [
44]. Finally, RMSEA is a population discrepancy index that compares the model fit obtained with sample measures (sample means and variances) to the model fit that would be obtained with population measures (population means and variances) [
44].
Table 7 presents the values obtained in the adjustment indices and the reference values referred to in the literature to consider a model with a good fit. In addition, the analyzed data allow us to verify that the BIA measurement model is outside the adjustment parameters, revealing an inferior quality of adjustment to the sample.
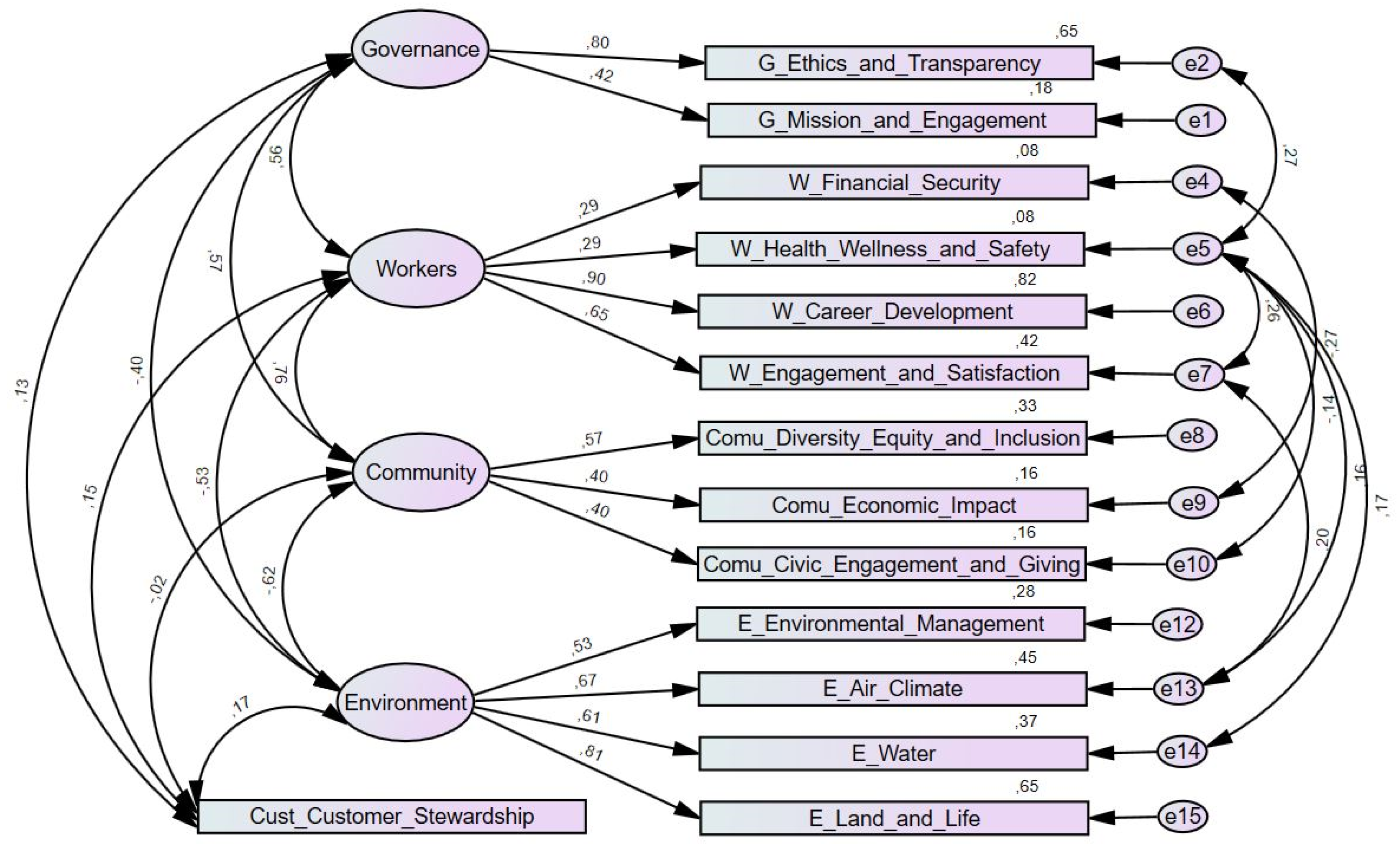
The variables “mission locked” from the governance indicator and “supply chain management” from the community indicator were eliminated to improve the model fit. Additionally, the modification indices were used, considering that values greater than 11 (
p < 0.001) indicate local adjustment problems (see
Table 8).
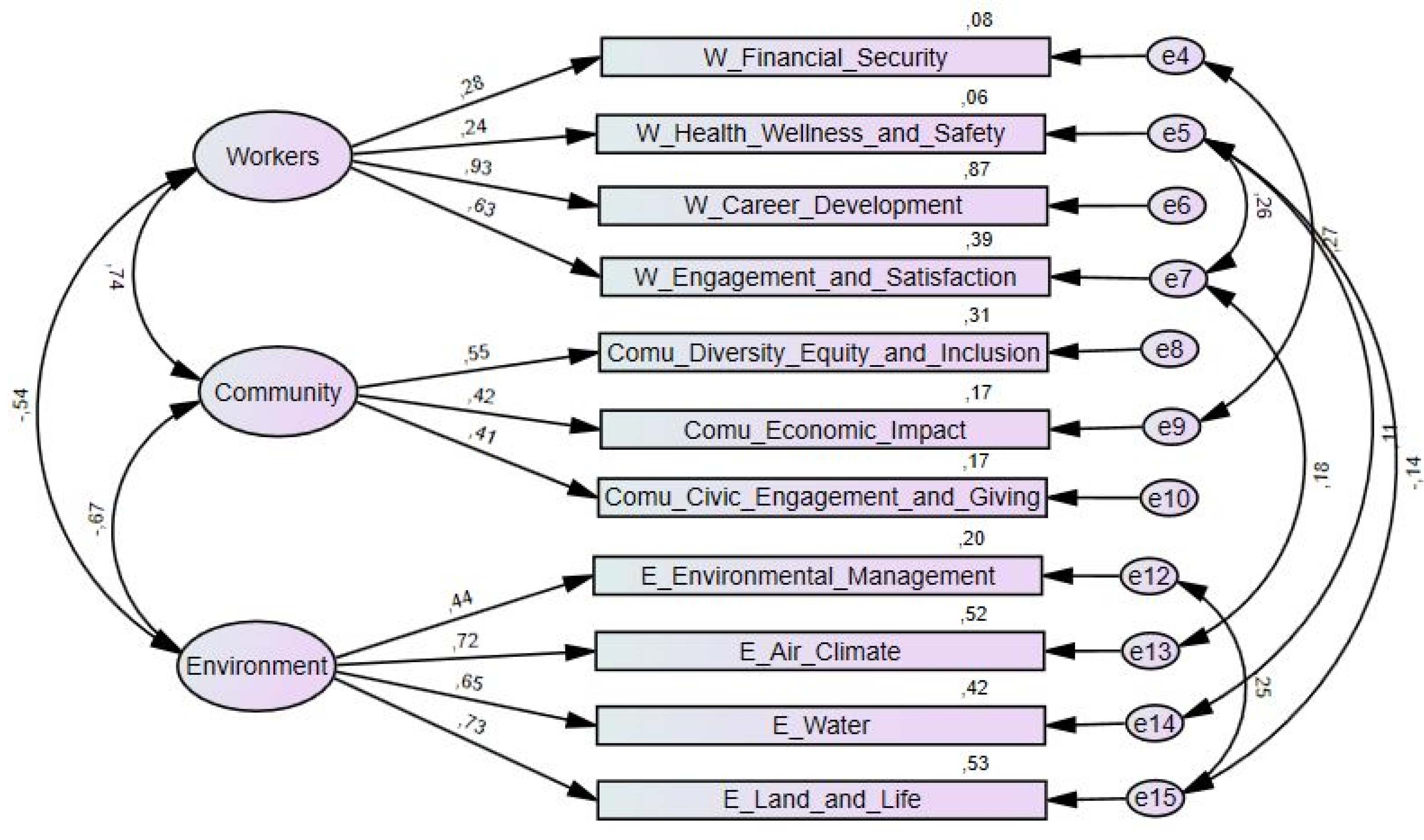
After assessing the theoretical plausibility of the modifications, the measurement errors were correlated, which led to a considerable improvement in the adjustment of the measurement model (see
Figure 7 and
Table 9).
These modifications improved the adjustment of the BIA model, especially regarding the CFI and RMSEA indices. The remaining indices (CMIN/DF and TLI) reveal a sufferable fit of the model to data (see
Table 9).
As explained in the method section, one of the fundamental assumptions of confirmatory factor analysis is data normality [
43]. When the normality assumption is verified, the maximum likelihood method exhibits properties of consistency, asymptotic efficiency, and asymptotic null bias [
44]. The univariate and multivariate normality analysis is shown in
Table 10.
According to [
44], the normality assessment should be made through the analysis of the asymmetry (Sk), kurtosis (Ku), and multivariate kurtosis (KuMult) values. In confirmatory factorial analysis, we can assume that there is a severe violation of normality whenever |Sk| > 2–3, |Ku| > 7–10 and |KuMult| > 10 [
44,
47]. Only in an extreme scenario of violation of normality are the quality of the adjustment indices and parameter estimates questionable [
44].
In this context, the variables fulfil the assumption of univariate and multivariate normality (skew values less than or equal to 1.3; kurtosis values less than or equal to 1 and multivariate kurtosis equal to 3.088).
Another aspect to consider in confirmatory factor analysis is the construct’s reliability. Reliability is a measure of internal consistency, i.e., it measures the degree to which the different observed variables analyze the same aspect. Cronbach’s alpha was used to determine the reliability of the latent variables, since it is one of the most commonly used measures to check the internal consistency of a set of items (see
Table 11).
Cronbach’s alpha ranges between 0 and 1, and it is acceptable to aggregate items with a value greater than 0.6 [
49]. However, as we can see, the latent variables present reliability problems since the values obtained for Cronbach’s alpha are lower than 0.6, except for the “environment” variable, which presents a higher value (0.723). These reliability problems of the latent variables lead us to conclude that the B Impact Assessment model, as a measurement tool used by B Labs to assess companies’ social and environmental impact, may not always give the same results when applied to structurally similar companies.
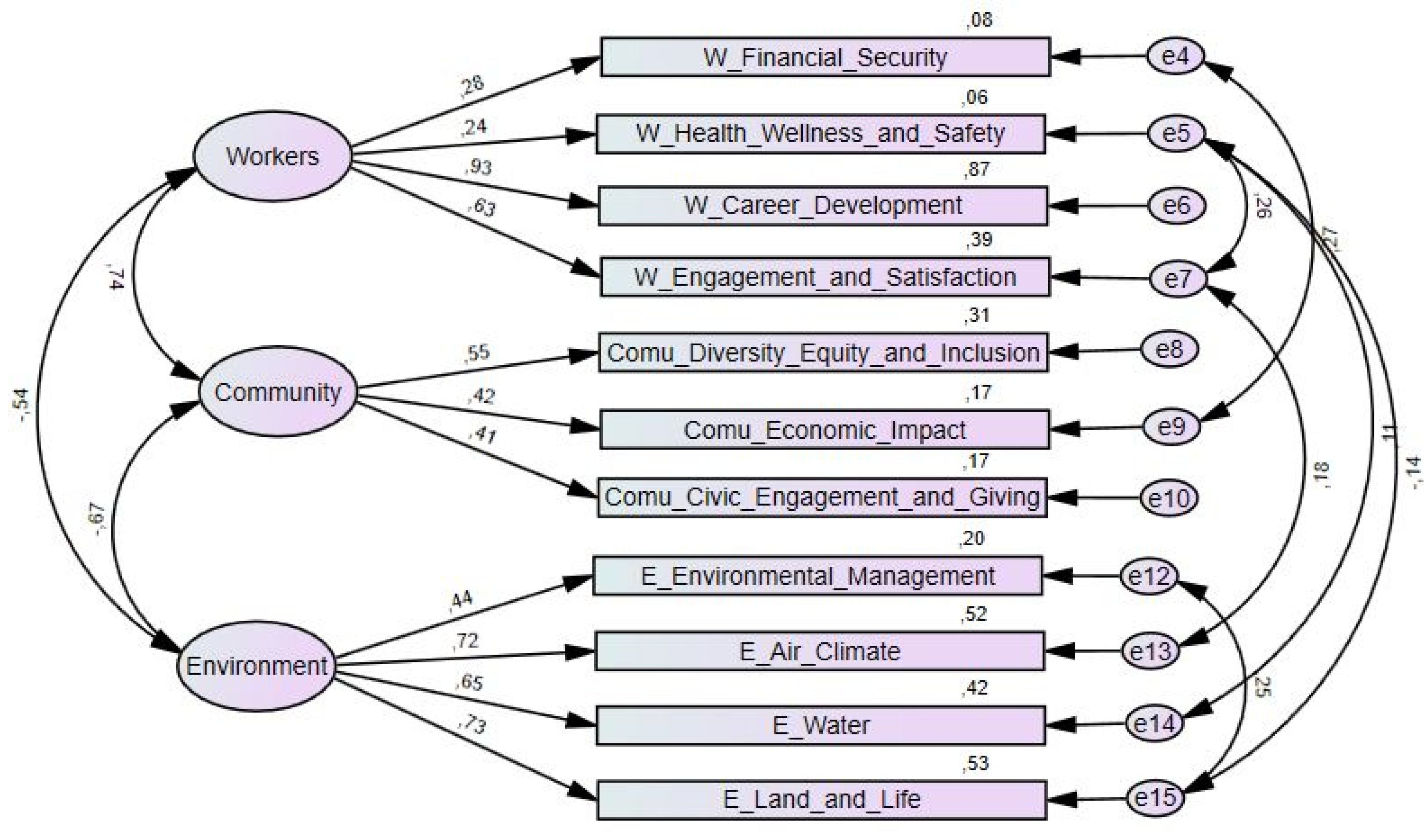
Several models were simulated in this research to understand which measurement model structure best fits the data. Of all the models studied, the one where it was possible to obtain the best adjustment indices was the following (see
Figure 8):
As can be seen, this model presents significant differences from the original model that was tested. First, there was a reduction in the number of latent variables from four to three by eliminating the governance indicator. Additionally, the observed variable (customer stewardship) was removed from the model.
These changes introduced in the B Impact Assessment model, according to
Figure 8, allowed us to achieve the final adjustment values mentioned in
Table 12. As a result, the simplified model exhibited a significantly higher quality of fit than the original model in the sample under study.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}