
Compound Positioning Method for Connected Electric Vehicles Based on Multi-Source Data Fusion

Abstract
:1. Introduction
- In the research of roadside-based traffic perception, the current studies mainly focus on the dynamic detection of vehicles with single sensors on the roadside;
- In the compound positioning research of vehicles, the current studies mainly focus on the multiple sensors of a single vehicle, and there is a gap in the cooperative compound positioning of multiple vehicles based on vehicle-infrastructure information fusion.
- A comprehensive system concept is provided based on the positioning accuracy requirements of CEVs.
- A reliable compound positioning approach is developed to achieve higher positioning accuracy among the data obtained from multiple roadside sensors and V2X units.
- Theoretical analysis and extensive experiment results, including the Dempster-Shafer (D-S) evidence theory-based multi-source data fusion method and hybrid neural networks, are provided to validate the proposed concept.
2. Multi-Source Data Fusion Based on D-S Evidence Theory
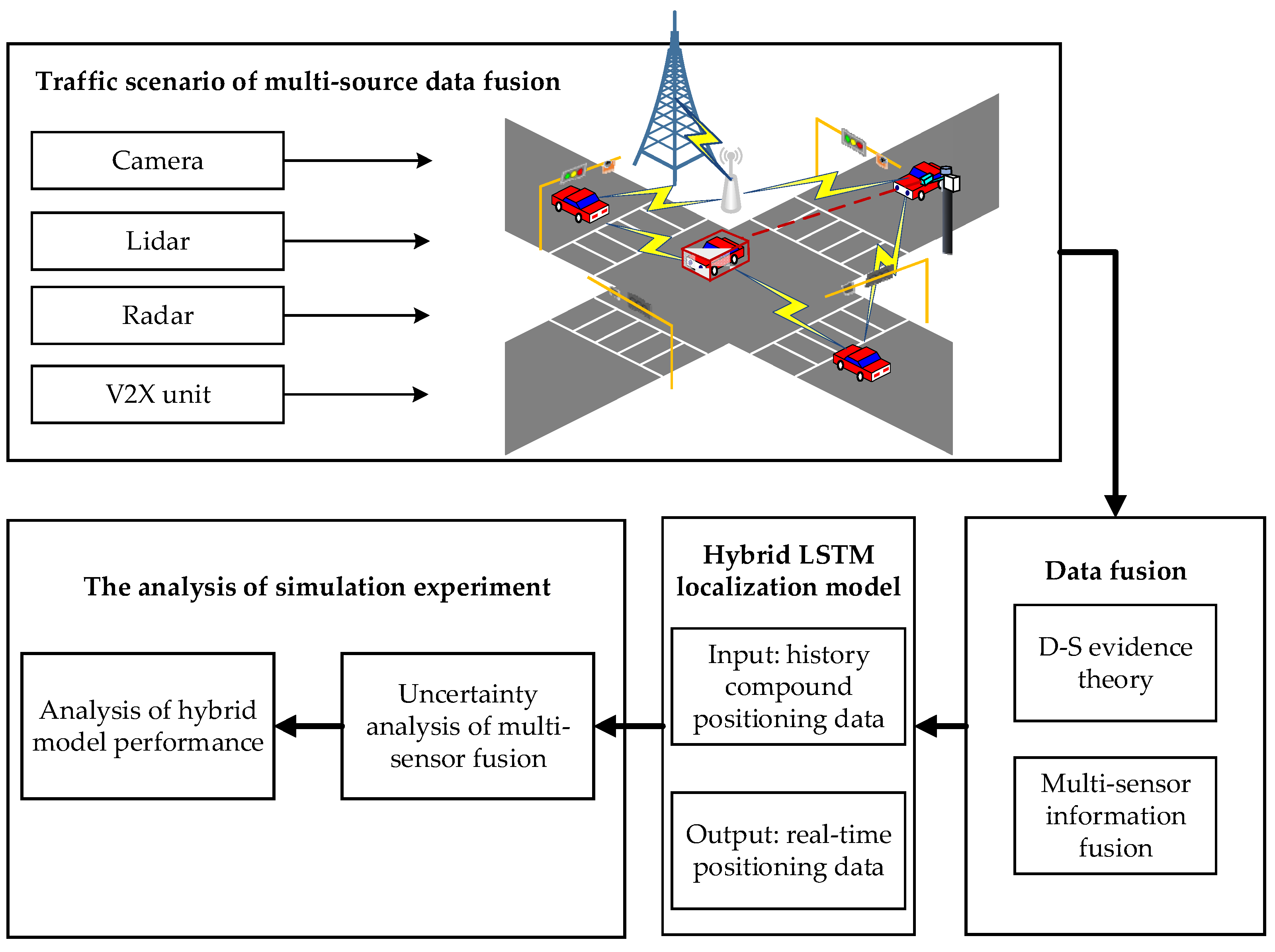
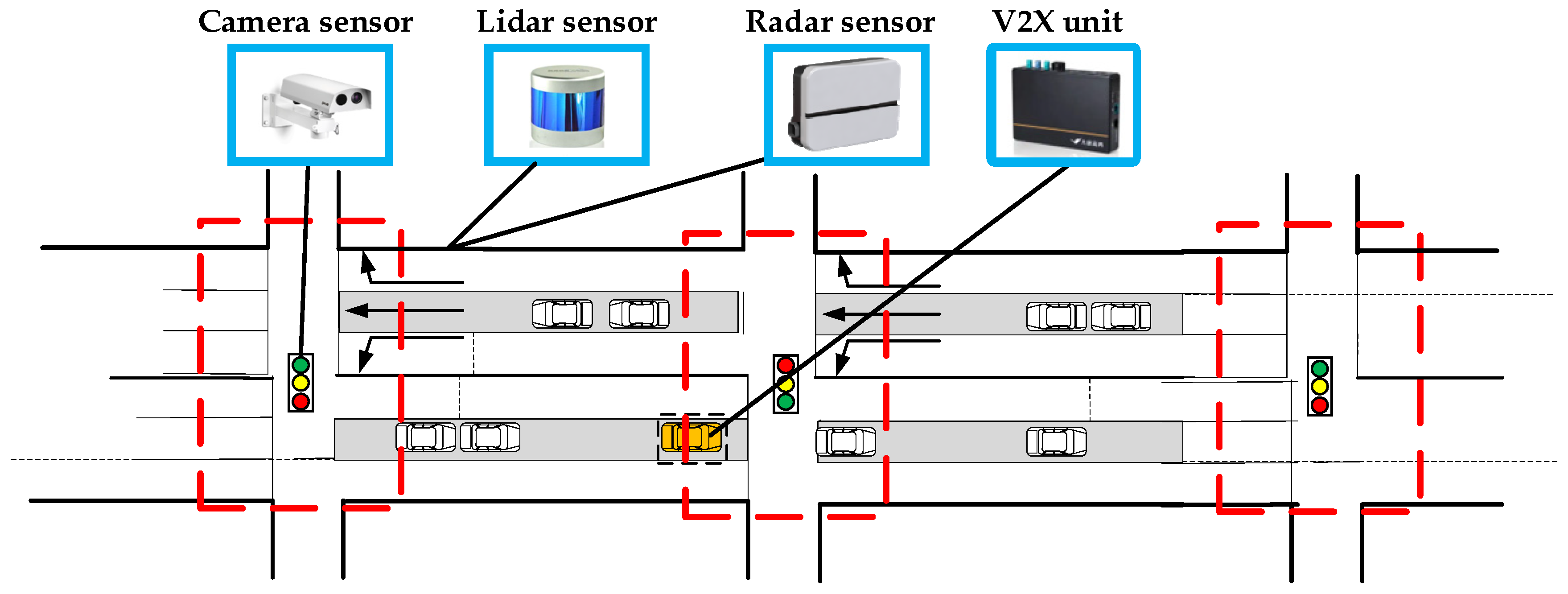
2.1. The Scenario of Multi-Source Data Fusion
2.2. Data Fusion Rules of D-S Evidence Theory
- For fusion, the normalized coefficient 1-K value is obtained using the D-S evidence fusion rule, which is shown in Equation (6).
- The values of the mass function for each hypothesis are obtained as follows:
- The confidence intervals are obtained as follows:
- Therefore, the credibility of fusion is
- According to D-S evidence theory, and are fused, which represent the combined credibility of camera, lidar, and radar is obtained: .
- In the same way, the credibility of four sensors fusion is finally obtained, which is .
3. The Perception Model of Compound Positioning Information
3.1. Date Preprocessing Layer
3.2. CNN Layer
- Input layer
- 2.
- Convolution layer
- 3.
- Pooling layer
- 4.
- Fully connected layer and output layer
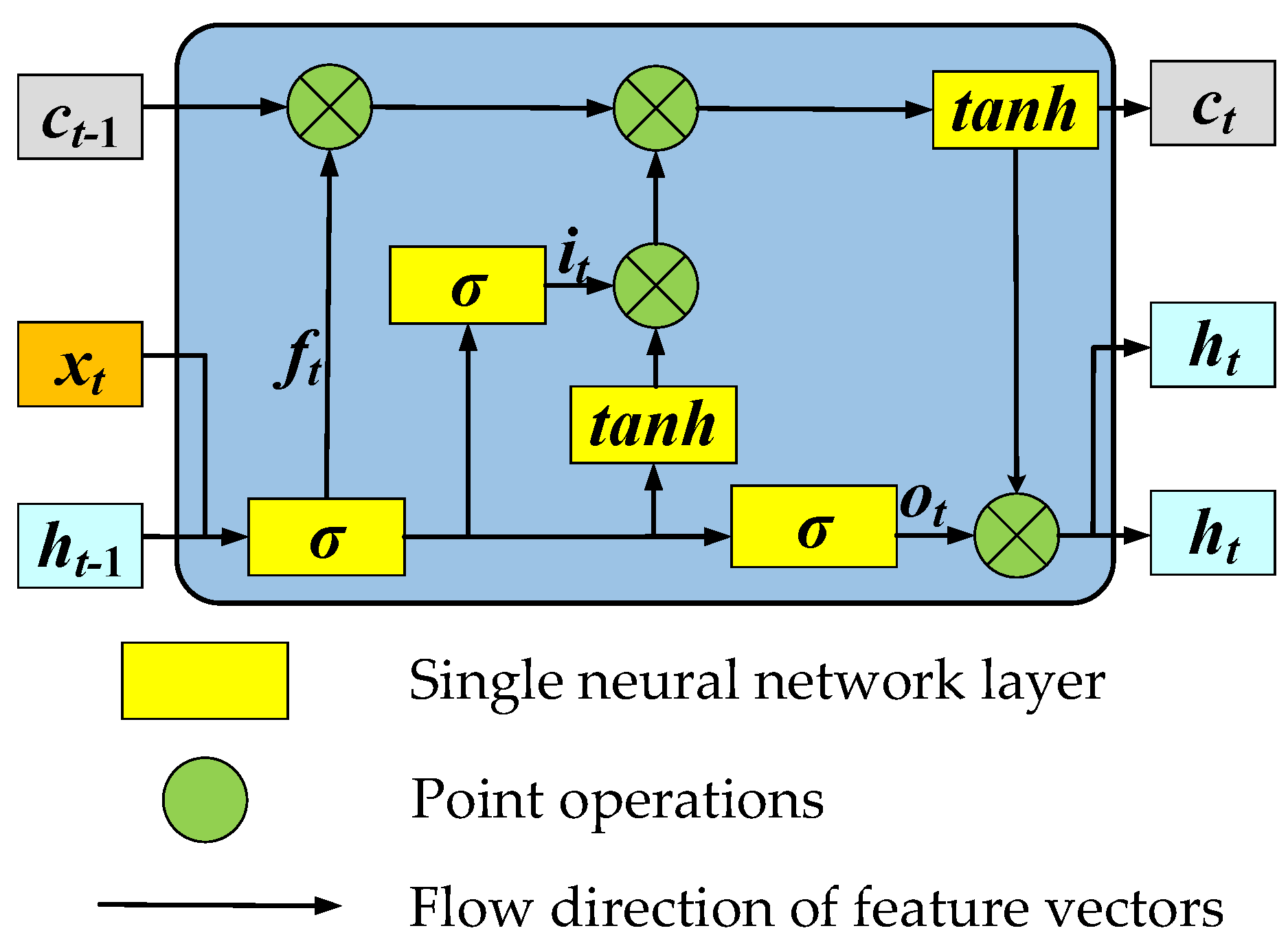
3.3. LSTM Layer
3.4. Self-Attention Layer
3.5. Dropout Layer
4. Field Experiment and Analysis
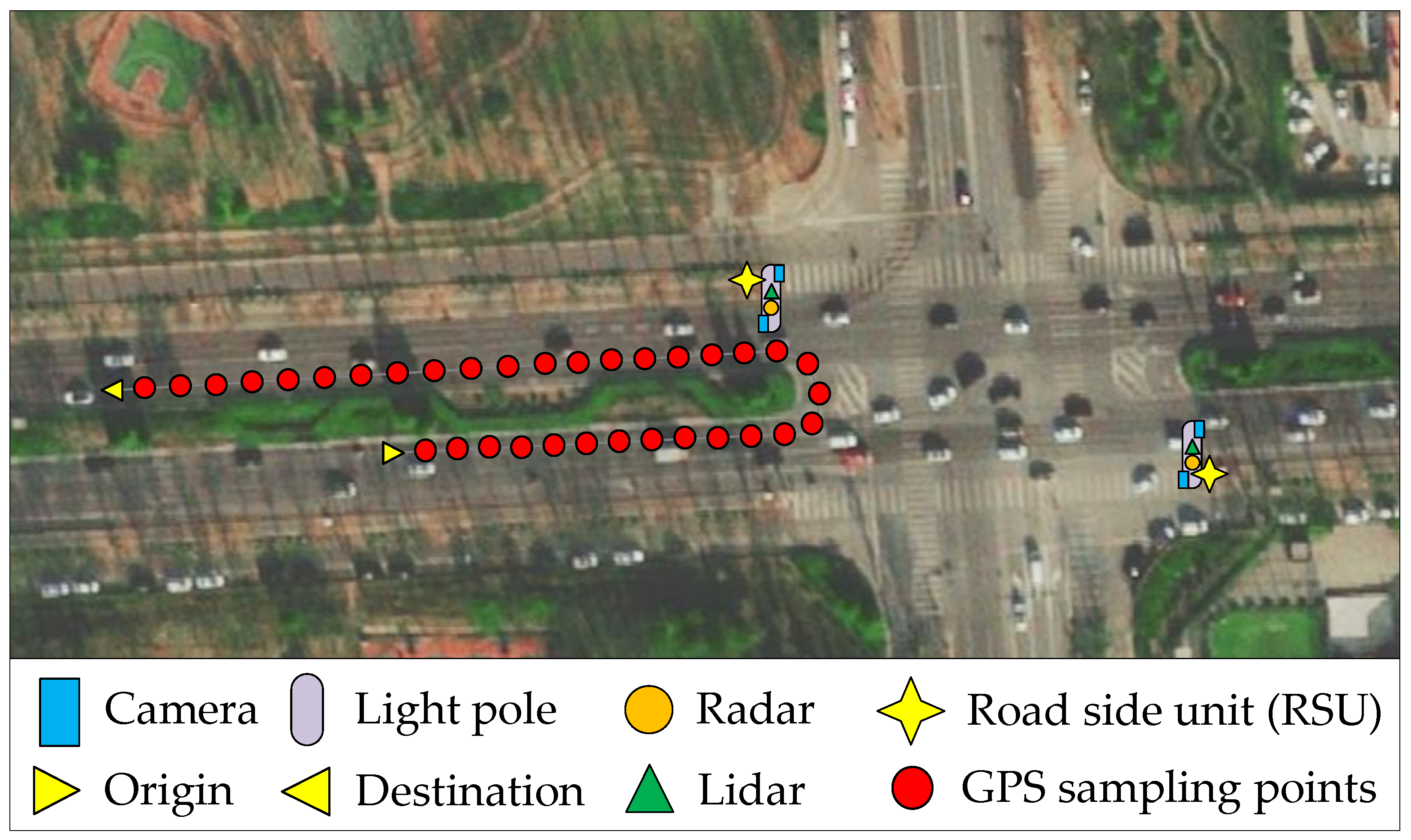
4.1. Test Field and Datasets
4.2. Parameter Setting and Evaluation Index
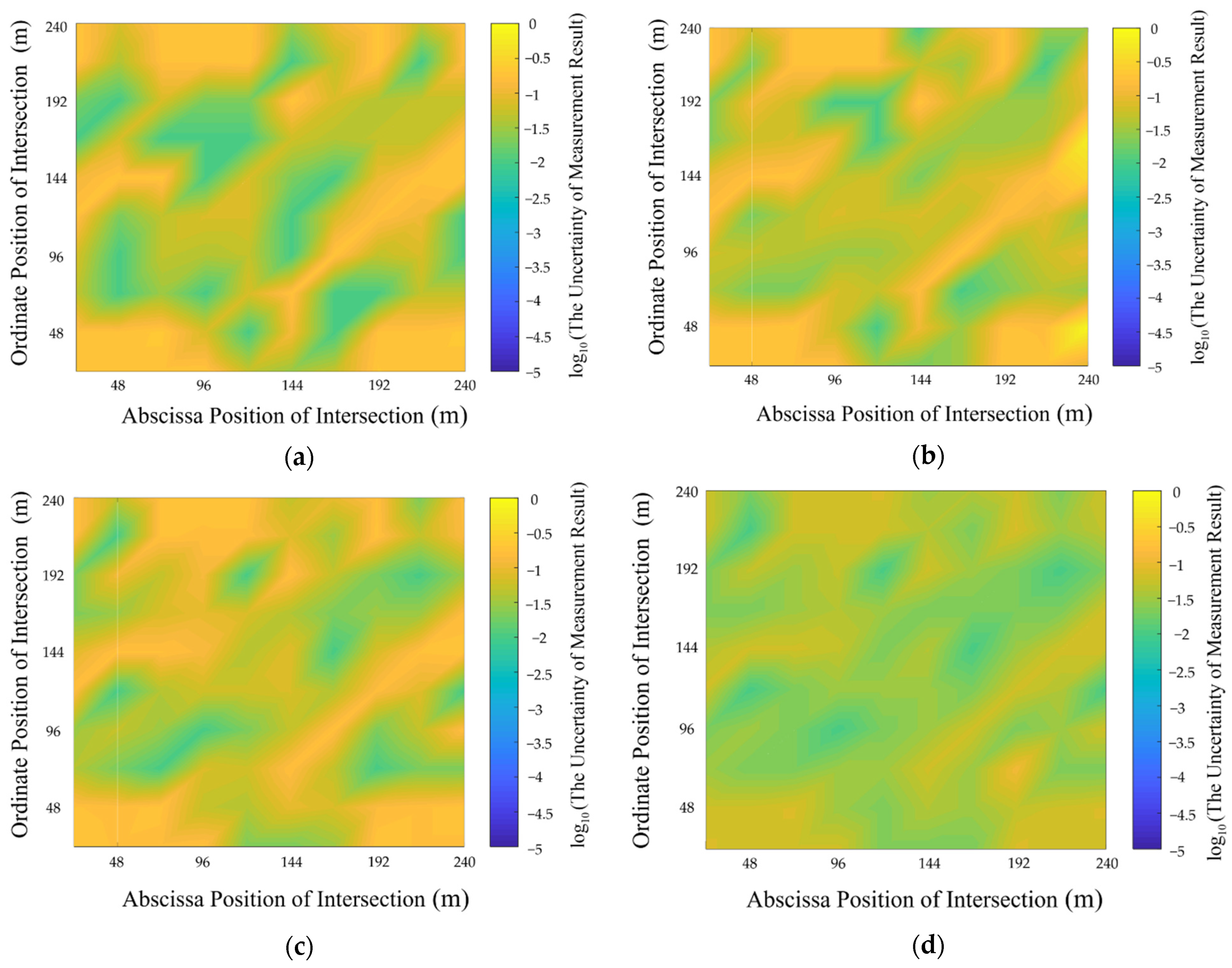
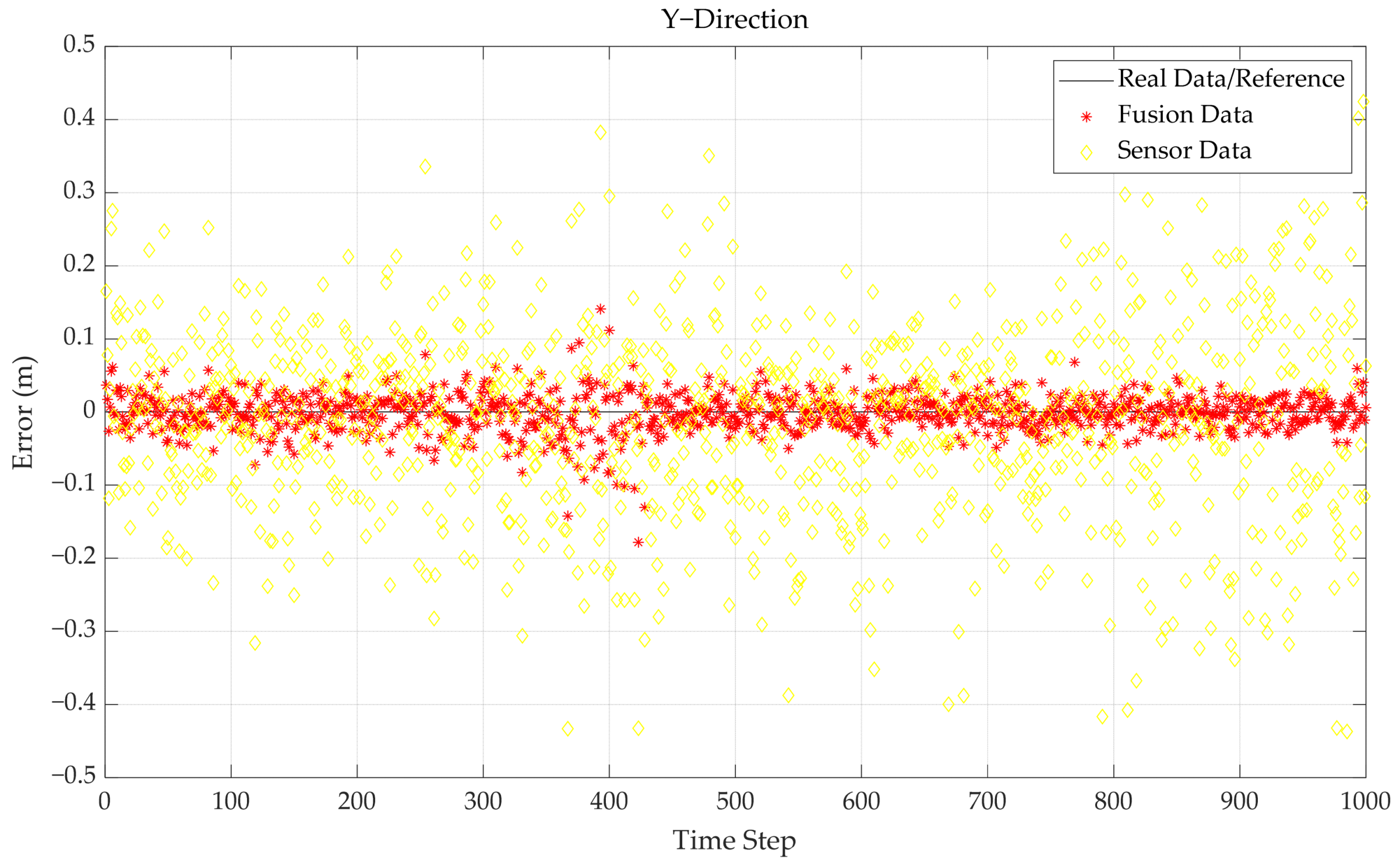
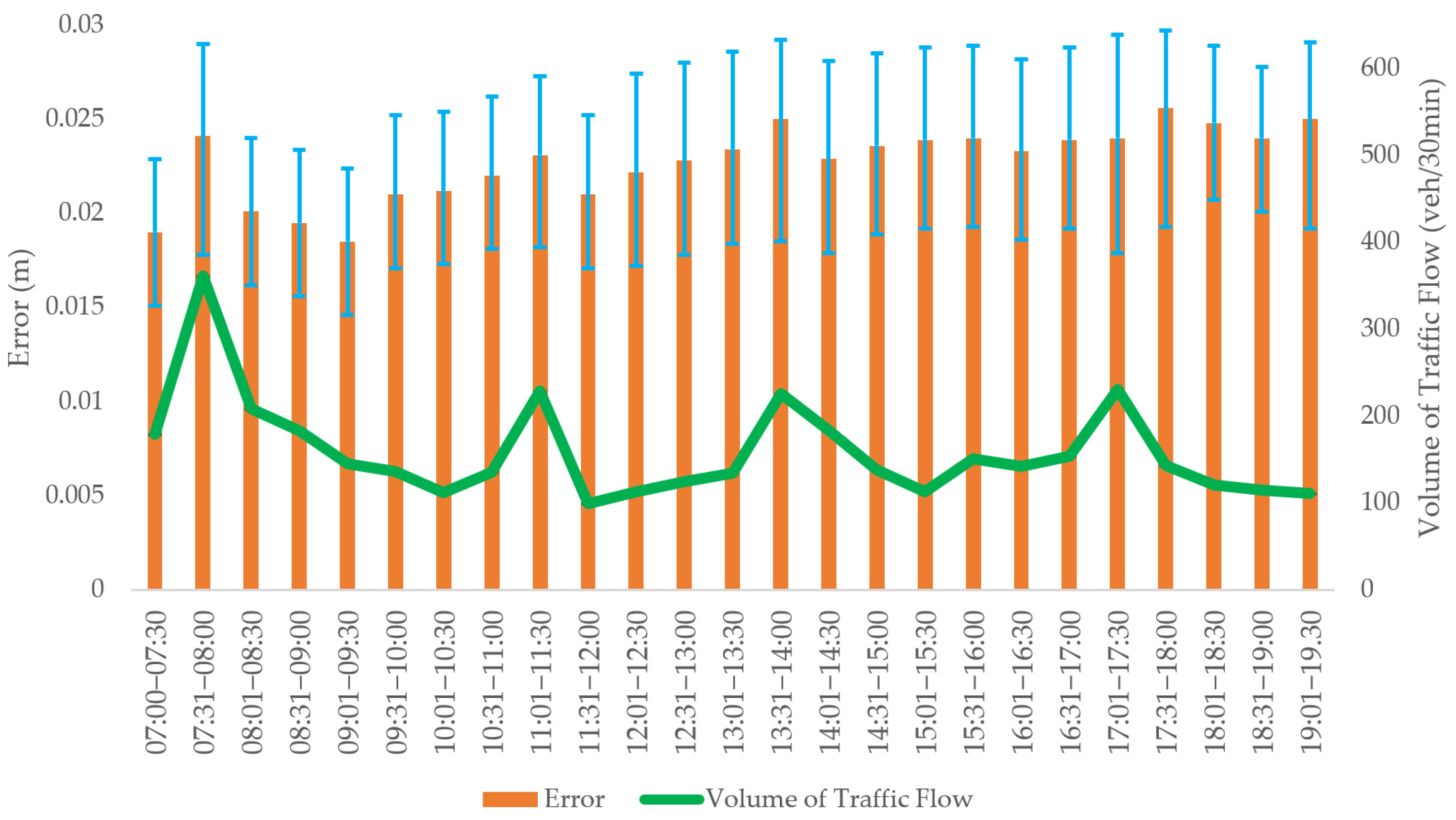
4.3. Uncertainty Analysis of Multi-Source Data Fusion
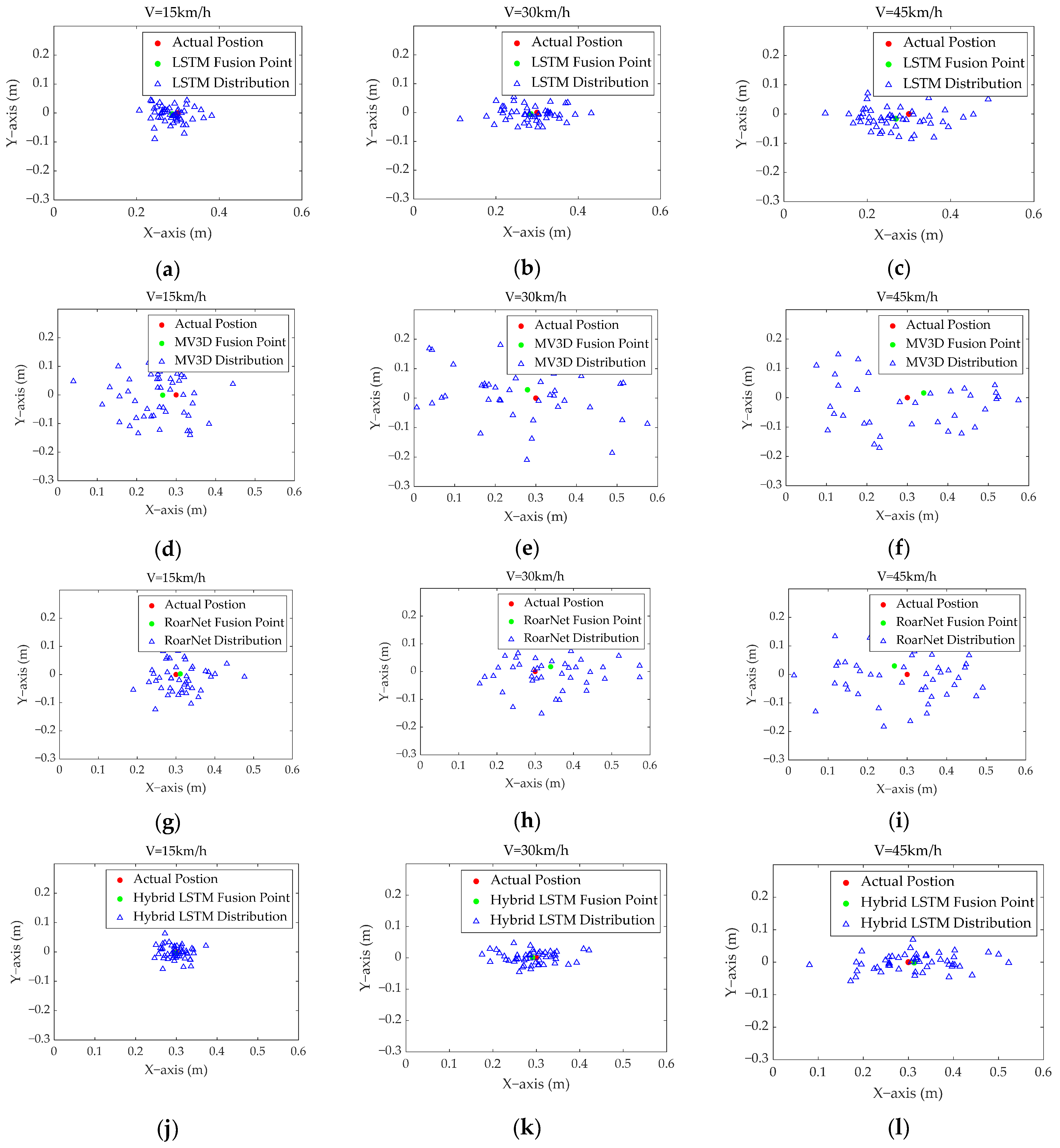
4.4. Analysis of Compound Positioning Model
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Scamarcio, A.; Metzler, M.; Gruber, P.; De Pinto, S.; Sorniotti, A. Comparison of anti-jerk controllers for electric vehicles with on-board motors. IEEE Trans. Veh. Technol. 2020, 69, 10681–10699. [Google Scholar] [CrossRef]
- Aiman, M.A.; Mohammed, N.A. Comparison of the overall energy efficiency for internal combustion engine vehicles and electric vehicles. Environ. Clim. Technol. 2020, 24, 669–680. [Google Scholar] [CrossRef]
- Machado, F.A.; Kollmeyer, P.J.; Barroso, D.G.; Emadi, A. Multi-speed gearboxes for battery electric vehicles: Current status and future trends. IEEE Trans. Veh. Technol. 2021, 2, 419–435. [Google Scholar] [CrossRef]
- Li, X.; Wang, Y.G.; Cui, H.J.; Zhu, M.Q.; Wang, X.T. Stability analysis of complex heterogeneous traffic flow under connected and autonomous environment. J. Transp. Syst. Eng. Inf. Technol. 2020, 20, 114–120. [Google Scholar] [CrossRef]
- An, Q.; Shen, Y. On the information coupling and propagation of visual 3d perception in vehicular networks with position uncertainty. IEEE Trans. Veh. Technol. 2021, 70, 13325–13339. [Google Scholar] [CrossRef]
- Bolufe, S.; Cesar, A.M.; Sandra, C.; Samuel, M.S.; Demo, R.; Evelio, M.G.F. POSaCC: Position-accuracy based adaptive beaconing algorithm for cooperative vehicular safety systems. IEEE Access 2020, 8, 15484–15501. [Google Scholar] [CrossRef]
- Wang, P.W.; Liu, X.; Wang, Y.F.; Wang, T.R.; Zhang, J. Short-term traffic state prediction based on mobile edge computing in V2X communication. Appl. Sci. 2021, 11, 11530. [Google Scholar] [CrossRef]
- Hossain, M.A.; Elshafiey, I.; Al-Sanie, A. Cooperative vehicle positioning with multi-sensor data fusion and vehicular communications. Wirel. Net. 2019, 25, 1403–1413. [Google Scholar] [CrossRef]
- Bounini, F.; Gingras, D.; Pollart, H.; Gruyer, D. From simultaneous localization and mapping to collaborative localization for intelligent vehicles. IEEE Int. Transp. Syst. Mag. 2021, 13, 196–216. [Google Scholar] [CrossRef]
- Jon, O.; Alfonso, B.; Iban, L.; Luis, E.D. Performance evaluation of different grade IMUs for diagnosis applications in land vehicular multi-sensor architectures. IEEE Sens. J. 2021, 21, 2658–2668. [Google Scholar] [CrossRef]
- Tao, X.; Zhu, B.; Xuan, S.; Zhao, J.; Jiang, H.; Du, J.; Deng, W. A multi-sensor fusion positioning strategy for intelligent vehicles using global pose graph optimization. IEEE Trans. Veh. Technol. 2022, 71, 2614–2627. [Google Scholar] [CrossRef]
- Milan, K.; František, S.; Michaela, K. Super-random states in vehicular traffic—Detection & explanation. Phys. A Stat. Mech. Appl. 2022, 585, 126418. [Google Scholar] [CrossRef]
- Sampath, V.; Karthik, S.; Sabitha, R. Position-based adaptive clustering model (PACM) for efficient data caching in vehicular named data networks (VNDN). Wirel. Pers. Commun. 2021, 117, 2955–2971. [Google Scholar] [CrossRef]
- Wang, Y.; Duan, X.; Tian, D.; Zhang, X.; Chen, M. Vehicular positioning enhancement. Connect. Veh. Syst. Commun. Data Control 2017, 1, 159–186. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, L.; Song, Y. A vehicular collision warning algorithm based on the time-to-collision estimation under connected environment. In Proceedings of the 2016 14th International Conference on Control, Automation, Robotics and Vision (ICARCV), IEEE, Phuket, Thailand, 13–15 November 2016; pp. 1–4. [Google Scholar] [CrossRef]
- Watta, P.; Zhang, X.; Murphey, Y.L. Vehicle position and context detection using V2V communication. IEEE Trans. Int. Veh. 2021, 6, 634–648. [Google Scholar] [CrossRef]
- Song, Y.; Fu, Y.; Yu, F.R.; Zhou, L. Blockchain-enabled internet of vehicles with cooperative positioning: A deep neural network approach. IEEE Int. Things J. 2020, 7, 3485–3498. [Google Scholar] [CrossRef]
- Kim, S.; Park, J.K.; Ahn, C.K. Learning and adaptation-based position-tracking controller for rover vehicle applications considering actuator dynamics. IEEE Trans. Ind. Electr. 2022, 69, 2976–2985. [Google Scholar] [CrossRef]
- Jung, K.; Min, S.; Kim, J.; Kim, N.; Kim, E. Evidence-theoretic reentry target classification using radar: A fuzzy logic approach. IEEE Access 2021, 9, 55567–55580. [Google Scholar] [CrossRef]
- Ye, Z.; Julia, V.; Gábor, F.; Peter, H. Vehicular positioning and tracking in multipath non-line-of-sight channels. arXiv 2022, arXiv:2203.17007. [Google Scholar] [CrossRef]
- Ko, S.; Chae, H.; Han, K.; Lee, S.; Seo, D.; Huang, K. V2X-based vehicular positioning: Opportunities, challenges, and future directions. IEEE Wirel. Commun. 2021, 28, 144–151. [Google Scholar] [CrossRef]
- Caltagirone, L.; Bellone, M.; Svensson, L.; Wahde, M. Lidar–camera fusion for road detection using fully convolutional neural networks. Robot. Auton. Syst. 2018, 111, 125–131. [Google Scholar] [CrossRef] [Green Version]
- Golestan, K.; Khaleghi, B.; Karray, F.; Kamel, M.S. Attention assist: A high-level information fusion framework for situation and threat assessment in vehicular ad hoc networks. IEEE Trans. Int. Transp. Syst. 2016, 17, 1271–1285. [Google Scholar] [CrossRef]
- Mostafavi, S.; Sorrentino, S.; Guldogan, M.B.; Fodor, G. Vehicular positioning using 5G millimeter wave and sensor fusion in highway scenarios. In Proceedings of the ICC 2020—2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020. [Google Scholar] [CrossRef]
- Onyekpe, U.; Palade, V.; Herath, A.; Kanarachos, S.; Fitzpatrick, M.E.; Christopoulos, S.G. WhONet: Wheel odometry neural network for vehicular localisation in GPS-deprived environments. Eng. Appl. Art. Int. 2021, 105, 104421. [Google Scholar] [CrossRef]
- Jiang, W.; Cao, Z.; Cai, B.; Li, B.; Wang, J. Indoor and outdoor seamless positioning method using uwb enhanced multi-sensor tightly-coupled integration. IEEE Trans. Veh. Technol. 2021, 70, 10633–10645. [Google Scholar] [CrossRef]
- Ding, X.; Wang, Z.; Zhang, L.; Wang, C. Longitudinal vehicle speed estimation for four-wheel-independently-actuated electric vehicles based on multi-sensor fusion. IEEE Trans. Veh. Technol. 2020, 69, 12797–12806. [Google Scholar] [CrossRef]
- Goli, S.A.; Far, B.H.; Fapojuwo, A.O. Cooperative multi-sensor multi-vehicle localization in vehicular adhoc networks. In Proceedings of the 2015 IEEE International Conference on Information Reuse and Integration (IRI), IEEE, San Francisco, CA, USA, 13–15 August 2015; pp. 142–149. [Google Scholar] [CrossRef]
- Altoaimy, L.; Mahgoub, I. Fuzzy logic based localization for vehicular ad hoc networks. In Proceedings of the 2014 IEEE Symposium on Computational Intelligence in Vehicles and Transportation Systems (CIVTS), Orlando, FL, USA, 9–12 December 2014; pp. 121–128. [Google Scholar] [CrossRef]
- Escalera, A.D.L.; Armingol, J.M. Sensor fusion methodology for vehicle detection. IEEE Int. Transp. Syst. Mag. 2017, 9, 123–133. [Google Scholar] [CrossRef]
- Broughton, G.; Majer, F.; Roucek, T.; Ruichek, Y.; Yan, Z.; Krajník, T. Learning to see through the haze: Multi-sensor learning-fusion system for vulnerable traffic participant detection in fog. Robot. Auton. Syst. 2021, 136, 103687. [Google Scholar] [CrossRef]
- Mo, Y.H.; Zhang, P.L.; Chen, Z.J.; Ran, B. A method of vehicle-infrastructure cooperative perception based vehicle state information fusion using improved Kalman filter. Multimed. Tools Appl. 2021, 81, 4603–4620. [Google Scholar] [CrossRef]
- Xiao, Z.Y.; Yang, D.G.; Wen, F.X.; Jiang, K. A unified multiple-target positioning framework for intelligent CEVs. Sensors 2019, 19, 1967. [Google Scholar] [CrossRef] [Green Version]
- Kim, H.; Liu, B.; Goh, C.Y.; Lee, S.; Myung, H. Robust vehicle localization using entropy-weighted particle filter-based data fusion of vertical and road intensity information for a large scale urban area. IEEE Robot. Auton. Lett. 2017, 2, 1518–1524. [Google Scholar] [CrossRef]
- Onyekpe, U.; Kanarachos, S.; Palade, V.; Christopoulos, S.G. Vehicular localisation at high and low estimation rates during GPS outages: A deep learning approach. Adv. Int. Syst. Comp. 2021, 1232, 229–248. [Google Scholar] [CrossRef]
- Wang, P.; Jiang, Y.; Xiao, L.; Zhao, Y.; Li, Y. A joint control model for connected vehicle platoon and arterial signal coordination. J. Intell. Transp. Syst. 2020, 24, 81–92. [Google Scholar] [CrossRef]
- Wang, P.; Deng, H.; Zhang, J.; Wang, L.; Zhang, M.; Li, Y. Model predictive control for connected vehicle platoon under switching communication topology. IEEE Trans. Intell. Transp. Syst. 2021, 1–4. [Google Scholar] [CrossRef]
- Kumar, G.V.; Chuang, C.H.; Lu, M.Z.; Liaw, C.M. Development of an electric vehicle synchronous reluctance motor drive. IEEE Trans. Veh. Technol. 2020, 69, 5012–5024. [Google Scholar] [CrossRef]
- Chaturvedi, S.; Makineni, R.R.; Fulwani, D.M.; Yadav, S.K. Regulation of electric vehicle speed oscillations due to uneven drive surfaces using ISMDTC. IEEE Trans. Veh. Technol. 2021, 70, 12506–12516. [Google Scholar] [CrossRef]
- Shan, M.; Narula, K.; Wong, Y.F.; Worrall, S.; Khan, M.; Alexander, P.; Nebot, E. Demonstrations of cooperative perception: Safety and robustness in connected and automated vehicle operations. Sensors 2021, 21, 200. [Google Scholar] [CrossRef]
- Wen, W.; Bai, X.; Zhang, G.; Chen, S.; Yuan, F.; Hsu, L. Multi-agent collaborative GNSS/Camera/INS integration aided by inter-ranging for vehicular navigation in urban areas. IEEE Access 2020, 8, 124323–124338. [Google Scholar] [CrossRef]
- Inoue, M.; Tang, S.; Obana, S. LSTM-based high precision pedestrian positioning. In Proceedings of the 2022 IEEE 19th Annual Consumer Communications & Networking Conference (CCNC), IEEE, Las Vegas, NV, USA, 8–11 January 2022; pp. 675–678. [Google Scholar] [CrossRef]
- Rubino, C.; Crocco, M.; Bue, A.D. 3D object localisation from multi-view image detections. IEEE Trans. Pattern Anal. Mach. Int. 2018, 40, 1281–1294. [Google Scholar] [CrossRef]
- Shin, K.; Kwon, Y.P.; Tomizuka, M. RoarNet: A robust 3D object detection based on region approximation refinement. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 2510–2515. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sensor State | Detected (A) | Undetected (B) | Uncertain (C) | |
|---|---|---|---|---|
| Sensor Type | ||||
| Camera sensor (1) | m1 (A) | m1 (B) | m1 (C) | |
| Lidar sensor (2) | m2 (A) | m2 (B) | m2 (C) | |
| Radar sensor (3) | m3 (A) | m3 (B) | m3 (C) | |
| V2X unit (4) | m4 (A) | m4 (B) | m4 (C) | |
| Combination Forms | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sensors | |||||||||||||||||
| Camera | Yes | Yes | Yes | Yes | No | Yes | Yes | No | Yes | No | No | No | No | No | No | No | |
| Lidar | Yes | Yes | Yes | No | Yes | Yes | No | No | No | Yes | Yes | Yes | Yes | No | No | No | |
| Radar | Yes | Yes | No | Yes | Yes | No | No | Yes | Yes | No | Yes | No | No | Yes | No | No | |
| V2X unit | Yes | No | Yes | Yes | Yes | No | Yes | Yes | No | Yes | No | Yes | No | No | Yes | No | |
| Combination Form | Sensor Number | m(A) | m(B) | m(Θ) | Fusion Result |
|---|---|---|---|---|---|
| 1 | 4 | 0.949350 | 0.050634 | 0.000016 | A |
| 2 | 3 | 0.777015 | 0.222413 | 0.000572 | A |
| 3 | 3 | 0.798684 | 0.200929 | 0.00387 | A |
| 4 | 2 | 0.419643 | 0.571429 | 0.008929 | B |
| 5 | 3 | 0.981207 | 0.018715 | 0.000078 | A |
| 6 | 2 | 0.906375 | 0.090504 | 0.003121 | A |
| 7 | 2 | 0.901087 | 0.098755 | 0.00159 | A |
| 8 | 1 | 0.65 | 0.28 | 0.07 | A |
| 9 | 3 | 0.901087 | 0.098755 | 0.000159 | A |
| 10 | 2 | 0.627191 | 0.36803 | 0.00478 | A |
| 11 | 2 | 0.657519 | 0.339188 | 0.003293 | A |
| 12 | 1 | 0.22 | 0.72 | 0.06 | B |
| 13 | 2 | 0.962065 | 0.037144 | 0.00079 | A |
| 14 | 1 | 0.82 | 0.15 | 0.03 | A |
| 15 | 1 | 0.84 | 0.14 | 0.02 | A |
| 16 | 0 | —— | —— | —— | Θ |
| ID | V2X | Longitude | Latitude | Steering Angle (°) | Speed (m/s) | Acceleration (m/s2) | Horizontal Distance (m) | Heading Angle (°) |
|---|---|---|---|---|---|---|---|---|
| 76 | Yes | 116.2138743 | 39.9306605 | 2.3 | 0.16 | −0.16 | 7.82 | 88.22 |
| 77 | No | 116.2139375 | 39.9306708 | —— | 2.11 | —— | 12.14 | 82.92 |
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
| 95 | No | 116.2127606 | 39.9306348 | —— | 2.14 | 0.20 | 17.17 | 154.52 |
| 96 | No | 116.2120122 | 39.9306519 | —— | 5.58 | —— | 15.17 | 82.59 |
| Parameters | Value | |
|---|---|---|
| CNN | Input layer size | 256 × 256 |
| Convolution layer size | 16 × 16 | |
| Pooling layer size | 8 × 8 | |
| LSTM | Number of hidden layers | 2 |
| Number of hidden layer nodes | 200 | |
| Epoch | 20 | |
| Batch Size | 100 | |
| Loss Function | MSE | |
| Learning Rate | 0.001 | |
| Optimizer | Adam | |
| Sensor Category | Camera | Lidar | Radar | V2X Unit | |
|---|---|---|---|---|---|
| Error | |||||
| Maximum (m) | 18.4623 | 0.8268 | 2.0168 | 20.9980 | |
| Minimum (m) | 0.1917 | 0.0082 | 0.0607 | 0.0488 | |
| Average (m) | 3.5881 | 0.2111 | 0.7138 | 8.1386 | |
| MAPE | 19.26% | 0.70% | 23.72% | 26.87% | |
| Model | Anchor 2 | Anchor 3 | Anchor 4 |
|---|---|---|---|
| LSTM | 0.1179 | 0.0821 | 0.0630 |
| MV3D | 0.1475 | 0.1322 | 0.1071 |
| RoarNet | 0.1121 | 0.0690 | 0.0610 |
| Hybrid LSTM | 0.0910 | 0.0609 | 0.0399 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, L.; Li, Z.; Fan, Q. Compound Positioning Method for Connected Electric Vehicles Based on Multi-Source Data Fusion. Sustainability 2022, 14, 8323. https://doi.org/10.3390/su14148323
Wang L, Li Z, Fan Q. Compound Positioning Method for Connected Electric Vehicles Based on Multi-Source Data Fusion. Sustainability. 2022; 14(14):8323. https://doi.org/10.3390/su14148323
Chicago/Turabian StyleWang, Lin, Zhenhua Li, and Qinglan Fan. 2022. "Compound Positioning Method for Connected Electric Vehicles Based on Multi-Source Data Fusion" Sustainability 14, no. 14: 8323. https://doi.org/10.3390/su14148323
APA StyleWang, L., Li, Z., & Fan, Q. (2022). Compound Positioning Method for Connected Electric Vehicles Based on Multi-Source Data Fusion. Sustainability, 14(14), 8323. https://doi.org/10.3390/su14148323