
Research on the Division Method of Signal Control Sub-Region Based on Macroscopic Fundamental Diagram


Abstract
1. Introduction
2. Methodology
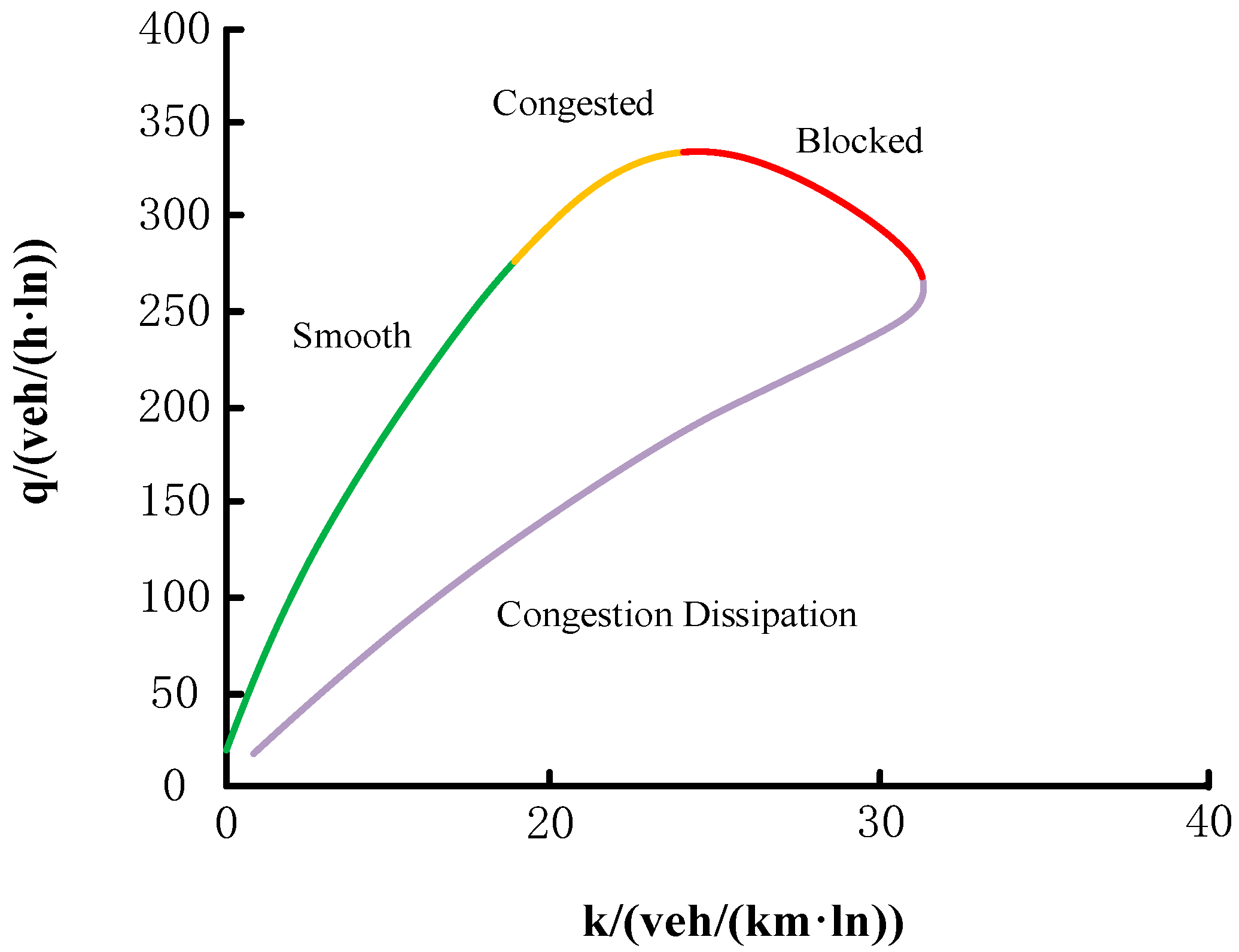
2.1. Urban Road Network Abstract Diagram
2.2. Segmenting
- Calculate the dissimilarity (wn,m) of each intersection to its adjacent intersection;
- Sort the dissimilarity of the intersection with all its adjacent intersections from small to large, and obtain a1, a2, a3, ∙∙∙;
- Select a1;
- Integrate the currently selected an, and the connected intersection is vi, vj. If the merge condition is met:
- (1)
- vi and vj do not belong to the same region, G(vi) ≠ G(vj);
- (2)
- The dissimilarity is more significant than the internal contrast. Wi,j ≤ MInt(Ci, Cj) performs step 5;
- Update the threshold and area label:
- Update the classification labels: unify the classification labels of G(vi), G(vj) into the titles of G(vi).
- Update the threshold of dissimilarity of this region to be:;
- Select an+1 in the order shown to go to step 4; otherwise, end.
2.3. Boundary Determination
- The clustering object of the proposed method is the intersection, while the clustering object of the previously proposed method is the section;
- The proposed method is different from the previous one because it is to cluster the intersections and improve the minimum spanning tree method for MFD division;
- The proposed method does not need complex boundary adjustment except for simple inter-regional road attribution judgment;
- Since the proposed method is to cluster the intersections, it is very beneficial to the implementation of signal control. However, when the results obtained by the previous plan are applied to signal control, the ownership of boundary intersection should be further processed.
3. Metrics Development
4. Implement
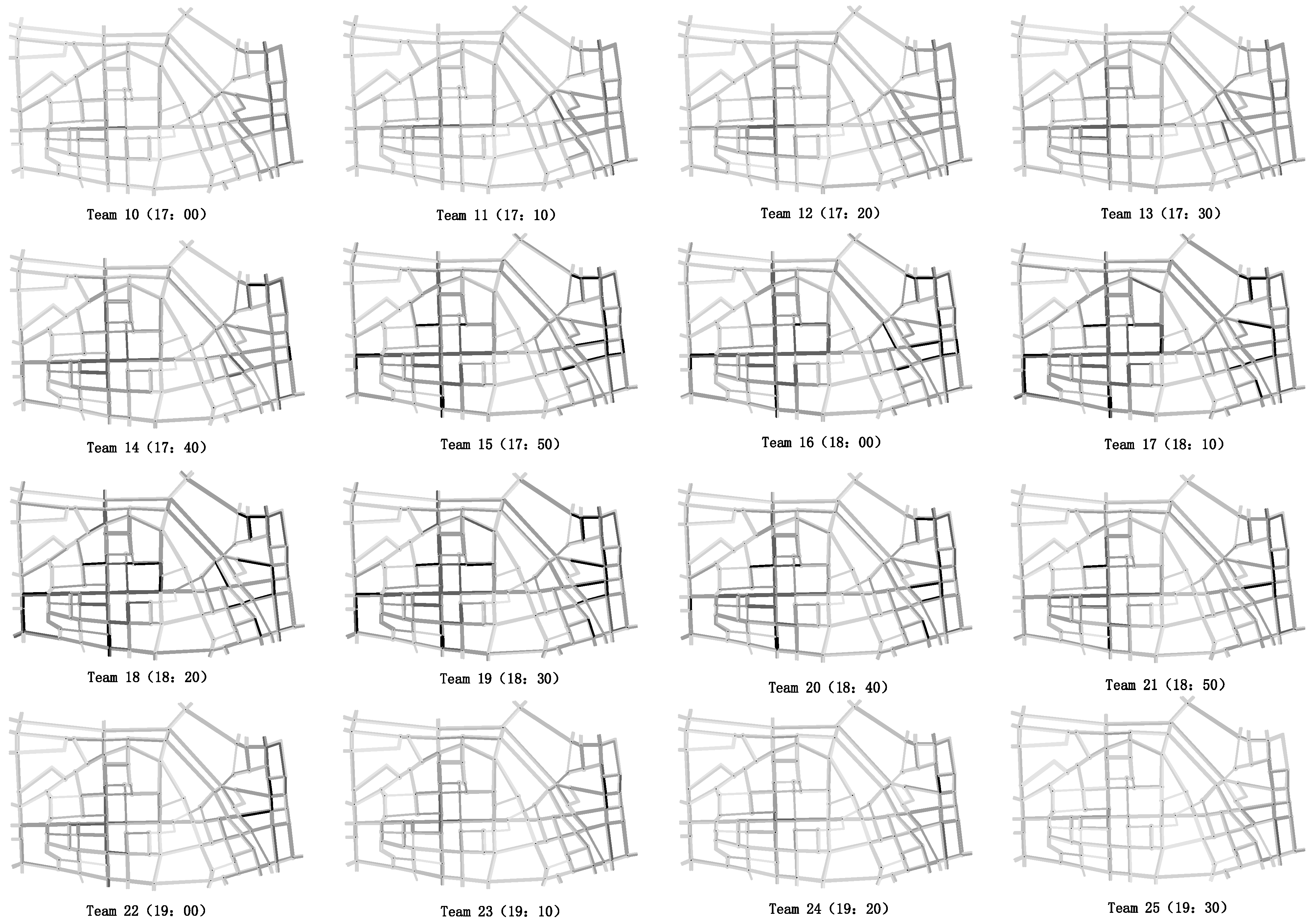
4.1. Network and Data Description
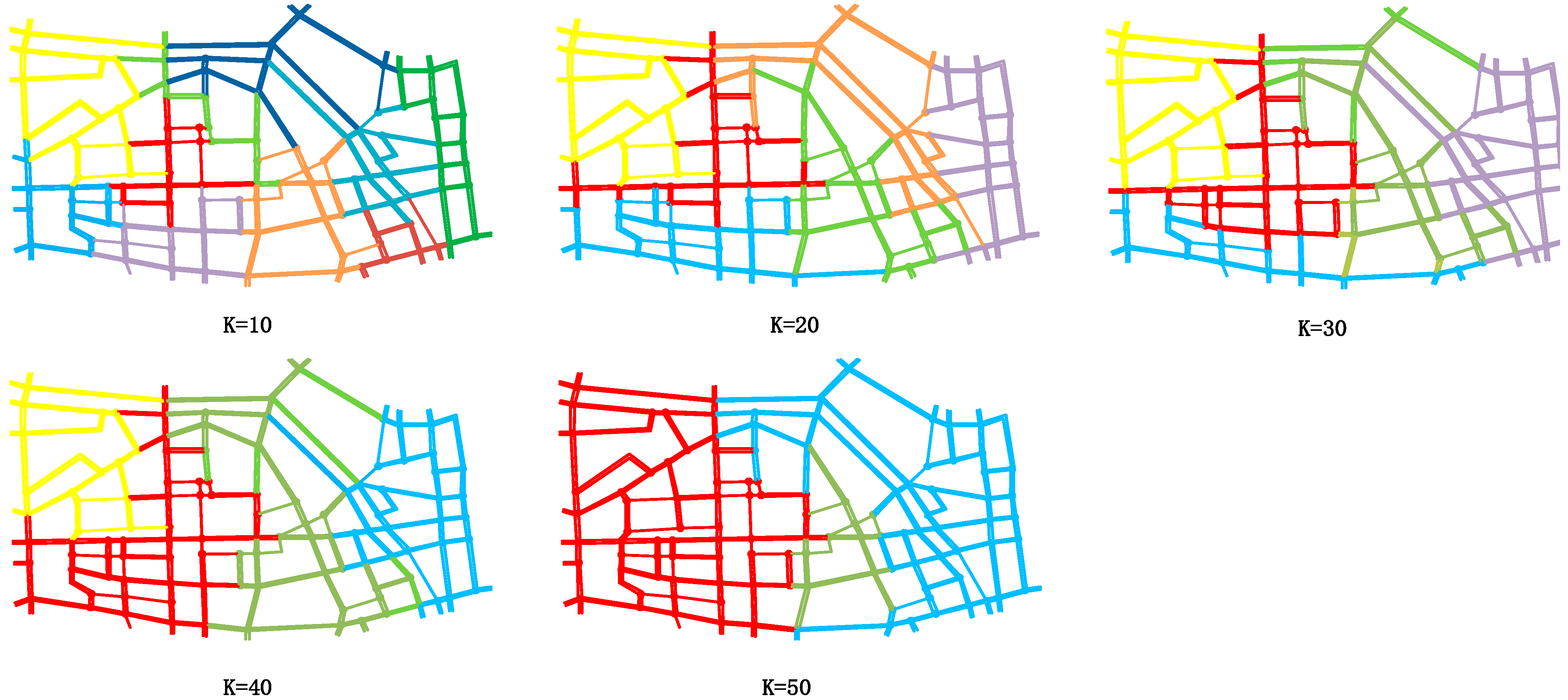
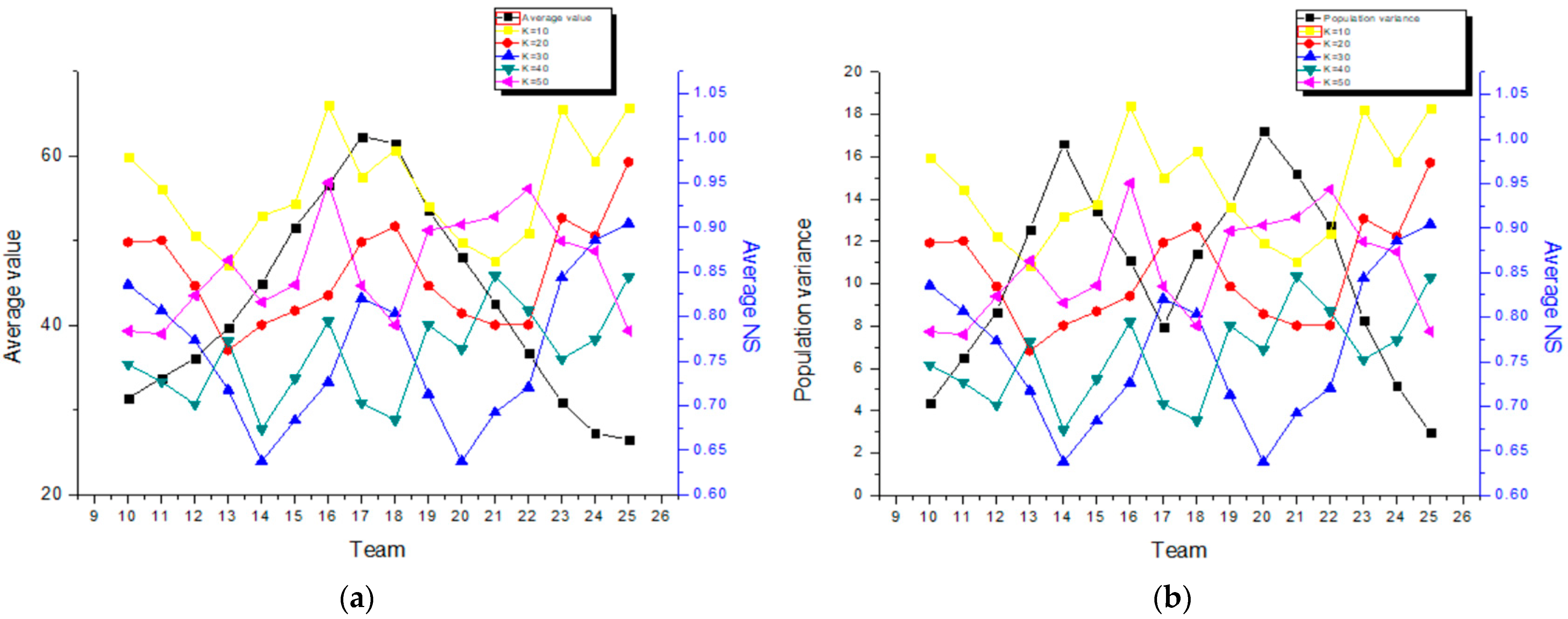
4.2. Result Analysis
4.3. Method Comparison
5. Conclusions and Future Development
5.1. Conclusions
5.2. Future Development
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Munoz, J.C.; Daganzo, C.F. Structure of the transition zone behind freeway queues. Transp. Sci. 2003, 37, 312–329. [Google Scholar] [CrossRef][Green Version]
- Daganzo, C.F. Urban gridlock: Macroscopic modeling and mitigation approaches. Transp. Res. B-Methodol. 2007, 41, 49–62. [Google Scholar] [CrossRef]
- Geroliminis, N.; Daganzo, C.F. Existence of urban-scale macroscopic fundamental diagrams: Some experimental findings. Transp. Res. B-Methodol. 2008, 42, 759–770. [Google Scholar] [CrossRef]
- Geroliminis, N.; Daganzo, C.F. Macroscopic modeling of traffic in cities. In Proceedings of the Transportation Research Board Meeting, Washington, DC, USA, 21–25 January 2007. [Google Scholar]
- Gayah, V.V.; Daganzo, C.F. Clockwise hysteresis loops in the Macroscopic Fundamental Diagram: An effect of network instability. Transp. Res. B-Methodol. 2011, 45, 643–655. [Google Scholar] [CrossRef]
- Geroliminis, N.; Boyaci, B. The effect of variability of urban systems characteristics in the network capacity. Transp. Res. B-Methodol. 2012, 46, 1607–1623. [Google Scholar] [CrossRef]
- Gan, W.J.; Gayah, V.V. A kinematic wave approach to traffic statics and dynamics in a double-ring network. Transp. Res. B-Methodol. 2013, 57, 114–131. [Google Scholar] [CrossRef]
- Buisson, C.; Ladier, C. Exploring the Impact of Homogeneity of Traffic Measurements on the Existence of Macroscopic Fundamental Diagrams. Transp. Res. Rec. 2009, 2124, 127–136. [Google Scholar] [CrossRef]
- Daganzo, C.F.; Gayah, V.V.; Gonzales, E.J. Macroscopic relations of urban traffic variables: Bifurcations, multivaluedness and instability. Transp. Res. Part B Methodol. 2011, 45, 278–288. [Google Scholar] [CrossRef]
- Tsubota, T.; Bhaskar, A.; Chung, E. Macroscopic Fundamental Diagram for Brisbane, Australia Empirical Findings on Network Partitioning and Incident Detection. Transp. Res. Rec. 2014, 2421, 12–21. [Google Scholar] [CrossRef]
- Hoai-Nam, N.; Fishbain, B.; Bitar, E.; Mahalel, D.; Gutman, P. Dynamic Model for estimating the Macroscopic Fundamental Diagram. PapersOnLine 2016, 49, 297–302. [Google Scholar] [CrossRef]
- Batista, S.F.A.; Seppecher, M.; Leclercq, L. Identification and characterizing of the prevailing paths on a urban network for MFD-based applications. Transp. Res. Part C Emerg. Technol. 2021, 127, 102953. [Google Scholar] [CrossRef]
- Gao, X.S.; Gayah, V.V. An analytical framework to model uncertainty in urban network dynamics using Macroscopic Fundamental Diagrams. Transp. Res. B-Methodol. 2018, 117, 660–675. [Google Scholar] [CrossRef]
- Shim, J.; Yeo, J.; Lee, S.; Hamdar, S.H.; Jang, K. Empirical evaluation of influential factors on bifurcation in macroscopic fundamental diagrams. Transport. Res. C-Emerg. 2019, 102, 509–520. [Google Scholar] [CrossRef]
- Yang, X.Z.; Guo, Y. Exploring the Relationship between Heterogeneity of Vehicle Distribution and the Macroscopic Fundamental Diagram under Segment Disruption Conditions. Procedia Comput. Sci. 2017, 109, 600–607. [Google Scholar]
- Wahaballa, A.M.; Hemdan, S.; Kurauchi, F. Relationship Between Macroscopic Fundamental Diagram Hysteresis and Network-Wide Traffic Conditions. Transp. Res. Procedia 2018, 34, 235–242. [Google Scholar] [CrossRef]
- Tak, S.K.; Yeo, H. Investigating Transfer Flow between Urban Networks Based on a Macroscopic Fundamental Diagram. Transp. Res. Rec. 2018, 2672, 75–85. [Google Scholar] [CrossRef]
- Jain, A.K. Data clustering: 50 years beyond K-means. Pattern Recogn. Lett. 2010, 31, 651–666. [Google Scholar] [CrossRef]
- Li, Y.; Zhu, L.; Sun, J.; Tian, Y. Generating a Spatiotemporal Dynamic Map for Traffic Analysis Using Macroscopic Fundamental Diagram. J. Adv. Transport. 2019, 2019, 9540386. [Google Scholar] [CrossRef]
- Saeedmanesh, M.; Geroliminis, N. Dynamic clustering and propagation of congestion in heterogeneously congested urban traffic networks. Transp. Res. Part B Methodol. 2017, 105, 193–211. [Google Scholar] [CrossRef]
- Saedi, R.; Saeedmanesh, M.; Zockaie, A.; Saberi, M.; Geroliminis, N.; Mahmassani, H.S. Estimating network travel time reliability with network partitioning. Transp. Res. Part C Emerg. Technol. 2020, 112, 46–61. [Google Scholar] [CrossRef]
- Lin, X. A Road Network Traffic State Identification Method Based on Macroscopic Fundamental Diagram and Spectral Clustering and Support Vector Machine. Math. Probl. Eng. 2019, 2019, 6571237. [Google Scholar] [CrossRef]
- Lentzakis, A.F.; Su, R.; Wen, C. Time-dependent partitioning of urban traffic network into homogeneous regions. In Proceedings of the International Conference on Control Automation Robotics & Vision, Singapore, 10–12 December 2014. [Google Scholar]
- Mori, G. Guiding Model Search Using Segmentation; IEEE: Piscataway, NJ, USA, 2005; pp. 1417–1423. [Google Scholar]
- Haddad, J.; Geroliminis, N. On the stability of traffic perimeter control in two-region urban cities. Transp. Res. B-Methodol. 2012, 46, 1159–1176. [Google Scholar] [CrossRef]
- Laval, J.A.; Castrillon, F. Stochastic approximations for the macroscopic fundamental diagram of urban networks. Transp. Res. B-Methodol. 2015, 81, 904–916. [Google Scholar] [CrossRef]
- Geroliminis, N.; Sun, J. Properties of a well-defined macroscopic fundamental diagram for urban traffic. Transp. Res. B-Methodol. 2011, 45, 605–617. [Google Scholar] [CrossRef]
- Geroliminis, N.; Haddad, J.; Ramezani, M. Optimal Perimeter Control for Two Urban Regions With Macroscopic Fundamental Diagrams: A Model Predictive Approach. IEEE Trans. Intell. Transp. Syst. 2013, 14, 348–359. [Google Scholar] [CrossRef]
- Aboudolas, K.; Geroliminis, N. Perimeter and boundary flow control in multi-reservoir heterogeneous networks. Transp. Res. B-Meth. 2013, 55, 265–281. [Google Scholar] [CrossRef]
- Li, D.; Liu, Z.; Lang, W.; Zhang, C.; Zhu, M.; He, Z. Consensus-Based Approach for Perimeter Control of Urban Road Traffic Networks. ACSR-Adv. Comput. Sci. Res. 2016, 52, 200–208. [Google Scholar]
- Felzenszwalb, P.F.; Huttenlocher, D.P. Efficient Graph-Based Image Segmentation. Int. J. Comput. Vis. 2004, 59, 167–181. [Google Scholar] [CrossRef]
- Van de Sande, K.E.; Uijlings, J.R.; Gevers, T.; Smeulders, A.W. Segmentation as selective search for object recognition. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Boykov, Y.Y.; Jolly, M.P. Interactive graph cuts for optimal boundary & region segmentation of objects in N-D images. In Proceedings of the Eighth IEEE International Conference on Compoter Vision, Vancouver, BC, Canada, 7–14 July 2001; Volume I, pp. 105–112. [Google Scholar]
- Zeng, J.W.; Qian, Y.S.; Yin, F.; Zhu, L.P. A multi-value cellular automata model for multi-lane traffic flow under lagrange coordinate. Comput. Math. Organ. Theory 2021, 28, 178–192. [Google Scholar] [CrossRef]
- Knoop, S.L.L.; Keyvan-Ekbatani, M. Using Taxi GPS Data for Macroscopic Traffic Monitoring in Large Scale Urban Networks: Calibration and MFD Derivation. Transp. Res. Procedia 2018, 34, 243–250. [Google Scholar]
- Ambuehl, L.; Loder, A.; Zheng, N.; Axhausen, K.W.; Menendez, M. Approximative Network Partitioning for MFDs from Stationary Sensor Data. Transp. Res. Rec. 2019, 2673, 94–103. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| k | 10 | 20 | 30 | 40 | 50 |
|---|---|---|---|---|---|
| Number of clusters | 10 | 6 | 5 | 4 | 3 |
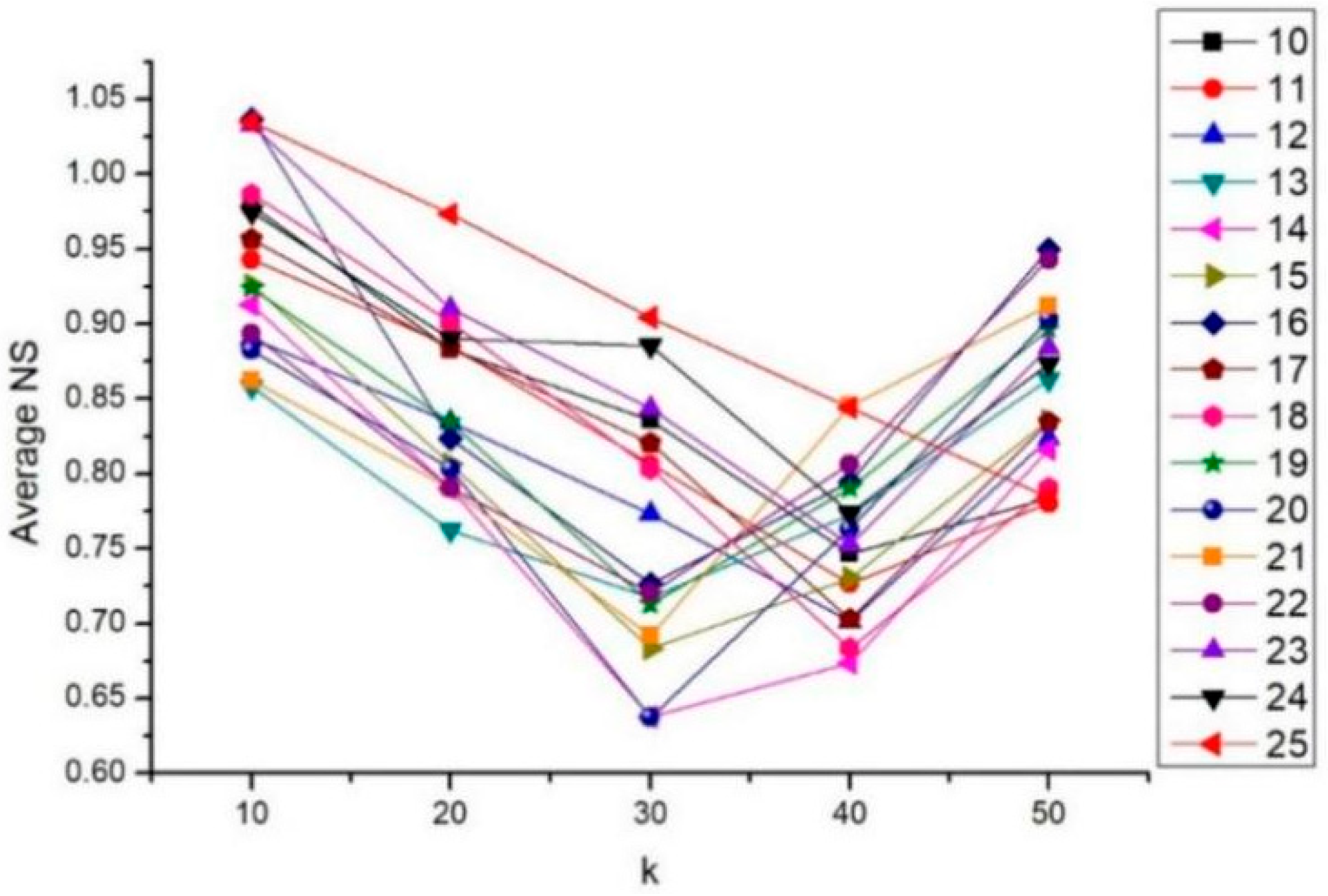
| Average NS | 0.9128 | 0.7904 | 0.6375 | 0.6734 | 0.8161 |
| Group Number | Average Value | Population Variance | Average NS | ||||
|---|---|---|---|---|---|---|---|
| 10 | 20 | 30 | 40 | 50 | |||
| 10 | 31.4 | 4.37 | 0.9788 | 0.8832 | 0.8357 | 0.7464 | 0.7836 |
| 11 | 33.8 | 6.48 | 0.9430 | 0.8853 | 0.8065 | 0.7266 | 0.78043 |
| 12 | 36.1 | 8.66 | 0.8902 | 0.8343 | 0.7732 | 0.7016 | 0.8235 |
| 13 | 39.7 | 12.57 | 0.8580 | 0.7621 | 0.7174 | 0.7724 | 0.8631 |
| 14 | 44.9 | 16.61 | 0.9128 | 0.7904 | 0.6375 | 0.6734 | 0.8161 |
| 15 | 51.6 | 13.43 | 0.9261 | 0.8065 | 0.6835 | 0.7302 | 0.8356 |
| 16 | 56.5 | 11.11 | 1.0367 | 0.8234 | 0.7265 | 0.7944 | 0.9501 |
| 17 | 62.3 | 7.95 | 0.9563 | 0.8834 | 0.8205 | 0.7028 | 0.8346 |
| 18 | 61.5 | 11.44 | 0.9867 | 0.9011 | 0.8034 | 0.6836 | 0.7903 |
| 19 | 53.6 | 13.63 | 0.9237 | 0.8345 | 0.7129 | 0.7904 | 0.8966 |
| 20 | 48.1 | 17.20 | 0.8827 | 0.8033 | 0.6374 | 0.7634 | 0.9032 |
| 21 | 42.6 | 15.18 | 0.8623 | 0.7904 | 0.6921 | 0.8455 | 0.9120 |
| 22 | 36.7 | 12.72 | 0.8936 | 0.7907 | 0.7204 | 0.8065 | 0.9431 |
| 23 | 30.9 | 8.28 | 1.0329 | 0.9106 | 0.8437 | 0.7523 | 0.8845 |
| 24 | 27.3 | 5.18 | 0.9744 | 0.8903 | 0.8854 | 0.7739 | 0.8732 |
| 25 | 26.5 | 2.97 | 1.0346 | 0.9734 | 0.9045 | 0.8439 | 0.7839 |
| K-Means | Figure 7a | Figure 7b | Figure 7c | Figure 7d | Our Method |
|---|---|---|---|---|---|
| Os/Od = 1 | Os/Od = 4 | Os/Od = 9 (1) | Os/Od = 9 (2) | ||
| Average NS | 0.1046 | 0.6439 | 0.9324 | 1.0471 | 0.6375 |
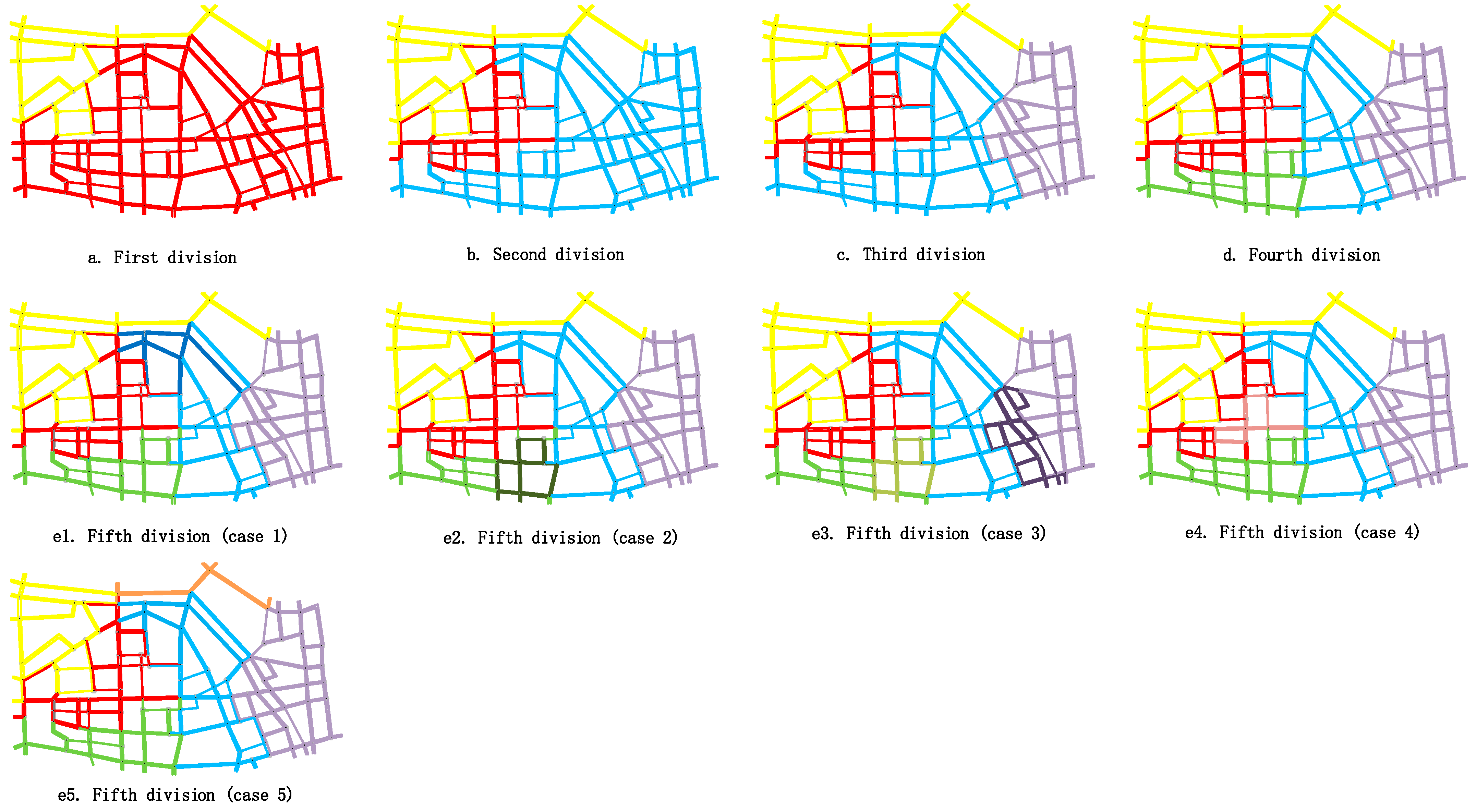
| Fifth Partition | 5-1 | 5-2 | 5-3 | 5-4 | 5-5 |
|---|---|---|---|---|---|
| Average NS | 0.7476 | 0.7205 | 0.8024 | 0.7706 | 0.7359 |
| Number of Partition | 1 | 2 | 3 | 4 | Our Method |
|---|---|---|---|---|---|
| Average NS | 0.9753 | 0.8945 | 0.8105 | 0.7024 | 0.6375 |
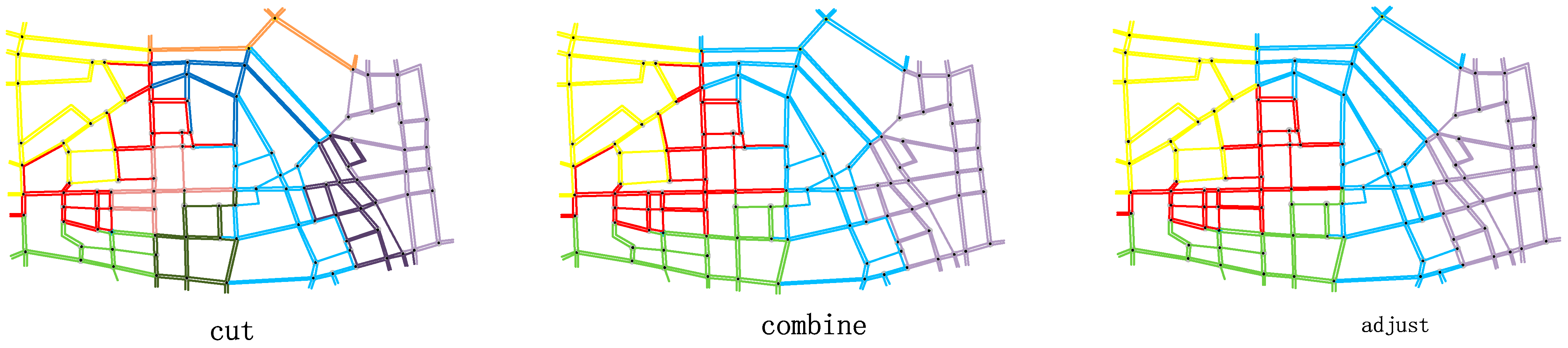
| Process | Partition | Merge | Adjustment | Our Method |
|---|---|---|---|---|
| Average NS | 0.9753 | 0.6724 | 0.7407 | 0.6375 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mo, X.; Jin, X.; Tian, J.; Shao, Z.; Han, G. Research on the Division Method of Signal Control Sub-Region Based on Macroscopic Fundamental Diagram. Sustainability 2022, 14, 8173. https://doi.org/10.3390/su14138173
Mo X, Jin X, Tian J, Shao Z, Han G. Research on the Division Method of Signal Control Sub-Region Based on Macroscopic Fundamental Diagram. Sustainability. 2022; 14(13):8173. https://doi.org/10.3390/su14138173
Chicago/Turabian StyleMo, Xianglun, Xiaohong Jin, Jinpeng Tian, Zhushuai Shao, and Gangqing Han. 2022. "Research on the Division Method of Signal Control Sub-Region Based on Macroscopic Fundamental Diagram" Sustainability 14, no. 13: 8173. https://doi.org/10.3390/su14138173
APA StyleMo, X., Jin, X., Tian, J., Shao, Z., & Han, G. (2022). Research on the Division Method of Signal Control Sub-Region Based on Macroscopic Fundamental Diagram. Sustainability, 14(13), 8173. https://doi.org/10.3390/su14138173