1.2. Related Work
The TSC problem has been tackled with several different approaches over time. The earliest solutions utilized rule-based systems. These algorithms determine key states with unique actions that can be used to reach a performance criterion. The authors in [
4] developed a Dynamic Traffic Signal Priority system that can handle real-time traffic and transit conditions. In [
5] a new system has been developed called REALBAND that identifies platoons in the network then predicts their arrival time to the intersection with the help of the fusion and filtering of traffic data. This paper also describes the solutions for the arrival of conflicting platoons. Another well-studied solution is Genetic Algorithms (GA). In [
6] the authors developed a group-based optimization model that tackles the safety and efficiency issues of the stage-based signal control approach in the case of mixed traffic flows with unbalanced volumes. Ref. [
7] proposes a novel Genetic Algorithm based approach that optimizes transit priority in scenarios with both transit and private traffic. Ref. [
8] utilizes a simulation-based Generic Algorithm with a multi-objective optimization model that considers both delays and emission. Simulation-based solutions are also widely applied for the TSC problem. In [
9] the authors have proposed a method that utilizes local communication between the sensors and the traffic lights and is capable of control them in a traffic responsive manner in complex real-world networks. Ref. [
10] analyzed the behavior of the CRONOS algorithm and showed that it decreases the total delay compared to a local and a centralized control strategy. A significant number of researchers applied Dynamic Programming (DP) to solve the TSC problem, primarily because of its adjustability and potential to be used in a vast set of traffic conditions and its virtue to utilize a diverse group of performance indicators. In [
11] the authors used an Approximate Dynamic Programming based approach that profoundly reduced the vehicle delays and also mitigated the required computational resources by approximating the value-function. Ref. [
12] presents RHODES that decomposes and reorganizes the TSC problem into hierarchical sub-problems. The paper also showed that RHODES outperforms semi-actuated controllers in terms of delay. Multi-Agent Systems (MAS) can also be considered a common approach for tackling the TSC problem. Ref. [
13] proposes a Group-Based signal control method where the signal groups are modeled as individual agents, and these agents can make decisions on the intersection level according to the given traffic scenario. Game Theory-based methods are well-explored in TSC applications. The authors in [
14] formulated the TSC problem as a noncooperative game where the agents’ goal is to minimize their queue length.
However, in recent trends, Reinforcement Learning (RL) algorithms have been used for solving the TSC problem. RL showed impressive results in this realm and also in several other transportation-related applications [
15,
16]. In [
17] the authors proposed utilization of high-resolution event-based data for state representation and outperformed both fixed-time and actuated controllers in terms of queue length and total delay. Ref. [
18] compared a Game Theory and RL-based solutions with fixed-time control for a single intersection set-up, and the results showed that both methods provide superior performance in queue length compared to the fixed-time controller. The authors in [
19] proposed a dynamically changing discount factor for the Bellman equation that is responsible for generating the target values for the DQN algorithm. They compared their results with the fixed-time controller and the original DQN agent. The results showed that their improved agent reached better results in total delay and average throughput than any other solution. Ref. [
20] compared conventional Reinforcement Learning algorithms with the DQN algorithm for the single-intersection TSC problem, and the results showed that the DQN algorithm mitigates more the total delay. Ref. [
21] proposes a novel state representation approach called discrete traffic state encoding (DTSE). Compared to the same algorithm with feature vector-based state-representation, the new representation reaches better performance in average cumulative delay and average queue length. The authors in [
22] developed an agent with hybrid action space that combines discrete and continuous action spaces and compared their solution to DRL algorithms with discrete and continuous action spaces and fixed-time control. The results showed that the proposed method outperformed all other methods in average travel time, queue length, and average waiting time. RL has also been applied for the multi-intersection TSC problem. Ref. [
23] proposes a novel cooperative DRL framework called Coder that decomposes the original RL problem into sub-problems that have straightforward RL goals. The papers compare the proposed method to other RL approaches and also to rule-based methods such as fixed-time control. The authors in [
24] proposed a new rewarding concept and the DQN algorithm, which is combined with a coordination algorithm for controlling multiple intersections. Ref. [
25] proposed a Multi-Agent A2C algorithm for solving the multi-intersection TSC problem and compared the results with other DRL algorithms both on synthetic traffic grid and real-word traffic network. For a more thorough review of algorithms that are applied for TSC, see [
26] and for purely RL solutions for the TSC problem see [
27,
28].
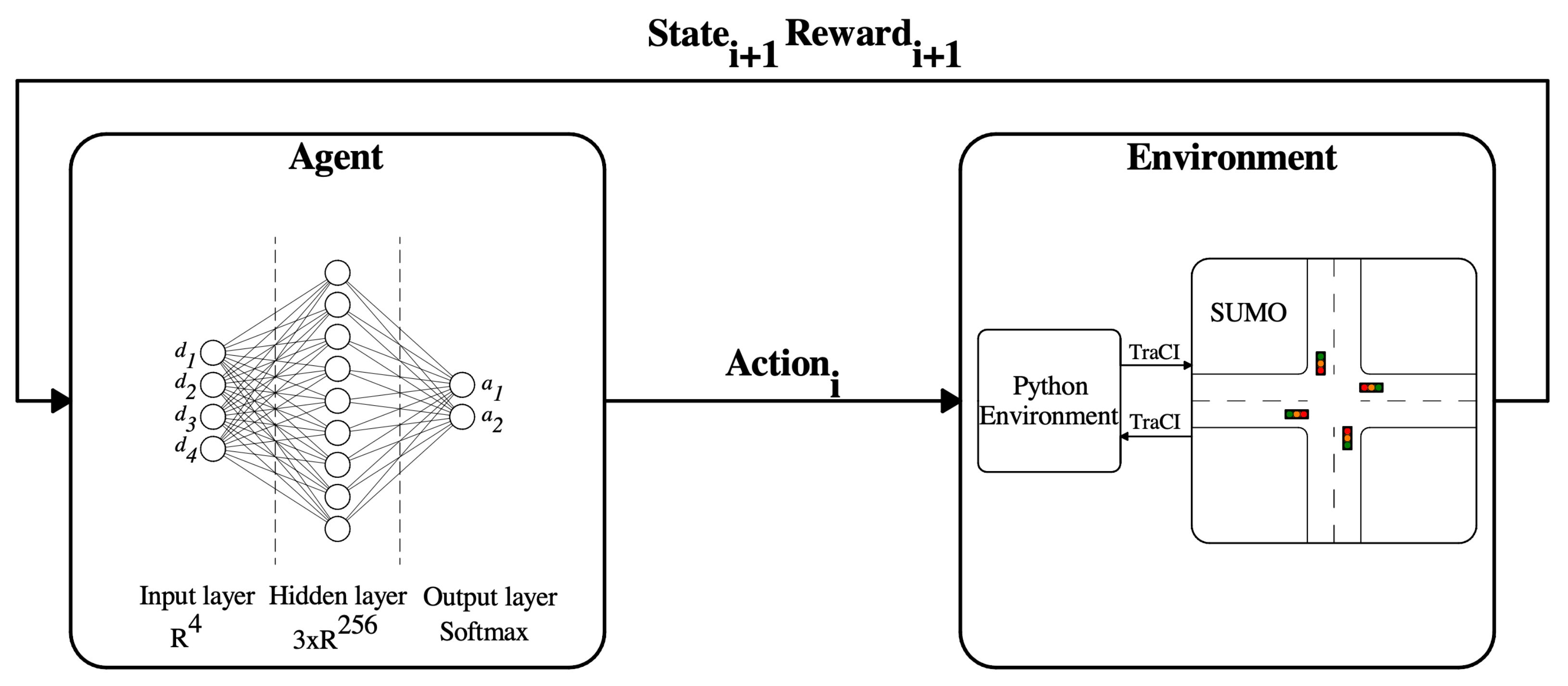
These papers prove that RL can be successfully applied in this field. The main reasons for the utilization of RL in the TSC problem are the vast versatility of essential features that the RL framework possesses for sequential decision-making problems. One of them is the scalability from single intersections to multi intersections and even to complex networks. Others are the generalization feature of function approximators and the low computational cost of inferencing already trained models supporting real-life implementation. The mentioned advantages are the main reason why RL-based solutions have a vast literature in this domain. The trend of suitable algorithms in the TSC problem evolved along with the advances in RL. It started from a simple value-based and policy-based solution, such as Deep Q-Network (DQN) and Policy Gradient (PG), followed by the Actor-Critic approaches. The same happened in the case of state representations. In addition to feature-based value vectors, image-like representations started to trend thanks to the tremendous result of Convolution Neural Networks (CNN).
From the aspect of performance, one could consider the applied rewarding concepts as one of the most influential components of RL, but they have not matured at the same pace. The prevailing trends in the rewarding concept are mainly transportation-related measures, such as waiting time, queue length, vehicle discharge, phase-frequency, and pressure. Exploiting the vacancy, this paper aims to develop a novel rewarding concept that can outperform a modern actuated control approach in classic measures and, in the meantime, pays attention to the environmental aspect of the TSC problem.
1.3. Contributions of the Paper
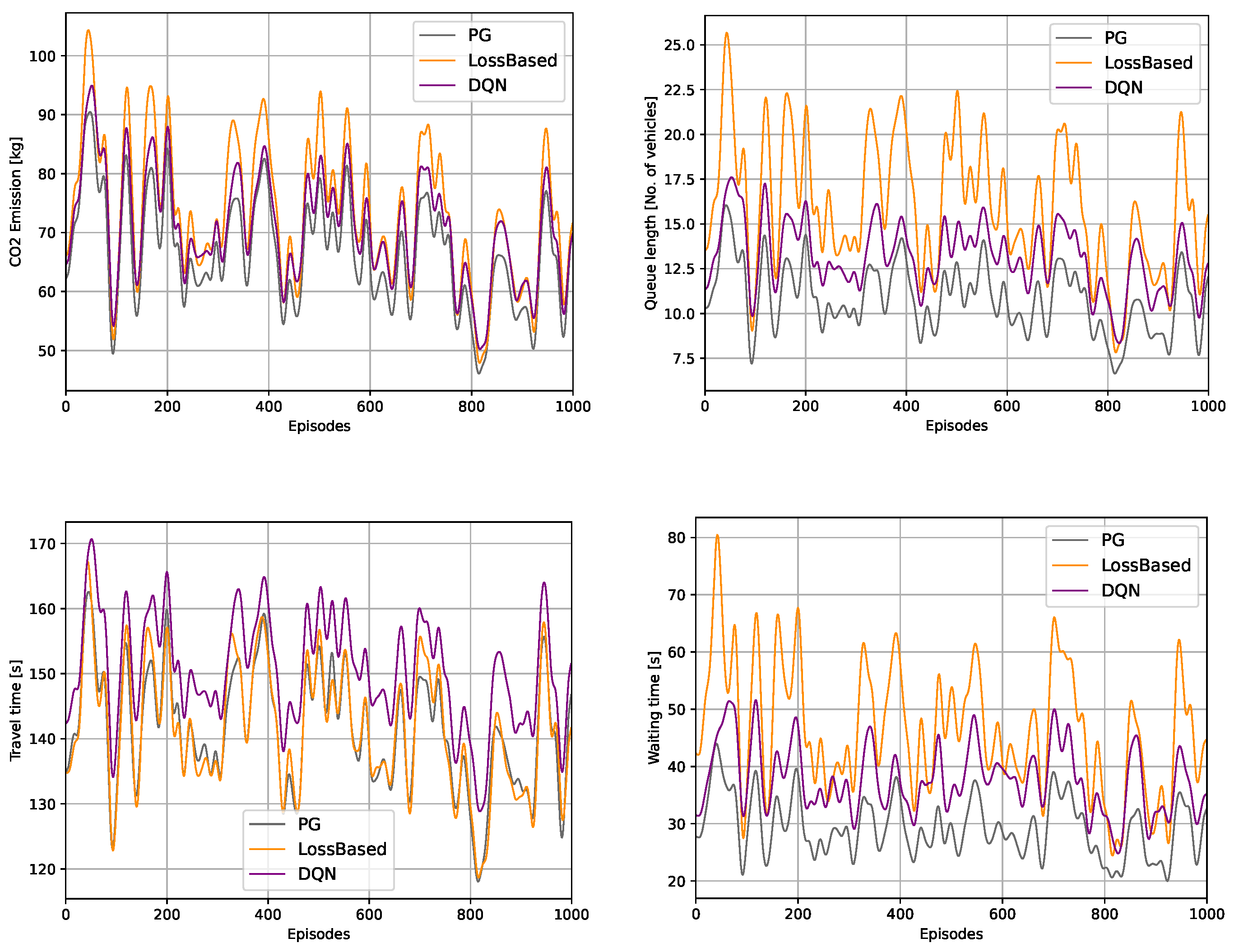
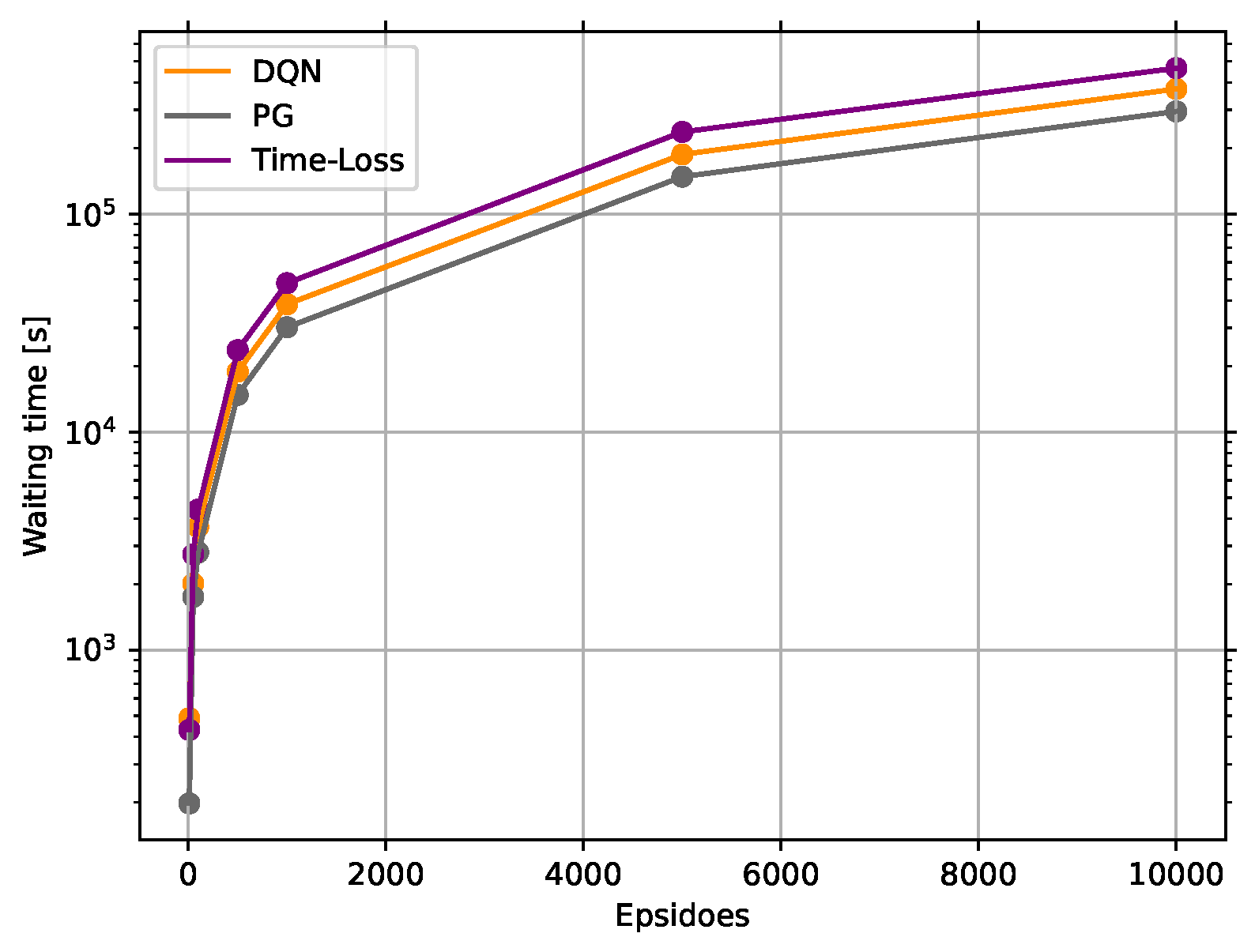
The contribution of the paper is twofold. First, a novel rewarding concept is presented for the TSC problem, which avoids any reward shaping, hence being considered a new insight into this particular control problem. Second, a PG and a DQN agent are trained with this new rewarding concept to show how the performance formulates. Furthermore, our proposed solutions are compared against a delay-based actuated control algorithm. Moreover, the evaluation of this paper covers not just the classic measures, e.g., waiting time, travel time, and queue length, but also compares the different solutions in sustainability measures, such as CO, NO, CO emission, etc. Such evaluation can be argued as necessary due to the sustainable transportation, and the reduction of transportation emission have grown into major concerns all around the globe.
The paper is organized as follows: First, in
Section 2 the utilized methodologies are detailed. Second,
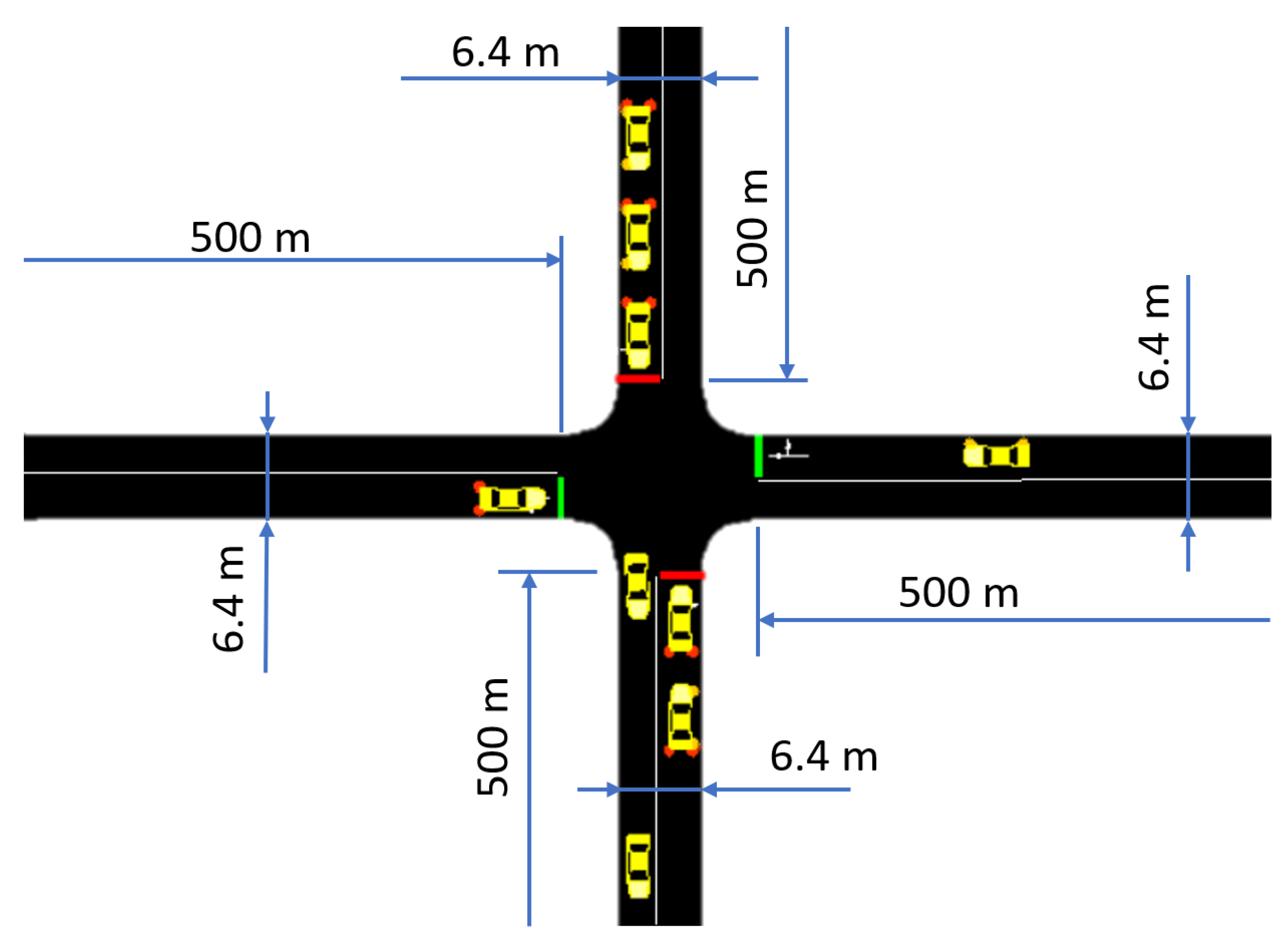
Section 3 the training environment along with its key components, such as the state representation, action space, and our novel rewarding concept, is presented. Last,
Section 4 compares the performances of the different methods. In
Section 5 the paper reveals a short conclusion about the results, discusses future endeavors, and ascertainment of the topic.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}