Discovering Spatio-Temporal Clusters of Road Collisions Using the Method of Fast Bayesian Model-Based Cluster Detection




Abstract
1. Introduction
2. Literature Review
3. Materials and Methods
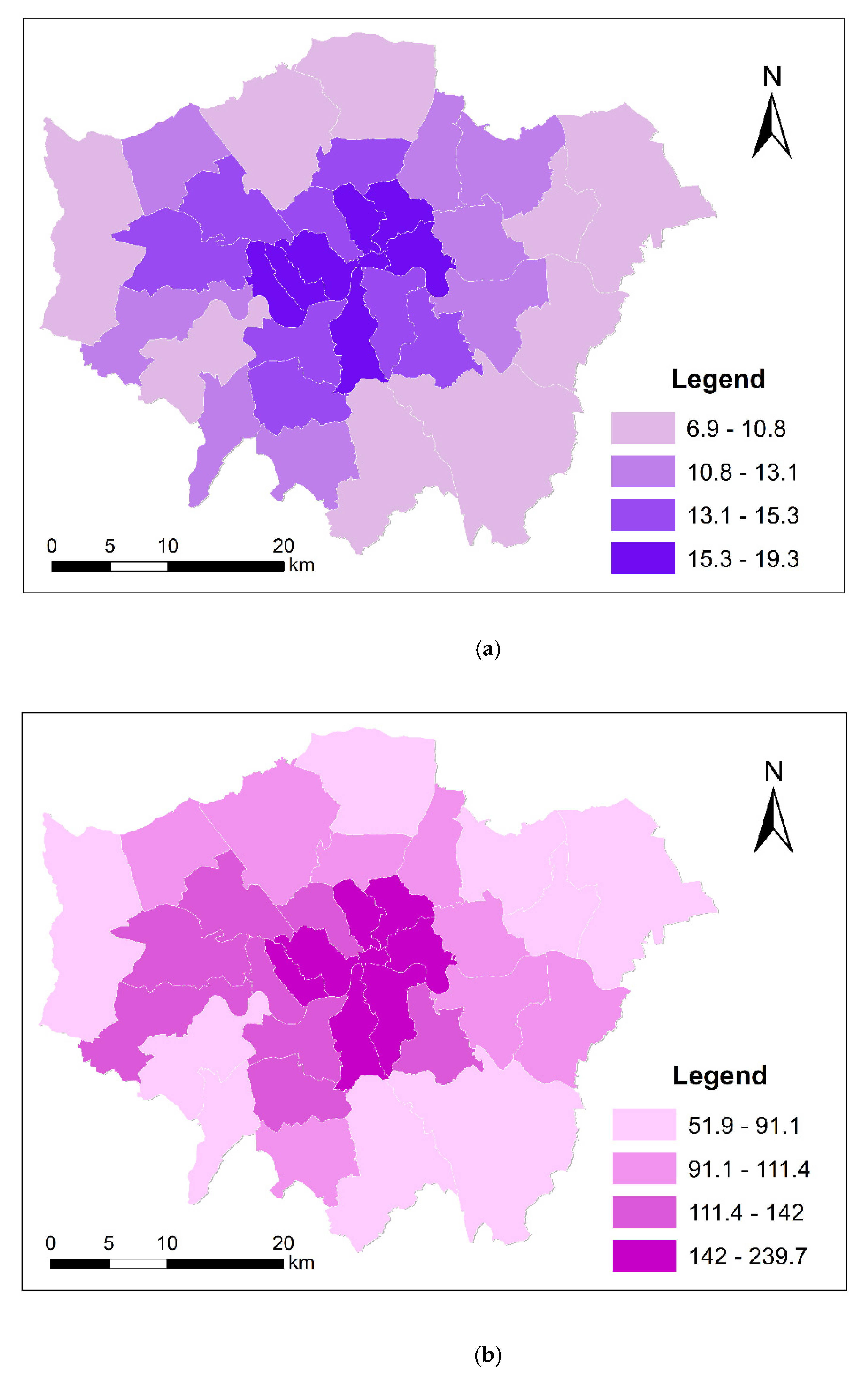
3.1. Data
3.2. Detecting Spatio-Temporal Clusters of Road Collisions
3.2.1. Fast Bayesian Model-Based Cluster Detection
3.2.2. Covariates
4. Results and Discussion
4.1. Cluster Detection: Spatio-Temporal Clusters of Road Collisions
4.1.1. Cluster Detection with no Covariates
4.1.2. Cluster Detection after Adjusting for Covariates
4.1.3. Comparison of Cluster Detection with and without Covariates
4.2. Cluster Detection: Spatio-Temporal Clusters of Serious Injury Collisions
4.3. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Bíl, M.; Andrášik, R.; Janoška, Z. Identification of hazardous road locations of traffic accidents by means of kernel density estimation and cluster significance evaluation. Accid. Anal. Prev. 2013, 55, 265–273. [Google Scholar] [CrossRef] [PubMed]
- Thakali, L.; Kwon, T.J.; Fu, L. Identification of crash hotspots using kernel density estimation and kriging methods: A comparison. J. Mod. Transp. 2015, 23, 93–106. [Google Scholar] [CrossRef]
- Chen, X.; Huang, L.; Dai, D.; Zhu, M.; Jin, K. Hotspots of road traffic crashes in a redeveloping area of Shanghai. Int. J. Inj. Control Saf. Promot. 2018, 25, 293–302. [Google Scholar] [CrossRef] [PubMed]
- Mohaymany, A.S.; Shahri, M.; Mirbagheri, B. GIS-based method for detecting high-crash-risk road segments using network kernel density estimation. Geo Spat. Inf. Sci. 2013, 16, 113–119. [Google Scholar] [CrossRef]
- Nie, K.; Wang, Z.; Du, Q.; Ren, F.; Tian, Q. A network-constrained integrated method for detecting spatial cluster and risk location of traffic crash: A case study from Wuhan, China. Sustainability 2015, 7, 2662–2677. [Google Scholar] [CrossRef]
- Fan, Y.; Zhu, X.; She, B.; Guo, W.; Guo, T. Network-constrained spatio-temporal clustering analysis of traffic collisions in Jianghan District of Wuhan, China. PLoS ONE 2018, 13, e0195093. [Google Scholar] [CrossRef]
- Ouni, F.; Belloumi, M. Spatio-temporal pattern of vulnerable road user’s collisions hot spots and related risk factors for injury severity in Tunisia. Transp. Res. Part F Traffic Psychol. Behav. 2018, 56, 477–495. [Google Scholar] [CrossRef]
- Kim, K.; Yamashita, E.Y. Using a k-means clustering algorithm to examine patterns of pedestrian involved crashes in Honolulu, Hawaii. J. Adv. Transp. 2007, 41, 69–89. [Google Scholar] [CrossRef]
- Warden, C.R. Comparison of Poisson and Bernoulli spatial cluster analyses of pediatric injuries in a fire district. Int. J. Health Geogr. 2008, 7, 51. [Google Scholar] [CrossRef]
- Minamisava, R.; Nouer, S.S.; de Morais Neto, O.L.; Melo, L.K.; Andrade, A.L.S. Spatial clusters of violent deaths in a newly urbanized region of Brazil: Highlighting the social disparities. Int. J. Health Geogr. 2009, 8, 66. [Google Scholar] [CrossRef]
- Gómez-Rubio, V.; Molitor, J.; Moraga, P. Fast Bayesian classification for disease mapping and the detection of disease clusters. In Quantitative Methods in Environmental and Climate Research; Springer: Cham, Switzerland, 2018; pp. 1–27. [Google Scholar]
- Petridou, E.; Moustaki, M. Human factors in the causation of road traffic crashes. Eur. J. Epidemiol. 2000, 16, 819–826. [Google Scholar] [CrossRef] [PubMed]
- Adanu, E.K.; Smith, R.; Powell, L.; Jones, S. Multilevel analysis of the role of human factors in regional disparities in crash outcomes. Accid. Anal. Prev. 2017, 109, 10–17. [Google Scholar] [CrossRef] [PubMed]
- Siskind, V.; Steinhardt, D.; Sheehan, M.; O’Connor, T.; Hanks, H. Risk factors for fatal crashes in rural Australia. Accid. Anal. Prev. 2011, 43, 1082–1088. [Google Scholar] [CrossRef]
- Yau, K.K. Risk factors affecting the severity of single vehicle traffic accidents in Hong Kong. Accid. Anal. Prev. 2004, 36, 333–340. [Google Scholar] [CrossRef]
- Zhang, G.; Yau, K.K.; Chen, G. Risk factors associated with traffic violations and accident severity in China. Accid. Anal. Prev. 2013, 59, 18–25. [Google Scholar] [CrossRef]
- Hsiao, H.; Chang, J.; Simeonov, P. Preventing emergency vehicle crashes: Status and challenges of human factors issues. Hum. Factors 2018, 60, 1048–1072. [Google Scholar] [CrossRef]
- Miranda-Moreno, L.F.; Morency, P.; El-Geneidy, A.M. The link between built environment, pedestrian activity and pedestrian–vehicle collision occurrence at signalized intersections. Accid. Anal. Prev. 2011, 43, 1624–1634. [Google Scholar] [CrossRef]
- Wang, X.; Yang, J.; Lee, C.; Ji, Z.; You, S. Macro-level safety analysis of pedestrian crashes in Shanghai, China. Accid. Anal. Prev. 2016, 96, 12–21. [Google Scholar] [CrossRef]
- Marshall, W.E.; Garrick, N.W. Does street network design affect traffic safety? Accid. Anal. Prev. 2011, 43, 769–781. [Google Scholar] [CrossRef]
- Castro, M.; Paleti, R.; Bhat, C.R. A latent variable representation of count data models to accommodate spatial and temporal dependence: Application to predicting crash frequency at intersections. Transp. Res. B-Meth. 2012, 46, 253–272. [Google Scholar] [CrossRef]
- Cai, Q.; Abdel-Aty, M.; Lee, J.; Wang, L.; Wang, X. Developing a grouped random parameters multivariate spatial model to explore zonal effects for segment and intersection crash modeling. Anal. Methods Accid. 2018, 19, 1–5. [Google Scholar] [CrossRef]
- Cai, Q.; Lee, J.; Eluru, N.; Abdel-Aty, M. Macro-level pedestrian and bicycle crash analysis: Incorporating spatial spillover effects in dual state count models. Accid. Anal. Prev. 2016, 93, 14–22. [Google Scholar] [CrossRef] [PubMed]
- Huang, H.; Zhou, H.; Wang, J.; Chang, F.; Ma, M. A multivariate spatial model of crash frequency by transportation modes for urban intersections. Anal. Methods Accid. 2017, 14, 10–21. [Google Scholar] [CrossRef]
- Zeng, Q.; Huang, H. Bayesian spatial joint modeling of traffic crashes on an urban road network. Accid. Anal. Prev. 2014, 67, 105–112. [Google Scholar] [CrossRef]
- Zeng, Q.; Wen, H.; Huang, H.; Abdel-Aty, M. A Bayesian spatial random parameters Tobit model for analyzing crash rates on roadway segments. Accid. Anal. Prev. 2017, 100, 37–43. [Google Scholar] [CrossRef] [PubMed]
- Liu, C.; Sharma, A. Exploring spatio-temporal effects in traffic crash trend analysis. Anal. Methods Accid. 2017, 16, 104–116. [Google Scholar] [CrossRef]
- Guo, Q.; Xu, P.; Pei, X.; Wong, S.C.; Yao, D. The effect of road network patterns on pedestrian safety: A zone-based Bayesian spatial modeling approach. Accid. Anal. Prev. 2017, 99, 114–124. [Google Scholar] [CrossRef] [PubMed]
- Xu, P.; Huang, H.; Dong, N.; Wong, S.C. Revisiting crash spatial heterogeneity: A Bayesian spatially varying coefficients approach. Accid. Anal. Prev. 2017, 98, 330–337. [Google Scholar] [CrossRef]
- Rhee, K.A.; Kim, J.K.; Lee, Y.I.; Ulfarsson, G.F. Spatial regression analysis of traffic crashes in Seoul. Accid. Anal. Prev. 2016, 91, 190–199. [Google Scholar] [CrossRef]
- Jung, I.A. Generalized linear models approach to spatial scan statistics for covariate adjustment. Stat. Med. 2009, 28, 1131–1143. [Google Scholar] [CrossRef]
- Gómez-Rubio, V.; Moraga, P.; Molitor, J.; Rowlingson, B. DClusterm: Model-based detection of disease clusters. J. Stat. Softw. 2019, 90, 1–26. [Google Scholar] [CrossRef]
- Rue, H.; Martino, S.; Chopin, N. Approximate Bayesian inference for latent gaussian models by using integrated nested laplace approximation (with discussion). J. R Stat. Soc. Ser. B 2009, 71, 319–392. [Google Scholar] [CrossRef]
- Kim, H.; Kim, Y.; Jang, K. Systematic relation of estimated travel speed and actual travel speed. IEEE Trans. Intell. Transpo. Syst. 2017, 18, 2780–2789. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | 2010 | 2011 | 2012 | 2013 | 2014 |
|---|---|---|---|---|---|
| Fatal injury | 1979 | 2107 | 1905 | 3342 | 3444 |
| Serious injury | 25,694 | 26,086 | 26,487 | 41,360 | 43,331 |
| Slight injury | 175,031 | 172,217 | 165,373 | 255,715 | 271,899 |
| Total | 202,704 | 200,410 | 193,765 | 300,417 | 318,674 |
| Category | Variable | Full Name | Mean | SD |
|---|---|---|---|---|
| Response | N_RC | Number of road collisions (count) | 737.36 | 253.96 |
| Covariates | RD | Road density (km/km2) | 13.04 | 3.31 |
| ID | Intersection density (count/km2) | 120.51 | 42.36 |
| Coefficient | GLM 1 | GLM 2 |
|---|---|---|
| Intercept | 6.477 × 10−12 | −0.937 *** |
| RD | 0.194 *** | |
| ID | −0.013 *** | |
| AIC | 19,438 | 15,086 |
| Cluster | Size | Start Time | End Time | Statistic | p-Value | Risk |
|---|---|---|---|---|---|---|
| 1 | 4 | 2010 | 2014 | 1318.03 | <0.001 | 0.391 |
| 2 | 3 | 2010 | 2014 | 1265.73 | <0.001 | 0.431 |
| 3 | 5 | 2010 | 2014 | 201.551 | <0.001 | 0.143 |
| 4 | 2 | 2010 | 2014 | 197.901 | <0.001 | 0.222 |
| 5 | 3 | 2010 | 2014 | 27.061 | <0.001 | 0.079 |
| Cluster | Size | Start Time | End Time | Statistic | p-Value | Risk |
|---|---|---|---|---|---|---|
| 1 | 2 | 2010 | 2014 | 1115.666 | <0.001 | 0.573 |
| 2 | 3 | 2010 | 2014 | 533.565 | <0.001 | 0.273 |
| 3 | 4 | 2010 | 2014 | 517.329 | <0.001 | 0.239 |
| 4 | 4 | 2010 | 2014 | 371.843 | <0.001 | 0.224 |
| 5 | 5 | 2010 | 2011 | 3.365 | <0.001 | 0.03 |
| 6 | 2 | 2012 | 2014 | 2.052 | <0.001 | 0.03 |
| Cluster | Size | Start Time | End Time | Statistic | p-Value | Risk |
|---|---|---|---|---|---|---|
| 1 | 10 | 2011 | 2012 | 59.633 | <0.001 | 0.242 |
| 2 | 13 | 2010 | 2010 | 29.287 | <0.001 | 0.234 |
| 3 | 1 | 2013 | 2014 | 10.867 | <0.001 | 0.490 |
| 4 | 4 | 2013 | 2013 | 5.659 | <0.001 | 0.175 |
| 5 | 1 | 2011 | 2013 | 2.830 | <0.001 | 0.193 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, Y.; Wang, Y.; Yuan, K.; Chan, T.O.; Huang, Y. Discovering Spatio-Temporal Clusters of Road Collisions Using the Method of Fast Bayesian Model-Based Cluster Detection. Sustainability 2020, 12, 8681. https://doi.org/10.3390/su12208681
Sun Y, Wang Y, Yuan K, Chan TO, Huang Y. Discovering Spatio-Temporal Clusters of Road Collisions Using the Method of Fast Bayesian Model-Based Cluster Detection. Sustainability. 2020; 12(20):8681. https://doi.org/10.3390/su12208681
Chicago/Turabian StyleSun, Yeran, Yu Wang, Ke Yuan, Ting On Chan, and Ying Huang. 2020. "Discovering Spatio-Temporal Clusters of Road Collisions Using the Method of Fast Bayesian Model-Based Cluster Detection" Sustainability 12, no. 20: 8681. https://doi.org/10.3390/su12208681
APA StyleSun, Y., Wang, Y., Yuan, K., Chan, T. O., & Huang, Y. (2020). Discovering Spatio-Temporal Clusters of Road Collisions Using the Method of Fast Bayesian Model-Based Cluster Detection. Sustainability, 12(20), 8681. https://doi.org/10.3390/su12208681