Urban Shape and Built Density Metrics through the Analysis of European Urban Fabrics Using Artificial Intelligence

 ,
,  and
and
Abstract
1. Introduction
2. Materials and Methods
2.1. Materials
2.2. Introduction to Artificial Intelligence Methods Used in Research
2.3. Obtaining Metrics Based on Case Studies Using Artificial Intelligence
2.3.1. Obtaining profiles
2.3.2. Characterization of the profiles: Obtaining the metrics of the density of each profile
3. Results
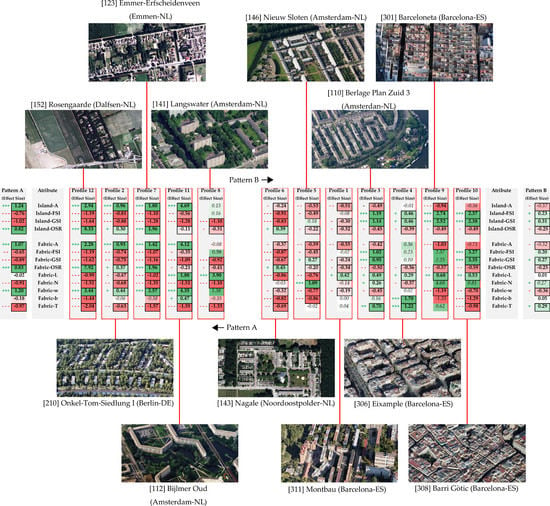
3.1. Classification of Urban Fabrics into Profiles
3.2. Characterization and Comparison of Profiles. Built Density Metrics Extraction
- Density Montbau Type [311] from Barcelona and similar fabrics: It presents metrics similar to the average of the totality of the fabrics. There are direct proportional relationships between FSI and GSI, between N and T, and an inverse relationship between w and T. This type of density also stands out in relation to other densities close to a relatively low OSR index, while GSI rises slightly, although it remains below the global average L, on the other hand, is significantly above average. Other neighborhoods studied that correspond to Montbau Type Density include Wildermanbuurt [170] (Amsterdam), Besos [302] (Barcelona), Rauchstrasse [213] (Berlin), Borrell I Solier [303] (Barcelona), Buurt Negen [115] (Amsterdam) and Troelstralaan [159] (Amsterdam). As for the spatial forms implied by this type of density, it can be said that its public space is largely reserved for car, although spaces for pedestrians can be observed of a certain quality and with signs of continuity in the network; there exists, although almost anecdotally, a slight typological variability in the neighborhood. The arrangement of slab buildings responds fundamentally to criteria of control of the sun and a certain interest in spatial formalization by means of their volumetric contours.
- Density Type Onkel-Tom-Siedlungen [210] from Berlin and similar fabrics: A moderately high w, and a moderately low FSI, GSI and L are observed. It also stands out in the different fabrics that the increase of FSI is accompanied by an increase of w. In summary, a moderate but generalized and proportional decrease of all the traditional density indicators is observed with an important increase of A. Other neighborhoods studied that correspond to the Onkel-Tom-Siedlungen Type Density include Siemensstadt [216] (Berlin), Hufeisensiedlung -Britz- [205] (Berlin), De Berg Zuid [117] (Amersfoort), Ijlst [134] (Wymbritseradeel), Staaken [217] (Berlin), Molenaarsgraaf [142] (Graafstrom) and Wageningen-Hoog [166] (Wageningen). The urban morphology of this density that has, among its specimens, several Siedlungen, is well known and has a remarkably high proportion of collective spaces, a relatively low amount of road and a relative typological variability, which generates interesting modes of interaction between the collective and the private spaces. Most of the configuration was developed through blocks of multi-family dwellings of open configuration and row layout, sometimes accompanying the road. In these Siedlungen, as in most of them, there is a relevant confluence between architectural values and the urban organization of the whole, that is to say, the position occupied by each building was perfectly studied for the elevation of certain urban goals, such as, for example, the enhancement of perspective, spatial containment or the control of the scale of collective space.
- Density Type Berlage Plan Zuid 3 [110] from Amsterdam and similar fabrics: Highlights by a high FSI and GSI, with a relatively low w. It also highlights the fact that when GSI increases, this does not necessarily lead to an increase in GSI. This is explained by the understanding that the FSI is usually increased by an increase in the number of floors, without necessarily transforming the footprint occupied by the buildings. The T is relatively high. Other neighborhoods studied that correspond to the Density Type Berlage Plan Zuid 3 are Vaillantlaan [160] (The Hague), Congres [305] (Barcelona), Gracia [309] (Barcelona), Java Island [135] (Amsterdam), Knsm Island [137] (Amsterdam) and Weena [169] (Rotterdam). The morphology that configures this density revolves around the idea of multi-family block buildings generally arranged around a pedestrian courtyard for collective use.
- Density Type Eixample from Barcelona [306] and similar fabrics: Highlights the important size of the road and a low correlation between L and the resulting FSI. This denotes interventions through additions to the original structure, probably increasing the constructed footprint or GSI of buildings over time. Other neighborhoods studied that correspond to this density: Zuidwest Kwadrant [177] (Amsterdam), Watergraafsmeer 2 [168] (Amsterdam), Venserpolder [161] (Amsterdam), Vila Olimpica [315] (Barcelona), Peperklip [151] (Rotterdam), Berlage Plan Zuid 1 [108] (Amsterdam), Karl-Marx-Allee 2 [206] (Berlin) and Grachtengordel [127] (Amsterdam). This urban morphology is configured by means of multi-family block buildings arranged around a pedestrian courtyard and generally for collective use. The difference with the previous density type of Berlage Plan Zuid, lies in that in the Eixample from Barcelona, we can find an FSI and a lower GSI, a higher W and consequently, a lower N, although the final computation of the proportion of road over the total is very similar. We could conclude that one of the main differences between the two densities is the greater distance between roads in the Eixample from Barcelona, although it is compensated for, in some way, with a greater width of the latter.
- Density Type Nieuw Sloten [146] from Amsterdam and similar fabrics: It emphasizes the importance of the road, presenting more interwoven (N), but smaller width (b) and reaching a lower percentage of road (T). There is also a relatively low Height of Buildings (L). Other neighborhoods studied that correspond to the Density Type Nieuw Sloten are Huisduinen [133] (Den Helder), Amsteldorp 1 [102] (Amsterdam), Stevensweert [158] (Maasgouw), Vreewijk [165] (Rotterdam), Colijnsplaat [116] (Noord-Beveland) and Amsteldorp 2 [103] (Amsterdam). The urban morphology is greatly influenced by the configuration of the terraced single-family buildings with the formation of private courtyards inside the block.
- Nagale Type Density [143] from Noordoostpolder and similar fabrics: Moderately low but generalized and proportional intensity indicators are observed. A and w are slightly lower than the average of all fabrics. Other neighborhoods studied that correspond to Nagale Type Density are Niehove [144] (Groningen) and Wolveschans [172] (Leek). The resulting urban morphology is relatively similar to the previous Density (Nieuw Sloten), although there is a very important difference in the amount of public space. In Nagele is superior, reducing the GSI and resulting in FSI. There is also a clear influence of a greater w in Nagele and simultaneously, the N descends, denoting collective spaces of great importance.
- Density Type Emmer-Erfscheidenveen [123] from Emmen and similar fabrics: Low-intensity indicators stand out, all with balanced levels with respect to the medium type fabric. It also produces a very high A, OSR, and w. On the other hand, there is a correlation that can be expressed as follows: lower A, imply higher L, i.e., the smaller the plot, the higher the height. Other neighborhoods studied that correspond to the Density Type Emmer-Erfscheidenveen are Hoog Soeren [132] (Apeldoorn) and Staphorst [157] (Staphorst). The urban form undergoes a very important transformation in this typical density as the urban intensity is reduced considerably. The characteristic typology consists of the detached single-family house with large gardens, most of which are of a private nature.
- Density Type Langswater [141] from Amsterdam and similar fabrics: They stand out for a high L, a low index of T and GSI, and FSI slightly below the reference average. Other neighborhoods studied that correspond to Langswater Type Density are Märkisches Viertel [209] (Berlin) and Berlage Plan Zuid 2 [109] (Amsterdam). The configuration of this type of density revolves around a block typology of high-rise multi-family dwellings without heterogeneity, which denotes a scarce typological and urban variability, probably leading to a certain social homogeneity.
- Density Barceloneta Type [301] from Barcelona and similar fabrics: It stands out for a high GSI and also a high Island-FSI, which are compensated with the wide road space, obtaining more contained data when referring to the fabric as a whole. The Ribera neighborhood [314] (Barcelona) corresponds to Barceloneta density. The morphology of this type of density is clearly marked by an extremely scarce public space and extremely high FSI. Curiously, most of the little space not occupied by buildings is occupied by roads, totally nullifying any possibility of socialization of public space.
- Gothic Quarter Type Density [308] from Barcelona and similar fabrics: It stands out on one hand for its high FSI and GSI, and on the other hand, for its low OSR, low w, reduced b, and low T. All of them are indicators of great intensity. Another neighborhood studied that corresponds to the Gothic Quarter Type Density is the neighborhood of Ciutat Vella [304] (Barcelona). The urban form differs from the previous typical density of the Barceloneta with a greater width of mesh and a consequent reduction in the percentage of road over the total land, which irremediably causes an improvement in public space. This can be observed by a certain sponging thanks to the appearance of a good number of places. Curiously, most of the indicators are similar to those of Barceloneta, although, as it is easy to see, the urban result is very different. Here, it was verified that a single indicator greatly transforms the resulting urban configuration.
- Density Type Bijlmer Oud [112] from Amsterdam and similar fabrics: It stands out for the exiguous and very limited road structure (N, T, and w), and for a high increase of L, but containing the FSI, up to a few levels below the average by means of a low GSI. Bijlmer Oud’s morphology is undoubtedly due to his extreme configuration. It hardly resembles any other of the neighborhoods studied. It stands out enormously for the very scarce amount of road and the great distance that it is necessary to cross until finding another axis of rolled accessibility. This results in enormous amounts of land destined for the collective. This issue has probably led to the well-known social problems of this unique proposal.
- Density Rosengaarde Type [152] from Dalfsen and similar fabrics: All indicators point to very low density and urban intensity. The morphology of Rosengaarde and Bijlmer Oud are clearly different from the rest of the urban fabrics analyzed. There is no doubt that this is a very low density; all parameters indicate this, leading to an equally low degree of urbanity and capacity for social interaction.
4. Discussion
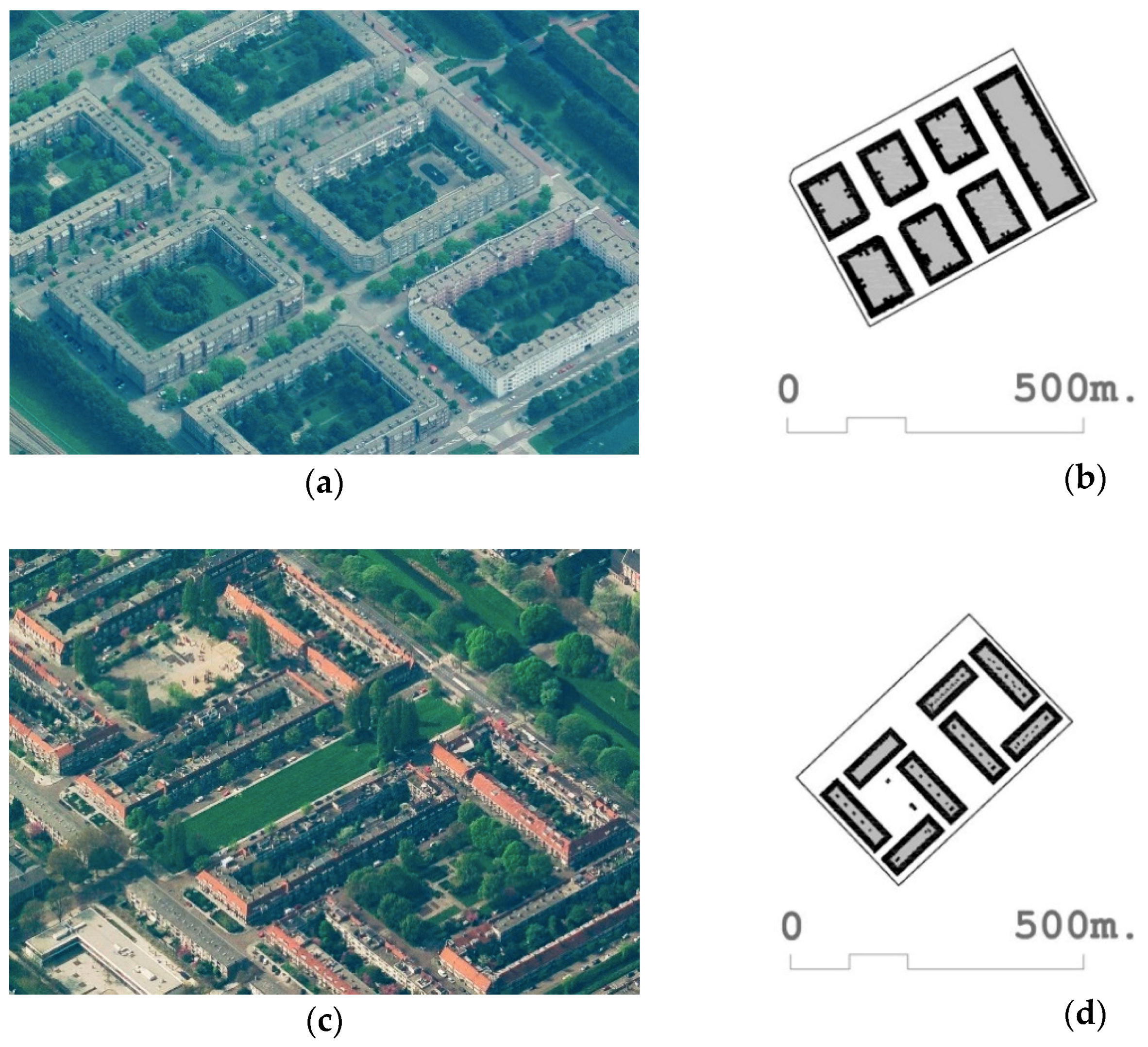
- In contemporary urban and spatial planning, multiple attempts have been made to define the urban form on the basis of one or two fundamental parameters, mainly through the use of the FSI variable and in a secondary and complementary manner with the GSI variable. It can be verified that the use of these parameters or variables sometimes produces an acceptable approach to the knowledge of urban forms and forms of urbanity, but in certain cases, it can be verified that they are not sufficient or adequate for that purpose. This insufficiency can be seen, for example, when comparing the fabric of [112] Bijlmer Oud and the fabric of [146] Nieuw Sloten, both in Amsterdam. Table 2 shows that Bijlmer Oud has a Fabric-FSI of 0.76 and [146] Nieuw Sloten of 0.77, which are, therefore, very similar. At the same time, they present very different urban forms, as can be verified in Figure 4. It is thus verified that the use of only one variable such as FSI is insufficient to define and qualify an urban fabric. This confirms the earlier work by Berghauser Pont and Haupt [29].
- If on the other hand, we take, from the same Table and Figure, the urban fabrics [146] Nieuw Stolen and [135] Java Island, also in Amsterdam; we can see that the GSI of both are very similar, 0.33 for the first and 0.34 for the second, but on the other hand, the second has an FSI of almost triple that the first (0.77 vs. 2.09). It is also observed that the GSI parameter in isolation does not provide enough information to determine or transmit the main characteristics of fabrics and their forms of urbanity, and can rather lead to misunderstandings if the parameters are handled in isolation. It is clear that an approach to density from a single parameter, such as FSI or GSI, is ill-advised to understand the intensities and urban forms that accompany them. This also confirms the earlier work by Berghauser Pont and Haupt [29].
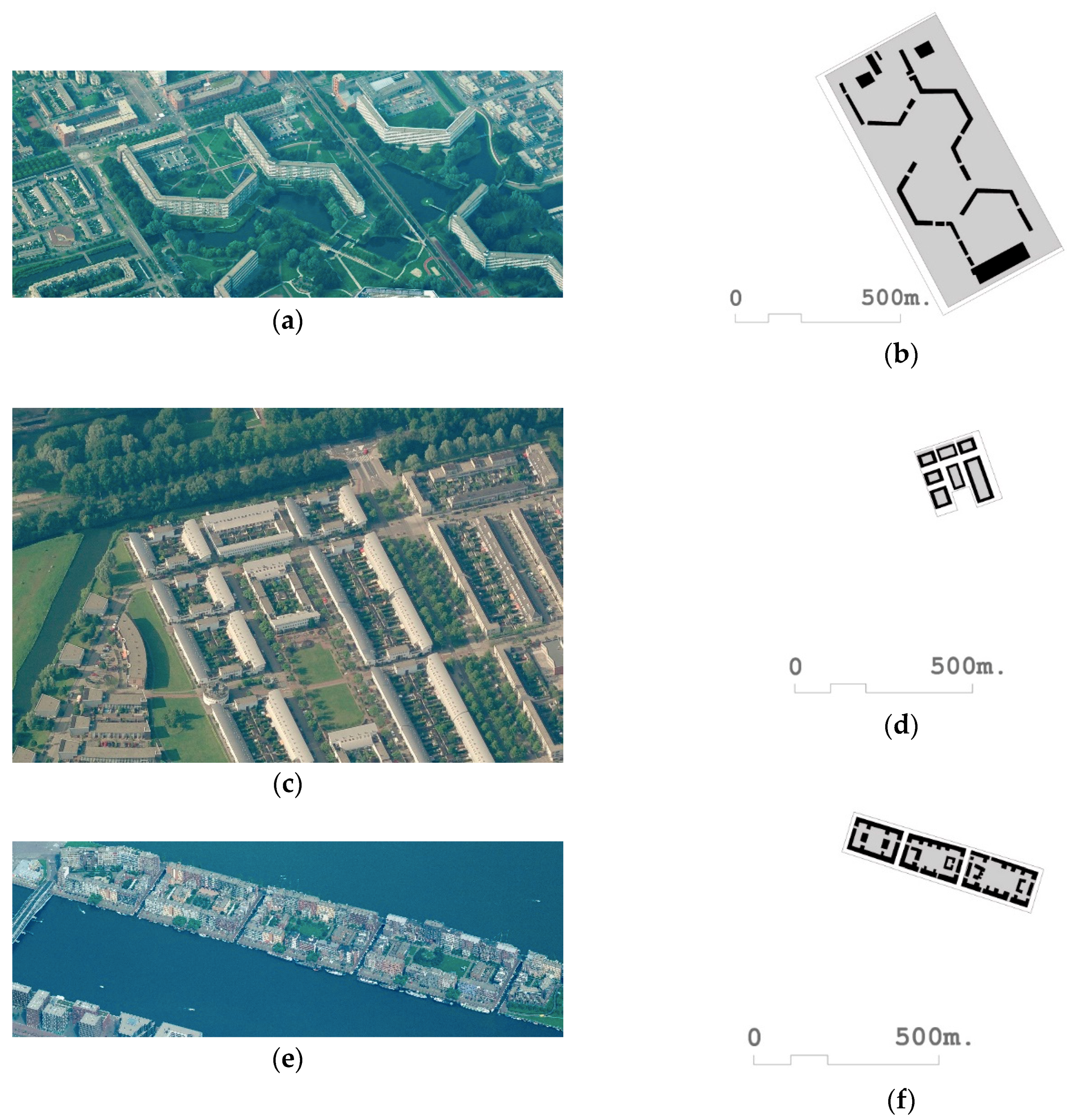
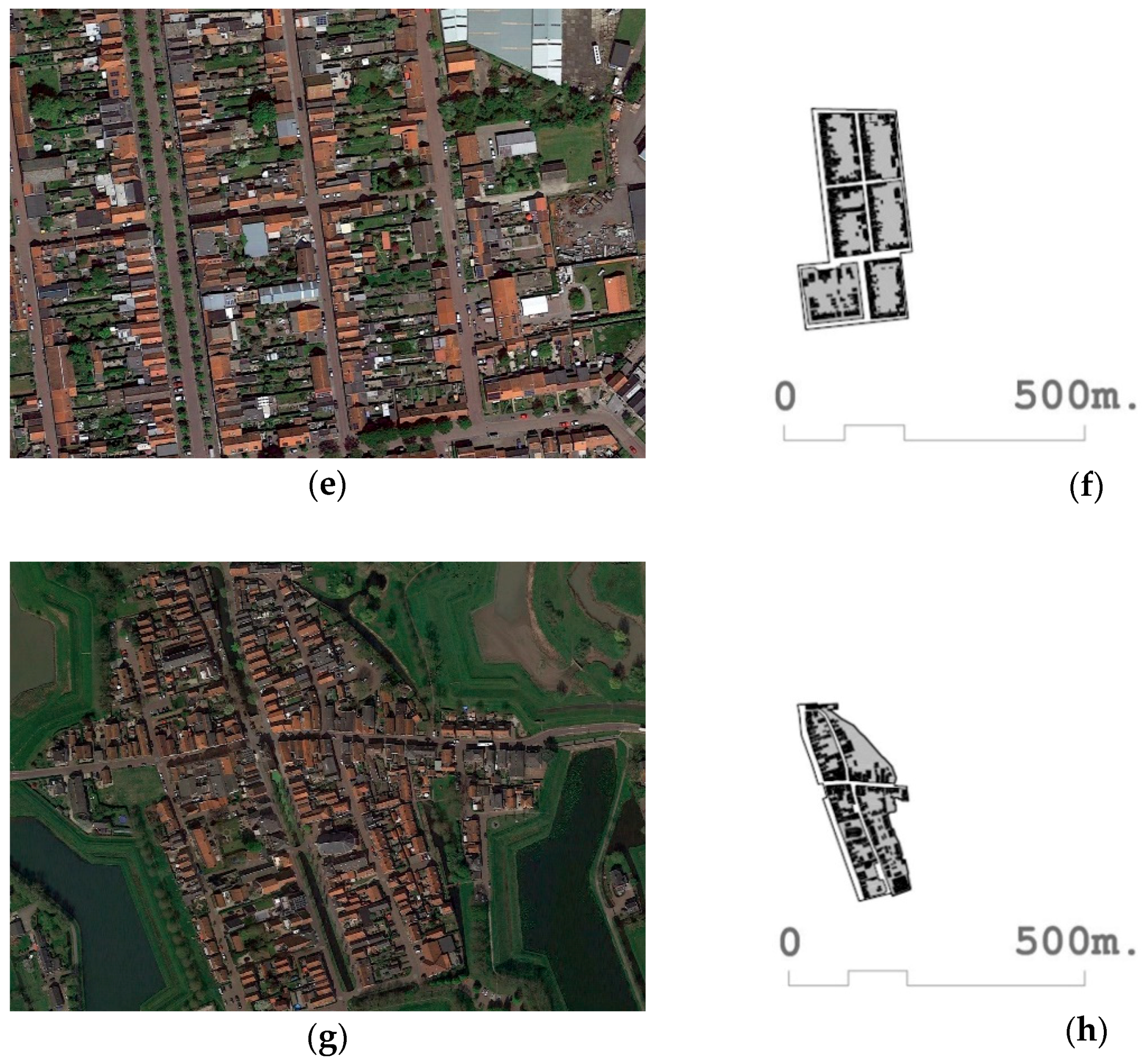
- In this section, we analyze what happens when we take three variables considered representative by Berghauser Pont and Haupt [29]. This research proposes the use of three fundamental indicators: FSI, GSI, and N. To verify the validity and robustness of the results of this research, we used the fabrics of the [168] Watergraafsmeer 2 and [116] Colijnspaat included in Table 3, the fabric of Watergraafsmeer 2 included in Figure 5c,d, the fabric of Colijnspaat included in Figure 5e,f. It can be observed that although the values of the FSI, GSI, and N of both fabrics are quite similar. For this purpose, the percentile and z-score are provided as indicators in Table 2. However, as can be seen through the floor plan and aerial photographs, the street designs, urban forms, and forms of urban life, and even architectural typologies are certainly shown to be different. In the fabric [168] Watergraafsmeer 2 (Figure 5c,d), the typology of multi-family housing around collective courtyards predominates, as opposed to single-family dwellings with a private plot of fabric [116] Colijnsplaat (Figure 5e,f). It can be seen that Berghauser Pont’s and Haupt’s [29] method of three fundamental indicators is not always optimal when it comes to characterizing and describing the fabrics it studies.
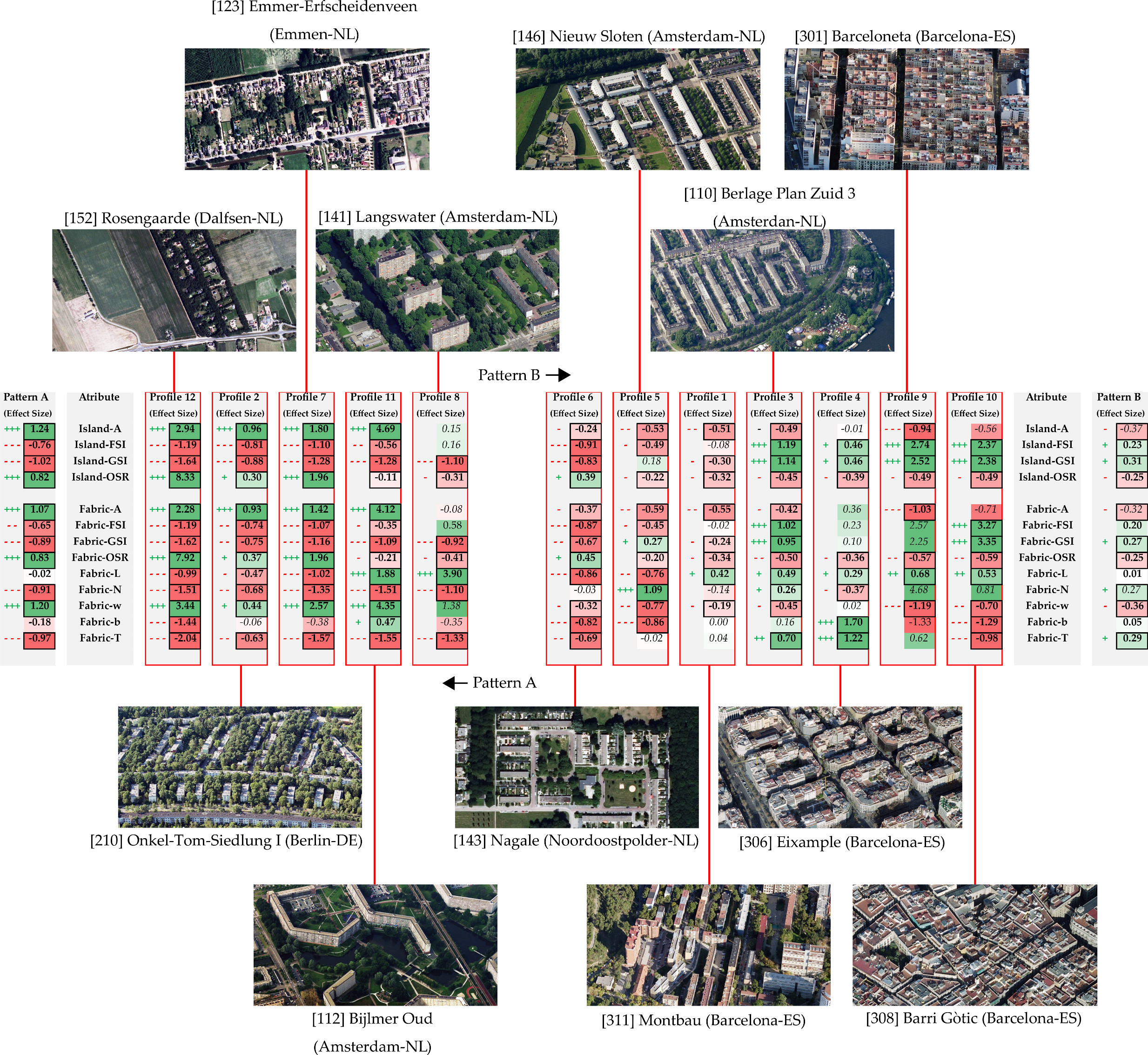
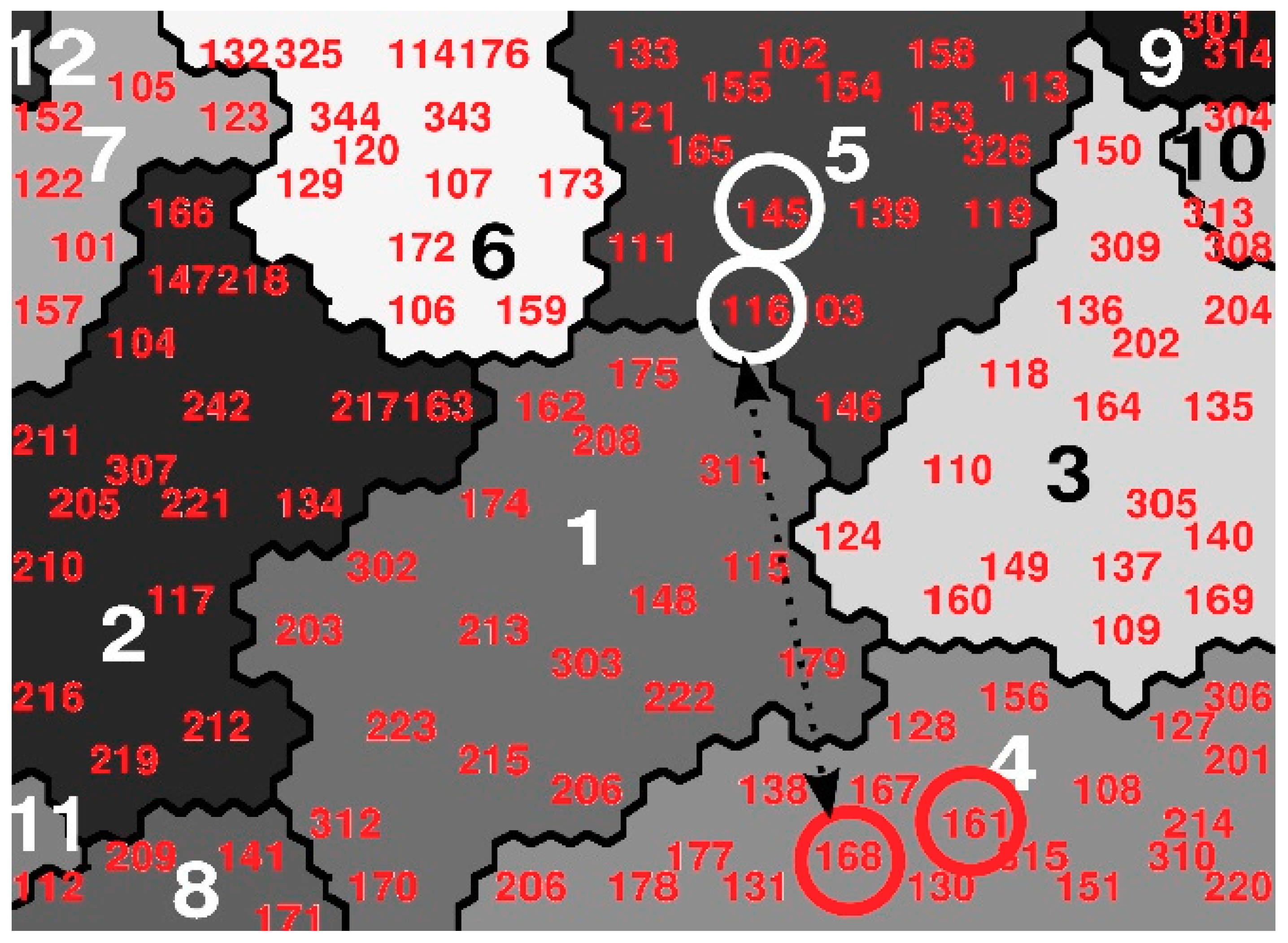
- One of the main characteristics of SOMs involves the semantic representation through which each entity studied is located on the SOM Map next to those similar entities. We can, thus, evaluate the degree of similarity of the two previous fabrics in relation to the next ones in the SOM map. Thus, in Figure 6, urban fabric circles are marked [161] Venserpolder, [168] Watergraafsmeer 2, [116] Colijnspaat, and [145] Niewpoort. If we first compared the fabric [116] Colijnspaat (Figure 5e,f) with the fabric [145] Niewpoort (Figure 5g,h); we can see that in the SOM map (Figure 6, white circles), they appear very close, as Table 2 verifies that their FSI, GSI, and N values are very similar. On the other hand, if we compare the fabric [168] Watergraafsmeer 2 (Figure 5c,d) with the fabric [161] Venserpolder (Figure 5a,b), which are also close to each other on the SOM map (Figure 6, red circles), Table 2 demonstrates that, unlike the previous ones, they have values of FSI and N with remarkable differences. In Figure 6 we can see that [168] Watergraafsmeer 2 and [161] Venserpolder belong according to SOM analysis to profile 4, and [116] Colijnspaat and [145] Niewpoort to profile 5. If we observe the statistical information in Figure 3, it can be verified, among other things, that the variables Fabric-b and Fabric-T have a special relevance in the definition of profile 4. This means that, for its correct identification, such variables should be used, and not only FSI, GSI, and N. We can conclude that the variables FSI, GSI, and N are not fully effective in characterizing urban fabrics. The methodology proposed in this paper, with the whole use of all the original Spacematrix indicators, is more robust.
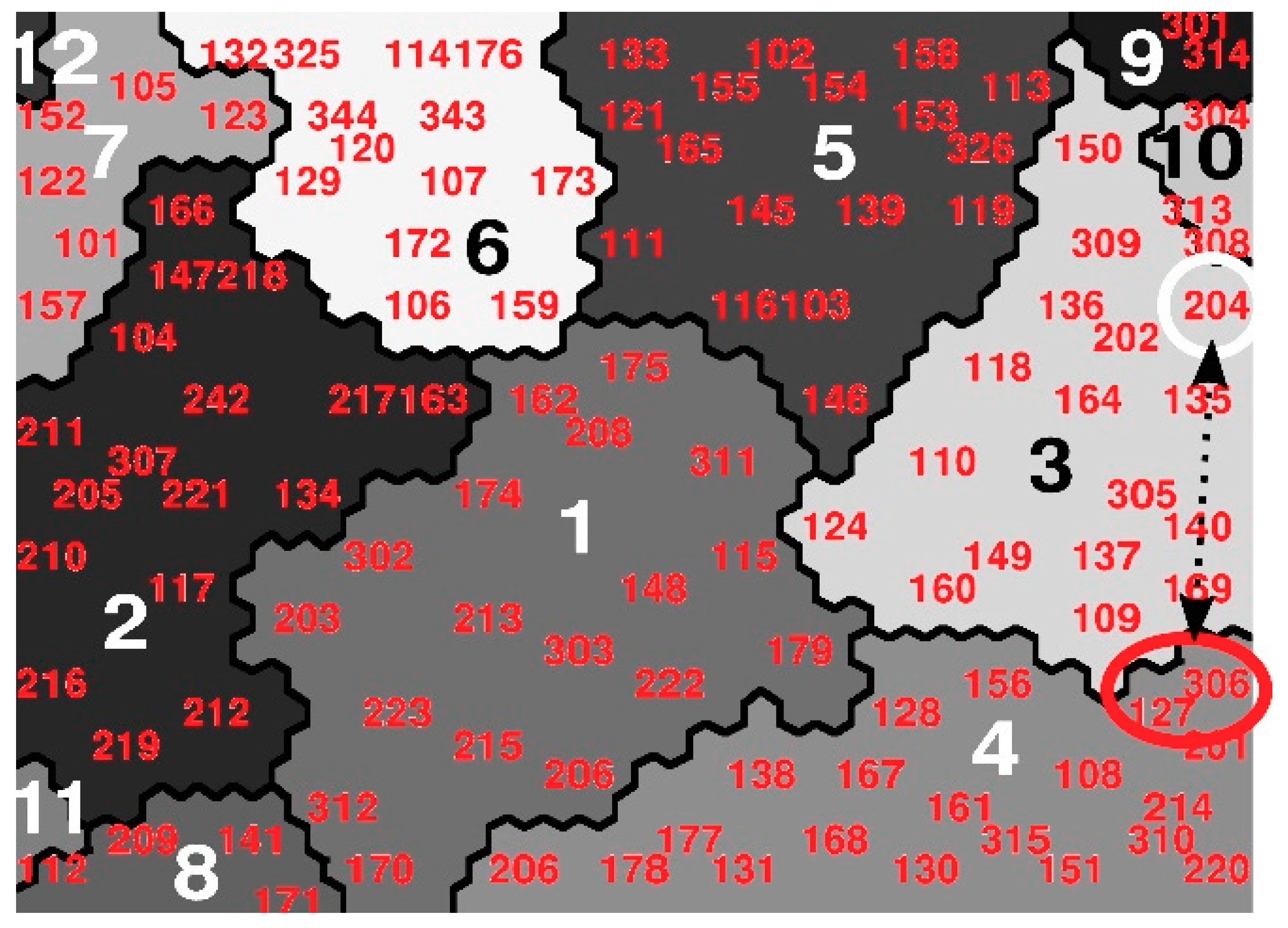
- If the results obtained in the cluster analysis of Berghauser Pont and Olsson [26] are compared with those obtained by means of the SOM methodology, it is possible to observe that, although certain parallelisms and similar classifications exist, certain differences are observed based on the greater robustness of the SOMs, but also due to the use only of the FSI, GSI, and N indicators, instead of the initial 17 indicators. One of the 12 clusters defined in the paper [26], namely Cluster 2, includes fabrics [127] Grachtengordel (Amsterdam), [306] Eixample (Barcelona), and [204] Hackesche Höpe (Berlin). On the other hand, according to the SOM methodology with its 12 clusters, fabrics [127] Grachtengordel and [306] Eixample are included in Profile 4, and, instead, fabric [204] Hackesche Höpe is framed in our work in Profile 3, as can be observed in Figure 7. If we analyze such fabrics, we can observe that there are indeed significant differences between them: [127] Grachtengordel and [306] Eixample show a ‘b’ between 29–32 m and ‘T’ between 35%–36%, and instead [204], Hackesche Höpe shows ‘b = 13 m’ and ‘T = 13%’. Those values are relevant in the definition of street type and public space, and Berghauser Pont and Olsson’s methodology does not use for clustering other indicators different from FSI, GSI, and L [26].
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Krehl, A.; Siedentop, S.; Taubenbsck, H.; Wurm, M. A comprehensive view on urban spatial structure: Urban density patterns of German city regions. ISPRS Int. J. Geo-Inf. 2019, 5, 76. [Google Scholar] [CrossRef]
- Kenworthy, J.R.; Laube, F.B. Automobile dependence in cities: An international comparison of urban transport and land use patterns with implications for sustainability. Environ. Impact Assess. Rev. 1996, 16, 279–308. [Google Scholar] [CrossRef]
- Kenworthy, J.R.; Laube, F.B. Patterns of Automobile Dependence in Cities: An International Overview of Key Physical and Economic Dimensions with Some Implications for Urban Policy. Transp. Res. Part A-Policy Pr. 1999, 33, 691–723. [Google Scholar] [CrossRef]
- Zhang, M. Travel Choice with No Alternative. J. Plan. Educ. Res. 2006, 25, 311–326. [Google Scholar] [CrossRef]
- Marshall, J.D. Energy-efficient urban form. Environ. Sci. Technol. 2008, 42, 3133–3137. [Google Scholar] [CrossRef] [PubMed]
- Naess, P. Residential Location, Travel Behaviour, and Energy Use: Hangzhou Metropolitan Area Compared to Copenhagen. Indoor Built Environ. 2009, 18, 382–395. [Google Scholar] [CrossRef]
- Calthorpe, P. The Next American Metropolis: Ecology, Community, and the American Dream; Princeton Architectural Press: New York, NY, USA, 1993; ISBN 9781878271686. [Google Scholar]
- Smyth, J. The economic power of sustainable development: Building the new American dream. In Sustainable Cities: Concepts and Strategies for Eco-City Development; Walter, B., Arkin, L., Crenshaw, R.W., Eds.; Eco-Home Media: Los Angeles, CA, 1992; p. 354. ISBN 9780963351104. [Google Scholar]
- Scully, V. The architecture of community. In The New Urbanism: Toward An Architecture of Community; Katz, P., Ed.; McGraw-Hill: New York, NY, USA, 1994. [Google Scholar]
- Churchman, A. A Study of Attitudes towards Housing Issues in the City of Tel Aviv; Technion, Center for Urban and Regional Studies: Haifa, Israel, 1998. [Google Scholar]
- Jacobs, J. The Death and Life of Great American Cities; Jonathan Cape: London, UK, 1962. [Google Scholar]
- Trigaux, D.; Allacker, K.; De Troyer, F. Life Cycle Assessment of Land Use in Neighborhoods. Procedia Environ. Sci. 2017, 38, 595–602. [Google Scholar] [CrossRef]
- Hossain, M.M. Towards Sustainable Urban Environment: An Investigation on the Relationship between Electrical Energy Consumption and Urban Morphology in Context of Dhaka City. In Proceedings of the 2nd International Conference on Sustainable Architecture and Urban Development (SAUD), Amman, Jordan, 12–14 July 2010; pp. 387–402. [Google Scholar]
- Hénon, A.; Mestayer, P.G.; Lagouarde, J.P.; Voogt, J.A. An urban neighborhood temperature and energy study from the CAPITOUL experiment with the SOLENE model: Part 1: Analysis of flux contributions. Appl. Clim. 2012, 110, 177–196. [Google Scholar] [CrossRef]
- Gusson, C.S.; Duarte, D.H.S. Effects of Built Density and Urban Morphology on Urban Microclimate - Calibration of the Model ENVI-met V4 for the Subtropical Sao Paulo, Brazil. Procedia Eng. 2016, 169, 2–10. [Google Scholar] [CrossRef]
- Ahmadian, E.; Sodagar, B.; Mills, G.; Byrd, H.; Bingham, C.; Zolotas, A. Sustainable cities: The relationships between urban built forms and density indicators. Cities 2019, 95, 102382. [Google Scholar] [CrossRef]
- Kang, C.D. Effects of spatial access to neighborhood land-use density on housing prices: Evidence from a multilevel hedonic analysis in seoul, South Korea. Environ. Plan. B Urban Anal. City Sci. 2019, 46, 603–625. [Google Scholar] [CrossRef]
- Jabareen, Y.R. Sustainable urban forms - Their typologies, models, and concepts. J. Plan. Educ. Res. 2006, 26, 38–52. [Google Scholar] [CrossRef]
- Churchman, A. Disentangling the concept of density. J. Plan. Lit. 1999, 13, 389–411. [Google Scholar] [CrossRef]
- Alexander, E.R. Density Measures: A Review and Analysis. J. Arch. Plann. Res. 1993, 10, 181–202. [Google Scholar] [CrossRef]
- Ahlfeldt, G.M.; Pietrostefani, E. The Compact City in Empirical Research: A Quantitative Literature Review; London School of Economics and Political Science, LSE Library: London, UK, 2017. [Google Scholar]
- Grosvenor, M.; O’Neill, P. The density debate in urban research: An alternative approach to representing urban structure and form. Geogr. Res. 2014, 52, 442–458. [Google Scholar] [CrossRef]
- Lehmann, S. Sustainable urbanism: Towards a framework for quality and optimal density? Futur. Cities Environ. 2016, 2, 8. [Google Scholar] [CrossRef]
- Moroni, S. Urban density after Jane Jacobs: The crucial role of diversity and emergence. CityTerrit. Arch. 2016, 3, 1–8. [Google Scholar] [CrossRef]
- Turok, I. Housing and the urban premium. Habitat Int. 2016, 54, 234–240. [Google Scholar] [CrossRef]
- Berghauser Pont, M. Typology based on three density variables central to Spacematrix using cluster analysis. In Proceedings of the 24th ISUF International Conference, Valencia, Spain, 27–29 September 2017; pp. 1337–1348. [Google Scholar]
- Haupt, P.; Berghauser Pont, M.; Vernez·Moudon, A. Spacemate: The Spatial Logic of Urban Density; Delft University Press: Delft, The Netherlands, 2002. [Google Scholar]
- Berghauser Pont, M.; Haupt, P.A. The relation between urban form and density. Urban Morphol. 2007, 11, 62–65. [Google Scholar]
- Berghauser Pont, M.; Haupt, P.A. Spacematrix: Space, Density and Urban Form; Nai Publishers: Rotterdam, The Netherlands, 2010. [Google Scholar]
- Berghauser Pont, M. Space, Density and Urban Form; Technische Universiteit Delft: Delft, The Netherlands, 2009. [Google Scholar]
- Southworth, M.; Ben Joseph, E. Street and Shaping of Towns and Cities; Island Press: Washington, DC, USA, 2003. [Google Scholar]
- Cerdà, I. Teoría General de la Urbanización, y Aplicación de sus Principios y Doctrinas a la Reforma y Ensanche de Barcelona; Imprenta Española: Madrid, Spain, 1867. [Google Scholar]
- Howard, E. Tomorrow: A Peaceful Path to Real Reform; Stout, F., Legates, R., Eds.; Routledge: London, UK, 1898; Volume 2, ISBN 0415160855. [Google Scholar]
- Unwin, R. Nothing Gained by Overcrowding! How the Garden City Type of Development May Benefit Both Owner and Occupier; King and Son: Wesminster, UK; Londres, UK, 1912. [Google Scholar]
- Whyte, I.B.; Frisby, D. Metropolis Berlin: 1880–1940; University of California Press: London, UK, 2012; ISBN 9780520270374. [Google Scholar]
- Lehnerer, A. Grand Urban Rules; 010 Publishers: Rotterdam, The Netherlands, 2009; ISBN 9789064506666. [Google Scholar]
- Radberg, J. Doktrin och Täthet i Svenskt Stadsbyggande 1875-1975; Statens rad för byggnadsforskning: Estocolmo, Swedish, 1988. [Google Scholar]
- Martin, L.; March, L. Urban Space and Structures; Cambridge University Press: Cambridge, UK, 1972. [Google Scholar]
- Steadman, P. Density and built form: Integrating “Spacemate” with the work of Martin and March. Environ. Plan. B Plan. Des. 2014, 41, 341–358. [Google Scholar] [CrossRef]
- Schirmer, P.M.; Axhausen, K.W. A multiscale classification of urban morphology. J. Transp. Land Use 2016, 9, 101–130. [Google Scholar] [CrossRef]
- Kohonen, T. Self-organized formation of topologically correct feature maps. Biol. Cybern. 1982, 43, 59–69. [Google Scholar] [CrossRef]
- Ritter, H.; Kohonen, T. Self-organizing semantic maps. Biol. Cybern. 1989, 61, 241–254. [Google Scholar] [CrossRef]
- Weiss, S.M.; Indurkhya, N. Predictive Data Mining: A Practical Guide; Morgan Kaufmann: San Francisco, United States, 1998; ISBN 1558604030. [Google Scholar]
- Demartines, P.; Blayo, F. Kohonen Self-Organizing Maps: Is the Normalization Necessary? Complex Syst. 1992, 6, 105–123. [Google Scholar]
- Jagric, T.; Bojnec, S.; Jagric, V. Optimized spiral spherical self-organizing map approach to sector analysis—The case of banking. Expert Syst. Appl. 2015, 42, 5531–5540. [Google Scholar] [CrossRef]
- Saitoh, F. Visualization of online customer reviews and evaluations based on self-organizing map. In Proceedings of the 2014 IEEE International Conference on Systems, Man, and Cybernetics (SMC), San Diego, CA, USA, 5–8 October 2014; pp. 176–181. [Google Scholar] [CrossRef]
- Tabrizi, T.S.; Khoie, M.R.; Sahebkar, E.; Rahimi, S.; Marhamatil, N. Towards a Patient Satisfaction Based Hospital Recommendation System. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 131–138. [Google Scholar]
- Martín Guerrero, J.D.; Marcelli, D.; Soria-Olivas, E.; Mari, F.; Martínez-Martínez, J.M.; Soley Bech, I.; Martínez-Sober, M.; Scatizzi, L.; Gómez-Sanchis, J.; Stopper, A.; et al. Self-Organising Maps: A new way to screen the level of satisfaction of dialysis patients. Expert Syst. Appl. 2012, 39, 8793–8798. [Google Scholar] [CrossRef]
- Park, D.H.; Kim, H.K.; Choi, I.Y.; Kim, J.K. A literature review and classification of recommender systems research. Expert Syst. Appl. 2012, 39, 10059–10072. [Google Scholar] [CrossRef]
- Bação, F.; Lobo, V.; Painho, M. Self-organizing maps as substitutes for k-means clustering. Comput. Sci. 2005, 3516, 476–483. [Google Scholar] [CrossRef]
- Vesanto, J. SOM-based data visualization methods. Intell. Data Anal. 1999, 3, 111–126. [Google Scholar] [CrossRef]
- Kohonen, T.; Oja, E.; Simula, O.; Visa, A.; Kangas, J. Engineering applications of the self-organizing map. Proc. IEEE 1996, 84, 1358–1384. [Google Scholar] [CrossRef]
- Kaski, S.; Kohonen, T. Exploratory Data Analysis By The Self-Organizing Map: Structures Of Welfare And Poverty In The World (1996). In Neural Networks in Financial Engineering. Proceedings of the Third International Conference on Neural Networks in the Capital Markets; World Scientific: Singapore, 1996; pp. 498–507. [Google Scholar]
- Kropp, J. A neural network approach to the analysis of city systems. Appl. Geogr. 1998, 18, 83–96. [Google Scholar] [CrossRef]
- Takatsuka, M. An application of the Self-Organizing Map and interactive 3-D visualization to geospatial data. In Proceedings of the 6th International Conference on Geocomputation, Brisbane, Australia, 24–26 September 2001. [Google Scholar]
- Diappi, L.; Bolchim, P.; Buscema, M. Improved Understanding of Urban Sprawl Using Neural Networks. In Recent Advances in Design and Decision Support Systems in Architecture and Urban Planning; Van-Leeuwen, J.P., Timmermans, H.J.P., Eds.; Springer: Milan, Italy, 2004; pp. 33–49. ISBN 1-4020-2408-8. [Google Scholar]
- Hatzichristos, T. Delineation of demographic regions with GIS and computational intelligence. Environ. Plan. B Plan. Des. 2004, 31, 39–49. [Google Scholar] [CrossRef]
- Kauko, T. Using the self-organising map to identify regularities across country-specific housing-market contexts. Environ. Plan. B Plan. Des. 2005, 32, 89–110. [Google Scholar] [CrossRef]
- Guo, D.; Chen, J.; MacEachren, A.M.; Liao, K. A Visualization System for Space-Time and Multivariate Patterns (VIS-STAMP). IEEE Trans. Vis. Comput. Graph. 2006, 12, 1461–1474. [Google Scholar] [CrossRef]
- Spielmans, S.E.; Thill, J.-C. Social area analysisss, data mining, and GIS. Comput. Environ. Urban Syst. 2008, 32, 110–122. [Google Scholar] [CrossRef]
- Behnisch, M.; Ultsch, A. Urban data-mining: Spatiotemporal exploration of multidimensional data. Build. Res. Inf. 2009, 37, 520–532. [Google Scholar] [CrossRef]
- Hagen-Zanker, A.; Timmermans, H.J.P. A Metric of Compactness of Urban Change Illustrated to 22 European Countries. In The European Information Society; Springer: Berlin/Heidelberg, Germany, 2009; pp. 181–200. [Google Scholar]
- Abarca-Alvarez, F.J.; Fernandez-Avidad, A. Generation of downtown planning-ordinances using self organizing maps. In Proceedings of the 10th International Conference on Design and Decision Support Systems in Architecture and Urban Planning, Eindhoven, The Nether lands, 19–22 July 2010; pp. 63–79. [Google Scholar]
- Skupin, A.; Esperbé, A. An alternative map of the United States based on an n-dimensional model of geographic space. J. Vis. Lang. Comput. 2011, 22, 290–304. [Google Scholar] [CrossRef]
- Abarca-Alvarez, F.J.; Osuna-Pérez, F. Cartografías semánticas mediante redes neuronales: Los mapas auto-organizados (SOM) como representación de patrones y campos. Ega. Rev. Expresión Gráfica Arquit. 2013, 18. [Google Scholar] [CrossRef]
- Campos-Sánchez, F.S.; Abarca-Álvarez, F.J.; Serra-Coch, G.; Chastel, C. Evaluación comparativa del nivel de Desarrollo Orientado al Transporte (DOT) en torno a nodos de transporte de grandes ciudades: Métodos complementarios de ayuda a la decisión. Eure. Rev. Lat. Estud. Urbanos Reg. 2019, 45, 5–30. [Google Scholar] [CrossRef]
- Abarca-Alvarez, F.J.; Navarro-Ligero, M.L.; Valenzuela-Montes, L.M.; Campos-Sánchez, F.S. European Strategies for Adaptation to Climate Change With the Mayors Adapt Initiative by Self-Organizing Maps. Appl. Sci. 2019, 9, 3859. [Google Scholar] [CrossRef]
- Abarca-alvarez, F.J.; Campos-Sánchez, F.S.; Mora-Esteban, R. Survey Assessment for Decision Support Using Self-Organizing Maps Profile Characterization with an Odds and Cluster Heat Map: Application to Children’s Perception of Urban School Environments. Entropy 2019, 21, 916. [Google Scholar] [CrossRef]
- Cherkassky, V.S.; Friedman, J.H. From Statics to Neural Networks: Theory and Pattern Recognition Appications; Wechsler, H., Ed.; Springer: Berlin, Germany, 1994. [Google Scholar]
- Pitarque, A.; Roy, J.F.; Ruiz, J.C. Redes neuronales vs modelos estadísticos: Simulaciones sobre tareas de predicción y clasificación. Psicológica 1998, 19, 387–400. [Google Scholar]
- Cottrell, M.; Letrémy, P. How to use the Kohonen algorithm to simultaneously analyze individuals and modalities in a survey. Neurocomputing 2005, 63, 193–207. [Google Scholar] [CrossRef]
- Hamaina, R.; Leduc, T.; Moreau, G. Towards Urban Fabrics Characterization based on Buildings Footprints. In Bridging the Geographic Information Sciences; Gensel, J., Ed.; Springer: Berlin, Germany, 2012; pp. 231–248. ISBN 978-3-642-29063-3. [Google Scholar]
- Yan, J.; Thill, J.-C. Visual data mining in spatial interaction analysis with self-organizing maps. Environ. Plan. B Plan. Des. 2009, 36, 466–486. [Google Scholar] [CrossRef]
- Cottrell, M.; Letrémy, P. Analyzing surveys using the Kohonen algorithm. In Proceedings of the ESANN 2003, 11th European Symposium on Artificial Neural Networks, Bruges, Belgium, 23–25 April 2003. [Google Scholar]
- Lagus, K.; Vatanen, T.; Kettunen, O.; Heikkil, A.; Heikkil, M.; Pantzar, M.; Honkela, T. Paths of wellbeing on self-organizing maps. In Advances in Self-Organizing Maps; Springer: Berlin, Germany, 2013; pp. 345–352. [Google Scholar] [CrossRef]
- Kamiura, N.; Saitoh, A.; Isokawa, T.; Matsui, N. Classification of Interview Sheets Using Self-Organizing. In Proceedings of the 19th International Conference on Neural Information Processing (ICONIP), Doha, Qatar, 12–15 November 2012; pp. 148–155. [Google Scholar]
- Ketchen, D.J.; Shook, C.L. The Application Of Cluster Analysis In Strategic Management Reseach: An Anlysis and Critique. Strat. Manag. J. 1996, 17, 441–458. [Google Scholar] [CrossRef]
- Zhao, Q.; Xu, M.; Fränti, P. Sum-of-Squares Based Cluster Validity Index and Significance Analysis. In Adaptative and Natural Computing Algorithms. 9th International Conference, ICANNGA 2009. Kuopio, Finland, April 2009; Springer: Berlin, Germany, 2009; Volume 9, pp. 313–322. ISBN 978-3-642-04920-0. [Google Scholar]
- Ball, G.H.; Hall, D.J. A Novel Method of Data Analysis Andpattern Classification; Standford Research Institute: Menlo Park, CA, USA, 1965. [Google Scholar]
- Calinski, T.; Harabasz, J. A Dendrite Method for Cluster Analysis. Commun. Stat. 1974, 3, 1–27. [Google Scholar]
- Davies, D.L.; Bouldin, D.W. A Cluster Separation Measure. IEEE Trans. Pattern Anal. Mach. Intell. 1979, PAMI-1, 224–227. [Google Scholar] [CrossRef]
- Lletí, R.; Ortiz, M.C.; Sarabia, L.A.; Sánchez, M.S. Selecting variables for k-means cluster analysis by using a genetic algorithm that optimises the silhouettes. Anal. Chim. Acta 2004, 515, 87–100. [Google Scholar] [CrossRef]
- Desgraupes, B. Clustering Indices. CRAN Package 2017, nov, 1–34. [Google Scholar]
- Arbelaitz, O.; Gurrutxaga, I.; Muguerza, J.; Pérez, J.M.; Perona, I. An extensive comparative study of cluster validity indices. Pattern Recognit. 2013, 46, 243–256. [Google Scholar] [CrossRef]
- Faggiano, L.; de Zwart, D.; García-Berthou, E.; Lek, S.; Gevrey, M. Patterning ecological risk of pesticide contamination at the river basin scale. Sci. Total Environ. 2010, 408, 2319–2326. [Google Scholar] [CrossRef] [PubMed]
- Wu, P.K.; Hsiao, T.C. Factor Knowledge Mining Using the Techniques of AI Neural Networks and Self-Organizing Map. Int. J. Distrib. Sens. Netw. 2015. [Google Scholar] [CrossRef]
- Wasserstein, R.L.; Lazar, N.A. The ASA’s statement on p-values: Context, process, and purpose. Am. Stat. 2016, 70, 129–133. [Google Scholar] [CrossRef]
- Coe, R.; Merino, C. Magnitud del efecto: Una guía para investigadores y usuarios. Rev. Psicol. 2003, 21, 147–177. [Google Scholar]
- Cohen, J. Statistical Power Analysis for the Behavioral Sciences; Academic Press: San Francisco, USA, 1977; ISBN 0-8058-0283-5. [Google Scholar]
- Sarlin, P. Exploiting the self-organizing financial stability map. Eng. Appl. Artif. Intell. 2013, 26, 1532–1539. [Google Scholar] [CrossRef]
- Hair, J.F., Jr.; Black, W.C.; Babin, B.J.; Anderson, R.E. Multivariate Data Analysis, 7th ed.; Prentice Hall: Upper Saddle River, NJ, USA, 2009; ISBN 9780138132637. [Google Scholar]
- Zevi, B. Saper Vedere L’città. Ferrara di Biagio Rossetti, la Prima Città Moderna Europea; Giulio Einaudi Editore: Torino, Italy, 1997. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Measurements | Population | Profile 2 | ||||||
|---|---|---|---|---|---|---|---|---|
| 117 Units. (100%) | 20 Units. (17.09%) | |||||||
| M | SD | M | SD | Conf. | T | ES | ES | |
| Island-A | 6.063 | 5.277 | 11.129 | 4.828 | *** | 4.327 | 0.960 | +++ |
| Island-FSI | 1.540 | 1.261 | 0.522 | 0.275 | *** | 15.228 | −0.807 | - - - |
| Island-GSI | 0.384 | 0.223 | 0.188 | 0.059 | *** | 13.808 | −0.883 | - - - |
| Island-OSR | 1.375 | 2.763 | 2.208 | 1.576 | * | 2.177 | 0.301 | + |
| Island-L | 3.800 | 2.197 | 2.756 | 1.152 | ** | 3.733 | −0.475 | - |
| Fabric-A | 8.086 | 6.148 | 13.79 | 5.969 | ** | 3.938 | 0.927 | +++ |
| Fabric-FSI | 1.056 | 0.852 | 0.428 | 0.245 | *** | 10.573 | −0.737 | - - |
| Fabric-GSI | 0.267 | 0.152 | 0.152 | 0.048 | *** | 9.974 | −0.754 | - - |
| Fabric-OSR | 1.792 | 2.919 | 2.861 | 2.025 | * | 2.178 | 0.366 | + |
| Fabric-L | 3.800 | 2.197 | 2.756 | 1.152 | ** | 3.732 | −0.475 | - |
| Fabric-N | 0.019 | 0.010 | 0.012 | 0.003 | *** | 8.988 | −0.680 | - - |
| Fabric-w | 141.890 | 92.800 | 183.180 | 62.280 | * | 2.733 | 0.445 | + |
| Fabric-b | 17.803 | 8.877 | 17.294 | 3.331 | ns | 0.630 | −0.057 | |
| Fabric-T | 26.966 | 12.234 | 19.235 | 5.562 | *** | 5.730 | −0.632 | - - |
| Sample of Urban Fabric (City) | Floor to Area Ratio (FSI) | Ground Space Index (GSI) | Profile (Pattern) |
|---|---|---|---|
| Units: m2/m2 | Units: m2/m2 | ||
| [112] Bijlmer Oud (Amsterdam) | 0.76 | 0.10 | 1 (A) |
| [146] Niew Sloten (Amsterdam) | 0.77 | 0.33 | 5 (B) |
| [135] Java Island (Amsterdam) | 2.09 | 0.34 | 3 (B) |
| Sample of Urban Fabric (City) | Floor Area Ratio | Ground Space Index | Network Density | Proposed Profile (Pattern) |
|---|---|---|---|---|
| FSI (Perc.) Z-Score | GSI (Perc.) Z-Score | N (Perc.) Z-Score | ||
| [161] Venserpolder (Amsterdam) | 1.17 (64.6) 0.134 | 0.26 (56.8) −0.043 | 0.016 (43.1) −0.264 | 4 (B) |
| [168] Watergraafsmeer 2 (Amsterdam) | 0.59 (36.2) −0.557 | 0.24 (51.7) −0.175 | 0.021 (66.3) 0.256 | 4 (B) |
| [116] Colijnsplaat (Noord-Beveland) | 0.58 (34.4) −0.568 | 0.30 (63.7) 0.219 | 0.022 (72.4) 0.360 | 5 (B) |
| [145] Nieuwpoort (Liesveld) | 0.67 (38.7) −0.453 | 0.36 (78.4) 0.613 | 0.020 (57.7) 0.152 | 5 (B) |
| Mean | 1.06 (60.2) 0 | 0.27 (59.2) 0 | 0.019 (54.3) 0 | - |
| Standard Deviation | 0.85 (-) - | 0.15 (-) - | 0.010 (-) - | - |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abarca-Alvarez, F.J.; Campos-Sánchez, F.S.; Osuna-Pérez, F. Urban Shape and Built Density Metrics through the Analysis of European Urban Fabrics Using Artificial Intelligence. Sustainability 2019, 11, 6622. https://doi.org/10.3390/su11236622
Abarca-Alvarez FJ, Campos-Sánchez FS, Osuna-Pérez F. Urban Shape and Built Density Metrics through the Analysis of European Urban Fabrics Using Artificial Intelligence. Sustainability. 2019; 11(23):6622. https://doi.org/10.3390/su11236622
Chicago/Turabian StyleAbarca-Alvarez, Francisco Javier, Francisco Sergio Campos-Sánchez, and Fernando Osuna-Pérez. 2019. "Urban Shape and Built Density Metrics through the Analysis of European Urban Fabrics Using Artificial Intelligence" Sustainability 11, no. 23: 6622. https://doi.org/10.3390/su11236622
APA StyleAbarca-Alvarez, F. J., Campos-Sánchez, F. S., & Osuna-Pérez, F. (2019). Urban Shape and Built Density Metrics through the Analysis of European Urban Fabrics Using Artificial Intelligence. Sustainability, 11(23), 6622. https://doi.org/10.3390/su11236622