Landslide Susceptibility Assessment by Novel Hybrid Machine Learning Algorithms

 ,
,  ,
,  , , ,
, , , 
Abstract
1. Introduction
2. Description of the Study Area
3. Landside Inventory Map
3.1. Landslide Conditioning Factors
3.1.1. Overburden Depth
3.1.2. Land Cover
3.1.3. Geomorphology
3.1.4. Distance to Rivers
3.1.5. Distance to Roads
3.1.6. Curvature
3.1.7. Aspect
3.1.8. Valley Depth
3.1.9. Slope
3.1.10. SFM
4. Machine Learning Algorithms
4.1. Base Classifier: Alternating Decision Tree (ADTree)
4.2. Meta/Ensemble Classifiers
4.2.1. Bagging Ensemble Classifier
4.2.2. Random Subspace Ensemble Classifier
4.2.3. Rotation Forest Ensemble Classifier
4.2.4. Selecting the Most Important Conditioning Factors Using Chi-Square Attribute Evaluation (CSEA) Technique
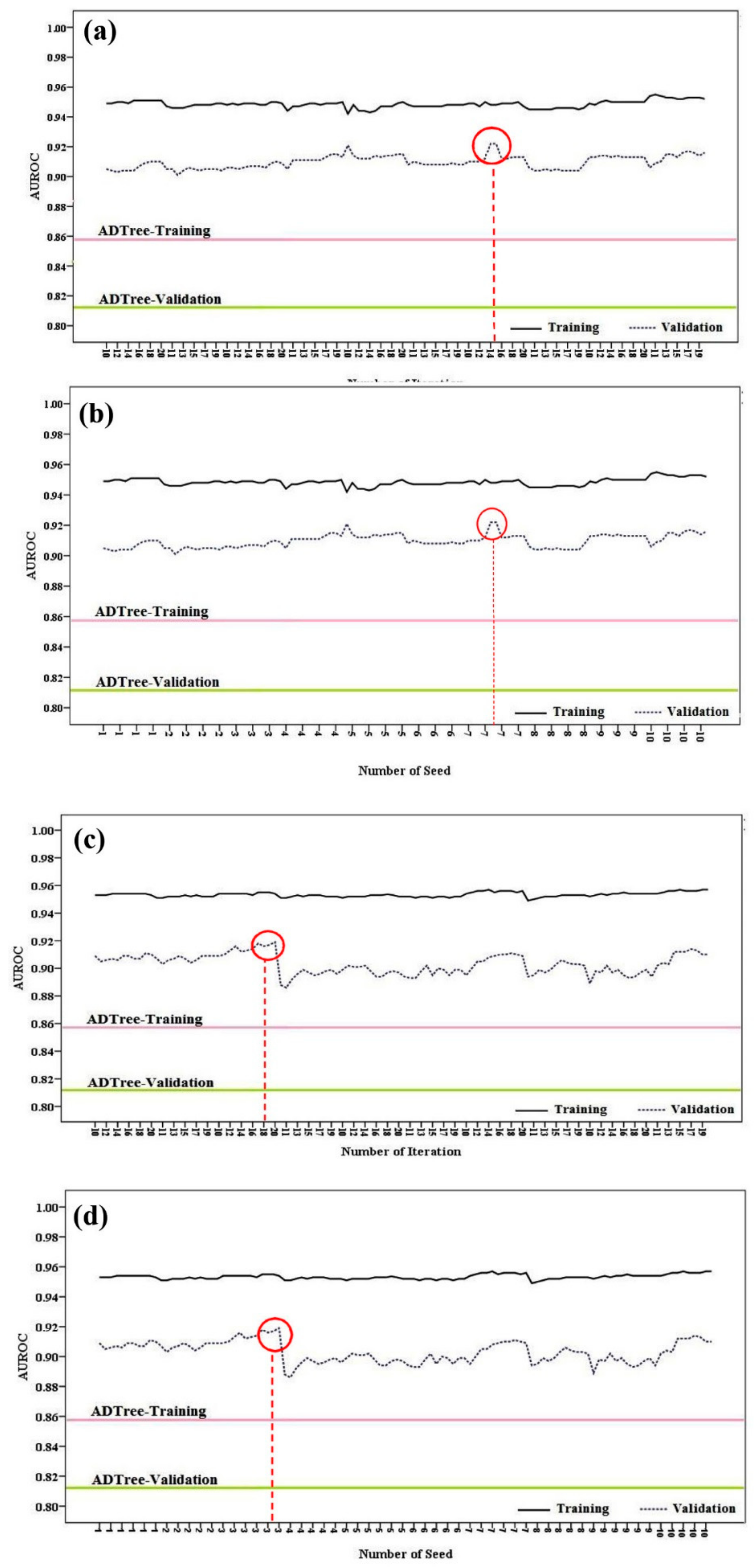
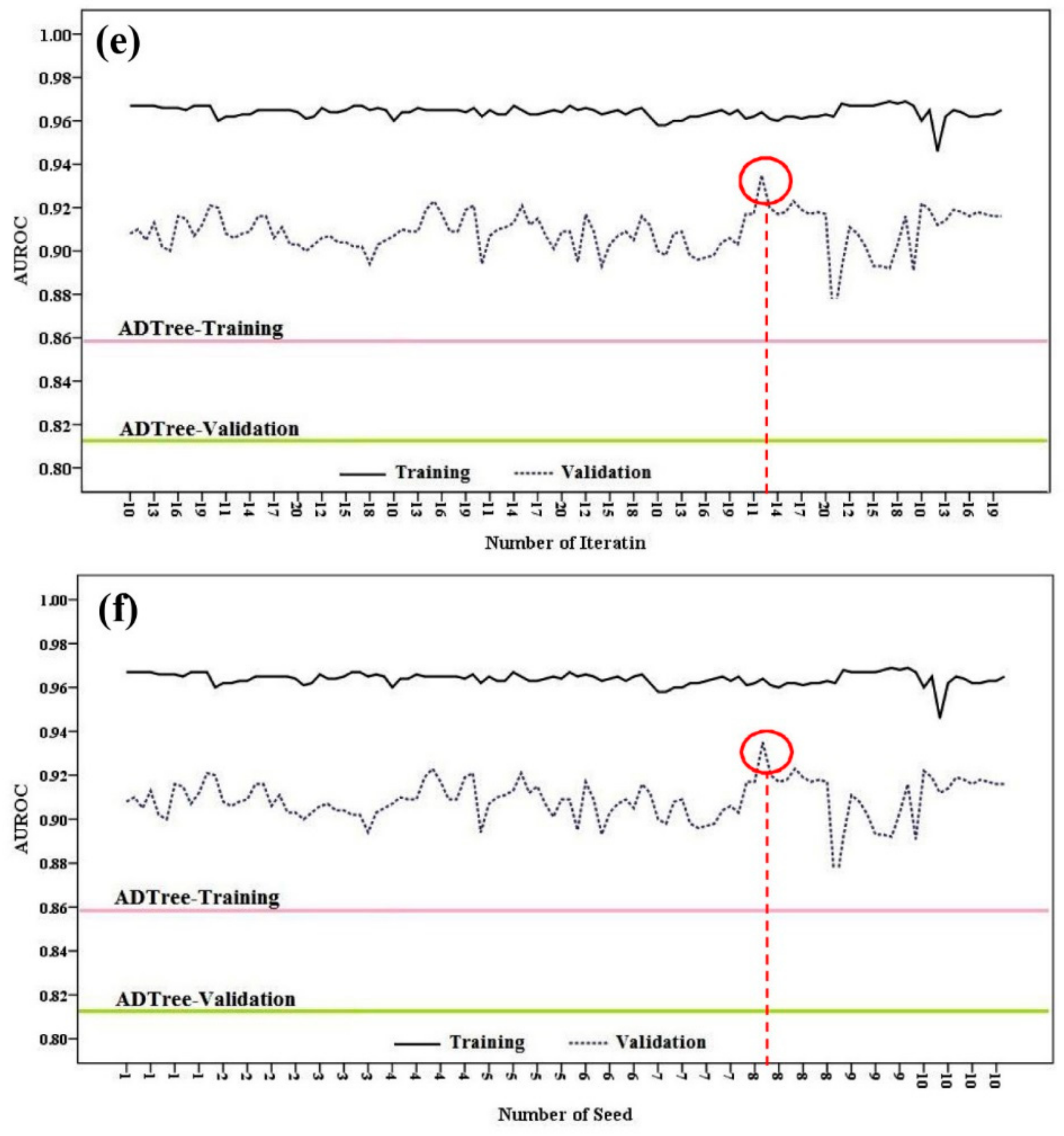
4.2.5. Model Validation and Comparison
5. Results and Analysis
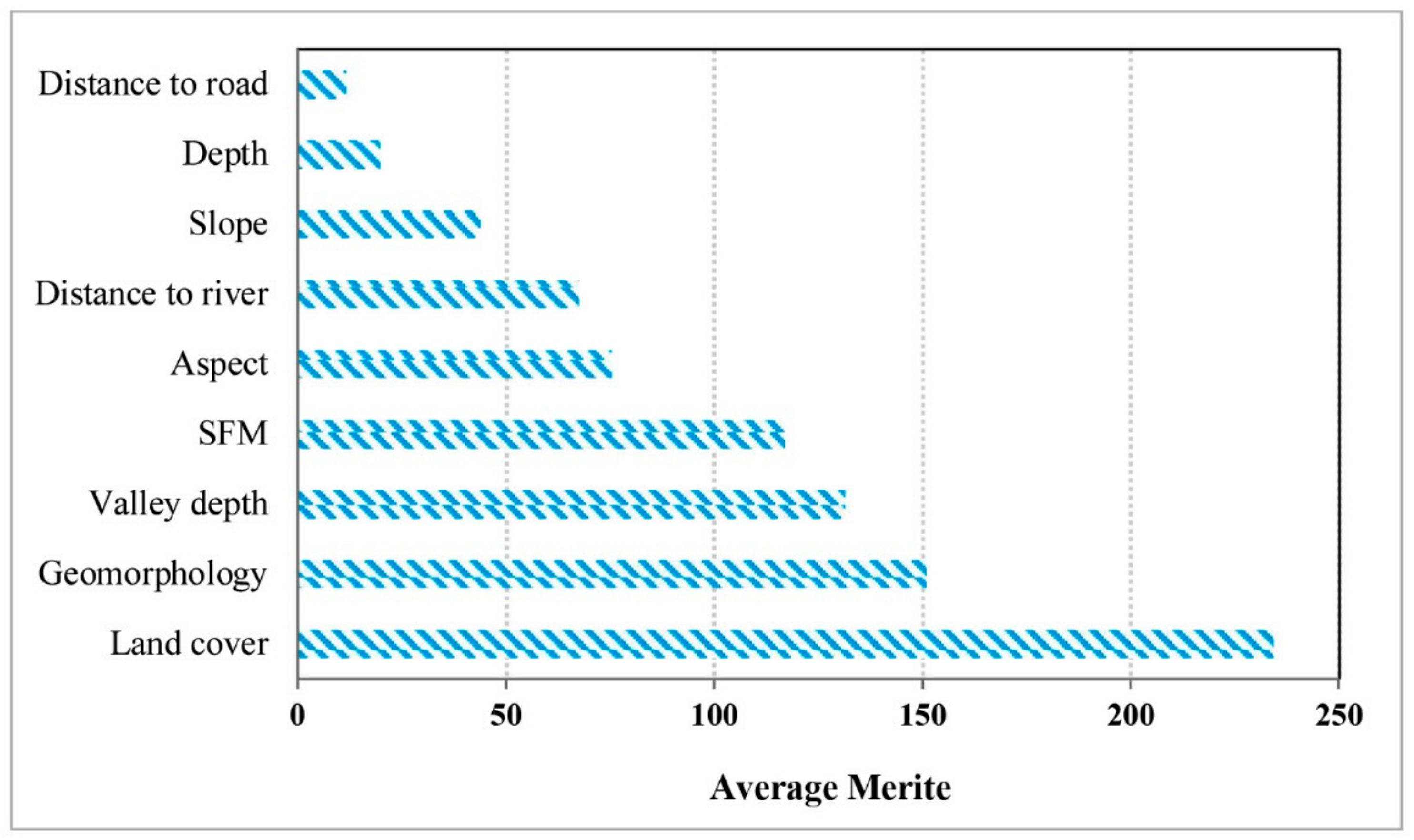
5.1. The Most Significant Conditioning Factors
5.2. Landslide Modelling, Evaluation and Comparison
5.3. Development of Landslide Susceptibility Maps
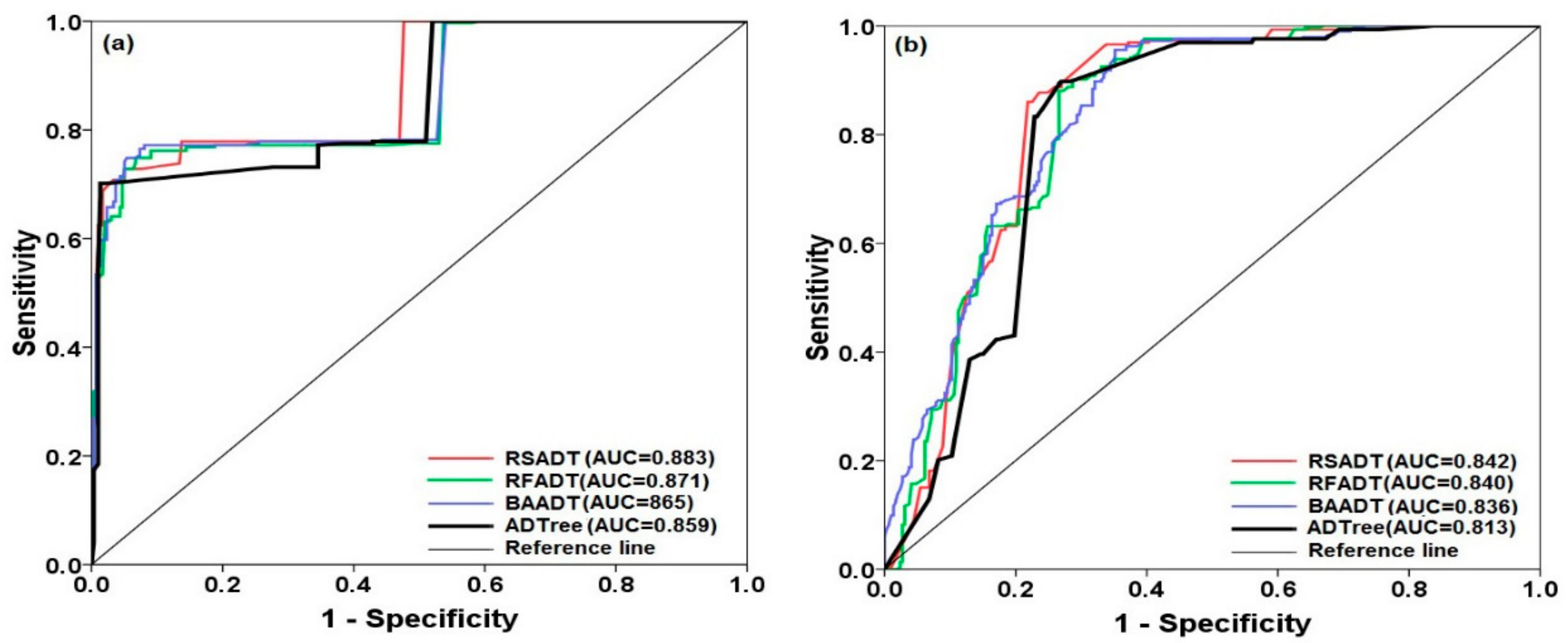
5.4. Evaluation of the Landslide Susceptibility Maps
6. Discussion
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Cruden, D.M. A suggested method for a landslide summary. Bull. Int. Assoc. Eng. Geol. 1991, 43, 101–110. [Google Scholar]
- Froude, M.J.; Petley, D.N. Global fatal landslide occurrence from 2004 to 2016. Nat. Hazards Earth Syst. Sci. 2018, 18, 2161–2181. [Google Scholar] [CrossRef]
- Pham, B.T.; Prakash, I.; Singh, S.K.; Shirzadi, A.; Shahabi, H.; Tran, T.-T.-T.; Bui, D.T. Landslide susceptibility modeling using Reduced Error Pruning Trees and different ensemble techniques: Hybrid machine learning approaches. Catena 2019, 175, 203–218. [Google Scholar] [CrossRef]
- Dilley, M.; Chen, R.S.; Deichmann, U.; Lerner-Lam, A.L.; Arnold, M. Natural Disaster Hotspots: A Global Risk Analysis; The World Bank: Washington, DC, USA, 2005. [Google Scholar]
- Kirschbaum, D.; Stanley, T. Satellite-Based Assessment of Rainfall-Triggered Landslide Hazard for Situational Awareness. Earth’s Futur. 2018, 6, 505–523. [Google Scholar] [CrossRef]
- Petley, D. Global patterns of loss of life from landslides. Geology 2012, 40, 927–930. [Google Scholar] [CrossRef]
- Klose, M.; Maurischat, P.; Damm, B. Landslide impacts in Germany: A historical and socioeconomic perspective. Landslides 2016, 13, 183–199. [Google Scholar] [CrossRef]
- Li, T.; Wang, S. Landslide Hazards and Their Mitigation in China; Science Press: Beijing, China, 1992. [Google Scholar]
- Highland, L.M.; Godt, J.; Howell, D.; Savage, W. El nino 1997-98; Damaging Landslides in the San Francisco Bay Area; US Dept. of the Interior, US Geological Survey, National Landslide: Denver, CO, USA, 1998; pp. 2327–6932. [Google Scholar]
- Kuriakose, S.L.; Sankar, G.; Muraleedharan, C. History of landslide susceptibility and a chorology of landslide-prone areas in the western Ghats of Kerala, India. Environ. Geol. 2009, 57, 1553–1568. [Google Scholar] [CrossRef]
- NASA. Global Landslide Catalog. Available online: https://data.nasa.gov/Earth-Science/Global-Landslide-Catalog/h9d8-neg4#About (accessed on 30 March 2019).
- Kaur, H.; Gupta, S.; Parkash, S. Comparative evaluation of various approaches for landslide hazard zoning: A critical review in Indian perspectives. Spat. Inf. Res. 2017, 25, 389–398. [Google Scholar] [CrossRef]
- Shirzadi, A.; Bui, D.T.; Pham, B.T.; Solaimani, K.; Chapi, K.; Kavian, A.; Shahabi, H.; Revhaug, I. Shallow landslide susceptibility assessment using a novel hybrid intelligence approach. Environ. Earth Sci. 2017, 76, 60. [Google Scholar] [CrossRef]
- Pourghasemi, H.R.; Yansari, Z.T.; Panagos, P.; Pradhan, B. Analysis and evaluation of landslide susceptibility: A review on articles published during 2005–2016 (periods of 2005–2012 and 2013–2016). Arab. J. Geosci. 2018, 11, 193. [Google Scholar] [CrossRef]
- Mousavi, S.Z.; Kavian, A.; Soleimani, K.; Mousavi, S.R.; Shirzadi, A. GIS-based spatial prediction of landslide susceptibility using logistic regression model. Geomat. Nat. Hazards Risk 2011, 2, 33–50. [Google Scholar] [CrossRef]
- Shirzadi, A.; Saro, L.; Joo, O.H.; Chapi, K. A GIS-based logistic regression model in rock-fall susceptibility mapping along a mountainous road: Salavat Abad case study, Kurdistan, Iran. Nat. Hazards 2012, 64, 1639–1656. [Google Scholar] [CrossRef]
- Shahabi, H.; Khezri, S.; Ahmad, B.B.; Hashim, M. Landslide susceptibility mapping at central Zab basin, Iran: A comparison between analytical hierarchy process, frequency ratio and logistic regression models. Catena 2014, 115, 55–70. [Google Scholar] [CrossRef]
- Chen, W.; Sun, Z.; Han, J. Landslide susceptibility modeling using integrated ensemble weights of evidence with logistic regression and random forest models. Appl. Sci. 2019, 9, 171. [Google Scholar] [CrossRef]
- Shirzadi, A.; Chapi, K.; Shahabi, H.; Solaimani, K.; Kavian, A.; Ahmad, B.B. Rock fall susceptibility assessment along a mountainous road: An evaluation of bivariate statistic, analytical hierarchy process and frequency ratio. Environ. Earth Sci. 2017, 76, 152. [Google Scholar] [CrossRef]
- Shahabi, H.; Hashim, M.; Bin Ahmad, B. Remote sensing and GIS-based landslide susceptibility mapping using frequency ratio, logistic regression, and fuzzy logic methods at the central Zab basin, Iran. Environ. Earth Sci. 2015, 73, 8647–8668. [Google Scholar] [CrossRef]
- Bourenane, H.; Guettouche, M.S.; Bouhadad, Y.; Braham, M. Landslide hazard mapping in the Constantine city, Northeast Algeria using frequency ratio, weighting factor, logistic regression, weights of evidence, and analytical hierarchy process methods. Arab. J. Geosci. 2016, 9, 154. [Google Scholar] [CrossRef]
- Shirzadi, A.; Shahabi, H.; Chapi, K.; Bui, D.T.; Pham, B.T.; Shahedi, K.; Ahmad, B.B. A comparative study between popular statistical and machine learning methods for simulating volume of landslides. Catena 2017, 157, 213–226. [Google Scholar] [CrossRef]
- Tian, Y.; Xu, C.; Hong, H.; Zhou, Q.; Wang, D. Mapping earthquake-triggered landslide susceptibility by use of artificial neural network (ann) models: An example of the 2013 Minxian (China) mw 5.9 event. Geomat. Nat. Hazards Risk 2019, 10, 1–25. [Google Scholar] [CrossRef]
- Yan, F.; Zhang, Q.; Ye, S.; Ren, B. A novel hybrid approach for landslide susceptibility mapping integrating analytical hierarchy process and normalized frequency ratio methods with the cloud model. Geomorphology 2019, 327, 170–187. [Google Scholar] [CrossRef]
- Mandal, S.; Mondal, S. Weighted overlay analysis (woa) model, certainty factor (cf) model and analytical hierarchy process (ahp) model in landslide susceptibility studies. In Statistical Approaches for Landslide Susceptibility Assessment and Prediction; Springer: Berlin, Germany, 2019; pp. 135–162. [Google Scholar]
- Liu, J.; Duan, Z. Quantitative assessment of landslide susceptibility comparing statistical index, index of entropy, and weights of evidence in the Shangnan area, China. Entropy 2018, 20, 868. [Google Scholar] [CrossRef]
- Tien Bui, D.; Shahabi, H.; Shirzadi, A.; Chapi, K.; Alizadeh, M.; Chen, W.; Mohammadi, A.; Ahmad, B.; Panahi, M.; Hong, H. Landslide detection and susceptibility mapping by airsar data using support vector machine and index of entropy models in cameron highlands, Malaysia. Remote Sens. 2018, 10, 1527. [Google Scholar] [CrossRef]
- Chen, W.; Pourghasemi, H.R.; Kornejady, A.; Xie, X. Gis-based landslide susceptibility evaluation using certainty factor and index of entropy ensembled with alternating decision tree models. In Natural Hazards Gis-Based Spatial Modeling Using Data Mining Techniques; Springer: Berlin, Germany, 2019; pp. 225–251. [Google Scholar]
- Shadman Roodposhti, M.; Aryal, J.; Shahabi, H.; Safarrad, T. Fuzzy shannon entropy: A hybrid gis-based landslide susceptibility mapping method. Entropy 2016, 18, 343. [Google Scholar] [CrossRef]
- Zhang, T.; Han, L.; Chen, W.; Shahabi, H. Hybrid integration approach of entropy with logistic regression and support vector machine for landslide susceptibility modeling. Entropy 2018, 20, 884. [Google Scholar] [CrossRef]
- Hong, H.; Shahabi, H.; Shirzadi, A.; Chen, W.; Chapi, K.; Ahmad, B.B.; Roodposhti, M.S.; Hesar, A.Y.; Tian, Y.; Bui, D.T. Landslide susceptibility assessment at the Wuning area, China: A comparison between multi-criteria decision making, bivariate statistical and machine learning methods. Nat. Hazards 2018, 1–40, 173–212. [Google Scholar] [CrossRef]
- Ghorbanzadeh, O.; Blaschke, T.; Gholamnia, K.; Meena, S.R.; Tiede, D.; Aryal, J. Evaluation of different machine learning methods and deep-learning convolutional neural networks for landslide detection. Remote Sens. 2019, 11, 196. [Google Scholar] [CrossRef]
- Wang, Y.; Hong, H.; Chen, W.; Li, S.; Panahi, M.; Khosravi, K.; Shirzadi, A.; Shahabi, H.; Panahi, S.; Costache, R. Flood susceptibility mapping in Dingnan county (China) using adaptive neuro-fuzzy inference system with biogeography based optimization and imperialistic competitive algorithm. J. Environ. Manag. 2019, 247, 712–729. [Google Scholar] [CrossRef] [PubMed]
- Khosravi, K.; Shahabi, H.; Pham, B.T.; Adamawoski, J.; Shirzadi, A.; Pradhan, B.; Dou, J.; Ly, H.-B.; Gróf, G.; Ho, H.L.; et al. A comparative assessment of flood susceptibility modeling using multi-criteria decision-making analysis and machine learning methods. J. Hydrol. 2019, 573, 311–323. [Google Scholar] [CrossRef]
- Chen, W.; Hong, H.; Li, S.; Shahabi, H.; Wang, Y.; Wang, X.; Bin Ahmad, B. Flood susceptibility modelling using novel hybrid approach of reduced-error pruning trees with bagging and random subspace ensembles. J. Hydrol. 2019, 575, 864–873. [Google Scholar] [CrossRef]
- Tien Bui, D.; Khosravi, K.; Shahabi, H.; Daggupati, P.; Adamowski, J.F.; Melesse, A.M.; Thai Pham, B.; Pourghasemi, H.R.; Mahmoudi, M.; Bahrami, S. Flood spatial modeling in northern Iran using remote sensing and gis: A comparison between evidential belief functions and its ensemble with a multivariate logistic regression model. Remote Sens. 2019, 11, 1589. [Google Scholar] [CrossRef]
- Bui, D.T.; Panahi, M.; Shahabi, H.; Singh, V.P.; Shirzadi, A.; Chapi, K.; Khosravi, K.; Chen, W.; Panahi, S.; Li, S. Novel hybrid evolutionary algorithms for spatial prediction of floods. Sci. Rep. 2018, 8, 15364. [Google Scholar] [CrossRef] [PubMed]
- Tien Bui, D.; Khosravi, K.; Li, S.; Shahabi, H.; Panahi, M.; Singh, V.; Chapi, K.; Shirzadi, A.; Panahi, S.; Chen, W. New hybrids of anfis with several optimization algorithms for flood susceptibility modeling. Water 2018, 10, 1210. [Google Scholar] [CrossRef]
- Shafizadeh-Moghadam, H.; Valavi, R.; Shahabi, H.; Chapi, K.; Shirzadi, A. Novel forecasting approaches using combination of machine learning and statistical models for flood susceptibility mapping. J. Environ. Manag. 2018, 217, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Chapi, K.; Singh, V.P.; Shirzadi, A.; Shahabi, H.; Bui, D.T.; Pham, B.T.; Khosravi, K. A novel hybrid artificial intelligence approach for flood susceptibility assessment. Environ. Model. Softw. 2017, 95, 229–245. [Google Scholar] [CrossRef]
- Rahmati, O.; Samadi, M.; Shahabi, H.; Azareh, A.; Rafiei-Sardooi, E.; Alilou, H.; Melesse, A.M.; Pradhan, B.; Chapi, K.; Shirzadi, A. Swpt: An automated gis-based tool for prioritization of sub-watersheds based on morphometric and topo-hydrological factors. Geosci. Front. 2019, 8, 47–62. [Google Scholar] [CrossRef]
- Jaafari, A.; Zenner, E.K.; Panahi, M.; Shahabi, H. Hybrid artificial intelligence models based on a neuro-fuzzy system and metaheuristic optimization algorithms for spatial prediction of wildfire probability. Agric. For. Meteorol. 2019, 266, 198–207. [Google Scholar] [CrossRef]
- Taheri, K.; Shahabi, H.; Chapi, K.; Shirzadi, A.; Gutiérrez, F.; Khosravi, K. Sinkhole susceptibility mapping: A comparison between bayes–based machine learning algorithms. Land Degrad. Dev. 2019, 30, 730–745. [Google Scholar] [CrossRef]
- Roodposhti, M.S.; Safarrad, T.; Shahabi, H. Drought sensitivity mapping using two one-class support vector machine algorithms. Atmos. Res. 2017, 193, 73–82. [Google Scholar] [CrossRef]
- Azareh, A.; Rahmati, O.; Rafiei-Sardooi, E.; Sankey, J.B.; Lee, S.; Shahabi, H.; Ahmad, B.B. Modelling gully-erosion susceptibility in a semi-arid region, Iran: Investigation of applicability of certainty factor and maximum entropy models. Sci. Total Environ. 2019, 655, 684–696. [Google Scholar] [CrossRef]
- Tien Bui, D.; Shirzadi, A.; Shahabi, H.; Chapi, K.; Omidavr, E.; Pham, B.T.; Talebpour Asl, D.; Khaledian, H.; Pradhan, B.; Panahi, M. A novel ensemble artificial intelligence approach for gully erosion mapping in a semi-arid watershed (Iran). Sensors 2019, 19, 2444. [Google Scholar] [CrossRef]
- Miraki, S.; Zanganeh, S.H.; Chapi, K.; Singh, V.P.; Shirzadi, A.; Shahabi, H.; Pham, B.T. Mapping groundwater potential using a novel hybrid intelligence approach. Water Resour. Manag. 2019, 33, 281–302. [Google Scholar] [CrossRef]
- Rahmati, O.; Naghibi, S.A.; Shahabi, H.; Bui, D.T.; Pradhan, B.; Azareh, A.; Rafiei-Sardooi, E.; Samani, A.N.; Melesse, A.M. Groundwater spring potential modelling: Comprising the capability and robustness of three different modeling approaches. J. Hydrol. 2018, 565, 248–261. [Google Scholar] [CrossRef]
- Rahmati, O.; Choubin, B.; Fathabadi, A.; Coulon, F.; Soltani, E.; Shahabi, H.; Mollaefar, E.; Tiefenbacher, J.; Cipullo, S.; Ahmad, B.B. Predicting uncertainty of machine learning models for modelling nitrate pollution of groundwater using quantile regression and uneec methods. Sci. Total Environ. 2019, 688, 855–866. [Google Scholar] [CrossRef] [PubMed]
- Singh, S.K.; Taylor, R.W.; Rahman, M.M.; Pradhan, B. Developing robust arsenic awareness prediction models using machine learning algorithms. J. Environ. Manag. 2018, 211, 125–137. [Google Scholar] [CrossRef] [PubMed]
- Chen, W.; Peng, J.; Hong, H.; Shahabi, H.; Pradhan, B.; Liu, J.; Zhu, A.-X.; Pei, X.; Duan, Z. Landslide susceptibility modelling using gis-based machine learning techniques for Chongren county, Jiangxi province, China. Sci. Total Environ. 2018, 626, 1121–1135. [Google Scholar] [CrossRef] [PubMed]
- Pham, B.T.; Prakash, I.; Bui, D.T. Spatial prediction of landslides using a hybrid machine learning approach based on random subspace and classification and regression trees. Geomorphology 2018, 303, 256–270. [Google Scholar] [CrossRef]
- Thai Pham, B.; Prakash, I.; Dou, J.; Singh, S.K.; Trinh, P.T.; Trung Tran, H.; Minh Le, T.; Tran, V.P.; Kim Khoi, D.; Shirzadi, A. A novel hybrid approach of landslide susceptibility modeling using rotation forest ensemble and different base classifiers. Geocarto Int. 2019, 1–25. [Google Scholar] [CrossRef]
- Pradhan, B. A comparative study on the predictive ability of the decision tree, support vector machine and neuro-fuzzy models in landslide susceptibility mapping using gis. Comput. Geosci. 2013, 51, 350–365. [Google Scholar] [CrossRef]
- Bui, D.T.; Tuan, T.A.; Klempe, H.; Pradhan, B.; Revhaug, I. Spatial prediction models for shallow landslide hazards: A comparative assessment of the efficacy of support vector machines, artificial neural networks, kernel logistic regression, and logistic model tree. Landslides 2016, 13, 361–378. [Google Scholar]
- Shafizadeh-Moghadam, H.; Minaei, M.; Shahabi, H.; Hagenauer, J. Big data in geohazard; pattern mining and large scale analysis of landslides in Iran. Earth Sci. Inform. 2019, 12, 1–17. [Google Scholar] [CrossRef]
- Nguyen, V.V.; Pham, B.T.; Vu, B.T.; Prakash, I.; Jha, S.; Shahabi, H.; Shirzadi, A.; Ba, D.N.; Kumar, R.; Chatterjee, J.M. Hybrid machine learning approaches for landslide susceptibility modeling. Forests 2019, 10, 157. [Google Scholar] [CrossRef]
- Park, I.; Lee, S. Spatial prediction of landslide susceptibility using a decision tree approach: A case study of the Pyeongchang area, Korea. Int. J. Remote Sens. 2014, 35, 6089–6112. [Google Scholar] [CrossRef]
- Bui, D.T.; Pradhan, B.; Revhaug, I.; Tran, C.T. A comparative assessment between the application of fuzzy unordered rules induction algorithm and j48 decision tree models in spatial prediction of shallow landslides at Lang Son city, Vietnam. In Remote Sensing Applications in Environmental Research; Springer: Berlin, Germany, 2014; pp. 87–111. [Google Scholar]
- Tsangaratos, P.; Ilia, I. Landslide susceptibility mapping using a modified decision tree classifier in the Xanthi Perfection, Greece. Landslides 2016, 13, 305–320. [Google Scholar] [CrossRef]
- Chen, W.; Xie, X.; Peng, J.; Shahabi, H.; Hong, H.; Bui, D.T.; Duan, Z.; Li, S.; Zhu, A.-X. Gis-based landslide susceptibility evaluation using a novel hybrid integration approach of bivariate statistical based random forest method. Catena 2018, 164, 135–149. [Google Scholar] [CrossRef]
- Chen, W.; Shahabi, H.; Shirzadi, A.; Hong, H.; Akgun, A.; Tian, Y.; Liu, J.; Zhu, A.X.; Li, S. Novel hybrid artificial intelligence approach of bivariate statistical-methods-based kernel logistic regression classifier for landslide susceptibility modeling. Bull. Int. Assoc. Eng. Geol. 2018, 1–23. [Google Scholar] [CrossRef]
- Pham, B.T.; Bui, D.T.; Prakash, I. Landslide Susceptibility Assessment Using Bagging Ensemble Based Alternating Decision Trees, Logistic Regression and J48 Decision Trees Methods: A Comparative Study. Geotech. Geol. Eng. 2017, 35, 2597–2611. [Google Scholar] [CrossRef]
- Khosravi, K.; Pham, B.T.; Chapi, K.; Shirzadi, A.; Shahabi, H.; Revhaug, I.; Prakash, I.; Bui, D.T. A comparative assessment of decision trees algorithms for flash flood susceptibility modeling at Haraz watershed, northern Iran. Sci. Total. Environ. 2018, 627, 744–755. [Google Scholar] [CrossRef] [PubMed]
- Chen, W.; Zhao, X.; Shahabi, H.; Shirzadi, A.; Khosravi, K.; Chai, H.; Zhang, S.; Zhang, L.; Ma, J.; Chen, Y.; et al. Spatial prediction of landslide susceptibility by combining evidential belief function, logistic regression and logistic model tree. Geocarto Int. 2019, 1–25. [Google Scholar] [CrossRef]
- Abedini, M.; Ghasemian, B.; Shirzadi, A.; Shahabi, H.; Chapi, K.; Pham, B.T.; Bin Ahmad, B.; Bui, D.T. A Novel Hybrid Approach of Bayesian Logistic Regression and Its Ensembles for Landslide Susceptibility Assessment. Geocarto Int. 2018, 1–44. [Google Scholar] [CrossRef]
- Tien Bui, D.; Shahabi, H.; Shirzadi, A.; Chapi, K.; Hoang, N.D.; Pham, B.; Bui, Q.T.; Tran, C.T.; Panahi, M.; Bin Ahamd, B. A novel integrated approach of relevance vector machine optimized by imperialist competitive algorithm for spatial modeling of shallow landslides. Remote Sens. 2018, 10, 1538. [Google Scholar] [CrossRef]
- Pham, B.T.; Shirzadi, A.; Bui, D.T.; Prakash, I.; Dholakia, M. A hybrid machine learning ensemble approach based on a Radial Basis Function neural network and Rotation Forest for landslide susceptibility modeling: A case study in the Himalayan area, India. Int. J. Sediment Res. 2018, 33, 157–170. [Google Scholar] [CrossRef]
- Shirzadi, A.; Soliamani, K.; Habibnejhad, M.; Kavian, A.; Chapi, K.; Shahabi, H.; Chen, W.; Khosravi, K.; Thai Pham, B.; Pradhan, B. Novel gis based machine learning algorithms for shallow landslide susceptibility mapping. Sensors 2018, 18, 3777. [Google Scholar] [CrossRef] [PubMed]
- Chen, W.; Shirzadi, A.; Shahabi, H.; Bin Ahmad, B.; Zhang, S.; Hong, H.; Zhang, N. A novel hybrid artificial intelligence approach based on the rotation forest ensemble and naïve Bayes tree classifiers for a landslide susceptibility assessment in Langao County, China. Geomat. Nat. Hazards Risk 2017, 8, 1955–1977. [Google Scholar] [CrossRef]
- Shirzadi, A.; Solaimani, K.; Roshan, M.H.; Kavian, A.; Chapi, K.; Shahabi, H.; Keesstra, S.; Ahmad, B.B.; Bui, D.T. Uncertainties of prediction accuracy in shallow landslide modeling: Sample size and raster resolution. Catena 2019, 178, 172–188. [Google Scholar] [CrossRef]
- Tien Bui, D.; Shahabi, H.; Shirzadi, A.; Chapi, K.; Pradhan, B.; Chen, W.; Khosravi, K.; Panahi, M.; Bin Ahmad, B.; Saro, L. Land subsidence susceptibility mapping in South Korea using machine learning algorithms. Sensors 2018, 18, 2464. [Google Scholar] [CrossRef] [PubMed]
- Freund, Y.; Mason, L. The Alternating Decision Tree Learning Algorithm; ICML: New Jersey, NY, USA, 1999; pp. 124–133. [Google Scholar]
- He, Q.; Shahabi, H.; Shirzadi, A.; Li, S.; Chen, W.; Wang, N.; Chai, H.; Bian, H.; Ma, J.; Chen, Y.; et al. Landslide spatial modelling using novel bivariate statistical based Naïve Bayes, RBF Classifier, and RBF Network machine learning algorithms. Sci. Total. Environ. 2019, 663, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Mohammadi, A.; Shahabi, H.; Bin Ahmad, B. Integration of insartechnique, google earth images and extensive field survey for landslide inventory in a part of Cameron highlands, Pahang, Malaysia. Appl. Ecol. Environ. Res. 2007, 16, 8075–8091. [Google Scholar] [CrossRef]
- An, K.; Kim, S.; Chae, T.; Park, D. Developing an accessible landslide susceptibility model using open-source resources. Sustainability 2018, 10, 293. [Google Scholar] [CrossRef]
- Lee, C.F.; Huang, W.K.; Chang, Y.L.; Chi, S.Y.; Liao, W.C. Regional landslide susceptibility assessment using multi-stage remote sensing data along the coastal range highway in northeastern Taiwan. Geomorphology 2018, 300, 113–127. [Google Scholar] [CrossRef]
- Martha, T.R.; Roy, P.; Govindharaj, K.B.; Kumar, K.V.; Diwakar, P.; Dadhwal, V. Landslides triggered by the june 2013 extreme rainfall event in parts of Uttarakhand state, India. Landslides 2015, 12, 135–146. [Google Scholar] [CrossRef]
- Ghosh, S.; Carranza, E.J.M.; van Westen, C.J.; Jetten, V.G.; Bhattacharya, D.N. Selecting and weighting spatial predictors for empirical modeling of landslide susceptibility in the Darjeeling Himalayas (India). Geomorphology 2011, 131, 35–56. [Google Scholar] [CrossRef]
- Prandini, L.; Guidiini, G.; Bottura, J.A.; Pançano, W.L.; Santos, A.R. Behavior of the vegetation in slope stability: A critical review. Bull. Int. Assoc. Eng. Geol. 1977, 16, 51–55. [Google Scholar] [CrossRef]
- Varnes, D.J. Slope movement types and processes. Spec. Rep. 1978, 176, 11–33. [Google Scholar]
- Pham, B.T.; Bui, D.T.; Pourghasemi, H.R.; Indra, P.; Dholakia, M. Landslide susceptibility assesssment in the Uttarakhand area (India) using gis: A comparison study of prediction capability of naïve bayes, multilayer perceptron neural networks, and functional trees methods. Theor. Appl. Climatol. 2017, 128, 255–273. [Google Scholar] [CrossRef]
- Yalcin, A.; Reis, S.; Aydinoglu, A.; Yomralioglu, T. A gis-based comparative study of frequency ratio, analytical hierarchy process, bivariate statistics and logistics regression methods for landslide susceptibility mapping in Trabzon, ne Turkey. Catena 2011, 85, 274–287. [Google Scholar] [CrossRef]
- Nefeslioglu, H.A.; Duman, T.Y.; Durmaz, S. Landslide susceptibility mapping for a part of tectonic kelkit valley (eastern black sea region of Turkey). Geomorphology 2008, 94, 401–418. [Google Scholar] [CrossRef]
- Pham, B.T.; Pradhan, B.; Bui, D.T.; Prakash, I.; Dholakia, M. A comparative study of different machine learning methods for landslide susceptibility assessment: A case study of Uttarakhand area (India). Environ. Model. Softw. 2016, 84, 240–250. [Google Scholar] [CrossRef]
- Kavzoglu, T.; Sahin, E.K.; Colkesen, I. An assessment of multivariate and bivariate approaches in landslide susceptibility mapping: A case study of Duzkoy district. Nat. Hazards 2015, 76, 471–496. [Google Scholar] [CrossRef]
- Dehnavi, A.; Aghdam, I.N.; Pradhan, B.; Varzandeh, M.H.M. A new hybrid model using step-wise weight assessment ratio analysis (swara) technique and adaptive neuro-fuzzy inference system (anfis) for regional landslide hazard assessment in Iran. Catena 2015, 135, 122–148. [Google Scholar] [CrossRef]
- Zhou, C.; Yin, K.; Cao, Y.; Ahmed, B.; Li, Y.; Catani, F.; Pourghasemi, H.R. Landslide susceptibility modeling applying machine learning methods: A case study from Longju in the three gorges reservoir area, China. Comput. Geosci. 2018, 112, 23–37. [Google Scholar] [CrossRef]
- Jaafari, A.; Panahi, M.; Pham, B.T.; Shahabi, H.; Bui, D.T.; Rezaie, F.; Lee, S. Meta optimization of an adaptive neuro-fuzzy inference system with grey wolf optimizer and biogeography-based optimization algorithms for spatial prediction of landslide susceptibility. Catena 2019, 175, 430–445. [Google Scholar] [CrossRef]
- Hong, H.; Pradhan, B.; Xu, C.; Bui, D.T. Spatial prediction of landslide hazard at the yihuang area (China) using two-class kernel logistic regression, alternating decision tree and support vector machines. Catena 2015, 133, 266–281. [Google Scholar] [CrossRef]
- Kavzoglu, T.; Colkesen, I.; Sahin, E.K. Machine learning techniques in landslide susceptibility mapping: A survey and a case study. In Landslides: Theory, Practice and Modelling; Springer: Berlin, Germany, 2019; pp. 283–301. [Google Scholar]
- Nefeslioglu, H.A.; Sezer, E.A.; Gokceoglu, C.; Bozkir, A.S.; Duman, T.Y.; Bozkır, A.S. Assessment of Landslide Susceptibility by Decision Trees in the Metropolitan Area of Istanbul, Turkey. Math. Probl. Eng. 2010, 2010, 1–15. [Google Scholar] [CrossRef]
- Pfahringer, B.; Holmes, G.; Kirkby, R. Pacific-Asia Conference on Knowledge Discovery and Data Mining. In Optimizing the Induction of Alternating Decision Trees; Springer: Berlin, Germany, 2001; pp. 477–487. [Google Scholar]
- Rodriguez, J.J.; Kuncheva, L.; Alonso, C.J. Rotation Forest: A New Classifier Ensemble Method. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1619–1630. [Google Scholar] [CrossRef] [PubMed]
- Truong, X.L.; Mitamura, M.; Kono, Y.; Raghavan, V.; Yonezawa, G.; Truong, X.Q.; Do, T.H.; Bui, D.T.; Lee, S. Enhancing Prediction Performance of Landslide Susceptibility Model Using Hybrid Machine Learning Approach of Bagging Ensemble and Logistic Model Tree. Appl. Sci. 2018, 8, 1046. [Google Scholar] [CrossRef]
- Vafaie, H.; Imam, I.F. Feature selection methods: Genetic algorithms vs. Greedy-like search. In International Conference on Fuzzy and Intelligent Control Systems; Walt Disney World: Orlando, FL, USA, 1994; p. 28. [Google Scholar]
- Karegowda, A.G.; Manjunath, A.; Jayaram, M. Comparative study of attribute selection using gain ratio and correlation based feature selection. Int. J. Inf. Technol. Knowl. Manag. 2010, 2, 271–277. [Google Scholar]
- Fawcett, T. An introduction to roc analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Shahabi, H.; Hashim, M. Landslide susceptibility mapping using gis-based statistical models and remote sensing data in tropical environment. Sci. Rep. 2015, 5, 9899. [Google Scholar] [CrossRef]
- Chen, W.; Xie, X.; Peng, J.; Wang, J.; Duan, Z.; Hong, H. Gis-based landslide susceptibility modelling: A comparative assessment of kernel logistic regression, naïve-bayes tree, and alternating decision tree models. Geomat. Nat. Hazards Risk. 2017, 8, 950–973. [Google Scholar] [CrossRef]
- Pham, B.T.; Bui, D.T.; Pham, H.V.; Le, H.Q.; Prakash, I.; Dholakia, M. Landslide hazard assessment using random subspace fuzzy rules based classifier ensemble and probability analysis of rainfall data: A case study at Mu Cang Chai district, Yen Bai province (Vietnam). J. Indian Soc. Remote Sens. 2017, 45, 673–683. [Google Scholar] [CrossRef]
- Skurichina, M.; Duin, R.P.W. Bagging, Boosting and the Random Subspace Method for Linear Classifiers. Pattern Anal. Appl. 2002, 5, 121–135. [Google Scholar] [CrossRef]
- Bui, D.T.; Ho, T.C.; Pradhan, B.; Pham, B.T.; Nhu, V.H.; Revhaug, I. Gis-based modeling of rainfall-induced landslides using data mining-based functional trees classifier with adaboost, bagging, and multiboost ensemble frameworks. Environ. Earth Sci. 2016, 75, 1101. [Google Scholar]
- Bui, D.T.; Ho, T.C.; Revhaug, I.; Pradhan, B.; Nguyen, D.B. Landslide susceptibility mapping along the national road 32 of Vietnam using gis-based j48 decision tree classifier and its ensembles. In Cartography from Pole to Pole; Springer: Berlin, Germany, 2014; pp. 303–317. [Google Scholar]
- Breiman, L. Arcing classifier (with discussion and a rejoinder by the author). Ann. Stat. 1998, 26, 801–849. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Indian State | Sum of Fatalities | Indian State | Sum of Fatalities |
|---|---|---|---|
| Uttarakhand | 5228 | Andhra Pradesh | 19 |
| Jammu and Kashmir | 590 | Manipur | 12 |
| Maharashtra | 251 | Orissa | 12 |
| Himachal Pradesh | 114 | Goa | 8 |
| Arunachal Pradesh | 88 | Uttar Pradesh | 6 |
| West Bengal | 73 | Gujarat | 5 |
| Assam | 72 | Nagaland | 5 |
| Sikkim | 66 | Tripura | 4 |
| Rajasthan | 54 | Jharkhand | 2 |
| Tamil Nadu | 46 | NCT | 2 |
| Kerala | 38 | Haryana | 1 |
| Meghalaya | 30 | Bihar | - |
| Karnataka | 29 | Odisha | - |
| Mizoram | 24 | Total | 6779 |
| Predicted Class | Actual Class | ||
| 1 | 0 | ||
| 1 | A (TP) | B (FP) | |
| 0 | C (FN) | D (TN) | |
| Column total: | P | N | |
| ADTree | BAADT | RSADT | RFADT | |
|---|---|---|---|---|
| TP Rate/Recall | 0.863 | 0.880 | 0.881 | 0.911 |
| FP Rate | 0.131 | 0.131 | 0.112 | 0.100 |
| Precision | 0.867 | 0.880 | 0.885 | 0.911 |
| Kappa | 0.722 | 0.752 | 0.751 | 0.815 |
| RMSE | 0.326 | 0.314 | 0.325 | 0.305 |
| AUC | 0.939 | 0.954 | 0.949 | 0.972 |
| ADTree | BAADT | RSADT | RFADT | |
|---|---|---|---|---|
| TP Rate/Recall | 0.711 | 0.714 | 0.717 | 0.717 |
| FP Rate | 0.291 | 0.288 | 0.276 | 0.285 |
| Precision | 0.734 | 0.773 | 0.759 | 0.771 |
| Kappa | 0.421 | 0.427 | 0.451 | 0.433 |
| RMSE | 0.404 | 0.400 | 0.398 | 0.397 |
| AUC | 0.897 | 0.919 | 0.915 | 0.931 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Thai Pham, B.; Shirzadi, A.; Shahabi, H.; Omidvar, E.; Singh, S.K.; Sahana, M.; Talebpour Asl, D.; Bin Ahmad, B.; Kim Quoc, N.; Lee, S. Landslide Susceptibility Assessment by Novel Hybrid Machine Learning Algorithms. Sustainability 2019, 11, 4386. https://doi.org/10.3390/su11164386
Thai Pham B, Shirzadi A, Shahabi H, Omidvar E, Singh SK, Sahana M, Talebpour Asl D, Bin Ahmad B, Kim Quoc N, Lee S. Landslide Susceptibility Assessment by Novel Hybrid Machine Learning Algorithms. Sustainability. 2019; 11(16):4386. https://doi.org/10.3390/su11164386
Chicago/Turabian StyleThai Pham, Binh, Ataollah Shirzadi, Himan Shahabi, Ebrahim Omidvar, Sushant K. Singh, Mehebub Sahana, Dawood Talebpour Asl, Baharin Bin Ahmad, Nguyen Kim Quoc, and Saro Lee. 2019. "Landslide Susceptibility Assessment by Novel Hybrid Machine Learning Algorithms" Sustainability 11, no. 16: 4386. https://doi.org/10.3390/su11164386
APA StyleThai Pham, B., Shirzadi, A., Shahabi, H., Omidvar, E., Singh, S. K., Sahana, M., Talebpour Asl, D., Bin Ahmad, B., Kim Quoc, N., & Lee, S. (2019). Landslide Susceptibility Assessment by Novel Hybrid Machine Learning Algorithms. Sustainability, 11(16), 4386. https://doi.org/10.3390/su11164386