1. Introduction
E-government is developing in today’s societies. Iran’s society is also not an exception, so it is necessary to carefully consider the concepts behind e-government [
1]. The critical purpose of e-government is to manage governments more efficiently [
2]. One of the important criteria of e-government is Citizen Relationship Management (CiRM) offering citizen-centric services [
3]. Citizens are, in fact, the true owner of the governments. Therefore, it is logical that governments should be citizen-centric [
4]. CiRM provides the information to specific people in a special time and with special methods. Through CiRM, organizations have an opportunity to manipulate and access up-to-date data collected by governments [
5].
Some research has approved the usefulness of CiRM [
6,
7,
8]. King mentioned CiRM as a basic element offering more citizen-centric public services to citizens [
7]. The author suggested the use of CiRM in predicting the needs. Dasilva and Batista identified CiRM as a tool to increase the response time of governmental organizations [
6]. Schellong and Langenberg used CiRM to predict natural hazards and emergencies like Wilma Hurricane [
8].
There are two essential points about CiRM. First, how to have citizen-centric management. Some studies concentrated on how to implement Citizen Relationship in society. Sasaki et al. studied the required environmental changes to make a Centre of the CiRM [
2]. In another study by Keramati et al. the success factors in the strategy of the CiRM were investigated, and some suggestions were presented to improve its implementation. They suggested that governments should present citizens’ science through a confirmed communication channel possible by the CiRM [
5].
The second essential point about CiRM is to observe that the communication channels and governmental services are not the only tools to CiRM. Making channels for communication and mutual interaction between citizens and government is, however, necessary. Many governments improve their services in several ways, but different services and communication channels do not equally satisfy the citizen’s needs. The true realization of citizens’ needs and demands and offering the appropriate services related to the demands are significant and need to be discussed. In fact, CiRM is a mixture of managerial and technological topics, both influencing citizens’ needs. Using information technology, the needs of citizens could be appreciated better [
1].
Using techniques and data-mining tools could be very useful. Data-mining helps related organizations like municipalities know the citizens better, to appreciate the differences among their needs; through this, they can more efficiently manage their resources and better coordinated concerning citizens. Data-mining could play a role in CiRM through improvement by offering urban services to citizens and enhancing their satisfaction [
9].
Researchers are increasingly using large-scale administrative data such as 137 data gathered by municipalities to better comprehend urban issues and their patterns over time and space [
10]. As citizens use various channels to increase their voice more frequently, it becomes difficult for citizens to comprehend the city’s urgent problems manually. ICT-enabled co-production aims to convert the architecture, system, and style of government management into a more citizen-centered and participatory strategy. Highly intelligent assessment of citizens’ demands and complaints can contribute to enhanced rates of service coordination and can assist officials in the decision-making mechanism. By extracting helpful patterns from big data, data analytics can provide information depictions. By extracting a couple of valuable pieces of information from big amounts of data, people can handle a relatively small amount of the information obtained to make inferences. Big data analysis is a helpful tool to comprehend realities by decreasing huge data to a small amount of valuable information. It can also help planners by using some widely known algorithms for descriptive purposes. For examples, clustering algorithms are used to organize the citizen’s service needs to groups. A couple of patterns recognized by these techniques provide perspectives that would not be evident using traditional approaches like manual scanning [
11].
In Iran the municipality, as one of the most important organizations related to citizens, has a major role in offering urban services. Using information technology and telecommunication systems, this organization has made a ‘137 phone system’. This system is a centre for controlling, establishing and investing urban problems. It also acts as a bridge between the municipality and citizens. In the database of this system, useful data are saved concerning the services presented to the citizens. It can be investigated as an important and appropriate resource for the management of analytical relations with citizens [
9].
Some studies analyzing ‘137 databases’ were performed. In a study done by Ahmadvand et al., 137 databases of Tehran municipality were used. In their study, the problems were firstly grouped by a K-means algorithm, and then the information related to citizens’ satisfaction with the services were analyzed by using association rules and an a priori algorithm. In addition, the relation between the parameters of citizens’ satisfaction with quality and speed of services was considered and also effective factors and conditions affecting the satisfaction and dissatisfaction of the citizens were determined [
12]. Minaei-Bidgoli and Akhondzadeh did similar research to the previous one on ‘137 databases’ of Tehran municipality. In the mentioned study, association rules and an a priori algorithm were used. In the first section of their study, the relation between the type of problem, time and geographical zone was investigated. In the next section, the relations between the type of complaints and demographic features, the cultural features and the type of problem were investigated [
13]. In another study performed by Akhondzade-Noughabi et al. on the ‘137 system’ of Tehran municipality, citizens’ complaints were categorized using a K-means algorithm. They also examined citizen satisfaction in their study [
14]. The mentioned studies have some drawbacks. First, they only used one clustering algorithm, and thus way it is not possible to guarantee an optimum algorithm. The way the satisfaction analysis was quantified and the fact that the method and parameters were non-generalizable were some other drawbacks.
In previous studies, clustering was done based on frequency and recency, and in the next stage, satisfaction was analyzed based on obtaining clusters. They have ignored this point in CiRM; we are looking for needs, which have more frequency and recency and satisfaction to a less degree. In practice, this is our objective function in CiRM. In other words, the first method cannot provide a guarantee for achieving CiRM objectives. In this regard, when prioritization and satisfaction analysis is done simultaneously, the third factor is considered in prioritizing needs. Also, we want to know how much its effect on CiRM objective function and can help us to better satisfy that and has a deeper insight into citizens’ needs. These issues increase the importance of our study.
To categorize the needs, various algorithms can be used. During recent decades, some new algorithms were developed for solving different problems. Among these methods are meta-heuristic algorithms. Meta-heuristic algorithms have been used in different engineering and management issues [
15]. Also, studies in CRM showed that meta-heuristic algorithms increase clustering quality. This makes sure that needs in the same cluster have a similar occurrence pattern [
16].
A comparison of genetic, bees and K-mean algorithms for clustering was done in a study by Pham et al. From their results, the priority of the bees algorithm (BA) is on the dataset in clustering [
17]. In another study, carried out by AbdelHamid et al. a comparison between BA, genetic algorithm and K-means in document clustering was done. Results showed the priority of BA [
18].
Hubert et al. developed methods for clustering and visually exploring citizens’ complaints. They used the Density-Based Spatial Clustering of Applications with Noise (DBSCAN) method for clustering. They used heat maps to depict the intensity of requests at geographical regions [
19]. Wang et al. developed a method for classifying urban locations based on the categorical and temporal structure of 311 Service Requests. They provided an urban classifier to predict the socioeconomic and demographic features of a neighborhood and estimate the economic performance and prosperity of defined spatial units [
20]. Xu et al. used a locally adaptive space-time kernel approach to model 311 requests. They provided an analytical model to predict 311 demands in space and time [
21].
White and Trump examined applications of 311 data for the purpose of studying citizens’ political participation and engagement [
22]. Hagen et al. discussed the potential advantages and constraints of 311 data and analytics outcomes. They took a clustering approach to group together tracts that share similar 311 request patterns by implementing K-means clustering. They investigated to what extent 311 request patterns can reveal socio-demographic structures. As a result, they found that 311 service request patterns indicate underlying socio-demographic factors within the area [
11]. Liu et al., used a factor analysis method for identifying different requests. They also mapped the spatial distribution of each request type. They used Exploratory Factor Analysis (EFA) and Confirmatory Factor Analysis (CFA) for factor analysis and used Kernel Density Estimate (KDE) for spatial analysis. They examined the change of spatial distributions of each type of request. In other words, they analyzed the spatial and temporal patterns of complaint [
10].
In CRM, due to customer’s diverse interests and backgrounds, mass marketing cannot satisfy the needs. Therefore, market segmentation has been considered in realizing prosperous modern marketing patterns [
16]. We can also develop this concept in governmental agencies. In this research, there were three factors to consider: request frequency (F), request recency (R), and satisfaction (executive function). We used the RFM model to identify and prioritize the requirements. Regarding citizen relationship management, the issues related to finance are not important; we can use satisfaction and executive function for revenue [
14].
In this research, the ‘137 databases’ of Bojnourd city, which is located in north-east of Iran, is analyzed. We utilized data-mining and CiRM approach for identification and prioritization of the citizen requirements, as well as how much their satisfaction is. This research used two methods. In the first, such as the study done by Ghodousi et al. [
23], prioritizing and estimating the satisfaction was done separately, but in the second method, through a new approach, optimizing and estimating the satisfaction was done simultaneously and the result was compared based on CiRM objectives. In this research, BA was used to optimize the clustering. In addition, the result of K-means as a popular clustering algorithm [
14], and BA was compared.
3. Materials and Methods
In many studies [
31,
32,
33], citizen satisfaction data has been gathered through qualitative measurement by survey questionnaires. The survey has a weakness which uses a limited amount of sample data and one cannot verify whether the survey represents the people’s true thoughts. On the other hand, one can overcome the survey’s drawbacks by using social network data that contains people’s opinions [
34]. However, in many places, people are self-conscious about their privacy and are often unwilling to share their location for deeper analysis. On the other hand, one can solve the survey’s disadvantages by the analysis of ‘137 databases’ which consists of a citizen’s frank opinions.
In this study, the database of ‘137 centres’ in Bojnourd municipality was utilized. The raw data were provided in Excel format by the IT department of the Bojnourd municipality. The data is not shared publicly. The data belong to District 1 of Bojnourd city for the month of July 2014. The Bojnourd 137 system has a relatively medium quantity of requests, averaging over 50 requests per day, for over 1500 requests in this period. The fields of ‘137 databases were the Tracking Code, Subject, Region, Date, Time and Executive response.
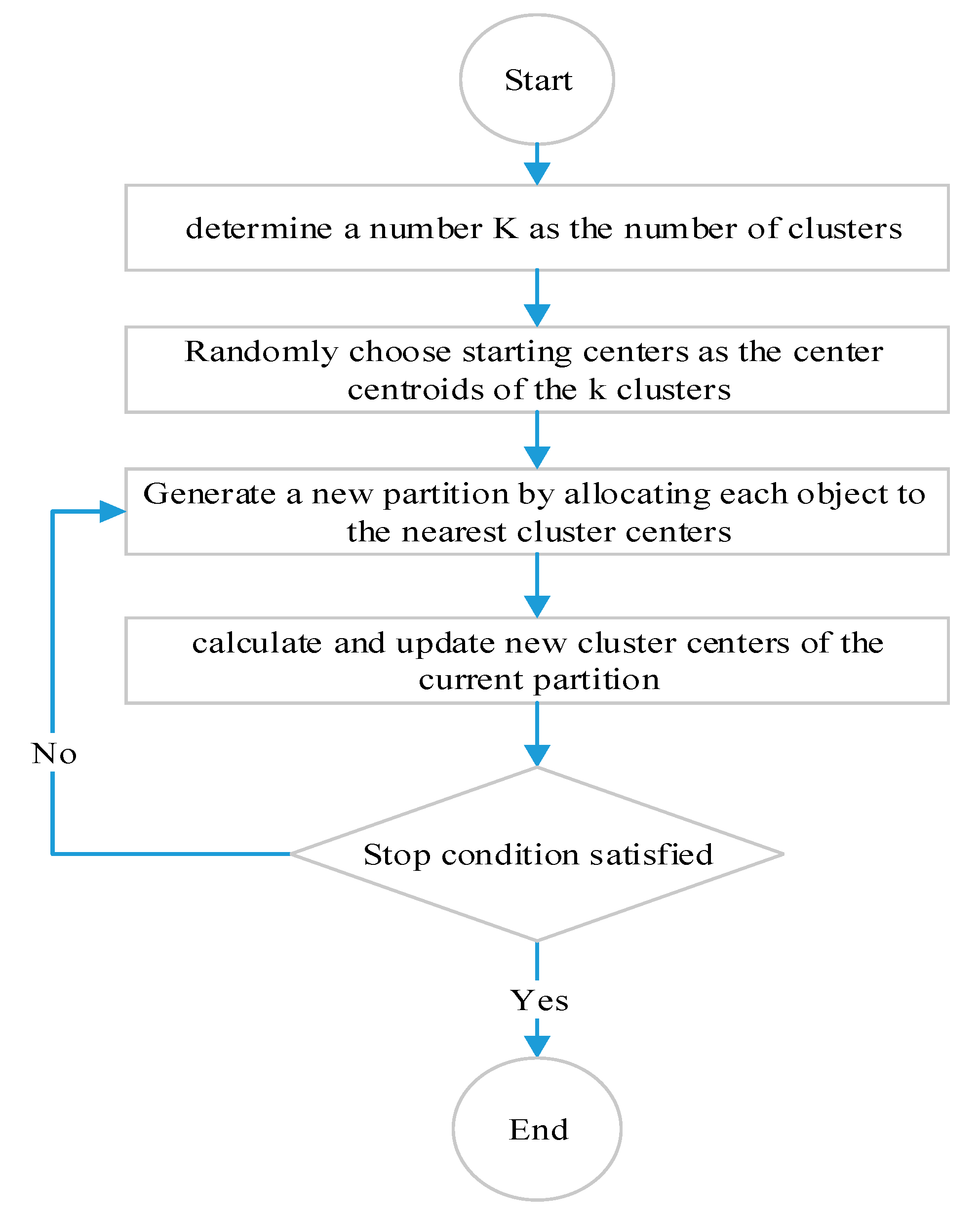
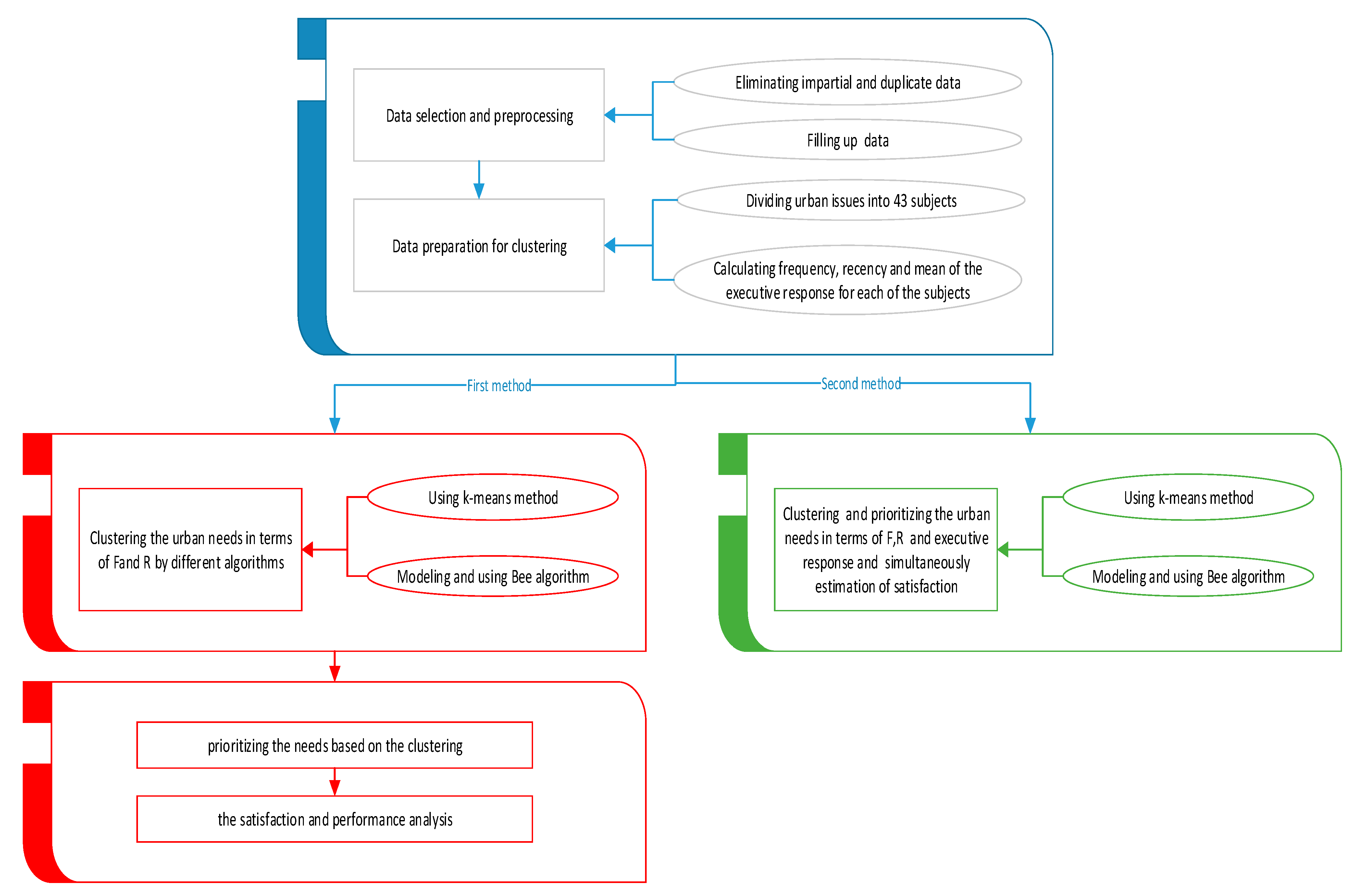
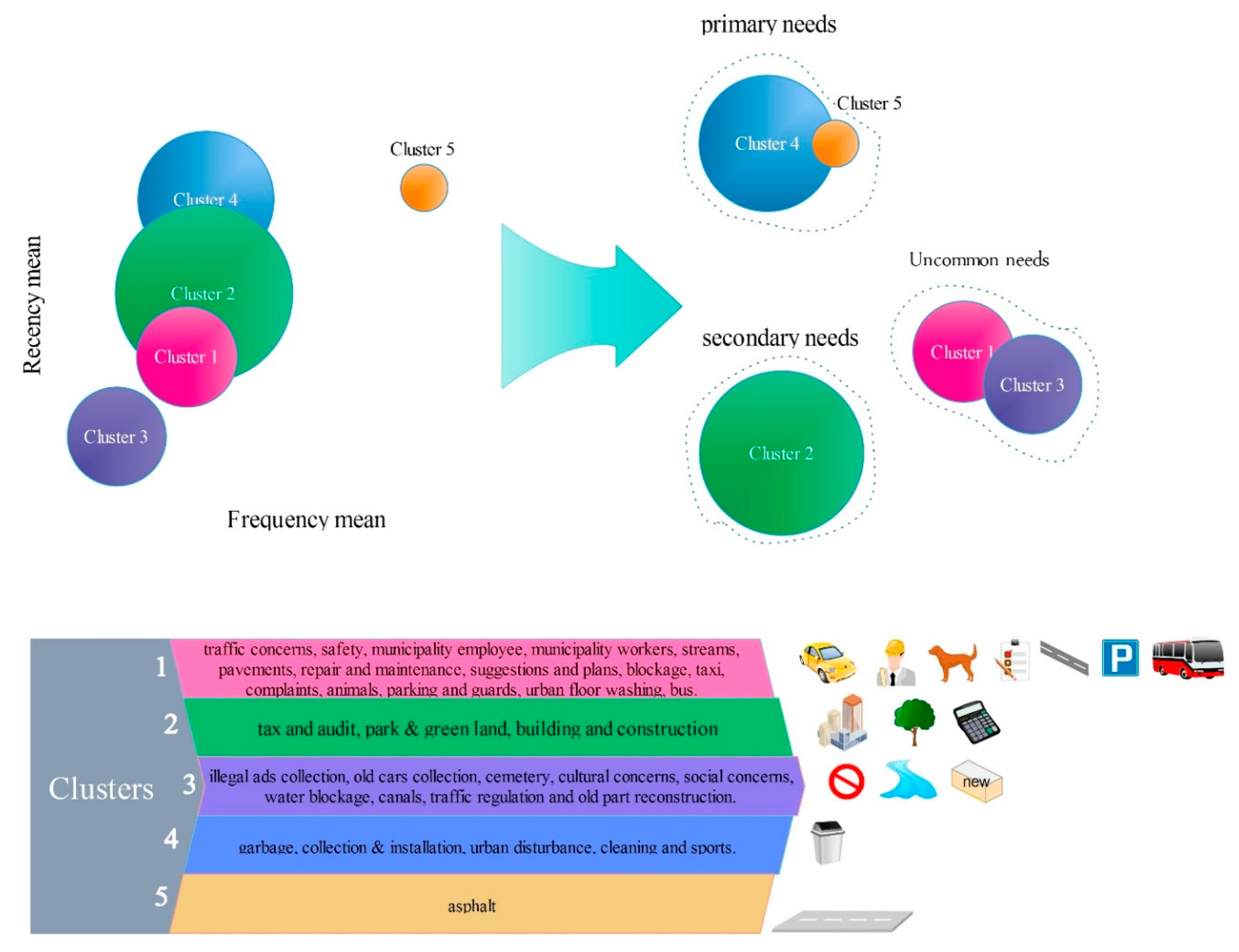
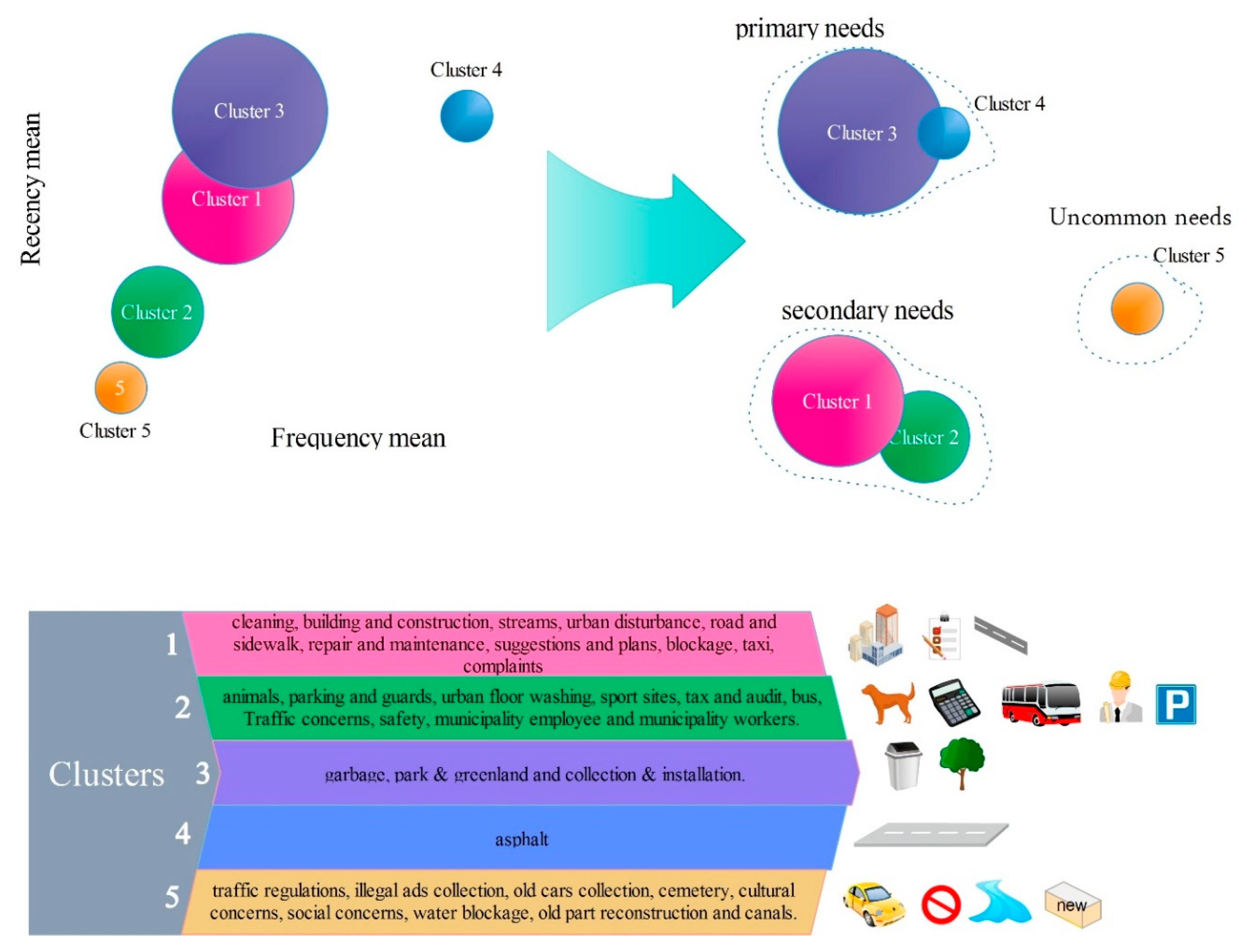
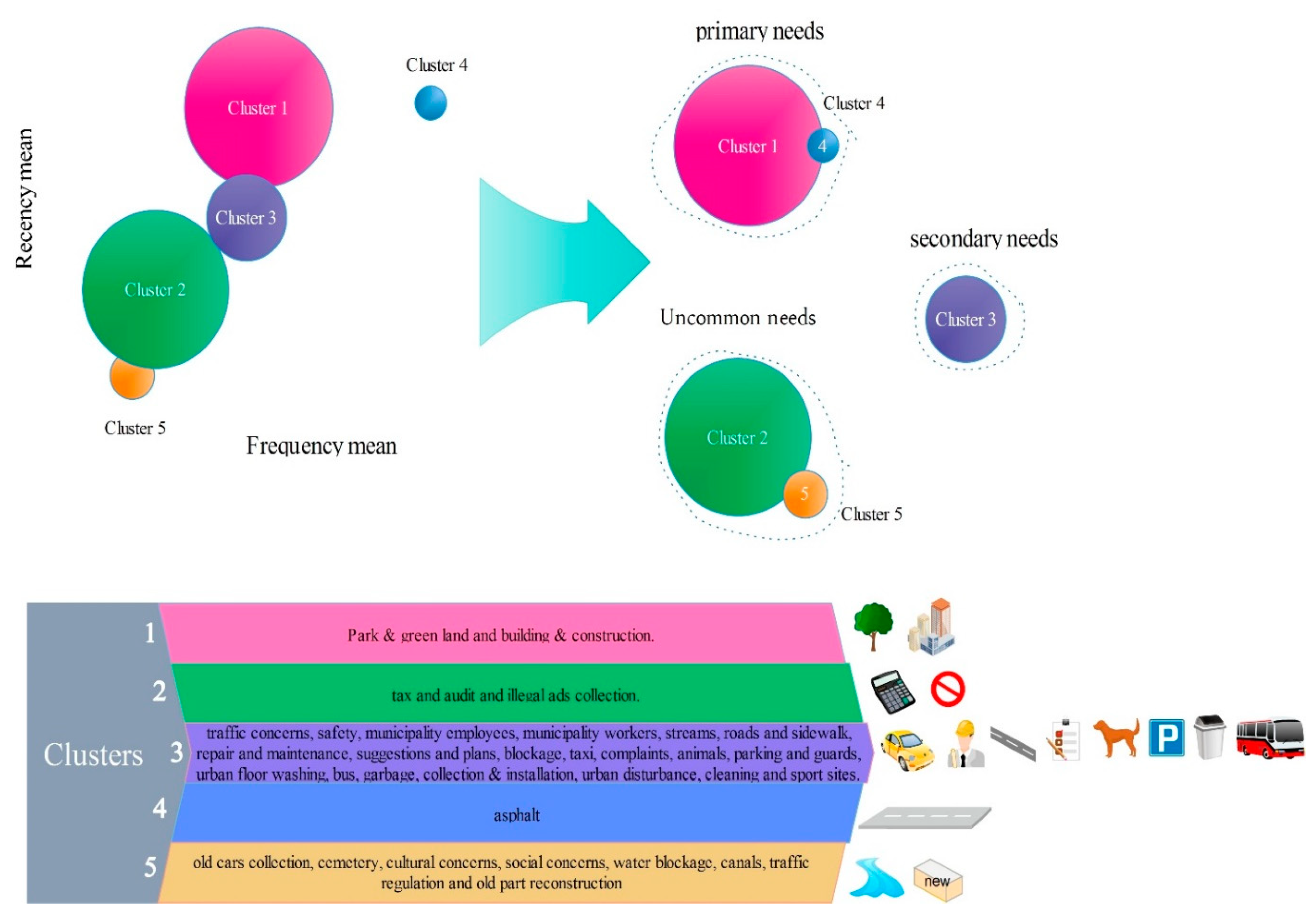
Figure 3 shows the overall methodology applied in this research.
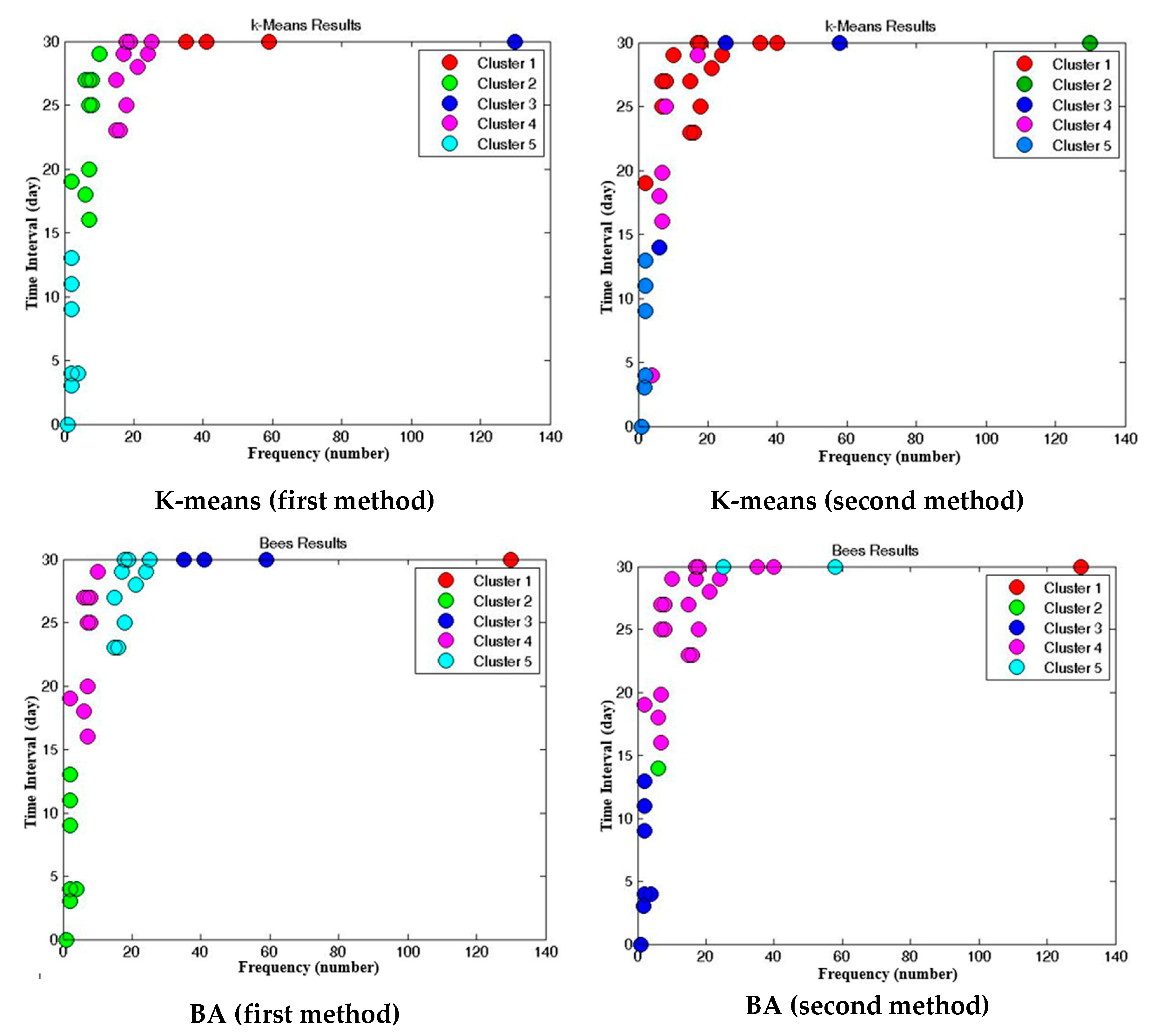
In the proposed method, the data was gathered and preprocessed, then it was transformed into a suitable format for clustering. After applying various algorithms with different methods, needs prioritization was defined next. In preparing the data, the impartial and repetitive data were deleted from the database, and those capable of filling up based on other fields were rebuilt. The data was primarily in the Persian language. Each country uses a different complaint/request coding convention, thus there is little consistency in the classification of particular complaint types. The research of Akhondzadeh-Noughabi et al. was used to translate the categories into English. The problem regarding urban were classified into 43 subjects; then, the number of contacts and recency and the mean of the relevant number to the executive response were made out for every subject. Ten subjects were without occurrence, while there were some requests for 33 issues. The reasons for having 10 subjects without reports were the temporal and spatial conflict with a time period and location of the study area. The temporal and spatial conflicting with a time period and location of the study explained why the 10 subjects were without reports. Actually, these issues did not take place in the study area for issues related to culture. According to the suggestion by Akhondzadeh et al. the best number of grouping for urban needs was 5, so this number was selected for this research [
14].
According to
Figure 3, two methods were executed. In the first method, similar to previous studies [
12,
17], concerning the prioritization of urban needs and estimation of satisfaction, needs were prioritized. First, this it was carried out according to the two factors of frequency and recency, and then the estimation of satisfaction was performed. In the second method, the need prioritization and clustering were done based on three factors (frequency, recency and executive response mean) and the satisfaction estimation was also done simultaneously. Then, the results of the two methods of prioritization in reaching CiRM objectives were compared.
In this study, three factors were utilized, which are known as the three RFM parameters: the first one is time interval or “recency” (R): the time interval between the first request of a subject and the last one within a month. The second one is frequency (F): the count of citizens’ contacts in case of an issue in a month. Finally, executive response means (M): the general function of the executive (for instance jobs done, impossible to carry out, needs more time to do, no response and so on). This factor was the result of the mean of all the responses provided by the executives for an issue within a month; which is quantified for better analysis.
Regarding the needs, prioritizing was performed within a month; the second-criteria range is 0 to 30. Subsequently examining different modes for answering to an issue, the classification of the third factor into four class was conducted according to the quality of executive response (
Table 1).
The subjects of further priorities (primary needs) have more frequency and recency and also less executive response (the definition for the objective of CiRM should be provided, based on these rules). Therefore, it should be specific measurements for these subjects. In other words, one should prioritize based on the type of subjects, the time of occurrence patterns and the performance of the executive. The RFM priority analysis highlighted more citizen-centric and assists decision-makers to revise their strategies [
14].
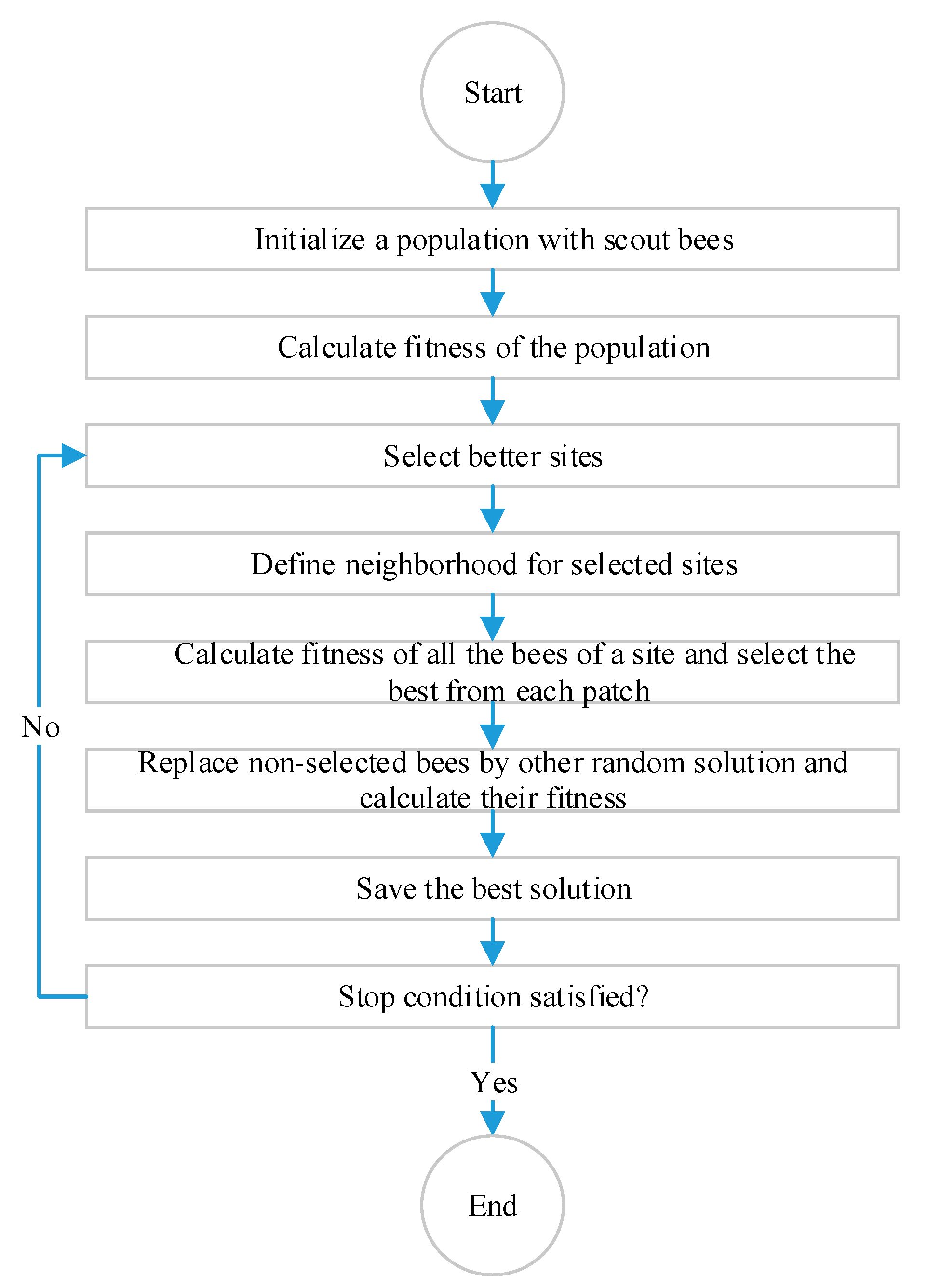
Modeling of BA
In this section, the clustering of subjects and urban problems are formulated in the context of the BA optimization algorithm:
Defining the problem and optimality (fitness) function: The aim is to divide subjects and urban problems into clusters. In addition, the centres and a number of subjects related to each cluster are unknown. The fitness function is defined as all the elements of a subject’s distance to the nearest centre according to the second norm (Equation (1)) [
23]:
In this relationship, xi were the subjects consisting of a frequency, recency, and the value of executive response and wj are unknowns (i.e., the centres of the clusters). To measure the distance to the nearest centre, at first the distance to all of the centres was calculated, then the lowest value was selected).
Create the initial population: firstly,
n (for example, 30) scout bees were considered for the first population. For defining each bee,
n centres were considered randomly in the space. Each centre defines a cluster. Then, the subjects were distributed in these clusters (centres) based on the least distance. The fitness of bee was the reciprocal of the sum of these distances [
35].
Selecting better responses and sending the worker bees to them: half of the solutions, i.e., 15 bees were considered as the better responses and six of them were chosen as an elite response. To each of the elite responses, 30 bees were assigned, and the best was chosen. Nine bees were given to those designated as not elite, among which the best was selected.
Defining the neighborhood: for each of the sites (responses) having some worker bees regarding being elite or being selected; a centre was chosen randomly and the width of the space of 0.1 was transferred. As it went forward, this amount was multiplied by 0.99 to close the optimal response with a small step, so the speed of performance increased [
35].
Comparing all the bees of a site and selecting the best: for each site, all the bees and the neighboring bees, which have been created, were compared and the best was selected.
Replacing the non-selected sites: those bees not selected were deleted, and replaced by random solutions.
Investigating stop condition (the number of a specific iteration): in case of reaching a specific number of iterations.
5. Conclusions
Cities can be seen as a complex systems comprising multiple levels of operation and relationships across different urban domains, so it is rather hard to discover a parsimonious depiction of civic function. However, city managers, policymakers and other kinds of social participants, including companies and shareholders, could profit from an intuitive proxy of neighborhood circumstances across the city. Simultaneously, such simple indices could provide useful data to help municipal decision-making. As the quantity and heterogeneity of urban data have increased, data mining has become a feasible tool to enhance our understanding of civic space to guide urban management and strategy. These data are commonly referred to as 137 requests in Iran, and represent a broad variety of issues posed by urban inhabitants, providing a distinctive measure of local civic features, situations, and service levels. While possibly influenced by the self-reported nature of demands and criticisms, these data provide a comparable metric of perceived local quality of life across space and time. These data, therefore, serve as a helpful tool for knowing the provision of critical urban services and circumstances in the neighborhood [
20].
Citizen Relationship Management (CiRM) is one of the key issues in citizen-centered e-government. E-governance can be extremely helpful in enhancing government operating effectiveness and enhancing the provision and quality of public service. Citizen-centered strategies such as Citizen Relationship Management (CiRM) will allow organizations to attain vital effectiveness profits, improve rates of service delivery, increase citizens’ use of public facilities, and improve the standard of living [
40].
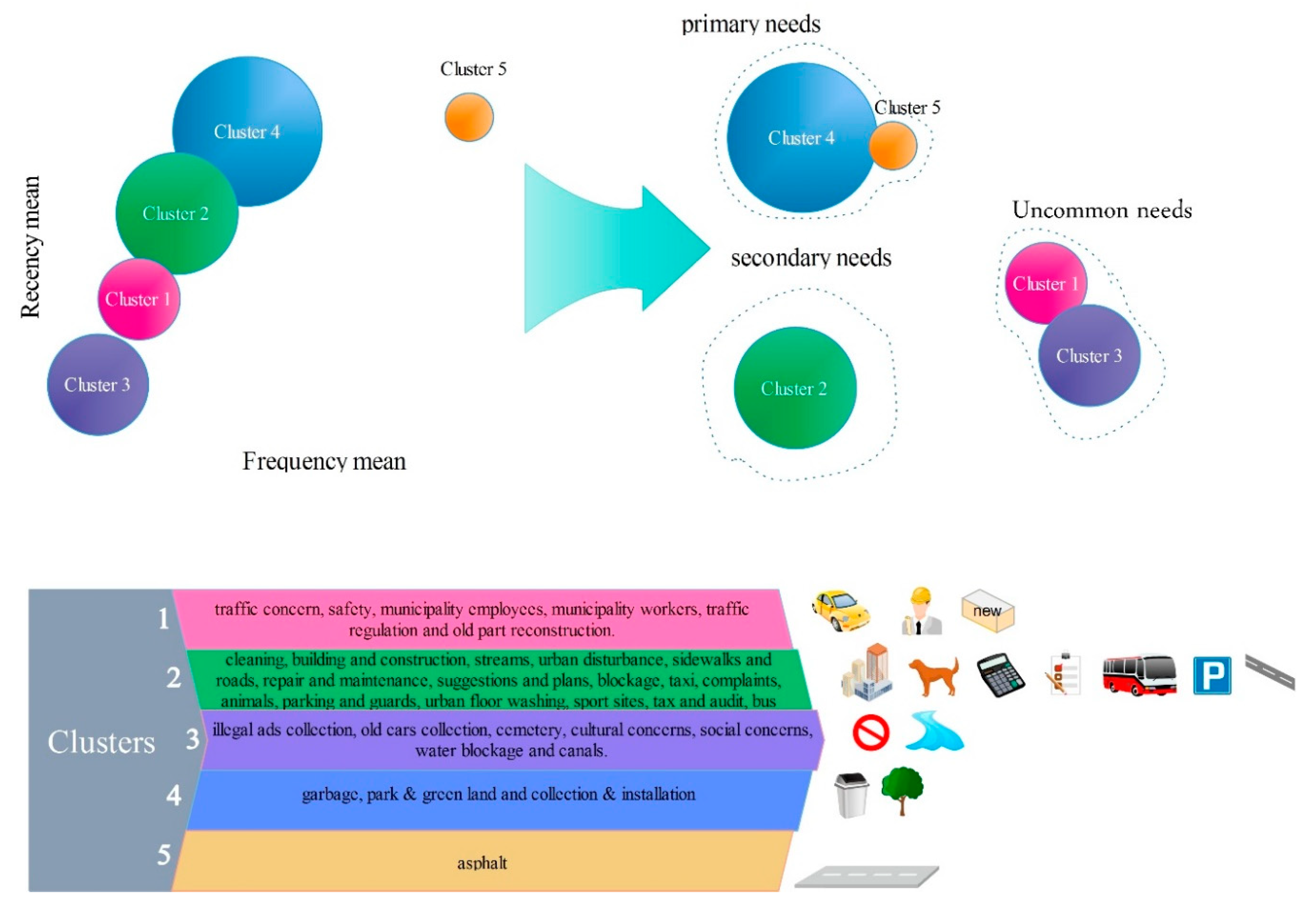
The main aim of this research was data-mining of a citizens’ complaint system, to prioritize the urban needs and to estimate citizens’ satisfaction. In this study, two methods for clustering, prioritizing the needs and estimating the satisfaction were implemented. In the first method, the needs, firstly, were prioritized according to two factors of frequency and recency and then the estimation of satisfaction was done. In the second method, through a new approach, the need prioritization and clustering was done according to three factors, and the estimation of satisfaction was done simultaneously. In the first method, if we want to estimate the primary needs, it is possible that the third condition (lowness of the executive response) is not satisfied; however, the increase in the frequency change domain and recency is one of the faults in the second method. In this study, to compare the clustering in the two methods, a quantitative index was presented. The result of the comparison of parameters showed the second method’s superiority. The index of the second method for the primary needs in K-means method was 0.299 more than the first method and in BA was the same in both methods.
The second proposed method could be used as a new method to prioritize. The municipality can use this method to identify citizens’ needs and estimate their satisfaction. In this research, two algorithms, K-means and BA, were used for clustering. To compare the results of these two CH and S indexes were used. BA had a higher CH and S index. Therefore, it was better in clustering. According to the final prioritization done by the two algorithms in two methods, the primary needs included asphalt, so specific schemes should be considered. Subjects like streams, sidewalks and roads, repair and maintenance, suggestions and plans, blockages, taxis, complaints, animals, parking and guards, traffic concerns, safety, municipality employee, urban street cleaning, municipality workers, tax and audits and buses are among secondary needs and uncommon needs were related to subjects like traffic regulation, illegal ads collection, old cars collection, cemeteries, cultural concerns, social concerns, water blockages, old part reconstruction and canals. Subjects like cleaning, building and construction, sport sites, urban disturbance, garbage, park and green land and collection and installation were among those needs that in both methods and algorithms have not shown a unitary priority and have varied between primary and secondary needs.
With the aid of the results, planners can analyze citizen service data to get a clearer knowledge of citizen satisfaction with municipal services performance. Also, they can identify citizens’ service needs and provide important information to government administrators. Furthermore, the results of algorithms can increase the effectiveness of city plans by informing short- and long-term resource allocation policies. The outcomes help to recognize what issues need immediate action. The results of prioritization can also be used as quantitative indicators of the perception of citizens on different urban-related issues. The findings can also be used to find the most affected regions. They can be used to design strategies for timely and proactively enhancing the service infrastructure in a community. This also leads to better use of government funds through smarter actions and stronger investments with measurable quantitative effects. This can inform the local government to be prepared for emergencies by knowing possible high demands on specific requests in particular areas. Our results demonstrate the importance of descriptive results in offering new perspectives into the needs of citizens.
6. Recommendations
Some issues and aspects were not considered in this study. The development of the method to incorporate these aspects can be the subject of future work.
In this research, in the presented index, the factors’ weight is considered the same. Regarding the municipality policies, the importance of this is changeable, so it is better to develop the model by considering a weight for factors.
The policies and plans which are adopted by the municipality are used throughout the city, while in this research the first district of Bojnourd city is under study. The results of this study can be helpful in deciding to plan for the first district municipality. However, these results cannot be used to decide and plan throughout the Bojnourd city, so it is better to data-mine throughout the city.
Other data analytics can be used to describe data by extracting useful patterns from 137 data. Association rule mining can be used to find pairs of request types that are frequently occurred together. Topic modeling can extract naturally emerging topics from large volumes of 137 text data. Also, 137 data can be used to assist policy decisions by making a prediction of an unknown future. 137 data can be used to investigate subjective perceptions of neighborhoods disorders.
Future research can also classify and analyze the spatial and temporal patterning of complaints across the city. In other words, they can predict the spatial and temporal variations of demand to optimally allocate resources and staff, reduce response time, and allow long-term dynamic planning. Another future research subject would be to examine the relationship between the concentration of complaints in a specific area and the socioeconomic characteristics and environmental features of those regions. Also for future research, 137 data can be combined with additional sources of data such as citizen opinions reflected in social media and prioritize citizens’ needs more comprehensively.

 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}