1. Introduction
Smart devices can be used to improve a wide range of services in ubiquitous computing. The gadgets that make up the “things” in the Internet of Things (IoT) can exist in any household, company, and city. The services based on IoT bring benefits but also security vulnerabilities in the form of blind spots and increased attack surfaces [
1]. Smart devices with security vulnerabilities can allow malicious users to infiltrate private computing networks. Most IoT devices are vulnerable to cyber-attacks because they are not equipped with sufficient security features. These IoT networks are vulnerable to several factors, such as technological limitations and the users associated with the IoT applications [
2].
Firstly, there are security vulnerabilities in IoT devices on the market because of their hardware limitations. IoT devices can only perform so much processing; their specific purpose is to provide minimized computing power (and constrained energy usage). Therefore, there are limited options for stronger data protection and security reinforcement. Secondly, diversity in the IoT device types brings challenges in establishing security protocols applicable to all IoT devices [
3,
4].
Most importantly, the lack of user control in IoT automation provides severe challenges to IoT security assurance [
5]. As IoT applications are applied to various fields, including medical services (e.g., monitoring patients) where security is of paramount importance, proactive and preventative security assurance is vital in future applications of Internet of Medical Things (IoMTs) [
6].
The purpose of this study is to identify practical solutions to these IoT security vulnerabilities. This paper focuses on the Internet of Medical Things (IoMT) [
7] because the IoT devices in this sector can have significant impacts on human lives and their well-being, and IoMT often lacks the most fundamental security assurance [
8]. In this article, IoMT security is first discussed. We describe several actual attacks carried out against commercial IoMT devices [
9,
10]. We review the processors, communication protocols, and cryptographic hardware/software used in commercial IoMT applications. It is absolutely necessary, in order to ensure the safety of IoMT devices, that ethical and privacy concerns be taken into account during the process of developing the IoMT. IoMT devices manage an astounding quantity of private and sensitive health information for their users. As a direct consequence of this, maintaining the secrecy of this information is of the utmost significance.
Patients, healthcare professionals, and regulators should all have complete access to and an understanding of IoMT and its operations because it is crucial from an ethical standpoint that they do. It is imperative that the specific data being used, the manner in which it is being processed, and the potential repercussions of improper data use all be made transparent. The likelihood of data bias, which could lead to unequal treatment for some patients, is another consideration that IoMT needs to take into account.
Concerns regarding the privacy of patients revolve around the necessity of preventing unauthorized access to sensitive information and maintaining compliance with legislation such as the Health Insurance Portability and Accountability Act (HIPAA) and the General Data Protection Regulation (GDPR) of the European Union. A number of potential remedies include using robust data encryption, stringent access limits, and anonymizing patient data whenever it is practicable to do so. There is also the possibility that IoMT networks will inadvertently divulge sensitive information. Additionally, there is the possibility that unauthorized access will be gained and data will be misused. Because of this, it is absolutely necessary to design and implement IoMT and its operation through (quantum) machine learning that includes tight protections, comprehensive testing, and regular monitoring, so that any possible issues may be located and resolved as soon as they appear.
This paper discusses various conventional machine learning models in IoMT and then considers quantum machine learning (QML) to overcome some of the limitations of conventional machine learning approaches in IoMT (due to its inherent complexity, heterogeneity, and data velocity). This paper proposes the framework for using a QML in IoMT vulnerability assessment. Some aspects of quantum physics, such as quantum entanglement, quantum superposition, and wide parallelism, are reviewed to discuss practical applications of QML [
11]. This paper also presents a detailed experimental analysis of vulnerability assessment in IoMT of the proposed QML model against the other state-of-the-art machine learning models. This paper further provides insight into the benefits and further challenges of QML in IoMT security. The contributions of this research work are as follows:
This research investigates and assesses the viability of using quantum machine learning to detect security flaws in IoMT systems.
This research provides an in-depth analysis of classical and quantum machine learning methods, with an emphasis on their use in assessing the security of IoMT.
This research proposes, develops, and evaluates a unique fused semi-supervised learning model for IoMT security and compares its efficacy to that of conventional and quantum machine learning techniques.
In the remainder of the paper,
Section 2 provides a comprehensive review of IoMT advances and its vulnerabilities, followed by an introduction to quantum machine learning.
Section 3 presents the proposed model utilizing innovative quantum machine learning in IoMT, followed by experimental analysis in
Section 3.7. The paper concludes in
Section 4 with further insight for future work.
3. Proposed Model and Research Framework
In this section, the proposed model using an innovative quantum deep learning algorithm is introduced alongside the other state-of-the-art machine learning models (both traditional and quantum). The proposed model is evaluated against the other machine learning model in detecting security vulnerabilities in IoMT applications. Due to the massivity, heterogeneity, and high velocity, IoMT security is considered challenging and the experimental analysis shows that the proposed quantum machine learning model can attain favorable security assessments.
The suggested system, which combines quantum computing with machine learning for the purpose of IoMT security evaluation, has several primary goals, the most important of which are optimizing data processing, boosting the accuracy of prediction, and beefing up security measures. The following constitute the primary components of the framework: Data Collection and Preprocessing: During this phase, data is collected from a wide variety of IoMT devices and then transmitted to a hub server. The readings from sensors, data from gadgets, and medical records are some examples of the types of information that could come under this category. Quantum techniques are utilized in order to clean and prepare the data. One of the most important characteristics of quantum computing is its capacity to process enormous volumes of data simultaneously.
Feature Extraction and Selection: After the data has been preprocessed, techniques based on quantum mechanics are employed to extract relevant characteristics from the data. The Quantum Feature Selection (QFS) method makes use of quantum bits (qubits) as an optimization tool for the purpose of selecting the features that are the most significant, decreasing the complexity of the problem, and improving the performance of the computation.
Security Vulnerability Assessment: This feature does security risk analysis with the use of a quantum machine learning (QML) model. The chosen attributes are used to teach the model how to identify dangers and weaknesses. Utilizing the increased processing capacity and greater pattern recognition capabilities of quantum computing, QSVMs, and QNNs can be employed for this purpose.
Threat Prediction and Classification: As soon as the QML model has been properly educated, it will be able to recognize and classify vulnerabilities and threats to the IoMT infrastructure. It is able to forecast future attacks by gaining knowledge from previous ones and by continuously monitoring data in real time. Response and Mitigation: The final component of the framework is taking action in response to the hazards that have been recognized. Quantum algorithms can, in a relatively short period of time, determine the best possible courses of action to adopt. Warnings may be issued by the system, compromised devices may be isolated, and additional precautions may be taken if the system deems it necessary.
Continuous Learning and Adaptation: The proposed method uses a feedback loop to continuously refine and update the QML model based on new data and threat trends. This makes the strategy still useful and effective as threats evolve over time. A novel architecture that is based on quantum machine learning has been designed in order to keep up with the constantly shifting nature of the IoMT security landscape. It makes use of quantum computing in order to manage the huge amount of data and the challenging nature of the security challenges linked to IoMT. This strategy makes it possible to recognize potential dangers early on and to respond quickly to mitigate them. As a result, it can potentially prevent catastrophic losses or interruptions to essential medical services.
In the remainder of
Section 3, the concepts of semi-supervised reinforced learning (RL) (
Section 3.1), Deep Q neural network (
Section 3.2), and semi-supervised Convolution Neural Network (CNN) (
Section 3.3) are presented, followed by the introduction to quantum machine learning (
Section 3.4), quantum semi-supervised reinforced learning (
Section 3.5) and the proposed model of quantum deep learning in altered form (
Section 3.6). The extensive experimental analysis is provided in
Section 3.7.
3.1. Semi-Supervised Reinforcement Learning (RL)
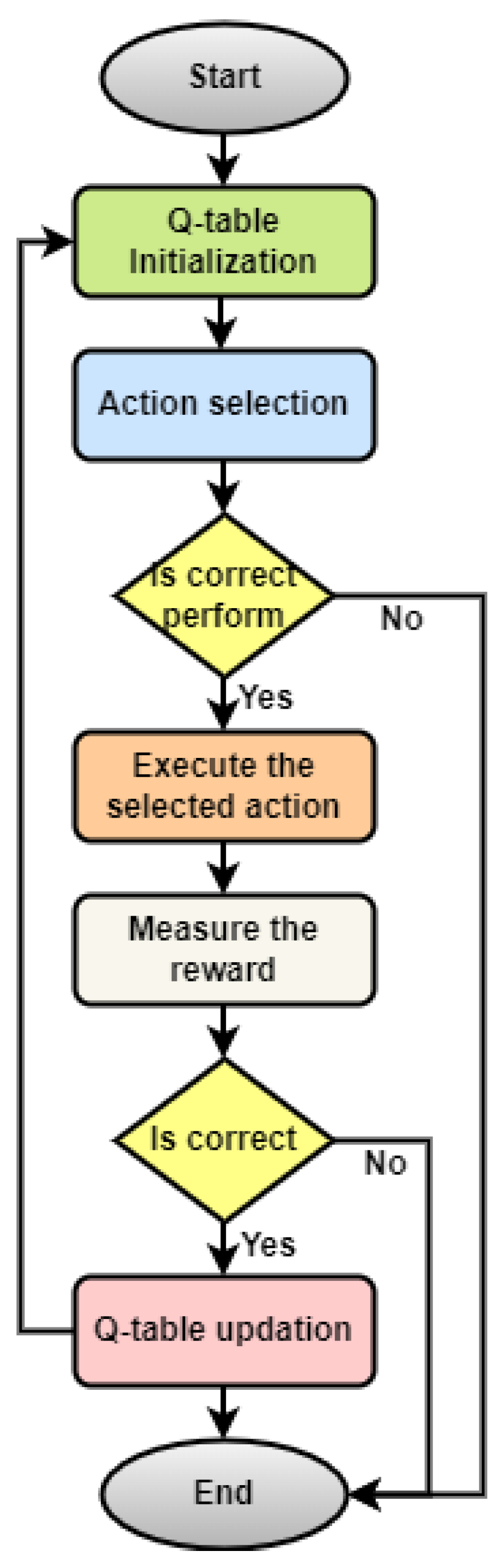
Semi-supervised RL is similar to the traditional proposed RL, but it has two types of episodes instead of just one: “Labeled” episodes are the same as “normal” episodes, but “unlabeled” attacks make it difficult for the agent to see how their actions help. We aim to find a strategy that provides a significant advantage at the end of each episode [
31]. There are two types of semi-supervised RL: a random label is assigned to each attack, and the label has a certain chance of being right. The agent learns by asking how it performed after each attack. The total amount of time spent on training and the number of feedback sessions required should be kept as low as possible. We filtered out events that were not annotated using a standard RL algorithm on the semi-supervised data. Most of the time, this means that people learn slowly. An interesting question is how to learn the most useful things from having no limits on what you can do. Semi-supervised RL is not only a key part of AI control, but also a major problem in the field of RL that needs to be studied. However, even if AI control is not considered, semi-supervised RL remains a significant challenge for the RL community. This gives us a new way to look at the success of RL algorithms and a different way to measure the progress of learning that is more “human-like.” The methods used for semi-supervised reinforcement learning are expected to be useful when dealing with the more general problems of a few and changing the reward signals. Even if we only consider RL issues under full monitoring, these are still major problems. Putting possible solutions in a clear setting will help us to better understand them. When AI is used for commands, this makes our tasks easier. It would be beneficial to use an experimental method to study counterfactual oversight and bootstrapping. Both methods require the optimization of costly ground truth, making it difficult to perform large-scale experiments on good semi-supervised RL.
Figure 1 provides an overview of Q-process learning. In the case of semi-supervised RL, there are some problems with data analysis, such as observing how the environment changes. If an agent learns to perform a new type of action in a different environment, the previous benefit estimates may no longer be accurate. To perform well in active semi-supervised RL, an agent must be taught to anticipate changes and ask for feedback in response to those changes. How can uncertain rewards be dealt with? A semi-supervised RL agent will ll not be very useful if it cannot perform well even when it has a rough idea of the reward function. There are times when the model of the dynamics of the environment is much better and more stable than the reward function. This topic is much more interesting when we track performance during training, instead of simply looking at how long it takes to converge. Obtaining information [
32] and talking to people. In different situations, one may need to act strategically to obtain a hidden reward. For example, if an agent wants to know what a human supervisor would find after a thorough inspection, they can ask the supervisor a series of questions. Thus, the supervisor can make quick, correct decisions, and it is important for the agent to be able to explain what he or she is thinking. This is how aligned the AI systems must act.
3.2. Deep Q Neural Network (DQNN)
Q-learning [
33] can be used as an off-policy RL technique in temporal-difference learning for prediction in IoMT-based applications [
34]. Temporal difference learning techniques can be used to compare the accuracy of the predictions made at different times.
The value function Q (S, a) is then learned. This function shows the value of performing a specific action (a) in a specific state (S) (s).
State action reward state action (SARSA) is an example of an on-policy temporal difference learning system for vulnerability prediction in IoMT-based applications. The on-policy control technique [
35] selects the best way to implement a policy in each state while the policy is being learned. The goal of the SARSA program is to calculate Q (s, a) for the selected policy and for all the permutations of s and a. (s-a) (s-a). The most significant difference between the SARSA and Q-learning algorithms is that in SARSA, the Q-value in the table does not need to be changed by knowing what the highest reward will be for the next state. SARSA decides what the next step and reward will be based on the same policy that determines the first action. This maintains consistency. The quintuple Q (s, a, r, s′, a′) used by the algorithm is, where the term SARSA is derived from. Where
s: the starting point a: The initial action taken r: what people hope to get out of following the rules The letters s and a represent a new combination of a state and an action.
DQN describes “Q-learning through Neural networks”. Defining and maintaining a Q-table in an environment with a vast state space is a difficult and time-consuming task owing to the complexity of the domain. When we use the DQN method, we can find an answer to this problem. In this example, the neural network approximatively calculates the Q-values for each action and state, rather than specifying a Q-table.
Q-learning is a popular model-free reinforcement-learning algorithm based on the Bellman equation. The goal of Q-major learning is to learn the policy that tells the agent what to do and when to do it to obtain the highest reward. This is an unofficial RL that tries to determine the best thing to do right now. In Q-learning, the agent’s goal is to make Q’s value as high as possible. With the help of the Bellman equation, you can figure out the value of the Q-learning algorithm. The Bellman equation is as follows:
Equation (
1) has several variables, such as the reward, discount factor (), probability, and end states (s′). However, it does not consider the Q-value; therefore, we start with the image above.
The letter V represents a variable with values s1, s2, or V. (s3). Because this is a Markov Decision Process, the agent only cares about the current state and what will happen in the future. The agent is free to go wherever he wants, so he has to choose between three possible routes to reach his destination as quickly as possible. Here, the agent acts based on the odds, which causes the system’s state to change. However, we will have to make some changes to the Q-value if we want our maneuvers to be accurate. Q is a way to determine how well the steps taken in the situation work. Therefore, instead of using a value at each stage, we used the letter Q to represent a set of states and actions (s, a). The agent decides what to do next by looking at the Q-value, which shows which action is more lubricating than the others. The Bellman equation was used to determine the Q-value.
When the agent performs an action, he either receives a reward of type R(s, a) or moves to a different state. Therefore, for the Q-value, we can write the following equation:
Hence, we can say that,
3.3. Semi-Supervised Convolutional Neural Networks
We combined the supervised CNN and CNN-encoder decoder models to obtain semi-supervised learning for vulnerability prediction in IoMT-based applications. Semi-supervised learning [
36] uses a set of labeled pairs (xi, ti) |1 I N along with unlabeled data xi |N+1 I N+M to train a classifier. This information was used to teach the classifier. In a semi-supervised CNN-encoder-decoder setup, labeled and unlabeled data can be processed in one of three ways: the clean encoder, noisy encoder, or decoder. The clean encoder path was used to determine the intermediate layer hidden variables, which are marked by z l I. This route is used for both labeled and unlabeled clean data. In the noisy encoder path, both labeled and unlabeled data are exposed to Gaussian noise before the noisy encoder converts them into a more abstract representation. The letters z, l, and I represent this representation, respectively. We used the cross-entropy cost to make predictions with the best softmax classifier for the has been labeled data (x I 1 I N). In the labeled dataset, the values of x range from 1 to N. Let us assume that the letters y I stand for the expected label. The decoder attempts to return the original, clean input from the noisy, unlabeled data (x i, N + 1 I N + M) (xi). The square error is used to measure the size of the reconstruction error. The clean encoder path and noisy encoder path both use the same parameters [
37]. The only difference is in the inputs, as shown in
Figure 1. (The CNN-Ladder shown in
Figure 2 can be simplified to a CNN-Encoder-Decoder structure by only looking at the vertical connections and the cost on the side). The cost function for the CNN-encoder decoder includes both the supervised cross-entropy cost from the labeled data in the supervised CNN and the unsupervised denoising square error cost between the clean input and its noisy reconstruction output. Supervised CNN must pay these two extra costs. This figure shows the cost function.
Given the input
, the average cross-entropy of the noisy output y I that meets goal
is equal to supervised cost Cs. The average squared error between the reconstructed output xi and original input xi can be considered as the unsupervised cost Cr. If we use a CNN-encoder–decoder that is only partially supervised, we can train both the network and the features simultaneously from the data, as described in
Figure 3.
There are two kinds of ties in CNN-Ladder. This kind of connection is shown by the reconstructed cost function C (l) r and the lateral connection g (l). A vertical link is the other kind of link that can be used.
3.4. Quantum Machine Learning
“Quantum-enhanced machine learning” means using quantum algorithms to solve problems in machine learning. This makes traditional machine-learning techniques [
38] more effective and, in many cases, speeds up the process [
39,
40,
41,
42]. When giving a classical dataset to a quantum computer for use, it is often encrypted for use in quantum information processing. The quantum computing results can be retrieved once the state of the quantum system is measured. For example, after an operation, the state of the qubit can be used to determine the results of a binary classification task. Many quantum machine-learning algorithms are still in the theoretical stage and can only be tested on a full-scale universal quantum computer. However, some quantum machine-learning algorithms have already been used for small-scale or purpose-built quantum devices. Quantum machine learning is a field of study that investigates how well quantum computing and machine learning work together. We would like to examine whether a quantum computer can evaluate [
38] and train a machine learning model faster than traditional methods. However, it is possible that machine learning can be used to find quantum error-correcting algorithms, evaluate the properties of quantum systems, and develop new quantum algorithms. The scientific community is currently facing several problems that cannot be solved using traditional methods of computing because they are too complicated or take too long to solve.
However, quantum systems today do not have enough qubits and cannot handle mistakes well enough to do these things. On the other hand, quantum computing could be useful in fields such as machine learning and biology with existing hardware. Most of the algorithms that have been found to date are quantum versions of traditional machine learning algorithms, such as support vector machines, and traditional deep learning methods, such as quantum neural networks. In a wide range of articles, the use of quantum devices and methods is considered a way to solve problems that are currently being solved by classical machine learning. Quantum machine learning has a long way to go before it can fully live up to its promise [
26], even though new research is encouraging. To realize the full promise of quantum computing, advances in quantum hardware are necessary because existing quantum computers lack the essential quality, speed, and scalability.
3.5. Quantum Semi-Supervised Reinforcement Learning (RL)
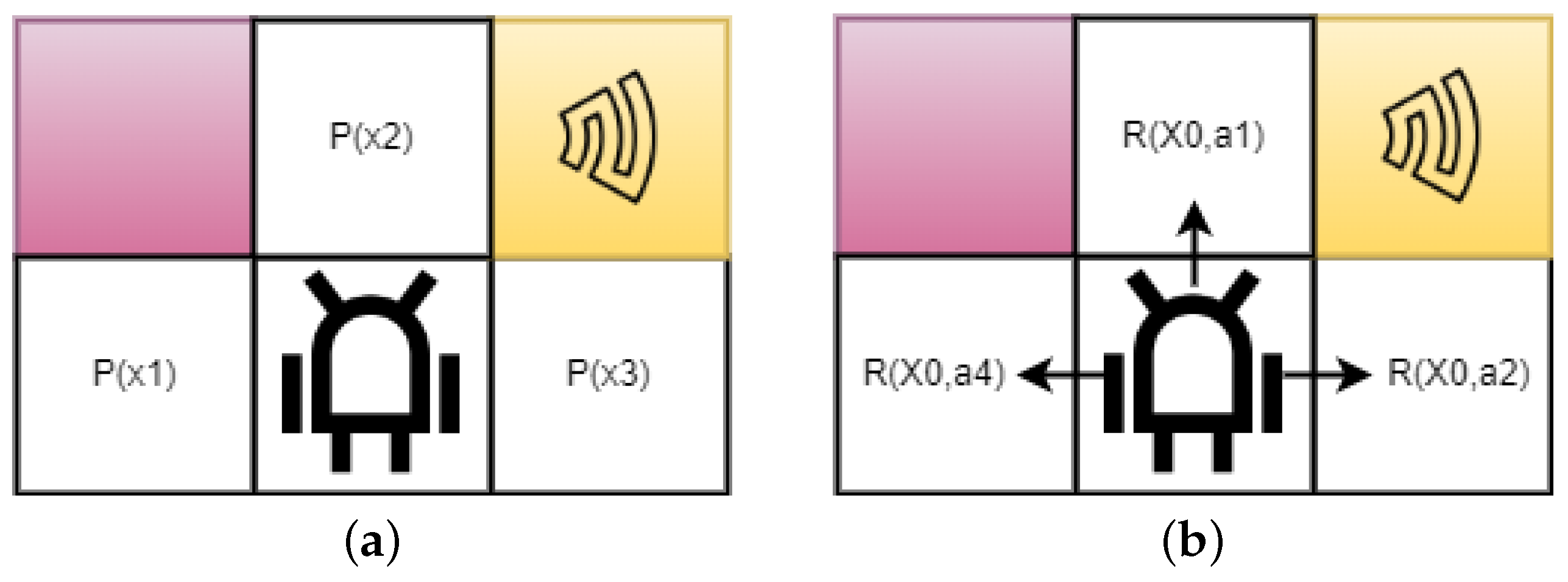
Quantum control involves making a series of choices in a certain order. To run a quantum system, the agent is a piece of software that must be installed and run on a regular workstation. The agent is part of a quantum environment composed of a quantum harmonic oscillator, which is the electromagnetic mode of a superconducting resonator, and an ancilla qubit, which is the two lowest energy levels of a transom. Both parts are brought to life as electromagnetic modes in the superconducting resonator. In quantum physics, “environment” means a dissipative bath that is connected to a quantum system. However, in Vulnerability prediction in IoMT-based applications, “environment” means the quantum system itself, which is the agent’s environment. Therefore, the word is used differently. A good way to save time is to use a circuit model of quantum control instead of learning the details of the control gear. This operational definition demonstrates how an agent interacts with its environment. This is performed by performing a parameterized control circuit in a series of discrete steps. To prepare for the next phase, the agent converts the observations into an action vector that is used to change the settings of the control circuit. An episode consists of T steps, in which the agent talks to their surroundings. depicts the pipeline for implementing classical RL in a quantum-observable setting. The agent (yellow box), which is a piece of software that runs on a classical computer and manages the quantum system, follows a policy defined in terms of a neural network. The quantum environment of an agent consists of a harmonic oscillator and its ancilla qubit. The agent’s goal [
43] is to move the oscillator from its initial state j0i to the target state jtargeti after a certain number of time steps T. The agent can only learn about its surroundings by making projective measurements of the ancilla qubit, which gives binary results, and not by directly observing the quantum state of its surroundings. This is because the agent cannot know what is going on in the quantum world.
3.6. Q-Deep Learning Model
To determine whether a cluster state is “excited,” you must first prepare the state and then train a quantum classifier. Even if the cluster state is highly complicated, it may still be possible to deal with it using a traditional approach. structures of traditional CNN to operate in quantum systems. When a quantum physics problem written in many-body Hilbert space is moved to a traditional computing environment [
44], the size of the data increases with the size of the system [
45]. Therefore, it cannot be used to find good answers to problems. Because data can be described with qubits in a quantum environment, this problem can be solved by providing a quantum computer with a CNN structure. This makes it possible to solve this problem. Once everything has been settled, we can look at what is inside the Q-deep CNN model.
Q-Deep CNN: For this classification of vulnerability prediction in IoMT-based applications, to make a Q-Deep CNN architecture:
A cluster state on a ring is also independent of translation, just like the Q-Deep CNN.
Also, the cluster state is very complicated.
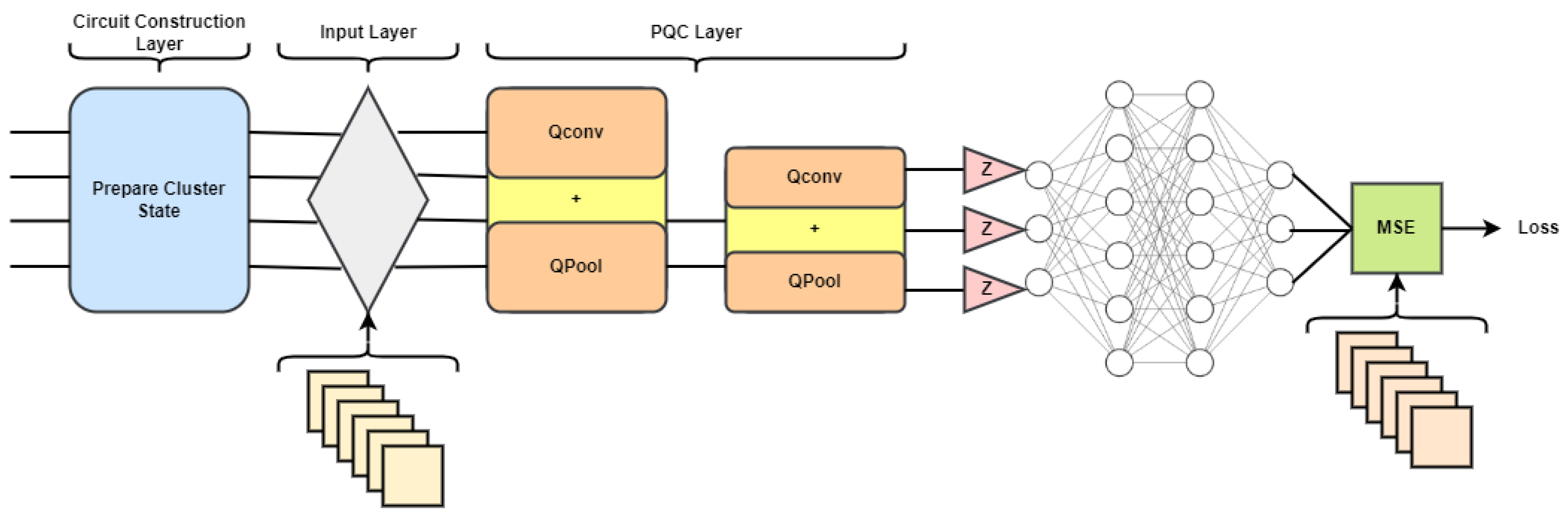
A mixture model with only one quantum filter. After performing one layer of quantum convolution and reading all the bits, a neural network with many connections is used as presented in
Figure 4.
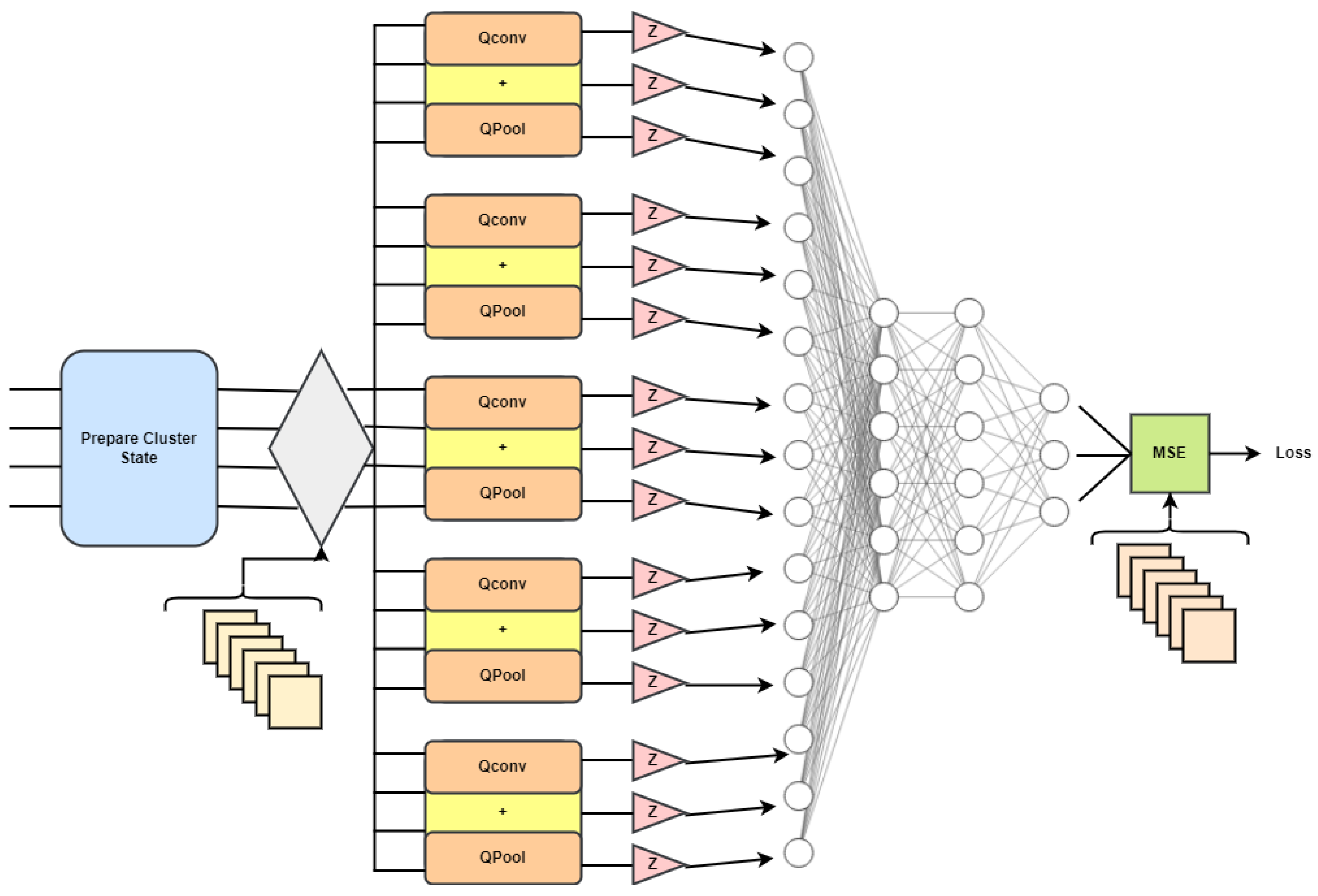
Let us attempt a method that combines the results of many quantum convolutions with a classical neural network, as presented in
Figure 5.
The Q-deep CNN model changes the core parts of the CNN, such as the convolution layer and pooling layer, so that they can be used with quantum computing. When multiple qubit gates are used on nearby qubits in the convolution circuit, a hidden state is observed. The pooling circuit can make the quantum system smaller in two ways: by keeping an eye on the qubit fraction or by using CNOT gates for only two-qubit gates, it leads to a size reduction in the quantum system that is exponentially smaller than the size of the data that enters it.
IoMT security evaluation carried out by means of quantum machine learning (QML) has demonstrated a significant amount of promise. The capabilities of its quantum-based system allow the analysis of data at scales that are unreachable to traditional computers. However, overfitting is a significant problem that needs to be considered before releasing QML models. When a model learns too much from its training data, it becomes overfit and is unable to generalize successfully to new data. This is because it has become overfit. This happens as a result of the model’s incorporation of noise or other random fluctuations that are present in the training data. As a result, it is not possible to generalize its findings, which leads to incorrect predictions when applied to new information. When QML is utilized for IoMT, overfitting presents a number of challenges for a variety of different reasons. Privacy of Information: IoMT data is frequently personal and sensitive due to the fact that it connects to the health of individuals. Inaccurate security vulnerability assessments may be the result of models that have been overfitted, which leaves a door open for possible security breaches and threats.
Environments that make use of the IoMTs are notoriously difficult to navigate due to the sheer number of devices that are involved. The utilization of an overfitted model that does not take into consideration the nuanced complexity of the context in an effective manner may lead to inaccurate judgments. The danger landscape in IoMT is in a state of perpetual flux as a result of the emergence of new threats and the evolution of existing risks. Models that have been overfitted, meaning that they are overly specialized to the training data, have difficulty coping with new dangers.
There are a few different avenues that can be pursued in order to cut down on the possibility of overfitting occurring in QML for IoMT:
Regularization approaches such as L1 and L2 are able to prevent overfitting by employing a penalty based on the complexity of the model.
The creation of fictional data points is a kind of data augmentation, which is performed with the intention of enhancing the ability of the model to generalize.
By utilizing cross-validation to fine-tune the model’s hyperparameters for optimal bias and variance, overfitting can be avoided. This allows for optimal bias and variance.
It is possible to prevent a model from picking up on random oscillations in the data by terminating the training phase of the process early.
Last, but not least, it is absolutely necessary to carry out routine audits of the models in order to guarantee that they will continue to be accurate and that they will be able to withstand any new security threats that arise within the IoMT ecosystem. Monitoring how well the model performs on a validation set is an excellent approach to identifying overfitting in its early stages and making the necessary adjustments to fix it.
3.7. Experimental Comparisons
We experimented with several machine-learning models. These models were constructed using Python 3.7.0, TensorFlow 1.10.0, and the Keras library on the web-based interactive computing platform Jupyter Notebook, version 5.6.0. The ML models were then separated using multi-class and binary-class methods. This resulted in two copies of the final labeled dataset as presented in
Table 2.
The following is a list of all of the parameters for the fields:
IoMT devices are what the name “IoMT Device” refers to in its most specific form.
The IoMT Device Type indicates the broad category that the device belongs to in its entirety (i.e., biometric, therapeutic, implantable, etc.)
Network Type: The configuration of the device’s network at the present time (i.e., ZigBee, Wi-Fi, Bluetooth, Cellular, etc.)
The speed in megabits per second (Mbps) at which the device can send and receive data.
Implementation of the Quantum ML Method: When assessing the safety of a network, specialists frequently use quantum machine learning techniques such as Quantum Support Vector Machine (SVM), Quantum Neural Network, Quantum Decision Tree, and a variety of other approaches.
Type of Security Threat Identified: Specifies the type of security threat, if any, that was determined to have been identified (i.e., Data Tampering, Denial of Service, Eavesdropping, No Threat, etc.)
The level of danger that the threat poses can be characterized as “High”, “Medium”, “Low”, or “Not Applicable”.
This metric will read “Correct Detection” (Yes/No) depending on whether the quantum ML algorithm accurately identified the threat or the absence of such a threat.
This dataset may be given with real or simulated data, depending on the resources that are available and the ethical considerations that must be taken into account.
The first one for testing is the quantum machine learning multi-class. The labels indicate whether the code is a security risk or not. There are some reasons you might want to use Quantum Machine learning (QML) classification. It is easier for the developer to keep up with vulnerable code if it is first put into the QML. This makes sense because QML has already been used as a standard for identifying vulnerabilities. We used binary classification to compare our experimental outcomes with those of other studies in the field that used the same method.
An experiment under controlled conditions was carried out, using data gathered from IoMT devices already in operation. It was determined whether or not the proposed Quantum-Deep Learning (Q-Deep Learning) model was capable of efficiently locating vulnerabilities in the IoMT infrastructure by putting it through its paces in a series of tests. For the purpose of this inquiry, data was gathered from a diverse assortment of medical devices and computer systems located in several different types of healthcare facilities.
IBM’s quantum machine learning capabilities were utilized throughout the tests. The quantum-enhanced model was trained and tested using the real-world dataset that was provided. The success of the model was evaluated based on how accurately it identified areas of data protection that needed improvement. Standard statistical methods were utilized in order to evaluate the performance of the model.
The well-respected quantum machine learning technology developed by IBM allowed the Q-Deep Learning model to execute complex calculations both more quickly and accurately than traditional machine learning approaches. The findings that were collected provided evidence that the method that was recommended was both useful and reliable in detecting security weaknesses in operational Internet of Things (IoMT) infrastructure. These findings illustrate the value of merging quantum computing with deep learning for the purpose of protecting applications used in the healthcare industry.
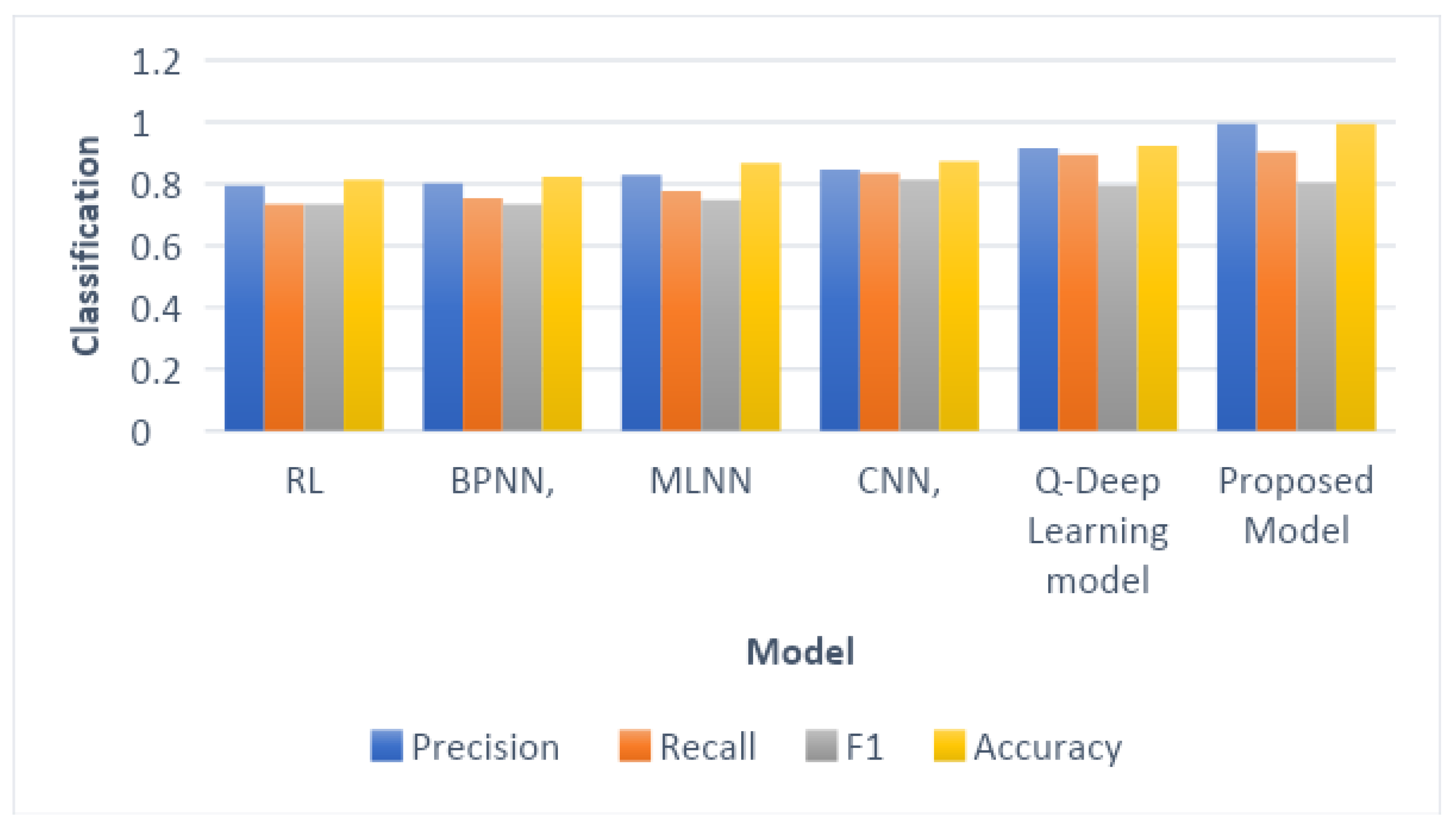
After Q-Deep QC was trained and verified, a set of measures was used to determine the best one. Our deep-learning model was built to make accurate predictions. The confusion matrix and classification model assessment metrics were used to determine whether the traffic on an IoMT network is harmful. Accuracy, precision, recall, and F1-score were also used to evaluate the classification Q-Deep QC models. Some of the measures considered were as follows:
Chaos in the Confusion Matrix Model (CMM) is used to determine how well the True Positives (TP), False Positives (FP), False Negatives (FN), and True Negatives (TN) work (TN). The CMM is also used to explain why the results of the classifier model make sense when they are applied to test data whose actual values are known.
Table 3 shows how we used the confusion matrix to estimate what might be dangerous and what might be safe to interact with.
The ROC curve, which stands for Receiver Operating Characteristic (ROC) curve, was used to show how clinical sensitivity and specificity trade-off against each other. The x-axis shows the number of false positives and the y-axis shows the number of true positives. ROC curve analysis uses measurements such as the Area Under the Curve (AUC) and the Area Between the Curves (ABC). The model can determine the difference between true positives and false positives if the area under the receiver operating characteristic curve (AUC) is greater than or equal to 0.70.
Experiments show how well different supervised machine-learning classification methods can predict whether IoT network traffic is harmful. So we can make sense of the test results, this is what will be carried out. Four main types of malicious software, namely Distributed Denial of Service (DDoS), Command and Control (C&C), Mirai, and Okiru were predicted for each category. Several different metrics, such as accuracy, precision, recall, and the F1-score, were used to judge the performance of a model. Before using it with a machine learning model, the IoT dataset was divided into thirds: 70% for training, 30% for testing, and 10% for 10-fold cross-validation. In the experiments, different ML classification methods were used, such as RL, BPNN, MLNN, CNN, QNN Q-Deep Learning model, and the proposed model. The IoT dataset was used to obtain the features used in these methods. This research also compares the evaluation criteria for the prediction models of the proposed technique with those of previous studies to predict whether IoT network traffic is malicious or harmless. Python was used to build the machine learning model and to put data mining strategies into action. IoT traffic can be both bad and good. Four measurements were used to determine the performance score: accuracy, precision, recall, and the F1 score.
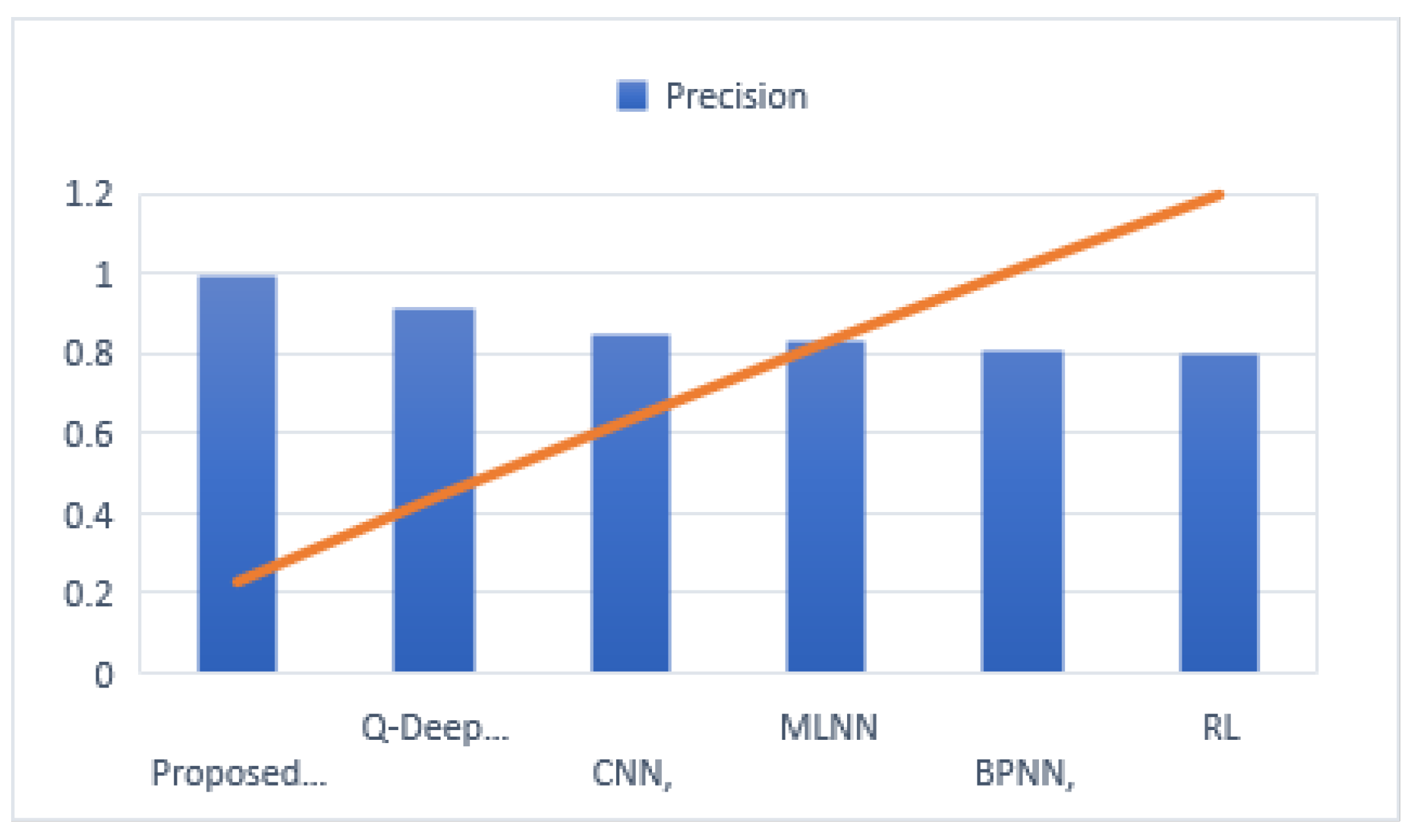
The precision of each experimental model is also compared in
Figure 7 with the proposed model outperforming the other models.
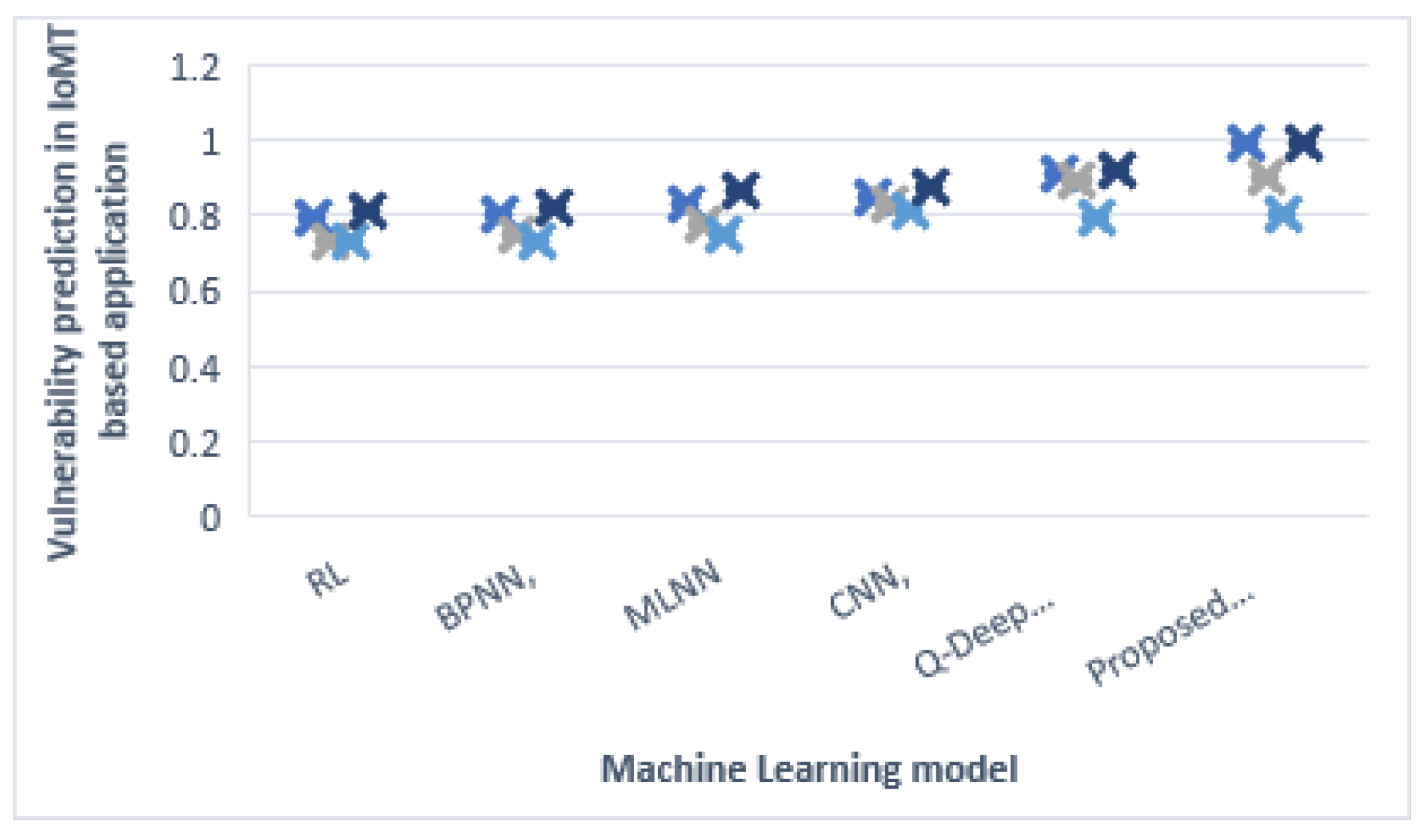
Vulnerability prediction in IoMT-based application in
Figure 8 shows a comparison of the machine-learning algorithms based on the behavior of IoT devices using an existing dataset.
Quantum machine learning (QML) exhibits promising results when evaluating the security of IoMT devices when compared to more typical machine learning techniques. Quantum computing makes possible the rapid processing and analysis of massive IoMT datasets, which QML leverages to substantially cut down the amount of time spent on challenging computations and pattern discovery.
Using typical approaches to machine learning could be proven challenging due to the vast dimensionality, interconnection, and highly sensitive nature of the data in an IoMT environment. On the other hand, the fact that QML is able to manage high-dimensional data fields makes it an effective instrument for locating security vulnerabilities in IoMT systems. In addition to this, it is capable of doing many calculations concurrently, which significantly accelerates the process of vulnerability assessment. QML has the ability to increase prediction and generalization as a result of its status as a probabilistic language that is capable of modeling complex quantum states. This increases the accuracy with which vulnerabilities are found and categorized, which in turn contributes to an improvement in the dependability of IoMT security. The quantum advantage has taken on new significance in light of the increasing intricacy of cyberattacks and the critical importance of maintaining data privacy in the medical industry. We might be able to entirely rethink the way in which we evaluate the safety of IoMT systems by utilizing quantum computing, which would contribute to the systems becoming more reliable and secure.


 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}