
A Survey on Big IoT Data Indexing: Potential Solutions, Recent Advancements, and Open Issues

 , ,
, ,  ,
,  , , and
, , and
Abstract
:1. Introduction
2. Motivation
- Identify and evaluate the main data indexing techniques in the IoT system.
- Classify the indexing techniques used in large data.
- Provide a structural comparison based on the construction and search algorithms related to these techniques.
- Design a taxonomy and analyze the indexing techniques according to the indexing needs of large data.
- Explore the opportunities and challenges for each of the reviewed methods and IoT environments.
- Review the emerging areas that would intrinsically benefit from Big data indexing and IoT.
2.1. Methodology for Selecting the Research Papers
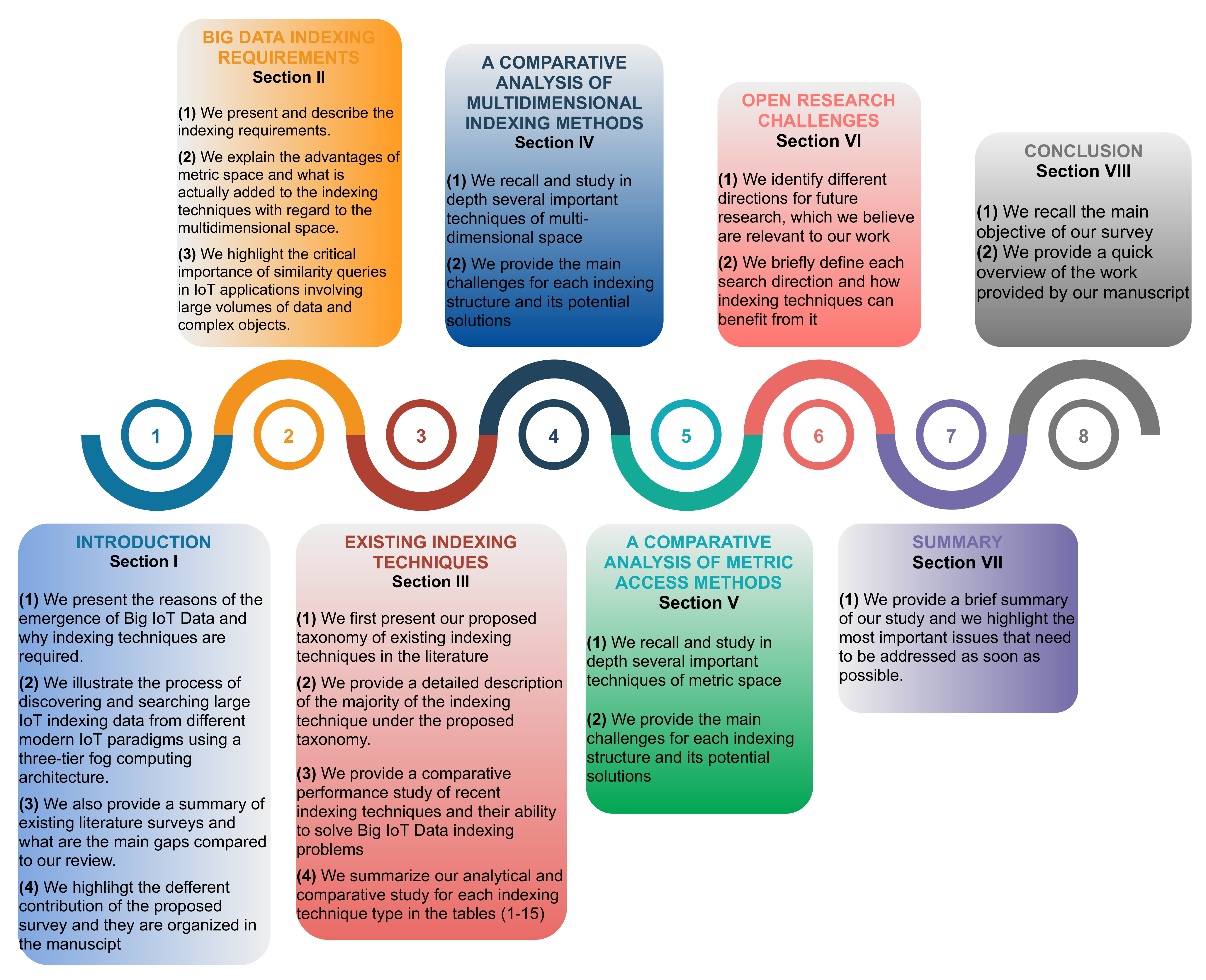
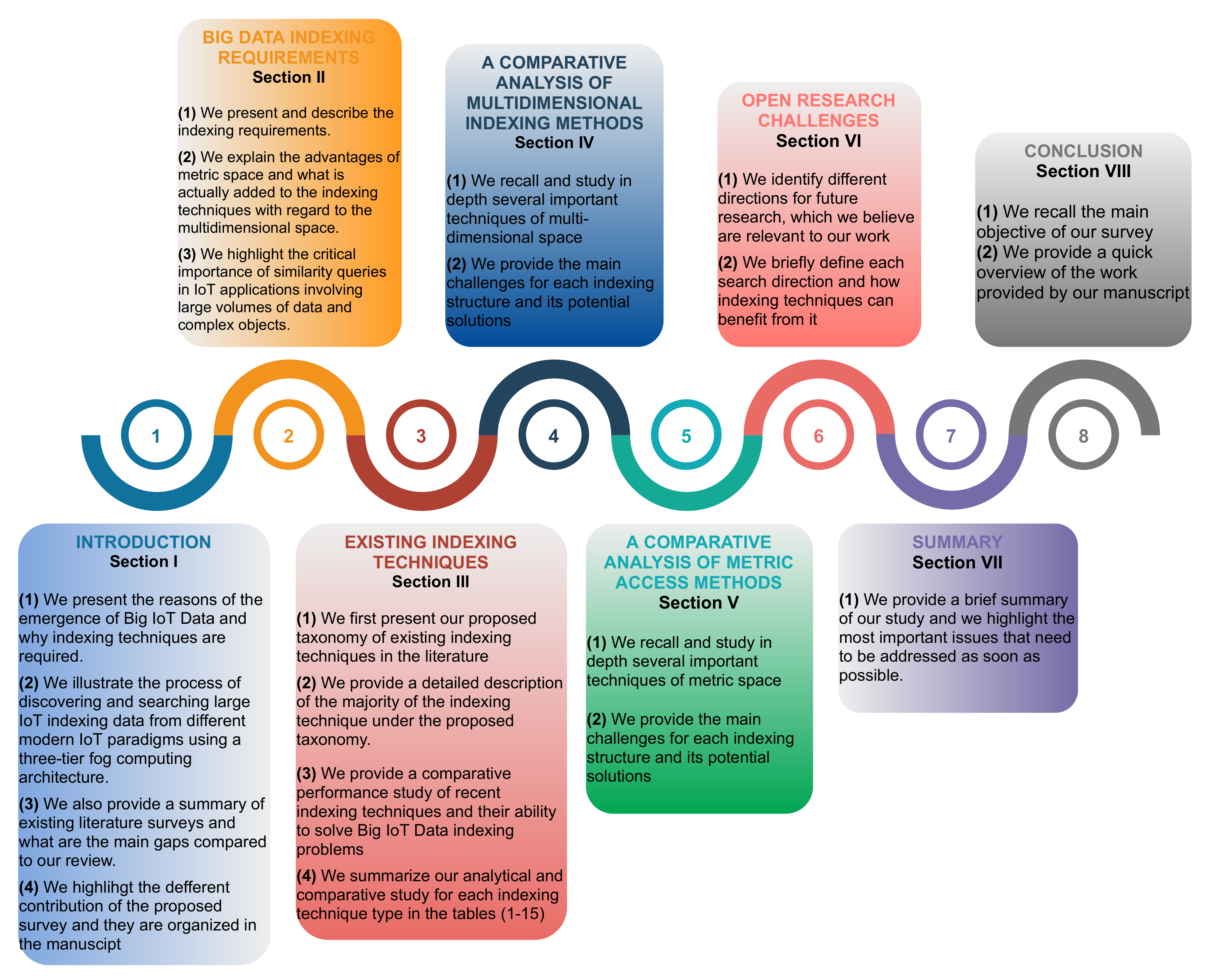
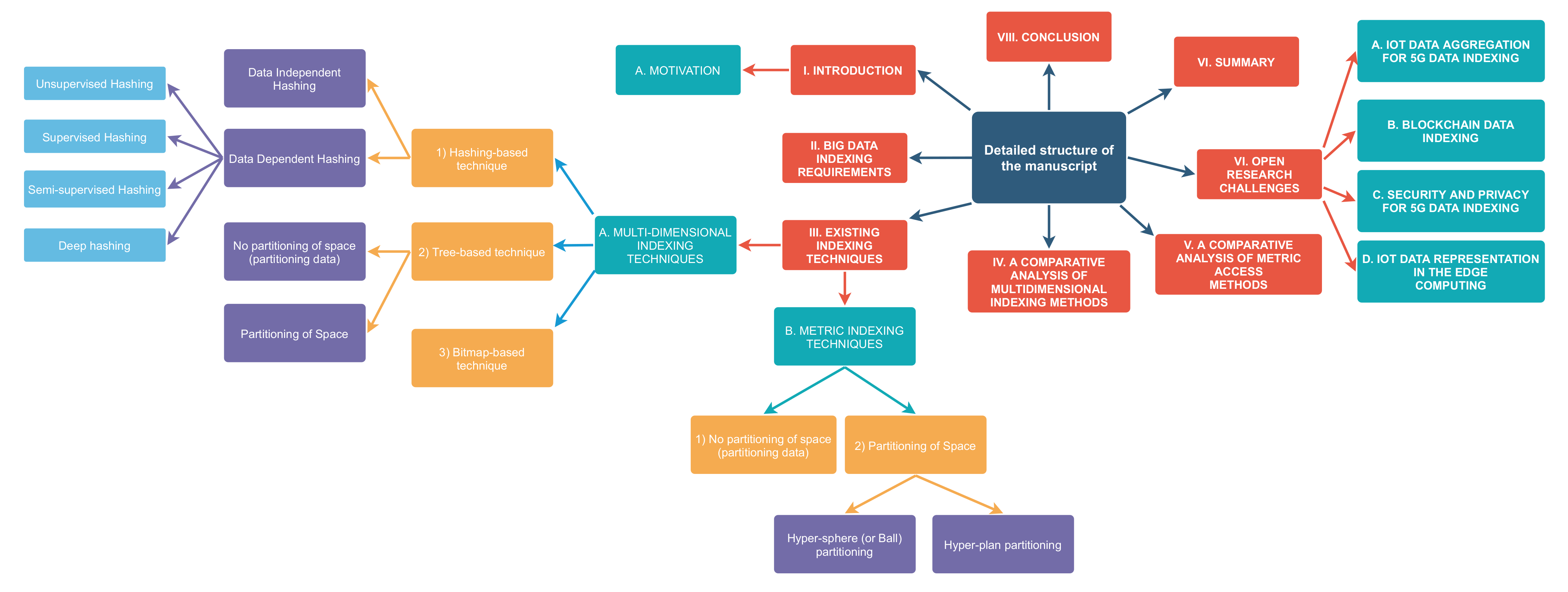
2.2. Survey Organization
- Section 1
- -
- We present the reasons of the emergence of Big IoT Data and why indexing techniques are required.
- -
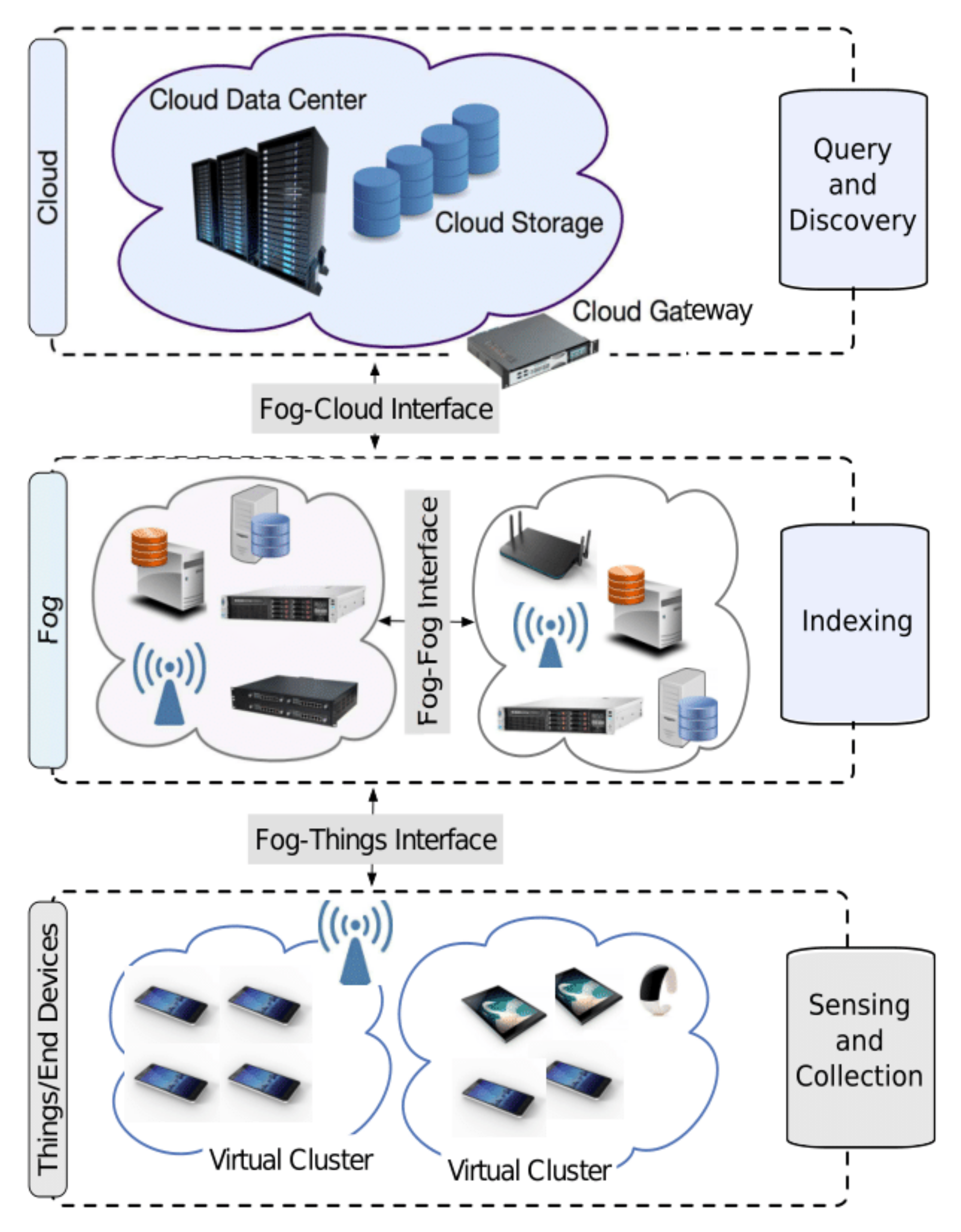
- We illustrate the process of discovering and searching large IoT indexing data from different modern IoT paradigms using a three-tier fog computing architecture.
- -
- We also provide a summary of existing literature surveys and what are the main gaps compared to our review.
- -
- We highlight the different contribution of the proposed survey and they are organized in the manuscript
- Section 2
- -
- We present and describe the indexing requirements.
- -
- We explain the advantages of metric space and what is actually added to the indexing techniques with regard to the multidimensional space.
- -
- We highlight the critical importance of similarity queries in IoT applications involving large volumes of data and complex objects.
- Section 3
- -
- We first present our proposed taxonomy of existing indexing techniques in the literature
- -
- We provide a detailed description of the majority of the indexing technique under the proposed taxonomy.
- -
- We provide a comparative performance study of recent indexing techniques and their ability to solve Big IoT Data indexing problems
- -
- We summarize our analytical and comparative study for each indexing technique type in the Tables 1–15
- Section 4
- -
- We recall and study in depth several important techniques of multidimensional space
- -
- We provide the main challenges for each indexing structure and its potential solutions
- Section 5
- -
- We recall and study in depth several important techniques of metric space
- -
- We provide the main challenges for each indexing structure and its potential solutions solutions
- Section 6
- -
- We identify different directions for future research, which we believe are relevant to our work
- -
- We briefly define each search direction and how indexing techniques can benefit from it
- Section 7
- -
- We provide a brief summary of our study and we highlight the most important issues that need to be addressed as soon as possible.
- Section 8
- -
- We recall the main objective of our survey.
- -
- We provide a quick overview of the work provided by our manuscript
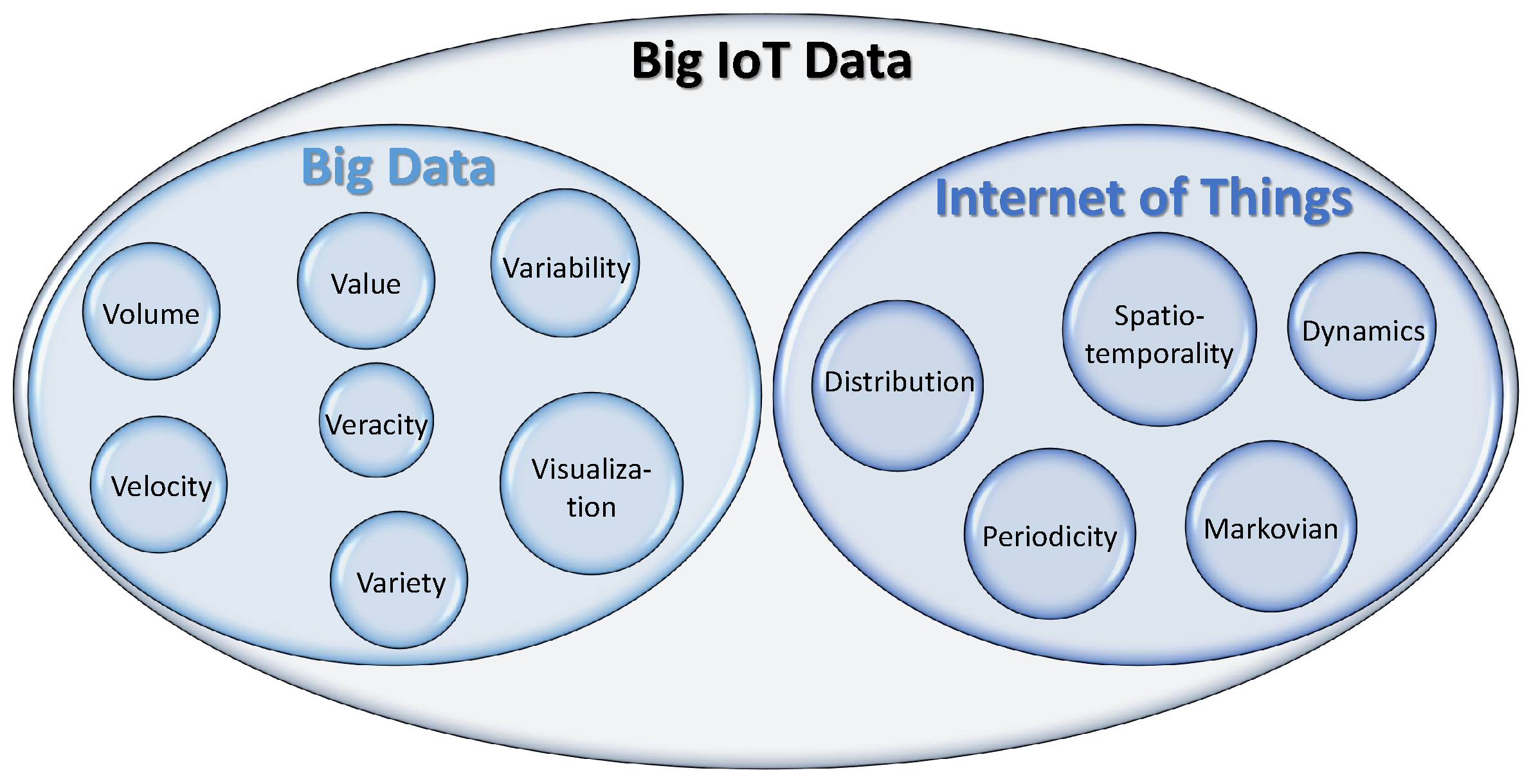
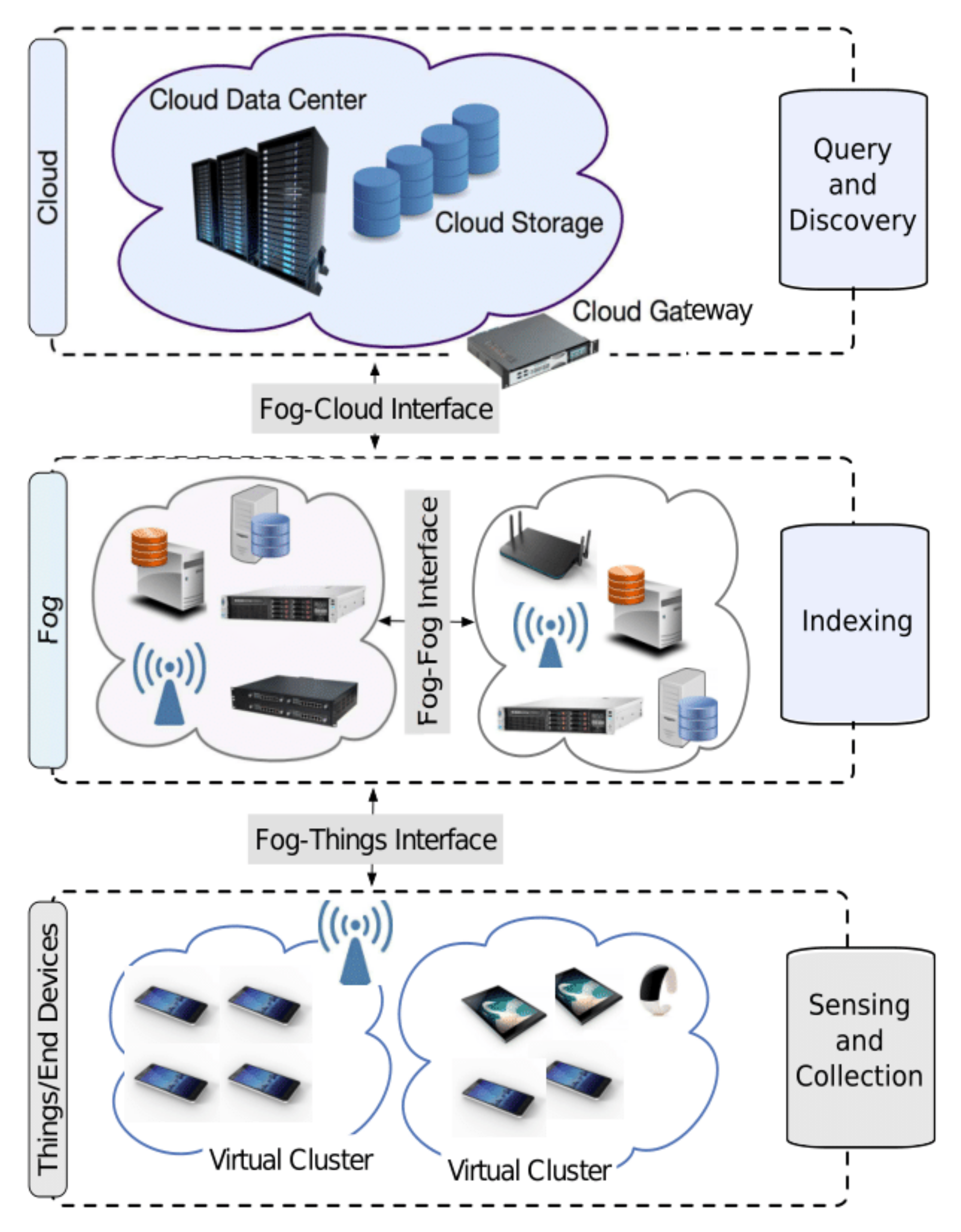
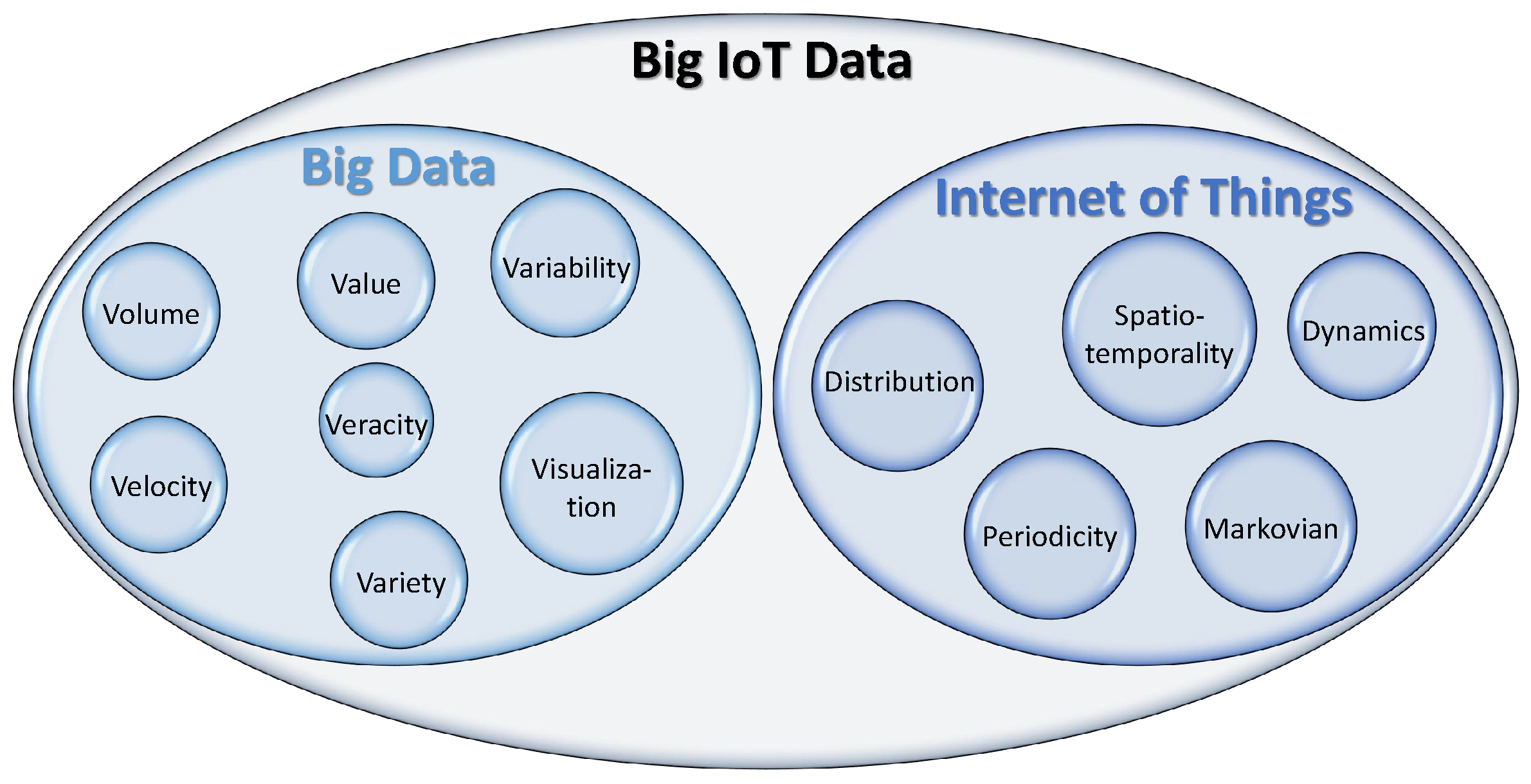
3. Big IoT Data
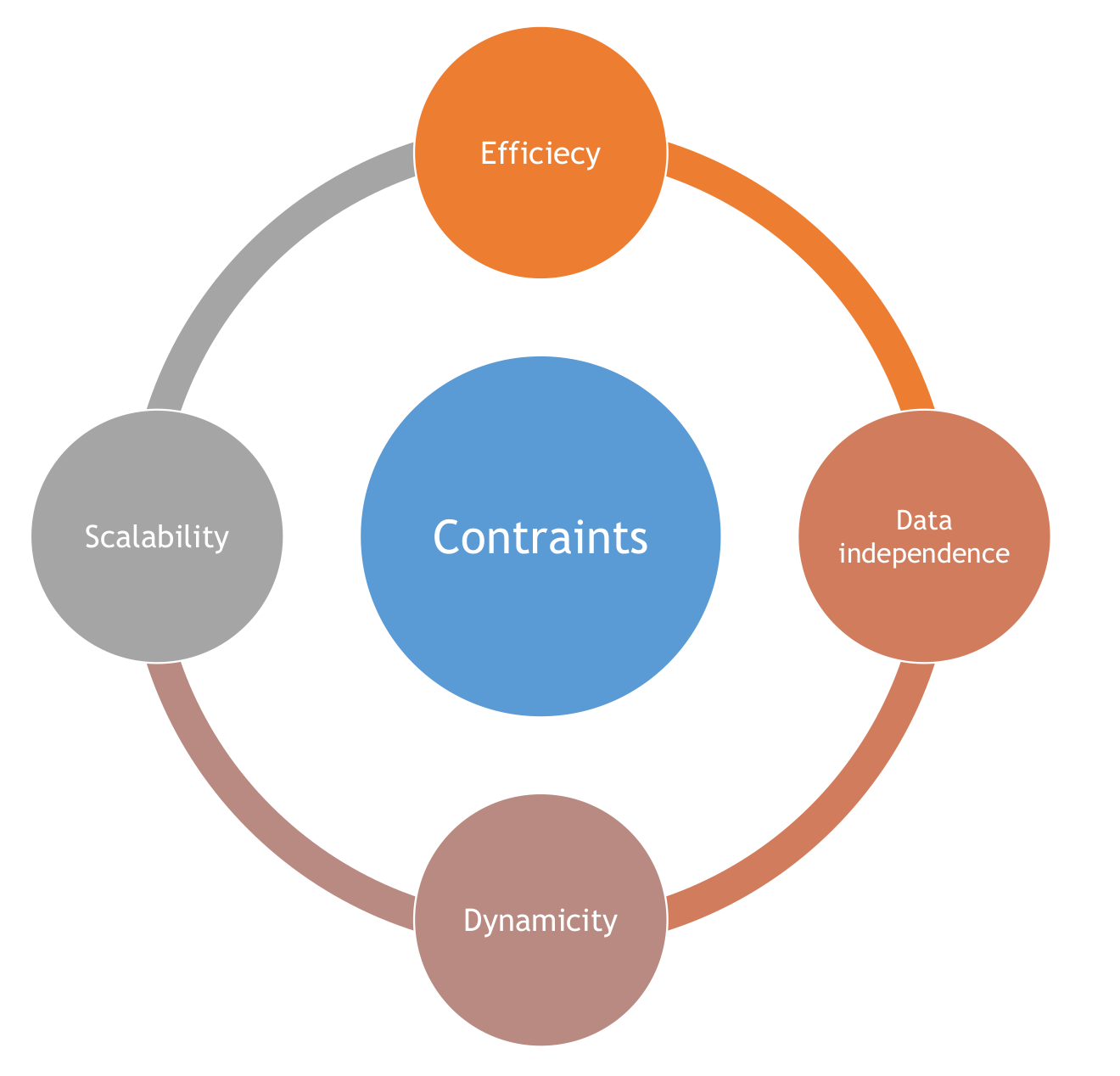
4. Big Data Indexing Requirements
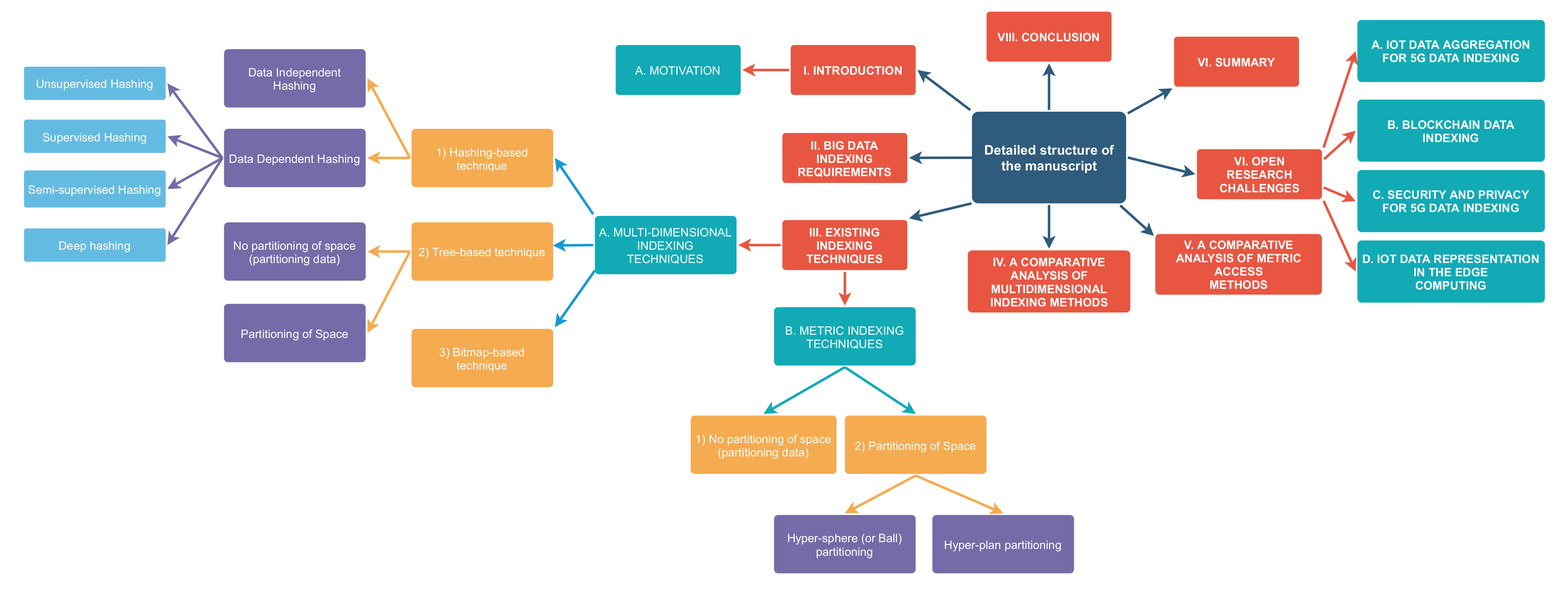
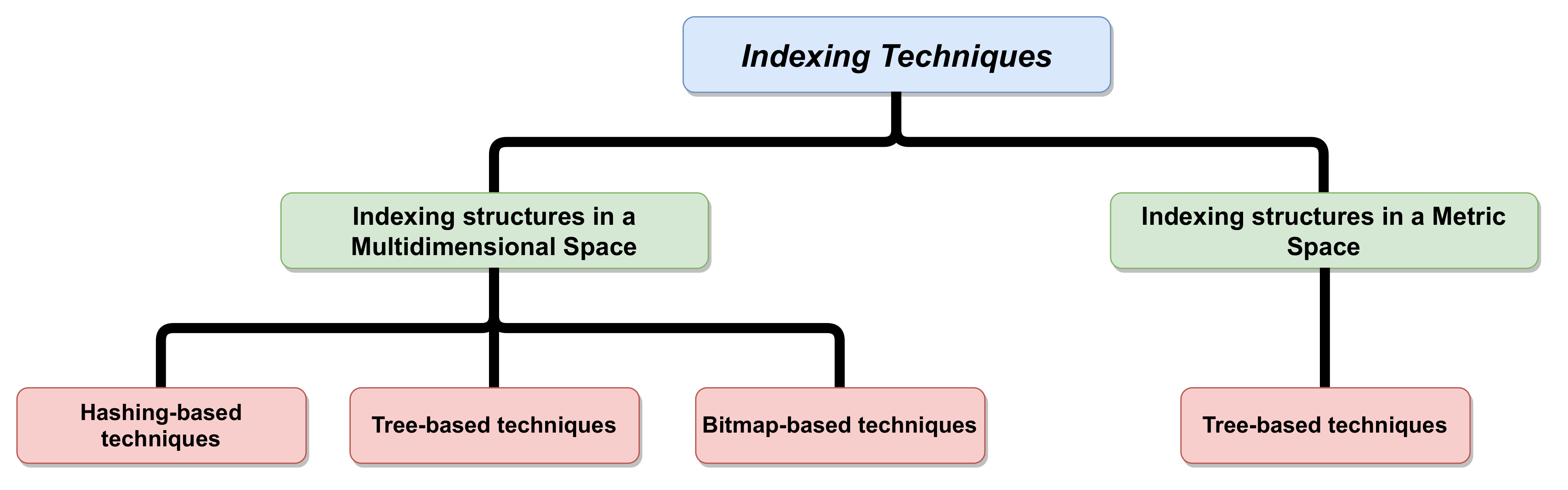
5. Existing Indexing Techniques
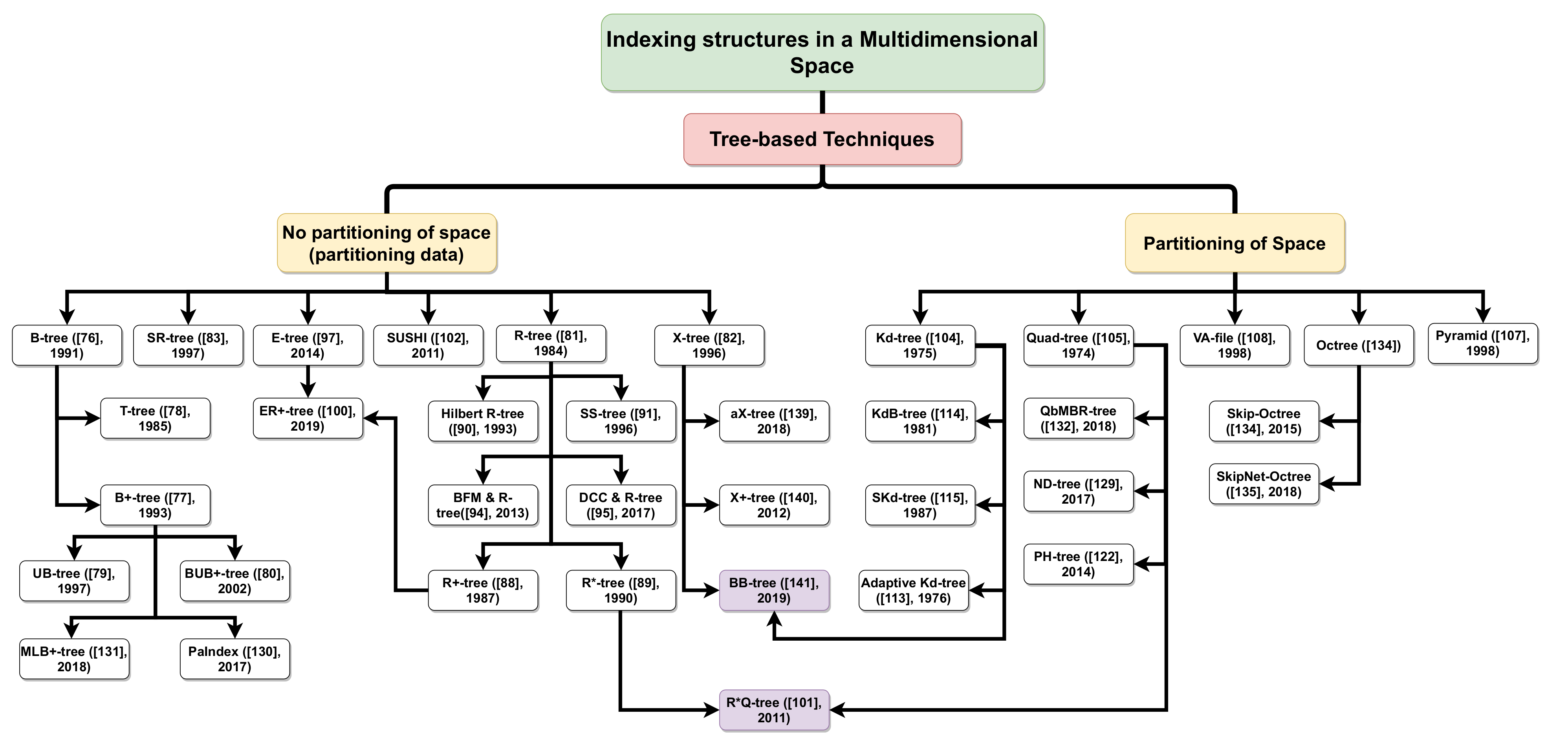
5.1. Multidimensional Indexing Techniques
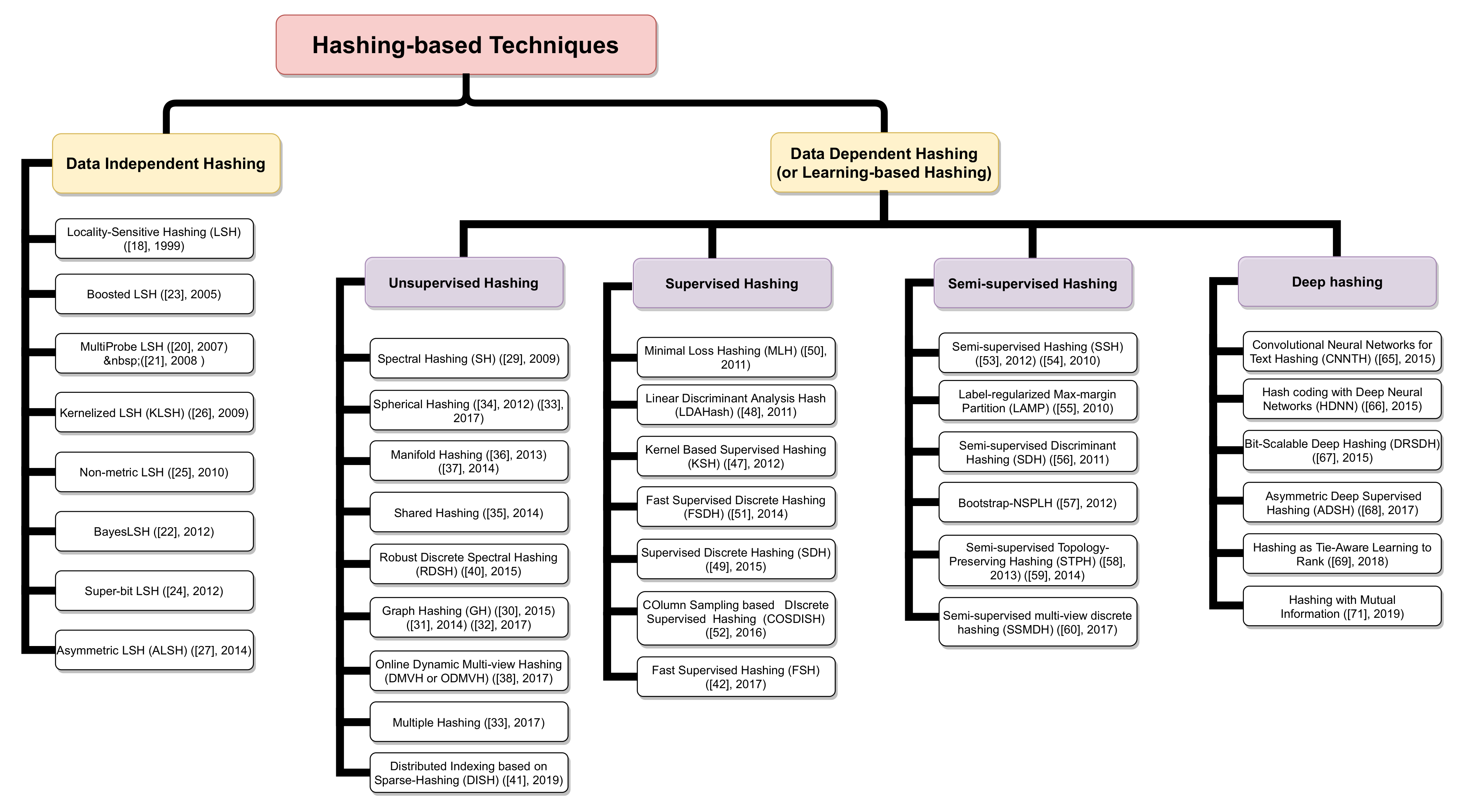
5.1.1. Hashing-Based Technique

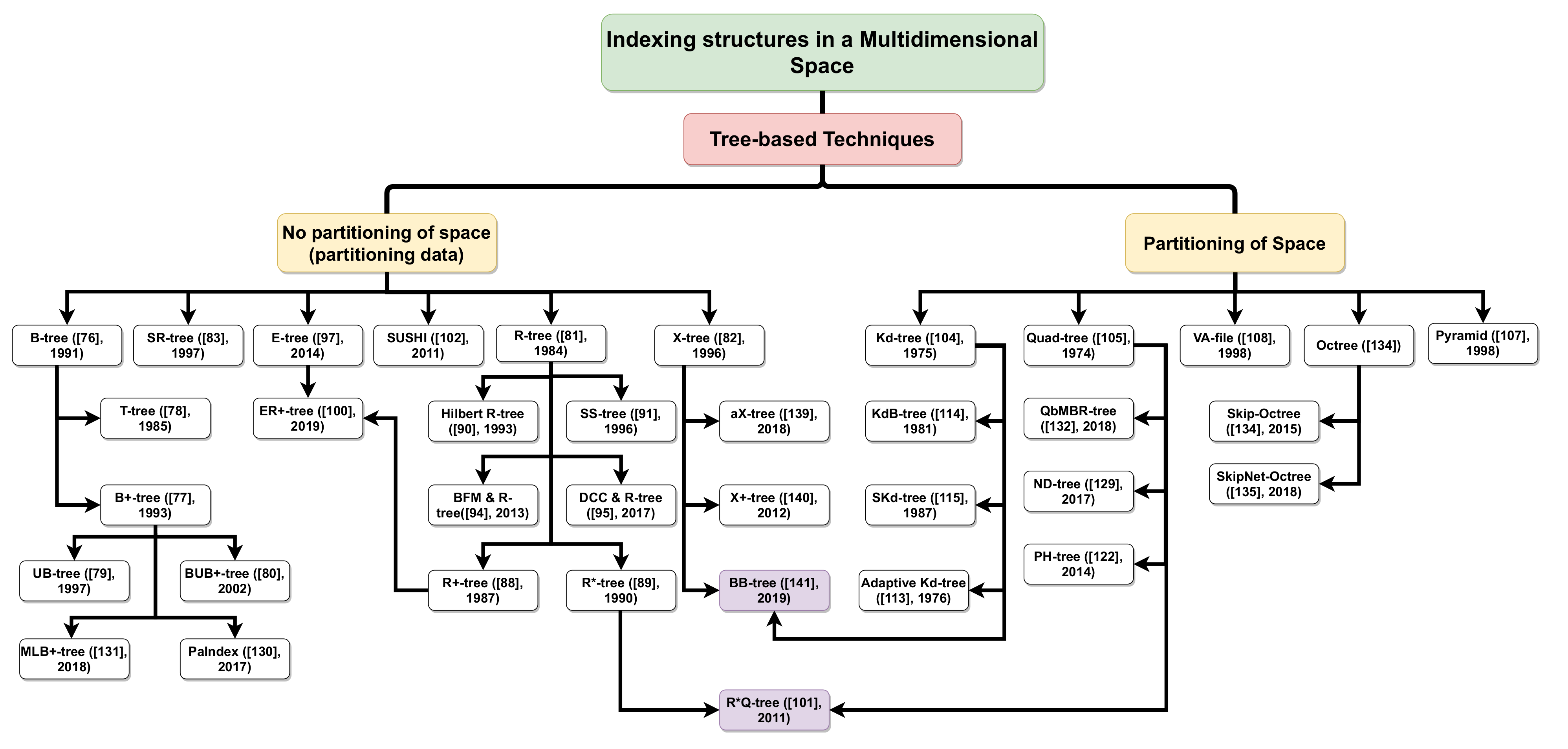
5.1.2. Tree-Based Technique
5.1.3. Bitmap-Based Technique
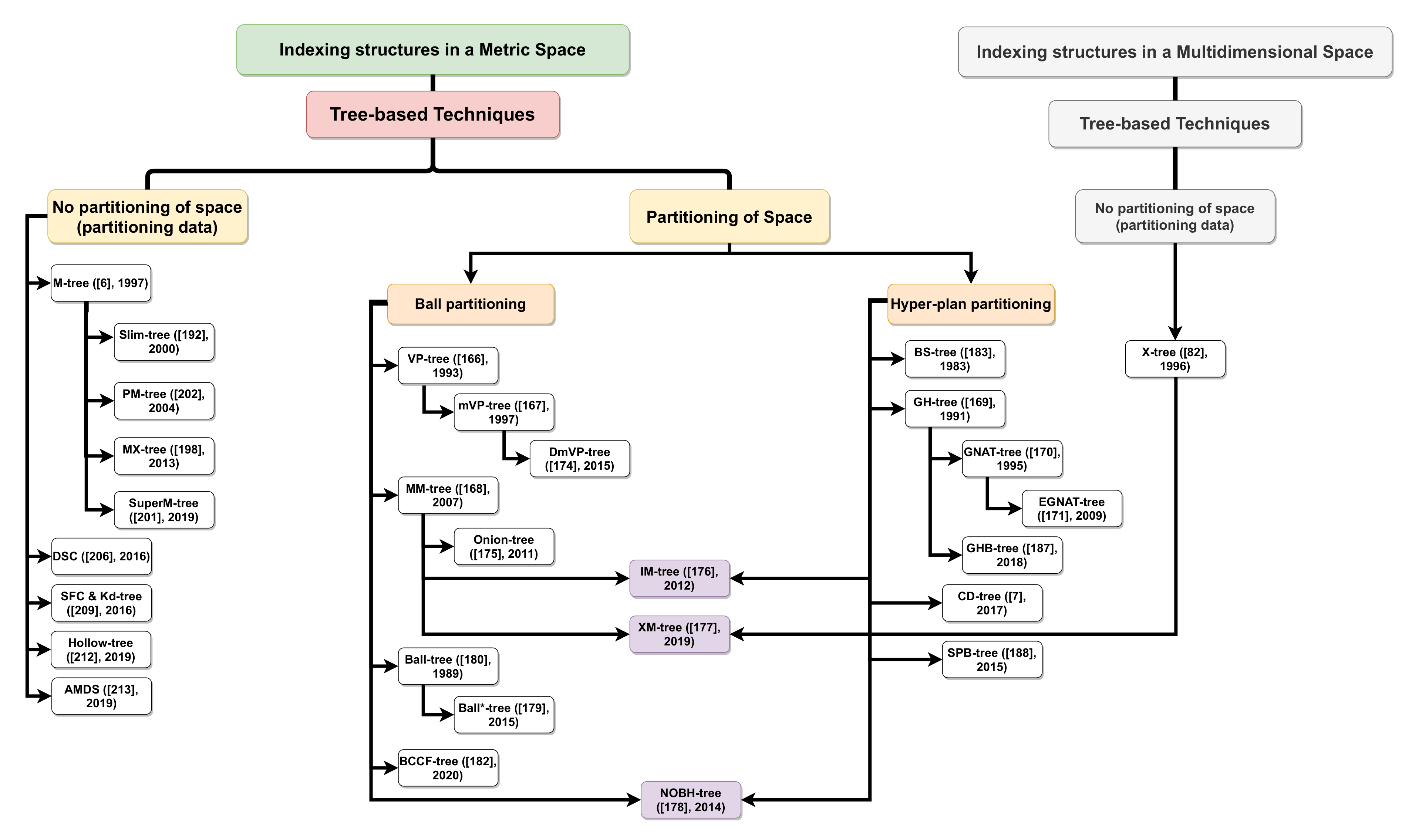
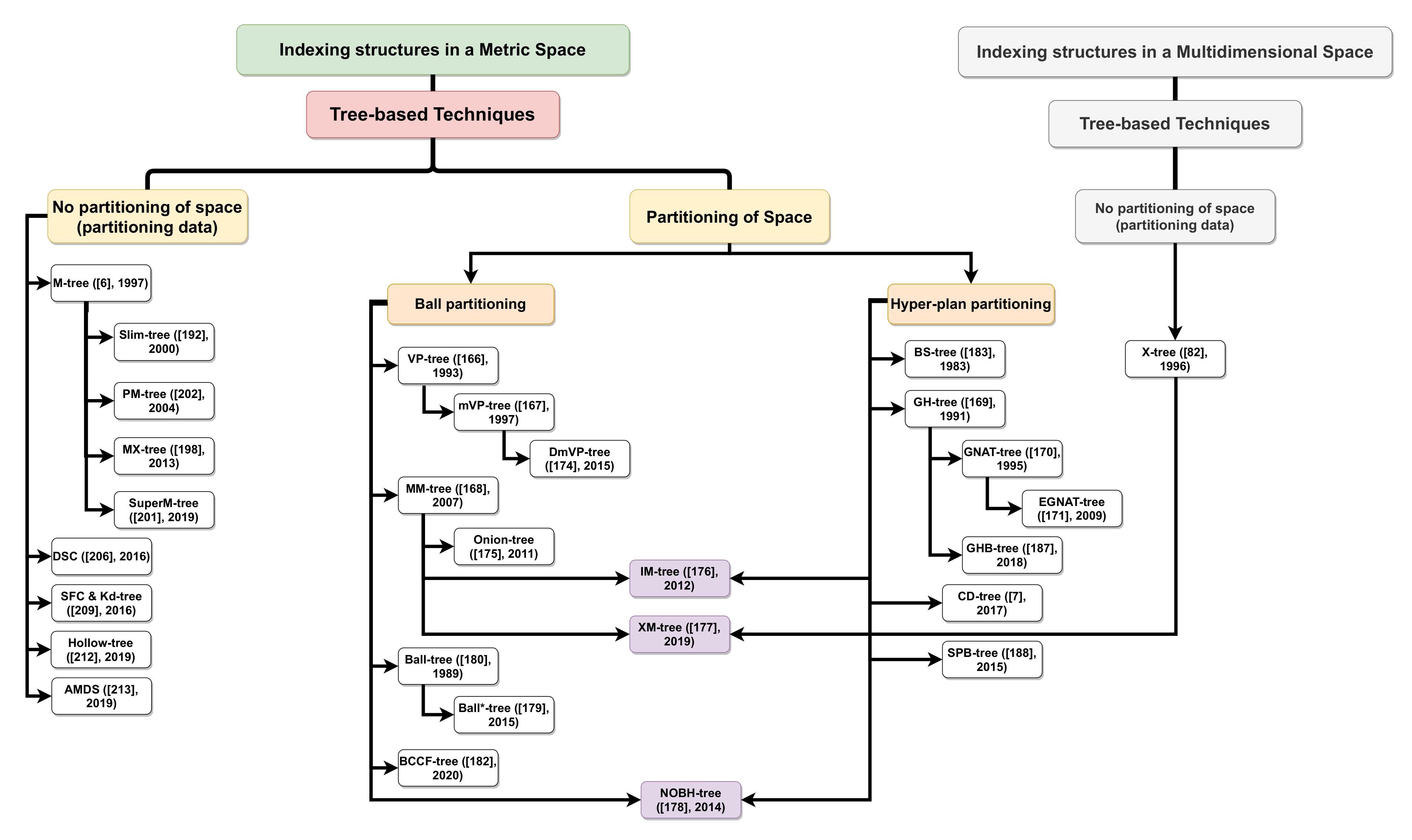
5.2. Metric Indexing Techniques
- Non-negativity: ;
- Identity: ;
- Symmetry: ;
- Triangle inequality: .
6. A Comparative Analysis of Multidimensional Indexing Methods
7. A Comparative Analysis of Metric Access Methods
8. Open Research Challenges
8.1. IoT Data Collection and Aggregation for 5G Data Indexing
8.2. Blockchain Data Indexing
8.3. Security and Privacy for 5G Data Indexing
- How to achieve efficient and privacy-preserving 5G data indexing?
- How to design an indexation protocol for achieving privacy-preserving priority classification on 5G Data?
- How to enhance trust management for 5G networks via data indexing in the era of big data?
- How to secure the multidimensional approaches in 5G data indexing (e.g., Pyramid, VA-file, kD-tree, X-tree, SR-tree, R-tree, and R-tree)?
8.4. Distributed Indexing for Large-Scale Data
- Is it possible to implement the structure at multiple levels?
- How to partition the indexing system load between these levels?
- To reduce the use of network bandwidth, overall cost, and efficiency, how to select the partition and the steps to be performed?
8.5. IoT Data Representation in the Edge Computing
8.6. Indexing Software Processes
- (1)
- Store encrypted data without decryption to maintain security.
- (2)
- To perform queries on encrypted data.
9. Summary
10. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Eltabakh, M.Y. Data Organization and Curation in Big Data. In Handbook of Big Data Technologies; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Zierenberg, M.; Schmitt, I. Optimizing the Distance Computation Order of Multi-Feature Similarity Search Indexing. In Proceedings of the Similarity Search and Applications—8th International Conference, SISAP 2015, Glasgow, UK, 12–14 October 2015. [Google Scholar]
- Gonzaga, A.S.; Cordeiro, R.L.F. The similarity-aware relational division database operator. In Proceedings of the Symposium on Applied Computing; ACM: New York, NY, USA, 2017; pp. 913–914. [Google Scholar]
- Gonzaga, A.S.; Cordeiro, R.L.F. A New Division Operator to Handle Complex Objects in Very Large Relational Datasets. In Proceedings of the 20th International Conference on Extending Database Technology (EDBT), Venice, Italy, 21–24 March 2017; pp. 474–477. [Google Scholar]
- Karima, B.; Ouarda, Z. Hybrid Metaheuristic for Optimization Job-Shop Scheduling Problem. Int. J. Inform. Appl. Math. 2018, 1, 1–9. [Google Scholar]
- Demchenko, Y.; Grosso, P.; De Laat, C.; Membrey, P. Addressing big data issues in scientific data infrastructure. In Proceedings of the 2013 International conference on collaboration technologies and systems (CTS), San Diego, CA, USA, 20–24 May 2013; pp. 48–55. [Google Scholar]
- Chen, C.P.; Zhang, C.Y. Data-intensive applications, challenges, techniques and technologies: A survey on Big Data. Inf. Sci. 2014, 275, 314–347. [Google Scholar] [CrossRef]
- Seddon, J.J.; Currie, W.L. A model for unpacking big data analytics in high-frequency trading. J. Bus. Res. 2017, 70, 300–307. [Google Scholar] [CrossRef]
- Friha, O.; Ferrag, M.A.; Shu, L.; Nafa, M. A Robust Security Framework based on Blockchain and SDN for Fog Computing enabled Agricultural Internet of Things. In Proceedings of the 2020 International Conference on Internet of Things and Intelligent Applications (ITIA), Zhenjiang, China, 27–29 November 2020; pp. 1–5. [Google Scholar]
- Yang, X.; Shu, L.; Chen, J.; Ferrag, M.A.; Wu, J.; Nurellari, E.; Huang, K. A Survey on Smart Agriculture: Development Modes, Technologies, and Security and Privacy Challenges. IEEE/CAA J. Autom. Sin. 2020, 8, 273–302. [Google Scholar] [CrossRef]
- Ferrag, M.A.; Ahmim, A. Security Solutions and Applied Cryptography in Smart Grid Communications; IGI Global: Pennsylvania, PA, USA, 2016. [Google Scholar]
- Wagner, I.; Eckhoff, D. Technical Privacy Metrics: A Systematic Survey. ACM Comput. Surv. 2018, 51, 1–38. [Google Scholar] [CrossRef] [Green Version]
- Fei Bua, N.W.B.J.H.L. “Privacy by Design” implementation: Information system engineers’ perspective. Int. J. Inf. Manag. 2020, 53, 102124. [Google Scholar]
- Atzori, L.; Iera, A.; Morabito, G. Siot: Giving a social structure to the internet of things. IEEE Commun. Lett. 2011, 15, 1193–1195. [Google Scholar] [CrossRef]
- Cauteruccio, F.; Cinelli, L.; Fortino, G.; Savaglio, C.; Terracina, G.; Ursino, D.; Virgili, L. An approach to compute the scope of a social object in a Multi-IoT scenario. Pervasive Mob. Comput. 2020, 67, 101223. [Google Scholar] [CrossRef]
- Baldassarre, G.; Giudice, P.L.; Musarella, L.; Ursino, D. A paradigm for the cooperation of objects belonging to different IoTs. In Proceedings of the 22nd International Database Engineering & Applications Symposium, Villa San Giovanni, Italy, 18–20 June 2018; pp. 157–164. [Google Scholar]
- Ursino, D.; Virgili, L. Humanizing IoT: Defining the profile and the reliability of a thing in a multi-IoT scenario. In Toward Social Internet of Things (SIoT): Enabling Technologies, Architectures and Applications; Springer: Berlin/Heidelberg, Germany, 2020; pp. 51–76. [Google Scholar]
- Baldassarre, G.; Giudice, P.L.; Musarella, L.; Ursino, D. The MIoT paradigm: Main features and an “ad hoc” crawler. Future Gener. Comput. Syst. 2019, 92, 29–42. [Google Scholar] [CrossRef]
- Mukherjee, M.; Matam, R.; Shu, L.; Maglaras, L.; Ferrag, M.A.; Choudhury, N.; Kumar, V. Security and privacy in fog computing: Challenges. IEEE Access 2017, 5, 19293–19304. [Google Scholar] [CrossRef]
- Xie, J.; Qian, C.; Guo, D.; Wang, M.; Shi, S.; Chen, H. Efficient indexing mechanism for unstructured data sharing systems in edge computing. In Proceedings of the IEEE INFOCOM 2019-IEEE Conference on Computer Communications, Paris, France, 29 April–2 May 2019; pp. 820–828. [Google Scholar]
- Wang, C.; Xie, M.; Bhowmick, S.S.; Choi, B.; Xiao, X.; Zhou, S. An indexing framework for efficient visual exploratory subgraph search in graph databases. In Proceedings of the 2019 IEEE 35th International Conference on Data Engineering (ICDE), Macao, China, 8–11 April 2019; pp. 1666–1669. [Google Scholar]
- Sunhare, P.; Chowdhary, R.R.; Chattopadhyay, M.K. Internet of things and data mining: An application oriented survey. J. King Saud Univ. Comput. Inf. Sci. 2020. [Google Scholar] [CrossRef]
- Busany, N.; van der Aa, H.; Senderovich, A.; Gal, A.; Weidlich, M. Interval-Based Queries over Lossy IoT Event Streams. ACM Trans. Data Sci. 2020, 1, 1–27. [Google Scholar] [CrossRef]
- Lv, z.; Kumar Singh, A. Big Data Analysis of Internet of Things System. ACM Trans. Internet Technol. 2021, 21, 1–15. [Google Scholar] [CrossRef]
- Schmeißer, S.; Schiele, G. CoSense: The Collaborative Sensing Middleware for the Internet-of-Things. ACM/IMS Trans. Data Sci. 2021, 1, 1–21. [Google Scholar] [CrossRef]
- Pattar, S.; Buyya, R.; Venugopal, K.R.; Iyengar, S.S.; Patnaik, L.M. Searching for the IoT Resources: Fundamentals, Requirements, Comprehensive Review, and Future Directions. IEEE Commun. Surv. Tutor. 2018, 20, 2101–2132. [Google Scholar] [CrossRef]
- Mohammadi, M.; Al-Fuqaha, A.; Sorour, S.; Guizani, M. Deep Learning for IoT Big Data and Streaming Analytics: A Survey. IEEE Commun. Surv. Tutor. 2018, 20, 2923–2960. [Google Scholar] [CrossRef] [Green Version]
- Saha, A.K.; Kumar, A.; Tyagi, V.; Das, S. Big Data and Internet of Things: A Survey. In Proceedings of the 2018 International Conference on Advances in Computing, Communication Control and Networking (ICACCCN), Greater Noida, India, 12–13 October 2018; pp. 150–156. [Google Scholar] [CrossRef]
- Shadroo, S.; Rahmani, A.M. Systematic survey of big data and data mining in internet of things. Comput. Netw. 2018, 139, 19–47. [Google Scholar] [CrossRef]
- Ettiyan, R.; Geetha, V. A Survey of Health Care Monitoring System for Maternity Women Using Internet-of-Things. In Proceedings of the 2020 3rd International Conference on Intelligent Sustainable Systems (ICISS), Coimbatore, India, 3–5 December 2020; pp. 1290–1296. [Google Scholar] [CrossRef]
- Eceiza, M.; Flores, J.L.; Iturbe, M. Fuzzing the Internet of Things: A Review on the Techniques and Challenges for Efficient Vulnerability Discovery in Embedded Systems. IEEE Internet Things J. 2021, 8, 10390–10411. [Google Scholar] [CrossRef]
- Li, W. A Comprehensive Survey on Machine Learning-Based Big Data Analytics for IoT-Enabled Smart Healthcare System. Mob. Netw. Appl. 2021, 26, 234–252. [Google Scholar] [CrossRef]
- Ji, B.; Wang, Y.; Song, K.; Li, C.; Wen, H.; Menon, V.G.; Mumtaz, S. A Survey of Computational Intelligence for 6G: Key Technologies, Applications and Trends. IEEE Trans. Ind. Inform. 2021, 17, 7145–7154. [Google Scholar] [CrossRef]
- Shah, S.D.A.; Gregory, M.A.; Li, S. Cloud-Native Network Slicing Using Software Defined Networking Based Multi-Access Edge Computing: A Survey. IEEE Access 2021, 9, 10903–10924. [Google Scholar] [CrossRef]
- Amin, S.U.; Hossain, M.S. Edge Intelligence and Internet of Things in Healthcare: A Survey. IEEE Access 2021, 9, 45–59. [Google Scholar] [CrossRef]
- Chegini, H.; Naha, R.K.; Mahanti, A.; Thulasiraman, P. Process Automation in an IoT–Fog–Cloud Ecosystem: A Survey and Taxonomy. IoT 2021, 2, 92–118. [Google Scholar] [CrossRef]
- Nahar, S.; Zhong, T.; Monday, H.N.; Mills, M.O.; Nneji, G.U.; Abubakar, H.S. A Survey on Data Stream Mining Towards the Internet of Things Application. In Proceedings of the 4th Technology Innovation Management and Engineering Science International Conference (TIMES-iCON), Bangkok, Thailand, 11–13 December 2019. [Google Scholar]
- Marjani, M. Big IoT Data Analytics: Architecture, Opportunities, and Open Research Challenges. IEEE Access 2017, 5, 5247–5261. [Google Scholar]
- Ferrag, M.A.; Kouahla, Z.; Seridi, H.; Kurulay, M. Big IoT Data Indexing: Architecture, Techniques and Open Research Challenges. In Proceedings of the 2019 International Conference on Networking and Advanced Systems (ICNAS), Annaba, Algeria, 26–27 June 2019; pp. 1–6. [Google Scholar]
- Plageras, A.P.; Psannis, K.E.; Stergiou, C.; Wang, H.; Gupta, B.B. Efficient IoT-based sensor BIG Data collection–processing and analysis in smart buildings. Future Gener. Comput. Syst. 2018, 82, 349–357. [Google Scholar] [CrossRef]
- Luong, N.C.; Hoang, D.T.; Wang, P.; Niyato, D.; Kim, D.I.; Han, Z. Data collection and wireless communication in Internet of Things (IoT) using economic analysis and pricing models: A survey. IEEE Commun. Surv. Tutor. 2016, 18, 2546–2590. [Google Scholar] [CrossRef] [Green Version]
- Lu, Y.; Misra, A.; Wu, H. Smartphone sensing meets transport data: A collaborative framework for transportation service analytics. IEEE Trans. Mob. Comput. 2017, 17, 945–960. [Google Scholar] [CrossRef]
- Huang, D.Y.; Apthorpe, N.; Li, F.; Acar, G.; Feamster, N. IoT Inspector: Crowdsourcing Labeled Network Traffic from Smart Home Devices at Scale. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2020, 4, 1–21. [Google Scholar] [CrossRef]
- Dinh, L.T.N.; Karmakar, G.; Kamruzzaman, J. A survey on context awareness in big data analytics for business applications. Knowl. Inf. Syst. 2020, 62, 3387–3415. [Google Scholar] [CrossRef]
- Abbasi, A.; Sarker, S.; Chiang, R.H. Big data research in information systems: Toward an inclusive research agenda. J. Assoc. Inf. Syst. 2016, 17, 3. [Google Scholar] [CrossRef] [Green Version]
- Canbay, Y.; Sağıroğlu, S. Big data anonymization with spark. In Proceedings of the 2017 International Conference on Computer Science and Engineering (UBMK), Antalya, Turkey, 5–8 October 2017; pp. 833–838. [Google Scholar]
- Omollo, R.; Alago, S. Data modeling techniques used for big data in enterprise networks. Int. J. Adv. Technol. Eng. Explor. 2020, 7, 79–92. [Google Scholar] [CrossRef]
- Niculescu, V. On the Impact of High Performance Computing in Big Data Analytics for Medicine. Appl. Med. Inform. 2020, 42, 9–18. [Google Scholar]
- Benrazek, A.E.; Farou, B.; Kurulay, M. Efficient Camera Clustering Method Based on Overlapping FoVs for WMSNs. Int. J. Inform. Appl. Math. 2019, 1, 10–23. [Google Scholar]
- Bolettieri, P.; Falchi, F.; Lucchese, C.; Mass, Y.; Perego, R.; Rabitti, F.; Shmueli-Scheuer, M. Searching 100M Images by Content Similarity. In Proceedings of the 5th Italian Research Conference on Digital Library Systems (IRCD), Modena, Italy, 26–27 January 2009; pp. 88–99. [Google Scholar]
- Batko, M.; Novak, D.; Falchi, F.; Zezula, P. On scalability of the similarity search in the world of peers. In Proceedings of the 1st International Conference on Scalable Information Systems (InfoScale); ACM Press: Hong Kong, China, 2006; pp. 20–31. [Google Scholar]
- Smeulders, A.; Worring, M.; Santini, S.; Gupta, A.; Jain, R. Content based image retrieval at the end of the early years. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1349–1380. [Google Scholar] [CrossRef]
- Bozkaya, T.; Özsoyoglu, M. Indexing large metric spaces for similarity search queries. ACM Trans. Database Syst. 1999, 24, 361–404. [Google Scholar] [CrossRef]
- Baral, C.; Gonzalez, G.; Son, T. Conceptual Modeling and Querying in Multimedia Databases. Multimed. Tools Appl. 1998, 7, 37–66. [Google Scholar] [CrossRef]
- Brin, S. Near neighbor search in large metric spaces. In Proceedings of the 21th International Conference on Very Large Data Bases (VLDB 1995), Zurich, Switzerland, 11–15 September 1995. [Google Scholar]
- Indyk, P.; Motwani, R. Approximate nearest neighbors: Towards removing the curse of dimensionality. In Proceedings of the Thirtieth Annual ACM Symposium on Theory of Computing, Dallas, TX, USA, 24–26 May 1998; pp. 604–613. [Google Scholar]
- Har-Peled, S.; Indyk, P.; Motwani, R. Approximate nearest neighbor: Towards removing the curse of dimensionality. Theory Comput. 2012, 8, 321–350. [Google Scholar] [CrossRef]
- Zineddine, K.; Ferrag, M.A.; Anjum, A. Indexing multimedia data with an extension of binary tree–Image search by content. Int. J. Inform. Appl. Math. 2021, 1, 54–63. [Google Scholar]
- Özsu, M.T.; Valudriez, P. Principles of Distributed Database Systems; Prentice-Hall: Hoboken, NJ, USA, 1991; 562p. [Google Scholar]
- Navarro, G. Searching in metric spaces by spatial approximation. VLDB J. 2002, 11, 28–46. [Google Scholar] [CrossRef]
- Chavez, E.; Navarro, G.; Marroquin, J.L.; Baeza-Yates, R. Searching in Metric Spaces. ACM Comput. Surv. 2001, 33, 273–321. [Google Scholar] [CrossRef]
- Pagh, R.; Silvestri, F.; Sivertsen, J.; Skala, M. Approximate Furthest Neighbor in High Dimensions. In Proceedings of the Similarity Search and Applications–8th International Conference, SISAP 2015, Glasgow, UK, 12–14 October 2015. [Google Scholar]
- Wang, J.; Shen, H.T.; Song, J.; Ji, J. Hashing for similarity search: A survey. arXiv 2014, arXiv:1408.2927. [Google Scholar]
- Desai, M.; Mehta, R.G.; Rana, D.P. A Survey on Techniques for Indexing and Hashing in Big Data. In Proceedings of the 2018 4th International Conference on Computing Communication and Automation (ICCCA), Greater Noida, India, 14–15 December 2018; pp. 1–6. [Google Scholar]
- Nashipudimath, M.M.; Shinde, S.K. Indexing in Big Data. In Computing, Communication and Signal Processing; Springer: Berlin/Heidelberg, Germany, 2019; pp. 133–142. [Google Scholar]
- Shang, L.; Yang, L.; Wang, F.; Chan, K.P.; Hua, X.S. Real-time large scale near-duplicate web video retrieval. In Proceedings of the 18th ACM International Conference on Multimedia, Virtual, 25–29 October 2010; pp. 531–540. [Google Scholar]
- Gionis, A.; Indyk, P.; Motwani, R. Similarity search in high dimensions via hashing. In Proceedings of the 25th International Conference on Very Large Data Bases (VLDB), Scotland, UK, 7–10 September 1999; Volume 99, pp. 518–529. [Google Scholar]
- Wang, J.; Liu, W.; Kumar, S.; Chang, S.F. Learning to hash for indexing big data—A survey. Proc. IEEE 2015, 104, 34–57. [Google Scholar] [CrossRef]
- Lv, Q.; Josephson, W.; Wang, Z.; Charikar, M.; Li, K. Multi-probe LSH: Efficient indexing for high-dimensional similarity search. In Proceedings of the 33rd international conference on Very large data bases. VLDB Endowment, Vienna, Austria, 23–27 September 2007; pp. 950–961. [Google Scholar]
- Dong, W.; Wang, Z.; Josephson, W.; Charikar, M.; Li, K. Modeling LSH for performance tuning. In Proceedings of the 17th ACM Conference on Information and Knowledge Management, Napa Valley, CA, USA, 26–30 October 2008; pp. 669–678. [Google Scholar]
- Satuluri, V.; Parthasarathy, S. Bayesian locality sensitive hashing for fast similarity search. Proc. Vldb Endow. 2012, 5, 430–441. [Google Scholar] [CrossRef] [Green Version]
- Shakhnarovich, G. Learning Task-Specific Similarity. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2005. [Google Scholar]
- Ji, J.; Li, J.; Yan, S.; Zhang, B.; Tian, Q. Super-bit locality-sensitive hashing. In Advances in Neural Information Processing Systems; Springer: Berlin/Heidelberg, Germany, 2012; pp. 108–116. [Google Scholar]
- Mu, Y.; Yan, S. Non-metric locality-sensitive hashing. In Proceedings of the Twenty-Fourth AAAI Conference on Artificial Intelligence, Atlanta, GE, USA, 11–15 July 2010. [Google Scholar]
- Kulis, B.; Grauman, K. Kernelized locality-sensitive hashing for scalable image search. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; Volume 9, pp. 2130–2137. [Google Scholar]
- Shrivastava, A.; Li, P. Asymmetric LSH (ALSH) for sublinear time maximum inner product search (MIPS). In Advances in Neural Information Processing Systems; Spinger: Berlin/Heidelberg, Germany, 2014; pp. 2321–2329. [Google Scholar]
- Li, Z.; Zhang, X.; Müller, H.; Zhang, S. Large-scale retrieval for medical image analytics: A comprehensive review. Med. Image Anal. 2018, 43, 66–84. [Google Scholar] [CrossRef] [Green Version]
- Weiss, Y.; Torralba, A.; Fergus, R. Spectral hashing. In Advances in Neural Information Processing Systems; Spinger: Berlin/Heidelberg, Germany, 2009; pp. 1753–1760. [Google Scholar]
- Jiang, Q.Y.; Li, W.J. Scalable graph hashing with feature transformation. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015. [Google Scholar]
- Liu, W.; Mu, C.; Kumar, S.; Chang, S.F. Discrete graph hashing. In Advances in Neural Information Processing Systems; Spinger: Berlin/Heidelberg, Germany, 2014; pp. 3419–3427. [Google Scholar]
- Shi, X.; Xing, F.; Xu, K.; Sapkota, M.; Yang, L. Asymmetric discrete graph hashing. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Tian, L.; Fan, C.; Ming, Y. Learning spherical hashing based binary codes for face recognition. Multimed. Tools Appl. 2017, 76, 13271–13299. [Google Scholar] [CrossRef]
- Heo, J.P.; Lee, Y.; He, J.; Chang, S.F.; Yoon, S.E. Spherical hashing. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 16–21 June 2012; pp. 2957–2964. [Google Scholar]
- Liu, X.; Mu, Y.; Zhang, D.; Lang, B.; Li, X. Large-scale unsupervised hashing with shared structure learning. IEEE Trans. Cybern. 2014, 45, 1811–1822. [Google Scholar] [CrossRef]
- Shen, F.; Shen, C.; Shi, Q.; Van Den Hengel, A.; Tang, Z. Inductive hashing on manifolds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1562–1569. [Google Scholar]
- Irie, G.; Li, Z.; Wu, X.M.; Chang, S.F. Locally linear hashing for extracting non-linear manifolds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2115–2122. [Google Scholar]
- Xie, L.; Shen, J.; Han, J.; Zhu, L.; Shao, L. Dynamic multi-view hashing for online image retrieval. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), Melbourne, Australia, 19–25 August 2017; Volume 437, pp. 3133–3139. [Google Scholar]
- Lu, X.; Zhu, L.; Cheng, Z.; Li, J.; Nie, X.; Zhang, H. Flexible Online Multi-modal Hashing for Large-scale Multimedia Retrieval. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 1129–1137. [Google Scholar]
- Yang, Y.; Shen, F.; Shen, H.T.; Li, H.; Li, X. Robust discrete spectral hashing for large-scale image semantic indexing. IEEE Trans. Big Data 2015, 1, 162–171. [Google Scholar] [CrossRef]
- Mourão, A.; Magalhães, J. Towards Cloud Distributed Image Indexing by Sparse Hashing. In Proceedings of the 2019 on International Conference on Multimedia Retrieval, Ottawa, ON, Canada, 10–13 June 2019; pp. 288–296. [Google Scholar]
- Lin, G.; Shen, C.; Shi, Q.; Van den Hengel, A.; Suter, D. Fast supervised hashing with decision trees for high-dimensional data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1963–1970. [Google Scholar]
- Xia, R.; Pan, Y.; Lai, H.; Liu, C.; Yan, S. Supervised hashing for image retrieval via image representation learning. In Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014. [Google Scholar]
- Kraska, T.; Beutel, A.; Chi, E.H.; Dean, J.; Polyzotis, N. The case for learned index structures. In Proceedings of the 2018 International Conference on Management of Data, Houston, TX, USA, 10–15 June 2018; pp. 489–504. [Google Scholar]
- Beutel, A.; Kraska, T.; Chi, E.; Dean, J.; Polyzotis, N. A Machine Learning Approach to Databases Indexes. In Proceedings of the ML Systems Workshop at NIPS 2017, Long Beach, CA, USA, 8 December 2017. [Google Scholar]
- Patel, F.S.; Kasat, D. Hashing based indexing techniques for content based image retrieval: A survey. In Proceedings of the 2017 International Conference on Innovative Mechanisms for Industry Applications (ICIMIA), Bengaluru, India, 21–23 February 2017; pp. 279–283. [Google Scholar]
- Liu, W.; Wang, J.; Ji, R.; Jiang, Y.G.; Chang, S.F. Supervised hashing with kernels. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 16–21 June 2012; pp. 2074–2081. [Google Scholar]
- Strecha, C.; Bronstein, A.; Bronstein, M.; Fua, P. LDAHash: Improved matching with smaller descriptors. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 66–78. [Google Scholar] [CrossRef] [Green Version]
- Shen, F.; Shen, C.; Liu, W.; Tao Shen, H. Supervised discrete hashing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 37–45. [Google Scholar]
- Norouzi, M.; Blei, D.M. Minimal loss hashing for compact binary codes. In Proceedings of the 28th International Conference on Machine Learning (ICML-11), Bellevue, WA, USA, 28 June–2 July 2011; pp. 353–360. [Google Scholar]
- Gui, J.; Liu, T.; Sun, Z.; Tao, D.; Tan, T. Fast supervised discrete hashing. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 490–496. [Google Scholar] [CrossRef]
- Kang, W.C.; Li, W.J.; Zhou, Z.H. Column sampling based discrete supervised hashing. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Wang, J.; Kumar, S.; Chang, S.F. Semi-supervised hashing for large-scale search. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2393–2406. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Kumar, S.; Chang, S.F. Sequential projection learning for hashing with compact codes. In Proceedings of the 27th International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Mu, Y.; Shen, J.; Yan, S. Weakly-supervised hashing in kernel space. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3344–3351. [Google Scholar]
- Kim, S.; Choi, S. Semi-supervised discriminant hashing. In Proceedings of the 2011 IEEE 11th International Conference on Data Mining, Vancouver, BC, Canada, 11 December 2011; pp. 1122–1127. [Google Scholar]
- Wu, C.; Zhu, J.; Cai, D.; Chen, C.; Bu, J. Semi-supervised nonlinear hashing using bootstrap sequential projection learning. IEEE Trans. Knowl. Data Eng. 2012, 25, 1380–1393. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, Y.; Tang, J.; Gu, X.; Li, J.; Tian, Q. Topology preserving hashing for similarity search. In Proceedings of the 21st ACM International Conference on Multimedia, Barcelona, Spain, 21–25 October 2013; pp. 123–132. [Google Scholar]
- Zhang, L.; Zhang, Y.; Gu, X.; Tang, J.; Tian, Q. Scalable similarity search with topology preserving hashing. IEEE Trans. Image Process. 2014, 23, 3025–3039. [Google Scholar] [CrossRef]
- Zhang, C.; Zheng, W.S. Semi-supervised multi-view discrete hashing for fast image search. IEEE Trans. Image Process. 2017, 26, 2604–2617. [Google Scholar] [CrossRef]
- Hu, W.; Huang, Y.; Wei, L.; Zhang, F.; Li, H. Deep convolutional neural networks for hyperspectral image classification. J. Sens. 2015, 2015. [Google Scholar] [CrossRef] [Green Version]
- Lakshmanaprabu, S.; Mohanty, S.N.; Shankar, K.; Arunkumar, N.; Ramirez, G. Optimal deep learning model for classification of lung cancer on CT images. Future Gener. Comput. Syst. 2019, 92, 374–382. [Google Scholar]
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Chen, J.; Liu, X.; Pietikäinen, M. Deep learning for generic object detection: A survey. arXiv 2018, arXiv:1809.02165. [Google Scholar] [CrossRef] [Green Version]
- Han, J.; Zhang, D.; Cheng, G.; Liu, N.; Xu, D. Advanced deep-learning techniques for salient and category-specific object detection: A survey. IEEE Signal Process. Mag. 2018, 35, 84–100. [Google Scholar] [CrossRef]
- Xu, J.; Wang, P.; Tian, G.; Xu, B.; Zhao, J.; Wang, F.; Hao, H. Convolutional neural networks for text hashing. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015. [Google Scholar]
- Lai, H.; Pan, Y.; Liu, Y.; Yan, S. Simultaneous feature learning and hash coding with deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 July 2015; pp. 3270–3278. [Google Scholar]
- Zhang, R.; Lin, L.; Zhang, R.; Zuo, W.; Zhang, L. Bit-scalable deep hashing with regularized similarity learning for image retrieval and person re-identification. IEEE Trans. Image Process. 2015, 24, 4766–4779. [Google Scholar] [CrossRef] [PubMed]
- Jiang, Q.Y.; Li, W.J. Asymmetric Deep Supervised Hashing. arXiv 2017, arXiv:1707.08325. [Google Scholar]
- He, K.; Cakir, F.; Adel Bargal, S.; Sclaroff, S. Hashing as tie-aware learning to rank. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4023–4032. [Google Scholar]
- Li, W.J.; Wang, S.; Kang, W.C. Feature learning based deep supervised hashing with pairwise labels. arXiv 2015, arXiv:1511.03855. [Google Scholar]
- Cakir, F.; He, K.; Bargal, S.A.; Sclaroff, S. Hashing with mutual information. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 2424–2437. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.; Li, C.; Shen, H. Equivalent Continuous Formulation of General Hashing Problem. IEEE Trans. Cybern. 2019, 51, 4089–4099. [Google Scholar] [CrossRef]
- Chi, L.; Zhu, X. Hashing techniques: A survey and taxonomy. ACM Comput. Surv. 2017, 50, 11. [Google Scholar] [CrossRef]
- Li, P.; Zhu, X.; Zhang, X.; Ren, P.; Wang, L. Hash Code Reconstruction for Fast Similarity Search. IEEE Signal Process. Lett. 2019, 26, 695–699. [Google Scholar] [CrossRef]
- Weber, R.; Blott, S. An Approximation Based Data Structure for Similarity Search; Technical Report; Eidgenössische Technische Hochschule Zürich: Zurich, Switzerland, 1997. [Google Scholar]
- Srinivasan, V.; Carey, M.J. Performance of B-tree concurrency control algorithms. In Proceedings of the 1991 ACM SIGMOD International Conference on management of Data, Denver, CO, USA, 29–31 May 1991; pp. 416–425. [Google Scholar]
- Srinivasan, V.; Carey, M.J. Performance of B+ tree concurrency control algorithms. VLDB J. 1993, 2, 361–406. [Google Scholar] [CrossRef] [Green Version]
- Lehman, T.J.; Carey, M.J. A Study of Index Structures for Main Memory Database Management Systems; Technical Report; University of Wisconsin-Madison Department of Computer Sciences: Madison, WI, USA, 1985. [Google Scholar]
- Bayer, R. The universal B-tree for multidimensional indexing: General concepts. In Proceedings of the International Conference on Worldwide Computing and Its Applications, Tsukuba, Japan, 10–11 March 1997; pp. 198–209. [Google Scholar]
- Fenk, R. The BUB-tree. In Proceedings of the VLDB’02, 28th International Conference on Very Large Data Bases, Hong Kong, China, 20–23 August 2002. [Google Scholar]
- Guttman, A. R-Trees: A Dynamic Index Structure for Spatial Searching; ACM: New York, NY, USA, 1984. [Google Scholar]
- Berchtold, S.; Keim, D.A.; Kriegel, H.P. The X-tree: An Index Structure for High-Dimensional Data. In Proceedings of the 22th International Conference on Very Large Data Bases; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1996; pp. 28–39. [Google Scholar]
- Katayama, N.; Satoh, S. The SR-tree: An index structure for high-dimensional nearest neighbor queries. ACM Sigmod Rec. 1997, 26, 369–380. [Google Scholar] [CrossRef]
- Abbasifard, M.R.; Ghahremani, B.; Naderi, H. A survey on nearest neighbor search methods. Int. J. Comput. Appl. 2014, 95. [Google Scholar]
- Watve, A.; Pramanik, S.; Shahid, S.; Meiners, C.R.; Liu, A.X. Topological transformation approaches to database query processing. IEEE Trans. Knowl. Data Eng. 2014, 27, 1438–1451. [Google Scholar] [CrossRef]
- Katayama, N.; Satoh, S.I. The SR-tree: An index structure for highdimensional nearest neighbor queries. In Proceedings of the 1997 ACM SIGMOD International Conference on Management of Data, Tucson, AZ, USA, 13–15 May 1997. [Google Scholar]
- Manolopoulos, Y.; Nanopoulos, A.; Papadopoulos, A.N.; Theodoridis, Y. R-Trees: Theory and Applications; Springer Science & Business Media: Berlin, Germany, 2010. [Google Scholar]
- Sellis, T.; Roussopoulos, N.; Faloutsos, C. The R+-Tree: A Dynamic Index for Multi-Dimensional Objects; Technical Report; Springer: Berlin, Germany, 1987. [Google Scholar]
- Beckmann, N.; Kriegel, H.P.; Schneider, R.; Seeger, B. The R*-tree: An efficient and robust access method for points and rectangles. ACM Sigmod Rec. 1990, 19, 322–331. [Google Scholar] [CrossRef]
- Kamel, I.; Faloutsos, C. Hilbert R-tree: An improved R-Tree Using Fractals; Technical Report; Springer: Berlin, Germany, 1993. [Google Scholar]
- White, D.A.; Jain, R. Similarity indexing with the SS-tree. In Proceedings of the Twelfth International Conference on Data Engineering, New Orleans, LA, USA, 26 February–1 March 1996; pp. 516–523. [Google Scholar]
- Böhm, C.; Berchtold, S.; Keim, D.A. Searching in high-dimensional spaces: Index structures for improving the performance of multimedia databases. ACM Comput. Surv. 2001, 33, 322–373. [Google Scholar] [CrossRef]
- Yang, Y.; Bai, P.; Ge, N.; Gao, Z.; Qiu, X. LAZY R-tree: The R-tree with lazy splitting algorithm. J. Inf. Sci. 2019, 46, 243–257. [Google Scholar] [CrossRef]
- Wang, Z.; Luo, T.; Xu, G.; Wang, X. A new indexing technique for supporting by-attribute membership query of multidimensional data. In Proceedings of the International Conference on Web-Age Information Management, Beidaihe, China, 14–16 June 2013; pp. 266–277. [Google Scholar]
- Wang, Y.; Yun, X.; Wang, X.; Wang, S.; Wu, Y. LBFM: Multi-Dimensional Membership Index for Block-Level Data Skipping. In Proceedings of the 2017 IEEE International Symposium on Parallel and Distributed Processing with Applications and 2017 IEEE International Conference on Ubiquitous Computing and Communications (ISPA/IUCC), Orlando, FL, USA, 29 May–2 June 2017; pp. 343–351. [Google Scholar]
- Wang, X.; Meng, W.; Zhang, M. A novel information retrieval method based on R-tree index for smart hospital information system. Int. J. Adv. Comput. Res. 2019, 9, 133–145. [Google Scholar] [CrossRef]
- Zhang, P.; Zhou, C.; Wang, P.; Gao, B.J.; Zhu, X.; Guo, L. E-tree: An efficient indexing structure for ensemble models on data streams. IEEE Trans. Knowl. Data Eng. 2014, 27, 461–474. [Google Scholar] [CrossRef]
- Tabassum, N.; Ahmed, T. A theoretical study on classifier ensemble methods and its applications. In Proceedings of the 2016 3rd International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 16–18 March 2016; pp. 374–378. [Google Scholar]
- Nalavade, J.E.; Murugan, T.S. HRNeuro-fuzzy: Adapting neuro-fuzzy classifier for recurring concept drift of evolving data streams using rough set theory and holoentropy. J. King Saud Univ. Comput. Inf. Sci. 2018, 30, 498–509. [Google Scholar] [CrossRef] [Green Version]
- Balasubramanian, B.; Durai, K.; Sathyanarayanan, J.; Muthukumarasamy, S. Tree Based Fast Similarity Query Search Indexing on Outsourced Cloud Data Streams. Int. Arab J. Inf. Technol. 2019, 16, 871–878. [Google Scholar]
- Jin, P.; Song, Q. A novel index structure r* q-tree based on lazy splitting and clustering. In Proceedings of the 2011 IEEE International Conference on Computer Science and Automation Engineering, Shanghai, China, 10–12 June 2011; pp. 405–407. [Google Scholar]
- Günnemann, S.; Kremer, H.; Lenhard, D.; Seidl, T. Subspace clustering for indexing high dimensional data: A main memory index based on local reductions and individual multi-representations. In Proceedings of the 14th International Conference on Extending Database Technology, Edinburgh, UK, 29 March–1 April 2011; pp. 237–248. [Google Scholar]
- Wang, Y.; Lin, Y.; Yang, J. KD-tree based clustering algorithm for fast face recognition on large-scale data. In Proceedings of the Seventh International Conference on Digital Image Processing (ICDIP 2015), Los Angeles, CA, USA, 9–10 April 2015; p. 96311I. [Google Scholar]
- Zhang, S.; Liu, X.; Zhang, M.; Wo, T. PaIndex: An online index system for vehicle trajectory data exploiting parallelism. In Proceedings of the 2017 4th International Conference on Systems and Informatics (ICSAI), Hangzhou, China, 11–13 November 2017; pp. 696–703. [Google Scholar]
- Wang, Y.; Zhao, C.; Wang, Z.; Du, J.; Liu, C.; Yan, H.; Wen, J.; Hou, H.; Zhou, K. MLB+-tree: A Multi-level B+-tree Index for Multidimensional Range Query on Seismic Data. In Proceedings of the 2018 5th International Conference on Systems and Informatics (ICSAI), Nanjing, China, 10–12 November 2018; pp. 1176–1181. [Google Scholar]
- Samson, G.; Joan, L.; Usman, M.M.; Showole, A.A.; Hadeel, H.J. Large Spatial Database Indexing with aX-tree. Int. J. Sci. Res. Comput. Sci. Eng. Inf. Technol. 2018, 3, 759–773. [Google Scholar]
- Doja, M.; Jain, S.; Alam, M.A. SAS: Implementation of scaled association rules on spatial multidimensional quantitative dataset. Int. J. Adv. Comput. Sci. Appl. 2012, 3, 130–135. [Google Scholar]
- Sprenger, S.; Schäfer, P.; Leser, U. BB-Tree: A Main-Memory Index Structure for Multidimensional Range Queries. In Proceedings of the 2019 IEEE 35th International Conference on Data Engineering (ICDE), Macao, China, 8–11 April 2019; pp. 1566–1569. [Google Scholar]
- Bentley, J.L. Multidimensional binary search trees used for associative searching. Commun. ACM 1975, 18, 509–517. [Google Scholar] [CrossRef]
- Finkel, R.A.; Bentley, J.L. Quad trees a data structure for retrieval on composite keys. Acta Inform. 1974, 4, 1–9. [Google Scholar] [CrossRef]
- Samet, H. The quadtree and related hierarchical data structures. ACM Comput. Surv. 1984, 16, 187–260. [Google Scholar] [CrossRef] [Green Version]
- Berchtold, S.; Böhm, C.; Kriegal, H.P. The pyramid-technique: Towards breaking the curse of dimensionality. ACM Sigmod Rec. 1998, 27, 142–153. [Google Scholar] [CrossRef]
- Weber, R.; Schek, H.J.; Blott, S. A quantitative analysis and performance study for similarity-search methods in high-dimensional spaces. In Proceedings of the 24rd International Conference on Very Large Data Bases (VLDB), New York, NY, USA, 24–27 August 1998; Volume 98, pp. 194–205. [Google Scholar]
- Ahn, H.K.; Mamoulis, N.; Wong, H.M. A Survey on Multidimensional Access Methods. Available online: https://www.researchgate.net/publication/2383731_A_Survey_on_Multidimensional_Access_Methods (accessed on 15 November 2021).
- Bentley, J.L. Multidimensional binary search trees in database applications. IEEE Trans. Softw. Eng. 1979, SE-5, 333–340. [Google Scholar] [CrossRef]
- Berg, M.d.; Cheong, O.; Kreveld, M.v.; Overmars, M. Computational Geometry: Algorithms and Applications, 3rd ed.; Springer TELOS: Santa Clara, CA, USA, 2008. [Google Scholar]
- Otair, D. Approximate k-nearest neighbour based spatial clustering using kd tree. arXiv 2013, arXiv:1303.1951. [Google Scholar]
- Friedman, J.H.; Bentley, J.L.; Finkel, R.A. An algorithm for finding best matches in logarithmic time. ACM Trans. Math. Softw. 1976, 3, 209–226. [Google Scholar] [CrossRef]
- Robinson, J.T. The KDB-tree: A search structure for large multidimensional dynamic indexes. In Proceedings of the 1981 ACM SIGMOD International Conference on Management of Data, Ann Arbor, MI, USA, 29 April–1 May 1981; pp. 10–18. [Google Scholar]
- Ooi, B.C. Spatial kd-tree: A data structure for geographic database. In Datenbanksysteme in Büro, Technik und Wissenschaft; Springer: Berlin, Germany, 1987; pp. 247–258. [Google Scholar]
- Visheratin, A.A.; Mukhina, K.D.; Visheratina, A.K.; Nasonov, D.; Boukhanovsky, A.V. Multiscale event detection using convolutional quadtrees and adaptive geogrids. In Proceedings of the 2nd ACM SIGSPATIAL Workshop on Analytics for Local Events and News, Seattle, WA, USA, 6 November 2018; p. 1. [Google Scholar]
- Böhm, C.; Berchtold, S.; Kriegel, H.P.; Michel, U. Multidimensional index structures in relational databases. J. Intell. Inf. Syst. 2000, 15, 51–70. [Google Scholar] [CrossRef]
- Yu, D.; Zhang, A. ClusterTree: Integration of Cluster Representation and Nearest Neighbor Search for Large Datasets with High Dimensionality. In Proceedings of the 2000 IEEE International Conference on Multimedia and Expo (ICME2000), New York, NY, USA, 30 July–2 August 2000; Volume 15, pp. 1316–1337. [Google Scholar]
- Pillai, K.G.; Sturlaugson, L.; Banda, J.M.; Angryk, R.A. Extending high-dimensional indexing techniques pyramid and iminmax (θ): Lessons learned. In British National Conference on Databases; Springer: Berlin, Germany, 2013; pp. 253–267. [Google Scholar]
- Zhang, R.; Ooi, B.C.; Tan, K.L. Making the pyramid technique robust to query types and workloads. In Proceedings of the 20th International Conference on Data Engineering, Boston, MA, USA, 2 April 2004; pp. 313–324. [Google Scholar]
- An, J.; Chen, Y.P.P.; Xu, Q.; Zhou, X. A new indexing method for high dimensional dataset. In International Conference on Database Systems for Advanced Applications; Springer: Berlin, Germany, 2005; pp. 385–397. [Google Scholar]
- Zäschke, T.; Zimmerli, C.; Norrie, M.C. The PH-tree: A space-efficient storage structure and multi-dimensional index. In Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data, Snowbird, UT, USA, 22–27 June 2014; pp. 397–408. [Google Scholar]
- Germann, U.; Joanis, E.; Larkin, S. Tightly packed tries: How to fit large models into memory, and make them load fast, too. In Proceedings of the NAACL HLT Workshop on Software Engineering, Testing, and Quality Assurance for Natural Language Processing, Boulder, CO, USA, 5 June 2009; pp. 31–39. [Google Scholar]
- Mahmood, A.R.; Punni, S.; Aref, W.G. Spatio-temporal access methods: A survey (2010–2017). GeoInformatica 2019, 23, 1–36. [Google Scholar] [CrossRef]
- Vancea, B.A. Cluster-Computing and Parallelization for the Multi-Dimensional PH-Index. Master’s Thesis, ETH Zurich, Zürich, Switzerland, 2015. [Google Scholar]
- Zäschke, T. The PH-Tree Revisited. Available online: https://www.researchgate.net/publication/283305212_The_PH-Tree_Revisited (accessed on 15 November 2021).
- Adrien, F.B. Data Preprocessing and Other Improvements for the Multi-Dimensional PH-Index. Master’s Thesis, ETH Zurich, Zürich, Switzerland, 2014. [Google Scholar]
- Lejsek, H. NV-Tree: A Scalable Disk-Based high-Dimensional Index. Ph.D. Dissertation, Reykjavík University, Reykjavík, Iceland, May 2015. [Google Scholar]
- Costa, F. ND-Tree: Multidimensional Indexing Structure; Novas Edições Acadêmicas: Chisinau, Moldova, 2017. [Google Scholar]
- Jo, B.; Jung, S. Quadrant-Based Minimum Bounding Rectangle-Tree Indexing Method for Similarity Queries over Big Spatial Data in HBase. Sensors 2018, 18, 3032. [Google Scholar] [CrossRef] [Green Version]
- Jang, H.J.; Kim, B.; Jung, S.Y. k-nearest reliable neighbor search in crowdsourced LBSs. Int. J. Commun. Syst. 2021, 34, e4097. [Google Scholar] [CrossRef]
- Dong, Y.; He, J.; Yao, S.; Zhou, W. The skip-octree: A dynamic cloud storage index framework for multidimensional big data systems. Int. J. Web Eng. Technol. 2015, 10, 393–407. [Google Scholar] [CrossRef]
- Malhotra, S.; Doja, M.N.; Alam, B.; Alam, M. Skipnet-Octree Based Indexing Technique for Cloud Database Management System. Int. J. Inf. Technol. Web Eng. 2018, 13, 1–13. [Google Scholar] [CrossRef]
- Harvey, N.J.; Dunagan, J.; Jones, M.; Saroiu, S.; Theimer, M.; Wolman, A. Skipnet: A scalable overlay network with practical locality properties. In Proceedings of the USITS’03: 4th USENIX Symposium on Internet Technologies and Systems, Seattle, WA, USA, 26–28 March 2003. [Google Scholar]
- Tang, X.; Han, B.; Chen, H. A hybrid index for multi-dimensional query in HBase. In Proceedings of the 2016 4th International Conference on Cloud Computing and Intelligence Systems (CCIS), Beijing, China, 17–19 August 2016; pp. 332–336. [Google Scholar]
- Feng, C.; Li, C.D.; Li, R. Indexing techniques of distributed ordered tables: A survey and analysis. J. Comput. Sci. Technol. 2018, 33, 169–189. [Google Scholar] [CrossRef]
- Sprenger, S.; Schäfer, P.; Leser, U. BB-Tree: A practical and efficient main-memory index structure for multidimensional workloads. In Proceedings of the 22nd International Conference on Extending Database Technology (EDBT), Lisbon, Portugal, 26–29 March 2019; pp. 169–180. [Google Scholar]
- Antoshenkov, G. Byte-aligned bitmap compression. In Proceedings of the DCC’95 Data Compression Conference, Snowbird, UA, USA, 28–30 March 1995; p. 476. [Google Scholar]
- Antoshenkov, G.; Ziauddin, M. Query processing and optimization in Oracle Rdb. VLDB J. 1996, 5, 229–237. [Google Scholar] [CrossRef]
- O’Neil, P.; Quass, D. Improved query performance with variant indexes. ACM Sigmod Rec. 1997, 26, 38–49. [Google Scholar] [CrossRef]
- MacNicol, R.; French, B. Sybase IQ multiplex-designed for analytics. In Proceedings of the Thirtieth international conference on Very large data bases-Volume 30. VLDB Endowment, Toronto, ON, Canada, 2–4 April 2004; pp. 1227–1230. [Google Scholar]
- Chan, C.Y.; Ioannidis, Y.E. Bitmap index design and evaluation. ACM Sigmod Rec. 1998, 27, 355–366. [Google Scholar] [CrossRef]
- Wu, Y.; Chen, Z.; Wen, Y.; Zheng, W.; Cao, J. Combat: A new bitmap index coding algorithm for big data. Tsinghua Sci. Technol. 2016, 21, 136–145. [Google Scholar] [CrossRef]
- Wu, K.; Otoo, E.J.; Shoshani, A. Compressing bitmap indexes for faster search operations. In Proceedings of the 14th International Conference on Scientific and Statistical Database Management, Scotland, UK, 24–26 July 2002; pp. 99–108. [Google Scholar]
- Wu, K.; Otoo, E.J.; Shoshani, A. Optimizing bitmap indices with efficient compression. ACM Trans. Database Syst. 2006, 31, 1–38. [Google Scholar] [CrossRef]
- Deliège, F.; Pedersen, T.B. Position list word aligned hybrid: Optimizing space and performance for compressed bitmaps. In Proceedings of the 13th international conference on Extending Database Technology, Lausanne, Switzerland, 22–26 March 2010; pp. 228–239. [Google Scholar]
- Lemire, D.; Kaser, O.; Aouiche, K. Sorting improves word-aligned bitmap indexes. Data Knowl. Eng. 2010, 69, 3–28. [Google Scholar] [CrossRef] [Green Version]
- Colantonio, A.; Di Pietro, R. Concise: Compressed ‘n’composable integer set. Inf. Process. Lett. 2010, 110, 644–650. [Google Scholar] [CrossRef] [Green Version]
- Guzun, G.; Canahuate, G.; Chiu, D.; Sawin, J. A tunable compression framework for bitmap indices. In Proceedings of the 2014 IEEE 30th International Conference on Data Engineering, Chicago, IL, USA, 31 March–4 April 2014; pp. 484–495. [Google Scholar]
- Wen, Y.; Chen, Z.; Ma, G.; Cao, J.; Zheng, W.; Peng, G.; Li, S.; Huang, W.L. SECOMPAX: A bitmap index compression algorithm. In Proceedings of the 2014 23rd International Conference on Computer Communication and Networks (ICCCN), Shanghai, China, 4–7 August 2014; pp. 1–7. [Google Scholar]
- Kim, S.; Lee, J.; Satti, S.R.; Moon, B. SBH: Super byte-aligned hybrid bitmap compression. Inf. Syst. 2016, 62, 155–168. [Google Scholar] [CrossRef]
- Chambi, S.; Lemire, D.; Kaser, O.; Godin, R. Better bitmap performance with roaring bitmaps. Softw. Pract. Exp. 2016, 46, 709–719. [Google Scholar] [CrossRef] [Green Version]
- Chang, J.; Chen, Z.; Zheng, W.; Cao, J.; Wen, Y.; Peng, G.; Huang, W.L. SPLWAH: A bitmap index compression scheme for searching in archival internet traffic. In Proceedings of the 2015 IEEE International Conference on Communications (ICC), London, UK, 8–12 June 2015; pp. 7089–7094. [Google Scholar]
- Li, C.; Chen, Z.; Zheng, W.; Wu, Y.; Cao, J. BAH: A bitmap index compression algorithm for fast data retrieval. In Proceedings of the 2016 IEEE 41st Conference on Local Computer Networks (LCN), Dubai, United Arab Emirates, 7–10 November 2016; pp. 697–705. [Google Scholar]
- Nagarkar, P.; Candan, K.S.; Bhat, A. Compressed spatial hierarchical bitmap (cSHB) indexes for efficiently processing spatial range query workloads. Proc. Vldb Endow. 2015, 8, 1382–1393. [Google Scholar] [CrossRef]
- Zheng, W.; Liu, Y.; Chen, Z.; Cao, J. CODIS: A New Compression Scheme for Bitmap Indexes. In Proceedings of the Symposium on Architectures for Networking and Communications Systems, Beijing, China, 18–19 May 2017; IEEE Press: Piscataway, NJ, USA, 2017; pp. 103–104. [Google Scholar]
- Keawpibal, N.; Preechaveerakul, L.; Vanichayobon, S. HyBiX: A novel encoding bitmap index for space-and time-efficient query processing. Turk. J. Electr. Eng. Comput. Sci. 2019, 27, 1504–1522. [Google Scholar] [CrossRef]
- Fusco, F.; Stoecklin, M.P.; Vlachos, M. Net-fli: On-the-fly compression, archiving and indexing of streaming network traffic. Proc. VLDB Endow. 2010, 3, 1382–1393. [Google Scholar] [CrossRef]
- Athanassoulis, M.; Yan, Z.; Idreos, S. Upbit: Scalable in-memory updatable bitmap indexing. In Proceedings of the 2016 International Conference on Management of Data, San Francisco, CA, USA, 26 June–1 July 2016; pp. 1319–1332. [Google Scholar]
- Sriharsha, C.; Kumar, P.; Jindal, A. Upbit with Parallelized Merge. In Proceedings of the 2019 9th International Conference on Cloud Computing, Data Science & Engineering (Confluence), Noida, India, 10–11 January 2019; pp. 625–629. [Google Scholar]
- Yianilos, P.N. Data Structures and Algorithms for Nearest Neighbor Search in General Metric Spaces. Available online: http://algorithmics.lsi.upc.edu/docs/practicas/p311-yianilos.pdf (accessed on 15 November 2021).
- Bozkaya, T.; Ozsoyoglu, M. Distance-based indexing for high-dimensional metric spaces. ACM Sigmod Rec. 1997, 26, 357–368. [Google Scholar] [CrossRef]
- Pola, I.R.V.; Traina, C., Jr.; Traina, A.J.M. The MM-Tree: A Memory-Based Metric Tree Without Overlap Between Nodes. In Proceedings of the East European Conference on Advances in Databases and Information Systems (ADBIS), Varna, Bulgaria, 29 September–3 October 2007; Volume 4690, pp. 157–171. [Google Scholar]
- Uhlmann, J.K. Satisfying general proximity/similarity queries with metric trees. Inf. Process. Lett. 1991, 40, 175–179. [Google Scholar] [CrossRef]
- Paredes, R.U.; Navarro, G. EGNAT: A Fully Dynamic Metric Access Method for Secondary Memory. In Proceedings of the 2009 Second International Workshop on Similarity Search and Applications, Prague, Czech Republic, 28–30 August 2009. [Google Scholar] [CrossRef]
- Zhou, X.; Wang, G.; Yu, J.X.; Yu, G. M+-tree: A new dynamical multidimensional index for metric spaces. In Proceedings of the 14th Australasian Database Conference-Volume 17, Adelaide, Australia, 1 February 2003; Australian Computer Society, Inc.: Darlinghurst, Australia, 2003; pp. 161–168. [Google Scholar]
- Cheng, H.; Yang, W.; Tang, R.; Mao, J.; Luo, Q.; Li, C.; Wang, A. Distributed indexes design to accelerate similarity based images retrieval in airport video monitoring systems. In Proceedings of the 2015 12th International Conference on Fuzzy Systems and Knowledge Discovery (FSKD), Zhangjiajie, China, 15–17 August 2015; pp. 1908–1912. [Google Scholar]
- Carélo, C.C.M.; Pola, I.R.V.; Ciferri, R.R.; Traina, A.J.M.; Traina, C., Jr.; de Aguiar Ciferri, C.D. Slicing the metric space to provide quick indexing of complex data in the main memory. Inf. Syst 2011, 36, 79–98. [Google Scholar] [CrossRef]
- Kouahla, Z.; Martinez, J. A new intersection tree for content-based image retrieval. In Proceedings of the 2012 10th International Workshop on Content-Based Multimedia Indexing (CBMI), Annecy, France, 27–29 June 2012; pp. 1–6. [Google Scholar]
- Kouahla, Z.; Anjum, A.; Akram, S.; Saba, T.; Martinez, J. XM-tree: Data driven computational model by using metric extended nodes with non-overlapping in high-dimensional metric spaces. Comput. Math. Organ. Theory 2019, 25, 196–223. [Google Scholar] [CrossRef]
- Pola, I.R.V.; Traina, C., Jr.; Traina, A.J.M. The NOBH-tree: Improving in-memory metric access methods by using metric hyperplanes with non-overlapping nodes. Data Knowl. Eng. 2014, 94, 65–88. [Google Scholar] [CrossRef]
- Dolatshah, M.; Hadian, A.; Minaei-Bidgoli, B. Ball*-tree: Efficient spatial indexing for constrained nearest-neighbor search in metric spaces. arXiv 2015, arXiv:1511.00628. [Google Scholar]
- Omohundro, S.M. Five Balltree Construction Algorithms; International Computer Science Institute Berkeley: Berkeley, CA, USA, 1989. [Google Scholar]
- Liu, T.; Moore, A.W.; Gray, A. New algorithms for efficient high-dimensional nonparametric classification. J. Mach. Learn. Res. 2006, 7, 1135–1158. [Google Scholar]
- Benrazek, A.E.; Kouahla, Z.; Farou, B.; Ferrag, M.A.; Seridi, H.; Kurulay, M. An efficient indexing for Internet of Things massive data based on cloud-fog computing. Trans. Emerg. Telecommun. Technol. 2020. [Google Scholar] [CrossRef]
- Kemouguette, I.; Kouahla, Z.; Benrazek, A.E.; Farou, B.; Seridi, H. Cost-Effective Space Partitioning Approach for IoT Data Indexing and Retrieval. In Proceedings of the 2021 International Conference on Networking and Advanced Systems (ICNAS), Annaba, Algeria, 26–27 June 2021; pp. 1–6. [Google Scholar]
- Khettabi, K.; Kouahla, Z.; Farou, B.; Seridi, H. QCCF-tree: A New Efficient IoT Big Data Indexing Method at the Fog-Cloud Computing Level. In Proceedings of the 2021 IEEE International Smart Cities Conference (ISC2), Online, 7–10 September 2021; pp. 1–7. [Google Scholar]
- Kalantari, I.; McDonald, G. A data structure and an algorithm for the nearest point problem. IEEE Trans. Softw. Eng. 1983, SE-9, 631–634. [Google Scholar] [CrossRef]
- Faloutsos, C.; Lin, K.I. FastMap: A Fast Algorithm for Indexing, Data-Mining and Visualization of Traditional and Multimedia Datasets; ACM: New York, NY, USA, 1995. [Google Scholar]
- McNames, J. A nearest trajectory strategy for time series prediction. In Proceedings of the International Workshop on Advanced Black-Box Techniques for Nonlinear Modeling, Leuven, Belgium, 8–10 July 1998; pp. 112–128. [Google Scholar]
- Merkwirth, C.; Parlitz, U.; Lauterborn, W. Fast nearest-neighbor searching for nonlinear signal processing. Phys. Rev. E 2000, 62, 2089. [Google Scholar] [CrossRef]
- Kouahla, Z.; Anjum, A. A Parallel Implementation of GHB Tree. In IFIP International Conference on Computational Intelligence and Its Applications; Springer: Berlin, Germany, 2018; pp. 47–55. [Google Scholar]
- Wan, Y.; Liu, X. CD-Tree: A clustering-based dynamic indexing and retrieval approach. Intell. Data Anal. 2017, 21, 243–261. [Google Scholar] [CrossRef]
- Chen, L.; Gao, Y.; Li, X.; Jensen, C.S.; Chen, G. Efficient metric indexing for similarity search. In Proceedings of the 2015 IEEE 31st International Conference on Data Engineering, Seoul, Korea, 13–17 April 2015; pp. 591–602. [Google Scholar]
- Chen, L.; Gao, Y.; Li, X.; Jensen, C.S.; Chen, G. Efficient Metric Indexing for Similarity Search and Similarity Joins. IEEE Trans. Knowl. Data Eng. 2015, 29, 556–571. [Google Scholar] [CrossRef]
- Perdacher, M.; Plant, C.; Böhm, C. Cache-oblivious high-performance similarity join. In Proceedings of the 2019 International Conference on Management of Data, Amsterdam, The Netherlands, 30 June–5 July 2019; pp. 87–104. [Google Scholar]
- Ciaccia, P.; Patella, M.; Zezula, P. M-tree: An Efficient Access Method for Similarity Search in Metric Spaces. In Proceedings of the 23rd VLDB Conference, Athens, Greece, 25–29 August 1997; pp. 426–435. [Google Scholar]
- Zhou, X.; Wang, G.; Zhou, X.; Yu, G. BM+-tree: A hyperplane-based index method for high-dimensional metric spaces. In International Conference on Database Systems for Advanced Applications; Springer: Berlin, Germany, 2005; pp. 398–409. [Google Scholar]
- Traina, C.; Traina, A.; Seeger, B.; Faloutsos, C. Slim-trees: High performance metric trees minimizing overlap between nodes. In International Conference on Extending Database Technology; Springer: Berlin, Germany, 2000; pp. 51–65. [Google Scholar]
- Traina, C.; Traina, A.; Faloutsos, C.; Seeger, B. Fast indexing and visualization of metric data sets using slim-trees. IEEE Trans. Knowl. Data Eng. 2002, 14, 244–260. [Google Scholar] [CrossRef]
- Skopal, T.; Pokornỳ, J.; Krátkỳ, M.; Snášel, V. Revisiting M-tree building principles. In East European Conference on Advances in Databases and Information Systems; Springer: Berlin, Germany, 2003; pp. 148–162. [Google Scholar]
- Zezula, P.; Amato, G.; Dohnal, V.; Batko, M. Similarity Search: The Metric Space Approach; Springer Science & Business Media: Berlin, Germany, 2006. [Google Scholar]
- Jin, S.; Kim, O.; Feng, W. MX-tree: A Double Hierarchical Metric Index with Overlap Reduction. In International Conference on Computational Science and Its Applications; Springer: Berlin, Germany, 2013; pp. 574–589. [Google Scholar]
- Ciaccia, P.; Patella, M.; Rabitti, F.; Zezula, P. Indexing metric spaces with m-tree. In Proceedings of the Convegno Nazionale Sistemi Evolluti per Basi di Dati (SEBD), Verona, Italy, 25–27 June 1997; Volume 97, pp. 67–86. [Google Scholar]
- Rachkovskij, D. Distance-based index structures for fast similarity search. Cybern. Syst. Anal. 2017, 53, 636–658. [Google Scholar] [CrossRef]
- Bachmann, J.P. The SuperM-Tree: Indexing metric spaces with sized objects. arXiv 2019, arXiv:1901.11453. [Google Scholar]
- Skopal, T.; Pokornỳ, J.; Snasel, V. PM-Tree: Pivoting Metric Tree for Similarity Search in Multimedia Databases. Available online: https://www.researchgate.net/publication/221651625_PM-tree_Pivoting_Metric_Tree_for_Similarity_Search_in_Multimedia_Databases (accessed on 15 November 2021).
- Skopal, T. Pivoting M-tree: A Metric Access Method for Efficient Similarity Search. In Proceedings of the 2004 Annual International Workshop on DAtabases, TExts, Specifications and Objects (DATESO), Desna, Czech Republic, 14–16 April 2004; Volume 4, pp. 27–37. [Google Scholar]
- Micó, M.L.; Oncina, J.; Vidal, E. A new version of the nearest-neighbour approximating and eliminating search algorithm (AESA) with linear preprocessing time and memory requirements. Pattern Recognit. Lett. 1994, 15, 9–17. [Google Scholar] [CrossRef]
- Razente, H.; Barioni, M.C.N. Storing Data Once in M-tree and PM-tree. In International Conference on Similarity Search and Applications; Springer: Berlin, Germany, 2019; pp. 18–31. [Google Scholar]
- Navarro, G.; Reyes, N. New dynamic metric indices for secondary memory. Inf. Syst. 2016, 59, 48–78. [Google Scholar] [CrossRef]
- Oliveira, P.H.; Traina, C., Jr.; Kaster, D.S. CLAP, ACIR and SCOOP: Novel techniques for improving the performance of dynamic Metric Access Methods. Inf. Syst. 2017, 72, 117–135. [Google Scholar] [CrossRef]
- Hanyf, Y.; Silkan, H. A queries-based structure for similarity searching in static and dynamic metric spaces. J. King Saud Univ. Comput. Inf. Sci. 2018, 32. [Google Scholar] [CrossRef]
- Chen, G.; Yang, K.; Chen, L.; Gao, Y.; Zheng, B.; Chen, C. Metric similarity joins using MapReduce. IEEE Trans. Knowl. Data Eng. 2016, 29, 656–669. [Google Scholar] [CrossRef]
- Barhoush, M.M.; AlSobeh, A.M.; Al Rawashdeh, A. A Survey on Parallel Join Algorithms Using MapReduce on Hadoop. In Proceedings of the 2019 IEEE Jordan International Joint Conference on Electrical Engineering and Information Technology (JEEIT), Amman, Jordan, 9–11 April 2019; pp. 381–388. [Google Scholar]
- Wu, J.; Zhang, Y.; Wang, J.; Lin, C.; Fu, Y.; Xing, C. Improving Distributed Similarity Join in Metric Space with Error-bounded Sampling. arXiv 2019, arXiv:1905.05981. [Google Scholar]
- Brinis, S.; Traina, C.; Traina, A.J. Hollow-tree: A metric access method for data with missing values. J. Intell. Inf. Syst. 2019, 53, 481–508. [Google Scholar] [CrossRef]
- Yang, K.; Ding, X.; Zhang, Y.; Chen, L.; Zheng, B.; Gao, Y. Distributed Similarity Queries in Metric Spaces. Data Sci. Eng. 2019, 4, 93–108. [Google Scholar] [CrossRef] [Green Version]
- Pola, I.R.; Traina, A.J.; Traina, C.; Kaster, D.S. Improving metric access methods with bucket files. In International Conference on Similarity Search and Applications; Springer: Berlin, Germany, 2015; pp. 65–76. [Google Scholar]
- Berchtold, S.; Böhm, C.; Jagadish, H.V.; Kriegel, H.P.; Sander, J. Independent quantization: An index compression technique for high-dimensional data spaces. In Proceedings of the 16th International Conference on Data Engineering, San Diego, CA, USA, 28 February–3 March 2000; pp. 577–588. [Google Scholar]
- Bok, K.S.; Song, S.I.; Yoo, J.S. Efficient k-Nearest Neighbor Searches for Parallel Multidimensional Index Structures. Database Syst. Adv. Appl. 2006, 3882, 870–879. [Google Scholar]
- Beyer, K.; Goldstein, J.; Ramakrishnan, R.; Shaft, U. When Is “Nearest Neighbor” Meaningful? In Proceedings of the International Conference on Database Theory (ICDT), Jerusalem, Israel, 10–12 January 1999; Beeri, C., Buneman, P., Eds.; Springer: Berlin, Germany, 1999; pp. 217–235. [Google Scholar]
- Fu, A.W.; Chan, P.M.-s.; Cheung, Y.-l.; Moon, Y.S. Dynamic vp-tree indexing for n-nearest neighbor search given pair-wise distances. VLDB J. 2002, 9, 154–173. [Google Scholar] [CrossRef]
- Agius, H.W.; Angelides, M.C. Spatial Color Indexing Using Rotation, Translation, and Scale Invariant Anglograms. Multimed. Tools Appl. 2001, 15, 5–37. [Google Scholar] [CrossRef]
- Almeida, J.; Valle, E.; Torres, R.D.S.; Leite, N.J. DAHC-tree: An Effective Index for Approximate Search in High-Dimensional Metric Spaces. J. Inf. Data Manag. 2010, 1, 375–390. [Google Scholar]
- Chen, L.; Gao, Y.; Li, X.; Jensen, C.S.; Chen, G. Efficient Metric Indexing for Similarity Search and Similarity Joins. In Proceedings of the IEEE Transactions on Knowledge and Data Engineering, Sydney, Australia, 4–6 June 2017; pp. 556–571. [Google Scholar]
- Gimenes, G.; Cordeiro, R.L.; Rodrigues, J.F., Jr. ORFEL: Efficient detection of defamation or illegitimate promotion in online recommendation. Inf. Sci. 2017, 379, 274–287. [Google Scholar] [CrossRef] [Green Version]
- Chen, Q.; Gao, H.; Cheng, S.; Li, J.; Cai, Z. Distributed non-structure based data aggregation for duty-cycle wireless sensor networks. In Proceedings of the IEEE INFOCOM 2017-IEEE Conference on Computer Communications, Atlanta, GE, USA, 1–4 May 2017; pp. 1–9. [Google Scholar]
- Zhuo, G.; Jia, Q.; Guo, L.; Li, M.; Li, P. Privacy-preserving verifiable data aggregation and analysis for cloud-assisted mobile crowdsourcing. In Proceedings of the IEEE INFOCOM 2016-The 35th Annual IEEE International Conference on Computer Communications, San Francisco, CA, USA, 10–14 April 2016; pp. 1–9. [Google Scholar]
- Jin, H.; Su, L.; Xiao, H.; Nahrstedt, K. Incentive mechanism for privacy-aware data aggregation in mobile crowd sensing systems. IEEE/ACM Trans. Netw. 2018, 26, 2019–2032. [Google Scholar] [CrossRef]
- Jin, H.; He, B.; Su, L.; Nahrstedt, K.; Wang, X. Data-driven pricing for sensing effort elicitation in mobile crowd sensing systems. IEEE/ACM Trans. Netw. 2019, 27, 2208–2221. [Google Scholar] [CrossRef]
- Shah, S.A.; Seker, D.Z.; Hameed, S.; Draheim, D. The rising role of big data analytics and IoT in disaster management: Recent advances, taxonomy and prospects. IEEE Access 2019, 7, 54595–54614. [Google Scholar] [CrossRef]
- Benrazek, A.E.; Farou, B.; Seridi, H.; Kouahla, Z.; Kurulay, M. Ascending hierarchical classification for camera clustering based on FoV overlaps for WMSN. IET Wirel. Sens. Syst. 2019, 9, 382–388. [Google Scholar] [CrossRef]
- Yuea, J.; Zhang, W.; Xiao, W.; Tang, D.; Tang, J. Energy efficient and balanced cluster-based data aggregation algorithm for wireless sensor networks. Procedia Eng. 2012, 29, 2009–2015. [Google Scholar] [CrossRef] [Green Version]
- Ferrag, M.A.; Derdour, M.; Mukherjee, M.; Derhab, A.; Maglaras, L.; Janicke, H. Blockchain Technologies for the Internet of Things: Research Issues and Challenges. IEEE Internet Things J. 2019, 6, 2188–2204. [Google Scholar] [CrossRef] [Green Version]
- Fathy, Y.; Barnaghi, P.; Tafazolli, R. Large-scale indexing, discovery, and ranking for the internet of things (IoT). ACM Comput. Surv. 2018, 51, 29. [Google Scholar] [CrossRef]
- Bursell, M. Trust in Computer Systems and the Cloud; John Wiley & Sons Inc.: Hoboken, NJ, USA, 2021; p. 352. [Google Scholar]
- Wu, L.; Ling, H.; Li, P.; Chen, J.; Fang, Y.; Zhou, F. Deep supervised hashing based on stable distribution. IEEE Access 2019, 7, 36489–36499. [Google Scholar] [CrossRef]
- Zhang, J.; Peng, Y. SSDH: Semi-supervised deep hashing for large scale image retrieval. IEEE Trans. Circuits Syst. Video Technol. 2017, 29, 212–225. [Google Scholar] [CrossRef] [Green Version]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Survey | Year | Architecture | Data Type | Dimension | Complexity | Application | Data Structure | Objectives |
|---|---|---|---|---|---|---|---|---|
| S. Pattar et al. [26] | 2018 | Yes | Yes | Partial | Partial | No | Partial |
|
| Mohammadi et al. [27] | 2018 | Yes | Yes | No | No | Yes | No |
|
| Saha et al. [28] | 2018 | No | No | No | No | Yes | No |
|
| Shabnam et al. [29] | 2018 | Yes | Yes | No | No | Yes | No |
|
| R. Ettiyan et al. [30] | 2020 | Yes | No | No | No | Yes | Yes |
|
| Eceiza et al. [31] | 2021 | Yes | Partial | Partiel | No | No | Partial |
|
| Wei et al. [32] | 2021 | Yes | No | No | No | Yes | No |
|
| Baofeng et al. [33] | 2021 | Yes | No | No | No | Yes | No |
|
| A.Shah et al. [34] | 2021 | Yes | No | No | No | Yes | No |
|
| S.Amin et al. [35] | 2021 | Yes | No | No | No | Yes | No |
|
| Chegini et al. [36] | 2021 | Yes | No | No | No | Yes | No |
|
| Our survey | / | Yes | Yes | Yes | Yes | Yes | Yes |
|
| Proposition | Refs | Advantages | Disadvantages and Challenges | |
|---|---|---|---|---|
| LHS | [67] | • Returns with high probabilities the same bit for nearby data points in the original space by storing similar data in the same bucket | • High storage cost • High search time • Not sufficient to processes high dimensional data. | Unsuitable to process large data |
| MultiProbe LSH | [69,70] | • Reduce the number of hash table, therefore, reduce space and time compared to LSH method | • Insufficient number of neighborhood candidates to respond to KNN’s requests | |
| Kernelized LSH | [75] | • Search for approximate similarity in sub-linear time • No data distribution or data entry assumptions are required | • High memory consumption • The search for the nearest neighbor is very difficult for high dimensional data | |
| BayesLSH | [71] | • High quality of search results | • Less effective performance | |
| Super-bit LSH | [73] | • Significant error reduction • More effective for approximate nearest neighbor recovery | • Requires long hash codes and more hash tables • High cost of space and time | |
| Asymmetric LSH | [76] | • Simple and easy • Efficient for maximum inner product research | • Does not support exact search |
| Proposition | Refs | Advantages | Disadvantages | |
|---|---|---|---|---|
| Spectral Hashing | [78] | • Does not require any labeled data • Solve a difficult non-linear optimization problem with a global optimum | • The assumption of a uniform distribution of data is usually not applicable in most cases of real-world data • Cannot directly applied in the kernel space • Does not work very well for high-dimensional data | • Less efficient than a (semi-) supervised hashing technique |
| Spherical Hashing | [82,83] | • Ensuring high accuracy and a highly scalable search for the nearest neighbor | • Not sufficient for high-dimensional data • Limited performance. • Requires an expensive learning process to learn the hash functions | • Unsuitable to process large data |
| Robust Discrete Spectral Hashing | [89] | • Robust hash functions • Very compact hash code compared to LSH | • Not appropriate for a large and dynamic database | |
| Graph Hashing | [79,80] | • Suitable for large-scale applications • high search precision | • Inefficient in the search of nearest neighbors • High learning costs | |
| Online Dynamic Multi-view Hashing | [87] | • More efficient hashing performance | • Limited performance | |
| Distributed Indexing based on Sparse-Hashing | [90] | • Distribution of requests in a balanced way | • High cost time | |
| Proposition | Refs | Advantages | Disadvantages | |
|---|---|---|---|---|
| Minimal Loss Hashing | [99] | • Efficient and adapts well to long code lengths • Higher search precision | • Training speed very slow Difficult to optimize | • Difficulty of finding the labeling of all data in the database |
| Linear Discriminant Analysis Hash | [97] | • Effective compact hashing • Less memory consumption and calculation cost | • Slower because of the extraction of SIFT descriptors | • Much slower in terms of time and effort compared to unsupervised techniques |
| Kernel Based Supervised Hashing | [96] | • Efficient hash functions • Higher retrieval accuracy | • Not sufficient for high-dimensional descriptors | |
| Fast Supervised Hashing | [91] | • Suboptimal | Not use all training points due to the complexity | • Unsatisfactory performance |
| • Fast ANN search | Unsatisfactory performance in real-world applications | |||
| Fast Supervised Discrete Hashing | [100] | • Highly efficient • Very fast and high precision • Low storage cost | • Require a significant degree of effort in large-scale applications | • Insufficient for high-dimensional data |
| Supervised Discrete Hashing | [98] | • Effective binary code learning | • Expensive training time • Insufficient precision rate | |
| Column sampling based discrete supervised hashing | [101] | • Capable to use all training data points | • Inefficient binary codes | |
| Proposition | Refs | Advantages | Disadvantages | |
|---|---|---|---|---|
| Semi-supervised Hashing | [102,103] | • Empirical Error Minimization • Variance and independence of binary codes maximized | • Not suitable for high dimensional data | • Much slower in terms of time and effort compared to unsupervised techniques |
| Label-regularized Max-margin Partition | [104] | • High-quality hash functions | ||
| Semi-supervised Discriminant Hashing | [105] | • Good separation between data labeled in different classes | ||
| Bootstrap-NSPLH | [106] | • Balanced partitioning of data points • Higher performance | • Expensive training time • Require storage space and a large amount of computation | • Impractical for high-dimensional data |
| Semi-supervised multi-view discrete hashing | [109] | • Minimizes the loss jointly on multi-view features when using relaxation on learning hashing codes • Increases the discrimination ability of the learned hash codes | • Not suitable for high dimensional data | |
| Proposition | Refs | Advantages | Disadvantages | |
|---|---|---|---|---|
| Convolutional Neural Networks for Text Hashing | [114] | • Better performance than traditional hashing methods | • Unsuitable for all real-world domain databases | • Performance decreases as the dimensionality of the data increases |
| • Not sufficient to processes high dimensional data | ||||
| Hash coding with Deep Neural Net | [115] | • Better performance | • Demand pairwise similarity labels | |
| • Good search precision rate | • Need a more complex configuration | |||
| Bit-Scalable Deep Hashing | [116] | • Better performance than traditional hashing methods | • Required labeled data and considerable human efforts | |
| Asymmetric Deep Supervised Hashing | [117] | • Reduce the complexity of training time | • Learns the hash function only for query points | |
| • High search precision rate | • Higher complexity |
| Proposition | Refs | Dataset Type | Data Dimension | Indexing Nature | Complexity (BigO) | |
|---|---|---|---|---|---|---|
| Insertion/Deletion | Search | |||||
| B-tree | [125] | Temporal | One-dimensional | Dynamic | ||
| B+-tree | [126] | ) | ||||
| B*-tree | [127] | |||||
| T-tree | [127] | |||||
| UB-tree | [128] | Spatio temporal data | Multi-dimensional | ) | ||
| PaIndex | [153] | |||||
| MLB+-tree | [154] | Seismic data | ||||
| SR-tree | [132] | Image feature vectors | ||||
| E-tree | [146] | Spatial | < | Not estimated | ||
| ER+-tree | [149] | OpinRank Review | Not estimated | Not estimated | ||
| SUSHI | [151] | Color histogram and Synthetic data | Not estimated | |||
| R-tree | [130] | Geographical and Multi-media | ||||
| R+-tree | [137] | |||||
| R*-tree | [138] | + Re-insertion complexity | ||||
| Hilbert R-tree | [139] | Spatial | ||||
| SS-tree | [140] | Multi-media data | + Re-insertion complexity | |||
| BFM & R-tree | [143] | Not mentioned | Not estimated | Not estimated | ||
| DCC & R-tree | [145] | Medical data | ||||
| X-tree | [131] | Spatial data and Synthetic data | Not estimated | Not estimated | ||
| aX-tree | [155] | Spatial data | Not estimated | Not estimated | ||
| X+-tree | [156] | Spatial data | Not estimated | Not estimated | ||
| R*Q-tree | [150] | Special data | Not estimated | |||
| BB-tree | [157] | Synthetic data, Sensor data and Genomic | Not estimated | ) for exact-match queries | ||
| Proposition | Refs | Advantages | Disadvantages | |
|---|---|---|---|---|
| B-tree | [125] | • Simple structure | • Consumes a lot of computing resources | • Support only one-dimensional data |
| • Balanced in insertion and deletion | • Requires large storage space | |||
| • Efficient for k-nn and range search | • Costly maintenance | |||
| B+-tree | [126] | • Storage at leaf nodes | • High complexity | • Requires a considerable amount of computing resources |
| • Storage cost reduced compared to B-tree | • Wasted storage space | |||
| • Non-optimal node splitting | ||||
| B*-tree | [127] | • Reduction of node splitting | • High complexity | • Limited performance |
| • Less storage space compared to B-tree and B+-tree | ||||
| T-tree | [127] | • Balanced structure • More efficient memory management, search and update performance than B+-tree | • Requires a considerable amount of space • Inefficient search • The problem of balance is still unresolved | • Degradation on large scale |
| UB-tree | [128] | • Efficient processing of multidimensional requests | • Unsatisfactory for queries covering dead spaces | • Degradation on large scale |
| PaIndex | [153] | • Effective and efficient update and query performance • Structure supports parallel insertions and queries | • Not suitable for large data | |
| MLB+-tree | [154] | • Higher performance on multi-dimensional range queries | • High complexity • Sub-optimal partitioning • Irregular and unpredictable structure | |
| SR-tree | [132] | • Simple construction | • Complexity of shapes | |
| • Refinement: (intersection S ⌃R) • Reduced overlap rate | • Costly insertion and search algorithm | |||
| E-tree | [146] | • Reduce time from linear to sublinear complexity | • High storage space | |
| ER+-tree | [149] | • Reduce computation time | • Costly maintenance | |
| • High quality of search results | • K-nn research is not evaluated | |||
| • More efficient structure | • Degradation on large scale | |||
| R-tree | [130] | • Creation of filter cells REM • MBR allows you to refine your search • Balanced hierarchical breakdown • Constraint of minimum coverage | • Overlap of REMs • Not effective for point queries • Require high space and time as well as computational complexities | • Degradation of the performance on large scale |
| R+-tree | [137] | • Reduced overlap rate | • Redundancy of objects in nodes • Clipping technique not optimized • More complex construction and maintenance | |
| R*-tree | [138] | • More efficient variant than the R-tree • Reduced overlap rate • Efficient use of space | • Complexity of the re-insertion algorithm and the split of nodes | |
| Hilbert R-tree | [139] | • Good performance results for both searches and updates | Performance deteriorates for larger data | |
| SS-tree | [140] | • Outperforming the R-tree • Calculate the nearest and approximately nearest neighbors efficiently | • High overlap in high-dimension space | |
| BFM & R-tree | [143] | • Solve the problem of decreasing index performance for high-dimensional data | • High space consumption | |
| DCC & R-tree | [145] | • Enhance R-tree’s search efficiency • Reduce multipath searches | • Require high space and computational complexities | |
| X-tree | [131] | • Overlap control (overlap-free) • No degeneration of the index • Reduced overlap rate | • Complexity of the max limit • Consumes a lot of memory space • Performance is limited with the data dimension | • Cannot function properly in higher-dimensional data |
| aX-tree | [155] | • Reduce the amount of empty space • Reduced overlap rate • Fast loading and better partitioning of space | • Supports only static data • Require more calculation | |
| X+-tree | [156] | • Reduces the complexity of linear scanning of super nodes compared to X-tree | • Suffers from data redundancy and replication problems | |
| R*Q-tree | [150] | • Improve space utilization • Reduce node overlap and the number of splits | • High complexity • Not suitable for the situation of frequent updates | |
| BB-tree | [157] | • Quasi-balanced structure | • Not support the k-nn search | |
| • Better performance compared to R*-tree, Kd-tree, PH-tree, and VA-file | ||||
| Proposition | Refs | Dataset Type | Data Dimension | Indexing Nature | Complexity (Estimation) | |
|---|---|---|---|---|---|---|
| Insertion and Deletion | Search | |||||
| Kd-tree | [158] | Geo-graphical | Multidimensio-nal | Dynamic | ||
| Adaptive Kd-tree | [167] | Files | ||||
| KdB-tree | [168] | Floating point numbers | ||||
| SKd-tree | [169] | Spatial | Not estimated | Not estimated | ||
| Quad-tree | [159,160] | Spatial | ||||
| PH-tree | [176] | Synthetic | ||||
| ND-tree | [183] | Synthetic | Not estimated | Not estimated | ||
| QbMBR-tree | [184,185] | Synthetic, spatial | Not estimated | Not estimated | ||
| VA-file | [162] | Synthetic data and images | Not estimated | Not estimated | ||
| Octree | [186] | Spatial | ||||
| Pyramid | [161] | Synthetic data | Not estimated | Not estimated | ||
| Proposition | Refs | Advantages | Disadvantages | |
|---|---|---|---|---|
| Kd-tree | [158] | • Balanced hierarchical split | • Costly and arbitrary | • Degradation on large scale |
| • Simple implementation | • Low use of allocated space | |||
| • Performance limited by data dimension | ||||
| Adaptive Kd-tree | [167] | • Lower-cost k-nn research • Storage at leaf nodes | • Not appropriate for frequent insertion and deletion | |
| KdB-tree | [168] | • Height-balanced structure • Efficient search for point queries | • Supports only point data • Cannot guarantee minimum storage utilization • Insufficient research performance | |
| SKd-tree | [169] | • Suitable for non-zero size spatial objects • Ensures good storage | • Slow performance even in high dimensional spaces | |
| Quad-tree | [159,160] | • Efficient storage and retrieval | • Not balanced structure • Does not consider the spatial distribution of the data during the partitioning phase • Not suitable for higher-dimensional data | |
| PH-tree | [176] | • Faster and more efficient in terms of space efficiency, query and update performance | • Supports point and range query only • High memory consumption | |
| ND-tree | [183] | • Support high-dimensional data | • Loss of information on the original data • Search performance limited by data dimensions | |
| QbMBR-tree | [184,185] | • Reduce the false positives in spatial query • Reduces the storage space • Reduce query execution times | • Overlap of MBRs | |
| VA-file | [162] | • Simple implementation • Sequential search improved | • Large dimension heavy coding • Degradation on large scale | |
| Octree | [186] | • Better spatial management and k-nn search | • Support only 3-dimensional data | |
| Pyramid | [161] | • Degradation on large scale • Linear increase of cells | • Poor request processing k-nn • Degradation on large scale | |
| Proposition | Refs | Dataset Type | Data Dimension | Indexing Nature | Complexity (Estimation) | |
|---|---|---|---|---|---|---|
| Insertion and Deletion | Search | |||||
| VP-tree | [215] | Images | Dynamic | Multidimensional | ||
| mVP-tree | [216] | Images | Static | |||
| MM-tree | [217] | Image and Geographic coordinates | Dynamic | |||
| Onion-tree | [222] | Image, Time-series and Geographic coordinates | ||||
| IM-tree | [223] | Image | ||||
| XM-tree | [224] | Geographic coordinates and Image | ||||
| Ball-tree | [227,228] | Not mentioned | ||||
| Ball*-tree | [226] | Synthetic and Point data | ||||
| NOBH-tree | [225] | Image and Synthetic | ||||
| BCCF-tree | [229] | Synthetic, Geographic coordinates and wearable action recognition database | ||||
| Proposition | Refs | Advantages | Disadvantages | |
|---|---|---|---|---|
| VP-tree | [215] | • Simple implementation | • Highest distance and time • Research costs increase in large dimensions | |
| mVP-tree | [216] | • Reduces research costs • Little affected on a large e scale | • Static structure • Support only range research | •Degradation on large scale |
| MM-tree | [217] | • Best space partitioning • Non-overlapping regions | • Degeneration of the index (fourth region) | |
| Onion-tree | [222] | • Better partitioning of space | • «Reinsertion» objects (semi-balancing) | |
| IM-tree | [223] | • Efficient compared to MM-tree and Slim-tree | • Index degeneration in massive data | |
| XM-tree | [224] | • Minimize the size of the search regions • Fast k-nn search | • Requires high memory space | |
| Ball-tree | [227] | • Efficient brute force search in large dimensions | • Unbalanced structure • Longer build times | • The problem of overlap not effectively addressed |
| Ball*-tree | [226] | • More balanced and efficient structure compared to Ball-tree | • Performance decreases as the dimensionality of the data increases | |
| NOBH-tree | [225] | • Non-overlapping division of the data space | • High cost of insertion and research | |
| BCCF-tree | [229] | • Non-overlapping division of the data space • Fast k-nn search • Balanced data partitioning | • Expensive construction | |
| Proposition | Refs | Dataset Type | Data Dimension | Indexing Nature | Complexity (Estimation) | |
|---|---|---|---|---|---|---|
| Insertion and Deletion | Search | |||||
| BS-tree | [232] | Point data | Multidimensional | Static | not estimated | |
| GH-tree | [218] | Not mentioned | ||||
| GNAT-tree | [55] | Image, text, Vectors | ||||
| EGNAT-tree | [219] | Words and coordinate space | Dynamic | |||
| GHB-tree | [236] | Geographic coordinates and Image | ||||
| CD-tree | [237] | Image | ||||
| SPB-tree | [238,239] | Words, Colors, DNA, Signature and Synthetic | not estimated | |||
| Proposition | Refs | Advantages | Disadvantages | |
|---|---|---|---|---|
| BS-tree | [232] | • Fast k-nn search and orthogonal queries | • Requiring linear space | • Degradation on large scale |
| GH-tree | [218] | • Simple partitioning Reduced overlap rate | • Complicated form to manipulate • Degeneration of the index • High cost search | |
| GNAT-tree | [55] | • Non-overlapping • Improve the search | • Static and complicated structure • High computational costs | • More difficult to maintain index balance |
| EGNAT-tree | [219] | • Non-overlapping• Requires less CPU time than the GNAT-tree | • Degradation on large scale • More difficult to maintain index balance | |
| GHB-tree | [236] | • Balanced structure | ||
| CD-tree | [237] | • Efficient re-construction time | • Ineffective in large dimensions • Ineffective search | • Degradation on large scale |
| SPB-tree | [238] | • Simple structure • Reduce the cost in terms of storage, construction and search • Effective similarity search | • Difficult to parallelize it | • More difficult to maintain index balance |
| Proposition | Refs | Dataset Type | Data Dimension | Indexing Nature | Complexity (Estimation) | |
|---|---|---|---|---|---|---|
| Insertion and Deletion | Search | |||||
| M-tree | [241] | Synthetic data | Multidimensional | Dynamic | O | O |
| Slim-tree | [243] | Spatial, Face vectors and Text | ||||
| Slim*-tree | [263] | Image and Spatial | ||||
| MX-tree | [247] | Image, Text | ||||
| SuperM-tree | [250] | Synthetic data | not estimated | not estimated | ||
| PM-tree | [251,252] | Synthetic data | ||||
| DSC | [255] | Vectors, Text and Colors | not estimated | not estimated | ||
| SFC & Kd-tree | [258] | Synthetic, Text, DNA and Color | ||||
| Hollow-tree | [261] | Synthetic | not estimated | not estimated | ||
| Proposition | Refs | Advantages | Disadvantages | |
|---|---|---|---|---|
| M-tree | [241] | • Balanced height structure • Reduction of distance calculations | • Problem of overlaps • High cost search • No adapted to highly grouped data | • Degradation on large scale |
| Slim-tree | [243] | • Efficient compared to M-tree • Reduced overlap rate | • The overall computational complexity | |
| Slim*-tree | [263] | • Reduces the cost of calculation during reconstructing • Avoids the unsatisfactory division | • Reinserting objects is largely costly | |
| MX-tree | [247] | • Reduces the cost of calculation during reconstructing • Avoids the unsatisfactory division | • High cost search | |
| SuperM-tree | [250] | • Capable of responding to approximate requests for subsequences or subsets | • Expensive construction • Evaluates only for research 1-nn | |
| PM-tree | [251] | • More efficient similarity search compared to M-tree | • Not support the k-nn search • Expensive construction compared to M-tree | |
| DSC | [255] | • Reduces memory consumption | • High amount of distance calculations | |
| SFC & Kd-tree | [258] | • High quality of the selected centroids • Effective partitioning • Better query performance | • Not support the k-nn search | |
| Hollow-tree | [261] | • Capable of managing missing data | • Lower accuracy in small data |
| Indexing Structure | Application |
|---|---|
| LSH | • Pattern matching |
| • Recommendation retrieval | |
| • Text processing | |
| • Natural language processing | |
| • Reducing the dimensionality of data | |
| • Image/Video retrieval | |
| • Content similarity deployment and discovery | |
| Kernelized LSH | • Content-based retrieval |
| • Speaker search | |
| • Image classification | |
| Robust Discrete Spectral Hashin | • Image semantic indexing |
| • Image retrieval | |
| Spectral Hashing | • Image retrieval |
| • Detection of region-duplication forgery in digital images | |
| • Fast approximate nearest neighbor | |
| • Classification | |
| Kernel Based Supervised Hashing | • Person re-identification |
| • Similarity search | |
| • Image retrieval | |
| Label-regularized Max-margin Partition | • Classification for large-scale datasets |
| Bit-Scalable Deep Hashin | • Similarity learning for image retrieval and person re-identification |
| Asymmetric Deep Supervised Hashing | • Image retrieval |
| M-tree | • Similarity search in multimedia Dataset |
| • Accelerator for database query | |
| • Recommendation System | |
| • Indexing the music data | |
| • Classification | |
| Slim-tree | • Video indexing and similarity search |
| SFC & Kd-tree | • Data cleaning and data mining |
| Hollow-tree | • Store and retrieve large volumes of complex data |
| AMDS | • Multimedia retrieval |
| • Computational biology | |
| • Location-based services | |
| VP-tree | • Pattern recognition and image processing |
| • Image indexing and retrieval | |
| • Storing neuronal morphology data | |
| • Similarity search on cloud computing | |
| • Malware detection | |
| • Clustering | |
| mVP-tree | • Images retrieval in airport video monitoring systems |
| MM-tree | • Image retrieval |
| XM-tree | • Web Information Retrieval |
| Ball-tree | • Face sketch recognition |
| • Classification in high dimensions | |
| • Clustering and matching for object class recognition | |
| BCCF-tree | • Image indexing and retrieval for person re-identification |
| • Indexing IoT sensor data | |
| GH-tree | • Image Search by Content |
| GNAT-tree | • Indexing and similarity search of face-images data |
| SPB-tree | • Multimedia retrieval |
| • Pattern recognition | |
| • Computational biology | |
| X-tree | • Image coding |
| • Classification | |
| Kd-tree | • Search and synchronization of sensor nodes |
| R-tree | • Classification |
| • Spatial indexing for the IoT data management | |
| • Images search and retriever | |
| • Geographical search | |
| Hilbert R-tree | • Visualization of 3D massive data |
| Open Research Challenges | Future Research Directions | |
|---|---|---|
| IoT Data Aggregation for 5G Data Indexing | • Reduced bandwidth | • Energy-balanced solution for cluster-based solution |
| • Increased energy consumption | • Development of future/5G networks | |
| • Network congestion | • Data networking solution based on emerging technologies (NFV, SDN, etc.) | |
| • Network saturation | ||
| Blockchain Data Indexing | • Centralized data storage | • Towards user-friendly Blockchain Data Indexing |
| • Degradation of memory usage and block validation in IoT networks | ||
| Security and Privacy for 5G Data Indexing | • No effective and confidential indexing of 5G data | • Design an indexation protocol for achieving privacy-preserving priority classification on 5G Data |
| • Enhance trust management for 5G networks via data indexing | ||
| • Secure the indexing approaches in 5G data indexing | ||
| Distributed Indexing for large-scale data | • The need for robustness, reliability, scalability, transferability and self-adaptation | • Distribute and balance system load across emerging IoT paradigms |
| • Reduce network bandwidth usage, overall cost and efficiency | • Towards multi-level indexing | |
| IoT Data Representation in the Edge computing | • The different representations of IoT data and their damage in the processing and analysis of indexing structures | • Standard or unified architecture to provide connectivity to IoT devices, especially in the case of large-scale indexing |
| Indexing Software Processes | • Secure data during transmission | • Store encrypted data |
| • Analytical queries on encrypted Spatio-temporal data |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kouahla, Z.; Benrazek, A.-E.; Ferrag, M.A.; Farou, B.; Seridi, H.; Kurulay, M.; Anjum, A.; Asheralieva, A. A Survey on Big IoT Data Indexing: Potential Solutions, Recent Advancements, and Open Issues. Future Internet 2022, 14, 19. https://doi.org/10.3390/fi14010019
Kouahla Z, Benrazek A-E, Ferrag MA, Farou B, Seridi H, Kurulay M, Anjum A, Asheralieva A. A Survey on Big IoT Data Indexing: Potential Solutions, Recent Advancements, and Open Issues. Future Internet. 2022; 14(1):19. https://doi.org/10.3390/fi14010019
Chicago/Turabian StyleKouahla, Zineddine, Ala-Eddine Benrazek, Mohamed Amine Ferrag, Brahim Farou, Hamid Seridi, Muhammet Kurulay, Adeel Anjum, and Alia Asheralieva. 2022. "A Survey on Big IoT Data Indexing: Potential Solutions, Recent Advancements, and Open Issues" Future Internet 14, no. 1: 19. https://doi.org/10.3390/fi14010019
APA StyleKouahla, Z., Benrazek, A.-E., Ferrag, M. A., Farou, B., Seridi, H., Kurulay, M., Anjum, A., & Asheralieva, A. (2022). A Survey on Big IoT Data Indexing: Potential Solutions, Recent Advancements, and Open Issues. Future Internet, 14(1), 19. https://doi.org/10.3390/fi14010019