
An In-Network Cooperative Storage Schema Based on Neighbor Offloading in a Programmable Data Plane


Abstract
:1. Introduction
- (1)
- To address high-speed data storage, we proposed an in-network storage service node structure to support cooperative storage in neighbor nodes, and designed an identifier (ID)-based cooperative storage protocol.
- (2)
- To support locally cooperative storage and the discovery of more in-network storage service nodes, we proposed a neighbor selection mechanism based on the Local Name Mapping and Resolution System, in which the node weights are computed by combining the link bandwidth and node storage capability, and determining whether to split traffic by comparing normalized weight values with thresholds.
- (3)
- To dynamically split the traffic among multiple targets, the cooperative storage strategy implemented in a programmable data plane is presented using the relative weights and ID suffix matching. Evaluation shows that our proposed schema is more efficient compared with end-to-end transmission and ECMP [10] in term of bandwidth usage and transfer time.
2. Background
2.1. Distributed Storage
2.2. Storage at the Edge
2.3. Current Scientific Data Management Systems
2.4. NDN Based Big Science
3. Proposed System Architecture
3.1. System Architecture
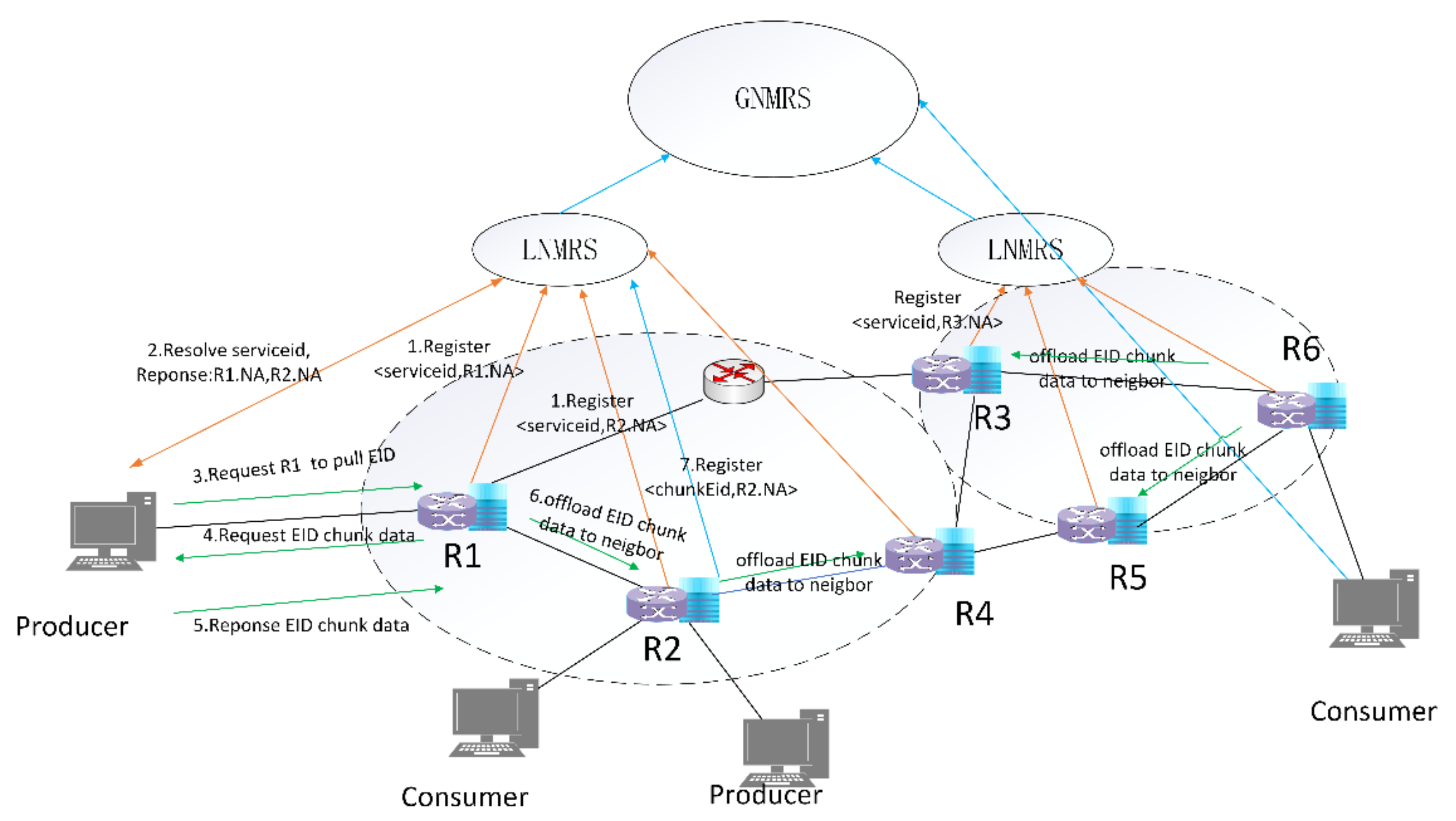
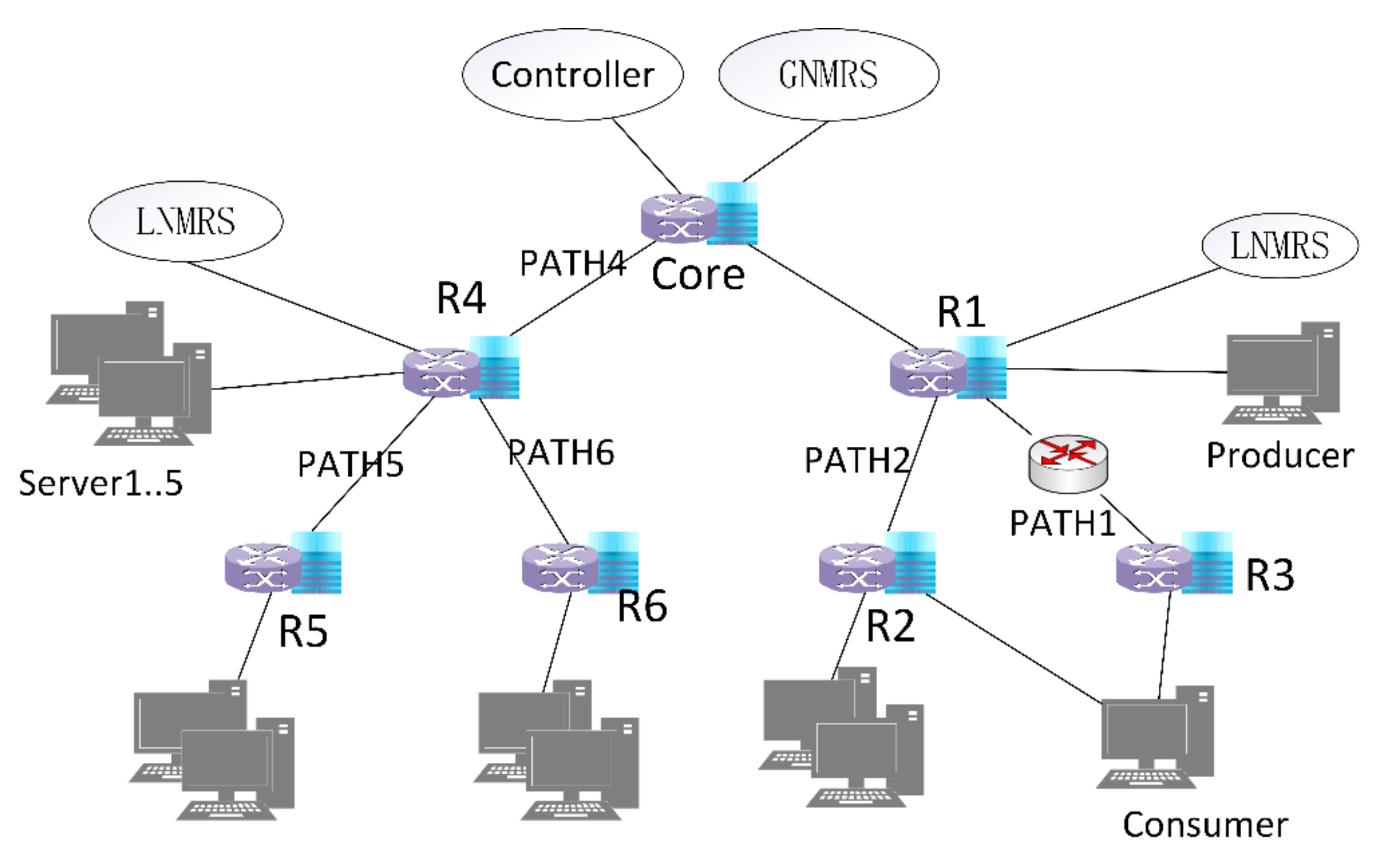
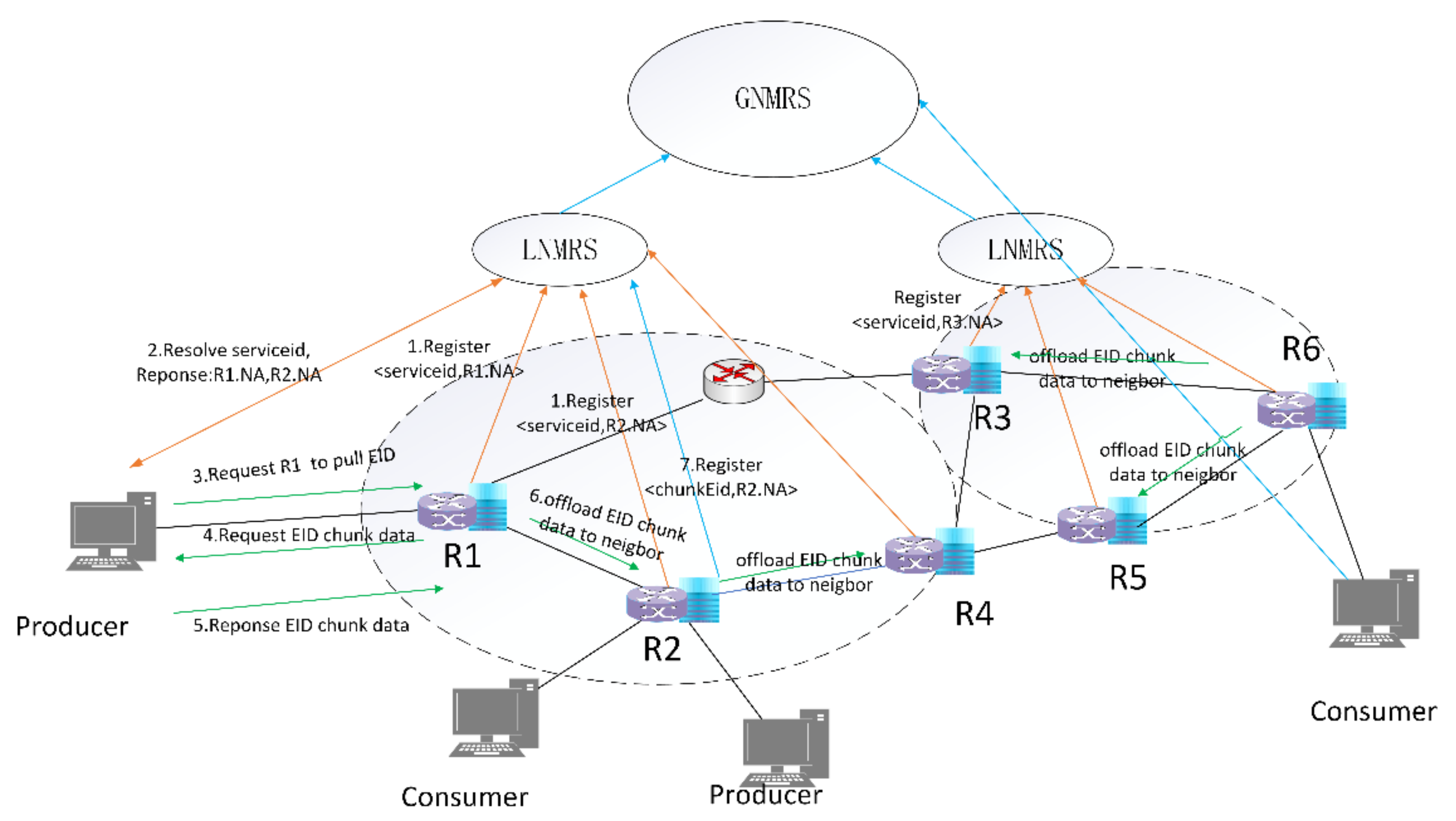
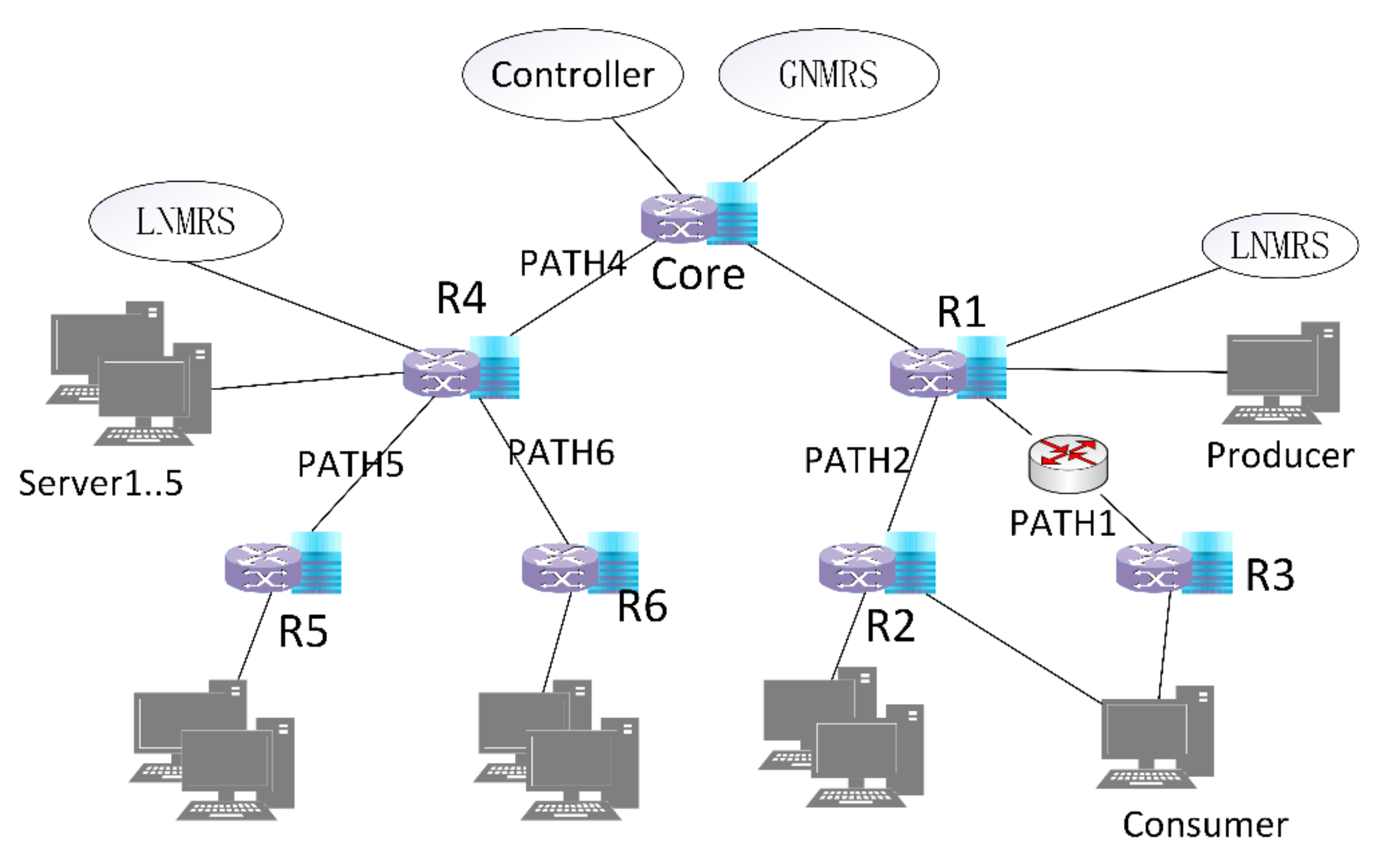
- An intermediate node with storage service capability, which has been deployed in the network, registers a mapping of a specific identifier indicating a storage service and its Network Address (NA) (selecting any one of the interface IP addresses as the node’s NA) with the LNMRS (step1). As shown in Figure 1, there are two local resolution areas marked with a dashed circle.
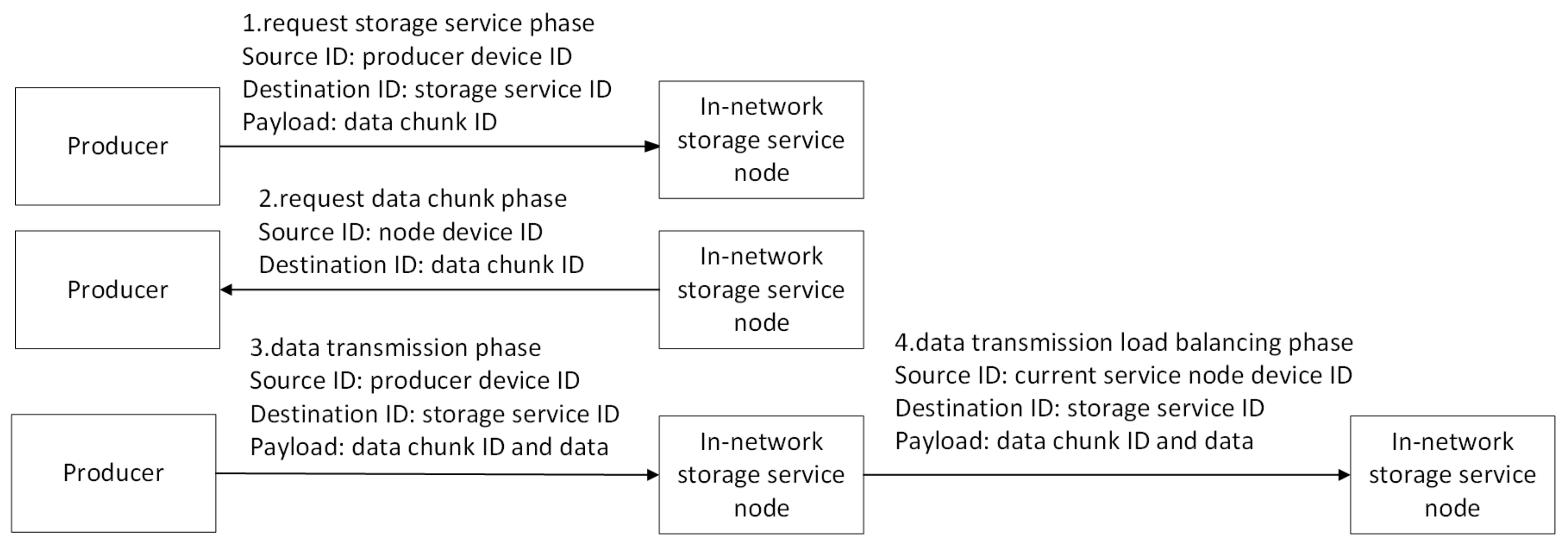
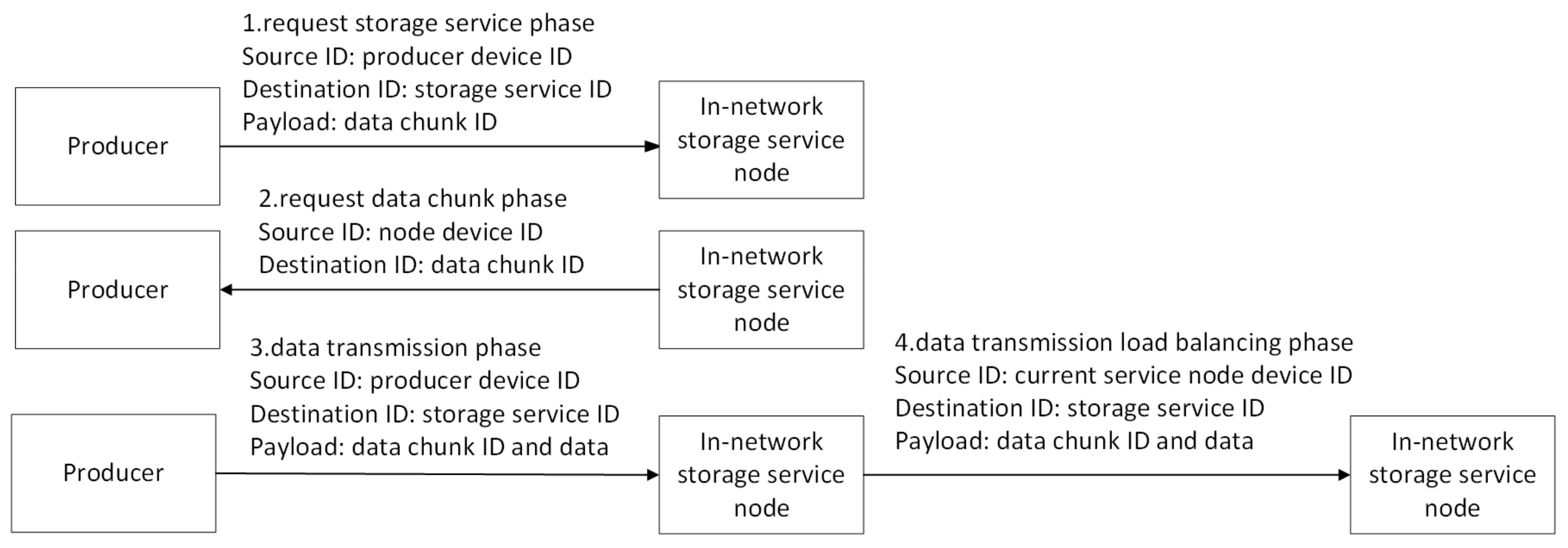
- Pull-based communications offer several advantages over push-based communications, such as built-in multicast delivery, receiver-oriented congestion control, and native support for client mobility [28]. To support proactive in-network storage, the producer initiates the sending of a “request for pull” message to a storage service node instance, which, in turn, triggers a pull request to be sent back to the producer by the instance. When the producer requests the in-network storage services, the producer first resolves the specific storage service identifier from the LNMRS to obtain the IP address list of storage service nodes (step2), which contains nearby nodes, such as R1 and R2. Then, the closest node (R1) is selected as the target according to latency, and the target (R1) is messaged to ask for the storage service (step3). The message includes the IDs of written data.
- After receiving the “request for pull” messages, the selected node parses the IDs from the messages and requests data chunks based on the IDs from the producer (step4).
- Then, the producer starts to send chunk data to the storage service node based on an ID-based protocol described in detail below (step5).
- Then, the extended cooperative storage schema begins to play a role. Based on the obtained information, the decision state of the current storage service node and the corresponding neighbor information are calculated. After the storage service node receives the data chunk, the storage service node first closes the context of the corresponding ID request, and decides to forward the data chunk to local storage or its neighbor storage node. If the storage service node decides to store in a neighbor node (R2), it selects the neighbor, modifies the destination address field in the packet, and then forwards the chunk data based on the destination address (step6). Otherwise, if the storage service node decides to store locally, it directly forwards the chunk data packets to the local storage module for chunk data storage.
- The selected neighbor node receives the chunk data and stores it locally. After chunk data is stored in the storage service node, the mapping of the ID of the data chunk and the NA of the storage service node is registered to LNMRS for further retrieval (step7).
- If there are no available neighbor nodes and the current node has no capability to deal with the data chunk packets, it will forward the packets to the least loaded neighbor and subtract 1 from the TTL field, which indicates the longest storage node path it can forward along. It is currently considered that the chunk data can only be offloaded once; thereafter, there is a need to wait for the data to be stored locally or forwarded to a unified flood discharge area in the cloud. The storage service nodes are assumed to have been deployed ahead of time, which is outside the scope of this paper.
- Similar processes can be executed in another local resolution area. It is assumed that traffic offloading is not possible between different resolution domains. Every storage service node can execute the offload process mentioned above in its own local resolution area, so that the entire network iteratively achieves load balancing.
- Then, the consumer queries the GNMRS or LNMRS for the data chunk ID, obtains the NA of R2, and obtains chunk data from R2.
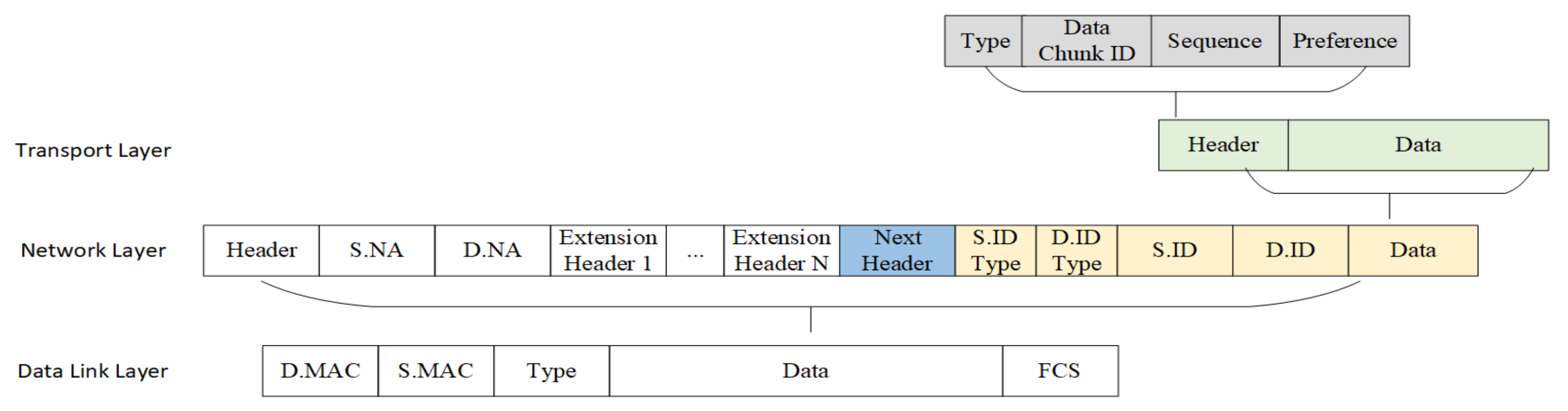
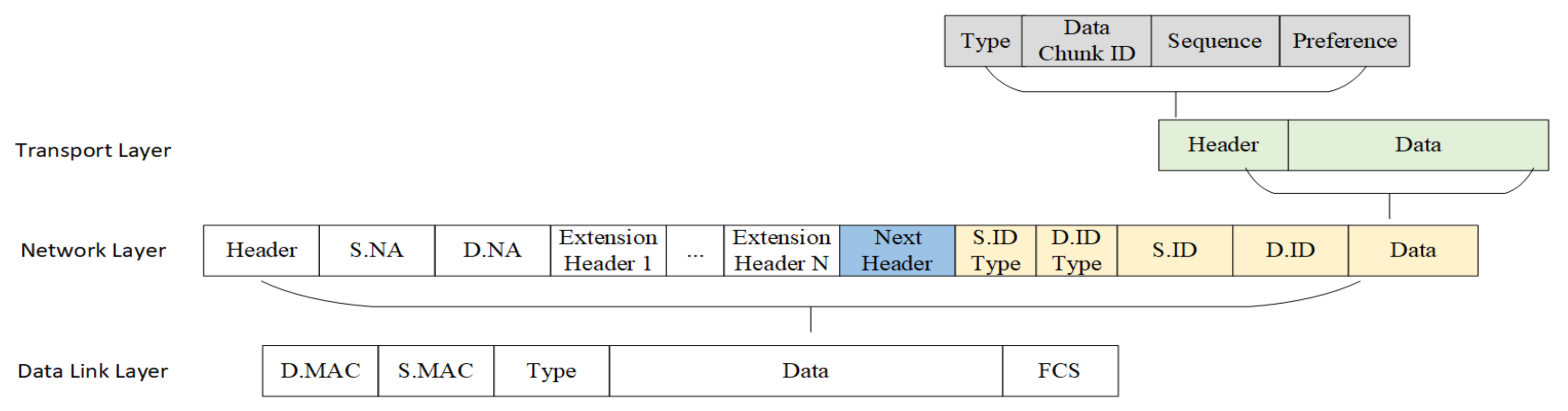
3.2. An ID-Based Cooperative Storage Protocol
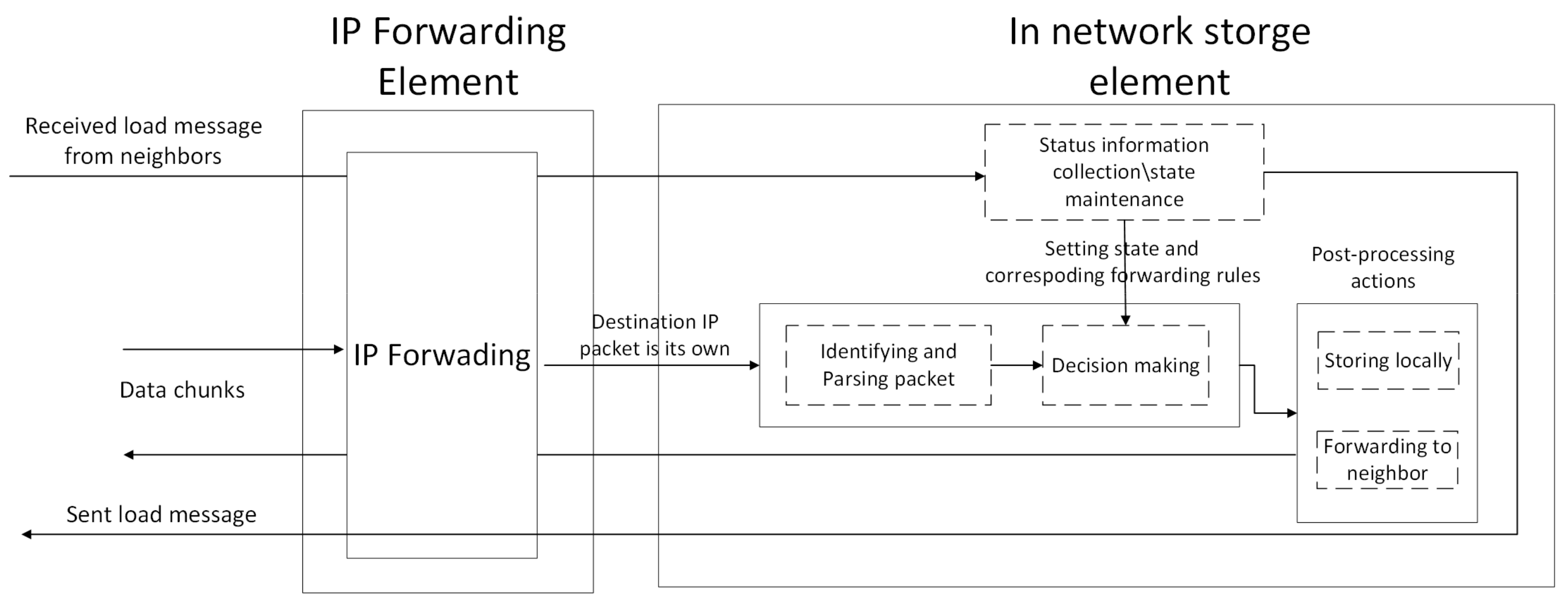
3.3. In-Network Storage Service Node Structure
- The “Identifying and Parsing packet” module needs to correctly identify our ID-based transport layer packet, parse packet fields, and obtain the storage service ID/data chunk ID, sequence, and preference;
- The “Decision making” module executes one of the “post-processing actions” according to the state sets. If the state is set to “forwarding to neighbor node”, the “Decision making” module executes the “Forwarding to neighbor” action; otherwise, the “Storing locally” action is invoked;
- The “Post-processing actions” module currently contains “Storing locally” and “Forwarding to neighbor”. The “Forwarding to neighbor” action will change the destination IP of the data chunk packet to a new destination according to the rules from the computation result of the “Status information collection/state maintenance” module and then forward it. The “Storing locally” action will ACK the received packet, and then request the next segment and reassemble the data chunk from segments for storage in the local file system;
- The core module is “Status information collection/state maintenance”. This module periodically collects neighbor status information and local status information, and parses packet information, then computes the state threshold and maps forwarding rules based on the ID. These results are set to shared memory that the forwarding pipeline can access according to the programmable interface. The time interval should be set at least as high as the maximum average RTT in the network [34].
4. In-Network Cooperative Storage Mechanism
4.1. Neighbor Selection Mechanism
| Algorithm 1 Neighbor selection algorithm. |
| Input: rtt , current rtt of each neighbor interface; , current bandwidth of each neighbor interface; , current writing throughput of each neighbor; |
| Output: state, target_list |
| 1: Initialize RTT0 = 0, α = 0.875, |
| 2: While k < K do |
| 3: calculate RTT(k) ← Equation (1) |
| 4: calculate neighbor_weight(k) ← Equation (2) |
| 5: EndWhile |
| 6: calculate |
| 7: calculate self_weight ← Equation (3) |
| 8: calculate normalized value ← Equation (4) |
| 9: if , then |
| 10: state ← “cooperative” |
| 11: sortedlist ← sort (neighbor_list|i) by weight desc |
| 12: sublist ← subsist (0, number_threshold-1) from sortedlist |
| 13: target_list ← sublist |
| 14: else |
| 15: state ← “local_storage” |
| 16: EndIf |
| 17: Return state, target_list |
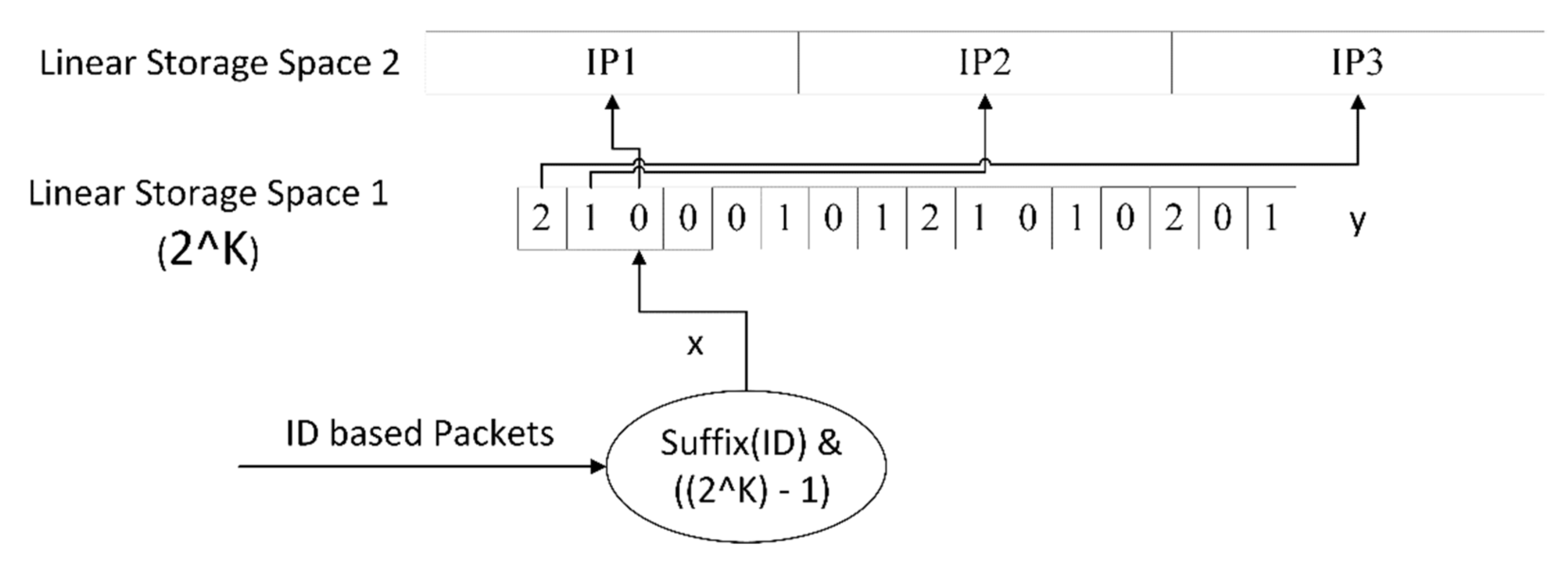
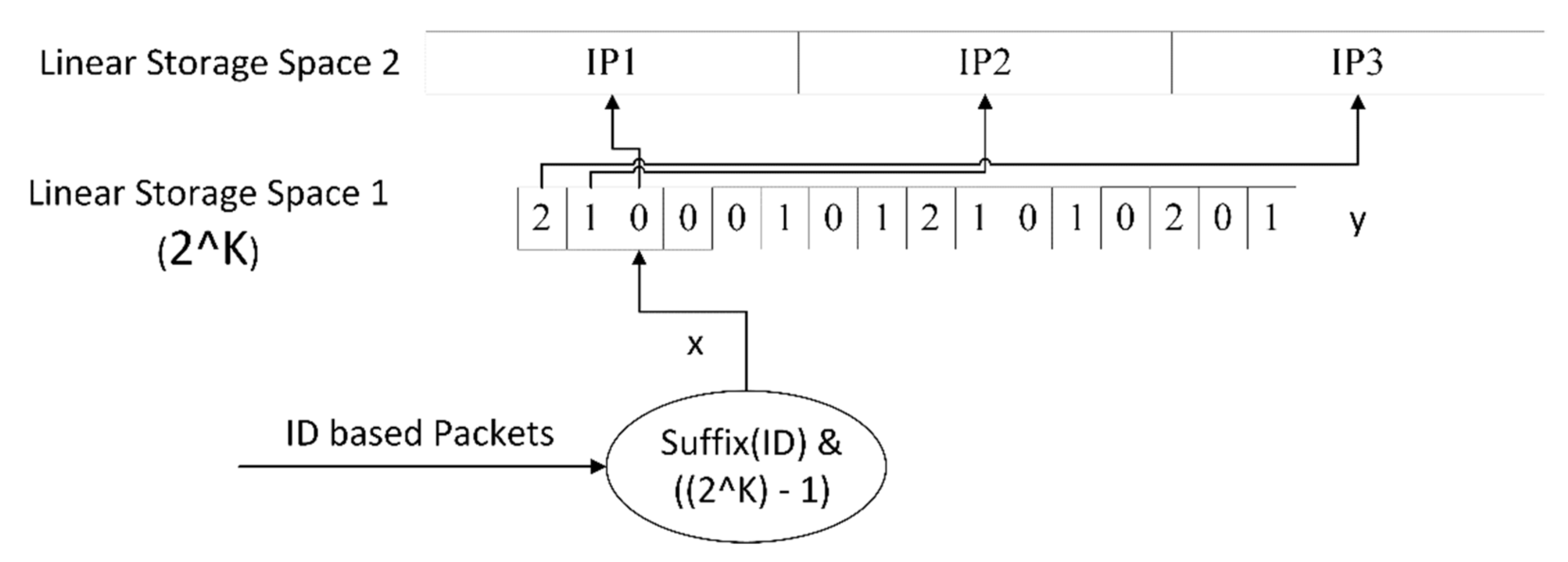
4.2. Cooperative Storage Strategy
| Algorithm 2 Cooperative storage algorithm. |
| Input: , node weight of selected targets; |
| Output: |
| 1: Initialize |
| 2: While n < N do |
| 3: calculate ← Equation (5) |
| 4: calculate ← Equation (6) |
| 5: EndWhile |
| 6: fill up linear storage space 1 |
| 7: fill up linear storage space 2 |
| 8: calculate index1=hash(ID) % N |
| 9: get index2 = linear_storage_space_1(index1) |
| 10: get destination = linear_storage_space2(index2) |
| 11: get Out_port from destination |
| 12: if packet.In_port == Out_port, then |
| 13: Local Storage |
| 14: else |
| 15: Forward to neighbor |
| 16: Return |
5. Evaluation
5.1. Network Environment Setup
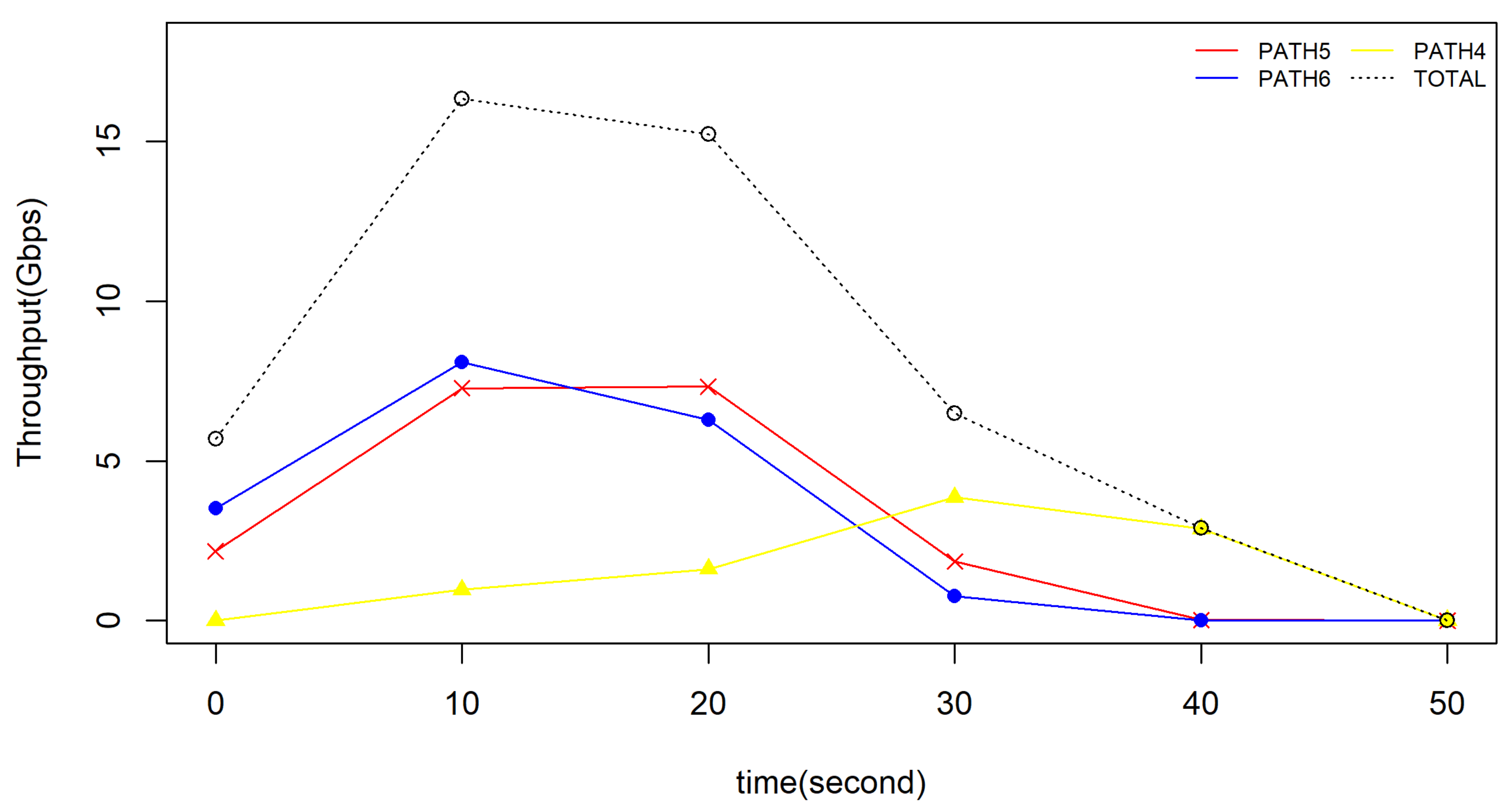
5.2. Performance Results
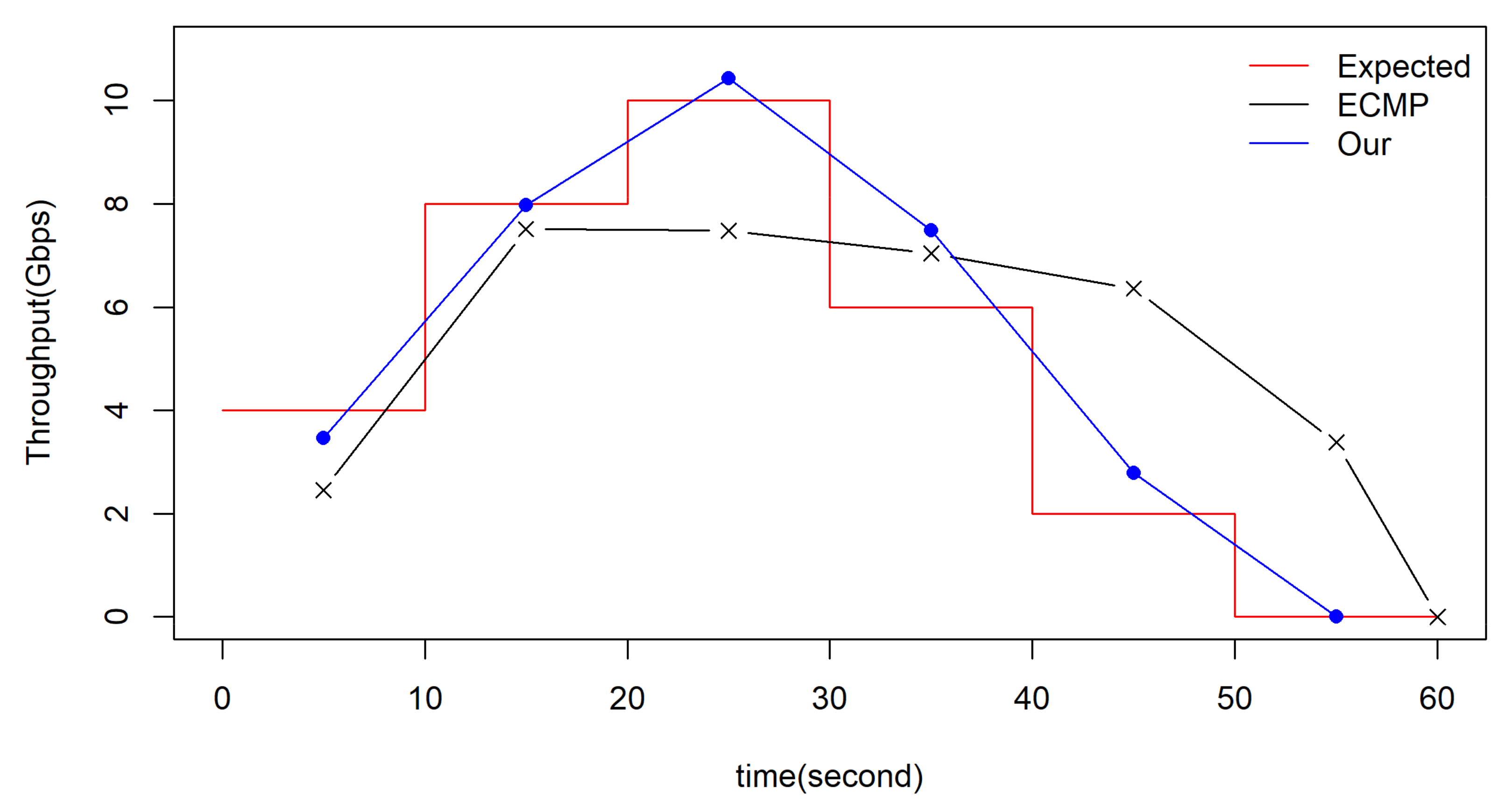
5.2.1. Evaluation of the Selection Mechanism
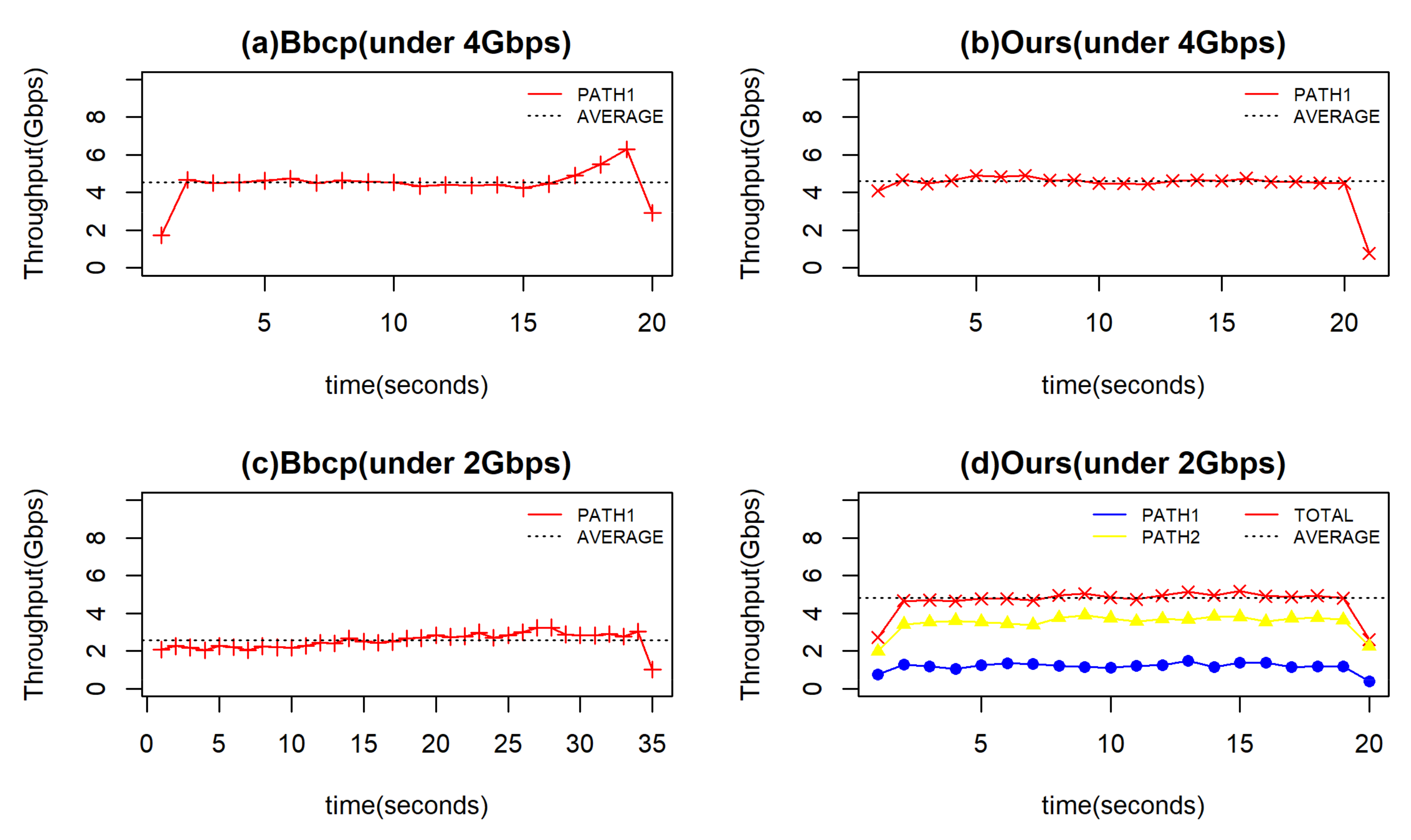
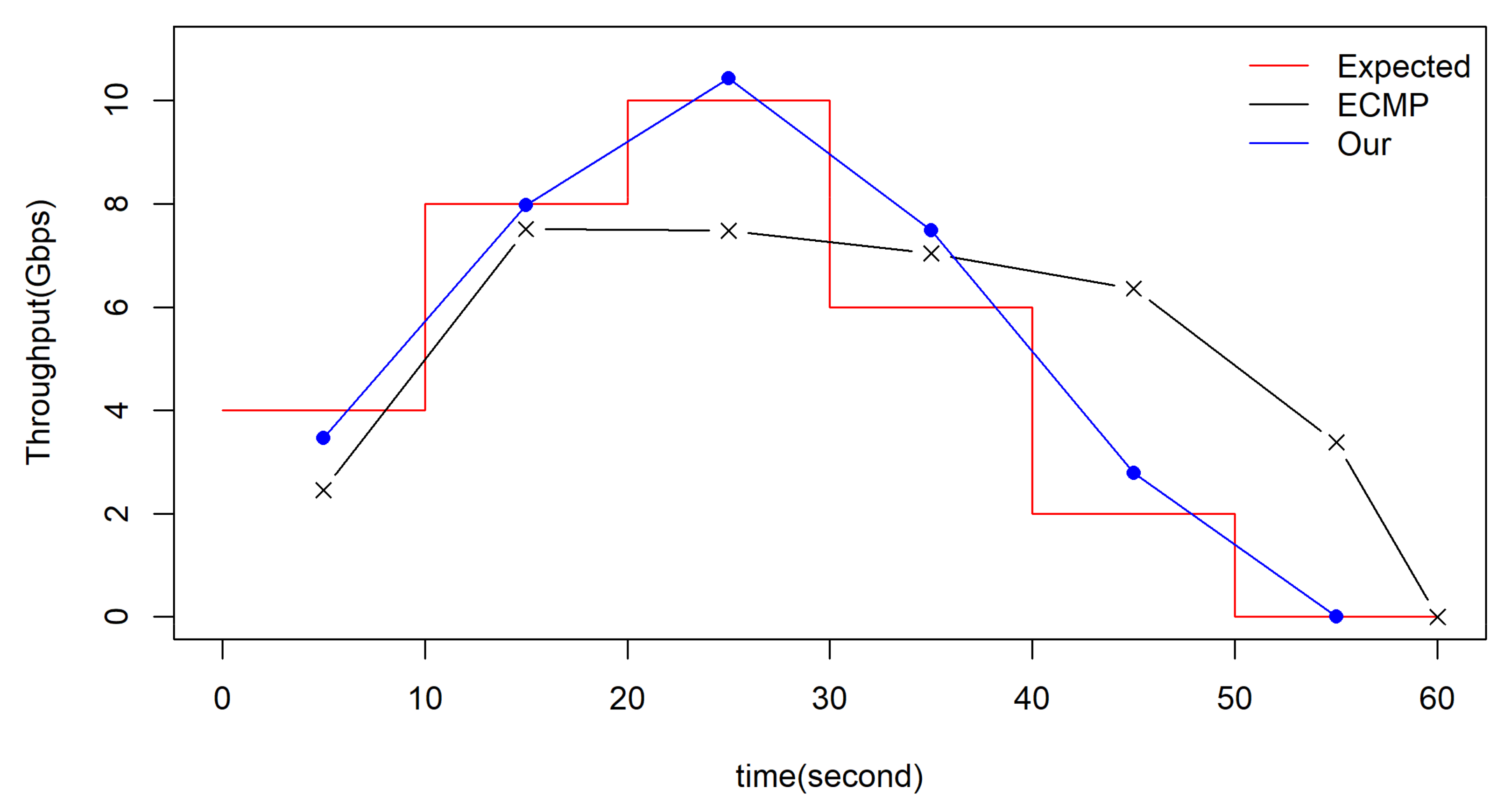
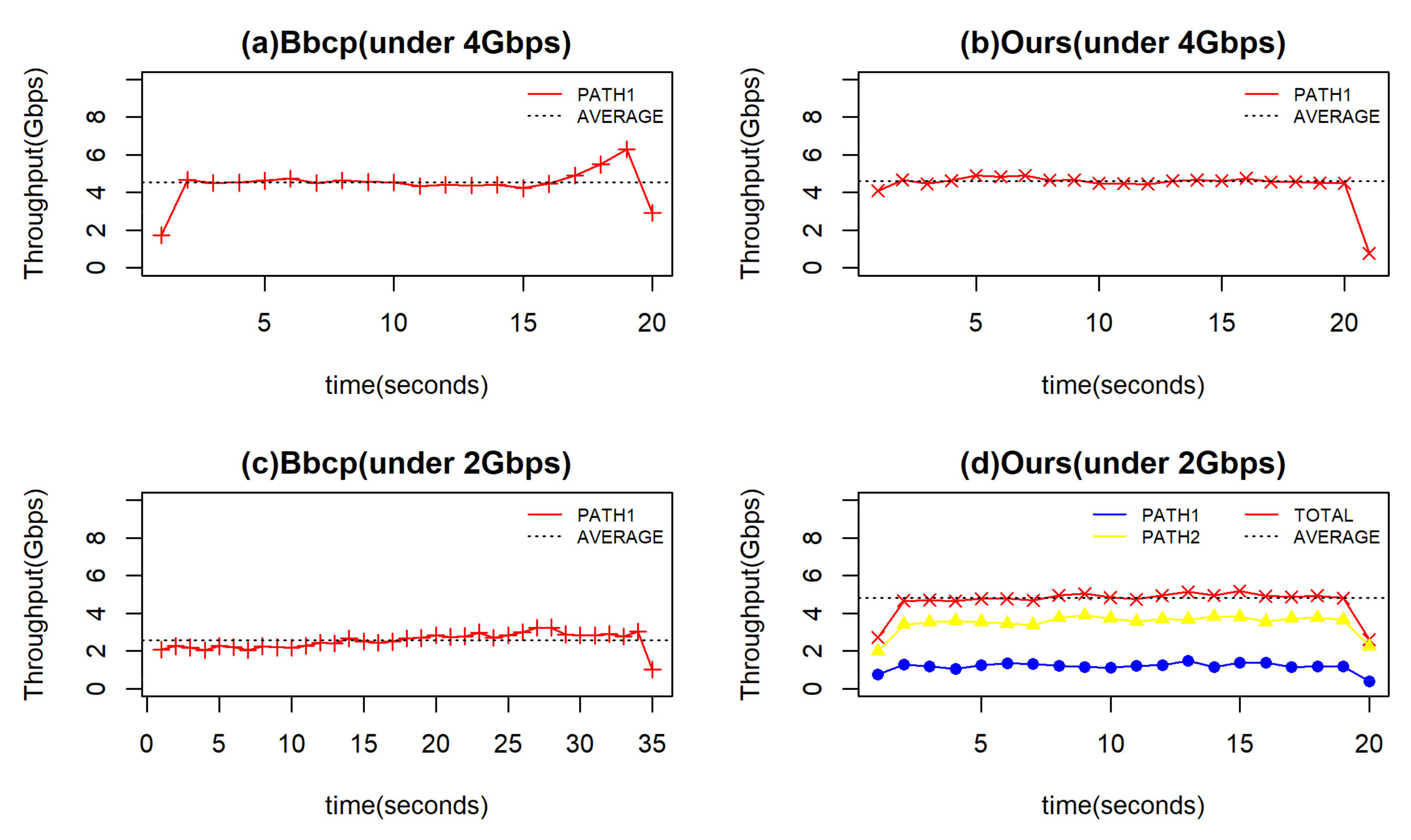
5.2.2. Comparison with End-to-End Transmission
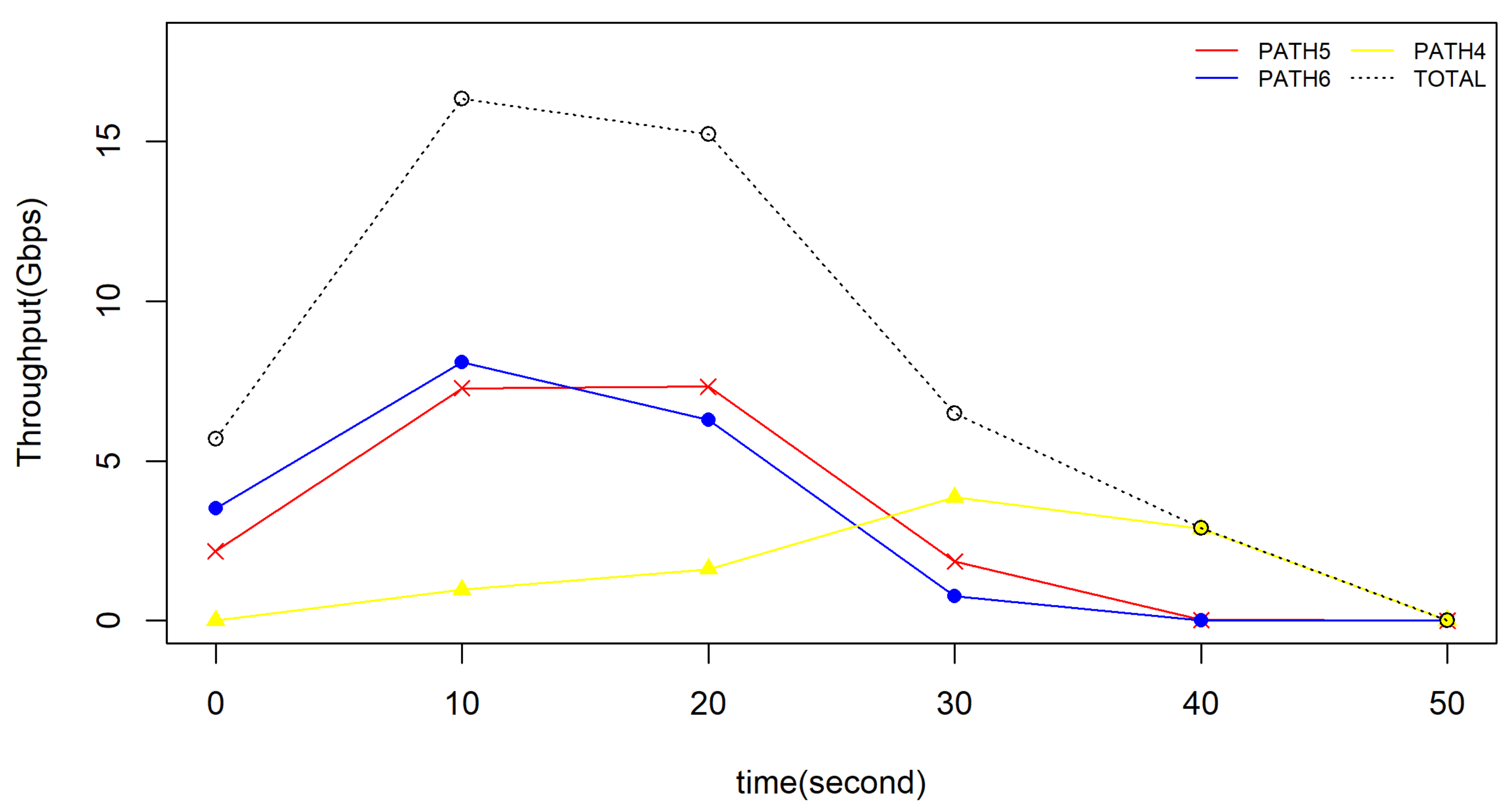
5.2.3. Influence of Cooperative Storage Schema
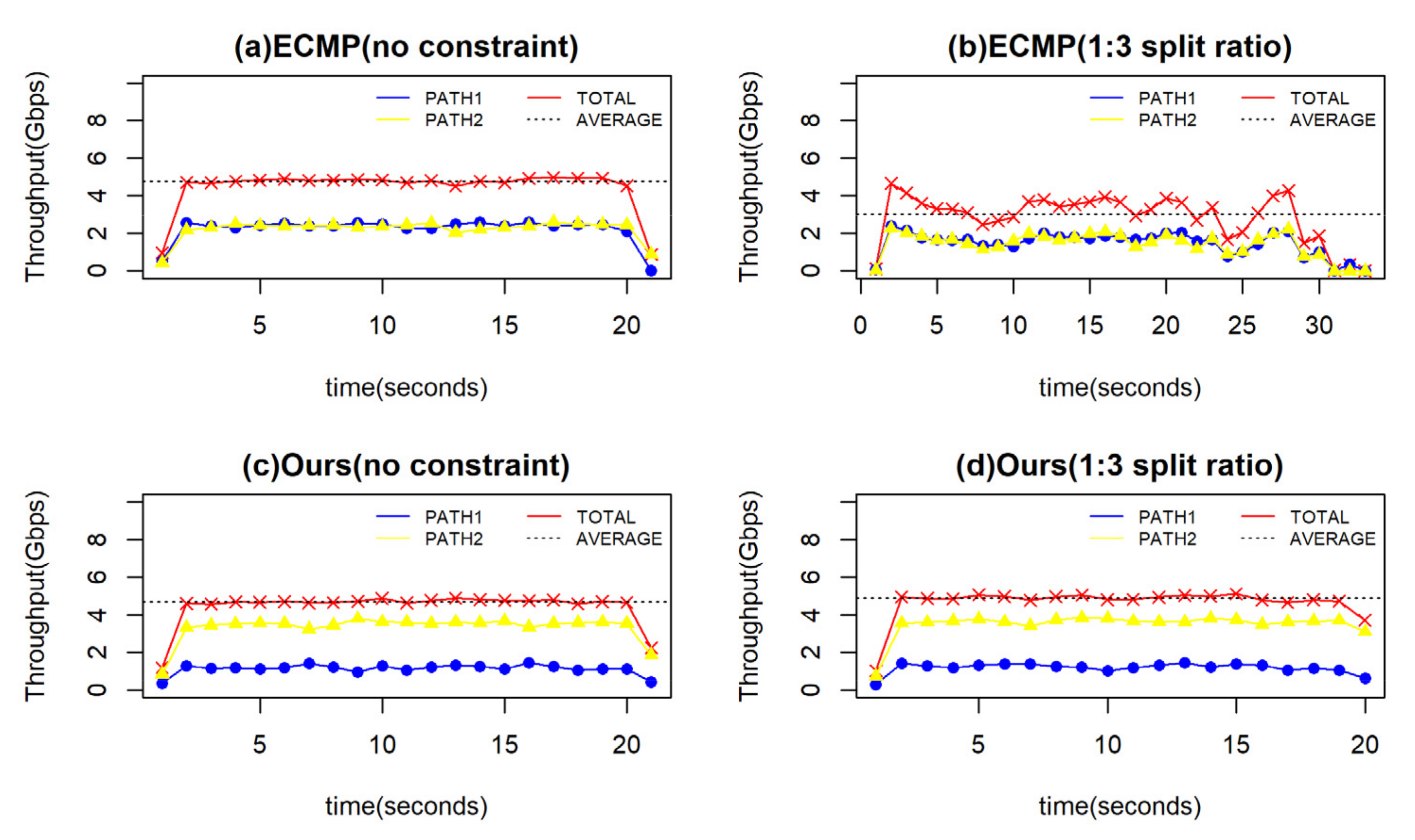
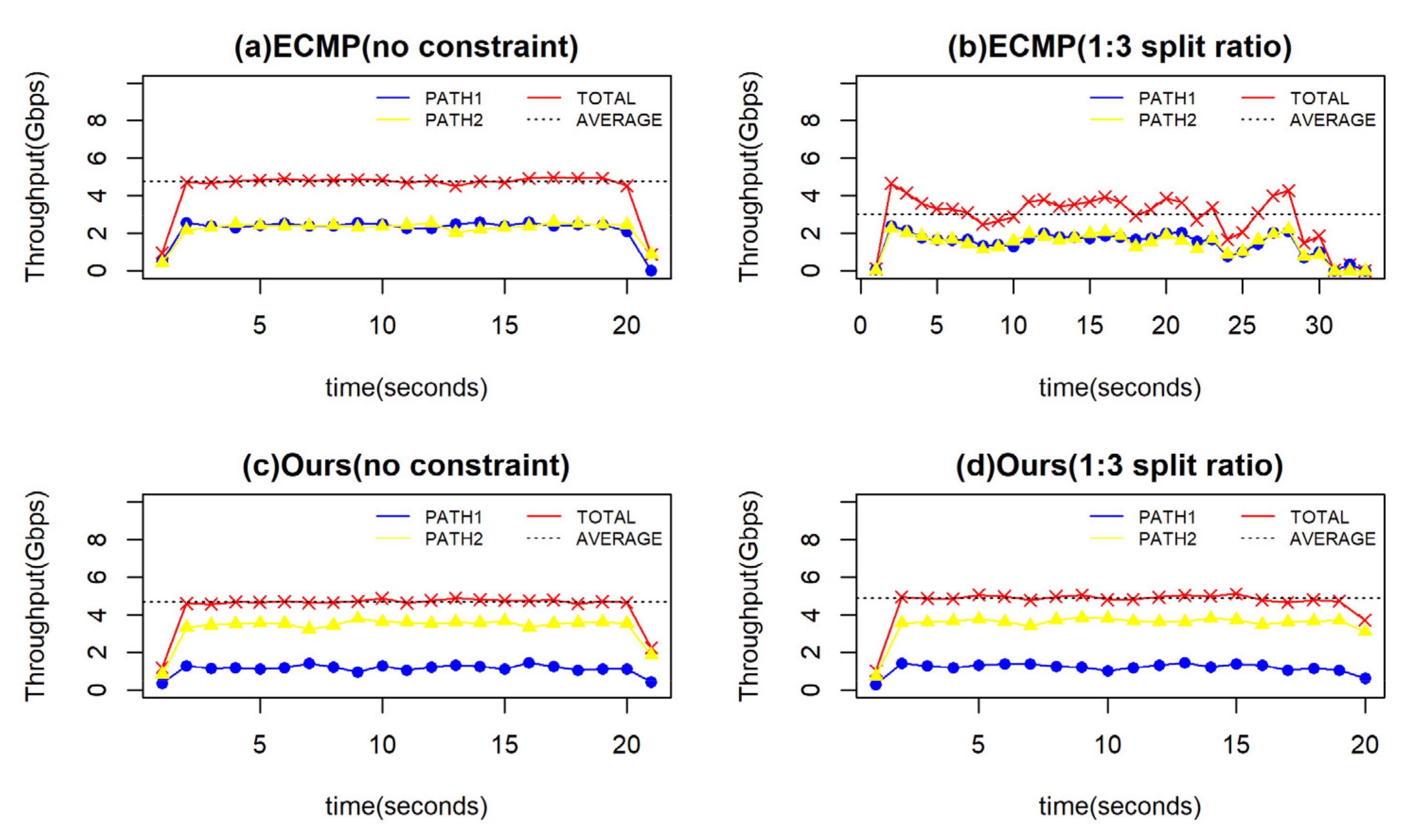
5.2.4. The Accuracy of Traffic Split Ratio
5.2.5. Comparison with Common File Systems
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ping, H. An Overview of SHINE Data System. Available online: https://indico.ihep.ac.cn/event/13035/contribution/4/material/slides/0.pdf (accessed on 10 December 2021).
- Chen, G. Challenges of big data in science researches. Chin. Sci. Bull. 2015, 60, 439–444. (In Chinese) [Google Scholar] [CrossRef]
- Jacobson, V.; Smetters, D.K.; Thornton, J.D.; Plass, M.F.; Briggs, N.H.; Braynard, R.L. Networking named content. In Proceedings of the 5th International Conference on Emerging Networking Experiments and Technologies, Rome, Italy, 1–4 December 2009; pp. 1–12. [Google Scholar]
- Zhang, L.; Alexander, A.; Jeffrey, B.; Jacobson, V.; Claffy, K.; Crowley, P.J.; Papadopoulos, C.; Wang, L.; Zhang, B. Named data networking. ACM SIGCOMM Comput. Commun. Rev. 2014, 44, 66–73. [Google Scholar] [CrossRef]
- Fan, C.; Shannigrahi, S.; DiBenedetto, S.; Olschanowsky, C.M.; Papadopoulos, C.; Newman, H.B. Managing scientific data with named data networking. In Proceedings of the Fifth International Workshop on Network-Aware Data Management, Austin, TX, USA, 15 November 2015; pp. 1–7. [Google Scholar]
- Dabin, K.; Inchan, H.; Vartika, S.; Young-Bae, K.; Huhnkuk, L. Implementation of a front-end and back-end NDN system for climate modeling application. In Proceedings of the 2015 International Conference on Information and Communication Technology Convergence (ICTC), Jeju, Korea, 28–30 October 2015; pp. 554–559. [Google Scholar]
- Catherine, O.; Susmit, S.; Christos, P. Supporting climate research using named data networking. In Proceedings of the IEEE 20th International Workshop on Local & Metropolitan Area Networks (LANMAN), Reno, NV, USA, 21–23 May 2014; pp. 1–6. [Google Scholar]
- Huhnkuk, L.; Alexander, N.; Dabin, K.; Young-Bae, K.; Susmit, S.; Christos, P. NDN Construction for Big Science: Lessons Learned from Establishing a Testbed. IEEE Netw. 2018, 32, 124–136. [Google Scholar]
- Susmit, S.; Chengyu, F.; Christos, P. Named Data Networking Strategies for Improving Large Scientific Data Transfers. In Proceedings of the IEEE International Conference on Communications Workshops, Kansas City, MO, USA, 20–24 May 2018; pp. 1–6. [Google Scholar]
- Christian, E. Analysis of an Equal-Cost Multi-Path Algorithm. Available online: https://datatracker.ietf.org/doc/html/rfc2992 (accessed on 10 December 2021).
- Liu, M.; Luo, L.; Nelson, J.; Ceze, L.; Krishnamurthy, A.; Atreya., K. IncBricks: Toward In-Network Computation with an In-Network Cache. In Proceedings of the Twenty-Second International Conference on Architectural Support for Programming Languages and Operating Systems, Xi’an, China, 8–12 April 2017; Volume 52, pp. 795–809. [Google Scholar]
- Stathis, M.; Bianca, S. The Evolution of the Hadoop Distributed File System. In Proceedings of the 2018 32nd International Conference on Advanced Information Networking and Applications Workshops (WAINA), Krakow, Poland, 16–18 May 2018; pp. 67–74. [Google Scholar]
- Ghemawat, S.; Gobioff, H.; Leung, S.-T. The Google File System. SIGOPS Oper. Syst. Rev. 2003, 37, 29–43. [Google Scholar] [CrossRef]
- Weil, S.A.; Brandt, S.A.; Miller, E.L.; Long, D.D.E.; Maltzahn, C. Ceph: A Scalable, High-Performance Distributed File System. In Proceedings of the 7th Symposium on Operating Systems Design and Implementation, Seattle, DC, USA, 6–8 November 2006; pp. 307–320. [Google Scholar]
- Onur, A.; Truong, K.P. On uncoordinated service placement in edge-clouds. In Proceedings of the 2017 IEEE International Conference on Cloud Computing Technology and Science (CloudCom), Hong Kong, 11–14 December 2017; pp. 41–48. [Google Scholar]
- Tao, O.; Zhi, Z.; Xu, C. Follow me at the edge: Mobilityaware dynamic service placement for mobile edge computing. IEEE J. Sel. Areas Commun. 2018, 36, 1–10. [Google Scholar]
- Carofiglio, G.; Morabito, G.; Muscariello, L.; Solis, I.; Varvello, M. From content delivery today to information centric networking. Comput. Netw. 2013, 57, 3116–3127. [Google Scholar] [CrossRef]
- Adrian-Cristian, N.; Spyridon, M.; Ioannis, P. Store Edge Networked Data (SEND): A Data and Performance Driven Edge Storage Framework. In Proceedings of the IEEE INFOCOM 2021-IEEE Conference on Computer Communications, Virtual Conference, 10–13 May 2021; pp. 1–10. [Google Scholar]
- Eve, M.; David, Z.; Jeff, S.; Moustafa, H.; Brown, A.; Ambrosin, M. An Architectural Vision for a Data-Centric IoT: Rethinking Things, Trust and Clouds. In Proceedings of the 2017 IEEE 37th International Conference on Distributed Computing Systems (ICDCS), Atlanta, GA, USA, 5–8 June 2017; pp. 1717–1728. [Google Scholar]
- Benet, J. IPFS—Content Addressed, Versioned, P2P File System. arXiv 2014, arXiv:1407.3561. [Google Scholar]
- Cinquini, L.; Crichton, D.; Mattmann, C.; Harney, J.; Shipman, G.; Wang, F.; Ananthakrishnan, R.; Miller, N.; Denvil, S.; Morgan, M.; et al. The earth system grid federation: An open infrastructure for access to distributed geospatial data. Future Gener. Comput. Syst. 2014, 36, 400–417. [Google Scholar] [CrossRef]
- Karl, E.; Ronald, J.; Gerald, A. An overview of cmip5 and the experiment design. Bull. Am. Meteorol. Soc. 2012, 93, 485–498. [Google Scholar]
- Alvise, D.; Peter, E.; Fabrizio, F.; Andrew, H. Xrootd-a highly scalable architecture for data access. WSEAS Trans. Comput. 2005, 4, 348–353. [Google Scholar]
- Ying, C.; Fan, L.; Edmund, Y.; Ran, L. Enhanced VIP Algorithms for Forwarding, Caching, and Congestion Control in Named Data Networks. In Proceedings of the 2016 IEEE Global Communications Conference (GLOBECOM), Washington, DC USA, 4–8 December 2016; pp. 1–7. [Google Scholar]
- Zeng, L.; Ni, H.; Han, R. An Incrementally Deployable IP-Compatible-Information-Centric Networking Hierarchical Cache System. Appl. Sci. 2020, 10, 6228. [Google Scholar] [CrossRef]
- Xu, Y.; Ni, H.; Zhu, X. An Effective Transmission Scheme Based on Early Congestion Detection for Information-Centric Network. Electronics 2021, 10, 2205. [Google Scholar] [CrossRef]
- You, J.; Ji, G.; Xiao, Z.; Jin, L. ITU-T Y.3075 Requirements and Capabilities of ICN Routing and Forwarding based on Control and User Plane Separation in IMT-2020. Available online: https://www.itu.int/rec/dologin_pub.asp?lang=e&id=T-REC-Y.3075-202009-I!!PDF-E&type=items (accessed on 12 December 2021).
- Psaras, I.; Ascigil, O.; Rene, S.; Pavlou, G.; Afanasyev, A.; Zhang, L. Mobile Data Repositories at the Edge. In Proceedings of the USENIX Workshop on Hot Topics in Edge Computing HotEdge ’18, Boston, MA, USA, 10 July 2018. [Google Scholar]
- Dang, S.; You, J.; Li, Y.Y. ICN-DOS, Requirements and Capabilities of Data Object Segmentation in Information Centric NETWORKING for IMT-2020. Available online: https://www.itu.int/md/T17-SG13-C-1318 (accessed on 12 December 2021).
- Raychaudhuri, D.; Nagaraja, K.; Venkataramani, A. MobilityFirst: A robust and trustworthy mobility-centric architecture for the future internet. ACM SIGMOBILE Mob. Comput. Commun. Rev. 2012, 16, 2–13. [Google Scholar] [CrossRef]
- Ye, X.; Cao, J.; Zhu, X.Y. ICN-TL Requirements and Mechanisms of Transport Layer for Information Centric Networking in IMT-2020. Available online: https://www.itu.int/md/T17-SG13-200720-TD-WP1-0589 (accessed on 12 December 2021).
- Wang, J.; Chen, G.; You, J.; Sun, P. SEANet: Architecture and Technologies of an On-site, Elastic, Autonomous Network. New Media 2020, 9, 1–8. [Google Scholar]
- Song, Y.; Ni, H.; Zhu, X. Analytical modelling of optimal chunk size for efficient transmission in information-centric network. Int. J. Innov. Comput. Inf. Control 2020, 16, 1511–1525. [Google Scholar]
- Schneider, K.; Zhang, B.; Mai, V.S.; Benmohamed, L. The Case for Hop-by-Hop Traffic Engineering. arXiv 2020, arXiv:2010.13198. [Google Scholar]
- You, J.; Zhang, J.; Li, Y.Y. ICN-NMR Framework of Locally Enhanced Name Mapping and Resolution for Information Centric Networking in IMT-2020. Available online: https://www.itu.int/md/T17-SG13-C-1319/ (accessed on 12 December 2021).
- Jacobson, V. Congestion avoidance and control. SIGCOMM Comput. Commun. Rev. 1988, 18, 314–329. [Google Scholar] [CrossRef]
- Zhou, J.; Tewari, M.; Zhu, M.; Kabbani, A.; Poutievski, L.; Singh, A.; Vahdat, A. WCMP: Weighted cost multipathing for improved fairness in data centers. EuroSys 2014, 5, 1–14. [Google Scholar]
- Qadir, J.; Ali, A.; Yau, K.L.; Sathiaseelan, A.; Crowcroft, J. Exploiting the Power of Multiplicity: A Holistic Survey of Network-Layer Multipath. IEEE Commun. Surv. Tutor. 2015, 17, 2176–2213. [Google Scholar] [CrossRef] [Green Version]
- Rottenstreich, O.; Kanizo, Y.; Kaplan, H.; Rexford, J. Accurate Traffic Splitting on SDN Switches. IEEE J. Sel. Areas Commun. 2018, 36, 2190–2201. [Google Scholar] [CrossRef]
- Tuncer, D.; Charalambides, M.; Clayman, S.; Pavlou, G. Flexible Traffic Splitting in OpenFlow Networks. IEEE Trans. Netw. Serv. Manag. 2016, 3, 407–420. [Google Scholar] [CrossRef] [Green Version]
- Kang, N.; Ghobadi, M.; Reumann, J.; Shraer, A.; Rexford, J. Efficient traffic splitting on commodity switches. In Proceedings of the 11th ACM Conference on Emerging Networking Experiments and Technologies, CoNEXT 2015, Heidelberg, Germany, 1–4 December 2015. [Google Scholar]
- Li, S.; Hu, D.; Fang, W.; Ma, S.; Chen, C.; Huang, H.; Zhu, Z. Protocol Oblivious Forwarding (POF): Software-Defined Networking with Enhanced Programmability. IEEE Netw. 2017, 31, 58–66. [Google Scholar] [CrossRef]
- Andy, H. Bbcp. Available online: https://www.slac.stanford.edu/~abh/bbcp/ (accessed on 10 December 2021).
- Liu, Y.; Qin, X.; Zhu, T.; Chen, X.; Wei, G. Improve MPTCP with SDN: From the perspective of resource pooling. J. Netw. Comput. Appl. 2019, 141, 73–85. [Google Scholar] [CrossRef]
- Klaus, S.; Bei, C.; Lotfi, B. Hop-by-Hop Multipath Routing: Choosing the Right Nexthop Set. In Proceedings of the IEEE INFOCOM 2020—IEEE Conference on Computer Communications, Virtual Conference, 6–9 July 2020; pp. 2273–2282. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
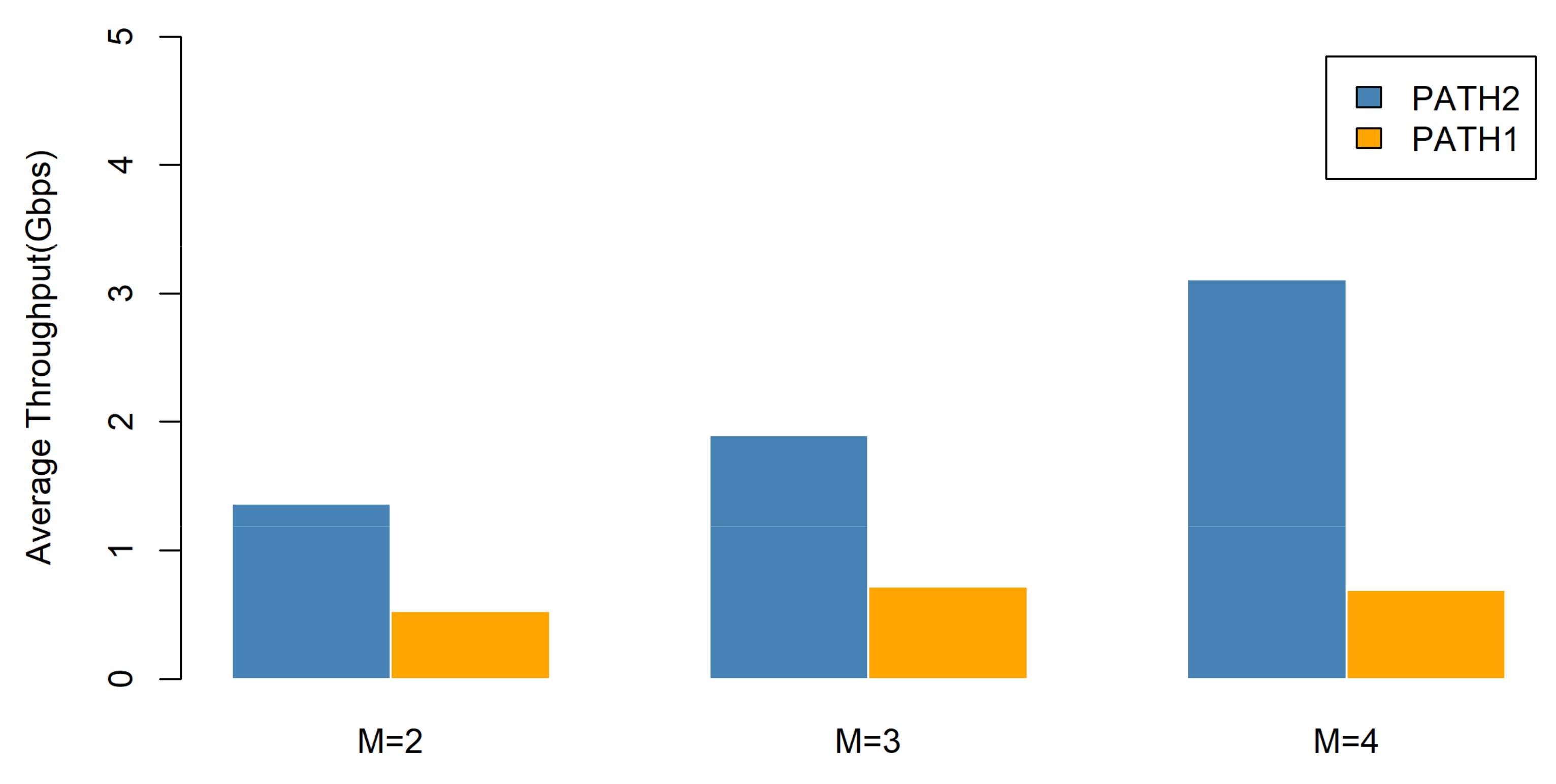{kind=link}
{kind=link}
| Experiments | Time(s) |
|---|---|
| Bbcp (under 4 Gbps) | 19 |
| Ours (under 4 Gbps) | 18.5 |
| Bbcp (under 2 Gbps) | 33.5 |
| Ours (under 2 Gbps) | 17.5 |
| Experiments | Time(s) |
|---|---|
| ECMP (no constraint) | 18 |
| ECMP (1:3 split ratio) | 28.5 |
| Ours (no constraint) | 18.3 |
| Ours (1:3 split ratio) | 17.6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dang, S.; Han, R. An In-Network Cooperative Storage Schema Based on Neighbor Offloading in a Programmable Data Plane. Future Internet 2022, 14, 18. https://doi.org/10.3390/fi14010018
Dang S, Han R. An In-Network Cooperative Storage Schema Based on Neighbor Offloading in a Programmable Data Plane. Future Internet. 2022; 14(1):18. https://doi.org/10.3390/fi14010018
Chicago/Turabian StyleDang, Shoujiang, and Rui Han. 2022. "An In-Network Cooperative Storage Schema Based on Neighbor Offloading in a Programmable Data Plane" Future Internet 14, no. 1: 18. https://doi.org/10.3390/fi14010018
APA StyleDang, S., & Han, R. (2022). An In-Network Cooperative Storage Schema Based on Neighbor Offloading in a Programmable Data Plane. Future Internet, 14(1), 18. https://doi.org/10.3390/fi14010018