2.2. Approximation-Estimation Test
For the next step of our methodology, we rethink the classification problem as a more complex classification and clustering problem of automated typology of texts. In this case, both the topics of the documents and the number of these topics are unknown; they are not pre-defined by the supervisor. As stated above, a possible approach to the automated typology of texts could be unsupervised learning while using cluster analysis methods. For cluster analysis of texts, hierarchical agglomerative algorithms [
13,
14] can be used.
In general, strict cluster analysis (without intersecting clusters as subsets) is understood as algorithmic typologization of the elements of a certain set (sample)
X by the “measure” of their similarity with each other. An arbitrary clustering algorithm is mapping
which maps to any element
from the set
X the only
k, which is the number of the cluster to which
belongs. The clustering process splits the
X into pairwise disjoint subsets of
called clusters:
where for
Therefore, the map
defines an equivalence relation on
X [
15,
16]. If an equivalence relation is given on some set
X, not all set
X can be considered, but only one element from each equivalence class. These elements are called “a representatives” of equivalence classes [
17,
18]. For cluster analysis, these are, for example, centroids or nearest neighbors. It greatly simplifies calculations and theoretical researchers of the map
.
One of the main problems when using agglomerative clustering methods is to calculate the preferred number of clusters and determine when the process stops. Moreover, a characteristic feature of these methods is the emergence of the so-called “chain effect” at the final stage of clustering. As we approach the end of the process, one large cluster is formed due to the addition of either previously created clusters or isolated points. If there is no criterion for stopping the clustering process, all points of the set
X will be combined into a single cluster [
19,
20].
The issue of defining the moment of completion of the clustering algorithm is the same moment that determines the optimal number of clusters. The problem of finding this moment can be solved within the framework of the theory of optimal stopping rules [
21,
22].
Before proceeding to the formal mathematical calculations, we will explain the logic of the research design. Thus, we need to detect the optimal number of text types or classes (by topicality, sentiment, etc.) within a certain corpus and assign the types or classes to the texts. Formally, the number of classes (topics, in our case) will coincide with the number of clusters. An adequate number of clusters can be obtained if hierarchical agglomerative clustering stops at the “right moment”. Agglomerative clustering methods are based on combining the elements of some set X that are located closest to each other. Moreover, the agglomerative process begins with the assumption that each point in X is a separate cluster. During clustering, the clusters “grow” according to the principle described above. The clusters are clumps (subsets of higher density) inside X. Obviously, with this approach, one of the main characteristics of the clustering process will be the function of minimum distances. While points close to each other are combined, the function of minimum distances slowly increases as a linear quantity. However, when the formed clusters begin to unite, the function of minimum distances increases sharply. In the vicinity of this point, the increase in the function of minimum distances ceases to be linear and becomes parabolic. By common sense, this is the moment of completion of the agglomerative clustering process. Analytically, this moment can be detected as a point at which an incomplete (without a linear term) parabolic approximation becomes more precise than the linear one.
In other words, in the neighborhood of this point, the quadratic error of incomplete parabolic approximation becomes smaller than the quadratic error of linear approximation. When clusters merge or one of the isolated points joins any of them, there should be a sharp jump in the minimum distance’s numerical value. It is the moment when the clustering process is complete. At such a moment, the values of the set of minimum distances are more accurately approximated by an incomplete quadratic parabola (without a linear term), rather than the direct line [
15,
16]. Within this approach, the iteration of the agglomerative process of clustering, at which there is a change in the nature of the increase in the function of minimum distances from linear to parabolic, is defined as the Markov stopping moment.
We now turn to formal mathematical notation. Consider the set of minimum distances obtained after iteration of any agglomerative clustering algorithm. It has the form ; for all of the agglomerative clustering methods, except for the centroid one, it is linearly ordered relative to numerical values of its elements: We use this set to derive the statistical criterion for completing the clustering process in an arbitrary Euclidean space .
We use the previously constructed parabolic approximation-estimation test in order to determine the moment when the character of a monotonic increase in the numerical sequence changes from linear to parabolic [
23,
24].
We distinguish between a linear approximation in the class of functions of the form
and an incomplete parabolic approximation (without a linear term) in the class of functions
The quadratic errors in
k nodes for linear and incomplete parabolic approximation will be, respectively, equal to:
If, in our reasoning, the number of approximation nodes is not essential or obvious from the context, then the corresponding quadratic errors will simply be denoted by , and .
When comparing and , there are three possible cases:
We say that the sequence has linear increase at the nodes (points): , if is monotonic and the quadratic errors of linear and incomplete parabolic approximation over these nodes are related by the inequality: .
If, under the same conditions, the inequality: , holds, then we say that the sequence has parabolic increase at points: .
If, for a set of approximation nodes: , the equality holds, then the point is called critical.
We calculate coefficients
of a linear function
and the coefficients
for an incomplete quadratic function
approximating the nodes
[
23,
24].
First, using the method of least squares, we calculate the coefficients
of the linear function
approximating the nodes
. For this, we find the local minimum of the function of two variables
We calculate the partial derivatives of the function
By equating them to zero, we obtain a system of linear equations for the unknown
a and
b:
which implies:
We calculate the coefficients
of the incomplete quadratic function
as the coordinates of the local minimum for:
Differentiating
, we find:
and
Subsequently, to determine the moment when the character of the increase in the monotonic sequence changes from linear to parabolic, we construct the parabolic approximation-estimation test .
By definition, we assume that, for approximation nodes:
the parabolic approximation-estimation test [
23,
24] is expressed by the formula:
Moreover, we assume that always
It is easy to achieve this condition at any approximation step while susing the transformation:
Now, we calculate, using the values of the coefficients
, the quadratic errors of the linear and incomplete parabolic approximations at four points
, and we obtain an explicit expression for
[
23,
24].
Thus, we have derived a quadratic form equal to the difference of the quadratic errors of linear and incomplete parabolic approximation. This quadratic form changes its sign when the character of an increase in the numerical sequence changes from linear to parabolic.
2.3. Cluster Analysis as a Random Process and the Markov Moment of Its Stopping
Now, we will formally determine the moment of stopping the clustering process using the theory of random processes and the theory of sequential statistical analysis. Here, the approximation-estimation test is used as the decisive statistical criterion.
Let be a bounded subset of the natural series, containing natural numbers: . Subsequently, the family of random variables defined for on the same probability space is called a discrete random process.
Each random variable
generates a
-algebra, which we denote as
. Subsequently, the
-algebra generated by the random process
is called the minimal
-algebra containing all
i.e.,
The discrete random process can be considered as a function of two variables , where t is the natural argument, is a random event. If we fix t, then, as indicated above, we obtain a random variable ; if we fix a random event , we obtain a function of the natural argument t, which is called the trajectory of the random process and is a random sequence of .
We consider the clustering of a finite set X from the Euclidean space as a discrete random process . A random event of will be the extraction of a sample of X from . Theoretically, any point can belong to the sample set X, therefore the -algebra from the probability space contains all , any finite set X from the space , all possible countable unions of such sets, and additions to it. We denote this set system as and call it selective -algebra, The same reasoning holds for any -algebra . Therefore,
Consider the binary problem of testing the statistical hypotheses and . Where the null hypothesis , or the random sequence of , increases linearly, and the alternative hypothesis , or the random sequence , increases non-linearly (parabolically). It is necessary to construct the criterion as a strict mathematical rule that tests the statistical hypothesis.
In the Euclidean space, during agglomerative clustering of sample data, one of the main characteristics of the process will be a set of minimum distances. It is natural to consider its values as a random variable , assuming that t is the iteration number of the agglomerative clustering algorithm . For any fixed random event , the corresponding trajectory is a monotonically increasing random sequence.
On the probability space the family of -algebras is called a filtration, if for . Moreover, if for , then the filtration is called natural. The random process is called consistent with the filtration , if for . Obviously, any random process is consistent with its natural filtration.
The mapping
is called Markov moment with respect to the filtering
, if for
the preimage of the set is
. If, in addition, the probability
, then
is called the Markov stopping time [
22].
In other words, let be the moment of the occurrence of some event in the random process . If for we can definitely say whether the event occurred or not, provided that the values of are only known in the past (to the left of ), then is the Markov moment relative to the natural filtering of the random process . If the moment of the occurrence of has a probability equal to one, then is the Markov stopping time.
For a random sequence of minimum distances
, when we cluster the sample
, the natural filtration consistent with the process is the “sample
-algebra”
. Subsequently, by definition, the Markov moment of stopping the agglomerative process of clustering will be statistics
Thus, the statistical criterion for the completion of the agglomerative process of clustering can be formulated, as follows. Let
be a linearly ordered set of minimum distances, and the set
be the “trend set” obtained using the transformation
, where
q is the “trend coefficient”, and
i is the iteration number of the agglomerative clustering algorithm
. The clustering process is considered to be completed at the
k-th iteration, if for the nodes
the inequality
, and for the set of points
, the inequality
.
In other words, the Markov moment of stopping the agglomerative clustering process is the minimum value
t at which the null hypothesis
is rejected (“the values of the elements of a linearly ordered trend set increase linearly”) and the alternative hypothesis is accepted
(“the values of the elements of a linearly ordered trend set increase parabolically”) [
15].
2.4. Clustering Stability and Determining the Preferred Number of Clusters: The Stopping Criterion
The clustering process is completed using the parabolic approximation-estimation test described above, which estimates the jumps of a monotonically increasing sequence of “trend set” values. The magnitude of the significant jump sufficient to stop the process depends on the sensitivity of the stopping criterion, which is set using the non-negative coefficient
q [
15,
16]. The higher the value of
q, the lower the criterion’s sensitivity for stopping the clustering process. The stopping criterion has the highest sensitivity at
, in this case, as a result of clustering, the most significant number of clusters will be obtained. By increasing
q, the stopping criterion’s sensitivity can be reduced so that the process continues until all
m vectors are combined into one cluster. In this case, intervals of stable clustering
will occur on which for
the same clustering results will be obtained.
Cluster analysis, in a sense, has a high degree of subjectivity. Therefore, the interpretation of its results largely depends on the researcher. So far, no rigorous definition of “sustainable/stable clustering” has been introduced; the scholars only speak of an intuitive concept. They argue that “clustering stability” shows how different the resulting partitions into equivalence classes become after using the clustering algorithms for the same data many times. A slight discrepancy between the results is interpreted as high stability [
25].
In our case, a quantitative measure of stability of clustering can be considered the value of the interval of variation of the coefficient q, within which the same result is obtained for the set X. Here, we note again that the “chain effect” arises at the final stage of the clustering process when already-formed clusters are added one after another to some other cluster. In this case, the correct choice of sensitivity threshold for the stopping criterion on the account of the non-negative coefficient q is essential. In the general case, the sequence of intervals of stable clustering, for various values of the coefficient q, is denoted by: where is the interval of stable clustering, and is the set of values of the coefficient q, in which all m points are combined into one cluster.
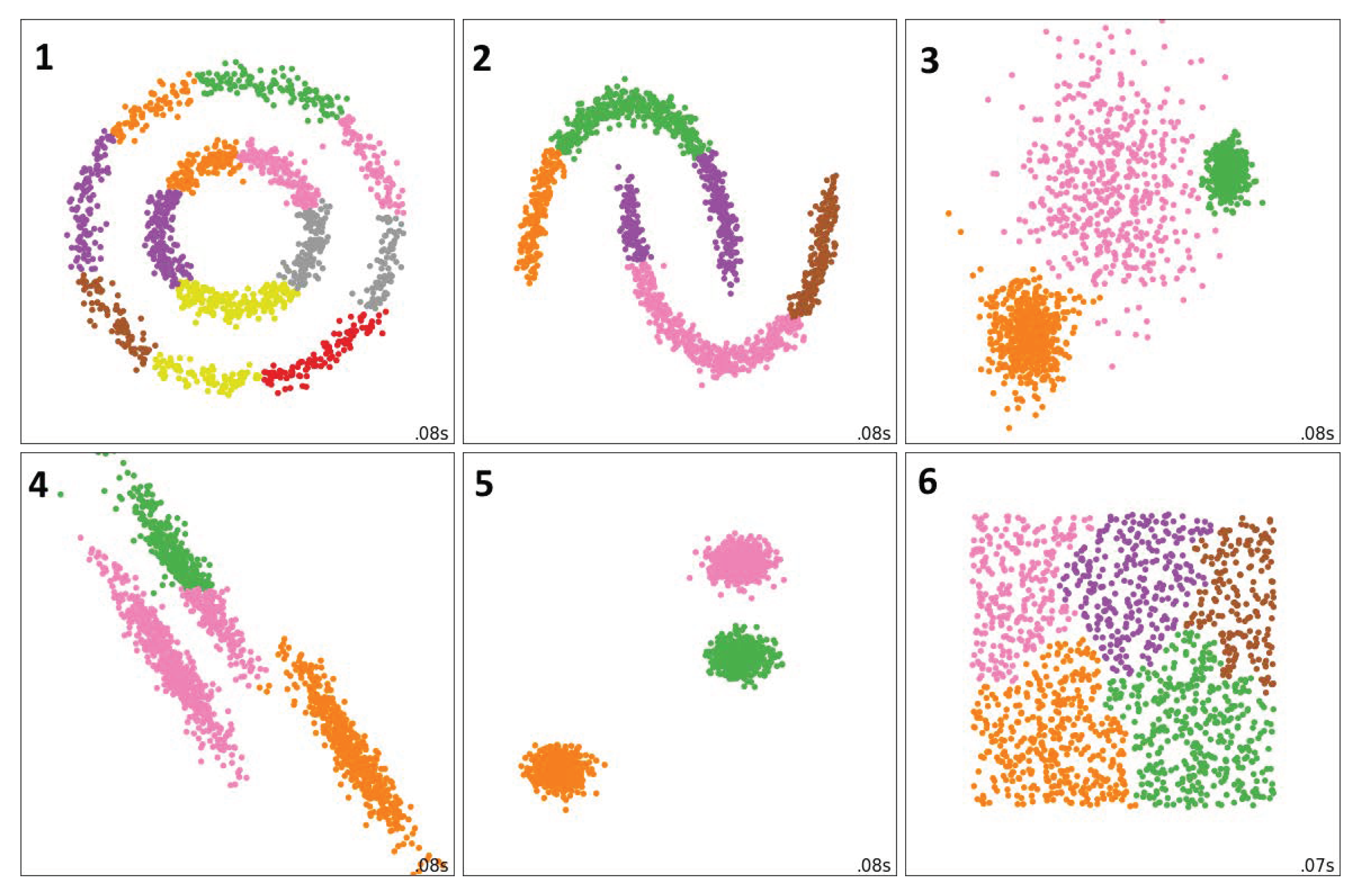
Clustering with Markov stopping time allows for automation of the procedure for determining the number of clusters in the text corpus. Based on the analysis of numerical experiments and general considerations, the following hypothesis was formulated earlier: “Preferred a number of clusters is formed at
” [
16]. The main motive for formulating this hypothesis was that a chain effect is manifested in the interval of stable clustering
, at which already formed clusters are combined.

 ,
, 




{kind=link}