



Plugging Small Models in Large Language Models for POI Recommendation in Smart Tourism



Abstract
1. Introduction
- To our knowledge, we are the first to use DL-based models as LLM plugins, combining their strengths for the next POI recommendation. By introducing target time and fully exploring time slot preferences, PSLM4ST can provide users with more accurate and user-friendly recommendations.
- The plugin model is a temporal knowledge graph reasoning model, built on multiple lightweight modules designed to capture fine-grained preferences. Hence, it generates more precise candidate sets for LLMs, derived from various preference sources.
- Extensive experiments on three real-world datasets demonstrate the superiority of our proposed PSLM4ST.
2. Related Work
2.1. Next POI Recommendation
2.1.1. Classic Methods
2.1.2. Time-Aware Methods
2.1.3. LLM-Based Methods
2.2. Temporal Knowledge Graph Reasoning
3. Preliminaries
3.1. Problem Definition
3.2. Check-In Behavior Data Analysis
4. Methodology
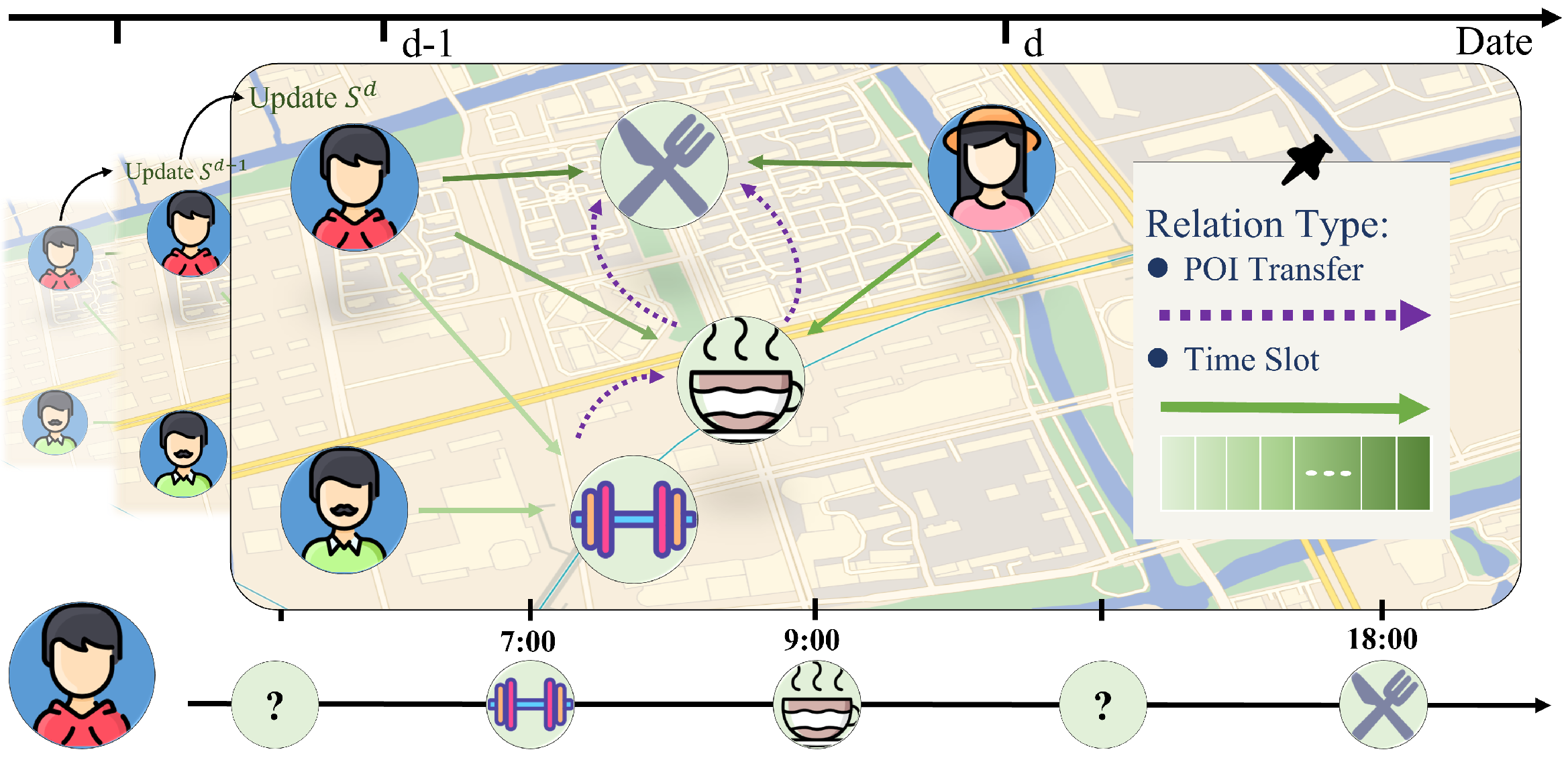
4.1. TKG and Schedule
4.2. User Profile
- Attributes. Some basic user attributes are intricately linked to their preferences with respect to POIs. For example, restaurants with different price ranges are tailored to customers who have diverse economic capacities. Chen et al. [36] found evidence that a chatbot develops internal representations of its users’ states, including the following basic attributes. Specifically, we use LLMs to predict the following four basic attributes: gender, age, education, and income level. Gender is categorized as male or female. Age is segmented into the following five groups: child, teen, young adult, middle-aged, and elderly. Education and income levels are classified into the following three levels: low, medium, and high.
- Summary. To more comprehensively capture the subtleties of user preferences, we instruct the LLM to generate a 200-word summary that simulates user check-in behavior for another LLM. The summary should include information on user behavior patterns, preferences, schedules, etc., such as whether the user tends to explore unfamiliar points of interest or prefers consistently checking in at familiar locations. This empowers the second LLM to simulate the user’s thought processes with greater depth and precision.
4.3. Plugin Model
4.3.1. User Personal Habit and Novelty Preferences
4.3.2. Personal and Global POI Transfer Preferences
4.3.3. Mirror Modules
4.4. Next POI Recommendation
4.4.1. Model Inference and Optimization
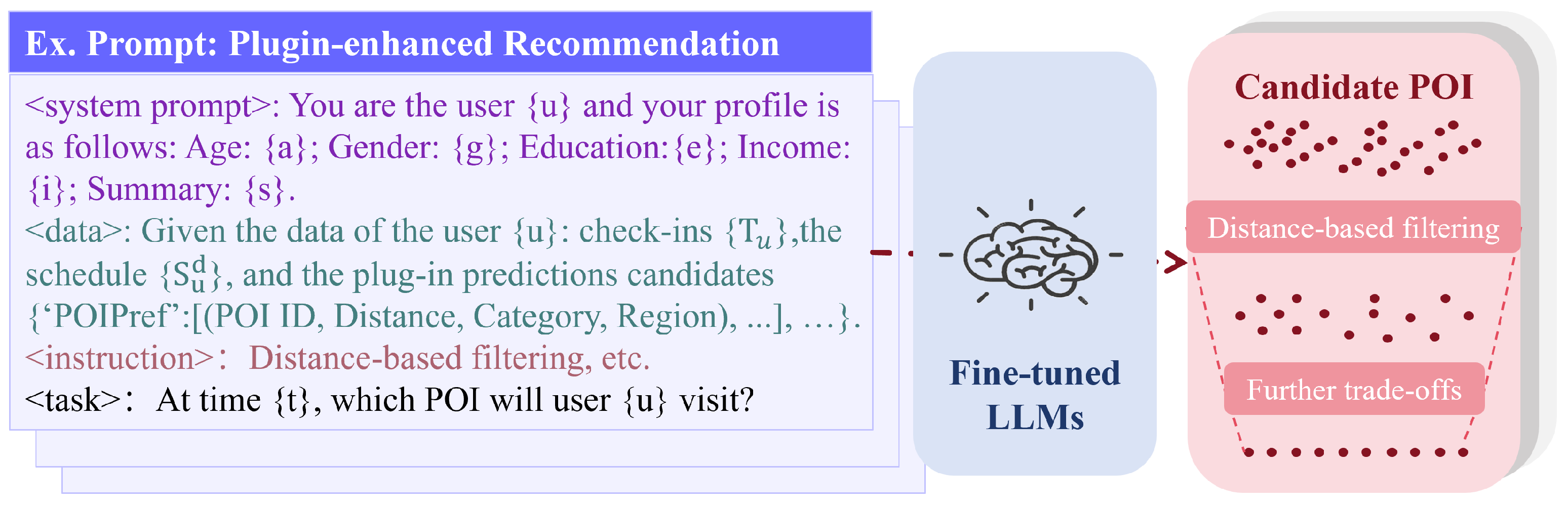
4.4.2. Plugin-Enhanced Prompt
4.4.3. Supervised Fine-Tuning
5. Experiments
5.1. Datasets and Experimental Settings
5.2. Baselines and Evaluation Metrics
- UTopRec counts the check-in frequency of each user for all POIs within each time slot according to our TKG.
- MTNet [5] is a time-aware state-of-the-art method that introduces a hierarchical check-in description method named Mobility Tree.
- ROTAN [6] is a time-aware method that proposes Time2Rotation, which encodes the given time slots as rotations.
- LLM-ZS [31] considers long- and short-term dependencies, solving the time-aware prediction problem by using temporal information.
- GenUP [32] is an LLM-based state-of-the-art model that focuses on user profile generation and fine-tuning.
5.3. Results and Analysis
5.3.1. Overall Comparison
5.3.2. Analysis of Preliminary Predictions’ Top-N Picks
5.3.3. Sensitivity Analysis
5.3.4. Ablation Study
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, W.; Kumar, N.; Chen, J.; Gong, Z.; Kong, X.; Wei, W.; Gao, H. Realizing the potential of the internet of things for smart tourism with 5G and AI. IEEE Netw. 2020, 34, 295–301. [Google Scholar] [CrossRef]
- Zhang, Y.; Sotiriadis, M.; Shen, S. Investigating the impact of smart tourism technologies on tourists’ experiences. Sustainability 2022, 14, 3048. [Google Scholar] [CrossRef]
- Zhang, Q.; Yang, P.; Yu, J.; Wang, H.; He, X.; Yiu, S.M.; Yin, H. A Survey on Point-of-Interest Recommendation: Models, Architectures, and Security. IEEE Trans. Knowl. Data Eng. 2025. [Google Scholar] [CrossRef]
- Rendle, S.; Freudenthaler, C.; Schmidt-Thieme, L. Factorizing personalized markov chains for next-basket recommendation. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; pp. 811–820. [Google Scholar]
- Huang, T.; Pan, X.; Cai, X.; Zhang, Y.; Yuan, X. Learning time slot preferences via mobility tree for next poi recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 26–27 February 2024; Volume 38, pp. 8535–8543. [Google Scholar]
- Feng, S.; Meng, F.; Chen, L.; Shang, S.; Ong, Y.S. Rotan: A rotation-based temporal attention network for time-specific next poi recommendation. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Barcelona, Spain, 25–29 August 2024; pp. 759–770. [Google Scholar]
- Luo, Y.; Duan, H.; Liu, Y.; Chung, F.L. Timestamps as prompts for geography-aware location recommendation. In Proceedings of the 32nd ACM International Conference on Information and Knowledge Management, Birmingham, UK, 21–25 October 2023; pp. 1697–1706. [Google Scholar]
- Manvi, R.; Khanna, S.; Mai, G.; Burke, M.; Lobell, D.; Ermon, S. Geollm: Extracting geospatial knowledge from large language models. arXiv 2023, arXiv:2310.06213. [Google Scholar]
- Gurnee, W.; Tegmark, M. Language models represent space and time. arXiv 2023, arXiv:2310.02207. [Google Scholar]
- Harte, J.; Zorgdrager, W.; Louridas, P.; Katsifodimos, A.; Jannach, D.; Fragkoulis, M. Leveraging large language models for sequential recommendation. In Proceedings of the 17th ACM Conference on Recommender Systems, Singapore, 18–22 September 2023; pp. 1096–1102. [Google Scholar]
- Wang, X.; Fang, M.; Zeng, Z.; Cheng, T. Where would i go next? large language models as human mobility predictors. arXiv 2023, arXiv:2308.15197. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Zhao, W.X.; Zhou, K.; Li, J.; Tang, T.; Wang, X.; Hou, Y.; Min, Y.; Zhang, B.; Zhang, J.; Dong, Z.; et al. A survey of large language models. arXiv 2023, arXiv:2303.18223. [Google Scholar]
- Feng, S.; Lyu, H.; Li, F.; Sun, Z.; Chen, C. Where to move next: Zero-shot generalization of llms for next poi recommendation. In Proceedings of the 2024 IEEE Conference on Artificial Intelligence (CAI), Singapore, 25–27 June 2024; pp. 1530–1535. [Google Scholar]
- Liu, Q.; Wu, S.; Wang, L.; Tan, T. Predicting the next location: A recurrent model with spatial and temporal contexts. In Proceedings of the AAAI conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Zhao, P.; Luo, A.; Liu, Y.; Xu, J.; Li, Z.; Zhuang, F.; Sheng, V.S.; Zhou, X. Where to go next: A spatio-temporal gated network for next poi recommendation. IEEE Trans. Knowl. Data Eng. 2020, 34, 2512–2524. [Google Scholar] [CrossRef]
- Xu, C.; Zhao, P.; Liu, Y.; Xu, J.; Sheng, V.S.S.; Cui, Z.; Zhou, X.; Xiong, H. Recurrent convolutional neural network for sequential recommendation. In Proceedings of the The World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 3398–3404. [Google Scholar]
- Yang, D.; Fankhauser, B.; Rosso, P.; Cudre-Mauroux, P. Location prediction over sparse user mobility traces using rnns. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, Yokohama, Japan, 11–17 July 2020; pp. 2184–2190. [Google Scholar]
- Yang, S.; Liu, J.; Zhao, K. GETNext: Trajectory flow map enhanced transformer for next POI recommendation. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Washington, DC, USA, 14–18 July 2022; pp. 1144–1153. [Google Scholar]
- Lim, N.; Hooi, B.; Ng, S.K.; Wang, X.; Goh, Y.L.; Weng, R.; Varadarajan, J. STP-UDGAT: Spatial-temporal-preference user dimensional graph attention network for next POI recommendation. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Virtual, 19–23 October 2020; pp. 845–854. [Google Scholar]
- Xia, J.; Yang, Y.; Wang, S.; Yin, H.; Cao, J.; Yu, P.S. Bayes-enhanced multi-view attention networks for robust POI recommendation. IEEE Trans. Knowl. Data Eng. 2023, 36, 2895–2909. [Google Scholar] [CrossRef]
- Zhang, J.; Li, Y.; Zou, R.; Zhang, J.; Jiang, R.; Fan, Z.; Song, X. Hyper-relational knowledge graph neural network for next POI recommendation. World Wide Web 2024, 27, 46. [Google Scholar] [CrossRef]
- Liu, S.; Qi, Y.; Li, G.; Chen, M.; Zhang, T.; Cheng, J.; Lei, J. STGIN: Spatial-Temporal Graph Interaction Network for Large-scale POI Recommendation. In Proceedings of the 32nd ACM International Conference on Information and Knowledge Management, Birmingham, UK, 21–25 October 2023; pp. 4120–4124. [Google Scholar]
- Han, H.; Zhang, M.; Hou, M.; Zhang, F.; Wang, Z.; Chen, E.; Wang, H.; Ma, J.; Liu, Q. STGCN: A spatial-temporal aware graph learning method for POI recommendation. In Proceedings of the 2020 IEEE International Conference on Data Mining (ICDM), Virtual, 17–20 November 2020; pp. 1052–1057. [Google Scholar]
- Wang, Z.; Zhu, Y.; Liu, H.; Wang, C. Learning graph-based disentangled representations for next POI recommendation. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, 11–15 July 2022; pp. 1154–1163. [Google Scholar]
- Yan, X.; Song, T.; Jiao, Y.; He, J.; Wang, J.; Li, R.; Chu, W. Spatio-temporal hypergraph learning for next POI recommendation. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, Taipei, Taiwan, 23–27 July 2023; pp. 403–412. [Google Scholar]
- Liu, Y.; Pham, T.A.N.; Cong, G.; Yuan, Q. An experimental evaluation of point-of-interest recommendation in location-based social networks. Proc. VLDB Endow. 2017, 10, 1010–1021. [Google Scholar] [CrossRef]
- Sánchez, P.; Bellogín, A. Point-of-interest recommender systems based on location-based social networks: A survey from an experimental perspective. ACM Comput. Surv. (CSUR) 2022, 54, 1–37. [Google Scholar] [CrossRef]
- Wang, X.; Sun, G.; Fang, X.; Yang, J.; Wang, S. Modeling Spatio-temporal Neighbourhood for Personalized Point-of-interest Recommendation. In Proceedings of the IJCAI, Vienna, Austria, 23–29 July 2022; pp. 3530–3536. [Google Scholar]
- Chen, W.; Wan, H.; Guo, S.; Huang, H.; Zheng, S.; Li, J.; Lin, S.; Lin, Y. Building and exploiting spatial–temporal knowledge graph for next POI recommendation. Knowl.-Based Syst. 2022, 258, 109951. [Google Scholar] [CrossRef]
- Beneduce, C.; Lepri, B.; Luca, M. Large language models are zero-shot next location predictors. arXiv 2024, arXiv:2405.20962. [Google Scholar] [CrossRef]
- Wongso, W.; Xue, H.; Salim, F.D. GenUP: Generative User Profilers as In-Context Learners for Next POI Recommender Systems. arXiv 2024, arXiv:2410.20643. [Google Scholar]
- Li, P.; de Rijke, M.; Xue, H.; Ao, S.; Song, Y.; Salim, F.D. Large language models for next point-of-interest recommendation. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, Washington, DC, USA, 14–18 July 2024; pp. 1463–1472. [Google Scholar]
- Zhu, C.; Chen, M.; Fan, C.; Cheng, G.; Zhang, Y. Learning from history: Modeling temporal knowledge graphs with sequential copy-generation networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 19–21 May 2021; Volume 35, pp. 4732–4740. [Google Scholar]
- Xu, Y.; Ou, J.; Xu, H.; Fu, L. Temporal knowledge graph reasoning with historical contrastive learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 4765–4773. [Google Scholar]
- Chen, Y.; Wu, A.; DePodesta, T.; Yeh, C.; Li, K.; Marin, N.C.; Patel, O.; Riecke, J.; Raval, S.; Seow, O.; et al. Designing a dashboard for transparency and control of conversational AI. arXiv 2024, arXiv:2406.07882. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | #Users | #POIs | #CATs | #COOs | #Check-ins | #Time Slots |
|---|---|---|---|---|---|---|
| NYC | 978 | 4959 | 318 | 60 | 91,872 | 96 |
| TKY | 2267 | 7831 | 289 | 60 | 364,408 | 96 |
| CA | 3695 | 9680 | 295 | 60 | 201,524 | 12 |
| Methods | NYC | TKY | CA | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Acc@1 | Acc@5 | Acc@10 | MRR | Acc@1 | Acc@5 | Acc@10 | MRR | Acc@1 | Acc@5 | Acc@10 | MRR | |
| UTopRec | 0.1654 | 0.3350 | 0.3588 | 0.2464 | 0.1490 | 0.3269 | 0.3590 | 0.2314 | 0.1311 | 0.2591 | 0.2983 | 0.1938 |
| FPMC | 0.1003 | 0.2126 | 0.2970 | 0.1701 | 0.0814 | 0.2045 | 0.2746 | 0.1344 | 0.0383 | 0.0702 | 0.1159 | 0.0911 |
| STGN | 0.1716 | 0.3381 | 0.4122 | 0.2598 | 0.1689 | 0.3391 | 0.3848 | 0.2422 | 0.0982 | 0.3167 | 0.4064 | 0.2040 |
| GETNext | 0.2435 | 0.5089 | 0.6143 | 0.3621 | 0.2254 | 0.4417 | 0.5287 | 0.3262 | 0.1357 | 0.2852 | 0.3590 | 0.2103 |
| STHGCN | 0.2734 | 0.5361 | 0.6244 | 0.3915 | 0.2950 | 0.5207 | 0.5980 | 0.3986 | 0.1730 | 0.3529 | 0.4191 | 0.2558 |
| MTNet | 0.2620 | 0.5381 | 0.6321 | 0.3855 | 0.2575 | 0.4977 | 0.5848 | 0.3659 | 0.1453 | 0.3419 | 0.4163 | 0.2367 |
| ROTAN | 0.3106 | 0.5281 | 0.6131 | 0.4104 | 0.2458 | 0.4626 | 0.5392 | 0.3475 | 0.2199 | 0.3718 | 0.4334 | 0.2931 |
| PSLM4ST | 0.3388 | 0.5894 | 0.6787 | 0.4464 | 0.3059 | 0.5596 | 0.6493 | 0.4172 | 0.1948 | 0.3794 | 0.4581 | 0.2855 |
| Method | Base Model | #params | NYC | TKY | CA |
|---|---|---|---|---|---|
| LLM-ZS | GPT-3.5 Turbo | N/A | 0.192 | 0.199 | N/A |
| GenUP | Llama 2 | 7B | 0.2575 | 0.1699 | 0.1094 |
| PSLM4ST | Llama 2 | 7B | 0.3388 | 0.3059 | 0.1948 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, H.; Xu, Z.; Pan, Q.; Zhao, Z.; Kong, X. Plugging Small Models in Large Language Models for POI Recommendation in Smart Tourism. Algorithms 2025, 18, 376. https://doi.org/10.3390/a18070376
Zheng H, Xu Z, Pan Q, Zhao Z, Kong X. Plugging Small Models in Large Language Models for POI Recommendation in Smart Tourism. Algorithms. 2025; 18(7):376. https://doi.org/10.3390/a18070376
Chicago/Turabian StyleZheng, Hong, Zhenhui Xu, Qihong Pan, Zhenzhen Zhao, and Xiangjie Kong. 2025. "Plugging Small Models in Large Language Models for POI Recommendation in Smart Tourism" Algorithms 18, no. 7: 376. https://doi.org/10.3390/a18070376
APA StyleZheng, H., Xu, Z., Pan, Q., Zhao, Z., & Kong, X. (2025). Plugging Small Models in Large Language Models for POI Recommendation in Smart Tourism. Algorithms, 18(7), 376. https://doi.org/10.3390/a18070376