1. Introduction
Early detection of diseases is crucial for medical and healthcare professionals to provide timely interventions with proactive preventive measures. Voice disorders, which affect millions of people around the world, are characterized by abnormal deviations in the voice, observable through changes in pitch, volume, loudness, voice quality, fatigue, and vocal flexibility. These disorders typically manifest through rough vocal quality, breathiness, tremulousness, and pulsed phonation [
1]. Artificial intelligence (AI)-driven solutions, therefore, assist voice pathologists and healthcare providers in automatically detecting and diagnosing pathological voices more efficiently and at lower costs [
2].
Feature selection is a crucial preprocessing step before developing any machine learning or deep learning model [
3]. The presence of irrelevant, redundant, or high-dimensional features can degrade the performance of algorithms. The objective of feature selection is to identify the optimal set of features that enhances algorithm performance. Feature selection techniques can be classified into filter-based, wrapper-based, and embedded-based approaches. Filter-based methods are based on ranking and statistical techniques for feature scoring and selection. On the other hand, wrapper methods utilize a learning algorithm during training to evaluate feature subsets. Lastly, embedded methods, such as genetic programming, learn to predict while training [
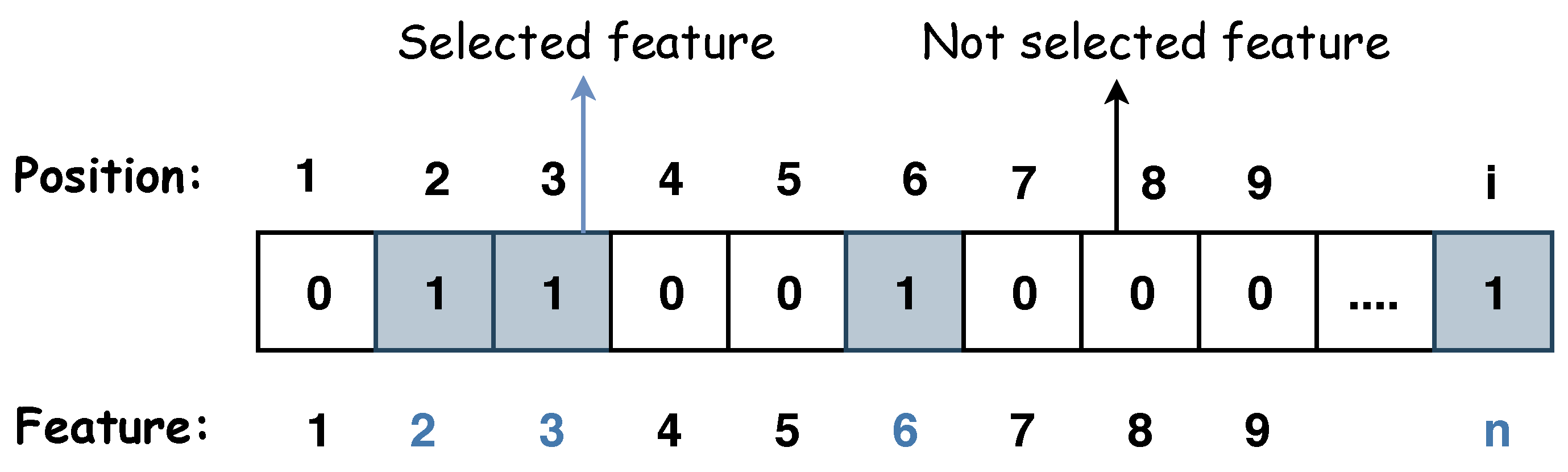
3]. The challenge with feature selection arises when the number of features is large (i.e.,
N), thus, the search space becomes exponentially complex, with a size of (
). Searching for the optimal feature set in such a vast space becomes computationally expensive, time-consuming, and requires more energy. One of the earlier approaches to address feature selection is the metaheuristic search algorithms. Metaheuristics are stochastic search algorithms incorporating randomization into the search process [
4]. Bio-inspired algorithms are metaheuristics and are widely used to solve the feature selection problem [
5]. Bioinspired algorithms dynamically search for the best set of features, which enables them to explore various regions in the search space and have more diverse solutions. Bio-inspired algorithms use randomization during the search for the best feature set, allowing exploration of different areas of the search space and leading to more diverse solutions. These algorithms balance exploration and exploitation. Exploration ensures that the algorithm searches globally and avoids getting trapped in local optima, while exploitation focuses on local search to refine solutions.
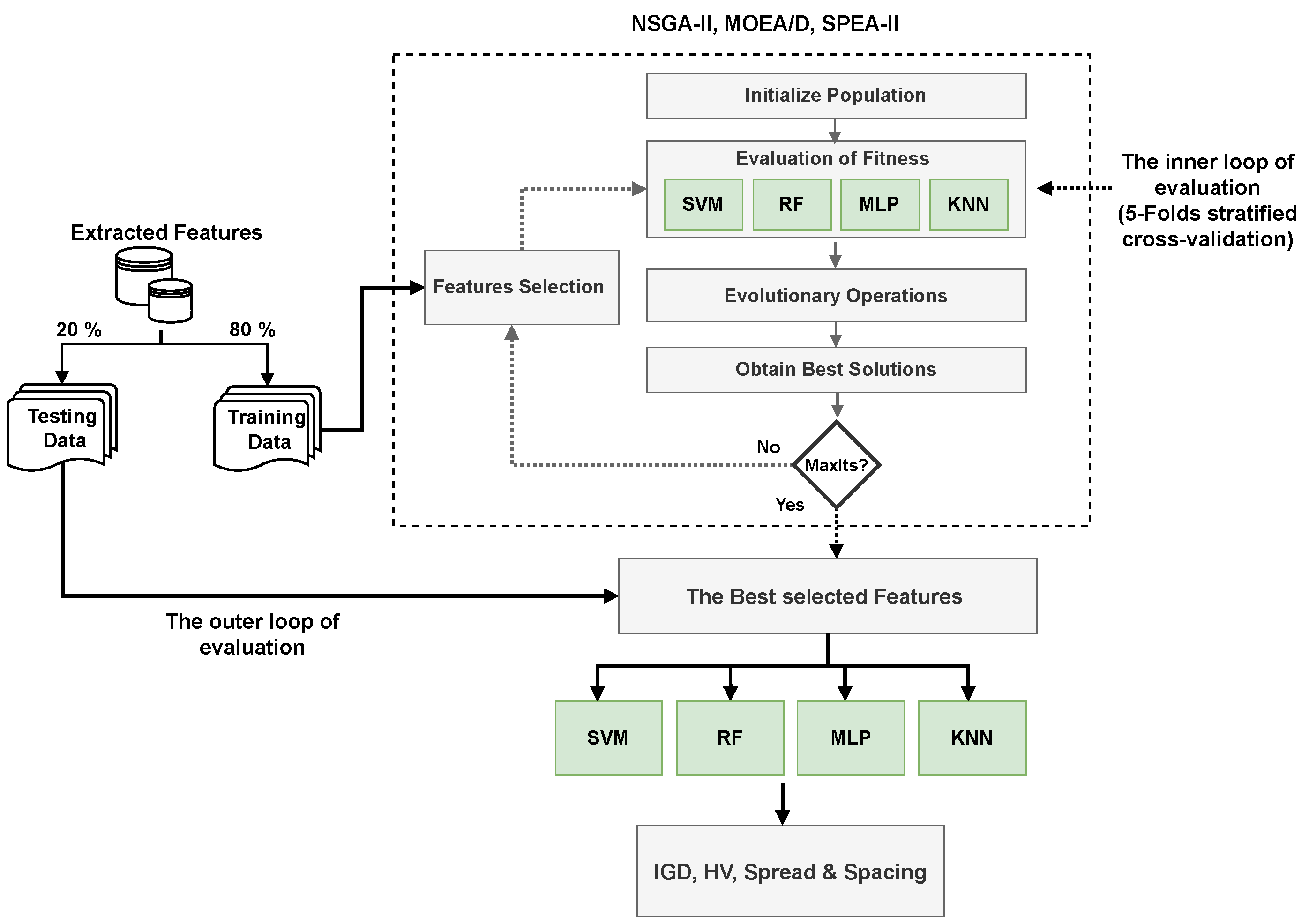
This paper aims to compare and find the best-performing combination of evolutionary optimizers and machine-learning classifiers for the optimization of feature selection and detection of voice disorders. Thus, the problem of feature selection to improve voice pathology detection is formulated as a multi-objective minimization problem, with two objectives: minimizing the number of features and the error rate. To this end, three well-regarded multi-objective evolutionary algorithms were utilized: NSGA-II [
6], SPEA-II [
7], and MOEA/D [
8]. In addition, four machine learning algorithms were experimented with and served as base learners or internal assessors. The algorithms include the KNN, SVM, MLP, and RF. The experiments were conducted using three datasets, which are the Speech Language Impairment (SLI) [
9], Saarbruecken Voice Database (SVD) [
10], and the VOice ICar fEDerico II database (VOICED) [
11]. Various features were extracted from the voice utterances, including the Mel Frequency Cepstral Coefficients (MFCCs), spectrograms, Linear Predictive Coefficients (LPC), and others [
12]. Nonetheless, measuring how ascertain predictive models are in their predictions is important to disclose their reliability in different tasks, such as diagnosing diseases, detecting fraudulent transactions, and others [
13]. However, this is not straightforward because models rely on probabilities rather than certainties. One approach to assess certainty is Conformal Prediction (CP). It is used to quantify uncertainty in machine learning models, providing statistically valid confidence estimates across various predictive tasks [
14]. By integrating CP, this research improves the robustness and interpretability of feature-selected models, ensuring that predictions in voice disorder detection are reinforced with well-calibrated confidence measures.
The remainder of the paper is organized as follows.
Section 2 reviews recent research on multi-objective optimization and voice disorder detection.
Section 3 describes the datasets, approach, experimental setup, and evaluation metrics.
Section 4 shows the conducted experiments, and discusses the results. Finally,
Section 5 is the conclusion and future remarks.
2. Related Works
The detection of voice disorders through machine learning and deep learning techniques has been explored extensively in recent years, as demonstrated in multiple studies. In a notable work by Junior et al. [
15], the authors focused on the extraction of hand-crafted features, such as energy, entropy, and zero-crossing rate, from the SVD dataset for multi-label detection of voice disorders. They trained several machine and deep learning models, using the Synthetic Minority Oversampling Technique (SMOTE) for oversampling, and found that the convolutional model achieved the highest accuracy of 94.3%. This success highlights the efficacy of machine learning techniques in the automatic detection of voice disorders. Similarly, Rehman et al. [
16] utilized several machine learning algorithms, such as decision trees, random forests, and support vector machines (SVM), specifically to detect dysphonia. They worked with both the SVD and Massachusetts Eye and Ear Infirmary (MEEI) datasets, applying filter-based feature selection, and achieved an impressive accuracy of 99.97% with the SVM classifier. These studies underscore the effectiveness of machine learning methods for voice disorder detection. However, the authors in [
17] applied Inductive CP with RF to improve the confidence and reliability of silent speech recognition using surface electromyography by providing valid uncertainty estimates with guaranteed error rates. Also, it introduced test-time data augmentation, utilizing unlabeled data to improve prediction performance. This emphasizes the potential of ICP for data augmentation and real-time applications in silent speech recognition.
Further contributions to the field include Yadav et al.’s work [
18], where they trained a Sequential Learning Resource Allocation Neural Network (SL-RANN) to detect vocal cord disorders, using discrete Fourier transforms and Mel Frequency Cepstral Coefficients (MFCCs) for preprocessing. The approach achieved a commendable accuracy of 94.35%. Similarly, Albadr et al. [
19] used Fast Learning Networks (FLN) in conjunction with MFCC features extracted from the SVD database, achieving a g-mean of 86.81%. Additionally, Sindhu et al. [
20] conducted a comprehensive review of deep learning approaches for voice disorder detection, identifying the prevalent use of deep learning for clinical diagnosis and assistive technologies. They also highlighted key gaps in current research, such as the lack of multi-modal approaches, the need to account for variabilities in speech signals (e.g., age, gender, and accent), and the absence of generalizable models that can detect multiple voice disorders simultaneously.
In the realm of optimization for voice disorder detection, several studies have employed evolutionary algorithms. For example, Yildirim et al. [
21] proposed an arithmetic optimization algorithm (AOA) for detecting Parkinson’s disease (PD), using feature maps extracted by eight convolutional neural network (CNN) architectures from spectrogram images. This approach, combined with machine learning algorithms like KNN and SVM, achieved an average accuracy of 96.62%. Similarly, Singh et al. [
22] introduced a whale-ant (WO-ANT) optimization algorithm for PD detection using speech samples, which achieved 90.29% accuracy. Akila et al. [
23] further explored PD detection using a neural network optimized with a multi-agent salp swarm (MASS) algorithm, obtaining an F1-score of 0.995. However, it is important to note that these studies were focused solely on Parkinson’s disease. Also, authors in [
24] enhanced the detection of Parkinson’s disease by using the Particle Swarm Optimization to assign weights for the acoustic features based on their relevance to the classifiers. Using the Oxford PD dataset and 5-fold cross-validation, the method improved the classification performance, where KNN achieved an accuracy of 97.44% and sensitivity of 98.02%.
Evolutionary multi-objective optimization (EMO) techniques have also been successfully applied in various domains, including voice disorder detection. Nasrolahzadeh et al. [
25] utilized the NSGA-II algorithm to select optimal wavelet features from spontaneous speech for early Alzheimer’s disease detection, achieving 98.33% accuracy. Additionally, Altay et al. [
26] applied a multi-objective evolutionary association-rule mining approach to acoustic voice characteristics for diagnosing PD, where the NICGAR algorithm performed the best among the methods tested. Sheth et al. [
27] proposed a multi-objective Jaya algorithm for PD detection, formulating the problem as a weighted sum fitness function for feature reduction and accuracy maximization, achieving 92.26% accuracy with a KNN classifier. Finally, Patra et al. [
28] demonstrated the effectiveness of MOEA/D for optimized feature selection in medical diagnosis.
Recently, despite the widespread use of machine learning methods in various fields, and specifically in voice disorder detection, there are some limitations. For instance, many research studies used machine and deep learning algorithms to detect pathological voices, a high proportion of them targeted Parkinson’s patients, disregarding other diseases. Nonetheless, many of the studies which used evolutionary optimizers formulated the optimization problem as a single-objective optimization problem to reduce the high dimensionality of the problem. Very few research studies examined evolutionary multi-objective optimization for pathological voice detection, where they emphasized Parkinson’s disease. This study attempts to address the limitation by employing multi-objective evolutionary optimization with various voice disorders that eventually reduce the number of features and power consumption.
Table 1 concludes related studies for voice disorder detection. As can be noticed in the table, most of the studies rely on accuracy to evaluate proposed methods. In this study, the generational distance and hypervolume metrics are employed solely to evaluate the effectiveness of optimization in the context of multi-objective evolutionary algorithms, and not to compare the classification performances among different models.
4. Results and Discussion
This section presents the experiments conducted and the results obtained for NSGA-II, MOEA-D, and SPEA-II on three datasets (SLI, SVD, and VOICED). The three optimizers were assessed using four base machine learning classifiers (RF, KNN, MLP, and SVM).
Table 5 presents the performance of three multi-objective optimization algorithms —NSGA-II, MOEA/D, and SPEA-II— when paired with the KNN classifier across three datasets: SLI, SVD, and VOICED. It provides the average (AVG) and standard deviation (STD) for four key metrics: Inverted Generational Distance (IGD), Hypervolume (HV), Spacing, and Spread. Analyzing the IGD metric, NSGA-II achieved the lowest IGD value on the SLI dataset (15.506), indicating that it closely approximates the Pareto-front in this case. On the other hand, SPEA-II performed best on the SVD and VOICED datasets, with IGD values of 31.787 and 30.161, respectively. This suggests that SPEA-II is effective at finding solutions near the Pareto-front in these datasets.
In terms of HV, which measures the volume covered by the solutions in objective space, both NSGA-II and SPEA-II obtained the highest values across all datasets. Specifically, NSGA-II performed best on the SLI dataset (20.139), while SPEA-II excelled on the SVD (15.245) and VOICED (21.192) datasets.
Regarding the Spacing and Spread metrics, which evaluate solution distribution and diversity, SPEA-II generally outperformed in Spacing, with values of 0.900 and 0.765 for the SLI and SVD datasets. This indicates a more evenly distributed set of solutions. Conversely, NSGA-II achieved lower values for Spread on the SLI dataset, signifying a balanced diversity across objectives.
Overall, NSGA-II performs robustly on the SLI dataset, while SPEA-II demonstrates strong performance on the SVD and VOICED datasets, highlighting the dataset-specific strengths of the different optimizers.
Table 6 displays the performance results of the RF classifier. Looking at IGD, SPEA-II achieves the lowest values on SLI and VOICED, suggesting more precise Pareto-front approximations, while NSGA-II performs similarly on SVD, with an IGD of 31.781. In the HV metric, SPEA-II consistently scores highest across all datasets, indicating a strong coverage in objective space. NSGA-II follows closely, particularly with VOICED where it achieves a high HV of 10.585. Spacing and Spread metrics indicate solution distribution and diversity. MOEA/D’s spacing is minimal on SVD and VOICED, with values near zero (0.032 and 0.031), implying evenly distributed solutions. In contrast, Spread is generally consistent across optimizers. Overall, SPEA-II demonstrates reliable performance across datasets with balanced spacing and spread.
Table 7 presents the results of the comparison between the three optimizers with the MLP classifier across three datasets. SPEA-II generally performed well, achieving the lowest IGD for SLI and SVD, suggesting strong proximity to the true Pareto-front, while NSGA-II had the lowest IGD for VOICED. For HV, SPEA-II consistently achieved the highest averages, especially on SVD and VOICED, indicating good coverage of the objective space. SPEA-II also excelled in Spacing, achieving the most uniform solution distribution, especially notable in the VOICED dataset. Spread results showed that both SPEA-II and NSGA-II maintained good solution diversity, with SPEA-II achieving the best values on SVD. Overall, SPEA-II shows strong and consistent optimization performance across metrics and datasets, suggesting it is the most robust algorithm for MLP-based multi-objective optimization.
Table 8 displays the optimization performance of NSGA-II, MOEA/D, and SPEA-II with the SVM classifier across (SLI, SVD, and VOICED). NSGA-II achieves the best IGD on SLI and VOICED, indicating the highest proximity to the true Pareto-front, while SPEA-II performs best on SVD. For HV, NSGA-II outperforms the other algorithms on SLI, and SPEA-II achieves a high HV on SVD, implying superior objective space coverage on those datasets. In terms of Spacing, SPEA-II performs well with the lowest variance across SLI and SVD, indicating a more uniform distribution. MOEA/D shows mixed performance, and all algorithms report zero values for all metrics on VOICED, likely due to convergence issues. Overall, NSGA-II and SPEA-II demonstrate strong performance across the metrics, particularly on SLI and SVD, with NSGA-II generally excelling in HV and IGD.
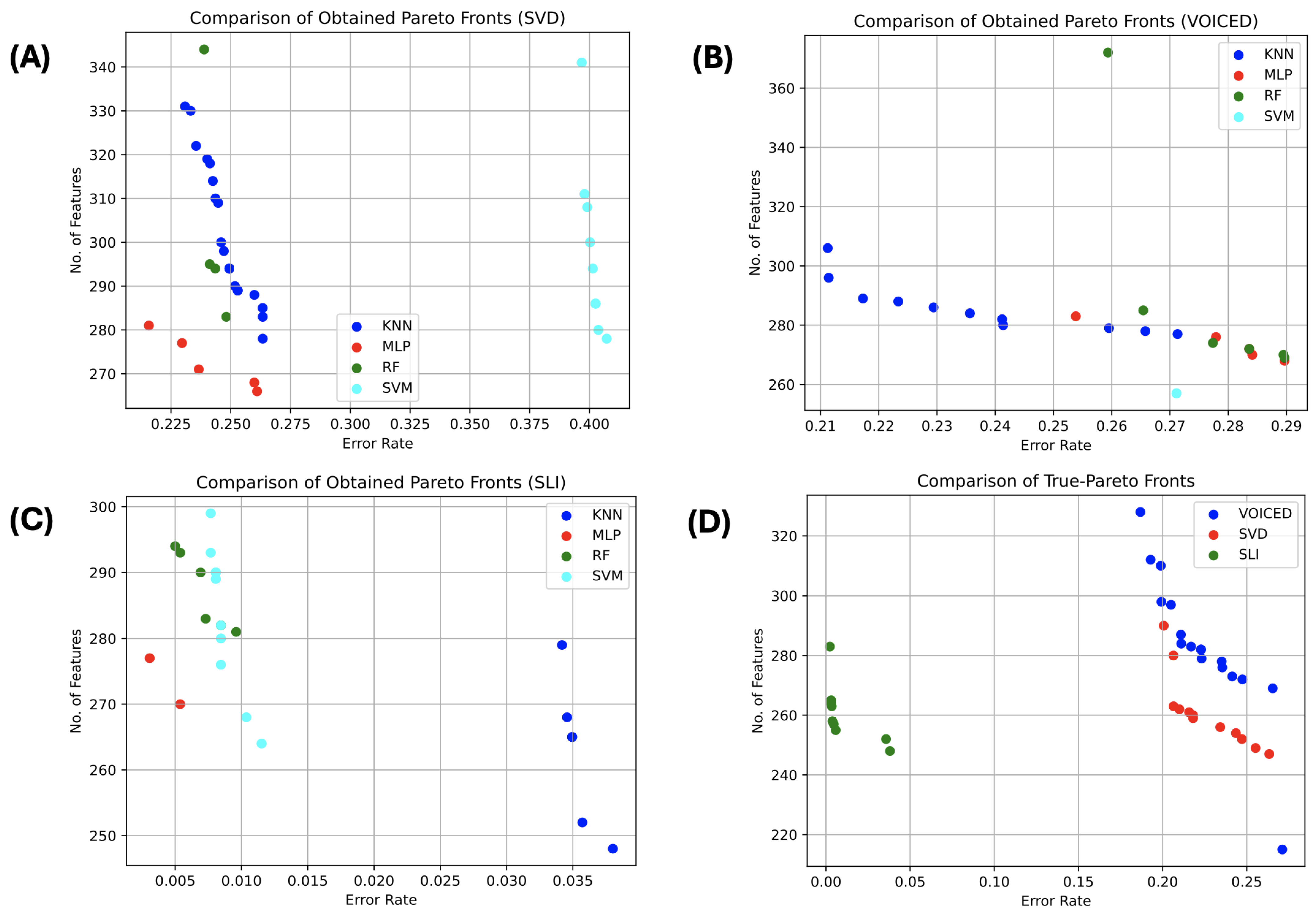
Figure 4 depicts the approximated Pareto-front for the three datasets from all optimizers and all classifiers.
Figure 4A–C present the best obtained Pareto-front from the NSGA-II for SVD, VOICED, and SLI, respectively, among all classifiers.
Figure 4D shows the actual Pareto-front (the non-dominated solutions) obtained by all classifiers over all runs.
Table 9 shows the required optimization time (i.e., training time) of the NSGA-II optimizer across KNN, MLP, RF, and SVM applied over the three datasets, with the average and standard deviation values computed. The optimization time represents the needed time for the optimization phase of the evolutionary algorithm to minimize the number of features and error rate. The results indicate significant variations in optimization time depending on the classifier and dataset. The MLP and RF classifiers are the most computationally intensive, particularly on the SLI dataset, with average times of 7619.2 s and 7936.3 s, respectively, which may reflect the higher complexity and resource demand of these models in training with NSGA-II. For smaller datasets like VOICED, all classifiers have lower optimization times, with KNN and SVM exhibiting particularly fast runtimes (8.319 s for KNN and 14.633 s for SVM). SVM shows consistently low optimization times across datasets, which may make it more practical for large-scale or real-time applications requiring NSGA-II optimization. The table highlights the computational demands of NSGA-II optimization, which vary substantially across classifiers and datasets, impacting its feasibility depending on the available resources and time constraints.
Furthermore, a statistical analysis is conducted to guarantee the significant difference in performance between the three evolutionary optimizers across the four machine learning algorithms and datasets. First, the Kolmogorov–Smirnov (KS) normality test is used to ensure the validity of the data distribution before computing the Analysis of Variance (ANOVA) test. If at least one dataset was abnormal, the Kruskal–Wallis test is calculated instead. The algorithms’ performance was evaluated using IGD and Hypervolume metrics over 15 independent runs. The test results exhibited a low p-value less than the significance level of 0.05, indicating a significant difference in the performance of the algorithms.
Generally speaking, NSGA-II is the best optimizer overall. While KNN performs best for SLI, MLP outperforms others in SVD, and SVM achieves the best IGD for VOICED, with MLP leading in HV, making NSGA-II and MLP a strong but not always the optimal solution. NSGA-II and MLP were used to compute the non-conformity scores for the three datasets. The split conformal prediction with softmax-based nonconformity scores is employed. Using the MAPIE Library [
35], the CPs for all runs and all Pareto-fronts were computed, with the average (Avg.) and standard deviation (Std.) were reported for the non-conformity scores, as shown in
Table 10. The results show a strong performance of the SLI dataset with a high accuracy of 0.987 and low nonconformity scores (0.015 ± 0.079), indicating well-calibrated predictions and reliable uncertainty estimates. Conversely, the SVD and VOICED datasets exhibit lower accuracy (0.743 and 0.706, respectively) and higher nonconformity scores (0.253–0.318), suggesting increased model uncertainty or data challenges.
Table 11 presents a comparative overview of our proposed methods along with recent State-of-the-Art approaches from the literature. Although we acknowledge that the comparison is not strictly fair due to differences in datasets, feature extraction strategies, and optimization objectives, the table is intended to provide a contextual reference to understand current trends.
In particular, while many previous studies report high performance—particularly on the full SVD or mixed datasets (e.g., SVD + MEEI)—our experiments were conducted on different bases. Specifically, we used a subset of the SVD dataset, employed distinct handcrafted features (849 in total), and focused on underexplored datasets such as VOICED and SLI, for which, to the best of our knowledge, no multi-objective evolutionary optimization approaches have been previously applied.
The approach designed in this study emphasizes a multi-objective formulation using algorithms like NSGA-II to jointly minimize classification error and reduce the feature set. Despite relatively lower classification metrics in some cases, our methods achieve a threefold reduction in dimensionality, improving computational efficiency and interpretability.
Overall, although the table does not represent a direct benchmarking effort, it reinforces the unique value of this study’s contributions. Specifically, it emphasizes the integration of multi-objective optimization and the exploration of lesser-studied datasets. Thus, adding diversity and new directions to the existing body of research.
5. Conclusions
This comparative research study presents a new multi-objective and bio-inspired machine learning optimization approach for improving the accuracy of voice disorder detection. Three datasets were utilized along with three multi-objective optimizers (NSGA-II, SPEA-II, and MOEA/D) and four base classifiers (RF, KNN, MLP, and SVM). In this study, the problem is formulated as a multi-objective feature selection, which aims to minimize the number of features and the error rate. Several spectral and time-domain features were extracted from SLI, SVD, and VOICED datasets and labelled as normal and abnormal. Comparing algorithms based on the IGD, HV, Spread, and Spacing metrics showed that the three optimizers exhibited competitive performance, while the NSGA-II algorithm disclosed a powerful capability for identifying pathological voices. Also, the best classifiers per dataset are KNN for SLI (best IGD & HV), MLP for SVD (best IGD), and SVM for VOICED (best IGD), with MLP also excelling in HV. Although NSGA-II with MLP is not always the best, it remains a strong choice. Furthermore, by integrating conformal prediction, this study ensures statistically feasible uncertainty quantification in feature-selected models, enhancing the reliability of voice disorder detection even in high-dimensional settings.
Future research will investigate optimizing parameters and refining feature selection more closely, as these are important steps for promoting the performance of speech disorder detection. Incorporating advanced algorithms, such as deep neural networks, can further improve performance. Additionally, recent studies have shown the effectiveness of large language models (LLMs) in automatic speech recognition and speech analysis. Thus, this motivates the utilization of LLMs or speech large models for detecting and reconstructing corrupted speech. Nonetheless, a future work could refine conformal predictions by tackling calibration issues in lower-accuracy datasets (such as SVD and VOICED) or developing adaptive nonconformity scores to improve the precision of prediction sets.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}